Сложность задачи заключается в том, что адресов дано 10 миллиардов. Сколько пространства понадобится для хранения 10 миллиардов URL-адресов? Если в среднем URL-адрес занимает 100 символов, а каждый символ представляется 4 байтами, то для хранения списка из 10 миллиардов URL понадобится около 4 Тбайт. Скорее всего, нам не понадобится хранить так много информации в памяти.
Давайте попробуем сначала решить упрощенную версию задачи. Представим, что в памяти хранится весь список URL. В этом случае можно создать хэш-таблицу, где каждому дублирующемуся URL ставится в соответствие значение true (альтернативное решение: можно просто отсортировать список и найти дубликаты, это займет некоторое время, но даст и некоторые преимущества).
Теперь, когда у нас есть решение упрощенной версии задачи, можно перейти к 400 Гбайт данных, которые нельзя хранить в памяти полностью. Давайте сохраним некоторую часть данных на диске или разделим данные между компьютерами.
Решение 1: хранение данных на диске
Если мы собираемся хранить все данные на одной машине, то нам понадобится двойной проход документа. На первом проходе мы разделим список на 400 фрагментов по 1 Гбайт в каждом. Простой способ — хранить все URL-адреса и в файле <x>.txt, где х = hash(u) % 400. Таким образом, мы разбиваем URL-адрсса по хэш-значениям. Все URL-адреса с одинаковым хэш-значением окажутся в одном файле.
На втором проходе можно использовать придуманное ранее решение: загрузить файл в память, создать хэш-таблицу URL-адресов и найти повторы.
Решение 2: много компьютеров
Этот алгоритм очень похож на предыдущий, но для хранения данных используются разные компьютеры. Вместо того чтобы хранить данные в файле <x>.txt, мы отправляем их на машину х.
У данного решения есть преимущества и недостатки.
Основное преимущество заключается в том, что можно организовать параллельную работу так, чтобы все 400 блоков обрабатывались одновременно. Для больших объемов данных мы получаем больший выигрыш во времени.
Недостаток заключается в том, что все 400 машин должны работать без сбоев, что на практике (особенно с большими объемами данных и множеством компьютеров) не всегда получается. Поэтому необходимо предусмотреть обработку отказов.
Оба решения хороши и оба имеют право на существование.
Разбор взят из книги Гейл Л. Макдауэлл «Cracking the Coding Interview» (есть в переводе).
Дубликаты контактов — это повторяющиеся адреса электронной почты в базе email-рассылки. Они могут быть полностью идентичны или отличаться по каким-то параметрам. Например, только именем получателя, при этом почта одинаковая.
В статье рассказали, откуда в базе email-рассылки берутся дубли контактов, чем вредят и как от них избавиться. В конце — несколько советов по работе с базой, которые помогут повысить эффективность email-маркетинга.
Откуда берутся дубли в базе email-адресов?
Это происходит по разным причинам.
Пользователи регистрируются несколько раз с одного email. Например, человек зарегистрировался на образовательной платформе и подписался на рассылку. В почту приходят многочисленные приглашения на вебинары. Пользователь не авторизуется в системе, но каждый раз просто заполняет поле email.
Снизить риск появления дублей в базе можно запретом на повторную регистрацию с одного адреса. Только позаботьтесь, чтобы зарегистрированный пользователь в этом случае мог легко и быстро авторизоваться или восстановить доступ. Например, можно отправлять письмо восстановления пароля в почтовый ящик.
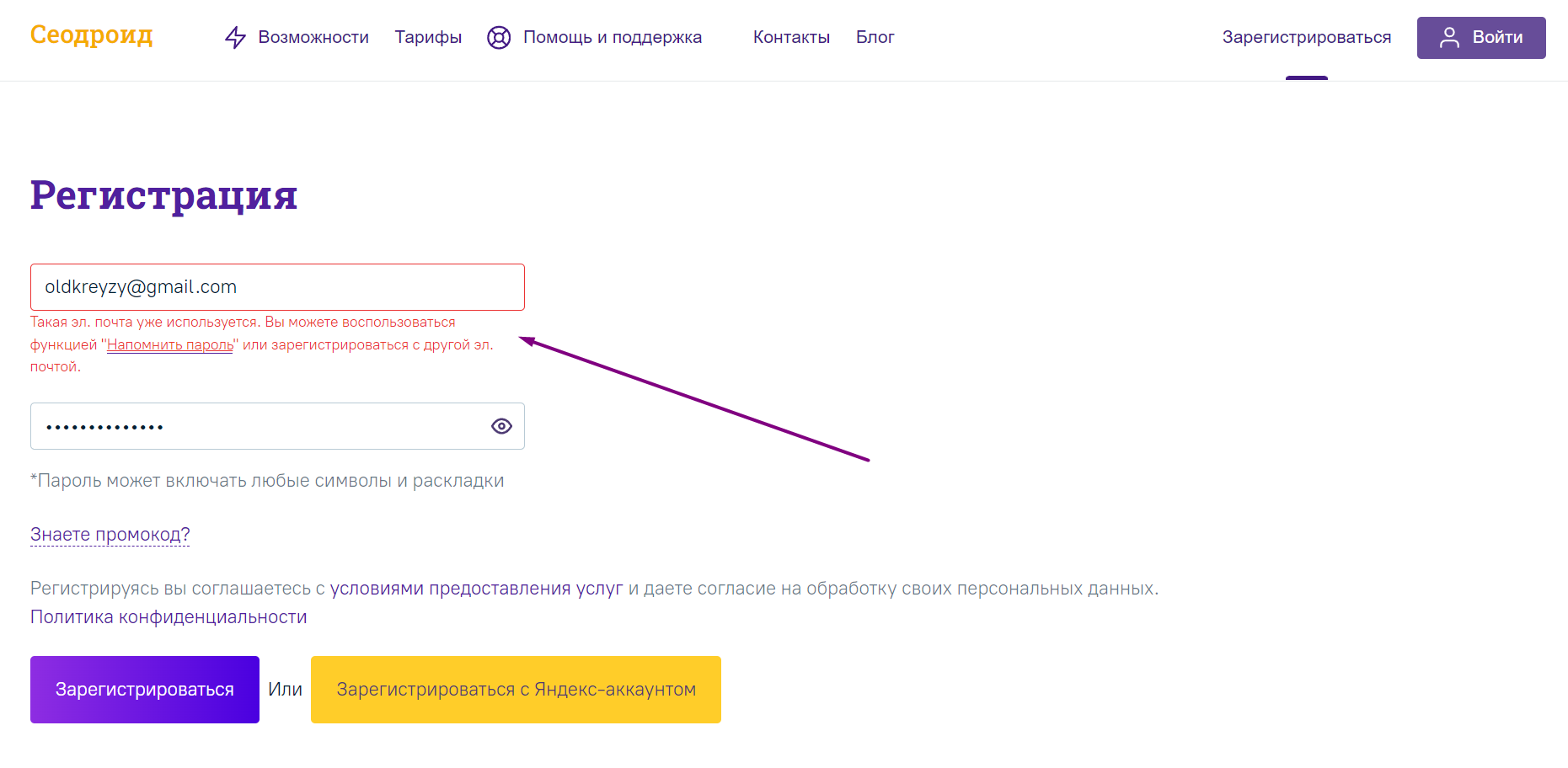
Предупреждение может выглядеть так
Если вы собираете адреса через форму подписки на рассылку, собранную в Sendsay, можете запретить показывать ее пользователям, которые уже заполняли.
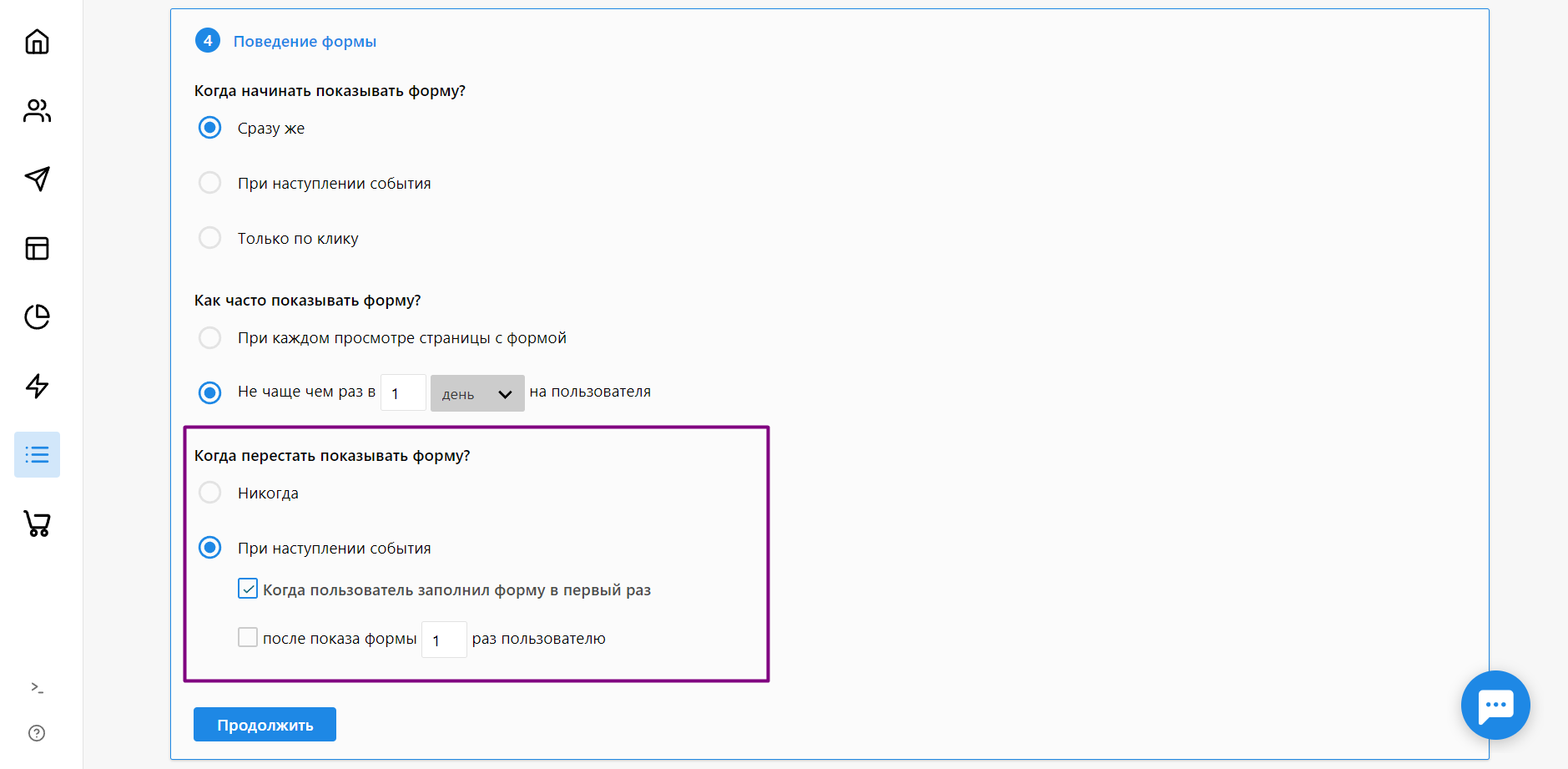
Настраиваем поведение формы подписки на рассылку в Sendsay
Базу контактов собирали из разных источников. Адреса могут дублироваться, даже если способы сбора и источники вполне легальные. Например, база email-рассылок собирается из пользователей, которые:
- регистрируются в сервисе и дают согласие на рассылку
- подписываются на рассылку в блоге и на лендинге
- заполняют лид-форму в таргетированной рекламе во ВКонтакте
Хорошо, если система email-маркетинга настроена: все адреса автоматически собираются в единую базу в сервисе email-рассылок. Данные по дублям объединяются. Но часто бывает по-другому: маркетолог вручную копирует все в один список. Если адресов много, визуально найти и убрать все дубли невозможно.
Два менеджера занесли в CRM одного и того же клиента. Конечно, современные CRM фиксируют дубликаты и объединяют записи в один контакт. Но только если клиентская база ведется не в электронных таблицах. В этом случае сохранятся обе записи. И если после подтверждения заказов по email клиент даст согласие на рассылку, будет получать их в двойном экземпляре.
Чем опасны дубликаты контактов?
Если повторяющихся адресов в базе контактов много, глобально проблемы примерно те же, что и с несуществующими email, неподтвержденными или неактивными подписчиками.
Ухудшение показателей рассылки. Если пользователь получил несколько одинаковых писем, откроет он только одно, перейдет по ссылке и сконвертируется тоже из одного. Чем больше дублей контактов, тем ниже будут метрики открываемости, кликабельности и коэффициент конверсий.
Повторные письма раздражают подписчиков и снижают лояльность. В почтовый ящик итак приходит слишком много сообщений, а обработка одинаковых рассылок — напрасная трата времени. В каждой нужно прочитать имя отправителя, тему, прехедер. Понять, что они идентичны и удалить лишнее или оба.
Подписчики могут жаловаться на спам. Если вы и без того часто отправляете письма, да еще и каждое приходит в нескольких экземплярах, рано или поздно терпение даже самых лояльных пользователей закончится. Посыпятся жалобы на спам, а это плохо для статистики и чревато блокировкой домена. Подробнее о том, чем опасны спам-рассылки и как не стать спамером, мы рассказывали в другой статье.
Бизнес тратит бюджет на дубликаты. Тарифы платформ email-маркетинга часто привязаны к объему базы. А значит, за каждый дубль контакта компания платит деньги, и общая стоимость email-рассылки растет.
Все это снижает эффективность email-маркетинга в целом, поэтому базу стоит регулярно чистить от дублей: находить и убирать повторяющиеся контакты. Однако ручной поиск занимает слишком много времени, поэтому этот процесс лучше автоматизировать.
Как удалить дубли в базе
Идеальный вариант — чтобы дубликаты контактов вообще не попадали в базу. Например, запретить повторную регистрацию с того же адреса. Однако и с таким способом дубли все равно могут проскакивать, если база на проекте собирается из нескольких источников. Решить эту проблему можно через специальные сервисы, платформы email-маркетинга и электронные таблицы.
Специальные сервисы валидации работают просто: загружаете базу и ждете проверки. На выходе получаете чистый список без дублей и несуществующих адресов. Стоимость зависит от количества получателей.
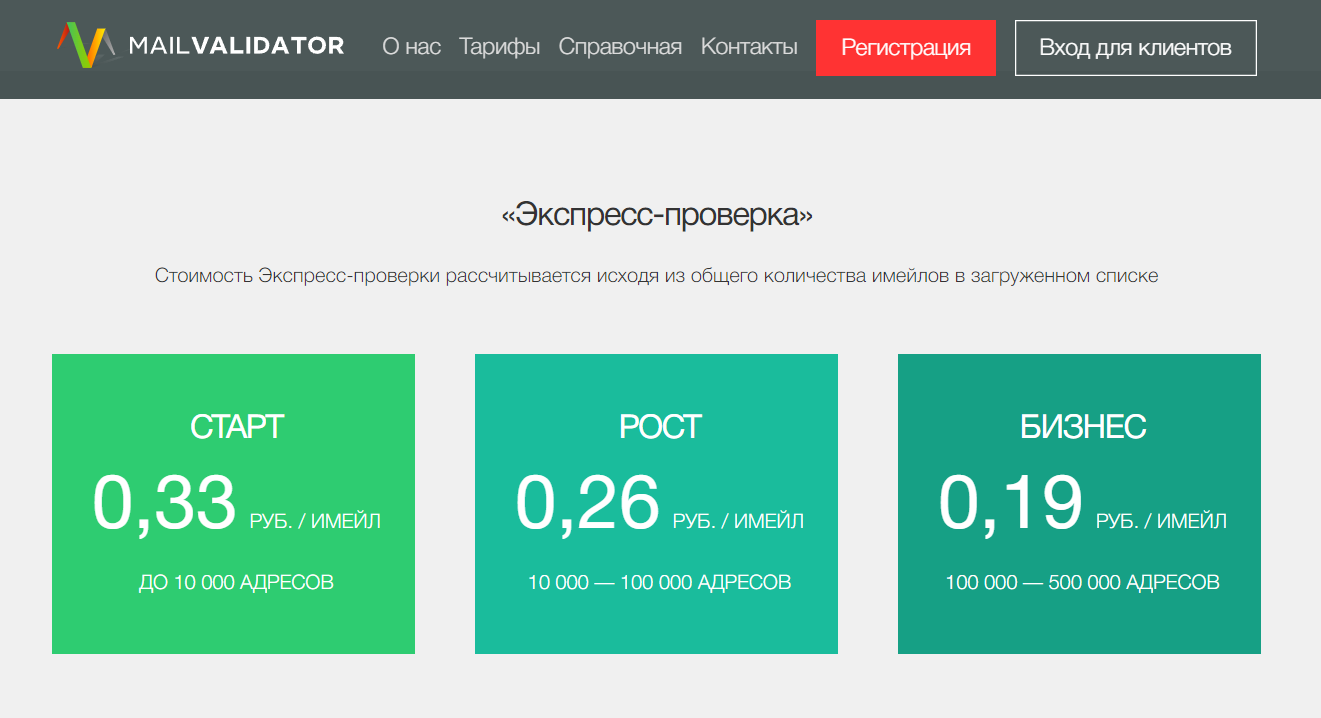
Пример тарифов валидатора email-баз
Платформы email-рассылок. Только нужно внимательно выбирать инструмент. Некоторые сервисы не удаляют дубликаты, и собранные через них базы приходится чистить. В других сервисах, например, в Sendsay работает встроенный валидатор по умолчанию. При сборе адресов через формы Sendsay повторяющиеся и несуществующие адреса отсеиваются автоматически. Пользователь может сколько угодно раз заполнять форму — дублей не будет. При импорте базы в Sendsay из сторонних источников дубликаты также удаляются автоматически.
В электронных таблицах для поиска и удаления дубликатов любых данных есть специальные опции. Чтобы очистить базу в Google Таблицах, выделите диапазон ячеек, который нужно проверить. Откройте меню «Данные» и выберите пункт «Очистка данных», затем — «Удалить повторы». В Excel опция «Удалить дубликаты» находится на вкладке «Данные» панели инструментов.
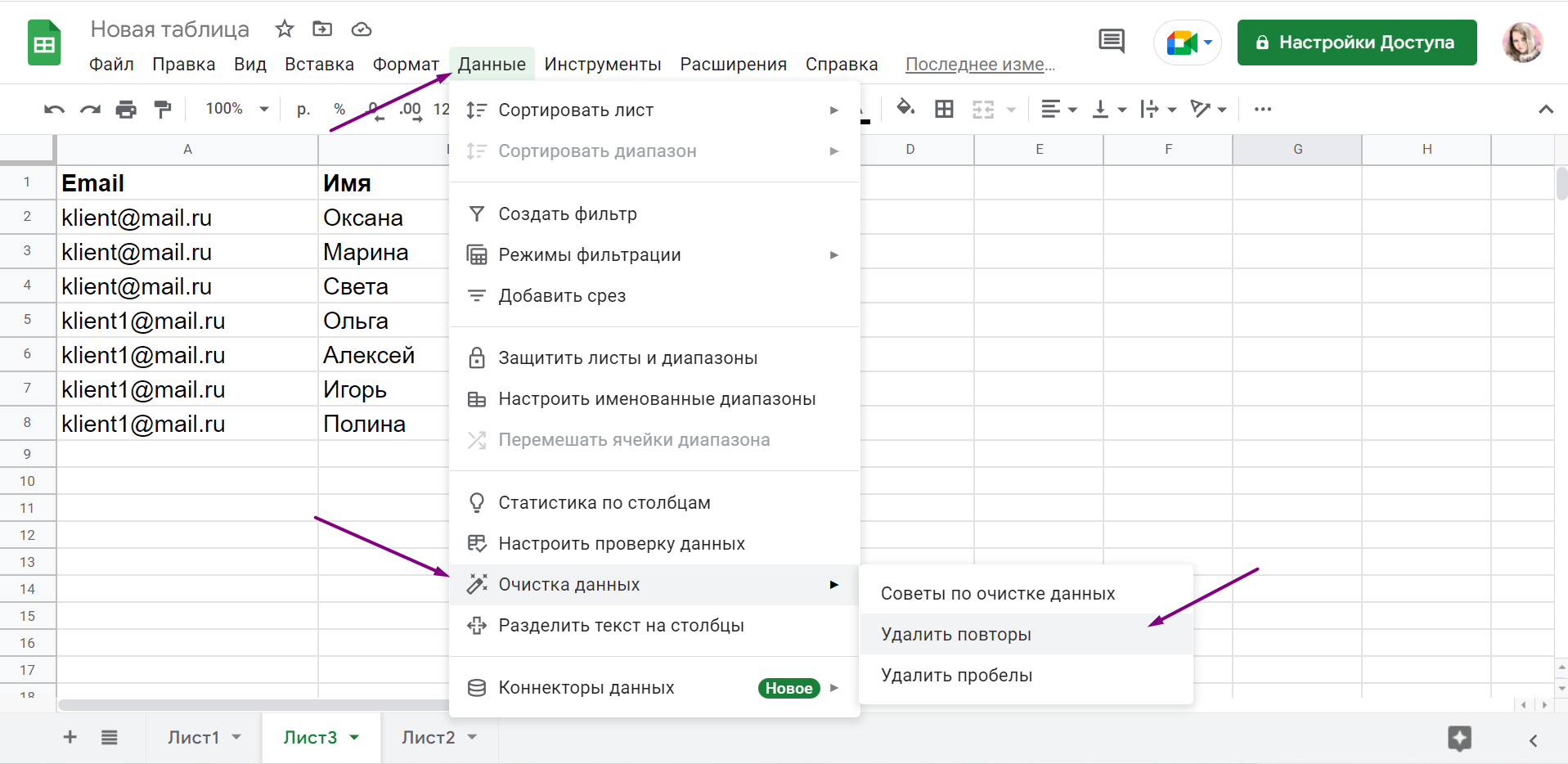
Удаляем дубликаты из базы email-рассылок в Google Таблицах
Что еще сделать с базой для повышения эффективности
Чтобы email-рассылки приносили бизнесу трафик, продажи и прибыль важно не только правильно собирать базу, но и грамотно с ней работать. Помимо удаления дублей полезно:
- Чистить базу от несуществующих адресов. Они могут попадать в базу, если пользователь ошибся в написании или хотел получить полезный лид-магнит, не оставляя свой реальный email. В хорошем сервисе email-рассылок с этим, как и с дублями, справляется валидатор. Несуществующие адреса удаляются автоматически. В других ситуациях проверить email на существование можно через специальные сервисы.
- Реактивировать. Неактивные подписчики тоже ухудшают статистику и напрасно расходуют бюджет на оплату сервиса email-рассылок. Но в отличие от дублей, автоматически удалять их не стоит. Сначала стоит попробовать разобраться, почему они не читают письма и вернуть их внимание с помощью реактивации подписчиков. Если все сделать правильно, в итоге количество активных получателей вырастет.
- Сегментировать. Это поможет привести базу в порядок и отправлять каждому подписчику более релевантный контент на основе его действий, событий, пола, возраста, интересов. Сегментация увеличивает открываемость, кликабельность и конверсию email-рассылок, а значит и общая эффективность этого канала возрастает.
Чтобы работать с базой было удобно и это не отнимало много времени, выбирайте соответствующий потребностям проекта сервис email-рассылок. Например, валидатор Sendsay умеет автоматически чистить списки от дубликатов и несуществующих адресов, а реактивацию и сегментацию можно автоматизировать.
Кроме того, мы делимся полезной информацией в сфере digital-маркетинга в нашем телеграм-канале, при подписке на который дарим книгу «Email-маркетинг для бизнеса». Подробнее о том, как ее получить, рассказали в закрепленном сообщении канала.
![]()
Подпишитесь
на новости блога
Статьи, кейсы и чек-листы по digital-маркетингу от ведущих экспертов рынка

Сегментация клиентов email-рассылки: как и для чего это нужно делать

Смотрите на ROI: почему не стоит зацикливаться на Open Rate и CTR email-рассылки
Присоединяйтесь к нам в соцсетях


Большие таблицы Эксель могут содержать повторяющиеся данные, что зачастую увеличивает объем информации и может привести к ошибкам в результате обработки данных при помощи формул и прочих инструментов. Это особенно критично, например, при работе с денежными и прочими финансовыми данными.
В данной статье мы рассмотрим методы поиска и удаления дублирующихся данных (дубликатов), в частности, строк в Excel.
Содержание
- Метод 1: удаление дублирующихся строк вручную
- Метод 2: удаление повторений при помощи “умной таблицы”
- Метод 3: использование фильтра
- Метод 4: условное форматирование
- Метод 5: формула для удаления повторяющихся строк
- Заключение
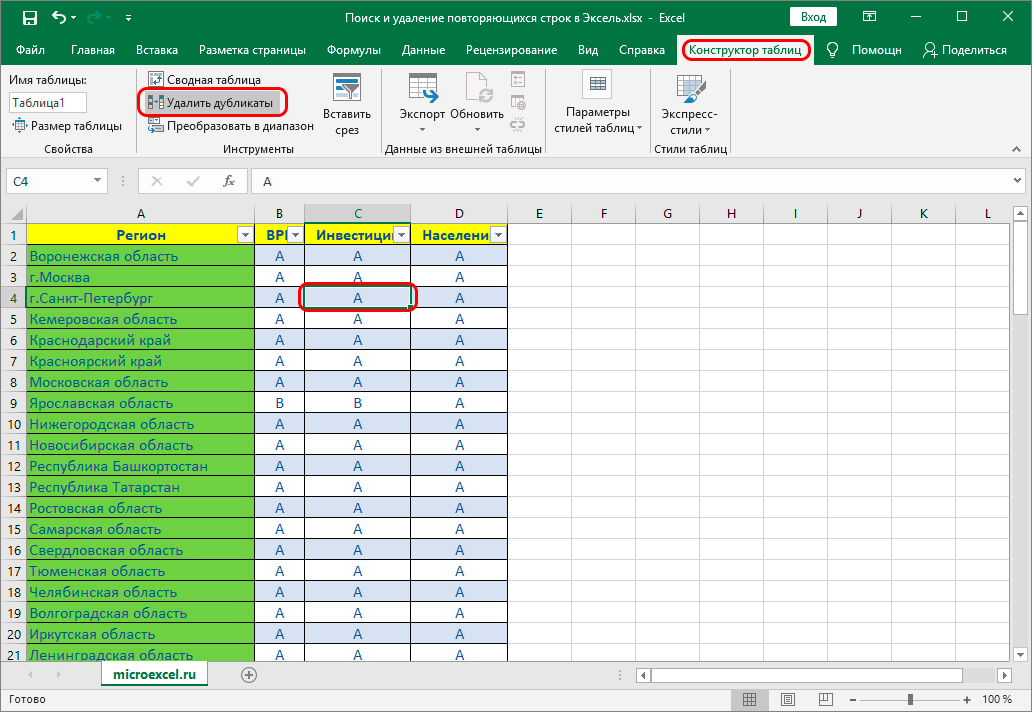
Метод 1: удаление дублирующихся строк вручную
Первый метод максимально прост и предполагает удаление дублированных строк при помощи специального инструмента на ленте вкладки “Данные”.
- Полностью выделяем все ячейки таблицы с данными, воспользовавшись, например, зажатой левой кнопкой мыши.
- Во вкладке “Данные” в разделе инструментов “Работа с данными” находим кнопку “Удалить дубликаты” и кликаем на нее.

- Переходим к настройкам параметров удаления дубликатов:
- Если обрабатываемая таблица содержит шапку, то проверяем пункт “Мои данные содержат заголовки” – он должен быть отмечен галочкой.
- Ниже, в основном окне, перечислены названия столбцов, по которым будет осуществляться поиск дубликатов. Система считает совпадением ситуацию, в которой в строках повторяются значения всех выбранных в настройке столбцов. Если убрать часть столбцов из сравнения, повышается вероятность увеличения количества похожих строк.
- Тщательно все проверяем и нажимаем ОК.

- Далее программа Эксель в автоматическом режиме найдет и удалит все дублированные строки.
- По окончании процедуры на экране появится соответствующее сообщение с информацией о количестве найденных и удаленных дубликатов, а также о количестве оставшихся уникальных строк. Для закрытия окна и завершения работы данной функции нажимаем кнопку OK.




Метод 2: удаление повторений при помощи “умной таблицы”
Еще один способ удаления повторяющихся строк – использование “умной таблицы“. Давайте рассмотрим алгоритм пошагово.
- Для начала, нам нужно выделить всю таблицу, как в первом шаге предыдущего раздела.

- Во вкладке “Главная” находим кнопку “Форматировать как таблицу” (раздел инструментов “Стили“). Кликаем на стрелку вниз справа от названия кнопки и выбираем понравившуюся цветовую схему таблицы.

- После выбора стиля откроется окно настроек, в котором указывается диапазон для создания “умной таблицы“. Так как ячейки были выделены заранее, то следует просто убедиться, что в окошке указаны верные данные. Если это не так, то вносим исправления, проверяем, чтобы пункт “Таблица с заголовками” был отмечен галочкой и нажимаем ОК. На этом процесс создания “умной таблицы” завершен.

- Далее приступаем к основной задаче – нахождению задвоенных строк в таблице. Для этого:
- ставим курсор на произвольную ячейку таблицы;
- переключаемся во вкладку “Конструктор” (если после создания “умной таблицы” переход не был осуществлен автоматически);
- в разделе “Инструменты” жмем кнопку “Удалить дубликаты“.
- Следующие шаги полностью совпадают с описанными в методе выше действиями по удалению дублированных строк.



Примечание: Из всех описываемых в данной статье методов этот является наиболее гибким и универсальным, позволяя комфортно работать с таблицами различной структуры и объема.
Метод 3: использование фильтра
Следующий метод не удаляет повторяющиеся строки физически, но позволяет настроить режим отображения таблицы таким образом, чтобы при просмотре они скрывались.
- Как обычно, выделяем все ячейки таблицы.
- Во вкладке “Данные” в разделе инструментов “Сортировка и фильтр” ищем кнопку “Фильтр” (иконка напоминает воронку) и кликаем на нее.
- После этого в строке с названиями столбцов таблицы появятся значки перевернутых треугольников (это значит, что фильтр включен). Чтобы перейти к расширенным настройкам, жмем кнопку “Дополнительно“, расположенную справа от кнопки “Фильтр“.
- В появившемся окне с расширенными настройками:
- как и в предыдущем способе, проверяем адрес диапазон ячеек таблицы;
- отмечаем галочкой пункт “Только уникальные записи“;
- жмем ОК.

- После этого все задвоенные данные перестанут отображаться в таблицей. Чтобы вернуться в стандартный режим, достаточно снова нажать на кнопку “Фильтр” во вкладке “Данные”.




Метод 4: условное форматирование
Условное форматирование – гибкий и мощный инструмент, используемый для решения широкого спектра задач в Excel. В этом примере мы будем использовать его для выбора задвоенных строк, после чего их можно удалить любым удобным способом.
- Выделяем все ячейки нашей таблицы.
- Во вкладке “Главная” кликаем по кнопке “Условное форматирование“, которая находится в разделе инструментов “Стили“.
- Откроется перечень, в котором выбираем группу “Правила выделения ячеек“, а внутри нее – пункт “Повторяющиеся значения“.

- Окно настроек форматирования оставляем без изменений. Единственный его параметр, который можно поменять в соответствии с собственными цветовыми предпочтениями – это используемая для заливки выделяемых строк цветовая схема. По готовности нажимаем кнопку ОК.

- Теперь все повторяющиеся ячейки в таблице “подсвечены”, и с ними можно работать – редактировать содержимое или удалить строки целиком любым удобным способом.


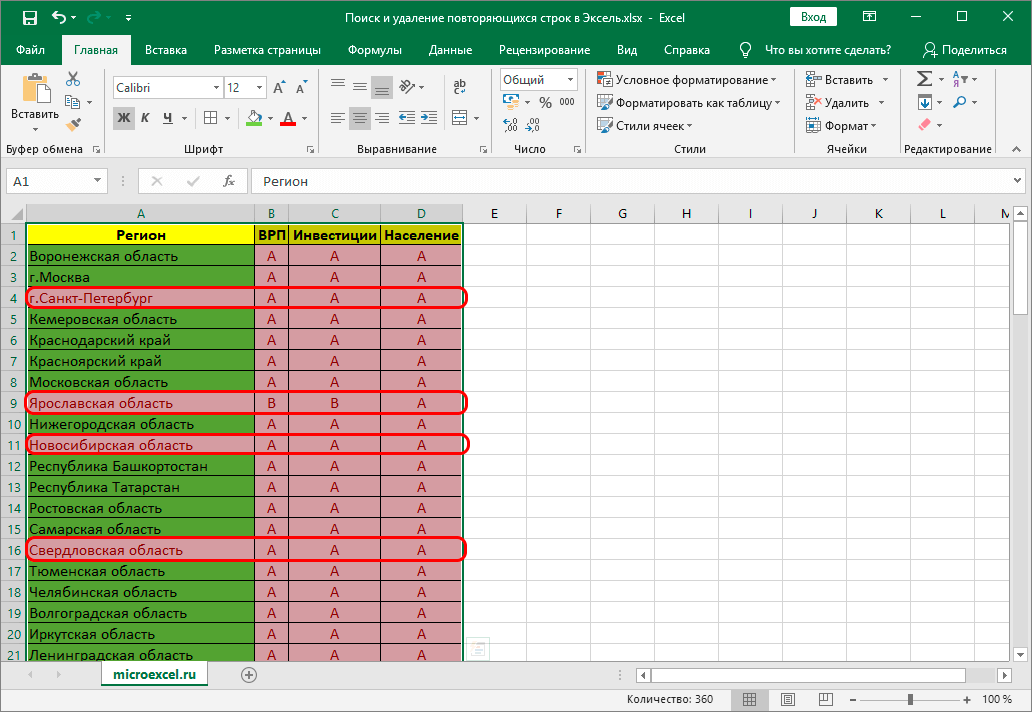
Важно! Этом метод не настолько универсален, как описанные выше, так как выделяет все ячейки с одинаковыми значениями, а не только те, для которых совпадает вся строка целиком. Это видно на предыдущем скриншоте, когда нужные задвоения по названиям регионов были выделены, но вместе с ними отмечены и все ячейки с категориями регионов, потому что значения этих категорий повторяются.
Метод 5: формула для удаления повторяющихся строк
Последний метод достаточно сложен, и им мало, кто пользуется, так как здесь предполагается использование сложной формулы, объединяющей в себе несколько простых функций. И чтобы настроить формулу для собственной таблицы с данными, нужен определенный опыт и навыки работы в Эксель.
Формула, позволяющая искать пересечения в пределах конкретного столбца в общем виде выглядит так:
=ЕСЛИОШИБКА(ИНДЕКС(адрес_столбца;ПОИСКПОЗ(0;СЧЁТЕСЛИ(адрес_шапки_столбца_дубликатов:адрес_шапки_столбца_дубликатов(абсолютный);адрес_столбца;)+ЕСЛИ(СЧЁТЕСЛИ(адрес_столбца;адрес_столбца;)>1;0;1);0));"")
Давайте посмотрим, как с ней работать на примере нашей таблицы:
- Добавляем в конце таблицы новый столбец, специально предназначенный для отображения повторяющихся значений (дубликаты).
- В верхнюю ячейку нового столбца (не считая шапки) вводим формулу, которая для данного конкретного примера будет иметь вид ниже, и жмем Enter:
=ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;A2:A90)>1;0;1);0));""). - Выделяем до конца новый столбец для задвоенных данных, шапку при этом не трогаем. Далее действуем строго по инструкции:
- ставим курсор в конец строки формул (нужно убедиться, что это, действительно, конец строки, так как в некоторых случаях длинная формула не помещается в пределах одной строки);
- жмем служебную клавишу F2 на клавиатуре;
- затем нажимаем сочетание клавиш Ctrl+SHIFT+Enter.
- Эти действия позволяют корректно заполнить формулой, содержащей ссылки на массивы, все ячейки столбца. Проверяем результат.



Как уже было сказано выше, этот метод сложен и функционально ограничен, так как не предполагает удаления найденных столбцов. Поэтому, при прочих равных условиях, рекомендуется использовать один из ранее описанных методов, более логически понятных и, зачастую, более эффективных.
Заключение
Excel предлагает несколько инструментов для нахождения и удаления строк или ячеек с одинаковыми данными. Каждый из описанных методов специфичен и имеет свои ограничения. К универсальным варианту мы, пожалуй, отнесем использование “умной таблицы” и функции “Удалить дубликаты”. В целом, для выполнения поставленной задачи необходимо руководствоваться как особенностями структуры таблицы, так и преследуемыми целями и видением конечного результата.
Спросите у SEO-шника без чего он, как без рук! Он наверняка ответит: без Excel! Эксель — лучший друг и помощник и для специалиста в SEO, и для вебмастера.
Одна из задач, которую тебе точно придётся решать при работе с большими массивами данных – это поиск дублей в Excel. Не вариант проверять тысячи ячеек руками – угробишь на это часы и выйдешь с работы, пошатываясь, будто пьяный. Я предложу тебе 2 способа, как выполнить эту работу в десяток раз быстрее. Они дают немного разные результаты, но в равной степени просты.
Оглавление
- 1 Как в Эксель найти повторяющиеся значения?
- 2 Как вычислить повторы при помощи сводных таблиц
- 3 Заключение
Как в Эксель найти повторяющиеся значения?
Для примера я распределил фамилии прославленных футболистов российской эпохи в пару столбцов. Нарочно сделал повторы в столбиках (иллюстрации кликабельны).

Наша цель – найти повторы в столбцах Excel и выделить их цветом.
Действуем так:
Шаг №1. Выделяем весь диапазон.
Шаг №2. Кликаем на раздел «Условное форматирование» в главной вкладке.

Шаг №3. Наводим на пункт «Правила выделения ячеек» и в появившемся списке выбираем «Повторяющиеся значения».

Шаг №4. Возникнет окно. Вам нужно выбрать, хотите ли вы подсветить повторяющиеся или уникальные значения. Также можно установить цвета заливки и текста.

Нажмите «ОК», и вы обнаружите: одинаковые ячейки в двух столбиках теперь выделены! Как видите, это вопрос 30 секунд.
Описанный вариант — самый удобный для пользователей Эксель версий 2013 и 2016.
Как вычислить повторы при помощи сводных таблиц
Метод хорош тем, что мы не только определяем повторяющиеся значения в Excel, но и пересчитываем их. Причём делаем это за считанные минуты. Правда, есть и минус – столбец с данными может быть всего один.
Вернёмся к нашим баранам футболистам. Я оставил один столбик, добавив в него ячейки-дубли, а также дописал заглавную строку (это обязательно).

Далее делаем следующее:
Шаг 1. В ячейках напротив фамилий проставляем единички. Вот так:

Шаг 2. Переходим в раздел «Вставка» главного меню и в блоке «Таблицы» выбираем «Сводная таблица».

Откроется окно «Создание сводной таблицы». Здесь нужно выбрать диапазон данных для анализа (1), указать, куда поместить отчёт (2) и нажать «ОК».

Только не ставьте галку напротив «Добавить эти данные в модель данных». Иначе Эксель начнёт формировать модель, и это парализует ваш комп на пару минут минимум.
Шаг 3. Распределите поля сводной таблицы следующим образом: первое поле (в моём случае «Футболисты») – в область «Строки», второе («Значение2») – в область «Значения». Используйте обычное перетаскивание (drag-and-drop).

Должно получиться так:

А на листе сформируется сама сводка — уже без дублированных ячеек. Зато во втором столбике будет указано, сколько ячеек-дублей с конкретным содержанием было обнаружено в первом столбике (например, Онопко – 2 шт.).

Этот метод «на бумаге» может выглядеть несколько замороченным, но уверяю: попробуете раз-два, набьёте руку, а потом все операции будете выполнять за минуту.
Заключение
При поиске дублей я, признаться, всегда пользуюсь первым из описанных мною способов – то есть действую через «Условное форматирование». Уж очень меня подкупает предельная простота этого метода.
Хотя на самом деле функционал программы Эксель настолько широк, что можно не только подсветить повторяющиеся значения в столбике, но и автоматически их все удалить. Я знаю, как это делается, но сейчас вам не скажу. Теперь на сайте есть отдельная статья об удалении повторяющихся строк в Excel — там и смотрите 😉.
Помогли ли тебе мои методы работы с данными? Или ты знаешь лучше? Поделись своим мнением в комментариях!
“Error, some other host already uses address” при выполнении команды «service network restart» или «ifup ethX» в системе CentOS / RHEL.
Содержание
- Как проверить наличие дублирующего IP-адреса в сети?
- Использование команды arping
- Как перезапуск сети ifup или службы обнаруживает дублирующийся IP-адрес
- Использование сервиса arpwatch
- Использование службы ipwatchd
Как проверить наличие дублирующего IP-адреса в сети?
Использование команды arping
Запустите команду arping с ключом -D, чтобы включить обнаружение повторяющихся адресов.
В следующем примере замените адрес, который, по вашему мнению, был продублирован, и интерфейс, на котором этот адрес включен.
# arping -D -w 5 -I ethX IP.ADDRESS.TO.TEST # echo $?
Команда «echo $?» Проверяет возвращаемое значение команды.
Если это сообщает 0, то IP-адрес не дублируется.
Если это сообщает 1, то IP-адрес дублируется.
Приведенный ниже пример проверяет наличие дубликатов 192.168.5.2 в сети, подключенной к интерфейсу eth0.
В этом примере адрес обнаружен в другой системе:
# arping -D -w 5 -I eth0 192.168.5.2 ARPING 192.168.5.2 from 0.0.0.0 eth0 Unicast reply from 192.168.5.2 [52:54:00:00:05:02] for 192.168.5.2 [52:54:00:00:05:02] 3.741ms Sent 1 probes (1 broadcast(s)) Received 1 response(s)
Как перезапуск сети ifup или службы обнаруживает дублирующийся IP-адрес
При выполнении ‘service network restart‘ или ‘ifup ethX команда ifup-eth в /etc/sysconfig/network-scripts/ выполняет то же самое обнаружение дублирующихся адресов, что и при использовании arping:
# cat /etc/sysconfig/network-scripts/ifup-eth
if ! LC_ALL=C ip addr ls ${REALDEVICE} | LC_ALL=C grep -q "${ipaddr[$idx]}/${prefix[$idx]}" ; then
[ "${REALDEVICE}" != "lo" ]
if ! /sbin/arping -q -c 2 -w 3 -D -I ${REALDEVICE} ${ipaddr[$idx]} ; then
echo $"Error, some other host already uses address ${ipaddr[$idx]}."
exit 1
fi
Если обнаружен повторяющийся адрес, печатается сообщение ‘Error, some other host already uses address [IP.ADDRESS]’
Использование сервиса arpwatch
Служба arpwatch отслеживает таблицы ARP в локальной системе и может регистрировать сообщение при обнаружении адреса “flip flop”
# yum install arpwatch # service arpwatch start # chkconfig arpwatch on
Проверьте, есть ли сообщения о «flip flop» в файле /var/log/messages:
Nov 1 15:42:42 hostname arpwatch: new station 10.00.100.108 01:13:gh:ef:cd:ab Nov 1 15:43:32 hostname arpwatch: changed ethernet address 10.00.100.108 01:13:gh:ef:cd:ab (01:13:gh:ef:cd:ab) Nov 1 15:43:59 hostname arpwatch: flip flop 10.00.100.108 01:13:gh:ef:cd:ab (01:13:gh:ef:cd:ac) From the above messages, this machine first records the ARP mapping information: 10.00.100.108 to MAC 01:13:gh:ef:cd:ab
Затем демон arpwatch находит, что MAC-адрес, который связывается с 10.00.100.108, изменился на 01: 13: gh: ef: cd: ac.
Использование службы ipwatchd
Сторонний сервис ipwatchd использует libpcap для перехвата всего трафика ARP и обнаружения дублированных IP-адресов.
Дополнительную информацию об этом инструменте можно найти по адресу https://ipwatchd.sourceforge.io/.
Если вы не можете найти сервер с дублирующимся IP-адресом с использованием arping и по-прежнему подозреваете наличие дублированного IP-адреса в сети, проверьте, не включены ли прокси-ARP на сетевых устройствах, таких как маршрутизаторы, брандмауэры и коммутаторы.
