Presenting the Cadillac of Diffs as an SP. See within for the basic template that was based on answer by @erikkallen. It supports
- Duplicate row sensing (most other answers here do not)
- Sort results by argument
- Limit to specific columns
- Ignore columns (e.g. ModifiedUtc)
- Cross database tables names
- Temp tables (use as workaround to diff views)
Usage:
exec Common.usp_DiffTableRows '#t1', '#t2';
exec Common.usp_DiffTableRows
@pTable0 = 'ydb.ysh.table1',
@pTable1 = 'xdb.xsh.table2',
@pOrderByCsvOpt = null, -- Order the results
@pOnlyCsvOpt = null, -- Only compare these columns
@pIgnoreCsvOpt = null; -- Ignore these columns (ignored if @pOnlyCsvOpt is specified)
Code:
alter proc [Common].[usp_DiffTableRows]
@pTable0 varchar(300),
@pTable1 varchar(300),
@pOrderByCsvOpt nvarchar(1000) = null, -- Order the Results
@pOnlyCsvOpt nvarchar(4000) = null, -- Only compare these columns
@pIgnoreCsvOpt nvarchar(4000) = null, -- Ignore these columns (ignored if @pOnlyCsvOpt is specified)
@pDebug bit = 0
as
/*---------------------------------------------------------------------------------------------------------------------
Purpose: Compare rows between two tables.
Usage: exec Common.usp_DiffTableRows '#a', '#b';
Modified By Description
---------- ---------- -------------------------------------------------------------------------------------------
2015.10.06 crokusek Initial Version
2019.03.13 crokusek Added @pOrderByCsvOpt
2019.06.26 crokusek Support for @pIgnoreCsvOpt, @pOnlyCsvOpt.
2019.09.04 crokusek Minor debugging improvement
2020.03.12 crokusek Detect duplicate rows in either source table
---------------------------------------------------------------------------------------------------------------------*/
begin try
if (substring(@pTable0, 1, 1) = '#')
set @pTable0 = 'tempdb..' + @pTable0; -- object_id test below needs full names for temp tables
if (substring(@pTable1, 1, 1) = '#')
set @pTable1 = 'tempdb..' + @pTable1; -- object_id test below needs full names for temp tables
if (object_id(@pTable0) is null)
raiserror('Table name is not recognized: ''%s''', 16, 1, @pTable0);
if (object_id(@pTable1) is null)
raiserror('Table name is not recognized: ''%s''', 16, 1, @pTable1);
create table #ColumnGathering
(
Name nvarchar(300) not null,
Sequence int not null,
TableArg tinyint not null
);
declare
@usp varchar(100) = object_name(@@procid),
@sql nvarchar(4000),
@sqlTemplate nvarchar(4000) =
'
use $database$;
insert into #ColumnGathering
select Name, column_id as Sequence, $TableArg$ as TableArg
from sys.columns c
where object_id = object_id(''$table$'', ''U'')
';
set @sql = replace(replace(replace(@sqlTemplate,
'$TableArg$', 0),
'$database$', (select DatabaseName from Common.ufn_SplitDbIdentifier(@pTable0))),
'$table$', @pTable0);
if (@pDebug = 1)
print 'Sql #CG 0: ' + @sql;
exec sp_executesql @sql;
set @sql = replace(replace(replace(@sqlTemplate,
'$TableArg$', 1),
'$database$', (select DatabaseName from Common.ufn_SplitDbIdentifier(@pTable1))),
'$table$', @pTable1);
if (@pDebug = 1)
print 'Sql #CG 1: ' + @sql;
exec sp_executesql @sql;
if (@pDebug = 1)
select * from #ColumnGathering;
select Name,
min(Sequence) as Sequence,
convert(bit, iif(min(TableArg) = 0, 1, 0)) as InTable0,
convert(bit, iif(max(TableArg) = 1, 1, 0)) as InTable1
into #Columns
from #ColumnGathering
group by Name
having ( @pOnlyCsvOpt is not null
and Name in (select Value from Common.ufn_UsvToNVarcharKeyTable(@pOnlyCsvOpt, default)))
or
( @pOnlyCsvOpt is null
and @pIgnoreCsvOpt is not null
and Name not in (select Value from Common.ufn_UsvToNVarcharKeyTable(@pIgnoreCsvOpt, default)))
or
( @pOnlyCsvOpt is null
and @pIgnoreCsvOpt is null)
if (exists (select 1 from #Columns where InTable0 = 0 or InTable1 = 0))
begin
select 1; -- without this the debugging info doesn't stream sometimes
select * from #Columns order by Sequence;
waitfor delay '00:00:02'; -- give results chance to stream before raising exception
raiserror('Columns are not equal between tables, consider using args @pIgnoreCsvOpt, @pOnlyCsvOpt. See Result Sets for details.', 16, 1);
end
if (@pDebug = 1)
select * from #Columns order by Sequence;
declare
@columns nvarchar(4000) = --iif(@pOnlyCsvOpt is null and @pIgnoreCsvOpt is null,
-- '*',
(
select substring((select ',' + ac.name
from #Columns ac
order by Sequence
for xml path('')),2,200000) as csv
);
if (@pDebug = 1)
begin
print 'Columns: ' + @columns;
waitfor delay '00:00:02'; -- give results chance to stream before possibly raising exception
end
-- Based on https://stackoverflow.com/a/2077929/538763
-- - Added sensing for duplicate rows
-- - Added reporting of source table location
--
set @sqlTemplate = '
with
a as (select ~, Row_Number() over (partition by ~ order by (select null)) -1 as Duplicates from $a$),
b as (select ~, Row_Number() over (partition by ~ order by (select null)) -1 as Duplicates from $b$)
select 0 as SourceTable, ~
from
(
select * from a
except
select * from b
) anb
union all
select 1 as SourceTable, ~
from
(
select * from b
except
select * from a
) bna
order by $orderBy$
';
set @sql = replace(replace(replace(replace(@sqlTemplate,
'$a$', @pTable0),
'$b$', @pTable1),
'~', @columns),
'$orderBy$', coalesce(@pOrderByCsvOpt, @columns + ', SourceTable')
);
if (@pDebug = 1)
print 'Sql: ' + @sql;
exec sp_executesql @sql;
end try
begin catch
declare
@CatchingUsp varchar(100) = object_name(@@procid);
if (xact_state() = -1)
rollback;
-- Disabled for S.O. post
--exec Common.usp_Log
--@pMethod = @CatchingUsp;
--exec Common.usp_RethrowError
--@pCatchingMethod = @CatchingUsp;
throw;
end catch
go
create function Common.Trim
(
@pOriginalString nvarchar(max),
@pCharsToTrim nvarchar(50) = null -- specify null or 'default' for whitespae
)
returns table
with schemabinding
as
/*--------------------------------------------------------------------------------------------------
Purpose: Trim the specified characters from a string.
Modified By Description
---------- -------------- --------------------------------------------------------------------
2012.09.25 S.Rutszy/crok Modified from https://dba.stackexchange.com/a/133044/9415
--------------------------------------------------------------------------------------------------*/
return
with cte AS
(
select patindex(N'%[^' + EffCharsToTrim + N']%', @pOriginalString) AS [FirstChar],
patindex(N'%[^' + EffCharsToTrim + N']%', reverse(@pOriginalString)) AS [LastChar],
len(@pOriginalString + N'~') - 1 AS [ActualLength]
from
(
select EffCharsToTrim = coalesce(@pCharsToTrim, nchar(0x09) + nchar(0x20) + nchar(0x0d) + nchar(0x0a))
) c
)
select substring(@pOriginalString, [FirstChar],
((cte.[ActualLength] - [LastChar]) - [FirstChar] + 2)
) AS [TrimmedString]
--
--cte.[ActualLength],
--[FirstChar],
--((cte.[ActualLength] - [LastChar]) + 1) AS [LastChar]
from cte;
go
create function [Common].[ufn_UsvToNVarcharKeyTable] (
@pCsvList nvarchar(MAX),
@pSeparator nvarchar(1) = ',' -- can pass keyword 'default' when calling using ()'s
)
--
-- SQL Server 2012 distinguishes nvarchar keys up to maximum of 450 in length (900 bytes)
--
returns @tbl table (Value nvarchar(450) not null primary key(Value)) as
/*-------------------------------------------------------------------------------------------------
Purpose: Converts a comma separated list of strings into a sql NVarchar table. From
http://www.programmingado.net/a-398/SQL-Server-parsing-CSV-into-table.aspx
This may be called from RunSelectQuery:
GRANT SELECT ON Common.ufn_UsvToNVarcharTable TO MachCloudDynamicSql;
Modified By Description
---------- -------------- -------------------------------------------------------------------
2011.07.13 internet Initial version
2011.11.22 crokusek Support nvarchar strings and a custom separator.
2017.12.06 crokusek Trim leading and trailing whitespace from each element.
2019.01.26 crokusek Remove newlines
-------------------------------------------------------------------------------------------------*/
begin
declare
@pos int,
@textpos int,
@chunklen smallint,
@str nvarchar(4000),
@tmpstr nvarchar(4000),
@leftover nvarchar(4000),
@csvList nvarchar(max) = iif(@pSeparator not in (char(13), char(10), char(13) + char(10)),
replace(replace(@pCsvList, char(13), ''), char(10), ''),
@pCsvList); -- remove newlines
set @textpos = 1
set @leftover = ''
while @textpos <= len(@csvList)
begin
set @chunklen = 4000 - len(@leftover)
set @tmpstr = ltrim(@leftover + substring(@csvList, @textpos, @chunklen))
set @textpos = @textpos + @chunklen
set @pos = charindex(@pSeparator, @tmpstr)
while @pos > 0
begin
set @str = substring(@tmpstr, 1, @pos - 1)
set @str = (select TrimmedString from Common.Trim(@str, default));
insert @tbl (value) values(@str);
set @tmpstr = ltrim(substring(@tmpstr, @pos + 1, len(@tmpstr)))
set @pos = charindex(@pSeparator, @tmpstr)
end
set @leftover = @tmpstr
end
-- Handle @leftover
set @str = (select TrimmedString from Common.Trim(@leftover, default));
if @str <> ''
insert @tbl (value) values(@str);
return
end
GO
create function Common.ufn_SplitDbIdentifier(@pIdentifier nvarchar(300))
returns @table table
(
InstanceName nvarchar(300) not null,
DatabaseName nvarchar(300) not null,
SchemaName nvarchar(300),
BaseName nvarchar(300) not null,
FullTempDbBaseName nvarchar(300), -- non-null for tempdb (e.g. #Abc____...)
InstanceWasSpecified bit not null,
DatabaseWasSpecified bit not null,
SchemaWasSpecified bit not null,
IsCurrentInstance bit not null,
IsCurrentDatabase bit not null,
IsTempDb bit not null,
OrgIdentifier nvarchar(300) not null
) as
/*-----------------------------------------------------------------------------------------------------------
Purpose: Split a Sql Server Identifier into its parts, providing appropriate default values and
handling temp table (tempdb) references.
Example: select * from Common.ufn_SplitDbIdentifier('t')
union all
select * from Common.ufn_SplitDbIdentifier('s.t')
union all
select * from Common.ufn_SplitDbIdentifier('d.s.t')
union all
select * from Common.ufn_SplitDbIdentifier('i.d.s.t')
union all
select * from Common.ufn_SplitDbIdentifier('#d')
union all
select * from Common.ufn_SplitDbIdentifier('tempdb..#d');
-- Empty
select * from Common.ufn_SplitDbIdentifier('illegal name');
Modified By Description
---------- -------------- -----------------------------------------------------------------------------
2013.09.27 crokusek Initial version.
-----------------------------------------------------------------------------------------------------------*/
begin
declare
@name nvarchar(300) = ltrim(rtrim(@pIdentifier));
-- Return an empty table as a "throw"
--
--Removed for SO post
--if (Common.ufn_IsSpacelessLiteralIdentifier(@name) = 0)
-- return;
-- Find dots starting from the right by reversing first.
declare
@revName nvarchar(300) = reverse(@name);
declare
@firstDot int = charindex('.', @revName);
declare
@secondDot int = iif(@firstDot = 0, 0, charindex('.', @revName, @firstDot + 1));
declare
@thirdDot int = iif(@secondDot = 0, 0, charindex('.', @revName, @secondDot + 1));
declare
@fourthDot int = iif(@thirdDot = 0, 0, charindex('.', @revName, @thirdDot + 1));
--select @firstDot, @secondDot, @thirdDot, @fourthDot, len(@name);
-- Undo the reverse() (first dot is first from the right).
--
set @firstDot = iif(@firstDot = 0, 0, len(@name) - @firstDot + 1);
set @secondDot = iif(@secondDot = 0, 0, len(@name) - @secondDot + 1);
set @thirdDot = iif(@thirdDot = 0, 0, len(@name) - @thirdDot + 1);
set @fourthDot = iif(@fourthDot = 0, 0, len(@name) - @fourthDot + 1);
--select @firstDot, @secondDot, @thirdDot, @fourthDot, len(@name);
declare
@baseName nvarchar(300) = substring(@name, @firstDot + 1, len(@name) - @firstdot);
declare
@schemaName nvarchar(300) = iif(@firstDot - @secondDot - 1 <= 0,
null,
substring(@name, @secondDot + 1, @firstDot - @secondDot - 1));
declare
@dbName nvarchar(300) = iif(@secondDot - @thirdDot - 1 <= 0,
null,
substring(@name, @thirdDot + 1, @secondDot - @thirdDot - 1));
declare
@instName nvarchar(300) = iif(@thirdDot - @fourthDot - 1 <= 0,
null,
substring(@name, @fourthDot + 1, @thirdDot - @fourthDot - 1));
with input as (
select
coalesce(@instName, '[' + @@servername + ']') as InstanceName,
coalesce(@dbName, iif(left(@baseName, 1) = '#', 'tempdb', db_name())) as DatabaseName,
coalesce(@schemaName, iif(left(@baseName, 1) = '#', 'dbo', schema_name())) as SchemaName,
@baseName as BaseName,
iif(left(@baseName, 1) = '#',
(
select [name] from tempdb.sys.objects
where object_id = object_id('tempdb..' + @baseName)
),
null) as FullTempDbBaseName,
iif(@instName is null, 0, 1) InstanceWasSpecified,
iif(@dbName is null, 0, 1) DatabaseWasSpecified,
iif(@schemaName is null, 0, 1) SchemaWasSpecified
)
insert into @table
select i.InstanceName, i.DatabaseName, i.SchemaName, i.BaseName, i.FullTempDbBaseName,
i.InstanceWasSpecified, i.DatabaseWasSpecified, i.SchemaWasSpecified,
iif(i.InstanceName = '[' + @@servername + ']', 1, 0) as IsCurrentInstance,
iif(i.DatabaseName = db_name(), 1, 0) as IsCurrentDatabase,
iif(left(@baseName, 1) = '#', 1, 0) as IsTempDb,
@name as OrgIdentifier
from input i;
return;
end
GO
Structured Query Language or SQL is a standard Database language that is used to create, maintain and retrieve the data from relational databases like MySQL, Oracle, etc. Here we are going to see how to Compare and Find Differences Between Two Tables in SQL
Here, we will first create a database named “geeks” then we will create two tables “department_old” and “department_new” in that database. After, that we will execute our query on that table.
Creating Database:.
Use the below SQL statement to create a database called geeks:
CREATE geeks;
Using Database :
USE geeks;
Table Definition for department_old table:
CREATE TABLE department_old( ID int, SALARY int, NAME Varchar(20), DEPT_ID Varchar(255));
Add values into the table:
Use the below query to add data to the table:
INSERT INTO department_old VALUES (1, 34000, 'ANURAG', 'UI DEVELOPERS'); INSERT INTO department_old VALUES (2, 33000, 'HARSH', 'BACKEND DEVELOPERS'); INSERT INTO department_old VALUES (3, 36000, 'SUMIT', 'BACKEND DEVELOPERS'); INSERT INTO department_old VALUES (4, 36000, 'RUHI', 'UI DEVELOPERS'); INSERT INTO department_old VALUES (5, 37000, 'KAE', 'UI DEVELOPERS');
To verify the contents of the table use the below statement:
SELECT * FROM department_old;
| ID | SALARY | NAME | DEPT_ID |
|---|---|---|---|
| 1 | 34000 | ANURAG | UI DEVELOPERS |
| 2 | 33000 | HARSH | BACKEND DEVELOPERS |
| 3 | 36000 | SUMIT | BACKEND DEVELOPERS |
| 4 | 36000 | RUHI | UI DEVELOPERS |
| 5 | 37000 | KAE | UI DEVELOPERS |
The result from SQL Server Management Studio:

Table Definition for department_new table:
CREATE TABLE department_new( ID int, SALARY int, NAME Varchar(20), DEPT_ID Varchar(255));
Add values into the table:
Use the below query to add data to the table:
INSERT INTO department_new VALUES (1, 34000, 'ANURAG', 'UI DEVELOPERS'); INSERT INTO department_new VALUES (2, 33000, 'HARSH', 'BACKEND DEVELOPERS'); INSERT INTO department_new VALUES (3, 36000, 'SUMIT', 'BACKEND DEVELOPERS'); INSERT INTO department_new VALUES (4, 36000, 'RUHI', 'UI DEVELOPERS'); INSERT INTO department_new VALUES (5, 37000, 'KAE', 'UI DEVELOPERS'); INSERT INTO department_new VALUES (6, 37000, 'REHA', 'BACKEND DEVELOPERS');
To verify the contents of the table use the below statement:
SELECT * FROM department_new;
| ID | SALARY | NAME | DEPT_ID |
|---|---|---|---|
| 1 | 34000 | ANURAG | UI DEVELOPERS |
| 2 | 33000 | HARSH | BACKEND DEVELOPERS |
| 3 | 36000 | SUMIT | BACKEND DEVELOPERS |
| 4 | 36000 | RUHI | UI DEVELOPERS |
| 5 | 37000 | KAE | UI DEVELOPERS |
| 6 | 37000 | REHA | BACKEND DEVELOPERS |
Output:

Comparing the Results of the Two Queries
Let us suppose, we have two tables: table1 and table2. Here, we will use UNION ALL to combine the records based on columns that need to compare. If the values in the columns that need to compare are the same, the COUNT(*) returns 2, otherwise the COUNT(*) returns 1.
Syntax:
SELECT column1, column2.... columnN FROM ( SELECT table1.column1, table1.column2 FROM table1 UNION ALL SELECT table2.column1, table2.column2 FROM table2 ) table1 GROUP BY column1 HAVING COUNT(*) = 1
Example:
Select ID from ( select * from department_old UNION ALL select * from department_new) department_old GROUP BY ID HAVING COUNT(*) = 1
Output:

If values in the columns involved in the comparison are identical, no row returns.
Last Updated :
23 Apr, 2021
Like Article
Save Article
Есть две таблицы.
Обе имеют два одинаковых поля.
Таблица 1
поле product_identificator
поле count
поле features
поле price
Таблица 2
поле product_identificator
поле count
поле remains
Нужно найти записи, которые имеют расхождения по полю count, то есть по идее значения должны соответствовать друг другу все, а этим запросом хочу найти расхождения
-
Вопрос заданболее двух лет назад
-
1065 просмотров
Пригласить эксперта
А что-то типа такого – не срабатывает?
SELECT *
FROM Таблица 1 AS t1
LEFT JOIN Таблица 2 AS t2
ON t1.product_identificator=t2.product_identificator
WHERE t1.count <> t2.countПредполагаю что-то вроде:
select table1.product_identificator, table1.count from table1 left join table2 on table1.product_identificator = table2.product_identificator where table1.count != table2.count;
(SELECT product_identificator, count
FROM Таблица 1
EXCEPT
SELECT product_identificator, count
FROM Таблица 2)
UNION
(SELECT product_identificator, count
FROM Таблица 2
EXCEPT
SELECT product_identificator, count
FROM Таблица 1)
-
Показать ещё
Загружается…
19 мая 2023, в 22:25
5000 руб./за проект
19 мая 2023, в 22:11
8000 руб./за проект
19 мая 2023, в 20:55
500 руб./за проект
Минуточку внимания
Introduction
If you’ve been developing in SQL Server for any length of time, you’ve no doubt hit this scenario: You have an existing, working query that produces results your customers or business owners say are correct. Now, you’re asked to change something, or perhaps you find out your existing code will have to work with new source data or maybe there’s a performance problem and you need to tune the query. Whatever the case, you want to be sure that whatever changes have been made (whether in your code or somewhere else), the changes in the output are as expected. In other words, you need to be sure that anything that was supposed to change, did, and that anything else remains the same. So, how can you easily do that in SQL Server?
In short, I’m going to look at an efficient way to just identify differences and produce some helpful statistics along with them. Along the way, I hope you learn a few useful techniques.
Setting up a test environment
We’ll need two tables to test with, so here is some simple code that will do the trick:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
USE [SQLShack] GO /****** Object: Table [dbo].[Original] Script Date: 9/14/2017 7:57:37 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Original]( [CustId] [int] IDENTITY(1,1) NOT NULL, [CustName] [varchar](255) NOT NULL, [CustAddress] [varchar](255) NOT NULL, [CustPhone] [numeric](12, 0) NULL, PRIMARY KEY CLUSTERED ( [CustId] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO /****** Object: Table [dbo].[Revised] Script Date: 9/14/2017 7:57:37 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Revised]( [CustId] [int] IDENTITY(1,1) NOT NULL, [CustName] [varchar](255) NOT NULL, [CustAddress] [varchar](255) NOT NULL, [CustPhone] [numeric](12, 0) NULL, PRIMARY KEY CLUSTERED ( [CustId] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO — Populate Original Table SET IDENTITY_INSERT [dbo].[Original] ON GO INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (1, N‘Salvador’, N‘1 Main Street North’, CAST(76197081653 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (2, N‘Edward’, N‘142 Main Street West’, CAST(80414444338 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (3, N‘Gilbert’, N’51 Main Street East’, CAST(23416310745 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (4, N‘Nicholas’, N‘7 Walnut Street’, CAST(62051432934 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (5, N‘Jorge’, N‘176 Washington Street’, CAST(58796383002 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (6, N‘Ernest’, N’39 Main Street’, CAST(461992109 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (7, N‘Stella’, N‘191 Church Street’, CAST(78584836879 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (8, N‘Jerome’, N‘177 Elm Street’, CAST(30235760533 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (9, N‘Ray’, N‘214 High Street’, CAST(57288772686 AS Numeric(12, 0))) INSERT [dbo].[Original] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (10, N‘Lawrence’, N’53 Main Street South’, CAST(92544965861 AS Numeric(12, 0))) GO SET IDENTITY_INSERT [dbo].[Original] OFF GO — Populate Revised Table SET IDENTITY_INSERT [dbo].[Revised] ON GO INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (1, N‘Jerome’, N‘1 Main Street North’, CAST(36096777923 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (2, N‘Lawrence’, N’53 Main Street South’, CAST(73368786216 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (3, N‘Ray’, N‘214 High Street’, CAST(64765571087 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (4, N‘Gilbert’, N‘177 Elm Street’, CAST(4979477778 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (5, N‘Jorge’, N‘7 Walnut Street’, CAST(88842643373 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (6, N‘Ernest’, N‘176 Washington Street’, CAST(17153094018 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (7, N‘Edward’, N‘142 Main Street West’, CAST(66115434358 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (8, N‘Stella’, N’51 Main Street East’, CAST(94093532159 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (9, N‘Nicholas’, N‘191 Church Street’, CAST(54482064421 AS Numeric(12, 0))) INSERT [dbo].[Revised] ([CustId], [CustName], [CustAddress], [CustPhone]) VALUES (10, N‘Salvador’, N’39 Main Street’, CAST(94689656558 AS Numeric(12, 0))) GO SET IDENTITY_INSERT [dbo].[Revised] OFF GO |
This code creates the tables Original and Revised that hold customer data. At the moment they are completely different, which you can see since they are small. But what if these tables had thousands or millions of rows? Eyeballing them wouldn’t be possible. You’d need a different approach. Enter set-based operations!
Set-based operations
If you remember your computer science classes, you’ll no doubt recall studying sets as mathematical objects. Relational databases combine set theory with relational calculus. Put them together and you get relational algebra, the foundation of all RDBMS’s (Thanks and hats-off to E.F. Codd). That means that we can use set theory. Remember these set operations?
A ∪ B Set union: Combine two sets into one
A ∩ B Set intersection: The members that A and B have in common
A − B Set difference: The members of A that are not in B
These have direct counterparts in SQL:
A ∪ B : UNION or UNION ALL (UNION eliminates duplicates, UNION ALL keeps them)
A ∩ B : INTERSECT
A − B : EXCEPT
We can use these to find out some things about our tables:
|
SELECT CustId, CustName, CustAddress, CustPhone FROM Original INTERSECT SELECT CustId, CustName, CustAddress, CustPhone FROM Revised |
Will show us what rows these two tables have in common (none, at the moment)
|
SELECT CustId, CustName, CustAddress, CustPhone FROM Original EXCEPT SELECT CustId, CustName, CustAddress, CustPhone FROM Revised |
Will show us all the rows of the Original table that are not in the Revised table (at the moment, that’s all of them).
Using these two queries, we can see if the tables are identical or what their differences may be. If the number of rows in the first query (INERSECT) is the same as the number of rows in the Original and Revised tables, they are identical, at least for tables having keys (since there can be no duplicates). Similarly, if the results from the second query (EXCEPT) are empty and the results from a similar query reversing the order of the selects is empty, they are equal. Saying it another way, if both sets have the same number of members and all members of one set are the same as all the members of the other set, they are equal.
Challenges with non-keyed tables
The tables we are working with are keyed so we know that each row must be unique in each table, since duplicate keys are not allowed. What about non-keyed tables? Here’s a simple example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @t1 TABLE (a INT, b INT); INSERT INTO @t1 VALUES (1, 2), (1, 2), (2, 3), (3, 4); DECLARE @t2 TABLE (a INT, b INT); INSERT INTO @t2 VALUES (1, 2), (2, 3), (2, 3), (3, 4); SELECT * FROM @t1 EXCEPT SELECT * FROM @t2; |
The last query, using EXCEPT, returns an empty result. But the tables are different! The reason is that EXCEPT, INTERSECT and UNION eliminate duplicate rows. Now this query:
|
SELECT * FROM @t1 INTERSECT SELECT * FROM @t2; |
Returns 3 rows:
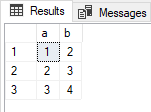
These are the three rows that the two tables have in common. However, since each table has 4 rows, you know they are not identical. Checking non-keyed tables for equality is a challenge I’ll leave for a future article.
Giving our tables something in common
Let’s go back to the first example using keyed tables. To make our comparisons interesting, let’s give our tables something in common:
|
SET IDENTITY_INSERT Revised ON; INSERT INTO Revised(CustId, CustName, CustAddress, CustPhone) SELECT TOP 50 PERCENT CustId, CustName, CustAddress, CustPhone FROM Original ORDER BY NEWID(); SET IDENTITY_INSERT Revised OFF; |
Here, we take about half the rows of the Original table and insert them into the Revised table. Using ORDER BY NEWID() makes the selection pseudo-random.
|
SET IDENTITY_INSERT Original ON; INSERT INTO Original(CustId, CustName, CustAddress, CustPhone) SELECT TOP 50 PERCENT CustId, CustName, CustAddress, CustPhone FROM Revised WHERE CustID NOT IN (SELECT CustId FROM Original) ORDER BY NEWID(); SET IDENTITY_INSERT Original OFF; |
This query takes some of the rows from the Revised table and inserts them into the Original table using a similar technique, while avoiding duplicates.
Now, the EXCEPT query is more interesting. Whichever table I put first, I should get 5 rows output. For example:
|
SELECT CustId, CustName, CustAddress, CustPhone FROM Revised EXCEPT SELECT CustId, CustName, CustAddress, CustPhone FROM Original |
Returns:
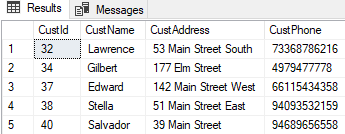
Now the two tables also have 10 rows in common:
|
SELECT CustId, CustName, CustAddress, CustPhone FROM Original INTERSECT SELECT CustId, CustName, CustAddress, CustPhone FROM Revised |
Returns:
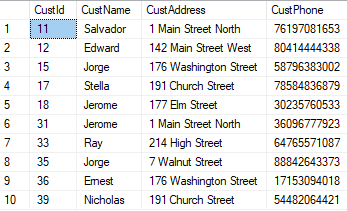
Depending on the change being implemented, these results may be either good or bad. But at least now you have something to show for your efforts!
Row-to-row changes
So far, we’ve only considered changes in whole rows. What if only certain columns are changing? For example, what if in the Revised table, for some customer id, the name or phone number changed? It would be great to be able to report the rows that changed and also to provide a summary of the number of changes by column and also some way to see what changed between two rows, not just visually, but programmatically. These sample tables are small and narrow. Imagine a table with 40 columns, not 4 and 1 million rows, not 10. Computing such a summary would be very tedious. I’m thinking about something like this:
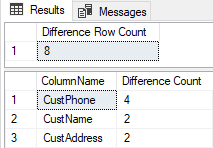
This shows me that there are 8 rows with the same customer id but different contents and that four of them have different phone numbers, two have different names and two have different addresses.
I’ll also want to produce a table of these differences that can be joined back to the Original and Revised tables.
Checking comparability with sys.columns
Just because two tables look the same at first glance, that doesn’t mean that they are the same. To do the kind of comparison I’m talking about here, I need to be sure that really are the same. To that end I can use the system catalog view sys.columns. This view returns a row for each column of an object that has columns, such as views or tables. Each row contains the properties of a single column, e.g. the column name, datatype, and column_id. See the references section for a link to the official documentation where you can find all the details.
Now, there are at least two columns in sys.columns that will likely be different: object_id, which is the object id of the table or view to which the column belongs, and default_object_id, which is the id of a default object for that column, should one exist. There are other id columns that may be different as well. When using these techniques in your own work, check the ones that apply.
How can we use sys.columns to see if two tables have the same schema? Consider this query:
|
SELECT * FROM sys.columns WHERE object_id = OBJECT_ID(N‘Original’) EXCEPT SELECT * FROM sys.columns WHERE object_id = OBJECT_ID(N‘Revised’); |
If the two tables really are identical, the above query would return no results. However, we need to think about the columns that may differ because they refer to other objects. You can eliminate the problem this way:
|
IF object_id(N‘tempdb..#Source’, N‘U’) IS NOT NULL DROP TABLE #Source; SELECT TOP (0) * INTO #Source FROM sys.columns; |
This script will create a temporary table from sys.columns for the Original table. Note that the “SELECT INTO” in this snippet just copies the schema of sys.columns to a new, temporary table. Now, we can populate it like this:
|
INSERT INTO #Source SELECT * FROM sys.columns c WHERE c.object_id = OBJECT_ID(N‘Original’) —AND c.is_identity = 0 |
I’ve commented out the check for an identity column. You might want to exclude identity columns since they are system generated and are likely to differ between otherwise-identical tables. In that case, you’ll want to match on the business keys, not the identity column. In the working example though, I explicitly set the customer ids so this does not apply, though it very well might in the next comparison. Now, so we don’t compare the columns that we know will be different:
|
ALTER TABLE #Source DROP COLUMN object_id, default_object_id, — and possibly others |
Repeat the above logic for the target table (The Revised table in the working example). Then you can run:
|
SELECT * FROM #Source EXCEPT SELECT * FROM #Target; |
In the working example, this will return no results. (In case you are wondering, SELECT * is fine in this case because of the way the temporary tables are created – the schema and column order will be the same for any given release of SQL Server.) If the query does return results, you’ll have to take those differences into account. For the purpose of this article, however, I expect no results.
Creating differences
Starting with the Original and Revised tables, I’ll create some differences and leave some things the same:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
WITH MixUpCustName(CustId, CustName, CustAddress, CustPhone) AS ( SELECT TOP 50 PERCENT CustId, SUBSTRING(CustName,6, len(CustName)) + LEFT(CustName,5), CustAddress, CustPhone FROM Original ORDER BY NEWID() ), MixUpCustAddress(CustId, CustName, CustAddress, CustPhone) AS ( SELECT TOP 50 PERCENT CustId, CustName, SUBSTRING(CustAddress,6, len(CustAddress)) + LEFT(CustAddress,5), CustPhone FROM Original ORDER BY NEWID() ), MixUpCustPhone(CustId, CustName, CustAddress, CustPhone) AS ( SELECT TOP 50 PERCENT CustId, CustName, CustAddress, CAST(CustPhone / 100 AS int) + 42 FROM Original ORDER BY NEWID() ), MixItUp(CustId, CustName, CustAddress, CustPhone) AS ( SELECT CustId, CustName, CustAddress, CustPhone FROM MixUpCustName UNION SELECT CustId, CustName, CustAddress, CustPhone FROM MixUpCustAddress UNION SELECT CustId, CustName, CustAddress, CustPhone FROM MixUpCustPhone ) — Main query to mix up the data UPDATE Revised SET Revised.CustName = MixItUp.CustName, Revised.CustAddress = MixItUp.CustAddress, Revised.CustPhone = MixItUp.CustPhone FROM Revised JOIN MixItUp ON Revised.CustId = MixItUp.CustId |
This query mixes up the data in the columns of the Revised table in randomly-selected rows by simple transpositions and arithmetic. I use ORDER BY NEWID() again to perform pseudo-random selection.
Computing basic statistics
Now that we know the tables are comparable, we can easily compare them to produce some basic difference statistics. For example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
WITH InOriginal AS ( SELECT * FROM Original EXCEPT SELECT * FROM Revised ), InRevised AS ( SELECT * FROM Revised EXCEPT SELECT * FROM Original ), InBoth AS ( SELECT * FROM Revised INTERSECT SELECT * from Original ) SELECT (SELECT COUNT(*) FROM Original) AS Original, (SELECT COUNT(*) FROM Revised) AS Revised, (SELECT COUNT(*) FROM InOriginal) AS InOriginal, (SELECT COUNT(*) FROM InRevised) AS InRevised, (SELECT COUNT(*) FROM InBoth) AS InBoth; |
Returns:

for the working example. However, I want to go deeper!
Using SELECT … EXCEPT to find column differences
Since SQL uses three-value logic (True, False and Null), you might have written something like this to compare two columns:
|
WHERE a.col <> b.col OR a.col IS NULL AND b.col IS NOT NULL OR a.col IS NOT NULL and b.col IS NULL |
To check if columns from two tables are different. This works of course, but here is a simpler way!
|
WHERE NOT EXISTS (SELECT a.col EXCEPT SELECT b.col) |
This is much easier to write, is DRYer (DRY = Don’t Repeat Yourself) and takes care of the complicated logic in the original WHERE clause. On top of that, this does not cause a performance problem or make for a suddenly-complicated execution plan. The reason is that the sub query is comparing columns from two rows that are being matched, as in a JOIN for example. You can use this technique anywhere you need a simple comparison and columns (or variables) are nullable.
Now, applying this to the working example, consider this query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
IF OBJECT_ID(N‘tempdb..#diffcols’, N‘U’) IS NOT NULL DROP TABLE #diffcols; SELECT src.CustId, CONCAT( IIF(EXISTS(SELECT src.CustId EXCEPT SELECT tgt.CustId ), RTRIM(‘, CustId ‘), ”), IIF(EXISTS(SELECT src.CustName EXCEPT SELECT tgt.CustName ), RTRIM(‘, CustName ‘), ”), IIF(EXISTS(SELECT src.CustAddress EXCEPT SELECT tgt.CustAddress ), RTRIM(‘, CustAddress ‘), ”), IIF(EXISTS(SELECT src.CustPhone EXCEPT SELECT tgt.CustPhone ), RTRIM(‘, CustPhone ‘), ”)) + ‘, ‘ AS cols INTO #diffcols FROM Original src JOIN Revised tgt ON src.CustId = tgt.CustId WHERE EXISTS (SELECT src.* EXCEPT SELECT tgt.*) ; |
At its heart, this query joins the Original and Revised tables on customer id. For each pair of rows joined, the query returns a new column (called ‘cols’) that contains a concatenated list of column names if the columns differ. The query uses the technique just described to make things compact and easy to read. Since the query creates a new temporary table, let’s look at the contents:
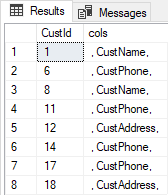
The eight rows that differ, differ in specific columns. For each row that differs, we have a CSV list of column names. (The leading and trailing commas make it easy to pick out column names, both visually and programmatically). Although there is only one column listed for each customer id, there could be multiple columns listed and in a real-world scenario likely would be. Since the newly-created temp table has the customer id in it, you can easily do a three-way join between the Original and Revised tables to see the context and content of these changes, e.g.
|
SELECT * FROM Original o JOIN Revised r ON o.CustId = r.CustId JOIN #diffcols d ON o.CustId = d.CustId |
Returns:
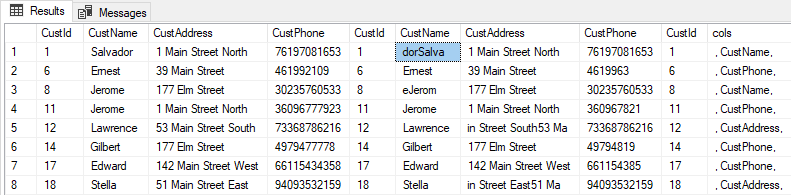
For a very-wide table, this makes it easy to zero in on the differences, since for each row, you have a neat list of the columns that differ and you can select them accordingly.
Generating detail difference statistics
There’s one other thing I can do with the temp table we just created. I can produce the table of differences I wanted. Here, I’m using those commas I inserted in the CSV column list to make it easy to search using a LIKE operator.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
WITH src AS ( SELECT SUM(IIF(d.cols LIKE ‘%, CustId, %’ , 1, 0)) AS CustId, SUM(IIF(d.cols LIKE ‘%, CustName, %’ , 1, 0)) AS CustName, SUM(IIF(d.cols LIKE ‘%, CustAddress, %’ , 1, 0)) AS CustAddress, SUM(IIF(d.cols LIKE ‘%, CustPhone, %’ , 1, 0)) AS CustPhone FROM #diffcols d ) SELECT ca.col AS ColumnName, ca.diff AS [Difference Count] FROM src CROSS APPLY ( VALUES (‘CustId ‘,CustId ), (‘CustName ‘,CustName ), (‘CustAddress ‘,CustAddress ), (‘CustPhone ‘,CustPhone ) ) ca(col, diff) WHERE diff > 0 ORDER BY diff desc ; |
This is an interesting query because I am not returning anything from the temp #diffcols table. Instead I use that table to create the sums of the differences then arrange the finally result using CROSS APPLY. You could do the same thing with UNPIVOT, but the CROSS APPLY VALUES syntax is shorter to write and easier on the eyes. Readability is always important, regardless of the language. There’s an interesting web site dedicated to writing obfuscated C. It’s interesting to see how much you can get done with a write-only program (one that you can’t read and make sense of). Don’t write obfuscated SQL, though!
This query returns:
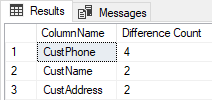
Just what I wanted!
Creating a stored procedure to help
If you’ve been following along, you’ve probably already realized that this will be tedious to write for anything but a trivial example. Help is on the way! I’ve included a stored procedure that constructs the queries discussed in this article, using nothing more than the table names and a list of key columns to use for the join predicate, that you are free to use or modify to suit.
Summary
Comparing tables or query results is a necessary part of database development. Whether you are modifying an application that should change the result or making a change that should not change the result, you need tools to do this efficiently.
Downloads
- GetComparisonScript
References
- Codd, E. F. (1970). “A relational model of data for large shared data banks”
- sys.columns
- The International Obfuscated C Code Contest
- Author
- Recent Posts

Gerald Britton is a Senior SQL Server Solution Designer, Author, Software Developer, Teacher and a Microsoft Data Platform MVP. He has many years of experience in the IT industry in various roles.
Gerald specializes in solving SQL Server query performance problems especially as they relate to Business Intelligence solutions. He is also a co-author of the eBook “Getting Started With Python” and an avid Python developer, Teacher, and Pluralsight author.
You can find him on LinkedIn, on Twitter at twitter.com/GeraldBritton or @GeraldBritton, and on Pluralsight
View all posts by Gerald Britton
How do you compare two SQL tables? Every SQL Developer or DBA knows the answer, which is ‘it depends’. It is not just the size of the table or the type of data in it but what you want to achieve. Phil sets about to cover the basics and point out some snags and advantages to the various techniques.
Introduction
There are several reasons why you might need to compare tables or results.
- Sometimes, one just needs to know whether the tables contain data that is the same or different; No details: just yes or no. This is typical with test assertions, where you just need to know whether your routine or batch produces a result with the right data in it. when provided with particular vales for the parameters. It is either wrong or right
- Occasionally, you need to know what rows have changed without, maybe, being particular about which columns changed and how.
- There are times when you have a large table in terms of both columns and rows, and you need something that shows you specifically the column(s) that changed their value. You might also want this when tracking down a bug in a routine that might otherwise require you to wasting time scanning ‘by eye’.
We’ll be tackling these three rather different tasks in SQL
If two tables have a different number of rows, they can’t of course be the same. However, there are times when you need to know whether Table_B contains all the rows of Table_A, without differences. If you wish more detail, you might even wish to know the rows in either table that aren’t in common, or the common rows, as indicated by the primary key, that were different. Why stick at comparing just two tables? There are ways of comparing as many as you need. (as, for example, when you’re comparing the metadata in several database snapshots). Yes, there are many variations
You’ve got tools and features to do this stuff, surely?
There is always a place for tools like SQL Data Compare, TableDiff, tSQLt or Change Data Capture. A lot depends on circumstances and the type of task. The problem of doing audits on changes to data in a live system is a separate topic, as is the synchronization of tables and databases. Comparison of XML documents are also out of scope. We are going to deal purely with the routine comparison of the data in tables
I’m most likely to use TSQL techniques to compare tables when:
Developing…
In the course of developing a database, a lot of tables get compared. It’s not just the big stuff: Every table-valued function, for example, needs a test harness in the build script that makes sure it does what you think it should do under all conceivable test circumstances, and incorporating all the nasty edge cases where it has been caught by the testers in the past. Every stored procedure needs a test to make sure that the process that it executes does exactly what is intended and nothing else.
There was a time that the build activity was rather leisurely, but when you’ve got a nightly build and integration test, it is best to automate it entirely and be rid of the chore.
ETL
When you are automating the loading of data into a system, you often need to test various conditions. Do you need to update existing versions of the rows as well as inserting the new ones? Do you need a trap to prevent duplicate entries, or even delete existing entries?
Setting up the test data.
The scripts in this article all use a table from the venerable PUBS database. We’re going to use the authors table, but will beef up the number of rows a bit to 5000 in order to get a size that is a bit more realistic. I’ve provided the source for the table with the article.
I then created a copy of the table …
|
SELECT * INTO authorsCopy FROM authors GO ALTER TABLE dbo.authorsCopy ADD CONSTRAINT PK_authorsCopy PRIMARY KEY CLUSTERED (au_id) ON PRIMARY GO |
And then altered some of the rows.
|
UPDATE authorsCopy SET address=STUFF(address,1,1,”) WHERE au_ID IN ( SELECT TOP 10 au_id FROM authorsCopy f ORDER BY phone) |
So now the two tables should be predominately the same with a few minor changes in the address field
Testing to see if tables are different.
Sometimes you just want to know if tables are the same. An example of this would be checking that a TVF is working properly by comparing its result to that of an existing table with the correct results. The usual way to do this is with the CHECKSUM()group of functions in SQL Server, because they are very quick.
Using Checksums
You can use the BINARY_CHECKSUM function to check whether tables are the same: well, roughly the same. It is fast, but it is not perfect, as I’ll demonstrate in a moment. If you have a series of tests, for example it is generally sufficient.
|
IF ( SELECT CHECKSUM_AGG(BINARY_CHECKSUM(*)) FROM authors)=( SELECT CHECKSUM_AGG(BINARY_CHECKSUM(*)) FROM authorsCopy) SELECT ‘they are probably the same’ ELSE SELECT ‘they are different’ |
For this to work, your table must not have TEXT, NTEXT, IMAGE or CURSOR (or a SQL_VARIANT with any of these types) as its base type. Nowadays, this is increasingly rare, but If you have any sort of complication, you can coerce any column with one of the unsupported types into a supported type. In practice, I generally use a routine that checks the metadata and does this automatically, but it isn’t pretty.
In a working version you would probably want to specify the list of columns, especially if you are having to do an explicit coercion of datatypes, or if you are checking just certain columns,
Neither BINARY_CHECKSUM() nor its plain sister CHECKSUM() are completely accurate in telling you if something has changed in a row or table. We’ll show this by looking at the common words of the English language, contained in a table called CommonWords.. You’d expect them all to have a different checksum, but that’s not the case.
|
SELECT string, BINARY_CHECKSUM(string) AS “Checksum“ FROM commonWords WHERE BINARY_CHECKSUM(string) IN ( SELECT BINARY_CHECKSUM(string) FROM commonwords GROUP BY BINARY_CHECKSUM(string) HAVING COUNT(*) > 2) ORDER BY BINARY_CHECKSUM(string) |
… giving the result …
|
string Checksum —————————— ———– nerd 426564 nest 426564 oust 426564 reed 475956 stud 475956 sued 475956 ousts 6825011 nests 6825011 nerds 6825011 |
Armed with this information, we can quickly demonstrate that different strings can have the same checksum
|
SELECT BINARY_CHECKSUM(‘reed the nerd’), BINARY_CHECKSUM(‘sued the nest’), BINARY_CHECKSUM(‘stud the oust’) |
All these will; have the same checksum, as would …
|
SELECT BINARY_CHECKSUM(‘accosted guards’), BINARY_CHECKSUM(‘accorded feasts’) |
….whereas…
|
SELECT BINARY_CHECKSUM(‘This looks very much like the next’), BINARY_CHECKSUM(‘this looks very much like the next’), BINARY_CHECKSUM(‘This looks very much like the Next’) |
… gives you different checksums like this…
|
———– ———– ———– –447523377 –447522865 –447654449 |
The sister function CHECKSUM() …
|
SELECT CHECKSUM(‘This looks very much like the next’), CHECKSUM(‘this looks very much like the next’), CHECKSUM(‘This looks very much like the Next’) |
… finds them to be all the same, because it is using the current collation and my collation for the database is case-insensitive. CHECKSUM() aims to find strings equal in checksum if they are equal in a string comparison.
|
———– ———– ———– –943581052 –943581052 –943581052 |
So, the best you can say is that there is a strong likelihood that the tables will be the same but if you need to be absolutely certain, then use another algorithm.
If you don’t mind difference in case in text strings, then you can use CHECKSUM() instead of BINARY_CHECKSUM()
The great value of this technique is that, once you’ve calculated the checksum that you need, you can store it as a value in the column of a table instead of needing the original table and therefore you can make the whole process even faster, and take less time. If you are storing the checksum value returned by CHECKSUM() make sure you check against the live table with a checksum generated with the same collation.
Here is a simple example of a ‘what’s changed’ routine.
|
–we’ll create a ‘checksum’ table ‘on the fly’ using a SELECT INTO. SELECT au_ID, BINARY_CHECKSUM(au_id, au_lname, au_fname, phone, [address], city, [state], zip, [contract]) AS [checksum] INTO auchk FROM authorscopy ORDER BY au_ID /* now we’ll put in a constraint just to check that we haven’t won the lottery (very unlikely but not completely impossible that we have two rows with the same checksum) */ ALTER TABLE AuChk ADD CONSTRAINT IsItUnique UNIQUE ([checksum]) UPDATE authorscopy SET au_fname=‘Arthur’ WHERE au_ID=‘327-89-2366’ SELECT authorscopy.* FROM authorscopy INNER JOIN AuChk ON authorscopy.au_ID=AuChk.au_ID WHERE [checksum]<>BINARY_CHECKSUM(authorscopy.au_id, au_lname, au_fname, phone, [address], city, [state], zip, [contract]) |
…which gives…
|
au_id au_lname au_fname phone address city state zip contract ———– ——— ——— ———— ————— ————- —– —– ——– 327–89–2366 Mendoza Arthur 529275–5757 15 Hague Blvd. Little Rock DE 98949 1 |
And then we just tidy up.
|
/* and we just pop it back to what it was, as part of the teardown */ UPDATE authorscopy SET au_fname=‘Arnold’ WHERE au_ID=‘327-89-2366’ |
Of course, you could use a trigger but sometimes you might want just a daily or weekly report of changes without the intrusion of a trigger into a table.
Using XML
One general possibility is to compare the XML version of the two tables, since this does the datatype translation into strings for you. It is slower than the Checksum approach but more reliable.
|
IF CONVERT(VARCHAR(MAX),( SELECT * FROM authors ORDER BY au_id FOR XML path, root)) = CONVERT(VARCHAR(MAX),( SELECT * FROM authorscopy ORDER BY au_id FOR XMLpath, root)) SELECT ‘they are the same’ ELSE SELECT ‘they are different’ |
Here, you can specify the type of comparison by specifying the collation.
or you can do this, comparing data in tables ..
|
IF BINARY_CHECKSUM(CONVERT(VARCHAR(MAX),( SELECT * FROM authors ORDER BY au_id FOR XML path, root))) = BINARY_CHECKSUM (CONVERT(VARCHAR(MAX),( SELECT * FROM authorscopy ORDER BY au_id FOR XML path, root))) SELECT ‘they are pretty much the same’ ELSE SELECT ‘they are different’ SELECT ‘they are different’ |
… by calculating a checksum of the XML version of the table. This allows you to store the checksum of the table you are comparing to.
Finding where the differences are in a table
The simplest task is where the tables have an identical number of rows, and an identical table structure. Sometimes you want to know which rows are different, and which are missing. You have, of course, to specify what you mean by ‘the same’, particularly if the two tables have different columns. The method you choose to do the comparison is generally determined by these details.
The UNION ALL … GROUP BY technique
The classic approach to comparing tables is to use a UNION ALL for the SELECT statements that include the columns you want to compare, and then GROUP BY those columns. Obviously, for this to work, there must be a column with unique values in the GROUP BY, and the primary key is ideal for this. Neither table are allowed duplicates. If they have different numbers of rows, these will show up as differences.
|
SELECT DISTINCT au_ID FROM ( SELECT au_ID FROM ( SELECT au_id, au_lname, au_fname, phone, address, city, state, zip, contract FROM authors UNION ALL SELECT au_id, au_lname, au_fname, phone, address, city, state, zip, contract FROM authorsCopy) BothOfEm GROUP BY au_id, au_lname, au_fname, phone, address, city, state, zip, contract HAVING COUNT(*)<2) f |
If one of the tables has a duplicate, then it will give you a false result, as here, where you have two tables that are very different and the result tells you that they are the same! For this reason, it is a good idea to include the column(s) that constitute the primary key, and only include the rows once!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT COUNT(*), Address_ID,TheAddress,ThePostCode FROM ( SELECT Address_ID,TheAddress,ThePostCode FROM ( VALUES (9, ‘929 Augustine lane, Staple Hill Ward South Gloucestershire UK’,‘BS16 4LL’), (10, ’45 Bradfield road, Parwich Derbyshire UK’,‘DE6 1QN’) ) TableA(Address_ID,TheAddress,ThePostCode) UNION ALL SELECT Address_ID,TheAddress,ThePostCode FROM ( VALUES (8, ”‘The Pippins’‘, 20 Gloucester Pl, Chirton Ward, Tyne & Wear UK’,‘NE29 7AD’), (8, ”‘The Pippins’‘, 20 Gloucester Pl, Chirton Ward, Tyne & Wear UK’,‘NE29 7AD’), (9, ‘929 Augustine lane, Staple Hill Ward South Gloucestershire UK’,‘BS16 4LL’), (10, ’45 Bradfield road, Parwich Derbyshire UK’,‘DE6 1QN’) ) TableB(Address_ID,TheAddress,ThePostCode) )f GROUP BY Address_ID,TheAddress,ThePostCode HAVING COUNT(*)<2 |
… giving …
|
TheCount Address_ID TheAddress ThePostCode ———– ———– ————————- ———— (0 row(s) affected) |
The technique can be used for comparing more than two tables. You’d just need to UNION ALL the tables you need to compare and change the HAVING clause to filter just the rows that aren’t in all the tables.
Using EXCEPT
You can now use the much cleaner and slightly faster EXCEPT.
|
SELECT * from authors EXCEPT SELECT * from authorsCopy |
This shows all the rows in authors that are not found in authorsCopy. If they are the same, it would return no rows
|
au_id au_lname au_fname phone address city state zip contract ———– ———– ——— ———— ————————– ———– —– —– ——– 041–76–1076 Sosa Sonja 000–198–8753 29 Second Avenue Omaha CT 23243 0 187–42–2491 Mc Connell Trenton 0003090766 279 Hague Way San Diego NY 94940 1 220–43–7067 Fox Judith 000–137–9418 269 East Hague Street Richmond VA 55027 0 505–28–2848 Hardy Mitchell 001–2479822 73 Green Milton Drive Norfolk WA 69949 1 697–84–0401 Montes Leanne 000–018–0454 441 East Oak Parkway San Antonio MD 38169 1 727–35–9948 Long Jonathon 000–8761152 280 Nobel Avenue Anchorage LA NULL 1 875–54–8676 Stone Keisha 000–107–1947 763 White Fabien Way Fremont ND 08520 0 884–64–5876 Keller Steven 000–2787554 45 White Nobel Boulevard Milwaukee NY 29108 1 886–75–9197 Ellis Marie 001032–5109 35 East Second Boulevard Chicago IL 32390 1 975–80–3567 Salazar Johanna 001–028–0716 17 New Boulevard Jackson ND 71625 0 (10 row(s) affected) |
I’m only using SELECT * to keep things simple for the article. You’d normally itemize all the columns you want to compare.
This will only work for tables with the same number of rows because, if authors had extra rows, it would still say that they were different since the rows in Authors that weren’t in authorsCopy would be returned. This is because EXCEPT returns any distinct values from the query to the left of the EXCEPT operand that are not also found from the query on the right
This, hopefully shows what I mean
|
SELECT Address_ID,TheAddress,ThePostCode FROM (VALUES (9, ‘929 Augustine lane, Staple Hill Ward South Gloucestershire UK’,‘BS16 4LL’), (10, ’45 Bradfield road, Parwich Derbyshire UK’,‘DE6 1QN’) ) TableA(Address_ID,TheAddress,ThePostCode) EXCEPT SELECT Address_ID,TheAddress,ThePostCode from (VALUES (8, ”‘The Pippins’‘, 20 Gloucester Pl, Chirton Ward, Tyne & Wear UK’,‘NE29 7AD’), (8, ”‘The Pippins’‘, 20 Gloucester Pl, Chirton Ward, Tyne & Wear UK’,‘NE29 7AD’), (9, ‘929 Augustine lane, Staple Hill Ward South Gloucestershire UK’,‘BS16 4LL’), (10, ’45 Bradfield road, Parwich Derbyshire UK’,‘DE6 1QN’) ) TableB(Address_ID,TheAddress,ThePostCode) |
…yields …
|
Address_ID TheAddress ThePostCode ———– ———————————————- ———– (0 row(s) affected) |
…whereas …
|
SELECT Address_ID,TheAddress,ThePostCode FROM (VALUES (8, ”‘The Pippins’‘, 20 Gloucester Pl, Chirton Ward, Tyne & Wear UK’,‘NE29 7AD’), (8, ”‘The Pippins’‘, 20 Gloucester Pl, Chirton Ward, Tyne & Wear UK’,‘NE29 7AD’), (9, ‘929 Augustine lane, Staple Hill Ward South Gloucestershire UK’,‘BS16 4LL’), (10, ’45 Bradfield road, Parwich Derbyshire UK’,‘DE6 1QN’) ) TableB(Address_ID,TheAddress,ThePostCode) EXCEPT SELECT Address_ID,TheAddress,ThePostCode FROM (VALUES (9, ‘929 Augustine lane, Staple Hill Ward South Gloucestershire UK’,‘BS16 4LL’), (10, ’45 Bradfield road, Parwich Derbyshire UK’,‘DE6 1QN’) ) TableA(Address_ID,TheAddress,ThePostCode) |
..results in …
|
Address_ID TheAddress ThePostCode ———– ————————————————————- ———– 8 ‘The Pippins’, 20 Gloucester Pl, Chirton Ward, Tyne & Wear UK NE29 7AD (1 row(s) affected) |
This feature of EXCEPT could be used to advantage if you particularly wish to check that TableA is contained within TableB. So where the tables have a different number of rows you can still compare them.
You might not want to compare all columns. You should always specify those columns you wish to compare to determine ‘sameness’. If you only wanted to compare the Address for example, you’d use …
|
SELECT address FROM authors EXCEPT SELECT address FROM authorsCopy |
The Outer Join technique
There is also the technique of the outer join. This is a more general technique that give you additional facilities. If, for example, you use the full outer join then you can get the unmatched rows in either table. This gives you a ‘before’ and ‘after’ view of alterations in the data. It is used more generally in synchronisation to tell you what rows to delete, insert and update.
We’ll just use the technique to get the altered rows in authorsCopy
|
SELECT authors.au_id, authors.au_lname, authors.au_fname, authors.phone, authors.address, authors.city, authors.state, authors.zip, authors.contract FROM authors LEFT OUTER JOIN authorsCopy ON authors.au_ID = AuthorsCopy.au_ID AND authors.au_lname =authorsCopy.au_lname AND authors.au_fname =authorsCopy.au_fname AND authors.phone =authorsCopy.phone AND COALESCE(authors.address,”)=COALESCE(authorsCopy.address,”) AND COALESCE(authors.city,”) =COALESCE(authorsCopy.city,”) AND COALESCE(authors.state,”) =COALESCE(authorsCopy.state,”) AND COALESCE(authors.zip,”) =COALESCE(authorsCopy.zip,”) AND authors.contract =authorsCopy.contract WHERE authorsCopy.au_ID IS NULL |
As you can see, there are difficulties with null columns with this approach, but it is as fast as the others and it gives you rather more versatility for your comparisons.
Locating the differences between tables
You may need a quick way of seeing what column and row has changed. A very ingenious way of doing this was published recently. It used XML. ‘Compare Tables And Report The Differences By Using Xml To Pivot The Data’ (editor’s note: link deprecated). It is clever, but too slow. The same thing can be done purely in SQL. Basically, you perform a column by column comparison of data based on the primary key, using a key/value pair. If you do the entire table at once it is rather slow: The best trick is to do this only on those rows where you know there is a difference.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
DECLARE @temp TABLE(au_id VARCHAR(11) PRIMARY KEY) /*this holds the primary keys of rows that have changed */ INSERT INTO @Temp(au_ID) –determine which rows have changed SELECT au_ID FROM –use the EXCEPT technique qhich is the quickest in our tests ( SELECT au_id, au_lname, au_fname, phone, [address], city, state, zip, [contract] FROM authors EXCEPT SELECT au_id, au_lname, au_fname, phone, address, city, state, zip, contract FROM authorsCopy )f–now we just SELECT those columns that have changed SELECT lefthand.au_id,lefthand.name,lefthand.value AS original,Righthand.value AS changed FROM (–now we just lay out the two tables as key value pairs, using the string versions of the data SELECT authors.au_id, ‘au_lname’ AS ‘name’,au_lname AS ‘value’ FROM authors INNER JOIN @Temp altered ON altered.au_id=authors.au_id UNION SELECT authors.au_id, ‘au_fname’ AS ‘name’,au_fname AS ‘value’ FROM authors INNER JOIN @Temp altered ON altered.au_id=authors.au_id UNION SELECT authors.au_id, ‘phone’,phone FROM authors INNER JOIN @Temp altered ON altered.au_id=authors.au_id UNION SELECT authors.au_id, ‘address’,address FROM authors INNER JOIN @Temp altered ON altered.au_id=authors.au_id UNION SELECT authors.au_id, ‘City’ AS ‘name’,City AS ‘value’ FROM authors INNER JOIN @Temp altered ON altered.au_id=authors.au_id UNION SELECT authors.au_id, ‘State’,state FROM authors INNER JOIN @Temp altered ON altered.au_id=authors.au_id UNION SELECT authors.au_id, ‘zip’,zip FROM authors INNER JOIN @Temp altered ON altered.au_id=authors.au_id UNION SELECT authors.au_id, ‘contract’,CONVERT(CHAR(1),contract) FROM authors INNER JOIN @Temp altered ON altered.au_id=authors.au_id) LeftHand INNER JOIN ( SELECT authorsCopy.au_id, ‘au_lname’ AS ‘name’,au_lname AS ‘value’ FROM authorsCopy INNER JOIN @Temp altered ON altered.au_id=authorsCopy.au_id UNION SELECT authorsCopy.au_id, ‘au_fname’,au_fname FROM authorsCopy INNER JOIN @Temp altered ON altered.au_id=authorsCopy.au_id UNION SELECT authorsCopy.au_id, ‘phone’,phone FROM authorsCopy INNER JOIN @Temp altered ON altered.au_id=authorsCopy.au_id UNION SELECT authorsCopy.au_id, ‘address’,address FROM authorsCopy INNER JOIN @Temp altered ON altered.au_id=authorsCopy.au_id UNION SELECT authorsCopy.au_id, ‘City’ AS ‘name’,City AS ‘value’ FROM authorsCopy INNER JOIN @Temp altered ON altered.au_id=authorsCopy.au_id UNION SELECT authorsCopy.au_id, ‘State’,state FROM authorsCopy INNER JOIN @Temp altered ON altered.au_id=authorsCopy.au_id UNION SELECT authorsCopy.au_id, ‘zip’,zip FROM authorsCopy INNER JOIN @Temp altered ON altered.au_id=authorsCopy.au_id UNION SELECT authorsCopy.au_id, ‘contract’,CONVERT(CHAR(1),contract) FROM authorsCopy INNER JOIN @Temp altered ON altered.au_id=authorsCopy.au_id) rightHand ON lefthand.au_ID=righthand.au_ID AND lefthand.name=righthand.name WHERE lefthand.value<>righthand.value |
in our example, this would give:
|
au_id name original changed ———– ——– —————————- ———————————— 041–76–1076 address 29 Second Avenue 9 Second Avenue 187–42–2491 address 279 Hague Way 79 Hague Way 220–43–7067 address 269 East Hague Street 69 East Hague Street 505–28–2848 address 73 Green Milton Drive 3 Green Milton Drive 697–84–0401 address 441 East Oak Parkway 41 East Oak Parkway 727–35–9948 address 280 Nobel Avenue 80 Nobel Avenue 875–54–8676 address 763 White Fabien Way 63 White Fabien Way 884–64–5876 address 45 White Nobel Boulevard 5 White Nobel Boulevard 886–75–9197 address 35 East Second Boulevard 5 East Second Boulevard 975–80–3567 address 17 New Boulevard 7 New Boulevard |
This technique rotates the rows of the tables that have differences into an Entity-attribute-value (EAV) table so that differences within a row can be compared and displayed. It does this rotation by UNIONing the name and string-value of each column. This technique works best where there are not a large number of differences.
Conclusions
There is no single ideal method of comparing the data in tables or results. One of a number of techniques will be the most relevant for any particular task. It is all down to precisely the answers you need and the type of task. Do you need a quick check that a table hasn’t changed, or do you need to know precisely what the changes are? SQL is naturally fast at doing this task and comparisons of tables and results is a familiar task to many database developers.
If there is a general rule, I’d say that exploratory or ad-hoc work needs a tool such as SQL Data Compare, whereas a routine process within the database requires a hand-cut SQL technique.
The source to the table, and the insert-statements to fill it to 5000 rows is in the link below.
