По мере того, как популярность RSS упала, стало меньше информации о том, что это такое и как вы можете использовать его. Многие люди даже не знают, что RSS-каналы существуют. Стандартный значок RSS, хотя и ярко-оранжевый, очень похож на WiFi и бесконтактные платежи.
Хуже того, многие веб-сайты больше не рекламируют свои URL-адреса RSS-каналов, хотя все еще поддерживают их. В этой статье давайте поговорим о том, как найти URL-адрес RSS-канала для веб-сайта, даже если он не рекламируется.
Расширения браузера RSS
Самый эффективный способ найти RSS-канал веб-страницы – установить стороннее расширение RSS для вашего браузера.
Эти расширения просто проверяют веб-страницу на наличие HTML-тега rel-link, который указывает на RSS-каналы страницы. Затем они представляют RSS-каналы в значке на панели расширений вашего браузера.
Еще несколько лет назад многие браузеры, такие как Firefox, поставлялись с предустановленной программой чтения RSS-каналов. Теперь вам нужно получить их от стороннего разработчика. Тем не менее, существует множество надежных вариантов, и в некоторых случаях эти расширения даже сделаны разработчиком браузера.
Расширение подписки RSS на Google – это готовое решение для использования в Chrome.
У Firefox есть несколько опций, среди которых Feedbro и Awesome RSS.
Для Safari простое приложение RSS Button для Safari отлично работает, но платный-0,99 $.
URL-хаки
Еще один простой способ быстро найти URL RSS канала- сделать предположение относительно о возможном URL.
Чаще всего RSS-каналы можно найти в подпапке ленты или домена rss. Например, если вы ищете RSS-канал для http://example.com/, попробуйте http://example.com/feed/ или http://example.com/rss/.
Исходный код
Если два предыдущих способа не помогли найти RSS-канал, пришло время копаться в первоисточнике. Хотя работа с исходным кодом требует некоторой сноровки, вычислить RSS-канал через исходный код веб-страницы невероятно легко.
Когда вы находитесь на веб-странице, к которой, как вы подозреваете, может быть прикреплен канал RSS, но вы не можете его найти, щелкните правой кнопкой мыши в любом месте страницы и найдите параметр, например «Просмотр исходного кода», как это выглядит в Chrome.
Это откроет окно, которое показывает все HTML, CSS и JavaScript текущей страницы. Если для вас это кажется чуждым и запутанным, не пугайтесь. Все, что вам нужно сделать, это открыть поиск (Ctrl + F в Windows) по термину «application/rss».
Если поиск по этим словам покажет результатов больше чем вы можете понять, тогда попытайтесь найти « rss » или « atom ». Если ничего не найдено, вероятно, на странице нет RSS-канала.
URL-адрес RSS-канала будет атрибутом href HTML-тега rel. На снимке экрана выше вы можете увидеть один канал, расположенный по адресу https://ex-hort.ru/board/rss, на который мы настоятельно рекомендуем подписаться!
Не важно, как часто вам нужно находить RSS-каналы, все эти варианты являются жизнеспособными и заслуживают внимания. Однако для обычного пользователя мы определенно рекомендуем расширение RSS-браузера, они чрезвычайно легки в установке и легко покажут именно то, что нужно.
Если вы все еще не можете найти URL-адрес RSS-канала, RSS-ленты, RSS-фид веб-страницы, следуя этим советам, скорее всего, он не существует.
✽ ✾ ✿❁ ❃ ❋ ❀
。 ° ˛ ˚ ˛ ˚ ˛ ˚ •
。
。 • ˚ ˚ ˛ ˚ ˛ 。 ° 。 ° 。
• ˚ ★карта канала★ *
˛ • • НачинающƎму • ˚ ˚ • ˚ ˚ ˚ ˚
。* ★2019★ • ˚ ˚
˛ *__Π___*。* ˚ ˚ ˛ ˚ ˛ • ˚ ˚
*/______/~。˚ ˚ ˛ ˚ ˛
*|田田 . .|門| ˚
✽ ✾ ✿❁ ❃ ❋ ❀ ✽ ✾ ✿❁ ❃ ❋ ❀
Есть что сказать об этой статье? Прокомментируйте ниже или поделитесь
![]()
Download Article
![]()
Download Article
This wikiHow teaches you how to find the address of a website’s RSS feed so you can add it to your newsreader, start page, or website. The steps vary by website, so you may have to try a few of these methods before you can find the feed.
-

1
Open the website in any web browser. This method will work on any website powered by WordPress, which is about 30% of websites on the internet.[1]
-

2
Click or tap at the end of the URL in the address bar. The cursor should now be on the last character of the URL.
Advertisement
-

3
Type /feed/ and press ↵ Enter or ⏎ Return. Adding this text to the end of the URL will take you to the RSS feed as long as the site uses WordPress. You’ll know you’ve found the feed when you see a white page containing a bunch of raw web code.
Advertisement
-

1
Open the website in any web browser. Many websites (but not all) display an RSS feed icon somewhere on the page.
-

2
Scroll down until you find the RSS icon. It’s an orange square with a white dot at the bottom-left corner and two white curved lines above the dot. The icon is usually small.
-

3
Click the icon (if found). If this icon appears on the page, clicking or tapping it should bring up a text-only version of the page in raw code. This means the URL of the RSS feed is currently in the browser’s address bar and you can copy and paste it anywhere you’d like.
Advertisement
-

1
Open the website in Firefox. Mozilla Firefox attempts to locate a website’s RSS feed automatically. If an RSS feed for the site is found, a link to the feed will appear near the top-right corner of the browser in the address bar.[2]
-

2
Click the RSS button (if found). Look at the far-right corner of the address bar (where you typed the URL). If you see an orange square with a white dot at the bottom-left corner and two white curved lines above the dot, click it to open the RSS feed. The URL of the feed will then appear in the address bar, ready to be copied.
Advertisement
-

1
Open the website in your preferred web browser. You should be able to find a link to a website’s RSS feed in its raw source code.
-

2
View the source code of the website. The steps to do this vary by browser.[3]
- In Chrome on a computer, right-click the page and select View page source.
- In Chrome for Android, tap your finger right before the URL in the address bar to insert the cursor before the first character, type view-source:, and then tap Enter or Go.[4]
- In Safari for macOS, you’ll have to enable the Develop menu to view source code. Open the Safari menu, click Preferences, click the Advanced tab, and then check the box next to ″Show Develop menu in menu bar.″ Now you can right-click the page and select Show Page Source.
- On an iPhone or iPad, you’ll need to install an app like HTML Viewer Q or iSource Browser from the App Store. Once installed, open the app and follow the on-screen instructions to find a page’s source code.
- In Firefox on a computer, right-click the page and select View Page Source.
- In Edge for Windows, right-click the page and select View Source. If you don’t see this option, click the ⋯ menu at the top-right corner, select Developer Tools, and then close the developer tools box by clicking the X at the top-right corner. This enables the View Source option.
-

3
Search the code for ″RSS.″
- On a computer, click somewhere in the code and press ⌘ Command+F (Mac) or Control+F (PC), type rss, and then press ↵ Enter or ⏎ Return. This should take you to a line that starts with <link rel and contains the text ″application/rss+xml.″
- In Chrome for Android, tap the menu, tap Find in Page, type rss and tap the magnifying glass.[5]
-

4
Find the URL in the line. The URL of the site’s RSS feed is the address that appears after ″href=″ in the line. Copy that URL and paste it into the desired location.
Advertisement
-

1
Go to http://createfeed.fivefilters.org/ in a web browser. If you can’t find a site’s RSS feed (or if a site doesn’t have one), you can create one for the site at no cost using this tool.
-

2
Enter the URL of the site. Type or paste the URL into the ″Enter page URL″ field near the top of the form.
-

3
Click or tap Preview. It’s the green button near the bottom of the form.
-

4
Scroll down and select RSS Feed. It’s the first gray button beneath the site’s title under the ″Results″ header. This opens the RSS feed in your web browser—it looks like raw website code. The URL for the RSS feed is now located in the address bar at the top of the browser, ready to be copied.
Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
About This Article
Thanks to all authors for creating a page that has been read 51,423 times.
Is this article up to date?

RSS – это удобный способ получать самые свежие новости сайта или блога. Вместо того, чтобы ежедневно посещать любимые сайты, вы получите новые статьи в специальном формате. Читать эти новости можно, используя браузер или при помощи специальных сервисов, которые называются RSS-агрегаторами. Сейчас такие подписки уже непопулярны, но до сих пор актуальны. Интернет-пользователи привыкли получать новости с помощью социальных сетей, пуш-рассылок. Однако, rss по-прежнему важно для вебмастеров, а также для небольшой группы подписчиков. В этой статье вы узнаете, как узнать RSS сайта, и как использовать поток.
XML-каналы
Существуют различные RSS-каналы XML, или расширяемый язык разметки, позволяет добавлять структурированные данные к их содержимому с помощью тегов. Структурированные данные облегчают поисковым системам понимать содержимое вашего веб-сайта. Вы можете использовать структурированные данные для указания авторов, заголовков, подзаголовков, списков и т. Д. Карта сайта XML использует ту же концепцию и объединяет все эти структурированные данные в одну карту сайта, которая позволит поисковым системам индексировать ваши сайты, просто сканируя её. XML-каналы переводят содержимое вашего блога для поисковых систем на более понятный уровень. Даже если новый контент будет добавлен в ваш блог, ваш фид XML также автоматически обновится.
RSS-каналы, или расширенная сводка по сайту, используют формат файла XML для адаптации вашего контента через программы чтения фид-ленты. RSS-каналы получают последнее обновление контента сайта и отправляют его вам по электронной почте или через программу чтения каналов, например Feedburner. Ваши читатели могут подписаться на RSS-каналы через ваш сайт.
Как подписаться на RSS
Подписаться на Фид ленту сайта можно, нажав на оранжевую иконку на портале, который вы читаете следующего вида:
![]()
и её все возможные вариации. Если Фид-канал пропущен через сервис Feedburner, то подписаться на него, можно, нажав на такую кнопку:

Для чтение RSS удобно пользоваться браузерными расширениями, такими, как RSS Feed Reader для Google Chrome, приложениями для мобильных и специальными агрегаторами лент (пример, feeder.co).
Как узнать адрес ссылки RSS
Чтобы узнать RSS-ленту сайта, вы можете искать значок RSS на сайте (обычно он находится в нижней части страницы) или добавить “/rss”, “/feed” или “/feed.xml” к концу URL-адреса сайта.
Как узнать url rss на различных платформах
Как узнать адрес RSS своего блога. Лучше “зажечь свой feed” через feedburner.com, и вы получите новый адрес подписки для своего блога, а также статистику подписчиков и некоторые другие услуги сервиса совершенно бесплатно. Однако, если этого не делать, то у каждого блога есть стандартный адрес потока:
- для блогов на Blogger (Blogspot) он выглядит так: https://***.blogspot.com/feeds/posts/default . Вместо звездочек подставляйте адрес своего сайта.
- для LiveInternet адрес – https://www.liveinternet.ru/users/***/rss/ . Вместо звездочек подставляем цифры из адреса вашего блога.
- для Живого Журнала (ЖЖ) –> https://***.livejournal.com/data/rss
- Для блогов на WordPress – адрес ленты RSS – https://вашблог/feed/
- Стандартная фид-лента DLE – https://вашсайт/rss.xml
- Чтобы узнать RSS-поток любого сайта – нужно просмотреть код страницы (нажать CTRL + U) и выполнить поиск по странице (CTRL + F). Будем искать “RSS” (без кавычек).
Покажу на примере моего блога, как вычленить адрес Фид сайта. У меня найден код: <link rel=”alternate” type=”application/rss+xml” title=”Азбука блогера » Лента” href=”https://mycrib.ru/feed”/> Значение href (выделено красным) и будет искомый адрес.
Как установить кнопку подписки на RSS-канал
Когда мы знаем адрес своей ленты, то идем на сервис поиск по иконкам (пример, https://icon-icons.com/) и выбираем себе иконку. Копируем адрес изображения и подставляем его в следующий код:
<a href=”адрес RSS ленты”><img src=”адрес иконки”></a>
Вставляем в любое место своего блога или сайта и любуемся результатом:
Для примера у меня получился следующий код:
<a href=”https://feeds.feedburner.com/my-crib”><img src=”https://icon-icons.com/icons2/791/PNG/32/RSS_icon-icons.com_65498.png“></a>
Время на прочтение
7 мин
Количество просмотров 4.9K

Покопался я ещё в своих старых и не очень проектах и нашёл одну интересную программку. Она ищет RSS ссылки новостных сайтов. Задача которая стояла — это найти как можно больше новостных RSS лент и собрать их всех в одну базу.
Когда встал вопрос о том как искать новостные сайты, пришла мысль о использовании сервиса news.google.com. От туда можно выдёргивать ссылки на новостные сайты, к тому же они постоянно добавляются и отсортированы по регионам, темам и т.д. Осталось пройтись по всем разделам news.google.com, выдернуть ссылки новостных сайтов, а затем найти все RSS каждого из них.
Сначала код. Он состоит из следующих файлов: main.cpp LinksReader.cpp LinksReader.h LinksReader.pro Sources.txt и файл который создастся автоматически и в котором сохранится результат RssLinks.txt. Вся логика содержится в файлах LinksReader.h и LinksReader.cpp, остальные файлы вспомогательные, для использования класса и компилирования проекта. Компилировал проект в с помощью компилятора g++, среда Qt creator, версия библиотек 5.1
LinksReader.h
#ifndef LINKSREADER_H
#define LINKSREADER_H
#include <QStringList>
#include <QFile>
#include <QNetworkReply>
#include <QEventLoop>
#include <QDebug>
class LinksReader: public QObject
{
Q_OBJECT
private:
void loadSources();
void loadRssLinks();
void readPage(QString url);
void takeLinks();
void takeRssLinks();
void saveRssLinks();
QNetworkAccessManager mNAManager;
QString mPage;
QString mPageUrl;
QStringList mSources;
QStringList mLinks;
QStringList mRssLinks;
private slots:
void onReplyFinished(QNetworkReply *pReply);
public:
LinksReader(QObject *pParent = 0);
void run();
};
#endif
LinksReader.cpp
#include "LinksReader.h"
void LinksReader::loadSources()
{
QString fileName = "Sources.txt";
QFile file(fileName);
if (!file.open(QIODevice::ReadOnly | QIODevice::Text))
{
qDebug() << "File " << fileName << " not found";
return;
}
QTextStream in(&file);
while(!in.atEnd())
mSources.push_back(in.readLine());
file.close();
qDebug() << mSources.size() << " sources loaded";
return;
}
void LinksReader::loadRssLinks()
{
QString fileName = "RssLinks.txt";
QFile file(fileName);
if (!file.open(QIODevice::ReadOnly | QIODevice::Text))
return;
QTextStream in(&file);
while(!in.atEnd())
mRssLinks.push_back(in.readLine());
file.close();
qDebug() << mRssLinks.size() << " rss links loaded";
return;
}
void LinksReader::readPage(QString url)
{
mPage = "";
mPageUrl = url;
mNAManager.get(QNetworkRequest(QUrl(url)));
QEventLoop loop;
QObject::connect(&mNAManager, SIGNAL(finished(QNetworkReply *)), &loop, SLOT(quit()));
loop.exec();
}
void LinksReader::takeLinks()
{
QStringList fullLinks;
QString links = "";
QString beginTN = "<link>";
QString endTN = "</link>";
QString tagContent = "";
int beginTP = 0;
int endTP = 0;
while(1)
{
beginTP = mPage.indexOf(beginTN);
endTP = mPage.indexOf(endTN);
if (beginTP == -1 || endTP == -1) break;
tagContent = mPage.mid(beginTP + beginTN.length(), endTP - beginTP - endTN.length() + 1);
links += tagContent;
mPage.remove(0, endTP + endTN.length());
}
fullLinks = links.split("http://");
fullLinks.removeFirst();
for(int i = 0; i < fullLinks.size(); i++)
{
fullLinks[i].remove(fullLinks[i].indexOf("/"), fullLinks[i].length());
mLinks.push_back(fullLinks[i]);
}
}
void LinksReader::takeRssLinks()
{
QString beginTN = "<link";
QString endTN = ">";
QString tagContent = "";
QString beginRssString = "href="";
QString endRssString = " ";
int beginTP = 0;
int endTP = 0;
while(1)
{
beginTP = mPage.indexOf(beginTN);
endTP = mPage.indexOf(endTN, beginTP);
if (beginTP == -1 || endTP == -1) break;
beginTP += beginTN.length();
tagContent = mPage.mid(beginTP, endTP - beginTP);
if (tagContent.indexOf("type="application/rss+xml"") != -1)
{
int beginRssPos = tagContent.indexOf(beginRssString);
int endRssPos = tagContent.indexOf(endRssString, beginRssPos);
beginRssPos += beginRssString.size();
QString rssString = tagContent.mid(beginRssPos, endRssPos - beginRssPos).remove(""");
if (rssString.size() > 0 && rssString[rssString.size() - 1] == '/')
rssString.remove(rssString.size() - 1, 1);
if (rssString.indexOf("http://") == -1)
rssString.push_front(mPageUrl);
qDebug() << rssString;
mRssLinks.push_back(rssString);
}
mPage.remove(0, endTP + endTN.length());
}
}
void LinksReader::saveRssLinks()
{
QFile file("RssLinks.txt");
file.open(QFile::ReadWrite);
QTextStream in(&file);
for(int i = 0; i < mRssLinks.size(); i++)
in << mRssLinks[i] << "n";
file.close();
}
void LinksReader::onReplyFinished(QNetworkReply *reply) {
mPage += reply->readAll();
}
LinksReader::LinksReader(QObject *pParent): QObject(pParent) {
QObject::connect(&mNAManager, SIGNAL(finished(QNetworkReply *)), this, SLOT(onReplyFinished(QNetworkReply *)));
}
void LinksReader::run()
{
loadSources ();
loadRssLinks();
qDebug() << "Please wait...";
for(int i = 0; i < mSources.size(); i++)
{
readPage(mSources[i]);
takeLinks();
}
mLinks.removeDuplicates();
for(int i = 0; i < mLinks.size(); i++)
{
readPage("http://" + mLinks[i]);
takeRssLinks();
}
mRssLinks.removeDuplicates();
saveRssLinks();
qDebug() << "Finish";
}
main.cpp
#include <QCoreApplication>
#include "LinksReader.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
LinksReader linksReader;
linksReader.run();
return a.exec();
}
LinksReader.pro
QT += core
QT += network
QT -= gui
TARGET = LinksReader
CONFIG += console
CONFIG -= app_bundle
TEMPLATE = app
SOURCES += main.cpp
LinksReader.cpp
HEADERS +=
LinksReader.h
Sources.txt
http://news.google.com/news?ned=au&output=rss
http://news.google.com/news?ned=in&output=rss
http://news.google.com/news?ned=en_il&output=rss
http://news.google.com/news?ned=en_my&output=rss
http://news.google.com/news?ned=nz&output=rss
http://news.google.com/news?ned=en_pk&output=rss
http://news.google.com/news?ned=en_ph&output=rss
http://news.google.com/news?ned=en_sg&output=rss
http://news.google.com/news?ned=ar_me&output=rss
http://news.google.com/news?ned=ar_ae&output=rss
http://news.google.com/news?ned=ar_lb&output=rss
http://news.google.com/news?ned=ar_sa&output=rss
http://news.google.com/news?ned=cn&output=rss
http://news.google.com/news?ned=hk&output=rss
http://news.google.com/news?ned=hi_in&output=rss
http://news.google.com/news?ned=ta_in&output=rss
http://news.google.com/news?ned=ml_in&output=rss
http://news.google.com/news?ned=te_in&output=rss
http://news.google.com/news?ned=iw_il&output=rss
http://news.google.com/news?ned=jp&output=rss
http://news.google.com/news?ned=kr&output=rss
http://news.google.com/news?ned=tw&output=rss
http://news.google.com/news?ned=vi_vn&output=rss
http://news.google.com/news?ned=nl_be&output=rss
http://news.google.com/news?ned=fr_be&output=rss
http://news.google.com/news?ned=en_bw&output=rss
http://www.google.com/news?ned=cs_cz&output=rss
http://news.google.com/news?ned=de&output=rss
http://news.google.com/news?ned=es&output=rss
http://news.google.com/news?ned=en_et&output=rss
http://news.google.com/news?ned=fr&output=rss
http://news.google.com/news?ned=en_gh&output=rss
http://news.google.com/news?ned=en_ie&output=rss
http://news.google.com/news?ned=it&output=rss
http://news.google.com/news?ned=en_ke&output=rss
http://news.google.com/news?ned=hu_hu&output=rss
http://news.google.com/news?ned=fr_ma&output=rss
http://news.google.com/news?ned=en_na&output=rss
http://news.google.com/news?ned=nl_nl&output=rss
http://news.google.com/news?ned=en_ng&output=rss
http://news.google.com/news?ned=no_no&output=rss
http://news.google.com/news?ned=de_at&output=rss
http://news.google.com/news?ned=pl_pl&output=rss
http://news.google.com/news?ned=pt-PT_pt&output=rss
http://news.google.com/news?ned=de_ch&output=rss
http://news.google.com/news?ned=fr_sn&output=rss
http://news.google.com/news?ned=en_za&output=rss
http://news.google.com/news?ned=fr_ch&output=rss
http://news.google.com/news?ned=sv_se&output=rss
http://news.google.com/news?ned=en_tz&output=rss
http://news.google.com/news?ned=tr_tr&output=rss
http://news.google.com/news?ned=en_ug&output=rss
http://news.google.com/news?ned=uk&output=rss
http://news.google.com/news?ned=en_zw&output=rss
http://news.google.com/news?ned=ar_eg&output=rss
http://news.google.com/news?ned=el_gr&output=rss
http://news.google.com/news?ned=ru_ru&output=rss
http://news.google.com/news?ned=sr_rs&output=rss
http://news.google.com/news?ned=ru_ua&output=rss
http://news.google.com/news?ned=uk_ua&output=rss
http://news.google.com/news?ned=es_ar&output=rss
http://news.google.com/news?ned=pt-BR_br&output=rss
http://news.google.com/news?ned=ca&output=rss
http://news.google.com/news?ned=fr_ca&output=rss
http://news.google.com/news?ned=es_cl&output=rss
http://news.google.com/news?ned=es_co&output=rss
http://news.google.com/news?ned=es_cu&output=rss
http://news.google.com/news?ned=es_us&output=rss
http://news.google.com/news?ned=es_mx&output=rss
http://news.google.com/news?ned=es_pe&output=rss
http://news.google.com/news?ned=us&output=rss
http://news.google.com/news?ned=es_ve&output=rss
После запуска программы, создания объекта класса LinksReader и вызова его метода run происходит следующее:
1. Загружаются источники.
2. Загружаются все найденные за прошлые разы RSS ссылки (чтобы не искать каждый раз по новой, а пополнять уже имеющуюся базу RSS).
3. Проходим по всем источником, читаем разметку и выдёргиваем все ссылки которые в разметке помечены тегом .
4. Удаляем все повторяющиеся ссылки.
5. Проходим по всем найденным новостным сайтам, читаем разметку каждого из них и выдёргиваем значения всех RSS тегов этого сайта.
6. Удаляем все повторяющиеся RSS ссылки.
7. И наконец сохраняем результат в файл.
По стандарту все RSS ссылки сайта, должны быть помечены тегом />, что намного облегчает поиск RSS.
Как видно программа достаточно проста, но хорошо делает своё дело. За один запуск находит 600-700 RSS лент. Повторные запуски увеличивают это количество, так-как в news.google.com постоянно добавляются ссылки на новые новостные сайты.
Не хотел подробно рассматривать каждую строку кода, думаю что он и так хорошо читается, даже не знающим Qt. Но, если есть непонятные места — спрашивайте и я с радостью помогу разобраться. Если есть замечания, критика — пишите.
github
Здравствуйте, сегодня поговорим как быстро определить, найти rss ленту сайта, так как у многих кнопки подписки на RSS отсутствуют или же скрыты.
Скачать исходники для статьи можно ниже
Способы как найти RSS ленту сайта:
1. Онлайн сервисы по определению RSS, вот один из них:
“ctrlq.org/rss/”

В строку поиска вводим url сайта и жмем кнопку “seach”, после чего происходит поиск всех rss лент сайта, например давайте отыщем rss ленту сайта, на которой нет кнопки подписки – “printgames.ru” (на нем нет ни кнопки, ни формы подписки):
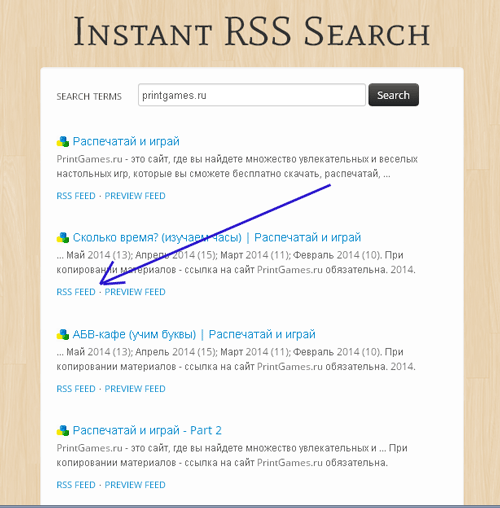
Вам сразу покажут последние rss сообщения в ленте, а также будут представлены ссылки на саму rss ленту, нажимаем на ссылку “RSS FEED”:

Здесь вы сможете отыскать ссылку на rss ленту (в адресной строке браузера или же в коде странички ленты) – в данном случае – это “printgames.ru/feed”.
2. Для движков (wordpress, joomla и др.) характерны стандартные url для rss лент:
– Для WordPress RSS лента расположена по url:
сайт/feed
Например: “mnogoblog.ru/feed”
К тому же если RSS лента сайта привязана к сервису управления RSS рассылок, например к “feedburner.google.com”, то вас перекинет на rss ленту на этом сервисе, попробуйте ввести:
“wpcafe.org/feed”
– Для Joomla RSS лента расположена по url:
сайт/?format=feed&type=rss
Например: “joomfans.com/?format=feed&type=rss”
3. Можно также отыскать url путь до RSS ленты сайта через его исходный код:
Для этого заходите на главную страницу сайта и открываете его исходный код, зажав одновременно две клавиши на клавиатуре “ctrl” и “u” (ctrl+u), а после с помощью строки поиска ищем в нем “rss”.
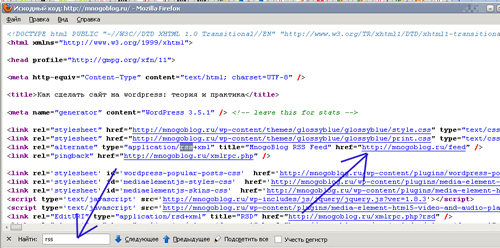
На этом все, красивых вам сайтов!
