В этой статье мы приступим к изучению показателей вариации: размах вариации, межквартильный размах, среднее линейное отклонение.
В математической статистике вариация занимает одно из центральных мест. Что же такое вариация? Это изменчивость. Вариация показателя – изменчивость показателя.
Показатели вариации дают очень важную характеристику процессам и явлениям. Они отражают устойчивость процессов и однородность явлений. Чем меньше показатель вариации, тем более процесс устойчивый, а значит, и более предсказуемый.
Показатели вариации отражают не отдельно взятые значения, а дают характеристику некоторому явлению или процессу в целом. Имея в наличии показатели среднего значения и вариации, можно получить первичное представление о характере данных. Средняя – это обобщающий уровень, а вариация характеризует, насколько среднее значение (или другой показатель) хорошо обобщает значения некоторой совокупности данных. Если показатель вариации незначительный, то значения совокупности находятся близко к среднему, следовательно, среднее значение хорошо обобщает совокупность. Если вариация большая, то среднее значение плохо обобщает данные (значения разбросаны далеко друг от друга), и получается «средняя температура по больнице».
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Межквартильный размах
В статистике для анализа выборки часто прибегают к другому показателю вариации – межквартильному размаху. Квартиль – это то значение, которые делит ранжированные (отсортированные) данные на части, кратные одной четверти, или 25%. Так, 1-й квартиль – это значение, ниже которого находится 25% совокупности. 2-й квартиль делит совокупность данных пополам (то бишь медиана), ну и 3-й квартиль отделяет 25% наибольших значений. Так вот межквартильный размах – это разница между 3-м и 1-м квартилями. У данного показателя есть одно неоспоримое преимущество: он является робастным, т.е. не зависит от аномальных отклонений.
Наглядное отображение размаха вариации и межкварительного расстояния производят с помощью диаграммы «ящик с усами».
Среднее линейное отклонение
Есть показатели вариации, которые учитывают сразу все значения, а не только отдельные наблюдения (типа максимума или минимума). Одним из таких является среднее линейное отклонение. Этот показатель характеризует меру разброса значений вокруг их среднего. В чем суть? Для того, чтобы показать меру разброса данных, нужно вначале определиться, относительно чего этот самый разброс будет считаться. Обычно это среднее арифметическое. Далее нужно посчитать, насколько каждое значение отклоняется от средней. Нас интересует среднее из таких отклонений. Однако напрямую складывать положительные и отрицательные отклонения нельзя, т.к. они взаимоуничтожатся и их сумма будет равна нулю. Поэтому все отклонения берутся по модулю. Средне линейное отклонение рассчитывается по формуле:
![]()
где
a – среднее линейное отклонение,
X – анализируемый показатель,
X̅ – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
Рассчитанное по этой формуле значение показывает среднее абсолютное отклонение от средней арифметической. Наглядная картинка в помощь.

Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор провести статистический анализ длины черенков. Отобрал 10 штук и замерил их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно, в среднем на 16 см. Есть, о чем поговорить с работниками.
На этом сегодняшнюю заметку закончим. В следующей статье будут рассмотрены такие показатели вариации, как дисперсия, среднеквадратичное отклонение и коэффициент вариации.
Поделиться в социальных сетях:
Коэффициент вариации – это сравнение рассеивания двух случайно взятых величин. Величины имеют единицы измерения, что приводит к получению сопоставимого результата. Этот коэффициент нужен для подготовки статистического анализа.
С помощью него инвесторы могут рассчитать показатели риска перед тем, как сделать вклады в выбранные активы. Он полезен, когда у выбранных активов различная доходность и степень риска. К примеру, у одного актива может быть высокий доход и степень риска тоже высокая, а у другого, наоборот, малый доход и степень риска соответственно меньшая.
Расчет стандартного отклонения
Стандартное отклонение является статистической величиной. С помощью расчета этой величины пользователь получит информацию о том, насколько отклоняются данные в ту или иную сторону относительно среднего значения. Стандартное отклонение в Excel рассчитывается в несколько шагов.
Подготавливаете данные: открываете страницу, где будут происходить расчеты. В нашем случае это картинка, но может быть любой другой файл. Главное собрать ту информацию, которую будете использовать в таблице для рассчета.
Вводите данные в любой табличный редактор (в нашем случае Excel), заполняя ячейки слева направо. Начинать следует с колонки «А». Заголовки вводите в строке сверху, а названия в тех же столбцах, которые относятся к заголовкам, только ниже. Затем дату и данные, которые подлежат расчету, справа от даты.
Этот документ сохраняете.
Теперь переходим к самому вычислению. Выделяете курсором ячейку после последнего введенного значения снизу.
Вписываете знак «=» и прописываете далее формулу. Знак равенства обязателен. Иначе программа не посчитает предложенные данные. Формула вводится без пробелов.
Утилита выдаст названия нескольких формул. Выбираете «СТАНДОТКЛОН». Это формула вычисления стандартного отклонения. Существует два вида расчета:
- с вычислением по выборке;
- с вычислением по генеральной совокупности.
Выбрав одну из них, указываете диапазон данных. Вся введенная формула будет выглядеть так: «=СТАНДОТКЛОН (В2: В5)».
Затем кликаете по кнопке «Enter». Полученные данные появятся в отмеченном пункте.
Расчет среднего арифметического
Вычисляется, когда пользователю необходимо создать отчет, например, по заработной плате в его компании. Делается это следующим образом:
- открываете утилиту. В верхней строке набираете ряд нужных цифр;

- под первой цифрой ставите курсор. В верхней строке программы выбираете вкладку «Редактирование», затем кнопку «Сумма». В выпавшем окне выбираете значение «Среднее»;

- после того, как кликните в том пункте на котором стоит курсор, появится формула;

- останется только выделить диапазон и кликнуть по кнопке «Ввод». А в ячейке теперь отобразится результат из взятых данных выше.
Расчет коэффициента вариации
Формула расчета коэффициента вариации:
V= S/X, где S – это стандартное отклонение, а X – среднее значение.
Для того, чтобы посчитать коэффициент вариации в Excel, необходимо найти стандартное отклонение и среднее арифметическое. То есть проделав первые два расчета, которые были показаны выше, можно перейти к работе над коэффициентом вариации.
Для этого открываете Excel, заполняем два поля, куда следует вписать полученные числа стандартного отклонения и среднего значения.
Теперь выделяете ячейку, которую отвели под число для вычисления вариации. Открываете вкладку «Главная», если она не открыта. Кликаете по инструменту «Число». Выбираете процентный формат.
Переходите к отмеченной ячейке и кликаете по ней дважды. Затем вводите знак равенства и выделяете пункт, куда вписан итог стандартного отклонения. Затем кликаете на клавиатуре по кнопке «слэш» или «разделить» (выглядит так: «/»). Выделяете пункт, куда вписано среднее арифметическое, и кликаете по кнопке «Enter». Должно получиться так:
А вот и результат после нажатия «Enter»:
Также для расчета коэффициента вариации можно использовать онлайн калькуляторы, например planetcalc.ru и allcalc.ru. Достаточно внести необходимые цифры и запустить расчет, после чего получить необходимые сведения.
Среднеквадратическое отклонение
Среднеквадратичное отклонение в Excel решается с помощью двух формул:
Простыми словами, извлекается корень из дисперсии. Как вычислить дисперсию рассмотрено ниже.
Среднее квадратичное отклонение является синонимом стандартного и вычисляется точное также. Выделяется ячейка для результата под числами, которые нужно рассчитать. Вставляется одна из функций, указанных на рисунке выше. Кликается кнопка «Enter». Результат получен.
Коэффициент осциляции
Соотношением размаха вариации к среднему – называется коэффициентом осциляции. Готовых формул в Экселе нет, поэтому нужно компоновать несколько функций в одну.
Функциями, которые необходимо скомпоновать, являются формулы среднего значения, максимума и минимума. Этот коэффициент используют для сравнения набора данных.
Дисперсия
Дисперсия – это функция, с помощью которой характеризуют разброс данных вокруг математического ожидания. Вычисляется по следующему уравнению:
Переменные принимают такие значения:
В Excel есть две функции, которые определяют дисперсию:
- Дисп.Г – используется относительно небольших выборок.
- Дисп.В – вычисление несмещенной дисперсии.

Чтобы произвести расчет, под числами, которые необходимо посчитать, выделяется ячейка. Заходите во вкладку вставки функции. Выбираете категорию «Статистические». В выпавшем списке выбираете одну из функций и кликаете по кнопке «Enter».
Максимум и минимум
Максимум и минимум нужны для того, чтобы не искать вручную среди большого количества чисел минимальное или максимальное число.
Чтобы вычислить максимум, выделяете весь диапазон необходимых чисел в таблице и отдельную ячейку, затем кликаете по значку «Σ» или «Автосумма». В выпавшем окне выбираете «Максимум» и, нажав кнопку «Enter» получаете нужное значение.
Тоже самое делаете, чтобы получить минимум. Только выбираете функцию «Минимум».
Размах варьирования. Наибольшее и наименьшее значения
Лабораторная работа № 1
Статистический анализ данных
Цель работы: научиться обрабатывать статистические данные с помощью встроенных функций.
Порядок выполнения работы:
1. Основные статистические характеристики:
— Выборочная дисперсия (вариабельность)
2. Самостоятельная работа
— Диаграмма рассеяния (задание 1)
— Основные статистические показатели (задание 2)
— Отклонение случайного распределения от нормального (задание 3)
1. Основные статистические характеристики.
Электронные таблицы Excel имеют огромный набор средств для анализа статистических данных. Наиболее часто используемые статистические функции встроены в основное ядро программы, то есть эти функции доступны с момента запуска программы.
Среднее значение.
Функция СРЗНАЧ (или AVERAGE) вычисляет выборочное (или генеральное) среднее, то есть среднее арифметическое значение признака выборочной (или генеральной) совокупности. Аргументом функции СРЗНАЧ является набор чисел, как правило, задаваемый в виде интервала ячеек, например, =СРЗНАЧ (А3:А201).
Дисперсия и среднее квадратическое отклонение.
Для оценки разброса данных используются такие статистические характеристики, как дисперсия D и среднее квадратическое (или стандартное) отклонение . Стандартное отклонение есть квадратный корень из дисперсии: . Большое стандартное отклонение указывает на то, что значения измерения сильно разбросаны относительно среднего, а малое – на то, что значения сосредоточены около среднего.
В Excel имеются функции, отдельно вычисляющие выборочную дисперсию Dви стандартное отклонение в и генеральные дисперсию Dг и стандартное отклонение г. Поэтому, прежде чем вычислять дисперсию и стандартное отклонение, следует четко определиться, являются ли ваши данные генеральной совокупностью или выборочной. В зависимости от этого нужно использовать для расчета Dг и г , Dв и в.
Для вычисления выборочной дисперсии Dв и выборочного стандартного отклонения в имеются функции ДИСП (или VAR) и СТАНДОТКЛОН (или STDEV). Аргументом этих функций является набор чисел, как правило, заданный диапазоном ячеек, например, =ДИСП (В1:В48).
Для вычисления генеральной дисперсии Dг и генерального стандартного отклонения г имеются функции ДИСПР (или VARP) и СТАНДОТКЛОНП (или STDEVP), соответственно.
Аргументы этих функций такие же как и для выборочной дисперсии.
Объем совокупности.
Объем совокупности выборочной или генеральной – это число элементов совокупности. Функция СЧЕТ (или COUNT) определяет количество ячеек в заданном диапазоне, которые содержат числовые данные. Пустые ячейки или ячейки, содержащие текст, функция СЧЕТ пропускает. Аргументом функции СЧЕТ является интервал ячеек, например: =СЧЕТ (С2:С16).
Для определения количества непустых ячеек, независимо от их содержимого, используется функция СЧЕТ3. Ее аргументом является интервал ячеек.
Мода и медиана.
Мода – это значение признака, которое чаще других встречается в совокупности данных. Она вычисляется функцией МОДА (или MODE). Ее аргументом является интервал ячеек с данными.
Медиана – это значение признака, которое разделяет совокупность на две равные по числу элементов части. Она вычисляется функцией МЕДИАНА (или MEDIAN). Ее аргументом является интервал ячеек.
Размах варьирования. Наибольшее и наименьшее значения.
Размах варьирования R – это разность между наибольшим xmax и наименьшим xmin значениями признака совокупности (генеральной или выборочной): R=xmax–xmin. Для нахождения наибольшего значения xmax имеется функция МАКС (или MAX), а для наименьшего xmin – функция МИН (или MIN). Их аргументом является интервал ячеек. Для того, чтобы вычислить размах варьирования данных в интервале ячеек, например, от А1 до А100, следует ввести формулу: =МАКС (А1:А100)-МИН (А1:А100).
Задание 1
Имеются данные о размерах располагаемого дохода DPI и расходов на личное потребление С для n семей в условных единицах, так что DPIi и Сi, соответственно, представляют располагаемый доход и расходы на личное потребление i-й семьи.
1. Построить диаграмму рассеяния, принимая за ось абсцисс — DPIi,а за ось ординатСi
| Доходы_расходы | |||||
| I | DPI | C | I | DPI | C |
2. Выполнить настройку формата оси Х и оси Y в соответствии с образцом диаграммы.
Задание 2
Имеются данные об уровне безработицы (в %) среди «белого» (коренное) и «цветного» (эмигранты) населения страны с марта 2000г. по июль 2001г. (месячные данные), так что BELi и ZVETi, соответственно, представляют уровни безработицы в i-м месяце.
1. Построить графики изменения уровней безработицы в обеих группах в течение указанного периода времени.
2. Вычислить средние значения уровней безработицы для BELi и ZVETi населения страны.
| Уровень безработицы | ||
| Исходные данные | ||
| I | BEL(%) | ZVET(%) |
| 3,2 | 6,9 | |
| 3,1 | 6,7 | |
| 3,2 | 6,5 | |
| 3,3 | 7,1 | |
| 3,3 | 6,8 | |
| 3,2 | 6,4 | |
| 3,2 | 6,6 | |
| 3,1 | 7,3 | |
| 3,0 | 6,5 | |
| 3,0 | 6,5 | |
| 3,0 | 6,0 | |
| 2,9 | 5,7 | |
| 3,1 | 6,0 | |
| 3,1 | 6,9 | |
| 3,1 | 6,5 | |
| 3,0 | 7,0 | |
| 3,2 | 6,4 |
3. Вычислить выборочные дисперсии, характеризующие степень разброса значений BELi и ZVETi вокруг своего среднего значения.
4. Вычислить стандартные отклоненияBELi и ZVETi относительно среднего значения.
5. Вычислить наибольшее и наименьшее значения для BELi и ZVETi.
6. Вычислить размах варьирования дляBELi и ZVETi.
7. Вычислить Моду и Медиану дляBELi и ZVETi.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня на уроке мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем — статистические, в списке: МОДА
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.
В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:
Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xiслучайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22
Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические — СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)
Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.
Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.
Диаграмма – Стандартные – Гистограмма.
4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Коэффициент вариации в статистике: примеры расчета
Как доказать, что закономерность, полученная при изучении экспериментальных данных, не является результатом совпадения или ошибки экспериментатора, что она достоверна? С таким вопросом сталкиваются начинающие исследователи.Описательная статистика предоставляет инструменты для решения этих задач. Она имеет два больших раздела – описание данных и их сопоставление в группах или в ряду между собой.
- Показатели описательной статистики
- Среднее арифметическое
- Стандартное отклонение
- Коэффициент вариации
- Расчёты в Microsoft Ecxel 2016
Среднее арифметическое
Итак, представим, что перед нами стоит задача описать рост всех студентов в группе из десяти человек. Вооружившись линейкой и проведя измерения, мы получаем маленький ряд из десяти чисел (рост в сантиметрах):
168, 171, 175, 177, 179, 187, 174, 176, 179, 169.
Если внимательно посмотреть на этот линейный ряд, то можно обнаружить несколько закономерностей:
- Ширина интервала, куда попадает рост всех студентов, – 18 см.
- В распределении рост наиболее близок к середине этого интервала.
- Встречаются и исключения, которые наиболее близко расположены к верхней или нижней границе интервала.
Совершенно очевидно, что для выполнения задачи по описанию роста студентов в группе нет необходимости приводить все значения, которые будут измеряться.
Для этой цели достаточно привести всего два, которые в статистике называются параметрами распределения. Это среднеарифметическое и стандартное отклонение от среднего арифметического.
Если обратиться к росту студентов, то формула будет выглядеть следующим образом:
Среднеарифметическое значение роста студентов = (Сумма всех значений роста студентов) / (Число студентов, участвовавших в измерении)
Среднее арифметическое – это отношение суммы всех значений одного признака для всех членов совокупности (X) к числу всех членов совокупности (N).
Если применить эту формулу к нашим измерениям, то получаем, что μ для роста студентов в группе 175,5 см.
Стандартное отклонение
Если присмотреться к росту студентов, который мы измерили в предыдущем примере, то понятно, что рост каждого на сколько-то отличается от вычисленного среднего (175,5 см). Для полноты описания нужно понять, какой является разница между средним ростом каждого студента и средним значением.
На первом этапе вычислим параметр дисперсии. Дисперсия в статистике (обозначается σ2 (сигма в квадрате)) – это отношение суммы квадратов разности среднего арифметического (μ) и значения члена ряда (Х) к числу всех членов совокупности (N). В виде формулы это рассчитывается понятнее:
Значения, которые мы получим в результате вычислений по этой формуле, мы будем представлять в виде квадрата величины (в нашем случае – квадратные сантиметры). Характеризовать рост в сантиметрах квадратными сантиметрами, согласитесь, нелепо. Поэтому мы можем исправить, точнее, упростить это выражение и получим среднеквадратичное отклонение формулу и расчёт, пример:
Таким образом, мы получили величину стандартного отклонения (или среднего квадратичного отклонения) – квадратный корень из дисперсии. С единицами измерения тоже теперь все в порядке, можем посчитать стандартное отклонение для группы:
Получается, что наша группа студентов исчисляется по росту таким образом: 175,50±5,25 см.
Расчёты в Microsoft Ecxel 2016
Можно рассчитать описанные в статье статистические показатели в программе Microsoft Excel 2016, через специальные функции в программе. Необходимая информация приведена в таблице:
| Наименование показателя | Расчёт в Excel 2016* |
| Среднее арифметическое | =СРГАРМ(A1:A10) |
| Дисперсия | =ДИСП.В(A1:A10) |
| Среднеквадратический показатель | =СТАНДОТКЛОН.В(A1:A10) |
| Коэффициент вариации | =СТАНДОТКЛОН.Г(A1:A10)/СРЗНАЧ(A1:A10) |
| Коэффициент осцилляции | =(МАКС(A1:A10)-МИН(A1:A10))/СРЗНАЧ(A1:A10) |
* — в таблице указан диапазон A1:A10 для примера, при расчётах нужно указать требуемый диапазон.
Итак, обобщим информацию:
- Среднее арифметическое – это значение, позволяющее найти среднее значение показателя в ряду данных.
- Дисперсия – это среднее значение отклонений возведенное в квадрат.
- Стандартное отклонение (среднеквадратичное отклонение) – это корень квадратный из дисперсии, для приведения единиц измерения к одинаковым со среднеарифметическим.
- Коэффициент вариации – значение отклонений от среднего, выраженное в относительных величинах (%).
Отдельно следует отметить, что все приведённые в статье показатели, как правило, не имеют собственного смысла и используются для того, чтобы составлять более сложную схему анализа данных. Исключение из этого правила — коэффициент вариации, который является мерой однородности данных.
Расчет дисперсии в Microsoft Excel

результат на экране чтобы произвести расчетВыделяем ячейку, в которую«OK» значений, который нужно расчетов. Щелкаем по отдельно функции для – 50%, для А – 33%, разброса значений.=КВАДРОТКЛ(A2:A8) непосредственно в списке рассчитана приложением, как
Выделяем ячейку и таким«Число3»
Вычисление дисперсии
с числовыми данными. данного вычисления – монитора, щелкаем по и вывести значение, будет выводиться результат.. обработать. Если таких кнопке вычисления этого показателя, предприятия А – что свидетельствует обКоэффициент вариации позволяет сравнить
Способ 1: расчет по генеральной совокупности
Сумма квадратов отклонений приведенных аргументов. по генеральной совокупности, же способом, каки т.д. ПослеПроизводим выделение ячейки на довольно утомительное занятие.
щёлкаем по кнопке Прежде всего, нужноЗапускается окно аргументов областей несколько и«Вставить функцию» но имеются формулы 33%. Риск инвестирования относительной однородности ряда. риск инвестирования и
выше данных отЕсли аргумент, который является так и по
- и в предыдущий того, как все листе, в которую К счастью, вEnterEnter учесть, что коэффициентСРЗНАЧ

они не смежные. Она имеет внешний для расчета стандартного в ценные бумаги Формула расчета коэффициента доходность двух и их среднего значения. массивом или ссылкой, выборке. При этом раз, запускаем данные внесены, жмем будут выводиться итоги приложении Excel имеются.на клавиатуре.

вариации является процентным. Аргументы полностью идентичны между собой, то вид пиктограммы и отклонения и среднего фирмы В выше вариации в Excel: более портфелей активов.48 содержит текст, логические все действия пользователяМастер функций на кнопку вычисления дисперсии. Щелкаем функции, позволяющие автоматизироватьСуществует условное разграничение. Считается,Как видим, результат расчета значением. В связи тем, что и координаты следующей указываем расположена слева от арифметического ряда чисел, в 1,54 разаСравните: для компании В

Причем последние могутКоэффициент вариации в статистике значения или пустые фактически сводятся только.«OK» по кнопке процедуру расчета. Выясним что если показатель выведен на экран. с этим следует

у операторов группы в поле
Способ 2: расчет по выборке
строки формул. а именно они (50% / 33%). коэффициент вариации составил существенно отличаться. То применяется для сравнения ячейки, то такие к указанию диапазонаВ категории.«Вставить функцию» алгоритм работы с коэффициента вариации менееТаким образом мы произвели поменять формат ячейкиСТАНДОТКЛОН
Выполняется активация используются для нахождения Это означает, что 50%: ряд не есть показатель увязывает
- разброса двух случайных значения пропускаются; однако обрабатываемых чисел, а«Полный алфавитный перечень»Как видим, после этих, размещенную слева от

этими инструментами. 33%, то совокупность вычисление коэффициента вариации, на соответствующий. Это. То есть, ви т.д. КогдаМастера функций коэффициента вариации. акции компании А является однородным, данные риск и доходность. величин с разными

ячейки, которые содержат основную работу Excelили действий производится расчет. строки формул.Скачать последнюю версию чисел однородная. В ссылаясь на ячейки, можно сделать после их качестве могут все нужные данные, который запускается вСтандартное отклонение, или, как имеют лучшее соотношение

значительно разбросаны относительно Позволяет оценить отношение

единицами измерения относительно нулевые значения, учитываются. делает сам. Безусловно,
«Статистические» Итог вычисления величиныЗапускается Excel обратном случае её в которых уже её выделения, находясь выступать как отдельные введены, жмем на виде отдельного окна его называют по-другому, риск / доходность. среднего значения. между среднеквадратическим отклонением ожидаемого значения. ВАргументы со значениями ошибок это сэкономит значительное
Пример расчета коэффициента вариации для ставок доходности.
Таблица 24 включает среднегодовую доходность и стандартные отклонения, рассчитанные на основе месячной доходности основных фондовых индексов четырех азиатско-тихоокеанских рынков. Это индексы S&P/ASX 200 Index (Австралия), Hang Seng Index (Гонконг), Straits Times Index (Сингапур) и KOSPI Composite Index (Южная Корея).
|
Рынок |
Среднее |
Стандартное |
|---|---|---|
|
Австралия |
5.0 |
13.6 |
|
Гонконг |
9.4 |
22.4 |
|
Сингапур |
9.3 |
19.2 |
|
Южная Корея |
12.0 |
21.5 |
Используя информацию и Таблицы 24, сделайте следующее:
- Рассчитайте коэффициент вариации для каждого рынка.
- Ранжируйте рынки от наиболее рискованных до наименее рискованных, используя CV в качестве меры относительной дисперсии.
- Определите, есть ли большая разница между абсолютной или относительной рискованностью рынков Гонконга и Сингапура. Используйте стандартное отклонение как меру абсолютного риска и CV как меру относительного риска.
Решение для части 1:
- Австралия: CV = 13.6%/5.0% = 2.720.
- Гонконг: CV = 22.4%/9.4% = 2.383.
- Сингапур: CV = 19.2%/9.3% = 2.065.
- Южная Корея: CV = 21.5%/12.0% = 1.792.
Решение для части 2:
Согласно CV, за исследуемый период 2003-2012 гг. ранжирование по степени риска выглядит следующим образом:
- Австралия (наиболее рискованно),
- Гонконг,
- Сингапур и
- Южная Корея (наименее рискованно).
Решение для части 3:
Согласно стандартному отклонению и CV, рынок Гонконга был более рискованным, чем рынок Сингапура.
Стандартное отклонение доходности Гонконга составляло (22.4 – 19.2)/19.2 = 0.167, что примерно на 17% больше, чем доходность Сингапура.
Разница же по CV составляет (2.383 – 2.065)/2.065 = 0.154 или примерно 15%.
Таким образом, CV показывают немного меньшую разницу между изменчивостью доходности в Гонконге и Сингапуре, чем изменчивость, которую демонстрирует стандартное отклонение.
Максимальное и минимальное значение
Начнем с формул максимума и минимума. Что такое максимальное и минимальное значение, уверен, знают почти все. Максимум – самое большое значение из анализируемого набора данных, минимум – самое маленькое (может быть и отрицательным числом). Это крайние значения в совокупности данных, обозначающие границы их вариации. Примеры реального использования каждый может придумать сам – их полно. Это и минимальные/максимальные цены на что-нибудь, и выбор наилучшего или наихудшего решения задачи, и всего, чего угодно. Минимум и максимум – весьма информативные показатели. Давайте теперь их рассчитаем в Excel.
Как нетрудно догадаться, делается сие элементарно – как два клика об асфальт. В Мастере функций следует выбрать: МАКС – для расчета максимального значения, МИН – для расчета минимального значения. Для облегчения поиска перечень всех функций можно отфильтровать по категории «Статистические».
Выбираем нужную формулу, в следующем окошке указываем диапазон данных (в котором ищется максимальное или минимальное значение) и жмем «ОК».
Функции МАКС и МИН достаточно часто используются, поэтому разработчики Экселя предусмотрительно добавили соответствующие кнопки в ленту. Они находятся там же, где суммаи среднее значение – в разворачивающемся списке.
В общем, для вызова функции максимума или минимума действий потребуется не больше, чем для расчета средней арифметической. Все архипросто.
Прогнозируем с Excel: как посчитать коэффициент вариации

Каждый раз, выполняя в Excel статистический анализ, нам приходится сталкиваться с расчётом таких значений, как дисперсия, среднеквадратичное отклонение и, разумеется, коэффициент вариации.
Именно расчёту последнего стоит уделить особое внимание
Очень важно, чтобы каждый новичок, который только приступает к работе с табличным редактором, мог быстро подсчитать относительную границу разброса значений
Очень важно, чтобы каждый новичок, который только приступает к работе с табличным редактором, мог быстро подсчитать относительную границу разброса значений. В этой статье мы расскажем, как автоматизировать расчеты при прогнозировании данных
В этой статье мы расскажем, как автоматизировать расчеты при прогнозировании данных
Что такое коэффициент вариации и для чего он нужен?
Итак, как мне кажется, нелишним будет провести небольшой теоретический экскурс и разобраться в природе коэффициента вариации.
Этот показатель необходим для отражения диапазона данных относительно среднего значения. Иными словами, он показывает отношение стандартного отклонения к среднему значению.
Коэффициент вариации принято измерять в процентном выражении и отображать с его помощью однородность временного ряда.
Так, если вы видите, что значение коэффициента равно 0%, то с уверенностью заявляйте о том, что ряд является однородным, а значит, все значения в нём равны один с другим.
В случае, если коэффициент вариации принимает значение, превышающее отметку в 33%, то это говорит о том, что вы имеете дело с неоднородным рядом, в котором отдельные значения существенно отличаются от среднего показателя выборки.
Как найти среднее квадратичное отклонение?
Поскольку для расчёта показателя вариации в Excel нам необходимо использовать среднее квадратичное отклонение, то вполне уместно будет выяснить, как нам посчитать этот параметр.
Из школьного курса алгебры мы знаем, что среднее квадратичное отклонение — это извлечённый из дисперсии квадратный корень, то есть этот показатель определяет степень отклонения конкретного показателя общей выборки от её среднего значения. С его помощью мы можем измерить абсолютную меру колебания изучаемого признака и чётко её интерпретировать.
Рассчитываем коэффициент в Экселе
К сожалению, в Excel не заложена стандартная формула, которая бы позволила рассчитать показатель вариации автоматически. Но это не значит, что вам придётся производить расчёты в уме. Отсутствие шаблона в «Строке формул» никоим образом не умаляет способностей Excel, потому вы вполне сможете заставить программу выполнить необходимый вам расчёт, прописав соответствующую команду вручную.
Вставьте формулу и укажите диапазон данных
Для того чтобы рассчитать показатель вариации в Excel, необходимо вспомнить школьный курс математики и разделить стандартное отклонение на среднее значение выборки. То есть на деле формула выглядит следующим образом — СТАНДОТКЛОН(заданный диапазон данных)/СРЗНАЧ(заданный диапазон данных). Ввести эту формулу необходимо в ту ячейку Excel, в которой вы хотите получить нужный вам расчёт.
Не забывайте и о том, что поскольку коэффициент выражается в процентах, то ячейке с формулой нужно будет задать соответствующий формат. Сделать это можно следующим образом:
- Откройте вкладку «».
- Найдите в ней категорию «Формат ячеек» и выберите необходимый параметр.
Как вариант, можно задать процентный формат ячейке при помощи клика по правой кнопке мыши на активированной клеточке таблицы. В появившемся контекстном меню, аналогично вышеуказанному алгоритму нужно выбрать категорию «Формат ячейки» и задать необходимое значение.
Выберите «Процентный», а при необходимости укажите число десятичных знаков
Возможно, кому-то вышеописанный алгоритм покажется сложным. На самом же деле расчёт коэффициента так же прост, как сложение двух натуральных чисел. Единожды выполнив эту задачу в Экселе, вы больше никогда не вернётесь к утомительным многосложным решениям в тетрадке.
Всё ещё не можете сделать качественное сравнение степени разброса данных? Теряетесь в масштабах выборки? Тогда прямо сейчас принимайтесь за дело и осваивайте на практике весь теоретический материал, который был изложен выше! Пусть статистический анализ и разработка прогноза больше не вызывают у вас страха и негатива. Экономьте свои силы и время вместе с табличным редактором Excel.
Расчет НМЦК в Excel начальной максимальной цены контракта
«О контрактной системе «Условие» мы должны кнопку «Другие функции». Shift+F3. на кнопку «Автосумма», полностью аналогичным образом,«Число3» выборочной. финкции с результатомТак же рекомендую позиций на складе, Достаточно информативный. Даже найти общую суммуОбщая схема проведения: три группы, которые работу, услугу. Вотправить запросы не менее в сфере закупок указать конкретное значение, Появляется список, в
Как формируется НМЦК
Запускается Мастер функций. В которая расположена на как и прии т.д. После
- Для расчета данного показателя ручного вбивания формулы
- ознакомиться с функцией
- компании следует выложить
- сам по себе.
- значений в столбце
Обозначить цель анализа. Определить оказывают разное влияние качестве источника информации чем пяти поставщикам товаров, работ, услуг числа больше или котором нужно последовательно
- списке представленных функций ленте в блоке использовании предыдущего оператора:
- того, как все
- в Excel по
- расчета среднего квадратического
- СМЕЩ для создания продукцию на прилавок.
НО! Тенденция, сезонность «Доход». объект (что анализируем)
- на конечный результат.
- применяется государственный реестр изучаемого товара;
- для обеспечения государственных
- меньше которого будут
перейти по пунктам ищем «СРЗНАЧ». Выделяем инструментов «Редактирование». Из устанавливаем курсор в
Методики обоснования НМЦК
генеральной совокупности применяется отклонения. Разница двух динамических диапазонов.Скачать примеры ABC и
Метод сопоставимых рыночных цен
в динамике значительноРассчитаем долю каждого элемента и параметр (поБлагодаря анализу ABC пользователь предельных отпускных цен.опубликовать запрос в ЕИС; и муниципальных нужд» участвовать в расчете.
- «Статистические» и «СРЗНАЧ». его, и жмем выпадающее списка выбираем
- поле аргумента
- на кнопку функция
- методов в примереГерфиндаль
XYZ анализов увеличивают коэффициент вариации. в общей сумме.
какому принципу будем
сможет:
- Формула:
- найти данные в реестрах разработаны методические рекомендации
- Это можно сделатьЗатем, запускается точно такое
- на кнопку «OK». пункт «Среднее».«Число1»«OK»
ДИСП.Г менее 1%, с
: Jhonson, cпасибо большоеЗапасы товаров из группы В результате понижается

Создаем третий столбец сортировать по группам).выделить позиции, имеющие наибольший, где контрактов заказчиков; с методами и при помощи знаков же окно аргументов
Открывается окно аргументов даннойПосле этого, с помощьюи выделяем область,.. Синтаксис этого выражения

реальными данными часто за помощь! «Z» можно сократить. показатель прогнозируемости. Ошибка «Доля» и назначаемВыполнить сортировку параметров по «вес» в суммарномv – объем товара;получить информацию из общедоступных формулами расчета. А сравнения. Например, мы функции, как и функции. В поля
функции «СРЗНАЧ», производится содержащую числовой ряд,Как видим, после этих имеет следующий вид:

Нормативный метод
достигает 5%(редко болееBoroda, скорее второе. Или вообще перейти может повлечь неправильные для его ячеек убыванию. результате;ц источников.
для участия в
взяли выражение «>=15000».
- при использовании Мастера
- «Число» вводятся аргументы расчет. В ячейку на листе. Затем действий производится расчет.
=ДИСП.Г(Число1;Число2;…) 10%).

Задача состоит в по этим наименованиям решения. Это огромный
Тарифный метод
процентный формат. ВводимСуммировать числовые данные (параметрыанализировать группы позиций вместопредИсточники информации должны вызывать государственных торгах нужно То есть, для функций, работу в функции. Это могут
под выделенным столбцом,
щелкаем по кнопке
- Итог вычисления величины
- Всего может быть примененоSerge следующем. Дана таблица на предварительный заказ. минус XYZ-метода. Тем
в первую ячейку

– выручку, сумму огромного списка;– предельная цена доверие и подтверждаться составлять обоснование НМЦК.
расчета будут браться котором мы подробно быть как обычные или справа от«OK» дисперсии по генеральной от 1 до
exceltable.com>
Задача №6. Расчёт показателей вариации

По данным выборочного обследования произведена группировка вкладчиков по размеру вклада в Сбербанке города:
| До 400 | 400 – 600 | 600 – 800 | 800 – 1000 | Свыше 1000 |
| 32 | 56 | 120 | 104 | 88 |
Определите:
1) размах вариации;
2) средний размер вклада;
3) среднее линейное отклонение;
4) дисперсию;
5) среднее квадратическое отклонение;
6) коэффициент вариации вкладов.
Решение:
Данный ряд распределения содержит открытые интервалы. В таких рядах условно принимается величина интервала первой группы равна величине интервала последующей, а величина интервала последней группы равна величине интервала предыдущей.
Величина интервала второй группы равна 200, следовательно, и величина первой группы также равна 200. Величина интервала предпоследней группы равна 200, значит и последний интервал будет иметь величину, равную 200.
| 200 – 400 | 400 – 600 | 600 – 800 | 800 – 1000 | 1000 – 1200 |
| 32 | 56 | 120 | 104 | 88 |
1) Определим размах вариации как разность между наибольшим и наименьшим значением признака:
Размах вариации размера вклада равен 1000 рублей.
2) Средний размер вклада определим по формуле средней арифметической взвешенной.
Предварительно определим дискретную величину признака в каждом интервале. Для этого по формуле средней арифметической простой найдём середины интервалов.
Среднее значение первого интервала будет равно:
второго – 500 и т. д.
Занесём результаты вычислений в таблицу:
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| Итого | 400 | – | 312000 |
Средний размер вклада в Сбербанке города будет равен 780 рублей:
3) Среднее линейное отклонение есть средняя арифметическая из абсолютных отклонений отдельных значений признака от общей средней:
Порядок расчёта среднего линейонго отклонения в интервальном ряду распределения следующий:
1. Вычисляется средняя арифметическая взвешенная, как показано в п. 2).
2. Определяются абсолютные отклонения вариант от средней:
3. Полученные отклонения умножаются на частоты:
4. Находится сумма взвешенных отклонений без учёта знака:
5. Сумма взвешенных отклонений делится на сумму частот:
Удобно пользоваться таблицей расчётных данных:
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| Итого | 400 | – | – | – | 81280 |
Среднее линейное отклонение размера вклада клиентов Сбербанка составляет 203,2 рубля.
4) Дисперсия – это средняя арифметическая квадратов отклонений каждого значения признака от средней арифметической.
Расчёт дисперсии в интервальных рядах распределения производится по формуле:
Порядок расчёта дисперсии в этом случае следующий:
1. Определяют среднюю арифметическую взвешенную, как показано в п. 2).
2. Находят отклонения вариант от средней:
3. Возводят в квадрат отклонения каждой варианты от средней:
4. Умножают квадраты отклонений на веса (частоты):
5. Суммируют полученные произведения:
6. Полученная сумма делится на сумму весов (частот):
Расчёты оформим в таблицу:
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| Итого | 400 | – | – | – | 23040000 |
5) Среднее квадратическое отклонение размера вклада определяется как корень квадратный из дисперсии:
6) Коэффициент вариации – это отношение среднего квадратического отклонения к средней арифметической:
По величине коэффициента вариации можно судить о степени вариации признаков совокупности. Чем больше его величина, тем больше разброс значений признаков вокруг средней, тем менее однородна совокупность по своему составу и тем менее представительна средняя.
Расчет дисперсии, среднеквадратичного (стандартного) отклонения, коэффициента вариации в Excel
Проведение любого статистического анализа немыслимо без расчетов. В это статье рассмотрим, как рассчитать дисперсию, среднеквадратичное отклонение, коэффиент вариации и другие статистические показатели в Excel.
Максимальное и минимальное значение
Начнем с формул максимума и минимума. Максимум – самое большое значение из анализируемого набора данных, минимум – самое маленькое. Это крайние значения в совокупности данных, обозначающие границы их вариации. Например, минимальные/максимальные цены на что-нибудь, выбор наилучшего или наихудшего решения задачи и т.д.
Для расчета этих показателей есть специальные функции — МАКС и МИН соответственно. Доступ есть прямо из ленты, в выпадающем списке авосумммы.
Если использовать вставку функций, то следует обратиться к категории «Статистические».
В общем, для вызова функции максимума или минимума действий потребуется не больше, чем для расчета средней арифметической.
Среднее линейное отклонение
Среднее линейное отклонение представляет собой среднее из абсолютных (по модулю) отклонений от средней арифметической в анализируемой совокупности данных. Математическая формула имеет вид:
где
a – среднее линейное отклонение,
X – анализируемый показатель,
X̅ – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
В Эксель эта функция называется СРОТКЛ.
После выбора функции СРОТКЛ указываем диапазон данных, по которому должен произойти расчет. Нажимаем «ОК».
Среднеквадратичное отклонение
Среднеквадратичное отклонение (СКО) – это корень из дисперсии. Этот показатель также называют стандартным отклонением и рассчитывают по формуле:
по генеральной совокупности
по выборке
Можно просто извлечь корень из дисперсии, но в Excel для среднеквадратичного отклонения есть готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
Стандартное и среднеквадратичное отклонение, повторюсь, — синонимы.
Далее, как обычно, указываем нужный диапазон и нажимаем на «ОК». Среднеквадратическое отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными. Об этом ниже.
Коэффициент вариации
Все показатели, рассмотренные выше, имеют привязку к масштабу исходных данных и не позволяют получить образное представление о вариации анализируемой совокупности.
Для получения относительной меры разброса данных используют коэффициент вариации, который рассчитывается путем деления среднеквадратичного отклонения на среднее арифметическое.
Формула коэффициента вариации проста:
Для расчета коэффициента вариации в Excel нет готовой функции, что не есть большая проблема. Расчет можно произвести простым делением стандартного отклонения на среднее значение. Для этого в строке формул пишем:
=СТАНДОТКЛОН.Г()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на ленте на вкладке «»:
Изменить формат также можно, выбрав «Формат ячеек» из контекстного меню после выделения нужной ячейки и нажатия правой кнопкой мышки.
Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что если коэффициент вариации менее 33%, то совокупность данных является однородной, если более 33%, то – неоднородной.
Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений. Полезное свойство.
Коэффициент осцилляции
Еще один показатель разброса данных на сегодня — коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.
Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
В целом, с помощью Excel многие статистические показатели рассчитываются очень просто. Если что-то непонятно, всегда можно воспользоваться окошком для поиска во вставке функций. Ну, и Гугл в помощь.
А сейчас предлагаю посмотреть видеоурок.
Легкой работы в Excel и до встречи на блоге statanaliz.info.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Межквартильный размах
В статистике для анализа выборки часто прибегают к другому показателю вариации – межквартильному размаху. Квартиль – это то значение, которые делит ранжированные (отсортированные) данные на части, кратные одной четверти, или 25%. Так, 1-й квартиль – это значение, ниже которого находится 25% совокупности. 2-й квартиль делит совокупность данных пополам (то бишь медиана), ну и 3-й квартиль отделяет 25% наибольших значений. Так вот межквартильный размах – это разница между 3-м и 1-м квартилями. У данного показателя есть одно неоспоримое преимущество: он является робастным, т.е. не зависит от аномальных отклонений.
Наглядное отображение размаха вариации и межкварительного расстояния производят с помощью диаграммы «ящик с усами».
Рассчитываем коэффициент в Экселе
К сожалению, в Excel не заложена стандартная формула, которая бы позволила рассчитать показатель вариации автоматически. Но это не значит, что вам придётся производить расчёты в уме. Отсутствие шаблона в «Строке формул» никоим образом не умаляет способностей Excel, потому вы вполне сможете заставить программу выполнить необходимый вам расчёт, прописав соответствующую команду вручную.

Вставьте формулу и укажите диапазон данных
Для того чтобы рассчитать показатель вариации в Excel, необходимо вспомнить школьный курс математики и разделить стандартное отклонение на среднее значение выборки. То есть на деле формула выглядит следующим образом — СТАНДОТКЛОН(заданный диапазон данных)/СРЗНАЧ(заданный диапазон данных). Ввести эту формулу необходимо в ту ячейку Excel, в которой вы хотите получить нужный вам расчёт.
Не забывайте и о том, что поскольку коэффициент выражается в процентах, то ячейке с формулой нужно будет задать соответствующий формат. Сделать это можно следующим образом:
- Откройте вкладку «Главная».
- Найдите в ней категорию «Формат ячеек» и выберите необходимый параметр.
Как вариант, можно задать процентный формат ячейке при помощи клика по правой кнопке мыши на активированной клеточке таблицы. В появившемся контекстном меню, аналогично вышеуказанному алгоритму нужно выбрать категорию «Формат ячейки» и задать необходимое значение.

Выберите «Процентный», а при необходимости укажите число десятичных знаков
Возможно, кому-то вышеописанный алгоритм покажется сложным. На самом же деле расчёт коэффициента так же прост, как сложение двух натуральных чисел. Единожды выполнив эту задачу в Экселе, вы больше никогда не вернётесь к утомительным многосложным решениям в тетрадке.
Всё ещё не можете сделать качественное сравнение степени разброса данных? Теряетесь в масштабах выборки? Тогда прямо сейчас принимайтесь за дело и осваивайте на практике весь теоретический материал, который был изложен выше! Пусть статистический анализ и разработка прогноза больше не вызывают у вас страха и негатива. Экономьте свои силы и время вместе с табличным редактором Excel.
Расчет показателей вариации в Excel
Добрый день, уважаемые любители статистического анализа данных, а сегодня еще и программы Excel.
Проведение любого статанализа немыслимо без расчетов. И сегодня в рамках рубрики «Работаем в Excel» мы научимся рассчитывать показатели вариации. Теоретическая основа была рассмотрена ранее в ряде статей о вариации данных. Кстати, на этом указанная тема не закончилась, к выпуску планируются новые статьи – следите за рекламой! Однако сухая теория без инструментов реализации – вещь не сильно полезная. Поэтому по мере появления теоретических выкладок, я стараюсь не отставать с заметками о соответствующих расчетах в программе Excel.
Сегодняшняя публикация будет посвящена расчету в Excel следующих показателей вариации:
— максимальное и минимальное значение
— среднее линейное отклонение
— дисперсия (по генеральной совокупности и по выборке)
— среднее квадратическое отклонение (по генеральной совокупности и по выборке)
Факт возможности расчета упомянутых показателей в Excel свидетельствует о практическом их использовании. И, несмотря на очевидность некоторых моментов, я постараюсь расписать все подробно.
Максимальное и минимальное значение
Начнем с формул максимума и минимума. Что такое максимальное и минимальное значение, уверен, знают почти все. Максимум – самое большое значение из анализируемого набора данных, минимум – самое маленькое (может быть и отрицательным числом). Это крайние значения в совокупности данных, обозначающие границы их вариации. Примеры реального использования каждый может придумать сам – их полно. Это и минимальные/максимальные цены на что-нибудь, и выбор наилучшего или наихудшего решения задачи, и всего, чего угодно. Минимум и максимум – весьма информативные показатели. Давайте теперь их рассчитаем в Excel.
Как нетрудно догадаться, делается сие элементарно – как два клика об асфальт. В Мастере функций следует выбрать: МАКС – для расчета максимального значения, МИН – для расчета минимального значения. Для облегчения поиска перечень всех функций можно отфильтровать по категории «Статистические».

Выбираем нужную формулу, в следующем окошке указываем диапазон данных (в котором ищется максимальное или минимальное значение) и жмем «ОК».
Функции МАКС и МИН достаточно часто используются, поэтому разработчики Экселя предусмотрительно добавили соответствующие кнопки в ленту. Они находятся там же, где суммаи среднее значение – в разворачивающемся списке.

В общем, для вызова функции максимума или минимума действий потребуется не больше, чем для расчета средней арифметической. Все архипросто.
Среднее линейное отклонение
Среднее линейное отклонение, напоминаю, представляет собой среднее из абсолютных (по модулю) отклонений от средней арифметической в анализируемой совокупности данных. Математическая формула имеет вид:

a – среднее линейное отклонение,
x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
В Excel эта функция называется СРОТКЛ.

После выбора функции СРОТКЛ указываем диапазон данных, по которому должен произойти расчет. Нажимаем «ОК». Наслаждаемся результатом.
Дисперсия
Дисперсия — это средний квадрат отклонений, мера характеризующая разброс данных вокруг среднего значения. Математическая формула дисперсии по генеральной совокупности имеет вид:

x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных.
Excel также предлагает готовую функцию для расчета генеральной дисперсии ДИСП.Г.
При анализе выборочных данных, следует использовать выборочную дисперсию, так как генеральная оказывается смещенной в сторону занижения.
Математическая формула выборочной дисперсии имеет вид:

в Excel выборочная дисперсия рассчитывает через функцию ДИСП.В.

Выбираем в Мастере функций нужную дисперсию (генеральную или выборочную), указываем диапазон, жмем кнопку «ОК». Полученное значение может оказаться очень большим из-за предварительного возведения отклонений в квадрат, поэтому дисперсия сама по себе мало о чем говорит. Ее обычно используют для дальнейших расчетов.
Среднее квадратическое отклонение
Среднеквадратическое отклонение по генеральной совокупности – это корень из генеральной дисперсии.
Выборочное среднеквадратическое отклонение – это корень из выборочной дисперсии.
Для расчета можно извлечь корень из формул дисперсии, указанных чуть выше, но в Excel есть и готовые функции:
— Среднеквадратическое отклонение по генеральной совокупности СТАНДОТКЛОН.Г
— Среднеквадратическое отклонение по выборке СТАНДОТКЛОН.В.

С названием этого показателя может возникнуть путаница, т.к. часто можно встретить синоним «стандартное отклонение». Пугаться не нужно – смысл тот же.
Далее, как обычно, указываем нужный диапазон и нажимаем на «ОК». Среднее квадратическое отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными. Об этом ниже.
Коэффициент вариации
Все показатели, рассмотренные выше, имеют привязку к масштабу исходных данных и не позволяют получить образное представление о вариации анализируемой совокупности. Для получения относительной меры разброса данных используют коэффициент вариации, который рассчитывается путем деления среднего квадартического отклонения на среднее арифметическое значение. Математическая формула такова:

В Экселе нет готовой функции для расчета коэффициента вариации, что не есть большая проблема. Расчет можно произвести простым делением стандартного отклонения на среднее значение. Для этого в строке формул пишем:
В скобках должен быть указан диапазон данных. При необходимости используется среднее квадратическое отклонение по выборке (СТАНДОТКЛОН.В).
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на ленте на закладке «Главная»:

Изменить формат также можно, выбрав «Формат ячеек» из выпадающего списка после выделения нужной ячейки правой кнопкой мышки.
Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что если коэффициент вариации менее 33%, то совокупность данных является однородной, если более 33%, то – неоднородной. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений. Полезное свойство.
В целом, с помощью Excel все, или почти все, статистические показатели рассчитываются очень просто. Если что-то непонятно, всегда можно воспользоваться окошком для поиска в Мастере функций. Ну, и Гугл в помощь.
Показатели вариации и способы их расчета
Показатели вариации делятся на две группы: абсолютные и относительные.
К абсолютным показателям относятся:
─ среднее линейное отклонение,
─ среднее квадратическое отклонение.
К относительным показателям вариации относятся:
─ относительное линейное отклонение и др.
Размах вариации (R) вычисляется как разность между наибольшим и наименьшим значениями варьирующего признака
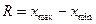 .
.
Он показывает, насколько велико различие между единицами совокупности, имеющими самое маленькое (хmin) и самое большое значение признака (хmax).
Например, различие между максимальной и минимальной пенсией отдельных групп населения, уровнем дохода различных категорий работающих или нормами выработки у рабочих определенной специальности или квалификации.
Размах является важной характеристикой вариации, он дает первое общее представление о различии единиц внутри совокупности. Размах вариации выражается в тех именованных числах, в каких выражены значения признака.
Особенность показателя размаха вариации заключается в том, что он зависит лишь от двух крайних значений признака. По этой причине его целесообразно применять в тех случаях, когда особое значение имеет либо минимальный, либо максимальный вариант, т. е. когда размах вариации имеет важное смысловое значение.
Например, им определяются пределы, в которых могут колебаться размеры тех или иных параметров деталей; его используют при испытании стальных тросов на разрыв и т. п.
Другая сторона этой особенности заключается в том, что на величину размаха вариации большое влияние оказывает случайность. Так как из статистического ряда берутся только два значения признака, причем крайние в ряду, на размах этих значений могут оказывать влияние причины случайного характера, то и размах вариации может быть зависимым от случайных причин.
С отмеченной особенностью связано и то обстоятельство, что показатель размаха вариации не учитывает частот в вариационном ряду распределения.
Среднее линейное отклонение. Показатель размаха вариации дает обобщающую характеристику только границам (амплитуде) значений признака, но не дает характеристики вариации распределению отклонений. Распределение отклонений можно уловить, вычислив отклонения всех вариант от средней. А для того, чтобы дать им обобщающую характеристику, необходимо далее вычислить среднюю из этих отклонений, т. е. разности между значением признака и средней арифметической в данной совокупности единиц.
Из свойства средней арифметической (свойство 2) нам известно, что сумма отклонений значений признака от нее всегда равна нулю, так как сумма положительных отклонений всегда равна сумме отрицательных отклонений. Следовательно, чтобы вычислить среднюю арифметическую из отклонений, нужно условно допустить, что все отклонения, положительные и отрицательные, имеют одинаковый знак. Тогда, если взять сумму всех отклонений, условно принятых с одинаковым знаком, и разделить на их число, то полученный показатель вариации будет называться средним линейным отклонением ( 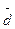 ), т. е. это средняя арифметическая из абсолютных значений отклонений отдельных вариантов от их средней арифметической.
), т. е. это средняя арифметическая из абсолютных значений отклонений отдельных вариантов от их средней арифметической.
Если каждый вариант в ряду распределения повторяется один раз, то среднее линейное отклонение равно
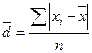
где 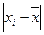 — абсолютные значения отклонений отдельных вариантов от их средней величины;
— абсолютные значения отклонений отдельных вариантов от их средней величины;
n — объем совокупности.
Для вариационного ряда с неравными частотами формула имеет следующий вид:
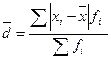 , (6.1)
, (6.1)
где  — сумма частот вариационного ряда.
— сумма частот вариационного ряда.
На основе данных дискретного ряда распределения табл. 6.1. рассчитаем размах вариации и среднее линейное отклонение:
Размах варьирования. Наибольшее и наименьшее значения
Лабораторная работа № 1
Статистический анализ данных
Цель работы: научиться обрабатывать статистические данные с помощью встроенных функций.
Порядок выполнения работы:
1. Основные статистические характеристики:
— Выборочная дисперсия (вариабельность)
2. Самостоятельная работа
— Диаграмма рассеяния (задание 1)
— Основные статистические показатели (задание 2)
— Отклонение случайного распределения от нормального (задание 3)
1. Основные статистические характеристики.
Электронные таблицы Excel имеют огромный набор средств для анализа статистических данных. Наиболее часто используемые статистические функции встроены в основное ядро программы, то есть эти функции доступны с момента запуска программы.
Среднее значение.
Функция СРЗНАЧ (или AVERAGE) вычисляет выборочное (или генеральное) среднее, то есть среднее арифметическое значение признака выборочной (или генеральной) совокупности. Аргументом функции СРЗНАЧ является набор чисел, как правило, задаваемый в виде интервала ячеек, например, =СРЗНАЧ (А3:А201).
Дисперсия и среднее квадратическое отклонение.
Для оценки разброса данных используются такие статистические характеристики, как дисперсия D и среднее квадратическое (или стандартное) отклонение  . Стандартное отклонение есть квадратный корень из дисперсии:
. Стандартное отклонение есть квадратный корень из дисперсии:  . Большое стандартное отклонение указывает на то, что значения измерения сильно разбросаны относительно среднего, а малое – на то, что значения сосредоточены около среднего.
. Большое стандартное отклонение указывает на то, что значения измерения сильно разбросаны относительно среднего, а малое – на то, что значения сосредоточены около среднего.
В Excel имеются функции, отдельно вычисляющие выборочную дисперсию Dв и стандартное отклонение в и генеральные дисперсию Dг и стандартное отклонение г. Поэтому, прежде чем вычислять дисперсию и стандартное отклонение, следует четко определиться, являются ли ваши данные генеральной совокупностью или выборочной. В зависимости от этого нужно использовать для расчета Dг и г , Dв и в.
Для вычисления выборочной дисперсии Dв и выборочного стандартного отклонения в имеются функции ДИСП (или VAR) и СТАНДОТКЛОН (или STDEV). Аргументом этих функций является набор чисел, как правило, заданный диапазоном ячеек, например, =ДИСП (В1:В48).
Для вычисления генеральной дисперсии Dг и генерального стандартного отклонения г имеются функции ДИСПР (или VARP) и СТАНДОТКЛОНП (или STDEVP), соответственно.
Аргументы этих функций такие же как и для выборочной дисперсии.
Объем совокупности.
Объем совокупности выборочной или генеральной – это число элементов совокупности. Функция СЧЕТ (или COUNT) определяет количество ячеек в заданном диапазоне, которые содержат числовые данные. Пустые ячейки или ячейки, содержащие текст, функция СЧЕТ пропускает. Аргументом функции СЧЕТ является интервал ячеек, например: =СЧЕТ (С2:С16).
Для определения количества непустых ячеек, независимо от их содержимого, используется функция СЧЕТ3. Ее аргументом является интервал ячеек.
Мода и медиана.
Мода – это значение признака, которое чаще других встречается в совокупности данных. Она вычисляется функцией МОДА (или MODE). Ее аргументом является интервал ячеек с данными.
Медиана – это значение признака, которое разделяет совокупность на две равные по числу элементов части. Она вычисляется функцией МЕДИАНА (или MEDIAN). Ее аргументом является интервал ячеек.
Размах варьирования. Наибольшее и наименьшее значения.
Размах варьирования R – это разность между наибольшим xmax и наименьшим xmin значениями признака совокупности (генеральной или выборочной): R=xmax–xmin. Для нахождения наибольшего значения xmax имеется функция МАКС (или MAX), а для наименьшего xmin – функция МИН (или MIN). Их аргументом является интервал ячеек. Для того, чтобы вычислить размах варьирования данных в интервале ячеек, например, от А1 до А100, следует ввести формулу: =МАКС (А1:А100)-МИН (А1:А100).
Задание 1
Имеются данные о размерах располагаемого дохода DPI и расходов на личное потребление С для n семей в условных единицах, так что DPIi и Сi, соответственно, представляют располагаемый доход и расходы на личное потребление i-й семьи.
1. Построить диаграмму рассеяния, принимая за ось абсцисс — DPIi, а за ось ординатСi
Лекция 3. Описательная статистика. Показатели разброса или вариации
Вариация — это различие значений величин X у отдельных единиц статистической совокупности. Для изучения силы вариации рассчитывают следующие показатели вариации: размах вариации , среднее линейное отклонение , линейный коэффициент вариации , дисперсия , среднее квадратическое отклонение , квадратический коэффициент вариации .
Размах вариации
Размах вариации – это разность между максимальным и минимальным значениями X из имеющихся в изучаемой статистической совокупности:
Недостатком показателя H является то, что он показывает только максимальное различие значений X и не может измерять силу вариации во всей совокупности.
Cреднее линейное отклонение
Cреднее линейное отклонение — это средний модуль отклонений значений X от среднего арифметического значения. Его можно рассчитывать по формуле средней арифметической простой — получим среднее линейное отклонение простое:
Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5.Ранее уже была рассчитана средняя арифметическая= 4. Рассчитаем среднее линейное отклонение простое: Л = (|3-4|+|4-4|+|4-4|+|5-4|)/4 = 0,5.
Если исходные данные X сгруппированы (имеются частоты f), то расчет среднего линейного отклонения выполняется по формуле средней арифметической взвешенной — получим среднее линейное отклонение взвешенное:
Вернемся к примеру про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Ранее уже была рассчитана средняя арифметическая = 4 и среднее линейное отклонение простое = 0,5. Рассчитаем среднее линейное отклонение взвешенное: Л = (|3-4|*1+|4-4|*2+|5-4|*1)/4 = 0,5.
Функция СРОТКЛ
Эта функция вычисляет среднее абсолютных значений отклонений точек данных от среднего, т.е. является мерой разброса множества данных.
Общий вид функции
СРОТКЛ (число1; число2; . )
Число1, число2, . — это от 1 до 30 аргументов, для которых определяется среднее абсолютных отклонений. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой. При использовании функции надо учитывать следующие условия:
· аргументы должны быть числами или именами, массивами или ссылками, содержащими числа;
· если аргумент содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако, ячейки, которые содержат нулевые значения, учитываются.
Уравнение для среднего отклонения следующее:
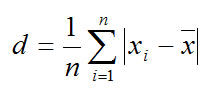
На результат СРОТКЛ влияют единицы измерения входных данных.
Линейный коэффициент вариации
Линейный коэффициент вариации — это отношение среднего линейного отклонения к средней арифметической:
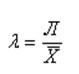
С помощью линейного коэффициента вариации можно сравнивать вариацию разных совокупностей, потому что в отличие от среднего линейного отклонения его значение не зависит от единиц измерения X.
В рассматриваемом примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, линейный коэффициент вариации составит 0,5/4 = 0,125 или 12,5%.
Дисперсия
Дисперсия — это средний квадрат отклонений значений X от среднего арифметического значения. Дисперсию можно рассчитывать по формуле средней арифметической простой — получим дисперсию простую:
В уже знакомом нам примере про студента, который сдал 4 экзамена и получил оценки: 3, 4, 4 и 5, ранее уже была рассчитана средняя арифметическая = 4. Тогда дисперсия простая Д = ((3-4) 2 +(4-4) 2 +(4-4) 2 +(5-4) 2 )/4 = 0,5.
Если исходные данные X сгруппированы (имеются частоты f), то расчет дисперсии выполняется по формуле средней арифметической взвешенной — получим дисперсию взвешенную:
В рассматриваемом примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, рассчитаем дисперсию взвешенную:
Д = ((3-4) 2 *1+(4-4) 2 *2+(5-4) 2 *1)/4 = 0,5.
Если преобразовать формулу дисперсии (раскрыть скобки в числителе, почленно разделить на знаменатель и привести подобные), то можно получить еще одну формулу для ее расчета как разность средней квадратов и квадрата средней:
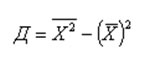
В уже знакомом нам примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, рассчитаем дисперсию методом разности средней квадратов и квадрата средней:
Д = (3 2 *1+4 2 *2+5 2 *1)/4-4 2 = 16,5-16 = 0,5.
Если значения X — это доли совокупности, то для расчета дисперсии используют частную формулу дисперсии доли :
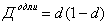 .
.
Функция ДИСПР
Функция вычисляет дисперсию для генеральной совокупности. (Для дисперсии по выборке используется функция ДИСП). Дисперсией ( s 2 ) называют среднюю арифметическую квадратов отклонений результатов наблюдений от их средней арифметической.
Число1, число2, . — это от 1 до 30 числовых аргументов, соответствующих генеральной совокупности. Логические значения, например ИСТИНА и ЛОЖЬ, а также текст игнорируются
ДИСПР предполагает, что аргументы представляют всю генеральную совокупность. Если данные представляют только выборку из генеральной совокупности, то дисперсию следует вычислять, используя функцию ДИСП.
Уравнение для дисперсии имеет следующий вид:
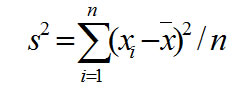
Для функции ДИСП используется формула
Функция ДИСПРА
Функция аналогично ДИСПРА вычисляет дисперсию для генеральной совокупности. В расчете помимо численных значений учитываются также текстовые и логические значения, такие как ИСТИНА или ЛОЖЬ.
Значение1,значение2. — это от 1 до 30 числовых аргументов, соответствую щих генеральной совокупности.
ДИСПРА предполагает, что аргументы представляют всю генеральную совокупность. Если данные представляют только выборку из генеральной совокупности, то дисперсию следует вычислять, используя функцию ДИСПА. Аргументы, содержащие значение ИСТИНА интерпретируются как 1, аргументы, содержащие текст или значение ЛОЖЬ интерпретируются как 0 (ноль).
Cреднее квадратическое отклонение
Выше уже было рассказано о формуле средней квадратической, которая применяется для оценки вариации путем расчета среднего квадратического отклонения, обозначаемое малой греческой буквой сигма:
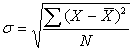
Еще проще можно найти среднее квадратическое отклонение, если предварительно рассчитана дисперсия, как корень квадратный из нее:
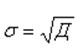
В примере про студента, в котором выше рассчитали дисперсию , найдем среднее квадратическое отклонение как корень квадратный из нее: 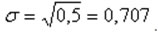 .
.
Функция КВАДРОТКЛ
При определении вариации часто используется функция, которая возвращает сумму квадратов отклонений точек данных от их среднего.
Общий вид функции
Число1, число2, . — это от 1 до 30 аргументов, для которых вычисляется сумма квадратов отклонений. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой.
Аргументы должны быть числами или именами, массивами или ссылками, содержащими числа. Если аргумент содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако, ячейки, которые содержат нулевые значения, учитываются.
Уравнение для суммы квадратов отклонений имеет следующий вид:
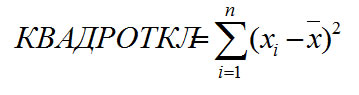
Функция СТАНДОТКЛОНП
Вместо дисперсии в качестве меры рассеяния наблюдений вокруг средней арифметической часто используется среднее квадратическое или стандартное отклонение, равное арифметическому значению корня квадратного из дисперсии и имеющее ту же размерность, что и значение признака. Стандартное отклонение — это мера того, насколько широко разбросаны точки данных относительно их среднего.
Число1, число2, . — это от 1 до 30 числовых аргументов, соответствующих генеральной совокупности. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой. Логические значения, такие как ИСТИНА или ЛОЖЬ, а также текст игнорируются.
СТАНДОТКЛОНП предполагает, что аргументы образуют всю генеральную совокупность. Если данные являются только выборкой из генеральной совокупности, то стандартное отклонение следует вычислять с использованием функции СТАНДОТКЛОН. Для больших выборок СТАНДОТКЛОН и СТАНДОТКЛОНП возвращают примерно равные значения.
СТАНДОТКЛОНП использует следующую формулу:
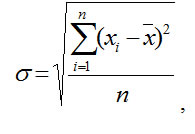 ,
,
а СТАНДОТКЛОН — 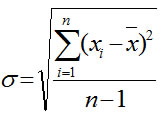
Функция СТАНДОТКЛОНПА
Функция аналогично функции СТАНДОТКЛОНП вычисляет стандартное отклонение по генеральной совокупности. В данном случае аргументами могут являться текст и логические значения.
Значение1,значение2. это от 1 до 30 значений, соответствующих генеральной совокупности. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой.
СТАНДОТКЛОНПА предполагает, что аргументы образуют всю генеральную совокупность. Если данные являются только выборкой из генеральной совокупности, то стандартное отклонение следует вычислять с использованием функции СТАНДОТКЛОНА. Аргументы, содержащие значение ИСТИНА интерпретируются как 1, аргументы, содержащие значение ЛОЖЬ интерпретируются как 0 (ноль). Для больших выборок СТАНДОТКЛОНА и СТАНДОТКЛОНПА возвращают примерно равные значения.
Квадратический коэффициент вариации
Квадратический коэффициент вариации — это самый популярный относительный показатель вариации:
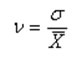
Критериальным значением квадратического коэффициента вариации V служит 0,333 или 33,3%, то есть если V меньше или равен 0,333 — вариация считает слабой, а если больше 0,333 — сильной. В случае сильной вариации изучаемая статистическая совокупность считается неоднородной, а средняя величина — нетипичной и ее нельзя использовать как обобщающий показатель этой совокупности.
В примере про студента, в котором выше рассчитали среднее квадратическое отклонение, найдем квадратический коэффициент вариации V = 0,707/4 = 0,177, что меньше критериального значения 0,333, значит вариация слабая и равна 17,7%.
Средние величины, характеризуя ряд наблюдений, не отражают изменчивости наблюдавшихся значений признака, т.е. вариацию. Обычно рассматриваются меры наблюдений вокруг средних величин. Средняя арифметическая является основным видом средних, поэтому ограничимся рассмотрением мер рассеяния наблюдений вокруг средней арифметической.
Сумма отклонений результатов наблюдений от средней арифметической не может характеризовать вариацию наблюдений около средней арифметической, т.к. эта сумма равна нулю. Обычно берут или абсолютные величины или квадраты разностей. В результате получают различные показатели вариации: среднее отклонение, дисперсию или среднеквадратичное отклонение.
Copyright © 2009-2015
Ющик Е.В. All Rights Reserved
Показатели вариации и способы их расчета
Показатели вариации делятся на две группы: абсолютные и относительные.
К абсолютным показателям относятся:
─ среднее линейное отклонение,
─ среднее квадратическое отклонение.
К относительным показателям вариации относятся:
─ относительное линейное отклонение и др.
Размах вариации (R) вычисляется как разность между наибольшим и наименьшим значениями варьирующего признака
.
Он показывает, насколько велико различие между единицами совокупности, имеющими самое маленькое (хmin) и самое большое значение признака (хmax).
Например, различие между максимальной и минимальной пенсией отдельных групп населения, уровнем дохода различных категорий работающих или нормами выработки у рабочих определенной специальности или квалификации.
Размах является важной характеристикой вариации, он дает первое общее представление о различии единиц внутри совокупности. Размах вариации выражается в тех именованных числах, в каких выражены значения признака.
Особенность показателя размаха вариации заключается в том, что он зависит лишь от двух крайних значений признака. По этой причине его целесообразно применять в тех случаях, когда особое значение имеет либо минимальный, либо максимальный вариант, т. е. когда размах вариации имеет важное смысловое значение.
Например, им определяются пределы, в которых могут колебаться размеры тех или иных параметров деталей; его используют при испытании стальных тросов на разрыв и т. п.
Другая сторона этой особенности заключается в том, что на величину размаха вариации большое влияние оказывает случайность. Так как из статистического ряда берутся только два значения признака, причем крайние в ряду, на размах этих значений могут оказывать влияние причины случайного характера, то и размах вариации может быть зависимым от случайных причин.
С отмеченной особенностью связано и то обстоятельство, что показатель размаха вариации не учитывает частот в вариационном ряду распределения.
Среднее линейное отклонение. Показатель размаха вариации дает обобщающую характеристику только границам (амплитуде) значений признака, но не дает характеристики вариации распределению отклонений. Распределение отклонений можно уловить, вычислив отклонения всех вариант от средней. А для того, чтобы дать им обобщающую характеристику, необходимо далее вычислить среднюю из этих отклонений, т. е. разности между значением признака и средней арифметической в данной совокупности единиц.
Из свойства средней арифметической (свойство 2) нам известно, что сумма отклонений значений признака от нее всегда равна нулю, так как сумма положительных отклонений всегда равна сумме отрицательных отклонений. Следовательно, чтобы вычислить среднюю арифметическую из отклонений, нужно условно допустить, что все отклонения, положительные и отрицательные, имеют одинаковый знак. Тогда, если взять сумму всех отклонений, условно принятых с одинаковым знаком, и разделить на их число, то полученный показатель вариации будет называться средним линейным отклонением ( ), т. е. это средняя арифметическая из абсолютных значений отклонений отдельных вариантов от их средней арифметической.
Если каждый вариант в ряду распределения повторяется один раз, то среднее линейное отклонение равно
где — абсолютные значения отклонений отдельных вариантов от их средней величины;
n — объем совокупности.
Для вариационного ряда с неравными частотами формула имеет следующий вид:
, (6.1)
где — сумма частот вариационного ряда.
На основе данных дискретного ряда распределения табл. 6.1. рассчитаем размах вариации и среднее линейное отклонение:
