Уже два десятка лет, работая в СМИ, я наблюдаю один и тот же феномен. А именно: одни журналисты совершенно не настроены осваивать новые технологии, и, похоже, до сих пор ностальгируют по печатающим машинкам.
А другие, наоборот, осваивают новые технологии с космической скоростью, опережая самых отъявленных техногиков. Этот текст – для второй категории.
Все мы привыкли для поиска необходимой нам информации использовать самую популярную в мире поисковую систему – Google. Ежедневно на сайтах Google, доступных примерно на 200 языках, регистрируются миллиарды поисковых запросов – не случайно основной сайт Google.com считается самым популярным интернет-ресурсом. Также довольно часто используется «Яндекс» и Bing.
Однако нужно признать: поисковая система Google рассчитана на массового потребителя, на того, кому в 99% случаев с лихвой хватает первых трех страниц поисковой выдачи. Но журналисты – это как раз те люди, которым бывает необходимо найти что-то не слишком распространенное, глубоко покопаться в вопросе. Однако даже самая совершенная поисковая система не способна одинаково хорошо искать в блогах и в научных статьях, в цифровых изображениях и кулинарных рецептах. Именно по этой причине существует множество не слишком известных поисковых систем, которые специализируются на каком-либо «узком» поиске, либо умеют искать там, где обычно не ищут традиционные поисковики. Ведь универсальные поисковые системы просто «не видят», например, уже не существующие веб-страницы, либо старые версии страниц, контент в социальных сетях, страницы, которые преднамеренно закрыты для «веб-пауков» и т.д.
Итак, чем мы можем воспользоваться?
1. Ответить на вопрос
Можно искать что-то по ключевым словам или фразам, а можно задать вопрос на естественном человеческом языке. Именно на такие вопросы отвечает Answers.com – поисковая система, позволяющая найти ответы на огромное количество вопросов. Результат поиска – это не набор ссылок, а статьи с Википедии, Оксфордовского университета и других авторитетных ресурсов. Вот только спрашивать придется на чистом английском языке.
2. Найти то, чего уже нет
Сегодня практически каждый продвинутый интернетчик умеет пользоваться кэшем Google или «Яндекса», когда у него возникает необходимость просмотреть (и/или представить в качестве доказательства) недавно удаленную либо измененную страницу в ее первоначальном виде. Ну или увидеть ее такой, какой она была в определенный момент времени. Однако есть определенная проблема: такой кэш доступен для поисковой выдачи только сравнительно короткое время. Это понятно: задача поискового робота – выдавать наиболее актуальную версию интернет-ресурса.
Однако иногда бывает нужно увидеть какой-то сайт так, как он выглядел, скажем, несколько лет назад. Для этого созданы специальные поисковые средства – такие, скажем, как веб-сервис Wayback Machine. Его работу поддерживает некоммерческая организация «Архив Интернета», которая с 1997 года собирает копии веб-страниц и размещаемый в Сети мультимедийный контент. Все эти копии, сохраненные на множестве серверов, бесплатно доступны для всех желающих. Wayback Machine позволяет отыскать не только старую версию ныне существующего сайта, но и те веб-страницы, которые давно не существуют – речь о закрытых сайтах. К сегодняшнему дню «Архив Интернета» собрал уже более 366 млрд страниц, так что найти требуемое можно с очень большой вероятностью.
3. Ищем картинку
Сегодня подавляющее большинство пользователей, которым нужно отыскать какое-то фото или иной графический файл, используют для этой цели Google Images. Но все-таки самый-большой-поисковик-в-мире «заточен» под текстовый поиск, а поиск картинок для него – только один из дополнительных сервисов.
Так что, если вы не смогли отыскать требуемое при помощи Google Images, имеет смысл использовать что-то специализированное. Например, сервис Picsearch. По заявлению его создателей, их детище на сегодняшний день проиндексировало уже более трех с половиной миллиардов цифровых картинок.
В числе преимуществ Picsearch – как многоязычный пользовательский интерфейс, так и полноценный многоязычный поиск, а также ряд очень практичных фильтров, например, возможность поиска только черно-белых или цветных изображений, картинок с преобладанием какого-то конкретного цвета, поиск «обоев» для рабочего стола, а также лиц или анимированных изображений.
Достойной альтернативой Google Images также может стать поисковая система Everystockphoto. С одной стороны, она намного меньше по размеру – содержит «всего» порядка 25 млн картинок, хранящихся на онлайновых фотосайтах, включая Flickr, Fotolia и Wikimedia Commons. Однако, как говорят специалисты, результаты ее работы по-настоящему впечатляют. Большинство из найденных снимков можно использовать бесплатно, правда, при условии, что будет указано имя фотографа или правообладателя.
Особняком стоит сервис поиска по содержимому картинок Picollator.ru. Когда вы вводите запрос в большинстве поисковиков, предлагающих поиск графических файлов, вы получаете результаты исходя из того, какой текст встречается на странице, а также на названиях файлов. Picollator работает принципиально иначе, идентифицируя то, что изображено на картинках. Понятно, что в этом случае поисковый запрос должен формулироваться не в виде слова или словосочетания, а быть картинкой.
То есть для поиска следует загрузить на сервер фотографию или указать ссылку на сайт, куда она уже загружена. В поисковой выдаче будут собраны эскизы изображений, похожих на загруженное фото. Правда, этот сервис работает только с фотографиями людей, причем хорошего качества.
4. Не только найти, но и подсчитать
К сожалению, слишком многие журналисты – особенно выходцы с журфака – «не дружат» с цифрами. Многие даже не видят разницы между процентами и процентными пунктами, из-за чего статьи по экономике порой превращаются в абракадабру. Помочь им может один из самых известных «альтернативных» поисковиков – WolframAlpha.
По сути, это «энциклопедическая» поисковая система, задача которой – давать ответы на действительно сложные вопросы в таких областях, как математика, физика, медицина, статистика, история, лингвистика и прочие области науки. По сути, WolframAlpha – это в большей степени колоссальная база данных, часть которой преобразована в вычислительные алгоритмы. Именно благодаря им пользователь поисковика может получить обстоятельные сведения о том, сколько граммов белков и калорий содержится в чашке какао, какова ожидаемая средняя продолжительность жизни в США, Франции и Австралии в следующем году или как решается алгебраическое уравнение.
Впрочем, чтобы полноценно использовать WolframAlpha, нужно хорошо владеть английским языком. Другие языки система, к сожалению, не поддерживает.
5. И снова наука
Научный мир всегда был в некоторой степени закрыт для непосвященных. Конечно, не отгораживается от широкой публики стальной стеной, но чтобы читать научные публикации, копаться в специфических базах данных и смотреть результаты экспериментов пользователям Сети обычно нужно пройти регистрацию и получить специальный доступ. То есть обычные поисковики эту информацию не индексируют – для них практически все научные статьи относятся к категории так называемого «глубокого Веба» (Deep Web).
Так что если вам действительно нужно покопаться в научной информации, непонятной большинству непосвященных, – используйте специализированную поисковую систему. Такую, как поисковик CompletePlanet, имеющий доступ более чем к 70.000 научных баз данных и узконаправленных поисковых систем.
6. Ищу человека!
Обычный поисковик вполне можно использовать только для поиска информации о какой-то знаменитости. Если вам нужна информация совсем не о публичной персоне, то шансы отыскать какие-либо данные резко падают. И тогда нужно использовать специализированную поисковую систему.
Самая известная из таких систем – поисковик Pipl. Она проводит поиск данных о людях в целом ряде публичных реестров, онлайновых баз данных, служб и социальных сетей. Большое преимущество сервиса Pipl – то, что он работает и с кириллицей, так что он достаточно эффективен и с русскоязычными фамилиями.
Альтернатива – российский сервис SpravkaRU.NET. Он может отыскать адрес и домашний телефон жителя не только России, но и Украины, Беларуси, Казахстана, Латвии и Молдовы. По сути, это большой электронный телефонный справочник крупных городов постсоветских стран, хотя далеко не полный. Однако, в отличие от многих подобных сервисов, SpravkaRU.NET содержит вполне актуальные базы. Так что если у вас есть хоть какая-то информация о родственниках или примерном месте проживания объекта вашего интереса, то это наверняка поможет его найти. Замечу, что сервис часто не работает.
Самый простой способ кого-то отыскать – использовать поисковик «Яндекс.Люди». Проверено: сильно много информации вы не получите, но самого человека разыщете почти наверняка.
7. Поиск по блогам
За последние полтора десятилетия блоги стали не просто общественно культурным явлением, но и просто бездонным источником самой разнообразной информации. Далеко не всегда достоверной и корректно поданной, но нередко все же очень интересной. Специализированный поиск по русскоязычным блогам – сервис «Яндекс.Блоги». Без особых наворотов, просто работающий поиск.
8. Держать свой поиск в секрете
Одна из выдающихся разработок 2010-х годов – анонимный поисковик DuckDuckGo. Это Это поисковая система с открытым исходным кодом, основанная в сентябре 2008 года. В своем пользовательском соглашении DDG особо подчеркивает конфиденциальность предоставляемых пользователями данных, отказ от записи и хранения пользовательской информации и от слежки за пользователями.
В технологическом плане DuckDuckGo отличается от универсальных поисковиков тем, что не использует «пузырь фильтров» (Filter bubble), то есть не учитывает прошлые запросы пользователя для определения того, какая информация ему наиболее интересна. DuckDuckGo по умолчанию использует работу между клиентом и сервером по протоколу HTTPS, работая по алгоритму шифрования RC4 с ключом 128 бит. Также DDG Поисковик не использует cookies и не хранит данные об IP-адресах пользователей, не предлагает залогиниться и по умолчанию шифрует передаваемые данные.
Хранящий анонимность поисковик – детище программиста Гэбриела Вайнберга. Он создал DDG в 2008 году, с самого начала решив, что тот не будет хранить данные пользователей, так как они содержат слишком много личной информации. «Если вы спросите людей о важности приватности их поиска, они ответят, что это очень важно, но при этом практически никто не пытается сделать свои поисковые запросы анонимными, – писал Вайнберг в своем блоге. – Google хранит не только поисковые запросы пользователей, но и IP-адреса, с которых они обращались. То, что Google обязательно должен хранить всю эту информацию, – миф. Почти все деньги, которые они получают, основаны на том, что пользователь набирает в строке поиска».
Сперва DuckDuckGo был малоизвестен: еще в начале июня 2013 года он обрабатывал только 1,7 млн запросов в день. Но затем случился скандал: в США была обнародована информация о программе PRISM – с ее помощью АНБ США получало доступ к серверам компаний, включая владельцев крупнейших в мире поисковых систем – Google, Microsoft и Yahoo. Вскоре после этого число ежедневных запросов к DuckDuckGo превысило 3 млн в день и продолжило быстро расти.
9. Хранить тайны
УаСу – поисковик, работающий по технологии Р2Р (peer-to-peer). Хранение поискового индекса и обработка запросов производятся не на центральном сервере, а в распределенной сети пиров Fгeewoгld. Присоединиться к сети может любой желающий, достаточно просто установить соответствующее ПО. Здесь царит полная анонимность: распределенная сеть и открытый код гарантируют УаСу устойчивость и защищают его от попыток цензуры.
Поисковая система Ixquick также делает приоритетом анонимность и безопасность пользователей. lxquick, как и DuckDuckGo, не сохраняет информацию ни о запросах пользователей, ни о них самих.
10. «Прошерстить» форумы и блоги
Omgili – поисковая система, специально созданная, чтобы индексировать форумы по всевозможным тематикам, а также тематические блоги. Используя этот поисковик можно будет быстрее найти уже опубликованные вопросы и получить на них ответы.
11. Найти звуки в Сети
Ресурс FindSounds.com специально создан для пользователей, которым требуется искать звуковые файлы разных форматов – wav, mp3, aiff, au. В базе данных ресурса есть самые разнообразные звуки – крики животных, скрежет машин, звон, стук, сирены, жужжание насекомых, грохот взрывов и стрельбы, всплеск воды и т.д. Звуковые файлы можно искать по разным критериям, например, по размеру, наличию двух или одного каналов звучания (стерео/моно), частоте дискретизации и разрядности звучания. В результатах поиска отображаются не только ссылки на найденные файлы, но и их основные характеристики, а также показывается график амплитуды звука, по которой можно судить о характере звучания данного семпла. Поисковик может пригодиться, например тем, кто создает интерактивную web-графику и желает внести разнообразие на сайт, сопроводив нажатие элементов навигации страниц различными звуками.
12. Ищем dll-файлы
Думаю, всякому доводилось хотя бы раз столкнуться с проблемой отсутствия в операционной системе какой-то библиотеки dll. В результате программы или игры отказываются запускаться, а на экран выводится сообщение «Couldn’t find *****.dll». Отсутствие нужного файла может быть вызвано некорректным удалением ранее установленного приложения, случайным повреждением файла и т.д. Кроме того, разработчик мог просто не включить в дистрибутив своего продукта эту библиотеку.
Исправить ситуацию очень просто – достаточно найти в интернете недостающий файл, загрузить его и скопировать в каталог программы, которая отказывается запускаться, либо в папку ..WINDOWSsystem32… Найти и скачать отсутствующий файл можно легко и быстро с помощью поисковика Alldll.net.
Это поисковая база данных по наиболее популярным библиотекам dll. Файлы рассортированы по алфавиту, присутствует функция поиска. Искомый файл можно отыскать, даже если известно только приблизительное название библиотеки.
13. Поиск медицинской информации
Сайт Medpoisk.ru – универсальный поисковик, который предназначен для поиска исключительно на медицинских сайтах. Использует движок поиска от Google. Это практичный инструмент не только для врачей, но и для каждого, кому нужен ответ на любой вопрос из области медицины. Как лечить ту или иную болезнь, какие противопоказания у того или иного лекарства, к какому врачу обратиться. Также в поисковик включена биржа труда для медицинских работников.
14. Космос – наше все
Астрономический поисковый сервис Astronet.ru специализируется на поиск информации по сайтам, тематика которых имеет отношение к астрономии и исследованию космоса. Всего в базе данных поисковой системы около пятисот сайтов астрономической тематики – сайты обсерваторий, любительские странички, библиотеки научной литературы и тому подобное.
Помимо функции поиска, на сайте есть масса других полезных сервисов, среди которых, например, англо-русско-английский астрономический словарь, биографический справочник с подробными сведениями обо всех ученых, внесших вклад в развитие астрономии, глоссарий астрономических терминов. Есть также удобная карта звездного неба, которая генерирует положение созвездий, в зависимости от широты и долготы точки наблюдения, а также времени суток.
Безусловно, это лишь небольшая часть альтернативных поисковых сервисов. Причем со временем одни из них прекращают работу, но появляются новые. Лучшие умы создают все более совершенные алгоритмы отбора результатов интернет-поиска. Впрочем, если научиться умело оперировать синтаксисом поискового запроса, то и Google, Yandex, Yahoo! и другие поисковые системы «общего назначения» могут выдавать результаты не хуже, чем это делают альтернативные поисковики.
Приветствую всех, кто заглянул на блог webmixnet.ru!!! С вами как обычно Максим Обухов и сегодня я расскажу вам о том, как найти тот запрос которого нет! 🙂 Кто-нибудь понял, о чем я? Да, я говорю, конечно же, о сео продвижение посредством тех ключевых фраз, у которых маленькая конкуренция или вообще ее нет!!!
Ведь трафик с поисковых систем будит целевым и тем самым он принесет больше пользы, чем, откуда либо еще!!! Знаю я одного человека, его зовут Дмитрий Смирнов, у него 70% трафика идет с поиска, а всего 1,5 % с соц сетей и оставшаяся часть из других мест! На мой взгляд это круто!!!
Те, кто уже очень долгое время занимаются сайтами и их продвижением, раскруткой, наверное, в какой-то момент задумывались о том: «А что если отыскать такой запрос, на который будет спрос, а вот предложения ни у кого не будит!» Да это же золотое дно ребята!!!! Тогда толпа народу повалит к вам, вам лишь остается грамотно всех встретить и все!!!!
Да, я и сам порой мечтаю отыскать такую ключевую фразу, по которой бы ко мне на блог заходило по 30 000 тысяч в день!!!! 🙂 🙂 🙂
Вы представьте только, одна статья принесет вам такое количество посетителей! А если у вас будет две, три, четыре, десять подобных статей!!! Тогда, наверное, сервер не выдержит нагрузки!!! J Что вы думаете по этому поводу?
Ну да, конечно же, это все мечты! А теперь давайте серьезно поговорим о том, как найти тот запрос, которого нет?
С такими мыслями, куда все идут? Да, конечно же, прямиком в поисковик в гугл или в яндекс!!! А там что? Да ничего там нет, только так, несколько предположений и высказываний. Потому что даже если кто то и знает о подобных золотых запросах, он ни кому об этом не расскажет и ни когда не продаст то, что нашел!!! Есть программа Key Collector,по цене кажется 1000 – 1500 или выше, но честно сказать не знаю, какой она дает эффект? Но суди по тому, что о ней идут хорошие отзывы, да и она платная, видимо все же есть эффект! Ну а я же стремлюсь найти такой запрос, который бы принес сразу 1000 посетителей в день!!! И причем конкуренция бы была равна нулю!!!
Как найти тот запрос которого нет специальными методами?
Итак, сейчас я расскажу, как найти чистый запрос, ну то есть без конкуренции. Но не думаю, что это будет новинкой.
Заходите на ворд стат (https://wordstat.yandex.ru) и соответственно методом подбора начинаете вбивать фразы по которым вам нужно что бы сайт вышел на первое место!
Пример:
Вводим фразу, «как заработать в интернете» И нам выходит много, много запросов. Естественно здесь допустим начинающему человеку, который только завел свой сайт, достаточно сложно пролезть, а чаще всего не возможно! Мест нет, все занято.

Вводим другую фразу, как заработать в интернете без знаний. Нам вышло все 44 запроса в месяц. Возможно, ли здесь пробиться? Кто-то скажет да, а кто-то нет.

Теперь идем и вбиваем этот запрос в яндекс.

Итак, что мы видим, а видим то, что по этой словесной форме уже есть статьи и достаточно статей. Где то похожие, где то более менее точные. Ну и как вы думаете, пробьется ли здесь новичок со своим 2 – 3 месячным сайтом? Ну, хотя бы в топ 5 -10? Я думаю, это возможно, но сложно. Потому что на первых местах стоят так сказать гиганты, многолетники! Первому, например 4 года с лишнем, второму 8 лет, третьему 1 год. Ну а дальше уже пошли не точные фразы, которые то же претендуют на первые места.
Как найти тот запрос которого нет и влияет стаж сайта?
Как вы думаете, влияет ли возраст сайта на поисковую выдачу? Я думаю все же да! Поэтому если писать статью на выше приведенную тему, то мы получим приблизительно 1-го человека в день! То есть одна статья один человек, это если двигаться и отыскивать такие фразы.
Как найти тот запрос которого нет в интернете, но спрос то на него есть? Ответ есть и это обычный метод тыка! То есть вбивайте любые запросы, которые соответствуют вашей теме в вордстат и ищите именно такой запрос, который вам приведет нужное количество людей. И тут же соответственно вбивайте его в яндекс и если там нет ничего подобного, то считайте вам повезло!!! Вы будите первым по этому запросу!!!
Но есть другой вариант, в интернете существую, различные базы ключей, вы можете отыскать и скачать. И по свободным ключам уже написать статью!!! Особенно как я понял, ценятся базы Постухова!
Вот еще один вариант как найти тот запрос, которого нет:
Вы просто вбиваете нужную фразу и не убирайте курсор, через какое-то время выйдут похожие фразы, которые ищут люди. Попробуйте их, а вдруг и что-нибудь найдете ценное!

Видите сколько вышло, а ведь какой-то из запросов может быть чист!
Что же касается меня лично, то я использую по старинке wordstat, вот и все! Обычный метод тыка, который в будущем думаю, принесет мне большой трафик с поисковых систем!!!
Ну, вот и все что я хотел сказать вам в этой статье из которой вы узнали как найти тот запрос которого нет! Надеюсь хоть немного, но статья для вас была полезной! Желаю всем всего доброго и побольше золотых ключивиков!
Читайте так же:
Как сделать баннер для сайта качественно онлайн?
Написание статьи за деньги для сайта
Сколько платят за сайт в интернете?
Хостинг для сайта с самым лучшим бесплатным тарифом
Что такое сайт в интернете и зачем он нужен?
Как создать сайт приносящий доход?
Как создать и установить иконку для сайта?
Что такое трафик на сайте?
Как проверить статистику сайта?
Каким должен быть сайт?
Из чего состоит сайт в интернете?
Как создать свой сайт новичку и зарабатывать на нем деньги? Пошаговая инструкция
С уважением, Максим Обухов!!!
Поделиться ссылкой:
Как найти скрытые страницы в интернете?
Светлана❤❤❤
10 октября 2020 · 326
Скрытые как и для чего?
-
Тегами для поисковых машин. Если страница прямо указывает поисковикам (служебным тегом noindex) что ее не нужно индексировать и показывать людям – попасть на нее можно зная прямой адрес этой страницы.
-
Если скрыта силами движка сайта (статус черновика или ограниченного доступа) – никак.
Если она когда-то была в свободном доступе, можно попытаться найти через web.archive.org, но это подразумевает что вы как минимум знаете адрес сайта, а ваш вопрос явно не об этом.
250
Комментировать ответ…Комментировать…
С расцветом цензуры и слежения альтернативы Google и Яндекс интересуют пользователей все больше и больше. Мы расскажем вам о трех поисковых системах без запретов, которые не собирают о вас личную информацию, а, напротив, защищают вашу приватность.
Startpage: самая дискретная поисковая система в мире
Startpage.com называет себя «самой дискретной поисковой системой в мире». С 2016 года сервис был объединен с сайтом Ixquick. В качестве доказательства безопасности своего поиска Startpage.com позиционирует себя как единственная поисковая система, имеющая сертификат ЕС о конфиденциальности.
Startpage.com обещает не сохранять IP-адреса пользователей и, по утверждению сервиса, не использует файлы cookie для трекинга. Кроме того, Startpage.com доступен из сети Tor. Серверы поисковой системы находятся в Нидерландах.
У сайта есть удобная особенность: результаты поиска можно просматривать при помощи опции «Прокси», которая шифрует соединение с соответствующей веб-страницей с помощью прокси-сервера. Таким образом, это настоящий поисковик без запретов: можно спокойно просматривать то, что блокирует ваш провайдер.
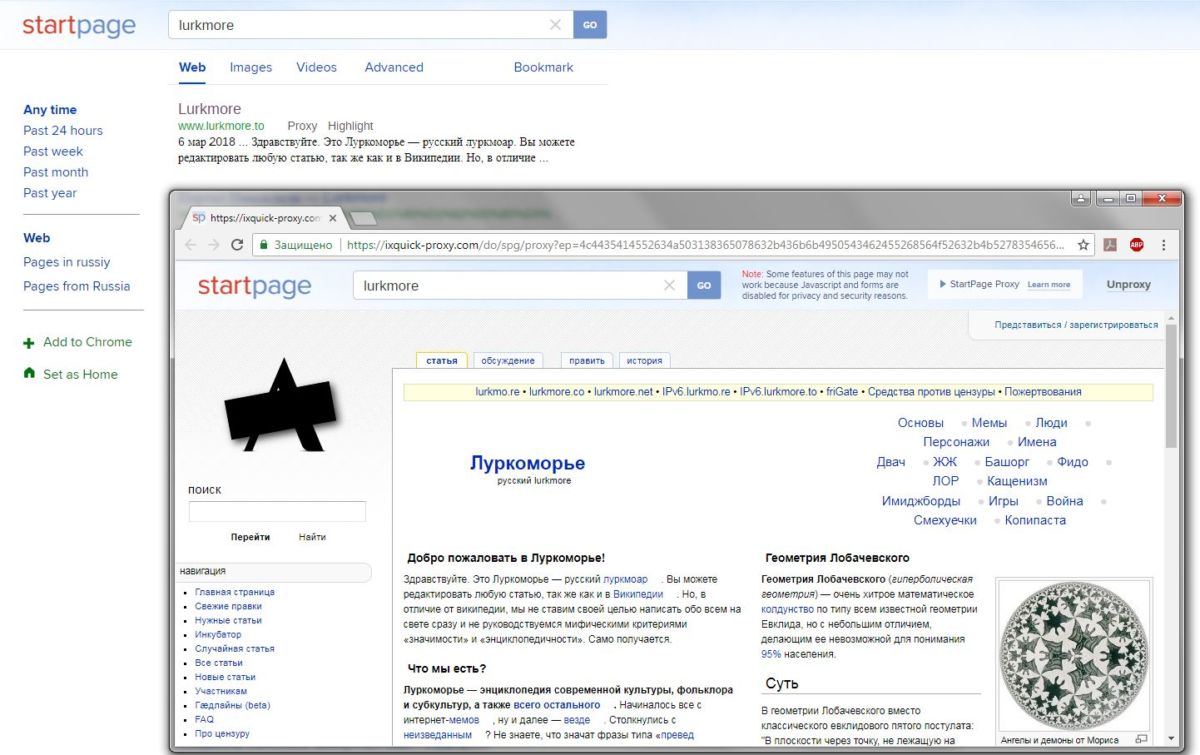
Поисковые прокси — главная фишка Startpage, которые делают его поисковиком без цензуры. Если вам необходимо искать без блокировок, этот сервис для вас.
Startpage
DuckDuckGo: анонимная поисковая система из США
DuckDuckGo — наиболее широко используемая безопасная альтернатива Google с более чем десятью миллионами запросов в день. Несмотря на то, что серверы поисковой системы находятся в США, DuckDuckGo.com, тем не менее, предлагает некоторые интересные функции.
При поиске через DuckDuckGo.com ваш IP-адрес не будет сохранен. Система также не использует файлы cookie для отслеживания. DuckDuckGo применяет шифрование с использованием HTTPS. В поисковую систему также можно ввести запрос через сеть Tor. Кроме того, можно использовать различные темы, чтобы настроить отображение поисковой страницы.
Открывать сайты через прокси тут нельзя. Но с учетом того, что система находится вне юрисдикции РФ, на него не распространяется, к примеру, «право на забвение» в том смысле, в котором оно понимается у нас. Результаты поиска могут быть не идеальными, но все же довольно полезными.
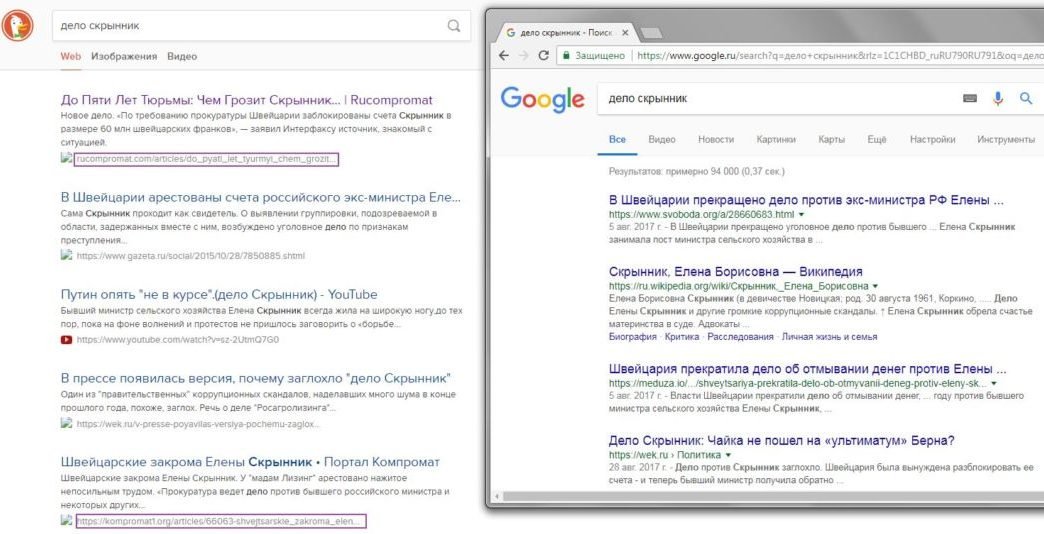
Этот сервис больше подойдет тем, кому в первую очередь важна анонимность и поиск без слежения. Либо тем, кто хочет найти информацию, исключенную из результатов поисковой выдачи в РФ. Однако, следует предупредить: в России DuckDuckGo стал партнером Яндекса, так что можно ожидать всего.
DuckDuckGo
notEvil: поиск по интернету, которого нет
Поисковик notEvil позволяет осуществлять поиск из интернета по анонимной сети Tor. Для этого не надо устанавливать никакого дополнительного программного обеспечения (хотя оно, понадобится для того, чтобы открывать результаты поиска).
Эта поисковая система позволяет искать по так называемому даркнету — той части Интернета, которая обычно недоступна среднему пользователю. В связи с блокировками в нее постепенно переезжают полезные сервисы, например, для скачивания контента.
Большинство веб-поисковиков по Tor бессовестно зарабатывают на рекламе: вы получаете результаты из Tor, и вдобавок — горсть рекламных объявлений и трекинг в подарок. notEvil принципиально этим не занимается. Понятное дело, что об отслеживании IP и использовании cookie речь тут вообще не идет.
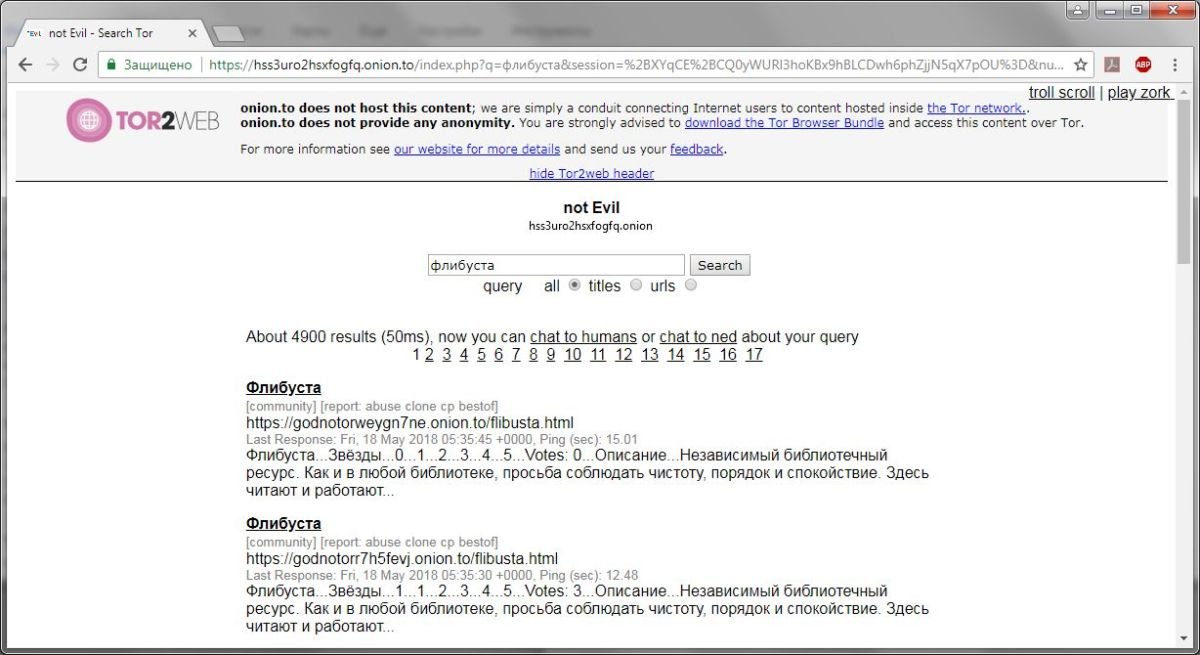
Сайт пригодится тем, кто хочет познакомиться с содержимым невидимого интернета; хардкорная анонимность гарантируется. Кстати, рекомендуем сразу сохранить себе ссылку в закладки — URL-адреса категории «Tor-to-web» очень недружелюбны в плане запоминания.
notEvil
Анонимные поисковые системы как безопасная альтернатива Google
Все три поисковых системы не регистрируют ваш IP-адрес и не используют файлы cookie для слежки. Шифрование с использованием HTTPS предоставляется всеми названными поставщиками.
Лучшие результаты поиска в тесте показал поисковик DuckDuckGo, а гарантированную безопасность при выборе альтернативного поисковика вы получите с системой Startpage.com. Сертификация защиты данных ЕС подтверждает, что поисковая система придерживается своих обещаний об анонимности поиска. Для поиска по даркнету, в свою очередь, пригодится notEvil.
Читайте также:
- RuTracker и другие запрещенные сайты навсегда исчезнут из выдачи поисковиков
- Интернет-поисковики: как устроены, как работают и как ими пользоваться с максимальной эффективностью
- Как обеспечить анонимность при серфинге в Сети
Фото: авторские, pixabay.com
Здравствуйте, дорогие читатели! Сегодня я, мистер Whoer, расскажу Вам о таком феномене Интернета, как «Глубокая паутина» или «Глубокий Интернет» .
Системы поиска, например, Yandex или Google, за время своего существования проиндексировали свыше триллиона страниц в Мировой паутине. Но наряду с огромным количеством открытых (проиндексированных) данных существует информация, к которой сложно подобраться через стандартные системы поиска. Зачастую такая информация располагается только на веб-хостингах. «Глубокий Интернет» (по-английски – «deep web») содержит данные о скрытых сайтах, которые предпочитают быть «в тени» и не вызывать к себе интереса. Это могут быть ресурсы, доступ к которым осуществляется только по инвайтам, или пиратские сайты. Также не индексируются странички, поиск которых запретил непосредственно владелец, и сайты, доступные только для зарегистрированных пользователей, например, почти все социальные сети.
Важно понять, что перечисленные ресурсы не являются анонимными или зашифрованными – к ним можно получить доступ, но это возможно лишь зная прямую ссылку на них, потому что поисковики не индексируют веб-страницы, на которые нет гиперссылок, размещенных на других ресурсах Интернета.
Как попасть в глубокий интернет? Сайты глубокого интернета.
Итак, как найти, как зайти и как попасть в глубокий Интернет? Для нахождения «глубинных» ресурсов нужно использовать специализированные технологии поиска баз данных «Deep web».
В качестве примера бесплатных или частично платных сайтов (баз данных) приведем следующие: Science.gov (для научных данных), FreeLunch (для экономических), и даже Википедия есть в глубоком интернете!
TOR поисковики
Более простым методом поиска onion сайтов является использование специальных поисковых систем. Наиболее известным примером является поисковик Grams.

Даже по логотипу понятно, что поисковик тщательно имитирует Google, и надо отметить, неплохо с этим справляется. Поисковая выдача достаточно обширна, ссылки выдаются как на onion сайты, так и на обычные странички в Интернете.
Использовать поисковик очень просто – вводите в поисковую строку запрос, ставите галочку “show only onion sites” и кликаете на значок «лупы».
Алгоритмы ранжирования полученной выдачи, как кажется, полностью повторяют гугловские, за тем лишь исключением, что на данном ресурсе вы никогда не увидите рекламных блоков. Так что смело можно сказать, что найти нужную информацию в «глубоком» интернете с этим поисковиком довольно просто.
На втором месте топ сайтов onion поисковиков находится Fess. В отличие от Grams этот сайт onion использует tor-движок в своей основе, что позволяет ему более гибко индексировать именно TOR-сайты.
Если вы на сайте в первый раз, то рекомендуем сначала узнать, что такое Tor, прочитав статью на эту тему.
Тем не менее, следует отметить, что ни одна из перечисленных и опробованных нами поисковых систем не идут ни в какое сравнение с Google или Yandex. О ранжировании сайтов в выдаче по различным критериям поведения, обратным ссылкам и прочим факторам можно забыть – сайты показываются так, как решили программисты. Правда почти везде присутствует ручная фильтрация — например, Fess просит присылать на e-mail найденные пользователями списки onion сайтов.
Как ещё открыть onion сайты?
Осуществлять поиск баз данных можно и при использовании специализированных сайтов. Такого рода ресурсы «глубокого интернета», как, например, Публичная библиотека интернета, Infomine, DirectSearch, как правило, содержат перечни ссылок на скрытые источники информации. Для того, чтобы найти список поисковиков глубокого Интернета, рекомендуем воспользоваться сервисом «searchengineguide.com».
Также существует вариант получения недоступной через обычный поисковик информации с помощью ресурсов в академических библиотеках. Библиотеки высших учебных заведений, как правило, имеют оплаченный доступ к уникальным базам данных, содержащих информацию, которую невозможно отыскать с помощью простой поисковой системы. Можно поинтересоваться у работника библиотеки, к какой информации открыт доступ, или, (если Вы студент) используя читательский билет, получить доступ к университетским базам данных.
Прекрасной возможностью найти редкие данные являются сайты, хранящие архивные копии Интернета. Например, выполняя поиск данных в проекте TheInternetArchive, который собирает, накапливает и хранит цифровую информацию, Вы сможете отыскать массу интересного – архивы веб-сайтов, которые прекратили свое существование, копии выпущенных игр, а также аудио и видео записи и ссылки на глубокий интернет.
Частью «глубокого Интернета», иногда нарекаемой «Darknet» (Темная паутина), является глубокая сеть Тор, которая используется для общения, торговли и хранения информации, доступность которой должна быть строго ограничена. Чтобы получить доступ к такой сети, нужно воспользоваться специальным программным обеспечением (браузер Tor, с помощью которого можно просматривать веб-сайты в зоне .onion).
Активность в сети Tor по большей части является полулегальной (то есть не совсем законной). Этой сетью пользуются люди, которые предпочитают максимальный уровень защиты своих данных, а также журналисты, при общении с анонимными источниками. Доступ к сети Tor является легальным, но активность пользователя в ней не считается таковой.
Браузер Tor значительно усложняет задачу отслеживания интернет-активности пользователя, и у Вас появляется возможность посещать веб-страницы анонимно. «Глубокий интернет» содержит есть множество сообществ, которые предпочитают конфиденциальность, поэтому они доступны только посредством браузера Tor.
Некоторые особенности onion-сети:
– интернет-страницы в сети Tor зачастую бывают вне зоны доступа в течение нескольких минут, иногда недель или вообще могут исчезнуть навсегда, что обуславливает их ненадежность. Также страницы достаточно медленно загружаются по причине подключения к сети Tor путем использования компьютеров других пользователей с целью обеспечения вашей анонимности.
– Tor-браузер не гарантирует Вам анонимность в поддерживаемых им операционных системах iOS и Android, и, следовательно, их использование не рекомендуется. Для других интернет-браузеров возможности Tor являются ненадежными и, как правило, не поддерживаются структурой Tor.
Отметим, что большинство людей пользуются «глубокой паутиной» с целью незаконной деятельности. Чтобы избежать отслеживания вашей активности, а также вредоносных атак на ваш компьютер, следует принять следующие меры предосторожности:
— В левой стороне адресной строки браузера Tor кликнуть «S», далее выбрать «Запретить скрипты в глобальном масштабе»;
— в операционной системе Windows или Mac OS активировать брандмауэр;
— замаскировать объектив веб-камеры, например, заклеив его лентой или скотчем, во избежание несанкционированного включения камеры без ведома пользователя;
— ни в коем случае не закачивать файлы с интернет-страниц в сети Tor, даже простые документы doc или excel, и не обмениваться через торрент-трекеры файлами, что весьма и весьма небезопасно.
Использование обычных поисковиков в «глубокой паутине» не будет эффективным и не принесет желаемых результатов. Хотя, если Вы ищите очень популярный сайт из глубокой паутины, то обычный поисковик (типа yandex или google) вполне может справиться с такой задачей.
Тем не менее, множество ссылок на сайты глубокого интернета, которые могут быть полезны в «глубокой паутине», Вы найдете на популярнейшем её сайте – HiddenWiki – и без помощи поисковика. В «глубокой паутине» также существуют как легальные сервисы, которые во многом похожи на сервисы обычной сети, (к примеру, сервис обмена изображениями) так и более специфичные, (например, сайты по разоблачению противоправных действий или коллекции книг по антиправительственной тематике).
Используем TOR + VPN
Чтобы войти в глубокий интернет абсолютно анонимно, помимо TOR следует использовать VPN, который будет шифровать переданные пакеты не только в браузере, но и через все другие программы, и скрывать использование анонимных серверов. VPN от Whoer.net имеет множество других положительных качеств, таких как отсутствие рекламы и записи логов.
Заключение
Важно запомнить, что использование обычных поисковиков в «глубокой паутине» не будет эффективным и не принесет желаемых результатов. Хотя, если Вы ищите очень популярный сайт из глубокой паутины, то обычный поисковик (типа yandex или google) вполне может справиться с такой задачей.
Тем не менее, множество ссылок на сайты глубокого интернета, которые могут быть полезны в «глубокой паутине», можно найти только на популярнейшем её сайте – HiddenWiki. Помните, что в «глубокой паутине» также существуют как легальные сервисы, которые во многом похожи на сервисы обычной сети, (к примеру, сервис обмена изображениями) так и более специфичные, (например, сайты по разоблачению противоправных действий или коллекции книг по антиправительственной тематике).
Предлагаем перейти в комментарии и поделиться известными вам ссылками на onion сайты. До встречи на страницах нашего блога … или в «глубоком интернете» 😉
