При работе с Dataframe в Pandas можно столкнуться с ситуацией, когда данные не полные (отсутствует часть значений) и это не позволяет их анализировать. В этом уроке мы рассмотрим, как найти строки в Dataframe, у которых часть информации отсутствует.

Для начала давайте загрузим наш учебный пример:
import pandas as pd
url=’https://drive.google.com/file/d/1KXfupiJKql5Lc-D73KiiS_jEd_CNIW44/view?usp=sharing’
url2=’https://drive.google.com/uc?id=’ + url.split(‘/’)[-2]
df = pd.read_csv(url2)
df.info()
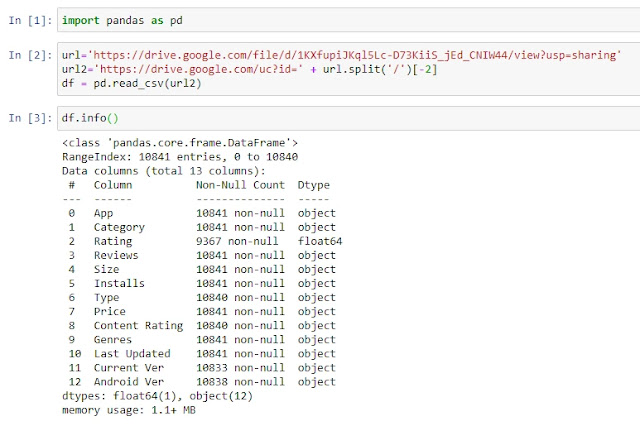
Это база данных по приложениям в Google Play и как вы видите, к примеру в столбце Rating, много пустых элементов.
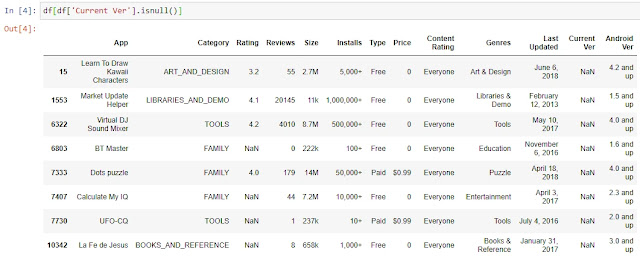
Для отбора строк, где в одном указанном столбце, отсутствуют данные, мы можем воспользоваться стандартным инструментом фильтрации. К примеру, отберем те строки, по которым в столбце Current Ver нет информации:
df[df[‘Current Ver’].isnull()]
Однако, что делать, если нам нужно отобрать все строки, в которых хотя бы в одном из столбцов отсутствуют значения?
Для начала создадим новый Dataframe, в который поместим проверку на то, является ли информация в ячейке пустой или нет:
is_null = df.isnull()
Для каждой позиции мы получим результат False или True, где False – в ячейке есть данные, True – в ячейке NaN.
Как мы видели выше, в 15 строке у нас отсутствует информация о Current Ver, давайте проверим при помощи функции iloc, какие данные по 15 строке у нас в Dataframe is_null:
is_null.iloc[15,]

Все верно, по всем столбцам, кроме Current Ver, у нас False, а по столбцу Current Ver у нас True, так как в нем нет какой-либо информации.
Далее нам надо сформировать Series, которая нам послужит в дальнейшем фильтром, в которой значение True будет в случае, если хотя бы в одном столбце в строке нет данных, а False, если информация есть во всех столбцах:
row_with_null = is_null.any(axis=1)
Используя эту Series как фильтр, мы создаем новый Dataframe, в который переносим только те строки, в которых хотя бы в одном из столбцов есть NaN:
rows_with_null = df[row_with_null]
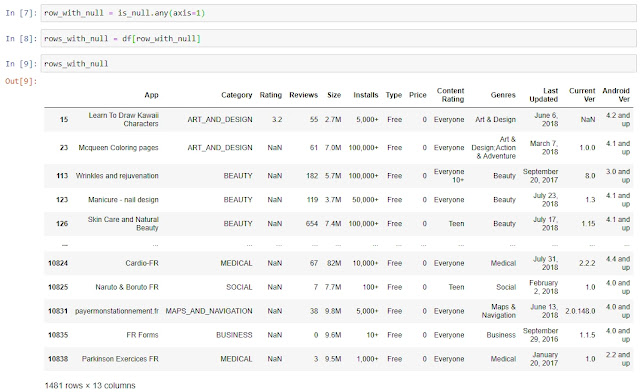
Готово, мы нашли все строки с отсутствующими данными в Dataframe. В качестве бонуса прикладываю
ноутбук
с текущего урока. Спасибо за внимание, комментарии приветствуются.
Your numpy.where construct is perfectly fine to use.
The issue you are facing is how to test a column versus an empty string. The answer is just check equality versus ''.
This is straightforward to implement:
df4['column3'] = np.where(df4['gender'] == '', df4['name'], df4['gender'])
pd.Series.empty tests if the series has no items, i.e. no rows, not whether its elements are empty strings.
Example
import pandas as pd, numpy as np
vals = {
'name' : ['n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7'],
'gender' : ['', '', '', 'f', 'f', 'c', 'c'],
'age' : [39, 12, 27, 13, 36, 29, 10]
}
df4 = pd.DataFrame(vals)
df4['column3'] = np.where(df4['gender'] == '', df4['name'], df4['gender'])
# age gender name column3
# 0 39 n1 n1
# 1 12 n2 n2
# 2 27 n3 n3
# 3 13 f n4 f
# 4 36 f n5 f
# 5 29 c n6 c
# 6 10 c n7 c
As part of our data wrangling process we might need to find, replace or even drop empty values in our data set so that these values don’t impact our analysis.
In this short tutorial, we’ll learn a few ways to use Python and the Pandas library to query our data and find data rows containing empty values.
Creating our example Data set
We’ll start by importing the Pandas library and creating a very simple dataset that you can use to follow along:
import pandas as pd
import numpy as np
city = ['DTW', 'NYC', 'SFO','ORD']
office = ['West', 'North', np.nan, 'East']
interviews = [10,104,210,np.nan]
#create the pandas dataframe
data_dict = dict(city=city, office=office, interviews=interviews)
hr = pd.DataFrame (data_dict)
print(hr.head())Here’s our DataFrame:
| city | office | interviews | |
|---|---|---|---|
| 0 | DTW | West | 10.0 |
| 1 | NYC | North | 104.0 |
| 2 | SFO | NaN | 210.0 |
| 3 | ORD | East | NaN |
Find rows with null values in Pandas Series (column)
To quickly find cells containing nan values in a specific Python DataFrame column, we will be using the isna() or isnull() Series methods.
Using isna()
nan_in_col = hr[hr['interviews'].isna()]Using isnull()
nan_in_col = hr[hr['interviews'].isnull()]Both methods will render the following result:
print(nan_in_col)| city | office | interviews | |
|---|---|---|---|
| 3 | ORD | East | NaN |
Select rows with missing values in a Pandas DataFrame
If we want to quickly find rows containing empty values in the entire DataFrame, we will use the DataFrame isna() and isnull() methods, chained with the any() method.
nan_rows = hr[hr.isna().any(axis=1)]or
nan_rows = hr[hr.isnull().any(axis=1)]Alternatively we can use the loc indexer to filter out the rows containing empty cells:
nan_rows = hr.loc[hr.isna().any(axis=1)]All the above will render the following results:
print(nan_rows)| city | office | interviews | |
|---|---|---|---|
| 2 | SFO | NaN | 210.0 |
| 3 | ORD | East | NaN |
Select DataFrame columns with NAN values
You can use the following snippet to find all columns containing empty values in your DataFrame.
nan_cols = hr.loc[:,hr.isna().any(axis=0)]
Find first row containing nan values
If we want to find the first row that contains missing value in our dataframe, we will use the following snippet:
hr.loc[hr.isna().any(axis=1)].head(1)Replace missing nan values with zero
Once found, we might decide to fill or replace the missing values according to specific login. We typically use the fillna() DataFrame or Series method for that. In this example we’ll going to replace the missing values in the interview column with 0.
hr.fillna({'interviews':0}, inplace=True)Additional learning
- How to replace values in Pandas DataFrame columns?
Я пытаюсь выполнить поиск в фрейме данных Pandas, чтобы найти, где отсутствует запись или запись NaN.
Вот фреймворк, с которым я работаю:
cl_id a c d e A1 A2 A3
0 1 -0.419279 0.843832 -0.530827 text76 1.537177 -0.271042
1 2 0.581566 2.257544 0.440485 dafN_6 0.144228 2.362259
2 3 -1.259333 1.074986 1.834653 system 1.100353
3 4 -1.279785 0.272977 0.197011 Fifty -0.031721 1.434273
4 5 0.578348 0.595515 0.553483 channel 0.640708 0.649132
5 6 -1.549588 -0.198588 0.373476 audio -0.508501
6 7 0.172863 1.874987 1.405923 Twenty NaN NaN
7 8 -0.149630 -0.502117 0.315323 file_max NaN NaN
ПРИМЕЧАНИЕ. Пустые записи представляют собой пустые строки – это потому, что в файле, из которого был получен фрейм данных, не было буквенно-цифрового содержимого.
Если у меня есть этот фрейм данных, как мне найти список с индексами, в которых встречается NaN или пустая запись?
11 ответов
Лучший ответ
np.where(pd.isnull(df)) возвращает индексы строки и столбца, где значение равно NaN:
In [152]: import numpy as np
In [153]: import pandas as pd
In [154]: np.where(pd.isnull(df))
Out[154]: (array([2, 5, 6, 6, 7, 7]), array([7, 7, 6, 7, 6, 7]))
In [155]: df.iloc[2,7]
Out[155]: nan
In [160]: [df.iloc[i,j] for i,j in zip(*np.where(pd.isnull(df)))]
Out[160]: [nan, nan, nan, nan, nan, nan]
Поиск значений, которые являются пустыми строками, можно выполнить с помощью applymap:
In [182]: np.where(df.applymap(lambda x: x == ''))
Out[182]: (array([5]), array([7]))
Обратите внимание, что использование applymap требует однократного вызова функции Python для каждой ячейки DataFrame. Это может быть медленным для большого DataFrame, поэтому было бы лучше, если бы вы могли организовать, чтобы все пустые ячейки содержали вместо этого NaN, чтобы вы могли использовать pd.isnull.
73
unutbu
27 Ноя 2014 в 00:42
Попробуй это:
df[df['column_name'] == ''].index
А для NaN вы можете попробовать:
pd.isna(df['column_name'])
45
Vyachez
16 Окт 2018 в 23:37
Проверьте, содержат ли столбцы Nan, используя .isnull(), и проверьте наличие пустых строк, используя .eq(''), затем соедините их вместе с помощью побитового оператора OR |.
Просуммируйте axis 0, чтобы найти столбцы с недостающими данными, затем просуммируйте axis 1 до позиций индекса для строк с отсутствующими данными.
missing_cols, missing_rows = (
(df2.isnull().sum(x) | df2.eq('').sum(x))
.loc[lambda x: x.gt(0)].index
for x in (0, 1)
)
>>> df2.loc[missing_rows, missing_cols]
A2 A3
2 1.10035
5 -0.508501
6 NaN NaN
7 NaN NaN
19
Alexander
3 Янв 2020 в 10:25
Я прибегал к
df[ (df[column_name].notnull()) & (df[column_name]!=u'') ].index
За последнее время. Это позволяет получить как пустые, так и пустые ячейки за один раз.
12
jeremy_rutman
3 Июн 2019 в 14:55
На мой взгляд, не тратьте время зря и просто замените на NaN! Затем найдите все записи с Na. (Это правильно, потому что пустые значения в любом случае отсутствуют).
import numpy as np # to use np.nan
import pandas as pd # to use replace
df = df.replace(' ', np.nan) # to get rid of empty values
nan_values = df[df.isna().any(axis=1)] # to get all rows with Na
nan_values # view df with NaN rows only
8
Zhannie
30 Июн 2021 в 23:46
Частичное решение: для однострочного столбца tmp = df['A1'].fillna(''); isEmpty = tmp=='' дает логическую серию True, если есть пустые строки или значения NaN.
4
lahoffm
27 Окт 2017 в 15:19
Ты тоже делаешь что-то хорошее:
text_empty = df['column name'].str.len() > -1
df.loc[text_empty].index
Результатом будут пустые строки и их порядковый номер.
2
Mohamed Abdelsalam
17 Май 2020 в 12:57
Еще одна возможность, охватывающая случаи, когда может быть несколько пробелов, – использование функции python isspace().
df[df.col_name.apply(lambda x:x.isspace() == False)] # will only return cases without empty spaces
Добавление значений NaN:
df[(df.col_name.apply(lambda x:x.isspace() == False) & (~df.col_name.isna())]
2
lukaszberwid
18 Авг 2020 в 00:54
Чтобы получить все строки, содержащие пустую ячейку в определенном столбце.
DF_new_row=DF_raw.loc[DF_raw['columnname']=='']
Это даст подмножество DF_raw, которое удовлетворяет условию проверки.
1
Shara
30 Июл 2019 в 08:33
Вы можете использовать строковые методы с регулярным выражением для поиска ячеек с пустыми строками:
df[~df.column_name.str.contains('w')].column_name.count()
1
blackgreen
7 Май 2021 в 01:23
Вот как проверить, являются ли все значения столбца пустыми или NAN, когда df является вашим фреймом данных
#Check if there is any empty columns
df = df.replace(' ', np.nan)
nan_cols = []
for col in df.columns:
x = pd.isna(df[col])
x = x.to_numpy()
if not False in x:
nan_cols.append(col)
print(nan_cols)
Этот код вернет массив cloumns, который пуст, или значения NAN во всех строках.
0
KapoNYC
3 Мар 2022 в 11:53

Рассмотрим задачу выявления и удаления незаполненных значений, которые в Pandas обозначаются служебным значением NaN. В демонстрационных целях будем использовать набор объявлений о продажах квартир в Республике Северная Осетия-Алания, имеющий следующий вид:
Для определения незаполненных значений используются методы isnull, notnull, возвращающие True/False для каждого объекта (обычно значение в столбце или элемент в строке) в зависимости от присутствия в нем пропущенных значений. Например, выведем строку нашей таблицы, в которой значение date_time не заполнено:
Для удаления незаполненных значений служит метод dropna, который позволяет задать ось удаления (строки, столбцы); порог минимального количества заполненных значений для принятия решения об удалении; подмножество полей, для которых удаляются незаполненные значения. Эти возможности реализуются посредством следующих параметров:
axis – определяет будут удаляться строки (значение 0) или столбцы (1) с недостающими значениями;
how – условие удаления при всех пустых значениях (значение all) или хотя бы одном (any);
thresh – пороговое количество непустых значений, меньше которого требуется удаление;
subset – задает группы имен столбцов или строк для удаления нулевых значений;
Например, так можно удалить строки, в которых столбец date_time содержит пустое значение (такая всего одна):
Другой пример – мы располагает таблицей со значениями нетипичного изменения стоимости недвижимости за неделю в различных категориях площадей (подробнее описывалось в статье), имеющей следующий вид:
Для того, чтобы оставить записи с количеством ненулевых значений не менее 3, потребуется вызвать метод dropna(thresh = 3). В результате получается таблица следующего вида:
Зачастую некоторые объекты с отсутствующими значениями следует сохранить и заполнить разумными значениями. Например, в таблице цен на недвижимость ячейки с отсутствующей «жилой площадью» («live_square») можно заполнить средним значением по жилым площадям в строках, «общая площадь» («total_square») в которых попадала в тот же диапазон что и в заданной. Это реализуется в следующем коде:
# очищаем столбцы и приводим их содержимое к типу с плавающей
# точкой
df.loc[df[‘total_square’].notnull(), ‘total_square’] = df.loc[df[‘total_square’].notnull(), ‘total_square’].map(
lambda x: x.replace(‘м²’, ”))
df.loc[df[‘live_square’].notnull(), ‘live_square’] = df.loc[df[‘live_square’].notnull(), ‘live_square’].map(
lambda x: x.replace(‘м²’, ”))
df[‘total_square’] = df[‘total_square’].astype(np.float32)
df[‘live_square’] = df[‘live_square’].astype(np.float32)
# ставим в соответствие каждому значению общей площади квартиры
# соответствующий ей диапазон
bins = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 1000]
cat = pd.cut(df[‘total_square’], bins)
# задаем столбец, содержащий среднее жилой площади для каждого
# диапазона
live_sq = df[‘live_square’].groupby(cat).transform(np.mean)
# для пустых ячеек с жил площадью вставляем значение, полученное на предыдущем шаге
df[‘live_square’] = np.where(df[‘live_square’].isnull(), live_sq, df[‘live_square’])
Отмечу, что способы разбивки по диапазонам значений (например, функция pandas.cut) описывались в статье, а обработка отдельных значений (метод map) в статье.
Напоследок продемонстрирую результаты преобразования нашей таблицы после выполнения указанного выше участка кода:
