- Печать
Страниц: [1] 2 Вниз

Тема: Как найти страницы без текста на сайте? (Прочитано 3434 раз)
Друзья, всем привет. Я сейчас работаю помощником seo специалиста. Часто бывают задачи написать ТЗ на тексты, например: найти на сайте пустые страницы и написать на них ТЗ. Специалист в компании делает это вручную, но по-моему это бред и куча времени тратится не эффективно. Пробовал Screaming Frog – interlal, фильтр HTML – вкладка word count, но там показывает очень мало страниц, не все пустые находит, если не сказать, что вообще пустых не видит (в основном 404 и 301 редирект) 
Пустые страницы имеется ввиду страницы, которые есть, но без текста (не 404).
Вопрос в том, как автоматизировать нахождение пустых страниц на тексте… может посоветуете программу или какой способ, главное чтобы не вручную перебирать.

Записан
А откуда они там берутся/взялись? Движок, что ли создает?
Записан
Те, кто делал сайт изначально. Они создали сразу много страниц, но не наполнили их контентом, вроде как на будущее. А сейчас надо найти все эти страницы и наполнить их контентом.
Записан
![]()
Те, кто делал сайт изначально. Они создали сразу много страниц, но не наполнили их контентом, вроде как на будущее.
Выход вижу один – попробуйте в автоматическом режиме создать sitemap.xml – он найдёт все ваши страницы, а там уже решите, что заполнить текстом, а что просто удалить.. 
Записан
![]()
go.seo, ну а сколько вообще страниц на сайте? 100, 1000, 10 000, и т.д.?
Может страницы на которых нет контента имеют какие-то характерные черты? Возможно, у них, в отличие от других страниц, не заполнены тайтлы, дескрипшны, кейворд. Может они без заголовка H1. А все другие страницы имеют заголовок. Может еще что-то?
Записан
vold57, страниц всего около 200. Все перечисленное тобой на пустышках имеется. Думаю, там нет заголовков h2-h6.
Записан
![]()
страниц всего около 200
тогда Вам лучше последовать совету LOGOS, и в первую очередь заняться наполнением страниц, которые уже попали в индекс…
Записан
![]()
200 страниц можно обойти вручную, максимум за два часа, а вообще быстрее.
Записан
vold57, знал, что такой ответ последует, но задач таких много, и не хочется столько времени тратить на ручную проверку.
Записан
![]()
Ну, если задачи аналогичные описанной, то смотрите в сторону парсеров.
Записан
- Печать
Страниц: [1] 2 Вверх

Поисковые системы хранят в базе бесконечное множество страниц с сайтов, но некоторые из них не включают в поиск, так как считают их малоценными, маловосстребованными – не несущими полезной информации для пользователей.
Например, Яндекс извещает, что
Малоценной страница может быть признана:
- если она является полным или частичным дублем;
- не содержит видимый роботу контент.
Маловостребованной, если робот решит, что:
- в поиске нет запросов, на которые данная страница могла бы ответить (даже если страница без ошибок в коде и содержит контент).
В обоих случаях страница может быть исключена из поиска. Давай разберем подробнее эти определения.
Малоценные страницы на сайте
Полные или частичные дубли на примере интернет-магазина – карточки товаров одного вида очень похожи и могут различаться лишь картинкой, парой фраз или предложений. Робот читает всю страницу целиком, все сквозные блоки (шапка, меню сайдбар, подвал) и из-за очень низкой уникальности признает ее дублем. Из поиска страница удаляется, а сайт получает минус к репутации.
Нет контента или мало контента – иногда на странице размещают только видео, фото, картинки без «живого» текста, или текста очень мало, 1-2 предложения, или текст размещен на картинке (афиши, объявления). А бывает и так, что вебмастера делают на будущее и публикуют пустыми целые разделы с пустыми (только заголовки) страницами. Потом они про них забывают, и образуется малоценная страница без контента.
Маловостребованные страницы
– например, когда заголовки и мета-теги прописаны неправильно или некорректно по отношению к самому тексту страницы. Другими словами – в заголовке, в h1 есть ключевое слово, а в тексте оно не упоминается вообще ни разу. Или когда автор придумывает от себя ключевую фразу к публикации, а такой запрос (по статистике) ни кто и никогда из пользователей интернета не задавал. ПС может посчитать, что информация никому не интересна и удалит страницу из выдачи.
Минусы для сайта от малоценных страниц
1. Снижается авторитет сайта.
Если на сайте много подобных страниц, в совокупности с другими техническими ошибками, авторитет площадки может снизиться.
2. Ухудшаются поведенческие факторы
Пользователь заходит на малоценную страницу и не находит нужную информацию. Он быстро закрывает сайт, что повышает показатель отказов — ухудшает поведенческие факторы.
3. Происходит каннибализация ключевых слов
Простыми словами – использования одних и тех же ключевых слов на разных страницах. Такие страницы будут конкурентами внутри ресурса, а это грозит негативными последствиями для видимости сайта в поиске.
4. Малоценные или маловостребованные страницы снижают краулинговый бюджет сайта
Краулинговый бюджет – это лимит, который выдается каждому сайту на индексацию. Предположим, что вашему сайту назначен лимит на индексацию 100 страниц. На сайте 50 этих «плохих» страниц. Если поисковый робот обойдет много страниц с низкой ценностью, он может и не добраться до важных, хороших страниц.
Как найти, определить малоценные страницы
C помощью сервиса Яндекс.Вебмастер
- Открываем Яндекс.Вебмастер и в левом меню переходим в раздел «Индексирование – Страницы в поиске».
- В верхнем меню выбираем «Исключенные»
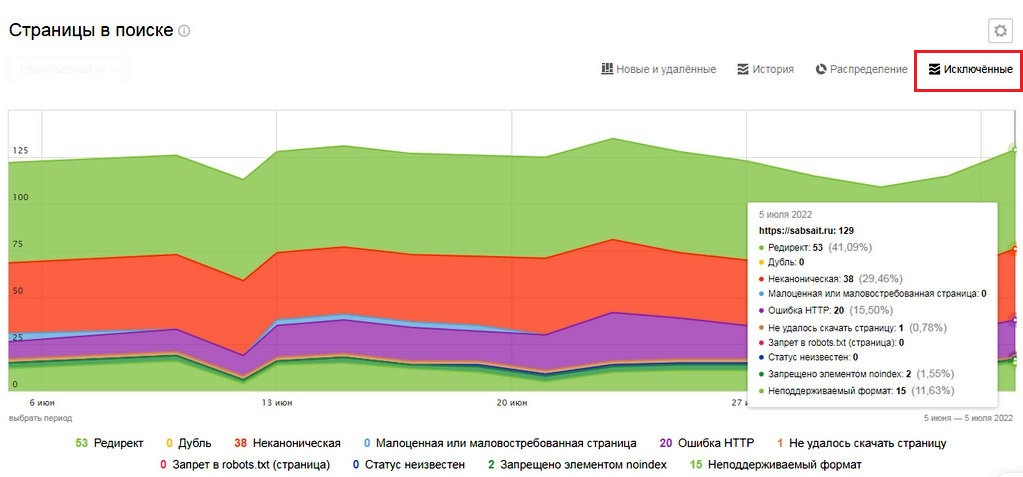
По графику несложно разобраться, а при наведении курсора – отобразятся данные на определенную дату
По малоценным страницам смотрим процент.
- если показатель от 0 до 20% — это в пределах нормы;
- если от 20 до 30% — пересматриваем проблемные страницы и отправляем их на «Переобход страниц»;
- показатель свыше 40% – делаем сами или заказываем технический аудит.
Отслеживаем отчеты Яндекс.Вебмастра.
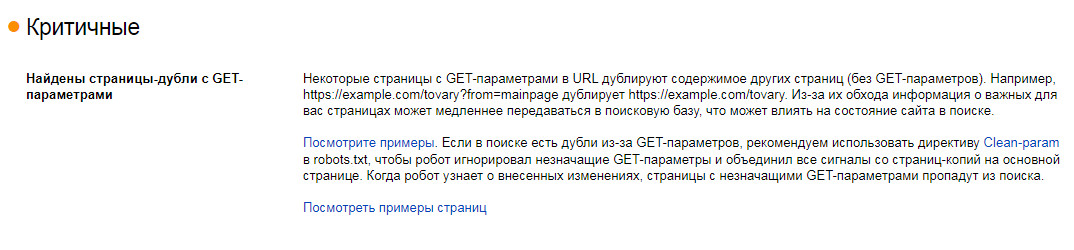
Если пришло такое сообщение «Некоторые страницы с GET-параметрами в URL дублируют содержимое других страниц (без GET-параметров)» — смотрим примеры страниц и решаем, что с ними делать:
- технические страницы и некоторые дубли можно закрыть через файл robots.txt или через метатег noindex;
- для страниц с параметрами (например, страницы сортировки) прописать rel=«canonical» или Clean-param в robots.txt
С помощью программы Screaming Frog SEO Spider

Если вы с ней незнакомы — в ближайшее время расскажу на сайте, а если уже пользовались – просканируйте свой сайт.
По результату можно отсортировать страницы по Word Count (количество слов) или Size (размер страницы):
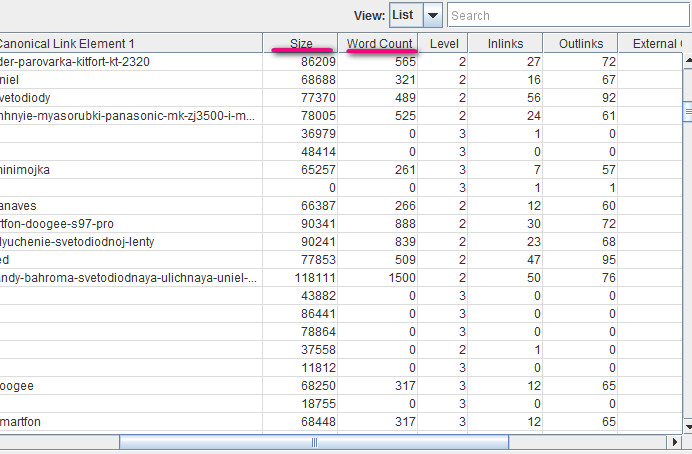
Смотрим, что это за страницы предполагая — чем меньше страница весит, тем меньше ее ценность и объем контента, так же и с количеством слов.
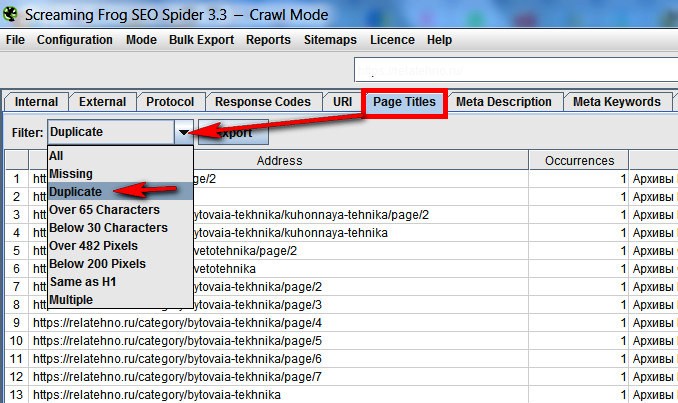
Там же можно проверить дублирующиеся теги, выявляя похожие страницы. Вкладка Title и в выпадающем меню Duplicate
С помощью Яндекс.Метрики или Google Analytics
Ищем страницы с плохими поведенческими факторами, один из вариантов – сортировка страниц по проценту отказов
Варианты исправления малоценных страниц
После выявления или получения уведомления о таких некачественных страницах, не следует сразу удалять, закрывать или переадресовывать их – нужно разобраться, выяснить причину.
Дубли страниц – там, где частично или полностью повторяется контент. Если их немного, можно перенаправить редиректом 301 через файл .htaccess или плагинами, со временем проиндексируется новый документ, а старый уйдет из поиска. Если дублей много – удаляем те, куда нет сторонних ссылок, а оставшиеся делаем каноническими.
Находим дубли Яндекс.Вебмастером (смотрите выше), программой Screaming Frog SEO Spider, и в Google Search Console — вкладка «Оптимизация Html» — список с потенциальными дублями – одинаковыми мета-описаниями.
Страницы с GET-параметрами (внутренний поиск, сортировка, фильтры) – лучший вариант прописать Clean-param или rel=«canonical» в robots.txt.
Технические страницы можно закрыть в файле robots.txt
Например: Disallow: *apply*
Это закроет страницы типа /catalog/rozetki_vyklyuchateli/legrand_plexo/filter/clear/apply/. Только желательно проверить наличие трафика на эти страницы, чтобы не потерять его.
Заключение
Работа над малоценными страницами не обязывает к большим затратам, но может принести неплохие результаты, особенно на больших сайтах.
Если статья была интересна для вас – ей можно поделиться
Получать новые публикации по электронной почте:
Количество просмотров: 12 155
Первой задачей перед поисковым продвижением сайта является технический аудит. Он является частью SEO аудита.
Основная задача технического аудита – выявить проблемные места с точки зрения seo и как следствие их исправить.

Мы подготовили пошаговое руководство, с помощью которого, вы сами сможете сделать технический аудит. Для этого понадобиться программа Screaming Frog SEO Spider. Это один из инструментов в нашем арсенале, который помогает проанализировать сайт.
Переходим к практике!
1. Настройка программы
Первоначальные настройки
Из нестандартных настроек Screaming Frog мы б рекомендовали установить следующие параметры:
В Configuration -> Spider на вкладке Advanced выставить галочки напротив Respect Noindex и Respect NoFollow

Что даст возможность смотреть на сайт так, как его в итоге будут индексировать поисковики. Кроме этого, это позволит сократить время на анализ сайта.
Настройки при парсинге больших сайтов
Если вы знаете, что вам нужно будет проанализировать сайт с довольно большим количеством страниц, то, процесс парсинга всех страниц сайта может затянуться на очень долго (вплоть до нескольких дней). Поэтому, так как в основном, ошибки будут иметь однотипный характер для разных «функциональных частей» сайта (страницы каталога, страницы товаров/статей) вы можете ограничить глубину парсинга до 4-5 уровня вложенности.
Для этого переходим Configuration -> Spider на вкладке Limits и ставим там уровень вложенности 4-5.

Кроме того, сразу можно отключить галочку остановки процесса парсинга при использовании значительного объема памяти.

В итоге, после полного парсинга вы сможете выявить все типичные ошибки на сайте.
Парсинг только определенного вида страниц
Если вдруг, вам нужно проанализировать только один раздел сайта или определенную часть сайта, то, с помощью регулярных выражения вы можете указать какие шаблоны урлов вам необходимо спарсить. Для этого вы должны перейти на Configuration -> Include и задать эти шаблоны.
Например, чтобы на сайте wikimart’a спарсить только раздел сайта Телефоны, нужно задать вот такое регулярное выражение:

Аналогично, используя регулярные выражения, вы можете исключить из парсинга некоторые разделы сайта или типы файлов. Для этого нужно воспользоваться вот этой настройкой Configuration -> Exclude и прописать, каким регулярным выражением, должны соответствовать те части сайта, которые не нужно парсить.
Благодаря этим настройкам вы можете значительно сократить как время парсинга, так и нагрузку на сайт.
Парсинг сайта на сервере разработчика
Так как желательно устранить все ошибки сайта перед его выкаткой на основной домен, то, итогда парсинг необходимо делать на сервере разработчика. Тут возникают следующие нюансы:
- Доступ к сайту через аутенификацию. К счастью эта проблема решена и после ввода логина и пароля можно спокойно проводит анализ сайта:

- Второй нюанс, что обычно, сайт полностью закрывается от индексации через robots.txt, а так как, даная программа, по-умолчанию, поддерживает инструкции из этого файла, то, процесс парсинга у вас не начнется. Для этого вы должны включить опции принудительно игнорировать данный файл:

Это позволит вам выявить основные ошибки уже на промежуточном этапе разработки. Но, после того, как вы настроите все инструкции в файле robots.txt и откроете для индексации основной контента сайта, нужно будет провести повторную проверку сайта уже учитывая все инструкции файла роботса.
Определение оптимальной скорости парсинга сайта
И последняя, но, наверно, одна из основных настроек — это скорость парсинга. Довольно мало сайтов выдерживают одновременно большое количество обращений, поэтому, изначально лучше всего в Configuration -> Speed выставить следующие параметры

При таких настройках вы сможете спарсить большинство сайтов. НО: как только вы включили процесс парсинга подождите 10-20 секунд и, в самом низу, проверьте насколько сайт выдерживает вашу нагрузку

Как видно, что сайт не выдерживает 10 обращений в секунду, поэтому, нужно ограничить кол-во обращений за секунду (при чем желательно не почти к самым пиковым значением, а оставить запас). В данном случае, лучше всего поставить значения Max URI/s = 2. Это позволит нам не уложить сайт и получить все данные по сайту.
Использование proxy
Если вы хотите скрыть свой ip или, что более вероятно, при парсинге заблокируют ваш ip, то, вы можете спокойно обойти это ограничение используя proxy сервер:

Настройка своих параметров поиска текста на страницах
С помощью этой вкладки вы можете задать некоторые свои параметры страницы, по которым вы б хотели получить данные. Например,

Таким образом мы можем получить список страниц
- Которые содержат текст «Нет в наличии»
- На которых отсутствует код Google Analytics.
Сохранение своих настроек
После того как вы сделаете настройку программы по своим параметрам, то, желательно из сохранить как «По умолчанию», чтобы каждый раз не вносить их заново:

Теперь давайте детально пройдемся по каждой вкладке и рассмотрим на что обращать внимание в первую очередь.
2. Internal
Данная вкладка содержит всю информацию по результатам парсинга (кроме, внешних ссылок и пользовательских значений).
Анализ пустых страниц и страниц, которые нужно закрыть от индексации
После полного анализа сайта мы можем проанализировать страницы, на которых минимальное количество контента. Это нам даст возможность понять
- какие страницы нужно закрыть от индексации, например, страницы корзины, авторизации и тд.
- на каких важных страницах отсутствует контент
Поэтому, чтобы быстро проанализировать пустые страницы лучше всего сделать экспорт в Excel, но, перед этим зафильтровать для анализа только HTML страницы.

После открытия файла
- переносим колонку WordCount (аналогично, можно потом проанализировать по колонке Size) поближе к url-адресам сайта и сортируем колонку по возрастанию
- фильтруем колонку Status Code (это ответы сервера) на значения

В итоге, сразу получаем список страниц, на которых явно меньше контента, чем в среднем по сайту:

Очевидно, что эти страницы не содержат никакой полезной информации для пользователей, поэтому, их нужно исключить из поисковых результатов. Для этого, например, добавляем в файл robots.txt следующие инструкции
Disallow: /cart
Disallow: /checkout
Disallow: /contact-us
Disallow: /forgot-password
Disallow: /login
Disallow: /search
Анализируем другие страницы и собираем список пустых страниц, на которых должен быть контент, но он отсутствует.

В данном случае, мы еще нашли
- пустые страницы совсем без текстовой информации
- пустые категории, где совсем нет товарных позиций
Соответственно, теперь нужно заполнить данные страницы информацией, а категории или заполнить товарами, или сделать их не активными для отображения.
Анализ перелинковки на сайте: уровень вложенности страниц, кол-во входящих и исходящих ссылок для конкретных страниц сайта
При проектировании или уже при настройке перелинковки очень важно, чтобы важные страницы сайта
- были как можно ближе к главной страницы (имели минимальный уровень вложенности). Тут мы или делаем сортировку по возрастанию по уровню вложенности = Level и смотрим все ли важные страницы находятся близко к топу, или через поиск вбиваем урл и проверяем его уровень вложенности на сайте

- имели как можно больше входящих ссылок и как меньше исходящих, при этом, на не важные страницы было как можно меньше ссылок (например, страницы с корзиной, регистрацией, авторизацией). Делаем сортировку по убыванию для колонки Inlinks и анализируем, какие страницы получают максимальное количество ссылок с сайта.
3. External
Данная вкладка включает всю информацию про внешние URI.
Анализ всех внешних ссылок с сайта
Очень важно понимать на какие ресурсы и с каких страниц сайта стоят внешние ссылки. Всю эту информацию мы получаем на данной вкладке и, желательно, чтобы все эти ссылки были у вас под контролем. Так как, или вебмастера могут проставить ссылки на свои ресурсы, или кто-то может взломать сайт и проставить кучу не видимых ссылок используя display:none. Поэтому, периодически очень желательно парсить весь сайт и проверять не появились ли какие-то новые не опознанные внешние ссылки.
Например, как на этом ресурсе

Мы видим:
- очень много исходящих ссылок 250+, которые нужно теперь детально проверить
- видим внешние ссылки, которые ссылаются на страницы с кодом ответа 404. Такие ссылки желательно или исправить, или совсем убрать со своего сайта.
Для того чтобы понять, какие именно страницы сайта ссылаются на определенную внешнюю страницу вы:
- нажимаете на интересующую вас страницу
- внизу во вкладке In Links получаете список страниц сайта, которые ссылаются по этой внешней ссылке.

Кроме такого точечного анализа во вкладке External, с помощью выгрузки Bulk Export -> All Out Links, вы можете сделать полную выгрузку в Excel по тому какая страница сайта на какую внешнюю страницу ссылается.
4. Response Codes
Эта вкладка содержит всю информацию по ответам сервера для внутренних и внешних ссылок. В идеальном варианте, нужно, чтобы 100% страниц были с 200 кодом ответа. Но, на практике часто имеем вот такую картину

Поэтому, рассмотрим, что делать в таком случае
Поиск страниц / url с ответом сервера 404 ошибка

В итоге получаем все страницы, которые отдают 4xx ответ сервера. Очевидно, что мы должны понять причину появления таких ошибок и исправить такие ссылки, которые приводят к ошибкам 4xx.
Кроме данных, по каким страницам у нас выдается 4xx ошибки, нам важно понимать с каких страниц стоят ссылки на эти страницы. Аналогично, пункту Анализа внешних ссылок мы или точечно, по каждой страницы, можем проанализировать внизу на вкладке In Links или можем воспользоваться экспортом (Bulk Export -> Client Error (4xx) in Links) по всем страницам, которые ссылаются на битые страницы и уже проводить детальный анализ с помощью Excel.
Поиск редиректов внутри сайта
Внутри сайта не должно быть редиректов, так как это негативно влияет на передачу веса по страницам сайта.
Анализ лучше всего проводить в Excel, для этого фильтруем на ошибки 3xx и делаем экспорт

Получаем файл с названием response_codes_redirection_(3xx).xlsx в котором
- все страницы, по которым происходит редирект указаны в колонке Address
- на какие страницы делается редирект указаны в колонке Redirect URI
Теперь, сделав еще выгрузку отчета из Bulk Export -> Client Error (4xx) in Links и получив файл с названием redirection_(3xx)_in_links.xlsx в котором
- все страницы, по которым происходят редиректы указаны в колонке Destination
- страницы с которых стоят ссылки на страницы по которым происходит редирект указаны в колонке Source
нужно сделать так, чтобы все страницы из колонки Source файла redirection_(3xx)_in_links.xlsx ссылались на правильные страницы Redirect URI из файла response_codes_redirection_(3xx).xlsx. По этому, алгоритму, конечно, есть разные нюансы (в основном, когда происходит 302 редирект для страниц с авторизацием, корзиной, личной информацией, а вы при этом не залогинены в системе), но, в общем он подходит для 95% и позволяет устранить редиректы внутри сайта.
Нюансы: что в выгруженных файлах будут также ссылки и на внешние сайта, но, в идеале, все такие не правильные ссылки тоже нужно исправить.
Поиск ошибок сервера у себя на сайте
Благодаря этому отчету вы сможете понять по каким uri у вас появляются ошибки, связанные с работой сервера. Тут разбираемся в причине появления и оперативно фиксим все такие проблемы. Часто причина возникновения может быть, что мы очень активно парсили сайт и сервер упал. Поэтому, сразу желательно проверить работоспособность сайта и парсить сайт уже при меньших нагрузках.
Страницы без ответа сервера – No Response
Аналогично, нужно разобраться в чем проблема, но, в основном, данная проблема по страницам возникает когда идет большая нагрузка от программы Screaming Frog и хостер просто блокирует ваш ip. Как раз в этом случае

При анализе сайта, хостер заблокировал наш ip J и мы получили такие ответы сервера. Эта проблема решается звонком в хостинг компанию или сменой ip (см. Использование proxy). Дальше значительно уменьшаем скорость парсинга, чтобы больше не получать такую проблему.
5. URL
На данной вкладке, можно проанализировать различные ошибки, непосредственно связанные со структурой url адреса.

Как найти ошибки связанные с url / url адресом
Рассмотрим какие данные мы можем оперативно получить по различным фильтрам на вкладке URI:
- Non ASCII Characters – список URI который имеет символы в нем, не включенные в схему кодирования ASCII символов. Важно всё исправить, так как потом появится масса проблем с простановкой ссылок на такие страницы
- Underscores – использование нижнего подчеркивания вместо использования дефиса в качестве разделителя между словами. В идеале, должен использоваться дефис, но, на данном этапе это уже не очень принципиально.
- Duplicate – важнейший фильтр, он нам сразу, на основе хеша страниц, показывает дублирующие страницы на сайте. Сразу необходимо разобраться в причинах появления таких дублирующих страниц и оперативно заняться исправлением причины их возникновения.
- Dynamic – список uri которые содержат параметры (типа ‘?’ или ‘&’ ). Желательно как минимум ознакомиться с этими страницами, но, в общем может быть, что всё нормально и ничего исправлять на сайте не нужно.
- Over 115 characters – страницы которые имеют длину больше 115 символов. Очень важно не переспамливать ключевыми словами в урл и проектировать сайт, чтобы таких больших uri не получалось, так как это один из сигналов для поисковых систем, чтобы более пристально проверить на переспам остальные параметры данной страницы. Фиксить на текущем сайте можно если вы четко понимаете, что санкции получены именно за переспам, а, лучше всего, этот момент учитывать на этапе проектирования сайта.
6. Page Title
Данная вкладка содержит различную информацию по мета-тегу title. Это один из важнейших элементов на сайте, поэтому, нужно довольно внимательно подойти к изучению всех нюансов.

Как найти все пустые и дублирующиеся в коде title на сайте
Зафильтров по Missing мы получим список страниц без тега title. Очевидно, что для всех таких страниц нужно прописать релевантный странице title.
По фильтру Multiple можно увидеть где используется больше одного раза мета-тег title. Это редкая ошибка, но, нужно не забывать проверять данный момент.
Дублирующиеся title или как найти дублирующиеся страницы
По дублирующемуся title мы можем быстро определить страницы с одинаковым контентом, после этого, выясняем типичные ошибки и оперативно вносим правки на сайт.
Например, в данном случае,

имеем классические примеры:
- Проблема с системными страницами сайта, которые отвечают уже за процесс покупки и, фактические, не должны быть в индексе
- Проблема связанная с пагинацией на сайте: на первую страницу каталога проставляется ссылка с параметром, которого, на самом деле, не должно быть
Одинаковые title и h1
Очень желательно, чтобы у вас на сайте были разными title и h1. В первую очередь это касается контентных проектов или контентных разделов на коммерческих сайтах. Вы должны просмотреть список всех страниц, зафильтровав по Same as H1, и подправить такие страницы.
Оптимизация title
После того, как внесены все основные правки, можно заняться мега оптимизацией title и исправить все тайтлы страниц которые не удовлетворяют этим параметрам

Ошибки Over 65 characters и Over 482 pixels показывают вам, что текущий тайтл не будет весь отображён в результатах выдачи, а Below 30 Characrers и Below 200 pixels показывают вам, что тайтл короткий и, в теории, его можно было бы увеличить, чтобы он более подробно раскрывал суть страницы.
7. Descripion
Данная вкладка содержит различную информацию по мета-тегу description. Данный мета-тег в основном используется для формирования описания к снипету на страницах результатов поиска, поэтому, грамотное его заполнение может значительно увеличить долю кликов по вашему сайту.
Кроме этого, например, Google довольно часто, при отсутствии или банальном шаблоне генерации description, берет это за один из сигналов и в результате отправляет страницы сайта в дополнительный индекс. Поэтому, данному мета-тегу тоже нужно уделять довольно много внимания.
По данным анализа тут всё аналогично к мета-тегу title.
8. Keywords
Вкладка с информацией по мета-тегу keywords.

Данный тег давно уже потерял свою значимость, поэтому, особого внимания, кроме некоторых случаев, не стоит ему уделять. Единственный нюанс, что если вы все-таки заполняете keywords, то, его содержимое должно быть уникальным и четко описывать текущую страницу.
H1
Подробная информация по использованию тега h1 на сайте. Хоть данный тег, уже, и не имеет большого значение для поисковой оптимизации, но, все-равно его нужно правильно использовать.

- Missing – все страницы на которых отсутствует тег h1. Желательно, чтобы все страницы содержали этот тег и четко описывали про что текущая страница. Это больше важно для пользователей, которые попадают на сайт, чтобы они могли быстро сориентироваться про что данная страница.
- Duplicate – все дублирующиеся h1 внутри сайта. Почти всегда h1 должен быть уникальным для каждой страницы. Данная проблема часто возникает, когда через этот заголовок делают лого или название сайта, тогда имеем проблему, что на всех страницах один и тот же h1.
- Over 70 characters – h1 с длиной больше чем 70 символов. В идеальном варианте, лучше не делать очень длинные заголовки страниц.
- Multiple – мы всегда должны помнить, что «тег h1 всегда один». Поэтому, мультииспользование данного тега не допустимо и все такие ошибки должны быть исправлены на сайте.
H2
Вся информация, связанная с использованием тега h2 на сайте.

Из данного раздела, оперативно, можно определить неправильно использование заголовков <h…> при верстке сайта. Это видно если мы имеем много дублирующихся h2, которые можно посмотреть по фильтру Duplicate.

В данном случае, мы видим, что при верстке был использован тег h2, чего не стоило делать, а желательно, использовать стили и тег <div>.
Images
С помощью этой вкладке можно проанализировать ошибки при использовании картинок на сайте

- Over 100kb – можно найти рисунки с размером больше 100kb.
- Missing Alt Text – рисунки с отсутствующими описаниями в ALT.
- Alt Text Over 100 Characters – рисунки с очень большим описанием (больше 100 символов).
Оптимизацией картинок можно заняться уже на финальном этапе, когда исправлены все технические нюансы и оптимизирована контентная часть сайта.
Directives
На данной вкладке собрана вся информация, связанная с использованием в meta заголовке, canonical, а также rel=“next” и rel=“prev”. Используя соответствующие фильтры, вы можете посмотреть на каких страницах используется та или иная директива для поисковых роботов. Рассмотрим в качестве примера, проверку использования rel=”canonica”.
Проверка правильности использования rel=”canonical”
На вкладке Directives воспользовавшись фильтрами Canonical, Canonicalised, No Canonical вы можете проверить правильность использования атрибута rel=”canonical”.

Желательно выборочно просмотреть страницы на которых стоит rel=”canonical” и проверить:
- правильно ли выбрана логика работы: правильно выбрана каноническая страница, ссылка ведет на релевантную страницу, страница на которую ведет каноническая ссылка имеет код ответа 200, …
- нет двойного использования данного параметра
Например, мы можем получить вот такую ситуацию

где:
- 2 раза используется атрибут rel=”canonical”.
- И во втором случае на всех страницах сайта каноническая ссылка ведет на главную страницу, что является очень критической ошибкой использования данного атрибута.
Кроме этого, с помощью отчета Reports -> Canonical Errors

Вы можете получить список ошибочного использования данного атрибута.
AJAX
Данная вкладка показывает все страницы, которые получены в результате использование AJAX.
Custom
С помощью данных этой вкладки вы можете увидеть список тех страниц, которые соответствуют заданным фильтрам из Настройка своих параметров поиска текста на страницах.
Анализ файла sitemap.xml
После аудита сайта путем его парсинга, желательно, проверить какие url указаны в файле sitemap.xml. Там могут быть
- несуществующие страницы,
- страницы, по которым происходят редиректы
- возможно, страницы, которые могут создавать дублирующий контент.
Для этого вы должны скачать файл sitemap.xml себе на компьютер и открыть его в режиме List:

После этого, произойдет, сбор данных по всем страницам, которые указаны в данной карте сайте и нужно, сделать заново все проверки, которые указаны выше, особенно уделив внимание разделу Response Codes, так как нужно, чтобы все страницы отдавали код ответа 200.
В заключение
В данном руководстве рассмотрены самые основные технические моменты в seo, на которые стоит обращать внимание. Их можно проверить как с помощью программы Screaming Frog Seo Spider, так и других.
Самое главное сделать все грамотно с технической части оптимизации. Тогда ваш сайт будет продвигаться в поисковых системах на порядок лучше и быстрее.
Оригинал статьи взят с сайта SeoProfy
Поиск пустых страниц

На сайте с 30.08.2012
Offline
80
1 ноября 2013, 08:02
2347
Доброго времени суток, есть какой нибудь быстрый способ искать пустые страницы на сайте?

На сайте с 18.10.2008
Offline
473
Sleepwalker15, для начала надо определить значение “пустой страницы” чтобы их искать ☝
– Здесь я покупаю вечные ссылки на свои сайты! (https://backlinkator.com) – сотни ссылок за копейки

[Удален]
1 ноября 2013, 19:18
#2
Зарегистрируйтесь в гуугл вебмастер, там показываются страницы сайта с ошибками. Если я правильно Вас понял.
В базе поисковых систем хранится бесконечное множество страниц с разных сайтов. Некоторые из них несут мало пользы. Подобные страницы Яндекс или Гугл считают малоценными и часто не включают в индекс.
Давайте разбираться, что это за страницы, как их искать и что произойдет, если эффективно с ними поработать.
Малоинформативная (малоценная) страница: понятие
Малоценные страницы (на сленге их называют зомби-страницами) имеют мало шансов быть востребованными у пользователей сети. Контент на этих страницах может дублировать уже известные роботу страницы. Также на подобных страницах может быть мало контента или не быть вовсе. Итак, повторим еще раз, зомби-страница – это:
-
пустая страница без контента (либо содержащая только сквозные блоки),
-
полупустая страница (где мало контента),
-
дублирующаяся страница (очень похожая на другую).
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Чем плохи эти страницы?
1
Малоценные или малоинформативные страницы снижают краулинговый бюджет сайта
Краулинговый бюджет – это лимит, который выдается каждому сайту на индексацию. Представим, что вашему сайту выдали лимит на индексацию 100 страниц. На вашем сайте 50 зомби-страниц. Если поисковая система обойдет много страниц с низкой ценностью, она может не добраться до важных страниц.
2
Происходит каннибализация ключевых слов
Этот термин означает негативное влияние использования одних и тех же ключевых слов на разных страницах. Некоторые страницы вашего сайта могут бороться за место в выдаче. Это касается страниц с дублирующимся или похожим контентом.
3
Может снижаться авторитет сайта
Если на сайте много зомби-страниц или есть другие технические ошибки, его авторитет может снизиться.
4
Ухудшаются поведенческие факторы
Пользователь заходит на малоинформативную страницу и не получает необходимую информацию. Он быстро закрывает сайт, что негативно сказывается на поведенческих факторах.
Какая перед нами стоит задача?
-
Найти малоценные или малоинформативные страницы.
-
Решить, что с ними делать.
-
Закрыть от индексации ненужные страницы.
-
Проработать страницы, которые нам нужны.
Как искать зомби-страницы?
Следует зайти в Яндекс.Вебмастер и посмотреть, какие страницы поисковая система считает малоценными. Заходим в «Индексирование» – «Страницы» в поиске и выбираем «Исключенные страницы».
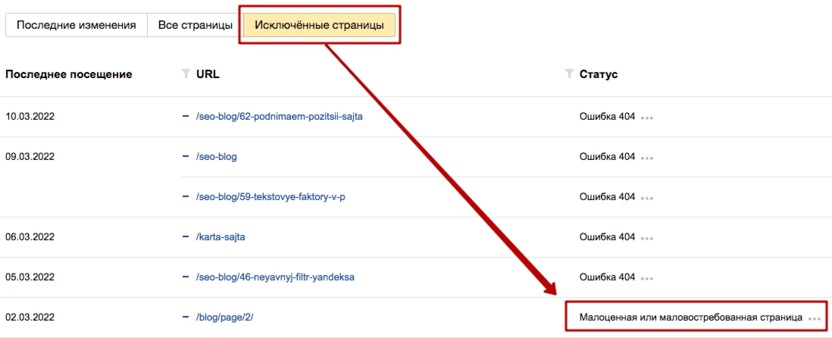
Как видно на скриншоте, в столбце «Статус» мы видим причину исключения из индекса. Чтобы было удобнее работать со страницами, можем выгрузить их из Яндекс.Вебмастера в таблицу. Если вы работаете с продуктами Google, возможно, данный способ вам не подойдет, поэтому рассмотрим другие варианты.
Существует программа Screaming Frog SEO Spider. Если вы занимаетесь продвижением сайтов, то наверняка про нее знаете. Если нет, устанавливайте ее и сканируйте сайт.
После сканирования вы можете отсортировать страницы по Word Count (количество слов) или Size (размер страницы):
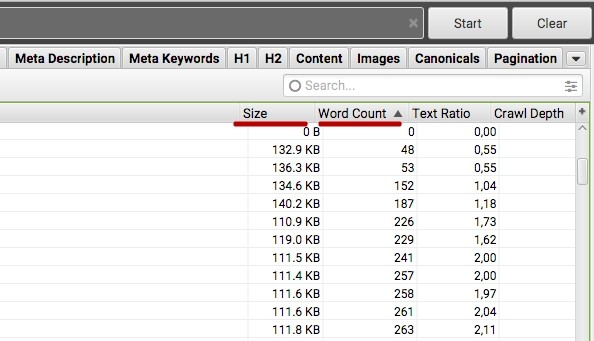
Предположение заключается в том, что чем меньше страница весит, тем меньше там контента и ценности. Аналогично и с количеством слов.
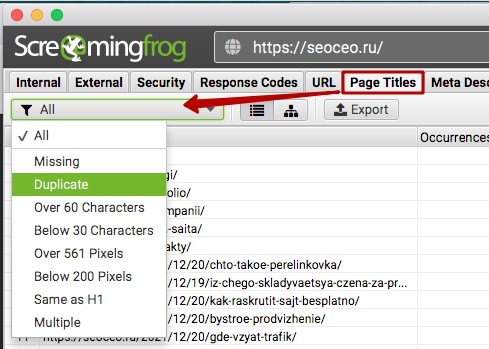
Также, разумеется, стоит проверить дублирующиеся теги, чтобы найти похожие страницы. Заходим на вкладку Title и ищем дублирующиеся мета-теги, как это показано на скриншоте.
Существует еще один способ для поиска зомби-страниц с помощью Яндекс.Метрики. Для этого нужно найти страницы с плохими поведенческими факторами. Например, отсортировать страницы по проценту отказов. Но мне хватает двух вышеперечисленных способов.
Варианты правок
-
Оптимизируем. Данный метод имеет смысл, когда есть ресурсы и оптимизация страниц может принести весомый профит. Обычно я не работаю с оптимизацией малоценных страниц, а приступаю к следующим вариантам.
-
Склеиваем. Если у нас имеются одинаковые или похожие страницы, мы склеиваем их с помощью редиректов и перенаправляем с одной страницы на другую.
-
Закрываем от индексации или удаляем. Существуют стандартные типы страниц: внутренний поиск, сортировка, пагинация, фильтры. Если у нас вылетают из индекса страницы фильтра или другие типы стандартных страниц, стоит закрыть их в файле robots.txt, даже несмотря на то, что они закрыты в canonicals. Для этого в robots.txt нужно прописать строчку:
Disallow: *apply*
Это актуально для страниц типа site.ru/filter/prop_2049-is-ks-set/apply/. Важный момент – прежде чем что-то закрывать, необходимо проверить подобные страницы на наличие трафика. Иначе можно его лишиться.
Работа с малоценными страницами способна принести хорошие результаты с малыми затратами. Чем больше сайт, тем больше даст работа с зомби-страницами. В любом случае советую воспользоваться советами из статьи и оценить результаты.
