Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
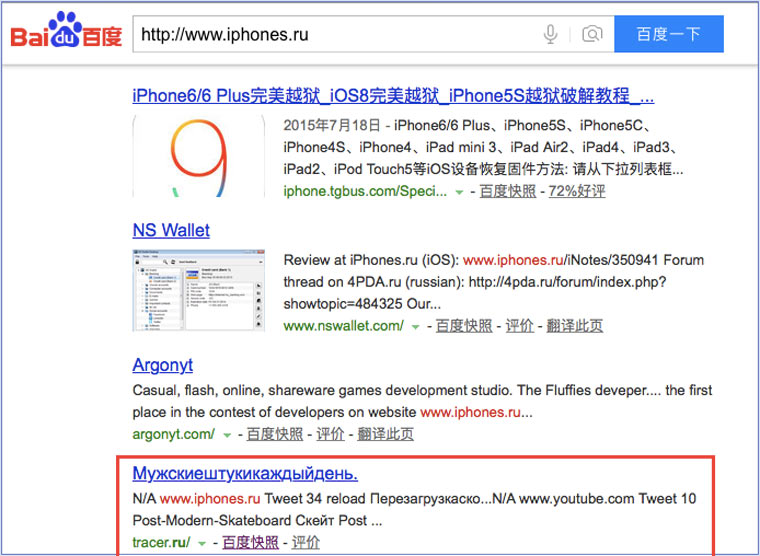
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
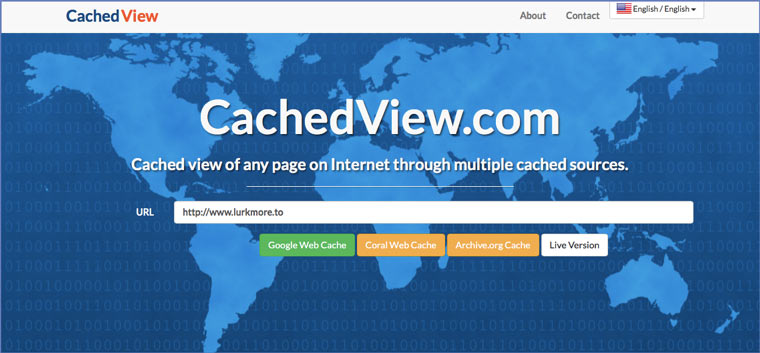
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
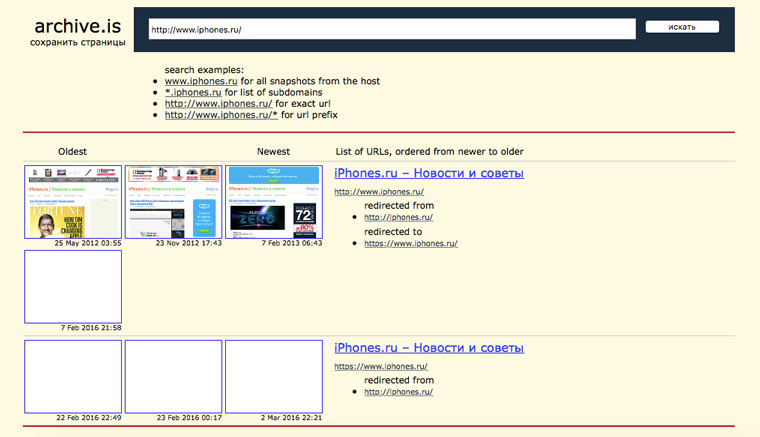
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
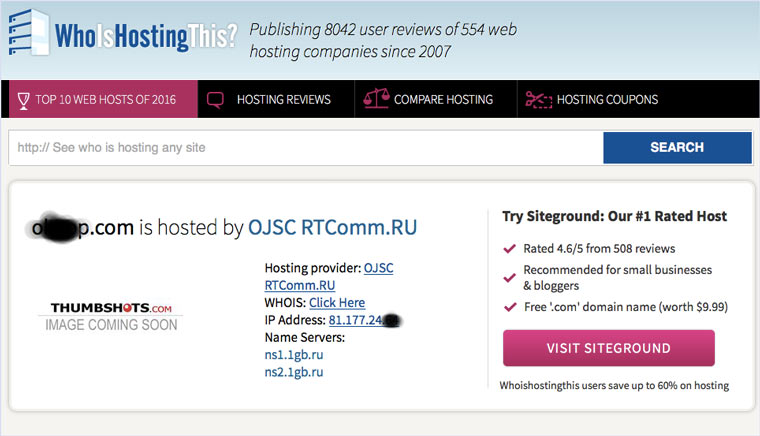
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
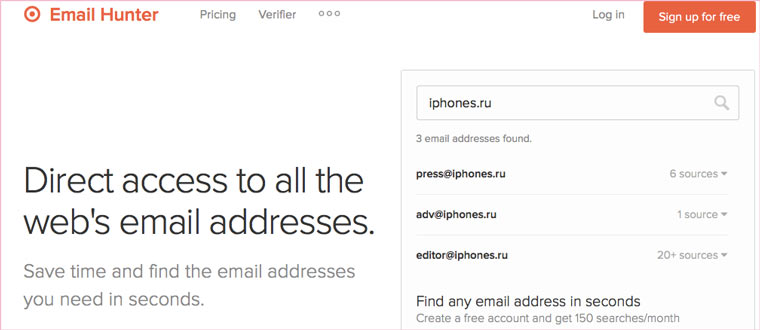
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
В статье мы расскажем, в каких случаях может понадобиться история сайта, как ее посмотреть. Приведем примеры основных сервисов, которые позволят заглянуть в прошлое страницы. Объясним, как посмотреть сохраненную копию страницы в поисковых систeмах и как восстановить сайт из архива.

Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
● Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
● Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
● Нужно восстановить сайт, когда нет его бэкапа.
● Нужно проанализировать конкурентов. Этот способ понадобится, чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие «фишки» стоит позаимствовать.
● Необходимо посмотреть страницу, если она теперь недоступна напрямую.
● Интересно, как выглядел ресурс 10-20 лет назад.
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Как посмотреть сайт в прошлом?
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.
График ниже показывает количество сохранений: первое было в 1998 году.
Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:
Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/и вводим данные в поиске по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:
Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
● использовать оператор site:, либо указать сразу необходимый URL
● найти страницу в выдаче
● нажать на стрелочку рядом с URL
● выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/и нажать кнопку «Восстановить».
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента, обращайтесь к нашим специалистам.
И до встречи в следующей публикации!
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
есть ли способ получить предыдущий URL в JavaScript? Что-то вроде этого:
alert("previous url is: " + window.history.previous.href);
есть что-то подобное? Или я должен просто хранить его в cookie? Мне нужно только знать, чтобы я мог делать переходы с предыдущего URL на текущий URL без якорей и все такое.
438
6
6 ответов:
document.referrerво многих случаях вы получите URL последней страницы, которую посетил пользователь, если они попали на текущую страницу, нажав на ссылку (вместо ввода непосредственно в адресную строку, или я считаю, что в некоторых случаях, отправив форму?). Указывается с помощью DOM Level 2. здесь.
window.historyразрешает навигацию, но не доступ к URL-адресам в сеансе по соображениям безопасности и конфиденциальности. Если была доступна более подробная история URL, то каждый сайт, который вы посещаете можно было увидеть все другие сайты, на которых вы были.Если вы имеете дело с состоянием, перемещающимся по вашему собственному сайту, то, возможно, менее хрупко и, безусловно, более полезно использовать один из обычных методов управления сеансами: данные cookie, параметры URL или информацию о сеансе на стороне сервера.
document.referrerЭто стандартный, он даст URL, с которого вы посетили.
document.referrerне совпадает с фактическим URL во всех ситуациях.у меня есть приложение, где мне нужно создать набор с 2 рамами. Один кадр известен, другой-это страница, с которой я связываюсь. Казалось бы, что
document.referrerбыло бы идеально, потому что вам не нужно будет передавать фактическое имя файла в документ набора фреймов.однако, если вы позже измените нижнюю рамку страницы, а затем использовать
history.back()он не загружает исходную страницу в нижнюю рамку, вместо этого он перезагружаетсяdocument.referrerи в результате набор фреймов исчез, и вы вернулись к исходному стартовому окну.мне потребовалось некоторое время, чтобы понять это. Так что в массиве истории,
document.referrer– Это не только URL, это, по-видимому, спецификация окна реферера. По крайней мере, это лучший способ, которым я могу понять это в настоящее время.
Если вы хотите перейти на предыдущую страницу, не зная url, вы можете использовать новый api истории.
history.back(); //Go to the previous page history.forward(); //Go to the next page in the stack history.go(index); //Where index could be 1, -1, 56, etc.но вы не можете управлять содержимым стека истории в браузере, который не поддерживает HTML5 History API
для получения дополнительной информации см. doc
те из вас, кто использует узел.js и Express могут установить cookie сеанса, который будет помнить текущий URL-адрес страницы, что позволит вам проверить реферер при следующей загрузке страницы. Вот пример, который использует
express-sessionmiddleware://Add me after the express-session middleware app.use((req, res, next) => { req.session.referrer = req.protocol + '://' + req.get('host') + req.originalUrl; next(); });затем вы можете проверить наличие файла cookie реферера следующим образом:
if ( req.session.referrer ) console.log(req.session.referrer);не предполагайте, что файл cookie реферера всегда существует с этим методом, поскольку он не будет доступен в тех случаях, когда предыдущий URL был другим сайт, сессия была очищена или просто создана (первая загрузка сайта).
document.referrerдаст URL предыдущей страницы, но он будет работать для всех браузеров, таких как Opera, Mozilla Firefox, Safari и т. д., но не работает в Internet Explorer. Это приведет к нулю, когда вы используете этоdocument.referrerв IE.
Is there any way to get the previous URL in JavaScript? Something like this:
alert("previous url is: " + window.history.previous.href);
Is there something like that? Or should I just store it in a cookie? I only need to know so I can do transitions from the previous URL to the current URL without anchors and all that.
![]()
asked Aug 20, 2010 at 5:06
![]()
document.referrer
in many cases will get you the URL of the last page the user visited, if they got to the current page by clicking a link (versus typing directly into the address bar, or I believe in some cases, by submitting a form?). Specified by DOM Level 2. More here.
window.history allows navigation, but not access to URLs in the session for security and privacy reasons. If more detailed URL history was available, then every site you visit could see all the other sites you’d been to.
If you’re dealing with state moving around your own site, then it’s possibly less fragile and certainly more useful to use one of the normal session management techniques: cookie data, URL params, or server side session info.
Steve
1,5641 gold badge17 silver badges32 bronze badges
answered Aug 20, 2010 at 5:08
![]()
Ben ZottoBen Zotto
69.9k23 gold badges141 silver badges204 bronze badges
8
If you want to go to the previous page without knowing the url, you could use the new History api.
history.back(); //Go to the previous page
history.forward(); //Go to the next page in the stack
history.go(index); //Where index could be 1, -1, 56, etc.
But you can’t manipulate the content of the history stack on browser that doesn’t support the HTML5 History API
For more information see the doc
answered Apr 16, 2014 at 20:00
![]()
RPDeshaiesRPDeshaies
1,8261 gold badge24 silver badges29 bronze badges
5
If you are writing a web app or single page application (SPA) where routing takes place in the app/browser rather than a round-trip to the server, you can do the following:
window.history.pushState({ prevUrl: window.location.href }, null, "/new/path/in/your/app")
Then, in your new route, you can do the following to retrieve the previous URL:
window.history.state.prevUrl // your previous url
answered May 17, 2019 at 10:18
Jonathan LinJonathan Lin
19.7k6 gold badges68 silver badges65 bronze badges
1
document.referrer is not the same as the actual URL in all situations.
I have an application where I need to establish a frameset with 2 frames. One frame is known, the other is the page I am linking from. It would seem that document.referrer would be ideal because you would not have to pass the actual file name to the frameset document.
However, if you later change the bottom frame page and then use history.back() it does not load the original page into the bottom frame, instead it reloads document.referrer and as a result the frameset is gone and you are back to the original starting window.
Took me a little while to understand this. So in the history array, document.referrer is not only a URL, it is apparently the referrer window specification as well. At least, that is the best way I can understand it at this time.
![]()
Scott
21.2k8 gold badges65 silver badges72 bronze badges
answered Sep 23, 2012 at 17:09
1
<script type="text/javascript">
document.write(document.referrer);
</script>
document.referrer serves your purpose, but it doesn’t work for Internet Explorer versions earlier than IE9.
It will work for other popular browsers, like Chrome, Mozilla, Opera, Safari etc.
answered Feb 7, 2012 at 12:46
565565
6152 gold badges10 silver badges19 bronze badges
1
If anyone is coming from React-world, I ended up solving my use-case using a combination of history-library, useEffect and localStorage
When user selects new project:
function selectProject(customer_id: string, project_id: string){
const projectUrl = `/customer/${customer_id}/project/${project_id}`
localStorage.setItem("selected-project", projectUrl)
history.push(projectUrl)
}
When user comes back from another website. If there’s something in localStorage, send him there.
useEffect(() => {
const projectUrl = localStorage.getItem("selected-project")
if (projectUrl) {
history.push(projectUrl)
}
}, [history])
When user has exited a project, empty localStorage
const selectProject = () => {
localStorage.removeItem("selected-project")
history.push("/")
}
answered Feb 11, 2021 at 9:11
Ilmari KumpulaIlmari Kumpula
7111 gold badge8 silver badges18 bronze badges
I had the same issue on a SPA Single Page App, the easiest way I solved this issue was with local storage as follows:
I stored the url I needed in local storage
useEffect(() => {
const pathname = window.location.href; //this gives me current Url
localstorage.setItem('pageUrl',JSON.stringify(pathname))
}, []);
On the next screen (or few screens later) I fetched the url can replaced it as follows
useEffect(() => {
const pathname = localstorage.getItem('pageUrl');
return pathname ? JSON.parse(pathname) : ''
window.location.href = pathname; //this takes prevUrl from local storage and sets it
}, []);
answered May 11, 2022 at 19:37
![]()
Those of you using Node.js and Express can set a session cookie that will remember the current page URL, thus allowing you to check the referrer on the next page load. Here’s an example that uses the express-session middleware:
//Add me after the express-session middleware
app.use((req, res, next) => {
req.session.referrer = req.protocol + '://' + req.get('host') + req.originalUrl;
next();
});
You can then check for the existance of a referrer cookie like so:
if ( req.session.referrer ) console.log(req.session.referrer);
Do not assume that a referrer cookie always exists with this method as it will not be available on instances where the previous URL was another website, the session was cleaned or was just created (first-time website load).
answered Jul 26, 2018 at 3:38
![]()
NadavNadav
1,0051 gold badge9 silver badges23 bronze badges
Wokaround that work even if document.referrer is empty:
let previousUrl = null;
if(document.referrer){
previousUrl = document.referrer;
sessionStorage.setItem("isTrickApplied",false);
}else{
let isTrickApplied= sessionStorage.getItem("isTrickApplied");
if(isTrickApplied){
previousUrl = sessionStorage.getItem("prev");
sessionStorage.setItem("isTrickApplied",false);
}else{
history.back(); //Go to the previous page
sessionStorage.setItem("prev",window.location.href);
sessionStorage.setItem("isTrickApplied",true);
history.forward(); //Go to the next page in the stack
}
}
answered Nov 6, 2022 at 15:06
![]()
