Те, кто давно занимается поисковой оптимизацией, хорошо знают об операторах расширенного поиска Google. Например, почти все знают об операторе site:, который ограничивает поисковую выдачу одним сайтом.
Большинство операторов легко запомнить, это короткие команды. Но уметь эффективно их использовать — совсем другая история. Многие специалисты знают основы, но немногие по-настоящему овладели этими командами.
В этой статье я поделюсь советами, которые помогут освоить поисковые операторы для 15 конкретных задач.
- Поиск ошибок индексации
- Поиск незащищённых страниц (не https)
- Поиск дубликатов контента
- Поиск нежелательных файлов и страниц на своём сайте
- Поиск возможностей для гостевой публикации
- Поиск страниц со списками ресурсов
- Поиск сайтов с примерами инфографики… так что можно предложить свою
- Поиск сайтов для размещения своих ссылок… и проверки, насколько они подходят
- Поиск профилей в социальных сетях
- Поиск возможностей для внутренних ссылок
- Поиск упоминаний конкурентов для своего пиара
- Поиск возможностей для спонсорских постов
- Поиск тем Q+A, связанных с вашим контентом
- Проверка, как часто конкуренты публикуют новый контент
- Поиск сайтов со ссылками на конкурентов
Сначала полный список всех поисковых операторов Google и их функций.
Операторы поиска Google: полный список
Вы знали, что Google постоянно удаляет полезные операторы? Именно поэтому большинство существующих списков устарели и неточны. Для этой статьи я лично проверил каждый оператор, что смог найти.
Вот полный список всех рабочих, частично рабочих и сломанных операторов расширенного поиска Google по состоянию на 2018 год.
Рабочие операторы
“поисковый запрос”
Принудительный поиск точного совпадения. Используйте его для уточнения неоднозначных результатов поиска или исключения синонимов при поиске отдельных слов.
Пример: “steve jobs”
OR
Поиск по X или Y. Вернёт результаты, связанные с X или Y, или и то, и другое. Вместо него можно использовать оператор (|).
Примеры: jobs OR gates / jobs | gates
AND
Поиск по X и Y. Вернёт только результаты, связанные как с X, так и с Y. Примечание: в реальности не имеет значения для обычного поиска, потому что Google по умолчанию вставляет AND. Но очень полезен в сочетании с другими операторами.
Пример: jobs AND gates
–
Исключение термина или фразы. В нашем примере все страницы будут упоминать Джобса, но не с Apple (компанией).
Пример: jobs -apple
*
Действует как подстановочный знак для произвольного слова или фразы.
Пример: steve * apple
( )
Группировка нескольких терминов или операторов, чтобы контролировать выдачу.
Пример: (ipad OR iphone) apple
$
Поиск цен. Также работает для евро (€), но не для британского фунта (£).
Пример: ipad $329
define:
По сути, это встроенный в Google словарь. Показывает значение слова.
Пример: define:entrepreneur
cache:
Возвращает последнюю кэшированную версию веб-страницы (при условии, что страница проиндексирована, конечно).
Пример: cache:apple.com
filetype:
Ограничивает результаты файлами определённого формата, например, pdf, docx, txt, ppt и т. д. Примечание: аналогично оператору “ext:”.
Пример: apple filetype:pdf / apple ext:pdf
site:
Результаты для определённого домена.
Пример: site:apple.com
related:
Поиск сайтов, связанных с данным доменом.
Пример: related:apple.com
intitle:
Найти страницы с определённым словом (или словами) в заголовке страницы. В нашем примере возвратятся все результаты со словом [apple] в теге title.
Пример: intitle:apple
allintitle:
Аналогично “intitle”, но будут возвращает результаты, содержащие все указанные слова в теге title.
Пример: allintitle:apple iphone
inurl:
Найти страницы с определённым словом (или словами) в URL. В этом примере будут возвращены все результаты, содержащие слово [apple] в URL.
Пример: inurl:apple
allinurl:
Аналогично “inurl”, но возвращает результаты со всеми указанными словами в URL.
Пример: allinurl:apple iphone
intext:
Найти страницы, содержащие определённое слово (или слова) где-то в содержании. В примере будут возвращены все результаты, содержащие слово [apple] на странице.
Пример: intext:apple
allintext:
Аналогично “intext”, но возвращает результаты со всеми указанными словами на странице.
Пример: allintext:apple iphone
AROUND(X)
Поиск поблизости. Страницы, содержащие два слова или фразы на расстоянии X слов друг от друга. В этом примере слова [apple] и [iphone] должны присутствовать в тексте на расстоянии не более четырёх слов друг от друга.
Пример: apple AROUND(4) iphone
weather:
Найти погоду для конкретного места. Отображается в погодном сниппете, но также возвращает результаты с других метеорологических сайтов.
Пример: weather:san francisco
stocks:
Биржевая информация (т. е., цена и т. д.) для любой акции по биржевому тикеру.
Пример: stocks:aapl
map:
Результаты поиска по картам.
Пример: map:silicon valley
movie:
Найти информацию о конкретном фильме. Также находит расписание сеансов, если фильм сейчас показывают недалеко от вас.
Пример: movie:steve jobs
in
Преобразует одну единицы измерения в другую. Работает с валютами, весами, температурой, расстояниями и т. д.
Пример: $329 in GBP
source:
Найти новостные результаты из определённого источника в Google News.
Пример: apple source:the_verge
_
Не совсем оператор поиска, но действует как подстановочный знак для автодополнения.
Пример: apple CEO _ jobs
Частично рабочие операторы
Вот операторы, которые не всегда дают желательный результат:
#..#
Поиск диапазона чисел. В приведённом примере возвращаются результаты [видео WWDC] за 2010-2014 годы, но не за 2015 год и последующие годы.
Пример: wwdc video 2010..2014
inanchor:
Поиск страниц, связанных с определённым текстом в ссылке. В этом примере будут возвращены все страницы, на которые есть ссылки со словами [apple] или [iphone].
Пример: inanchor:apple iphone
allinanchor:
Аналогично inanchor, но возвращает результаты, содержащие все указанные слова во входящих ссылках.
Пример: allinanchor:apple iphone
blogurl:
Поиск URL блога в определённом домене. Использовался в поиске Google по блогам, но кое-как работает и в обычном поиске.
Пример: blogurl:microsoft.com
Примечание. Поиск Google по блогам закрыт в 2011 году.
loc:placename
Найти результаты из заданного места.
Пример: loc:”san francisco” apple
Примечание. Официально не закрыт, но результаты противоречивы.
location:
Найти результаты из заданного места в Google News.
Пример: location:”san francisco” apple
Примечание. Официально не закрыт, но результаты противоречивы.
Сломанные операторы
Операторы поиска Google, которые удалены и больше не работают.
+
Принудительный поиск по одному слову или фразе.
Пример: jobs +apple
Примечание. То же самое делается с помощью кавычек.
~
Включить синонимы. Не работает, потому что Google теперь включает синонимы по умолчанию. (Подсказка: для исключения синонимов используйте двойные кавычки).
Пример: ~apple
inpostauthor:
Найти сообщения в блоге, написанные конкретным автором. Работало только в поиске по блогам.
Пример: inpostauthor:”steve jobs”
Примечание. Поиск Google по блогам закрыт в 2011 году.
allinpostauthor:
Аналогично предыдущему, но устраняет необходимость в кавычках (если вы хотите найти конкретного автора, включая фамилию).
Пример: allinpostauthor:steve jobs
inposttitle:
Найти сообщения в блоге с конкретными словами в названии. Больше не работает, так как этот оператор был уникальным для поиска по блогам.
Пример: inposttitle:apple iphone
link:
Поиск страниц, которые ссылаются на определённый домен или URL. Google убила этот оператор в 2017 году, но он по-прежнему возвращает некоторые результаты — вероятно, не особо точные (поддержка прекращена в 2017 году)
Пример: link:apple.com
info:
Найти информацию о конкретной странице, включая время последнего кэширования, похожие страницы и т. д. (поддержка завершена в 2017 году). Примечание: идентичен оператору id:.
Примечание. Хотя изначальная функциональность этого оператора устарела, он по-прежнему полезен для поиска канонической индексированной версии. Благодарю @glenngabe за информацию!
Пример: info:apple.com / id:apple.com
daterange:
Найти результаты по определённому диапазону дат. Почему-то использует юлианский формат даты.
Пример: daterange:11278–13278
Примечание. Официально не закрыт, но, похоже, не работает.
phonebook:
Найди чей-то номер телефона (поддержка прекращена в 2010 году).
Пример: phonebook:tim cook
#
Поиск по хэштегу. Появился вместе с Google+, теперь устарел.
Пример: #apple
15 вариантов использования операторов поиска Google
Теперь рассмотрим несколько способов эффективного применения этих операторов, в том числе в сочетании друг с другом. Не стесняйтесь отклоняться от приведённых примеров, можете найти что-то новое.
Поехали!
1. Поиск ошибок индексации
На большинстве сайтов есть страницы, которые Google проиндексирвоал некорректно. Возможно, какой-то страницы нет в индексе или наоборот, там присутствует что-то лишнее. Воспользуемся оператором site:, чтобы узнать количество проиндексированных страниц на моём сайте.

Около 1040.
Примечание. Google здесь даёт примерное количество. Точную информацию см. в Google Search Console.
Но сколько из них являются статьями в блоге?
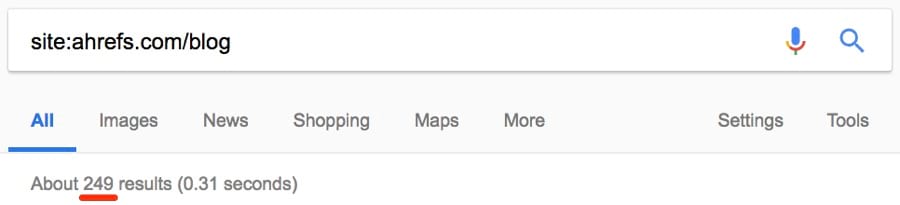
Примерно четверть: около 249.
Я отлично знаю свой блог, поэтому уверен, что у меня статей реально меньше.
Исследуем дальше.

Кажется, проиндексировано несколько странных страниц.
(Это даже не реальная страница — она выдаёт 404)
Такие страницы следует удалить из индекса. Сузим поиск до поддоменов и посмотрим, что получится.
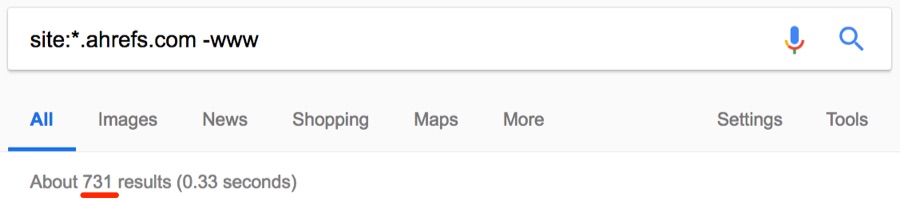
Примечание. Здесь мы используем подстановочный знак (*), чтобы найти все поддомены, принадлежащие домену, в сочетании с оператором исключения (-), чтобы исключить обычные результаты www.
Примерно 731 результат.
Вот страница на поддомене, которая определённо не должна индексироваться. Она сразу выдаёт 404.

Есть несколько других способов выявить ошибки индексации:
site:yourblog.com/category— найти страницы рубрик в блоге WordPress;site:yourblog.com inurl:tag— найти странице тегов в блоге WordPress.
2. Поиск незащищённых страниц (не https)
HTTPS в наше время стал обязательным требованием, особенно для сайтов электронной коммерции. Но вы знали, что с помощью оператора site: можно найти незащищённые страницы? Проверим на примере asos.com.
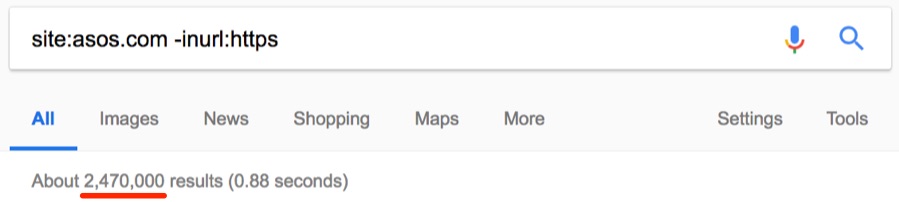
О боже, около 2,47 млн незащищённых страниц.
Похоже, что Asos вообще не используют SSL — невероятно для такого большого сайта.

Примечание. Клиентам Asos волноваться не стоит — страницы оформления заказа безопасны.
Но вот ещё одна вещь: Asos доступен в версиях https и http.
И мы узнали это с помощью простого оператора site:!
Примечание. Иногда страницы индексируются без https, но после перехода по ссылке происходит редирект на версию https.
3. Поиск дубликатов контента
Дубликаты — это плохо. Вот пара джинсов Abercrombie & Fitch на сайте Asos со стандартным описанием:

Стандартные описания сторонних брендов часто дублируются на других сайтах. Но интересно, сколько раз текст встречается на asos.com.
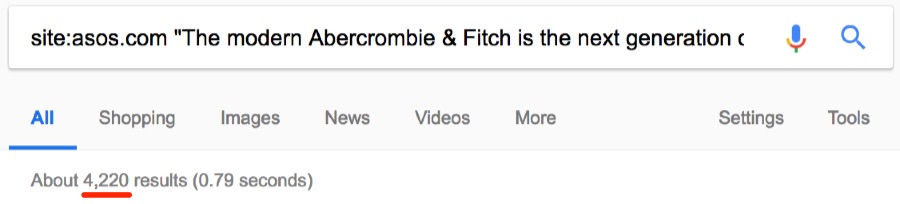
Примерно 4200 раз.
Теперь интересно, является ли текст уникальным для Asos. Проверим.

Нет, он не уникален. Есть 15 других сайтов с точно таким же текстом, то есть дублированным контентом. Иногда дубли присутствуют на страницах с похожими товарами. Например, аналогичные продукты или тот же товар в упаковках с разным количеством. Вот пример на сайте Asos:
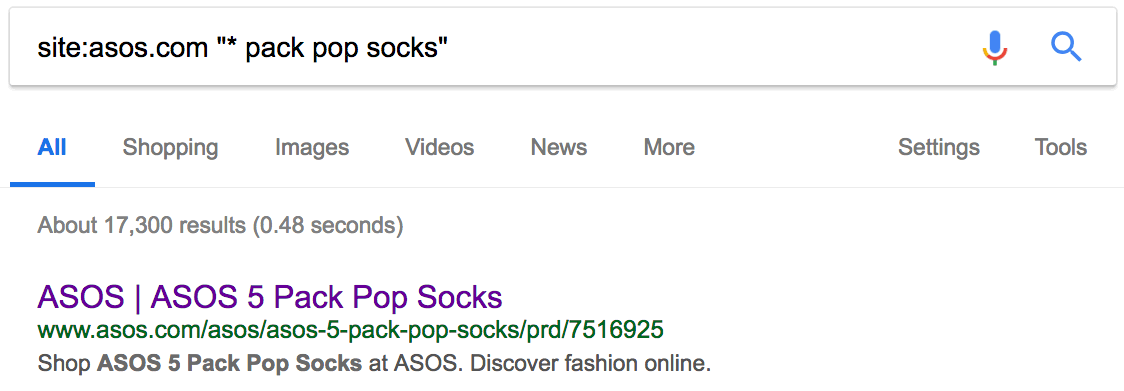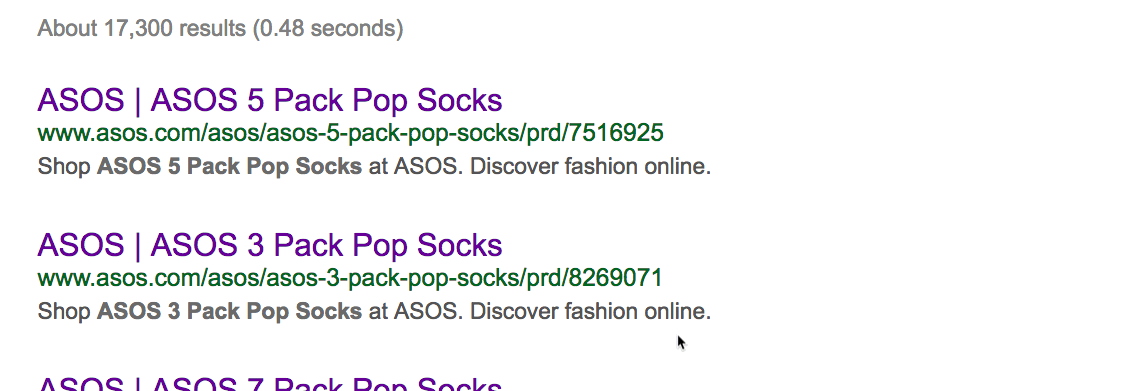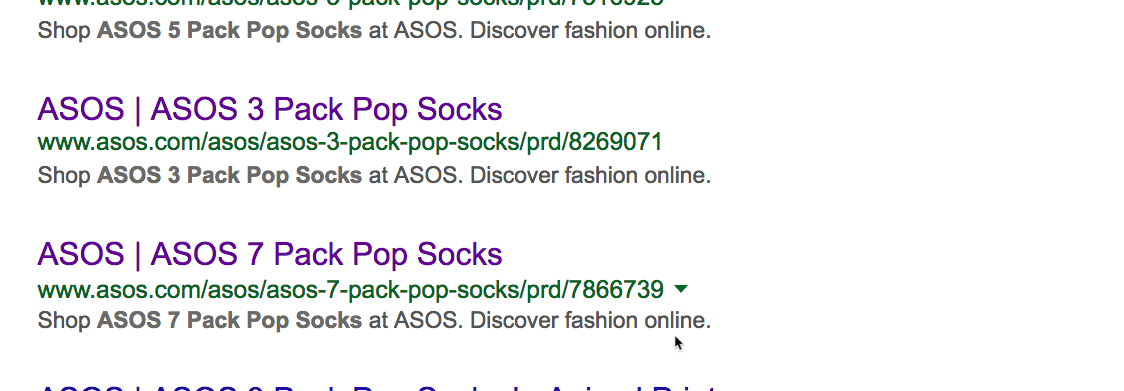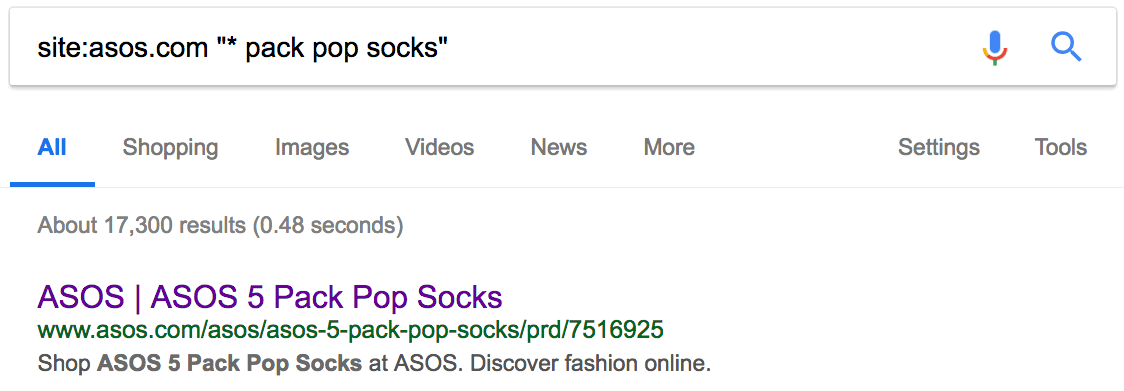
Как видим, за исключением количества, страницы одинаковые. Но дубликаты встречаются не только на сайтах электронной коммерции. Если у вас есть блог, то люди могут красть и публиковать ваш контент без надлежащей ссылки. Посмотрим, может кто-то украл и опубликовал наш список советов по SEO.
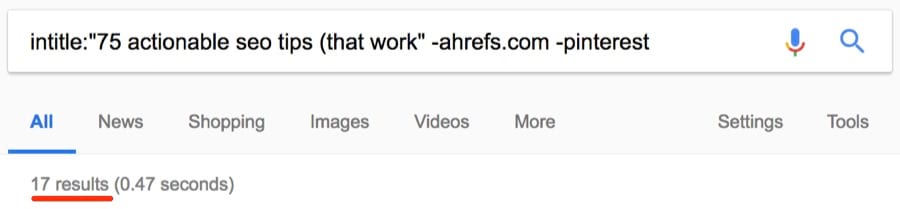
Около 17 результатов.
Примечание. Как видите, я исключил ahrefs.com из результатов с помощью оператора исключения (-), а также исключил слово [pinterest], потому что по запросу выдаётся много результатов с сайта Pinterest, которые не имеют отношения к нашей задаче. Можно было исключить только pinterest.com (-pinterest.com), но у него много доменов, так что это не особо поможет. Исключение слова [pinterest] оказалось лучшим способом очистки результатов.
Большинство страниц, наверное, созданы в результате синдикации. Всё-таки стоит проверить, что они ссылаются на вас.
4. Поиск нежелательных файлов и страниц на своём сайте (о которых вы могли забыть)
Трудно уследить за всем на большом сайте, поэтому легко забыть о каких-то старых загруженных файлах: PDF, документы Word, презентации PowerPoint, текстовые файлы и т. д. Оператор filetype: поможет их найти.
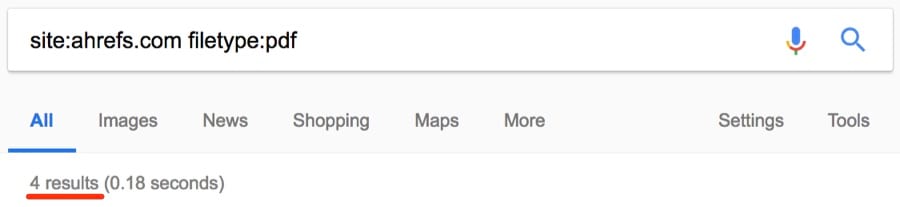
Примечание. Помните, что аналогичная функциональность у оператора ext:.
Вот одна находка:

Никогда раньше не видел этой статьи, а вы? Комбинируя несколько операторов, можно одновременно выводить результаты для разных типов файлов.

Примечание. Этот оператор также поддерживает .asp, .php, .html и др.
Важно удалить или деиндексировать их, чтобы они не попадались людям на глаза.
5. Поиск возможностей для гостевой публикации
Возможность публикации на других сайтах… есть много способов найти такие ресурсы:

Но вы уже знали об этом методе, верно!? 😉
Примечание. Этот метод находит страницы с предложением написать статью. Такие страницы создают многие сайты, которые ищут авторов.
Так что применим более творческий подход. Во-первых: не ограничивайтесь одной фразой. Также можете использовать такие поисковые запросы:
[become a contributor][contribute to][write for me](да, есть отдельные блогеры, которые тоже приглашают авторов!)[guest post guidelines]inurl:guest-postinurl:guest-contributor-guidelines- и др.
Многие забывают один классный совет: можно искать всё сразу.

Примечание. На этот раз я использую оператор (“|”) вместо AND, он делает то же самое.
Можно даже искать эти фразу с учётом тематики.

Нужна конкретная страна? Просто добавьте оператор site:.tld .

Вот ещё один метод: если знаете конкретного блоггера в своей нише, попробуйте такой способ:
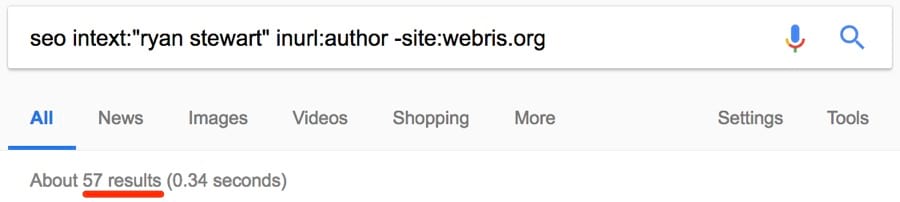
Так найдутся все сайты, где публиковался этот автор.
Примечание. Не забудьте исключить его сайт из выдачи, чтобы сохранить чистоту результатов!
Наконец, если вам интересно, принимает ли конкретный сайт статьи от сторонних авторов, попробуйте это:
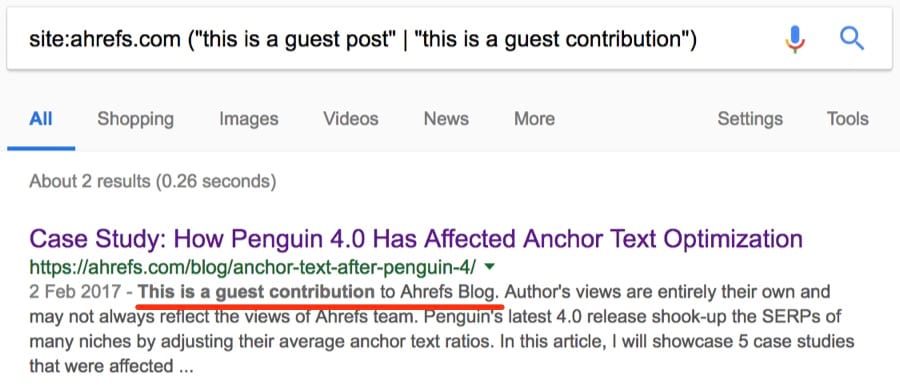
Примечание. В список можно добавить много других фраз.
6. Поиск страниц со списками ресурсов
Такие страницы собирают списки ресурсов по определённой теме.

Всё это — ссылки на сторонние ресурсы. По иронии, учитывая тему этой конкретной страницы — многие ссылки там не работают.
Так что если у вас есть крутой ресурс, можно найти соответствующие «ресурсные» страницы и подать заявку на добавление туда своей ссылки.
Вот один из способов найти их:

Но это может вернуть много мусора. Сужаем поиск:

Ещё больше сужаем:

Примечание. Здесь allintitle: гарантирует, что тег title содержит слова [fitness] и [resources], а также число от 5 до 15.
Примечание об операторе #..#
Я знаю, о чем вы думаете: почему бы вместо этой длинной последовательности чисел не использовать оператор
#..#. Хорошая мысль, попробуем:
Странно, да? Дело в том, что этот оператор плохо сочетается с большинством других операторов. Да и вообще не всегда работает. Поэтому я рекомендую использовать последовательность чисел с оператором OR или вертикальной чертой (“|”). Это немного трудоёмкая процедура, зато работает.
7. Поиск сайтов с примерами инфографики… так что можно предложить свою
У инфографики плохая репутация. Скорее всего, потому что многие создают некачественную, дешёвую инфографику, которая не служит никакой реальной цели… кроме как «привлекать ссылки». Но не вся инфографика такая.
Кому вы можете предложить свою инфографику? Любым известным сайтам в своей нише?
НЕТ.
Надо обратиться к сайтам, которые действительно захотят её опубликовать. Лучший способ — найти сайты, где уже публиковались такие материалы:

Примечание. Есть смысл поискать в пределах диапазона недавних дат, например, за последние три месяца. Если сайт публиковал инфографику два года назад, это не означает, что они таким занимаются до сих пор. Но если сайт публиковал её в последние несколько месяцев, то есть вероятность, что примет и вашу. Поскольку оператор daterange: больше не работает, придётся указать диапазон дат во встроенном фильтре поиска Google.
Но опять же, придётся отфильтровать мусор.
Вот быстрый трюк:
- использовать вышеуказанный запрос для поиска качественной инфографики по заданной теме;
- найти, где она размещалась.
Пример:

Нашлось два результата за последние три месяца. И более 450 результатов за всё время. Проведите такой поиск для нескольких конкретных иллюстраций — и получите хороший список.
8. Поиск сайтов для размещения своих ссылок… и проверки, насколько они подходят
Предположим, вы нашли сайт, где хотите разместить ссылку. Вручную проверили актуальность… всё выглядит хорошо. Вот как найти список похожих сайтов или страниц:

Получаем около 49 результатов, все похожие.
Примечание. В приведённом примере мы ищем сайты, похожие именно на блог Ahrefs, а не на весь сайт Ahrefs.
Вот один из результатов: yoast.com/seo-blog.
Я хорошо знаю Yoast, поэтому уверен, что это подходящий сайт для наших целей. Но предположим, что я ничего не знаю об этом сайте, Как проверить, что он подходит? Вот как:
- запустить
site:domain.comнайдите и записать количество результатов; - запустить
site:domain.com [niche], опять записать количество результатов; - делим второе число на первое: если оно выше 0,5, это подходящий вариант; если выше 0.75, то это просто супер.
Попробуем на примере yoast.com. Вот количество результатов для простого поиска:
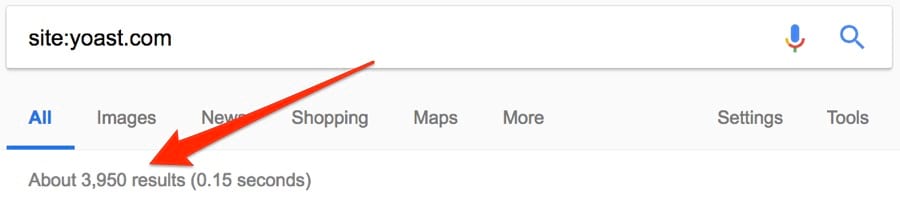
И site: [niche]:

Итак, 3950 / 3330 = ~0,84. Отличный результат.
Теперь проверим на сайтах, которые точно нам не подходят.
Количество результатов для поиска site:greatist.com: ~18,000
Количество результатов для поиска site:greatist.com SEO: ~7
(18000 / 7 = ~0,0004 = совершенно нерелевантный сайт)
Важно! Это отличный способ быстро устранить крайне нерелевантные результаты, но он не всегда надёжно работает. Конечно же, это не замена ручной проверке потенциального кандидата: их всегда следует просматривать вручную, прежде чем обращаться с предложением. Иначе вы начнёте генерировать спам.
9. Поиск профилей в социальных сетях
Хотите с кем-то связаться? Попробуйте найти контактную информацию таким способом:

Примечание. Имя человека обычно легко найти, а вот контактную информацию сложно.
Четыре лучших результата:
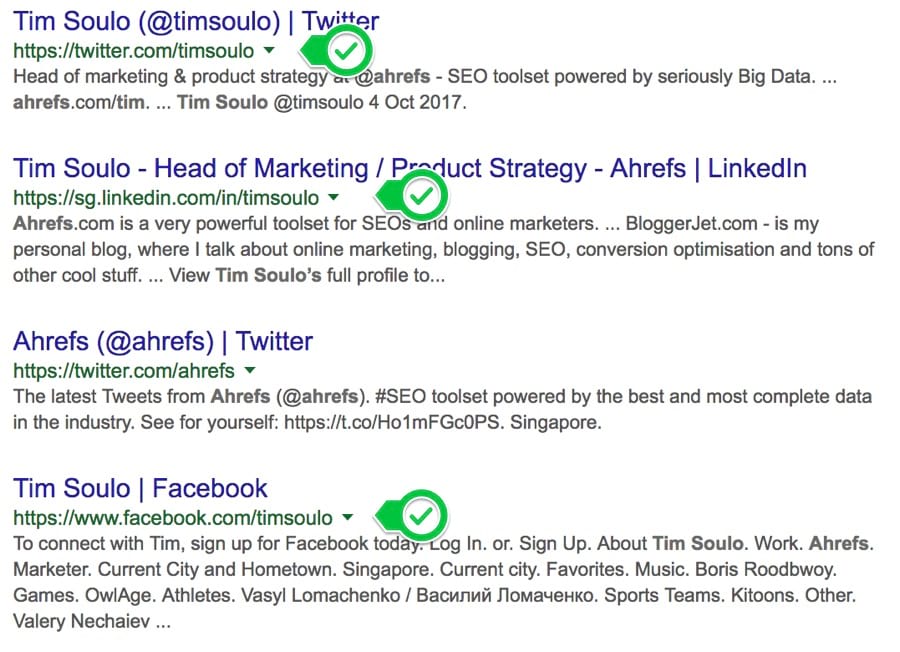
БИНГО.
Затем можете связаться с человеком напрямую через социальные медиа. Или воспользуйтесь советами 4 и 6 из этой статьи для поиска адреса электронной почты.
10. Поиск возможностей для внутренних ссылок
Внутренние ссылки очень важны. Они помогают в навигации посетителей по вашему сайту, а также полезны для SEO (при разумном использовании). Но нужно убедиться, что вы добавляете внутренние ссылки только там, где это уместно. Допустим, вы только опубликовали большой список советов по SEO. Разве не здорово добавить внутреннюю ссылку на эту статью со всех страниц, где упоминаются советы по SEO?
Определённо.
Но не так легко найти соответствующие места для добавления этих ссылок, особенно на больших сайтах. Вот быстрый трюк:

Для тех, кто ещё не освоил операторы поиска, здесь мы делаем следующее:
- Ограничиваем поиск определённым сайтом.
- Исключаем страницу/публикацию, на которую требуется создать внутренние ссылки.
- Ищем определённое слово или фразу в тексте.
Вот одна из подходящих страниц, которую я нашёл таким запросом:

Поиск занял три секунды.
11. Поиск упоминаний конкурентов для своего пиара
Вот страница, на которой упоминается наш конкурент — Moz.

Найдено с помощью такого расширенного поиска:

Но почему нет упоминания блогов Ahrefs? 🙁
С помощью site: и intext: я вижу, что этот сайт раньше упоминал нас пару раз.
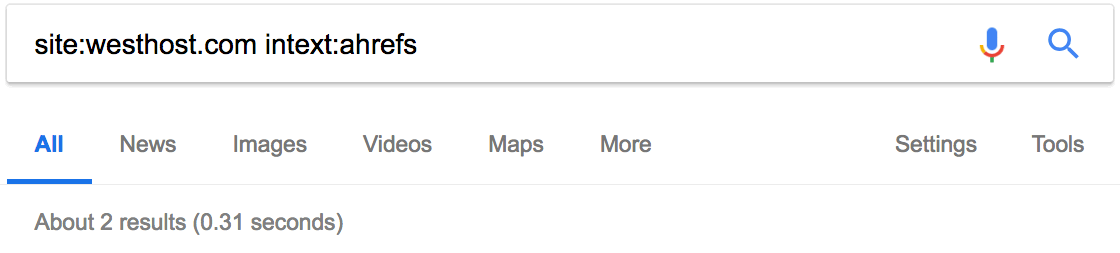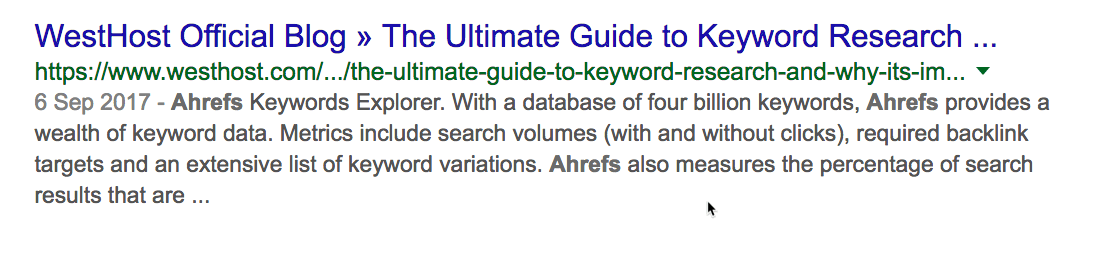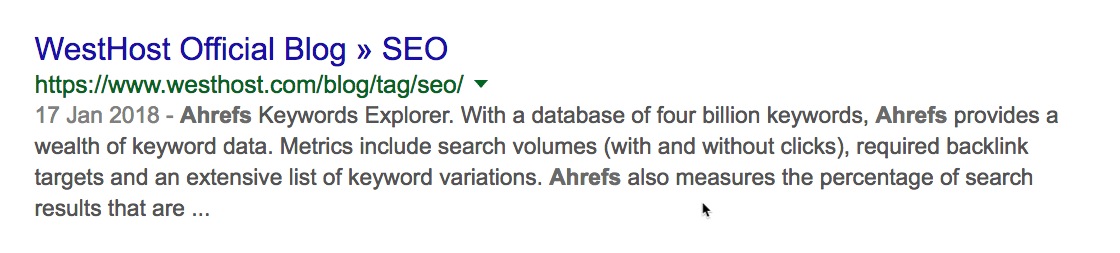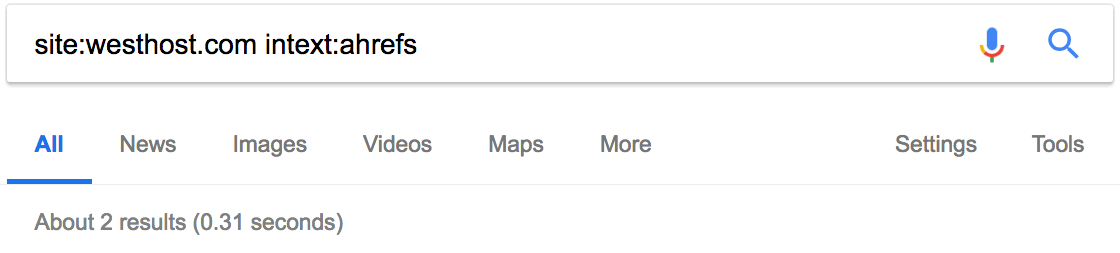
Но они не разместили никакой статьи с обзором наших инструментов, как в случае с Moz. Это даёт возможность. Свяжитесь с ними, пообщайтесь. Возможно, они напишут также про Ahrefs.
Вот ещё один классный запрос, который можно использовать для поиска отзывов о конкурентах:

Примечание. Поскольку мы используем [allintitle], а не [intitle], то получим результаты со словом [review] и названием одного из конкурентов в теге заголовка.
Можете пообщаться с этими людьми, чтобы они повторно рассмотрели ваш товар/услугу.
Вот ещё один совет. Оператор daterange: устарел, но на странице поиска можно добавить фильтр для дат, чтобы найти последние упоминания конкурентов. Просто используйте этот встроенный фильтр.
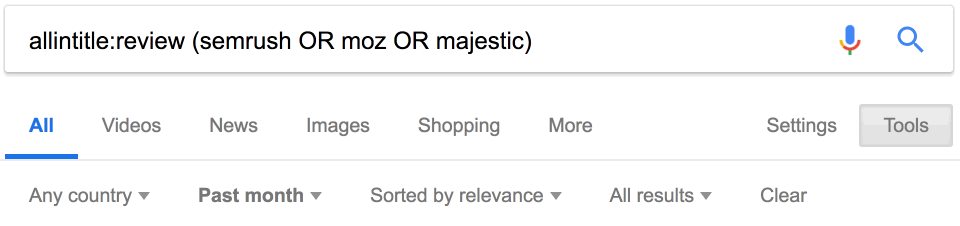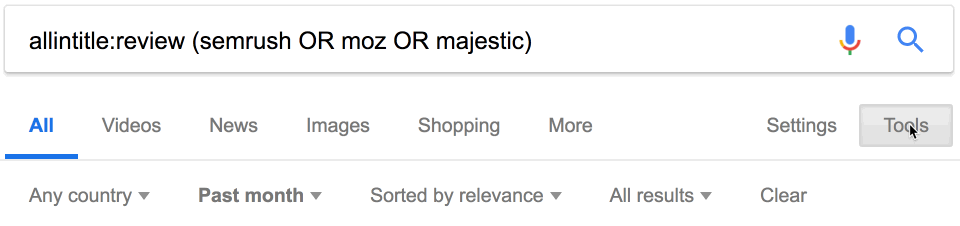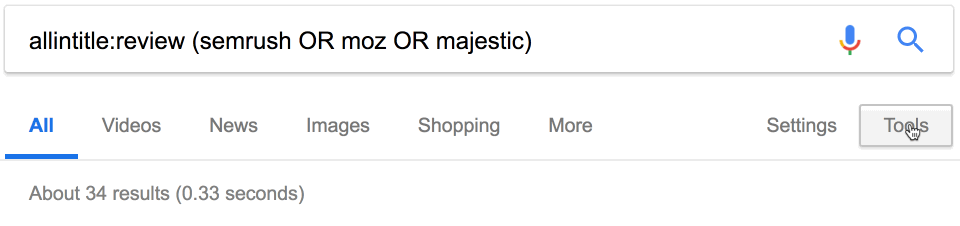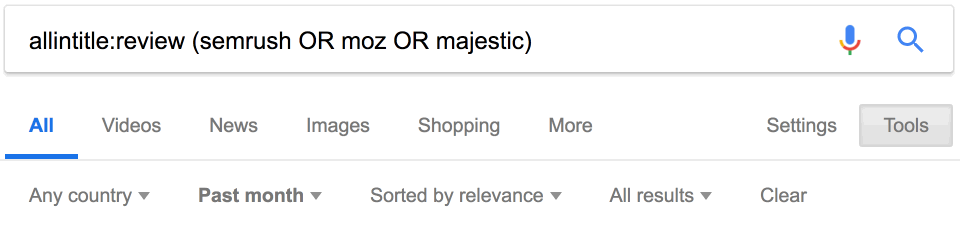
Похоже, за последний месяц опубликовано 34 отзыва о наших конкурентах.
12. Поиск возможностей для спонсорских постов
Спонсорские посты — это платные статьи, продвигающие ваш бренд, продукт или услугу. Такой вариант не предназначен для размещения ссылок.
В руководстве Google явно запрещено:
Покупка или продажа ссылок, которые передают PageRank. Это включает в себя передачу денег на ссылки или сообщения, содержащие ссылки; передачу товаров или услуг в обмен на ссылки; отправку кому-то «бесплатного» продукта в обмен на то, что они напишут о нём и поставят ссылку.
Вот почему вы всегда должны следить за ссылками в спонсорских статьях.
Но истинная ценность этих статей всё равно не сводится к ссылкам. Это пиар, то есть демонстрация свого бренда перед нужными людьми. Вот один из способов найти возможности для спонсорских публикаций с помощью операторов поиска Google:
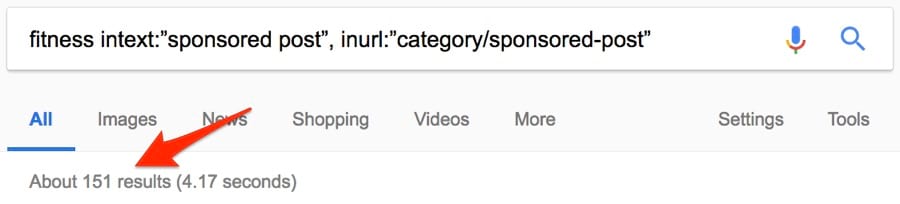
Примерно 151 результат. Неплохо.
Несколько других комбинаций операторов:
[niche] intext:”this is a sponsored post by”[niche] intext:”this post was sponsored by”[niche] intitle:”sponsored post”[niche] intitle:”sponsored post archives” inurl:”category/sponsored-post”“sponsored” AROUND(3) “post”
Примечание. Приведённые примеры — именно примеры. Почти наверняка эти сообщения можно найти по другим фразам. Не бойтесь проверять различные идеи.
13. Поиск тем Q+A, связанных с вашим контентом
Форумы, а также сайты с вопросами и ответами отлично подходят для продвижения контента.
Примечание. Продвижение != спам. Не заходите на эти сайты только для того, чтобы добавить свои ссылки. Публикуйте ценную информацию, а по ходу дела иногда — уместные ссылки.
На ум приходит Quora, которая разрешает публиковать в своих ответах релевантные ссылки.
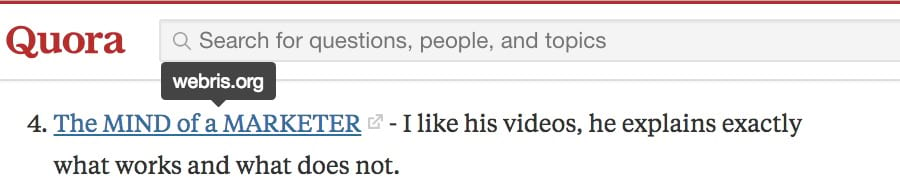
Ответ в Quora со ссылкой на SEO-блог
Правда, этим ссылкам проставляется тег nofollow. Но мы не пытаемся здесь строить базу ссылок, это пиар! Вот один из способов найти подходящие темы:

Это можно сделать на любом форуме или сайте с вопросами и ответами. Такой же поиск для Warrior Forum:

Я знаю, что там есть раздел о поисковой оптимизации. У каждой темы в этом разделе в URL указано .com/search‐engine‐optimization/. Так что я могу ещё больше уточнить запрос с помощью оператора inurl:.

Такие операторы даже лучше находят темы на форуме, чем встроенный поиск на сайте.
14. Проверка, как часто конкуренты публикуют новый контент
Большинство блогов находятся в подпапке или поддомене, например:
ahrefs.com/blogblog.hubspot.comblog.kissmetrics.com
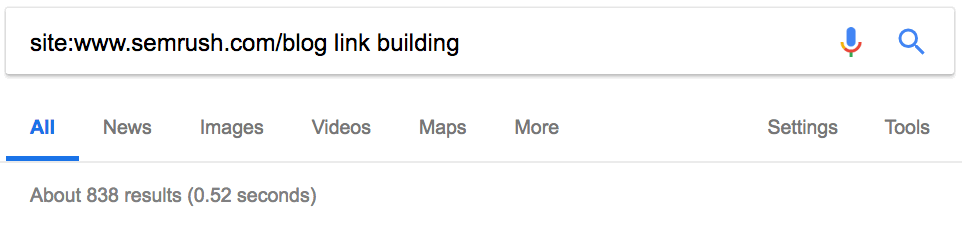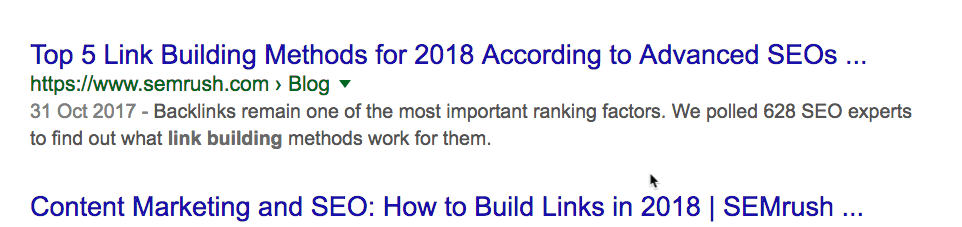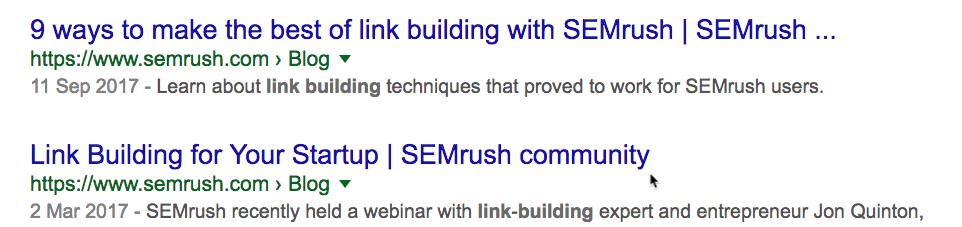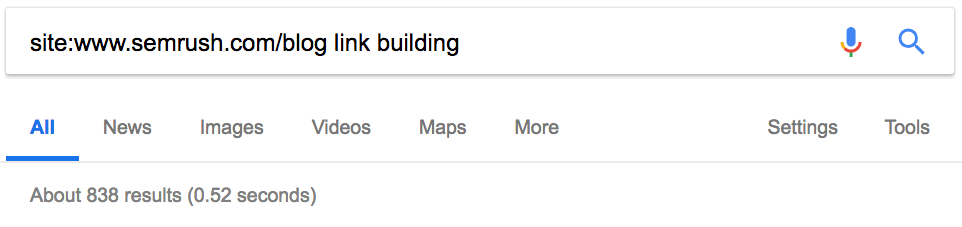
Это позволяет легко проверить, насколько регулярно конкуренты публикуют новый контент. Проверим на одном из наших конкурентов: SEMrush.
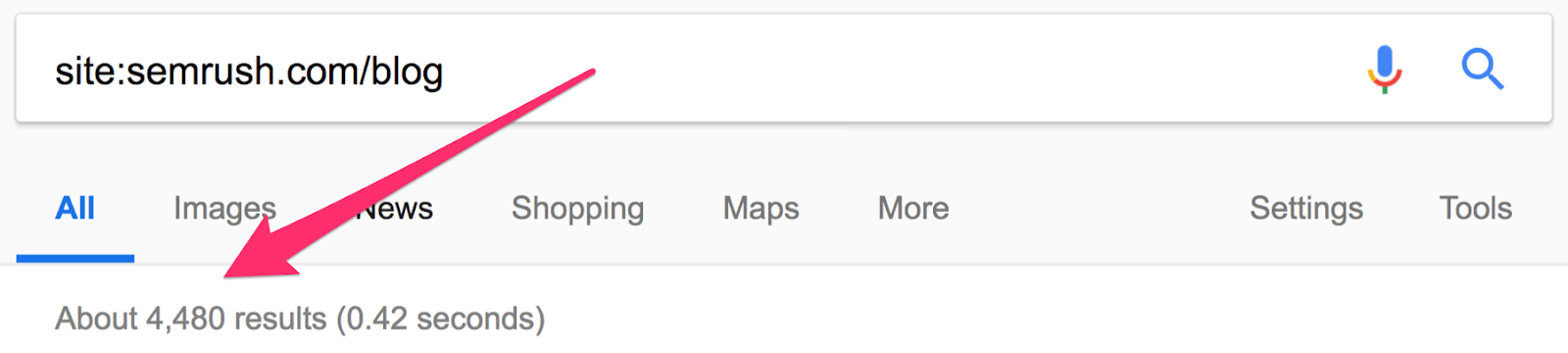
Похоже, у них уже около 4500 статей. Но это не совсем так. Сюда входят версии блога на разных языках, которые находятся на поддоменах.
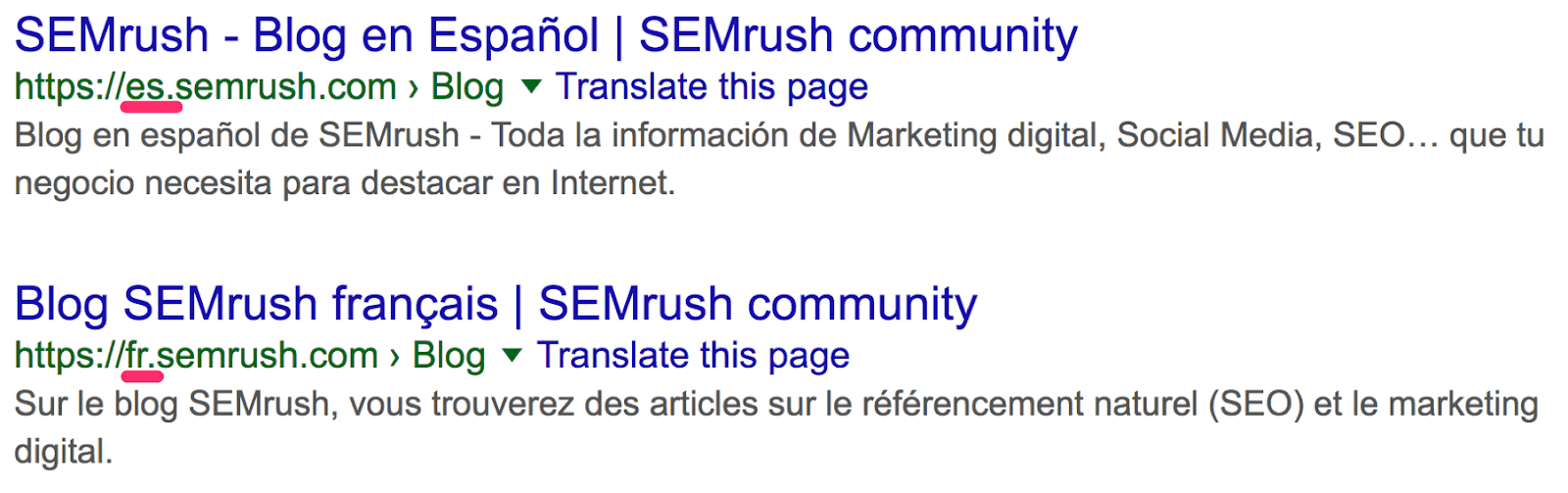
Отфильтруем их.
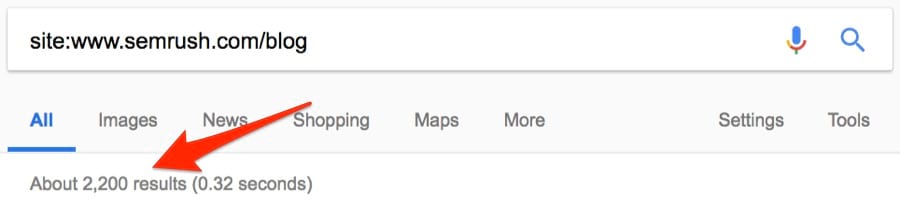
Это больше похоже на правду: около 2200 постов. Посмотрим, сколько опубликовано за последний месяц. Поскольку оператор daterange: больше не работает, используем встроенный фильтр Google.

Примечание. Можно указать любой диапазон дат. Просто выберите “Custom”.
Около 29 постов. Интересно. Это примерно вчетверо больше, чем у нас. И у них в целом примерно в 15 раз больше постов, чем у нас. Но мы всё равно получаем больше трафика… с двукратным превосходством по ценности.

Качество важнее количества, верно!?
Оператор site: в сочетании с поисковым запросом покажет, сколько статей конкурент опубликовал по определённой теме.
15. Поиск сайтов со ссылками на конкурентов
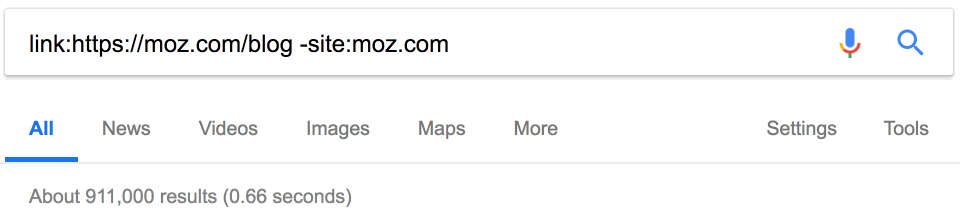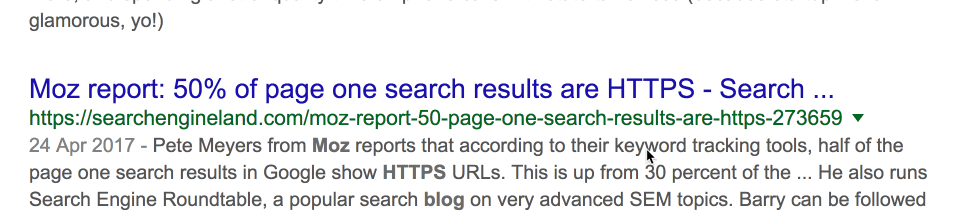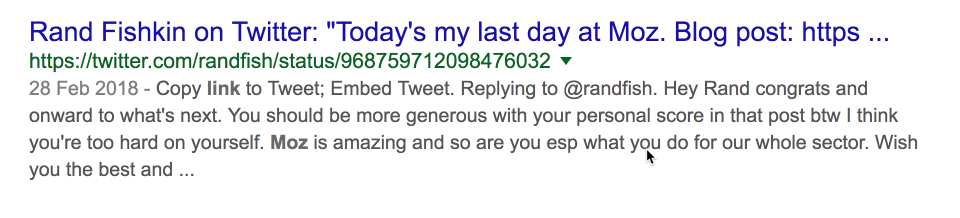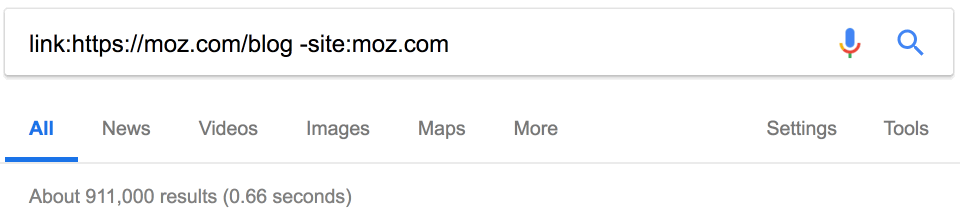
На конкурентов ставят ссылки? Может быть, мы тоже можем их получить? Google прекратил поддержку оператора link в 2017 году, но он по-прежнему возвращает некоторые результаты.
Примечание. Обязательно исключайте сайт конкурента, чтобы отфильтровать внутренние ссылки.
Около 900 тыс. ссылок. Здесь тоже пригодится фильтр по дате. Например, за последний месяц на Moz поставили 18 тыс. новых ссылок.
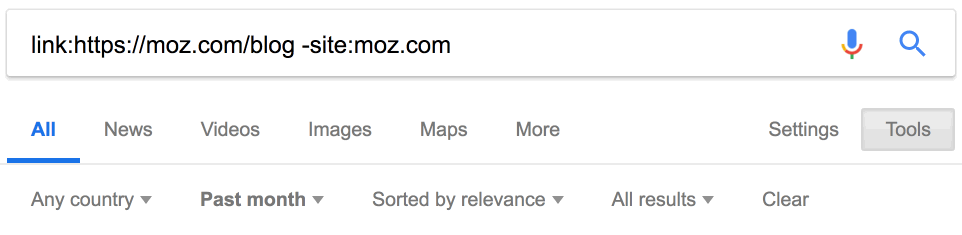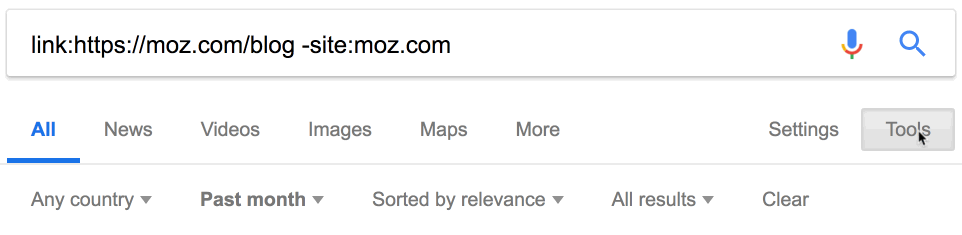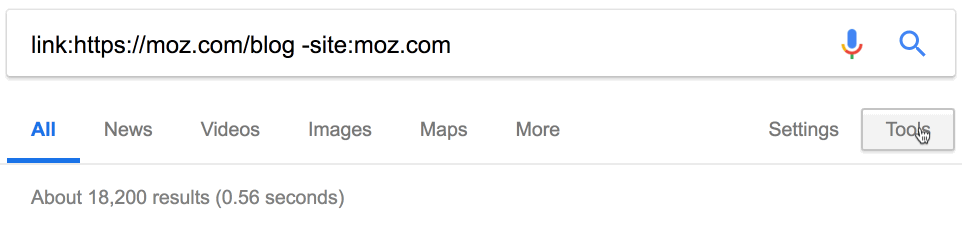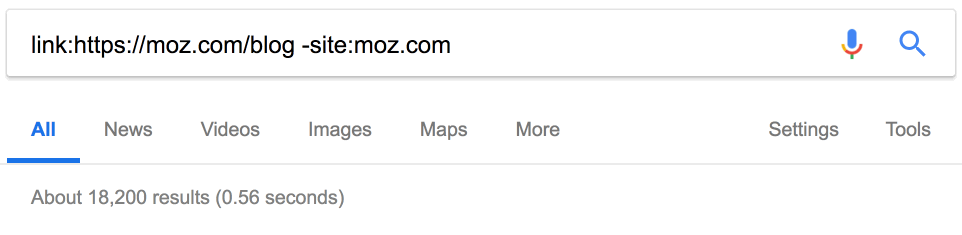
Очень полезная информация. Но эти данные тоже могут быть неточными.
Заключение
Операторы расширенного поиска Google безумно мощные. Просто надо знать, как их использовать. Но я должен признать, что некоторые полезнее других, особенно в поисковой оптимизации. Я практически ежедневно использую site:, intitle:, intext: и inurl:, но очень редко прибегаю к помощи AROUND(X), allintitle: и многих других более мутных операторов.
Я бы ещё добавил, что многие операторы бесполезны, если не применяются в сочетании с другим оператором… или двумя-тремя. Так что поиграйте с ними и напишите, как ещё их можно использовать. Я с радостью добавлю в статью любые полезные комбинации, какие вы найдёте.

Тегирование сайта — процесс создания страниц для группировки материалов/товаров по схожим признакам.
Этот метод подходит для таких типов сайтов, как:
- интернет-магазины,
- доски объявлений,
- информационные сайты с большим количеством статей,
- порталы.
Целями создания тегов являются:
- увеличение трафика путем создания дополнительных страниц (точек входа);
- улучшение навигации;
- рост конверсии и удовлетворенности пользователя.
В данной статье мы рассмотрим способы, как можно быстро собрать теги для сайта.
Как быстро собрать теги
1. Собрать список сайтов для сбора тегов.
2. Получить теги с выбранного списка сайтов.
3. Подготовить файл с названием тега, URL страницы, h1, title, description, хлебными крошками.
Как найти сайты для сбора тегов
1. Выдача поисковых систем по основному запросу
Вводим в поисковую систему (Яндекс, Google) основной запрос, изучаем сайты на предмет тегов.
Пример основного запроса — «платья».
В некоторых случаях присутствуют карты сайта, где имеются ссылки на страницы всех тегов, имеет смысл их поискать. Эти же сайты в дальнейшем можно использовать для поиска тегов и для других запросов.
2. Выдача поисковых систем по запросу для страницы тега
Вводим в поисковую систему (Яндекс, Google) запрос для страницы тега, изучаем сайты на предмет тегов.
Пример запроса для страницы тега — «платья с длинным рукавом».
3. Сервисы
Можно использовать сервисы, где видно конкурентов со схожими ключами.
Например — keys.so.
В качестве примера приведу список сайтов-конкурентов для интернет-магазина по продаже одежды. Параметры похожести и тематичности подбираются в зависимости от проекта.
В данном примере:
- Мы оставляем сайты с тематичностью от 30 %. Тематичность — сколько процентов наших ключей имеется на сайте конкурента.
- Фильтрацию по похожести не производим, так как наш сайт находится на начальной стадии развития, а конкуренты, продающие одежду, имеют очень большое количество запросов в топе. Похожесть — процент общих ключей от всех ключей сайта конкурента.
- Проходимся по сайтам и убираем те, которые нам не подходят.

Выгрузка по фильтрам из сервиса keys.so
Как получить теги с выбранного списка сайтов
Для сбора большего количества тегов во всех способах рекомендуется использовать как минимум несколько сайтов. Есть разные варианты, как можно получить теги с определенного сайта.
1. Скопировать вручную
Заходим на сайты конкурентов и вручную копируем названия.
Я рассмотрю тему на примере небольшого количества запросов, чтобы было проще воспринимать информацию, при этом максимально усложню задачу, добавив основные сложности, с которыми можно столкнуться.
Создаем Excel-файл, «столбик А» называем «Название». Копируем туда теги с разных сайтов.

Теги с разных сайтов
Далее удаляем явные дубли (на молнии = на молнии), понимая, что у нас еще останутся неявные дубли.

Теги без явных дублей
Заполняем названия остальных столбиков:
B — URL
C — h1
D — description
E — Ч
F — Ч “”
G — Путь

Заголовки таблицы
В итоге получаем поля:
Название — название тега, которое будет показываться на странице, где на него будет стоять ссылка. Например, на странице «Платья» выводятся ссылки на теги.
![]()
Вывод тегов на сайте
URL — URL тега
h1 — h1, он же заголовок страницы
description — поле, данные из которого будут использоваться для генерации метатега description
Ч — общая частотность по Вордстату (запрос)
«Ч» — частотность данной фразы с учетом всех морфологических форм («запрос»)
Путь — расположение тега на сайте = хлебные крошки
Заполняем по порядку.
h1 — к значению в поле «Название» добавляем слово «платья».

Таблица со значениями h1
В данном случае для генерации title используется значение из поля h1, поэтому он не представлен в таблице.
description — используем данные из столбика h1 и делаем первую букву маленькой. Для этого используем функцию «СТРОЧН» в Excel.

Таблица со значениями h1 и description
С использованием значений из этого поля пишем генератор description.
Запросы из столбика description добавляем в Key Collector. Отмечаем неявные дубли.
Вручную удаляем неявные дубли из нашей таблицы. Обычно неявные дубли встречаются в небольших количествах, поэтому это несложно сделать.
В итоге остается:

Столбик description
URL — генерируем, используя функцию URL от Seo-Excel из поля description.

Поля для ввода данных при генерации URL в SEO-Excel
Получаем:

Сгенерированные URL
Ч и «Ч» — снимаем частотность любым удобным инструментом или сервисом.
Ч — используем для удаления запросов, не имеющих частотности. Для сезонных запросов можно дополнительно снимать частотность по месяцам.
«Ч» — используем для понимания, не является ли данный запрос составляющей другого запроса (возможно такого запроса не существует).
Путь — для данного проекта теги лежат внутри основного раздела.
Добавляем «Главная — Платья — » и потом то, что идет в h1.
В случае с вложенными тегами (когда один тег вложен в другой) путь может меняться.
Например, для запроса «Короткие вечерние платья» путь будет «Главная — Платья — Вечерние платья — Короткие вечерние платья».

Таблица с заполненным столбиком «Путь»
Там же в зависимости от выбранного метода вывода ссылок может меняться название:
- если оно выводится на странице всех платьев, оно может иметь название «короткие вечерние»;
- если на странице вечерних платьев, то «короткие».
С примером, разобранным в задаче, можно ознакомиться в Google Docs.
Плюсы:
- просто;
- не требуются дополнительные программы;
- хорошо подходит для сайтов с нестандартной URL-структурой.
Минусы:
- больше ручной работы.
2. Парсинг программой Screaming Frog SEO Spider
Для выполнения данного пункта потребуется программа Screaming Frog SEO Spider (платная).
Настройка
Рассмотрим пример парсинга тегов со страницы Платья на сайте www.wildberries.ru.
Для начала в программе нам нужно заполнить две настройки.
Configuration — Include (Правила включения)
Сюда мы добавим URL, с которых начинаются теги. Эти теги будет добавлять программа.
Все теги на странице платьев начинаются с такого URL: https://www.wildberries.ru/catalog/zhenshchinam/odezhda/platya/tags/
Добавляем таким образом:
https://www.wildberries.ru/catalog/zhenshchinam/odezhda/platya/tags/.*

Окно для ввода параметров в «Правила включения» в Screaming Frog SEO Spider
Configuration — Exclude (Правила исключения)
Наша задача состоит в том, чтобы исключить страницы пагинации, сортировки и страницы такого типа, которые по смыслу дублируют основную страницу. Такие страницы не несут смысла для нашей задачи.
Исключаем по элементам, которые содержатся в URL: .*%элемент в URL%.*
У меня получилось так:
.*page-.*
.*page=.*
.*pagesize=.*

Окно для ввода параметров в «Правила исключения» в Screaming Frog SEO Spider
Со временем соберется большой список таких параметров, и это упростит работу.
Парсинг
Вбиваем URL основной страницы и нажимаем «Start»: https://www.wildberries.ru/catalog/zhenshchinam/odezhda/platya
![]()
Окно ввода URL в Screaming Frog SEO Spider
Получаем список из 313 страниц тегов по Платьям с названиями.

Значения вкладки «h1» в Screaming Frog SEO Spider
Дальше уже можем работать с тегами h1.

Значения столбика H1-1 вкладки «h1» в Screaming Frog SEO Spider
С примером полученного результата можно ознакомиться в Google Docs.
Скорость ответа сервера у большинства сайтов с тегами быстрая. Поэтому скорость парсинга будет зависеть от:
- настроек программы,
- мощности компьютера,
- наличия защиты от DDoS на сайтах.
Плюсы:
- программный сбор информации.
Минусы:
- нужна платная программа Screaming Frog SEO Spider;
- требуется настройка параметров исключения для страниц, дублирующих основную (пагинация, фильтры, сортировки);
- не у всех сайтов удобная URL-структура для парсинга тегов.
3. Парсинг из поисковой системы
Сбор страниц, начинающихся с определенного URL, из выдачи поисковой системы.
Для просмотра страниц нужно задать запрос вида:
url:%URL с которого начинаются страницы тегов%*
Например, чтобы посмотреть теги со страницы Платья на сайте www.wildberries.ru, нужно задать запрос вида:
url:https://www.wildberries.ru/catalog/zhenshchinam/odezhda/platya/tags/*
Ограничение Яндекса — не более 1000 результатов, поэтому если в выдаче более 1000 результатов, то парсим, каким-либо образом ограничивая количество результатов, например, побуквенно.
Если бы у нас было более 1000 результатов, мы собирали таким образом:
url:https://www.wildberries.ru/catalog/zhenshchinam/odezhda/platya/tags/a*
url:https://www.wildberries.ru/catalog/zhenshchinam/odezhda/platya/tags/b*
Парсить выдачу можно через Key Collector.
Для совсем небольших сайтов при парсинге по буквам или по каким-то небольшим кластерам можно использовать выгрузку ТОП-100 сайтов по запросу в ПС Yandex от сайта Arsenkin.ru (быстро и бесплатно). Далее для этих страниц парсим h1 через SeoPult.
Плюсы:
- программный сбор информации
Минусы:
- не все страницы, которые есть на сайте, могут быть проиндексированы;
- для некоторых сайтов требуется удалить страницы, дублирующие основную (пагинация, фильтры, сортировки);
- не у всех сайтов удобная URL-структура для парсинга тегов.
4. Парсинг по элементу URL в keys.so
Сбор страниц с определенным URL в сервисе keys.so.
1. Делаем отчет по сайту.
2. Смотрим отчет, где показываются все страницы сайта.
3. Фильтруем по полю «Адрес содержит», вбивая нужный элемент URL, чтобы показывались только теги.
Фильтр в примере:
/catalog/zhenshchinam/odezhda/platya/tags

Поле для задания фильтров в сервисе keys.so

Список отфильтрованных страниц в сервисе keys.so
Далее для этих страниц парсим h1 через SeoPult.
Плюсы:
- сбор информации через сервис;
- обычно отсутствуют страницы, дублирующие основную (пагинация, фильтры, сортировки).
Минусы:
- нужен доступ в Keys.so (платный);
- сервис показывает не все страницы, которые есть на сайте, а только те, где есть хотя бы 1 ключевое слово в ТОП 50;
- не у всех сайтов удобная URL-структура для парсинга тегов.
Вывод
Мы рассмотрели 4 способа быстрого сбора тегов для сайта. Эти способы позволяют сэкономить время на сборе и создании страниц тегов, сделав это быстрее, чем занимаясь ручной разгруппировкой семантического ядра. У каждого метода свои плюсы и минусы. Выбор способа зависит от задачи и имеющегося набора инструментов и сервисов.
Если есть какие-то вопросы или предложения, как можно сделать лучше, предлагаю обсудить в комментариях.
Как это работает в обычном поиске
Введите ключевые слова: Иван Федорович Крузенштерн
Заключите словосочетание в кавычки: “книга Иван Крузенштерн”
Вставьте оператор OR между словами: человек OR пароход
Поставьте знак минуса перед словами: -пароход, -“книга о пароходе”
Вставьте две точки между числами и укажите единицу измерения: 300..1000 рублей, 1812..1846
Поиск страниц на выбранном языке.
Поиск страниц, созданных в определенной стране.
Поиск страниц, которые были созданы или обновлены в течение указанного времени.
Поиск на определенном сайте (например, wikipedia.org ) или в домене (например, .edu, .org или .gov).
Поиск по тексту, заголовку или адресу страниц, а также по ссылкам на них.
Показывать все результаты
Используйте Безопасный поиск, чтобы избавиться от неприятных и непристойных сайтов и картинок в результатах поиска.
Поиск страниц и файлов определенного формата.
Поиск страниц, которые можно бесплатно использовать, распространять и изменять.
Галина, доброго утра!
Очень радует то, что сайт небезразличен игрокам.
В том, что Вы написали, вижу четыре проблемы, или задачи: это удобная классификация или организация, поиск, бардак и технические проблемы 🙂
Начну с последнего пункта. За службу поиска на сайте отвечает отдельный модуль, технически это небольшая программа, которая работает постоянно. Иногда после перезапуска сервера эта программа автоматически не запускается, и тогда поиск работать перестает. Исправляется ошибка очень быстро – запуском службы.
Теперь классификация: жесткая структура гораздо менее удобна по сравнению с тегами. Например, возьмем два верхних уровня: живопись и здания.
Есть домик в лесу, который нарисован маслом, т.е. домик попадает и в живопись, и в здания. И тогда подуровень “дома” будет и в живописи, и в зданиях, что неудобно. Гораздо более гибко будет у домика сделать теги “Живопись”, “Здания”. Дело в том, что подуровень одного объединяющего уровня может относиться и к другому подуровню. Если так сделать, то мы получим ну очень большое дерево, разбираться в котором будет неудобно.
Для того, чтобы была удобная навигация по картинкам, нужен поиск. То, что поиск он сейчас неудобен, очевидно, и Вы полностью правы. Я не смог найти в интернете пример того, каким вижу поиск по тегам я, поэтому объясню на пальцах. Сейчас на странице тегов представлено облако: puzzleit.ru/puzzles/tags. Удобно было бы сделать так, чтобы игрок мог мышкой выделить несколько тегов сразу, например, хочу я собрать пазл, на котором нарисован домик, есть лес и река, и девушка. Значит, мне надо выделить тег “Дома”, “Реки”, “Лес” и “Девушки”, всего 4 тега, и я получу ровно то, что мне надо. В жесткой структуре такой поиск организовать невозможно.
Ну и плюс поиск по количеству пазлинок, названию/описанию.
Ну и напоследок – бардак 🙂 Я уже писал где-то, что беспорядок в том или ином виде присутствует постоянно. А Вы можете на примере одной неразобранной кучи написать, каким видите наведение порядка Вы?
gogolik, добрый день. Спустя долгие часы раскопок, кажется я понял в чём дело, но я не знаю как это исправить. Пожалуйста, подскажите в чем дело?
| PHP | ||
|
Вывод var_dump($query) приведён в сообщении выше
При вводе в строку поиска #android #viktor #developer, var_dump(explode(‘#’, $s)) выводит следующий результат
Код
array(4) {
[0]=>
string(0) ""
[1]=>
string(8) "android "
[2]=>
string(7) "viktor "
[3]=>
string(9) "developer"
}
var_dump($terms); Почему-то выводит NULL. Может ли такое быть что в предыдущем массиве первый элемент “” пустой и он поэтому ищет пустоту и ничего не находит?
var_dump(strpos($s, ‘#’)); Выводит
var_dump($s); Выводит
Код
string(27) "#android #viktor #developer"
