Here is my cat /proc/cpuinfo output:
...
processor : 15
vendor_id : GenuineIntel
cpu family : 6
model : 26
model name : Intel(R) Xeon(R) CPU E5520 @ 2.27GHz
stepping : 5
cpu MHz : 1600.000
cache size : 8192 KB
physical id : 1
siblings : 8
core id : 3
cpu cores : 4
apicid : 23
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic ...
bogomips : 4533.56
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management :
This machine has two CPUs, each with 4 cores with hyperthreading capability, so the total processor number is 16(2 CPU * 4 core * 2 hyperthreading). These processors have same output, to keep clean, I just show the last one’s info and omit part of flags in the flags line.
So how do I calculate the peak performance of this machine in terms of GFlops?
Let me know if more info should be supplied.
Thanks.
![]()
Brendan Long
52.9k21 gold badges144 silver badges186 bronze badges
asked Jun 9, 2011 at 7:57
![]()
2
You can check the Intel export spec.
The GFLOP in the chart is usually referred as the peak of a single chip.
It shows 36.256 Gflop/s for E5520.
This single chip has 4 physical cores with SSE.
So this GFLOP can also be calculated as:
2.26GHz*2(mul,add)*2(SIMD double precision)*4(physical core) = 36.2.
You system has two CPUs, so your peak is 36.2*2 = 72.4 GFLOP/S.
![]()
answered Nov 28, 2012 at 16:48
![]()
TomTom
2312 silver badges9 bronze badges
2
Оценка и оптимизация производительности вычислений на многоядерных системах
Время на прочтение
10 мин
Количество просмотров 9.7K

Данная публикация является переводом первой части статьи Characterization and Optimization Methodology Applied to Stencil Computations инженеров компании Intel. Эта часть посвящена анализу производительности и построению roofline модели на примере довольно распространенного вычислительного ядра, которая позволяет оценить перспективы оптимизации приложения на данной платформе.
В следующей части будет описано, какие оптимизации были применены для того, чтобы приблизиться к ожидаемому значению производительности. Техники оптимизации, описанные в данной статье, включают, к примеру:
- масштабируемое распараллеливание (collaborative thread blocking)
- увеличение пропускной способности памяти (cache blocking, переиспользование регистров)
- увеличение производительности процессора (векторизация, переразбиение циклов).
В третьей части статьи будет описан алгоритм, позволяющий автоматически подобрать оптимальные параметры запуска и построения приложения. Эти параметры обычно связаны с изменениями исходного кода программы (например, loop blocking значения), с параметрами для компилятора (например, фактор развертки цикла) и характеристиками вычислительной системы (например, размеры кэшей). Получившийся алгоритм оказался быстрее, чем традиционные тяжеловесные техники поиска. Начиная с простейшей реализации и до самой оптимизированной, было получено 6-кратное улучшение производительности на процессоре Intel Xeon E5-2697v2 и примерно 3-кратное на сопроцессорах Intel Xeon Phi первого поколения. В дополнение к этому, приведенная методология автоматического тюнинга выбирает оптимальные параметры запуска для любого набора входных данных.
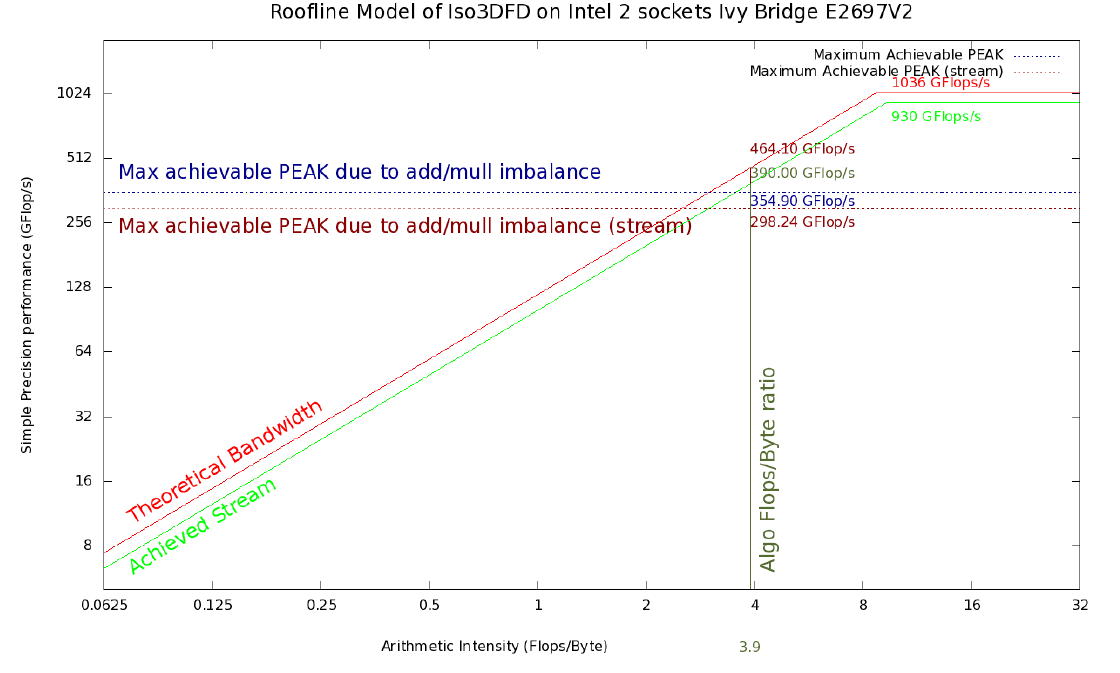
Рисунок 1. Roofline модель Iso3DFD для Ivy Bridge 2S E5-2697 v2. Красная и светло-зеленые линии обозначают верхний теоретический и достижимый предел на текущей платформе соответственно. Горизонтальная синяя линия отражает максимально достижимые значения пропускной способности памяти принимая во внимание определенный дисбаланс сложений и умножений (#ADD;#MUL) и усредненные с помощью Stream triad бенчмарка (горизонтальная коричневая линия). Вертикальная темно-зеленая линия соответствует арифметической интенсивности для ядра Iso3DFD алгоритма. Пересечения с остальными линиями дают соответствующие достижимые пределы.
Краткий обзор
Статья описывает характеризацию (прим. переводчика — характеризация — выявление характерных признаков) и методологию оптимизации 3D алгоритма конечных разностей (3DFD), который используется для решения акустического волнового уравнения с константной или переменной плотностью изотропной среды (Iso3DFD). Начиная с простейшей реализации 3DFD, мы опишем методологию для оценки наилучшей производительности, которая может быть получена для данного алгоритма, с помощью его характеризации на конкретной вычислительной системе.
Введение
Метод конечных разностей во временной области – широко применяемая техника моделирования волн, например, для анализа волновых явлений и сейсморазведки. Этот метод популярен при использовании таких техник сейсмического анализа, как обратная временная миграция (reverse time migration) и полноволновая инверсия (full waveform inversion). Разновидности метода включают рассмотрение волн как акустических или упругих, а среда распространения может являться анизотропной, при этом плотность может также варьироваться.
Как известно, выбор конкретной численной схемы для аппроксимации частных производных имеет сильное влияние на производительность реализации [1]. В частности, это влияет на арифметическую интенсивность (число операций с плавающей запятой на каждое пересланное машинное слово) 3DFD алгоритма. Данная арифметическая интенсивность может быть далее связана с ожидаемой производительностью, используя методологию roofline моделирования [2]. Эта методология позволяет оценить уровень производительности реализации относительно максимально достижимой на конкретной вычислительной системе. То есть, roofline модель устанавливает рамки роста производительности, которая может быть достигнута с помощью оптимизации исходного кода программы. После того, как производительность реализации достигла определенного уровня, дальнейший рост производительности может быть получен только с помощью изменения самого алгоритма.
Для любого данного компьютера, его спецификация определяет
пиковые
значения для количества операций с плавающей запятой (FLOP/s) и для пересылок данных из памяти или в память (пропускная способность памяти). Соответствующие максимально
достижимые
показатели могут быть получены путем запуска стандартных бенчмарков как LINPACK [3] и STREAM triad [4].
Первая часть статьи будет нацелена на оценку максимально достижимой производительности ядра алгоритма Iso3DFD на двухсокетном сервере и сопроцессоре. Далее мы опишем несколько техник которые могут иметь важное влияние на производительность. Как обычно, такие оптимизации могут потребовать некоторых усилий и модификации исходного кода. После этого мы покажем вспомогательное средство для нахождения, если не наилучшего, то в какой-то степени оптимального набора параметров для компиляции и запуска приложения.
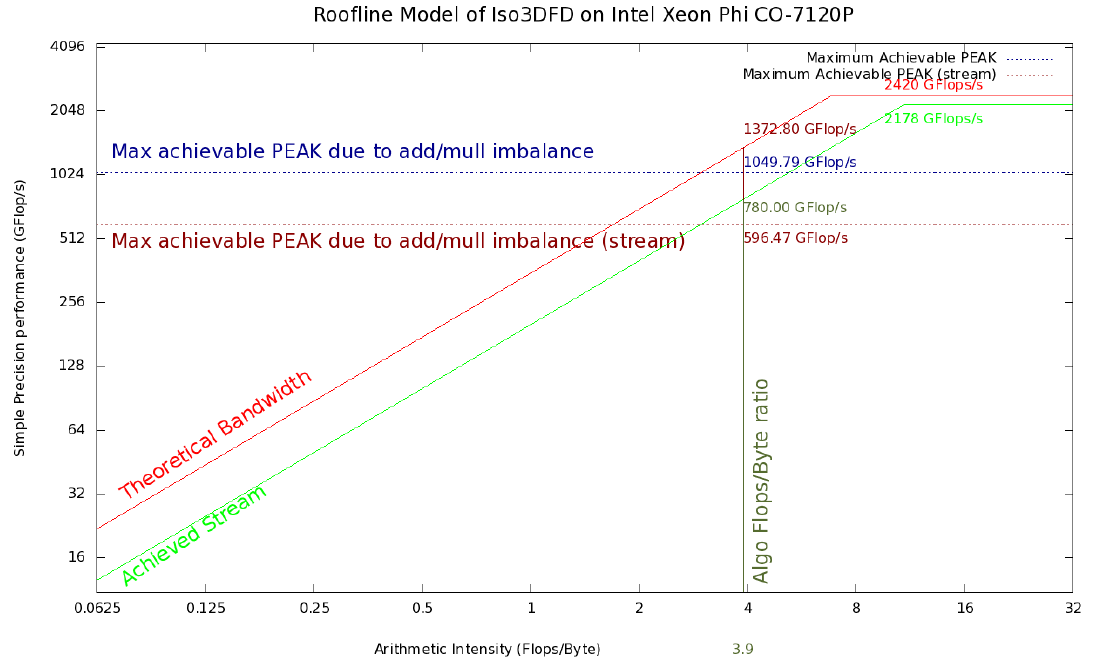
Рисунок 2. Roofline модель Iso3DFD для сопроцессора Xeon Phi 7120P. Красная и светло-зеленые линии обозначают верхний теоретический и достижимый предел на текущей платформе соответственно. Горизонтальная синяя линия отражает максимально достижимые значения пропускной способности памяти, принимая во внимание определенный дисбаланс сложений и умножений (#ADD;#MUL) и усредненные с помощью Stream triad бенчмарка (горизонтальная коричневая линия). Вертикальная темно-зеленая линия соответствует арифметической интенсивности для ядра Iso3DFD алгоритма. Пересечения с остальными линиями дают соответствующие достижимые пределы.
Оценка производительности
Наше ядро алгоритма Iso3DFD решает акустическое изотропное волновое уравнение 16 порядка дискретизации по пространству и 2 порядка дискретизации по времени. Стандартная реализация данного 3DFD ядра обычно достигает менее чем 10% от пиковой производительности вычислительной системы на операциях с плавающей запятой в секунду (FLOP/s). Мы рассмотрим способ получения roofline модели [2] для вычислительного ядра Iso3DFD на CPU и сопроцессоре Xeon Phi. Для нахождения максимальной производительности данного приложения нам необходимо найти:
- Пиковое значение производительности и пропускной способности памяти (теоретические): 2420 GFLOP/s в одинарной точности и 352 GB/s для Intel Xeon Phi 7120A; 1036 GFLOP/s в одинарной точности и 119 GB/s для 2 процессоров Intel Xeon E5-2697v2 с 1866 MHz DDR3 памятью.
- Значения полученные на Linpack (или GEMM) and STREAM triad бенчмарках дают нам соответствующие показатели максимальной производительности на платформе: 2178 GFLOP/s и 200 GB/s для Intel Xeon Phi 7120A; 930 GFLOP/s и 100 GB/s для 2 процессоров Intel Xeon E5-2697v2 с 1866 MHz DDR3 памятью.
- Арифметическая интенсивность приложения рассчитывается на базе количества сложений и умножений (ADD, MUL) чисел с плавающей запятой и количества байт пересланных из памяти и определенной количеством загрузок и записей в память (LOAD, STORE).
Последний пункт следует из предположения, что вычислительная система имеет кэш с бесконечной пропускной способностью памяти и размером, а также имеет нулевую задержку на доступ к данным (latency). Это определяет своего рода безупречную подсистему памяти, где любой массив загружается полностью даже в том случае, если требуется всего 1 элемент.
Несколько других факторов также могут влиять на производительность всего приложения, использующая 3DFD ядро – выбор граничных условий, IO схема при обращении во времени, а также технология или модель параллельного программирования. Однако, в приведенном здесь анализе мы не рассматриваем граничные условия и IO. Параллельная реализация решения данной задачи использует метод domain decomposition для распределенных систем с использованием MPI стандарта вместе с параллелизмом по потокам на вычислительном узле с использованием OpenMP. В данной работе рассматривается вычисления в подобласти на одном узле вычислительной системы.
Арифметическая интенсивность платформы
Наша тестовая система состоит из двух CPU Xeon E5-2697 (2S-E5) с 12 ядрами на один CPU, каждый запущен с частотой 2.7 ГГц без турбо режима. Данные процессоры поддерживают AVX расширение набора инструкций с 256-битной шириной векторных регистров. Данные инструкции могут выполнять вычисления с 8 числами с плавающей запятой в одинарной точности (32 бита) одновременно (за один такт CPU). Таким образом, теоретическую пиковую производительность можно посчитать как 2.7 (GHz) x 8 (SP FP) x 2 (ADD/MULL) x 12 (cores) x 2 (CPUs) = 1036,8 GFLOP/s. Пиковая пропускная способность рассчитывается с помощью частоты памяти (1866 ГГц), количества каналов памяти [4], количества байт пересылаемых в один такт (8), что дает 1866 x 4 x 8 x 2(CPUs) = 119 GB/s для двухпроцессорного узла 2S-E5. Также, нам необходимо оценить реально достижимые значения пропускной способности и производительности для характеризации поведения приложения. В качестве первого приближения допустим, что производительность любого реального приложения может быть ограничена пропускной способностью памяти (totally bandwidth bound), что в данной работе оценивается с помощью Stream triad или быстродействием процессора (totally FLOP/s bound или compute bound или CPU bound), что показывает бенчмарк Linpack. Выбор именно этих двух бенчмарков является чисто гипотетическим, но мы можем утверждать, что если они и далеки от идеальных оценок, то уж точно они лучше подходят в качестве приближения, чем пиковые теоретические значения вычислительной системы.
На 2S-E5 системе Linpack дает 930 GFLOP/s, а Stream triad 100 GB/s. Далее мы можем посчитать арифметическую интенсивность (AI) для теоретических и реальных максимальных показателей соответственно, как:
AI (theoretical, CPU) = 1036,8 / 119 = 8,7 FLOP/byte
AI (achievable, CPU) = 930 / 100 = 9,3 FLOP/byte
С данными значениями мы можем характеризовать любое вычислительное ядро следующим образом: если арифметическая интенсивность ядра больше (меньше) чем 9,3 FLOP/byte мы можем сказать, что это ядро ограничено быстродействием процессора — CPU bound (пропускной способностью памяти – memory bound).
Аналогичные расчеты на Linpack и Stream triad для Xeon Phi дают 2178 GFLOP/s и 200 GB/s соответственно. Теоретические пиковые оценки — 2420 GFLOP/s и 352 GB/s. Таким образом, арифметическая интенсивность будет равна:
AI (theoretical, Phi) = 2420,5 / 352 = 6,87 FLOP/byte
AI (achievable, Phi) = 2178 / 200 = 10,89 FLOP/byte
Арифметическая интенсивность вычислительного ядра
Roofline модель также требует вычисления арифметической интенсивности данного приложения. Она может быть получена через подсчет количества арифметических операций и доступов в память путем визуальной инспекции кода или с помощью специальных средств имеющих доступ к счетчикам вычислительной системы. В рамках стандартного вычислительного ядра схемы конечных разностей [5] мы можем найти 4 загрузки (coeff, prev, next, vel), 1 запись (next), 51 сложение (вычисления индексов не берутся в расчет) и 27 умножений (рисунок 3).
for(int bz=HALF_LENGTH; bz<n3; bz+=n3_Tblock)
for(int by=HALF_LENGTH; by<n2; by+=n2_Tblock)
for(int bx=HALF_LENGTH; bx<n1; bx+=n1_Tblock) {
int izEnd = MIN(bz+n3_Tblock, n3);
int iyEnd = MIN(by+n2_Tblock, n2);
int ixEnd = MIN(n1_Tblock, n1-bx);
int ix;
for(int iz=bz; iz<izEnd; iz++) {
for(int iy=by; iy<iyEnd; iy++) {
float* next = ptr_next_base + iz*n1n2 + iy*n1 + bx;
float* prev = ptr_prev_base + iz*n1n2 + iy*n1 + bx;
float* vel = ptr_vel_base + iz*n1n2 + iy*n1 + bx;
for(int ix=0; ix<ixEnd; ix++) {
float value = 0.0;
value += prev[ix]*coeff[0];
for(int ir=1; ir<=HALF_LENGTH; ir++) {
value += coeff[ir] * (prev[ix + ir] + prev[ix - ir])
;
value += coeff[ir] * (prev[ix + ir*n1] + prev[ix -
ir*n1]);
value += coeff[ir] * (prev[ix + ir*n1n2] + prev[ix -
ir*n1n2]);
}
next[ix] = 2.0f* prev[ix] - next[ix] + value*vel[ix];
}
}}}
Рисунок 3. Исходный код вычислительного ядра с cache blocking
Арифметическая интенсивность может быть рассчитана по формуле:
AI = (#ADD + #MUL) / ((#LOAD + #STORE) x word size) (1)
Это дает арифметическую интенсивность, равную 3,9 FLOP/byte, которую мы умножим на теоретическую пропускную способность каждой платформы для получения первой оценки максимально достижимой производительности для данного алгоритма. Получим 1372,8 GFLOP/s на Xeon Phi и 461,1 GFLOP/s на 2S-E5. Однако теоретическое пиковое значение производительности предполагает параллельное использование двух конвейеров (один для ADD, другой для MUL), что невозможно в данном вычислительном ядре из-за дисбаланса между сложениями и умножениями, таким образом, данный код не сможем достичь этого оцененного максимального значения. А это значит, что достижимое максимальное значение следует усреднить с помощью:
(#ADD + #MUL) / (2 x max(add, mul)), (2)
что отражает отношение общего возможного количества операций при 16 операциях с плавающей запятой на такт (ops/cycle) и максимально количества сложений и умножений, которые исполняются при 8 ops/cycle, предполагая использование одной 256-битной AVX SIMD вычислительной единицы. Это даст теоретическую оценку пиковой производительности, учитывающую дисбаланс сложений и умножений.
Рисунки 1 и 2 показывают Roofline модель с верхними границами в 354,9 GFLOP/s и 1049,8 GFLOP/s для 2S-E5 и Xeon Phi соответственно, полученных с помощью этой усредненной версией арифметической интенсивности.
Более реалистичная roofline модель может быть получена при использовании пропускной способности Stream triad бенчамарка умноженной на арифметическую интенсивность вычислительного ядра (390 GFLOP/s и 780 GFLOP/s соответственно). Еще более реалистичную модель можно получить, если учесть некоторый дисбаланс сложений и умножений (с помощью (2)), что показано красной пунктирной линией. Новая верхняя граница будет равна около 298 GFLOP/s для 2S-E5 и 596 GFLOP/s для Xeon Phi. Так как наша модель основана на безупречной модели кэш-памяти, мы предполагаем, что получившиеся значения все еще являются грубой оценкой максимально достижимых значений производительности. Как продемонстрировано в [2], можно улучшить получившийся roofline добавлением некоторых новых сущностей в характеризацию вычислительной системы, как, например, влияние и ограничения кэш памяти.
Продолжение следует…
Список литературы
- D. Imbert, K. Immadouedine, P. Thierry, H. Chauris, and L. Borges, “Tips and tricks for finite difference and i/o-less fwi,” in Expanded Abstracts. Soc. Expl. Geophys., 2011, pp. 3174–3178.
- S. Williams, A. Waterman, and D. Patterson, “Roofline: an insightful visual performance model for multicore architectures,” Communications of the ACM — A Direct Path to Dependable Software, vol. 52, pp. 65–76, April 2009.
- J. Dongarra, P. Luszczek, and A. Petitet, “The linpack benchmark: past, present and future,” Concurrency and Computation: Practice and Experience, vol. 15, no. 9, pp. 803–820, 2003, doi:10.1002/cpe.728.
- J. D. McCalpin, “Stream: Sustainable memory bandwidth in high performance computers,” University of Virginia, Charlottesville, Virginia, Tech. Rep., 1991-2007, a continually updated technical report. www.cs.virginia.edu/stream
- L. Borges, “Experiences in developing seismic imaging code for Intel Xeon Phi coprocessor.”, 2012. software.intel.com/en-us/blogs/2012/10/26/experiences-in-developing-seismic-imaging-code-for-intel-xeon-phi-coprocessor
- J. H. Holland, “Genetic algorithms and the optimal allocation of trials,” SIAM Journal of Computing, vol. 2, no. 2, pp. 88–105, 1973.
Главной
отличительной особенностью многопроцессорной
вычислительной системы является ее
производительность, т.е. количество
операций, производимых системой за
единицу времени. Различают пиковую и
реальную производительность. Под пиковой
понимают величину, равную произведению
пиковой производительности одного
процессора на число таких процессоров
в данной машине. При этом предполагается,
что все устройства компьютера работают
в максимально производительном режиме.
Пиковая производительность компьютера
вычисляется однозначно, и эта характеристика
является базовой, по которой производят
сравнение высокопроизводительных
вычислительных систем. Чем больше
пиковая производительность, тем
теоретически быстрее пользователь
сможет решить свою задачу. Пиковая
производительность есть величина
теоретическая и, вообще говоря, не
достижимая при запуске конкретного
приложения. Реальная же производительность,
достигаемая на данном приложении,
зависит от взаимодействия программной
модели, в которой реализовано приложение,
с архитектурными особенностями машины,
на которой приложение запускается.
Существуют
два способа оценки пиковой производительности
компьютера. Один из них опирается на
число команд, выполняемых компьютером
в единицу времени. Единицей измерения,
как правило, является MIPS (Million Instructions
Per Second). Производительность, выраженная
в MIPS, говорит о скорости выполнения
компьютером своих же инструкций. Но,
во-первых, заранее не ясно, в какое
количество инструкций отобразится
конкретная программа, а, во-вторых,
каждая программа обладает своей
спецификой, и число команд от программы
к программе может меняться очень сильно.
В связи с этим данная характеристика
дает лишь самое общее представление о
производительности компьютера.
Другой
способ измерения производительности
заключается в определении числа
вещественных операций, выполняемых
компьютером в единицу времени. Единицей
измерения является Flops (Floating point operations
per second) – число операций с плавающей
точкой, производимых компьютером за
одну секунду. Такой способ является
более приемлемым для пользователя,
поскольку последний знает вычислительную
сложность своей программы и, пользуясь
этой характеристикой, может получить
нижнюю оценку времени ее выполнения.
Однако
пиковая производительность получается
при работе компьютера в идеальных
условиях, т.е. при отсутствии конфликтов
при обращении к памяти при равномерной
загрузке всех устройств. В реальных
условиях на выполнение конкретной
программы влияют такие аппаратно-программные
особенности данного компьютера, как:
особенности структуры процессора,
системы команд, состав функциональных
устройств, реализация ввода/вывода,
эффективность работы компиляторов.
Одним
из определяющих факторов является время
взаимодействия с памятью, которое
определяется ее строением, объемом и
архитектурой подсистем доступа в память.
В большинстве современных компьютеров
организации наиболее эффективного
доступа к памяти используется так
называемая многоуровневая иерархическая
память. В качестве уровней используются
регистры и регистровая память, основная
оперативная память, кэш-память, виртуальные
и жесткие диски, ленточные роботы. При
этом выдерживается следующий принцип
формирования иерархии: при повышении
уровня памяти скорость обработки данных
должна увеличиваться, а объем уровня
памяти – уменьшаться. Эффективность
использования такого рода иерархии
достигается за счет хранения наиболее
часто используемых данных в памяти
верхнего уровня, время доступа к которой
минимально. А поскольку такая память
обходится достаточно дорого, ее объем
не может быть большим. Иерархия памяти
относится к тем особенностям архитектуры
компьютеров, которые оказывают огромное
значение для повышения их производительности.
Для
того, чтобы оценить эффективность работы
вычислительной системы на реальных
задачах, был разработан фиксированный
набор тестов. Наиболее известным из них
является LINPACK – программа, предназначенная
для решения системы линейных алгебраических
уравнений с плотной матрицей с выбором
главного элемента по строке. LINPACK
используется для формирования списка
Top500 – пятисот самых мощных компьютеров
мира.
В
настоящее время большое распространение
получили тестовые программы, взятые из
разных предметных областей и представляющие
собой либо модельные, либо реальные
промышленные приложения. Такие тесты
позволяют оценить производительность
компьютера действительно на реальных
задачах и получить наиболее полное
представление об эффективности работы
компьютера с конкретным приложением.
Наиболее
распространенными тестами, построенными
по этому принципу, являются: набор из
24 Ливерморских циклов (The Livermore Fortran
Kernels, LFK) и пакет NAS Parallel Benchmarks (NPB), в состав
которого входят две группы тестов,
отражающих различные стороны реальных
программ вычислительной гидродинамики.
Организация ЭВМ и периферийные устройства

В данной части учебного пособия излагаются основы организации и функционирования компьютеров. Рассматриваются показатели производительности компьютеров и процессоров, приведена структура компьютера, описаны её основные компоненты. Подробно рассмотрен центральный процессор, включая его структуру, особенности системы команд, принцип конвейерной обработки команд, основные режимы работы, особенности построения и функционирования современных микропроцессоров. Рассмотрены основные характеристики и разновидности устройств памяти, принципы их построения и функционирования. Проиллюстрировано функционирование компьютера при выполнении команд. Настоящее учебное пособие предназначено для студентов, обучающихся по направлению 09.03.02 «Информационные системы и технологии», а также может быть полезно студентам, обучающихся по другим направлениям, связанным с применением компьютеров в различных прикладных областях.
Оглавление
2. Производительность компьютеров и её оценка
Производительность компьютера является объективной мерой эффективности его функционирования и используется в качестве одного из основных его технических параметров. Производительность определяется архитектурой и рабочей частотой процессора, пропускной способностью системной шины, типом и объёмом оперативной и кэш-памяти и другими особенностями конфигурации. Кроме того, она зависит от типа используемой ОС, применённых для получения программы трансляторов с языков программирования, конкретных приложений и др.
Таким образом, понятие производительности компьютера является весьма многоплановым, в связи с чем для её оценки используется целый ряд различных показателей.
2.1. Показатели производительности
Различают следующие показатели производительности:
1. Пиковая — максимально достижимая производительность процессорной подсистемы компьютера, включающей процессор, кэш — и оперативную память.
2. Номинальная — средняя производительность процессорной подсистемы компьютера.
3. Системная — средняя производительность всей аппаратно-программной системы ПК в целом, т.е. с учётом обмена данными с жёстким диском, видеосистемой, и другими внешними устройствами, взаимодействия с ОС.
4. Эксплуатационная — производительность компьютера на реальной рабочей нагрузке, с учётом конкретных используемых приложений, например текстовых процессоров, систем автоматизации проектирования, компиляторов и др.
Очевидно, что для обычного пользователя наибольший интерес представляет именно эксплуатационная производительность компьютера на наиболее часто используемых приложениях. Если же набор таких приложений не определён, то используются значения системной, номинальной и пиковой производительности.
2.2. Методы определения показателей производительности
2.2.1. Пиковая производительность
Пиковая производительность — производительность процессорной подсистемы компьютера при выполнении коротких команд, т.е. команд, не выполняющих обращений к оперативной и кэш-памяти. Такие команды обычно связаны с выполнением различных регистровых операций (например, инкремент регистра INC AX, пересылка данных MOV AX, BX) и могут выполняться за один цикл работы процессора.
Таким образом, пиковая производительность — число команд типа «регистр — регистр», выполняемых процессорной подсистемой в единицу времени без учета статистического веса таких команд в реальных программах. Обычно пиковая производительность оценивается для команды типа «Нет операции» (NOP — No OPeration)2.
Пиковая производительность зависит как от тактовой частоты процессора, так и от его архитектуры и микроархитектуры. Для выявления эффективности архитектуры и микроархитектуры целесообразно проводить сравнение пиковой производительности процессоров при одинаковой частоте.
2.2.2. Номинальная производительность
Номинальная производительность — среднее число команд, включая команды обмена с оперативной памятью, выполняемых в единицу времени процессорной подсистемой. Используемые при этом наборы команд подбирают с учетом их статистического веса (частоты использования) в популярных приложениях и имитируют реальную нагрузку на процессорную подсистему.
Номинальная производительность измеряется при помощи как абсолютных (количество операций в секунду), так и относительных единиц (программные тесты).
В качестве абсолютных используются следующие единицы:
• количество миллионов инструкций (команд) в секунду, MIPS (Million Instructions Per Second);
• количество операций в секунду над числами с плавающей точкой, FLOPS (FLoating-point Operations Per Second), а также производные единицы MFLOPS, GFLOPS, TFLOPS, PFLOPS и др.
Для оценки номинальной производительности широко используется тестовый пакет SPEC CPU от фирмы SPEC (Standard Performance Evaluation Corporation)3. Пакет вычисляет две оценки — SPECint и SPECfp, представляющие целочисленные вычисления и вычисления над числами с плавающей точкой соответственно.
Тест SPECint использует универсальные наборы команд над числами с фиксированной точкой и сбалансирован по типам операций, глобальных и локальных переменных и констант в результате статистического исследования и усреднения по большому числу реальных программ (архивация, компиляция с С, комбинаторная оптимизация, искусственный интеллект, игра в шахматы, сжатие видео). Таким образом, тест фактически оценивает производительность процессорной подсистемы без учёта математического сопроцессора.
Тест SPECfp использует базовые арифметические команды над числами с фиксированной и плавающей точками одинарной и двойной точности с равновероятным распределением команд, операции вычисления тригонометрических функций, логарифмов и др. (распознавание речи, уравнение Максвелла, вычисление 3-мерных моделей в гидравлике, моделирование биомолекулярных систем, имитация отжига, симплес-метод).
Результат измерения выдается в виде коэффициента соотношения производительности тестируемой системы к производительности эталонной системы. В качестве эталонной системы корпорация SPEC выбрала систему Sun «Ultra Enterprise 2» на базе процессора Sun UltraSPARC II с частотой 296 МГц (1997 г.), но с увеличенным объемом кэша и оперативной памяти.
2.2.3. Системная производительность
Результаты оценки системной производительности некоторого компьютера обычно приводятся относительно базового компьютера стандартной конфигурации либо относительно некоторого набора компьютеров. Результаты оформляются в виде сравнительных таблиц, двухмерных и трёхмерных графиков и диаграмм.
Одним из известных тестов системной производительности является Business Winstone4. Тест Winstone измеряет среднюю производительность компьютера при выполнении популярных офисных Windows — приложений с учётом величины занимаемого этими приложениями сектора рынка (текстовые процессоры, электронные таблицы, системы управления базами данных, программы деловой графики, издательские системы и т.д.). Результаты теста Winstone представляются в виде индекса производительности относительно базового ПК.
Примечание
Сектор рынка, занимаемый некоторым приложением, косвенно определяет удельный вес общего компьютерного времени, используемого данным приложением.
Популярным тестом системной производительности является также пакет SYSmark. Он широко используется специалистами по информационным технологиям, производителями компьютерного оборудования, аналитиками и журналистами. Тесты SYSmark SE разделены на два сценария: создание интернет-контента и офисная производительность. В тесте создания интернет-контента можно выделить три тестовые группы: 3D-графика, 2D-графика и web-публикация. Сценарий офисной производительности также разделён на три тестовые группы: связь (электронная почта, календарь и просмотр web-страниц), создание документов и анализ данных. Приложения запускаются не последовательно, одно за другим (как в предыдущих версиях), а одновременно, и в процессе прохождения теста осуществляется переключение между ними, что точнее соответствует реальным условиям типичной офисной работы.
2.2.4. Эксплуатационная производительность
Эксплуатационная производительность — производительность компьютера (либо его компонента или подсистемы) при выполнении конкретных приложений. Так, например, если компьютер предполагается использовать преимущественно для решения задач автоматизации проектирования, то целесообразно протестировать его тестами AutoCAD, которые интегрально оценивают производительность ПК на этой нагрузке. Соответственно оценивается производительность тестами С Сomplier (тест компиляции с языка Си), Adobe Photoshop (тест фотоэффектов программы PhotoShop), текстовых процессоров (загрузка, прокрутка, печать документов, поиск/замена фрагментов текста), Quake (игровой тест) и т.д.
В случае систематического использования на компьютере нескольких приложений для оценки эксплуатационной производительности может быть сформирован интегральный показатель на основе определения весовых коэффициентов отдельных приложений.
2.3. Производительность процессоров
Достаточно продолжительное время основной мерой производительности процессоров и компьютеров в целом служила их тактовая частота. Однако по мере усложнения внутренней организации микропроцессоров (кэш-память, конвейерная обработка, суперскалярность, многоядерность и т.д.) этот параметр утратил своё определяющее значение. В настоящее время для оценки производительности процессоров используется ряд специальных единиц.
Для измерения производительности своих 32-разрядных процессоров фирма Intel в 1992 г. предложила следующую единицу: индекс относительной производительности микропроцессоров Intel, называемый iCOMP Index (Intel COmparative Microprocessor Performance Index).
В 1996 г. была введена новая единица — iCOMP Index 2.0, ориентированная на Pentium (MMX) — процессоры. При вычислении этого индекса полностью исключены 16-битные операции и добавлен мультимедийный тест (≈20 %).
Конец ознакомительного фрагмента.
Примечания
2
Данная команда выбирается из оперативной памяти, декодируется и не выполняет никаких действий, в связи с чем имеет минимальное время вполнения.
3
Последняя версия тестового пакета SPEC CPU2006 V 1.2 (2011 г.) вычисляет оценки SPECint2006 и SPECfp2006.
4
Последняя версия пакета Winstone вышла в 2004 г.
Смотрите также
Пиковая производительность процессора
Несмотря на то, что VTune имеет множество встроенных профилей, специального профиля для измерения FLOPS у него пока нет. Но никто не мешает нам создать наш собственный пользовательский профиль за 30 секунд. Не утруждая вас основами работы с интерфейсом VTune (их можно изучить в прилагающимся к нему Getting Started Tutorial), сразу опишу процесс создания профиля и сбора данных.
- Создаем новый проект и указываем в качестве target application наше приложение matrix
. - Выбираем профиль Lightweight Hotspots (который использует технологию сэмплирования счетчиков процессора Hadware Event-based Sampling) и копируем его для создания пользовательского профиля. Обзываем его My FLOPS Analysis.
- Редактируем профиль, добавляем туда новые процессорные счетчики событий процессора Sandy Bridge (Events). На них остановимся чуть подробнее. В их названии зашифрованы исполнительные устройства (x87, SSE, AVX) и тип данных, над которыми выполнялась операция. Каждый такт процессора счетчики складывают количество вычислительных операций, назначенных на исполнение. На всякий случай мы добавили счетчики на все возможные операции с FP:
- FP_COMP_OPS_EXE. SSE_PACKED_DOUBLE – векторы (PACKED) данных двойной точности (DOUBLE)
- FP_COMP_OPS_EXE. SSE_PACKED_SINGLE – векторы данных одинарной точности
- FP_COMP_OPS_EXE. SSE_SCALAR_DOUBLE – скалярые DP
- FP_COMP_OPS_EXE. SSE_ SCALAR _SINGLE – скалярные SP
- SIMD_FP_256.PACKED_DOUBLE – векторы AVX данных DP
- SIMD_FP_256.PACKED_SINGLE – векторы AVX данных SP
- FP_COMP_OPS_EXE.x87 – скалярые данные x87
Нам остается только запустить анализ и подождать результатов. В полученных результатах переключаемся в Hardware Events viewpoint и копируем количетво events, собранных для функции multiply3
: 34,648,000,000.

Далее мы просто подсчитываем значения FLOPS по формулам. Данные у нас были собраны для всех процессоров, поэтому умножение на их количество здесь не требуется. Операции данными двойной точности выполняются одновременно над четырмя 64-битными DP операндами в 256-битном регистре, поэтому умножаем на коэффициент 4. Данные с одинарной точностью, соответственно, умножаем на 8. В последней формуле не умножаем количество инструкций на коэффициент, так как операции сопроцессора x87 выполняются только со скалярными величинами. Если в программе выполняется несколько разных типов FP операций, то их количество, умноженное на коэффициенты, суммируется для получения результирующего FLOPS.
FLOPS = 4 * SIMD_FP_256.PACKED_DOUBLE / Elapsed Time
FLOPS = 8 * SIMD_FP_256.PACKED_SINGLE / Elapsed Time
FLOPS = (FP_COMP_OPS_EXE.x87) / Elapsed Time
В нашей программе выполнялись только AVX инструкции, поэтому в результатах есть значение только одного счетчика SIMD_FP_256.PACKED_DOUBLE.
Удостоверимся, что данные события собраны для нашего цикла в функции multiply3
(переключившись в Source View):

FLOPS = 4 *34.6Gops/7s = 19.7 GFlops
Значение вполне соответствует оценочному, подсчитанному в предыдущем пункте. Поэтому с достаточной долей точности можно говорить о том, что результаты оценочного метода и измерительного совпадают. Однако, существуют случаи, когда они могут не совпадать. При определенном интересе читателей, я могу заняться их исследованием и рассказать, как использовать более сложные и точные методы. А взамен очень хочется услышать о ваших случаях, когда вам требуется измерение FLOPS в программах.
Заключение
FLOPS – единица измерения производительности вычислительных систем, которая характеризует максимальную вычислительную мощность самой системы для операций с плавающей точкой. FLOPS может быть заявлена как теоретическая, для еще не существующих систем, так и измерена с помощью бенчмарков. Разработчики высокопроизводительных программ, в частности, решателей систем линейных дифференциальных уравнений, оценивают производительность реализации своих алгоритмов в том числе и по значению FLOPS программы, вычисленному с помощью теоретически/эмпирически известного количества FP операций, необходимых для выполнения алгоритма, и измеренному времени выполнения теста. Для случаев, когда сложность алгоритма не позволяет оценить количество FP операций алгоритма, их можно измерить с помощью счетчиков производительности, встроенных в микропроцессоры Intel.
Значение, происхождение слова терафлопс. Формула, вычисление производительности компьютера в терафлопсах. Teraflops = tera – греческое слово обозначающее математическую величину 10 в 12 степени (1 000 000 x 1 000 000) + английский акроним flops – fl
oating point o
perations p
er s
econd (с англ. – количество операций над числом с плавающей запятой в секунду).
Терафлопс – терафлоп (TFLOPS – Teraflops) – это величина, значение дающее оценку производительности компьютера, показатель вычислительной мощи компьютера в расчетах с плавающей запятой за секунду. Один Teraflops – Терафлопс равен одному триллиону операций за одну секунду или тысяче миллиардов операций. 1 Терафлопс = 1 000 000 000 000 операций в секунду.
Формула расчета производительности Teraflops.
Расчет пиковой производительности компьютера выполняется по формуле:
1 терафлопс = F x N x I x 10 6 . Где:
F – тактовая частота процессора в MHz,
N – число процессоров (ядер),
I – количество обрабатываемых инструкций за такт,
10 6 = 1 000 000.
Реальная производительность компьютера будет, находится в районе 70-80% от пиковой Терафлопс.
На сегодняшний день самым мощным суперкомпьютером является Cray XT (Jaguar). Его производительность составляет 1 790 терафлопс.
MILKY WAY ONE – Супер Компьютер в Китае. Терафлопсы наступают.
Национальный Университет (с суровыми дядьками) Оборонных Технологий объявил о запуске программы по созданию суперкомпьютера с расчетной мощностью на уровне 1 петафлопса (терафлопс 10 12 flops, петафлопс = 10 15 flops). Китай станет 2 государством, на шарике Земля, с такой «игрушкой». В основе суперкомпьютера – 6144 4-х ядерных CPU Intel — Xeon Quad-Core E5450 (50%) и Xeon Quad-Core E5540 (50%). Добавим сюда 5120 GPU AMD/ ATI в лице 2560 видеокарт ATI Radeon HD 4870 Х2 575МГц.
Суммарная мощность этой гремучей смеси 1,206 петафлопса или 1206 терафлопс (teraflops). Вес супер железяки 155 тонн, занимает помещение площадью 1000 кв. метров. Обойдется Китаю в 88 млн. долларов. Невольно вспомнился Терминатор.
Первой видеокартой (графический процессор), покорившей рубеж производительности в 1 Терафлопс, является ATI Radeon HD 4850.
Самой производительной видеокартой современности (на начало 2010 года) является ATI Radeon HD 5870, с быстродействием 2,72 Teraflops (Терафлопс).
Власть меняется. К лету 2010 компания Asus выпускает сдвоенную видеокарту Asus Ares Radeon HD 5870 x2. Тандем двух полноценных Radeon HD5870 развивают мощность 5,44 терафлопс. Видео карта Asus ARES/2DIS/4GD5 — .
Teraflops — максимальное, пиковое значение производительности процессора — терафлопс
. Вычисляем производительность в терафлопсах.
С наилучшими $ пожеланиями
Denker.
С тех самых времён, когда появился самый первый компьютер (его подобие), началась погоня за мозностями, производительностью и в наши дни по прежднему ничего в этом плане не изменилось, ведь каждый владелец персонального компьютера чья работа связана с нагрузкой на вычислительные мощности ПК мечтает о ещё более производительном железе.
Все компьютеры которые существуют разделяются на несколько категорий, начиная от микрочипов и заканчивая суперкомпьютерами, которые потребляют десятки киловатт электроэнергии и являются топовыми в вычислительных можностях. В этом материале вы узнаете как можно измерить производительность персонального компьютера.
С самых ранних пор для того чтобы измерять производительность того или иного компьютера, решили использовать количество выполняемых операций с плавающей точкой за 1 секунду времени. На практике это оказалось действительно весьма показательным результатом. Единицу измерения 1 операции назвали Flops (Флопс). Однако компьютеры являются весьма производительными устройствами, поэтому перед флопс используется приставка кило/мега/Гига/Пета/Экса и тд. Каждая перечисленная операция больше предыдущей в 1000 раз. Для конечной оценки выдаются результаты Флопс/с, т.е. флопс в секунду. Если вы хотите почитать про Flops больше, то вам сюда .
Замер производительности персонального ПК
Существует немало инструментов для того чтобы измерить производительность во флопсах персонального компьютера или ноутбука. Однако все инструменты основаны на одном и том же принципе работы.
Из возможных интерфейсов есть анализ производительности через командную строку, через компиляторы Фортран и С++ и тд. Но мы пойдём более лёгким путём и будем использовать уже скомпилированный exe файл программв Linpack, которая является самой популярной в замерах производительности компьютеров на Windows.
Ниже мы представляем вашему вниманию 2 версии программы Linpack, которая поможет вам определить сколько ваш компьютер делает операций с плавающей точкой в секунду времени.
Как проверить?
Сначала распакуйте архив и запустите программу (файл LinX.exe). Интерфейс программы очень прост и вы легко с ним разберётесь. Для начала зайдите в настройки и дайте пргграмме самый высокий приоритет. После этого постарайтесь выключить ресурсоёмие программы. В интерфейсе LinX вы можете выбрать сколько раз или минут проводить тест и каким объёмом данных орудовать во время его проведения. Когда все настройки выставлены – жмите Тест
. После завершения вы скорее всего увидите результат в GFlops/s (Гигафлопсов в секунду).
Для того чтобы представлять сколько это: 1 Флопс=1 Операция с плавающей точкой; 1ГФлопс= 1 000 000 000 Операций с плавающей точкой.
