Разброс (иногда
эту величину называют размахом)
выборки
обозначается буквой R.
Это самый
простой показатель, который можно
получить для выборки — разность между
максимальной и минимальной величинами
данного конкретного вариационного
ряда, т.е.
R
= X
– X
тaх
тiт
Понятно, что чем
сильнее варьирует измеряемый признак,
тем больше величина R,
и наоборот.
Однако может
случиться так, что у двух выборочных
рядов и средние, и размах совпадают,
однако характер варьирования этих рядов
будет различный. Например, даны две
выборки:
X
= 10 15 20 25
30 35 40 45 50
= 30 R
= 40
Y
= 10 28 28 30
30 30 32 32 50
![]()
= 30 R
= 40
При равенстве
средних и разбросов для этих двух
выборочных рядов характер их варьирования
различен. Для того чтобы более четко
представлять характер варьирования
выборок, следует обратиться к их
распределениям.
4.5. Дисперсия
Рассмотрим еще
одну очень важную числовую характеристику
выборки, называемую дисперсией.
Дисперсия
представляет собой наиболее часто
использующуюся меру рассеяния случайной
величины (переменной). Дисперсия
это среднее
арифметическое квадратов отклонений
значений переменной от её среднего
значения.
49
![]()
(4.4)
где
п — объем
выборки
i—
индекс суммирования
– среднее,
вычисляемое по формуле (4.1).
Вычислим дисперсию
следующего ряда
2 4 6 8 10
(4.5)
Прежде всего найдем
среднее ряда (4.5). Оно равно X
= 6.
Рассмотрим величины:
(Xj
— X)
для каждого
элемента ряда. Иными словами, из каждого
элемента ряда 4.5 вычтем величину среднего
этого ряда. Полученные величины
характеризуют то, насколько каждый
элемент отклоняется от средней величины
в данном ряду. Обозначим полученную
совокупность разностей как множество
Т. Тогда
Г есть:
T
= (2 – 6 = -4; 4 – 6 = -2; 6 – 6 = 0; 8 – 6 = 2; 10 – 6 = 4).
Так образуется
новый ряд чисел. Его особенность в том,
что при сложении этих чисел обязательно
получится ноль. Проверим: (-4) + (-2) + 0 +
2 + 4 = 0.
Отметим, что сумма
такого ряда ∑(Xi
—
)
всегда будет
равна нулю.
Для того чтобы
избавиться от нуля, каждое значение
разности (Xi
—
)
возводят в
квадрат, все их суммируют и затем делят
на число элементов, т.е. применяют формулу
4.4. В нашем примере получится следующее:
![]()
=
(-4)
(-4)+(-2)-(-2)+ = 16 + 4 + 0 + 4 + 16 = 40
![]()
Это и есть искомая
дисперсия.
Общий алгоритм
вычисления дисперсии для одной выборки
следующий:
50
1. Вычисляется
среднее по выборке.
2. Для каждого
элемента выборки вычисляется его
отклонение от
средней, т.е.
получается множество Т.
3. Каждый элемент
множества T
возводят в квадрат.
4. Находится сумма
этих квадратов.
5. Эта сумма, как
и в случае вычисления среднего, делится
на общее количество членов ряда — я. В
ряде случаев, особенно когда величина
выбоки мала, деление осуществляется не
на величину п,
а на величину
п — 1.
Величина, получающаяся
после пятого шага, и есть искомая
дисперсия.
Расчет дисперсии
для таблицы чисел осуществляется по
формуле 4.6:
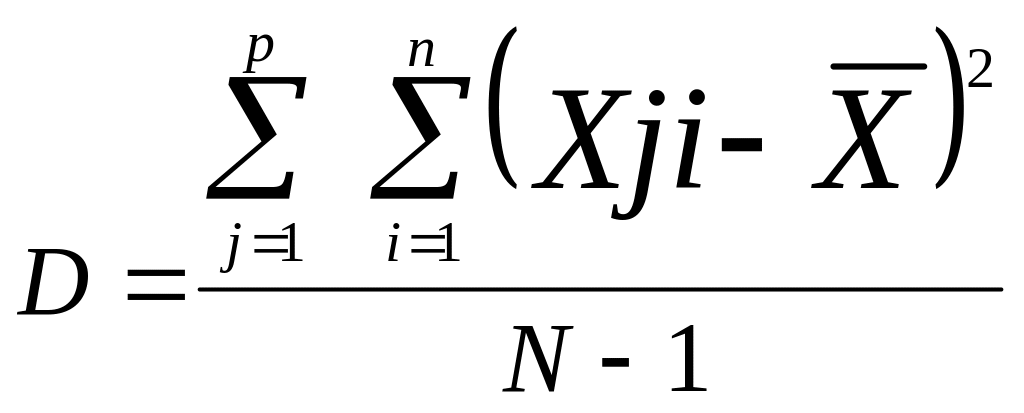
(4.6)
где ху
— значения
всех переменых, полученных в эксперименте,
или все элементы таблицы;
индексу меняется
от 1 до p,
где р число
столбцов в таблице, а индекс i
меняется
от 1 до п, где
п — число
испытуемых или число строк в таблице.
—общая средняя
всех элементов таблицы, вычисленная по
формуле 4.3;
N — общее
число всех элементов в таблице
(анализируемой совокупности
экспериментальных данных) и в общем
случае N = р
-п.
Дисперсию для
генеральной совокупности принято
обозначать как σ2,
а дисперсию выборки как
![]()
,
причем индекс
х обозначает,
что дисперсия характеризует варьирование
числовых значений признака вокруг их
средней арифметической.
Преимущество
дисперсии перед размахом в том, что
дисперсию можно представить как
сумму ряда чисел (согласно ее оп-
51
ределению), т.е.
разложить на составные компоненты,
позволяя тем самым более подробно
охарактеризовать исходную выборку.
Важная характеристика дисперсии
заключается также и в том, что с её
помощью можно сравнивать выборки,
различные по объему.
Однако сама
дисперсия, как характеристика отклонения
от среднего, часто неудобна для
интерпретации. Так, например, предположим,
что в эксперименте измерялся рост в
сантиметрах, тогда размерность
дисперсии будет являться характеристикой
площади, а не линейного размера (поскольку
при подсчете дисперсии сантиметр
возводится в квадрат).
Для того чтобы
приблизить размерность дисперсии к
размерности измеряемого признака
применяют операцию извлечения квадратного
корня из дисперсии. Полученную величину
называют стандартным
отклонением.
Из суммы квадратов,
деленных на число членов ряда извлекается
квадратный корень.

(4.7)
Другими словами,
стандартное отклонение выборки Sx
представляет
собой корень квадратный, извлеченный
из дисперсии
выборки
. Стандартное отклонение для генеральной
совокупности обозначают также
символом а. Подчеркнем еще раз, что
размерность стандартного отклонения
и размерность исходного ряда совпадают.
В нашем примере
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
![]()
Загрузить PDF
![]()
Загрузить PDF
Вычислив среднеквадратическое отклонение, вы найдете разброс значений в выборке данных.[1]
Но сначала вам придется вычислить некоторые величины: среднее значение и дисперсию выборки. Дисперсия – мера разброса данных вокруг среднего значения.[2]
Среднеквадратическое отклонение равно квадратному корню из дисперсии выборки. Эта статья расскажет вам, как найти среднее значение, дисперсию и среднеквадратическое отклонение.
-

1
Возьмите наборе данных. Среднее значение – это важная величина в статистических расчетах.[3]
- Определите количество чисел в наборе данных.
- Числа в наборе сильно отличаются друг от друга или они очень близки (отличаются на дробные доли)?
- Что представляют числа в наборе данных? Тестовые оценки, показания пульса, роста, веса и так далее.
- Например, набор тестовых оценок: 10, 8, 10, 8, 8, 4.
-

2
Для вычисления среднего значения понадобятся все числа данного набора данных.[4]
- Среднее значение – это усредненное значение всех чисел в наборе данных.
- Для вычисления среднего значения сложите все числа вашего набора данных и разделите полученное значение на общее количество чисел в наборе (n).
- В нашем примере (10, 8, 10, 8, 8, 4) n = 6.
-

3
Сложите все числа вашего набора данных.[5]
- В нашем примере даны числа: 10, 8, 10, 8, 8 и 4.
- 10 + 8 + 10 + 8 + 8 + 4 = 48. Это сумма всех чисел в наборе данных.
- Сложите числа еще раз, чтобы проверить ответ.
-

4
Разделите сумму чисел на количество чисел (n) в выборке. Вы найдете среднее значение.[6]
- В нашем примере (10, 8, 10, 8, 8 и 4) n = 6.
- В нашем примере сумма чисел равна 48. Таким образом, разделите 48 на n.
- 48/6 = 8
- Среднее значение данной выборки равно 8.
Реклама
-

1
Вычислите дисперсию. Это мера разброса данных вокруг среднего значения.[7]
- Эта величина даст вам представление о том, как разбросаны данные выборки.
- Выборка с малой дисперсией включает данные, которые ненамного отличаются от среднего значения.
- Выборка с высокой дисперсией включает данные, которые сильно отличаются от среднего значения.
- Дисперсию часто используют для того, чтобы сравнить распределение двух наборов данных.
-

2
Вычтите среднее значение из каждого числа в наборе данных. Вы узнаете, насколько каждая величина в наборе данных отличается от среднего значения.[8]
- В нашем примере (10, 8, 10, 8, 8, 4) среднее значение равно 8.
- 10 – 8 = 2; 8 – 8 = 0, 10 – 2 = 8, 8 – 8 = 0, 8 – 8 = 0, и 4 – 8 = -4.
- Проделайте вычитания еще раз, чтобы проверить каждый ответ. Это очень важно, так как полученные значения понадобятся при вычислениях других величин.
-

3
Возведите в квадрат каждое значение, полученное вами в предыдущем шаге.[9]
- При вычитании среднего значения (8) из каждого числа данной выборки (10, 8, 10, 8, 8 и 4) вы получили следующие значения: 2, 0, 2, 0, 0 и -4.
- Возведите эти значения в квадрат: 22, 02, 22, 02, 02, и (-4)2 = 4, 0, 4, 0, 0, и 16.
- Проверьте ответы, прежде чем приступить к следующему шагу.
-

4
Сложите квадраты значений, то есть найдите сумму квадратов.[10]
- В нашем примере квадраты значений: 4, 0, 4, 0, 0 и 16.
- Напомним, что значения получены путем вычитания среднего значения из каждого числа выборки: (10-8)^2 + (8-8)^2 + (10-2)^2 + (8-8)^2 + (8-8)^2 + (4-8)^2
- 4 + 0 + 4 + 0 + 0 + 16 = 24.
- Сумма квадратов равна 24.
-

5
Разделите сумму квадратов на (n-1). Помните, что n – это количество данных (чисел) в вашей выборке. Таким образом, вы получите дисперсию.[11]
- В нашем примере (10, 8, 10, 8, 8, 4) n = 6.
- n-1 = 5.
- В нашем примере сумма квадратов равна 24.
- 24/5 = 4,8
- Дисперсия данной выборки равна 4,8.
Реклама
-

1
Найдите дисперсию, чтобы вычислить среднеквадратическое отклонение.[12]
- Помните, что дисперсия – это мера разброса данных вокруг среднего значения.
- Среднеквадратическое отклонение – это аналогичная величина, описывающая характер распределения данных в выборке.
- В нашем примере дисперсия равна 4,8.
-

2
Извлеките квадратный корень из дисперсии, чтобы найти среднеквадратическое отклонение.[13]
- Как правило, 68% всех данных расположены в пределах одного среднеквадратического отклонения от среднего значения.
- В нашем примере дисперсия равна 4,8.
- √4,8 = 2,19. Среднеквадратическое отклонение данной выборки равно 2,19.
- 5 из 6 чисел (83%) данной выборки (10, 8, 10, 8, 8, 4) находится в пределах одного среднеквадратического отклонения (2,19) от среднего значения (8).
-

3
Проверьте правильность вычисления среднего значения, дисперсии и среднеквадратического отклонения. Это позволит вам проверить ваш ответ.[14]
- Обязательно записывайте вычисления.
- Если в процессе проверки вычислений вы получили другое значение, проверьте все вычисления с самого начала.
- Если вы не можете найти, где сделали ошибку, проделайте вычисления с самого начала.
Реклама
Об этой статье
Эту страницу просматривали 64 646 раз.
Была ли эта статья полезной?
Тема: Меры разброса
1. Отклонением от среднего называют разность между рассматриваемым значением
случайной величины и средним значением выборки.
Например: задана
выборка: 52, 54, 50, 48, 46.
Пусть значение
величины X1=52, а значение среднего![]() =(
=(![]() )=50, отклонение от
)=50, отклонение от
среднего X1−![]() =52−50=2.
=52−50=2.
2.
Для случайной величины Х,
принимающей N различных
значений и имеющей среднее значение ![]() , дисперсия
, дисперсия
находится по формуле
![]()
Например:
задана выборка: 6,8,10,12.
Найти дисперсию выборки.
Решение
Найдем среднее
значение: ![]() =(
=(![]() )=9
)=9
Найдем
дисперсию:
![]()
Повторение и обобщение пройденного:
Размах (R) – разница между
наибольшим и наименьшим значениями случайной величины.
Мода (обозначают Mo) — это
значение случайной величины, имеющее наибольшую частоту в рассматриваемой
выборке.
Пример: Mода выборки 7,6,2,5,6,1 равна 6; a выборка
2,3,8,2,8,5 имеет две моды: Mo=2, Mo=8.
Медиана (обозначают Me) — это
число (значение случайной величины), разделяющее упорядоченную выборку на две
равные по количеству данных части. Если в упорядоченной выборке нечётное
количество данных, то медиана равна серединному из них. Если в упорядоченной
выборке чётное количество данных, то медиана равна среднему арифметическому
двух серединных чисел.
Среднее (или среднее арифметическое) выборки
( обозначают ![]() ) — это число,
) — это число,
равное отношению суммы всех чисел выборки к их количеству.
![]() =(
=(![]() )
)
Среднее
квадратичное отклонение случайной величины определяется
по формуле: ![]()
Работа на уроке
1. (№1201) Найти размах выборки:
a)
15, -7,
13, -6, 8, 2, 1, -8, -2;
b)
21, 12, -1,
7, -3, 20, 14, 0, 1;
2.
(№1202) Найти дисперсию выборки:
a)
10, 12, 7,
11;
b)
16, 14, 13,
17;
c)
11, 14, 11,
12, 12;
d)
5, 13, 8,
12, 12;
3.
(№1203) Найти дисперсию совокупности
значений случайной величины X,
заданной частотным распределением:
|
a) |
X |
2 |
3 |
4 |
6 |
b) |
X |
-1 |
2 |
3 |
4 |
5 |
|
|
M |
3 |
2 |
2 |
3 |
M |
3 |
1 |
2 |
3 |
1 |
4. (№1204) Найти
среднее квадратичное отклонение от среднего значения элементов выборки:
a) 3, 5, 5, 8, 4;
b) 12, 10, 7, 12, 9;
5. (№1205) Сравнить
дисперсии двух выборок, имеющих одинаковые квадратичные отклонения:
a) 6, 10, 7, 8, 9 и 8, 9, 5, 10;
b) 5, 12, 7, 8, 18 и 17, 6, 3 11, 7, 9, 10;
Самостоятельная работа
1. (№1214-1217)Найти размах, моду, медиану и среднее
выборки:
1) 1, 5, 5, 8, 10;
2) 3, 10, 12, 12, 18;
3) -8, -8, -5, -5, 0, 2;
4) -4, -4, 0, 2, 9, 9;
5) -1, 12, -6, -7, 13, -2, 10, -2, -9;
6) 4, -10, 13, 8, -6, -3, -1, 13, -6;
7) -5, -15, 12, -7, 8, 13, -1, -7;
8) 16, -2, -8, 10, 14, -6, -2, 11.
2. (№1218)Найти дисперсию и среднее квадратичное
отклонение выборки:
1) 3, 8, 5,6;
2) 4, 7, 3, 9;
3) 4, 1, 3, 2, 2;
4) 3, 2, 1, 1, 5;
5) -2, 4, -3, -1, 6.
Онлайн калькулятор для расчета выборочной дисперсии (дисперсия выборки). Выборочная дисперсия - это показатель разброса, наблюдаемого в определенной выборке данных. С вычислительной точки зрения ее можно объяснить как – среднее арифметическое квадратов отклонения наблюдаемых значений признака от их среднего значения.
Для того, чтобы оценить дисперсию по выборке необходимо:
– Вычислить математические ожидания данных (выборочное среднее – среднее арифметическое значений вариант в выборке).
– Вычитаем математическое ожидание из исходного значения для всех данных из выборки и возводим результат в квадрат.
– Складываем все полученные в предыдущем шаге значения и делим сумму на N-1.
×
Пожалуйста напишите с чем связна такая низкая оценка:
×
Для установки калькулятора на iPhone – просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android – просто добавьте страницу
«На главный экран»

Смотрите также
Уровень сложности
Простой
Время на прочтение
10 мин
Количество просмотров 2K

Автор статьи: Артем Михайлов
Дисперсионный анализ (ANOVA) — это статистический метод, который используется для сравнения средних значений двух или более выборок. Он позволяет определить, различаются ли средние значения между группами, или же различия случайны. ANOVA используется в различных областях, включая науку, инженерию, медицину, социологию и многие другие, где необходимо доказать связь между переменными.
ANOVA является мощным инструментом, который может использоваться в статистическом анализе для оценки влияния исследуемого фактора на зависимую переменную. Это помогает установить, является ли фактор значимым, и позволяет идентифицировать взаимодействие между переменными. ANOVA также позволяет определить, насколько сильно различия между группами, что может быть полезно при выборе стратегий манипулирования факторами.
Правильное применение ANOVA может доставить большую пользу и сделать исследование намного более информативным.
Теория дисперсионного анализа
ANOVA может быть использован для различных целей, например, для сравнения средних значений для разных групп или для проверки влияния факторов на исходы. Для проведения ANOVA необходимо определить несколько гипотез:
Нулевая гипотеза – это гипотеза, согласно которой никаких статистически значимых различий между группами не существует. В контексте дисперсионного анализа (ANOVA) она утверждает, что средние значения всех групп равны между собой.
Например, при проведении исследования по сравнению среднего уровня дохода людей в разных группах (например, по возрасту или образованию) нулевая гипотеза будет звучать так: “Средний уровень дохода во всех группах одинаков”.
Установление нулевой гипотезы является важным шагом в проведении статистического тестирования, поскольку это позволяет определить статистическую значимость различий между группами. Если результаты тестирования указывают на то, что нулевую гипотезу можно отвергнуть, то это говорит о том, что существует статистически значимое различие между группами.
Нулевая гипотеза может быть отвергнута при помощи статистических инструментов, таких как p-значение, которое оценивает вероятность того, что различия между группами являются случайными. Чем меньше p-значение, тем больше вероятность того, что нулевая гипотеза является ложной и существуют статистически значимые различия между группами. Обычно, если p-значение меньше 0,05, то нулевая гипотеза считается отвергнутой.
Альтернативная гипотеза – это гипотеза, которая предполагает, что статистически значимые различия между группами существуют. В контексте дисперсионного анализа (ANOVA), альтернативная гипотеза утверждает, что хотя бы одно из средних значений групп отличается от среднего значения других групп.
Важно отметить, что нулевая гипотеза всегда предполагается исходной (default hypothesis), и ее опровержение ставит вопрос об альтернативной гипотезе. Поэтому при проведении дисперсионного анализа, рассматриваемые гипотезы обычно выглядят так: “Нулевая гипотеза: средние значения всех групп равны между собой.” и “Альтернативная гипотеза: хотя бы одно из средних значений групп отличается от среднего значения других групп.”
Нулевая и альтернативная гипотезы в ANOVA используются для оценки различий между группами и определения статистической значимости этих различий. Результаты теста ANOVA могут помочь исследователям выявить факторы, влияющие на исходы исследования. Если нулевая гипотеза была отвергнута, то это означает, что между группами есть статистически значимые различия, и изучение этих различий может помочь исследователям понять, какой фактор оказывает наибольшее влияние на исходы.
ANOVA использует три типа дисперсии: межгрупповая дисперсия, внутригрупповая дисперсия и общая дисперсия. Межгрупповая дисперсия представляет различия между средними значениями групп, внутригрупповая дисперсия представляет изменчивость внутри каждой группы, а общая дисперсия – это сумма межгрупповой и внутригрупповой дисперсий.
Для проведения ANOVA существует несколько типов тестов, каждый из которых может быть использован в зависимости от типа данных и количества групп. Например, однофакторный дисперсионный анализ используется для сравнения средних значений при одном факторе, а двухфакторный дисперсионный анализ используется для сравнения средних значений при двух или более факторах.
Типы ANOVA
-
Однофакторный ANOVA (однофакторный дисперсионный анализ) – это метод статистического анализа данных, который используется для определения наличия статистически значимых различий между двумя или более группами по одной независимой переменной.
Данный метод широко используется в научных исследованиях, маркетинговых исследованиях и других областях, где необходимо определить различия между двумя или более группами объектов или явлений.

Входными данными для однофакторного ANOVA являются значения зависимой переменной и групповой фактор, на основе которых проводится анализ. Фактор может быть любой номинальной или порядковой переменной, которая разделяет выборку на группы (в простом случае, это может быть пол, возраст, уровень образования и т.д.). Зависимая переменная – это та переменная, которую мы хотим сравнить в различных группах.
Однофакторный ANOVA проверяет нулевую гипотезу о том, что среднее значение зависимой переменной одинаково во всех группах. Если p-значение меньше заданного уровня значимости (обычно 0.05), тогда мы можем сделать вывод о том, что средние значения по группам различаются статистически значимо друг от друга. Кроме того, однофакторный ANOVA дает множество других статистических показателей, включая среднее значение, стандартное отклонение, диапазон, размах, медиану, аномальные значения и т.д.
В качестве дополнительного анализа для определения различий между группами могут быть использованы такие методы, как Т-тест, АНКОВА и другие.
Однофакторный ANOVA является базовым методом анализа для исследования факторов, которые влияют на зависимые переменные в различных группах. Использование этого метода помогает объективно оценивать результаты и достоверно определять, какие факторы играют ключевую роль в исследуемом явлении или процессе.
-
Двухфакторный ANOVA (двухфакторный дисперсионный анализ) – это метод статистического анализа данных, который позволяет определить наличие статистически значимых различий между группами по двум независимым переменным (факторам). Такой подход позволяет оценить влияние каждой независимой переменной на зависимую переменную, а также выявить возможное взаимодействие между факторами. В случае значимых различий, производится дополнительный анализ, чтобы установить, между какими группами существуют различия.
-
Многовариантный ANOVA (analysis of variance) — это статистический метод, который используется для анализа различий между группами (факторами) и влияния различных переменных (факторов) на исследуемую зависимую переменную. Он позволяет выявить, есть ли статистически значимое влияние одного или нескольких факторов на зависимую переменную, и определить, какие из факторов оказывают наибольшее влияние.
Многовариантный ANOVA может использоваться для анализа различных типов данных, включая непрерывные, дискретные и категориальные переменные. Он также может рассчитываться для различных уровней взаимодействия между факторами, что позволяет учитывать сложные взаимодействия между переменными.
Основная идея многовариантного ANOVA заключается в том, что общее количество изменений в зависимой переменной разделяется на две части: изменения, связанные с факторами, и изменения, которые не могут быть объяснены факторами (остаток). Факторы могут быть любого типа, но обычно они бывают двух типов: факторы, которые могут быть контролируемыми или экспериментальными (например, воздействие на здоровье человека разных типов диет), и факторы, которые являются неконтролируемыми или наблюдаемыми (например, пол, возраст, образование).
Метод многовариантного ANOVA может быть выполнен в несколько шагов. Сначала нужно провести анализ на уровне каждого фактора (унимодальный анализ — one-way ANOVA). Затем производится многовариантный анализ, который позволяет оценить влияние всех факторов на зависимую переменную одновременно. Для этого используется многовариантный тестовый показатель F-статистики.
Многовариантный ANOVA также может использоваться для оценки взаимодействия между факторами, например, могут ли переменные влиять друг на друга или быть нелинейными. Для этого используется двуфакторный или трехфакторный ANOVA, в котором изучается влияние нескольких факторов на зависимую переменную.
Многовариантный ANOVA является полезным инструментом для исследования дисперсии и определения значимости факторов в зависимой переменной. Он также может использоваться в более сложных исследованиях, таких как оценка взаимодействия между группами и изучения различных факторов, влияющих на зависимую переменную.
Шаги проведения ANOVA
-
Определение гипотезы – это основной шаг, который необходимо проделать перед проведением ANOVA. Гипотеза должна содержать утверждение о том, что средние значения переменной одинаковы в нескольких группах.
Например, предположим, что мы хотим узнать, есть ли статистически значимые различия в среднем росте людей в трех группах: мужчинах, женщинах и детях. Тогда нулевая гипотеза будет состоять в том, что средний рост одинаков во всех трех группах. Альтернативная гипотеза будет заключаться в том, что средний рост отличается в двух или более группах.
Нулевая гипотеза всегда формулируется таким образом, что она может быть отвергнута на основе статистических данных. Например, если p-value меньше выбранного уровня значимости, то можно отбросить нулевую гипотезу и предположить, что существуют различия между группами.
Важно, чтобы гипотеза была четкой и такой, которую можно проверить с помощью статистических данных. В противном случае, проведение ANOVA становится бессмысленным.
-
Сбор данных – это следующий шаг после определения гипотезы, который необходимо выполнить перед проведением ANOVA. Для сбора данных нужно определить, какие переменные изучаются, какие группы данных будут сравниваться и какой размер выборки необходим.
Выбор уровня значимости – это важный шаг ANOVA, который определяет вероятность того, что различия между группами являются случайными. Обычно уровень значимости принимается равным 0,05 (5%), что означает, что различия между группами, имеющие вероятность меньше 5%, считаются статистически значимыми.
Выбор правильного уровня значимости очень важен, так как неправильно выбранный уровень значимости может привести к неверным выводам. Если уровень значимости выбран слишком высоким, то могут быть найдены статистически значимые различия, которых на самом деле нет. Если уровень значимости слишком низкий, то могут быть пропущены настоящие статистически значимые различия.
Правильный выбор уровня значимости зависит от цели исследования, характеристик групп и размеров выборки. Этот выбор должен быть продуманным и основываться на знаниях и опыте в данной области.
-
Определение степеней свободы и критических значений: степени свободы – это количество наблюдений, которые могут быть свободно изменены в каждой группе данных. Критическое значение – это значение, при котором различия между группами становятся статистически значимыми.
-
После сбора данных и выбора уровня значимости необходимо рассчитать статистические показатели для проведения ANOVA. Статистические показатели, которые используются в ANOVA – это F-статистика и p-value.
F-статистика (F-значение) измеряет различия между группами, то есть отношение между средними значениями в группах и дисперсией внутри групп. Если F-значение большое, то это указывает на статистически значимые различия между группами.
p-value (вероятность) – это вероятность того, что различия между группами были случайными и не связаны с фактором, который изучается. Если p-value меньше выбранного уровня значимости, то можно отбросить нулевую гипотезу и утверждать, что между группами есть статистически значимые различия.
Важно знать, что F-статистика и p-value не являются самостоятельными критериями для определения статистической значимости. Они должны использоваться вместе с другими статистическими методами для получения более точных результатов.
-
Оценка результатов и интерпретация полученных данных: после проведения ANOVA необходимо проанализировать полученные результаты. Если значение p-value меньше уровня значимости, то можно отбросить нулевую гипотезу и утверждать, что между группами есть статистически значимые различия. Интерпретируя эти различия, можно выйти на конкретный вывод, касающийся фактора, который изучается.
Пример применения ANOVA
Представим, что у нашего интернет-магазина есть три различных дизайна для главной страницы сайта, и мы хотим определить, какой из них наиболее эффективен в увеличении количества продаж. В этом случае мы можем провести эксперимент, в котором будут участвовать три группы покупателей, каждой группе будет показан только один из дизайнов главной страницы.
Для начала, мы должны определить, сколько покупателей нужно включить в каждую группу. Чтобы определить размер каждой группы, мы можем использовать статистические методы для расчета минимального размера выборки. Допустим, мы решили, что каждая группа должна состоять из 1000 покупателей.
Для этого эксперимента мы должны также определить, какие метрики будут измеряться. Для нашего примера мы будем измерять среднее количество продаж на каждого покупателя в каждой группе.
Когда эксперимент будет завершен, мы будем иметь данные о количестве продаж для каждой группы. Мы можем использовать ANOVA для анализа данных и определения, есть ли значимые различия между группами.
Перед проведением анализа необходимо проверить данные на нормальность распределения и выполнить другие необходимые условия для проведения анализа.
После проведения ANOVA мы получаем статистические показатели, такие как F-значение и p-значение. F-значение показывает различия между средними значениями групп, а p-значение показывает статистическую значимость различий между группами. Если p-значение меньше заданного уровня значимости (обычно 0,05), то мы можем сделать вывод о наличии значимых различий между группами.
Например, если мы получили F-значение 3,5 и p-значение 0,02, то мы можем сделать вывод о наличии статистически значимых различий между группами. Это означает, что один дизайн главной страницы сильнее влияет на увеличение продаж, чем другие.
Дополнительно, если у нас есть статистически значимые различия между группами, мы можем провести дополнительный анализ, например, сравнение каждой группы с другой с помощью теста Тюрки или Холма, чтобы определить, где именно находятся различия. Также мы можем рассмотреть другие важные метрики, такие как время проведения эксперимента и влияние внешних факторов на продажи. Важно понимать, что ANOVA – это только инструмент, который помогает нам делать выводы на основе данных. Поэтому проведение эксперимента должно быть тщательно спланировано и осуществлено в соответствии с научными методами для того, чтобы результаты были надежными и полезными для бизнеса.
Заключение
ANOVA очень важен для статистического анализа данных и исследований. Этот метод позволяет определить, какие факторы влияют на изменения в группах и имеет множество применений.
Рекомендации по применению ANOVA:
-
Необходимо тщательно выбирать данные для анализа и проверять их на соответствие критериям ANOVA.
-
Всегда проводите тесты на нормальность, чтобы проверить, являются ли данные нормально распределенными.
-
При использовании ANOVA следует учитывать влияние других факторов, которые не связаны с переменной, которую вы исследуете.
-
Помните, что ANOVA рассчитывает только показатели среднего значения, поэтому может не учитывать взаимодействие между переменными.
-
Всегда проверяйте статистическую значимость результата ANOVA и учитывайте размер выборки и разброс данных.
-
Используйте ANOVA для сравнения трех или более групп, но не забывайте о других методах анализа, таких как t-тест, если вы хотите сравнить всего две группы.
-
Наконец, не забывайте, что результаты ANOVA могут быть интерпретированы по-разному и, если это возможно, используйте другие методы анализа для проверки ваших выводов.
В целом, ANOVA является мощным методом статистического анализа, который можно использовать для исследования различий между группами. Он помогает находить значимые различия и определить факторы, влияющие на результаты исследования. Однако, для более точных результатов, необходимо учитывать все факторы влияния и применять другие методы анализа, если это необходимо.
В завершение хочу порекомендовать бесплатный вебинар от OTUS, где преподаватели покажут как настроить мониторинг PostgreSQL с помощью grafana и Prometheus.
-
Подробнее о вебинаре
