Поиск текстов, не соответствующих тематике и нахождение похожих статей
Время на прочтение
5 мин
Количество просмотров 28K
У меня есть сайт со статьями схожей тематики. На сайте было две проблемы: спамерские сообщения и дубликаты статей, причём дубликаты часто являлись не точными копиями.
Данный пост повествует о том, как я решил эти проблемы.
Дано:
- общее количество статей 140 000;
- количество спама: примерно 16%;
- количество не чётких дубликатов: примерно 63%;
Задача: избавиться от спама и дубликатов, а так же не допустить их дальнейшего появления.

Часть 1. Классификация на спам/не спам
Все статьи на моём сайте относятся к одной и той же тематике и, как правило, спамерсие/рекламные сообщения прилично отличаются по содержанию. Я решил вручную отсортировать некоторое количество статей. И на их основе построить классификатор. Для классификации будем считать косинусное расстояние между вектором проверяемой статьи и векторами двух групп (спам/не спам). К какой группе проверяемая статья ближе, к той и будем относить статью.
Сначала надо вручную классифицировать статьи. Набросал для этого форму с чекбоксами и собрал за несколько часов 650 статей спама и 2000 не спама.
Все посты очищаются от мусора – шумовых слов, которые не несут полезной нагрузки (причастия, междометия и пр). Для этого я собрал из разных словарей, которые нашёл в интернете, свой словарь шумовых слов.
Чтобы минимизировать количество различных форм одного слова, можно использовать стеммиг Портера. Я взял готовую реализацию на Java отсюда. Спасибо, Edunov
Из слов классифицированных статей, очищенных от шумовых слов и прогнанных через стемминг надо собрать словарь.
Из словаря удалим слова, которые встречаются только в одной статье.
Для каждой классифицированной вручную статьи считаем количество вхождений каждого слова из словаря. Получатся векторы, похожие на следующие:

Усиливаем в каждом векторе веса слов, считая для них TF-IDF. TF-IDF считается отдельно для каждой группы спам/не спам.
Сначала считаем TF (term frequency — частота слова) для каждой статьи. Это отношение количества вхождений конкретного слова к общему числу слов в статье:

где ni есть число вхождений слова в документ, а в знаменателе — общее число слов в данном документе.

Дальше считаем IDF (inverse document frequency — обратная частота документа). Инверсия частоты, с которой некоторое слово встречается в документах группы (спам/не спам). IDF уменьшает вес слов, которые часто употребляются в группе. Считается для каждой группы.

где
- |D| — количество документов в группе;
- di⊃ti — количество документов, в которых встречается ti (когда ni≠0).

Считаем TF-IDF:
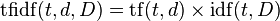
Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.
Для каждой группы формируем по одному вектору, считая среднее арифметическое каждого параметра внутри группы:

Чтобы проверить статью на спам, надо получить для нее количество вхождений слов из словаря. Посчитать для этих слов TF-IDF для спама и не спама. Получится два вектора (на изображении TF-IDF не спам и TF-IDF спам). IDF для расчётов, берём тот, который считали для классифицирующей выборки.

Для каждого вектора считаем косинусное расстояние с векторами для спама и не спама, соответственно. Косинусное расстояние – это мера похожести двух векторов. Скалярное произведение векторов и косинус угла θ между ними связаны следующим соотношением:

Имея два вектора A и B, получаем косинусное расстояние – cos(θ)

Код на Java
public static double cosine(double[] a, double[] b) {
double dotProd = 0;
double sqA = 0;
double sqB = 0;
for (int i = 0; i < a.length; i++) {
dotProd += a[i] * b[i];
sqA += a[i] * a[i];
sqB += b[i] * b[i];
}
return dotProd/(Math.sqrt(sqA)*Math.sqrt(sqB));
}
В результате получается диапазон от -1 до 1. -1 означает, что вектора полностью противоположны, 1, что они одинаковы.
Какое из полученных значений (для спама и не спама) будет ближе к 1, к той группе и будем относить статью.
При проверке схожести на не спам получилось число 0.87:

на спам – 0.62:

Следовательно, считаем, что статья – не спам.
Для тестирования я вручную отобрал ещё 700 записей. Точность результатов была 98%. При этом то, что классифицировалось ошибочно даже мне было сложно отнести к той или иной категории.
Часть 2. Поиск нечётких дубликатов
После очистки от спама осталось 118 000 статей.
Для поиска дубликатов я решил использовать инвертированный индекс (Inverted index). Индекс представляет собой структуру данных, где для каждого слова указывается, в каких документах оно содержится. Соответственно, если у нас есть набор слов, можно легко сделать запрос документов, содержащих эти слова.
Пример с Вики. Допустим, у нас есть следующие документы:
T[0] = "it is what it is"
T[1] = "what is it"
T[2] = "it is a banana"
Для этих документов построим индекс, указав, в каком документе содержится слово:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
Все слова «what», «is» и «it» находятся в документах 0 и 1:
{0,1} ∩ {0,1,2} ∩ {0,1,2} = {0,1}
Индекс я сохранял в БД MySQL. Индексирование заняло около 2-х дней.
Для поиска похожих статей не надо, чтобы совпадали все слова, поэтому при запросе по индексу получаем все статьи, у которых совпало хотя бы 75% слов. В найденных содержатся похожие дубликаты, а так же другие статьи, которые включают в себя 75% слов изначальной, например, это могут быть очень длинные статьи.
Чтобы отсеять то, что дубликатом не является, надо посчитать косинусное расстояние между исходной и найденными. То, что совпадает больше, чем на 75% считаю дубликатом. Число в 75% выводил эмпирически. Оно позволяет находить достаточно изменённые версии одной и той же статьи.
Пример найденных дубликатов:
Вариант 1:
Чизкейк со сгущенкой (без выпечки)
Ингредиенты:
* 450 гр Сметана от 20 % жирности
* 300 гр печенья
* 100 гр растопленного сливочного масла
* 300 гр хорошего сгущенного молока
* 10 гр быстрорастворимого желатина
* 3/4 стакана холодной кипяченой воды
Приготовление:
Разборную форму выстелить пергаментной бумагой.
Размельченное в мелкую крошку печенье смешать с растопленным маслом. Смесь должна быть не жирной, но и не сухой. Выложить смесь в форму и хорошо уплотнить. Убрать в холодильник на 30 минут.
Сметану смешать со сгущенным молоком.
Желатин залить 3/4 стакана воды и поставить на 10 минут набухать. Затем растопить его на водяной бане так, чтобы он весь растворился.
В смесь сгущенки и сметаны осторожно влить желатин, тщательно помешивая. Перелить затем в форму. И убрать в холодильник до полного застывания примерно на 2-3 часа.
При застывании можно добавить ягоды свежей клюквы или посыпать тертым шоколадом или орехами.
Приятного аппетита!
Вариант 2:
«Чизкейк» без выпечки со сгущенкой
Ингредиенты:
-Сметана от 20 % жирности 450 гр
-300 гр печенья ( я брала овсяные)
-100 гр растопленного сливочного масла
-300 гр качественного сгущенного молока
-10 гр быстрорастворимого желатина
-3/4 стакана холодной кипяченой воды
Приготовление:
1). Форму (лучше разъёмную) застелить пергаментной бумагой.
2). Печенье измельчить в мелкую крошку и смешать с растопленным маслом. Масса не должна быть жирной, но и не слишком сухой. Уложить массу в форму и хорошо утрамбовать. Поставить в холодильник на полчаса.
3). Сметану смешать со сгущенным молоком (можно добавить больше или меньше сгущенки, это уже дело вкуса).
4) Желатин залить 3/4 стакана воды и оставить на 10 мин. набухать. Затем растопить его на водяной бане так, чтобы он полностью растворился.
5) В сметано-сгущенную массу потихоньку ввести желатин, хорошо помешивая. Перелить затем в форму. И отправить в холодильник до полного застывания. У меня застыл быстро. Где-то 2 часа.
Я при застывании добавила еще ягоды свежей клюквы — это придало пикантность и кислинку. Можно посыпать тертым шоколадом или орехами.
Полная чистка заняла около 5 часов.
Чтобы обновлять индекс для поиска дубликатов, не надо перестраивать уже существующие данные. Индекс достраивается инкрементально.
Из-за ограниченного количества оперативки на сервере у меня нет возможности держать индекс в памяти, поэтому я и держу его MySQL-е, где хранятся сами статьи. Проверка одной статьи, если не грузить всё в память, занимает у программы около 9 сек. Это долго, но т.к. новых статей в сутки появляется лишь несколько десятков, решил не заморачиваться со скоростью, пока этого не потребуется.
10 Января 2015
 Good Name
Good Name
0
4
В избр.
Сохранено
Вы ему, типа, ссылку на статью, а он, вам, типа, похожие статьи
Ну, собственно, вот, вопрос.
Для поиска похожих сайтов есть сервисы. Вот, например.
А для поисках похожих статей? Поделитесь ссылками?
Спасибо!

Медведев Владлен
Ммм. Я не совсем про это.
Я про поиск похожих по содержанию статей, а не про проверку уникальности. То есть, например. Есть статья. У нее есть заголовок. Вы вставляете заголовок в Яндекс, он ищет документы по введеным словам. Но ведь могут существовать статьи, у которых заголовок совсем другой, а содержание похожее. Я в этом смысле. Что думаете?
Дмитрий
По всей видимости вы решили не утруждать себя и не кликать по ссылке, которую я дал вам выше =) Это именно то, о чем вы спрашиваете. Вставляете ссылку на статью и сервис выдает вам похожие статьи, при этом абсолютно не важно какие у них там заголовки.
Медведев Владлен

Почему, утрудился. ) Могли бы вы привести пример? Взять любую статью, по которой понятно, что таких статей по смыслу много и показать результаты. У меня результаты -100% уникальный текст, похожих статей нет. Мне показалось, это просто проверка уникальности текста.
Блог проекта
Расскажите историю о создании или развитии проекта, поиске команды, проблемах и решениях
Написать
Личный блог
Продвигайте свои услуги или личный бренд через интересные кейсы и статьи
Написать
Один из вариантов поиска похожих статей в базе данных основан на схождении слов в двух текстах.
Данный алгоритм не обладает точным результатом, но позволяет выявить явные дубли.
Для поиска понадобится функция, которая очистит текст от html-кода, лишних слов и вернёт массив слов.
function get_minification_array($text)
{
// Удаление экранированных спецсимволов
$text = stripslashes($text);
// Преобразование мнемоник
$text = html_entity_decode($text);
$text = htmlspecialchars_decode($text, ENT_QUOTES);
// Удаление html тегов
$text = strip_tags($text);
// Все в нижний регистр
$text = mb_strtolower($text);
// Удаление лишних символов
$text = str_ireplace('ё', 'е', $text);
$text = mb_eregi_replace("[^a-zа-яй0-9 ]", ' ', $text);
// Удаление двойных пробелов
$text = mb_ereg_replace('[ ]+', ' ', $text);
// Преобразование текста в массив
$words = explode(' ', $text);
// Удаление дубликатов
$words = array_unique($words);
// Удаление предлогов и союзов
$array = array(
'без', 'близ', 'в', 'во', 'вместо', 'вне', 'для', 'до',
'за', 'и', 'из', 'изо', 'из', 'за', 'под', 'к',
'ко', 'кроме', 'между', 'на', 'над', 'о', 'об', 'обо',
'от', 'ото', 'перед', 'передо', 'пред', 'предо', 'по', 'под',
'подо', 'при', 'про', 'ради', 'с', 'со', 'сквозь', 'среди',
'у', 'через', 'но', 'или', 'по'
);
$words = array_diff($words, $array);
// Удаление пустых значений в массиве
$words = array_diff($words, array(''));
return $words;
}PHP
Пример работы функции:
$array = get_minification_array('
<p>Сегодня существует огромное множество разнообразных диет,
отличающихся степенью строгости и результатами, которых с их
помощью добиваются худеющие. Существует одна эффективная диета
творог + яблоки, которая позволит легко скинуть 4 кг за 4 дня.</p>
');
print_r($array);PHP
Результат:
Array
(
[0] => сегодня
[1] => существует
[2] => огромное
[3] => множество
[4] => разнообразных
[5] => диет
[6] => отличающихся
[7] => степенью
[8] => строгости
[10] => результатами
[11] => которых
[13] => их
[14] => помощью
[15] => добиваются
[16] => худеющие
[18] => одна
[19] => эффективная
[20] => диета
[21] => творог
[22] => яблоки
[23] => которая
[24] => позволит
[25] => легко
[26] => скинуть
[27] => 4
[28] => кг
[31] => дня
)Для более точного результата можно удалить из текста все стоп-слова.
Теперь, нужно получить проверяемую статью и сверить с остальными. В примере используется таблица `articles`, с полями `id`, `name`, `text`:
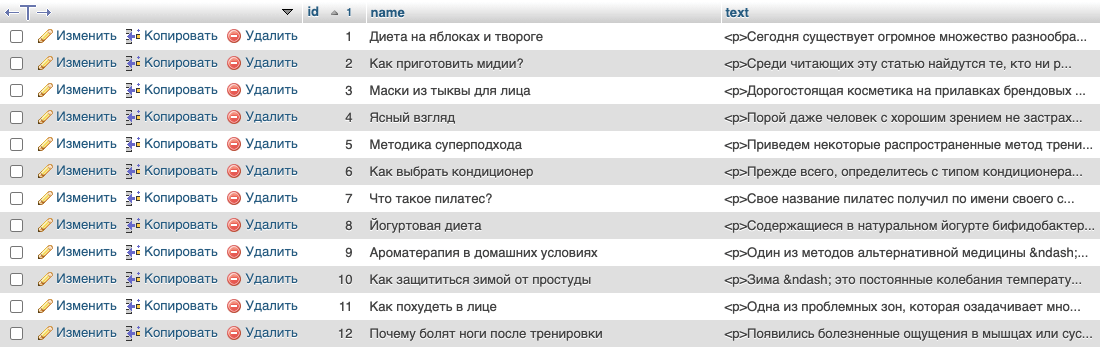
Поиск будет осуществляется для статьи `id` = 1, причём для теста в базе есть копия этой статьи с немного измененным текстом.
// Подключение к БД
$dbh = new PDO('mysql:dbname=db_name;host=localhost', 'логин', 'пароль');
// Получаем статью
$sth = $dbh->prepare("SELECT * FROM `articles` WHERE `id` = 1");
$sth->execute(array());
$article = $sth->fetch(PDO::FETCH_ASSOC);
// Получаем для неё массив слов
$text = get_minification_array($article['name'] . ' ' . $article['text']);
$count = count($text);
$out = array();
// Проход по всем статьям в таблице
$sth = $dbh->prepare("SELECT * FROM `articles`");
$sth->execute();
$list = $sth->fetchAll(PDO::FETCH_ASSOC);
foreach($list as $row) {
$verifiable = get_minification_array($row['name'] . ' ' . $row['text']);
$similar_counter = 0;
foreach ($text as $text_row) {
foreach ($verifiable as $verifiable_row){
if($text_row == $verifiable_row) {
$similar_counter++;
break;
}
}
}
$out[$row['name']] = $similar_counter * 100 / $count;
}
// Сортировка результатов и ограничение до 15шт
arsort($out);
$out = array_slice($out, 0, 15, true);
print_r($out);PHP
Результат поиска:
Array
(
[Диета на яблоках и твороге] => 100
[Диета на яблоках и твороге (test)] => 97,368421052632
[Диета Ларисы Гузеевой] => 21,052631578947
[Как похудеть в лице] => 19,736842105263
[Соевый соус: польза и вред] => 17,105263157895
[Сырная диета] => 14,473684210526
[Какую обувь выбрать для сильных морозов?] => 13,157894736842
[Какие мышцы работают на эллиптическом тренажере?] => 10,526315789474
[Боль в коленном суставе при нагрузке] => 9,2105263157895
[Польза и вред дыни для организма человека] => 9,2105263157895
[Разгрузочная диета после праздников] => 9,2105263157895
[Вредно ли загорать на солнце?] => 7,8947368421053
[Йогуртовая диета] => 7,8947368421053
[Как стирать пуховое одеяло?] => 7,8947368421053
[Какие витамины в укропе] => 6,5789473684211
)В результате видно, что статья схожа сама с собой на 100%, с тестовой статьей на 97%, с остальными не более 21%.
Поиск похожих статей не является легкой прогулкой, но если вы знаете тактику и имеете немного терпения, это тоже не сложно. Существует несколько способов поиска похожих статей в исследование.
От гугления ключевых слов и название Помимо поиска автора, вы можете использовать различные методы для выявления похожих статей. Прочитайте статью, чтобы определить как найти похожие научные работы для эффективного проведения исследований.
Как найти похожие научные работы
Чтобы провести исследование, исследователю необходимо знать тему, и он должен сделать обзор литературы. Здесь на первый план выходят похожие научные работы, которые помогают исследователю получить точную информацию за короткий промежуток времени.
Научный журналы, журналы, газеты, книги и интервью – вот некоторые из платформ, где можно найти подобные исследования. Вы даже можете искать в академический поисковые системы, такие как Google Scholar, Наука Прямой и Pubmed (специально для наук о жизни), IEEE (электроника, электрика, электротехника). Инжиниринг, информатика), и Agricola для сельского хозяйства, чтобы определить исследовательские статьи.
Вот несколько лучших практик, которым вы можете следовать для выявления релевантных исследовательских работ.
- Уточните свои ключевые слова, чтобы получить точные результаты.
- Просмотрите ссылки на похожие ресурсы и связанные статьи.
- Определите релевантные ключевые слова, используя синонимы или подобрав несколько ключевых слов из статьи, и выполните поиск в Google по этим словам.
- Просмотрите аннотации и указатели, чтобы получить представление о похожих статьях.
- Найдите статью в индексе и прочитайте ее описание. Теперь выполните поиск по этой релевантной информации, и вы получите похожую статью.
- Ищите библиография. Это отличный способ найти похожие статьи, поскольку в них содержатся ссылки на статьи, которые автор просмотрел для проведения своего исследования.
- Просмотрите тематические базы данных, чтобы найти темы и аналогичный контент, который вы ищете.
- Вы также можете изучить работы схожих авторов или соавторов и, возможно, получить какую-то информацию из других их работ.
Могут ли быть две исследовательские работы на одну и ту же тему?
Вы можете найти множество похожих исследовательских работ, и публикация таких работ абсолютно этична. Поэтому очевидно, что на одну и ту же тему может быть две или более исследовательских работ.
Выбор схожих тем исследований ускорит процесс исследования, а также поможет в развитии науки, когда исследователи выявляют пробелы в предыдущих исследованиях и работают над ними.
Однако, если вы исследователь, вам нужно следить за тем, чтобы не повторять одни и те же данные, а работать над поиском подходящей исследовательской проблемы и сосредоточиться на ней.
Как сделать поиск в Google более точным?
В Google есть множество статей, которые появляются в результатах поиска, как только вы вводите любое ключевое слово в строку поиска. Но эти результаты могут быть не теми, которые вы ищете.
Чтобы получить соответствующие результаты поиска в Google, необходимо знать искусство поиска. Вот несколько советов, которые необходимо соблюдать для поиска в Google и получения релевантных результатов.
1. Используйте режим приватного просмотра
Режим приватного просмотра Google обрабатывает данные, фокусируясь только на ваших основных ключевых словах и исключая другие факторы, такие как история просмотров, различные данные из других сервисов Google и т. д.
Вот сочетания клавиш, которые необходимо использовать для переключения в режим частного просмотра:
Хром: CTRL + SHIFT + N или Главное меню > Новое окно инкогнито
Internet Explorer: CTRL + SHIFT + P или InPrivate Browsing (приватный просмотр)
Firefox: CTRL + SHIFT + P или Инструменты > Запустить приватный просмотр
2. Добавьте символ * между ключевыми словами
Добавление звездочки (*) между двумя словами в ключевом слове помогает искать релевантные темы, которые могут соответствовать этим словам.
Пример: Если вы ищете “устойчивое сельское хозяйство”, набрав “устойчивое* сельское хозяйство”, вы получите похожие результаты, как “устойчивая практика в сельском хозяйстве”; устойчивый продовольствие и сельское хозяйство; устойчивые цели в сельском хозяйстве”.
3. Измените настройки страны по умолчанию в Google
Google настраивает результаты поиска в зависимости от страны, из которой вы ищете. Поэтому вам необходимо изменить этот параметр для получения точных результатов.
Пример: Если вы осуществляете поиск с сайта Google.in, поисковая система настроена на индийский регион, и ваши результаты будут в большей степени относиться к Индии. Поэтому вы можете использовать браузер Google.uk (Великобритания) или Google.fr (Франция) и т.д.
Кроме того, если вы ищете лучшую альтернативу, вы можете зайти на сайт Google.com. Это дает результаты по всему миру.
4. Включите расширенные результаты поиска в Google
Вы можете настроить поисковую систему так, чтобы она показывала желаемые результаты, включив расширенные настройки, которые помогут вам выбрать местоположение, период времени, форму исследования и т.д. Вы также можете применить фильтры для сканирования и отбора информации в соответствии с темой.
5. Изменение последовательности или повторение ключевых слов
Если вы не получаете релевантных результатов, вы можете либо повторить условия, либо изменить последовательность ключевых слов, чтобы посмотреть результаты.
Пример: Повторение – “Urban farming” можно искать как “Urban farming farming farming” Изменение последовательности – “benefits of vertical gardening” можно искать как “vertical gardening benefits”.
Что такое Связанные бумаги?
Связанные бумаги это визуальный инструмент, используемый для поиска научных и академических работ на единой платформе и упрощающий процесс поиска.
Создавайте научно точные инфографики за считанные минуты
Mind the Graph это эксклюзивный инструмент для исследователей, который помогает упростить исследования с помощью наглядной инфографики. Подпишитесь на этот инструмент и сделайте процесс исследования легким и увлекательным.

Подпишитесь на нашу рассылку
Эксклюзивный высококачественный контент об эффективных визуальных
коммуникация в науке.
– Эксклюзивный гид
– Советы по дизайну
– Научные новости и тенденции
– Учебники и шаблоны
It depends upon your definition of similiar.
The edit-distance algorithm is the standard algorithm for (latin language) dictionary suggestions, and can work on whole texts. Two texts are similiar if they have basically the same words (eh letters) in the same order. So the following two book reviews would be fairly similiar:
1) “This is a great book”
2) “These are not great books”
(The number of letters to remove, insert, delete or alter to turn (2) into (1) is termed the ‘edit distance’.)
To implement this you would want to visit every review programmatically. This is perhaps not as costly as it sounds, and if it is too costly you could do the comparisions as a background task and store the n-most-similiar in a database field itself.
Another approach is to understand something of the structure of (latin) languages. If you strip short (non-capitialised or quoted) words, and assign weights to words (or prefixes) that are common or unique, you can do a Bayesianesque comparision. The two following book reviews might be simiplied and found to be similiar:
3) “The french revolution was blah blah War and Peace blah blah France.” -> France/French(2) Revolution(1) War(1) Peace(1) (note that a dictionary has been used to combine France and French)
4) “This book is blah blah a revolution in french cuisine.” -> France(1) Revolution(1)
To implement this you would want to identify the ‘keywords’ in a review when it was created/updated, and to find similiar reviews use these keywords in the where-clause of a query (ideally ‘full text’ searching if the database supports it), with perhaps a post-processing of the results-set for scoring the candidates found.
Books also have categories – are thrillers set in France similiar to historical studies of France, and so on? Meta-data beyond title and text might be useful for keeping results relevant.
