Если вы знаете URL нужной страницы, то задача очень простая. Просто введите этот URL в после поиска в ВебАрхиве. В календаре будут видны сохранения этого URL. Если ничего не покажет, значит данный URL никогда не был сохранен.
Если URL не известен, то по ключевым словам найти будет крайне сложно. У Веб-Архива есть поиск по тексту, но он настолько плохо работает, что покажет единичные результаты вхождения на очень древних сохраненных страницах. Но чаще не найдет ничего, как сильно не сужай параметры в поиске.
Если ключевые слова содержатся в ЧПУ, то можно открыть таблицу сохраненных урлов:
https://web.archive.org/web/*/habr.com/*
Внимание, у больших сайтов таблица будет загружаться долго, подгрузит лишь 100 000 урлов. Дождитесь загрузки таблицы. Сверху справа над таблицей после её подгрузки можно ввести часть ЧПУ которая отфильтрует результаты.
О том, как работает ВебАрхив и как работать с его инструментами можно посмотреть видео здесь:
Как работать с Веб-Архивом
Как найти информацию в Интернете, которую не отображают такие продвинутые поисковые системы как Google или Яндекс? Можно ли найти сайты, которые когда-то существовали в сети, но уже не работают, удалены или же заменены новыми? На эти вопросы мы постараемся дать ответ в этой статье.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Как скачать сайт из веб архива
Если вы желаете восстановить сайт из веб-архива, то вам в этом поможет программа Web Archive Downloader 6.0
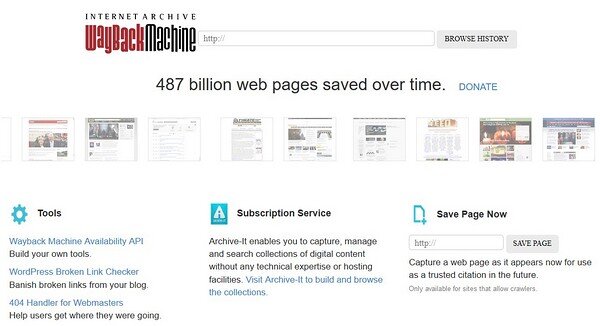
Все течет — все меняется. В свое время я пользовался довольно интересным веб-сайтом. Потом необходимость в нем исчезла. А сейчас информация с сайта снова понадобилась. А сайта уже нет. Вместо него открывается рекламная страница. Можно ли как-то посмотреть искомый сайт, если вы сами не делали копии? Оказывается, можно. Нужно искать этот сайт в веб-архиве — web.archive.org.
Этот проект по сохранению интернет-сайтов под названием The Wayback Machine работает с середины 90-х годов. К настоящему времени накоплено около 500 млрд веб-страниц.
Запускаем сайт web.archive.org, вводим нужный вам адрес и нажимаем на кнопку Browse History. Через секунды вы увидите результаты: временную шкалу с календарем, где отмечены даты, когда сохранялись копии страниц. К примеру, страница http://na-svyazi.ru сохранялась 569 раз с 29 октября 2011 года до наших дней.
Вам остается выбрать дату и просмотреть сохраненную информацию. К сожалению, сервис не всегда сохраняет все страницы веб-сайта. Может слететь форматирование сайта, отсутствовать некоторые изображения. Но это все мелочи, если вы найдете необходимую вам информацию.
P.S. Вы можете сами отправить в архив любую интернет-страницу. Для этого на главной странице проекта The Wayback Machine нужно ввести адрес в блоке Save Page Now.
навигация по статье
- Что такое веб-архив
- Зачем нужен web archive и как его можно использовать
- Как просмотреть старые версии сайтов на Wayback Machine
- Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
- Уникальный контент из веб-архива
Создание и наполнение онлайн-ресурса — это многоэтапный системный процесс. Контент фирменного сайта, интернет-магазина, лэндинга или портала должен постоянно обновляться с учетом целей и задач компании, изменений предпочтений целевой аудитории и алгоритмов поисковых систем. Но иногда старые тексты могут пригодиться, и тогда их можно найти на веб-архивах.



Что такое веб-архив
Веб-архив (web archive, internet archive) — это онлайн-платформа Wayback Machine, созданная в 1996 году. Здесь хранятся копии контента сайтов, интернет-магазинов, блогов, информационных и развлекательных порталов и других интернет-ресурсов, которые разрешены для сохранения. Это бесплатная онлайн-библиотека web.archive.org, где можно найти разные версии всех веб-ресурсов и просмотреть, как выглядел их контент, сохраненный на дату посещения сайта роботом сервиса.
Со времени создания веб-архива, здесь накопилось и на данный момент хранится больше 330 миллиардов файлов:
- интернет-страниц;
- аудио;
- видео;
- электронных книг и пр.

Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.

Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
Предназначение веб-архивов:
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).

Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.

Табл. 1. Для каких целей можно использовать более ранний контент
| Цели | Особенности применения |
| Восстановление сайта | Бывают случаи непоправимого повреждения онлайн-ресурса — из-за вирусов, хакерских атак. Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве |
| Наполнение сайта по похожей тематике | Старый экспертный текст по своей тематике может понадобиться при создании лэндинга, вспомогательного онлайн-ресурса. Если тексты неуникальны, их нужно рерайтить |
| Ведение блога | Для привлечения трафика на профильный сайт нужно вести блог с текстами узкой тематики. Это могут быть советы по выбору товаров, использованию продукции и другой контент. Для написания таких текстов может потребоваться информация со старых копий веб-ресурса |
| Публикации на странице в социальных сетях | Бизнес-аккаунт в соцсетях помогает поднять узнаваемость бренда и компании, привлечь новых покупателей, расширить рынки сбыта. Для постов в социальных сетях можно использовать тексты, которые ранее были опубликованы на сайте (если они не дублируются с новыми) |

Как просмотреть старые версии сайтов на Wayback Machine
Если вам необходимо найти старую версию страниц какого-либо веб сайта, выполните следующие действия:
- Наберите в поисковой строке адрес https://web.archive.org/.
- С главной страницы архива сайтов перейдите по ссылке на нужный раздел (файлы, видео, изображения и пр.), укажите адрес домена и нажмите «BROWSE HISTORY».
- Во временной шкале будут отображены все копии сайтов. Словно с помощью машины времени, здесь можно найти любую созданную ранее архивную копию и даже скачать ее при помощи специальных инструментов.
- В открывшемся календаре можно выбрать дату, отмеченную зеленым или голубым кружком (диаметр этого кружка зависит от числа обращений робота сервиса к онлайн-проекту в указанный день). Зеленым кружком обозначены редиректы.

Важно! Если веб-страницу через некоторое время не удается просмотреть, это может быть вызвано несколькими причинами:
- Правообладатель обратился на платформу архива интернета с требованием удалить копии.
- Сам веб-проект был закрыт из-за нарушения авторских прав и закона об использовании интеллектуальной собственности.
- Разработчики закрыли страницы своего онлайн-ресурса от индексации роботами поисковых систем.
Если вы хотите посмотреть, как выглядел веб-сайт, но на сохраненной копии нет изображений или других элементов дизайна (иногда они не сохраняются), нужно открыть другую версию, которую веб-архив сохранил в другой день.

Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots.txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |


Уникальный контент из веб-архива
Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
Приветствую вас, любознательные читатели блога seo-ap.ru! Недавно я рассказывал, что такое Википедия. Это виртуальная энциклопедия, которая завоевала всенародную любовь. Невзирая на то, что она постоянно подвергается критике со стороны ученых мужей
Одно то, что этот проект вот уже не один десяток лет «пашет» на пользу всего прогрессивного человечества, питает его полезной информацией на безвозмездной основе, заслуживает большого уважения и длинных дифирамбов.

Но в сети есть еще один некоммерческий проект, не менее грандиозный – web.archive.org. Он создан, чтобы надежно хранить сайты, печатные материалы, аудио и видеопродукцию. Все, чем сегодня наполнен интернет. И то, что было во всемирной паутине много лет назад. Разве такое возможно?
Да. Более того, сайты архивируются не в виде мертвых скриншотов. Они реально работают! На веб-страницах имеются все картинки, ссылки, сохраняется стилевое оформление CSS. Сайты в веб-архиве имеют еще и сотни копий. Они накопились за все время, пока сайты еще функционировали, и содержат всю их эволюцию, от рождения и до последнего вздоха.
Какую пользу веб-архив сайтов может дать лично вам?
Вы можете отправиться в путешествие по страничкам сайта вашей юности, поностальгировать. Проследить, как изменялся и развивался не только ваш, но и любой другой сайт в интернете. К примеру, материалы для своих статей о поисковой системе Апорт, которая уже приказала долго жить, я брал как раз в этом веб-архиве сайтов, в его потаенных закромах. И все скриншоты, наглядно показывающие хронологию главной страницы всеми любимого Яндекса, взяты оттуда же.
Следующий сюрприз. Допустим, вы добавили в закладку сайт, а в нем страница не открывается. Тогда вы обращаетесь к Гуглу или Яндексу, пытаясь извлечь страницу из кеша (изучите информацию о том, как эффективнее искать что-либо в Google – пригодится!). Но если к вашему ресурсу уже давно нет доступа, мертвые ссылки оживить поможет только archive.org. Хотя и там этот ресурс может отсутствовать. Почему? Об этом напишу чуть далее по тексту.
Если звезды сошлись так, что вы не сделали резервную копию своего сайта (бэкап), то вы сможете восстановить его из web archive. И это будет единственный способ решить проблему. При этом можно убрать из ссылок все привязки к web.archive.org, они могут стать прямыми для вашего сайта. Более подробно о ссылках и привязках читайте ниже.
И еще одно полезное свойство веб-архива сайтов. Он дает доступ к поиску готовых уникальных текстов. Если написание статей – не ваше призвание, то здесь вы найдете их целые залежи, настоящие Клондайк и Эльдорадо, вместе взятые! Но чтобы ими разжиться, кое-какие телодвижения совершить все же придется.
Мертвые сайты с их внутренним наполнением недоступны в действующей сети интернета. Но вы можете зайти в веб-архив, отыскать нужные вам тексты и вытащить их с того света. А затем прогнать через проверку на уникальность и опубликовать на своих страницах. Никто не обвинит вас в воровстве (плагиате) и нарушении авторских прав в копирайтинге. Однако этот увлекательный поиск некоторым может показаться долгим и тернистым.
Webarchive появился в интернете, страшно сказать – в далеком 1996 году! Еще в прошлом веке. На то время задача, стоящая перед разработчиками проекта, казалась архисложной, как говорил вождь мирового пролетариата. Несмотря на то, что интернет тогда еще не вошел в полную силу, сайтов было в сотни и тысячи раз меньше. И архивировались они гораздо реже. Как говорится, миссия невыполнима. Но мало-помалу, постепенно увеличивая вместимость своих «сусеков» и «кладовых», сервис успешно копировал и резервировал сайты.
Уже в следующем, 1997 году Webarchive поместил в базу сам себя. Посмотрите, как выглядела его главная страница более двадцати лет назад:

- Сейчас вся информация веб-архива занимает дисковое пространство объемом в 1015 Тбайт. Это гигантское число носит название квадриллион. Чтобы вам было легче его представить – примерно столько муравьев живет во всех муравейниках нашей планеты. Сервис Web.archive.org имеет официальный статус библиотеки. У него зеркала во многих центрах хранения и обработки данных.
- Если считать только архивы разных интернет-страниц, то их количество уже приближается к ста миллиардам. В это число входят все копии, которые были хоть однажды сняты и сохранены.
- Wayback Machine (обратная машина). Это архив страниц интернета. Он находится на главной странице сайта и доступен каждому. Здесь же хранятся телевизионные архивы, аудиоматериалы, отсканированные книги:

Просмотр сайта в Web.arhive
Но в данном случае нас интересуют возможности Wayback Machine. В строку формы, которая там имеется, можно вставить URL (адрес вашего сайта или отдельной страницы) или домен сайта, который вам нужен. Перед этим разберитесь с тем, что представляют собой домен и URL , чем они отличаются друг от друга. И тогда вы окажетесь на странице с календариком:

Здесь я вижу, что мой блог в первый раз был за архивирован в марте 2015 г. Ровно через пять дней после того, как я зарегистрировал (купил) свое доменное имя seo-ap.ru. Много воды утекло с той памятной даты. За все это время архивное копирование сайта выполнялось 100 раз, и каждую копию можно посмотреть и пощупать, переходя со страницы на страницу (все ссылки работают).
Как открыть мертвые ссылки? Для этого сайт должен находиться в archive.org.

Смотрим на календарь. Цифры в голубых кружочках обозначают даты создания так называемых слепков – веб-архивов сайта. Разумеется, в процессе снятия копии не будут учитываться изменения, которые производились на ресурсе после того, как запущено архивирование. А время его проведения Webarchive устанавливает в соответствии с собственными таймерами и заложенными программами.
Поэтому не всегда имеет смысл использовать веб-архив в качестве способа открытия сайтов, недоступных лишь временно. В Яндексе можно тоже просмотреть их архивы:

Такая же возможность просмотра копий веб-страниц есть и в Гугле:

А к помощи мощного сервиса, о котором идет речь, надо прибегать в случаях, когда в существующем пространстве интернета уже давно нет страниц, которые вы ищете. Но их можно извлечь из дальних закромов, если отправиться туда на машине времени под названием Webarchive .
Но чтобы сайт попал в archive.org, необходимы два условия:
- В файле robots.txt должен отсутствовать запрет для его индексации роботом с web.archive.org. Табу прописано следующим образом:
User-agent: ia_archiver
Disallow: /
Когда мне понадобилось написать статью об электронной почте mail.ru, я не нашел в веб-архиве никаких копий этого сайта именно по этой причине. В его файле robots.txt как раз был подобный запрет:

- Шансы попадания сайта в архивную базу возрастут, если его добавить в каталог под названием Dmoz (УЖЕ НЕ ВОЗМОЖНО ПРАВДА). Также очень хорошо, если на ваш ресурс ссылаются другие хорошо посещаемые сайты, находящиеся в Webarchive. Даже если с главной страницы этого сервиса был сделан простой запрос на ваш сайт, к нему будет привлечено внимание архиватора.
Как найти и восстановить нужный сайт без бэкапа web-архива?
В верхней части страницы расположена временная шкала, с помощью которой можно легко перемещаться по архивам. Слепки, которые есть для этого сайта, обозначены черными вертикальными черточками. Бывает, что веб-архив битый. Тогда надо открыть другой слепок, который находится к нему ближе.
Если мы кликнем по голубому кружочку, то увидим все архивы в пределах выбранной даты:

Может быть, архивирование выполнялось неоднократно в течение суток для более надежного сохранения информации. Жесткие диски не вечны. Если посмотреть любой из веб-архивов, то перед вашим взором предстанет копия сайта (в данном случае моего), со всеми ссылками и переходами. Они работают. Но, как я убедился, не всегда идеально. Особенно часто бывают проблемы с страницами сайтов использующих JS.
Но все это можно пережить, поскольку в начальном коде страницы с сервиса web.archive.org указанное меню никуда не делось. Но взять и скопировать себе на существующий сайт контент с этой страницы не получится. Потому что прогулку по ретро-сайту нельзя совершить без замены всех внутренних ссылок на те, что генерирует Webarchive. Иначе при переходе по ссылкам вы неизбежно окажетесь на страницах современной версии сайта.
Вот какие они, эти ссылки:
![]() Конечно, можно и даже нужно сократить ссылки, вручную стереть лишнее. И тогда мы получим облегченный рабочий вариант, в нашем примере такой:
Конечно, можно и даже нужно сократить ссылки, вручную стереть лишнее. И тогда мы получим облегченный рабочий вариант, в нашем примере такой:
Если лень это делать вручную, можно прибегнуть к автоматизации. В этом поможет текстовый редактор Notepad. В него еще встроена автоматическая система, позволяющая заменить внутренние ссылки оригинальными. Воспользоваться ею еще проще.
Для этого нужно всего лишь зайти в адресную строку браузера, которая начинается с http://web.archive.org/. Скопировать из нее адрес страницы, где находится нужный слепок вашего сайта. В моем случае он будет выглядеть так:
После этого надо после даты (20170902102223) поставить две буквы с низкой чертой « id_», и у вас получится такая конструкция:
В таком виде вы вновь вставляете адрес в браузер, после чего давите на клавишу Enter.
![]()
К чему приведут все эти действия? Обновится страница с архивом вашего сайта. Все проставленные ссылки будут прямыми. Это даст возможность копировать контент прямо из исходного кода Webarchive.
На восстановление обширного сайта с помощью этого сервиса придется убить уйму времени. Но поскольку других возможностей нет, этот способ можно считать даром небес.
С проблемой безвозвратного исчезновения контента обычно сталкиваются новички. Умудренные опытом владельцы сайтов, неоднократно испытав эту прелесть на себе, во избежание такой ситуации делают резервное копирование своих файлов и всей базы ежедневно. И не один раз, а пять.
Если у вас появится желание просмотреть все страницы сайта (и не обязательно своего), которые спрятаны в этих гигантских вместилищах информации, достаточно будет вбить в строку браузера такой адрес:
Понятно, что вместо моего домена надо вписать тот, который вас интересует. И нажать на клавишу Enter.
Появится страница, на которой вы можете отфильтровать искомую информацию в предложенной форме:

Меня, например, интересовали только текстовые файлы моего блога. Их без предупреждения загрузил Webarchive. Не спрашивайте меня, почему.
Как вытащить из веб-архива уникальный контент для своего сайта?
Способ, о котором сейчас расскажу, я еще не применял на практике. Но работать он должен, так как эту идею я почерпнул из надежного ресурса, хоть и молодого. Метод основывается на том, что ежедневно в интернете уходят в мир иной и никогда не восстают из пепла десятки сайтов.
Содержание большинства этих ресурсов не представляет никакой ценности для тех, кто их создал и забросил, а для других и подавно. Но не исключено, что и среди этой кучи хлама, выброшенного на помойку истории, вы найдете свои золотые самородки. Надо только просматривать исчезнувшие сайты и выбирать приличные тексты. Если в веб-архиве сохранилась хотя бы одна копия такого сайта, этого вполне хватит.
Тексты с мертвых сайтов уже находятся вне поля зрения поисковых систем, (а значит уникален). И вы можете стать законным владельцем такого контента, вытянув его из недр веб-архива. Поисковые системы будут воспринимать его как новый и уникальный. Конечно, если еще при жизни ретро-сайта этот контент не успели жесточайше откопипастить. Поэтому надо всегда проверять его на плагиат.
Но сначала необходимо найти нужный сайт. Авторы метода, о котором я рассказываю, советуют зайти на сайт Nic.ru или Reg.ru. И скачать оттуда перечень освободившихся или освобождающихся доменов. Простыми словами, это сайты, которые уже умерли или собрались в последний путь.
Список представлен в виде примера таблицы. В ее последней колонке видно, сколько архивов каждого сайта имеется в Webarchive. На других сервисах тоже можно проверить, есть ли такие домены в веб-архиве. К примеру, здесь и здесь.

Готовые списки очень быстро становятся бесполезными, по этому лучше подбирать площадки для грабинга веб-архива самому. А потом просмотреть их содержание и выбрать тексты, которые нравятся. Проверить их на плагиат, после чего контент можно смело использовать или на своем сайте, или продать на текстовой бирже.
Да, метод нелегкий но мною уже не раз опробованный. Уверен! Многие после прочтения предыдущего абзаца наверняка сообразили, что при должной сноровке и разумном подходе это дело можно поставить на поток. А потом наслаждаться проливным дождем из денежных купюр. Разве я не прав?
Post Views:
13 118
Это уникальная SEO-запись.
