У меня есть DataFrame, который содержит различные значения.
import pandas as pd
df = pd.DataFrame({"data": [1, 1, 1, 1, 0, 0, 0, 2, 2, 3]})
Я хочу посчитать, сколько процентов от общих данных занимает каждое значение, то есть получить таблицу вида:
value | percent
_____________________
0 | 30 ( или 0.3)
1 | 40 ( или 0.4)
2 | 20 ( или 0.2)
3 | 10 ( или 0.1)
Я могу посчитать так:
# Добавляю еще одну колонку, чтобы нормально посчитать count()
df['column'] = 1
df2 = df.groupby('data').count()
df2['percent'] = df2['column'] / len(df.index)
И получаю искомое:
column percent
data
0 3 0.3
1 4 0.4
2 2 0.2
3 1 0.1
Однако, меня не покидает ощущение, что я все делаю не так. И подобные вопросы должны решаться намного проще.
Подскажите, как лучше решить мою задачу?
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
A Percentage is calculated by the mathematical formula of dividing the value by the sum of all the values and then multiplying the sum by 100. This is also applicable in Pandas Dataframes. Here, the pre-defined sum() method of pandas series is used to compute the sum of all the values of a column.
Syntax: Series.sum()
Return: Returns the sum of the values.
Formula:
df[percent] = (df['column_name'] / df['column_name'].sum()) * 100
Example 1:
Python3
import pandas as pd
import numpy as np
df1 = {
'Name': ['abc', 'bcd', 'cde',
'def', 'efg', 'fgh',
'ghi'],
'Math_score': [52, 87, 49,
74, 28, 59,
48]}
df1 = pd.DataFrame(df1,
columns = ['Name',
'Math_score'])
df1['percent'] = (df1['Math_score'] /
df1['Math_score'].sum()) * 100
df1
Output:
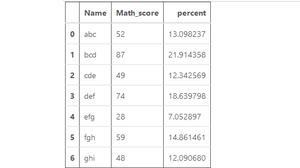
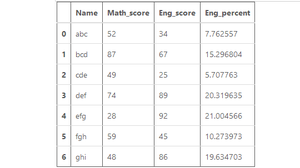
Example 2:
Python3
import pandas as pd
df1 = {
'Name': ['abc', 'bcd', 'cde',
'def', 'efg', 'fgh',
'ghi'],
'Math_score': [52, 87, 49,
74, 28, 59,
48],
'Eng_score': [34, 67, 25,
89, 92, 45,
86]
}
df1 = pd.DataFrame(df1,
columns = ['Name',
'Math_score','Eng_score'])
df1['Eng_percent'] = (df1['Eng_score'] /
df1['Eng_score'].sum()) * 100
df1
Output:
Last Updated :
28 Jul, 2020
Like Article
Save Article
17 авг. 2022 г.
читать 1 мин
Вы можете использовать следующий синтаксис для расчета процента от общего числа внутри групп в pandas:
df['values_var'] / df.groupby('group_var')['values_var']. transform('sum')
В следующем примере показано, как использовать этот синтаксис на практике.
Пример. Вычисление процента от общего числа внутри группы
Предположим, у нас есть следующий кадр данных pandas, который показывает очки, набранные баскетболистами в разных командах:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B'],
'points': [12, 29, 34, 14, 10, 11, 7, 36, 34, 22]})
#view DataFrame
print(df)
team points
0 A 12
1 A 29
2 A 34
3 A 14
4 A 10
5 B 11
6 B 7
7 B 36
8 B 34
9 B 22
Мы можем использовать следующий синтаксис для создания нового столбца в DataFrame, который показывает процент от общего количества набранных очков, сгруппированных по командам:
#calculate percentage of total points scored grouped by team
df['team_percent'] = df['points'] / df.groupby('team')['points']. transform('sum')
#view updated DataFrame
print(df)
team points team_percent
0 A 12 0.121212
1 A 29 0.292929
2 A 34 0.343434
3 A 14 0.141414
4 A 10 0.101010
5 B 11 0.100000
6 B 7 0.063636
7 B 36 0.327273
8 B 34 0.309091
9 B 22 0.200000
Столбец team_percent показывает процент от общего количества очков, набранных этим игроком в своей команде.
Например, игроки команды А набрали в сумме 99 очков.
Таким образом, игрок в первой строке DataFrame, набравший 12 очков, набрал в сумме 12/99 = 12,12% от общего количества очков для команды A.
Точно так же игрок во второй строке DataFrame, набравший 29 очков, набрал в общей сложности 29/99 = 29,29% от общего количества очков для команды A.
И так далее.
Примечание.Полную документацию по функции GroupBy можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Pandas: как рассчитать совокупную сумму по группе
Pandas: как подсчитать уникальные значения по группам
Pandas: как рассчитать режим по группе
Pandas: как рассчитать корреляцию по группе
You can use the following syntax to calculate the percentage of a total within groups in pandas:
df['values_var'] / df.groupby('group_var')['values_var'].transform('sum')
The following example shows how to use this syntax in practice.
Example: Calculate Percentage of Total Within Group
Suppose we have the following pandas DataFrame that shows the points scored by basketball players on various teams:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B'],
'points': [12, 29, 34, 14, 10, 11, 7, 36, 34, 22]})
#view DataFrame
print(df)
team points
0 A 12
1 A 29
2 A 34
3 A 14
4 A 10
5 B 11
6 B 7
7 B 36
8 B 34
9 B 22
We can use the following syntax to create a new column in the DataFrame that shows the percentage of total points scored, grouped by team:
#calculate percentage of total points scored grouped by team
df['team_percent'] = df['points'] / df.groupby('team')['points'].transform('sum')
#view updated DataFrame
print(df)
team points team_percent
0 A 12 0.121212
1 A 29 0.292929
2 A 34 0.343434
3 A 14 0.141414
4 A 10 0.101010
5 B 11 0.100000
6 B 7 0.063636
7 B 36 0.327273
8 B 34 0.309091
9 B 22 0.200000
The team_percent column shows the percentage of total points scored by that player within their team.
For example, players on team A scored a total of 99 points.
Thus, the player in the first row of the DataFrame who scored 12 points scored a total of 12/99 = 12.12% of the total points for team A.
Similarly, the player in the second row of the DataFrame who scored 29 points scored a total of 29/99 = 29.29% of the total points for team A.
And so on.
Note: You can find the complete documentation for the GroupBy function here.
Additional Resources
The following tutorials explain how to perform other common operations in pandas:
Pandas: How to Calculate Cumulative Sum by Group
Pandas: How to Count Unique Values by Group
Pandas: How to Calculate Mode by Group
Pandas: How to Calculate Correlation By Group
Pandas is a powerful Python library for data manipulation and analysis, and one of its most useful features is the ability to create pivot tables. Pivot tables can help you summarize and analyze large datasets quickly and efficiently, and Pandas makes it easy to create them using the pivot_table() function. You can check out the Pandas Pivot Tutorial if you haven’t already
One common task when working with pivot tables is to calculate percentages. In this blog post, we’ll look at a few examples of how to do that using Pandas.
Lets create some data for us to then pivot
import pandas as pd
data = {'salesperson': ['Alice', 'Bob', 'Charlie', 'Alice', 'Charlie', 'Bob'],
'product': ['A', 'B', 'C', 'A', 'B', 'C'],
'sales_amount': [100, 200, 300, 150, 250, 200]}
df = pd.DataFrame(data)
Use Lambda to Create Percentage in Python Pandas Pivot Tables
We use a lambda function to calculate the percentage of column for each dimension in the row. The lambda function takes the values in the pivot table as input and applies the calculation that we can insert into aggfunc section of the pivot table. Here is an example of a lambda function lambda x: sum(x) / sum(df['column']) * 100) to them.
Suppose you have a dataset of sales data, with columns for the salesperson’s name, the product sold, and the sales amount. You want to create a pivot table that shows the percentage of total sales for each salesperson. Here’s how to do it:
Percent of Grand Total in a Pandas Pivot Table
pivot_table = pd.pivot_table(df,
values='sales_amount',
index='salesperson',
columns='product',
fill_value=0, aggfunc=lambda x: round(sum(x)/sum(df['sales_amount']) * 100, 2))
pivot_tableNote that we are using the fill_value parameter to add zeros to avoid the NA values.

Percent of Column Total in a Pandas Pivot Table
To get the percent of the column total we can use the same lambda function. However, we will need to apply it to the function to the columns. We can do this using the apply function. This needs to be applied after the table has been created. Use the pandas data frame from above to practice.
pd.pivot_table(data=df, index='Salesperson',
columns='Product',
values='Sales',
aggfunc=sum,
fill_value=0).apply(lambda x: x*100/sum(x))
Percent of Row Total in a Pandas Pivot Table
Now we will need to take a few extra steps to achieve this. We will create the pandas pivot table as we did in the first section. Once the table has been completed, we can now use the div() function. The div function will allow us specify how to divide the values in one DataFrame by the values in another DataFrame or a scalar value. The div() function takes several parameters, including other, fill_value, level, and axis. Since we can specify the axis we do take the percent of the row total. However, we need the row total which we can get with the margins function in our pivot table. Lets see how all this works together
table = pd.pivot_table(data=df, index='Salesperson',
columns='Product',
values='Sales',
aggfunc=sum,
fill_value=0,
margins=True)
table.div(table.iloc[:,-1], axis=0 )
Using margins = True parameter will give us the total sum of the columns in a new column and specifying thata column using iloc[:,-1] within the divide function to get the percent of row total.
