В специальной
литературе можно встретить различные
рекомендации для обнаружения грубых
погрешностей измерений и отсева промахов.
Если имеется
выборка небольшого объёма n,
то можно воспользоваться методом
сравнения максимального относительного
отклонения |![]()
–
|![]()
/S
с
критическим (при выбранном уровне
значимости и числе степеней свободы
f
= n
– 2),
значение которого
определяют по таблице.
Здесь мы впервые
сталкиваемся с понятием о статистической
гипотезе.
Статистической
называют гипотезу
о виде неизвестного распределения
случайных величин или о параметрах
известных распределений. Решение на
основе выборочных наблюдений о том,
таков ли параметр генеральной совокупности
или нет, называется проверкой гипотезы.
Если выдвинутая гипотеза неверна, мы
её отбрасываем.
Наряду с выдвинутой
гипотезой, которую обычно называют
нулевой или основной и обозначают Н0,
рассматривают и альтернативную гипотезу
Н1,
противоречащую нулевой.
Вероятность
того, что будет отброшена верная гипотеза
Н0,
называют уровнем значимости и обычно
обозначают α.
Величина α
выбирается равной 0,05
или 0,01
и связана
с величиной надёжности статистической
оценки
следующим
соотношением:
α
= 1
–
.
(5.74)
Так, α
= 0,05, т.е.
5%-ный уровень значимости соответствует
доверительной вероятности (надёжности)
вывода
=
0,95.
Ошибка, при
которой гипотеза неверно отбрасывается,
называемую ошибкой
первого рода.
Принимая гипотезу, которая на самом
деле неверна, мы совершаем ошибку,
которая называется ошибкой
второго рода,
её вероятность обычно обозначается β.
Возвратимся к
названному выше методу обнаружения
промахов. Вычисляют абсолютную величину
максимального относительного отклонения
![]()
(5.75)
и выдвигают
гипотезу о том, что оно меньше критической
величины τ,
определяемой по таблицам при выбранном
уровне значимости α
и числе степеней свободы f
= n
– 2:
τ
≤ τтабл.α;f.
(5.76)
Если это соотношение
соблюдается, то проверяемый результат
измерения признаётся доброкачественным.
В противном случае гипотеза о
доброкачественности проверяемого
результата измерения отбрасывается.
Этот результат должен быть исключён из
выборки.
Сначала проверяют
наибольший и/или наименьший по абсолютной
величине элементы выборки, по которой
рассчитывались
и S,
затем процедуру проверки можно повторить
и для следующих по величине результатов
измерений и их отклонений.
Допускается
исключение одного или двух промахов из
выборки. При этом целесообразно, по
возможности, выполнить дополнительные
измерения для восстановления
первоначального объёма выборки. Если
же обнаруживается более двух промахов,
то вся выборка признаётся недоброкачественной.
После исключения
того или иного наблюдения характеристики
эмпирического распределения должны
быть пересчитаны по доброкачественным
данным.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В статье рассмотрены различные критерии отбрасывания грубых погрешностей измерений, применяемые в практической деятельности, на основе рекомендаций ведущих специалистов-метрологов, а также с учетом действующих в настоящий момент нормативных документов.
Приведен пример использования Excel при оценке грубых погрешностей по критериям Стьюдента и Романовского при обработке реальных результатов измерений.
Ключевые слова:
грубые погрешности, критерии согласия, сомнительные значения, уровень значимости, нормальное распределение, критерий согласия Стьюдента, критерий Романовского, выборка, отклонения, Excel.
Одним из важнейших условий правильного применения статистических оценок является отсутствие грубых ошибок при наблюдениях. Поэтому все грубые ошибки должны быть выявлены и исключены из рассмотрения в самом начале обработки наблюдений.
Единственным достаточно надежным способом выявления грубых ошибок является тщательный анализ условий самих испытаний. При этом наблюдения, проводившиеся в нарушенных условиях, должны отбрасываться, независимо от их результата. Например, если при проведении эксперимента, связанного с электричеством, в лаборатории на некоторое время был выключен ток, то весь эксперимент обязательно нужно проводить заново, хотя результат, быть может, не сильно отличается от предыдущих измерений. Точно так же отбрасываются результаты измерений на фотопластинках с поврежденной эмульсией и вообще на любых образцах с обнаруженным позднее дефектом.
На практике, однако, не всегда удается провести подобный анализ условий испытания. Чаще всего приходится иметь дело с окончательным цифровым материалом, в котором отдельные данные вызывают сомнение лишь своим значительным отклонением от остальных. При этом сама «значительность» отклонения во многом субъективна — зачастую приходится сталкиваться со случаями, когда исследователь отбрасывает наблюдения, которые ему не понравились, как ошибочные исключительно по той причине, что они нарушают уже созданную им в воображении картину изучаемого процесса.
Строгий научный анализ готового ряда наблюдений может быть проведен лишь статистическим путем, причем должен быть достаточно хорошо известен характер распределения наблюдаемой случайной величины. В большинстве случаев исследователи исходят из нормального распределения. Каждая грубая ошибка будет соответствовать нарушению этого распределения, изменению его параметров, иными словами, нарушится однородность испытаний (или, как говорят
,
однородность наблюдений), поэтому выявление грубых ошибок можно трактовать как проверку однородности наблюдений.
Промахи, или грубые погрешности, возникают при единичном измерении и обычно устраняются путем повторных измерений. Причиной их возникновения могут быть:
- Объективная реальность (наш реальный мир отличается от идеальной модели мира, которую мы принимаем в данной измерительной задаче);
- Внезапные кратковременные изменения условий измерения (могут быть вызваны неисправностью аппаратуры или источников питания);
- Ошибка оператора (неправильное снятие показаний, неправильная запись и т. п.).
В третьем случае, если оператор в процессе измерения обнаружит промах, он вправе отбросить этот результат и провести повторные измерения.
В настоящее время определение грубой погрешности приведено в ГОСТ Р 8.736–2011: «Грубая погрешность измерения: Погрешность измерения, существенно превышающая зависящие от объективных условий измерений значения систематической и случайной погрешностей» [1, с. 6].
Общие подходы к методам отсеивания грубых погрешностей, как это уже давно принято в практике измерений, заключаются в следующем.
Задаются вероятностью
Р
или уровнем значимости
α
(
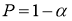
) того, что результат наблюдения содержит промах. Выявление сомнительного результата осуществляют с помощью специальных критериев. Операция отбрасывания удаленных от центра выборки сомнительных значений измеряемой величины называется «цензурированием выборки».
Проверяемая гипотеза состоит в утверждении, что результат наблюдения
x
i
не содержит грубой погрешности, т. е. является одним из значений случайной величины
x
с законом распределения Fx(x), статистические оценки параметров которого предварительно определены. Сомнительным может быть в первую очередь лишь наибольший x
max
или наименьший xmin из результатов наблюдений.
Предложим для практического использования наиболее простые методы отсева грубых погрешностей.
Если в распоряжении экспериментатора имеется выборка небольшого объема
n
≤ 25, то можно воспользоваться методом вычисления максимального относительного отклонения [2, с. 149]:
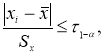
(1)
где
x
i
— крайний (наибольший или наименьший) элемент выборки, по которой подсчитывались оценки среднего значения
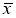
и среднеквадратичного отклонения
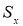
;
τ
1-
p
— табличное значение статистики
τ
, вычисленной при доверительной вероятности
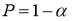
.
Таким образом, для выделения аномального значения вычисляют значение статистики,
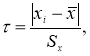
(2)
которое затем сравнивают с табличным значением
τ
1-α
:
τ
≤
τ
1-α
. Если неравенство
τ
≤
τ
1-α
соблюдается, то наблюдение не отсеивают, если не соблюдается, то наблюдение исключают. После исключения того или иного наблюдения или нескольких наблюдений характеристики эмпирического распределения должны быть пересчитаны по данным сокращенной выборки.
Квантили распределения статистики
τ
при уровнях значимости
α
= 0,10; 0,05; 0,025 и 0,01 или доверительной вероятности
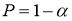
=
0,90; 0,95; 0,975 и 0,99 приведены в таблице 1. На практике очень часто используют уровень значимости
α
= 0,05 (результат получается с 95 %-й доверительной вероятностью).
Функции распределения статистики
τ
определяют методами теории вероятностей. По данным таблицы, приведенной в источниках [2, с. 283; 3, с. 184] при заданной доверительной вероятности
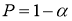
или уровне значимости
α
можно для чисел измерения п = 3–25 найти те наибольшие значения
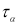
которые случайная величина
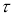
может еще принять по чисто случайным причинам.
Процедуру отсева можно повторить и для следующего по абсолютной величине максимального относительного отклонения, но предварительно необходимо пересчитать оценки среднего значения
и среднеквадратичного отклонения
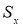
для выборки нового объема
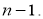
Таблица 1
Квантили распределения максимального относительного отклонения при отсеве грубых погрешностей [2, с. 283]
|
|
Уровень значимости |
|
Уровень значимости |
||||||
|
0,10 |
0,05 |
0,025 |
0,01 |
0,10 |
0,05 |
0,025 |
0,01 |
||
|
3 |
1,41 |
1,41 |
1,41 |
1,41 |
15 |
2,33 |
2,49 |
2,64 |
2,80 |
|
4 |
1,65 |
1,69 |
1,71 |
1,72 |
16 |
2,35 |
2,52 |
2,67 |
2,84 |
|
5 |
1,79 |
1,87 |
1,92 |
1,96 |
17 |
2,38 |
2,55 |
2,70 |
2,87 |
|
6 |
1,89 |
2,00 |
2,07 |
2,13 |
18 |
2,40 |
2,58 |
2,73 |
2,90 |
|
7 |
1,97 |
2,09 |
2,18 |
2,27 |
19 |
2,43 |
2,60 |
2,75 |
2,93 |
|
8 |
2,04 |
2,17 |
2,27 |
2,37 |
20 |
2,45 |
2,62 |
2,78 |
2,96 |
|
9 |
2,10 |
2,24 |
2,35 |
2,46 |
21 |
2,47 |
2,64 |
2,80 |
2,98 |
|
10 |
2,15 |
2,29 |
2,41 |
2,54 |
22 |
2,49 |
2,66 |
2,82 |
3,01 |
|
11 |
2,19 |
2,34 |
2,47 |
2,61 |
23 |
2,50 |
2,68 |
2,84 |
3,03 |
|
12 |
2,23 |
2,39 |
2,52 |
2,66 |
24 |
2,52 |
2,70 |
2,86 |
3,05 |
|
13 |
2,26 |
2,43 |
2,56 |
2,71 |
25 |
2,54 |
2,72 |
2,88 |
3,07 |
|
14 |
2,30 |
2,46 |
2,60 |
2,76 |
|||||
В литературе можно встретить большое количество методических рекомендаций для проведения отсева грубых погрешностей измерений, подробно рассмотренных в [4, с. 25]. Обратим внимание на некоторые из существующих критериев отсеивания грубых погрешностей.
- Критерий «трех сигм» применяется для случая, когда измеряемая величина
x
распределена по нормальному закону. По этому критерию считается, что с вероятностью
Р
= 0,9973 и значимостью
α
= 0,0027 появление даже одной случайной погрешности, большей, чем
маловероятное событие и ее можно считать промахом, если

−
x
i
> 3
S
x
, где
S
x
—
оценка среднеквадратического отклонения (СКО) измерений. Величиныи
S
x
вычисляют без учета экстремальных значений
x
i
. Данный критерий надежен при числе измерений
n
≥ 20…50 и поэтому он широко применяется. Это правило обычно считается слишком жестким, поэтому рекомендуется назначать границу цензурирования в зависимости от объема выборки: при
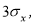
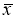
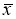
6 <
n
≤100 она равна 4
S
x
; при 100 <
n
≤1000 − 4,5
S
x
; при 1000 <
n
≤10000–5
Sx
. Данное правило также используется только при нормальном распределении.
Практические вычисления проводят следующим образом [5, с. 65]:
- Выявляют сомнительное значение измеряемой величины. Сомнительным значением может быть лишь наибольшее, либо наименьшее значение наблюдения измеряемой величины.
- Вычисляют среднее арифметическое значение выборки

без учета сомнительного значения

измеряемой величины.
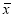
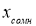
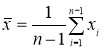
(3)
- Вычисляют оценку СКО выборки

без учета сомнительного значения
измеряемой величины.
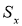
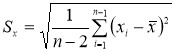
(4)
- Вычисляют разность среднеарифметического и сомнительного значения измеряемой величины и сравнивают.
Если
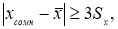
то сомнительное значение отбрасывают, как промах.
Если
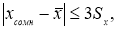
то сомнительное значение оставляют как равноправное в ряду наблюдений.
Данный метод «трех сигм» среди метрологов-практиков является самым популярным, достаточно надежным и удобным, так как при этом иметь под рукой какие-то таблицы нет необходимости.
- Критерий В. И. Романовского применяется, если число измерений невелико,
n
≤ 20. При этом вычисляется соотношение
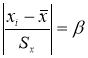
(5)
где
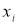
— результат, вызывающий сомнение,
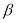
— коэффициент, предельное значение которого
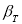
определяют по таблице 2. Если
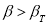
, сомнительное значение
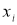
исключают («отбрасывают») как промах. Если

,
сомнительное значение оставляют как равноправное в ряду наблюдений [5, с. 65].
Таблица 2
Значение критерия Романовского
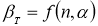
|
Уровень значимости, |
Число измерений, |
||||||
|
|
|
|
|
|
|
|
|
|
0,01 |
1,73 |
2,16 |
2,43 |
2,62 |
2,75 |
2,90 |
3,08 |
|
0,02 |
1,72 |
2,13 |
2,37 |
2,54 |
2,66 |
2,80 |
2,96 |
|
0,05 |
1,71 |
2,10 |
2,27 |
2,41 |
2,52 |
2,64 |
2,78 |
|
0,10 |
1,69 |
2,00 |
2,17 |
2,29 |
2,39 |
2,49 |
2,62 |
Несмотря на многообразие существующих и применяемых на практике методов отсеивания грубых погрешностей в настоящее время действует национальный стандарт ГОСТ Р 8.736–2011, который является основным нормативным документом в данной области. В новом стандарте для исключения грубых погрешностей применяется критерий Граббса.
- Статистический критерий Граббса (Смирнова) исключения грубых погрешностей основан на предположении о том, что группа результатов измерений принадлежит нормальному распределению [1, с. 8]. Для этого вычисляют критерии Граббса (Смирнова) G1 и G2, предполагая, что наибольший хmax или наименьший xmin результат измерений вызван грубыми погрешностями.
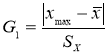
и
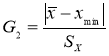
(6)
Сравнивают G1 и G2 с теоретическим значением GT критерия Граббса (Смирнова) при выбранном уровне значимости α. Таблица критических значений критерия Граббса (Смирнова) приведена в приложении к стандарту [1, с. 12]. Следует отметить, что критические значения критерия Граббса (Смирнова) GT отличаются от критических значений критериев
t
-статистик или значений критериев Стьюдента при одних и тех же величинах уровней значимости, что может вызывать некоторые трудности у пользователей при выборе конкретного метода отсеивания погрешностей, соответствующего нормативным документам.
Если G1>GТ, то хmax исключают как маловероятное значение. Если G2>GТ, то xmin исключают как маловероятное значение. Далее вновь вычисляют среднее арифметическое и среднее квадратическое отклонение ряда результатов измерений и процедуру проверки наличия грубых погрешностей повторяют.
Если G1
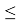
GТ, то хmax не считают промахом и его сохраняют в ряду результатов измерений. Если G2
GТ, то xmin не считают промахом и его сохраняют в ряду результатов измерений.
Отсев грубых погрешностей можно производить и для больших выборок (
n
= 50…100). Для практических целей лучше всего использовать таблицы распределения Стьюдента. Этот метод исключения аномальных значений для выборок большого объема отличается простотой, а таблицы распределения Стьюдента имеются практически в любой книге по математической статистике, кроме того, распределение Стьюдента реализовано в пакете Excel. Распределение Стьюдента относится к категории распределений, связанных с нормальным распределением. Подробно эти распределения рассмотрены в учебниках по математической статистике [3, с. 24].
Известно, что критическое значение
τ
p
(
p
— процентная точка нормирования выборочного отклонения) выражается через критическое значение распределения Стьюдента
t
α, n-2
[6, с. 26]:
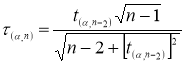
(7)
Учитывая это, можно предложить следующую процедуру отсева грубых погрешностей измерения для больших выборок (
n
= 100):
1) из таблицы наблюдений выбирают наблюдение имеющее наибольшее отклонение;
2)
по формуле
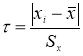
вычисляют значение статистики
τ
;
3)
по таблице (или в программе Excel) находят процентные точки
t
-распределения Стьюдента
t
(
α,
n
-2
)
:
t
(95
%, 98)
= 1,6602, и
t
(
99
%, 98)
= 3,1737;
По предыдущей формуле в программе Excel вычисляют соответствующие точки
t
(95
%, 100)
= 1,66023и
t
(99
%, 100)
=3,17374.
Сравнивают значение расчетной статистики с табличными критическими значениями и принимают решение по отсеву грубых погрешностей.
Рекомендуемый метод отсева грубых погрешностей удобен еще тем, что максимальные относительные отклонения могут быть разделены на три группы: 1)
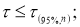
2)
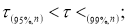
3)
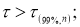
.
Наблюдения, попавшие в первую группу, нельзя отсеивать ни в коем случае. Наблюдения второй группы можно отсеять, если в пользу этой процедуры имеются еще и другие соображения экспериментатора (например, заключения, сделанные на основе изучения физических, химических и других свойств изучаемого явления). Наблюдения третьей группы, как правило, отсеивают всегда.
Рассмотрим далее пример с использованием средств программного пакета Excel, который позволяет снизить трудоемкость расчетов при осуществлении данной процедуры. К сожалению, в настоящее время средства Excel не позволяют автоматизировать расчеты по всем известным критериям отсеивания грубых погрешностей, поэтому проиллюстрируем рассмотренные методы с использованием доступных в Excel критериев Стьюдента.
Пример 1.
Имеется выборка из 100 шт. резисторов с номинальным сопротивлением
R
н
= (150,0 ± 5 %) кОм, которая используется для оценки качества партии резисторов (генеральная совокупность). Используя критерий Стьюдента, отсеем грубые погрешности (промахи) при измерениях.
- Заносим данные измерений в таблицу Excel в ячейки В2:В101
- Составляем вариационный ряд — располагаем данные в порядке возрастания с помощью функции «Сортировка по возрастанию» в ячейках С2:С101 (рис. 1)
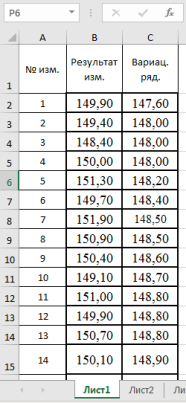
Рис. 1. Фрагмент диалогового окна с данными измерений и вариационного ряда
3. Находим среднее значение выборки с помощью мастера функций в категории «Статистические» и функции — СРЗНАЧ, результат в ячейке Н3 (рис. 2).
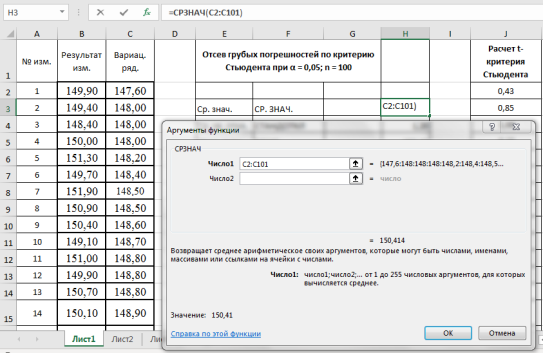
Рис. 2. Фрагмент диалогового окна при нахождении среднего значения выборки
- Находим среднеквадратическое отклонение —
S
x
. Выделяем ячейку Н4, вызываем «Мастер функций», категория «Статистические», функция — СТАНДОТКЛОН, результат в ячейке Н4–1,20 (рис. 3).
Рис. 3. Фрагмент диалогового окна при нахождении среднего квадратического отклонения
- Находим максимальное значение в выборке —
x
макс
. Выделяем ячейку Н5, в категории «Статистические», функция — МАКС, выделяем мышкой вариационный ряд C2:С101, результат в ячейке Н5–153,10 (рис. 4).
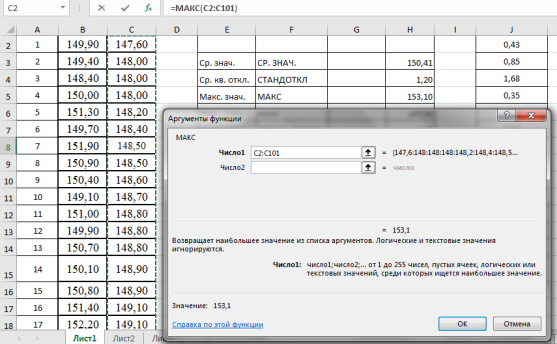
Рис. 4. Фрагмент диалогового окна при нахождении максимального значения
- Находим минимальное значение в выборке —
x
мин
. Выделяем ячейку Н6, в категории «Статистические», функция — МИН, выделяем мышкой вариационный ряд C2:С101, результат в ячейке Н6–147,6 (рис. 5).
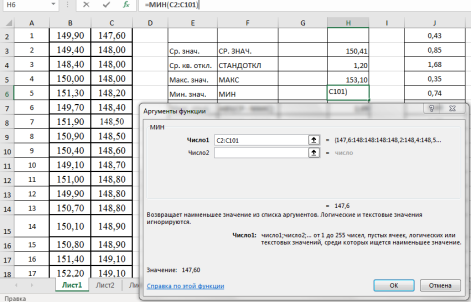
Рис. 5. Фрагмент диалогового окна при нахождении минимального значения
- Находим максимальное и минимальное отклонения — Δ
макс
и Δ
мин
. Вводим в ячейки Н7 и Н8 формулы:
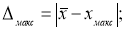
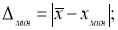
- Находим теоретическое значение —
t
теор
. для максимального и минимального отклонений. Вводим в ячейки Н9 и Н12 формулу
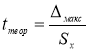
. и
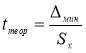
- Находим табличное значение
t
табл.
Выделяем ячейку Н10, вызываем в категории «Статистические» функцию — СТЬЮДЕНТ.ОБР, «Вероятность» — 0,95, степени свободы (
n
-2) — 98, результат в ячейке Н10–1,66 (рис. 6).
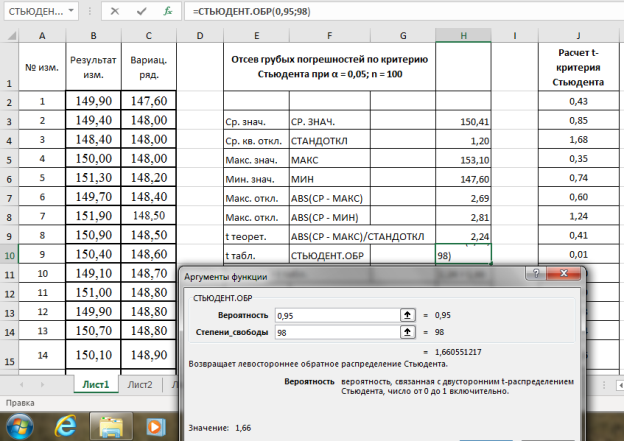
Рис. 6. Фрагмент диалогового окна при нахождении табличного значения критерия Стьюдента
- Сравниваем теоретическое значение
t
теор
= 2,24 критерия Стьюдента для максимального значения — 153,1 кОм с табличным значением:
t
табл
.= 1,6605. - Аналогично п. 9 проверим на наличие грубой погрешности у минимального значения в выборке — 147,6 кОм. Результат в ячейке Н12–2,35 (рис. 7).
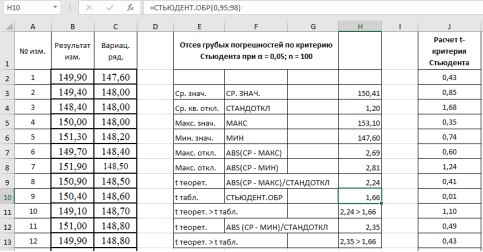
Рис. 7. Фрагмент диалогового окна при окончательном анализе данных
- Делаем вывод о наличии грубых ошибок в данных измерениях. Рассмотренная процедура подтвердила наши сомнения относительно достоверности максимального и минимального значений в данной выборке, т. е., указанные результаты могут быть отброшены из результатов измерений, и проверка может быть повторена снова без этих данных.
Пример расчета теоретического критерия Романовского по аналогичным формулам в Excel и диалоговое окно представлены на рис. 8, при условии α = 0,05, число измерений
n
= 20, β
табл
= 2,78 (из таблицы 2).

Рис. 8. Фрагмент диалогового окна при расчете критерия Романовского
Выводы
- Для использования различных критериев отбрасывания грубых погрешностей измерений необходимо учитывать требования действующих нормативных документов.
- Рассмотренный пример показал, что расчеты погрешностей по критерию Стьюдента с использованием таблиц и формул Excel значительно упрощаются, а процесс отбрасывания грубых погрешностей можно осуществить наиболее качественно и быстро.
Литература:
1. ГОСТ Р 8.736–2011 Государственная система обеспечения единства измерений. Измерения прямые многократные. Методы обработки результатов измерений. Основные положения. — М.: ФГУП Стандартинформ, 2013. — 24 с.
2. Пустыльник Е. И. Статистические методы анализа и обработки наблюдений. — М.: Наука, 1968. — 288 с.
3. Львовский Е. Н. Статистические методы построения эмпирических формул: Учеб. пособие. — М.: Высш. школа, 1982. — 224 с.
4. Фаюстов А. А. Ещё раз о критериях отсеивания грубых погрешностей. — Законодательная и прикладная метрология, 2016, № 5, с. 25–30.
5. Сергеев А. Г. Метрология: Учебник. — М.: Логос, 2005. — 272 с.
6. Большев Л. Н., Смирнов Н. В. Таблицы математической статистики. — М.: Наука, Главная редакция физико-математической литературы, 1983. — 416 с.
Основные термины (генерируются автоматически): диалоговое окно, сомнительное значение, уровень значимости, измеряемая величина, погрешность, критерий, нормальное распределение, ячейка, вариационный ряд, минимальное значение.
4.2.1. Определение и исключение грубых погрешностей (промахов)
В литературе приведены различные методы оценки и исключения грубых погрешностей. Рассмотрим два наиболее простых для практического использования метода.
Исключение грубых промахов по Q-критерию
При малых выборках с числом измерений п < 10 определение грубых погрешностей лучше оценивать при помощи размаха варьирования по Q-критерию. Для этого составляют отношение:
Q = |х1 – х2|R, (4.11)
|
где х1 – |
подозрительно выделяющийся результат определения (измерения); |
|
х2 – |
результат единичного определения, ближайший по значению к х1; |
|
R – |
размах варьирования, R = хmax –хmin разница между наибольшим и наименьшим значением. |
При малой выборке (n < 10) размах варьирования служит также одной из характеристик рассеяния результатов измерений.
Таблица 4.1
Значения – Q критерия в зависимости от пi и 
|
пi |
Доверительная вероятность |
||
|
0,90 |
0,95 |
0,99 |
|
|
3 |
0,89 |
0,94 |
0,99 |
|
4 |
0,68 |
0,77 |
0,89 |
|
5 |
0,56 |
0,64 |
0,76 |
|
6 |
0,48 |
0,56 |
0,70 |
|
7 |
0,43 |
0,51 |
0,64 |
|
8 |
0,40 |
0,48 |
0,58 |
Вычисленное значение Q сопоставляют с табличным значением Q (, пi) (табл. 4.1). Наличие грубой погрешности доказано, если Q > Q (, пi)
Исключение грубых погрешностей методом вычисления максимального относительного отклонения. Статистический критерий обнаружения грубых погрешностей основан на предположении, что выборка взята из генеральной совокупности, распределенной нормально. Это позволяет использовать распределение наибольшего по абсолютному значению нормированного отклонения:
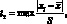 (4.12)
(4.12)
где tт – теоретическое значение квантиля распределения статистики.
Для уровней значимости р = >>0,10; 0,05; 0,01 или доверительной вероятности 1 – р = 0,90; 0,95; 0,99 и п ? 25 значения tт приведены в табл. 4.2. Уровень значимости р = (1 – Р) – максимальная вероятность того, что погрешность превзойдет некое предельное (критическое) значение ±?xkj, т.е. такое значение, что появление этой погрешности можно рассматривать как следствие значимой (неслучайной) причины. На практике обычно используют уровень значимости р = 0,05 (результат получается с 95 %-й доверительной вероятностью).
Для того, чтобы в группе из п наблюдений х1 х2, …, хп отбросить результат хmax (или хmin), надо:
а) вычислить дробь 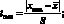
б) по табл. 4.2 найти теоретическое значение tт в зависимости от п и выбранного уровня значимости р;
в) сравнить рассчитанное по п. «а» значение tmax с tт. Если tmax > tт, то результат tmax следует отбросить как промах.
Таблица 4.2
Значения квантилей распределения максимального отклонения,
|
n |
Уровни значимости p |
n |
Уровни значимости p |
||||||
|
0,1 |
0,05 |
0,025 |
0,01 |
0,1 |
0,05 |
0,025 |
0,01 |
||
|
3 |
1,41 |
1,41 |
1,41 |
1,41 |
15 |
2,33 |
2,49 |
2,64 |
2,80 |
|
4 |
1,65 |
1,69 |
1,71 |
1,72 |
16 |
2,35 |
2,52 |
2,67 |
2,84 |
|
5 |
1,79 |
1,87 |
1,92 |
1,96 |
17 |
2,38 |
2,55 |
2,70 |
2,87 |
|
6 |
1,89 |
2,00 |
2,07 |
2,13 |
18 |
2,40 |
2,58 |
2,73 |
2,90 |
|
7 |
1,97 |
2,09 |
2,18 |
2,27 |
19 |
2,43 |
2,60 |
2,75 |
2,93 |
|
8 |
2,04 |
2,17 |
2,27 |
2,37 |
20 |
2,45 |
2,62 |
2,78 |
2,96 |
|
9 |
2,10 |
2,24 |
2,35 |
2,46 |
21 |
2,47 |
2,64 |
2,80 |
2;98 |
|
10 |
2,15 |
2,29 |
2,41 |
2,54 |
22 |
2,49 |
2,66 |
2,82 |
3,01 |
|
11 |
2,19 |
2,34 |
2,47 |
2,61 |
23 |
2,50 |
2,68 |
2,84 |
3,03 |
|
12 |
2,23 |
2,39 |
2,52 |
2,66 |
24 |
2,52 |
2,70 |
2,86 |
3,05 |
|
13 |
2,26 |
2,43 |
2,56 |
2,71 |
25 |
2,54 |
2,72 |
2,88 |
3,07 |
|
14 |
2,30 |
2,46 |
2,60 |
2,76 |
Процедуру исключения промахов можно повторить и для следующего по абсолютному значению максимального относительного отклонения, но предварительно необходимо пересчитать  и s для выборки нового объема n – 1.
и s для выборки нового объема n – 1.
Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
(Высокий импакт-фактор РИНЦ, тематика журналов охватывает все научные направления)
Критерий Смирнова для определения промахов в выборке. Параметрические критерии
Страницы работы
Содержание работы
Критерий Смирнова
Применяется для определения
промахов в выборке в предположении нормального распределения случайной
измеренной величины, для которой генеральные параметры неизвестны, а известны
лишь их оценки, полученные по выборочным результатам наблюдений.
1.
Определить случайные отклонения: ![]() .
.
2.
Определить оценку среднего
квадратического отклонения результатов наблюдений: 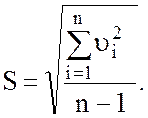
3.
Определить отношение максимального
по модулю значения случайного отклонения к оценке СКО и сравнить с допустимым
из таблицы: 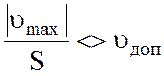 . Если частное меньше
. Если частное меньше ![]() , то
, то
проверяемое значение промахом не является, если больше, то проверяемое значение
– промах, которое необходимо исключить из выборки и пересчитать оценку САЗ и
СКО.
n |
q = 0,10 (Pдов = 0,90) |
q = 0,05 (Pдов = 0,95) |
q = 0,01 (Pдов = 0,99) |
3 |
1,15 |
1,15 |
1,15 |
4 |
1,42 |
1.46 |
1.49 |
5 |
1,60 |
1,67 |
1,75 |
6 |
1,73 |
1,82 |
1,94 |
7 |
1,83 |
1,94 |
2,10 |
8 |
1,91 |
2,03 |
2,22 |
9 |
1,98 |
2,11 |
2,32 |
10 |
2,03 |
2,18 |
2,41 |
11 |
2,09 |
2,23 |
2,48 |
12 |
2,13 |
2,29 |
2,55 |
13 |
2,17 |
2,33 |
2,61 |
14 |
2,21 |
2,37 |
2,66 |
15 |
2,25 |
2,41 |
2,70 |
16 |
2,28 |
2,44 |
2,75 |
17 |
2,31 |
2,48 |
2,78 |
18 |
2,34 |
2,50 |
2,82 |
19 |
2,36 |
2,53 |
2,85 |
20 |
2,38 |
2,56 |
2,88 |
21 |
2,41 |
2,58 |
2,91 |
22 |
2,43 |
2,60 |
2,94 |
23 |
2,45 |
2,62 |
2,96 |
24 |
2,47 |
2,64 |
2,99 |
25 |
2,49 |
2,66 |
3,01 |
30 |
2,70 |
2,93 |
3,40 |
40 |
2,79 |
3,02 |
3,48 |
50 |
2,86 |
3,08 |
3,54 |
100 |
3,08 |
3,29 |
3,72 |
250 |
3,34 |
3,53 |
3,95 |
500 |
3,53 |
3,70 |
4,11 |
Распределение Стьюдента
|
k/Pдов |
0.80 |
0.90 |
0.95 |
0.98 |
0.99 |
0.995 |
0.999 |
|
1 |
3.08 |
6.31 |
12.71 |
31.82 |
63.66 |
127.32 |
636.62 |
|
2 |
1.89 |
2.92 |
4.30 |
6.93 |
9.53 |
14.09 |
31.60 |
|
3 |
1.64 |
2.35 |
3.18 |
4.54 |
5.84 |
7.45 |
12.94 |
|
4 |
1.53 |
2.13 |
2.78 |
3.75 |
4.60 |
5.60 |
8.61 |
|
5 |
1.48 |
2.02 |
2.57 |
3.37 |
4.03 |
4.77 |
6.86 |
|
6 |
1.44 |
1.94 |
2.45 |
3.14 |
3.71 |
4.32 |
5.96 |
|
7 |
1.42 |
1.90 |
2.37 |
3.00 |
3.50 |
4.03 |
5.41 |
|
8 |
1.40 |
1.86 |
2.31 |
2.90 |
3.36 |
3.83 |
5.04 |
|
9 |
1.38 |
1.83 |
2.26 |
2.82 |
3.25 |
3.69 |
4.78 |
|
10 |
1.37 |
1.81 |
2.23 |
2.76 |
3.17 |
3.58 |
4.59 |
|
11 |
1.36 |
1.80 |
2.20 |
2.72 |
3.11 |
3.50 |
4.44 |
|
12 |
1.36 |
1.78 |
2.18 |
2.68 |
3.06 |
3.43 |
4.32 |
|
13 |
1.35 |
1.77 |
2.16 |
2.651 |
3.01 |
3.37 |
4.22 |
|
14 |
1.34 |
1.76 |
2.15 |
2.62 |
2.98 |
3.33 |
4.14 |
|
15 |
1.34 |
1.75 |
2.13 |
2.60 |
2.95 |
3.29 |
4.07 |
|
16 |
1.34 |
1.75 |
2.12 |
2.58 |
2.92 |
3.25 |
4.02 |
|
17 |
1.33 |
1.74 |
2.11 |
2.57 |
2.90 |
3.22 |
3.97 |
|
18 |
1.33 |
1.73 |
2.10 |
2.55 |
2.88 |
3.20 |
3.92 |
|
19 |
1.33 |
1.73 |
2.09 |
2.54 |
2.86 |
3.17 |
3.88 |
|
20 |
1.33 |
1.73 |
2.09 |
2.53 |
2.85 |
3.15 |
3.85 |
|
21 |
1.32 |
1.72 |
2.08 |
2.52 |
2.83 |
3.14 |
3.82 |
|
22 |
1.32 |
1.72 |
2.07 |
2.51 |
2.82 |
3.12 |
3.79 |
|
23 |
1.32 |
1.71 |
2.07 |
2.50 |
2.81 |
3.10 |
3.77 |
|
24 |
1.32 |
1.71 |
2.06 |
2.49 |
2.80 |
3.09 |
3.75 |
|
25 |
1.32 |
1.71 |
2.06 |
2.48 |
2.79 |
3.08 |
3.73 |
|
26 |
1.32 |
1.71 |
2.06 |
2.48 |
2.78 |
3.07 |
3.71 |
|
27 |
1.31 |
1.70 |
2.05 |
2.47 |
2.77 |
3.06 |
3.69 |
|
28 |
1.31 |
1.70 |
2.04 |
2.46 |
2.76 |
3.05 |
3.67 |
|
29 |
1.31 |
1.70 |
2.04 |
2.46 |
2.76 |
3.04 |
3.66 |
|
30 |
1.31 |
1.70 |
2.04 |
2.46 |
2.75 |
3.03 |
3.65 |
|
40 |
1.30 |
1.68 |
2.02 |
2.42 |
2.70 |
2.97 |
3.55 |
|
60 |
1.30 |
1.67 |
2.00 |
2.39 |
2.66 |
2.91 |
3.46 |
|
90 |
1.29 |
1.66 |
1.98 |
2.36 |
2.62 |
2.86 |
3.37 |
|
120 |
1.28 |
1.64 |
1.96 |
2.33 |
2.58 |
2.81 |
3.29 |
Число
степеней свободы определяют какk=n –1,
K=N–m, К =n–m,
где n – количество измерений в
выборке;
N – суммарное количество измерений
в нескольких сериях (объединяемых) при неравноточных измерениях;
m – количество серий (выборок)
при неравноточных измерениях
Похожие материалы
- Обработка результатов двух групп многократных измерений
- Обработка результатов нескольких групп прямых многократных измерений
- Разработка операции контроля дополнительной погрешности при изменении напряжения питания сети
Информация о работе
Тип:
Задания на контрольные работы
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание – внизу страницы.
