Любая задача машинного обучения — это задача оптимизации, а задачи оптимизации удобнее всего решать градиентными методами (если это возможно, конечно). Поэтому важно уметь находить производные всего, что попадается под руку. Казалось бы, в чём проблема: ведь дифференцирование — простая и понятная штука (чего не скажешь, например, об интегрировании). Зачем же как-то специально учиться дифференцировать матрицы?
Да в принципе-то никаких проблем: в этой главе вы не узнаете никаких секретных приёмов или впечатляющих теорем. Но, согласитесь, если исходная функция от вектора $x$ имела вид $f(x) = vertvert Ax – bvertvert^2$ (где $A$ — константная матрица, а $b$ — постоянный вектор), то хотелось бы уметь и производную выражать красиво и цельно через буквы $A$, $x$ и $b$, не привлекая отдельные координаты $A_{ij}$, $x_k$ и $b_s$. Это не только эстетически приятно, но и благотворно сказывается на производительности наших вычислений: ведь матричные операции обычно очень эффективно оптимизированы в библиотеках, чего не скажешь о самописных циклах по $i, j, k, s$. И всё, что будет происходить дальше, преследует очень простую цель: научиться вычислять производные в удобном, векторно-матричном виде. А чтобы сделать это и не сойти с ума, мы должны ввести ясную систему обозначений, составляющую ядро техники матричного дифференцирования.
Основные обозначения
Вспомним определение производной для функции $f:mathbb{R}^mrightarrowmathbb{R}^n$. Функция $f(x)$ дифференцируема в точке $x_0$, если
$$f(x_0 + h) = f(x_0) + color{#348FEA}{left[D_{x_0} f right]} (h) + bar{bar{o}} left(left| left| hright|right|right),$$
где $color{#348FEA}{big[D_{x_0} fbig]}$ — дифференциал функции $f$: линейное отображение из мира $x$-ов в мир значений $f$. Грубо говоря, он превращает «малое приращение $h=Delta x$» в «малое приращение $Delta f$» («малые» в том смысле, что на о-малое можно плюнуть):
$$f(x_0 + h) – f(x_0)approxcolor{#348FEA}{left[D_{x_0} f right]} (h)$$
Отметим, что дифференциал зависит от точки $x_0$, в которой он берётся: $color{#348FEA}{left[D_{color{red}{x_0}} f right]} (h)$. Под $vertvert hvertvert$ подразумевается норма вектора $h$, например корень из суммы квадратов координат (обычная евклидова длина).
Давайте рассмотрим несколько примеров и заодно разберёмся, какой вид может принимать выражение $color{#348FEA}{big[D_{x_0} fbig]} (h)$ в зависимости от формы $x$. Начнём со случаев, когда $f$ — скалярная функция.
Примеры конкретных форм $big[D_{x_0} fbig] (h)$, когда $f$ — скалярная функция
-
$f(x)$ — скалярная функция, $x$ — скаляр. Тогда
$$f(x_0 + h) – f (x_0) approx f'(x_0) (h)$$
$$color{#348FEA}{left[D_{x_0} fright] (h)} = f'(x_0) h = h cdot f'(x_0)$$
Здесь $h$ и $f'(x_0)$ — просто числа. В данном случае $color{#348FEA}{left[D_{x_0} fright]}$ — это обычная линейная функция.
-
$f(x)$ — скалярная функция, $x$ — вектор. Тогда
$$f(x_0 + h) – f(x_0) approx sumlimits_i left.frac{partial f}{partial x_i} right|_{x=x_0} h_i,$$
то есть
$$
color{#348FEA}{left[D_{x_0} fright]}(h) = left(color{#FFC100}{nabla_{x_0} f}right)^T h = langlecolor{#FFC100}{nabla_{x_0} f}, h rangle,
$$где $langlebullet, bulletrangle$ — операция скалярного произведения, а $color{#FFC100}{nabla_{x_0} f} = left(frac{partial f}{partial x_1}, ldots, frac{partial f}{partial x_n}right)$ — градиент функции $f$.
-
$f(x)$ — скалярная функция, $X$ — матрица. Дифференциал скалярной функции по матричному аргументу определяется следующим образом:
$$
f(X_0 + H) – f(X_0) approx sumlimits_{i,j} left.frac{partial f}{partial X_{ij}} right|_{X=X_0} H_{ij}
$$Можно заметить, что это стандартное определение дифференциала функции многих переменных для случая, когда переменные — элементы матрицы $X$. Заметим также один интересный факт:
$$
sum_{ij} A_{ij} B_{ij} = text{tr}, A^T B,
$$где $A$ и $B$ — произвольные матрицы одинакового размера. Объединяя оба приведённых выше факта, получаем:
$$
color{#348FEA}{left[D_{X_0} f right]} (H)
= sum limits_{ij}
left.
frac{partial f}{partial X_{ij}}
right|_{X = X_0}
left(
X – X_0
right)_{ij}
= text{tr},
left( left[left. frac{partial f}{partial X_{ij}}right|_{X=X_0}right]^T Hright).
$$Можно заметить, что здесь, по аналогии с примерами, где $x$ — скаляр и где $x$ — вектор (и $f(x)$ — скалярная функция), получилось на самом деле скалярное произведение градиента функции $f$ по переменным $X_{ij}$ и приращения. Этот градиент мы записали для удобства в виде матрицы с теми же размерами, что матрица $X$.
В примерах выше нам дважды пришлось столкнуться с давним знакомцем из матанализа: градиентом скалярной функции (у нескалярных функций градиента не бывает). Напомним, что градиент $color{#FFC100}{nabla_{x_0} f}$ функции в точке $x_0$ состоит из частных производных этой функции по всем координатам аргумента. При этом его обычно упаковывают в ту же форму, что и сам аргумент: если $x$ — вектор-строка, то и градиент записывается вектор-строкой, а если $x$ — матрица, то и градиент тоже будет матрицей того же размера. Это важно, потому что для осуществления градиентного спуска мы должны уметь прибавлять градиент к точке, в которой он посчитан.
Как мы уже имели возможность убедиться, для градиента скалярной функции $f$ выполнено равенство
$$
left[D_{x_0} f right] (x-x_0) = langlecolor{#FFC100}{nabla_{x_0} f}, x-x_0rangle,
$$
где скалярное произведение — это сумма попарных произведений соответствующих координат (да-да, самое обыкновенное).
Посмотрим теперь, как выглядит дифференцирование для функций, которые на выходе выдают не скаляр, а что-то более сложное.
Примеры конкретных форм $big[D_{x_0} fbig] (h)$, где $f$ — это вектор или матрица
-
$f(x) = begin{pmatrix} f(x_1) vdots f(x_m) end{pmatrix}$, $x$ — вектор. Тогда
$$
f(x_0 + h) – f(x_0) =
begin{pmatrix}
f(x_{01} + h_1) – f(x_{01})
vdots
f(x_{0m} + h_m) – f(x_{0m})
end{pmatrix}
approx
begin{pmatrix}
f'(x_{01}) h_1
vdots
f'(x_{0m}) h_m
end{pmatrix}
=
begin{pmatrix}
f'(x_{01})
vdots
f'(x_{0m})
end{pmatrix}
odot
h.
$$В последнем выражении происходит покомпонентное умножение:
$$color{#348FEA}{big[D_{x_0} fbig]} (h) = f'(x_0) odot h = h odot f'(x_0)$$
-
$f(X) = XW$, где $X$ и $W$ — матрицы. Тогда
$$f(X_0 + H) – f(X_0) = (X_0 + H) W – X_0 W = H W,$$
то есть
$$color{#348FEA}{big[D_{X_0} fbig]} (H) = H W$$
-
$f(W) = XW$, где $X$ и $W$ — матрицы. Тогда
$$f(W_0 + H) – f(W_0) = X(W_0 + H) – XW_0 = X H,$$
то есть
$$color{#348FEA}{big[D_{W_0} fbig]} (H) = X H$$
-
$f(x) = (f_1(x),ldots,f_K(x))$ — вектор-строка, $x = (x_1,ldots,x_D)$ — вектор-строка. Тогда
$$
color{#348FEA}{big[D_{x_0} fbig]}(h)
= left(sum_j
left.
frac{partial f_1}{partial y_j}
right|_{y=x_0}h_j, ldots, sum_j left. frac{partial f_K}{partial y_j} right|_{y=x_0}h_j right) = \
= h cdot
begin{pmatrix}
left.
frac{partial f_1}{partial y_1}
right|_{y=x_0} & ldots &
left.
frac{partial f_k}{partial y_1}
right|_{y=x_0} \
vdots & & vdots \
left.
frac{partial f_1}{partial y_D}
right|_{y=x_0} & ldots &
left.
frac{partial f_k}{partial y_D}
right|_{y=x_0}\
end{pmatrix}
= h cdot
left.
frac{partial f}{partial y}right|_{y = x_0}
$$Матрица, выписанная в предпоследней выкладке, — это знакомая вам из курса матанализа матрица Якоби.
Простые примеры и свойства матричного дифференцирования
-
Производная константы. Пусть $f(x) = a$. Тогда
$$f(x_0 + h) – f(x_0) = 0,$$
то есть $color{#348FEA}{big[D_{x_0} fbig]}$ — это нулевое отображение. А если $f$ — скалярная функция, то и $color{#FFC100}{nabla_{x_0} f} = 0.$
-
Производная линейного отображения. Пусть $f(x)$ — линейное отображение. Тогда
$$f(x_0 + h) – f(x_0) = f(x_0) + f(h) – f(x_0) = f(h)$$
Поскольку справа линейное отображение, то по определению оно и является дифференциалом $color{#348FEA}{big[D_{x_0} fbig]}$. Мы уже видели примеры таких ситуаций выше, когда рассматривали отображения умножения на матрицу слева или справа. Если $f$ — (скалярная) линейная функция, то она представляется в виде $langle a, vrangle$ для некоторого вектора $a$ — он и будет градиентом $f$.
-
Линейность производной. Пусть $f(x) = lambda u(x) + mu v(x)$, где $lambda, mu$ — скаляры, а $u, v$ — некоторые отображения, тогда
$$color{#348FEA}{big[D_{x_0} fbig]} = lambda color{#348FEA}{big[D_{x_0} ubig]} + mu color{#348FEA}{big[D_{x_0} vbig]}$$
Попробуйте доказать сами, прежде чем смотреть доказательство.
$$f(x_0 + h) – f(x_0) = (lambda u(x_0 + h) + mu v(x_0 + h)) – (lambda u(x_0) + mu v(x_0)) =$$
$$ = lambda(u(x_0 + h) – u(x_0)) + mu(v(x_0 + h) – v(x_0)) approx $$
$$approx lambda color{#348FEA}{big[D_{x_0} ubig]}(h) + mu color{#348FEA}{big[D_{x_0} vbig]}(h)$$
-
Производная произведения. Пусть $f(x) = u(x) v(x)$, где $u, v$ — некоторые отображения, тогда
$$color{#348FEA}{big[D_{x_0} fbig]} = color{#348FEA}{big[D_{x_0} ubig]} cdot v(x_0) + u(x_0) cdot color{#348FEA}{big[D_{x_0} vbig]}$$
Попробуйте доказать сами, прежде чем смотреть доказательство.
Обозначим для краткости $x = x_0 + h$. Тогда
$$u(x)v(x) – u(x_0)v(x_0) = u(x)v(x) – u(x_0)v(x) + u(x_0)v(x) – u(x_0)v(x_0) =$$
$$ (u(x) – u(x_0))v(x) + u(x_0)(v(x) – v(x_0))approx $$
$$approx color{#348FEA}{big[D_{x_0} ubig]}(h) cdot v(x) + u(x_0)cdot color{#348FEA}{big[D_{x_0} vbig]}(h)$$
И всё бы хорошо, да в первом слагаемом $v(x)$ вместо $v(x_0)$. Придётся разложить ещё разок:
$$color{#348FEA}{big[D_{x_0} ubig]}(h) cdot v(x) approx $$
$$color{#348FEA}{big[D_{x_0} ubig]}(h) cdot left(v(x_0) + color{#348FEA}{big[D_{x_0} vbig]}(h) + o(vertvert hvertvert)right) =$$
$$color{#348FEA}{big[D_{x_0} ubig]}(h) cdot v(x_0) + bar{bar{o}}left(vertvert hvertvertright)$$
Это же правило сработает и для скалярного произведения:
$$color{#348FEA}{big[D_{x_0} langle u, vranglebig]} = langlecolor{#348FEA}{big[D_{x_0} ubig]}, vrangle + langle u, color{#348FEA}{big[D_{x_0} vbig]}rangle$$
В этом нетрудно убедиться, повторив доказательство или заметив, что в доказательстве мы пользовались лишь дистрибутивностью (= билинейностью) умножения.
-
Производная сложной функции. Пусть $f(x) = u(v(x))$. Тогда
$$f(x_0 + h) – f(x_0) = u(v(x_0 + h)) – u(v(x_0)) approx $$
$$approxleft[D_{v(x_0)} u right] (v(x_0 + h) – v(x_0)) approx left[D_{v(x_0)} u right] left( left[D_{x_0} vright] (h)right)$$
Здесь $D_{v(x_0)} u$ — дифференциал $u$ в точке $v(x_0)$, а $left[D_{v(x_0)} u right]left(ldotsright)$ — это применение отображения $left[D_{v(x_0)} u right]$ к тому, что в скобках. Итого получаем:
$$left[D_{x_0} color{#5002A7}{u} circ color{#4CB9C0}{v} right](h) = color{#5002A7}{left[D_{v(x_0)} u right]} left( color{#4CB9C0}{left[D_{x_0} vright]} (h)right)$$
-
Важный частный случай: дифференцирование перестановочно с линейным отображением. Пусть $f(x) = L(v(x))$, где $L$ — линейное отображение. Тогда $left[D_{v(x_0)} L right]$ совпадает с самим $L$ и формула упрощается:
$$left[D_{x_0} color{#5002A7}{L} circ color{#4CB9C0}{v} right](h) = color{#5002A7}{L} left( color{#4CB9C0}{left[D_{x_0} vright]} (h)right)$$
Простые примеры вычисления производной
-
Вычислим дифференциал и градиент функции $f(x) = langle a, xrangle$, где $x$ — вектор-столбец, $a$ — постоянный вектор.
Попробуйте вычислить сами, прежде чем смотреть решение.
Вычислить производную можно непосредственно:
$$f(x_0 + h) – f(x_0) = langle a, x_0 + hrangle – langle a, x_0rangle = langle a, hrangle$$
Но можно и воспользоваться формулой дифференциала произведения:
$$color{#348FEA}{big[D_{x_0} langle a, xranglebig]} (h) = $$
$$ =langlecolor{#348FEA}{big[D_{x_0} abig]}(h), xrangle + langle a, color{#348FEA}{big[D_{x_0} xbig]}(h)rangle$$
$$= langle 0, xrangle + langle a, hrangle = langle a, hrangle$$
Сразу видно, что градиент функции равен $a$.
-
Вычислим производную и градиент $f(x) = langle Ax, xrangle$, где $x$ — вектор-столбец, $A$ — постоянная матрица.
Попробуйте вычислить сами, прежде чем смотреть решение.
Снова воспользуемся формулой дифференциала произведения:
$$color{#348FEA}{big[D_{x_0} langle Ax, xranglebig]}(h) = $$
$$ = langlecolor{#348FEA}{big[D_{x_0} Axbig]}(h), x_0rangle + langle Ax_0, color{#348FEA}{big[D_{x_0} xbig]}(h)rangle$$
$$= langle Ah, x_0rangle + langle Ax_0, hrangle$$
Чтобы найти градиент, нам надо это выражение представить в виде $langle ?, hrangle$. Для этого поменяем местами множители первого произведения и перенесём $A$ в другую сторону ($A$ перенесётся с транспонированием):
$$langle A^Tx_0, hrangle + langle Ax_0, hrangle = $$
$$= langle (A^T + A)x_0, hrangle$$
Получается, что градиент в точке $x_0$ равен $(A^T + A)x_0$.
-
Вычислим производную обратной матрицы: $f(X) = X^{-1}$, где $X$ — квадратная матрица.
Попробуйте вычислить сами, прежде чем смотреть решение.
Рассмотрим равенство $I = Xcdot X^{-1} = I$ и продифференцируем его:
$$0 = color{#348FEA}{big[D_{X_0} left( Xcdot X^{-1}right)big]}(H) = $$
$$ = color{#348FEA}{big[D_{X_0} Xbig]}(H)cdot X_0^{-1} + X_0cdot color{#348FEA}{big[D_{X_0} X^{-1}big]}(H)$$
Отсюда уже легко выражается
$$color{#348FEA}{big[D_{X_0} X^{-1}big]}(H) = -X_0^{-1}cdotcolor{#348FEA}{big[D_{X_0} Xbig]}(H)cdot X_0^{-1}$$
Осталось подставить $color{#348FEA}{big[D_{X_0} Xbig]}(H) = H$, но запомните и предыдущую формулу, она нам пригодится.
-
Вычислим градиент определителя: $f(X) = text{det}(X)$, где $X$ — квадратная матрица.
Попробуйте вычислить сами, прежде чем смотреть решение.
В предыдущих примерах мы изо всех сил старались не писать матричных элементов, но сейчас, увы, придётся. Градиент функции состоит из её частных производных: $color{#FFC100}{nabla_{x_0} f} = left(frac{partial f}{partial{x_{ij}}}right)_{i,j}$. Попробуем вычислить $frac{partial f}{partial{x_{ij}}}$. Для этого разложим определитель по $i$-й строке:
$$text{det}(X) = sum_{k}x_{ik}cdot(-1)^{i + k}M_{ik},$$
где $M_{ik}$ — это определитель подматрицы, полученной из исходной выбрасыванием $i$-й строки и $k$-го столбца. Теперь мы видим, что определитель линеен по переменной $x_{ij}$, причём коэффициент при ней равен $cdot(-1)^{i + k}M_{ik}$. Таким образом,
$$frac{partial f}{partial{x_{ij}}} = (-1)^{i + k}M_{ik}$$
Чтобы записать матрицу, составленную из таких определителей, покороче, вспомним, что
$$X^{-1} = frac1{text{det}(X)}left((-1)^{i+j}M_{color{red}{ji}}right)_{i,j}$$
Обратите внимание на переставленные индексы $i$ и $j$ (отмечены красным). Но всё равно похоже! Получается, что
$$color{#FFC100}{nabla_{x_0} f} = text{det}(X)cdot X^{-T},$$
где $X^{-T}$ — это более короткая запись для $(X^{-1})^T$.
-
Вычислим градиент функции $f(x) = vertvert Ax – bvertvert^2$. С этой функцией мы ещё встретимся, когда будем обсуждать задачу линейной регрессии.
Попробуйте вычислить сами, прежде чем смотреть решение.
Распишем квадрат модуля в виде скалярного произведения:
$$vertvert Ax – bvertvert^2 = langle Ax – b, Ax – brangle$$
Применим формулу дифференциала произведения и воспользуемся симметричностью скалярного произведения:
$$color{#348FEA}{big[D_{x_0} langle Ax – b, Ax – branglebig]}(h) = $$
$$ langle color{#348FEA}{big[D_{x_0} (Ax – b)big]}(h), Ax_0 – brangle + langle Ax_0 – b, color{#348FEA}{big[D_{x_0} (Ax – b)big]}(h)rangle$$
$$ = 2langle Ax_0 – b, color{#348FEA}{big[D_{x_0} (Ax – b)big]}(h)rangle =$$
$$ = 2langle Ax_0 – b, Ahrangle = langle 2A^T(Ax_0 – b), hrangle$$
Получаем, что
$$color{#FFC100}{nabla_{x_0} f} = 2A^T(Ax_0 – b)$$
Примеры вычисления производных сложных функций
-
Вычислим градиент функции $f(X) = text{log}(text{det}(X))$.
Попробуйте вычислить сами, прежде чем смотреть решение.
Вспомним формулу производной сложной функции:
$$left[D_{X_0} u circ v right](H) = left[D_{v(X_0)} u right] left( left[D_{X_0} vright] (H)right)$$
и посмотрим, как её тут можно применить. В роли функции $u$ у нас логарифм:
$$u(y) = text{log}(u),quad left[D_{y_0} uright](s) = frac1y_0cdot s,$$
а в роли $v$ — определитель:
$$v(X) = text{det}(X),quad left[D_{y_0} vright](H) = langle text{det}(X_0)cdot X_0^{-T}, Hrangle,$$
где под скалярным произведением двух матриц понимается, как обычно,
$$langle A, Brangle = sum_{i,j}a_{ij}b_{ij} = text{tr}(A^TB)$$
Подставим это всё в формулу произведения сложной функции:
$$left[D_{X_0} u circ v right](H) = frac1{text{det}(X)}cdotlangle text{det}(X)cdot X^{-T}, Hrangle =$$
$$= langle frac1{text{det}(X)}cdottext{det}(X)cdot X^{-T}, Hrangle =
langle X_0^{-T}, Hrangle$$Отсюда сразу видим, что
$$color{#FFC100}{nabla_{X_0} f} = X_0^{-T}$$
-
Вычислим градиент функции $f(X) = text{tr}(AX^TX)$.
Попробуйте вычислить сами, прежде чем смотреть решение.
Воспользуемся тем, что след — это линейное отображение (и значит, перестановочно с дифференцированием), а также правилом дифференцирования сложной функции:
$$left[D_{X_0} f right](H) = text{tr}left(left[D_{X_0} AX^TX right](H)right) =$$
$$=text{tr}left(Acdotleft[D_{X_0} X^T right](H)cdot X_0 + AX_0^Tleft[D_{X_0} X right](H)right) =$$
$$=text{tr}left(AH^TX_0 + AX_0^THright)$$
Чтобы найти градиент, мы должны представить это выражение в виде $langle ?, Hrangle$, что в случае матриц переписывается, как мы уже хорошо знаем, в виде $text{tr}(?^Tcdot H) = text{tr}(?cdot H^T)$. Воспользуемся тем, что под знаком следа можно транспонировать и переставлять множители по циклу:
$$ldots=text{tr}left(AH^TX_0right) + text{tr}left(AX_0^THright) =$$
$$=text{tr}left(X_0AH^Tright) + text{tr}left(H^TX_0A^Tright) =$$
$$=text{tr}left(X_0AH^Tright) + text{tr}left(X_0A^TH^Tright) =$$
$$=text{tr}left((X_0A + X_0A^T)H^Tright)$$
Стало быть,
$$color{#FFC100}{nabla_{X_0} f} = X_0A + X_0A^T$$
-
Вычислим градиент функции $f(X) = text{det}left(AX^{-1}Bright)$.
Подумайте, кстати, почему мы не можем расписать определитель в виде произведения определителей и тем самым сильно упростить себе жизнь
Расписать у нас может не получиться из-за того, что $A$ и $B$ могут быть не квадратными, и тогда у них нет определителей и представить исходный определитель в виде произведения невозможно.
Воспользуемся правилом дифференцирования сложной функции для $u(Y) = text{det}(Y)$, $v(X) = AX^{-1}B$. А для этого сначала вспомним, какие дифференциалы у них самих. С функцией $u$ всё просто:
$$left[D_{Y_0} uright](S) = langle text{det}(Y_0)Y_0^{-T}, Srangle =$$
$$= text{tr}left(text{det}(Y_0)Y_0^{-1}Sright)$$
Функция $v$ сама является сложной, но, к счастью, множители $A$ и $B$ выносятся из-под знака дифференциала, а дифференцировать обратную матрицу мы уже умеем:
$$left[D_{X_0} vright](H) = – AX_0^{-1}HX_0^{-1} B$$
С учётом этого получаем:
$$left[D_{X_0} f right](H) = left[D_{v(X_0)} u right] left( left[D_{X_0} vright] (H)right) =$$
$$=text{tr}left(text{det}(AX_0^{-1}B)(AX_0^{-1}B)^{-1}left(- AX_0^{-1}HX_0^{-1} Bright)right)$$
$$=text{tr}left(-text{det}(AX_0^{-1}B)(AX_0^{-1}B)^{-1}AX_0^{-1}HX_0^{-1} Bright)$$
Чтобы найти градиент, мы должны, как обычно, представить это выражение в виде $text{tr}(?^Tcdot H)$.
$$ldots=text{tr}left(-text{det}(AX_0^{-1}B)X_0^{-1} B(AX_0^{-1}B)^{-1}AX_0^{-1}Hright)$$
Стало быть,
$${nabla_{X_0} f} = left(-text{det}(AX_0^{-1}B)X_0^{-1} B(AX_0^{-1}B)^{-1}AX_0^{-1}right)^T =$$
$$=-text{det}(AX_0^{-1}B)X_0^{-T} A^T(AX_0^{-1}B)^{-T}B^TX_0^{-T}$$
Вторая производная
Рассмотрим теперь не первые два, а первые три члена ряда Тейлора:
$$f(x_0 + h) = f(x_0) + color{#348FEA}{left[D_{x_0} f right]} (h) + frac12color{#4CB9C0}{left[D_{x_0}^2 f right]} (h, h) + bar{bar{o}} left(left|left| hright|right|^2right),$$
где $color{#4CB9C0}{left[D_{x_0}^2 f right]} (h, h)$ — второй дифференциал, квадратичная форма, в которую мы объединили все члены второй степени.
Вопрос на подумать. Докажите, что второй дифференциал является дифференциалом первого, то есть
$$left[D_{x_0} color{#348FEA}{left[D_{x_0} f right]} (h_1) right] (h_2) = left[D_{x_0}^2 f right] (h_1, h_2)$$
Зависит ли выражение справа от порядка $h_1$ и $h_2$?
Этот факт позволяет вычислять второй дифференциал не с помощью приращений, а повторным дифференцированием производной.
Вторая производная может оказаться полезной при реализации методов второго порядка или же для проверки того, является ли критическая точка (то есть точка, в которой градиент обращается в ноль) точкой минимума или точкой максимума. Напомним, что квадратичная форма $q(h)$ называется положительно определённой (соответственно, отрицательно определённой), если $q(h) geqslant 0$ (соответственно, $q(h) leqslant 0$) для всех $h$, причём $q(h) = 0$ только при $h = 0$.
Теорема. Пусть функция $f:mathbb{R}^mrightarrowmathbb{R}$ имеет непрерывные частные производные второго порядка $frac{partial^2 f}{partial x_ipartial x_j}$ в окрестности точки $x_0$, причём $color{#FFC100}{nabla_{x_0} f} = 0$. Тогда точка $x_0$ является точкой минимума функции, если квадратичная форма $color{#348FEA}{D_{x_0}^2 f} $ положительно определена, и точкой максимума, если она отрицательно определена.
Если мы смогли записать матрицу квадратичной формы второго дифференциала, то мы можем проверить её на положительную или отрицательную определённость с помощью критерия Сильвестра.
Примеры вычисления и использования второй производной
-
Рассмотрим задачу минимизации $f(x) = vertvert Ax – bvertvert^2$ по переменной $x$, где $A$ — матрица с линейно независимыми столбцами. Выше мы уже нашли градиент этой функции; он был равен $color{#FFC100}{nabla_{x_0} f} = 2A^T(Ax – b)$. Мы можем заподозрить, что минимум достигается в точке, где градиент обращается в ноль: $x_* = (A^TA)^{-1}A^Tb$. Отметим, что обратная матрица существует, так как $text{rk}(A^TA) = text{rk}{A}$, а столбцы $A$ по условию линейно независимы и, следовательно, $text{rk}(A^TA)$ равен размеру этой матрицы. Но действительно ли эта точка является точкой минимума? Давайте оставим в стороне другие соображения (например, геометрические, о которых мы упомянем в главе про линейные модели) и проверим аналитически. Для этого мы должны вычислить второй дифференциал функции $f(x) = vertvert Ax – bvertvert^2$.
Попробуйте вычислить сами, прежде чем смотреть решение.
Вспомним, что
$$color{#348FEA}{big[D_{x_0} vertvert Ax – bvertvert^2big]}(h_1) = langle 2A^T(Ax_0 – b), h_1rangle$$
Продифференцируем снова. Скалярное произведение — это линейная функция, поэтому можно занести дифференцирование внутрь:
$$color{#348FEA}{big[D_{x_0} langle 2A^T(Ax – b), h_1ranglebig]}(h_2) =
langle color{#348FEA}{big[D_{x_0} (2A^TAx – 2A^Tb)big]}(h_2), h_1rangle =$$$$=langle 2A^TAh_2, h_1rangle = 2h_2^T A^TA h_1$$
Мы нашли квадратичную форму второго дифференциала; она, оказывается, не зависит от точки (впрочем, логично: исходная функция была второй степени по $x$, так что вторая производная должна быть константой). Чтобы показать, что $x_*$ действительно является точкой минимума, достаточно проверить, что эта квадратичная форма положительно определена.
Попробуйте сделать это сами, прежде чем смотреть решение.
Хорошо знакомый с линейной алгеброй читатель сразу скажет, что матрица $A^TA$ положительно определена для матрицы $A$ с линейно независимыми столбцами. Но всё же давайте докажем это явно. Имеем $h^TA^TAh = (Ah)^TAh = vertvert Ahvertvert^2 geqslant 0$. Это выражение равно нулю тогда и только тогда, когда $Ah = 0$. Последнее является однородной системой уравнений на $h$, ранг которой равен числу переменных, так что она имеет лишь нулевое решение $h = 0$.
-
Докажем, что функция $f(X) = log{text{det}(X)}$ является выпуклой вверх на множестве симметричных, положительно определённых матриц. Для этого мы должны проверить, что в любой точке квадратичная форма её дифференциала отрицательно определена. Для начала вычислим эту квадратичную форму.
Попробуйте сделать это сами, прежде чем смотреть решение.
Выше мы уже нашли дифференциал этой функции:
$$color{#348FEA}{big[D_{X_0} log{text{det}(X)}big]}(H_1) = langle X_0^{-T}, H_1rangle$$
Продифференцируем снова:
$$color{#348FEA}{big[D_{X_0} langle X^{-T}, H_1ranglebig]}(H_2) =
langle color{#348FEA}{big[D_{x_0} X^{-T}big]}(H_2), h_1rangle =$$$$=langle -X_0^{-1}H_2X_0^{-1}, H_1rangle$$
Чтобы доказать требуемое в условии, мы должны проверить следующее: что для любой симметричной матрицы $X_0$ и для любого симметричного (чтобы не выйти из пространства симметричных матриц) приращения $Hne 0$ имеем
$$color{#348FEA}{big[D^2_{X_0} log{text{det}(X)}big]}(H, H) < 0$$
Покажем это явно. Так как $X_0$ — симметричная, положительно определённая матрица, у неё есть симметричный и положительно определённый квадратный корень: $X_0 = X_0^{1/2}cdot X_0^{1/2} = X_0^{1/2}cdot left(X_0^{1/2}right)^T.$ Тогда
$$langle -X_0^{-1}HX_0^{-1}, Hrangle = -text{tr}left(X_0^{1/2} left(X_0^{1/2}right)^THX_0^{1/2} left(X_0^{1/2}right)^TH^Tright) =$$
$$-text{tr}left(left(X_0^{1/2}right)^THX_0^{1/2} left(X_0^{1/2}right)^TH^TX_0^{1/2}right) = $$
$$=-text{tr}left( left(X_0^{1/2}right)^THX_0^{1/2} left[left(X_0^{1/2}right)^THX_0^{1/2}right]^Tright) =$$
$$=-vertvertleft(X_0^{1/2}right)^THX_0^{1/2}vertvert^2,$$
что, конечно, меньше нуля для любой ненулевой $H$.
Обновление: 8 января 2020
Обновление: 16 февраля 2020

Но наибольший успех достигается с помощью такого приема: из готовой рукописи вы вырываете две страницы выкладок, а вместо них вставляете слово “следовательно” и двоеточие. Гарантирую, что читатель добрых два дня будет гадать, откуда взялось это “следствие”. Еще лучше написать “очевидно” вместо “следовательно”, поскольку не существует читателя, который отважился бы спросить у кого-нибудь объяснение очевидной вещи. Этим вы не только сбиваете читателя с толку, но и прививаете ему комплекс неполноценности, а это одна из главных целей.
– Н.Вансерг «Математизация».
Вместо введения
С момента прошлой заметки по данной теме прошло много времени, но интерес к изложенному в ней не утихал. Разобравшись с основной проблемой (как, собственно, реализовать дифференцирование) читатели стали задавать вопросы о двух приведённых в тексте формулах. На этих формулах построен весь вывод, но сами они не выводятся, а сопровождены комментарием о простоте их получения при должной внимательности. Настало время.
Замечание о качестве
Мне никогда не попадался вывод этих формул. Обычно, если у вас проблемы с матрицей, то надо обращаться либо к Нео, либо к Гантмахеру [?]
Ф.Р. Гантмахер “ТЕОРИЯ МАТРИЦ”
. Но в этот раз – мне никто не помог. Так что, не обессудьте: вывел как умею.
Технология
Подобные формулы (“Нагромождение из матриц” – “знак равенства” – “некоторая функция от матриц”) выводятся стандартно: вы опускаетесь на уровень ниже – до компонент объектов (разбирая что там “под капотом” происходит), аккуратно (я бы даже сказал “осторожно”) проделываете все преобразования с позиции компонент, получаете некий, более-менее конечный, результат и поднимаетесь на уровень выше (пытаясь интерпретировать формулы из компонент с позиции исходных объектов).
Первая формула
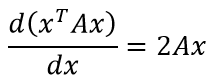
Отмечу, что это частный случай для симметричной матрицы A. В более же общем случае, формула имеет вид:
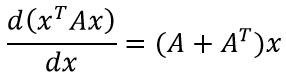
Для того, чтобы выражение в скобках можно было вычислить, необходимо, чтобы объекты имели следующие размеры:
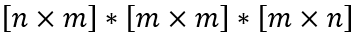
Так как x – вектор, то min(m,n) = 1.
Зададимся конкретикой: пусть x – вектор-столбец, тогда n=1.
Объекты, таким образом, будут иметь вид:

Теперь, наконец-то, можно приступить к выводу. Здесь главное ничего не потерять, поэтому сперва аккуратно проделаем умножение xTA, а затем домножим результат на x.

Ожидаемо, мы получаем скаляр, зависящий от вектора. Возьмём производную скалярной функции от векторного аргумента:
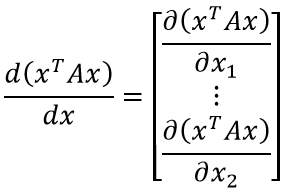
Чтобы получить данное выражение, необходимо найти общий вид производной по k-ой компоненте вектора. Попробуем сгруппировать слагаемые дифференцируемого выражения по компонентам вектора, опираясь на выражение для xTAx, полученное ранее:
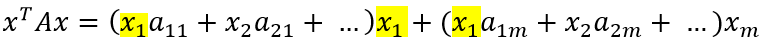
Очевидно, что раскрытие первых скобок даст нам x1 в квадрате с множителем a11 плюс сумму произведений x1 со всеми остальными слагаемыми внутри первых скобок. Также, x1 входит в остальные скобки по одному разу, что образует ещё слагаемые вида x1*a…*x….
Таким образом:
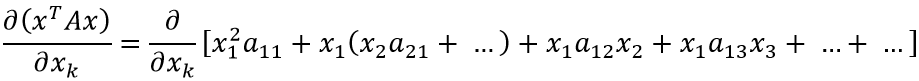
Если присмотреться, можно заметить закономерность (приведены множители xk: оставшаяся часть выражения скрыта за многоточием):
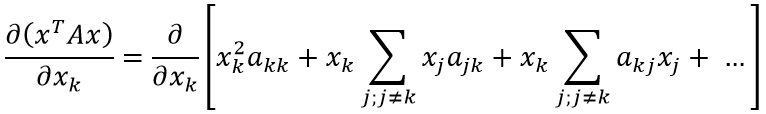
Теперь найти производную не составит труда:
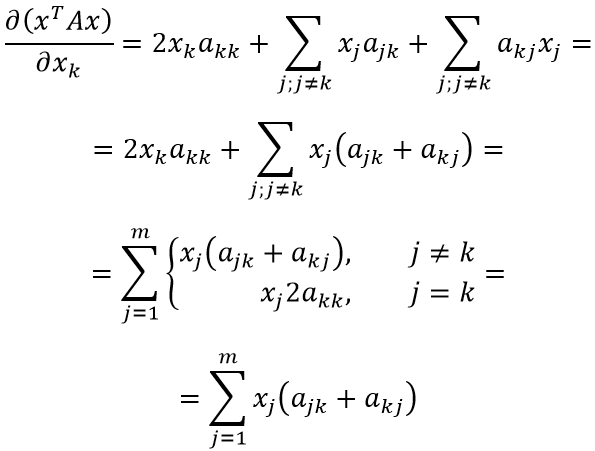
В преобразованиях выше мы сначала объединили две сумму в одну (т.к. индексы, по которым идёт суммирование совпадают), затем первое слагаемое внесли как частный случай суммы под знак суммирования (в соответствии с индексом при x). Последняя операция изменяет условия суммирования: теперь сумма определена для всех возможных значений индекса j.
Наконец, можно заметить, что (ajk+akj) при выполнении j=k соответствует (akk+akk) = 2akk. Таким образом, выражение для первого условия покрывает и выражение для второго условия – сумму можно переписать без ветвления. Для всех компонент вектора x формула коэффициента оказалась одинакова.
Теперь несложно продолжить дифференцирование:
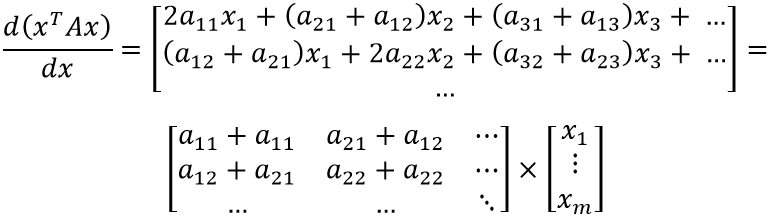
Осталось заметить, что левый множитель представляет собой специфическое суммирование элементов матрицы. Несложно догадаться, что компонент jk складывается с kj при сложении матрицы с её транспонированным вариантом:
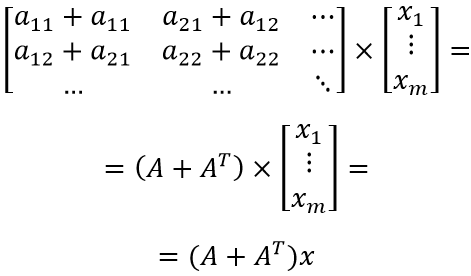
Оставляя начальное и конечное выражения, получаем:
ЧТД
Вторая формула
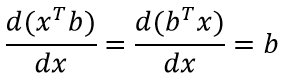
Формула (особенно, по сравнению с предыдущей) достаточна проста для восприятия и объясняется “на пальцах”. xTb и bTx – это просто сумма попарного произведения компонент двух векторов (первый вектор приходится транспонировать для существования соответствующего матричного произведения). Ну и, не менее очевидное – скорость изменения от x каждой компоненты результирующего вектора определяется соответствующей компонентой вектора b.
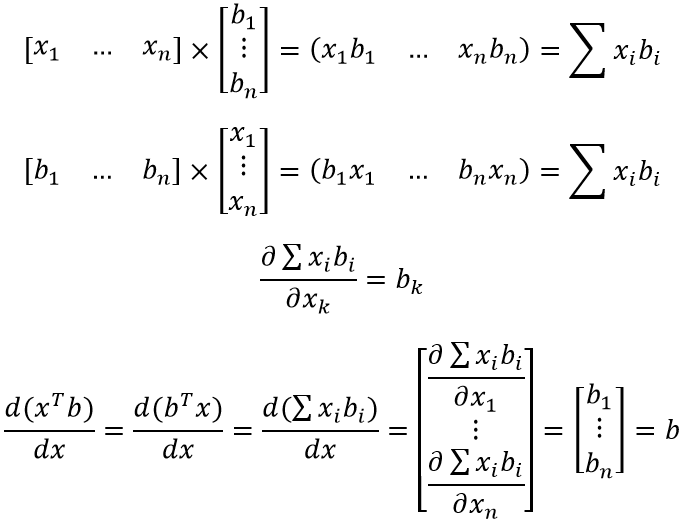
ЧТД
Вместо выводов
Профессор, стоя у доски, был погружен в длиннейший вывод. В каком-то месте он произнес стандартную фразу “отсюда с очевидностью вытекает следующее” и написал длинное и сложное выражение, абсолютно не похожее ни на что из написанного ранее. Затем он заколебался, на его лице появилось озадаченное выражение, он что-то пробормотал и прошел из аудитории в свой кабинет. Появившись оттуда через полчаса, он с довольным видом объяснил аудитории: “Я был прав. Это, действительно, совершенно очевидно”.
– Дуайт Е.Грэй «Отчеты, которые я читал… и, возможно, писал».
1. Учимся искать производные#
Когда мы работаем с одномерными функциями, для поиска любых производных нам хватает небольшой таблицы со стандартными случаями и пары правил. Для случая матриц все эти правила можно обобщить, а таблицы дополнить специфическими функциями вроде определителя.
Удобнее всего оказывается работать в терминах «дифференциала» — с ним можно не задумываться о промежуточных размерностях, а просто применять стандартные правила.
Мы будем работать в этом конспекте со скалярами, векторами и матрицами. Нас будет интересовать, что именно мы дифференцируем, по чему мы дифференцируем и что получается в итоге.
Строчными буквами мы будем обозначать векторы-столбцы и константы. Заглавными буквами мы будем обозначать матрицы. Производная столбца — это столбец. Производная по столбцу — это столбец.
[begin{split}
x = begin{pmatrix}x_1 \ ldots \ x_n end{pmatrix} qquad X = begin{pmatrix}x_{11} & ldots & x_{1n} \ ldots & ddots & ldots \ x_{n1} & ldots & x_{nn} end{pmatrix}.
end{split}]
Мы рассмотрим постепенно много разных входов и выходов, и получим таблицу из канонических случаев. По строчкам будем откладывать то, откуда бьёт функция, то есть входы. По столбцам будем откладывать то, куда бьёт функция, то есть выходы. Для ситуаций обозначенных прочерками обобщения получить не выйдет.
|
скаляр |
вектор |
матрица |
|
|---|---|---|---|
|
скаляр |
(f'(x) dx) |
(mathfrak{J} dx) |
– |
|
вектор |
(nabla_x f(x)^T dx) |
(mathfrak{J} dx) |
– |
|
матрица |
(tr(nabla_X f(X)^T dX)) |
– |
– |
Символом (nabla_x f) обозначается градиент (вектор из производных). Символом (mathfrak{J}) обозначена матрица Якоби. Символом (H) мы будем обозначать матрицу Гессе из вторых производных.
Найдём производную и дифференциал функции (f(x) = x^2), где (x) скаляр. Функция бьёт из скаляров в скаляры
[
f(x) : mathbb{R} to mathbb{R}.
]
Примером такой функции может быть (f(x) = x^2). Мы знаем, что по таблице производных (f'(x) = 2x). Также мы знаем, что дифференциал – это линейная часть приращения функции, а производная – это предел отношения приращения функции к приращению аргумента при приращении аргумента стремящемся к нулю.
Грубо говоря, дифференциал помогает представить приращение функции в линейном виде
[
d{f(x)} = f'(x) dx.
]
Если мы находимся в какой-то точке (x_0) и делаем из неё небольшое приращение (dx,) то наша функция изменится примерно на (df(x)). Оказывается, что именно в терминах дифференциалов удобно работать с матричными производными.
Свойства матричных дифференциалов очень похожи на свойства обычных. Надо только не забыть, что мы работаем с матрицами.
[begin{equation*}
begin{aligned}
& d{(XY)} = d{X}Y + X cdot d{Y}, quad d{X} cdot Y ne Y cdot d{X} \
& d{(alpha X + beta Y)} = alpha d{X} + beta d{Y} \
& d{(X^T)} = (d{X})^T \
& d{A} = 0, quad A – text{матрица из констант}
end{aligned}
end{equation*}]
Чтобы доказать все эти свойства достаточно просто аккуратно расписать их. Кроме этих правил нам понадобится пара трюков по работе со скалярами. Если (s) — скаляр размера (1 times 1), тогда (s^T = s) и (tr(s) = s), где (tr) — операция взятия следа матрицы.
С помощью этих преобразований мы будем приводить дифференциалы к каноническому виду и вытаскивать из них производные.
а) Найдите производную (nabla_x f(x)), где (f(x) = a^T x), где (a) и (x) векторы размера (1 times n)
Рассмотрим вторую ситуацию из таблицы, функция бьёт из векторов в скаляры. Это обычная функция от нескольких аргументов
[
f(x) : mathbb{R}^n to mathbb{R}.
]
Мы уже умеем брать такие производные. Если мы хотим найти производную функции (f(x_1, x_2, ldots, x_n)), нам надо взять производную по каждому аргументу и записать их все в виде вектора. Такой вектор называют градиентом.
[begin{split}
nabla_x f(x) = begin{pmatrix} frac{partial f(x)}{partial x_1} \ frac{partial f(x)}{partial x_2} \ ldots \ frac{partial f(x)}{partial x_n} end{pmatrix}
end{split}]
Если умножить градиент на вектор приращений, у нас получится дифференциал
[begin{multline*}
d{f(x)} = nabla_x f(x)^T dx = begin{pmatrix} frac{partial f(x)}{partial x_1} & frac{partial f(x)}{partial x_2} & ldots & frac{partial f(x)}{partial x_n} end{pmatrix} begin{pmatrix} dx_1 \ dx_2 \ ldots \ dx_n end{pmatrix} = \ = frac{partial f(x)}{partial x_1} cdot dx_1 + frac{partial f(x)}{partial x_2} cdot dx_2 + ldots +frac{partial f(x)}{partial x_n} cdot dx_n.
end{multline*}]
При маленьком изменении (x_i) на (dx_i) функция будет при прочих равных меняться пропорционально соответствующей частной производной. Посмотрим на конкретный пример, скалярное произведение. Можно расписать умножение одного вектора на другой в виде привычной нам формулы
[begin{equation*}
underset{[1 times 1]}{f(x)} = underset{[1 times n]}{a^T} cdot underset{[n times 1]}{x} = begin{pmatrix} a_1 & a_2 & ldots &a_n end{pmatrix} cdot begin{pmatrix} x_1 \ x_2 \ ldots \ x_n end{pmatrix} = a_1 cdot x_1 + a_2 cdot x_2 + ldots + a_n cdot x_n.
end{equation*}]
Из неё чётко видно, что (frac{partial f(x)}{partial x_i} = a_i). Увидев это мы можем выписать градиент функции
[begin{split}
nabla_x f(x) = begin{pmatrix} frac{partial f(x)}{partial x_1} \ frac{partial f(x)}{partial x_2} \ ldots \ frac{partial f(x)}{partial x_n} end{pmatrix} = begin{pmatrix} a_1 \ a_2 \ ldots \ a_n end{pmatrix} = a,
end{split}]
теперь можно записать дифференциал
[begin{multline*}
df(x) = a^T dx = frac{partial f(x)}{partial x_1} cdot dx_1 + frac{partial f(x)}{partial x_2} cdot dx_2 + ldots +frac{partial f(x)}{partial x_n} cdot dx_n = \ = a_1 cdot dx_1 + a_2 cdot dx_2 + ldots + a_n cdot dx_n.
end{multline*}]
В то же самое время можно было бы просто воспользоваться правилами нахождения матричных дифференциалов
[
df(x) = dx{a^T x} = a^T dx = nabla f(x)^T dx,
]
откуда ( nabla_x f(x) = a). Производная найдена. При таком подходе нам не надо анализировать каждую частную производную по отдельности. Мы находим одним умелым движением руки сразу же все производные.
б) Найдите первую и вторую производные функции (f(x) = x^T A x), где (x) вектор размера (1 times n), (A) матрица размера (n times n)
Функция по-прежнему бьёт из векторов в скаляры. Попробуем перемножить все матрицы и расписать её в явном виде по аналогии со скалярным произведением
[begin{equation*}
underset{[1 times 1]}{f(x)} = underset{[1 times n]}{x^T} cdot underset{[n times n]}{A} cdot underset{[n times 1]}{x} = sum_{i = 1}^n sum_{j=1}^n a_{ij} cdot x_i cdot x_j.
end{equation*}]
Если продолжить в том же духе, мы сможем найти все частные производные, а потом назад вернём их в матрицу. Единственное, что смущает – мы делаем что-то неестественное. Всё было записано в красивом компактном матричном виде, а мы это испортили. А что, если множителей будет больше? Тогда суммы станут совсем громоздкими, и мы легко запутаемся.
При этом, если воспользоваться тут правилами работы с матричными дифференциалами, мы легко получим красивый результат
[
df(x) = d{x^T A x} = d(x^T) cdot A cdot x + x^T cdot d(Ax) = d(x^T) cdot A cdot x + x^T underset{d{A} = 0}{d{(A)}} x + x^T A dx(x).
]
Заметим, что (d(x^T) A x) это скаляр. Мы перемножаем матрицы с размерностями (1 times n), (n times n) и (n times 1). В результате получается размерность (1 times 1). Мы можем смело транспонировать скаляр, когда нам это надо. Эта операция никак не повлияет на результат
[
df(x) = d(x^T) A x + x^T A dx = x^T A^T dx + x^T A dx = x^T(A^T + A) dx.
]
Мы нашли матричный дифференциал и свели его к каноничной форме
[
df(x) = nabla^T_x f dx = x^T(A^T + A) dx
]
Получается, что искомая производная (nabla_x f(x) = (A + A^T) x). Обратите внимание, что размерности не нарушены и мы получили столбец из производных, то есть искомый градиент нашей функции (f(x)).
По аналогии мы легко можем найти вторую производную. Для этого надо взять производную производной. Функция (g(x) = (A + A^T) x) бьёт из векторов в вектора
[
f(x) : mathbb{R}^n to mathbb{R}^m.
]
На самом деле с такой ситуацией мы также знакомились на математическом анализе. Если (n=1) то у нас есть (m) функций, каждая из которых применяется к (x). На выходе получается вектор
[begin{split}
begin{pmatrix} f_1(x) \ f_2(x) \ ldots \ f_m(x). end{pmatrix}
end{split}]
Если мы хотим найти производную, нужно взять частную производную каждой функции по (x) и записать в виде вектора. Дифференциал также будет представлять из себя вектор, так как при приращении аргумента на какую-то величину изменяется каждая из функций
[begin{split}
df(x) = begin{pmatrix} frac{partial f_1}{partial x} \ frac{partial f_2}{partial x} \ ldots \ frac{partial f_m}{partial x} end{pmatrix} cdot begin{pmatrix} dx \ dx \ ldots \ dx end{pmatrix} = begin{pmatrix} frac{partial f_1}{partial x} dx \ frac{partial f_2}{partial x} dx \ ldots \ frac{partial f_m}{partial x} dx end{pmatrix}.
end{split}]
Если (n > 1), то аргументов на вход в такой вектор из функций идёт несколько, на выходе получается матрица
[begin{split}
begin{pmatrix} f_1(x_1) & f_1(x_2) & ldots & f_1(x_n) \ f_2(x_1) & f_2(x_2) & ldots & f_2(x_n) \ ldots & ldots & ddots & ldots \ f_m(x_1) & f_m(x_2) & ldots & f_m(x_n) end{pmatrix}
end{split}]
Производной такой многомерной функции будет матрица из частных производных каждой функции по каждому аргументу
[begin{split}
begin{pmatrix} frac{partial f_1}{partial x_1} & frac{partial f_1}{partial x_2} & ldots & frac{partial f_1}{partial x_n} \ frac{partial f_2}{partial x_1} & frac{partial f_2}{partial x_2} & ldots & frac{partial f_2}{partial x_n} \ ldots & ldots & ddots & ldots \ frac{partial f_m}{partial x_1} & frac{partial f_m}{partial x_2} & ldots & frac{partial f_m}{partial x_n} end{pmatrix}.
end{split}]
Дифференциал снова будет представлять из себя вектор
[begin{split}
df(x) = begin{pmatrix} frac{partial f_1}{partial x_1} & frac{partial f_1}{partial x_2} & ldots & frac{partial f_1}{partial x_n} \ frac{partial f_2}{partial x_1} & frac{partial f_2}{partial x_2} & ldots & frac{partial f_2}{partial x_n} \ ldots & ldots & ddots & ldots \ frac{partial f_m}{partial x_1} & frac{partial f_m}{partial x_2} & ldots & frac{partial f_m}{partial x_n} end{pmatrix} cdot begin{pmatrix} dx_1 \ dx_2 \ ldots \ dx_n end{pmatrix} = begin{pmatrix} frac{partial f_1}{partial x_1} dx_1 + frac{partial f_1}{partial x_2} dx_2 + ldots + frac{partial f_1}{partial x_n} dx_n \ frac{partial f_2}{partial x_1} dx_1 + frac{partial f_2}{partial x_2} dx_2 + ldots + frac{partial f_2}{partial x_n} dx_n \ ldots \ frac{partial f_m}{partial x_1} dx_1 + frac{partial f_m}{partial x_2} dx_2 + ldots + frac{partial f_m}{partial x_n} dx_n end{pmatrix}.
end{split}]
В обоих ситуациях мы можем записать дифференциал через матричное произведение. Вернёмся к поиску второй производной
[
dg(x) = (A + A^T) dx.
]
Выходит, что матрица из вторых производных для функции (f(x)) выглядит как (A + A^T.) Обратите внимание, что для этой ситуации в каноническом виде нет транспонирования. Когда мы вытаскиваем из записи дифференциала производную, нам не надо его применять.
в) Найдите производную (nabla_x f(x)), где (f(x) = ln(x^T A x)), где (x) вектор размера (1 times n), (A) матрица размера (n times n)
Когда мы хотим найти производную (f(x) = ln(x^T A x)), мы просто можем применить правила взятия производной от сложной функции (f(y) = ln(y).) К логарифму на вход идет скаляр, а значит его производная равна (frac{1}{y}). Выходит, что
[
df(x) = dln(y) = frac{1}{y} dy = frac{1}{y} d(x^T A x) = frac{1}{x^T A x} cdot x^T(A^T + A) dx.
]
Если отображение бьёт в матрицы или вектора, производная будет браться аналогичным образом. Надо будет чуть аккуратнее следить за размерностями. На такой кейс мы посмотрим немного позже.
г) Найдите производную (f(x) = a^TXAXa), где (x) вектор размера (1 times n), (A) матрица размера (n times n)
Движемся к следующей ситуации. Функция бьёт из матриц в скаляры
[
f(X) : mathbb{R}^{n times k} to mathbb{R}.
]
В таком случае нам надо найти производную функции по каждому элементу матрицы, то есть дифференциал будет выглядеть как
[
d{f(X)} = f’_{x_{11}} dx_{11} + f’_{x_{12}} dx_{12} + ldots + f’_{x_{nk}} dx_{nk}.
]
Его можно записать в компактном виде через след матрицы как
[
df(X) = tr(nabla f(X)^T dX),
]
где
[begin{split}
nabla_X f(X) = begin{pmatrix} f’_{x_{11}} & ldots & f’_{x_{1k}} \
ldots & ddots & ldots \
f’_{x_{n1}} & ldots & f’_{x_{nk}}
end{pmatrix}
end{split}]
Вполне естественен вопрос, почему это можно записать именно так? Давайте попробуем увидеть этот факт на каком-нибудь простом примере. Пусть у нас есть две матрицы
[begin{split}
A_{[2 times 3]} = begin{pmatrix} a_{11} & a_{12} & a_{13} \ a_{21} & a_{22} & a_{23} end{pmatrix} qquad X_{[2 times 3]} = begin{pmatrix} x_{11} & x_{12} & x_{13} \ x_{21} & x_{22} & x_{23} end{pmatrix}.
end{split}]
Посмотрим на то, как выглядит (tr(A^T dX)). Как это не странно, он совпадает с дифференциалом
[begin{split}
tr(A^T dX) = tr left( begin{pmatrix} a_{11} & a_{21} \ a_{12} & a_{22} \ a_{13} & a_{23} end{pmatrix} begin{pmatrix} dx_{11} & dx_{12} & dx_{13} \ dx_{21} & dx_{22} & dx_{23} end{pmatrix} right),
end{split}]
при произведении на выходе получаем матрицу размера (3 times 3)
[begin{split}
begin{pmatrix} a_{11} dx_{11} + a_{21} dx_{21} & a_{11} dx_{12} + a_{21} dx_{22} & a_{11} dx_{13} + a_{21} dx_{23} \ a_{12} dx_{11} + a_{22} dx_{21} & a_{12} dx_{12} + a_{22} dx_{22} & a_{12} dx_{13} + a_{22} dx_{23} \ a_{13} dx_{11} + a_{23} dx_{21} & a_{13} dx_{12} + a_{23} dx_{22} & a_{13} dx_{13} + a_{23} dx_{23} end{pmatrix}.
end{split}]
Когда мы берём её след, остаётся сумма элементов по диагонали. Это и есть требуемый дифференциал. Дальше мы периодически будем пользоваться таким приёмом. Например, норму Фробениуса
[
||X-A||_F^2 = sum_{i,j} (x_{ij} – a_{ij})^2
]
можно записать в матричном виде как
[
||X-A||_F^2 = tr((X-A)^T (X-A)).
]
Итак, найдём производную от (f(X) = a^TXAXa). Нам нужно выписать дифференциал и привести его к каноническому виду
Обратим внимание на то, что мы бьём из матриц в скаляры. Дифференциал будет по своей размерности совпадать со скаляром. Производная будет размера матрицы
[
df(X) = d(a^TXAXa) = underset{[1 times 1]}{a^Td(X)AXa} + underset{[1 times 1]}{a^TXA cdot d(X)a}.
]
Оба слагаемых, которые мы получаем после перехода к дифференциалу – скаляры. Мы хотим представить дифференциал в виде (tr(text{нечто} d{X})). След от скаляра это снова скаляр. Получается, что мы бесплатно можем навесить над правой частью наешго равенство знак следа и воспользоваться его свойствами
[begin{multline*}
df(X) = d(a^TXAXa) = tr(a^T cdot d(X) cdot AXa) + tr(a^TXA cdot d(X) cdot a) = \ = tr(AXaa^T cdot d(X)) + tr(aa^TXA cdot d(X)) = \ = tr(AXaa^T cdot d(X) + aa^TXA cdot dX) = tr((AXaa^T + aa^TXA)dX).
end{multline*}]
Производная найдена, оказалось что это
[
nabla_X f(X) = (AXaa^T + aa^TXA)^T = aa^TX^TA^T + A^TXaa^T.
]
Как бы мы нашли это, всё по-честному перемножив, даже боюсь себе представлять.
д) Найдите производную (f(x) = x x^T x), где (x) вектор размера (1 times n)
Ещё один пример на ситуацию, когда функция бьёт из векторов в вектора
[
underset{[n times 1]}{f(x)} = underset{[n times 1]}{x} underset{[1 times n]}{x^T} underset{[n times 1]}{x}.
]
В нём надо аккуратно вести себя со сложением матриц со скалярами. Берём дифференциал
[
df(x) = d{xx^Tx} = dx cdot x^Tx + x dx^T cdot x + xx^T cdot dx.
]
В первом слагаемом пользуемся тем, что (x^Tx) скаляр и его можно вынести перед дифференциалом. Этот скаляр умножается на каждый элемент вектора. Дальше мы захотим вынести дифференциал за скобку, чтобы не испортить матричное сложение, подчеркнём факт этого перемножения на каждый элемент единичной матрицей. Во втором слагаемом пользуемся тем, что (dx^T cdot x) скаляр и транспонируем его
[
df(x) = underset{[1 times 1]}{x^Tx} underset{[n times n]}{I_n} underset{[n times 1]}{dx} + x x^T dx + xx^T dx = (x^Tx I_n + 2 x x^T)dx.
]
Обратите внимание, что без единичной матрицы размерности у сложения поломаются. Получается, что наша производная выглядит как
[begin{split}
mathfrak{J} = x^Tx I_n + 2 x x^T = begin{pmatrix} sum x_i^2 + 2 x_1^2 & 2 x_1 x_2 & ldots & 2 x_1 x_n \
2 x_1 x_2 & sum x_i^2 + 2 x_2^2 & ldots & 2 x_2 x_n \
ldots & ldots & ddots &ldots \
2 x_1 x_n & 2 x_n x_2 & ldots & sum x_i^2 + 2 x_n^2 \
end{pmatrix}.
end{split}]
Как и ожидалось, на выходе получилась матрица.
В нашей таблице. осталось ещё несколько ситуаций, которые остались вне поля нашего зрения. Давайте их обсудим более подробно. Например, давайте посмотрим на ситуацию когда отображение бьёт из матриц в вектора
[
f(X) : mathbb{R}^{n times k} to mathbb{R}^m.
]
Тогда (X) матрица, а (f(X)) вектор. Нам надо найти производную каждого элемента из вектора (f(X)) по каждому элементу из матрицы (X). Получается, что (frac{partial f}{partial X}) – это трёхмерная структура. Обычно в таких ситуациях ограничиваются записью частных производных либо прибегают к более сложным, многомерным методикам. Мы такие ситуации опустим.
Макеты страниц
Пусть дана матрица  где членами
где членами  матрицы являются функции некоторого аргумента
матрицы являются функции некоторого аргумента 

или коротко будем это записывать так:

Пусть члены матрицы имеют производные 

Определение 1. Производной от матрицы  называется матрица, обозначим ее через
называется матрица, обозначим ее через  члены которой являются производными от членов матрицы
члены которой являются производными от членов матрицы  , т. е.
, т. е.

Заметим, что такое определение производной от матрицы получается естественным путем, если наряду с введенными операциями вычитания матриц и умножения на число (см. § 4) присоединить операцию предельного перехода:

Символически коротко равенство (3) можно записать так:

Определение 2. Интегралом от матрицы  называется матрица, обозначим ее через
называется матрица, обозначим ее через

члены которой равны интегралам от членов данной матрицы:

более кратко:

Производные скалярной, векторной и матричной функций по векторному аргументу
Рассмотрим скалярную (числовую) функцию нескольких переменных . Упорядоченный набор переменных
будем называть векторным аргументом этой функции и обозначать
. Первый дифференциал функции
имеет вид:
(6.1)
Сумму в правой части можно представить как произведение строки на столбец
, либо как произведение строки
на столбец
.
Матрица-строка или матрица-столбец
определяют производную скалярной функции по векторному аргументу (градиент скалярной функции). Двойственность определения относится только к форме записи, поскольку векторный аргумент функции можно считать столбцом (в этом случае дифференциал
— столбец) или понимать как строку. В любом случае для первого дифференциала получаем одно и то же выражение (6.1).
Второй дифференциал функции имеет вид
(6.2)
Обозначим через матрицу частных производных второго порядка (матрицу Гессе). Тогда правую часть (6.2) можно записать в виде произведения
Замечания 6.1
1. Для записи производных можно использовать символические векторы (столбцы или строки):
При этом дифференцирование функции формально записывается как умножение функции на символический вектор производных. Например, градиент функции есть произведение вектора на функцию
, а матрица Гессе есть произведение символической матрицы
на функцию
.
2. Определитель матрицы Гессе называется гессианом.
3. Свойства градиента функции и матрицы Гессе используются в методах поиска экстремума функции.
Пример 6.2. Найти первую и вторую производные сложной функции , применяя матричные обозначения.
Решение. Находим производные функции , заменяя суммирование операциями умножения соответствующих матриц:
Сравним матричную форму записи этих производных с производными в случае скалярной функции
Выражения для первой производной совпадают, а для второй производной -отличаются незначительно, причем полное совпадение будет, если учесть, что для скалярной величины
.
Производные векторной функции по векторному аргументу
Пусть задан столбец функций нескольких переменных (говорят, что задана вектор-функция векторного аргумента). Первый дифференциал вектор-функции имеет вид:
Обозначим через матрицу частных производных первого порядка заданных функций (матрицу Якоби). Тогда выражение для первого дифференциала можно записать в виде
, т.е.
— производная вектор-функции векторного аргумента.
Как и в случае с аргументом , упорядоченный набор функций можно считать не матрицей-столбцом, а матрицей-строкой
. Этот случай сводится к предыдущему, учитывая, что операции дифференцирования и транспонирования можно выполнять в любом порядке, так как
(здесь и далее аргумент
для упрощения записи опущен). Поэтому из равенства
получаем
, где
— транспонированная матрица Якоби вектор-функции .
Заметим, что из равенства следует правило транспонирования производных вектор-функции:
.
Правила дифференцирования по векторному аргументу
Векторный аргумент , его приращение
считаем матрицами-столбцами размеров
.
1. Первый дифференциал скалярной функции имеет вид:
где — градиент функции, а
.
2. Второй дифференциал скалярной функции имеет вид
где
— матрица Гессе.
3. Первый дифференциал вектор-функции {матрицы-столбца) имеет вид:
, где
— матрица Якоби.
Первый дифференциал матрицы-строки: .
4. В частном случае, когда , получаем
, где
— единичная матрица n-го порядка.
5. Числовую матрицу (соответствующих размеров) можно выносить за знак производной:
Последняя формула следует из правила транспонирования производных:
6. Производные суммы, разности и произведения вектор-функций и
одинаковых размеров
Докажем, например, последнее равенство. Найдем частную производную скалярной функции по переменной
Тогда первый дифференциал функции имеет вид
Запишем это выражение, используя матричные обозначения
Сравнивая полученное выражение с , приходим к равенству
, что и требовалось доказать.
7. Производная сложной функции , где
и
вычисляется по формуле:
или, опуская аргументы,
.
Действительно, запишем первый дифференциал вектор-функции: . Заметим, что матрицы Якоби в правой части формулы согласованы: матрица
имеет размеры
, матрица
. Найдем, используя обычные правила дифференцирования, частную производную
. В правой части стоит произведение i-й строки матрицы
на j-й столбец матрицы
, что и требовалось показать.
Использование матричных обозначений позволяет записывать и применять правила дифференцирования по векторному аргументу аналогично правилам дифференцирования в скалярном случае. Например, правило 7 дифференцирования сложной вектор-функции формально совпадает с обычным “цепным” правилом дифференцирования скалярной сложной функции одной переменной. Разумеется, что формальное совпадение правил становится фактическим в скалярном случае, когда все матрицы имеют размеры
.
Пример 6.3. Применяя правила дифференцирования по векторному аргументу, найти производные следующих функций:
а) ; б)
; в)
; г)
; д)
,
где — квадратная числовая матрица n-го порядка;
— столбцы размеров
, причем столбец
числовой.
Решение. а) Вынося постоянный множитель (матрицу-строку) по правилу 5 и учитывая правило 4, получаем:
б) Учитывая, что величина скалярная, т.е.
, получаем
. Заметим, что
.
в) По правилам 4 и 5 находим: .
г) По правилам 4 и 5 находим: .
д) Представляя скалярное выражение как произведение строки
на столбец
, по правилу 6 (где
) получаем
с учетом правила транспонирования производных
Учитывая результат п. “б”, имеем .
Замечания 6.2
1. В некоторых областях прикладной математики, например, в методах оптимизации и теории управления, часто используются другие соглашения, совпадающие с изложенными с точностью до операции транспонирования. Производная (градиент функции
) считается матрицей-столбцом, а производная
— матрицей-строкой:
Тогда соответствующие формулы дифференцирования, аналогичные полученным в примере 6.3, имеют вид:
2. Если матрица Якоби квадратная , то ее определитель называется якобианом.
3. След матрицы Якоби (при ) определяет
дивергенцию вектор-функции
векторного аргумента
.
Производные матричной функции по векторному аргументу
Рассмотрим функциональную матрицу , элементами которой служат функции
векторного аргумента
. Дифференциал этой функции имеет вид
где — частная производная матрицы по одной переменной. Совокупность частных производных (градиент функциональной матрицы) представляет объект, элементы которого
нумеруются тремя индексами: номер строки, номер столбца и номер переменной дифференцирования. Поэтому заменить операцию суммирования в правой части формулы операцией умножения матриц в данном случае не представляется возможным. Необходимо вводить другие объекты — тензоры и операции над ними. Поясним формальную сторону получения удобных формул дифференцирования на примере функциональных матриц. Примем следующие правила индексирования:
1) элементы матрицы обозначаются
, где
— номер строки, а
— номер столбца. В частности,
— матрица-столбец (или просто столбец), а
— матрица-строка (или просто строка);
2) частную производную функции (скалярной, векторной или матричной) по переменной
будем обозначать, приписывая нижний индекс
в скобках:
;
3) если в произведении одинаковые индексы встречаются сверху и снизу, то по ним производится суммирование (хотя знак суммы не указывается). Например, если — матрица размеров
,
— столбец размеров
,
— строка размеров
, то
т.е. — i-й элемент столбца
,
— j-й элемент строки
,
— число
.
Применяя эти соглашения, запишем дифференциалы:
— скалярной функции: ;
— вектор-функции (функции-столбца):
;
— функциональной матрицы , где
— частная производная первого порядка элемента
функциональной матрицы
по переменной
.
Одним из преимуществ принятых соглашений является получение простого вида формул. Другие преимущества раскрываются и используются в тензорном анализе.
Математический форум (помощь с решением задач, обсуждение вопросов по математике).
Если заметили ошибку, опечатку или есть предложения, напишите в комментариях.
