
Одним из основных статистических показателей последовательности чисел является коэффициент вариации. Для его нахождения производятся довольно сложные расчеты. Инструменты Microsoft Excel позволяют значительно облегчить их для пользователя.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.
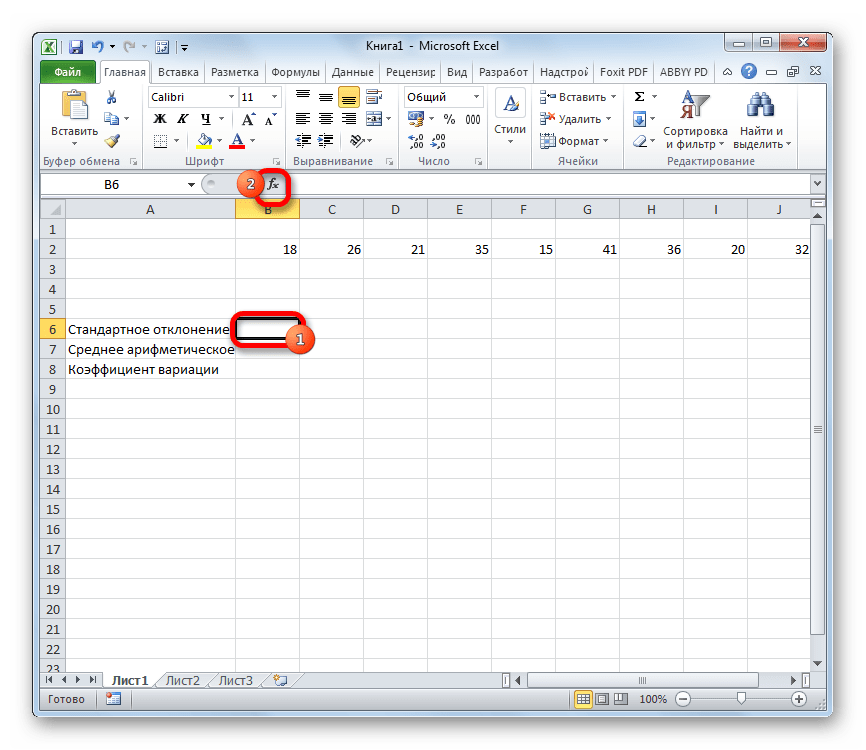
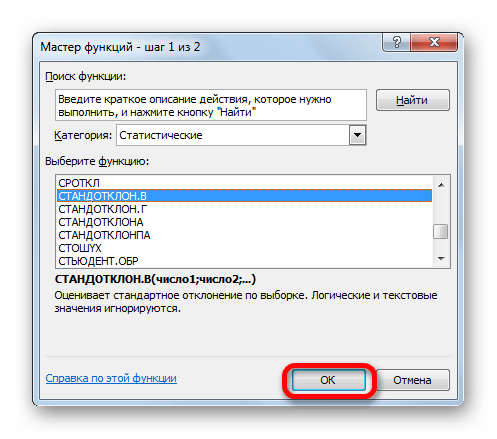
Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».
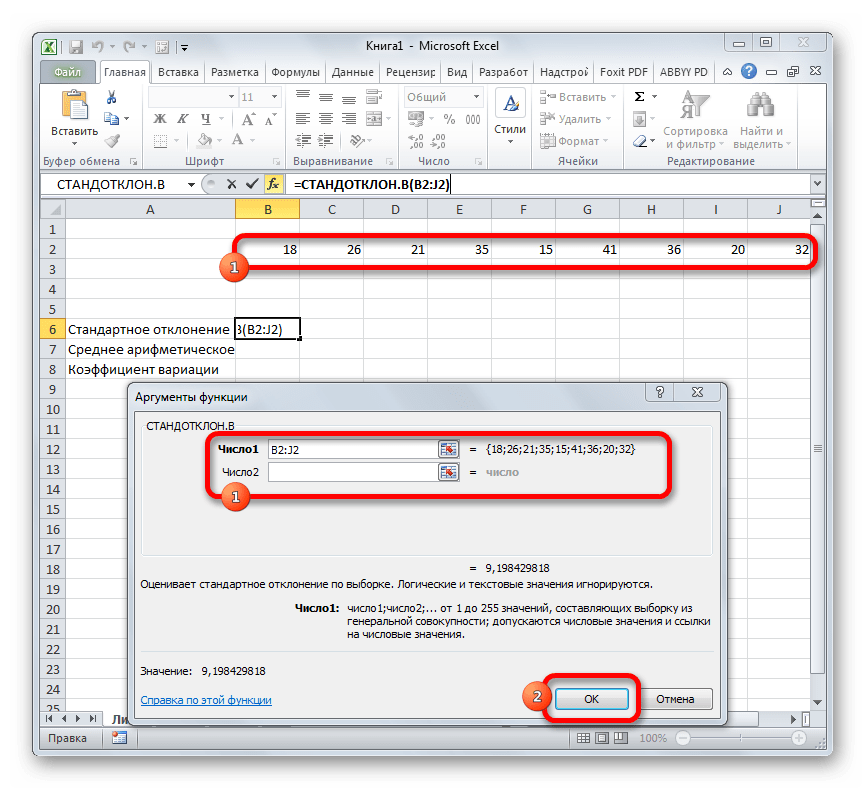
Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»
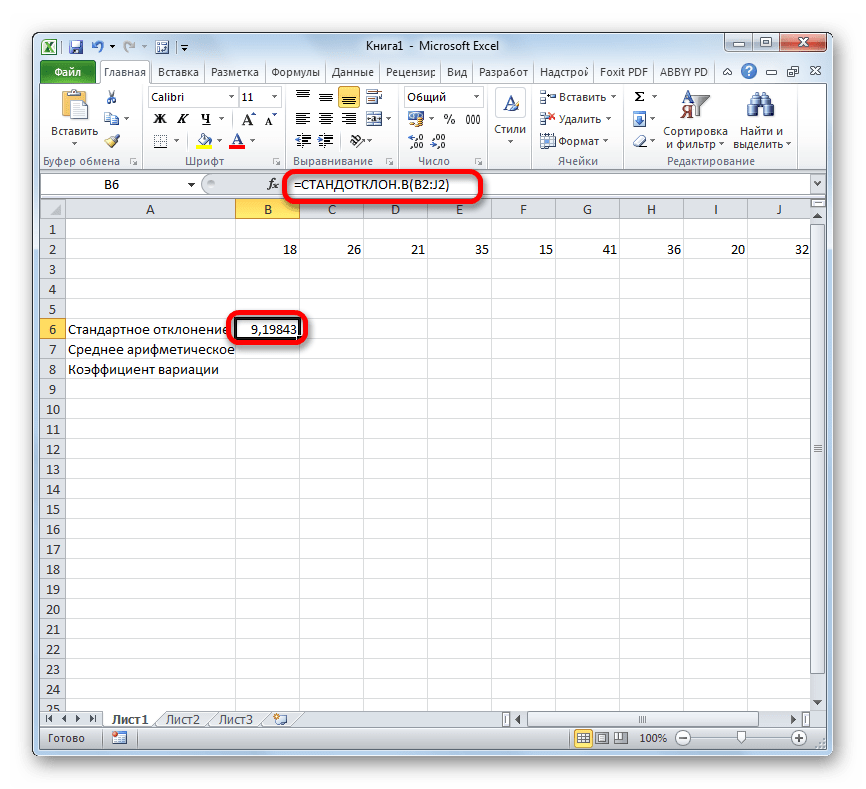
Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».
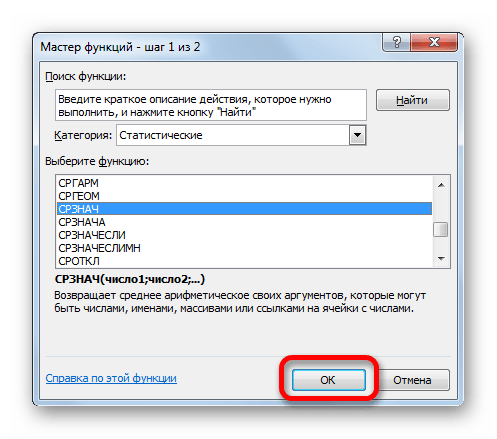
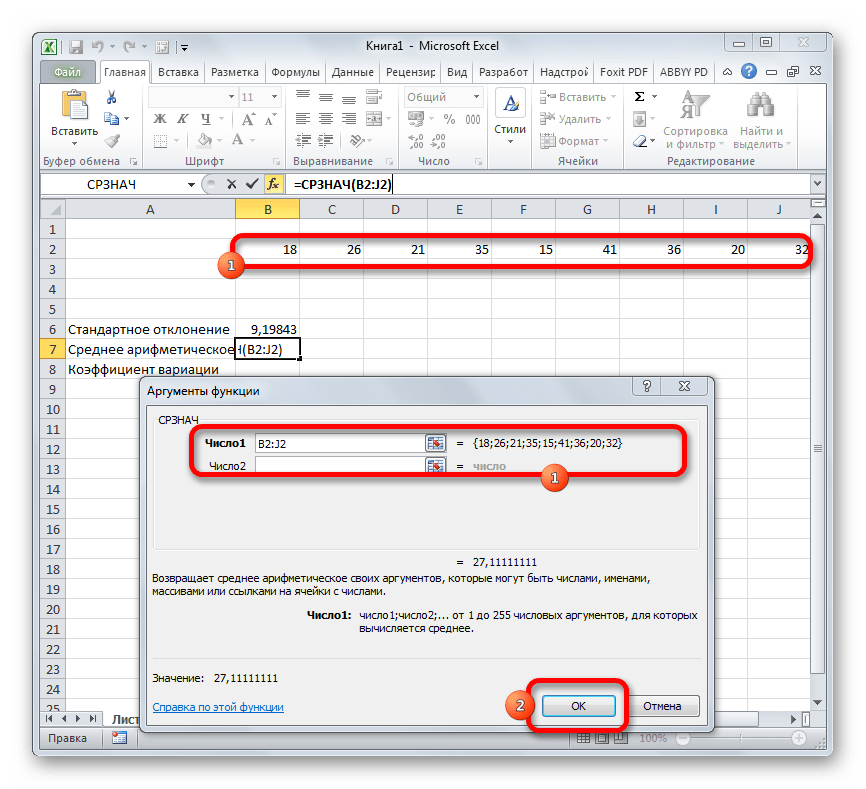
Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».
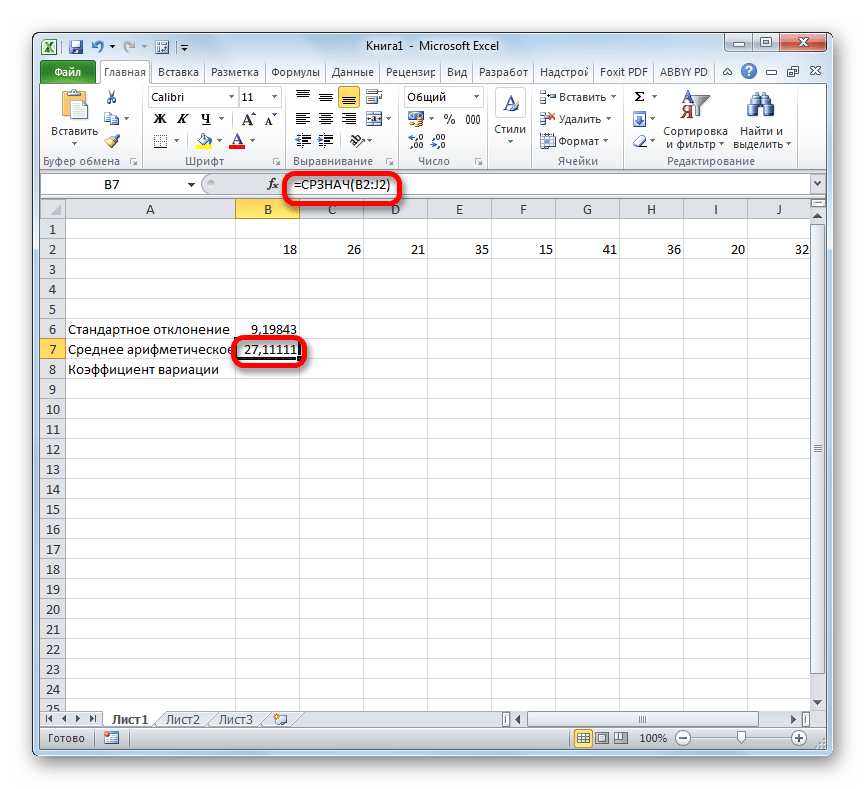
Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.
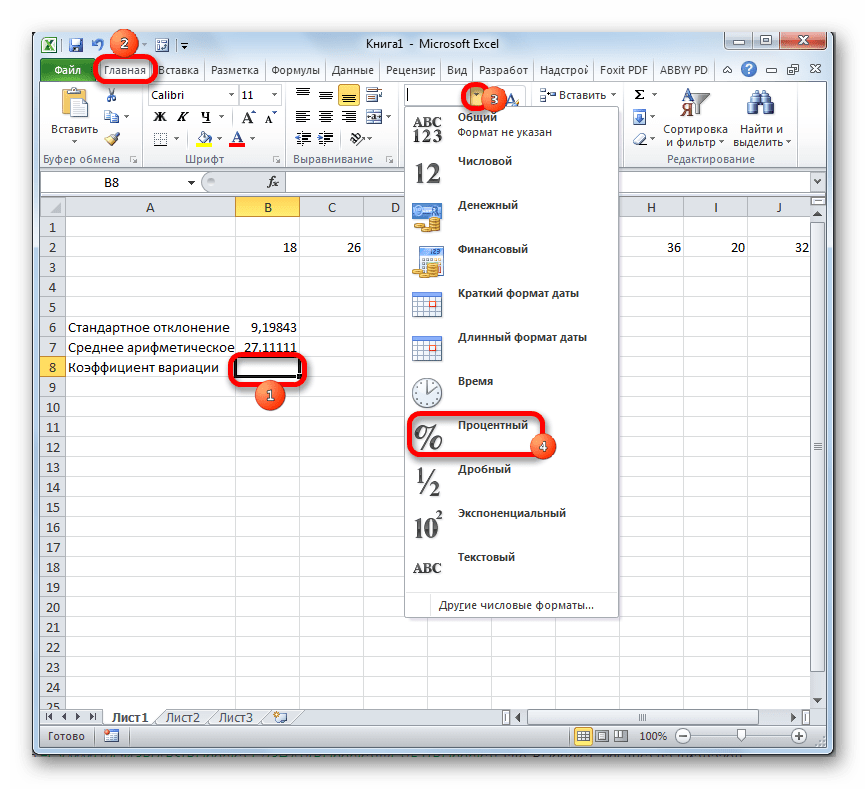
Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.
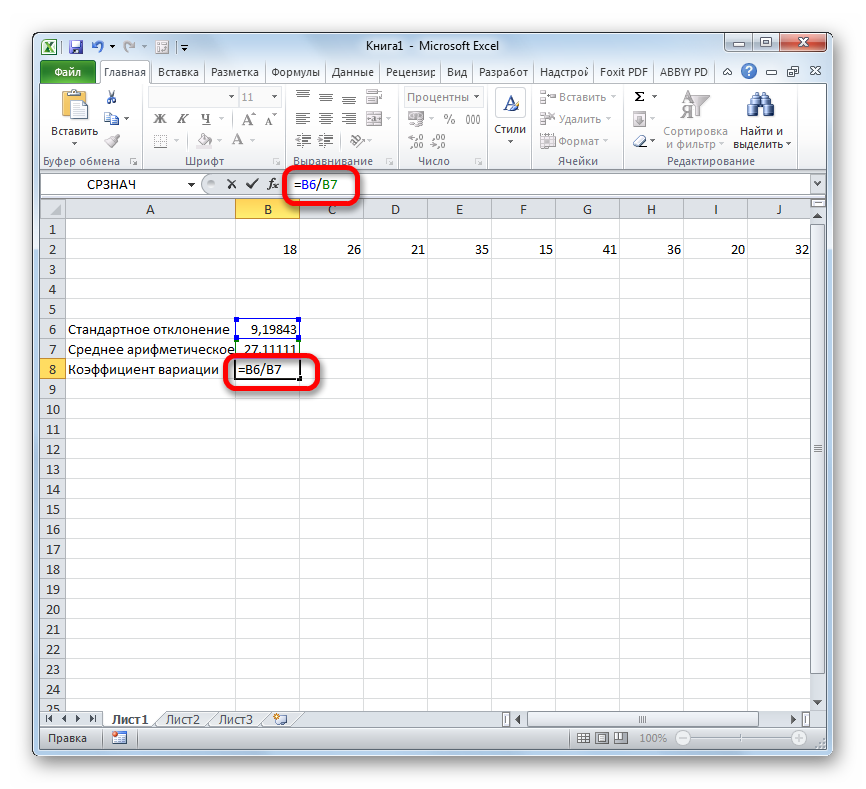
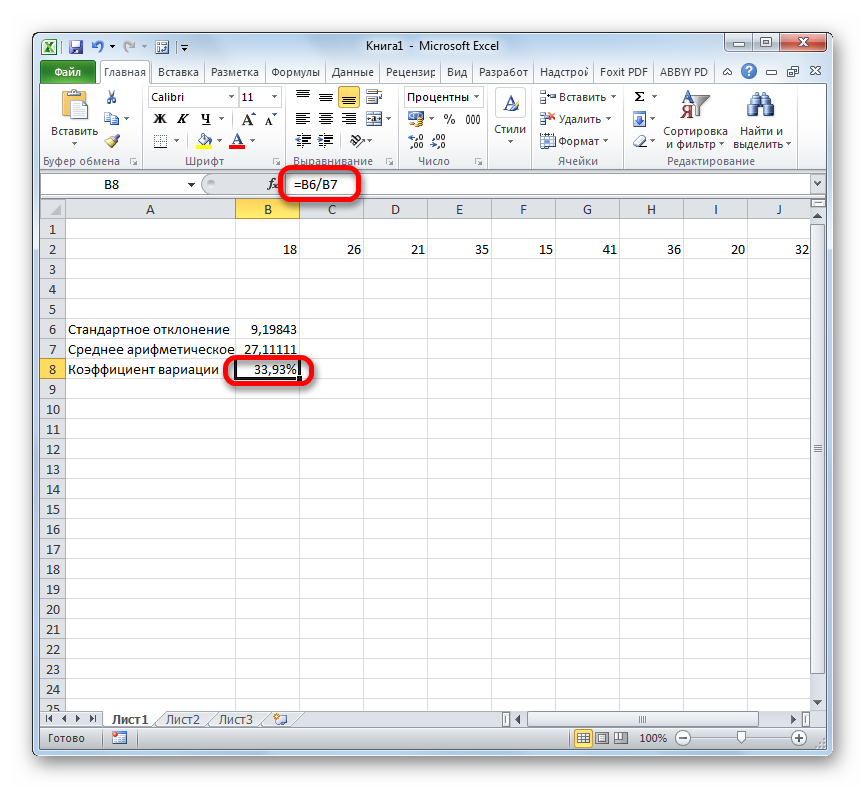
Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.
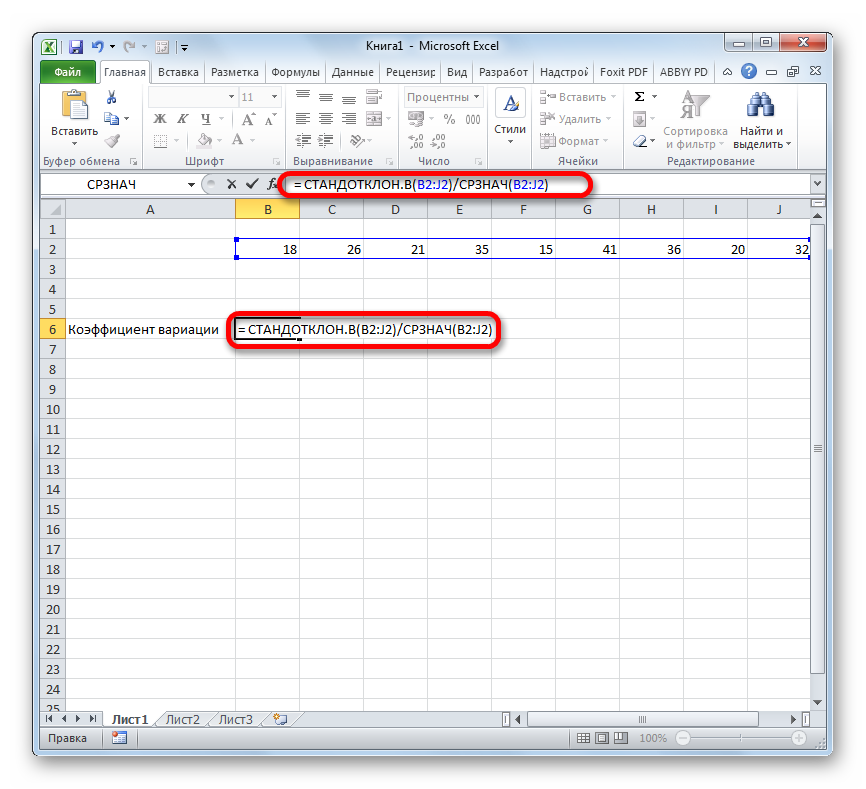
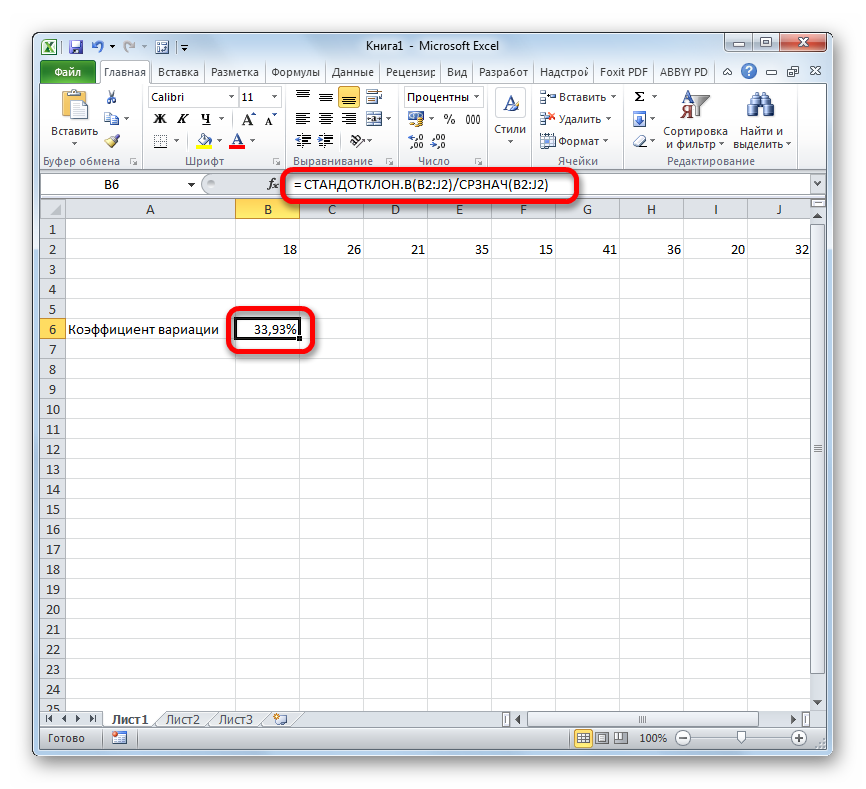
Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем — статистические, в списке: МОДА
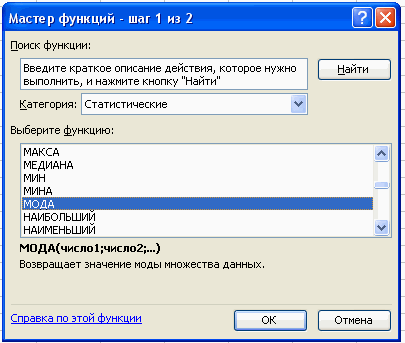
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
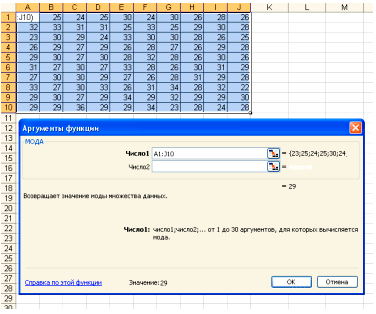
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
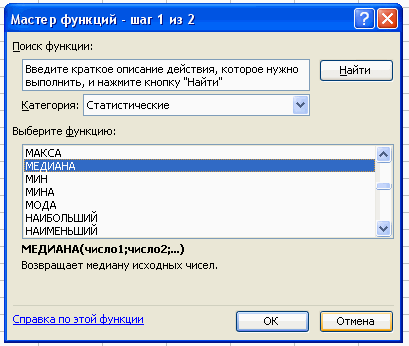
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
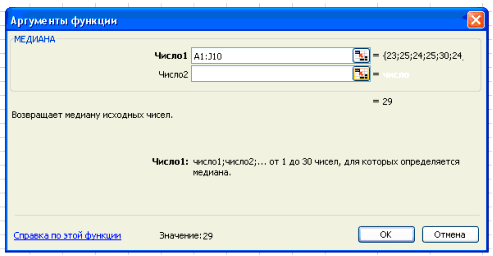
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
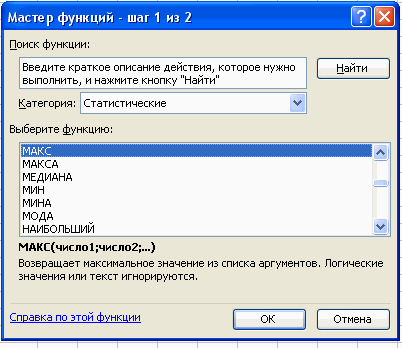
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
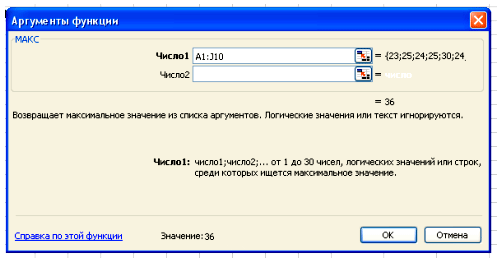
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.
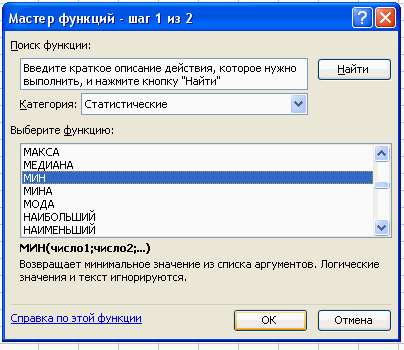
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
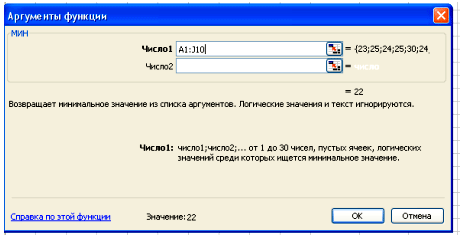
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22
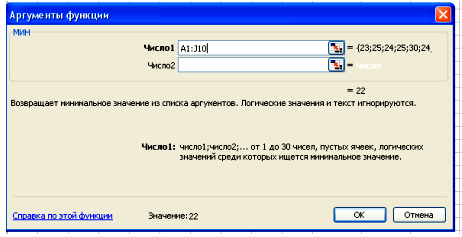
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
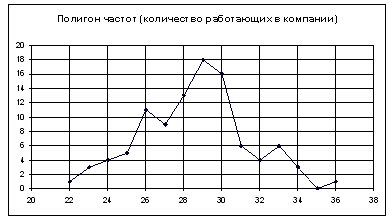
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические — СУММА). Должно получиться 100 (количество всех фирм).
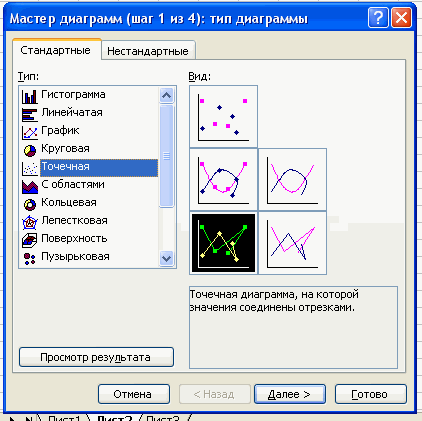
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)
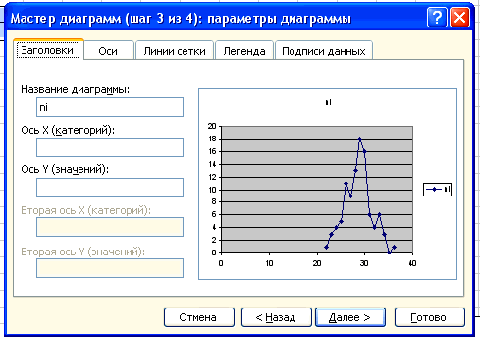
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
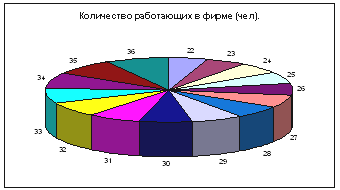
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Основная идея
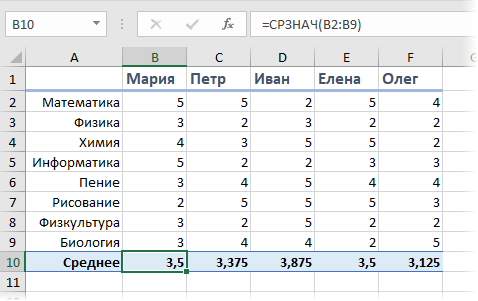
Предположим, что мы с вами сидим в приемно-экзаменационной комиссии и оцениваем абитуриентов, которые хотят поступить в наш ВУЗ. Оценки по различным предметам у наших кандидатов следующие:
Свободное место, допустим, только одно, и наша задача — выбрать достойного.
Первое, что обычно приходит в голову — это рассчитать классический средний балл с помощью стандартной функции Excel СРЗНАЧ (AVERAGE).
На первый взгляд кажется, что лучше всех подходит Иван, т.к. у него средний бал максимальный. Но тут мы вовремя вспоминаем, что факультет-то наш называется “Программирование”, а у Ивана хорошие оценки только по рисованию, пению и прочей физкультуре, а по математике и информатике как раз не очень. Возникает вопрос: а как присвоить нашим предметам различную важность (ценность), чтобы учитывать ее при расчете среднего? И вот тут на помощь приходит средневзвешенное значение.
Средневзвешенное — это среднее с учетом различной ценности (веса, важности) каждого из элементов.
В бизнесе средневзвешенное часто используется в таких задачах, как:
- оценка портфеля акций, когда у каждой из них своя ценность/рисковость
- оценка прогресса по проекту, когда у задач не равный вес и важность
- оценка персонала по набору навыков (компетенций) с разной значимостью для требуемой должности
- и т.д.
Расчет средневзвешенного формулами
Добавим к нашей таблице еще один столбец, где укажем некие безразмерные баллы важности каждого предмета по шкале, например, от 0 до 9 при поступлении на наш факультет программирования. Затем расчитаем средневзвешенный бал для каждого абитурента, т.е. среднее с учетом веса каждого предмета. Нужная нам формула будет выглядеть так:
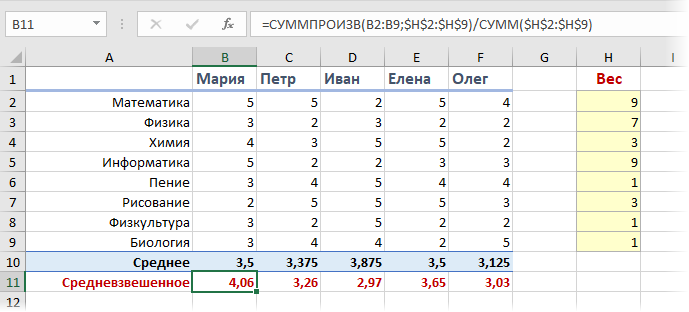
Функция СУММПРОИЗВ (SUMPRODUCT) попарно перемножает друг на друга ячейки в двух указанных диапазонах — оценки абитурента и вес каждого предмета — а затем суммирует все полученные произведения. Потом полученная сумма делится на сумму всех баллов важности, чтобы усреднить результат. Вот и вся премудрость.
Так что берем Машу, а Иван пусть поступает в институт физкультуры 😉
Расчет средневзвешенного в сводной таблице
Поднимем ставки и усложним задачу. Допустим, что теперь нам нужно подсчитать средневзвешенное, но не в обычной, а в сводной таблице. Предположим, что у нас есть вот такая таблица с данными по продажам:
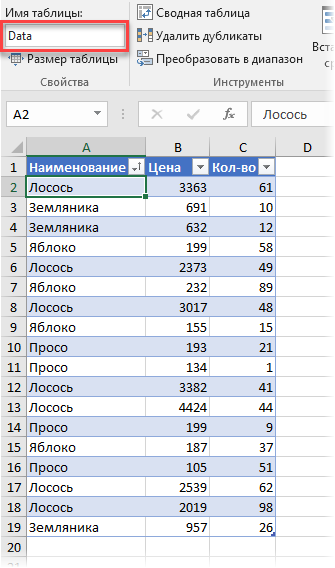
Обратите внимание, что я преобразовал ее в “умную” таблицу с помощью команды Главная — Форматировать как таблицу (Home — Format as Table) и дал ей на вкладке Конструктор (Design) имя Data.
Заметьте, что цена на один и тот же товар может различаться. Наша задача: рассчитать средневзвешенные цены для каждого товара. Следуя той же логике, что и в предыдущем пункте, например, для земляники, которая продавалась 3 раза, это должно быть:
=(691*10 + 632*12 + 957*26)/(10+12+26) = 820,33
То есть мы суммируем стоимости всех сделок (цена каждой сделки умножается на количество по сделке) и потом делим получившееся число на общее количество этого товара.
Правда, с реализацией этой нехитрой логики именно в сводной таблице нас ждет небольшой облом. Если вы работали со сводными раньше, то, наверное, помните, что можно легко переключить поле значений сводной в нужную нам функцию, щелкнув по нему правой кнопкой мыши и выбрав команду Итоги по (Summarize Values By) :
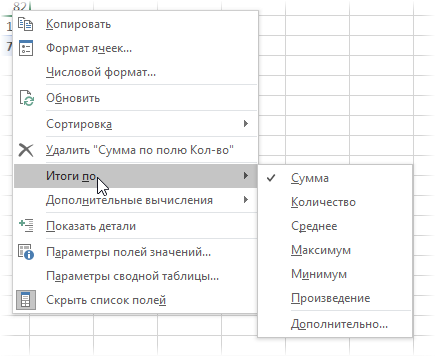
В этом списке есть среднее, но нет средневзвешенного 🙁
Можно частично решить проблему, если добавить в исходную таблицу вспомогательный столбец, где будет считаться стоимость каждой сделки:
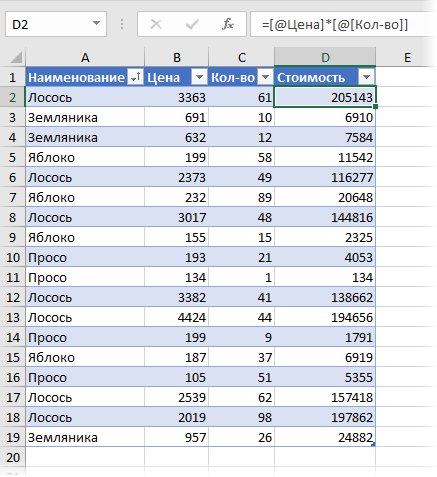
Теперь можно рядом закинуть в область значений стоимость и количество — и мы получим почти то, что требуется:
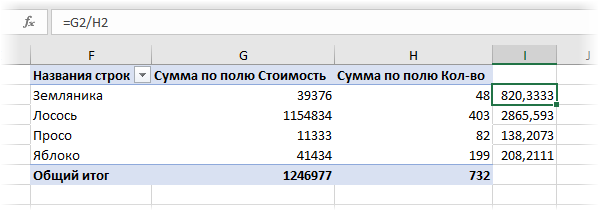
Останется поделить одно на другое, но сделать это, вроде бы, простое математическое действие внутри сводной не так просто. Придется либо добавлять в сводную вычисляемое поле (вкладка Анализ — Поля, элементы, наборы — Вычисляемое поле), либо считать обычной формулой в соседних ячейках или привлекать функцию ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ (GET.PIVOT.DATA) , о которой я уже писал. А если завтра изменятся размеры сводной (ассортимент товаров), то все эти формулы придется вручную корректировать.
В общем, как-то все неудобно, трудоемко и нагоняет тоску. Да еще и дополнительный столбец в исходных данных нужно руками делать. Но красивое решение есть.
Расчет средневзвешенного в сводной таблице с помощью Power Pivot и языка DAX
Если у вас Excel 2013-2016, то в него встроен супермощный инструмент для анализа данных — надстройка Power Pivot, по сравнению с которой сводные таблицы с их возможностями — как счеты против калькулятора. Если у вас Excel 2010, то эту надстройку можно совершенно бесплатно скачать с сайта Microsoft и тоже себе установить. С помощью Power Pivot расчет средневзвешенного (и других невозможных в обычных сводных штук) очень сильно упрощается.
1. Для начала, загрузим нашу таблицу в Power Pivot. Это можно сделать на вкладке Power Pivot кнопкой Добавить в модель данных (Add to Data Model) . Откроется окно Power Pivot и в нем появится наша таблица.
2. Затем щелкните мышью в строку формул и введите туда формулу для расчета средневзвешенного:
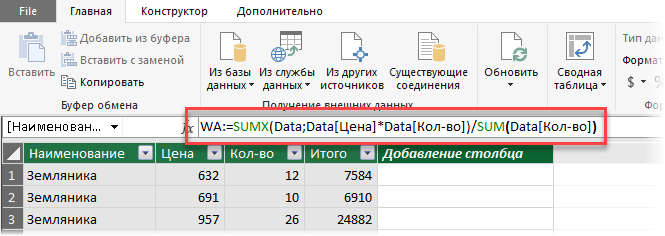
Несколько нюансов по формуле:
- В Power Pivot есть свой встроенный язык с набором функций, инструментов и определенным синтаксисом, который называется DAX. Так что можно сказать, что эта формула — на языке DAX.
- Здесь WA — это название вычисляемого поля (в Power Pivot они еще называются меры), которое вы придумываете сами (я называл WA, имея ввиду Weighted Average — “средневзвешенное” по-английски).
- Обратите внимание, что после WA идет не равно, как в обычном Excel, а двоеточие и равно.
- При вводе формулы будут выпадать подсказки — используйте их.
- После завершения ввода формулы нужно нажать Enter , как и в обычном Excel.
3. Теперь строим сводную. Для этого в окне Power Pivot выберите на вкладке Главная — Сводная таблица (Home — Pivot Table). Вы автоматически вернетесь в окно Excel и увидите привычный интерфейс построения сводной таблицы и список полей на панели справа. Осталось закинуть поле Наименование в область строк, а нашу созданную формулой меру WA в область значений — и задача решена:
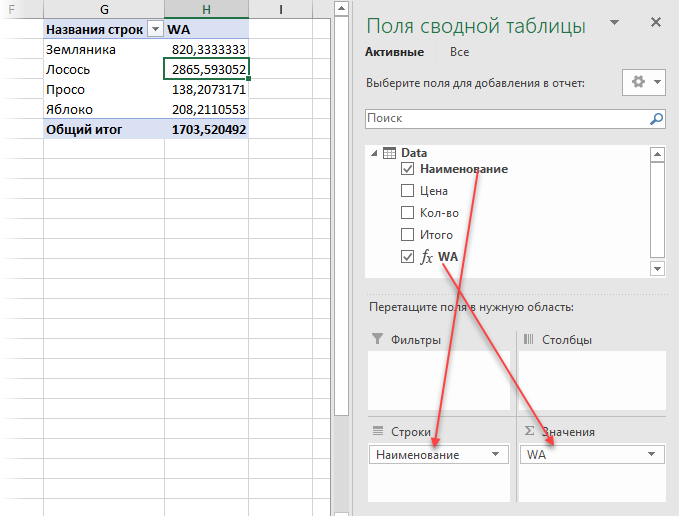
Вот так — красиво и изящно.
Общая мораль: если вы много и часто работаете со сводными таблицами и вам их возможности “тесноваты” — копайте в сторону Power Pivot и DAX — и будет вам счастье!
Содержание
- Как легко найти выбросы в Excel
- Метод 1: используйте межквартильный диапазон
- Способ 2: использовать z-показатели
- Как обращаться с выбросами
- Как найти объем выборки в excel
- Использование Excel для расчета статистических характеристик случайной величины
- Как рассчитать размер выборки в Excel — Вокруг-Дом — 2021
- Шаг 1
- Шаг 2
- Шаг 3
- Шаг 4
Как легко найти выбросы в Excel
Выброс — это наблюдение, которое лежит аномально далеко от других значений в наборе данных. Выбросы могут быть проблематичными, поскольку они могут повлиять на результаты анализа.
Мы будем использовать следующий набор данных в Excel, чтобы проиллюстрировать два метода поиска выбросов:
Метод 1: используйте межквартильный диапазон
Межквартильный размах (IQR) — это разница между 75-м процентилем (Q3) и 25-м процентилем (Q1) в наборе данных. Он измеряет разброс средних 50% значений.
Мы можем определить наблюдение как выброс, если оно в 1,5 раза превышает межквартильный размах, превышающий третий квартиль (Q3), или в 1,5 раза превышает межквартильный размах меньше, чем первый квартиль (Q1).
На следующем изображении показано, как рассчитать межквартильный диапазон в Excel:
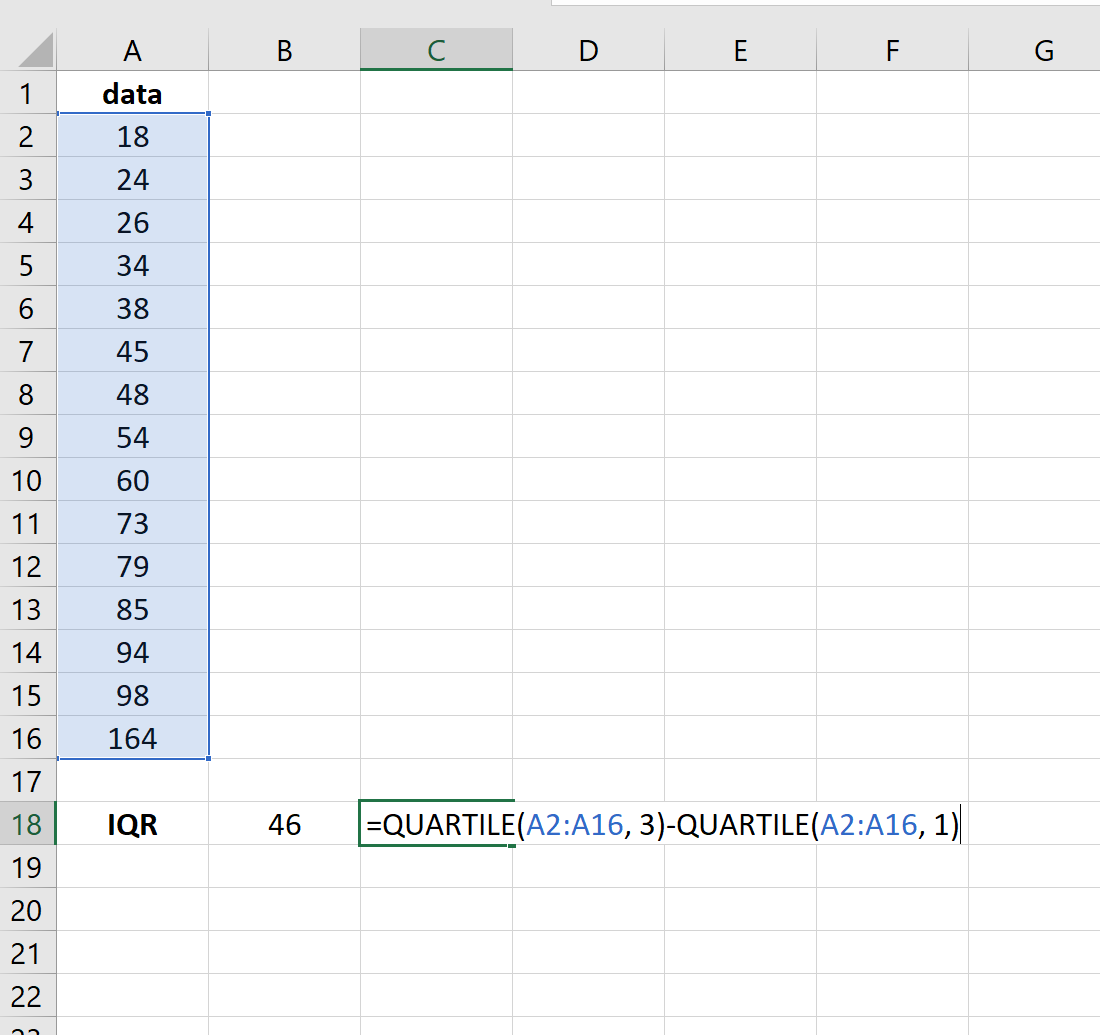
Затем мы можем использовать формулу, упомянутую выше, чтобы присвоить «1» любому значению, которое является выбросом в наборе данных:
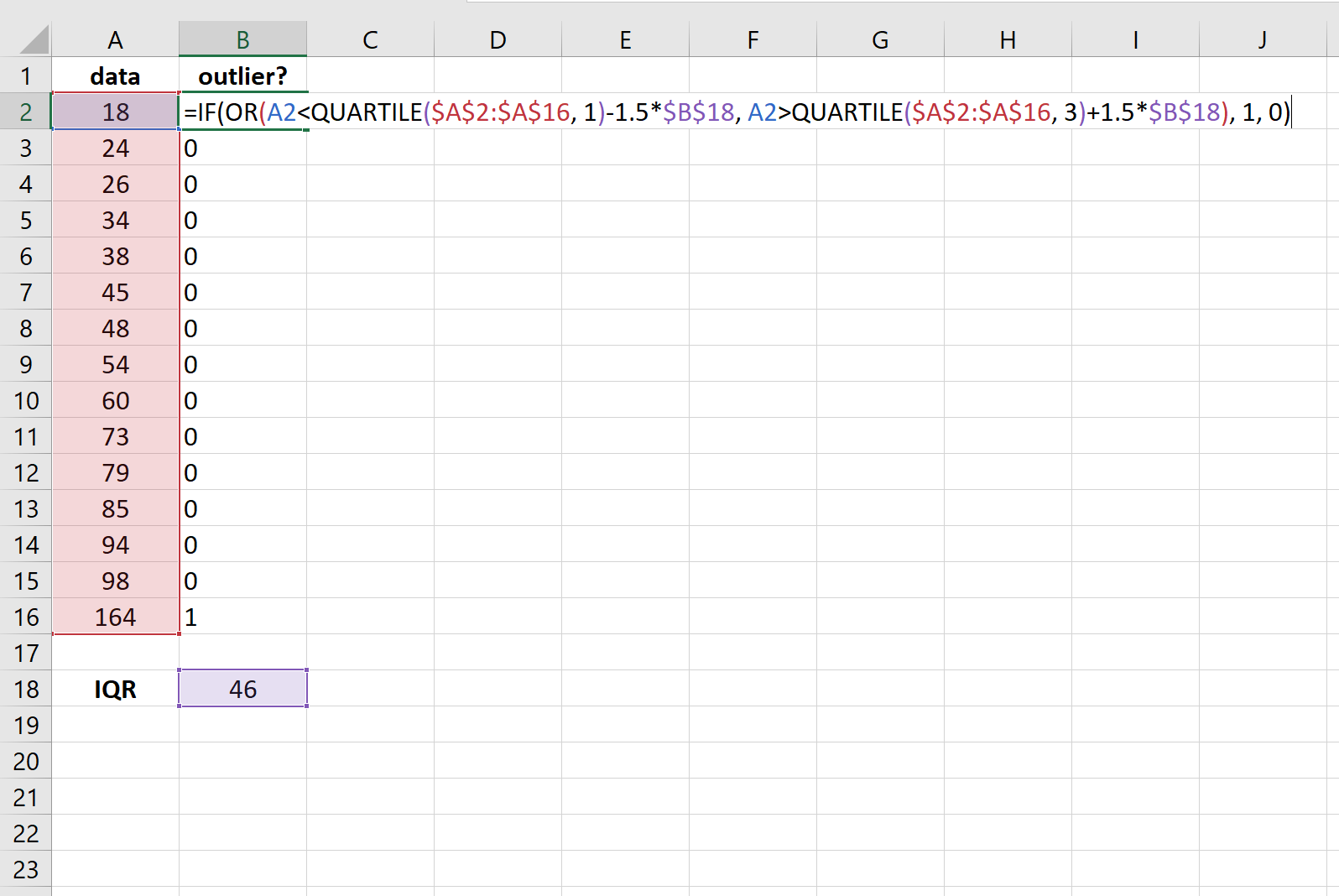
Мы видим, что только одно значение — 164 — оказывается выбросом в этом наборе данных.
Способ 2: использовать z-показатели
Z-оценка показывает, сколько стандартных отклонений данного значения от среднего. Мы используем следующую формулу для расчета z-показателя:
z = (X — μ) / σ
- X — это одно необработанное значение данных.
- μ — среднее значение населения
- σ — стандартное отклонение населения
Мы можем определить наблюдение как выброс, если его z-оценка меньше -3 или больше 3.
На следующем изображении показано, как рассчитать среднее значение и стандартное отклонение для набора данных в Excel:
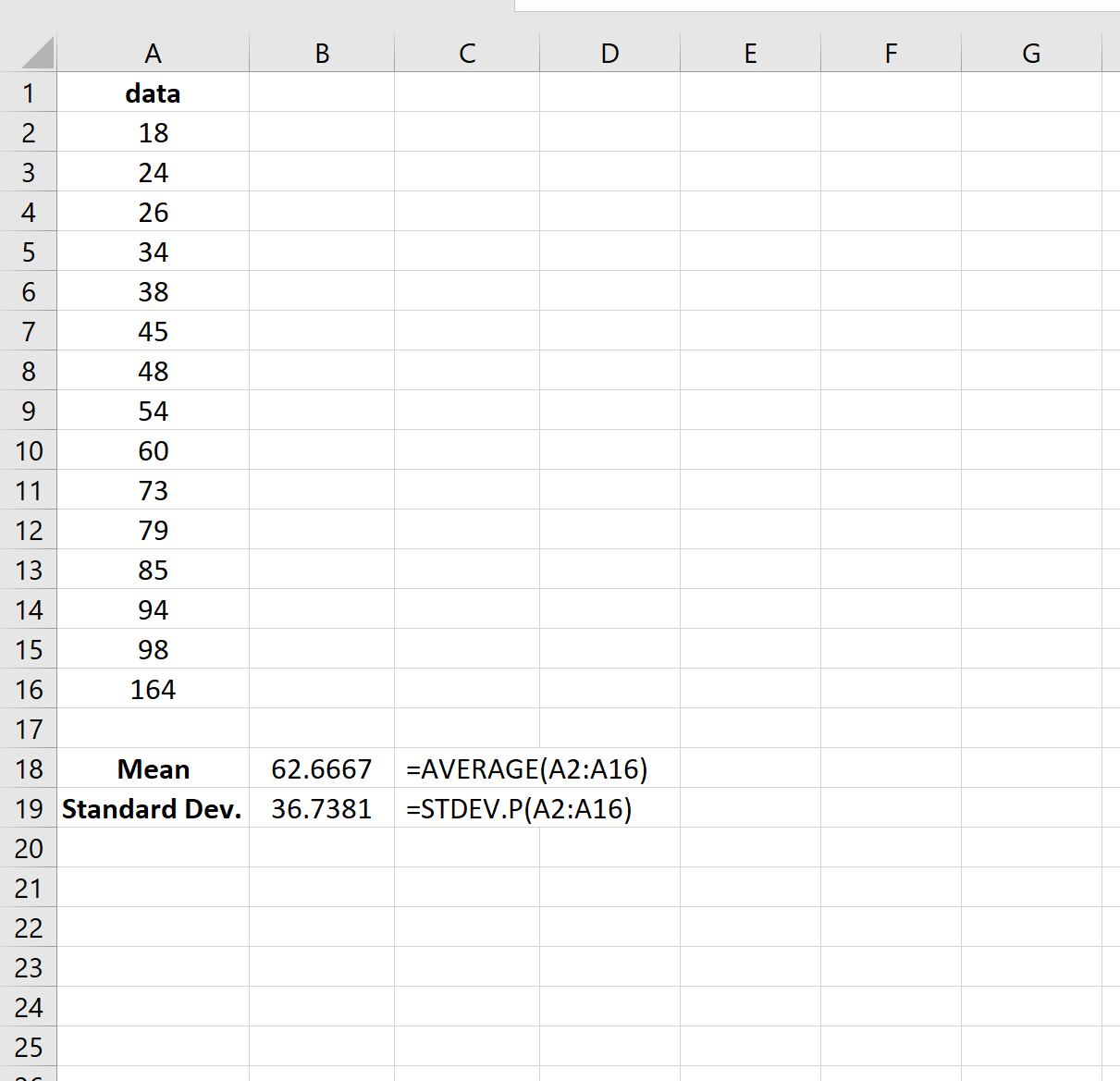
Затем мы можем использовать среднее значение и стандартное отклонение, чтобы найти z-оценку для каждого отдельного значения в наборе данных:
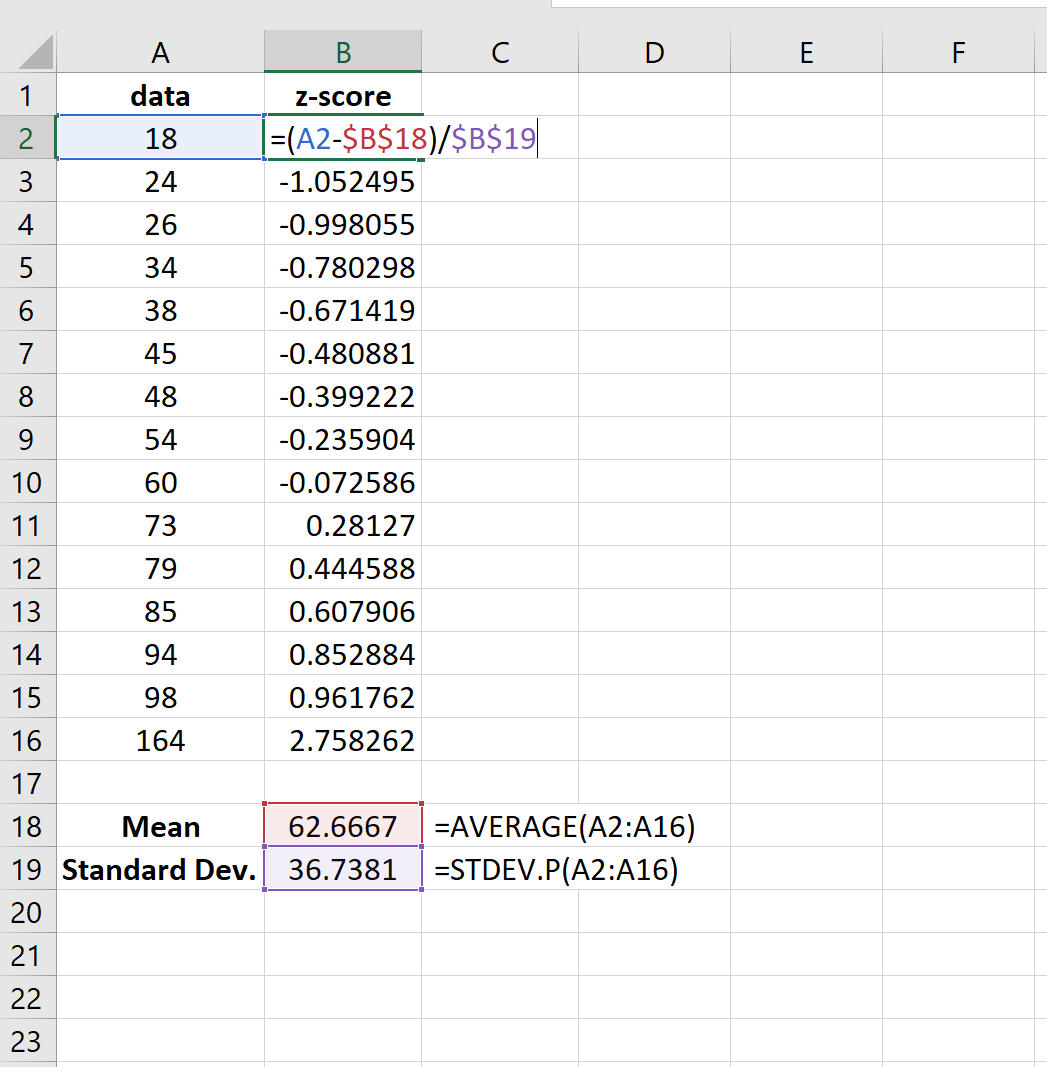
Затем мы можем присвоить «1» любому значению, которое имеет z-оценку меньше -3 или больше 3:
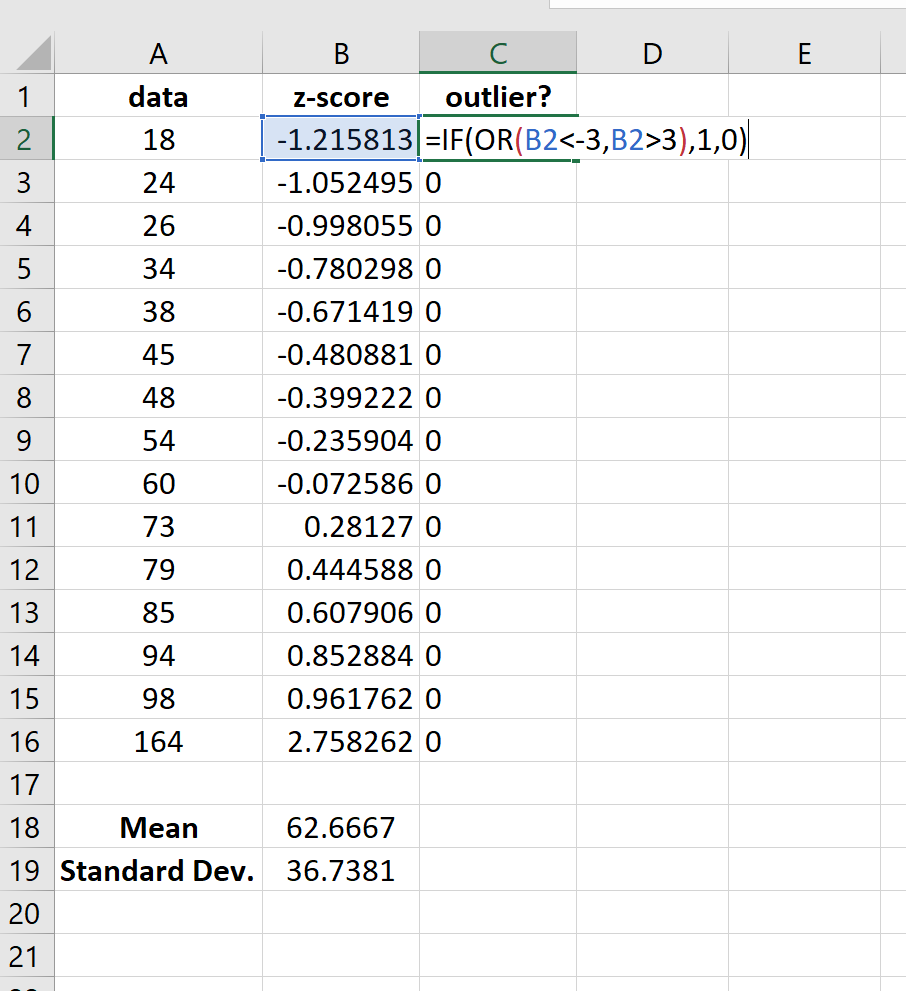
Используя этот метод, мы видим, что в наборе данных нет выбросов.
Примечание. Иногда вместо 3 используется z-показатель 2,5. В этом случае отдельное значение 164 будет считаться выбросом, поскольку его z-показатель больше 2,5. При использовании метода z-показателя руководствуйтесь своим здравым смыслом, какое значение z-показателя вы считаете выбросом.
Как обращаться с выбросами
Если в ваших данных присутствует выброс, у вас есть несколько вариантов:
1. Убедитесь, что выброс не является результатом ошибки ввода данных.
Иногда человек просто вводит неправильное значение данных при записи данных. Если присутствует выброс, сначала убедитесь, что значение было введено правильно и что это не ошибка.
2. Удалите выброс.
Если значение является истинным выбросом, вы можете удалить его, если оно окажет значительное влияние на общий анализ. Просто не забудьте упомянуть в своем окончательном отчете или анализе, что вы удалили выброс.
3. Присвойте новое значение выбросу .
Если выброс является результатом ошибки ввода данных, вы можете решить присвоить ему новое значение, такое как среднее или медиана набора данных.
Источник
Как найти объем выборки в excel
Использование Excel для расчета статистических характеристик случайной величины
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем — статистические, в списке: МОДА
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xiслучайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические — СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
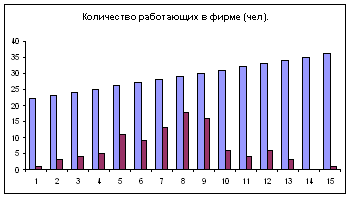
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Как рассчитать размер выборки в Excel — Вокруг-Дом — 2021
Table of Contents:
Microsoft Excel имеет десять основных статистических формул, таких как размер выборки, среднее значение, медиана, стандартное отклонение, максимум и минимум. Размер выборки — это число наблюдений в наборе данных, например, если опрашивающая компания опрашивает 500 человек, то размер выборки данных составляет 500. После ввода набора данных в Excel формула = COUNT вычислит размер выборки. , Размер выборки полезен для вычислений, таких как стандартные ошибки и уровни достоверности. Использование Microsoft Excel позволит пользователю быстро рассчитать статистические формулы, поскольку статистические формулы, как правило, длиннее и сложнее, чем другие математические формулы.
Excel облегчает сложные статистические вычисления.
Шаг 1
Введите данные наблюдений в Excel, по одному наблюдению в каждой ячейке. Например, введите данные в ячейки с A1 по A24. Это обеспечит вертикальный столбец данных в столбце А.
Шаг 2
Введите «= COUNT (» в ячейку B1.
Шаг 3
Выделите диапазон ячеек данных или введите диапазон ячеек данных после «(», введенного на шаге 2 в ячейку B1, затем завершите формулу знаком «)». Диапазон ячеек — это любые ячейки, в которых есть данные. В этом примере диапазон ячеек от A1 до A24. Формула в примере — это «= COUNT (A1: A24)»
Шаг 4
Нажмите «Enter», и размер ячейки появится в ячейке с формулой. В нашем примере ячейка B1 будет отображать 24, поскольку размер выборки будет 24.
Источник
Содержание
- Квартили и интерквартильный интервал (IQR) в EXCEL
- Интерквартильный размах
- Квартили непрерывного распределения
- Квартили в MS EXCEL
- Среднее арифметическое, размах и мода
- Вариация, размах, межквартильный размах, среднее линейное отклонение
- Размах вариации
- Межквартильный размах
- Среднее линейное отклонение
Квартили и интерквартильный интервал (IQR) в EXCEL
history 20 ноября 2016 г.
Для вычисления квартилей в MS EXCEL существует специальная функция КВАРТИЛЬ() . В этой статье дадим определение квартилей и научимся их вычислять для выборки и для непрерывного распределения. Также вычислим интерквартильный интервал.
Квартили (Quartiles) — значения, которые делят выборку (набор значений) на четыре части, содержащие приблизительно равное количество наблюдений (по 25%).
Поясним определение квартиля на примере. Пусть имеется выборка , состоящая из 50 значений в ячейках А7:А56 (см. файл примера , лист Квартиль-выборка). Для наглядности отсортируем значения по возрастанию и построим гистограмму . 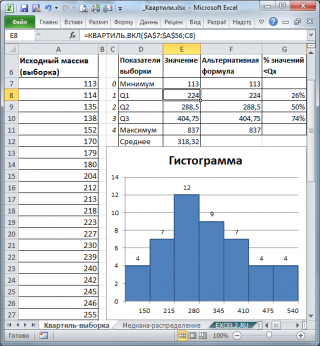
Чтобы разделить выборку на 4 части достаточно 3-х квартилей .
Первый квартиль (или нижний квартиль , Q1) делит выборку , на 2 части: примерно 25% значений в выборке меньше Q1, остальные 75% — больше. Для вычисления 1-го квартиля используйте формулу =КВАРТИЛЬ.ВКЛ(A7:A56;1) . Для нашей выборки формула вернет значение 224. Значения 224 нет в выборке , формула произвела интерполяцию на основе 2-х соседних значений 223 и 227.
Примечание : Функция КВАРТИЛЬ.ВКЛ() появилась в MS EXCEL 2010. В более ранних версиях использовалась аналогичная ей функция КВАРТИЛЬ() .
Чтобы убедиться, что примерно 25% значений меньше, чем 224, используем формулу =СЧЁТЕСЛИ(A7:A56;» . В результате получим, что 26% меньше, чем 1-й квартиль .
Чем в выборке больше значений и меньше повторов , тем точнее деление выборки квартилями на четверти.
Примечание : Первый квартиль — это то же самое, что и 25-я процентиль . Подробнее см. статью про процентили .
Второй квартиль (или медиана , Q2) также делит выборку , на 2 равные части: половина чисел множества больше, чем медиана , а половина чисел меньше, чем медиана . Для вычисления 2-го квартиля используйте формулу =КВАРТИЛЬ.ВКЛ(A7:A56;2) или =МЕДИАНА(A7:A56)
Третий квартиль (или верхний квартиль , Q3) делит выборку , на 2 части: примерно 75% значений в выборке меньше Q3, остальные 25% — больше. Для вычисления 3-го квартиля используйте формулу =КВАРТИЛЬ.ВКЛ(A7:A56;3) или =ПРОЦЕНТИЛЬ.ВКЛ(A7:A56;0,75)
Примечание : Третий квартиль — это то же самое, что и 75-я процентиль .
Второй аргумент функции КВАРТИЛЬ.ВКЛ() может также принимать значения 0 и 4. В первом случае функция вернет минимальное значение , во втором – максимальное .
Интерквартильный размах
Интерквартильным размахом или интерквартильным интервалом (InterQuartile range, IQR) называется разность между третьим и первым квартилями (Q3 — Q1). Интерквартильный размах является характеристикой разброса значений в выборке .
Примечание : Характеристикой разброса значений в выборке является также дисперсия и стандартное отклонение .
Интерквартильный размах , а также квартили используются при построении Блочной диаграммы , которая полезна для оценки разброса значений (variation) в небольших выборках или для сравнения нескольких выборок имеющих сходные распределения. 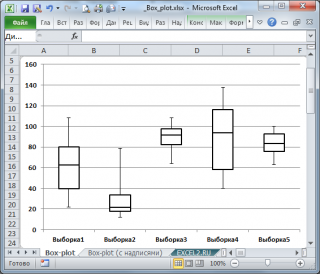
Подробнее о построении Блочной диаграммы см. статью Блочная диаграмма в MS EXCEL .
Квартили непрерывного распределения
Если функция распределения F (х) случайной величины х непрерывна, то 1-й квартиль является решением уравнения F(х) =0,25, второй — F(х) =0,5, а третий F(х) =0,75.
Если известна функция плотности вероятности p (х) , то 1-й квартиль можно найти из уравнения: 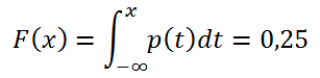
Например, решив аналитическим способом это уравнение для Логнормального распределения lnN(μ; σ 2 ), получим, что медиана (2-й квартиль ) вычисляется по формуле e μ или в MS EXCEL =EXP(μ). При μ=1, медиана равна 2,718. 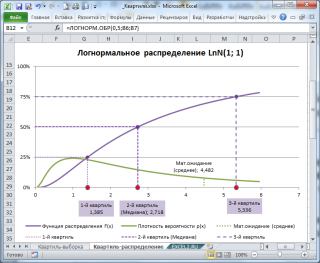
Обратите внимание на точку Функции распределения , для которой F(х)=0,5 (см. картинку выше или файл примера , лист Квартиль-распределение) . Абсцисса этой точки равна 2,718. Это и есть значение 2-го квартиля ( медианы ), что естественно совпадает с ранее вычисленным значением по формуле e μ .
Примечание : Напомним, что интеграл от функции плотности вероятности по всей области задания случайной величины равен единице: 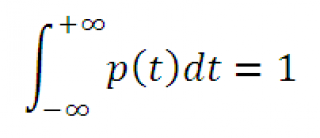
Поэтому, линии квартилей ( х=квартиль ) делят площадь под графиком функции плотности вероятности на 4 равные части.
Квартили в MS EXCEL
Чтобы вычислить в MS EXCEL квартили заданного распределения необходимо использовать соответствующую обратную функцию распределения .
При вычислении квартилей в MS EXCEL используются обратные функции распределения : НОРМ.СТ.ОБР() , ЛОГНОРМ.ОБР() , ХИ2.ОБР() , ГАММА.ОБР() и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье Распределения случайной величины в MS EXCEL .
Например, в MS EXCEL 1-й квартиль для логнормального распределения LnN(1;1) можно вычислить по формуле =ЛОГНОРМ.ОБР(0,25;1;1) , а 3-й квартиль для стандартного нормального распределения по формуле =НОРМ.СТ.ОБР(0,75) .
Источник
Среднее арифметическое, размах и мода
При изучении учебной нагрузки учащихся выделили группу из 12 семиклассников. Их попросили отметить в определенный день время (в минутах), затраченное на выполнение домашнего задания по алгебре. Получили такие данные:
23, 18, 25, 20, 25, 25, 32, 37, 34, 26, 34, 25.
Имея этот ряд данных, можно определить, сколько минут в среднем затратили учащиеся на выполнение домашнего задания по алгебре.
Для этого указанные числа надо сложить и сумму разделить на 12:
 =
= 
Число 27, полученное в результате, называют средним арифметическим рассматриваемого ряда чисел.
Средним арифметическим ряда чисел называется частное от деления суммы этих чисел на число слагаемых.
Мы нашли, что на выполнение домашнего задания по алгебре учащиеся затратили в среднем по 27 минут. Проводя аналогичные наблюдения за группой учащихся, можно проследить, какова была средняя затрата времени на выполнение домашнего задания по алгебре в течение недели, сравнить среднюю затрату времени на выполнение в какой-либо день домашних заданий по алгебре и русскому языку и т.п.
Обычно среднее арифметическое находят тогда, когда хотят определить среднее значение для некоторого ряда данных. Заметим, что среднее арифметическое находят только для однородных величин. Не имеет, например, смысла использовать в качестве обобщающего показателя среднюю урожайность зерновых и бахчевых культур в фермерском хозяйстве. Причем и для однородных величин вычисление среднего арифметического бывает иногда лишено смысла, например, нахождение средней температуры больных в госпитале, среднего размера обуви, которую носят учащиеся школы.
В рассмотренном примере мы нашли, что в среднем учащиеся затратили на выполнение домашнего задания по алгебре по 27 минут. Однако анализ приведенного ряда данных показывает, что время, затраченное некоторыми учащимися, существенно отличается от 27 минут, т.е. от среднего арифметического. Наибольший расход равен 37, а наименьший – 18 минутам. Разность между наибольшим и наименьшим расходом времени составляет 19 минут. В этом случае говорят, что размах ряда равен 19.
Размахом ряда чисел называется разность между наибольшим и наименьшим из этих чисел.
Размах ряда находят тогда, когда хотят определить, как велик разброс данных в ряду. Пусть, например, в течение суток отмечали каждый час температуру воздуха в городе. Для полученного ряда данных полезно не только вычислить среднее арифметическое, показывающее, какова среднесуточная температура, но и найти размах ряда, характеризующий колебания температуры в течение этих суток.
При анализе сведений о времени, затраченном семиклассниками на выполнение домашнего задания по алгебре, нас могут интересовать не только среднее арифметическое и размах полученного ряда данных, но и другие показатели. Интересно, например, знать, какой расход времени является типичным для выделенной группы учащихся, то есть какое число встречается в ряду данных чаще всего. Нетрудно заметить, что таким числом является число 25. говорят, что число 25 – мода рассматриваемого ряда.
Модой ряда чисел называется число, чаще других встречающееся в данном ряду.
Ряд чисел может иметь более одной моды или не иметь моды совсем.
Например, в ряду чисел
47, 46, 50, 52, 47, 52, 49, 45, 43, 53
две моды – это числа 47 и 52,
а в ряду чисел 69, 68, 66, 80, 67, 65, 71, 74, 63, 73, 72 моды нет.
Моду ряда данных обычно находят тогда, когда хотят выявить некоторый типичный показатель. Например, если изучаются данные о размерах мужских сорочек, проданных в определенный день в универмаге, то удобно воспользоваться таким показателем, как мода, который характеризует размер, пользующийся наибольшим спросом. Находить в этом случае среднее арифметическое не имеет смысла. Мода является наиболее приемлемым показателем при выявлении, например, расфасовки некоторого товара, которой отдают предпочтение покупатели; цены на товар данного вида, наиболее распространенный на рынке, и т.п.
Рассмотрим еще пример. Пусть, проведя учет деталей, изготовленных за смену рабочими одной бригады, получили такой ряд данных:
36, 36, 36, 36, 37, 37, 36, 37, 38, 36, 36, 36, 39, 39, 37, 39, 38, 38, 36, 39, 36.
Найдем для него среднее арифметическое, размах и моду. Для этого удобно предварительно составить из полученных данных упорядоченный ряд чисел, т.е. такой ряд, в котором каждое последующее число не меньше (или не больше) предыдущего. Получим: 35, 35, 36, 36, 36, 36, 36, 36, 36, 36, 37, 37, 37, 37, 38, 38, 38, 39, 39, 39, 39.
Вычислим среднее арифметическое:

Размах ряда равен 39-35=4. Мода данного ряда равна 36, так как число 36 чаще всего встречается в этом ряду.
Итак, средняя выработка рабочих за смену составляет примерно 37 деталей; различие в выработке рабочих не превосходит 4 деталей; типичной является выработка, равная 36 деталям.
Заметим, что среднее арифметическое ряда чисел может не совпадать ни с одним из этих чисел, а мода, если она существует, обязательно совпадает с двумя или более числами ряда. Кроме того, в отличие от среднего арифметического, понятие «мода» относится не только к числовым данным. Например, проведя опрос учащихся, можно получить ряд данных, показывающий, каким видом спорта они предпочитают заниматься, какую из развлекательных телевизионных программ они считают наиболее интересной. Модой будут служить те ответы, которые встретятся чаще всего. Этим и объясняется само название «мода».
Найдите среднее арифметическое и размах ряда чисел:
Источник
Вариация, размах, межквартильный размах, среднее линейное отклонение
В этой статье мы приступим к изучению показателей вариации: размах вариации, межквартильный размах, среднее линейное отклонение.
В математической статистике вариация занимает одно из центральных мест. Что же такое вариация? Это изменчивость. Вариация показателя – изменчивость показателя.
Показатели вариации дают очень важную характеристику процессам и явлениям. Они отражают устойчивость процессов и однородность явлений. Чем меньше показатель вариации, тем более процесс устойчивый, а значит, и более предсказуемый.
Показатели вариации отражают не отдельно взятые значения, а дают характеристику некоторому явлению или процессу в целом. Имея в наличии показатели среднего значения и вариации, можно получить первичное представление о характере данных. Средняя – это обобщающий уровень, а вариация характеризует, насколько среднее значение (или другой показатель) хорошо обобщает значения некоторой совокупности данных. Если показатель вариации незначительный, то значения совокупности находятся близко к среднему, следовательно, среднее значение хорошо обобщает совокупность. Если вариация большая, то среднее значение плохо обобщает данные (значения разбросаны далеко друг от друга), и получается «средняя температура по больнице».
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:

Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Межквартильный размах
В статистике для анализа выборки часто прибегают к другому показателю вариации – межквартильному размаху. Квартиль – это то значение, которые делит ранжированные (отсортированные) данные на части, кратные одной четверти, или 25%. Так, 1-й квартиль – это значение, ниже которого находится 25% совокупности. 2-й квартиль делит совокупность данных пополам (то бишь медиана), ну и 3-й квартиль отделяет 25% наибольших значений. Так вот межквартильный размах – это разница между 3-м и 1-м квартилями. У данного показателя есть одно неоспоримое преимущество: он является робастным, т.е. не зависит от аномальных отклонений.
Наглядное отображение размаха вариации и межкварительного расстояния производят с помощью диаграммы «ящик с усами».
Среднее линейное отклонение
Есть показатели вариации, которые учитывают сразу все значения, а не только отдельные наблюдения (типа максимума или минимума). Одним из таких является среднее линейное отклонение. Этот показатель характеризует меру разброса значений вокруг их среднего. В чем суть? Для того, чтобы показать меру разброса данных, нужно вначале определиться, относительно чего этот самый разброс будет считаться. Обычно это среднее арифметическое. Далее нужно посчитать, насколько каждое значение отклоняется от средней. Нас интересует среднее из таких отклонений. Однако напрямую складывать положительные и отрицательные отклонения нельзя, т.к. они взаимоуничтожатся и их сумма будет равна нулю. Поэтому все отклонения берутся по модулю. Средне линейное отклонение рассчитывается по формуле:

a – среднее линейное отклонение,
X – анализируемый показатель,
X̅ – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
Рассчитанное по этой формуле значение показывает среднее абсолютное отклонение от средней арифметической. Наглядная картинка в помощь.

Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор провести статистический анализ длины черенков. Отобрал 10 штук и замерил их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно, в среднем на 16 см. Есть, о чем поговорить с работниками.
На этом сегодняшнюю заметку закончим. В следующей статье будут рассмотрены такие показатели вариации, как дисперсия, среднеквадратичное отклонение и коэффициент вариации.
Источник
Размах варьирования. Наибольшее и наименьшее значения
Лабораторная работа № 1
Статистический анализ данных
Цель работы: научиться обрабатывать статистические данные с помощью встроенных функций.
Порядок выполнения работы:
1. Основные статистические характеристики:
— Выборочная дисперсия (вариабельность)
2. Самостоятельная работа
— Диаграмма рассеяния (задание 1)
— Основные статистические показатели (задание 2)
— Отклонение случайного распределения от нормального (задание 3)
1. Основные статистические характеристики.
Электронные таблицы Excel имеют огромный набор средств для анализа статистических данных. Наиболее часто используемые статистические функции встроены в основное ядро программы, то есть эти функции доступны с момента запуска программы.
Среднее значение.
Функция СРЗНАЧ (или AVERAGE) вычисляет выборочное (или генеральное) среднее, то есть среднее арифметическое значение признака выборочной (или генеральной) совокупности. Аргументом функции СРЗНАЧ является набор чисел, как правило, задаваемый в виде интервала ячеек, например, =СРЗНАЧ (А3:А201).
Дисперсия и среднее квадратическое отклонение.
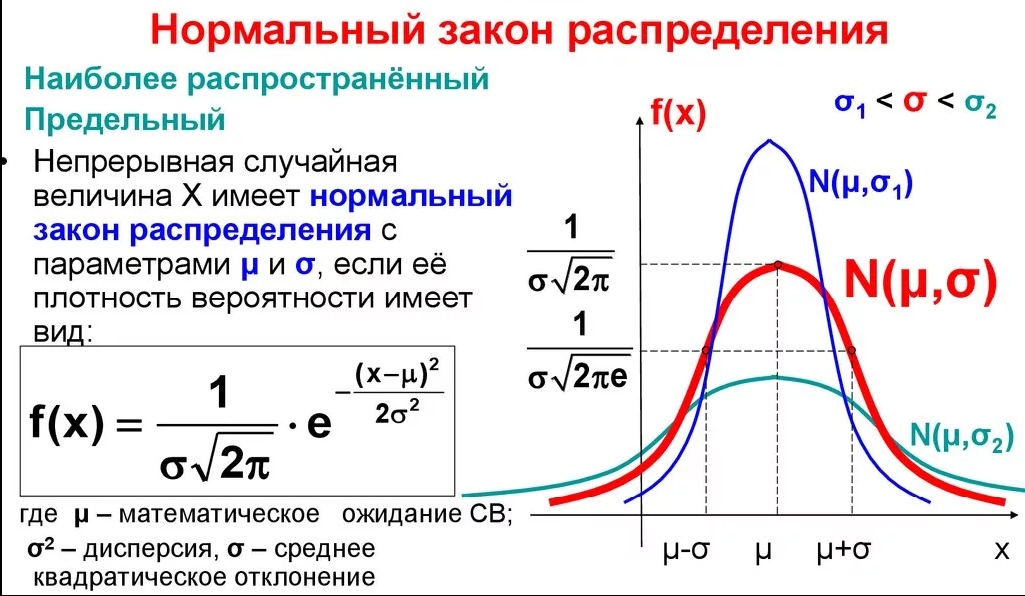
Для оценки разброса данных используются такие статистические характеристики, как дисперсия D и среднее квадратическое (или стандартное) отклонение . Стандартное отклонение есть квадратный корень из дисперсии: . Большое стандартное отклонение указывает на то, что значения измерения сильно разбросаны относительно среднего, а малое – на то, что значения сосредоточены около среднего.
В Excel имеются функции, отдельно вычисляющие выборочную дисперсию Dви стандартное отклонение в и генеральные дисперсию Dг и стандартное отклонение г. Поэтому, прежде чем вычислять дисперсию и стандартное отклонение, следует четко определиться, являются ли ваши данные генеральной совокупностью или выборочной. В зависимости от этого нужно использовать для расчета Dг и г , Dв и в.
Для вычисления выборочной дисперсии Dв и выборочного стандартного отклонения в имеются функции ДИСП (или VAR) и СТАНДОТКЛОН (или STDEV). Аргументом этих функций является набор чисел, как правило, заданный диапазоном ячеек, например, =ДИСП (В1:В48).
Для вычисления генеральной дисперсии Dг и генерального стандартного отклонения г имеются функции ДИСПР (или VARP) и СТАНДОТКЛОНП (или STDEVP), соответственно.
Аргументы этих функций такие же как и для выборочной дисперсии.
Объем совокупности.
Объем совокупности выборочной или генеральной – это число элементов совокупности. Функция СЧЕТ (или COUNT) определяет количество ячеек в заданном диапазоне, которые содержат числовые данные. Пустые ячейки или ячейки, содержащие текст, функция СЧЕТ пропускает. Аргументом функции СЧЕТ является интервал ячеек, например: =СЧЕТ (С2:С16).
Для определения количества непустых ячеек, независимо от их содержимого, используется функция СЧЕТ3. Ее аргументом является интервал ячеек.
Мода и медиана.
Мода – это значение признака, которое чаще других встречается в совокупности данных. Она вычисляется функцией МОДА (или MODE). Ее аргументом является интервал ячеек с данными.
Медиана – это значение признака, которое разделяет совокупность на две равные по числу элементов части. Она вычисляется функцией МЕДИАНА (или MEDIAN). Ее аргументом является интервал ячеек.
Размах варьирования. Наибольшее и наименьшее значения.
Размах варьирования R – это разность между наибольшим xmax и наименьшим xmin значениями признака совокупности (генеральной или выборочной): R=xmax–xmin. Для нахождения наибольшего значения xmax имеется функция МАКС (или MAX), а для наименьшего xmin – функция МИН (или MIN). Их аргументом является интервал ячеек. Для того, чтобы вычислить размах варьирования данных в интервале ячеек, например, от А1 до А100, следует ввести формулу: =МАКС (А1:А100)-МИН (А1:А100).
Задание 1
Имеются данные о размерах располагаемого дохода DPI и расходов на личное потребление С для n семей в условных единицах, так что DPIi и Сi, соответственно, представляют располагаемый доход и расходы на личное потребление i-й семьи.
1. Построить диаграмму рассеяния, принимая за ось абсцисс — DPIi,а за ось ординатСi
| Доходы_расходы | |||||
| I | DPI | C | I | DPI | C |
2. Выполнить настройку формата оси Х и оси Y в соответствии с образцом диаграммы.
Задание 2
Имеются данные об уровне безработицы (в %) среди «белого» (коренное) и «цветного» (эмигранты) населения страны с марта 2000г. по июль 2001г. (месячные данные), так что BELi и ZVETi, соответственно, представляют уровни безработицы в i-м месяце.
1. Построить графики изменения уровней безработицы в обеих группах в течение указанного периода времени.
2. Вычислить средние значения уровней безработицы для BELi и ZVETi населения страны.
| Уровень безработицы | ||
| Исходные данные | ||
| I | BEL(%) | ZVET(%) |
| 3,2 | 6,9 | |
| 3,1 | 6,7 | |
| 3,2 | 6,5 | |
| 3,3 | 7,1 | |
| 3,3 | 6,8 | |
| 3,2 | 6,4 | |
| 3,2 | 6,6 | |
| 3,1 | 7,3 | |
| 3,0 | 6,5 | |
| 3,0 | 6,5 | |
| 3,0 | 6,0 | |
| 2,9 | 5,7 | |
| 3,1 | 6,0 | |
| 3,1 | 6,9 | |
| 3,1 | 6,5 | |
| 3,0 | 7,0 | |
| 3,2 | 6,4 |
3. Вычислить выборочные дисперсии, характеризующие степень разброса значений BELi и ZVETi вокруг своего среднего значения.
4. Вычислить стандартные отклоненияBELi и ZVETi относительно среднего значения.
5. Вычислить наибольшее и наименьшее значения для BELi и ZVETi.
6. Вычислить размах варьирования дляBELi и ZVETi.
7. Вычислить Моду и Медиану дляBELi и ZVETi.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем — статистические, в списке: МОДА
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xiслучайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические — СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Видео с уроком:
Генерируем с помощью надстройки «анализа данных» -«генерация случайных чисел» нормально распределённую случайную величину мат.ожиданием равным 0 и стандартным отклонением 1.
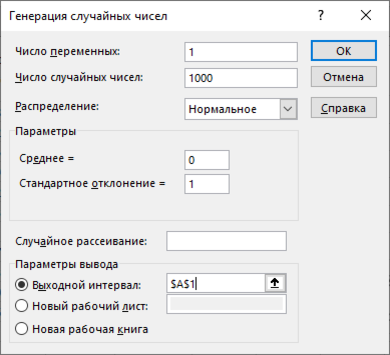
В ячейках А1-А1000 получаем значения случайной величины, подчинённой нормальному закону распределения с параметрами: мат.ожиданием = 0 и стандартным отклонением =1.
Построим на основании полученных данных дискретный вариационный ряд.
С помощью функции МИН находим минимальное значение из полученных данных: D1 =МИН(A1:A1000).
С помощью функции МАКС находим максимальное значение из полученных данных: D2 =МАКС(A1:A1000).
Находим размах вариации (R= Хмакс – Хмин): D3 =D2-D1.
Число интервалов определяем по формуле Стерджесса:
D4 =1+3,322*LOG(1000).
Определяем величину интервала: l=R/n
Определяем границы интервалов.
Первый нижний интервал равен минимальному значению ряда (G2 =D1). Первый верхний интервал равен значение нижнего плюс величина интервала (H2= =D1+D5). И так далее.
Последний верхний интервал равен максимальному значению ряда.
С помощью функции ЧАСТОТА находим число попаданий случайной величины в полученные интервалы вариационного ряда.
Что бы заполнились все клетки частот необходимо одновременно нажать:
Получим частоты ряда распределения.
Видим, что сумма частот не равна 1000. Не хватает одного наблюдения. Это произошло из за того, что верхний интервал ряда не считается, и последний верхний интервал не был посчитан. Что бы его учесть прибавляем малое число к верхней границе последнего интервала.
H12 =H11+D$5+0,000001
Теперь сумма частот равна 1000.
Находим среднее значение массива данных с помощью функции СРЗНАЧ:
G16 =СРЗНАЧ(A1:A1000)
Стандартное отклонение массива данных находим с помощью функции СТАНДОТКЛОН.В:
G17 =СТАНДОТКЛОН.В(A1:A1000)
Найдём среднее и стандартное отклонение построенного интервального вариационного ряда. Находим середину интервала:
j2 =(G2+H2)/2
аналогично для других интервалов.
Находим произведение середины интервала на частоту:
K2 =J2*I2
аналогично для других интервалов.
Находим произведение квадрата середины интервала на частоту:
L2 = =J2^2*I2
аналогично для других интервалов.
Далее суммируем полученные столбцы и получаем таблицу.
Среднее значение определяем по формуле:
H16= =K13/I13
Стандартное отклонение определяем по формуле:
Полученные значения среднего и стандартного отклонения по массиву данных и по интервальному ряду имеют небольшое расхождение. Так и должно быть, так как методики определения различны.
Далее нами была построена гистограмма интервального ряда распределения.
P.S.
На следующем занятии мы проверим, подчиняется ли полученный интервальный ряд нормальному распределению, будем использовать функции НОРМРАСП и ХИ2.ОБР https://dzen.ru/a/Y4cyLlERd0hh00_s
Материал подготовлен сайтом: https://pro-smysl.ru/
Онлайн помощь в решении задач, консультации, создание обучающих роликов.
Подписывайтесь на наши каналы:
https://vk.com/sm_smysl
https://www.youtube.com/@SMYS_L
