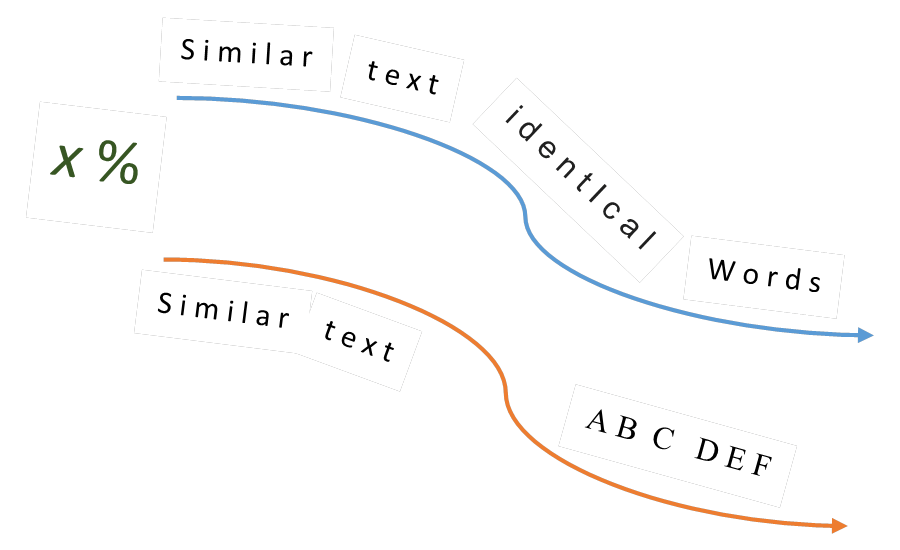
Один из вариантов поиска похожих статей в базе данных основан на схождении слов в двух текстах.
Данный алгоритм не обладает точным результатом, но позволяет выявить явные дубли.
Для поиска понадобится функция, которая очистит текст от html-кода, лишних слов и вернёт массив слов.
function get_minification_array($text)
{
// Удаление экранированных спецсимволов
$text = stripslashes($text);
// Преобразование мнемоник
$text = html_entity_decode($text);
$text = htmlspecialchars_decode($text, ENT_QUOTES);
// Удаление html тегов
$text = strip_tags($text);
// Все в нижний регистр
$text = mb_strtolower($text);
// Удаление лишних символов
$text = str_ireplace('ё', 'е', $text);
$text = mb_eregi_replace("[^a-zа-яй0-9 ]", ' ', $text);
// Удаление двойных пробелов
$text = mb_ereg_replace('[ ]+', ' ', $text);
// Преобразование текста в массив
$words = explode(' ', $text);
// Удаление дубликатов
$words = array_unique($words);
// Удаление предлогов и союзов
$array = array(
'без', 'близ', 'в', 'во', 'вместо', 'вне', 'для', 'до',
'за', 'и', 'из', 'изо', 'из', 'за', 'под', 'к',
'ко', 'кроме', 'между', 'на', 'над', 'о', 'об', 'обо',
'от', 'ото', 'перед', 'передо', 'пред', 'предо', 'по', 'под',
'подо', 'при', 'про', 'ради', 'с', 'со', 'сквозь', 'среди',
'у', 'через', 'но', 'или', 'по'
);
$words = array_diff($words, $array);
// Удаление пустых значений в массиве
$words = array_diff($words, array(''));
return $words;
}PHP
Пример работы функции:
$array = get_minification_array('
<p>Сегодня существует огромное множество разнообразных диет,
отличающихся степенью строгости и результатами, которых с их
помощью добиваются худеющие. Существует одна эффективная диета
творог + яблоки, которая позволит легко скинуть 4 кг за 4 дня.</p>
');
print_r($array);PHP
Результат:
Array
(
[0] => сегодня
[1] => существует
[2] => огромное
[3] => множество
[4] => разнообразных
[5] => диет
[6] => отличающихся
[7] => степенью
[8] => строгости
[10] => результатами
[11] => которых
[13] => их
[14] => помощью
[15] => добиваются
[16] => худеющие
[18] => одна
[19] => эффективная
[20] => диета
[21] => творог
[22] => яблоки
[23] => которая
[24] => позволит
[25] => легко
[26] => скинуть
[27] => 4
[28] => кг
[31] => дня
)Для более точного результата можно удалить из текста все стоп-слова.
Теперь, нужно получить проверяемую статью и сверить с остальными. В примере используется таблица `articles`, с полями `id`, `name`, `text`:
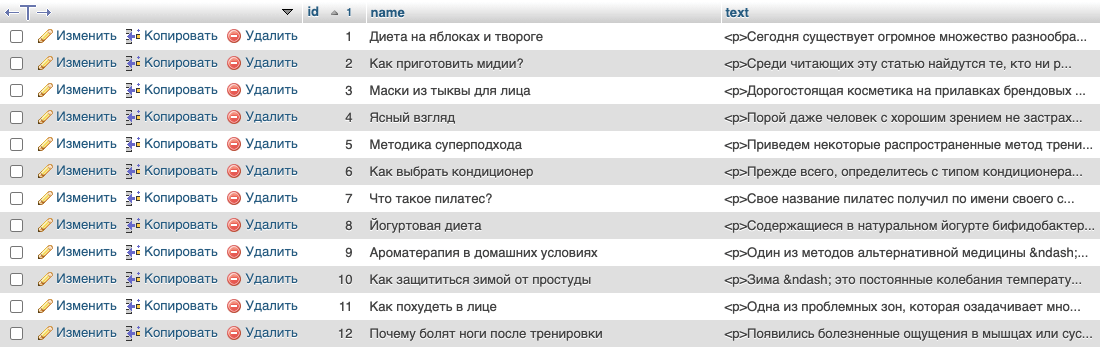
Поиск будет осуществляется для статьи `id` = 1, причём для теста в базе есть копия этой статьи с немного измененным текстом.
// Подключение к БД
$dbh = new PDO('mysql:dbname=db_name;host=localhost', 'логин', 'пароль');
// Получаем статью
$sth = $dbh->prepare("SELECT * FROM `articles` WHERE `id` = 1");
$sth->execute(array());
$article = $sth->fetch(PDO::FETCH_ASSOC);
// Получаем для неё массив слов
$text = get_minification_array($article['name'] . ' ' . $article['text']);
$count = count($text);
$out = array();
// Проход по всем статьям в таблице
$sth = $dbh->prepare("SELECT * FROM `articles`");
$sth->execute();
$list = $sth->fetchAll(PDO::FETCH_ASSOC);
foreach($list as $row) {
$verifiable = get_minification_array($row['name'] . ' ' . $row['text']);
$similar_counter = 0;
foreach ($text as $text_row) {
foreach ($verifiable as $verifiable_row){
if($text_row == $verifiable_row) {
$similar_counter++;
break;
}
}
}
$out[$row['name']] = $similar_counter * 100 / $count;
}
// Сортировка результатов и ограничение до 15шт
arsort($out);
$out = array_slice($out, 0, 15, true);
print_r($out);PHP
Результат поиска:
Array
(
[Диета на яблоках и твороге] => 100
[Диета на яблоках и твороге (test)] => 97,368421052632
[Диета Ларисы Гузеевой] => 21,052631578947
[Как похудеть в лице] => 19,736842105263
[Соевый соус: польза и вред] => 17,105263157895
[Сырная диета] => 14,473684210526
[Какую обувь выбрать для сильных морозов?] => 13,157894736842
[Какие мышцы работают на эллиптическом тренажере?] => 10,526315789474
[Боль в коленном суставе при нагрузке] => 9,2105263157895
[Польза и вред дыни для организма человека] => 9,2105263157895
[Разгрузочная диета после праздников] => 9,2105263157895
[Вредно ли загорать на солнце?] => 7,8947368421053
[Йогуртовая диета] => 7,8947368421053
[Как стирать пуховое одеяло?] => 7,8947368421053
[Какие витамины в укропе] => 6,5789473684211
)В результате видно, что статья схожа сама с собой на 100%, с тестовой статьей на 97%, с остальными не более 21%.
Не забудьте ознакомиться с правилами и условиями модерирования сообщений данной темы.
Вы прочитали книгу и хотите прочитать другие, похожие по сюжету. Оставляйте тут подобные запросы с названием прочитанной книги или именем понравившегося автора.
Но, прежде чем сделать запрос, попробуйте самостоятельно поискать, давали ли уже рекомендации на ту же книгу.
1. Внизу темы есть кнопка Поиск по сообщениям . Нажмите и введите в окно поиска название своей книги. Если будут найдены сообщения с этой книгой, нажимайте кнопку Перейти на форум и увидите, есть ли там рекомендации.
2. Посмотрите форум Посоветуйте книги и авторов . Возможно, там уже есть тема, название которой отражает сюжет вашей книги. Или тоже воспользуйтесь кнопкой Поиск по сообщениям внизу страницы форума. Инструкция
3. На страницах описания книг слева есть столбец Похожие книги . Часто там выдаются случайные книги из того же жанра. Но могут быть и уже закрепленные книги, которые кто-то из читателей сознательно пометил как похожие. Обновите пару раз страницу и если увидите, что некоторые книги не меняются, это и есть похожие.
Просьба к зарегистрированным читателям! Используя рекомендации в данной теме, каждый из вас может поучаствовать в улучшении сервисов ЛитЛайф, добавляя ID похожих книг на страницах описания книг и голосуя кнопками похожа и не похожа . Инструкция.
Благодарим всех, кто помогает с рекомендациями и отмечает похожие книги!

Время прочтения: 9 мин.
«Досмотрю вот это видео на YouTube и пойду спать! Ой, в рекомендациях еще одно интересное. Сон, прости…». «Закажу в IKEA только стулья. Ах, сайт показал мне еще посуду, постельное белье и новую кухню в сборке. Когда там следующая зарплата?». «Бесконечный плейлист любимых музыкальных жанров в СберЗвуке заряжает меня позитивом! Как специалистам удается создавать выборку специально для меня?».
Согласитесь, вы сталкивались с подобными мыслями при использовании интернет сервисов. Магическим образом пользователю предлагают новые и новые объекты: видеоролики, музыку, товары. Никакого волшебства здесь нет — это рутинная работа рекомендательных систем. Алгоритмы поиска похожих объектов в больших массивах данных органично вплелись в нашу жизнь и помогают нам делать почти осознанный выбор в той или иной области повседневных дел.
Модели рекомендаций можно использовать для поиска похожих объектов вне контекста продаж. Например, выявлять однообразные ответы операторов в чатах, распознавать будущих злостных неплательщиков кредитных обязательств по косвенным признакам или находить различные группы сотрудников, которым требуется рекомендовать курсы повышения квалификации, в зависимости от текущих навыков. Не стоит забывать и о сайтах знакомств, где рекомендательные алгоритмы будут подбирать собеседника по указанным критериям.
TL:DR
Статья описывает основные подходы к поиску схожих объектов в наборе данных и содержит вводный курс в мир рекомендательных систем. Представлены варианты подготовки данных. Информация будет полезна аналитикам, которые изучают python, и начинающим data-scientist’ам. Мы не будем останавливаться на подробном описании каждого метода и разбирать отличия контентных и коллаборативных рекомендательных систем. Базовая теоретических часть находится здесь, здесь и здесь. Нас интересует применение алгоритмов матчинга (matching, англ. Поиск схожих объектов) в повседневных задачах. К статье прилагается ноутбук на платформе Kaggle с основным кодом, который рекомендуем запускать одновременно с изучением текста.
Коэффициенты корреляции
Самым простым способом вычисления схожести объектов по числовым характеристикам является расчет коэффициента корреляции. Этот метод работает в большинстве повседневных задач, когда у каждого объекта исследования присутствует одинаковый набор метрик. Такая последовательность числовых характеристик называется вектор. Например, мы ищем похожие квартиры в городе: можно банально сравнивать общую и жилые площади, высоту потолков и количество комнат. Для разбора кода возьмем датасет (dataset, англ. Набор данных), в котором содержится информация об объектах недвижимости Сиднея и Мельбурна. Каждая строка таблицы – это отдельный вектор с числовыми характеристиками.

Схожесть характеристик можно рассчитать несколькими способами. Если вы работаете с табличными данными – pandas.corr() является самым удобным. Сравним три объекта, выставленных на продажу.
>>> df_10.loc[0].corr(df_10.loc[9]), df_10.loc[0].corr(df_10.loc[6])
(0.9927410539735818, 0.8090015299374259)
Мы рассчитали схожесть двух пар объектов: нулевого с девятым и нулевого с шестым. Посмотрите на рисунок выше. Действительно, дома в первой паре подобны по характеристикам. У второй пары объектов заметно различаются общая площадь, год постройки и ренновации, количество спален.
По умолчанию pandas.corr() рассчитывает коэффициент корреляции Пирсона. Его можно сменить на метод Спирмена или Кендала. Для этого нужно ввести аттрибут method.
>>> df_10.loc[0].corr(df_10.loc[9], method='spearman')
>>> df_10.loc[0].corr(df_10.loc[6], method='kendall')
0.9976717081331427
0.7013664474559794
Для обработки нескольких строк можно создать матрицу корреляции, в которой будут отражены сразу все объекты, находящиеся в датасете. По опыту работы замечу, что метод визуализации хорошо работает с выборками до 100 строк. Далее график становится слабо читаемым. Тепловую матрицу можно рисовать с помощью специализированных библиотек или применить метод style.background_gradient() к таблице. Создадим матрицу корреляции с 10 записями. Чем темнее цвет ячейки – тем выше корреляция.
>>> df_10.T.corr().style.background_gradient(cmap='YlOrBr')
Метод pandas.corr() сравнивает таблицу по столбцам. Обратите внимание, что для правильного рассчета корреляций между объектами недвижимости, исходную таблицу необходимо транспонировать — повернуть на 90*. Для этого применяется метод dataframe.T.
Сравнивать объекты парами интересно, но непродуктивно. Попробуем написать небольшую рекомендательную систему, которая подберет 10 объектов недвижимости, которые максимально похожи на образцовый. За эталон примем случайный дом, например, с порядковым номером 574.
# создаем матрицу корреляции для всей таблицы, выбираем столбец со значениями корреляции для образца.
# сортируем коэффициенты по убыванию и выбираем лучшие одиннадцать значений. Первая запись равна единице - это строка образца.
# сохраняем индексы лучших совпадений и выбираем эти строки из общей таблицы.
>>> obj = df.loc[574]
>>> corrs = df.T.corr()[idx].sort_values(ascending=False)[:11].rename('corrs')
>>> df_res = df.query('index in @corrs.index')
# присоединяем значения рассчитанных коэффициентов к результатам и сортируем их в порядке убывания
>>> df_res = df_res.join(corrs)
>>> df_res.sort_values('corrs', ascending=False)

Алгоритм отобрал 10 наиболее похожих на образец домов. Все представленные объекты недвижимости имеют одинакое количество спален и ванных комнат, примерно равные жилые и общие площади, и занимают только один этаж. В дополнении на Kaggle представлен второй вариант решения задачи, который последовательно перебирает все строки таблицы.
Метод pandas.corr() может сравнивать векторы (объекты), у которых отсутствуют некоторые значения. Это свойство удобно применять, когда нет времени или смысла искать варианты заполнения пропусков.
>>> x = pd.Series([1,2,3,4,5])
>>> y = pd.Series([np.nan, np.nan,5,6,6])
>>> print(x.corr(y))
0.8660254037844385
Косинусное расстояние
Эту метрику схожести объектов в математике обычно относят к методам расчета корреляции и рассматривают вместе с коэффициентами корреляции. Мы выделили ее в отдельный пункт, так как схожесть векторов по косинусу помогаем в решении задач обработки естественного языка. Например, с помощью данного алгоритма можно находить и предлагать пользователю похожие новости. Косинусное расстояние так же часто называют конисусной схожестью, диапазон значений метрики лежит в пределах от 0 до 1.
Разберем простейший алгоритм поиска похожих текстов и начнем с предобработки. В статье приведем некоторые моменты, полный код находится здесь. Для расчета косинусного расстояния необходимо перевести слова в числа. Применим алгоритм токенизации. Для понимания этого термина представьте себе словарь, в котором каждому слову приставлен порядковый номер. Например: азбука – 1348, арбуз – 1349. В процессе токенизации заменяем слова нужными числами. Есть более современный и более удачный метод превращения текста в числовой вектор — создание эмбеддингов с помощью моделей-трансформеров. Не углубляясь в тему трансформаций, отметим, что в этом случае каждое предложение предложение преврящается в числовой вектор длиной до 512 символов. При этом числа отражают взаимодействие слов друг с другом. Звучит, как черная магия, но здесь работает чистая алгебра. Советуем ознакомиться с базовой теорией о трансформерах, эмбеддингах и механизме «внимания» здесь и здесь.
В процессе преобразования новостных статей в токены и эмбеддинги получаем следующие результаты.
Исходное предложение
'рынок европы начал рекордно восстанавливаться'
Токенизированное предложение (числа 101 и 102 обозначают начало и конец фразы)
[101, 18912, 60836, 880, 4051, 76481, 101355, 102]
Первые пять значений эмбеддинга предложения
array([-0.29139647, 0.10100818, -0.05670362, 0.05141545, 0.29009324], dtype=float32)
После векторизации текста можно сравнивать схожесть заголовков. Рассмотрим работу метода cosine_similarityиз библиотеки sklearn. Выведем два заголовка и узнаем, насколько они похожи.
>>> print(df_news.loc[17, 'title'])
>>> print(df_news.loc[420, 'title'])
>>> from sklearn.metrics.pairwise import cosine_similarity
>>> cosine_similarity(embeddings[417], embeddings[420])
Samsung выпустила смартфон с рекордной батареей
«Ювентус» уволил главного тренера после вылета из Лиги чемпионов
array([[0.23828188]], dtype=float32)
Новости из мира техники и футбола далеки друг от друга. Косинусная схожесть равна 0.24%. Действительно, южнокорейский IT гигант и туринский футбольный клуб идейно практически не пересекаются.
Вернемся к первичной задаче раздела – поиску схожих статей для пользователя новостного сайта. Рассчитываем косинусное расстояние между векторизированными заголовками и показываем те, где коэффициент максимальный. В результате для новости под индексом 18 получаем следующие рекомендации.

С высокой вероятностью пользователю, прочитавшему про восстанавливающийся рынок Европы будет интересно узнать про мировой кризис, рост цен и проблемы с валютой в азиатском регионе. Задача выполнена, переходим к заключительному алгоритму поиска схожих объектов.
Кластеризация
Третьим эффективным методом матчинга в большом объеме данных является кластеризация. Алгоритм разделяет записи по установленному количеству групп – кластеров. Задача кластеризации сводится к поиску идеального расположения центров групп — центроидов. Так, чтобы эти центры как бы группировали вокруг себя определенные объекты. Дистанция объекта от центра кластера рассчитывается целевой функцией. Подробнее о ней рекомендуем прочитать здесь. Алгоритм кластеризации представлен фукцией kMeans (англ, к-Средних) библиотеки sklearn.
Для примера алгоритма кластеризации возьмем 300 домов из первичного датасета с австралийской недвижимостью.
df_300 = df[:300]Первый шаг метода – поиск оптимального количества кластеров. Последовательно перебираем группы в диапазоне от 1 до 20 и рассчитываем значение целевой функции.
distortion = []
K = range(1, 20)
# последовательно рассчитываем значения целевой функции по всем объектам с разным
# количеством кластеров
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42) # определяем модель kMeans
kmeans.fit(df_300) # применяем модель kMeans к выборке
distortion.append(kmeans.inertia_)
Отрисовываем значения целевой функции, получаем, так называемый, «локтевой график». Нас интересует точка, в которой происходит самый сильный изгиб. На рисунке 5 представлен искомый узел. При увеличении числа кластеров больше 4, значительного улучшения целевой функции не происходит.

Заново обучаем модель kMeans с необходимым числом кластеров. Для каждого объекта устанавливаем причастность к группе и сохраняем ее номер. Выбираем объекты одной группы.
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(df_300)
df_300['label'] = kmeans.labels_ # присваиваем каждому объекту номер его группы
Посмотрим на количество домов в группах.
>>> df_300['label'].value_counts()
0 267
3 22
1 8
2 3
«Нулевая» группа самая многочисленная и содержит типовые дома. В группы «один» и «два» попали объекты с громадной жилой площадью (столбец sqft_lot). Выборки представлены на рисунке 6.

Задача группировки объектов недвижимости с помощью алгоритма kMeans выполнена. Переходим к итогам.
Заключение
Мы рассмотрели три метода поиска схожих объектов в данных: коэффициенты корреляции, косинусное расстояние и метод k-средних. С помощью представленных инструментов можно решить большинство повседневных задач: найти схожие объекты с числовыми характеристиками, обработать текстовые записи или разбить массив данных на кластеры. Мы изучили основы матчинга и рекомендательных алгоритмов. В заключение отметим, что самые современные системы YouTube и TikTok в своей основе используют комбинации и улучшения указанных методов. Как видите, никакой магии в подборе любимых песен и роликов. Только чистая математика!
It depends upon your definition of similiar.
The edit-distance algorithm is the standard algorithm for (latin language) dictionary suggestions, and can work on whole texts. Two texts are similiar if they have basically the same words (eh letters) in the same order. So the following two book reviews would be fairly similiar:
1) “This is a great book”
2) “These are not great books”
(The number of letters to remove, insert, delete or alter to turn (2) into (1) is termed the ‘edit distance’.)
To implement this you would want to visit every review programmatically. This is perhaps not as costly as it sounds, and if it is too costly you could do the comparisions as a background task and store the n-most-similiar in a database field itself.
Another approach is to understand something of the structure of (latin) languages. If you strip short (non-capitialised or quoted) words, and assign weights to words (or prefixes) that are common or unique, you can do a Bayesianesque comparision. The two following book reviews might be simiplied and found to be similiar:
3) “The french revolution was blah blah War and Peace blah blah France.” -> France/French(2) Revolution(1) War(1) Peace(1) (note that a dictionary has been used to combine France and French)
4) “This book is blah blah a revolution in french cuisine.” -> France(1) Revolution(1)
To implement this you would want to identify the ‘keywords’ in a review when it was created/updated, and to find similiar reviews use these keywords in the where-clause of a query (ideally ‘full text’ searching if the database supports it), with perhaps a post-processing of the results-set for scoring the candidates found.
Books also have categories – are thrillers set in France similiar to historical studies of France, and so on? Meta-data beyond title and text might be useful for keeping results relevant.
Подобное делал для поиска цен из стима на игры из моей базы.
Для этого написал функцию, которая сравнивает приводя к одной форме полученные строки:
- В нижний регистр
- Удаление постфикса (необходимость из-за стандарта названий игр в базе)
- Удаление символов кроме буквенных, цифр и
_
Например, в функцию передаются строки The Witcher 3: Wild Hunt и The Witcher® 3: Wild Hunt. После обработки эти строку станут thewitcher3wildhunt.
Пример:
def smart_comparing_names(name_1, name_2):
"""
Функция для сравнивания двух названий игр.
Возвращает True, если совпадают, иначе -- False.
"""
# Приведение строк к одному регистру
name_1 = name_1.lower()
name_2 = name_2.lower()
def remove_postfix(text, postfix='(dlc)'):
if text.endswith(postfix):
text = text[:-len(postfix)]
return text
def clear_name(name):
import re
return re.sub(r'W', '', name)
name_1 = remove_postfix(name_1)
name_2 = remove_postfix(name_2)
return clear_name(name_1) == clear_name(name_2)
# Пример функции поиска цены для игры
def get_price(game):
game_price = None
# Пример спарсенного списка игр из стима по предварительному запросу
steam_games = [
('The Witcher® 3: Wild Hunt', 1199),
('Call of Cthulhu®: Dark Corners of the Earth', 199),
('South Park™: The Stick of Truth™', 1499),
('Dishonored®: Death of the Outsider™', 859),
('Dishonored - The Knife of Dunwall', 199),
('Dishonored: The Brigmore Witches', 199),
]
# Сначала пытаемся найти игру по полному совпадению
for name, price in steam_games:
if game == name:
game_price = price
break
# Если по полному совпадению на нашли, пытаемся найти предварительно очищая названия игр
# от лишних символов
if game_price is None:
for name, price in steam_games:
# Если нашли игру, запоминаем цену и прерываем сравнение с другими найденными играми
if smart_comparing_names(game, name):
game_price = price
break
return game_price
my_games = [
'The Witcher 3: Wild Hunt',
'Call of Cthulhu: Dark Corners of the Earth',
'South Park: The Stick of Truth',
'Dishonored: Death of the Outsider',
'Dishonored: The Knife of Dunwall (DLC)',
'Dishonored: The Brigmore Witches (DLC)',
]
for game in my_games:
print('{:44} -> {}'.format(game, get_price(game)))
Результат:
The Witcher 3: Wild Hunt -> 1199
Call of Cthulhu: Dark Corners of the Earth -> 199
South Park: The Stick of Truth -> 1499
Dishonored: Death of the Outsider -> 859
Dishonored: The Knife of Dunwall (DLC) -> 199
Dishonored: The Brigmore Witches (DLC) -> 199
PS. конечно не всегда это работало, но в этом случае руками искалась цена для игры.
