Определить объём текста
Онлайн калькулятор легко и непринужденно вычислит объем текста в битах, байтах и килобайтах. Для перевода в другие единицы измерения данных воспользуйтесь онлайн конвертером.
Информационный вес (объем) символа текста определяется для следующих кодировок:
Unicode UTF-8
Unicode UTF-16
ASCII, ANSI, Windows-1251
| Текст |
|
Символов 0 Символов без учета пробелов 0 Уникальных символов 0 Слов 0 Слов (буквенных) 0 Уникальных слов 0 Строк 0 Абзацев 0 Предложений 0 Средняя длина слова 0 Время чтения 0 сек Букв 0 Русских букв 0 Латинских букв 0 Гласных букв 0 Согласных букв 0 Слогов 0 Цифр 0 Чисел 0 Пробелов 0 Остальных знаков 0 Знаков препинания 0 Объем текста (Unicode UTF-8) бит 0 Объем текста (Unicode UTF-8) байт 0 Объем текста (Unicode UTF-8) килобайт 0 Объем текста (Unicode UTF-16) бит 0 Объем текста (Unicode UTF-16) байт 0 Объем текста (Unicode UTF-16) килобайт 0 Объем текста (ASCII, ANSI, Windows-1251) бит 0 Объем текста (ASCII, ANSI, Windows-1251) байт 0 Объем текста (ASCII, ANSI, Windows-1251) килобайт 0 |
|
|
Почему на windows сохраняя текст блокноте перенос строки занимает – 4 байта в юникоде или 2 байта в анси?
Это историческое явление, которое берёт начало с дос, последовательность OD OA (nr ) в виндовс используются чтоб был единообразный вывод на терминал независимо консоль это или принтер. Но для вывода просто на консоль достаточно только n.
В юникоде есть символы которые весят 4 байта, например эмоджи: 🙃
×
Пожалуйста напишите с чем связна такая низкая оценка:
×
Для установки калькулятора на iPhone – просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android – просто добавьте страницу
«На главный экран»

Калькулятор считает, сколько бит занимает введенный текст.
Результат выдается сразу в двух кодировках: UTF-8/cp1251/KOI8/CP866 и UTF-16. В UTF-16 текст занимает в два раза больше места.
Введите текст (любой набор символов) *
Текст
Укажите символы, которые следует убрать из текста
Исключить символы
Регистр букв (для уникальных слов и букв)
Учитывать регистр букв
Выберите информацию, которую хотите получить
Задачи
* – обязательно заполнить
Обратите внимание на другие текстовые калькуляторы: https://calcon.ru/category/text/

Информационный объем текста складывается из информационных весов составляющих его символов.
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется всего два символа 0 и 1. Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц — машинным языком.
Какой длины должен быть двоичный код, чтобы с его помощью можно было закодировать васе символы клавиатуры компьютера?
Достаточный алфавит
В алфавит мощностью 256 символов можно поместить практически все символы, которые есть на клавиатуре. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице в 8 бит присвоили свое название — байт.
1 байт = 8 бит.
Таким образом, информационный вес одного символа достаточного алфавита равен 1 байту.
Для измерения больших информационных объемов используются более крупные единицы измерения информации:
Единицы измерения количества информации:
1 килобайт = 1 Кб = 1024 байта
1 мегабайт = 1 Мб = 1024 Кб
1 гигабайт = 1 Гб = 1024 Гб
Информационный объем текста
Книга содержит 150 страниц.
На каждой странице — 40 строк.
В каждой строке 60 символов (включая пробелы).
Найти информационный объем текста.
1. Количество символов в книге:
60 * 40 * 150 = 360 000 символов.
2. Т.к. 1 символ весит 1 байт, информационный объем книги равен
3. Переведем байты в более крупные единицы:
360 000 / 1024 = 351,56 Кб
351,56 / 1024 = 0,34 Мб
Ответ: Информационный объем текста 0,34 Мб.
Задача:
Информационный объем текста, подготовленного с помощью компьютера, равен 3,5 Кб. Сколько символов содержит этот текст?
Информационный объем текста 3,5 Мб. Найти количество символов в тексте.
1. Переведем объем из Мб в байты:
3,5 Мб * 1024 = 3584 Кб
3584 Кб * 1024 = 3 670 016 байт
2. Т.к. 1 символ весит 1 байт, количество символов в тексте равно


SEO-анализ текста от Text.ru — это уникальный сервис, не имеющий аналогов. Возможность подсветки «воды», заспамленности и ключей в тексте позволяет сделать анализ текста интерактивным и легким для восприятия.
SEO-анализ текста включает в себя:
С помощью данного онлайн-сервиса можно определить число слов в тексте, а также количество символов с пробелами и без них.
Возможность нахождения поисковых ключей в тексте и определения их количества полезна как для написания нового текста, так и для оптимизации уже существующего. Расположение ключевых слов по группам и по частоте сделает навигацию по ключам удобной и быстрой. Сервис также найдет и морфологические варианты ключей, которые выделятся в тексте при нажатии на нужное ключевое слово.
Данный параметр отображает процент наличия в тексте стоп-слов, фразеологизмов, а также словесных оборотов, фраз, соединительных слов, являющихся не значимыми и не несущими смысловой нагрузки. Небольшое содержание «воды» в тексте является естественным показателем, при этом:
- до 15% — естественное содержание «воды» в тексте;
- от 15% до 30% — превышенное содержание «воды» в тексте;
- от 30% — высокое содержание «воды» в тексте.
Процент заспамленности текста отражает количество поисковых ключевых слов в тексте. Чем больше в тексте ключевых слов, тем выше его заспамленность:
- до 30% — отсутствие или естественное содержание ключевых слов в тексте;
- от 30% до 60% — SEO-оптимизированный текст. В большинстве случаев поисковые системы считают данный текст релевантным ключевым словам, которые указаны в тексте.
- от 60% — сильно оптимизированный или заспамленный ключевыми словами текст.
Данный параметр показывает количество слов, состоящих из букв различных алфавитов. Часто это буквы русского и английского языка, например, слово «стол», где «о» — буква английского алфавита. Некоторые копирайтеры заменяют в русских словах часть букв на английские, чтобы обманным путем повысить уникальность текста. SEO-анализ текста от Text.ru успешно выявляет такие слова.
SEO-анализ текста доступен через API. Подробнее в API-проверке.

К огда человек только начинает учиться копирайтингу, автор испытывает уйму сложностей даже в таких простых вещах, как определение объёма текста. Кажется: сущая мелочь, но и с ней надо уметь справиться.
Как узнать объём текста? Предлагаю вашему вниманию несколько удобных вариантов.
Редактор Word (или другая программа для работы с текстом). Когда вы набираете символы в Office, внизу страницы ведётся подсчёт слов и символов с пробелами.
- Чтобы посчитать объём текста частично, выделите нужный фрагмент мышкой и снова посмотрите на параметры внизу листа. Удобно, правда?
Чтоб увидеть всю статистику, кликните на надпись внизу, и перед глазами появится табличка, как на картинке (изображение увеличивается).
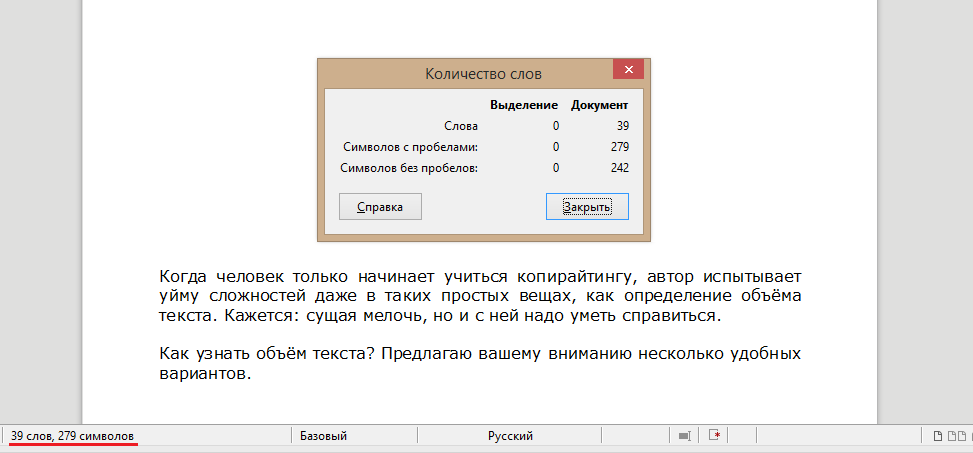
Подсчёт объёма текста в Word
TextAnalyzer. Об этом сервисе для вебмастеров я уже писала. Онлайн-инструмент выручает меня в работе над SEO-статьями. Закиньте контент в редактор, кликните на кнопку, и всего через две секунды вы сможете узнать объём текста (с пробелами и без).
Также посчитать объём текста легко в Istio.com, Content Watch, 1y.ru, text.ru или других сервисах для «сеошников», копирайтеров, журналистов.
Как видите, узнать объём текста не составляет никакого труда. В следующий раз расскажу в блоге о том, как определить объём текста с учётом ключевых слов. Этот материал будет полезен тем, кто осваивает SEO-копирайтинг. Удачи начинающим авторам!
Каждый объект в компьютере (или любом другом электронном устройстве) имеет свой информационный объём, то есть то количество информации, которое он занимает в памяти устройства.
Например, текстовый документ на (2)–(3) страницы может иметь информационный объём (150) Кб.
Изображение в хорошем качестве — (2)–(4) Мб.
Аудиофайл с песней на (3) минуты — около (6) Мб.
Рассмотрим измерение текстовой информации в компьютере.
Размер текстового сообщения зависит от того, с помощью какого алфавита он был написан и сколько в нём символов.
Алфавит (N) — это количество символов в некотором языке.
Чем больше алфавит, тем больше информационный вес одного символа.
Информационный вес одного символа (i) — это количество информации, которое отводится на один символ.
Обрати внимание!
Они связаны формулой:
N=2i
.
Например, в русском алфавите (33) буквы, вычислим информационный вес одного символа по формуле:
33=2i,i≈5
бит. То есть вес одного символа (буквы) — (5) бит.
Представим, что в тетрадке записана следующая строка: «Мама сидела за столом».
Как посчитать, сколько информации несёт в себе это сообщение?
Нам известно, сколько весит один символ — (5) бит, можно подсчитать количество символов в данном сообщении — (18), соответственно, чтобы найти, сколько всего информации несёт в себе это сообщение, нужно перемножить информационный вес одного символа и количество символов в сообщении.
Обрати внимание!
Можно вывести формулу:
I=K×i
,
где (I) — информационный объём сообщения;
(K) — количество символов в сообщении;
(i) — информационный вес одного символа.
Но мы будем работать с компьютерным текстом. Там алфавит намного больше.
Как ты думаешь, сколько всего символов можно ввести с клавиатуры?
Ты скажешь «много» и будешь прав: с клавиатуры можно ввести русские/английские буквы, цифры, специальные знаки и т. д. Всего (256) символов.
Посчитаем информационный вес одного символа компьютерного алфавита.
N=2i.256=2i.256=28.
Один символ компьютерного алфавита весит (8) бит или (1) байт.
Решим задачу.
Найди информационный объём текста (в битах), написанного с помощью компьютера:
«Информация — это сведения об окружающем нас мире».
Текст напечатан на компьютере, поэтому один символ весит (8) бит или (1) байт.
Всего символов в сообщении между кавычками: (48). При подсчёте символов учитываются все символы и пробелы.
Запишем решение:
I=K×i.I=48×8.I=384бит.
Ответ: (384) бита.
Задача
Найди информационный объём сообщения (в байтах), который напечатали школьники на уроке информатики, если оно содержит (2) страницы, на каждой странице по (12) строк, и в каждой строке (28) символов.
Оформим решение задачи.
|
Дано: K=2×12×28.i=1байт. |
Чтобы посчитать, сколько символов всего в сообщении, нужно умножить количество страниц на количество строк и на количество символов в каждой строке. В условии сказано, что текст напечатали, поэтому один символ равен (1) байту. I=K×i.I=2×12×28×1.I=672байта. |
| Найти: (I) — ? | Ответ: (672) байта. |
Как посчитать длину текста и не привлекать внимание санитаров
Время на прочтение
10 мин
Количество просмотров 29K

Привет! Меня зовут Ивасюта Алексей, я фронтенд-разработчик в Авито в кластере Seller Experience. В этой статье я расскажу, как правильно рассчитать длину текста в Java Script. Эта статья будет одинаково полезна как начинающим разработчикам, так и весьма опытным. Благодаря ей вы поймете устройство Unicode и особенности его работы в JS.
Немного предыстории
На нашей платформе можно размещать объявления и давать им описание в виде текста. Обычно для таких полей есть ограничение на максимальное количество вводимых символов. Если пользователь напечатал больше знаков, чем положено, сработает валидация и объявление нельзя будет разместить.
В целом, достаточно тривиальная практика. Жили мы, не тужили, разрешали вводить в поля только кириллицу, латиницу и цифры — и все работало прекрасно. Однажды мы подумали: «Почему бы не разрешить пользователям добавлять в описание эмодзи?». Сделали правочки, разрешили ввод новых символов и продолжили жить дальше. Но тут началось интересное: некоторые пользователи стали жаловаться, что они вводят символов меньше лимита, но валидацию описание все равно не проходит. Путем нехитрых проверок удалось найти интересные вещи. Давайте посмотрим на код:
'Фотоаппарат'.length
// 11
'Фотоаппарат📷'.length
// 13Длина слова «Фотоаппарат» равна 11. Если в конец добавить эмодзи, то длина становится равной 13. Может показаться, что это какой-то баг языка, но нет — всё правильно. И вот тут нам с вами придется нырнуть на самое дно Unicode.
Щепотка теории по Unicode
Unicode — это достаточно старый формат кодирования символов, который максимально широко распространился на данный момент. Он решает сложную задачу перекодирования текста, которая раньше стояла перед всеми разработчиками.
Особенность этого стандарта заключается в том, что за каждым символом, который добавлен в него объединением Unicode Consortium, навсегда закрепляется уникальный идентификатор. При помощи него любая программа на любой машине с любой локализацией может определить, какой символ представлен в тексте. Эти идентификаторы называются кодовыми точками. Значению кодовой точки соответствует всегда один и тот же символ.
В Unicode кодовую точку принято записывать в шестнадцатеричном виде и использовать не менее 4 цифр с ведущими нулями при необходимости. Например, число 0 в шестнадцатеричной системе счисления также имеет значение 0 и будет записано в виде U+0000 (U+ — префикс, обозначающий Unicode-символ). Это пустой символ или же аналог null/nil в Unicode. Обычно этот символ используется для обозначения конца null-терминированных строк в языке С (Си-строки).
null-терминированные строки
В языке С обработка строки произвольной длины происходит до того момента, пока не встретится нулевой символ.
Четыре разряда в шестнадцатеричной системе позволяют закодировать 164 комбинаций (или 216) — это 65 536 значений, каждое из которых является кодовой точкой. Значения находятся в диапазоне U+0000 — U+FFFF в шестнадцатеричной системе счисления. Этот диапазон значений называется «Базовой многоязычной плоскостью» или BMP. Она включает в себя символы из алфавитов самых распространенных языков мира, математические операторы, геометрические фигуры, специальные символы и многое другое. Важно заметить, что некоторые точки являются зарезервированными, некоторые из них не имеют графического представления, как например U+200D, а некоторые вообще не используются.
После того, как мы изучили теорию, давайте посмотрим на несколько примеров и пощупаем Unicode на практике.
Для получения значения кодовой точки в JS есть метод String.prototype.codePointAt(). Если мы вызовем метод на строке с заглавной кириллической буквой «А», то получим значение кодовой точки в десятичной системе счисления.
'А'.codePointAt(0) // 1040Теперь переведем полученное значение в шестнадцатеричную систему счисления.
'А'.codePointAt(0).toString(16) // '410'В JS шестнадцатиразрядные числа можно записывать в формате 0x0000. Таким образом наше число можно записать в виде 0x410.
0x410 // 1040
typeof 0x410 === 'number' // trueДля получения Unicode-символа по значению кодовой точки JS предоставляет статический метод String.fromCodePoint(). Давайте получим нашу букву обратно.
String.fromCodePoint(0x410) // 'А'Для записи символов Unicode можно использовать формат u0000. Если число меньше четырех знаков, то недостающие заполняются нулями слева. Таким образом нашу букву также можно представить в виде строки.
'u0410' // 'А'Теперь мы можем даже составить целое слово. Вставьте эту строку в консоль и посмотрите на результат.
'u041fu0440u0438u0432u0435u0442'Нормализация и комбинируемые символы
Перейдем к неочевидному поведению строк в Java Script. Возьмем для примера такой экзотический символ, как «Слог Хангыль ggag» из слогового письма Хангыля и посчитаем его длину.
'깍'.length // 3Ого! Символ один, а длина строки почему-то равна трем. На самом деле, этот символ состоит из трех кодовых точек U+1101, U+1161 и U+11A8. Вместе эти знаки в Хангыльском письме образуют иероглиф 깍, который сам является отдельным символом и имеет кодовую точку U+AE4D.
Здесь мы приходим к двум важным выводам:
-
Длина строки в JS считается по количеству кодовых точек, из которых она состоит.
-
При подсчете длины строки надо учитывать количество графем, а не кодовых точек.
Так, у нас появилось новое понятие. Графема — это минимальная единица письменности. В нашем случае, три кодовые точки образуют одну графему, которая отображается в виде иероглифа 깍.
В Unicode для таких случаев описаны алгоритмы нормализации, когда комбинируемые символы могут быть заменены на один составной. JS предоставляет метод String.prototype.normalize, который позволяет проводить нормализацию строк по описанным в Unicode алгоритмам. После выполнения нормализации три кодовые точки будут заменены на одну — U+AE4D.
'깍'.normalize()
.codePointAt(0)
.toString(16) // 'ae4d'
'깍'.normalize('NFC').length // 1Можно комбинировать различные символы в Unicode, но для результата комбинации может не быть предусмотрено отдельной кодовой точки.
'ко̅д'.normalize().length // 4Длина строки в этом случае равна 4, а видим мы всего три графемы. Символ о̅ состоит из обычной кириллической буквы «о» и Unicode-символа комбинируемого надчеркивания U+0305.
'коu0305д' // ко̅дВ таких случаях при учете длины строки нужно исключать из расчета комбинируемые символы. Они не создают отдельных графем, а просто видоизменяют отображение рядом стоящих. Для этого можем воспользоваться экранированием свойств Unicode в регулярках JS.
const regexSymbolWithCombiningMarks = /(P{Mark})(p{Mark}+)/ug;
const countTextLength = (text) => {
const normalizedText = text
.normalize('NFC')
.replace(regexSymbolWithCombiningMarks, function(_, symbol) {
return symbol;
});
return normalizedText.length;
};
countTextLength('ко̅д') // 3
countTextLength('깍') // 1Селекторы начертания
В Unicode есть диапазон кодовых точек U+FE00 — U+FE0F для селекторов начертания. Это невидимые символы, которые изменяют начертание предшествующих им. Самый интересный — U+FE0F. Этот селектор указывает, что предыдущий символ должен отображаться в виде эмодзи, если предыдущий символ по умолчанию имеет текстовое представление. Например, кодовая точка U+2764 по умолчанию будет отображаться как закрашенное жирное сердечко ❤. Если мы добавим к нему селектор начертания U+FE0F, то отображаться он уже будет в виде эмодзи сердечка ❤️.
'❤ufe0f' // ❤️Отображение в консоли браузера
В консоли браузера и здесь в примере кода вы все равно увидите отображение в виде закрашенного черного сердечка, но если скопировать полученный символ в мессенджер, то там будет эмодзи.
То же самое можно проделать со снеговиком.
'☃ufe0f' // ☃️Селекторы начертания не создают отдельных графем, а лишь изменяют отображение предшествующих. Они не должны учитываться при подсчете длины текста. В вычислениях их можно убрать, например, регуляркой.
'❤ufe0E'.replace(/[u{FE00}-u{FE0F}]/ug, '').length // 1Суррогаты
Однажды IT-сообществу захотелось добавить в Unicode больше символов, а диапазон в 65К кодовых точек стал тесноват. Ребята из Unicode Consortium призадумались и решили заложить в стандарт больше возможностей для дальнейшего расширения.
Так как надо было сохранить совместимость с уже существующими значениями и сильно увеличить количество допустимых, диапазон кодовых точек расширили до U+10FFFF. В Unicode появилось еще 16 плоскостей по 65 536 символов в каждой. Таким образом, количество возможных значений увеличилось до 1 114 112. Сейчас в Unicode есть эмодзи, кости для маджонга, алхимические символы, символы «Канона великого сокровенного» и куча всего другого.
Теперь нам надо немного вспомнить азы программирования. Для кодирования каждого символа необходимо n бит. Число 1 в двоичной системе счисления будет иметь вид 1, а для его кодирования нужен 1 бит. Число 65535 будет иметь вид 1111111111111111. У него 16 разрядов, соответственно, для хранения нужно 16 бит, то есть 2 байта.
Существует кодировка UTF-8, которая использует 8 бит на кодирование каждого символа. При помощи нее можно закодировать 256 различных знаков (28). Строки в этой кодировке занимают очень мало места: текст в 10 000 знаков будет занимать 10 000 байт или 9,77 КБ. Это позволяет оптимизировать использование памяти.
Есть кодировка UTF-32, которая использует 32 бита на кодирование каждого символа. Здесь больше 4 миллиардов комбинаций. Как можно догадаться, любой символ из любой плоскости Unicode может быть с легкостью закодирован, но строки в ней занимают много памяти. Так текст в 10 000 знаков уже будет занимать больше 32 КБ.
Самое интересное происходит в системах, которые используют шестнадцатибитную кодировку представления. JavaScript использует именно кодировку UTF-16, которая позволяет выделять на хранение каждого символа 2 байта. Для хранения кодовой точки из BMP этого достаточно, но для точек из других плоскостей нужно больше бит.
Число 10000 в шестнадцатеричной системе преобразуется в 10000000000000000 в двоичной. У числа 17 разрядов, а значит для кодирование уже нужно 17 бит. Уместить 17 бит в 2 байта никак нельзя.
Чтобы кодировать символы из астральных плоскостей в 16-битных кодировках были придуманы суррогатные пары. Суррогаты — это зарезервированный диапазон значений в базовой плоскости Unicode, который делится на две части:
-
U+D800 – U+DBFF — верхние суррогаты;
-
U+DC00 – U+DFFF — нижние суррогаты.
В каждый диапазон входит 210 символов. То есть всего возможно 220 комбинаций — это 1 048 576 значений. Добавим сюда 65 536 значений из BMP и получим 1 114 112 значений. Таким образом мы можем закодировать кодовые точки из всех плоскостей Unicode.
Точки из BMP кодируются «как есть». Если же надо закодировать кодовую точку из астральной плоскости, то для нее вычисляется пара суррогатов по формуле:
const highSurrogate = Math.floor((codepoint - 0x10000) / 0x400) + 0xD800;
const lowSurrogate = (codepoint - 0x10000) % 0x400 + 0xDC00;Для обратного преобразования из суррогатной пары в кодовую точку используется следующая формула:
const codePoint = (highSurrogate - 0xD800) * 0x400 + lowSurrogate - 0xDC00 + 0x10000;Таким образом, ухмыляющийся смайлик U+1F600 будет преобразован в суррогатную пару U+D83D + U+DE00.
'😀' === 'u{d83d}u{de00}'
// trueИменно поэтому длина этого эмодзи равна 2.
Формат записи кодовых точек
До этого момента вы видели запись кодовых точек в строках только в виде u0000. Такой формат записи является устаревшим и будет работать только для кодовых точек из BMP. Вместо него используйте запись вида u{0000}. Такой формат работает для кодовых точек из любой плоскости.
'😀'.length === 2
// trueЧтобы учитывать эмодзи при подсчёте, в JavaScript есть итератор строк, который учитывает суррогатные пары и итерирует их, как одну графему. Это значит, что длину строки с учетом эмодзи можно подсчитать итерируясь по строке и запоминая количество итераций.
const countGraphemes = (text) => {
let count = 0;
for(const _ of text) {
count++;
}
return count;
}
countGraphemes('текст 😀') // 7То же самое можно сделать разбив строку на массив.
Array.from('текст 😀').length // 7
// или
[...'текст 😀'].length // 7Модификаторы цвета
В Unicode есть пять модификаторов цвета кожи по шкале Фитцпатрика в диапазоне U+1F3FB —U+1F3FF.

При помощи этих модификаторов можно персонифицировать «базовые» эмодзи.
'👩u{1f3fb}'
// '👩🏻'
'👧u{1f3fc}'
// '👧🏼'
'🧒u{1f3fd}'
// '🧒🏽'
'👶u{1f3fe}'
// '👶🏾'
'👨u{1f3ff}'
// '👨🏿'Как вы уже могли догадаться, модификаторы цвета при подсчете длины текста учитывать не надо.
Объединитель нулевой ширины
Давайте подсчитаем длину эмодзи семьи из трех человек.
'👨👩👦'.length
// 8Весьма неожиданный результат. Давайте теперь разобьем строку на массив символов.
[...'👨👩👦']
// ['👨', '', '👩', '', '👦']Теперь мы видим настоящую магию: эмодзи семьи из трех человек на самом деле состоит из трех базовых эмодзи, которые соединены объединителем нулевой ширины или ZWJ. Этот символ не имеет графического отображения и представлен кодовой точкой U+200D. А при помощи такой хитрой конструкции мы можем собрать новый эмодзи из базовых.
['👨', 'u{200d}', '👧', 'u{200d}', '👦'].reduce((prev, curr) => prev + curr)
// '👨👧👦'Мы получили эмодзи отца-одиночки с двумя детьми.
В этом случае уже сложнее подсчитать правильную длину текста с учетом составных эмодзи, поэтому придется разбивать строку на массив и итерироваться по нему. При этом комбинации, которые состоят из нескольких символов, соединенных ZWJ, необходимо считать за одну графему.
Собираем все вместе
const regex = /[u{FE00}-u{FE0F}]|[u{1F3FB}-u{1F3FF}]/ug;
// u{FE00}-u{FE0F} -- селекторы начертания
// u{1F3FB}-u{1F3FF} - модификаторы цвета
const regexSymbolWithCombiningMarks = /(P{Mark})(p{Mark}+)/ug; // Поиск комбинируемых символов
const joiner = '200d'; // Объединитель нулевой ширины («Zero Width Joiner», ZWJ)
// Проверяет, является ли символ ZWJ
const isJoiner = (char) => char.charCodeAt(0).toString(16) === joiner;
const countGraphemes = (text) => {
const normalizedText = text
// нормализуем строку
.normalize('NFC')
// удаляем селекторы начертания и модификаторы цвета
.replace(regex, '')
// удаляем комбинируемые символы
.replace(regexSymbolWithCombiningMarks, function(_, symbol) {
return symbol;
});
// Разделяем строку на токены. Кодовые точки из суррогатных пар будут корректно
// выделены в одну графему.
const tokens = Array.from(normalizedText);
let length = 0;
let isComplexChar = false; // Обработка комплексных символов, склеенных через ZWJ
// Итеррируемся по массиву токенов и комбинации, склеенные через ZWJ
// считаем за одиу графему
for (let i = 0; i < tokens.length; i++) {
const char = tokens[i];
const nextChar = tokens[i + 1];
if (!nextChar) {
length += 1;
continue;
}
if (isJoiner(nextChar)) {
isComplexChar = true;
continue;
}
if (!isJoiner(char) && isComplexChar) {
isComplexChar = false;
}
if (!isComplexChar) {
length += 1;
}
}
return length;
}
countGraphemes('test😄') // 5
countGraphemes('👦🏾👨👩👧👦') // 2
countGraphemes('깍') // 1
// и так далееКонечно, это не самая оптимальная реализация и приведенный выше код необходим лишь для примера и наглядности. К тому же, мы все еще не учитываем множество особенностей Unicode. Этот алгоритм будет работать для подавляющего большинства обычных приложений, но по настоящему честный подсчет для всех возможных языков и начертаний он сделать не сможет.
Intl.Segmenter
Как вы видите, алгоритм подсчета количества графем получается не самым простым. Здесь требуется учитывать множество деталей и быть глубоко погруженным в тему. И вот наконец-то настает очередь Intl.Segmenter — специальный класс, который включает сегментацию текста с учетом языковых стандартов. Это позволяет получать значимые элементы из строки, например, графемы, слова или предложения.
const segmenter = new Intl.Segmenter();
const text = '👨👨👦👦깍ко̅д👨🏿';
const iterator = segmenter.segment(text)[Symbol.iterator]();
let count = 0;
for (const symbol of iterator) {
count++;
}
console.log(count) // 6Вот так легко и непринуждённо мы смогли в несколько строчек проделать ту же работу. По умолчанию сегментер бьет текст на графемы, но ему можно дополнительно задать локаль и степень сегментации, например, по словам.
const segmenter = new Intl.Segmenter('fr', { granularity: 'word' });У меня для вас только одна плохая новость: Intl.Segmenter не поддерживается в Firefox, поэтому кроссбраузерное решение сделать на нем не получится. Пока что вам остается искать рабочий полифил для него и подключать в нужном месте при выполнении кода. Также нужно убедиться в работоспособности сегментации через полифил.
Что в результате
Честный подсчет длины введенного пользователем текста — дело непростое из-за особенностей Unicode и 16-битной кодировки. Если вы хотите сделать по-настоящему интернациональное приложение, например, мессенджер, вам придется учитывать все эти сценарии. Эту проблему призван решить Intl.Segmenter, поэтому с нетерпением ждем его поддержки в Firefox.
Полезные ссылки
Таблица символов Unicode
Подробнее о графемах
Алгоритмы нормализации Unicode
Документация Intl.Segmenter на MDN
Подробнее про Intl.Segmenter
Экранирование свойств Unicode
