Время на прочтение
16 мин
Количество просмотров 236K
Добрый день, уважаемые хаброжители!
Время от времени некоторым (а может и более, чем некоторым) из нас приходится сталкиваться с задачами по обработке небольших массивов данных, начиная от составления и анализа домашнего бюджета и заканчивая какими-либо расчетами по работе, учебе и т.д. Пожалуй, наиболее подходящим инструментом для этого является Microsoft Excel (или возможно иные его аналоги, но они менее распространены).
Поиск выдал мне всего одну статью на Хабре по схожей тематике — «Талмуд по формулам в Google SpreadSheet». В ней дано хорошее описание базовых вещей для работы в excel (хотя он и не 100% про сам excel).
Таким образом, накопив определенный пул запросов/задач, появилась идея их типизировать и предложить возможные решения (пусть не все возможные, но быстро дающие результат).
Речь пойдет о решении наиболее распространенных задач, с которыми сталкиваются пользователи.
Описание решений построено следующим образом – дается кейс, содержащий исходное задание, которое постепенно усложняется, к каждому шагу дано развернутое решение с пояснениями. Наименования функций будут даваться на русском языке, но в скобках при первом упоминании будет приводиться оригинальное наименование на английском языке (т.к. по опыту у подавляющего большинства пользователей установлена русскоязычная версия).
Кейс_1: Логические функции и функции поиска совпадений
«У меня есть набор значений в табличке и необходимо что бы при выполнении определенного условия/набора условий выводилось определенное значение» (с) Пользователь
Данные, как правило, представлены в табличной форме:
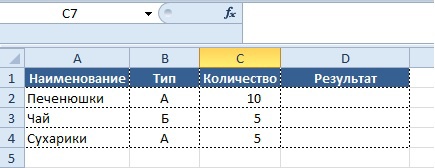
Условие:
- если значение в столбце «Количество» больше 5,
- то нужно вывести в колонке «Результат» значение «Заказ не требуется»,
В этом нам поможет формула «ЕСЛИ» (IF), которая относится к логическим формулам и может выдавать в решении любые значения, которые мы заранее записываем в формуле. Обращаю внимание, что любые текстовые значения записываются, используя кавычки.
Синтаксис формулы следующий:
ЕСЛИ(лог_выражение, [значение_если_истина], [значение_если_ложь])
- Лог_выражение — выражение, дающее в результате значение ИСТИНА или ЛОЖЬ.
- Значение_если_истина — значение, которое выводится, если логическое выражение истинно
- Значение_если_ложь — значение, которое выводится, если логическое выражение ложно
Синтаксис формулы для решения:
Вывод результата в ячейку D2:
=ЕСЛИ(C5>5;«Заказ не требуется»;«Необходим заказ»)
На выходе получаем результат:

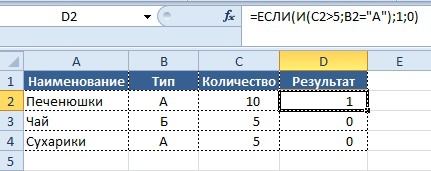
Бывает, что условие носит более сложный характер, например выполнение 2-х и более условий:
- если значение в столбце «Количество» больше 5, а значение в колонке «Тип» равно «А»
- то нужно вывести в колонке «Результат» значение «1», в обратном случае «0».
В данном случае мы уже не можем ограничиться использованием одной только формулы «ЕСЛИ», необходимо добавить в ее синтаксис другую формулу. И это будет еще одна логическая формула «И» (AND).
Синтаксис формулы следующий:
И(логическое_значение1, [логическое_значение2], …)
- Логическое_значение1-2 и т.д. — проверяемое условие, вычисление которого дает значение ИСТИНА или ЛОЖЬ
Синтаксис решения будет следующим:
Вывод результата в ячейку D2:
=ЕСЛИ(И(C2>5;B2=«А»);1;0)
Таким образом, используя сочетание 2-х формул, мы находим решение нашей задачи и получаем результат:
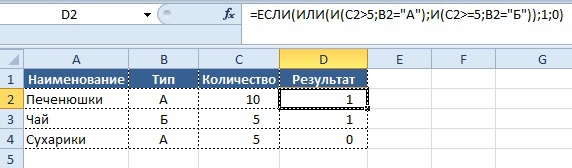
Попробуем усложнить задачу – новое условие:
- если значение в столбце «Количество» равно 10, а значение в колонке «Тип» равно «А»
- или же значение в столбце «Количество» больше или равно 5, а значение «Тип» равен «Б»
- то нужно вывести в колонке «Результат» значение «1», в обратном случае «0».
Синтаксис решения будет следующим:
Вывод результата в ячейку D2:
=ЕСЛИ(ИЛИ(И(C2=10;B2=«А»); И(C2>=5;B2=«Б»));1;0)
Как видно из записи, в формулу «ЕСЛИ» включено одно условие «ИЛИ» (OR) и два условия с использованием формулы «И», включенных в него. Если хотя бы одно из условий 2-го уровня имеет значение «ИСТИНА», то в колонку «Результат» будет выведен результат «1», в противном случае будет «0».
Результат:
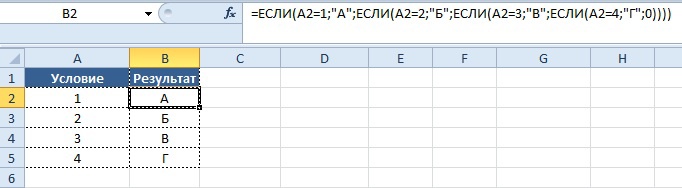
Теперь перейдем к следующей ситуации:
Представим, что в зависимости от значения в столбце «Условие» должно выводиться определенное условие в столбце «Результат», ниже приведено соответствие значений и результата.
Условие:
- 1 = А
- 2 = Б
- 3 = В
- 4 = Г
При решении задачи с помощью функции «ЕСЛИ», синтаксис будет следующим:
Вывод результата в ячейку B2:
=ЕСЛИ(A2=1;«А»; ЕСЛИ(A2=2;«Б»; ЕСЛИ(A2=3;«В»; ЕСЛИ(A2=4;«Г»;0))))
Результат:
Как видно, написание подобной формулы не только не очень удобно и громоздко, но и может занять некоторое время на ее редактирование у неопытного пользователя в случае ошибки.
Минус подобного подхода в том, что он применим для небольшого количества условий, ведь, все их придется набирать вручную и «раздувать» нашу формулу до больших размеров, однако подход отличает полная «всеядность» к значениям и универсальность использования.
Альтернативное решение_1:
Использование формулы «ВЫБОР» (CHOOSE),
Синтаксис функции:
ВЫБОР(номер_индекса, значение1, [значение2], …)
- Номер_индекса — номер выбираемого аргумента-значения. Номер индекса должен быть числом от 1 до 254, формулой или ссылкой на ячейку, содержащую число в диапазоне от 1 до 254.
- Значение1, значение2,… — значение от 1 до 254 аргументов-значений, из которых функция «ВЫБОР», используя номер индекса, выбирает значение или выполняемое действие. Аргументы могут быть числами, ссылками на ячейки, определенными именами, формулами, функциями или текстом.
При ее использовании, мы сразу заносим результаты условий в зависимости от указанных значений.
Условие:
- 1 = А
- 2 = Б
- 3 = В
- 4 = Г
Синтаксис формулы:
=ВЫБОР(A2;«А»;«Б»;«В»;«Г»)
Результат аналогичен решению с цепочкой функций «ЕСЛИ» выше.
При применении этой формулы существуют следующие ограничения:
В ячейку «А2» (номер индекса) могут быть указаны только цифры, а значения результата будут выводиться в порядке возрастания от 1 до 254 значений.
Иными словами, функция будет работать только если в ячейке «А2» указаны цифры от 1 до 254 в порядке возрастания и это накладывает определенные ограничения при использовании этой формулы.
Т.е. если мы захотим, что бы значение «Г» выводилось при указании числа 5,
- 1 = А
- 2 = Б
- 3 = В
- 5 = Г
то формула будет иметь следующий синтаксис:
Вывод результата в ячейку B2:
=ВЫБОР(A31;«А»;«Б»;«В»;;«Г»)
Как видно, значение «4» в формуле нам приходится оставить пустым и перенести результат «Г» на порядковый номер «5».
Альтернативное решение_2:
Вот мы и подошли к одной из самых популярных функций Excel, овладение которой автоматически превращает любого офисного работника в «опытного пользователя excel» /sarcasm/.
Синтаксис формулы:
ВПР(искомое_значение, таблица, номер_столбца, [интервальный_просмотр])
- Искомое_значение – значение, поиск которого осуществляется функцией.
- Таблица – диапазон ячеек, содержащий данные. Именно в этих ячейках будет происходить поиск. Значения могут быть текстовыми, числовыми или логическими.
- Номер_столбца — номер столбца в аргументе «Таблица», из которого будет выводиться значение в случае совпадения. Важно понимать, что отсчет столбцов происходит не по общей сетке листа (A.B,C,D и т.д.), а внутри массива, указанного в аргументе «Таблица».
- Интервальный_просмотр — определяет, какое совпадение должна найти функция — точное или приблизительное.
Важно: функция «ВПР» ищет совпадение только по первой уникальной записи, если искомое_значение присутствует в аргументе «Таблица» несколько раз и имеет разные значения, то функция «ВПР» найдет только самое ПЕРВОЕ совпадение, результаты по всем остальным совпадениям показаны не будутИспользование формулы «ВПР» (VLOOKUP) связано с еще одним подходом в работе с данными, а именно с формированием «справочников».
Суть подхода в создании «справочника» соответствия аргумента «Искомое_значение» определенному результату, отдельно от основного массива, в котором прописываются условия и соответствующие им значения:
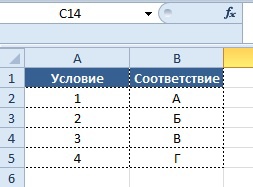
Затем в рабочей части таблицы уже прописывается формула со ссылкой на справочник, заполненный ранее. Т.е. в справочнике в столбце «D» происходит поиск значения из столбца «А» и при нахождении соответствия выводится значение из столбца «Е» в столбец «В».
Синтаксис формулы:
Вывод результата в ячейку B2:
=ВПР(A2;$D$2:$E$5;2;0)
Результат:
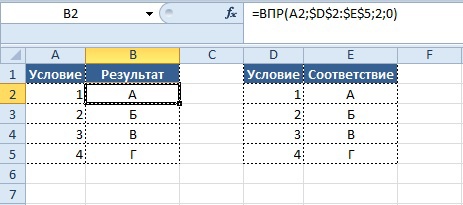
Теперь представим ситуацию, когда необходимо подтянуть данные в одну таблицу из другой, при этом таблицы не идентичны. См. пример ниже
Видно, что строки в столбцах «Продукт» обеих таблиц не совпадают, однако, это не является препятствием для использования функции «ВПР».
Вывод результата в ячейку B2:
=ВПР($A3;$H$3:$M$6;2;0)
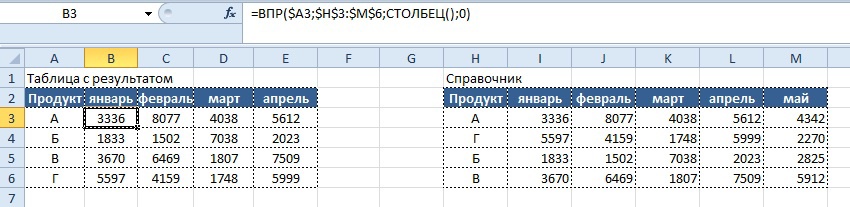
Но при решении сталкиваемся с новой проблемой – при «протягивании» написанной нами формулы вправо от столбца «В» до столбца «Е», нам придется вручную заменять аргумент «номер_столбца». Дело это трудоемкое и неблагодарное, потому, на помощь нам приходит другая функция — «СТОЛБЕЦ» (COLUMN).
Синтаксис функции:
СТОЛБЕЦ([ссылка])
- Ссылка — ячейка или диапазон ячеек, для которых требуется возвратить номер столбца.
Если использовать запись типа:
=СТОЛБЕЦ()
то функция выведет номер текущего столбца (в ячейке которого написана формула).
В результате получается число, которое можно использовать в функции «ВПР», чем мы и воспользуемся и получаем следующую запись формулы:
Вывод результата в ячейку B2:
=ВПР($A3;$H$3:$M$6; СТОЛБЕЦ();0)
Функция «СТОЛБЕЦ» определит номер текущего столбца, который будет использоваться аргументом «Номер_столбца» для определения номера столбца поиска в справочнике.
Кроме того, можно использовать конструкцию:
=СТОЛБЕЦ()-1
Вместо числа «1» можно использовать любое число (а также не только вычитать его, но и прибавлять к полученному значению), для получения желаемого результата, если нет желания ссылаться на определенную ячейку в столбце с нужным нам номером.
Получившийся результат:
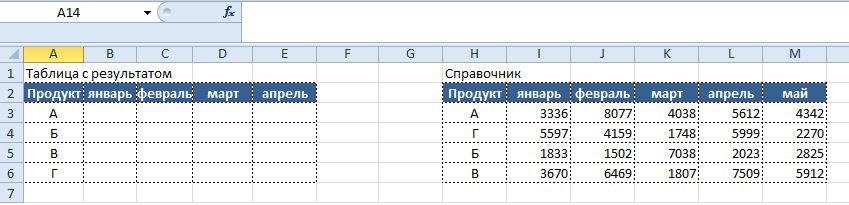
Продолжаем развивать тему и усложняем условие: представим, что у нас есть два справочника с разными данными по продуктам и необходимо вывести в таблицу с результатом значения в зависимости от того, какой тип справочника указан в колонке «Справочник»
Условие:
- Если в столбце «Справочник» указано число 1, данные должны тянуться из таблицы «Справочник_1», если число 2, то из таблицы «Справочник_2» в соответствии с указанным месяцем
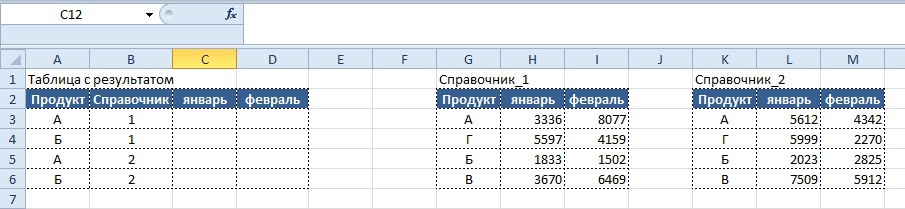
Вариант решения, который сразу приходит на ум, следующий:
Вывод результата в ячейку C3:
=ЕСЛИ($B3=1; ВПР($A3;$G$3:$I$6; СТОЛБЕЦ()-1;0); ВПР($A3;$K$3:$M$6; СТОЛБЕЦ()-1;0))
Плюсы: наименование справочника может быть любым (текст, цифры и их сочетание), минусы – плохо подходит, если вариантов более 3-х.
Если же номера справочников всегда представляют собой числа, имеет смысл использовать следующее решение:
Вывод результата в ячейку C3:
=ВПР($A3; ВЫБОР($B3;$G$3:$I$6;$K$3:$M$6); СТОЛБЕЦ()-1;0)
Плюсы: формула может включать до 254 наименований справочников, минусы – их наименование должно быть строго числовым.
Результат для формулы с использованием функции «ВЫБОР»:
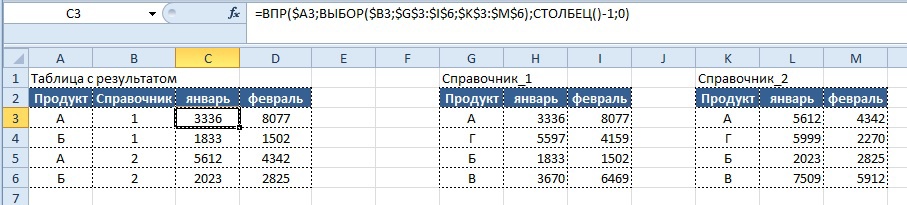
Бонус: ВПР по двум и более признакам в аргументе «искомое_значение».
Условие:
- Представим, что у нас как всегда есть массив данных в табличной форме (если нет, то мы к нему приводим данные), из массива по определенным признакам необходимо получить значения и поместить их в другую табличную форму.
Обе таблицы приведены ниже:
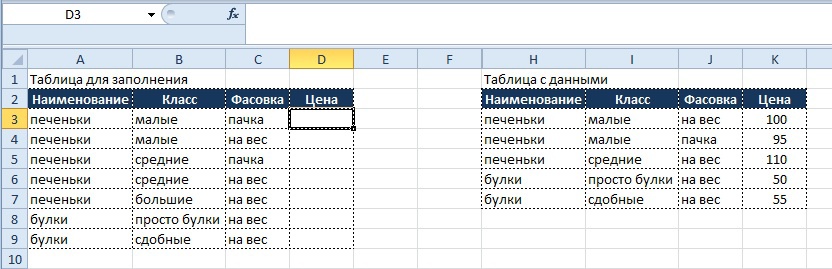
Как видно из табличных форм, каждая позиция имеет не только наименование (которое не является уникальным), но также и относится к определенному классу и имеет свой вариант фасовки.
Используя сочетание имени и класса и фасовки, мы можем создать новый признак, для этого в таблице с данными создаем дополнительный столбец «Доп.признак», который заполняем при помощи следующей формулы:
=H3&”_”&I3&”_”&J3
Используя символ «&», объединяем три признака в один (разделитель между словами может быть любым, как и не быть вовсе, главное использовать аналогичное правило и для поиска)
Аналогом формулы может быть функция «СЦЕПИТЬ» (CONCATENATE), в этом случае она будет выглядеть следующим образом:
=СЦЕПИТЬ(H3;”_”;I3;”_”;J3)
После того, как дополнительный признак создан для каждой записи в таблице с данными, приступаем к написанию функции поиска по этому признаку, которая будет иметь вид:
Вывод результата в ячейку D3:
=ЕСЛИОШИБКА(ВПР(A2&”_”&B2&”_”&C2;$G$2:$K$6;5;0);0)
В функции «ВПР» в качестве аргумента «искомое_значение» используем все ту же связку трех признаков (наименование_класс_фасовка), но берем ее уже в таблице для заполнения и заносим непосредственно в аргумент (как вариант, можно было бы выделить значение для аргумента в дополнительный столбец в таблице для заполнения, но это действие будет излишним).
Напоминаю, что использование функции «ЕСЛИОШИБКА» (IFERROR) необходимо, если искомое значение так и не будет найдено, и функция «ВПР» выведет нам значение «#Н/Д» (об этом ниже).
Результат на картинке ниже:
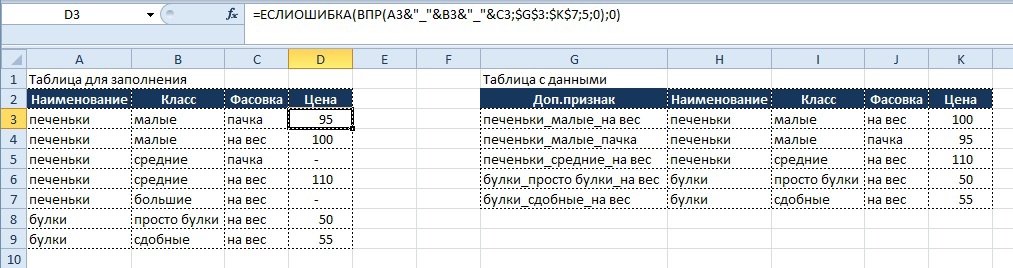
Данный прием можно использовать и для большего количества признаков, единственное условие – уникальность получаемых комбинаций, если она не соблюдается, то результат будет некорректным.
Кейс_3 Поиск значения в массиве, или когда ВПР не в силах нам помочь
Рассмотрим ситуацию, когда необходимо понять, есть ли в массиве ячеек нужные нам значения.
Задача:
- в столбце «Условие поиска» указано значение и необходимо определить, присутствует ли оно в столбце «Массив для поиска»
Визуально все выглядит в следующем виде:
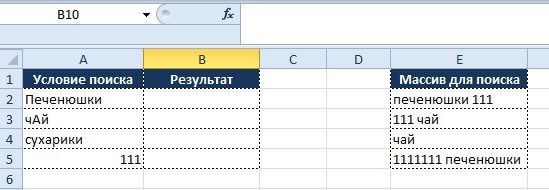
Как мы видим, функция «ВПР» тут бессильна, т.к. мы ищем не точное совпадение, а именно наличие в ячейке нужного нам значения.
Для решения задачи необходимо использовать комбинацию нескольких функций, а именно:
«ЕСЛИ»
«ЕСЛИОШИБКА»
«СТРОЧН»
«НАЙТИ»
По порядку обо всех, «ЕСЛИ» мы уже разобрали ранее, потому перейдем к функции «ЕСЛИОШИБКА» (IFERROR)
ЕСЛИОШИБКА(значение, значение_при_ошибке)
- Значение — аргумент, проверяемый на возникновение ошибок.
- Значение_при_ошибке — значение, возвращаемое при ошибке при вычислении по формуле. Возможны следующие типы ошибок: #Н/Д, #ЗНАЧ!, #ССЫЛКА!, #ДЕЛ/0!, #ЧИСЛО!, #ИМЯ? и #ПУСТО!.
Важно: данная формула практически всегда обязательна при работе с массивами информации и справочниками, т.к. зачастую бывает, что искомое значение не находится в справочнике и в этом случае функция возвращает ошибку. Если же в ячейке выводится ошибка и ячейка участвует, например, в вычислении, то оно так же произойдет с ошибкой. Плюс ко всему, ячейкам, где формула возвратила ошибку можно присваивать различные значения, которые облегчают их статистическую обработку. Также, в случае ошибки можно выполнять другие функции, что очень удобно при работе с массивами и позволяет строить формулы с учетом довольно разветвленных условий.
«СТРОЧН» (LOWER)
СТРОЧН(текст)
- Текст — текст, преобразуемый в нижний регистр.
Важно: функция «СТРОЧН» не заменяет знаки, не являющиеся буквами.
Роль в формуле: поскольку функция «НАЙТИ» (FIND) осуществляет поиск и учетом регистра текста, то необходимо привести весь текст к одному регистру, в противном случае «чАй» будет не равно «чай» и т.д. Это актуально, если значение регистра не является условием поиска и отбора значений, в противном случае формулу «СТРОЧН» можно не использовать, так поиск будет более точным.
Теперь подробнее о синтаксисе функции «НАЙТИ» (FIND).
НАЙТИ(искомый_текст, просматриваемый_текст, [нач_позиция])
- Искомый_текст — текст, который необходимо найти.
- Просматриваемый_текст — текст, в котором нужно найти искомый текст.
- Нач_позиция — знак, с которого нужно начать поиск. Первый знак в тексте «просматриваемый_текст» имеет номер 1. Если номер не указан, он по умолчанию считается равным 1.
Синтаксис формулы-решения будет иметь вид:
Вывод результата в ячейку B2:
=ЕСЛИ(ЕСЛИОШИБКА(НАЙТИ(СТРОЧН(A2); СТРОЧН(E2);1);0)=0;«fail»;«bingo!»)
Разберем логику формулы по действиям:
- СТРОЧН(A2) – преобразует аргумент «Искомый_текст» в ячейке в А2 в текст с нижним регистром
- Функция «НАЙТИ» начинает поиск преобразованного аргумента «Искомый_текст» в массиве «Просматриваемый_текст», который преобразовывается функцией «СТРОЧН(E2)», также в текст с нижним регистром.
- В случае если, функция находит совпадение, т.е. возвращает порядковый номер первого символа совпадающего слова/значения, срабатывает условие ИСТИНА в формуле «ЕСЛИ», т.к. полученное значение не равно нулю. Как результат, в столбце «Результат» будет выведено значение «Bingo!»
- Если же, функция не находит совпадение т.е. порядковый номер первого символа совпадающего слова/значения не указывается и вместо значения возвращается ошибка, срабатывает условие, заложенное в формулу «ЕСЛИОШИБКА» и возвращается значение равное «0», что соответствует условию ЛОЖЬ в формуле «ЕСЛИ», т.к. полученное значение равно «0». Как результат, в столбце «Результат» будет выведено значение «fail».
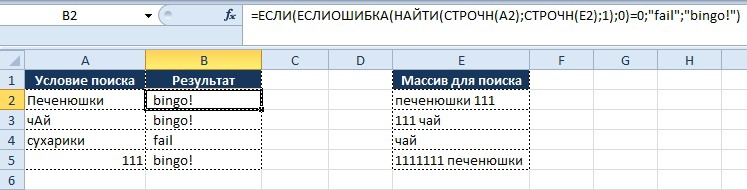
Как видно из рисунка выше, благодаря функциям «СТРОЧН» и «НАЙТИ» мы находим искомые значения вне зависимости от регистра символов, и места нахождения в ячейке, но необходимо обратить внимание на строку 5.
Условие поиска задано как «111», но в массиве поиска указано значение «1111111 печенюшки», однако формула выдает результат «Bingo!». Это происходит потому, что значение «111» входит в ряд значений «1111111», как следствие находится совпадение. В обратном случае данное условие не сработает.
Кейс_4 Поиск значения в массиве по нескольким условиям, или когда ВПР тем более не в силах нам помочь
Представим ситуацию, когда необходимо найти значение из «Таблица с результатом» в двумерном массиве «Справочник» по нескольким условиям, а именно по значению «Наименование» и «Месяц».
Табличная форма задания будет иметь следующий вид:
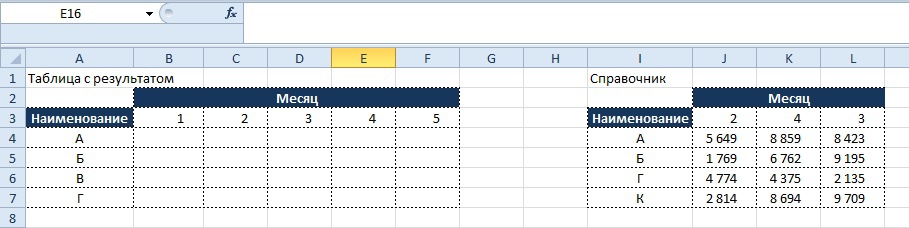
Условие:
- В таблицу с результатом необходимо подтянуть данные в соответствии с совпадением условий «Наименование» и «Месяц».
Для решения подобной задачи подойдет комбинация функций «ИНДЕКС» и «ПОИСКПОЗ»
Синтаксис функции «ИНДЕКС» (INDEX)
ИНДЕКС(массив, номер_строки, [номер_столбца])
- Массив — диапазон ячеек, из которого будут показываться значения в случае совпадения условий их поиска.
- Если массив содержит только одну строку или один столбец, аргумент «номер_строки» или «номер_столбца» соответственно не является обязательным.
- Если массив занимает больше одной строки и одного столбца, а из аргументов «номер_строки» и «номер_столбца» задан только один, то функция «ИНДЕКС» возвращает массив, состоящий из целой строки или целого столбца аргумента «массив».
- Номер_строки — номер строки в массиве, из которой требуется возвратить значение.
- Номер_столбца — номер столбца в массиве, из которого требуется возвратить значение.
Иными словами функция возвращает из указанного массива в аргументе «Массив» значение, которое находится на пересечении координат, указанных в аргументах «Номер_строки» и «Номер_столбца».
Синтаксис функции «ПОИСКПОЗ» (MATCH)
ПОИСКПОЗ(искомое_значение, просматриваемый_массив, [тип_сопоставления])
- Искомое_значение — значение, которое сопоставляется со значениями в аргументе просматриваемый_массив. Аргумент искомое_значение может быть значением (числом, текстом или логическим значением) или ссылкой на ячейку, содержащую такое значение.
- Просматриваемый_массив — диапазон ячеек, в которых производится поиск.
- Тип_сопоставления — необязательный аргумент. Число -1, 0 или 1.
Функция ПОИСКПОЗ выполняет поиск указанного элемента в диапазоне ячеек и возвращает относительную позицию этого элемента в диапазоне.
Суть использования комбинации функций «ИНДЕКС» и «ПОИСКПОЗ» в том, то мы производим поиск координат значений по их наименованию по «осям координат».
Осью Y будет столбец «Наименование», а осью X – строка «Месяцы».
часть формулы:
ПОИСКПОЗ($A4;$I$4:$I$7;0)
возвращает число по оси Y, в данном случае оно будет равно 1, т.к. значение «А» присутствует в искомом диапазоне и имеет относительную позицию «1» в этом диапазоне.
часть формулы:
ПОИСКПОЗ(B$3;$J$3:$L$3;0)
возвращает значение #Н/Д, т.к. значение «1» отсутствует в просматриваемом диапазоне.
Таким образом, мы получили координаты точки (1; #Н/Д) которые функция «ИНДЕКС» использует для поиска в аргументе «Массив».
Полностью написанная функция для ячейки B4 будет иметь следующий вид:
=ИНДЕКС($J$4:$L$7; ПОИСКПОЗ($A4;$I$4:$I$7;0); ПОИСКПОЗ(B$3;$J$3:$L$3;0))
По сути, если бы мы знали координаты нужного нам значения, функция выглядела бы следующим образом:
=ИНДЕКС($J$4:$L$7;1;#Н/Д))
Поскольку, аргумент «Номер_столбца» имеет значение «#Н/Д», то результат для ячейки «B4» будет соответствующий.
Как видно из получившегося результата не все значения в таблице с результатом находят совпадение со справочником и в итоге мы видим, что часть значений в таблице выводится в виде «#Н/Д», что затрудняет использование данных для дальнейших расчетов.
Результат:
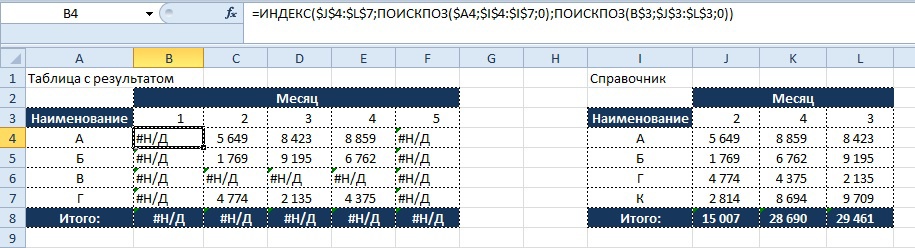
Что бы нейтрализовать этот негативный эффект используем функцию «ЕСЛИОШИБКА», о которой мы читали ранее, и заменяем значение, возвращающееся при ошибке на «0», тогда формула будет иметь вид:
Вывод результата в ячейку B4:
=ЕСЛИОШИБКА(ИНДЕКС($J$4:$L$7; ПОИСКПОЗ($A4;$I$4:$I$7;0); ПОИСКПОЗ(B$3;$J$3:$L$3;0));0)
Демонстрация результата:
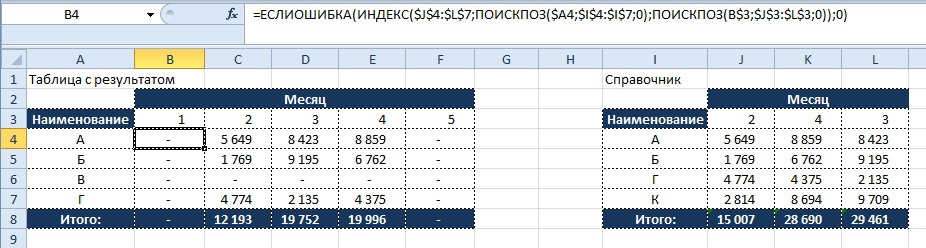
Как видно на картинке, значения «#Н/Д» более не мешают нам в последующих вычислениях с использованием значений в таблице с результатом.
Кейс_5 Поиск значения в диапазоне чисел
Представим, что нам необходимо дать определенный признак числам, входящим в определенный диапазон.
Условие:
В зависимости от стоимости продукта ему должна присваиваться определенная категория
Если значение находится в диапазоне
- От 0 до 1000 = А
- От 1001 до 1500 = Б
- От 1501 до 2000 = В
- От 2001 до 2500 = Г
- Более 2501 = Д

Функция ПРОСМОТР (LOOKUP) возвращает значение из строки, столбца или массива. Функция имеет две синтаксических формы: векторную и форму массива.
ПРОСМОТР(искомое_значение; просматриваемый_вектор; [вектор_результатов])
- Искомое_значение — значение, которое функция ПРОСМОТР ищет в первом векторе. Искомое_значение может быть числом, текстом, логическим значением, именем или ссылкой на значение.
- Просматриваемый_вектор — диапазон, состоящий из одной строки или одного столбца. Значения в аргументе просматриваемый_вектор могут быть текстом, числами или логическими значениями.
- Значения в аргументе просматриваемый_вектор должны быть расположены в порядке возрастания: …, -2, -1, 0, 1, 2, …, A-Z, ЛОЖЬ, ИСТИНА; в противном случае функция ПРОСМОТР может возвратить неправильный результат. Текст в нижнем и верхнем регистрах считается эквивалентным.
- Вектор_результатов — диапазон, состоящий из одной строки или столбца. Вектор_результатов должен иметь тот же размер, что и просматриваемый_вектор.
Вывод результата в ячейку B3:
=ПРОСМОТР(E3;$A$3:$A$7;$B$3:$B$7)

Аргументы «Просматриваемый_вектор» и «Вектор_результата» можно записать в форме массива – в этом случае не придется выводить их в отдельную таблицу на листе Excel.
В этом случае функция будет выглядеть следующим образом:
Вывод результата в ячейку B3:
=ПРОСМОТР(E3;{0;1001;1501;2001;2501};{«А»;«Б»;«В»;«Г»;«Д»})
Кейс_6 Суммирование чисел по признакам
Для суммирования чисел по определенным признакам можно использовать три разных функции:
СУММЕСЛИ (SUMIF) – суммирует только по одному признаку
СУММЕСЛИМН (SUMIFS) – суммирует по множеству признаков
СУММПРОИЗВ (SUMPRODUCT) – суммирует по множеству признаков
Существует также вариант с использованием «СУММ» (SUM) и функции формулы массивов, когда формула «СУММ» возводится в массив:
({=СУММ(()*())}
но такой подход довольно неудобен и полностью перекрывается по функционалу формулой «СУММПРОИЗВ»
Теперь подробнее по синтаксису «СУММПРОИЗВ»:
СУММПРОИЗВ(массив1, [массив2], [массив3],…)
- Массив1 — первый массив, компоненты которого нужно перемножить, а затем сложить результаты.
- Массив2, массив3… — от 2 до 255 массивов, компоненты которых нужно перемножить, а затем сложить результаты.
Условие:
- Найти общую сумму по стоимости отгрузок по каждому из продуктов за определенный период:

Как видно из таблицы с данными, что бы посчитать стоимость необходимо цену умножить на количество, а полученное значение, применив условия отбора переносить в таблица с результатом.
Однако, формула «СУММПРОИЗ» позволяет проводить такие расчеты внутри формулы.
Вывод результата в ячейку B4:
=СУММПРОИЗВ(($A4=$H$3:$H$11)*($K$3:$K$11>=B$3)*($K$3:$K$11<C$3);($M$3:$M$11)*($L$3:$L$11))
Разберем формулу по частям:
($A4=$H$3:$H$11)
– задаем условие по отбору в столбце «Наименование» таблицы с данными по столбцу «Наименование» в таблице с результатом
($K$3:$K$11>=B$3)*($K$3:$K$11<C$3)
– задаем условие по временным рамкам, дата больше или равна первого числа текущего месяца, но меньше первого числа месяца следующего. Аналогично – условие в таблице с результатом, массив – в таблице с данными.
($M$3:$M$11)*($L$3:$L$11)
– перемножаем столбцы «Количество» и «Цена» в таблице с данными.
Несомненным плюсом данной функции является свободный порядок записи условий, их можно записывать в любом порядке, на результат это не повлияет.
Результат:
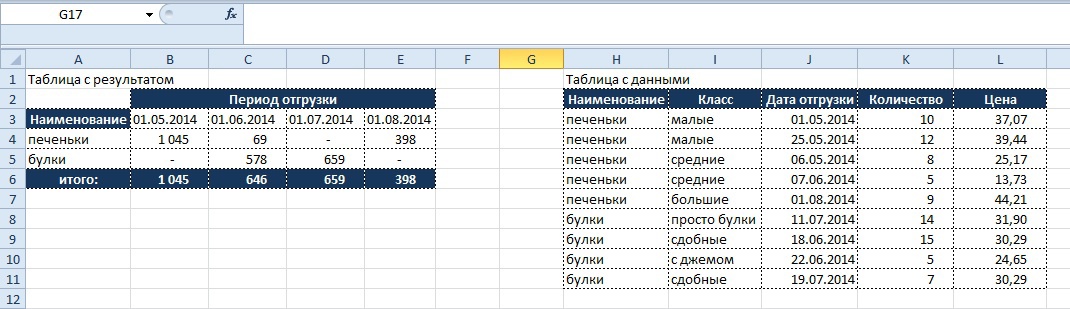
Теперь усложним условие и добавим требование, что бы отбор по наименованию «печеньки» происходил только по классам «малые» и «большие», а по наименованию «булки» все, кроме по классу «с джемом»:
Вывод результата в ячейку B4:
=СУММПРОИЗВ(($A4=$H$3:$H$11)*($J$3:$J$11>=B$3)*($J$3:$J$11<C$3)*(($I$3:$I$11=«малые»)+($I$3:$I$11=«большие»));($L$3:$L$11*$K$3:$K$11))
В формуле для отбора по печенькам добавилось новое условие:
(($I$3:$I$11=«малые»)+($I$3:$I$11=«большие»))
– как видно, два или более условия по одному столбцу выделяются в отдельную группу при помощи символа «+» и заключения условий в дополнительные скобки.
В формуле для отбора по булкам также добавилось новое условие:
=СУММПРОИЗВ(($A5=$H$3:$H$11)*($J$3:$J$11>=B$3)*($J$3:$J$11<C$3)*($I$3:$I$11<>«с джемом»);($L$3:$L$11)*($K$3:$K$11))
это:
($I$3:$I$11<>«с джемом»)
– на самом деле, в данной формуле можно было написать условие отбора также как и при отборе по печенькам, но тогда, пришлось бы перечислять три условия в формуле, в данном случае, проще написать исключение – не равно «с джемом» для этого используем значение «<>».
Вообще, если группы признаков/классов заранее известны, то лучше объединять их в эти группы, создавая справочники, чем записывать все условия в функцию, раздувая ее.
Результат:

Что ж, вот мы и подошли к концу нашего краткого мануала, который на самом деле мог бы быть намного больше, но целью было все-таки дать решение наиболее встречающихся ситуаций, а не описывать решение частных (но гораздо более интересных случаев).
Надеюсь, что мануал поможет кому-нибудь в решении задач при помощи Excel, ведь это будет значить, что мой труд не пропал зря!
Спасибо за уделенное время!
-
Главная
-
Инструкции
-
JavaScript
-
Методы поиска в массивах JavaScript

Поиск в массиве — довольно несложная задача для программиста. На ум сразу приходит перебор через цикл for или бинарный поиск в отсортированном массиве, для элементов которого определены операции «больше» и «меньше». Но, как и любой высокоуровневый язык программирования, JavaScript предлагает разработчику встроенные функции для решения различных задач. В этой статье мы рассмотрим четыре метода поиска в массивах JavaScript: find, includes, indexOf и filter.
indexOf
indexOf — это функция поиска элемента в массиве. Этот метод с помощью перебора ищет искомый объект и возвращает его индекс или “-1”, если не находит подходящий.
Синтаксис
Функция имеет такой синтаксис:
Array.indexOf (search element, starting index)где:
- Array — массив;
- search element — элемент, который мы ищем;
- starting index — индекс, с которого начинаем перебор. Необязательный аргумент, по умолчанию работа функции начинается с индекса “0”, т.е. метод проверяет весь Array. Если starting index больше или равен Array.length, то метод сразу возвращает “-1” и завершает работу.
Если starting index отрицательный, то JS трактует это как смещение с конца массива: при starting index = “-1” будет проверен только последний элемент, при “-2” последние два и т.д.
Практика
Опробуем метод на практике. Запустим такой код и проверим результаты его работы:
let ExampleArray = [1,2,3,1,'5', null, false, NaN,3];console.log("Позиция единицы", ExampleArray.indexOf(1) );
console.log("Позиция следующей единицы", ExampleArray.indexOf(1,2) );
console.log("Позиция тройки", ExampleArray.indexOf(3) );
console.log("Позиция тройки, если starting index отрицательный", ExampleArray.indexOf(3,-2) );
console.log("Позиция false", ExampleArray.indexOf(false) );
console.log("Позиция 5", ExampleArray.indexOf("5") );
console.log("Позиция NaN", ExampleArray.indexOf(NaN));
В результате работы этого кода мы получили такой вывод:
Позиция единицы 0
Позиция следующей единицы 3
Позиция тройки 2
Позиция тройки, если starting index отрицательный 8
Позиция false 6
Позиция 5 -1
Позиция NaN -1indexOf осуществляет поиск элемента в массиве слева направо и останавливает свою работу на первом совпавшем. Отчетливо это проявляется в примере с единицей. Для того, чтобы идти справа налево, используйте метод LastIndexOf с аналогичным синтаксисом.
Для сравнения искомого и очередного объекта применяется строгое сравнение (===). При использовании строгого сравнения для разных типов данных, но с одинаковым значение, например 5, ‘5’ и “5” JavaScript даёт отрицательный результат, поэтому IndexOf не нашел 5.
Также стоит помнить, что indexOf некорректно обрабатывает NaN. Так что для работы с этим значением нужно применять остальные методы.
includes
includes не совсем проводит поиск заданного элемента в массиве, а проверяет, есть ли он там вообще. Работает он примерно также как и indexOf. В конце работы includes возвращает «True», если нашел искомый объект, и «False», если нет. Также includes правильно обрабатывает NaN
Синтаксис
includes имеет следующий синтаксис:
Array.includes (search element, starting index)где:
- Array — массив;
- search element — элемент, который мы ищем;
- starting index — индекс, с которого начинаем перебор. Необязательный аргумент, по умолчанию работа функции начинается с индекса “0”, т.е. метод проверяет весь Array. Если starting index больше или равен Array.length, то метод сразу возвращает «False» и завершает работу.
Если starting index отрицательный, то JS трактует это как смещение с конца массива: при starting index = “-1” будет проверен только последний элемент, при “-2” последние два и т.д.
Практика
Немного изменим код из предыдущего примера и запустим его:
let Example = [1,2,3,1,'5', null, false,NaN, 3];console.log("Наличие единицы", Example.includes(1) );
console.log("Наличие следующей единицы", Example.includes(1,2) );
console.log("Наличие тройки", Example.includes(3) );
console.log("Наличие тройки, если starting index отрицательный", Example.includes(3,-1) );
console.log("Наличие false", Example.includes(false) );
console.log("Наличие 5", Example.includes(5) );
console.log("Наличие NaN", Example.includes(NaN));
Вывод:
Наличие единицы true
Наличие следующей единицы true
Наличие тройки true
Наличие тройки, если starting index отрицательный true
Наличие false true
Наличие 5 false
Наличие NaN trueДля includes отсутствует альтернативная функция, которая проводит поиск по массиву js справа налево, которая, в общем-то, и не очень актуальна.
find
Предположим, что нам нужно найти в массиве некий объект. Но мы хотим найти его не по значению, а по его свойству. Например, поиск числа в массиве со значением между 15 и 20. Как и прежде, мы можем воспользоваться перебором с помощью for, но это не слишком удобно. Для поиска с определенным условием в JavaScript существует метод find.
Синтаксис
Array.find(function(...){
//если элемент соответствует условиям (true), то функция возвращает его и прекращает работу;
//если ничего не найдено, то возвращает undefined
})- Array — массив;
- function(…) — функция, которая задает условия.
Практика
Как и в прошлых примерах, напишем небольшой код и опробуем метод:
let ExampleArray = ["Timeweb", 55555, "Cloud", "облачный провайдер", "буквы"];console.log(ExampleArray.find(element => element.length == 5))
Вывод:
CloudВ этом примере мы искали строки с длиной в 5 символов. Для числовых типов данных длина не определена, поэтому 55555 не подходит. find находит первый элемент и возвращает его, поэтому «буквы» также не попали в результат работы нашей функции. Для того, чтобы найти несколько элементов, соответствующих некоторому условию, нужно использовать метод filter.
Также не стоит забывать о методе findIndex. Он возвращает индекс подходящего элемента. Или -1, если его нет. В остальном он работает точно также, как и find.
filter
find ищет и возвращает первый попавшийся элемент, соответствующий условиям поиска. Для того, чтобы найти все такие элементы, необходимо использовать метод filter. Результат этой функции — массив (если ничего не найдено, то он будет пустым).
Синтаксис
Array.find(function(...){
//если элемент соответствует условиям (true), то добавляем его к конечному результату и продолжаем перебор;
})- Array — массив;
- function(…) — функция, которая задает условия.
Практика
Представим следующую задачу: у нас есть список кубоидов (прямоугольных параллелепипедов) с длинами их граней и нам нужно вывести все кубоиды с определенным объемом. Напишем код, реализующий решение данной задачи:
let ExampleArray = [
[10, 15, 8],
[11, 12, 6],
[5, 20, 1],
[10, 10, 2],
[16,2, 4]
];console.log(ExampleArray.filter(element=> element[0]*element[1]*element[2]>300))
Вывод:
[ [ 10, 15, 8 ],
[ 11, 12, 6 ] ]В этом примере мы нашли прямоугольные параллелепипеды с объемом больше 300. В целом, метод filter в JS позволяет реализовывать всевозможные условия для поиска.
Заключение
В этой статье узнали о методах поиска в JavaScript и научились ими пользоваться. Все перечисленные методы — универсальные инструменты для разработчиков. Но, как и любые универсальные инструменты, они не всегда являются самыми производительными. Так, например, бинарный поиск будет куда эффективнее, чем find и filter.
В этом посте мы обсудим, как найти значение в массиве объектов в JavaScript.
1. Использование Array.prototype.find() функция
Рекомендуемое решение — использовать find() метод, который возвращает первое вхождение элемента в массиве, удовлетворяющего заданному предикату. Следующий пример кода демонстрирует это, находя человека с именем John.
|
var obj = [ { name: ‘Max’, age: 23 }, { name: ‘John’, age: 20 }, { name: ‘Caley’, age: 18 } ]; var found = obj.find(e => e.name === ‘John’); console.log(found); /* результат: { name: ‘John’, age: 20 } */ |
Скачать Выполнить код
2. Использование Array.prototype.findIndex() функция
В качестве альтернативы вы можете использовать findIndex() метод, аналогичный методу find() метод, но возвращает индекс первого вхождения элемента или -1 если элемент не найден.
|
var obj = [ { name: ‘Max’, age: 23 }, { name: ‘John’, age: 20 }, { name: ‘Caley’, age: 18 } ]; var index = obj.findIndex(e => e.name === ‘John’); if (index !== –1) { console.log(obj[index]); } /* результат: { name: ‘John’, age: 20 } */ |
Скачать Выполнить код
3. Использование Array.prototype.forEach() функция
Здесь идея состоит в том, чтобы перебрать заданный массив, используя forEach() метод и определить, присутствует ли объект в массиве.
|
var obj = [ { name: ‘Max’, age: 23 }, { name: ‘John’, age: 20 }, { name: ‘Caley’, age: 18 } ]; obj.forEach(o => { if (o.name === ‘John’) { console.log(o); } }); /* результат: { name: ‘John’, age: 20 } */ |
Скачать Выполнить код
4. Использование Array.prototype.filter() функция
Другой вероятный способ — отфильтровать массив, чтобы вернуть все объекты, которые передают указанный предикат. Это можно легко сделать с помощью filter() метод.
|
var obj = [ { name: ‘Max’, age: 23 }, { name: ‘John’, age: 20 }, { name: ‘Caley’, age: 18 } ]; var found = obj.filter(e => e.name === ‘John’); if (found.length > 0) { console.log(found[0]); } /* результат: { name: ‘John’, age: 20 } */ |
Скачать Выполнить код
5. Использование jQuery
jQuery $.grep метод работает аналогично собственному JavaScript filter() метод.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
const { JSDOM } = require(“jsdom”); const { window } = new JSDOM(); var $ = require(“jquery”)(window); var obj = [ { name: ‘Max’, age: 23 }, { name: ‘John’, age: 20 }, { name: ‘Caley’, age: 18 } ]; var found = $.grep(obj, e => e.name === ‘John’); if (found.length > 0) { console.log(found[0]); } /* результат: { name: ‘John’, age: 20 } */ |
Скачать код
6. Использование библиотеки Lodash/Underscore
Библиотеки Underscore и Lodash имеют _.filter метод, аналогичный собственному JavaScript filter() метод. В следующем примере кода показано использование _.filter метод.
|
var _ = require(‘lodash’); var obj = [ { name: ‘Max’, age: 23 }, { name: ‘John’, age: 20 }, { name: ‘Caley’, age: 18 } ]; var found = _.filter(obj, e => e.name === ‘John’); if (found.length > 0) { console.log(found[0]); } /* результат: { name: ‘John’, age: 20 } */ |
Скачать код
Вот и все, что нужно для поиска значения в массиве объектов в JavaScript.
Перевод статьи 4 Methods to Search Through Arrays in JavaScript.
В JavaScript существует несколько довольно эффективных способов поиска элементов в массивах. В самом простом случае вы всегда можете прибегнуть помощи базового цикла for, однако в стандарте ES6 + предусмотрено гораздо большое число методов, предназначенных для циклического перебора элементов массива и поиска среди них тех, что нам нужны.
С таким количеством различных методов поиска и перебора, какой из них рациональнее использовать в каждом из отдельных случаев? Например, в ходе поиска в массиве вы хотите просто узнать, находится ли нужный нам элемент в массиве вообще? А может вам нужен только индекс этого элемента или же он сам?
В отношении каждого отдельного метода, который мы рассмотрим далее, важно понимать, что все они являются встроенными, то есть доступны через свойство прототип Array.prototype. Это означает, что вы можете вызвать их для любого массива, используя точечную нотацию. Это также означает, что все эти методы недоступны для объектов или других типов данных, кроме массивов (хотя частично они могут использоваться для строк).
Далее мы рассмотрим следующие методы массивов Array:
- Array.includes
- Array.find
- Array.indexOf
- Array.filter
includes
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout"];
alligator.includes("thick scales"); // вернет true
Метод .include() возвращает логическое значение и идеально подходит для определения факта наличия искомого элемента в массиве. То есть он просто отвечает true или false. Ниже представлен общий вид его синтаксиса:
arr.includes(valueToFind, [fromIndex]);
Как мы можем заметить, этот метод принимает только один обязательный параметр — valueToFind. Это значение затем используется для сопоставления со значениями элементов массива arr. Необязательный параметр fromIndex — это целое число, предписывающее с какого индекса будет начат поиск. По умолчанию это значение равно 0, и поэтому поиск будет осуществляться по всему массиву.
Итак, поскольку в нашем примере выше элемент, с которого начнется поиск имеет индекс 0, то возвращается true. А вот следующая инструкция вернет ложное значение: alligator.include ("thick scales", 1);, так как в этом случае поиск начинается с элемента с индексом 1.
Теперь подробнее рассмотрим несколько важных деталей, на которые стоит обратить внимание. Первое — метод .includes() использует строгое сравнение. Это означает, с учетом уже рассмотренного нами выше примера, что следующая инструкция: alligator.includes('80'); вернет false . Это происходит потому, что хотя вычисление логического выражения 80 == '80' приведет к получению результата true, однако, так как в нашем случае используется строгое сравнение, то 80 === '80' вернет false, то есть значения с разными типами никогда не будут проходить эту проверку.
find
Чем же метод .find() отличается от .include()? Так если бы мы в нашем примере выше изменили название метода «include» на «find», то получили бы следующую ошибку:
Uncaught TypeError: thick scales is not a function
Это произошло потому, что метод .find() требует передачи в качестве параметра функцию. Метод .find() использует не просто оператор сравнения, он передает каждый элемент массива в функцию, передаваемую ему в качестве параметра, и проверяет, возвращает ли она значение true или false.
Таким образом, и хотя следующая инструкция будет работать корректно: alligator.find (() => 'thick scale');, но вы, вероятно, захотите добавить в качестве функции-аргумента свой собственный оператор сравнения для того, чтобы он возвращал что-то нужное нам.
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout"]; alligator.find(el => el.length < 12); // вернет '4 foot tail'
Эта простая функция, передаваемая нашему методу .find(), проверяет каждый элемент массива, доступный по присваиваемому псевдониму el. Перебор элементов прекращается, когда находится первое совпадение. В нашем случае возвращается true для такого элемента массива, у которого есть свойство length, и его значение менее 12 (напомним, что числа не имеют свойства length). Конечно же, вы можете сделать эту функцию настолько сложной, насколько вам это необходимо, и возвращаемое ей значение соответствовало вашим требованиям.
Заметьте, что результат выполнения нашего кода, из примера выше, не возвращает true, как это было ранее. Это происходит потому, что метод .find() не возвращает логическое значение, а возвращает первый элемент, который соответствует критерию, определенному в функции. Если соответствующего элемента, который соответствует критериям, определенным в вашей функции, то метод вернет undefined. Также обратите внимание, что он возвращает только первый элемент, соответствующий критерию. Таким образом если в массиве более одного элемента, соответствующего критерию в функции, то все равно будет возвращаться только первый, соответствующий критерию в функции. В нашем примере, если бы после элемента со значением 4 foot tail, был другой со значением, в виде строки длиной менее 12 символов, то это ни как не изменило бы наш результат.
В нашем примере мы по сути использовали функцию обратного вызова, но только с одним параметром. При вызове метода .find() вы можете использовать еще один параметр у функции: ссылку на индекс текущего элемента нашего массива. Еще одним параметром может быть ссылка на наш массив, но я нахожу, что его использование может пригодиться в очень редких случаях. Вот пример использования ссылки на индекс нашего обрабатываемого массива:
alligator.find((el, idx) => typeof el === "string" && idx === 2); // вернет '4 foot tall'
И так в нашем массиве три различных элемента, которые удовлетворяют условию (typeof el === 'string'). Если бы это было наше единственное условие, то наш скрипт вернул бы первый элемент массива: thick scales. Но дело в том, что только у одного из элементов нашего массива индекс равен 2 и это элемент со значением 4 foot tall.
Говоря об индексах элементов, схожим методом перебора элементов массива является .findIndex(). Этот метод тоже в качестве параметра принимает функцию, но, как вы уже можете догадаться, он возвращает индекс соответствующего ее критерию элемента, а не его значение.
indexOf
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout"];
alligator.indexOf("rounded snout"); // будет возвращено 3
Как и .include(), метод .indexOf() использует строгое сравнение, а не функцию, как мы это видели рассматривая особенности использования метода .find(). Но, в отличие от метода include(), он возвращает индекс элемента, а не логическое значение. Также вы можете указать, с какого индекса в массиве начинать поиск.
Лично я считаю, что метод .indexOf() может оказаться весьма полезен. Он позволяет легко определить местоположение искомого элемент в массиве, а также проверить присутствует ли в нем элемент с указанным значением. Как же нам понять существует ли указанный элемент в массиве или нет? По сути, мы можем легко определить это, то есть в случае его наличия метод вернет положительное число, и если нет — то -1, что указывает на его отсутствие.
alligator.indexOf("soft and fluffy"); // вернет -1
alligator.indexOf(80); // вернет 1
alligator.indexOf(80, 2); // вернет -1
И, как вы можете видеть, хотя мы могли бы получить методы .find() или .findIndex(), чтобы предоставить нам ту же информацию, писать это намного меньше. Нам не нужно выписывать функцию для сравнения, так как она уже есть в методе .indexOf().
Теперь мы знаем что, метод indexOf() возвращает индекс первого элемента, соответствующего нашему критерию. Тем не менее JavaScript предоставляет нам альтернативный метод поиска элемента в массиве: .lastIndexOf(). Как вы можете догадаться, он делает то же самое, что и метод indexOf(), но начинает поиск с последнего элемента массива в обратном направлении. У этого метода вы также можете указать второй параметр, но помните, что порядок индексов массива остается прежним, не смотря на обратное направление его перебора.
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout", 80]; alligator.indexOf(80); // вернет 1 alligator.lastIndexOf(80); // вернет 4 alligator.indexOf(80, 2); // вернет 4 alligator.lastIndexOf(80, 4); // вернет 4 alligator.lastIndexOf(80, 3); // вернет 1
filter
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout", 80]; alligator.filter(el => el === 80); //вернет [80, 80]
Метод .filter() похож на метод .find() тем, что требует передачи в качестве параметра функции, которая определяет критерий для выбора элементов массива, возвращаемых методом. Основное отличие этих методов состоит в том, что .filter() всегда возвращает массив, даже если найден только один, соответствующий критерию выбора, элемент. То есть он вернет все найденные элементы, тогда как .find() вернет только первый найденный элемент.
Говоря о методе .filter() важно понимать, что он возвращает все элементы, соответствующие вашему критерию, то есть все элементы, которые вы хотите “отфильтровать”.
Заключение
В самом простом случае, когда мне необходимо найти в массиве какое-либо значение я использую метод .find(), но, как вы могли заметить, применение какого-либо метода зависит от конкретного случая.
Вам нужно только узнать существует ли в массиве элемент с определенным значением? Используйте метод .includes().
Вам нужно получить сам элемент массива, значение которого соответствует определенному критерию? Используйте методы .find() или .filter() для получения элементов.
Вам нужно найти индекс какого-либо элемента? Используйте методы .indexOf() или .findIndex() для использования более сложного критерия поиска.
Массивы в примерах, которые мы здесь рассмотрели на самом деле простые. Однако на практике вы можете столкнуться с более сложными случаями, например, с массивами объектов. Вот несколько простых примеров практик, которые вам могут пригодится, для работы с массивами, состоящими из вложенных объектов:
const jungle = [
{ name: "frog", threat: 0 },
{ name: "monkey", threat: 5 },
{ name: "gorilla", threat: 8 },
{ name: "lion", threat: 10 }
];
// разберем объект, перед использованием методов поиска .include () или .indexOf ()
const names = jungle.map(el => el.name); // веренет ['frog', 'monkey', 'gorilla', 'lion']
console.log(names.includes("gorilla")); // веренет true
console.log(names.indexOf("lion")); // веренет 3 - что будет соответствовать верному положению элемента, при условии, что сортировка нового массива names не проводилась
// methods we can do on the array of objects
console.log(jungle.find(el => el.threat == 5)); // веренет объект - {name: "monkey", threat: 5}
console.log(jungle.filter(el => el.threat > 5)); // вернет массив - [{name: "gorilla", threat: 8}, {name: 'lion', threat: 10}]
В общем, это отличный пример для ознакомления с методами поиска в массивах. Изучив их, возможно скоро вы сможете стать настоящими профессионалами эффективного использования массивов JavaScript!
Содержание
- 1 Array.includes() — есть ли элемент в массиве
- 2 Array.indexOf() — индекс элемента в массиве
- 3 Array.find() — найти элемент по условию
- 4 Array.findIndex() — найти индекс элемента в массиве
- 5 Поиск всех совпадений в массиве
- 6 Поиск в массиве объектов
- 7 Заключение
Для поиска по массиву в JavaScript существует несколько методов прототипа Array, не считая что поиск можно выполнить и методами для перебора массива и в обычном цикле.
Итак, мы сегодня рассмотрим следующие варианты:
- Array.includes()
- Array.indexOf()
- Array.find()
- Array.findIndex()
- Array.filter()
- Array.forEach()
Array.includes() — есть ли элемент в массиве
Данный метод ищет заданный элемент и возвращает true или false, в зависимости от результата поиска. Принимает два параметра:
element— то, что мы будем искатьfromIndex(необязательный) — с какого индекса начинать поиск. По умолчанию с 0.
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry'];
console.log(arr.includes('Apple')); // true
console.log(arr.includes('Apple', 1)); // falseКак видно из примера выше, в первом случае мы получим true, т.к. начали с нулевого элемента массива. Во втором случае мы передали второй параметр — индекс, с которого нужно начать поиск — и получили false, т.к. дальше элемент не был найден.
Array.indexOf() — индекс элемента в массиве
Данный метод, в отличие от предыдущего, возвращает индекс первого найденного совпадения. В случае если элемент не найден, будет возвращено число -1
Также принимает два параметра:
element— элемент, который мы будем искатьfromIndex(необязательный) — с какого индекса начинать поиск. По умолчанию с 0.
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
console.log(arr.indexOf('Apple')); // 0
console.log(arr.indexOf('Apple', 1)); // 4
console.log(arr.indexOf('Orange', 2)); // -1Как видно из примера выше, в первом случае мы получаем 0, т.к. сразу нашли первый элемент массива (первое совпадение, дальше поиск уже не выполняется). Во втором случае 4, т.к. начали поиск с индекса 1 и нашли следующее совпадение. В третьем примере мы получили результат -1, т.к. поиск начали с индекса 2, а элемент Orange в нашем массиве под индексом 1.
Так как данный метод возвращает индекс или -1, мы можем присвоить результат в переменную для дальнейшего использования:
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
const index = arr.indexOf('Lemon');
if (index !== -1) {
// сделать что-то
}Чтобы произвести какие-то действия над найденным элементом массива, мы можем использовать следующий синтаксис:
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
const index = arr.indexOf('Lemon');
arr[index] = 'Lime'; // заменяем найденный элемент
console.log(arr)ж // ['Apple', 'Orange', 'Lime', 'Cherry', 'Apple']Примеры использования данного метода вы можете также найти в посте про удаление элемента из массива
Array.find() — найти элемент по условию
Данный метод callback и thisArg в качестве аргументов и возвращает первое найденное значение.
Callback принимает несколько аргументов:
item — текущий элемент массива
index — индекс текущего элемента
currentArray — итерируемый массив
Пример использования:
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
const apple = arr.find(item => item === 'Apple');
console.log(apple); // AppleДанный метод полезен тем, что мы можем найти и получить сразу и искомый элемент, и его index
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
let indexOfEl;
const apple = arr.find((item, index) => {
if (item === 'Apple') {
indexOfEl = index;
return item;
}
});
console.log(apple, indexOfEl); // Apple 0Также работа кода прекратиться как только будет найден нужный элемент и второй элемент (дубликат) не будет найден.
В случае если ничего не найдено будет возвращен undefined.
Array.findIndex() — найти индекс элемента в массиве
Этот метод похож на метод find(), но возвращать будет только индекс элемента, который соответствует требованию. В случае, если ничего не найдено, вернет -1
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
const index = arr.findIndex(item => item === 'Apple');
console.log(index); // 0Ну и по аналогии с предыдущим методом, поиск завершается после первого совпадения.
Поиск всех совпадений в массиве
Метод filter() кроме всего остального также можно использовать для поиска по массиву. Предыдущие методы останавливаются при первом соответствии поиска, а данный метод пройдется по массиву до конца и найдет все элементы. Но данный метод вернет новый массив, в который войдут все элементы соответствующие условию.
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
const filteredArr = arr.filter(item => item === 'Apple');
console.log(filteredArr); // ['Apple', 'Apple']
console.log(arr); // ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];Как видите из примера выше, первоначальный массив не будет изменен.
Подробнее про метод JS filter() можете прочитать в этом посте.
Для этих же целей можно использовать метод forEach(), который предназначен для перебора по массиву:
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
let indexes = [];
arr.forEach((item, index) => {
if (item === 'Apple') indexes.push(index)
});
console.log(indexes); // [0, 4]В массив indexes мы получили индексы найденных элементов, это 0 и 4 элементы. Также в зависимости от вашей необходимости, можно создать объект, где ключом будет индекс, а значением сам элемент:
const arr = ['Apple', 'Orange', 'Lemon', 'Cherry', 'Apple'];
let arrObjMap = {};
arr.forEach((item, index) => {
if (item === 'Apple') {
arrObjMap[index] = item;
}
});
console.log(arrObjMap); // {0: 'Apple', 4: 'Apple'}Поиск в массиве объектов
Если у вас массив состоит не из примитивных типов данных, а к примеру, каждый элемент это объект со своими свойствами и значениями, тогда можно использовать следующие варианты для получения индекса элемента.
Первый способ. С использованием метода map для массива
const arr = [
{ name: 'Ben', age: 21 },
{ name: 'Clif', age: 22 },
{ name: 'Eric', age: 18 },
{ name: 'Anna', age: 27 },
];
const index = arr.map(item => item.name).indexOf('Anna');
console.log(index); //3
console.log(arr[index]); // {name: 'Anna', age: 27}В данном случае по массиву arr мы проходим и на каждой итерации из текущего элемента (а это объект со свойствами name и age) возвращаем имя человека в новый массив и сразу же выполняем поиск по новому массиву на имя Anna. При совпадении нам будет возвращен индекс искомого элемента в массиве.
Второй способ. Данный вариант будет немного проще, т.к. мы можем сразу получить индекс при совпадении:
const index = arr.findIndex(item => item.name === 'Anna');
console.log(index); //3
console.log(arr[index]); // {name: 'Anna', age: 27}Заключение
Как видите любой из вышеприведенных методов можно использовать для поиска по массиву. Какой из них использовать зависит от вашей задачи и того, что вам нужно получить — сам элемент или его индекс в массиве, найти только первое совпадение или все совпадения при поиске.
