Как найти похожую картинку, фотографию, изображение в интернет
12.07.2019
Допустим у Вас есть какое-то изображение (рисунок, картинка, фотография), и Вы хотите найти такое же (дубликат) или похожее в интернет. Это можно сделать при помощи специальных инструментов поисковиков Google и Яндекс, сервиса TinEye, а также потрясающего браузерного расширения PhotoTracker Lite, который объединяет все эти способы. Рассмотрим каждый из них.
Поиск по фото в Гугл
Тут всё очень просто. Переходим по ссылке https://www.google.ru/imghp и кликаем по иконке фотоаппарата:

Дальше выбираем один из вариантов поиска:
- Указываем ссылку на изображение в интернете
- Загружаем файл с компьютера
На открывшейся страничке кликаем по ссылке «Все размеры»:

В итоге получаем полный список похожих картинок по изображению, которое было выбрано в качестве образца:

Есть еще один хороший способ, работающий в браузере Chrome. Находясь на страничке с интересующей Вас картинкой, подведите к ней курсор мыши, кликните правой клавишей и в открывшейся подсказке выберите пункт «Найти картинку (Google)»:

Вы сразу переместитесь на страницу с результатами поиска!
Статья по теме: Поисковые сервисы Google, о которых Вы не знали!
Поиск по картинкам в Яндекс
У Яндекса всё не менее просто чем у Гугла 🙂 Переходите по ссылке https://yandex.by/images/ и нажимайте значок фотоаппарата в верхнем правом углу:

Укажите адрес картинки в сети интернет либо загрузите её с компьютера (можно простым перетаскиванием в специальную области в верхней части окна браузера):
![]()
Результат поиска выглядит таким образом:
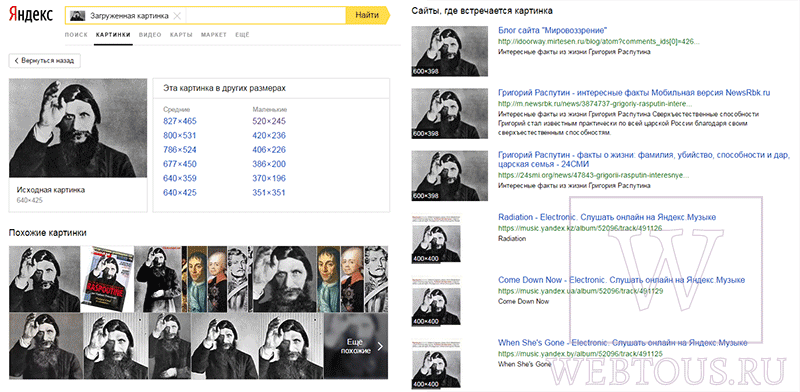
Вы мгновенно получаете доступ к следующей информации:
- Какие в сети есть размеры изображения, которое Вы загрузили в качестве образца для поиска
- Список сайтов, на которых оно встречается
- Похожие картинки (модифицированы на основе исходной либо по которым алгоритм принял решение об их смысловом сходстве)
Поиск похожих картинок в тинай
Многие наверняка уже слышали об онлайн сервисе TinEye, который русскоязычные пользователи часто называют Тинай. Он разработан экспертами в сфере машинного обучения и распознавания объектов. Как следствие всего этого, тинай отлично подходит не только для поиска похожих картинок и фотографий, но их составляющих.
Проиндексированная база изображений TinEye составляет более 10 миллиардов позиций, и является крупнейших во всем Интернет. «Здесь найдется всё» — это фраза как нельзя лучше характеризует сервис.

Переходите по ссылке https://www.tineye.com/, и, как и в случае Яндекс и Google, загрузите файл-образец для поиска либо ссылку на него в интернет.

На открывшейся страничке Вы получите точные данные о том, сколько раз картинка встречается в интернет, и ссылки на странички, где она была найдена.
PhotoTracker Lite – поиск 4в1
Расширение для браузера PhotoTracker Lite (работает в Google Chrome, Opera с версии 36, Яндекс.Браузере, Vivaldi) позволяет в один клик искать похожие фото не только в указанных выше источниках, но и по базе поисковика Bing (Bing Images)!
Скриншот интерфейса расширения:
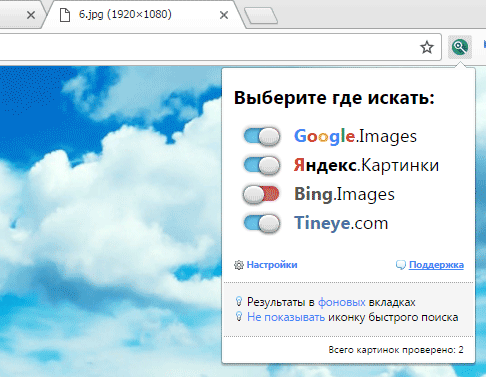
В настройках приложения укажите источники поиска, после чего кликайте правой кнопкой мыши на любое изображение в браузере и выбирайте опцию «Искать это изображение» PhotoTracker Lite:
![]()
Есть еще один способ поиска в один клик. По умолчанию в настройках приложения активирован пункт «Показывать иконку быстрого поиска». Когда Вы наводите на какое-то фото или картинку, всплывает круглая зеленая иконка, нажатие на которую запускает поиск похожих изображений – в новых вкладках автоматически откроются результаты поиска по Гугл, Яндекс, Тинай и Бинг.

Расширение создано нашим соотечественником, который по роду увлечений тесно связан с фотографией. Первоначально он создал этот инструмент, чтобы быстро находить свои фото на чужих сайтах.
Когда это может понадобиться
- Вы являетесь фотографом, выкладываете свои фото в интернет и хотите посмотреть на каких сайтах они используются и где возможно нарушаются Ваши авторские права.
- Вы являетесь блогером или копирайтером, пишите статьи и хотите подобрать к своему материалу «незаезженное» изображение.
- А вдруг кто-то использует Ваше фото из профиля Вконтакте или Фейсбук в качестве аватарки на форуме или фальшивой учетной записи в какой-либо социальной сети? А ведь такое более чем возможно!
- Вы нашли фотографию знакомого актера и хотите вспомнить как его зовут.
На самом деле, случаев, когда может пригодиться поиск по фотографии, огромное множество. Можно еще привести и такой пример…
Как найти оригинал заданного изображения
Например, у Вас есть какая-то фотография, возможно кадрированная, пожатая, либо отфотошопленная, а Вы хотите найти её оригинал, или вариант в лучшем качестве. Как это сделать? Проводите поиск в Яндекс и Гугл, как описано выше, либо средствами PhotoTracker Lite и получаете список всех найденных изображений. Далее руководствуетесь следующим:
- Оригинальное изображение, как правило имеет больший размер и лучшее качество по сравнению с измененной копией, полученной в результате кадрирования. Конечно можно в фотошопе выставить картинке любой размер, но при его увеличении относительно оригинала, всегда будут наблюдаться артефакты. Их можно легко заметить даже при беглом визуальном осмотре.
Статья в тему: Как изменить размер картинки без потери в качестве.
- Оригинальные фотографии часто имеют водяные знаки, обозначающие авторство снимка (фамилия, адрес сайта, название компании и пр.). Конечно водяной знак может добавить кто угодно на абсолютно на любое изображение, но в этом случае можно поискать образец фото на сайте или по фамилии автора, наверняка он где-то выкладывает своё портфолио онлайн.
- И наконец, совсем простой признак. Если Ваш образец фото черно-белый (сепия и пр.), а Вы нашли такую же, но полноцветную фотографию, то у Вас явно не оригинал. Добавить цветность ч/б фотографии гораздо более сложнее, чем перевести цветную фотографию в черно-белую 🙂
Уважаемые читатели, порекомендуйте данный материал своим друзьям в социальных сетях, а также задавайте свои вопросы в комментариях и делитесь своим мнением!
Похожие публикации:
- 3 способа изменить шрифт в Telegram
- Можно ли включить плагины NPAPI в браузере Хром?
- Что делать, если Хром не хочет обновляться до свежей версии?
- Как раз и навсегда поставить обновления Windows 10 под полный контроль
- Как решить проблему нечеткого размытого шрифта в новых версиях Google Chrome
Понравилось? Поделитесь с друзьями!

Сергей Сандаков, 42 года.
С 2011 г. пишу обзоры полезных онлайн сервисов и сайтов, программ для ПК.
Интересуюсь всем, что происходит в Интернет, и с удовольствием рассказываю об этом своим читателям.
Определяйте породу
соседской кошки, вид
растения или
малоизвестного животного,
даже если это трубкозуб

Яндекс подскажет название фильма, картины или музея, а ещё распознает знаменитость, будь то Симба
или Мик Джаггер

С поиском по фото
можно найти похожее
кресло или узнать, где
купить кроссовки
с картинки среди товаров
на Яндекс.Маркете
Разбираться в искусстве,
языках и технологиях


Яндекс определит название
музея или напомнит автора
картины

Умная камера покажет
контакты, текст или ссылку по QR-коду, а приложение Яндекс с ней — поможет
оплатить услуги ЖКХ
и получить кэшбэк в Едадиле

Распознавание текста
поможет скопировать
его в документ или
отправить в поиск,
а перевод — понять меню
в азиатском ресторане
Найти что-то похожее
или уникальное


Нашли фото красивой
квартиры в объявлении
о сдаче в аренду — проверьте,
не скопирована ли она
с других сайтов

Ищите вдохновение,
просматривая похожие
фото интерьеров, природы
или детских поделок
Подбирайте картинки
нужного размера — для
аватарки или рабочего
стола
Как найти и сравнить похожие изображения автоэнкодером
Время на прочтение
10 мин
Количество просмотров 3.8K
Привет, Хабр!
Меня зовут Владимир Паймеров, я Data Scientist и являюсь участником профессионального сообщества NTA.
Играл ли ты в детстве в игру, в которой необходимо было найти отличия на изображениях? Сегодня рассмотрю похожую задачу, называемую поиском изображений, в которой нужно будет найти все похожие изображения из датасета на загруженную фотографию из того же датасета.

Модель поиска похожих изображений
Поиск похожих изображений – очень активная и быстро развивающаяся область исследований в последнее десятилетие. Исследования в данной области позволили разработать модели, которые могут помочь в работе в различных областях, например:
-
чтобы найти похожие изображения;
-
поиск фотографий-плагиатов;
-
создание возможностей для обратных ссылок;
-
знакомство с людьми, местами и продуктами;
-
поиск товаров по фотографии;
-
обнаружение поддельных аккаунтов, поиск преступников и т.д.
Наиболее известными системами являются Google Image Search и Pinterest Visual Pin Search. Познакомлю с созданием очень простой системы поиска похожих изображений с использованием специального типа нейронной сети, называемой автоэнкодер.
Изображения в данном способе не используют меток, т.е. дополнительных текстовых или числовых элементов, которые классифицируют изображения по категориям. Извлечение признаков из изображения будет происходить только с помощью их визуального содержимого (текстуры, формы, …). Этот тип извлечения изображений называется поиск изображений на основе содержимого (CBIR), в отличие от поиска ключевых слов или изображений на основе текста.
CBIR при использовании глубокого обучения и поиска изображений можно назвать формой обучения без учителя:
-
При обучении автоэнкодера не используется никаких меток для классов
-
Автоэнкодер используется для преобразования изображения в векторное представление (т. е. нашего “вектора признаков” для данного изображения)
-
Затем, во время поиска похожих изображений, вычисляется расстояние между векторами преобразованных изображений — чем меньше расстояние, тем более релевантными/визуально похожими являются два изображения.
Расскажу информацию по следующим разделам:
1) Загрузка данных и работа с данными
2) Сверточные автоэнкодеры для извлечения признаков из изображения
3) Построение модели подобия изображений при помощи K ближайших соседей
4) Использование предобученных моделей для извлечения признаков из изображения
5) Выводы
Загрузка данных и работа с ними
Для построения модели нужны данные – изображения, с которыми будет проведена работа. В качестве данных был использован открытый набор изображений, который называется Caltech-101, который содержит около 9000 изображений, которые разделены на 101 тему (самолеты, машины, животные и т.д.).
Работа начинается с импорта необходимых библиотек и модулей из Keras и Tensorflow.
import os
import keras
from keras.preprocessing import image
from keras.applications.imagenet_utils import decode_predictions, preprocess_input
from keras.models import Model
from tensorflow.keras import applications
import tensorflow as tf
from tensorflow.keras.models import save_model
import tensorflow.keras.layers as L
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import cv2
import pandas as pd
import tqdm
from skimage import io
import glob
После импорта библиотек нужно загрузить сами изображения. Для этого нужно полностью прописать путь до папки, где хранятся изображения, и создать список из путей до каждого изображения.
path ="/Users/Desktop/Python_Scripts/101_ObjectCategories"
#we shall store all the file names in this list
filelist = []
for root, dirs, files in os.walk(path):
for file in files:
#append the file name to the list
filelist.append(os.path.join(root,file))
Далее, при помощи написанной функции было загружено 200 изображений (для экономии времени и ресурсов компьютера, если характеристики компьютера позволяют, то можно загрузить все 9000). Для этого были выполнены следующие шаги:
1) Чтение изображений с помощью открытого модуля cv2;
2) Преобразование изображений из BGR (синий, зеленый, красный) в RGB (красный, зеленый, синий);
3) Изменение размера формы изображения на (224,224,3);
4) Нормализация данных.
def image2array(filelist):
image_array = []
for image in filelist[:200]:
img = io.imread(image)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224,224))
image_array.append(img)
image_array = np.array(image_array)
image_array = image_array.reshape(image_array.shape[0], 224, 224, 3)
image_array = image_array.astype('float32')
image_array /= 255
return np.array(image_array)
train_data = image2array(filelist)
print("Length of training dataset:", train_data.shape)
В датасете почти ~ 9 тыс. изображений. Загрузка его в оперативную память и обработка каждого изображения с любым другим изображением потребует больших вычислительных затрат и может привести к сбою системы (GPU или TPU), или запуск модели будет очень дорогостоящим с вычислительной точки зрения.
Таким образом, в качестве решения можно интегрировать как сверточные нейронные сети, так и идеи автоэнкодирования для уменьшения информации из данных на основе изображений. Это будет рассматриваться как этап предварительной обработки для применения к кластеру.
Сверточные автоэнкодеры для извлечения признаков из изображения

Сверточные автоэнкодеры (CAEs) – это тип сверточных нейронных сетей. Основное различие между ними заключается в том, что CAE – это неконтролируемые модели обучения (без учителя).
Он пытается сохранить пространственную информацию входных данных изображения такой, какая она есть, и аккуратно извлекать информацию.
-
Энкодеры: преобразование входного изображения в представление скрытого пространства с помощью серии сверточных операций.
-
Декодеры: пытаются восстановить исходное изображение из скрытого пространства с помощью серии операций свертки с повышением дискретизации / транспонирования. Также известен как деконволюция.
Подробнее о сверточных автокодерах можно прочитать здесь.
Сам автоэнкодер строится при помощи соединения сверточных слоев и слоёв пуллинга, которые уменьшают размерность изображения (сворачивают его) и извлекают наиболее важные признаки. На выходе возвращаются encoder и decoder. Для задачи кодирования изображения в вектор, нам нужен слой после автоэнкодера, т.е. векторное представление изображения, которое в дальнейшем будет использоваться для поиска похожих изображений.
Применение функции summary() к модели покажет описание работы модели слой за слоем. Нужно следить за тем, чтобы размер изображения на входе соответствовал размеру изображения на выходе декодера.
IMG_SHAPE = x.shape[1:]
def build_deep_autoencoder(img_shape, code_size):
H,W,C = img_shape
# encoder
encoder = tf.keras.models.Sequential() # инициализация модели
encoder.add(L.InputLayer(img_shape)) # добавление входного слоя, размер равен размеру изображения
encoder.add(L.Conv2D(filters=32, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=64, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=128, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Conv2D(filters=256, kernel_size=(3, 3), activation='elu', padding='same'))
encoder.add(L.MaxPooling2D(pool_size=(2, 2)))
encoder.add(L.Flatten())
encoder.add(L.Dense(code_size))
# decoder
decoder = tf.keras.models.Sequential()
decoder.add(L.InputLayer((code_size,)))
decoder.add(L.Dense(14*14*256))
decoder.add(L.Reshape((14, 14, 256)))
decoder.add(L.Conv2DTranspose(filters=128, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=64, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=32, kernel_size=(3, 3), strides=2, activation='elu', padding='same'))
decoder.add(L.Conv2DTranspose(filters=3, kernel_size=(3, 3), strides=2, activation=None, padding='same'))
return encoder, decoder
encoder, decoder = build_deep_autoencoder(IMG_SHAPE, code_size=32)
encoder.summary()
decoder.summary()

Параметры и обучение модели:
inp = L.Input(IMG_SHAPE)
code = encoder(inp)
reconstruction = decoder(code)
autoencoder = tf.keras.models.Model(inputs=inp, outputs=reconstruction)
autoencoder.compile(optimizer="adamax", loss='mse')
autoencoder.fit(x=train_data, y=train_data, epochs=10, verbose=1)В качестве оптимизатора модель использует ‘adamax’, в качестве функции потерь метрику mse. Автоэнкодер проходит 10 эпох (т.е. 10 раз) по данным для лучшего обучения.
Извлечение признаков из изображения, как было сказано выше, состоит из того, что после того как сработал энкодер и перед обратным декодированием, нужно взять слой из модели, который отвечает за кодирование изображения и сохранить его. Таким образом, сохраняться все кодированные представления изображения.
images = train_data
codes = encoder.predict(images)
assert len(codes) == len(images)Построение модели подобия изображений при помощи K ближайших соседей (NearestNeighbours)
После получения представления сжатых данных всех изображений мы можем применить алгоритм N-ближайших соседей для поиска похожих изображений. Он основан на расчете евклидового расстояния между изображениями, те расстояния, которые будут меньше всего, будут означать, что изображения похожи.
from sklearn.neighbors import NearestNeighbors
nei_clf = NearestNeighbors(metric="euclidean")
nei_clf.fit(codes)Для отображения похожих изображений были написаны две функции, которые показывают 5 ближайших/похожих фотографий на ту, с которой идет сравнение.
def get_similar(image, n_neighbors=5):
assert image.ndim==3,"image must be [batch,height,width,3]"
code = encoder.predict(image[None])
(distances,),(idx,) = nei_clf.kneighbors(code,n_neighbors=n_neighbors)
return distances,images[idx]
def show_similar(image):
distances,neighbors = get_similar(image,n_neighbors=3)
plt.figure(figsize=[8,7])
plt.subplot(1,4,1)
plt.imshow(image)
plt.title("Original image")
for i in range(3):
plt.subplot(1,4,i+2)
plt.imshow(neighbors[i])
plt.title("Dist=%.3f"%distances[i])
plt.show()Результаты работы автоэнкодеров можно оценить положительно, т.к. были найдены похожие фотографии:

(первое изображение то же самое, т.к. фотография сравнивает с изображениями из одного датасета)

Использование предобученных моделей для извлечения признаков из изображения
Помимо использования автоэнкодеров для получения признаков из изображения можно использовать уже предобученные модели для классификации. Таких моделей очень много, и они также используют сверточные слои и слои пуллинга для получения признаков. Возникает логичный вопрос, зачем же тогда использовать автоэнкодеры?
Во-первых, предобученные модели могли быть созданы для других целей и могут не подойти по входным параметрам или по самой конструкции нейронной сети для вашей задачи, поэтому придется её перестраивать или строить сеть самому.
Во-вторых, предобученные модели на выходе могут получать не тот размер изображения, который нужен и при загрузке датасета и преобразовании изображений в вектор может не хватить памяти и мощности компьютера, а также это будет занимать много времени. Поэтому, если использовать предобчуенные модели, то нужно использовать метод понижения размерности PCA, который уменьшит размерность полученных векторов и позволит не нагружать компьютер. При этом автоэнкодеры сразу понижают размерность и можно его настроить таким образом, чтобы на выходе получался вектор необходимого размера.
Плюсами применения предобученных моделей является то, что нет необходимости строить нейронную сеть, настраивать сверточные слои, нужно просто взять нужный слой и использовать его для своих целей. Также такие модели были обучены на больших датасетах и имеют лучшие веса (настройки) для извлечения необходимых признаков, они лучше выделяют важные области на изображении.
Для того, чтобы использовать предобученные модели, для начала их нужно загрузить. В качестве примеры, была взята модель VGG16 – сверточная сеть, с 13-ю слоями, которая была обучена на миллионных датасетах.
model = keras.applications.vgg16.VGG16(weights='imagenet', include_top=True)
model.summary()Для загрузки изображений была написана специальная функция:
def load_image(path):
img = image.load_img(path, target_size=model.input_shape[1:3])
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return img, xМодель VGG16 используется для классификации изображений, т.е. определение темы, к которой относится изображение (самолет, вертолет и т.д.), поэтому в конце она имеет слой для классификации. Все предыдущие слои сворачивают и кодируют изображение в вектор, поэтому они нужны. Данную модель можно полностью скопировать с удалением последнего слоя, таким образом получим модель, которая только кодирует изображение в вектор.
feat_extractor = Model(inputs=model.input, outputs=model.get_layer("fc2").output)
feat_extractor.summary()
После того как модель построена, применяем её к данным, получаем вектор признаков каждого изображения, применяем метод понижения размерности PCA.
import time
tic = time.perf_counter()
features = []
for i, image_path in enumerate(filelist[:200]):
if i % 500 == 0:
toc = time.perf_counter()
elap = toc-tic;
print("analyzing image %d / %d. Time: %4.4f seconds." % (i, len(images),elap))
tic = time.perf_counter()
img, x = load_image(path);
feat = feat_extractor.predict(x)[0]
features.append(feat)
print('finished extracting features for %d images' % len(images))
from sklearn.decomposition import PCA
features = np.array(features)
pca = PCA(n_components=100)
pca.fit(features)
pca_features = pca.transform(features)Следующий код показывает, как случайно выбирается картинка из датасета, сравнивается расстояние от этой картинки до всех изображений в датасете, данные расстояния сортируются по возрастанию расстояния и выбираются наиболее близкие/похожие.
Как можно заметить предобученные модели также хорошо справляются с поставленной задачей по поиску похожих изображений.
from scipy.spatial import distance
similar_idx = [ distance.cosine(pca_features[80], feat) for feat in pca_features ]
idx_closest = sorted(range(len(similar_idx)), key=lambda k: similar_idx[k])[1:6] # отображение первых 6 похожих изображений
thumbs = []
for idx in idx_closest:
img = image.load_img(filelist[idx])
img = img.resize((int(img.width * 100 / img.height), 100))
thumbs.append(img)
# concatenate the images into a single image
concat_image = np.concatenate([np.asarray(t) for t in thumbs], axis=1)
# show the image
plt.figure(figsize = (16,12))
plt.imshow(concat_image)

Выводы
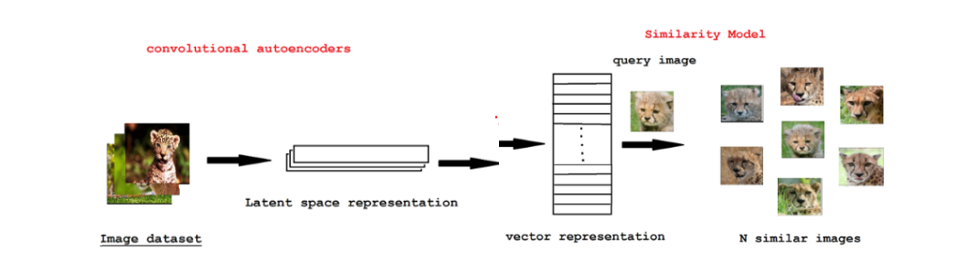
Таким образом был построен алгоритм для распознавания и поиска похожих изображений в наборе данных при помощи кодирования изображений в векторную форму. Данный алгоритм хорошо работает, но его всегда можно улучшить, например, путем добавления новых слоев или предварительной обработки изображений. В целом алгоритм можно представить следующими шагами:
Шаг 1: Берем имя файла или URL-адрес и преобразуем это изображение в нужную векторную форму.
Шаг 2: используя эту форму, извлекаем признаки важные признаки из изображения и преобразуем его в вектор при помощи автоэнкодера или предобученной модели.
Шаг 3: извлеченные признаки-вектора сравниваются с набором других векторов и находятся похожие изображения на основе расстояний: чем меньше расстояния, тем более похожи изображения.
Шаг 4: Отображение результатов.
Полезные ссылки
http://www.vision.caltech.edu/datasets/ – ссылки на датасет
https://pgaleone.eu/neural-networks/2016/11/24/convolutional-autoencoders/ – о сверточных автоэнкодерах
https://habr.com/ru/post/348000/ – про построение сверточных нейронных сетей
Как искать похожие изображения: лучшие сервисы
1 звезда
2 звезды
3 звезды
4 звезды
5 звезд
Если вы хотите найти похожие изображения с помощью какой-то картинки, то вы можете сделать это только на нескольких веб-сайтах. Рассказываем, как работают подобные сервисы.



Проще и удобнее всего это работает с Google.
- Откройте веб-страницу Google и выберите категорию «Картинки» в правом верхнем углу.
- Теперь перетащите изображение в строку поиска или щелкните значок камеры справа.
- Сюда вы можете загрузить изображение со своего компьютера или ввести его URL-адрес, если нашли картинку где-то в Сети. Затем Google будет искать похожие изображения и отображать связанные с ними веб-страницы.
TinEye
TinEye — это поисковая система, специализирующаяся исключительно на изображениях. Подобно Google, она ведет поиск картинок во всему интернету.
- Откройте сайт TinEye и загрузите слева изображение с вашего компьютера или введите справа ссылку на фото. Вы также можете перетащить сюда картинку.
- Затем вы увидите похожие изображения и связанные с ними веб-страницы.
- Если вы нажмете под изображением на ссылку «Compare», вы сможете сравнить две картинки друг с другом.
Reverse Image Search
Сервис Reverse Image Search использует сразу несколько поисковых систем при поиске изображений и объединяет результаты.
- Откройте веб-страницу Reverse Image Search.
- Выберите изображение с вашего компьютера или облачного хранилища, например, с Google Диск, или введите URL-адрес картинки.
- Затем вы можете выбрать, хотите ли вы искать изображение во всех доступных или только через определенные поисковые системы. Для этого уберите галочки напротив иконок поисковиков или выберите «All Search Engines».
- После нажатия на кнопку «Search Images» («Искать изображения»), вы увидите результаты поиска.
Яндекс
Отечественный поисковик также поддерживает поиск по картинкам.
- Перейдите на главную страницу Яндекса и откройте вкладку «Картинки».
- Перетащите изображение в окно с браузером или кликните на иконку с камерой в поисковой строке.
- Здесь вы можете выбрать файл на компьютере или вставить ссылку на фото из интернета. Если вы используете поиск по ссылке, то нажмите кнопку «Найти» для отображения результатов. При загрузке картинки на сервис страница с похожими изображениями откроется автоматически.
Читайте также:
- Законно ли скачивать видео с YouTube?
- Как перенести данные с Андроида на Айфон: пошаговая инструкция
Была ли статья интересна?
Оказывается, есть множество интересных сервисов, которые помогают искать людей по изображению, фотографии. Эти инструменты можно использовать как для поиска конкретных персон, так и людей, которые похожи на вас (и даже двойников).
Данная технология поиска весьма неточная, но тем не менее, может выдать толковый результат. Используя эти данные, вы быстро найдете информацию о человеке, его возраст и биографию, если это публичная персона. Итак, в нашем списке имеются следующие сервисы:
- PicTriev
- Поиск по картинкам Google
- PimEyes
- Поиск по картинкам Яндексе
- Betaface
Любопытно ли вам узнать, на кого из звезд вы похожи? (Пишите в комментариях, к чему привел вас поиск и какой из поисковиков вы считаете лучшим).
Полная версия руководства доступна здесь.
PicTriev
Этот сервис предназначен в первую очередь для поиска похожих знаменитостей. Дополнительная функция поисковика – проверить сходство изображений, принадлежат ли они одной и той же персоне. Сделать это просто: загрузите обе фотографии, и на индикаторе similarity meter отобразится показатель схожести.
Работает основная функция поиска PicTriev следующим образом – вы “кормите” поисковик ссылкой на фото или собственно загружаете файл на сервис – в результате получаете звезд, которые в чем-то схожи с исходным фото.
При этом учитывайте лимиты сервиса: размер картинки не должен превышать 200 кб. Вам будет полезно прочесть руководство, как поменять размер картинки.
Лучше всего подготовить фото для загрузки, приведя его по формату при подаче на паспорт или визу. Вполне достаточно фото головы на светлом фоне.
По опыту скажу, что PicTriev действительно показывает похожие фото со знаменитостями. Дополнительно указывается предполагаемый возраст. В нашем случае все данные выглядели корректно.
Советую использовать сервис PicTriev, если ваша цель – найти похожих на себя селебрити или проверить фотографии на принадлежность одному человеку. PicTriev отличит оригинал от фейка.
Поиск по картинкам в Google
Очевидно, поисковик Google можно использовать для поиска и распознавания лиц. В результатах Гугл представит подборку похожих изображений, нажав на каждое из которых, вы получите детальную информацию о контексте: кто это, данные профиля в соцсети и т. п. К слову, похожая функция уже имеется в сервисе Google Photos.
Несколько советов при поиске похожих людей:
- Для поиска нажмите на значок камеры или вставьте ссылку на фото / изображение в Сети.
- Нажмите на поиск, чтобы ознакомиться с похожими результатами.
- В поиске Google можно использовать изображения не очень хорошего качества – правда, при этом нет гарантии, что будут подобраны корректные результаты.
- Если добавить в строку с результатами оператор “&imgtype=face”, Google отобразит именно лица, схожие с загруженной картинкой.
PimEyes
PimEyes – специализированный поисковик по картинкам, где присутствуют лица. Используется технология распознавания лиц и реверсивный поиск. Можно найти лицо и проверить, где оно засветилось в интернете.
Советы, как пользоваться поисковиком по фото:
- Для более точного поиска загрузите несколько фотографий – в результатах отобразятся релевантные персоны.
- Хороший результат достигается, если сходство достигает 70 процентов и выше.
- Можно посмотреть и менее релевантные результаты, но в таком случае нужно самостоятельно фильтровать среди множества неподходящих картинок.
Одна из важных функций PimEyes – защита конфиденциальности. Если быть точнее, сервис помогает найти ваши фотографии в интернете или отслеживать их на постоянной основе. Найденный контент можно удалить массово со всех ресурсов, где ваше фото использовалось несанкционированно.
Сервис PimEyes – платный, но 24 часа можно тестировать без особых ограничений.
Поиск по картинкам в Яндексе
Здесь просматривается аналогия с Google, работает поиск по картинкам примерно так же:
- Заходите на Яндекс.Картинки
- Нажимаете на значок с изображением увеличительного стекла (можно как вариант указать ссылку на фото с лицом)
- В результатах будут показаны все схожие изображения и контекст, в котором они упомянуты.
- Можно сортировать результаты по размеру и другим критериям.
Betaface
Еще один сервис по распознаванию лиц называется Betaface. Работает схоже с вышеназванными.
- Загружаете фотографию с телефона, ПК или по ссылке
- Betaface использует поисковый механизм и в результатах выдает схожие лица. Данные отображаются в удобном виде.
- В Betaface можно загружать множество фотографий одновременно.
- Есть сортировка и фильтрация, так проще найти наиболее подходящий результат по релевантности.
Бонусные возможности:
- Сравнение двух лиц
- Поиск информации о распознанных лицах в Википедии
- Отображение данных в виде таблицы
Несмотря на то, что скорость поиска по фотографии невысока, Betaface радует относительно высоким качеством и достоверностью распознавания.
***
Пишите, уважаемые читатели, какие сервисы понравились вам, а что показалось бесполезным. Буду рад услышать критику и пожелания в комментариях!
