Как узнать владельца сайта
В статье разберём, как найти владельца сайта легальными способами. А также рассмотрим, как узнать данные владельца сайта.
В 2021 году конфиденциальность в сети — весьма условное понятие. Многие сайты (с помощью cookie) собирают информацию о пользователях. В Telegram периодически появляются боты со сливами персональных данных. Там можно найти почти любого человека, стоит только указать его ФИО. Сразу оговоримся, что мы будем рассказывать исключительно о «белых» способах найти владельцев сайтов в сети: без шпионажа, покупки данных и других запрещённых приёмов.
Домен занят? Не проблема
Закажите услугу «Доменный брокер», и мы свяжемся с текущим администратором, проведём переговоры и договоримся о покупке домена за вас.
Заказать

Кого считать владельцем сайта
Владелец сайта — человек или организация, которым принадлежит домен и/или хостинг. В зависимости от статуса он может быть физическим и юридическим лицом. Мы не будем разделять эти понятия в статье, потому что, зная некоторые данные компании, вы сможете связаться с её представителями.
Какие данные владельца сайта можно узнать
Пользуясь способами, описанными ниже, о владельце можно выяснить следующую информацию (полностью или частично):
- имя и фамилию или название компании,
- email (почтовый адрес),
- телефон,
- физический адрес,
- страницу человека/компании в соцсетях.
Зачем искать владельца сайта
Есть несколько распространённых сценариев, для чего может потребоваться поиск:
- Нарушение авторских прав. Например, вы встретили в интернете ресурс, на котором опубликован ваш материал (текст, фотография, видео и т. п.). Данные владельца будут нужны, чтобы связаться с ним и предъявить претензию.
- Предложение о сотрудничестве. Например, если вас заинтересовали материалы анонимного автора (иллюстрация, статья и т. п.), встреченные на чужом сайте. Данные потребуются, чтобы выйти на автора напрямую или через владельца ресурса.
- Покупка домена. Например, если домен, который вы хотели зарегистрировать, занят. И вы хотите побольше узнать о его владельце, чтобы предложить релевантную цену.
Способы найти владельца сайта
Контактные данные владельца могут размещаться в подвале сайта (в самом низу) или на странице «Контакты». Прежде чем приступать к поискам, проверьте, не просмотрели ли вы интересующую вас информацию.
Кто собственник сайта: как узнать
Зачастую данные не публикуются открыто, но владельцы оставляют форму обратной связи, и вы можете обратиться через неё. Однако это не будет гарантировать, что вам ответят.

Как узнать владельца сайта по домену
Если же контактных данных нет или владелец вам не отвечает, воспользуйтесь одним из следующих способов:
- через Whois,
- через хостинг-провайдера или регистратора домена (на основании судебного запроса),
- с помощью сторонних сервисов.
Рассмотрим каждый из них подробнее.
Как узнать данные через Whois
Whois — это открытый сетевой протокол, через который в большинстве случаев можно узнать, кто зарегистрировал домен. Разные компании создают свои «оболочки» и интерфейсы Whois. В REG.RU также есть своё решение. Мы посвятили отдельную статью Whois и его возможностям.
Как проверить данные владельца сайта:
- 1.
-
2.
Введите домен и нажмите Проверить:

Как узнать, кто владеет сайтом
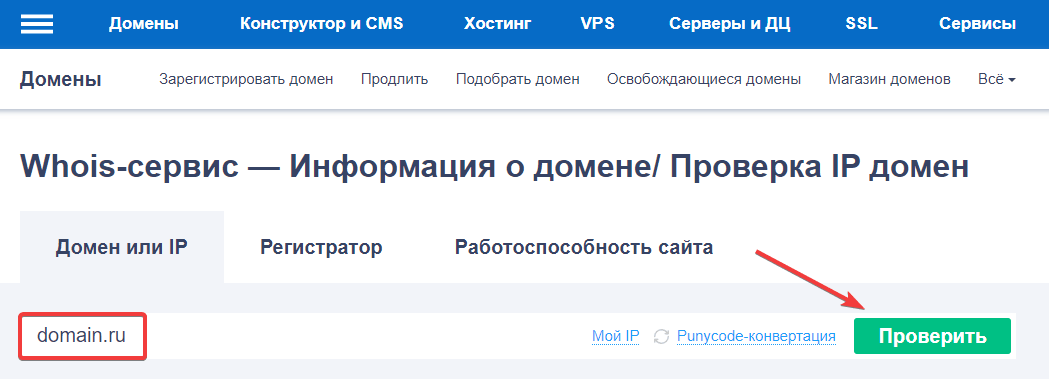
Готово! Через несколько секунд вы получите необходимую информацию. Если этот человек или организация зарегистрировали домен в REG.RU и оставили данными открытыми, вы сможете узнать имя и фамилию (название компании), адрес, телефон и email.
Как выйти на администратора, если данные скрыты
Если человек/организации пожелали сохранить инкогнито (заказали услугу «Скрытие персональных данных»), данные посмотреть не получится. Воспользуйтесь формой обратной связи с администратором домена, чтобы написать ему письмо:
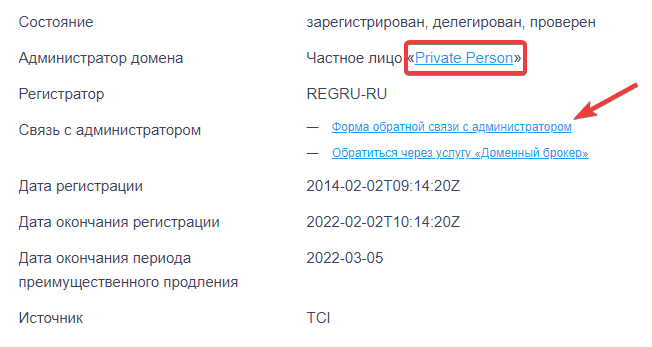
Как узнать, кто создал сайт
Если вы разыскиваете владельца, потому что хотите приобрести занятый домен, воспользуйтесь услугой REG.RU «Доменный брокер». В этом случае мы возьмём все переговоры с владельцем на себя.
Если вы не смогли узнать необходимую информацию или владелец сайта не вышел на связь, выяснить данные о нём будет сложнее. Мы расскажем о других способах ниже. Обратите внимание, что они не гарантируют успех.
Как узнать данные через регистратора домена и хостинг-провайдера
Регистратор домена — компания, через которую клиенты регистрируют домены. Хостинг-провайдер — это компания, у которой владелец ресурса заказал хостинг. Например, REG.RU является регистратором доменов и хостинг-провайдером.
Регистратор может предоставить информацию об администраторе домена только на основании письменного запроса от правоохранительных и судебных органов. Если у вас такой случай, вы можете обратиться к регистратору. Для этого посмотрите в Whois, какая именно компания помогла c регистрацией домена:
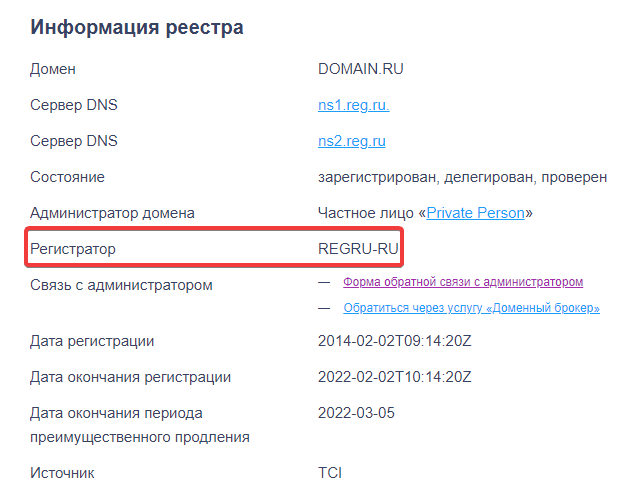
Установить хостинг-провайдера можно с помощью бесплатного сервиса HostAdvice.
Как узнать хозяина сайта с помощью сторонних сервисов
Если предыдущие способы не сработали, воспользуйтесь сервисами, которые помогают выяснить информацию «косвенно». Обратим ваше внимание на то, что они не гарантируют 100% успеха. Если владелец сайта скрытен (пользуется псевдонимами, не афиширует связь с компанией), результата не будет.
Через поиск ссылок (бэклинков) на сайт
С помощью сервиса Semrush можно посмотреть список ресурсов, доменов и IP-адресов, которые ссылаются на нужный сайт. Это даёт возможность найти личный блог или страницу в социальных сетях, если владелец указывал в них ссылку на свой сайт.
- 1.
-
2.
Перейдите на страницу Анализ обратных ссылок.
-
3.
Введите домен или URL-адрес сайта и нажмите Анализ:
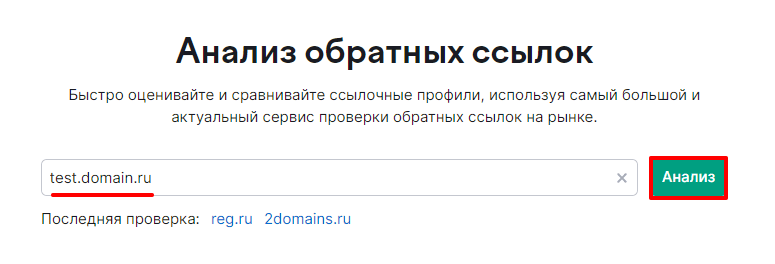
На вкладке «Обратные ссылки» и «Ссыл.домены» будут списки ресурсов, среди которых может найтись владелец сайта. Изучите ссылки и контекст, в котором упоминается ресурс.
Через связанные email-адреса
Сервис hunter помогает определить почтовые адреса, которые имеют отношение к домену. Например, для домена site.ru, связанными почтовыми адресами будут: manager@site.ru, career@site.ru и т. д. Вы сможете связаться с владельцем сайта по адресам из списка. В hunter можно зарегистрировать бесплатный аккаунт: вам будут доступны 25 проверок в месяц.
-
1.
Зарегистрируйтесь и/или авторизуйтесь.
-
2.
Введите домен и нажмите значок лупы:
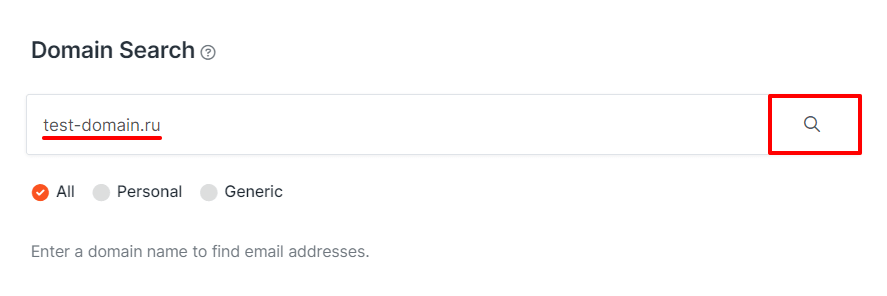
Попробуйте выйти на связь с владельцем по указанным почтовым адресам.
Через поиск по файлам в Google
В Google можно искать не только сайты, но и текстовые файлы в форматах pdf, ppt, doc, rtf, xls. Выполнив такой поиск, вы можете скачать их на свой компьютер и посмотреть в свойствах имя автора. Часто люди используют в системе настоящие имена. Так у вас будет отправная точка для дальнейших поисков (например, в соцсетях).
Чтобы найти файлы, в поисковую строку введите запрос «filetype:doc site:domain.ru», где doc — нужный текстовый формат, а domain.ru — адрес.
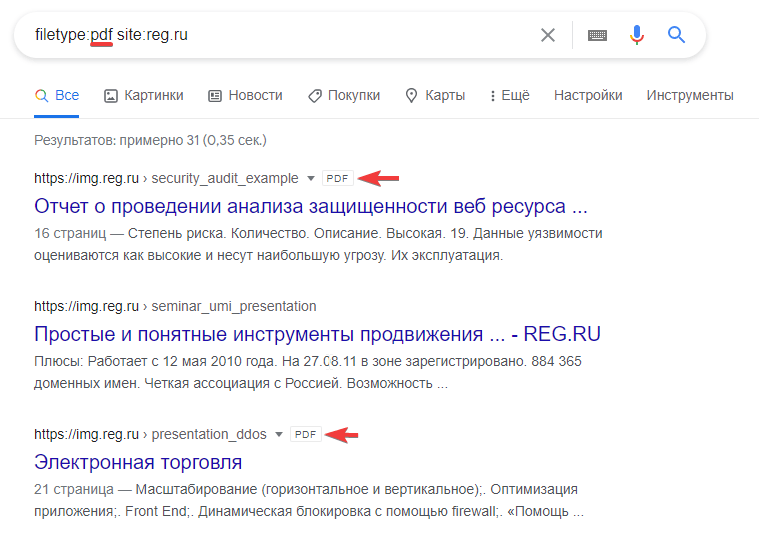
Пример поиска pdf-файлов по сайту reg.ru
Через скрытые файлы/папки в robots.txt
robots.txt — текстовый файл, в котором прописывается, как роботам поисковых систем работать со страницами: какие файлы и страницы нельзя смотреть, а какие, наоборот, нужно просматривать в первую очередь. Эти файлы используется для того, чтобы сайты быстрее индексировались, то есть как можно раньше начинали отображаться в списках поисковиков Google и Яндекс. Иногда владельцы используют свой ресурс как бесплатное облачное хранилище и добавляют туда файлы и папки, закрытые от публичного просмотра. В robots.txt можно посмотреть их названия и открыть в браузере напрямую.
-
1.
Чтобы открыть robots.txt, введите в браузере domain.ru/robots.txt, где domain.ru — нужный домен.
-
2.
Просмотрите все строки, которые начинаются с команды Disallow (она означает, что файл нельзя просматривать поисковым роботам).
-
3.
Если нашлось что-то, что поможет установить личность владельца (например, файл contacts.html с перечнем контактных данных), откройте соседнюю вкладку браузера и введите domain.ru/contacts.html. Этот файл можно будет просмотреть и скачать.
Через exif-данные о фотографиях на сайте
Exif-данные — это дополнительная информация о фотографиях: дата создания и место съёмки. Если владелец не оптимизировал изображения перед тем, как загрузить их в сеть, и не очистил exif-данные, вы сможете посмотреть эту информацию. Например, если на сайте есть фотографии из офиса компании, вы узнаете его адрес и сможете установить название организации или физическое лицо, которое искали.
Чтобы узнать exif-данные:
-
1.
Откройте сервис exif-regex.info.
-
2.
Введите url-адрес фотографии. Чтобы узнать его, кликните по фотографии правой кнопкой мыши и выберите «Открыть в новой вкладке». Url-адрес будет указан в поисковой строке браузера.
Также вы можете загрузить файл, если уже скачали его на свой компьютер. Затем пройдите антибот-проверку и нажмите View Image Data:
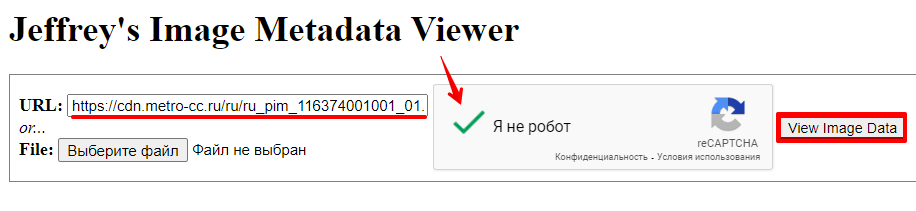
В результатах проверки можно найти нужную информацию.
Мы перечислили способы, которые помогут найти владельца сайта. Они не гарантируют успеха на 100%. Особенно если человек, которого вы ищете, следит за конфиденциальностью и старается оставлять как можно меньше «следов». Также вы можете проверить свой ресурс по пунктам перечисленным выше, чтобы понять, насколько тяжело/легко найти его владельца.
Очередной мануал для начинающих разведчиков.
Информация о владельце домена является конфиденциальной и предоставляется регистратором только по запросу органов власти. Но есть несколько возможных способов выведать ее. О них и расскажем в этой статье.
Зачем это нужно: найти управу на человека, который нагло ворует ваш контент, оценить платежеспособность владельца сайта перед тем как сделать ему предложение о покупке, найти специалиста в узкой области, который пишет для своего блога толковые статьи, но подписывается обезличенным никнейном и т.п.
1. Смотрим историю whois
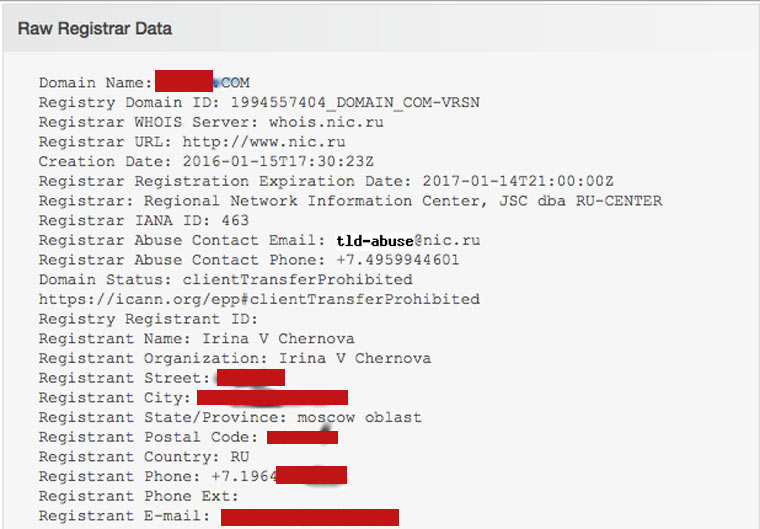
Начать стоит с проверки сайта на who.is. На скрине показан пример, когда c помощью этого сервиса стал известен не только email, но также мобильный телефон и адрес владельца (такое бывает, если очень повезет). Я в шоке от политики приватности своего хостера! В большинстве случаев отображается только ссылка, по которой можно отправить сообщение владельцу домена через регистратора. И с ее помощью есть шанс узнать много интересного.
2. Пытаемся связаться с ним официальным способом
Отправив сообщение через регистратора, можно выведать действующий email человека, его фамилию/имя, контактный телефон и IP-адрес, которые помогут полностью идентифицировать его личность (см. статью 15 фишек для сбора информации о человеке в интернете).
Результат зависит от удачи. Неизвестно проверяет ли человек ту почту, которую указал при регистрации домена и насколько достоверные предоставлены им данные. Также важны ваши навыки социнженерии. Можно предлагать инвестиции, представляться ассистентом Юрия Мильнера:-), убеждать что нужно непременно созвониться по телефону или скайпу, спросить о возможности личной встречи. Главное убедить человека, что судьба подкинула ему реальный шанс заработать и выпросить максимум данных, которые можно применить в дальнейшей разведке.
Желательно добавить фразу: «Пожалуйста, дайте мне знать, что предложение вам не интересно». Это увеличивает шанс того, что человек из вежливости черкнет пару строк, засветив свою почту, имя и IP-адрес.
Также стоит написать всем предыдущим владельцам домена, с просьбой дать контакты тех людей, которым они передали его. Если повезет, то в ответе будет: «Продал Васе N, его телефон +791612345…». Но, к сожалению, люди часто бывают скрытны. Но также часто бывают вежливы и отписываются: «Простите, но я не могу поделиться этой информацией». И это уже нам на руку.
Зная электронную почту бывшего владельца (и его никнейм), можно найти его объявление о продаже сайта/домена на специализированном форуме и список пользователей, которые на него откликнулись. Из них можно составить круг возможных нынешних владельцев домена.
3. Ищем сайты, зарегистрированные на имя владельца
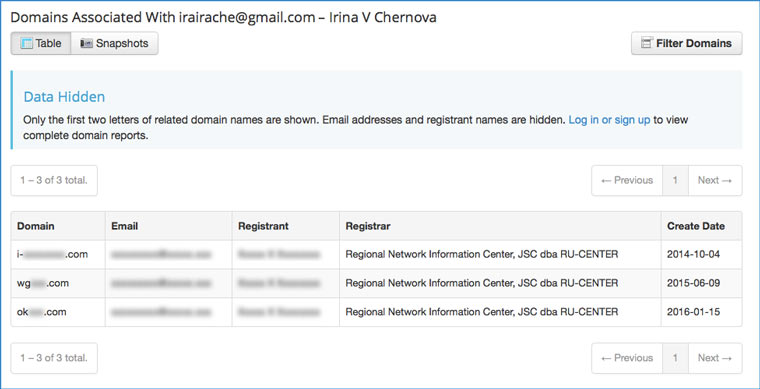
Зная адрес электронной почты человека, можно узнать, какие домены на него зарегистрированы. Сделать это можно на domainiq.com. Не исключено, что одним из этих сайтов окажется личный блог, по которому можно установить личность человека.
4. Обращаемся к хостеру
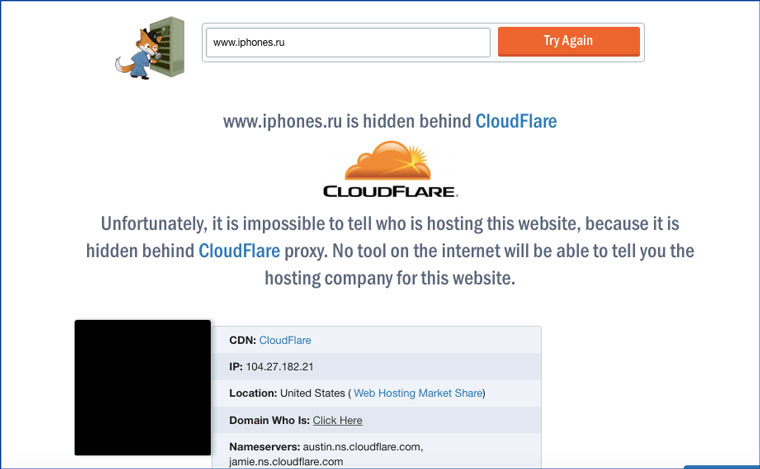
На hostadvice.com можно узнать хостинг-провайдера сайта. Если вы сможете письменно обосновать необходимость предоставления вам данных о владельце, то есть шанс, что хостер поделится ими с вами. Или будет очень упорны (недели настойчивых писем должно хватить).
Обращаясь к кому-то из сферы IT по интернету лучше представляться женщиной (и ставить в профиль скромное фото со светлыми волосами). Неопытные мужчины думают, что блондинки недалеки, не представляют никакой опасности и с радостью оказывают им мелкие услуги.
5. Смотрим информацию о создателях файлов
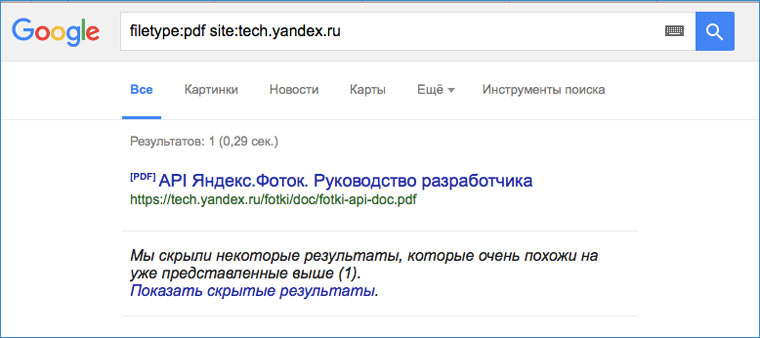
Google умеет искать не только по html-страницам, но и по разным типам файлов. Вот пример запроса для поиска пдфок на определенном сайте: filetype:pdf site:tech.yandex.ru
Найденные на сайте файлы нужно скачать на компьютер и в свойствах посмотреть их автора, создателя и т.п. Очень многие люди в информации о компьютере указывают свои реальные имя и фамилию, а при выкладке файлов со своей машины в интернете забывают стереть эту информацию.
Google умеет искать файлы со следующими расширениями:
- doc;
- ppt;
- xls;
- pdf;
- rtf;
- swf.
6. Ищем «полезные» файлы в robots.txt
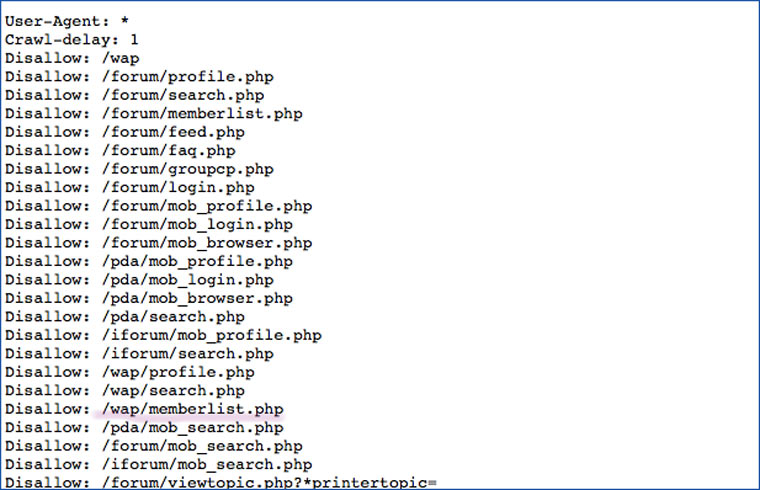
В этом файле владельцы указывают файлы и папки, которые они закрывают от индексации поисковиками. Иногда там могут быть указаны старые страницы с личными данными или фотографиями. Мой опыт показывает, что есть определенная категория людей, которые использует свои сервера в качестве облачного хранилища и кладут туда что попало. Как правило, файл robots.txt лежит в корневом каталоге сайта.
7. Ищем «полезные» страницы в sitemap.xml
В файле с картой сайта: sitemap.xml, который часто располагается в той же папке, что и robots.txt также можно найти страницы, которые могут содержать полезную информацию. К примеру, страницу с контактами, ссылка на которую была убрана с главной страницы.
8. Ищем почтовые адреса, связанные с доменом
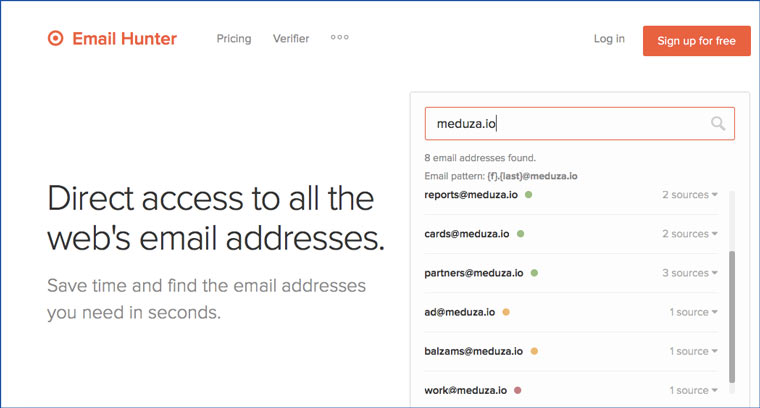
Указываем адрес сайта на emailhunter.co и получаем список адресов, связанных с ним.
9. Ищем сайты, которые ссылаются на домен
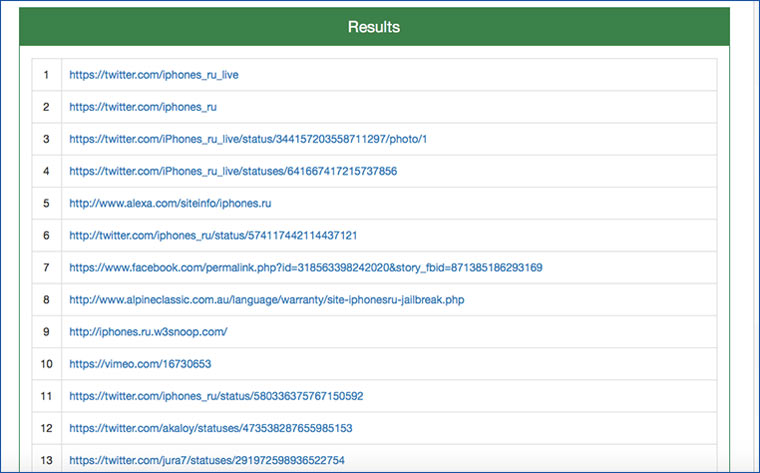
Указываем сайт в форму поиска на Backlink Checker и получаем 50 ссылок на страницы, которые ссылаются на него. Есть шанс отыскать среди них профили в соцсетях, а также другие проекты владельца ресурса.
10. Проверяем exif-данные фотографий
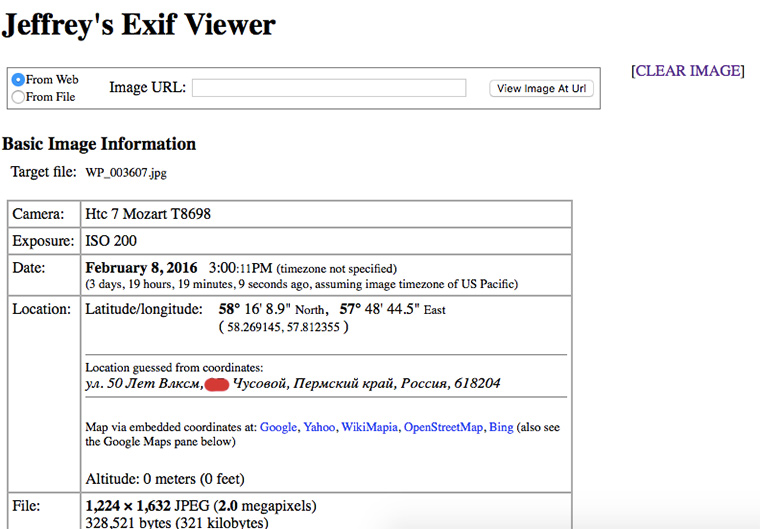
Иногда люди выкладывают на свои сайты фотографий без их предварительной оптимизации для веба. Можно попробовать посмотреть пару снимков с помощью Jeffry’s Exif Viewer. Таким образом можно узнать адрес владельца и модель его мобильного телефона.
11. Идентифицируем владельца по лицу
Если сайт небольшой, то можно с помощью поиска Google по картинкам и оператора site: посмотреть все изображения которые есть на нем. Не исключено, что среди них может быть его фотография (какой-нибудь admin.jpg пятилетней давности). Личность человека по фото можно установить с помощью findface.ru.
12. Читаем комментарии в исходном коде
Заходим на сайт, нажимаем Shift + Command + U (или выбираем из меню пункт Показать программный код страницы). Сначала просматриваем HTML-код на предмет палевных комментов с именами и никнеймами. К примеру: «BigFatNagibator, проверь это место пожалуйста!». Попутно ищем js-скрипты, которые были написаны владельцем сайта специально для этого ресурса. Не исключено, что в них может оказаться торжественная надпись «Created by Sasha Petrov. Irkutsk» и ссылка на его профиль в Github.
Результативность всех этих методов зависит большой частью от вашего упорства и смекалки. Если владелец сайта не конченый параноик и живет онлайн-жизнью, то обязательно должна быть ниточка, которая поможет найти его.
Если вам не нужно никого искать, но у вас есть проект, владение которым вы хотели бы скрыть, то рекомендую проверить по всем пунктам из статьи степень сложности идентификации своей личности. Может, будете удивлены.

 (25 голосов, общий рейтинг: 4.88 из 5)
(25 голосов, общий рейтинг: 4.88 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Очередной мануал для начинающих разведчиков. Информация о владельце домена является конфиденциальной и предоставляется регистратором только по запросу органов власти. Но есть несколько возможных способов выведать ее. О них и расскажем в этой статье. Зачем это нужно: найти управу на человека, который нагло ворует ваш контент, оценить платежеспособность владельца сайта перед тем как сделать ему предложение…
- Безопасность,
- Подборки,
- сеть,
- хаки
![]()
Как найти сайт человека
Наверно, каждый человек, который подключает к своему компьютеру интернет, имеет желание завести себе электронную почту и зарегистрироваться в социальной сети. «Социалка» дает шанс найти тех людей, с кем вы учились, дружили или работали. Создав аккаунт в социальной сети, вы автоматически приобретаете свою личную страничку, которую можно назвать «своим» сайтом. После регистрации и активации аккаунта вы можете сделать поиск людей, которых вы хотели бы увидеть и пообщаться.

Вам понадобится
- Регистрация в социальной сети.
Инструкция
Среди всех социальных сетей, можно сказать, что есть 3 самых известных на просторах рунета: «Вконтакте», «Одноклассники» и «Мой мир». Чтобы выполнить поиск на сайте «Вконтакте», необходимо зайти в аккаунт, нажать кнопку «Поиск» на главной странице (находится в верхней панели). В открывшейся странице введите имя и фамилию искомого человека и нажмите кнопку «Поиск» или кнопку Enter на клавиатуре. В загрузившемся списке окажется большое количество результатов. Их можно отсортировать: в правой колонке выберите пункт «Люди». Затем в графе «Город» выберите страну и город проживания. В разделе «Пол» выберите «мужской» или «женский». Список должен значительно уменьшиться. Также можно добавить данные о возрасте человека, об учебных заведениях, работе и мест пребывания.
В «Одноклассниках» нет такого четкого ранжирования по всем данным анкеты, но поиск нужного человека выполняется также за небольшой промежуток времени. После входа в свой аккаунт, наведите курсор на поле «Искать на сайте», введите имя и фамилию искомого человека и нажмите кнопку с изображением лупы или кнопку Enter на клавиатуре. На этой же страницы будут загружены результаты поиска. В верхнем меню можно выбрать категорию поиска: люди, группы, сообщества и т.д.
В социальной сети «Мой мир» поиск осуществляется вызовом одноименной страницы: войдите в аккаунт, нажмите кнопку «Поиск» в верхнем левом углу страницы. В открывшейся странице можно произвести поиск по многим категориям анкеты: город, школа, Вуз, колледж, работа и т.д. Также можно произвести поиск по e-mail. В строку поиска введите имя и фамилию искомого человека и нажмите кнопку «Найти» или кнопку Enter на клавиатуре.
Видео по теме
Источники:
- Как найти человека по фотографии – обзор действенных способов
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Время на прочтение
9 мин
Количество просмотров 904K
В очередной статье нашего цикла публикаций, посвященного интернет-разведке, рассмотрим, как операторы продвинутого поиска Google (advanced search operators) позволяют быстро находить необходимую информацию о конкретном человеке.
В комментариях к первой нашей статье, читатели просили побольше практических примеров и скриншотов, поэтому в этой статье практики и графики будем много. Для демонстрации возможностей «продвинутого» поиска Google в качестве целей были выбраны личные аккаунты автора. Сделано это, чтобы никого не обидеть излишним интересом к его частной жизни. Хочу сразу предупредить, что никогда не задавался целью скрыть свое присутствие в интернете, поэтому описанные методы подойдут для сбора данных об обычных людях, и могут быть не очень эффективны для деанонимизации фэйковых аккаунтов, созданных для разовых акций. Интересующимся читателям предлагаю повторить приведенные примеры запросов в отношении своих аккаунтов и оценить насколько легко собирать информацию по ним.
Прежде чем заниматься сбором и анализом информации о конкретном человеке необходимо представить всю картину того, какие данные о человеке существуют.

Подобную карту нужно детализировать до уровня, необходимого для решения конкретной задачи. Любой поиск информации начинается с некоторого начального набора данных. В нашем случае это будет фамилия, имя и место работы. Остальные данные где-то есть, но связать их с имеющимися мы пока не можем. Поэтому мы формируем гипотезы и проверяем с помощью поисковых запросов.
Источниками информации о человеке могут быть:
- он сам: аккаунты в соцсетях, блог и т.п.;
- государство: базы данных налоговой, судебных приставов, судов и т.п. См. ссылки в статье
- кто-то еще (друзья, враги, СМИ, работодатель и т.п.)
В настоящей статье рассмотрим п.1. – будем вычислять аккаунты автора в социальных сетях.
Цель номер один: ники пользователя
Что такое ник и как мы его выбираем?
Ник представляет собой наше имя в интернете: мы выбираем его, создавая свой личный почтовый ящик, а потом часто используем и в различных сервисах.
Мы ничем не ограничены при выборе ников, но есть любимые алгоритмы формирования наших интернет-имен:
- Игры со своим именем: фамилия, имя+фамилия, имя+год рождения, имя+дата, инициалы;
- Игры с именами любимых персонажей (tovbender, napoleon);
- Немного о себе: профессия, психология (coolhacker, murmur);
- Демонстрация увлечений: footballer, boxer;
- “Чтобы никто не догадался”: слово наоборот, русское слово в английской раскладке, слово на латыни и т.п.
Если мы не знаем ник, но знаем кое-что о человеке, мы уже можем строить предположения и проверять их.
Хорошим способом вычислить ник пользователя является поиск и анализ его страниц в соцсетях и поиск адреса личной электронной почты.
Начать поиск информации о конкретном пользователе можно с простого запроса, подобного следующему:
джон смит ромашкагде «ромашка» — название компании.
На текущий момент мы должны вспомнить, что некоторые особенности работы поисковика Google:
- Google читает запрос слева направо.
- Google не различает регистр: «Земля» и «земля» для него одно и то же;
- длина запроса не должна превышать 32 слов;
- * представляет одно слово в запросе;
- можно искать точную фразу, взяв ее в кавычки;
- между словами в запросе стоит невидимое логическое «И»;
- Google сам умеет склонять слова;
- Оператор «-» исключает из выдачи результаты, которые содержат выражение, помещенное сразу за данным оператором (обязательно без пробела).
- в верху выдачи находятся страницы, которые, по мнению Google, являются самыми релевантными. Тем не менее это его догадка, так как наших мыслей он читать пока не умеет;
- для уточнения параметров поиска необходимо владеть операторами продвинутого поиска (advanced search operators).
Теперь можно ввести аналогичный запрос по автору статьи и получить массу страниц, среди которых должна быть и искомые страницы в социальных сетях:
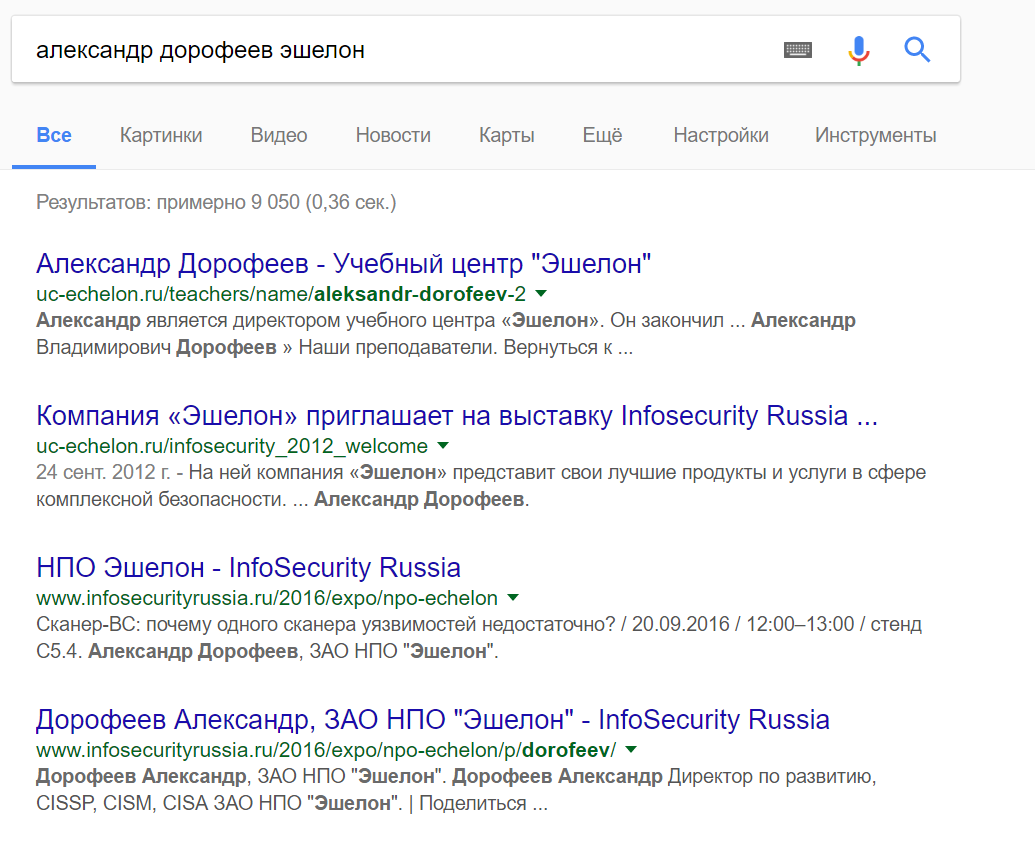
Информации в выдаче поисковика достаточно много, и чтобы найти страницы в социальных сетях нам придется пересмотреть большое количество страниц.
Примечание:
Кстати, а что делать, если мы хотим найти человека из определенной компании, но забыли его фамилию? Тут может помочь оператор звездочка:
джон * ромашкаА если мы ищем человека из ООО «Ромашка», а таких «Ромашек» — миллион: и АО «Ромашка», и АНО «Ромашка», и ФГУП «Ромашка» и т.д.
Вариант 1. Искать полную фразу «ООО Ромашка».
Вариант 2. «Минусовать» ненужные слова: -АНО – АО –ФГУП (но так можно «заминусовать» и нужные результаты, например если на странице говорится, что наша «Ромашка» подружилась с ФГУП «Апельсин».
Теперь нам необходимо сузить выдачу и найти страницу автора статьи в социальной сети «ВКонтакте». Это позволит нам определить один из ников пользователя, а затем и вычислить адрес электронной почты. Для этого будет полезно использовать такой оператор, как site. Он ограничивает поиск определенным доменом любого уровня.
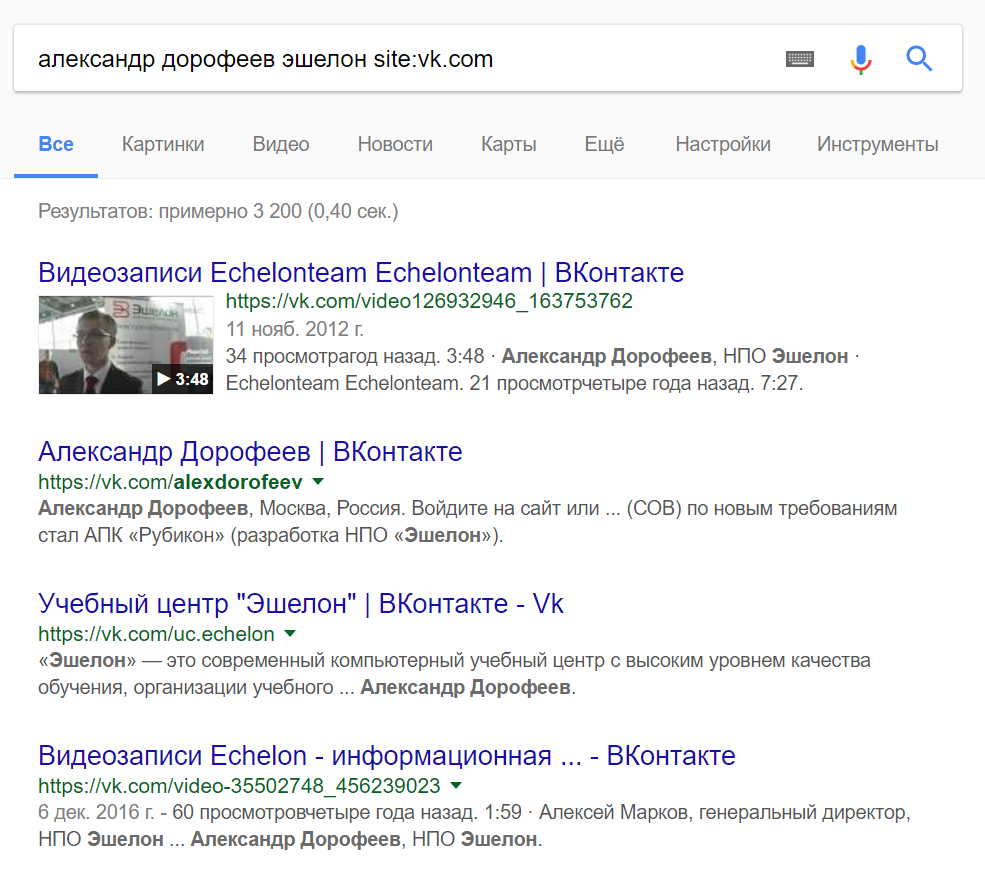
Вторая ссылка уже ведет на страницу автора статьи в сети «ВКонтакте». Обратите внимание, что автор сознательно выбрал короткий ник: alexdorofeev. Не все интернет-ресурсы дают возможность самим задать ссылку на свою страницу, иногда она формируется автоматически, но может содержать в себе ник, взятый из адреса электронной почты.
Используя добытую информацию и знания, постараемся найти аналогичную страницу в сети Facebook.
Сначала на удачу в браузере введем следующий URL: https://www.facebook.com/alexdorofeev, но, к сожалению, увидим, что страница принадлежит кому-то другому. Тогда воспользуемся проверенным приемом и добавим в запрос site:facebook.com.
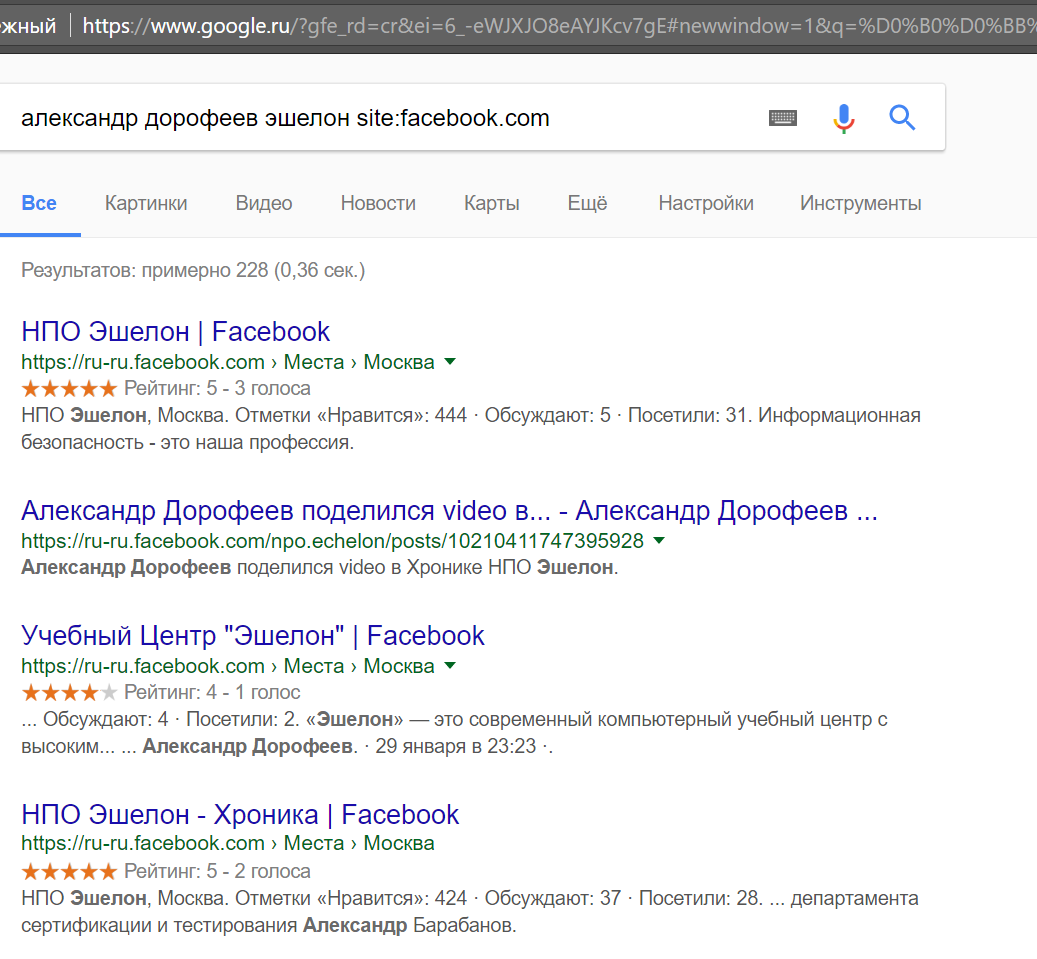
В результатах выдачи отсутствует прямая ссылка на профиль, который мы ищем, так как пользователь проявил в свое время бдительность и запретил «сдачу» его странички поисковикам

Здесь необходимо снова сделать небольшое отступление и вспомнить как работают поисковики и в том числе Google.
Что поисковики сделать могут, а что не могут?
Поисковики в общих чертах работают по следующему алгоритму:
- боты поисковых машин обходят сайты;
- содержимое страниц индексируется;
- по запросу пользователей извлекаются ссылки на релевантные страницы.
Поисковики не могут:
- проиндексировать информацию, доступ к которой возможен только авторизованным пользователям;
- данные, которые доступны после заполнения форм, например, результаты выгрузки из различных баз данных;
- качественно извлечь информацию из видео, фото, аудио-материалов.
Еще некоторые нюансы:
- контекст: результат выдачи зависит от запроса пользователя, от истории его предыдущих запросов и от истории просмотров страницы другими пользователями;
- поиск осуществляется только на том языке, на котором пользователь ввел свой запрос;
- имеется некоторый конфликт интересов: поисковики зарабатывают на рекламе, на которую кликают пользователи, потому что нужные им страницы оказались не в самом верху выдачи;
- действует цензура из-за нарушения чьих-либо прав (авторские, право на забвение и т.п.).
Facebook относится к той категории интернет-ресурсов, которые не очень жалуют индексацию своего сайта и о чем непосредственно сообщают в robots.txt:

Для обнаружения страницы скрытного пользователя на Facebook нам потребуется авторизоваться в данной сети и воспользоваться встроенным функционалом поиска. Ссылка на страницу пользователя может «утечь» и оказаться в выдаче поисковика, но только если пользователь сознательно опубликовал материал за своим авторством на всеобщее обозрение.
С помощью поиска страница автора легко обнаруживается:
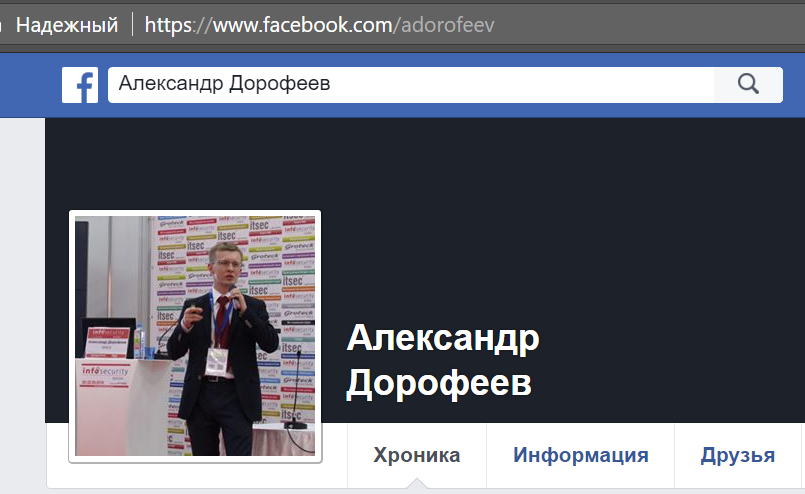
Анализируя URL страницы, мы можем определить еще один ник пользователя: adorofeev.
Таким образом, мы уже раздобыли два ника: alexdorofeev и adorofeev. Так как пользователей на популярных ресурсах очень много, то ник может отличаться от того, что реально любит использовать человек, так его «родной» идентификатор уже кем-то занят. По этой причине у автора статьи ник на Хабре: alexdorofeeff, хотя больше нравится adorofeev.
Зная ник, мы можем поискать еще страницы, потенциально связанные с нужным человеком.
Здесь мы снова отвлечемся на Google и вспомним следующие моменты:
- По умолчанию Google ищет выражение (слово или фразу, взятую в кавычки) во всех частях страницы: в URL, в заголовке, в тексте, в тексте ссылок. В то же время специальные «продвинутые» операторы позволяют указать где именно нам нужно, что бы был искомый текст. Для этого нам необходимо использовать операторы: inurl:, intext:, intitle:, inanchor:, а также их собратьев с приставкой all.
- Google понимает логические выражения и скобки. AND – логическое «И», по умолчанию именно оно стоит между словами разделенными пробелами в строке поиска. OR или I – логическое «ИЛИ».
- Если мы применяем оператор, то после двоеточия должно быть искомое выражение без пробела.
- Операторы с приставкой all позволяют их применить к ряду выражений после двоеточия, разделенных пробелами. Для этих же задач можно использовать операторы без all, но со скобками и логическими выражениями.
Поиграемся с оператором inurl, который ищет страницы, содержащие в URL страницы нужное слово. Так как мы уже знаем несколько ников автора, то можем сделать следующий запрос:
inurl:(adorofeev | alexdorofeeff | alexdorofeev)В результатах выдачи мы тут же обнаружим страницы соответствующих аккаунтов и часть страниц будет принадлежать автору. Таким образом, если у нас есть предположения об используемых никах, мы можем в самом начале наших изысканий получить список потенциально интересных страниц.
Закрывая тему с никами, хочу обратить ваше внимание на сервисы, позволяющие быстро узнать используется ли данный ник в ряде популярных ресурсов. Так мы можем найти дополнительные страницы конкретного человека. Пример подобного сервиса: https://namechk.com/
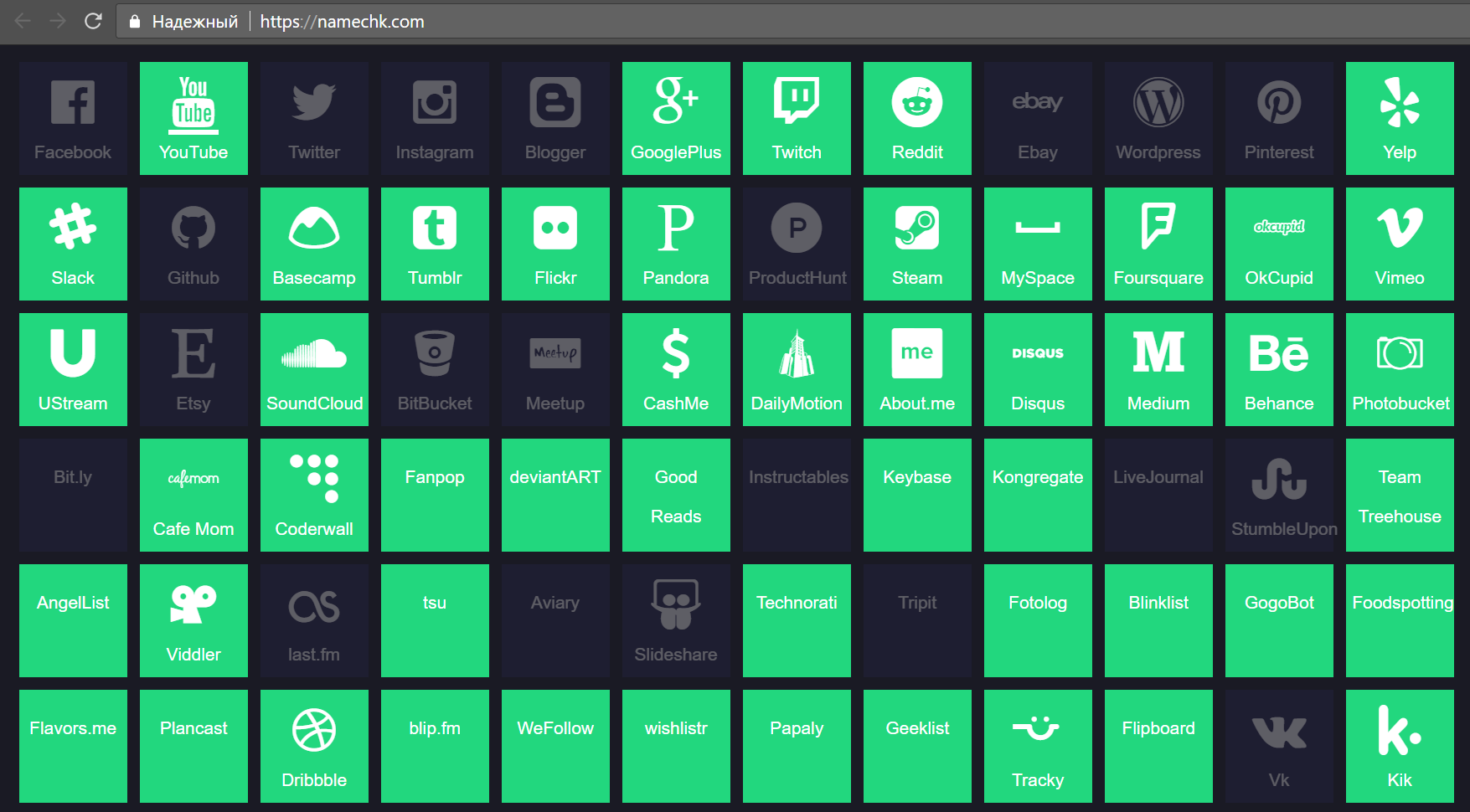
Как узнать e-mail?
Теперь, заполучив набор любимых ников пользователя, мы можем попробовать узнать его личный e-mail. Зачем он нужен? Иногда нужно выяснить принадлежит ли конкретный e-mail данному человеку, чтобы определить авторство письма. Также е-mail будет полезен для поиска объявлений, оставленных пользователем на форумах и т.п.
Мы знаем ники, но пока не знаем домены почтовых служб. Так давайте сделаем предположения и проверим. Раз пользователь из России, то вероятнее всего что он использует один или несколько следующих сервисов:
- Mail.ru
- Яндекс.Почта
- Google Gmail
- Рамблер Почта
Соответственно мы можем сгенерировать адреса (наши гипотезы на данный момент) с никами adorofeev, alexdorofeev и alexdorofeeff.
Как мы можем проверить, а существуют ли подобные адреса на самом деле? Один из вариантов: немного «пообщаться» с почтовыми серверами каждого сервиса по протоколу SMTP:
Шаг 1. Находим почтовый сервер для конкретного домена.
nslookup -type=mx "имя домена"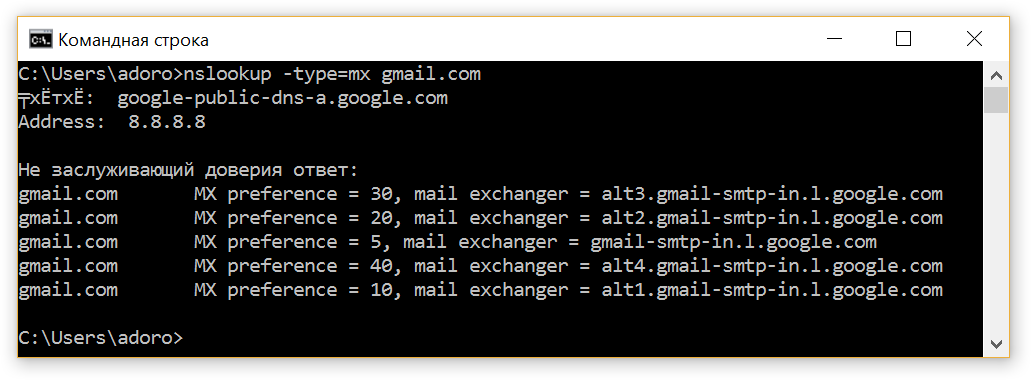
Шаг 2. Подключаемся к почтовому серверу и имитируем начало отправки сообщения. Если сервер на имя получателя ответит «ОК», значит есть такая учетная запись.
Вариант 1: e-mail существует.
telnet gmail-smtp-in.l.google.com 25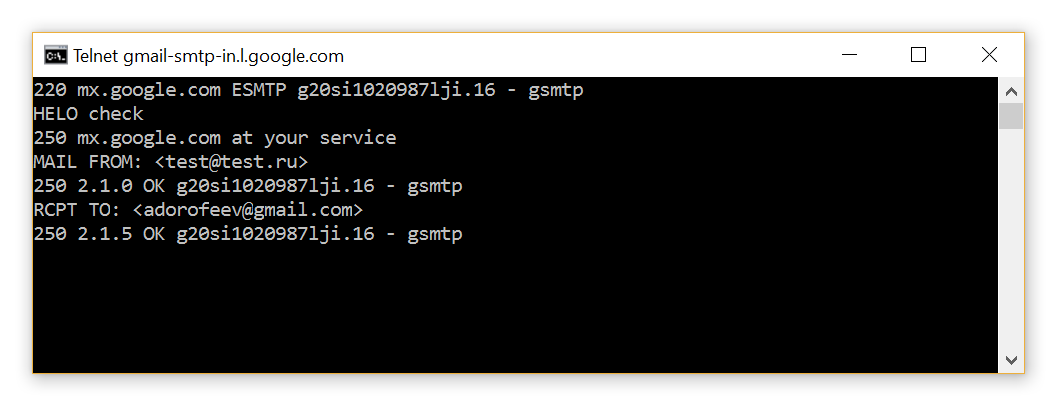
Вариант 2: e-mail не существует.
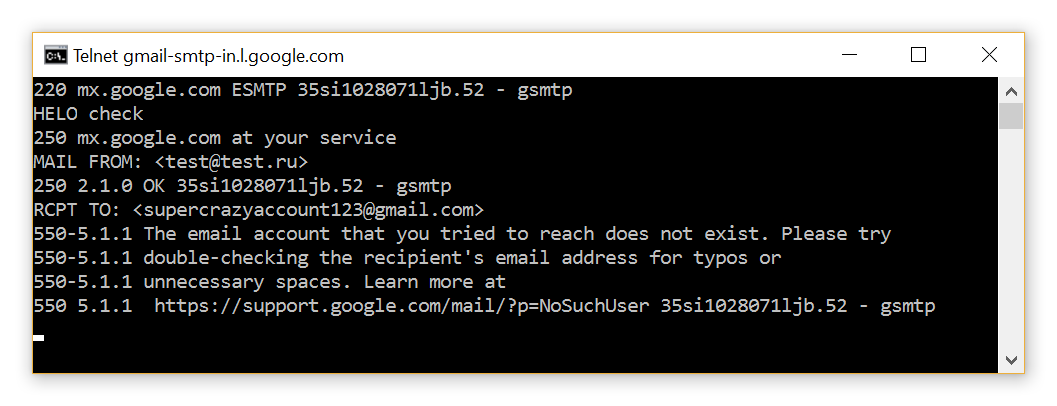
Верификация e-mail
Определив существуют ли почтовые адреса, мы можем попробовать определить связан ли конкретный адрес с нужным нам человеком.
На mail.ru некоторые пользователи создают свои страницы, к которым можно обратиться следующим образом my.mail.ru/mail/nick/
«Пробиваем» один из адресов:
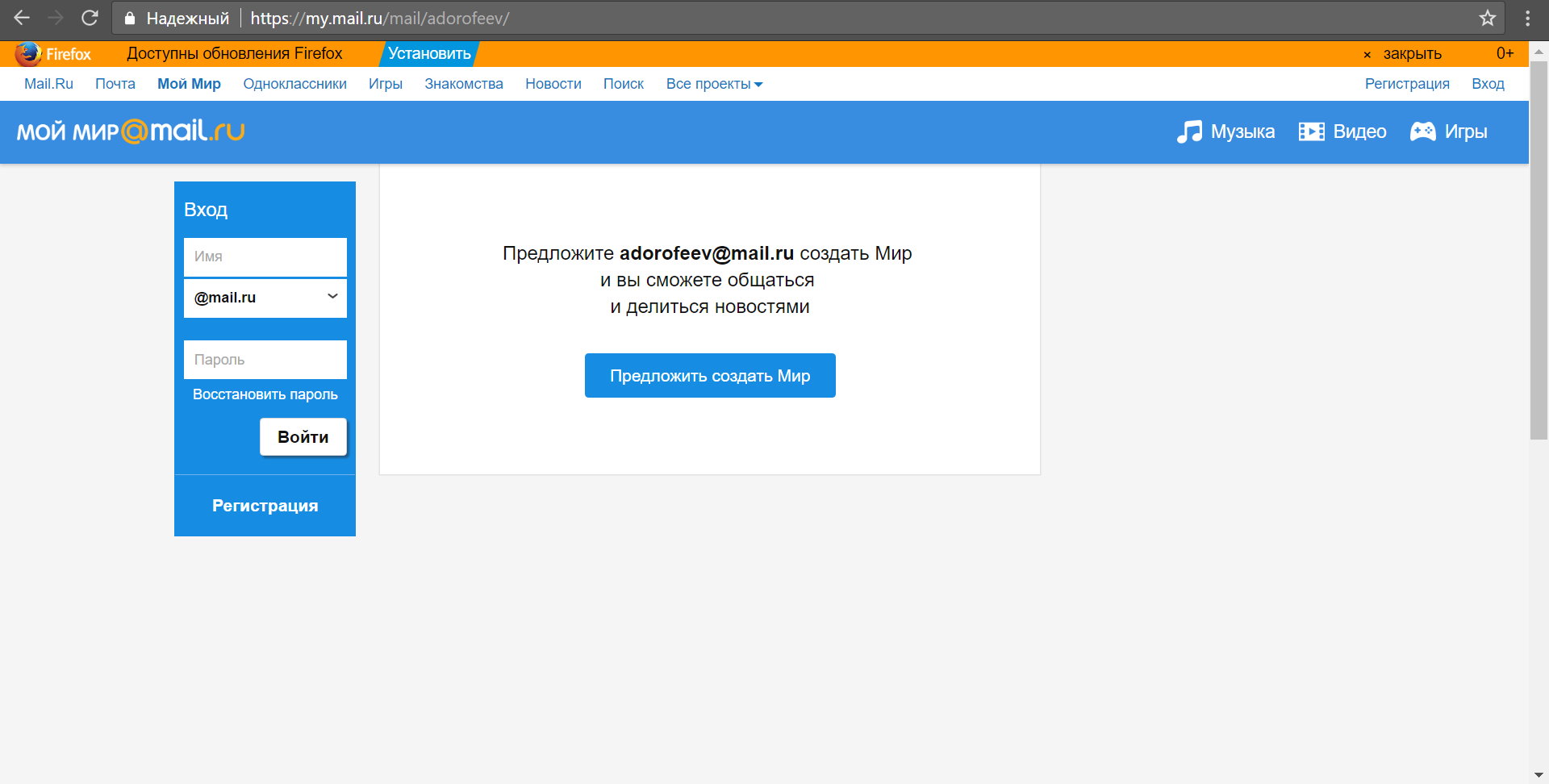
Также можно посмотреть страницы пользователей на всех проектах Mail.ru, воспользовавшись комбинацией уже известных нам операторов inurl: и site:
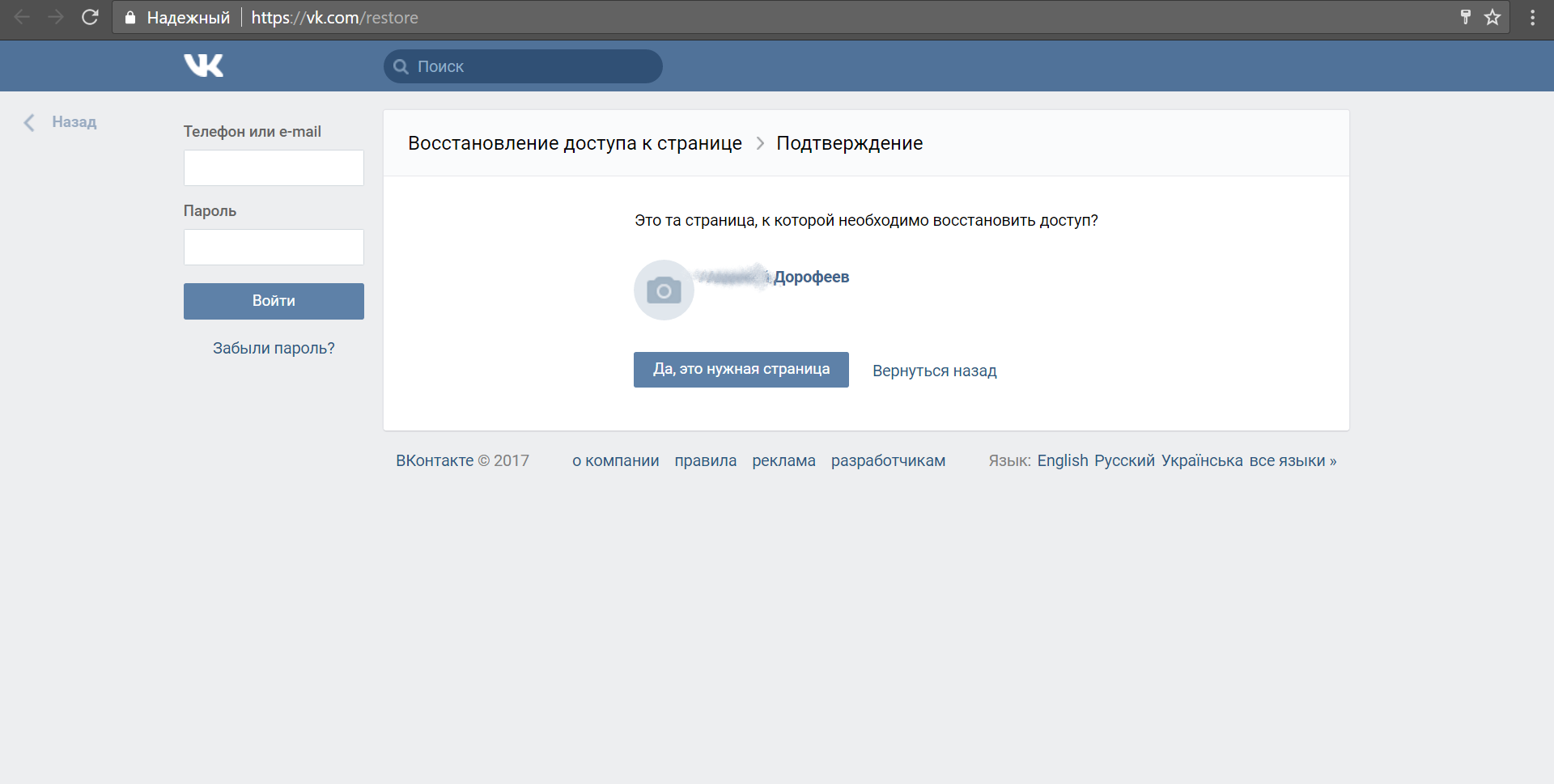
inurl:ник site:mail.ruЕсли мы знаем, как выглядит человек, знаем его имя или даже уже нашли его страницу в социальной сети ВКонтакте (наш случай), то задача проверки принадлежности определенного email-адреса значительно упрощается. Мы можем воспользоваться механизмом восстановления доступа к странице. Нам потребуется удача: пользователь с таким адресом должен существовать, ну и разместить свое фото.
Давайте проверим четыре варианта адресов для ника «adorofeev» и увидим, что для двух адресов страниц не существует вовсе, для одного – другое имя:
А вот для соответствующего адреса на Gmail.com мы находим страницу автора:
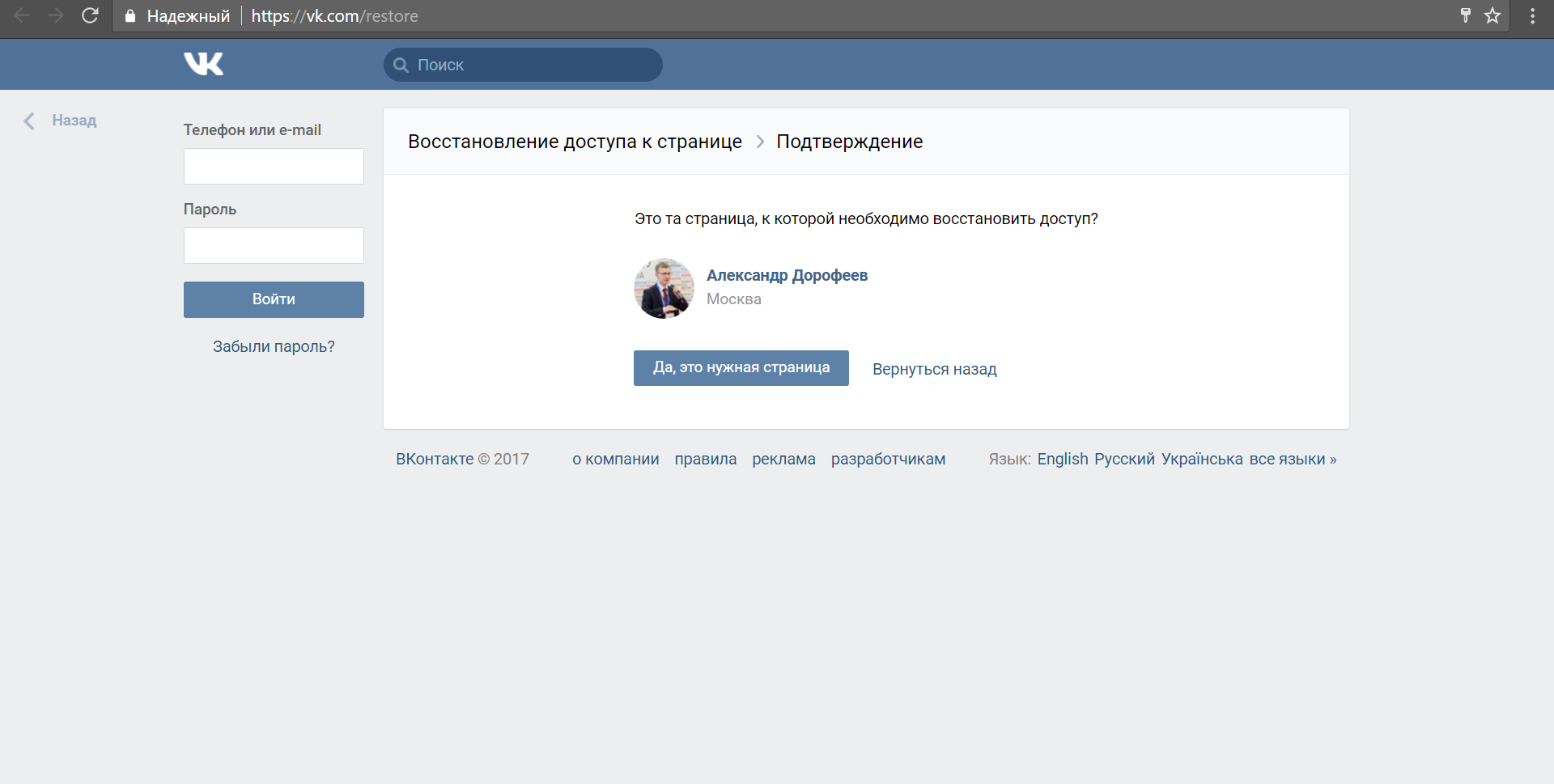
Итак, мы вычислили реальный личный адрес электронной почты.
Как вычислить корпоративный адрес электронной почты?
Здесь ситуация намного проще. Все дело в том, что многие организации имеют свои правила формирования имен учетных записей электронной почты, которые не отличаются особым разнообразием: инициалы + фамилия, первая буква имени + фамилия и т.п. Нам нужно лишь понять какое правило используется в конкретной компании, чтобы по нему сформировать адрес нужного нам человека.
Отправляем в Google запрос следующего вида:
email @доменПролистывая результаты выдачи, находим индивидуальные адреса сотрудников и все становится очевидным.
Как вычислить пользователя instagram по гео-меткам?
Теперь попробуем вычислить аккаунт автора в Instagram. Сначала проверяем самые очевидные варианты: https://www.instagram.com/adorofeev/, https://www.instagram.com/alexdorofeeff и https://www.instagram.com/alexdorofeev/ Видим, что это не те аккаунты.
Определив, что человек работает в конкретной компании, мы можем искать фотографии с соответствующей гео-меткой. В нашем случае это будет «НПО Эшелон».
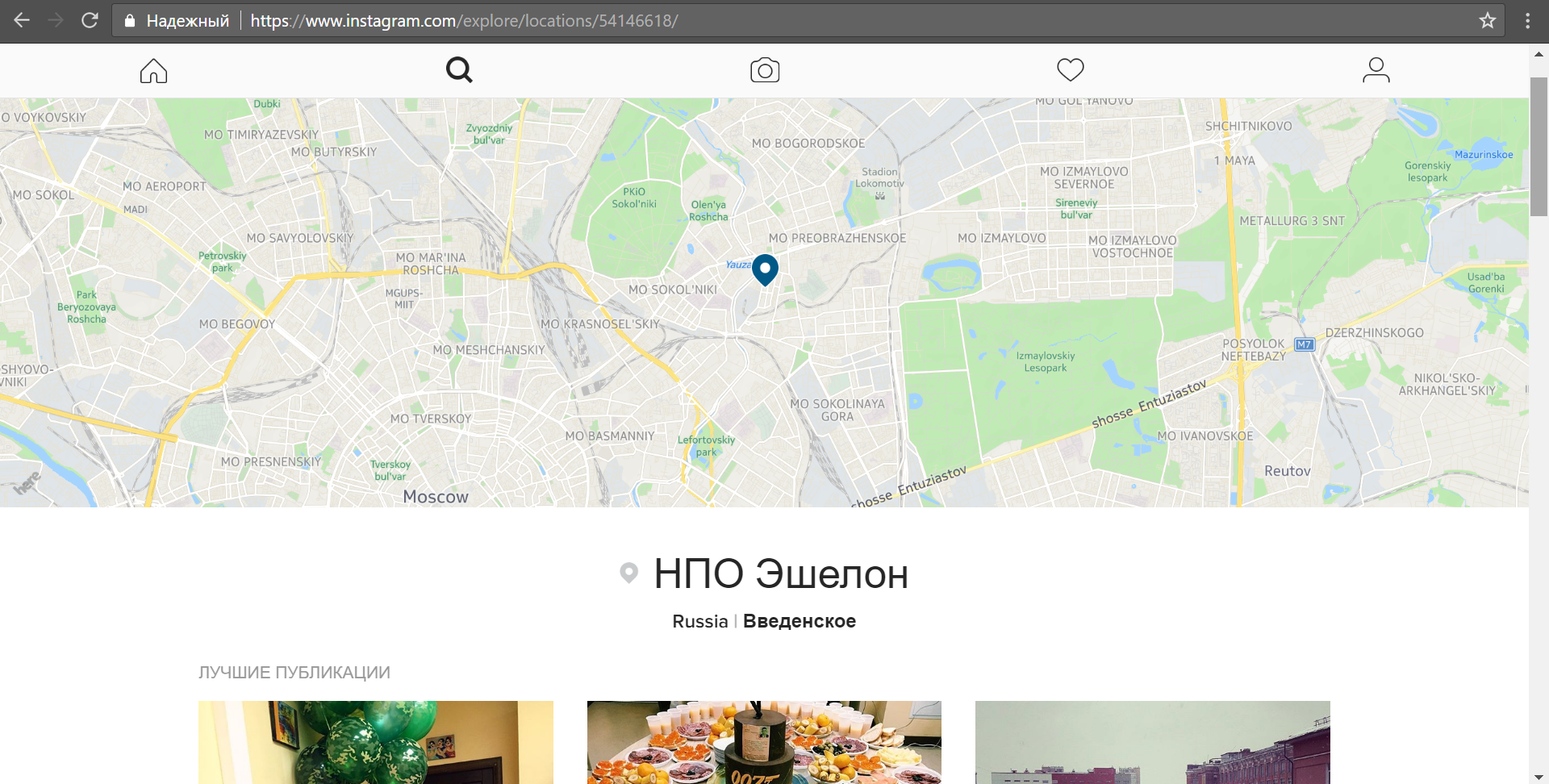
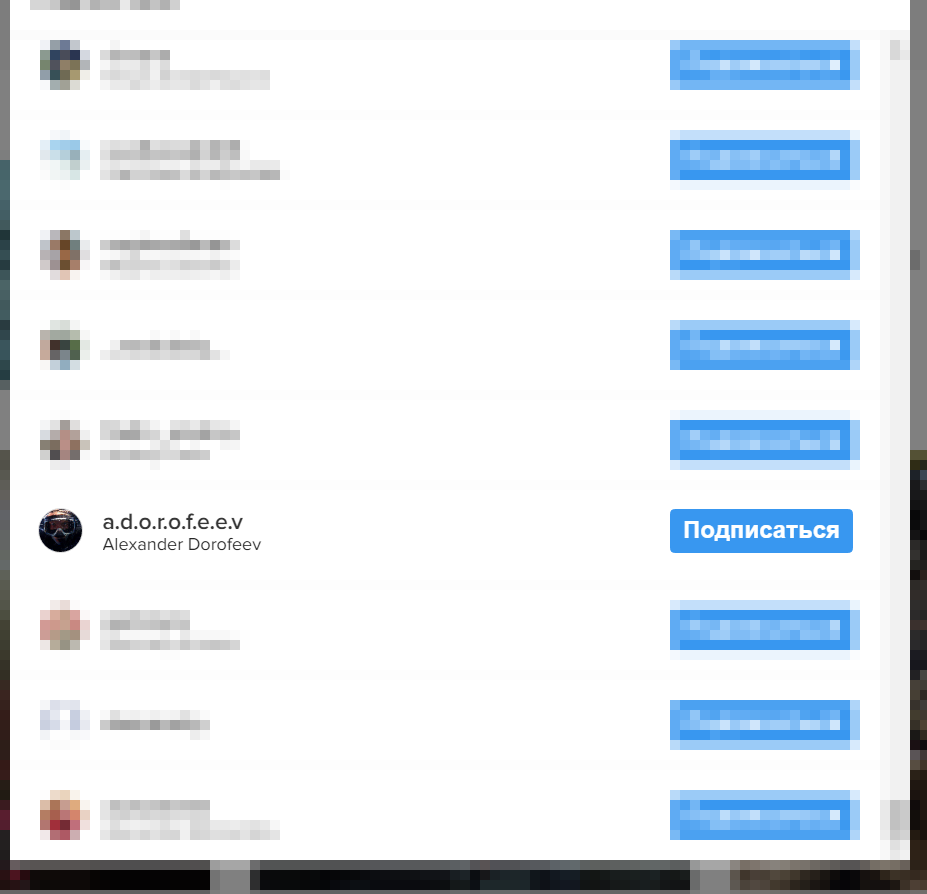
Мы видим, что публикации с данной гео-меткой в основной своей массе сделаны сотрудниками компании. Логично предположить, что среди подписчиков многих сотрудников компании «Эшелон» должен быть и аккаунт автора, который мы без труда и находим:
Как пользоваться машиной времени?
Проведя аналогичный анализ в отношении аккаунта в twitter, можно обнаружить, что автор вел сайт adorofeev.ru, который сейчас не доступен. Что делать в этой ситуации? Ведь материалы исчезнувшего сайта могут представлять реальный интерес. В практике автора была ситуация, когда подобный исчезнувший сайт содержал опубликованные материалы уголовного дела, с которым было интересно ознакомиться.
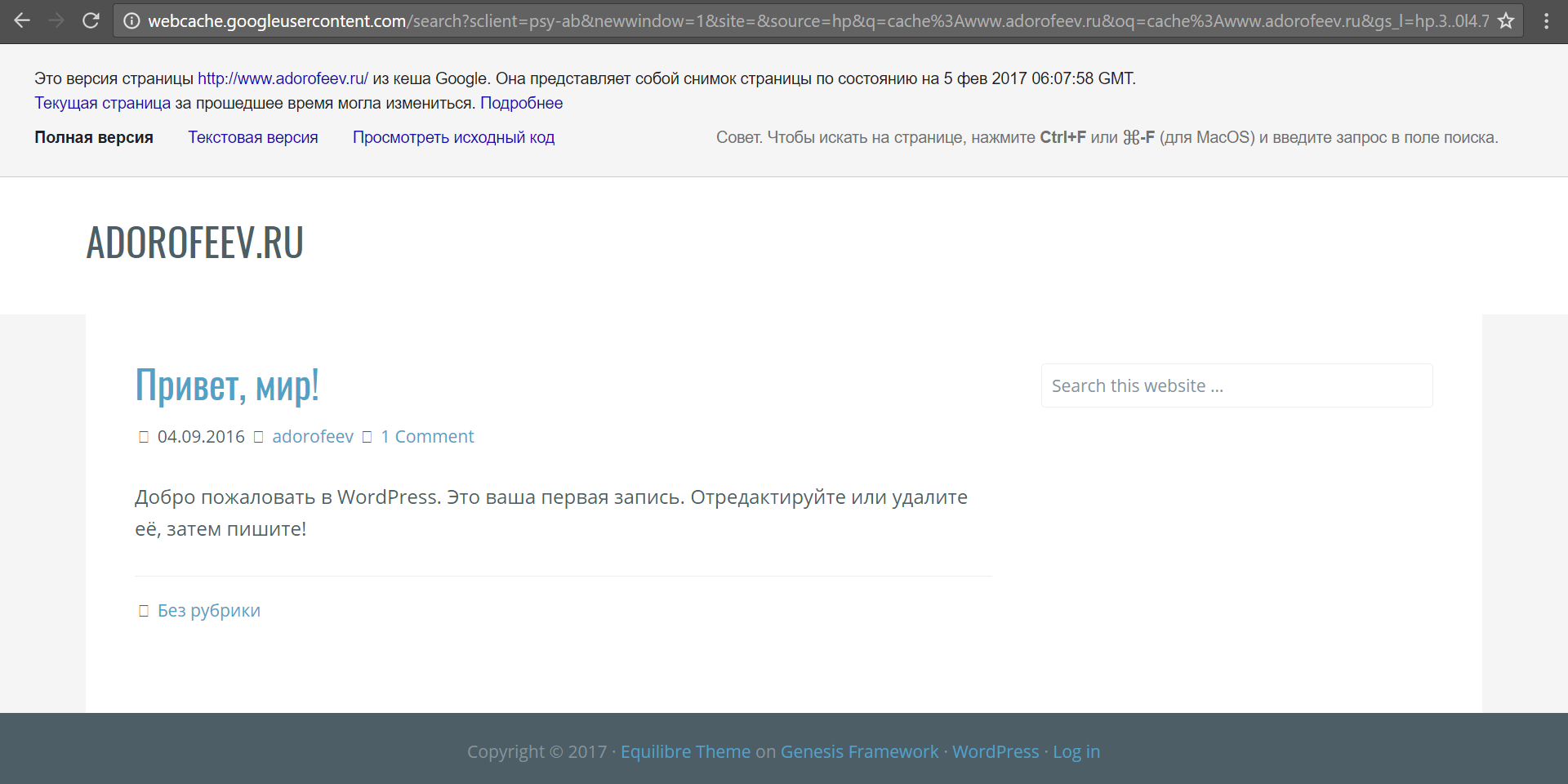
Если сайт выключили совсем недавно, то нам может помочь опять таки Google, предлагающий оператор cache: с помощью которого можно извлечь закэшированные страницы, добытые поисковиком.
cache:www.adorofeev.ru/Мы видим, что сайт 5-го февраля еще был включен, но ничего интересного из себя не представлял.
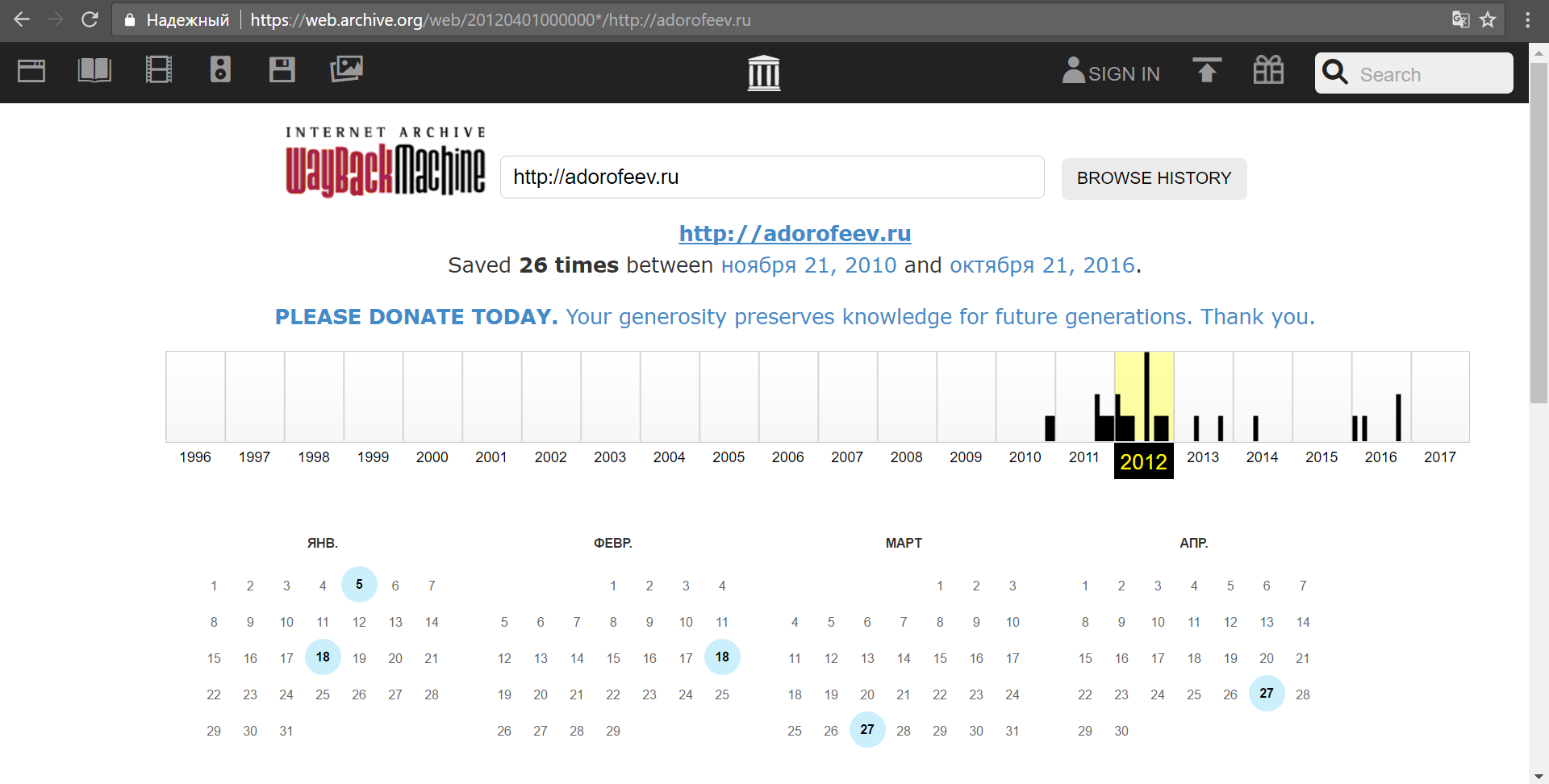
Очень хочется заглянуть в более далекое прошлое – на несколько лет назад. Для этого подошла бы машина времени и, как ни странно, она есть и доступна любому любознательному пользователю по адресу: https://archive.org/web/
«Пробивая» сайт автора, можно увидеть, что в прошлом там были какие-то материалы:
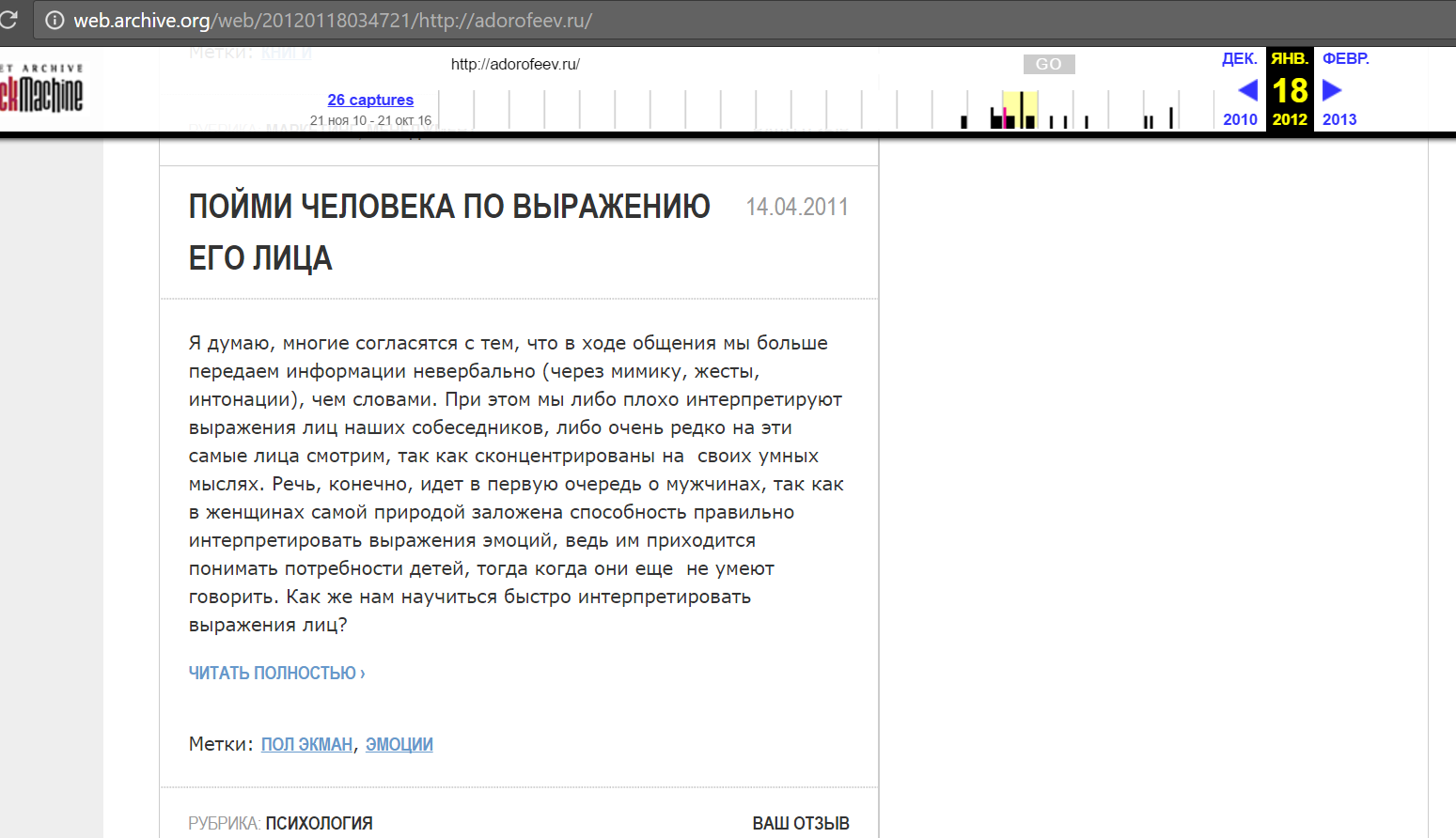
Причем, выбрав определенные даты, можно увидеть контент сайта на конкретный момент:
Вместо заключения: несколько слов об автоматизации процесса и других операторах Google
Можно ли процесс поиска интересной информации с помощью Google автоматизировать? Можно, и неплохие попытки уже есть: скрипт theHarvester.
Надо отметить, что Google это не приветствует и борется, поэтому надежность результатов применения всевозможных скриптов придется дополнительно проверять. Даже просто играясь с вполне легальными операторами, которые мы рассмотрели выше, вы постоянно будете видеть капчу и будете доказывать, что вы не робот.
Статья получилась довольно объемной и мы не стали рассматривать многие другие операторы продвинутого поиска Google , которые могут быть также полезны в интернет-разведке. Если применение операторов в подобном ключе интересно, то мы обязательно продолжим эту тему в одной из следующих статей.
Литература
- Что в имени тебе моем: как качественно «пробить» человека в сети Интернет?
- Интернет-разведка в действии: who is Mr./Ms. Habraman?
- Social Media in Identifying Threats to Ensure Safe Life in a Modern City Aleksandr Dorofeev, Alexey Markov, Valentin Tsirlov
- Google Hacking for Penetration Testers, Third Edition 3rd Edition by Johnny Long, Bill Gardner, Justin Brown.

SEO,Performance Marketing
29 июня 2020
Давайте сегодня немного поиграем в частных детективов. Все знают что в сети интернет достаточно легко растворится и быть практически анонимным. Но иногда высплывают задачи по поиску человека в сети и всем что с ним связано. Очень часто некоторые сайты размещают заведомо ложную или компрометирующую информацию и комуто нужно найти хозяина сайта. А что делать если в контактах есть только форма обратной связи? Казалось бы — ситуация патова. Но сегодня мы расскажем как найти хозяина сайта с помощью специальных сервисов.
Допустим, вы нашли в сети анонимный веб-сайт и хотите узнать, кто его создал. Воспользовавшись уникальным кодом, вы можете найти связь между этим ресурсом и другими сайтами и даже узнать, кто является их собственником. С правильными инструментами найти интересующую вас информацию будет очень легко.
Как найти хозяина сайта по коду на странице
При помощи популярного сервиса Google Analytics веб-разработчики собирают данные о посещаемости (такие как страна, тип браузера и оперативной системы) по пользователям разных доменов. Для этого в html-код каждой страницы добавляется уникальный идентификационный номер (код) – именно благодаря ему можно проследить связь между различными сайтами. По такому же принципу работают Google AdSense, Amazon и AddThis.
Существует несколько ресурсов, позволяющих выполнить обратный поиск этого уникального кода и найти связанные сайты. Лично мне больше всего нравится работать с sameid.net (производит поиск не только по коду Analytics и AdSense, но и по коду Amazon, Clickbank и Addthis) и с spyonweb.com. SpyOnWeb совершенно бесплатный, а вот на SameID без оплаты предоставляются только пять запросов в день.

Более продвинутым пользователям могу посоветовать ресурс NerdyData search.nerdydata.com, который ищет совпадения по любому введенному фрагменту кода. В платной версии есть очень удобная функция сохранения результатов поиска. Но иногда этот сайт отображает один и тот же результат несколько раз, и из-за этого на поиск уходит много времени.
Meanpath.com – аналогичный по функциональности сайт для поиска кодов, в бесплатной версии выводится не более 100 результатов.
Советую использовать сразу несколько инструментов, потому что они иногда предоставляют разные результаты. В ходе эксперимента я выяснил, что SpyOnWeb выдает меньше результатов, чем SameID, а в Meanpath было два результата, которых не нашли ни SpyOnWeb, ни SameID.
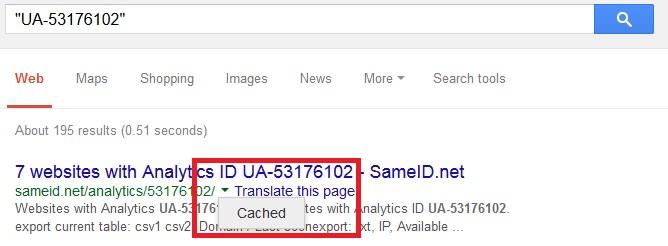
Еще коды Analytics или AdSense можно ввести в поиск в Google – только не забудьте заключить их в кавычки (например, “UA-12345678”). Таким образом вы получите результаты обратного поиска из других инструментов. Кроме того, если адрес или код Analytics сайта недавно был изменен, через Google вам, возможно, удастся найти сохраненные в кэш результаты из сервисов по типу SameID и все-таки выйти на связанный сайт. Чтобы просмотреть сохраненную копию, нажмите на зеленую направленную вниз стрелку рядом с результатом:
Сверка с кодом страницы
Результаты, выданные средствами поиска по коду, необходимо проверить. Делается это просто – при просмотре кода домашней страницы веб-сайта.
Для этого в браузерах Firefox, Chrome, Internet Explorer и Opera нажмите правой кнопкой мыши на любое место на странице и в появившемся контекстном меню выберите View Source или Source (Просмотр кода страницы / Исходный код / Просмотр HTML-кода).
В браузере Safari для этого нужно открыть меню Page (Страница) в правом верхнем углу окна и выбрать аналогичную команду.

После этого появится окно с исходным кодом – в нем мы будем искать код Analytics. Для этого выберите Edit (Изменить / Редактировать) > Find (Найти) или воспользуйтесь комбинацией клавиш CTRL + F для Windows (аналогичная комбинация для Mac: ? + F). Введите в строку поиска следующие теги:
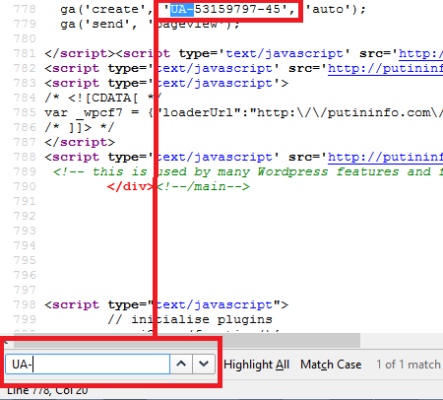
Поиск связанных сайтов через сервисы WHOIS
Из данных о том, на кого зарегистрирован домен, мы можем извлечь ценную информацию о лицах, связанных с интересующим нас сайтом. Эти данные включают имена, адреса электронной почты, почтовые адреса, номера телефонов. Конечно, не исключено, что они уже устарели, но для нас это не принципиально – мы просто ищем связь между сайтами.
Существует множество сервисов WHOIS, рекомендую вам всегда проверять найденную информацию по нескольким сервисам. Мне нравится who.is, который отображает как историю регистрации сайта, так и текущие данные. Это оказывается особенно полезным в том случае, если сайт недавно был переведен на анонимную регистрацию.

Есть еще whois.domaintools.com, где, помимо прочего, указаны тип и версия серверного программного обеспечения, используемого на сайте, и примерное количество размещенных на нем изображений. Whoisology выдает не только архивные результаты, но и домены, зарегистрированные по определенным адресам электронной почты.

Некоторые сервисы WHOIS не распознают кириллические URL-адреса. Для преобразования адреса воспользуйтесь этим инструментом: Verisign IDN Conversion Tool.
Использование метаданных
Основная масса изображений и документов, загруженных в сеть, содержит метаданные – информацию, записанную при создании или редактировании файла. Один из журналистов Bellingcat Мелисса Хэнхем уже написала о том, как использовать метаданные при геолокации. Нас же интересует, как метаданные помогут нам найти связанные сайты.
В социальных сетях, таких как Facebook и Twitter, метаданные удаляются автоматически, но на большинстве других ресурсов такого нет. Метаданные часто сохраняются на небольших веб-сайтах и в блогах.
Два, на мой взгляд, наиболее удобных инструмента для просмотра метаданных – fotoforensics.com (только для фотографий) и Jeffrey’s EXIF Viewer (также анализирует документы, в том числе PDF, Word и OpenOffice.)

Существует много разных видов метаданных, но нас в первую очередь интересуют EXIF, Maker Notes, ICC Profile, Photoshop и XMP.
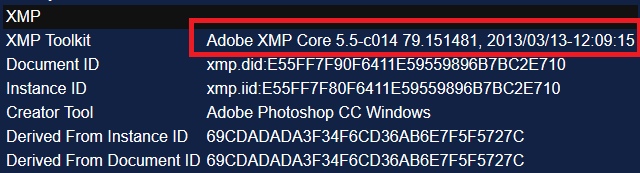
В них содержится такая информация, как точная версия редактора изображений. Например, в поле XMP «Creator Tool» может стоять «Microsoft Windows Live Photo Gallery 15.4.3555.308». В поле «XMP Toolkit» часто отображаются похожие данные, например «Adobe XMP Core 5.3-c011 66.145661, 2012/02/06-14:56:27». Главное – выбрать поля, где указана конкретная и подробная информация. При анализе фотографии иногда отображается модель фотоаппарата, на который она была сделана (например, «KODAK DX4330 DIGITAL CAMERA»).
Разумеется, одна и та же версия Photoshop или одинаковый фотоаппарат могут быть у миллионов разных людей, так что эту информацию следует использовать только при наличии других надежных доказательств, таких как код Google Analytics. Но в метаданных документа встречаются и более конкретные сведения, например имя автора.

Иногда в метаданных фотографии даже может быть указан уникальный серийный номер фотоаппарата. Проведите обратный поиск по такой информации при помощи инструментов stolencamerafinder.com и cameratrace.com, чтобы найти другие снимки, сделанные этим же устройством.
Сохранение страниц
Часто бывает такое, что веб-контент неожиданно изменяется или исчезает – а вместе с ним и все важные для нас коды Analytics. К счастью, у нас есть возможность сохранять веб-страницы. Предпочтительно сохранять не только сайты, которые вы изучаете, но и результаты поиска из SameID и других сервисов.
Для быстрого и удобного сохранения воспользуйтесь Internet Archive Wayback Machine. После архивации содержание страницы нельзя изменить, так что вряд ли кто-то возьмется оспаривать ее подлинность.

Кроме того, Wayback Machine вставляет дату и время в код архивированной страницы, так что этому инструменту доверяют даже криминалисты.

Сервис WebCite похож на Wayback Machine, но здесь пользователю разрешается редактировать некоторые данные. Для просмотра кода архивной страницы вместо View Source вам придется использовать View Frame Source (This Frame в браузере Firefox). Но плюсы у этого сервиса тоже есть – он отправляет адреса архивированных страниц в ваш почтовый ящик. Существует также Archive.is, он очень удобен для сохранения профилей из социальных сетей.
Есть одна загвоздка – все эти инструменты позволяют архивировать вручную только отдельные страницы, но не весь сайт. Кроме того, они не будут работать, если ресурс защищен от поисковых роботов или автоматического копирования контента с целью его размещения на других сайтах. В этом случае лучше всего будет сохранить отдельные страницы на компьютер и/или сделать скриншот. Я пользуюсь бесплатным инструментом Web Page Saver с сайта Magnet Forensics, хотя в некоторых случаях подойдут также Windows Snipping Tool и DropBox.
Кроме того, имеет смысл вручную добавить страницу в индекс Google. Тогда она с больше вероятностью будет сохранена в кэш Google, где вы потом сможете ее найти.
Графическое отображение
Если вы изучаете большую группу сайтов, то в связях между ними легко запутаться. Для удобства организуйте их в диаграмму.
Бесплатное приложение yEd Graph Editor (для операционных систем Windows, OS X и Linux) – очень удобный инструмент для составления как простых, так и сложных графиков и диаграмм. Чтобы сделать диаграмму, просто перетащите иконки мышкой в нужное место и обозначьте связь между ними.



Для начала внесите все элементы, которые вам удалось найти: адреса сайтов, имена, названия организаций и уникальные коды. Если вы узнали что-то новое, не забудьте добавить эту информацию в диаграмму. В приложении yEd есть иконки, обозначающие компьютеры, файлы, людей и т. д., так что можете дать волю креативности.
Выбор диаграмм и графиков достаточно большой. В этом примере я воспользовался диаграммами Circular и BCC Isolated, отобразив в виде круга сайты, каждый из которых связан с расположенным в центре кодом Analytics.
Выводы
В этой статье мы рассмотрели открытые источники информации и инструменты, которые показывают как найти хозяина сайта и позволяют найти связь между сайтами, на первый взгляд не имеющими ничего общего. Мы также выяснили, что чтобы никто не сомневался в результатах нашего расследования, необходимо искать подтверждение в других источниках и всегда сохранять найденные страницы.
