Подобное делал для поиска цен из стима на игры из моей базы.
Для этого написал функцию, которая сравнивает приводя к одной форме полученные строки:
- В нижний регистр
- Удаление постфикса (необходимость из-за стандарта названий игр в базе)
- Удаление символов кроме буквенных, цифр и
_
Например, в функцию передаются строки The Witcher 3: Wild Hunt и The Witcher® 3: Wild Hunt. После обработки эти строку станут thewitcher3wildhunt.
Пример:
def smart_comparing_names(name_1, name_2):
"""
Функция для сравнивания двух названий игр.
Возвращает True, если совпадают, иначе -- False.
"""
# Приведение строк к одному регистру
name_1 = name_1.lower()
name_2 = name_2.lower()
def remove_postfix(text, postfix='(dlc)'):
if text.endswith(postfix):
text = text[:-len(postfix)]
return text
def clear_name(name):
import re
return re.sub(r'W', '', name)
name_1 = remove_postfix(name_1)
name_2 = remove_postfix(name_2)
return clear_name(name_1) == clear_name(name_2)
# Пример функции поиска цены для игры
def get_price(game):
game_price = None
# Пример спарсенного списка игр из стима по предварительному запросу
steam_games = [
('The Witcher® 3: Wild Hunt', 1199),
('Call of Cthulhu®: Dark Corners of the Earth', 199),
('South Park™: The Stick of Truth™', 1499),
('Dishonored®: Death of the Outsider™', 859),
('Dishonored - The Knife of Dunwall', 199),
('Dishonored: The Brigmore Witches', 199),
]
# Сначала пытаемся найти игру по полному совпадению
for name, price in steam_games:
if game == name:
game_price = price
break
# Если по полному совпадению на нашли, пытаемся найти предварительно очищая названия игр
# от лишних символов
if game_price is None:
for name, price in steam_games:
# Если нашли игру, запоминаем цену и прерываем сравнение с другими найденными играми
if smart_comparing_names(game, name):
game_price = price
break
return game_price
my_games = [
'The Witcher 3: Wild Hunt',
'Call of Cthulhu: Dark Corners of the Earth',
'South Park: The Stick of Truth',
'Dishonored: Death of the Outsider',
'Dishonored: The Knife of Dunwall (DLC)',
'Dishonored: The Brigmore Witches (DLC)',
]
for game in my_games:
print('{:44} -> {}'.format(game, get_price(game)))
Результат:
The Witcher 3: Wild Hunt -> 1199
Call of Cthulhu: Dark Corners of the Earth -> 199
South Park: The Stick of Truth -> 1499
Dishonored: Death of the Outsider -> 859
Dishonored: The Knife of Dunwall (DLC) -> 199
Dishonored: The Brigmore Witches (DLC) -> 199
PS. конечно не всегда это работало, но в этом случае руками искалась цена для игры.
How do I get the probability of a string being similar to another string in Python?
I want to get a decimal value like 0.9 (meaning 90%) etc. Preferably with standard Python and library.
e.g.
similar("Apple","Appel") #would have a high prob.
similar("Apple","Mango") #would have a lower prob.
![]()
smci
32k19 gold badges113 silver badges146 bronze badges
asked Jun 30, 2013 at 7:35
![]()
5
There is a built in.
from difflib import SequenceMatcher
def similar(a, b):
return SequenceMatcher(None, a, b).ratio()
Using it:
>>> similar("Apple","Appel")
0.8
>>> similar("Apple","Mango")
0.0
answered Jun 30, 2013 at 8:18
![]()
Inbar RoseInbar Rose
41.3k24 gold badges83 silver badges130 bronze badges
7
Solution #1: Python builtin
use SequenceMatcher from difflib
pros:
native python library, no need extra package.
cons: too limited, there are so many other good algorithms for string similarity out there.
example :
>>> from difflib import SequenceMatcher
>>> s = SequenceMatcher(None, "abcd", "bcde")
>>> s.ratio()
0.75
Solution #2: jellyfish library
its a very good library with good coverage and few issues.
it supports:
– Levenshtein Distance
– Damerau-Levenshtein Distance
– Jaro Distance
– Jaro-Winkler Distance
– Match Rating Approach Comparison
– Hamming Distance
pros:
easy to use, gamut of supported algorithms, tested.
cons: not native library.
example:
>>> import jellyfish
>>> jellyfish.levenshtein_distance(u'jellyfish', u'smellyfish')
2
>>> jellyfish.jaro_distance(u'jellyfish', u'smellyfish')
0.89629629629629637
>>> jellyfish.damerau_levenshtein_distance(u'jellyfish', u'jellyfihs')
1
answered Sep 8, 2017 at 22:49
![]()
Iman MirzadehIman Mirzadeh
12.5k2 gold badges40 silver badges44 bronze badges
1
TheFuzz is a package that implements Levenshtein distance in python, with some helper functions to help in certain situations where you may want two distinct strings to be considered identical. For example:
>>> fuzz.ratio("fuzzy wuzzy was a bear", "wuzzy fuzzy was a bear")
91
>>> fuzz.token_sort_ratio("fuzzy wuzzy was a bear", "wuzzy fuzzy was a bear")
100
answered Jan 18, 2017 at 22:26
![]()
BLTBLT
2,4821 gold badge23 silver badges33 bronze badges
3
You can create a function like:
def similar(w1, w2):
w1 = w1 + ' ' * (len(w2) - len(w1))
w2 = w2 + ' ' * (len(w1) - len(w2))
return sum(1 if i == j else 0 for i, j in zip(w1, w2)) / float(len(w1))
![]()
answered Jun 30, 2013 at 7:41
![]()
3
Note, difflib.SequenceMatcher only finds the longest contiguous matching subsequence, this is often not what is desired, for example:
>>> a1 = "Apple"
>>> a2 = "Appel"
>>> a1 *= 50
>>> a2 *= 50
>>> SequenceMatcher(None, a1, a2).ratio()
0.012 # very low
>>> SequenceMatcher(None, a1, a2).get_matching_blocks()
[Match(a=0, b=0, size=3), Match(a=250, b=250, size=0)] # only the first block is recorded
Finding the similarity between two strings is closely related to the concept of pairwise sequence alignment in bioinformatics. There are many dedicated libraries for this including biopython. This example implements the Needleman Wunsch algorithm:
>>> from Bio.Align import PairwiseAligner
>>> aligner = PairwiseAligner()
>>> aligner.score(a1, a2)
200.0
>>> aligner.algorithm
'Needleman-Wunsch'
Using biopython or another bioinformatics package is more flexible than any part of the python standard library since many different scoring schemes and algorithms are available. Also, you can actually get the matching sequences to visualise what is happening:
>>> alignment = next(aligner.align(a1, a2))
>>> alignment.score
200.0
>>> print(alignment)
Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-Apple-
|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-|||-|-
App-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-elApp-el
answered Dec 4, 2019 at 9:36
![]()
Chris_RandsChris_Rands
38.4k13 gold badges82 silver badges116 bronze badges
Package distance includes Levenshtein distance:
import distance
distance.levenshtein("lenvestein", "levenshtein")
# 3
answered Apr 10, 2017 at 22:02
![]()
You can find most of the text similarity methods and how they are calculated under this link: https://github.com/luozhouyang/python-string-similarity#python-string-similarity
Here some examples;
-
Normalized, metric, similarity and distance
-
(Normalized) similarity and distance
-
Metric distances
- Shingles (n-gram) based similarity and distance
- Levenshtein
- Normalized Levenshtein
- Weighted Levenshtein
- Damerau-Levenshtein
- Optimal String Alignment
- Jaro-Winkler
- Longest Common Subsequence
- Metric Longest Common Subsequence
- N-Gram
- Shingle(n-gram) based algorithms
- Q-Gram
- Cosine similarity
- Jaccard index
- Sorensen-Dice coefficient
- Overlap coefficient (i.e.,Szymkiewicz-Simpson)
answered Apr 9, 2020 at 14:38
![]()
MikeMike
1751 silver badge8 bronze badges
BLEUscore
BLEU, or the Bilingual Evaluation Understudy, is a score for comparing
a candidate translation of text to one or more reference translations.A perfect match results in a score of 1.0, whereas a perfect mismatch
results in a score of 0.0.Although developed for translation, it can be used to evaluate text
generated for a suite of natural language processing tasks.
Code:
import nltk
from nltk.translate import bleu
from nltk.translate.bleu_score import SmoothingFunction
smoothie = SmoothingFunction().method4
C1='Text'
C2='Best'
print('BLEUscore:',bleu([C1], C2, smoothing_function=smoothie))
Examples: By updating C1 and C2.
C1='Test' C2='Test'
BLEUscore: 1.0
C1='Test' C2='Best'
BLEUscore: 0.2326589746035907
C1='Test' C2='Text'
BLEUscore: 0.2866227639866161
You can also compare sentence similarity:
C1='It is tough.' C2='It is rough.'
BLEUscore: 0.7348889200874658
C1='It is tough.' C2='It is tough.'
BLEUscore: 1.0
answered Feb 15, 2021 at 11:53
![]()
Reema Q KhanReema Q Khan
8781 gold badge7 silver badges20 bronze badges
The builtin SequenceMatcher is very slow on large input, here’s how it can be done with diff-match-patch:
from diff_match_patch import diff_match_patch
def compute_similarity_and_diff(text1, text2):
dmp = diff_match_patch()
dmp.Diff_Timeout = 0.0
diff = dmp.diff_main(text1, text2, False)
# similarity
common_text = sum([len(txt) for op, txt in diff if op == 0])
text_length = max(len(text1), len(text2))
sim = common_text / text_length
return sim, diff
answered Apr 30, 2018 at 14:24
![]()
damiodamio
5,9813 gold badges39 silver badges57 bronze badges
Textdistance:
TextDistance – python library for comparing distance between two or more sequences by many algorithms. It has Textdistance
- 30+ algorithms
- Pure python implementation
- Simple usage
- More than two sequences comparing
- Some algorithms have more than one implementation in one class.
- Optional numpy usage for maximum speed.
Example1:
import textdistance
textdistance.hamming('test', 'text')
Output:
1
Example2:
import textdistance
textdistance.hamming.normalized_similarity('test', 'text')
Output:
0.75
Thanks and Cheers!!!
answered Oct 19, 2020 at 19:38
![]()
DRVDRV
6241 gold badge8 silver badges21 bronze badges
There are many metrics to define similarity and distance between strings as mentioned above. I will give my 5 cents by showing an example of Jaccard similarity with Q-Grams and an example with edit distance.
The libraries
from nltk.metrics.distance import jaccard_distance
from nltk.util import ngrams
from nltk.metrics.distance import edit_distance
Jaccard Similarity
1-jaccard_distance(set(ngrams('Apple', 2)), set(ngrams('Appel', 2)))
and we get:
0.33333333333333337
And for the Apple and Mango
1-jaccard_distance(set(ngrams('Apple', 2)), set(ngrams('Mango', 2)))
and we get:
0.0
Edit Distance
edit_distance('Apple', 'Appel')
and we get:
2
And finally,
edit_distance('Apple', 'Mango')
and we get:
5
Cosine Similarity on Q-Grams (q=2)
Another solution is to work with the textdistance library. I will provide an example of Cosine Similarity
import textdistance
1-textdistance.Cosine(qval=2).distance('Apple', 'Appel')
and we get:
0.5
answered Sep 10, 2020 at 22:48
![]()
George PipisGeorge Pipis
1,37215 silver badges10 bronze badges
Adding the Spacy NLP library also to the mix;
@profile
def main():
str1= "Mar 31 09:08:41 The world is beautiful"
str2= "Mar 31 19:08:42 Beautiful is the world"
print("NLP Similarity=",nlp(str1).similarity(nlp(str2)))
print("Diff lib similarity",SequenceMatcher(None, str1, str2).ratio())
print("Jellyfish lib similarity",jellyfish.jaro_distance(str1, str2))
if __name__ == '__main__':
#python3 -m spacy download en_core_web_sm
#nlp = spacy.load("en_core_web_sm")
nlp = spacy.load("en_core_web_md")
main()
Run with Robert Kern’s line_profiler
kernprof -l -v ./python/loganalysis/testspacy.py
NLP Similarity= 0.9999999821467294
Diff lib similarity 0.5897435897435898
Jellyfish lib similarity 0.8561253561253562
However the time’s are revealing
Function: main at line 32
Line # Hits Time Per Hit % Time Line Contents
==============================================================
32 @profile
33 def main():
34 1 1.0 1.0 0.0 str1= "Mar 31 09:08:41 The world is beautiful"
35 1 0.0 0.0 0.0 str2= "Mar 31 19:08:42 Beautiful is the world"
36 1 43248.0 43248.0 99.1 print("NLP Similarity=",nlp(str1).similarity(nlp(str2)))
37 1 375.0 375.0 0.9 print("Diff lib similarity",SequenceMatcher(None, str1, str2).ratio())
38 1 30.0 30.0 0.1 print("Jellyfish lib similarity",jellyfish.jaro_distance(str1, str2))
answered Apr 21, 2022 at 8:05
![]()
Alex PunnenAlex Punnen
5,0013 gold badges57 silver badges69 bronze badges
Here’s what i thought of:
import string
def match(a,b):
a,b = a.lower(), b.lower()
error = 0
for i in string.ascii_lowercase:
error += abs(a.count(i) - b.count(i))
total = len(a) + len(b)
return (total-error)/total
if __name__ == "__main__":
print(match("pple inc", "Apple Inc."))
answered Dec 1, 2020 at 21:22
![]()
Python3.6+=
No Libuary Imported
Works Well in most scenarios
In stack overflow, when you tries to add a tag or post a question, it bring up all relevant stuff. This is so convenient and is exactly the algorithm that I am looking for. Therefore, I coded a query set similarity filter.
def compare(qs, ip):
al = 2
v = 0
for ii, letter in enumerate(ip):
if letter == qs[ii]:
v += al
else:
ac = 0
for jj in range(al):
if ii - jj < 0 or ii + jj > len(qs) - 1:
break
elif letter == qs[ii - jj] or letter == qs[ii + jj]:
ac += jj
break
v += ac
return v
def getSimilarQuerySet(queryset, inp, length):
return [k for tt, (k, v) in enumerate(reversed(sorted({it: compare(it, inp) for it in queryset}.items(), key=lambda item: item[1])))][:length]
if __name__ == "__main__":
print(compare('apple', 'mongo'))
# 0
print(compare('apple', 'apple'))
# 10
print(compare('apple', 'appel'))
# 7
print(compare('dude', 'ud'))
# 1
print(compare('dude', 'du'))
# 4
print(compare('dude', 'dud'))
# 6
print(compare('apple', 'mongo'))
# 2
print(compare('apple', 'appel'))
# 8
print(getSimilarQuerySet(
[
"java",
"jquery",
"javascript",
"jude",
"aja",
],
"ja",
2,
))
# ['javascript', 'java']
Explanation
comparetakes two string and returns a positive integer.- you can edit the
alallowed variable incompare, it indicates how large the range we need to search through. It works like this: two strings are iterated, if same character is find at same index, then accumulator will be added to a largest value. Then, we search in the index range ofallowed, if matched, add to the accumulator based on how far the letter is. (the further, the smaller) lengthindicate how many items you want as result, that is most similar to input string.
answered Oct 29, 2021 at 14:06
![]()
WeiloryWeilory
2,48316 silver badges31 bronze badges
I have my own for my purposes, which is 2x faster than difflib SequenceMatcher’s quick_ratio(), while providing similar results. a and b are strings:
score = 0
for letters in enumerate(a):
score = score + b.count(letters[1])
answered Jan 6 at 11:52
![]()
HCLivessHCLivess
1,0051 gold badge13 silver badges21 bronze badges
Недавно мы обсуждали расчет расстояния Левеншейна, настало время испытать его применение на практике. Библиотека FuzzyWuzzy содержит набор функций для нечеткого поиска строк, дедупликации (удаления копий), корректировки ошибок. Она позволяет стать поиску умнее, помогая преодолеть влияние человеческого фактор.
Начнем с установки:
pip install fuzzywuzzy python-Levenshtein
Модуль python-Levenshtein можно устанавливать по желанию: работать будет и без него, но с ним гораздо быстрее (в разы). Поэтому советую его установить, он мелкий, порядка 50 Кб.
Похожесть двух строк
Задача: есть две строки, требуется вычислить степень их похожести числом от 0 до 100. В FuzzyWuzzy для этого есть несколько функций, отличающихся подходом к сравнению и вниманием к деталям. Не забудем импортировать:
from fuzzywuzzy import fuzz
Функция fuzz.ratio – простое посимвольное сравнение. Рейтинг 100 только если строки полностью равны, любое различие уменьшает рейтинг, будь то знаки препинания, регистр букв, порядок слов и так далее:
>>> fuzz.ratio("я люблю спать", "я люблю спать")
100
>>> fuzz.ratio("я люблю спать", "Я люблю cпать!")
81
>>> fuzz.ratio("я люблю спать", "я люблю есть")
88
Обратите внимание, что рейтинг второго примера ниже, чем у третьего, хотя по смыслу должно быть наоборот.
Следующая функция fuzz.token_sort_ratio решает эту проблему. Теперь акцент именно на сами слова, игнорируя регистр букв, порядок слов и даже знаки препинания по краям строки.
>>> fuzz.token_sort_ratio("я люблю спать", "я люблю есть")
56
>>> fuzz.token_sort_ratio("я люблю спать", "Я люблю спать!")
100
>>> fuzz.token_sort_ratio("я люблю спать", "спать люблю я...")
100
>>> fuzz.token_sort_ratio("Мал да удал", "удал да МАЛ")
100
>>> fuzz.token_sort_ratio("Мал да удал", "Да Мал Удал")
100
Однако, смысл пословицы немного изменился, а рейтинг остался на уровне полного совпадения.
Функция fuzz.token_set_ratio пошла еще дальше: она игнорирует повторяющиеся слова, учитывает только уникальные.
>>> fuzz.token_set_ratio("я люблю спать", "люблю я спать, спать, спать...")
100
>>> fuzz.token_set_ratio("я люблю спать", "люблю я спать, спать и спать...")
100
>>> fuzz.token_set_ratio("я люблю спать", "но надо работать")
28
# повторы в token_sort_ratio роняют рейтинг!
>>> fuzz.token_sort_ratio("я люблю спать", "люблю я спать, спать и спать.")
65
# но вот это странно:
>>> fuzz.token_set_ratio("я люблю спать", "люблю я спать, но надо работать")
100
>>> fuzz.token_set_ratio("я люблю спать", "люблю я спать, люблю я есть")
100
Последние два примера вернули 100, хотя добавлены новые слова, и это странно. Тут следует вспомнить о fuzz.partial_ratio, которая ведет себя также. А именно, проверяет вхождение одной строки в другую. Лишние слова игнорируются, главное – оценить, чтобы ядро было одно и тоже.
>>> fuzz.partial_ratio("одно я знаю точно", "одно я знаю")
100
>>> fuzz.partial_ratio("одно я знаю точно", "одно я знаю!")
92
>>> fuzz.partial_ratio("одно я знаю точно", "я знаю")
100
Еще еще более навороченный метод fuzz.WRatio, который работает ближе к человеческой логике, комбинируя несколько методов в один алгоритм в определенными весами (отсюда и название WRatio = Weighted Ratio).
>>> fuzz.WRatio("я люблю спать", "люблю Я СПАТЬ!")
95
>>> fuzz.WRatio("я люблю спать", "люблю Я СПАТЬ и есть")
86
>>> fuzz.WRatio("я люблю спать", "!!СПАТЬ ЛЮБЛЮ Я!!")
95
Нечеткий поиск
Задача: найти в списке строк одну или несколько наиболее похожих на поисковый запрос.
Импортируем подмодуль и применим process.extract или process.extractOne:
from fuzzywuzzy import process
strings = ['привет', 'здравствуйте', 'приветствую', 'хай', 'здорова', 'ку-ку']
process.extract("Прив", strings, limit=3)
# [('привет', 90), ('приветствую', 90), ('здравствуйте', 45)]
process.extractOne("Прив", strings)
# ('привет', 90)
Удаление дубликатов
Очень полезная функция для обработки данных. Представьте, что вам досталась 1С база номенклатуры запчастей, там полный бардак, и вам нужно поудалять лишние повторяющиеся позиции товара, но где-то пробелы лишние, где-то буква перепутана и тому подобное. Тут пригодится process.dedupe.
dedupe(contains_dupes, threshold=70, scorer=token_set_ratio)Первый аргумент – исходный список, второй – порог исключения (70 по умолчанию), третий – алгоритм сравнения (token_set_ratio по умолчанию).
Пример:
arr = ['Гайка на 4', 'гайка 4 ГОСТ-1828 оцинкованная', 'Болты на 10', 'гайка 4 ГОСТ-1828 оцинкованная ...', 'БОЛТ'] print(list(process.dedupe(arr))) # ['гайка 4 ГОСТ-1828 оцинкованная ...', 'Болты на 10', 'БОЛТ']
FuzzyWuzzy можно применять совместно с Pandas. Например так (без особых подробностей):
def get_ratio(row):
name = row['Last/Business Name']
return fuzz.token_sort_ratio(name, "Alaska Sea Pilot PAC Fund")
df[df.apply(get_ratio, axis=1) > 70]
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈
7 919
Перейти к содержимому
Меню
Находим соответствия в строках
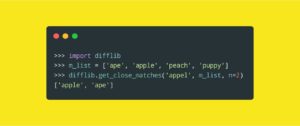
Предположим, мы попали в ситуацию, когда нам понадобилось найти в списке слова, похожие на некую входную строку. Решить эту задачу можно с помощью built-in модуля difflib.
Данный метод ищет «наилучшие» возможные совпадения. Первый аргумент задаёт искомую строку, второй аргумент задаёт список, в котором выполняется поиск.
Также в метод можно передать необязательный аргумент n, который задаёт максимальное число возвращаемых совпадений.
В этом руководстве мы узнаем, как сопоставить строки, используя встроенную библиотеку fuzzyWuzzy в Python, и определим, насколько они похожи, на различных примерах.
Python предоставляет несколько методов для сравнения двух строк. Ниже приведены основные методы:
- использование Regex;
- простое сравнение;
- использование dfflib.
Но есть еще один метод для нечеткого сравнения строк, который можно эффективно использовать, он называется fuzzywuzzy. Этот метод довольно эффективен для различения двух строк, относящихся к одному и тому же объекту, но написанных немного по-разному. Иногда нам нужна программа, которая может автоматически определять неправильное написание.
Это процесс поиска строк, соответствующих заданному шаблону. Он использует расстояние Левенштейна для вычисления разницы между последовательностями.
Эта библиотека может помочь сопоставить базы данных, в которых отсутствует общий ключ, например, объединить две таблицы по названию компании, и они по-разному отображаются в обеих таблицах.
Посмотрим на следующий пример.
Str1 = "Welcome to Javatpoint" Str2 = "Welcome to Javatpoint" Result = Str1 == Str2 print(Result)
Выход:
True
Приведенный выше код возвращает истину, потому что строки совпадают точно(100%), что, если мы внесем изменения в str2.
Str1 = "Welcome to Javatpoint" Str2 = "welcome to Javatpoint" Result = Str1 == Str2 print(Result)
Выход:
False
Здесь приведенный выше код возвращает ложь, строки почти идентичны для человеческого глаза, но не для интерпретатора. Однако мы можем решить эту проблему, преобразовав обе строки в нижний регистр.
Str1 = "Welcome to Javatpoint" Str2 = "welcome to Javatpoint" Result = Str1.lower() == Str2.lower() print(Result)
Выход:
True
Но если мы внесем изменения в кодировку, у нас возникнет другая проблема.
Str1 = "Welcome to javatpoint." Str2 = "Welcome to javatpoint" Result = Str1.lower() == Str2.lower() print(Result)
Выход:
True
Чтобы решить такие проблемы, нам нужны более эффективные инструменты для сравнения строк. И fuzzywuzzy – лучший инструмент для вычисления строк.
Расстояние Левенштейна
Расстояние Левенштейна используется для вычисления расстояния между двумя последовательностями слов. Оно вычисляет минимальное количество правок, которые нам нужно изменить в данной строке. Эти изменения могут быть вставкой, удалением или заменой.
Пример –
import numpy as np
def levenshtein_distance(s1, t1, ratio_calculation = False):
# Initialize matrix of zeros
rows = len(s1)+1
cols = len(t1)+1
calc_distance = np.zeros((rows,cols),dtype = int)
# Populate matrix of zeros with the indeces of each character of both strings
for i in range(1, rows):
for k in range(1,cols):
calc_distance[i][0] = i
calc_distance[0][k] = k
for col in range(1, cols):
for row in range(1, rows):
if s1[row-1] == t1[col-1]:
cost = 0
if ratio_calculation == True:
cost = 2
else:
cost = 1
calc_distance[row][col] = min(calc_distance[row-1][col] + 1, # Cost of deletions
calc_distance[row][col-1] + 1, # Cost of insertions
calc_distance[row-1][col-1] + cost) # Cost of substitutions
if ratio_calculation == True:
# Computation of the Levenshtein calc_distance Ratio
Ratio =((len(s)+len(t)) - calc_distance[row][col]) /(len(s)+len(t))
return Ratio
else:
return "The strings are {} edits away".format(calc_distance[row][col])
Мы будем использовать указанную выше функцию в предыдущем примере, где мы пытались сравнить «Добро пожаловать в javatpoint» и «Добро пожаловать в javatpoint». Мы видим, что обе строки, скорее всего, совпадают, потому что длина Левенштейна мала.
Str1 = "Welcome to Javatpoint" Str2 = "welcome to Javatpoint" Distance = levenshtein_distance(Str1,Str2) print(Distance) Ratio = levenshtein_distance(Str1,Str2,ratio_calc = True) print(Ratio)
Название этой библиотеки какое-то странное и забавное, но она очень полезна. Она имеет уникальный способ сравнения обеих строк и возвращает результат из 100 возможных для соответствия количеству строк. Для работы с этой библиотекой нам необходимо установить ее в нашей среде Python.
Установка
Мы можем установить эту библиотеку с помощью команды pip.
pip install fuzzywuzzy
Collecting fuzzywuzzy Downloading fuzzywuzzy-0.18.0-py2.py3-none-any.whl(18 kB) Installing collected packages: fuzzywuzzy Successfully installed fuzzywuzzy-0.18.0
Теперь введите следующую команду и нажмите ввод.
pip install python-Levenshtein
Давайте разберемся в следующих методах библиотеки fuzzuwuzzy.
Модуль Fuzz
Модуль fuzz используется для одновременного сравнения двух заданных строк. Он возвращает оценку из 100 после сравнения с использованием различных методов.
Fuzz.ratio()
Это один из важных методов модуля fuzz. Он сравнивает строку и оценку на основе того, насколько данная строка соответствует. Давайте разберемся в следующем примере.
Пример –
from fuzzywuzzy import fuzz Str1 = "Welcome to Javatpoint" Str2 = "welcome to javatpoint" Ratio = fuzz.ratio(Str1.lower(),Str2.lower()) print(Ratio)
Выход:
100
Как видно из приведенного выше кода, метод fuzz.ratio() вернул оценку, что означает очень небольшую разницу между строками.
Fuzz.partial_ratio()
Библиотека fuzzywuzzy предоставляет еще один мощный метод – partial_ratio(). Он используется для обработки сложного сравнения строк, такого как сопоставление подстрок. Посмотрим на следующий пример.
#importing the module from the fuzzywuzzy library from fuzzywuzzy import fuzz str1 = "Welcome to Javatpoint" str2 = "tpoint" Ratio = fuzz.ratio(str1.lower(),str2.lower()) Ratio_partial = fuzz.partial_ratio(str1.lower(),str2.lower()) print(Ratio) print(Ratio_partial)
Выход:
44 100
Объяснение:
Метод partial_ratio() может обнаружить подстроку. Таким образом, дает 100% сходство. Он следует оптимальной частичной логике, в которой для короткой строки k и более длинной строки m алгоритм находит наилучшую совпадающую длину k-подстроки.
Fuzz.token_sort_ratio
Этот метод не гарантирует получения точного результата, потому что если мы внесем изменения в порядок строк, это может не дать точного результата.
Но модуль fuzzywuzzy предоставляет решение. Давайте разберем следующий пример.
str1 = "united states v. nixon" str2 = "Nixon v. United States" Ratio = fuzz.ratio(str1.lower(),str2.lower()) Ratio_Partial = fuzz.partial_ratio(str1.lower(),str2.lower()) Ratio_Token = fuzz.token_sort_ratio(str1,str2) print(Ratio) print(Ratio_Partial) print(Ratio_Token)
Выход:
59 74 100
Объяснение:
В приведенном выше коде мы использовали метод token_sort_ratio(), который дает преимущество перед partial_ratio. В этом методе строковые токены сортируются в алфавитном порядке и объединяются. Но есть и другая ситуация, например, когда строки сильно различаются по длине.
Пример –
str1 = "The supreme court case of Democratic vs Congress" str2 = "Congress v. Democratic" Ratio = fuzz.ratio(str1.lower(),str2.lower()) Partial_Ratio = fuzz.partial_ratio(str1.lower(),str2.lower()) Token_Sort_Ratio = fuzz.token_sort_ratio(str1,str2) Token_Set_Ratio = fuzz.token_set_ratio(str1,str2) print(Ratio) print(Partial_Ratio) print(Token_Sort_Ratio) print(Token_Set_Ratio)
Выход:
40 64 61 95
В приведенном выше коде мы использовали другой метод, называемый fuzz.token_set_ratio(), который выполняет операцию набора и извлекает общий токен, а затем выполняет попарное сравнение ratio().
Пересечение отсортированного токена всегда одно и то же, потому что подстрока или меньшая строка состоит из больших фрагментов исходной строки, или оставшийся токен находится близко к другому.
Пакет fuzzywuzzy предоставляет модуль процесса, который позволяет нам вычислять строку с наибольшим сходством. Давайте разберемся в следующем примере.
from fuzzywuzzy import process strToMatch = "Hello Good Morning" givenOpt = ["hello","Hello Good","Morning","Good Evenining"] ratios = process.extract(strToMatch,givenOpt) print(ratios) # We can choose the string that has highest matching percentage high = process.extractOne(strToMatch,givenOpt) print(high)
Выход:
[('hello', 90),('Hello Good', 90),('Morning', 90),('Good Evenining', 59)] ('hello', 90)
Приведенный выше код вернет наивысший процент совпадений для данного списка строк.
Fuzz.WRatio
Модуль процесса также предоставляет WRatio, который дает лучший результат, чем простое соотношение. Он обрабатывает нижний и верхний регистры, а также некоторые другие параметры. Давайте разберемся в следующем примере.
Пример –
from fuzzywuzzy import process
fuzz.WRatio('good morning', 'Good Morning')
fuzz.WRatio('good morning!!!','good Morning')
Выход:
100
Заключение
В этом уроке мы обсудили, как сопоставить строки и определить, насколько они схожи. Мы проиллюстрировали простые примеры, но их достаточно, чтобы понять, как компьютер обрабатывает несовпадающие строки. Многие реальные приложения, такие как проверка орфографии, биоинформатика для сопоставления, последовательность ДНК и т. д., основаны на нечеткой логике.


Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
