При работе с Dataframe в Pandas можно столкнуться с ситуацией, когда данные не полные (отсутствует часть значений) и это не позволяет их анализировать. В этом уроке мы рассмотрим, как найти строки в Dataframe, у которых часть информации отсутствует.

Для начала давайте загрузим наш учебный пример:
import pandas as pd
url=’https://drive.google.com/file/d/1KXfupiJKql5Lc-D73KiiS_jEd_CNIW44/view?usp=sharing’
url2=’https://drive.google.com/uc?id=’ + url.split(‘/’)[-2]
df = pd.read_csv(url2)
df.info()
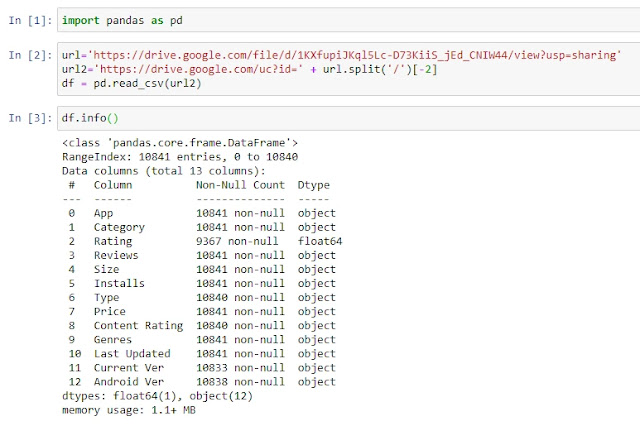
Это база данных по приложениям в Google Play и как вы видите, к примеру в столбце Rating, много пустых элементов.
Для отбора строк, где в одном указанном столбце, отсутствуют данные, мы можем воспользоваться стандартным инструментом фильтрации. К примеру, отберем те строки, по которым в столбце Current Ver нет информации:
df[df[‘Current Ver’].isnull()]
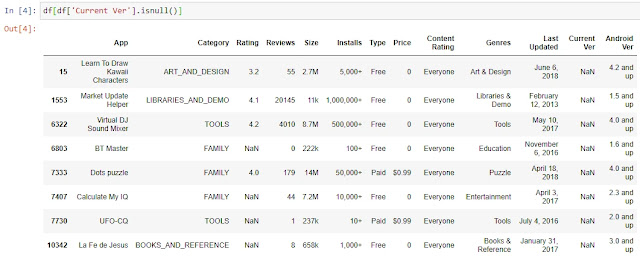
Однако, что делать, если нам нужно отобрать все строки, в которых хотя бы в одном из столбцов отсутствуют значения?
Для начала создадим новый Dataframe, в который поместим проверку на то, является ли информация в ячейке пустой или нет:
is_null = df.isnull()
Для каждой позиции мы получим результат False или True, где False – в ячейке есть данные, True – в ячейке NaN.
Как мы видели выше, в 15 строке у нас отсутствует информация о Current Ver, давайте проверим при помощи функции iloc, какие данные по 15 строке у нас в Dataframe is_null:
is_null.iloc[15,]

Все верно, по всем столбцам, кроме Current Ver, у нас False, а по столбцу Current Ver у нас True, так как в нем нет какой-либо информации.
Далее нам надо сформировать Series, которая нам послужит в дальнейшем фильтром, в которой значение True будет в случае, если хотя бы в одном столбце в строке нет данных, а False, если информация есть во всех столбцах:
row_with_null = is_null.any(axis=1)
Используя эту Series как фильтр, мы создаем новый Dataframe, в который переносим только те строки, в которых хотя бы в одном из столбцов есть NaN:
rows_with_null = df[row_with_null]
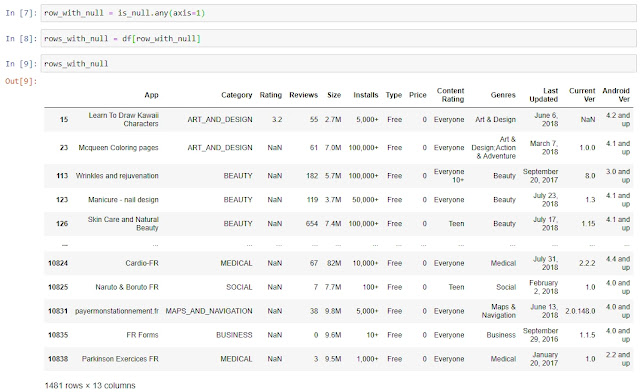
Готово, мы нашли все строки с отсутствующими данными в Dataframe. В качестве бонуса прикладываю
ноутбук
с текущего урока. Спасибо за внимание, комментарии приветствуются.
Your numpy.where construct is perfectly fine to use.
The issue you are facing is how to test a column versus an empty string. The answer is just check equality versus ''.
This is straightforward to implement:
df4['column3'] = np.where(df4['gender'] == '', df4['name'], df4['gender'])
pd.Series.empty tests if the series has no items, i.e. no rows, not whether its elements are empty strings.
Example
import pandas as pd, numpy as np
vals = {
'name' : ['n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7'],
'gender' : ['', '', '', 'f', 'f', 'c', 'c'],
'age' : [39, 12, 27, 13, 36, 29, 10]
}
df4 = pd.DataFrame(vals)
df4['column3'] = np.where(df4['gender'] == '', df4['name'], df4['gender'])
# age gender name column3
# 0 39 n1 n1
# 1 12 n2 n2
# 2 27 n3 n3
# 3 13 f n4 f
# 4 36 f n5 f
# 5 29 c n6 c
# 6 10 c n7 c

Рассмотрим задачу выявления и удаления незаполненных значений, которые в Pandas обозначаются служебным значением NaN. В демонстрационных целях будем использовать набор объявлений о продажах квартир в Республике Северная Осетия-Алания, имеющий следующий вид:
Для определения незаполненных значений используются методы isnull, notnull, возвращающие True/False для каждого объекта (обычно значение в столбце или элемент в строке) в зависимости от присутствия в нем пропущенных значений. Например, выведем строку нашей таблицы, в которой значение date_time не заполнено:
Для удаления незаполненных значений служит метод dropna, который позволяет задать ось удаления (строки, столбцы); порог минимального количества заполненных значений для принятия решения об удалении; подмножество полей, для которых удаляются незаполненные значения. Эти возможности реализуются посредством следующих параметров:
axis – определяет будут удаляться строки (значение 0) или столбцы (1) с недостающими значениями;
how – условие удаления при всех пустых значениях (значение all) или хотя бы одном (any);
thresh – пороговое количество непустых значений, меньше которого требуется удаление;
subset – задает группы имен столбцов или строк для удаления нулевых значений;
Например, так можно удалить строки, в которых столбец date_time содержит пустое значение (такая всего одна):
Другой пример – мы располагает таблицей со значениями нетипичного изменения стоимости недвижимости за неделю в различных категориях площадей (подробнее описывалось в статье), имеющей следующий вид:
Для того, чтобы оставить записи с количеством ненулевых значений не менее 3, потребуется вызвать метод dropna(thresh = 3). В результате получается таблица следующего вида:
Зачастую некоторые объекты с отсутствующими значениями следует сохранить и заполнить разумными значениями. Например, в таблице цен на недвижимость ячейки с отсутствующей «жилой площадью» («live_square») можно заполнить средним значением по жилым площадям в строках, «общая площадь» («total_square») в которых попадала в тот же диапазон что и в заданной. Это реализуется в следующем коде:
# очищаем столбцы и приводим их содержимое к типу с плавающей
# точкой
df.loc[df[‘total_square’].notnull(), ‘total_square’] = df.loc[df[‘total_square’].notnull(), ‘total_square’].map(
lambda x: x.replace(‘м²’, ”))
df.loc[df[‘live_square’].notnull(), ‘live_square’] = df.loc[df[‘live_square’].notnull(), ‘live_square’].map(
lambda x: x.replace(‘м²’, ”))
df[‘total_square’] = df[‘total_square’].astype(np.float32)
df[‘live_square’] = df[‘live_square’].astype(np.float32)
# ставим в соответствие каждому значению общей площади квартиры
# соответствующий ей диапазон
bins = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 1000]
cat = pd.cut(df[‘total_square’], bins)
# задаем столбец, содержащий среднее жилой площади для каждого
# диапазона
live_sq = df[‘live_square’].groupby(cat).transform(np.mean)
# для пустых ячеек с жил площадью вставляем значение, полученное на предыдущем шаге
df[‘live_square’] = np.where(df[‘live_square’].isnull(), live_sq, df[‘live_square’])
Отмечу, что способы разбивки по диапазонам значений (например, функция pandas.cut) описывались в статье, а обработка отдельных значений (метод map) в статье.
Напоследок продемонстрирую результаты преобразования нашей таблицы после выполнения указанного выше участка кода:
As part of our data wrangling process we might need to find, replace or even drop empty values in our data set so that these values don’t impact our analysis.
In this short tutorial, we’ll learn a few ways to use Python and the Pandas library to query our data and find data rows containing empty values.
Creating our example Data set
We’ll start by importing the Pandas library and creating a very simple dataset that you can use to follow along:
import pandas as pd
import numpy as np
city = ['DTW', 'NYC', 'SFO','ORD']
office = ['West', 'North', np.nan, 'East']
interviews = [10,104,210,np.nan]
#create the pandas dataframe
data_dict = dict(city=city, office=office, interviews=interviews)
hr = pd.DataFrame (data_dict)
print(hr.head())Here’s our DataFrame:
| city | office | interviews | |
|---|---|---|---|
| 0 | DTW | West | 10.0 |
| 1 | NYC | North | 104.0 |
| 2 | SFO | NaN | 210.0 |
| 3 | ORD | East | NaN |
Find rows with null values in Pandas Series (column)
To quickly find cells containing nan values in a specific Python DataFrame column, we will be using the isna() or isnull() Series methods.
Using isna()
nan_in_col = hr[hr['interviews'].isna()]Using isnull()
nan_in_col = hr[hr['interviews'].isnull()]Both methods will render the following result:
print(nan_in_col)| city | office | interviews | |
|---|---|---|---|
| 3 | ORD | East | NaN |
Select rows with missing values in a Pandas DataFrame
If we want to quickly find rows containing empty values in the entire DataFrame, we will use the DataFrame isna() and isnull() methods, chained with the any() method.
nan_rows = hr[hr.isna().any(axis=1)]or
nan_rows = hr[hr.isnull().any(axis=1)]Alternatively we can use the loc indexer to filter out the rows containing empty cells:
nan_rows = hr.loc[hr.isna().any(axis=1)]All the above will render the following results:
print(nan_rows)| city | office | interviews | |
|---|---|---|---|
| 2 | SFO | NaN | 210.0 |
| 3 | ORD | East | NaN |
Select DataFrame columns with NAN values
You can use the following snippet to find all columns containing empty values in your DataFrame.
nan_cols = hr.loc[:,hr.isna().any(axis=0)]
Find first row containing nan values
If we want to find the first row that contains missing value in our dataframe, we will use the following snippet:
hr.loc[hr.isna().any(axis=1)].head(1)Replace missing nan values with zero
Once found, we might decide to fill or replace the missing values according to specific login. We typically use the fillna() DataFrame or Series method for that. In this example we’ll going to replace the missing values in the interview column with 0.
hr.fillna({'interviews':0}, inplace=True)Additional learning
- How to replace values in Pandas DataFrame columns?
Example
Consider the following DataFrame:
df = pd.DataFrame({"A":[np.nan,3,np.nan],"B":[4,5,6],"C":[np.nan,7,8]}, index=["a","b","c"])
df
A B C
a NaN 4 NaN
b 3.0 5 7.0
c NaN 6 8.0
Rows with at least one missing value
Solution
To get rows with missing values in df:
df[df.isna().any(axis=1)]
A B C
a NaN 4 NaN
c NaN 6 8.0
Explanation
The isna() method returns a DataFrame of booleans where True indicates the presence of a missing value:
df.isna()
A B C
a True False True
b False False False
c True False False
We then use any(axis=1) to obtain a Series where True represents the presence of at least one True in each row:
df.isna().any(axis=1)
a True
b False
c True
dtype: bool
The parameter axis=1 is needed here since the default behaviour of any(~) is to scan through each column (as opposed to each row).
With this boolean mask, we can then extract rows that correspond to True using [] syntax:
df[df.isna().any(axis=1)]
A B C
a NaN 4 NaN
c NaN 6 8.0
Rows with missing value for a certain column
We show the same df here for your reference:
df = pd.DataFrame({"A":[np.nan,3,np.nan],"B":[4,5,6],"C":[np.nan,7,8]}, index=["a","b","c"])
df
A B C
a NaN 4 NaN
b 3.0 5 7.0
c NaN 6 8.0
Solution
To get rows with missing value in column C:
df[df["C"].isna()]
A B C
a NaN 4 NaN
Explanation
We first begin by extracting column C as a Series:
df["C"]
a NaN
b 7.0
c 8.0
Name: C, dtype: float64
Next, we use the Series’ isna() method to get a Series of booleans where True indicates the presence of NaN:
df["C"].isna()
a True
b False
c False
Name: C, dtype: bool
Finally, we pass in this boolean mask to extract the rows corresponding to True using [~] syntax:
df[df["C"].isna()]
A B C
a NaN 4 NaN
Rows with missing value for multiple columns
We show the same df here for your reference:
df = pd.DataFrame({"A":[np.nan,3,np.nan],"B":[4,5,6],"C":[np.nan,7,8]}, index=["a","b","c"])
df
A B C
a NaN 4 NaN
b 3.0 5 7.0
c NaN 6 8.0
Solution
To get rows with missing value in columns A and C:
df[df[["A","C"]].isna().all(axis=1)]
A B C
a NaN 4 NaN
Explanation
We first fetch columns A and C as a DataFrame using [~] syntax:
df[["A","C"]]
A C
a NaN NaN
b 3.0 7.0
c NaN 8.0
We then use the isna() method to get a DataFrame of booleans where True indicates the presence of NaN:
df[["A","C"]].isna()
A C
a True True
b False False
c True False
Next, we use all(axis=1) get a Series of booleans where True indicates a row with all Trues:
df[["A","C"]].isna().all(axis=1)
a True
b False
c False
dtype: bool
Finally, we use the [] syntax to extract the rows corresponding to True:
df[df[["A","C"]].isna().all(axis=1)]
A B C
a NaN 4 NaN
Rows with missing values for all columns
Consider the following DataFrame:
df = pd.DataFrame({"A":[np.nan,np.nan],"B":[np.nan,4]}, index=["a","b"])
df
A B
a NaN NaN
b NaN 4.0
Solution
To get rows with missing values for all columns:
df[df.isna().all(axis=1)]
A B
a NaN NaN
Explanation
The logic is exactly the same as the case for getting rows with at least one missing value, except that we use all(~) instead of any(~). The difference is as follows:
-
all(~)returns a Series of booleans whereTrueindicates a row with all missing column values(axis=1). -
any(~)returns a Series of booleans whereTrueindicates a row with at least one missing column value.
