Полнотекстовый поиск и его возможности
Время на прочтение
6 мин
Количество просмотров 181K
Многие СУБД поддерживают методы полнотекстового поиска (Fulltext search), которые позволяют очень быстро находить нужную информацию в больших объемах текста.
В отличие от оператора LIKE, такой тип поиска предусматривает создание соответствующего полнотекстового индекса, который представляет собой своеобразный словарь упоминаний слов в полях. Под словом обычно понимается совокупность из не менее 3-х не пробельных символов (но это может быть изменено). В зависимости от данных словаря может быть вычислена релевантность – сравнительная мера соответствия запроса найденной информации.
В статье рассказывается как работать с полнотекстовым поиском на примере БД MySQL, а так же приведу примеры «нестандартного» использования данного механизма.
В MySQL возможности полнотекстового поиска (только для MyISAM-таблиц) поддерживаются начиная с версии 3.23.23. В последующих версиях механизм потерпел существенные доработки и расширения, в тоге превратившись в мощное средство для создания поисковых механизмов веб-приложений. Главная особенность – быстрый поиск слов в очень больших объемах текстовой информации.
Индекс FULLTEXT
Итак, чтобы работать с полнотекстовым поиском, сначала нам нужно создать соответствующий индекс. Он называется FULLTEXT, и может быть наложен на поля CHAR, VARCHAR и TEXT. Причем, как и в случае с обычным индексом – если происходит поиск по 2-м полям, то нужен объединенный индекс 2-х полей, используйте поиск по одному полю – нужен индекс только этого поля. Например:
CREATE TABLE `articles` (
`id` int(10) unsigned NOT NULL auto_increment,
`title` varchar(200) default NULL,
`body` text,
PRIMARY KEY (`id`),
FULLTEXT KEY `ft1` (`title`,`body`),
FULLTEXT KEY `ft2` (`body`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
В этом примере создается таблица с 2-мя полнотекстовыми индексами: ft1 и ft2, которые можно использовать для поиска в полях title и body, или только в body. Только в поле title искать не получится.
Конструкция MATCH-AGAINST
Собственно для самого полнотекстового поиска в MySQL используется конструкция MATCH(filelds)… AGAINST(words). Она может работать в различных режимах, которые достаточно сильно между собой отличаются. Для всех действует следующее правило: данная конструкция возвращает условную релевантность, но способ вычисления которой может быть разным в зависимости от режима. Еще стоит добавить что во всех режимах поиск всегда регистрозависимый. Далее более подробно о каждом из них.
MATCH-AGAINST IN NATURAL LANGUAGE MODE
— это основной вид поиска, который используется по умолчанию, т.е. если режим не указан:
SELECT * FROM `articles` WHERE MATCH (title,body) AGAINST ('database');
В этом примере мы ищем слово database в полях title и body таблицы articles на основе индекса ft1 (см. пример создания таблицы выше). Выборка будет автоматически отсортирована по релевантности – это происходит в случае указания конструкции MATCH-AGAINST внутри блока WHERE и не задано условие сортировки ORDER BY.
Кстати, несмотря на возможности алиасов, при запросах конструкцию приходится повторять в разных местах, что усложняет запросы. Вот например нельзя написать так:
SELECT *, MATCH (title,body) AGAINST ('database') as REL
FROM `articles`
WHERE REL > 0;
— этот запрос выдаст ошибку: поле Rel не определено. Что бы работало, придется продублировать данную конструкцию:
SELECT *, MATCH (title,body) AGAINST ('database') as REL
FROM `articles`
WHERE MATCH (title,body) AGAINST ('database') > 0;
Однако, сколько бы вы не использовали одну и туже конструкцию (разумеется с одинаковыми параметрами) она будет вычислена только один раз.
В примере выше в переменной REL будет вычислена релевантность. Эта величина зависит прежде всего от количества слов в полях tilte и body, того насколько близко данное слово встречается к началу текста, отношения количества встретившихся слов к количеству всех слов в поле и др.
Например, релевантность будет не нулевая, если слово database встретится либо в title, либо body, но если оно встретится и там и там, значение релевантности будет выше, нежели если оно два раза встретится в body.
Сама по себе релевантность ничего не определяет. Это лишь сравнительная характеристика, по которой можно сортировать результат выборки, не более того.
Еще следует заметить что для IN NATURAL LANGUAGE MODE действует так называемое «50% threshold». Это означает, что если слово встречается более чем в 50% всех просматриваемых полей, то оно не будет учитываться, и поиск по этому слову не даст результатов.
MATCH-AGAINST IN BOOLEAN MODE
В бинарном режиме, в отличие от других режимов, релевантность вычисляется несколько иначе — как условная мера совпадения заданного шаблона. Положение искомого шаблона в тексте, количество встретившихся вариантов роли не играют.
Самая важная особенность бинарного режима – возможность указания логических операторов. Сами операторы я приводить не буду, о них хорошо рассказано в оригинальной документации по MySQL.
Еще особенностями бинарного режима является отсутствие автоматической сортировки в случае указания условия WHERE, однако для сортировки можно использовать алиас:
SELECT *,
MATCH (title,body) AGAINST ('+database MySQL' IN BOOLEAN MODE) as REL
FROM `articles`
WHERE MATCH (title,body) AGAINST ('+database MySQL' IN BOOLEAN MODE)
ORDER BY REL;
Пример выведет все записи содержащие слово database, но если в записи присутствует слово MySQL, то его релевантность будет выше. Записи будут отсортированы по релевантности.
В бинарном режиме отсутствует ограничение «50% threshold». Бинарный режим можно использовать и без создания полнотекстового индекса, однако это будет работать очень медленно.
MATCH-AGAINST IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
Или просто «WITH QUERY EXPANSION». Работает примерно также, как NATURAL LANGUAGE MODE, с той лишь разницей, то в результат поиска попадают не только совпадения с шаблоном, но и возможные логические совпадения. Это работает примерно так:
Сначала MySQL выполняет запрос аналогичный NATURAL LANGUAGE MODE и формирует результат. По этому результату производится попытка вычислить слова, которые так же имеют высокую релевантность для полученной выборки. В случае, если эти слова присутствуют производится поиск и по ним тоже, но значение их на релевантность будет существенно ниже. Отдается смешанная выборка – сначала те результаты, где слово присутствует, а потом те, которые были получены в результате «повторного» поиска.
WITH QUERY EXPANSION не рекомендуется использовать для больших объемов информации, так как в результат может попасть очень много лишнего.
Использование FULLTEXT SEARCH
Пара слов об алгоритмах поиска
Ну, конечно полнотекстовый поиск можно использовать прежде всего для написания алгоритмов поиска. 🙂 Я не буду заострять на них внимание, скажу просто что при индексации текстовой информации может понадобиться сложный алгоритм обработки, например такой:
- убрать все HTML-теги
- убрать все непечатные символы, знаки препинания и тому подобное
- убрать все слова длинной менее 3-х символов
- перевести все слова в нижний регистр
— это только в самом простом случае, без учета морфологии, подсветки, учета ключевых слов и кодировки.
Соответственно, с поисковым запросом надо сделать тоже самое. Режим поиска используется любой – как удобнее… А вообще поиск – это отдельная тема, про которую нужна отдельная статья.
Раскрытие связок многое-ко-многим
В некоторых случаях – не во всех – с помощью полнотекстового поиска можно раскрывать соотношения многое-ко-многим без привлечения третьей таблицы.
Допустим, у нас есть две большие таблицы: с пользователями и группами пользователей. Причем, каждый пользователь имеет отношение к большому количеству различных групп, в свою очередь группы включают в себя большое количество пользователей. При нормальном соотношении (т.е. раскрытии через 3-ю таблицу), что бы выбрать все группы, которые принадлежат к некоторому пользователю понадобиться сделать запрос, объединяющий 2 или 3 таблицы, что даже при присутствии индексов очень накладно.
Однако можно выполнить денормализацию по следующей схеме:

Теперь, что бы выбрать группы, принадлежащие к пользователю 2 можно сделать:
SELECT *
FROM `groups`
WHERE MATCH (groups) AGAINST ('+user2' IN BOOLEAN MODE);
Это будет работать намного быстрее, чем исходный вариант (с 3-ей таблицей). Аналогично с группами, но если подобные выборки нам в принципе не нужны, то можно обойтись без соответствующего поля в таблице групп. Тогда получится что-то вроде «односторонней» связи M:N. То есть можно вычислить все M, которые принадлежат к N, не нельзя сделать обратного.
В этом случае, как правило, используется IN BOOLEAN MODE.
— Кстати, на эту схему очень хорошо ложится тегирование информации, но там не все так просто и это опять же отдельная тема.
Использование релевантности как меры отношения одного объекта к другому
Один из алгоритмов для вычисления статей, «похожих» на данную статью. Всё просто: берутся теги данной статьи, и делается полнотекстовый запрос по полю с тегами всех остальных статей с сортировкой по релевантности (если она нужна). Естественно, сначала вылезут те, которые содержат максимальное совпадение по тегам.
Можно и без учета тегов. Если статьи индексированы для полнотекстового поиска, из индекса выбираются с десяток наиболее употребляемых слов, после чего делается поиск по ним.
Или вот еще пример – интересы пользователей. Используя точно такую же схему можно легко найти других пользователей, у которых интересы наиболее соответствуют вашим.
И кое-что в заключение:
Несмотря на все возможности полнотекстовых индексов, стоит учитывать, что сами индексы занимают очень значительное место на диске, и изменения таблиц с ними будет выполняться значительно дольше.
Содержание:
1. Что такое полнотекстовый поиск данных?
2. Как включить доступность полнотекстового поиска в 1С?
3. Как осуществляется полнотекстовый поиск данных?
1. Что такое полнотекстовый поиск данных?
Полнотекстовый поиск данных- это функция/инструмент программы 1С, с помощью которого в информационной базе выполняется поиск объектов (справочников, документов, присоединенных текстовых файлов и т.д.), в которых присутствует введенный в строку поиска текст.
Так, например, если вам нужно быстро найти все объекты системы, где упоминается определенное название номенклатуры, воспользуйтесь строкой поиска и введите название этой номенклатуры и система предложит документы и справочники, где выбрана эта номенклатура.
Текст, вводимый в строку, может быть простым, т.е. надо вписать одно слово, часть слова, несколько слов. А также может быть сложный запрос для функции поиска данных, например, можно найти объекты, в которых используется одно из слов, либо оба слова или найти слова с учетом допущения ошибок ввода.
2. Как включить доступность полнотекстового поиска в 1С?
Механизм полнотекстового поиска будет доступен при включенном флаге «Полнотекстовый поиск данных». Данный флаг доступен в настройках базы и расположен в разделе «Администрирование» → «Общие настройки» → «Полнотекстовый поиск данных» (в зависимости от конфигурации, расположение настройки может отличаться, тогда включить/отключить флаг поиска можно в меню «Все функции»)

Полнотекстовый поиск данных в 1С
Для открытия окна поиска надо нажать «лупу» в панели инструментов или вызвать сочетанием клавиш Ctrl+Shift+F.

Открытие окна поиска
3. Как осуществляется полнотекстовый поиск данных?
Для полнотекстового поиска в 1С наберите часть слова, слово или словосочетание.

Процесс полнотекстового поиска в 1С
Помимо точного текста допускается использование более сложных поисковых запросов (правила использования поисковых операторов для осуществления запросов полнотекстового поиска в данных смотри на рисунке ниже)

Язык запросов полнотекстового поиска данных
Прежде чем начать поиск область полнотекстового поискав 1С 8.3 Предприятие можно сократить, для этого надо перейти по гиперссылке в строке «Области поиска», перевести переключатель в положение «В разделах» и выбрать разделы или отдельные объекты разделов установив на них флажки.

Сокращение области полнотекстового поиска в 1С
После того как область поиска ограничена и искомый текст введен для использования функции поиска в строке, надо нажать кнопку «Найти».

Использование полнотекстового поиска данных
В результате в окне результата поиска будут выведены все объекты, содержащие указанный текст.

Окно результатов поиска
Любой из отображенных объектов можно открыть, нажав на его название.

Открытие объектов в окне результатов поиска
Если найденных объектов окажется много, для перехода к следующим страницам окна поиска файлов используйте «стрелочки».

Перемещение в окне результатов поиска
Специалист компании «Кодерлайн»
Зоя Косьяненко
Управление полнотекстовым поиском

Брагина Жастина
Специалист линии консультации франчайзинговой сети “ИнфоСофт”.
05.05.2022
Время прочтения – 3 мин.
Получить бесплатную консультацию
В программе “1С:Бухгалтерия 8” реализован механизм полнотекстового поиска, что позволяет быстро найти нужную информацию в справочниках, документах, отчётах или в информационной базе.
Чтобы начать поиск необходимо установить курсор в поле «Поиск» или нажать сочетание клавиш “Ctrl” и “F”. Начните набирать текст и поиск будет запущен автоматически. Ниже представлен пример поиска в справочнике «Номенклатура».
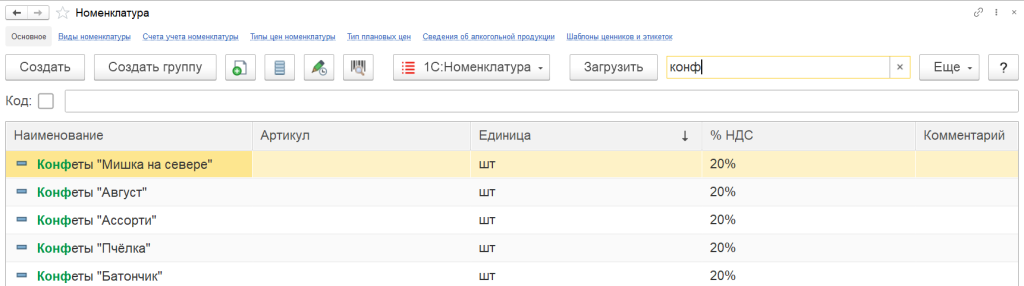
По кнопке со значком лупы (сочетанием клавиш “Alt” и “F” или по кнопке “Ещё”) можно выбрать “Расширенный поиск” и установить параметры поиска.
При работе с полнотекстовым поиском у пользователя могут возникнуть следующие трудности:
1) Поиск работает некорректно – пользователь начинает вводить символ, программа осуществляет поиск, после ввода следующих символов список формируется пустым, несмотря на то, что в программе есть объекты, удовлетворяющие критериям поиска.
2) Поиск осуществляется медленно.
3) Поиск не работает.
Для устранения вышеуказанных проблем необходимо:
-
Проверить корректность ввода данных в поисковую строку – убедится, что все буквы вводятся на одной раскладке клавиатуры, проверить нет ли отбора в списке и т.д.
-
Проверить включен ли полнотекстовый поиск данных, для этого необходимо перейти в раздел «Администрирование» – «Общие настройки».
Подпишитесь на дайджест!
Подпишитесь на дайджест, и получайте ежемесячно подборку полезных статей.
Открыть подраздел «Поиск данных» и установить галочку в поле «Полнотекстовый поиск данных».
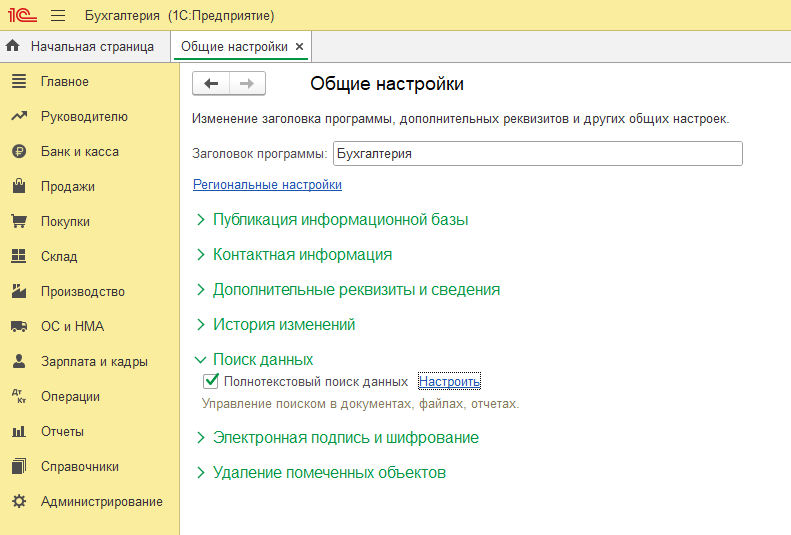
Если галочка установлена, но трудности с использованием поиска сохранились, то необходимо перейти по ссылке «Настроить» и нажать на кнопку «Очистить индекс», данные действия доступны пользователю только с полными правами.
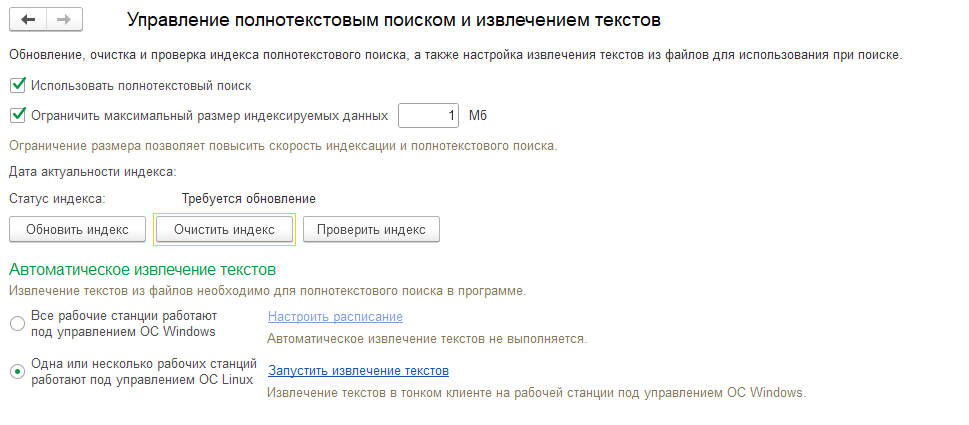
При нажатии на кнопку «Очистить индекс» программа оповестит о том, что все индексы будут очищены, необходимо нажать на кнопку «Да».

После этого необходимо дождаться оповещения от программы о том, что индекс успешно очищен.

Далее необходимо обновить индекс, нажав на соответствующую кнопку, когда индекс обновится, кнопка «Обновить индекс» станет недоступна, а статус индекса сменится на «Обновление не требуется».
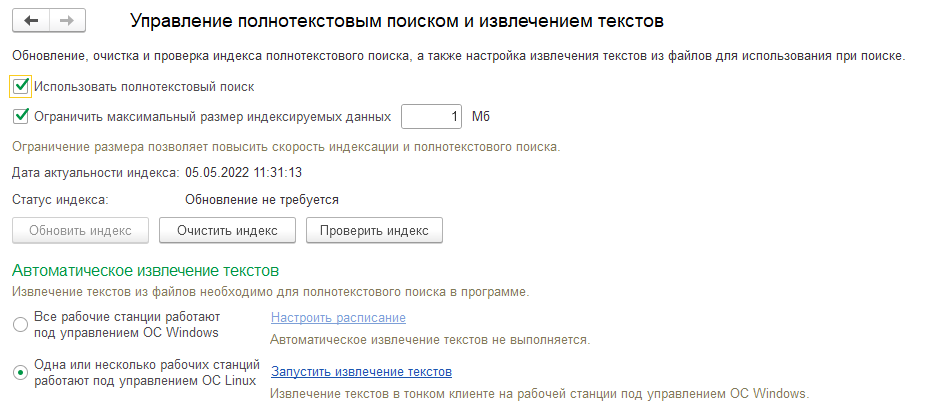
Для того что бы вышеуказанные трудности не возникали и поиск работал корректно, необходимо настроить выполнение двух регламентных заданий – «Обновление индекса ППД» и «Слияние индекса ППД».
Необходимо зайти в раздел «Администрирование» – «Обслуживание».
Открыть подраздел «Регламентные операции» – «Регламентные и фоновые задания».
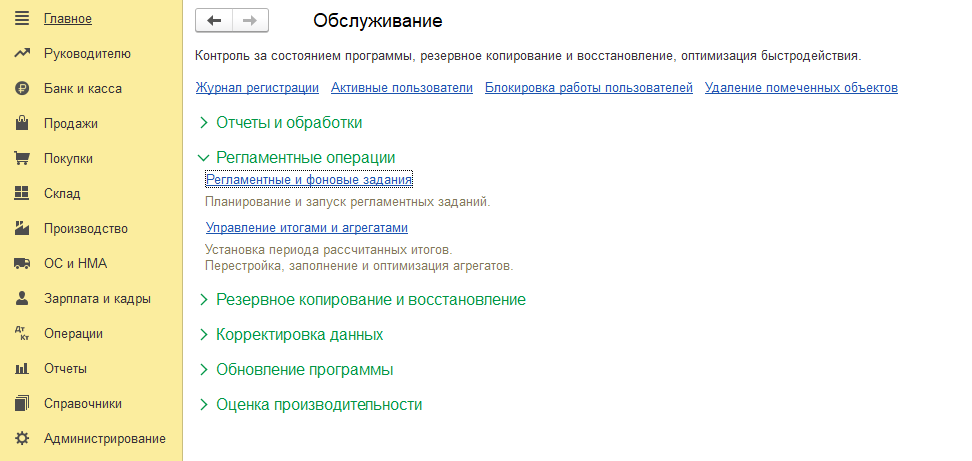
На закладе «Регламентные задания» необходимо найти «Обновление индекса ППД» и «Слияние индекса ППД» нажать двойным щелчком мыши, поставить галочку «Включено».
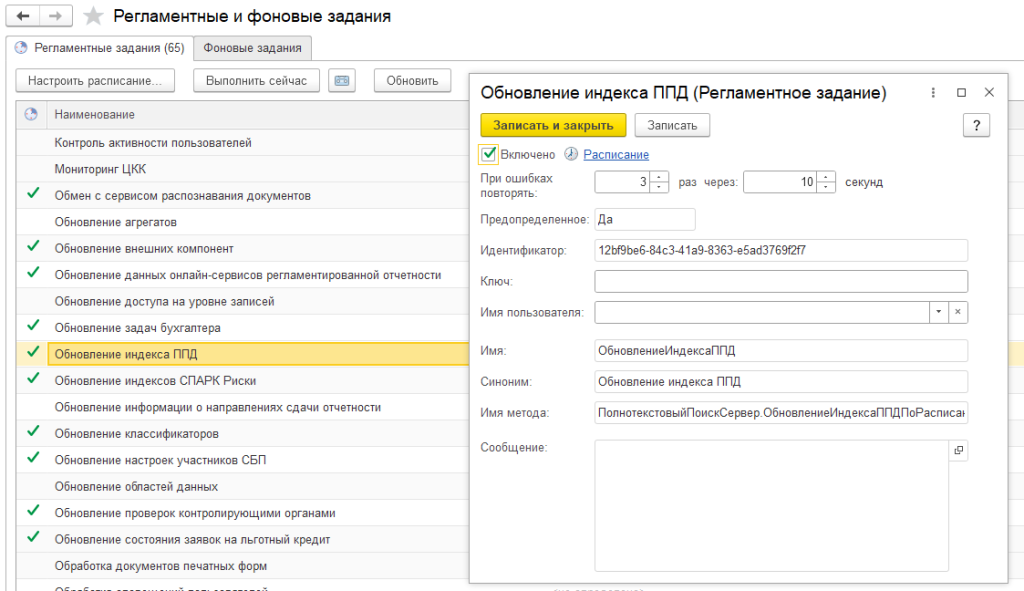
После этого необходимо настроить расписание выполнения регламентных заданий, нажав на ссылку «Расписание».
Переключаясь между вкладками «Общие», «Дневное», «Недельное» и «Месячное» можно задать своё расписание. В примере настроено на каждый день с 8:00:00 каждые 60 секунд.
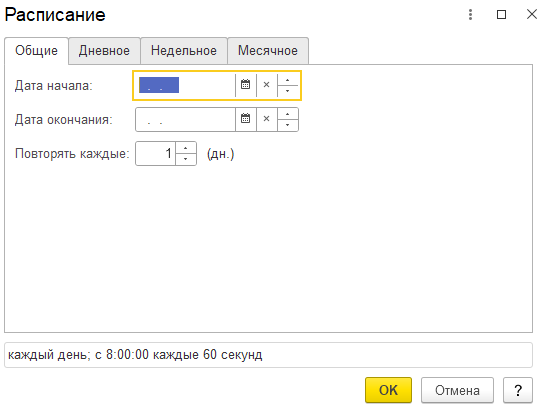
После настройки расписания необходимо нажать на кнопку «ОК» и сохранить изменения, нажав на кнопку «Записать и закрыть».
Всем привет! Продолжаем изучать возможности SQL Server от компании Microsoft, и на очереди у нас компонент Full-Text Search, в русском варианте это «Полнотекстовый поиск». И сейчас мы узнаем, для чего он нужен, и как же реализовать этот самый полнотекстовый поиск в Microsoft SQL Server, используя этот компонент.
И начнем мы, конечно же, с рассмотрения основ полнотекстового поиска, т.е. что это такое и для чего он вообще нужен.

Содержание
- Что такое полнотекстовый поиск?
- Возможности полнотекстового поиска в Microsoft SQL Server
- Подготовка к реализации полнотекстового поиска в Microsoft SQL Server
- Установка компонента «Полнотекстовый поиск» в Microsoft SQL Server
- Исходные данные для создания полнотекстового поиска
- Создание полнотекстового каталога в SQL Server
- Создание полнотекстового каталога на T-SQL
- Создание полнотекстового каталога в графическом интерфейсе Management Studio
- Удаление и изменение полнотекстового каталога в SQL Server
- Создание полнотекстового индекса в Microsoft SQL Server
- Создание полнотекстового индекса на T-SQL
- Создание полнотекстового индекса в графическом интерфейсе Management Studio
- Изменение и удаление полнотекстового индекса
- Создание полнотекстового каталога и индекса с помощью мастера
- Примеры полнотекстовых запросов
Что такое полнотекстовый поиск?
Полнотекстовый поиск – это поиск слов или фраз в текстовых данных. Обычно такой вид поиска используется для поиска текста в большом объёме данных, например, таблица с миллионом и более строк, так как он значительно быстрей обычного поиска, который можно осуществить, используя конструкцию LIKE.
Полнотекстовый поиск подразумевает создание специального индекса (он отличается от обычных индексов) текстовых данных, который представляет собой некий словарь слов, которые встречаются в этих данных.
С помощью полнотекстового поиска можно реализовать своего рода поисковую систему документов (т.е. строк), по словам или фразам в базе данных своего предприятия. Так как помимо своей быстрой работы он обладает еще и возможностью ранжировать найденные документы, т.е. выставлять ранг каждой найденной строке, другими словами, можно найти самые релевантные записи, т.е. самые подходящие под Ваш запрос.
- В полнотекстовом поиске SQL сервера можно осуществлять поиск не только по отдельным словам или фразам, но и по префиксным выражениям, например, задать текст начала слова или фразы;
- Также можно искать слова по словоформам, например, различные формы глаголов или существительные в единственном и во множественном числе, т.е. по производным выражениям;
- Можно построить запрос так, чтобы найти слова или фразы, находящиеся рядом с другими словами или фразами, т.е. выражения с учетом расположения;
- Есть возможность искать синонимические формы конкретного слова (тезаурус) т.е., например, если в тезаурусе определено, что «Автомобиль» и «Машина» – это синонимы, то при поиске слова «Автомобиль» в результирующий набор войдут и строки, содержащие слово «Машина»;
- В запросе можно указывать слова или фразы с взвешенными значениями, например, если в запросе указано несколько слов или фраз, то им можно присвоить важность от 0,0 до 1,0 (1,0 означает, что это самое важное слово или фраза);
- Для того чтобы не учитывать в поиске некоторые слова можно использовать «список стоп-слов» т.е. по словам, включенным в этот список, поиск выполняться не будет.
Подготовка к реализации полнотекстового поиска в Microsoft SQL Server
Перед тем как приступать к созданию полнотекстового поиска, необходимо знать несколько важных моментов:
- Для реализации полнотекстового поиска компонент Full-Text Search (Полнотекстовый поиск) должен быть установлен;
- У таблицы может быть только один полнотекстовый индекс;
- Чтобы создать полнотекстовый индекс, таблица должна содержать один уникальный индекс, который включает один столбец и не допускает значений NULL. Рекомендовано использовать уникальный кластеризованный индекс (или просто первичный ключ), первый столбец которого должен иметь целочисленный тип данных;
- Полнотекстовый индекс можно создавать на столбцах с типом данных: char, varchar, nchar, nvarchar, text, ntext, image, xml, varbinary или varbinary(max);
- Для того чтобы создать полнотекстовый индекс, сначала необходимо создать полнотекстовый каталог. Начиная с SQL Server 2008 полнотекстовый каталог – это логическое понятие, обозначающее группу полнотекстовых индексов, т.е. является виртуальным объектом и не входит в файловую группу (есть способ создания полнотекстового индекса, используя «Мастер», при котором каталог можно создать одновременно с индексом, этот способ мы будем рассматривать чуть ниже).
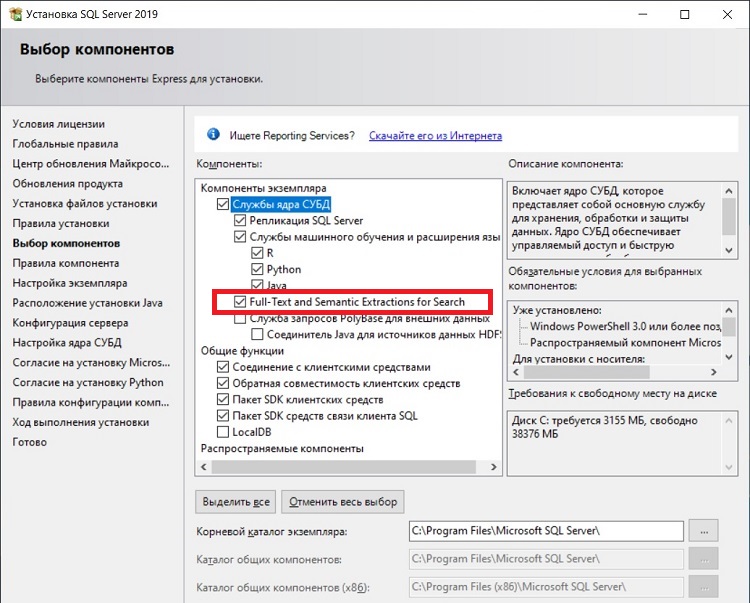
Установка компонента «Полнотекстовый поиск» в Microsoft SQL Server
Чтобы установить компонент Full-Text Search, необходимо в процессе установки Microsoft SQL Server поставить галочку напротив «Full—Text and Semantic Extractions for Search».
Заметка! Подробно весь процесс установки SQL Server мы рассматривали в статье «Установка Microsoft SQL Server 2019». Реализовывать полнотекстовый поиск мы будем как раз на примере Microsoft SQL Server 2019.
В случае если в процессе установки SQL Server компонент Вы не отметили, то это можно сделать и потом, т.е. доустановить необходимый компонент. Для этого запустите «Центр установки SQL Server», так же, как и в процессе установки SQL Server, выберите «Новая установка изолированного экземпляра SQL Server или добавление компонентов к существующей установке» и на этапе выбора компонентов поставьте соответствующую галочку.
Исходные данные для создания полнотекстового поиска
Итак, компонент полнотекстовый поиск у нас установлен, кроме этого у нас установлена среда SQL Server Management Studio, с помощью которой мы и будем выполнять все действия для создания и управления полнотекстовыми каталогами и индексами.
Допустим, что у нас есть база данных TestDB, а в ней есть таблица TestTable, в которой всего два столбца: первый (Id) – это первичный ключ, а второй (TextData) – это текстовые данные, по которым мы и будем осуществлять полнотекстовый поиск.
Для примера она будет содержать несколько текстовых определений технологий.
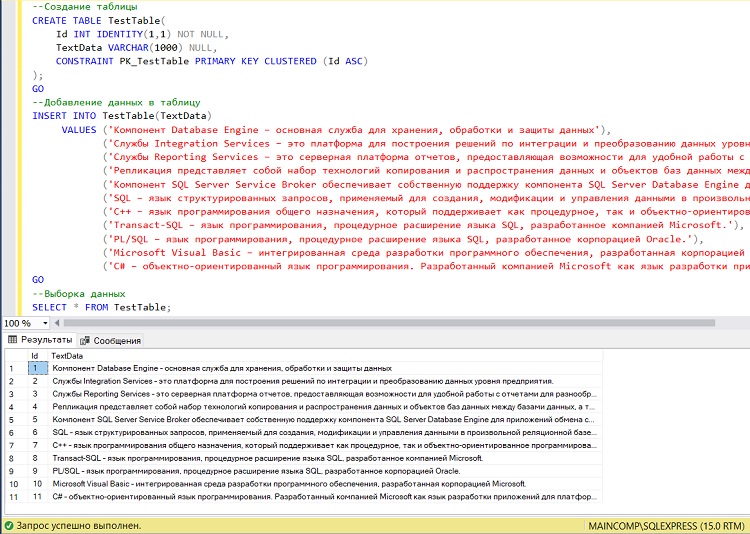
--Создание таблицы
CREATE TABLE TestTable(
Id INT IDENTITY(1,1) NOT NULL,
TextData VARCHAR(1000) NULL,
CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (Id ASC)
);
GO
--Добавление данных в таблицу
INSERT INTO TestTable(TextData)
VALUES ('Компонент Database Engine – основная служба для хранения, обработки и защиты данных'),
('Службы Integration Services – это платформа для построения решений по интеграции и преобразованию данных уровня предприятия.'),
('Службы Reporting Services – это серверная платформа отчетов, предоставляющая возможности для удобной работы с отчетами для разнообразных источников данных.'),
('Репликация представляет собой набор технологий копирования и распространения данных и объектов баз данных между базами данных, а также синхронизации баз данных для поддержания согласованности.'),
('Компонент SQL Server Service Broker обеспечивает собственную поддержку компонента SQL Server Database Engine для приложений обмена сообщениями и приложений с очередями сообщений.'),
('SQL – язык структурированных запросов, применяемый для создания, модификации и управления данными в произвольной реляционной базе данных.'),
('C++ – язык программирования общего назначения, который поддерживает как процедурное, так и объектно-ориентированное программирование.'),
('Transact-SQL – язык программирования, процедурное расширение языка SQL, разработанное компанией Microsoft.'),
('PL/SQL – язык программирования, процедурное расширение языка SQL, разработанное корпорацией Oracle.'),
('Microsoft Visual Basic – интегрированная среда разработки программного обеспечения, разработанная корпорацией Microsoft.'),
('C# – объектно-ориентированный язык программирования. Разработанный компанией Microsoft как язык разработки приложений для платформы Microsoft .NET Framework.');
GO
--Выборка данных
SELECT * FROM TestTable;
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
Создание полнотекстового каталога в SQL Server
Для создания полнотекстового каталога, как, впрочем, и индекса, можно использовать или графический интерфейс SSMS, или инструкции T-SQL, мы с Вами разберем оба способа.
Создание полнотекстового каталога на T-SQL
--Создание полнотекстового каталога
CREATE FULLTEXT CATALOG TestCatalog
WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
AUTHORIZATION dbo
GO
Где,
- CREATE FULLTEXT CATALOG – команда создания полнотекстового каталога;
- TestCatalog – имя нашего полнотекстового каталога;
- WITH ACCENT_SENSITIVITY {ON|OFF} – опция указывает, будет ли полнотекстовый каталог учитывать диакритические знаки для полнотекстового индексирования. По умолчанию ON;
- AS DEFAULT – опция, для того чтобы указать, что каталог является каталогом по умолчанию. В случае создания полнотекстового индекса без явного указания каталога используется каталог по умолчанию;
- AUTHORIZATION dbo – устанавливает владельца полнотекстового каталога, им может быть пользователь или роль базы данных. В данном случае мы указали роль dbo.
Создание полнотекстового каталога в графическом интерфейсе Management Studio
Точно такой же полнотекстовый каталог можно создать и в графическом интерфейсе Management Studio. Для этого открываем базу данных, переходим в контейнер «Хранилище –> Полнотекстовые каталоги», щелкаем правой кнопкой мыши по данному пункту и выбираем «Создать полнотекстовый каталог».
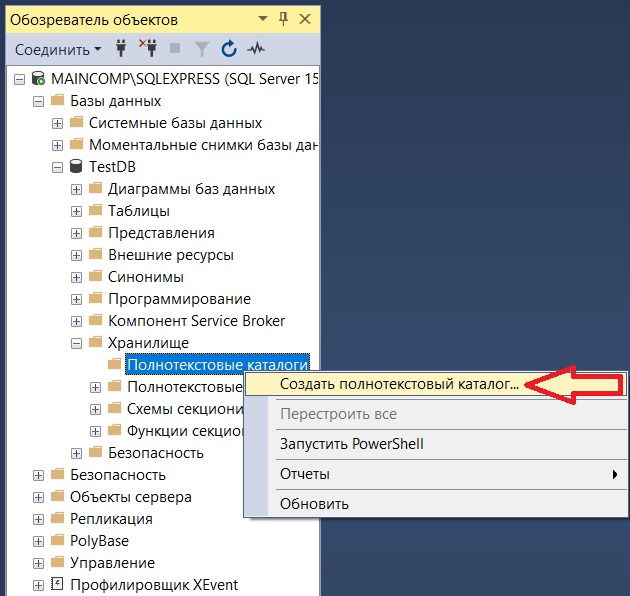
Откроется окно создания каталога, где мы указываем название каталога и его опции. Нажимаем «ОК».
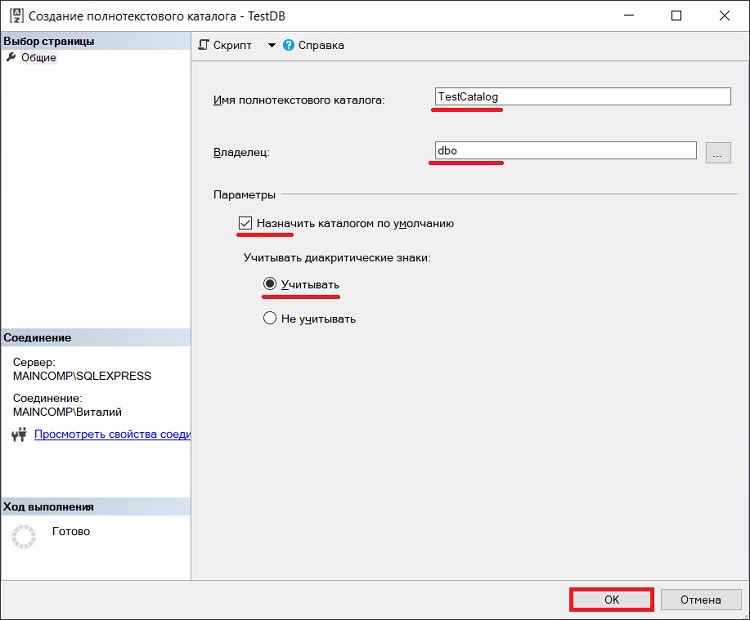
Удаление и изменение полнотекстового каталога в SQL Server
Для изменения параметров каталога можно использовать инструкцию ALTER FULLTEXT CATALOG, например, давайте сделаем так, чтобы наш каталог перестал учитывать диакритические знаки, для этого пишем SQL инструкцию, которая перестроит наш каталог с новым значением параметра.
--Изменение полнотекстового каталога
ALTER FULLTEXT CATALOG TestCatalog
REBUILD WITH ACCENT_SENSITIVITY=OFF
GO
Возвращаем назад.
ALTER FULLTEXT CATALOG TestCatalog
REBUILD WITH ACCENT_SENSITIVITY=ON
GO
В случае необходимости удалить полнотекстовый каталог, мы можем использовать инструкцию DROP FULLTEXT CATALOG.
DROP FULLTEXT CATALOG TestCatalog;
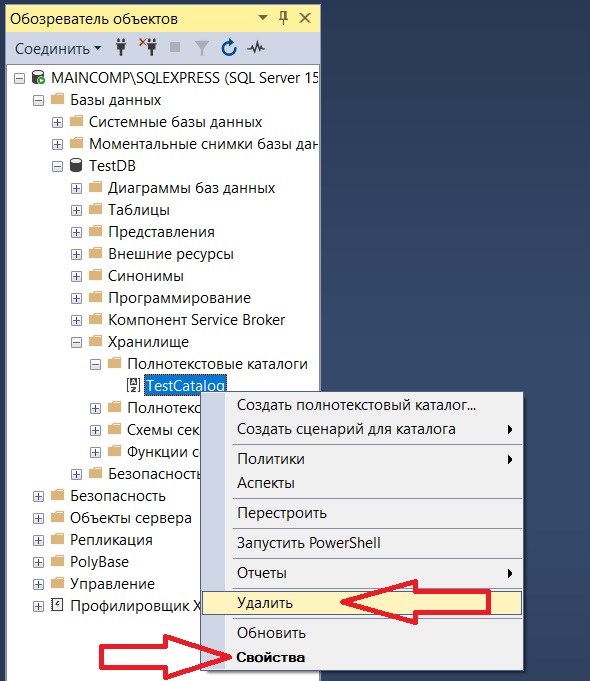
Все это можно было сделать и в графическом интерфейсе Management Studio (для изменения параметров каталога «Свойства», для удаления «Удалить»).
Создание полнотекстового индекса в Microsoft SQL Server
После того как полнотекстовый каталог мы создали, мы можем переходить к созданию полнотекстового индекса. В нашем случае для столбца TextData нашей тестовой таблицы.
Создание полнотекстового индекса на T-SQL
Для того чтобы создать полнотекстовый индекс, мы пишем инструкцию CREATE FULLTEXT INDEX.
--Создание полнотекстового индекса
CREATE FULLTEXT INDEX ON TestTable(TextData)
KEY INDEX PK_TestTable ON (TestCatalog)
WITH (CHANGE_TRACKING AUTO)
GO
Где
- CREATE FULLTEXT INDEX – команда создания полнотекстового индекса;
- TestTable(TextData) – таблица и столбец, включенные в индекс;
- KEY INDEX PK_TestTable – имя уникального индекса таблицы TestTable;
- ON (TestCatalog) – указываем, что полнотекстовый индекс будет создан в полнотекстовом каталоге TestCatalog. Если не указать этот параметр, то индекс будет создан в полнотекстовом каталоге по умолчанию;
- WITH (CHANGE_TRACKING AUTO) – это мы говорим, что все изменения, которые будут вноситься в базовую таблицу (TestTable), автоматически отобразятся и в нашем полнотекстовом индексе, т.е. автоматическое заполнение.
Заметка! Подробно про все типы индексов мы разговаривали в материале – Основы индексов в Microsoft SQL Server.
Создание полнотекстового индекса в графическом интерфейсе Management Studio
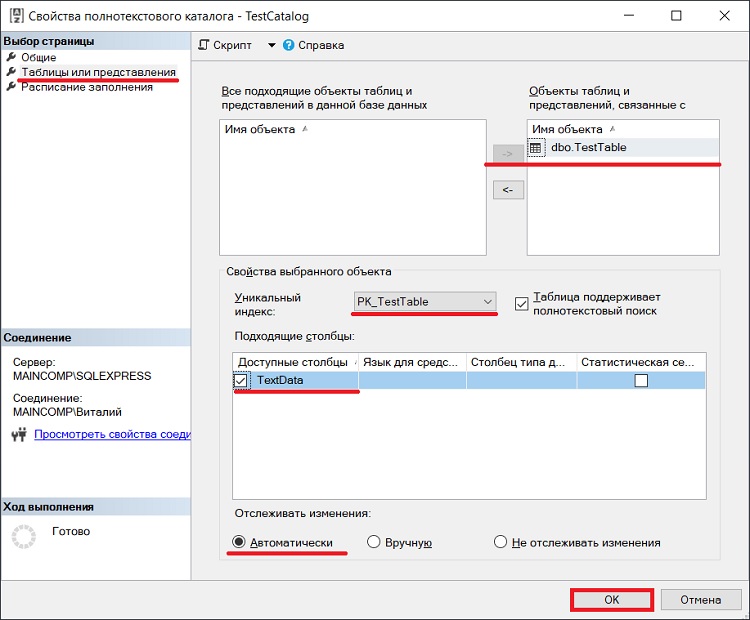
Полнотекстовый индекс можно создать, используя и графические инструменты, для этого открываем свойства полнотекстового каталога и переходим в пункт «Таблицы или представления», выбираем нужную таблицу, столбец, уникальный индекс и способ отслеживания изменений. В нашем случае у нас всего одна доступная таблица и один столбец. Нажимаем «ОК».

Изменение и удаление полнотекстового индекса
В случае необходимости можно изменить параметры полнотекстового индекса. Давайте в качестве примера, изменим способ отслеживания изменений с автоматического на ручной. Для изменения в графическом интерфейсе можно использовать окно «Свойства полнотекстового каталога -> Таблицы или представления», которое мы использовали при создании полнотекстового индекса.
Или можно написать следующий код.
--Изменение полнотекстового индекса
ALTER FULLTEXT INDEX ON TestTable
SET CHANGE_TRACKING = MANUAL
Чтобы вернуть назад, используйте значение параметра AUTO.
ALTER FULLTEXT INDEX ON TestTable
SET CHANGE_TRACKING = AUTO
Для того чтобы удалить полнотекстовый индекс, достаточно просто удалить таблицу из списка объектов, связанных с полнотекстовым каталогом в том же окне «Свойства полнотекстового каталога -> Таблицы или представления»
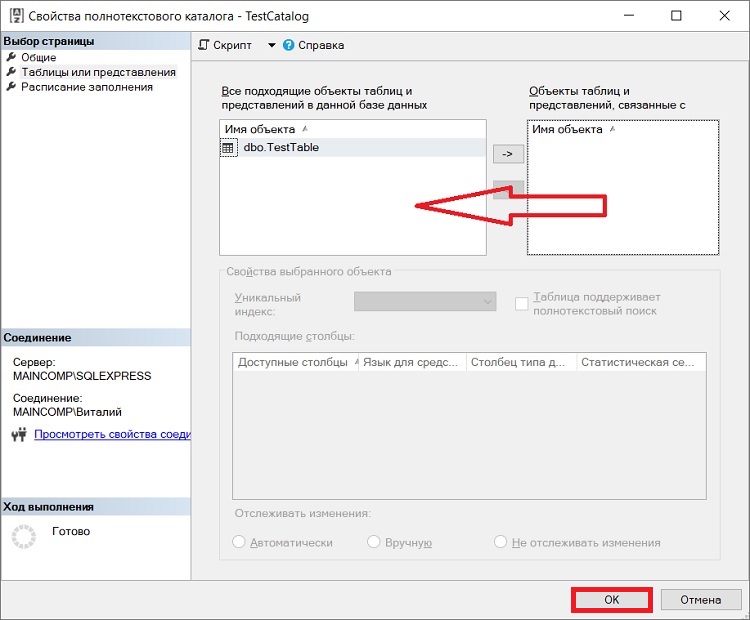
Или написать код T-SQL
--Удаление полнотекстового индекса DROP FULLTEXT INDEX ON TestTable;
Создание полнотекстового каталога и индекса с помощью мастера
Как я уже упоминал ранее, полнотекстовый каталог и индекс можно создать, используя мастер, т.е. по шагам, для этого щелкаем правой кнопкой мыши по таблице, которую мы хотим включить в полнотекстовый поиск, и выбираем «Полнотекстовый поиск -> Определить полнотекстовый индекс».
Примечание! Перед этим я удалил и индекс, и каталог, которые мы создавали в предыдущих примерах.
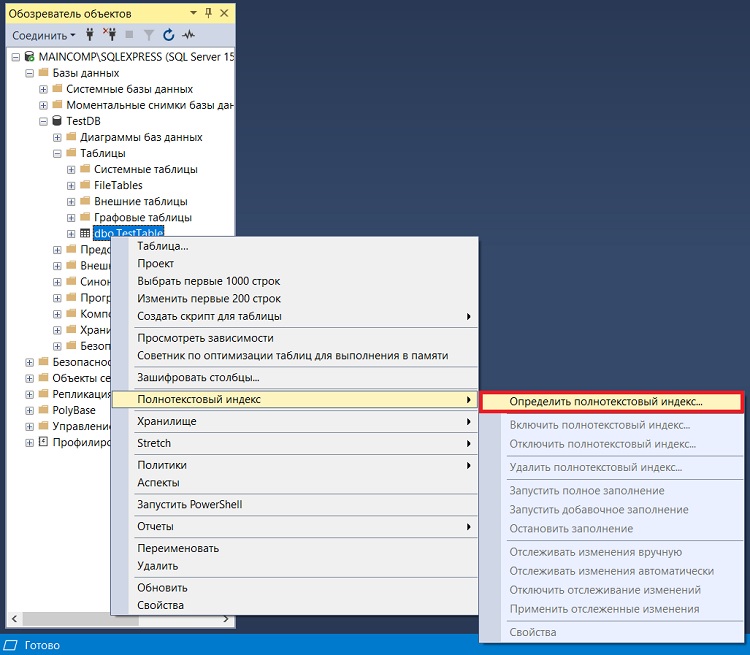
В итоге запустится мастер полнотекстового индексирования SQL Server, нажимаем «Далее».
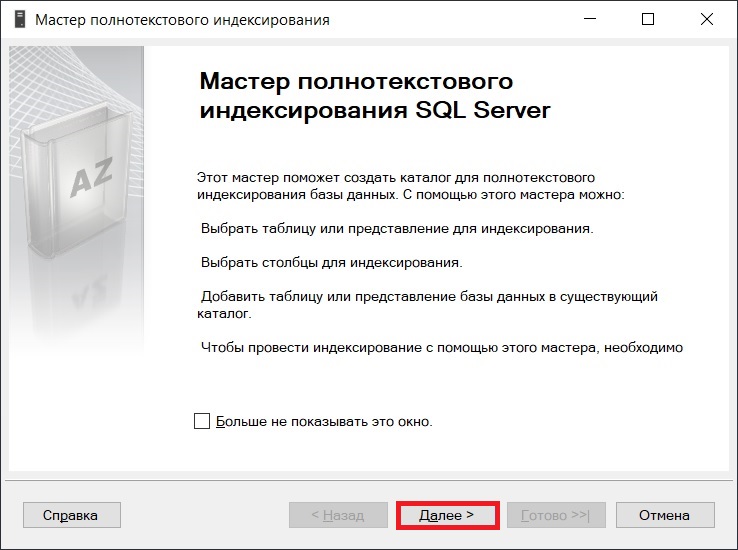
Далее выбираем уникальный индекс и нажимаем «Далее».
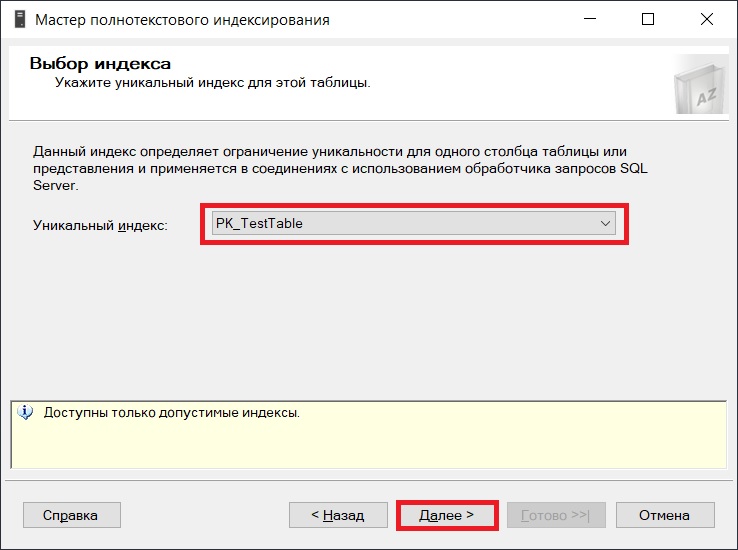
Затем столбец, который будет включен в полнотекстовый индекс, нажимаем «Далее».
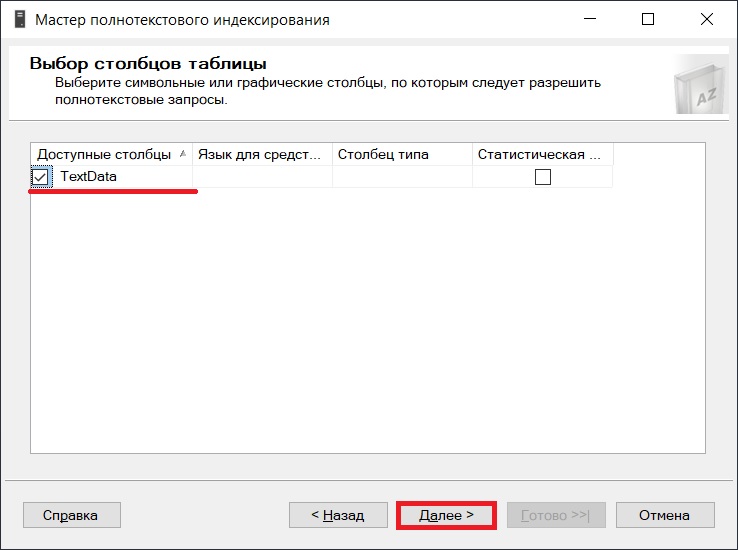
Потом необходимо выбрать способ отслеживания изменений. Нажимаем «Далее».
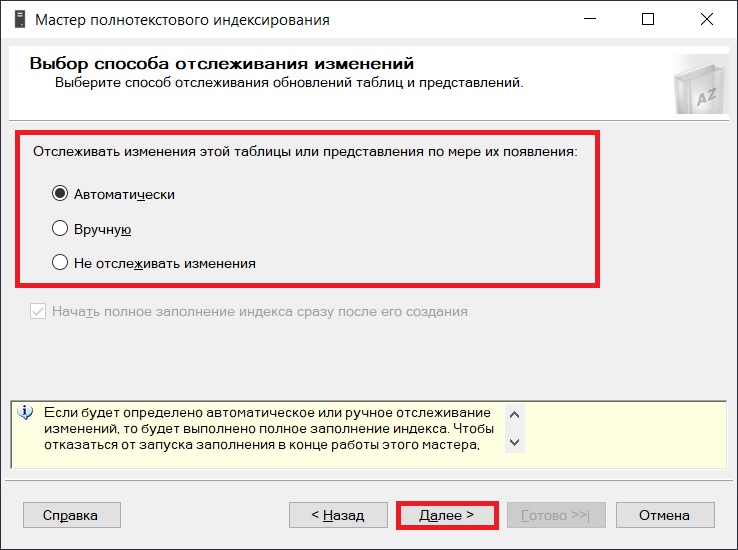
Указываем название каталога и его опции, для того чтобы его создать, так как предполагается, что у нас каталога нет, если бы он был, то мы могли бы его выбрать. Нажимаем «Далее».
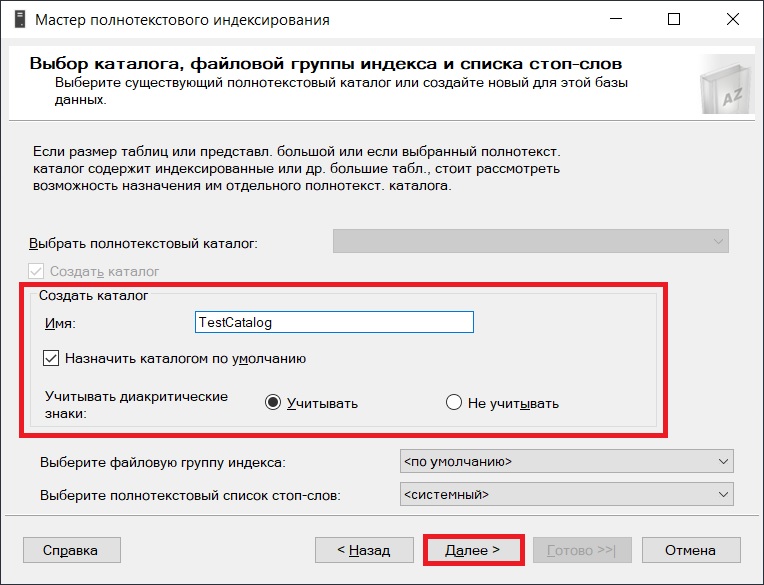
Для создания каталога и индекса осталось нажать «Готово».
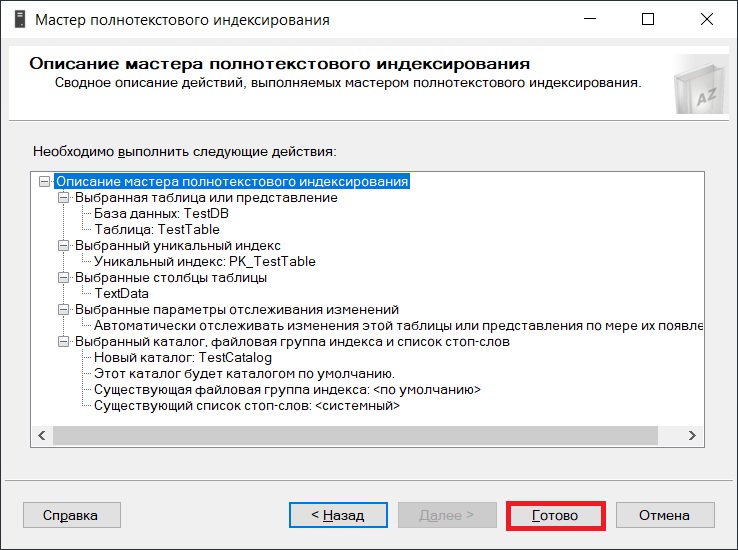
В следующем окне мы увидим результат выполнения операций по созданию полнотекстового каталога и индекса. В моем случае все прошло успешно. Нажимаем «Закрыть».
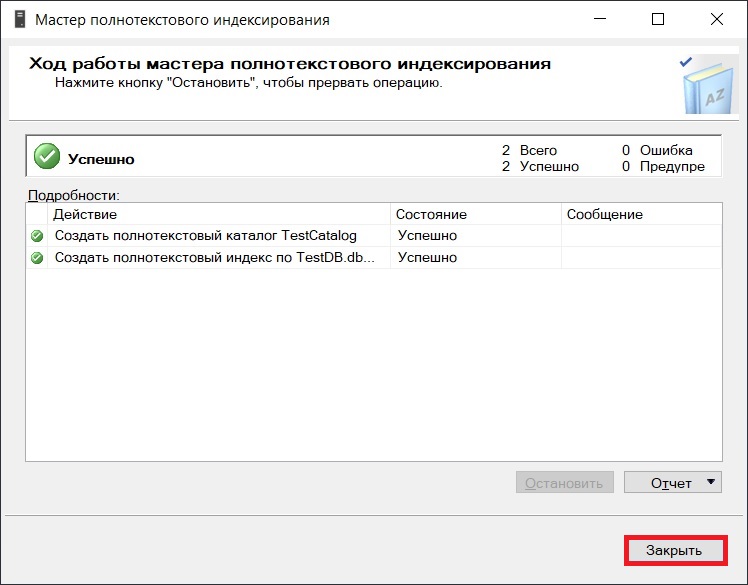
Таким образом, мы выполнили создание полнотекстового каталога и индекса одновременно с помощью мастера.
Примеры полнотекстовых запросов
Более подробно полнотекстовые запросы мы будем рассматривать в отдельном материале, а пока, в качестве примера и подтверждения того, что наш полнотекстовый поиск работает, давайте напишем пару простых полнотекстовых запросов.
Если помните, наша таблица TestTable содержит определения технологий, языков программирования, в общем, определений, связанных со сферой IT. Допустим, что мы хотим получить все записи, где есть упоминание о компании Microsoft, для этого мы пишем полнотекстовый запрос с ключевым словом CONTAINS, например
SELECT Id, TextData FROM TestTable WHERE CONTAINS (TextData, 'Microsoft');
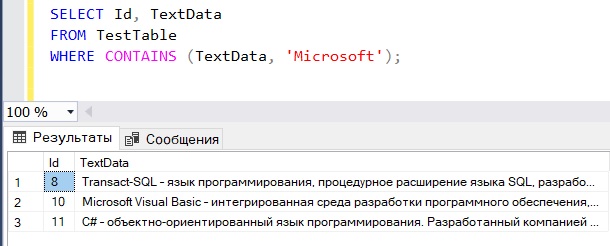
Мы получили результат, но допустим, нам также необходимо отсортировать его по релевантности, другими словами, какие строки больше соответствуют нашему запросу. Для этого мы будем использовать функцию CONTAINSTABLE, которая проставляет ранг для каждой найденной записи.
SELECT Table1.Id AS [Id],
RowRank.Rank AS [RANK],
Table1.TextData AS [TextData]
FROM TestTable AS Table1
INNER JOIN CONTAINSTABLE(TestTable, TextData, 'Microsoft') AS RowRank
ON Table1.Id=RowRank.[KEY]
ORDER BY RowRank.RANK DESC;
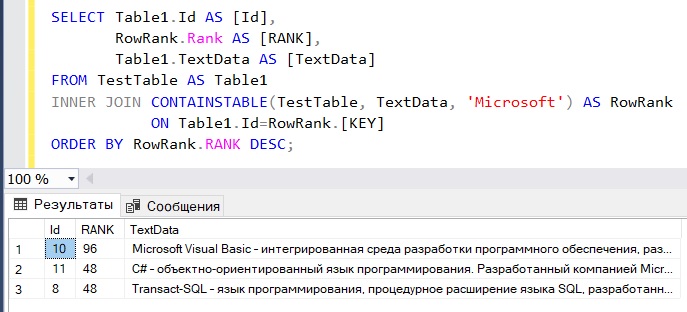
Как видим, ранг проставлен и по нему отсортированы строки. Сам алгоритм ранжирования, как и более подробную информацию о полнотекстовом поиске, можно найти в электронной документации по SQL Server.
Заметка! Еще больше статей по Microsoft SQL Server и языку T—SQL Вы можете найти в специальном сборнике статей – Сборник статей для изучения Microsoft SQL Server.
На этом предлагаю завершить, надеюсь, все было понятно, удачи!
Почему с помощью обычного полнотекстового поиска сложно искать очень короткие документы и как быть, если хочется это сделать.

Введение
Мы все постоянно сталкиваемся с так называемым полнотекстовым поиском — нахождением документов по поисковой фразе. Самый известный пример — это поиск Google.
Существует немало инструментов для построения полнотекстового поиска документов. Достаточно популярным решением является, например, Elasticsearch. На его основе можно организовать поиск по огромным базам данных с десятками миллионов документов.
Мы в DD Planet разрабатываем сервисы поиска и аналитики по базам данных B2B-закупок и активно используем Elasticsearch. Но когда мы попытались организовать поиск и сопоставление очень коротких документов (наименований товаров), то столкнулись с рядом проблем.
Как работает полнотекстовый поиск
Большинство систем полнотекстового поиска, в том числе и Elasticsearch, основаны на обратном индексе — структуре данных, где для каждого слова из базы документов хранятся все документы, в которых оно встречается. Обратный индекс используется для поиска по текстам.
Пусть у нас есть корпус из базы из трех текстов:
T0="синяя ручка»",
T1="синее дерево",
T2="красное дерево",тогда обратный индекс будет выглядеть следующим образом:
"синий": {0, 1}
"ручка": {0}
"дерево": {1, 2}
"красный": {2}Поиск по одному слову очевиден — это просто список всех документов, соответствующих поисковому слову. При поиске фразы можно производить как пересечение, так объединение результатов поиска по отдельным словам с целью ранжировать результаты по релевантности. Рассмотрим, например, поиск фразы «красная ручка». Поиск по слову «красный» дает результат {2}, по слову «ручка» — {0}. Пересечение пусто, поэтому точно совпадения нет. Если считать частичное совпадение, то получится два документа {0, 2} c степенью соответствия ½. В реальных поисковых системах обычно применяются более сложные методики ранжирования, например, с учетом TF-IDF, однако в результаты выдачи не может попасть документ без текстового совпадения с поисковым запросом.
Проблемы полнотекстового поиска
Если нам необходимо не просто искать внутри данных, а сопоставлять их, находить похожую информацию или те же данные, только написанные по-другому, то мы сталкиваемся со следующими проблемами:
- Контекстная значимость слов.
Вернемся к предыдущему примеру: словосочетания «синяя ручка» и «красное дерево» отличаются от фразы «красная ручка» одинаково одним слово, имеют примерно одну релевантность, однако семантически «красная ручка» намного ближе к «синей ручке», чем к «красному дереву». На мой взгляд, с этим сложнее всего бороться.
Можно применить технику с весами слов в поисковом запросе. Но такое решение переводит одну задачу в другую: непонятно, как определить эти веса адекватно. Самым простым вариантом является, как уже отмечалось, вычисление TF-IDF, но этот подход как минимум не учитывает порядка слов. - Разное написание одинаковых по значению слов.
Другая проблема — сокращения и синонимы в наименованиях товарных позиций, например, не только «лист бумаги А4», а также «А4», «бумага для принтера», «лист А4» и т. д.
Решение проблемы — загрузка в Elasticsearch словарей синонимов. Однако сборка обширных библиотек синонимов если и реальна, то очень трудоемка, особенно в узкоспециализированных областях. - Разное значение одинаковых по написанию слов.
Обратной проблемой является то, что исходя из контекста слова могут иметь разное значение. Например, во фразах «ключ дверной» и «ключ активации Windows» слово «ключ» имеет совершенно разное значение.
NLP как решение проблем
Одним из технологичных способов решить вышеупомянутые задачи является применение NLP подходов. NLP (Natural Language Processing) — общее направление искусственного интеллекта и математической лингвистики, которое изучает проблемы компьютерного анализа и синтеза естественных языков.
NLP использует семантико-синтаксический анализ введенного текста, учитывает естественно-языковые средства. Сейчас существует множество готовых моделей, фреймворков и уже решенных проблем в этой области.
Как определить степень «похожести» фраз
В NLP есть следующая задача — Paraphrase Identification — это изучение двух текстовых объектов (например, предложений) и определения, имеют ли они одинаковое значение (то есть являются парафразами). Пример парафраз: «Завтра кафе работает до 17:00» и «На следующий день кафетерий будет работать до пяти вечера». Почему это нам интересно? С помощью парафразирования мы можем анализировать текстовые описания товаров и выяснять, связаны ли они с одним товаром или нет.
Эта задача хорошо исследована. Существуют большие базы данных парафраз на русском и английском языках. В качестве инструмента для решения этой проблемы мы обратились к библиотеке DeepPavlov.ai [1], мощному фреймворку, разработанному в МФТИ. В нем собраны различные подходы и модели, связанные с обработкой русского языка.
Следующим шагом было получение базы парафраз. Так как наша тематика достаточна специфична (поиск товаров), нам нужна собственная база данных. Мы воспользовались агрегаторами магазинов вида Яндекс.Маркета. Взяли одно название товара с Маркета и другое название этого же товара в интернет-магазине.
Экспериментируя с разными моделями, имеющимися в DeepPavlov, мы поняли — основной вклад в результат дают не настройки модели, а качество наших данных.
Как организовать поиск, когда у нас почти ничего нет
Однако нам нужно не просто определять степени соответствия, а находить наиболее похожие товары. Как это сделать? Можно использовать полный перебор, однако он имеет сложность поиска $inline$O(N)$inline$ и занимает много времени, тогда как обратный индекс Elasticsearch имеет сложность поиска $inline$O(log N)$inline$. Попробуем достичь такой же скорости поиска.
Что мы имеем: множество строк и некоторую функцию, описывающую степень соответствия между этими строками. Будем далее называть эту функцию расстоянием.
Если покопаться в теории, можно наткнуться на следующую математическую структуру: метрическое пространство — это множество, на котором определена функция $inline$d$inline$ такая, что выполняются следующие аксиомы:
- Расстояние равно нулю только при равенстве двух объектов $inline$d(x, y) = 0$inline$, если $inline$x=y$inline$.
- Расстояние симметрично $inline$d(x, y) = d(y, x).$inline$
- Самая сложная из аксиом — неравенство треугольника $inline$d(x,z)≤ d(x,y)+d(y,z).$inline$ Это значит, что сумма расстояний не меньше, чем расстояние между крайними объектами.
Зачем нам нужна такая сложная структура? Она нужна для эффективного решения задач поиска ближайших соседей (Nearest neighbor search) — в нашем случае поиска похожих товаров. Такая задача может быть решена в метрическом пространстве с помощью структуры vantage-point tree, поиск в которой имеет асимптотику поиска $inline$O(log N)$inline$ [2]. Заметим, если бы речь шла о векторах, эта задача решилась намного проще, например, с помощью Kd-деревьев. Однако так как наши объекты более абстрактны, все гораздо сложнее.
Vantage-point tree
Посмотрим, как работает vantage-point tree [3]. Оно напоминает ball-tree, используемый в векторных пространствах. Его структура представляет собой бинарное дерево. Рассмотрим, как оно строится. Мы берем в качестве вершины некоторый объект из множества (vantage-point) и рисуем вокруг него окружность (изображена на рисунке ниже).

Все объекты, находящиеся внутри окружности (то есть на расстоянии $inline$≤S$inline$ от vantage-point), идут в левую часть дерева. Остальные — в правую часть. Далее процедура повторяется для каждого поддерева. Чтобы дерево было сбалансировано, надо стараться выбирать S так, чтобы исходное множество объектов делилось на примерно равные части. Это несложно сделать, если заранее просчитать все расстояния и найти их медиану.
Предположим, мы хотим найти K ближайших соседей к точке $inline$X$inline$ (отмечена красным крестиком на рисунке). Мы еще не нашли ни одной точки, поэтому в качестве ближайшего кандидата берем вершину дерева (возможно, потом мы удалим эту точку). Запоминаем значение $inline$D$inline$ — текущее расстояние до самого дальнего кандидата. Теперь надо решить, нужно ли нам искать в обоих поддеревьях или достаточно проверить только одно и них.

Так как точка $inline$X$inline$ находится внутри нашей окружности, мы должны сначала проверить «внутреннее» поддерево. Находим в этом поддереве синюю точку и обновляем $inline$D$inline$. Надо ли нам проверять «внешнее» поддерево? Мы рассмотрели все точки внутри окружности, но так как $inline$D > T$inline$ (расстояние от X до окружности), за пределами окружности могут существовать более близкие точки. Значит, нам надо проверить «внешнее» поддерево.

Однако если мы уже собрали K ближайших точек, а $inline$D ≤ T$inline$, то проверять «внешнее» поддерево нет необходимости. Это и обеспечивает выигрыш в производительности по сравнению с полным перебором.
Метрическая функция
Мы решили использовать нашу функцию парафразирования $inline$left(f(x,y)right)$inline$ в качестве расстояния для построения vantage-point tree и столкнулись с рядом проблем:
-
Не выполняется первая аксиома — расстояние между точками равно нулю только при условии, что они равны. Это условие не выполняется уже на обучающей выборке, так как мы полагали, что некоторые фразы означают одно и то же при их разном написании. Для решения проблемы мы добавили к основному расстоянию cosine расстояние по Doc2Vec с небольшим весом — оно будет гарантировано различно для разных объектов.
$$display$$d(x,y)=f(x,y)+ε cdot S_{Doc2Vec}(x cdot y )$$display$$
Однако вопрос подбора весового коэффициента ε остается открытым — с этим надо экспериментировать на реальных данных.
-
Модель несимметрична. Почему? Понять это достаточно сложно, но, скорее всего, проблема в ошибке округления float32. Из-за сложности модели ошибка накапливается в слоях нейронов. Эта проблема легко решается вычислением сначала расстояния от $inline$x$inline$ до $inline$y$inline$, а потом наоборот, и суммированием результата.
$$display$$d(x,y)=f(x,y)+f(y,x)$$display$$
-
Не всегда выполняется неравенство треугольника $inline$d(x,z)≤ d(x,y)+d(y,z)$inline$. Причиной этого являются особенности обучения нашей модели парафразирования. Например, рассмотрим фразы
x="красная машина", y="синяя машина", z="синий микроавтобус"Это наглядный пример, когда $inline$d(x,z) ≥ d(x,y)+d(y,z).$inline$ Из-за этого поисковая выдача иногда получается неупорядоченной. Исправить аналитически это не получается, но компенсировать это может увеличение веса расстояния Doc2Vec — для него неравенство треугольника выполняется всегда.
Выполнив формальные критерии, описанные выше, мы столкнулись на практике с другой проблемой — время поиска росло линейно, а не логарифмически, как мы ожидали. Покопавшись в литературе, мы выяснили: логарифмическая скорость поиска имеет место для примерно равномерного распределения точек в пространстве [2]. А у нас объекты распределены неравномерно — они чаще дальше, чем ближе.
Поэтому нам пришла следующая идея. Посчитаем все возможные пары расстояний и нанесем их на график (на рисунке слева). Если мы растянем верхнюю часть графика, а нижнюю сожмем, то точки будут распределены примерно одинаково (как показано на рисунке справа). Заметим, что порядок в множестве расстояний от такого преобразования не изменится. Можно при необходимости увеличить количество интервалов и получить «идеальное» распределение расстояний.

Итоги
Пока что мы проводили тестирование на небольших базах данных (до миллиона объектов), и там наш поиск работает достаточно хорошо. Время сборки дерева растет практически линейно с небольшим логарифмическим коэффициентом.

Рост времени поиска близок к логарифмическому. Почему рост времени поиска не всегда равномерен? Дело в том, что работа поиска зависит от распределения точек в пространстве. Возникает интересный вопрос: если бы мы могли управлять распределением точек в пространстве, то какое распределение было бы оптимальным? В литературе по vantage-point tree этот вопрос обычно не обсуждается, но обсуждается смежный вопрос — как оптимально выбрать vantage-point.

Например, в метрическом пространстве нужно брать самую крайнюю точку[2], тогда на границе будет меньше всего точек и поиск станет лучше. Но эта идея реализуема только в пространстве с понятиями лево, право и край. В пространстве без порядка объектов эта идея не работает.
Наше решение не является «серебряной пулей». Мы пробовали его для поиска товаров, и получилось отлично. Если выбрать другую тематику, результаты могут быть совершенно другими.
Сейчас мы работаем над развитием и оптимизацией технологии. Мы хотим создать не просто алгоритмические или математические структуры, а реально работающие поисковые системы. Текущие результаты можно посмотреть на GitHub или попробовать через pip install nlp-text-search.
Литература
[1] http://docs.deeppavlov.ai/en/master/.
[2] Yianilos (1993). Data structures and algorithms for nearest neighbor search in general metric spaces. Fourth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics Philadelphia, PA, USA. pp. 311–321. pny93. http://web.cs.iastate.edu/~honavar/nndatastructures.pdf.
[3] http://stevehanov.ca/blog/?id=130
Автор: Басалов Юрий
Источник
