What is a good way to find the index of an element in a list in Python?
Note that the list may not be sorted.
Is there a way to specify what comparison operator to use?
![]()
asked Mar 3, 2009 at 1:45
![]()
2
From Dive Into Python:
>>> li
['a', 'b', 'new', 'mpilgrim', 'z', 'example', 'new', 'two', 'elements']
>>> li.index("example")
5
![]()
stivlo
83.2k31 gold badges142 silver badges199 bronze badges
answered Mar 3, 2009 at 1:52
![]()
3
If you just want to find out if an element is contained in the list or not:
>>> li
['a', 'b', 'new', 'mpilgrim', 'z', 'example', 'new', 'two', 'elements']
>>> 'example' in li
True
>>> 'damn' in li
False
answered Feb 17, 2011 at 10:00
![]()
EduardoEduardo
1,7811 gold badge11 silver badges5 bronze badges
0
The best way is probably to use the list method .index.
For the objects in the list, you can do something like:
def __eq__(self, other):
return self.Value == other.Value
with any special processing you need.
You can also use a for/in statement with enumerate(arr)
Example of finding the index of an item that has value > 100.
for index, item in enumerate(arr):
if item > 100:
return index, item
Source
![]()
tedder42
23.2k12 gold badges86 silver badges99 bronze badges
answered Mar 3, 2009 at 1:51
![]()
Brian R. BondyBrian R. Bondy
337k124 gold badges592 silver badges635 bronze badges
Here is another way using list comprehension (some people might find it debatable). It is very approachable for simple tests, e.g. comparisons on object attributes (which I need a lot):
el = [x for x in mylist if x.attr == "foo"][0]
Of course this assumes the existence (and, actually, uniqueness) of a suitable element in the list.
answered Sep 24, 2010 at 9:35
![]()
ThomasHThomasH
22.1k13 gold badges60 silver badges61 bronze badges
3
assuming you want to find a value in a numpy array,
I guess something like this might work:
Numpy.where(arr=="value")[0]
![]()
Jorgesys
124k23 gold badges329 silver badges264 bronze badges
answered Jan 27, 2011 at 15:03
![]()
2
There is the index method, i = array.index(value), but I don’t think you can specify a custom comparison operator. It wouldn’t be hard to write your own function to do so, though:
def custom_index(array, compare_function):
for i, v in enumerate(array):
if compare_function(v):
return i
answered Mar 3, 2009 at 1:50
![]()
David ZDavid Z
127k27 gold badges252 silver badges277 bronze badges
I use function for returning index for the matching element (Python 2.6):
def index(l, f):
return next((i for i in xrange(len(l)) if f(l[i])), None)
Then use it via lambda function for retrieving needed element by any required equation e.g. by using element name.
element = mylist[index(mylist, lambda item: item["name"] == "my name")]
If i need to use it in several places in my code i just define specific find function e.g. for finding element by name:
def find_name(l, name):
return l[index(l, lambda item: item["name"] == name)]
And then it is quite easy and readable:
element = find_name(mylist,"my name")
answered Oct 20, 2011 at 12:30
![]()
jkijki
4,6171 gold badge34 silver badges29 bronze badges
0
The index method of a list will do this for you. If you want to guarantee order, sort the list first using sorted(). Sorted accepts a cmp or key parameter to dictate how the sorting will happen:
a = [5, 4, 3]
print sorted(a).index(5)
Or:
a = ['one', 'aardvark', 'a']
print sorted(a, key=len).index('a')
answered Mar 3, 2009 at 1:52
![]()
Jarret HardieJarret Hardie
94.4k10 gold badges132 silver badges126 bronze badges
how’s this one?
def global_index(lst, test):
return ( pair[0] for pair in zip(range(len(lst)), lst) if test(pair[1]) )
Usage:
>>> global_index([1, 2, 3, 4, 5, 6], lambda x: x>3)
<generator object <genexpr> at ...>
>>> list(_)
[3, 4, 5]
answered Mar 3, 2009 at 2:06
![]()
2
I found this by adapting some tutos. Thanks to google, and to all of you 😉
def findall(L, test):
i=0
indices = []
while(True):
try:
# next value in list passing the test
nextvalue = filter(test, L[i:])[0]
# add index of this value in the index list,
# by searching the value in L[i:]
indices.append(L.index(nextvalue, i))
# iterate i, that is the next index from where to search
i=indices[-1]+1
#when there is no further "good value", filter returns [],
# hence there is an out of range exeption
except IndexError:
return indices
A very simple use:
a = [0,0,2,1]
ind = findall(a, lambda x:x>0))
[2, 3]
P.S. scuse my english
answered Oct 16, 2011 at 11:41
![]()
На чтение 4 мин Просмотров 5.2к. Опубликовано 03.03.2023
Содержание
- Введение
- Поиск методом count
- Поиск при помощи цикла for
- Поиск с использованием оператора in
- В одну строку
- Поиск с помощью лямбда функции
- Поиск с помощью функции any()
- Заключение
Введение
В ходе статьи рассмотрим 5 способов поиска элемента в списке Python.
Поиск методом count
Метод count() возвращает вхождение указанного элемента в последовательность. Создадим список разных цветов, чтобы в нём производить поиск:
colors = ['black', 'yellow', 'grey', 'brown']Зададим условие, что если в списке colors присутствует элемент ‘yellow’, то в консоль будет выведено сообщение, что элемент присутствует. Если же условие не сработало, то сработает else, и будет выведена надпись, что элемента отсутствует в списке:
colors = ['black', 'yellow', 'grey', 'brown']
if colors.count('yellow'):
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск при помощи цикла for
Создадим цикл, в котором будем перебирать элементы из списка colors. Внутри цикла зададим условие, что если во время итерации color приняла значение ‘yellow’, то элемент присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
for color in colors:
if color == 'yellow':
print('Элемент присутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с использованием оператора in
Оператор in предназначен для проверки наличия элемента в последовательности, и возвращает либо True, либо False.
Зададим условие, в котором если ‘yellow’ присутствует в списке, то выводится соответствующее сообщение:
colors = ['black', 'yellow', 'grey', 'brown']
if 'yellow' in colors:
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!В одну строку
Также можно найти элемент в списке при помощи оператора in всего в одну строку:
colors = ['black', 'yellow', 'grey', 'brown']
print('Элемент присутствует в списке!') if 'yellow' in colors else print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Или можно ещё вот так:
colors = ['black', 'yellow', 'grey', 'brown']
if 'yellow' in colors: print('Элемент присутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с помощью лямбда функции
В переменную filtering будет сохранён итоговый результат. Обернём результат в список (list()), т.к. метода filter() возвращает объект filter. Отфильтруем все элементы списка, и оставим только искомый, если он конечно присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
filtering = list(filter(lambda x: 'yellow' in x, colors))Итак, если искомый элемент находился в списке, то он сохранился в переменную filtering. Создадим условие, что если переменная filtering не пустая, то выведем сообщение о присутствии элемента в списке. Иначе – отсутствии:
colors = ['black', 'yellow', 'grey', 'brown']
filtering = list(filter(lambda x: 'yellow' in x, colors))
if filtering:
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с помощью функции any()
Функция any принимает в качестве аргумента итерабельный объект, и возвращает True, если хотя бы один элемент равен True, иначе будет возвращено False.
Создадим условие, что если функция any() вернёт True, то элемент присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
if any(color in 'yellow' for color in colors):
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Внутри функции any() при помощи цикла производится проверка присутствия элемента в списке.
Заключение
В ходе статьи мы с Вами разобрали целых 5 способов поиска элемента в списке Python. Надеюсь Вам понравилась статья, желаю удачи и успехов! 🙂
Create a generator
Generators are fast and use a tiny memory footprint. They give you flexibility in how you use the result.
def indices(iter, val):
"""Generator: Returns all indices of val in iter
Raises a ValueError if no val does not occur in iter
Passes on the AttributeError if iter does not have an index method (e.g. is a set)
"""
i = -1
NotFound = False
while not NotFound:
try:
i = iter.index(val, i+1)
except ValueError:
NotFound = True
else:
yield i
if i == -1:
raise ValueError("No occurrences of {v} in {i}".format(v = val, i = iter))
The above code can be use to create a list of the indices: list(indices(input,value)); use them as dictionary keys: dict(indices(input,value)); sum them: sum(indices(input,value)); in a for loop for index_ in indices(input,value):; …etc… without creating an interim list/tuple or similar.
In a for loop you will get your next index back when you call for it, without waiting for all the others to be calculated first. That means: if you break out of the loop for some reason you save the time needed to find indices you never needed.
How it works
- Call
.indexon the inputiterto find the next occurrence of
val - Use the second parameter to
.indexto start at the point
after the last found occurrence - Yield the index
- Repeat until
indexraises aValueError
Alternative versions
I tried four different versions for flow control; two EAFP (using try - except) and two TBYL (with a logical test in the while statement):
- “WhileTrueBreak”:
while True:…except ValueError: break. Surprisingly, this was usually a touch slower than option 2 and (IMV) less readable - “WhileErrFalse”: Using a bool variable
errto identify when aValueErroris raised. This is generally the fastest and more readable than 1 - “RemainingSlice”: Check whether val is in the remaining part of the input using slicing:
while val in iter[i:]. Unsurprisingly, this does not scale well - “LastOccurrence”: Check first where the last occurrence is, keep going
while i < last
The overall performance differences between 1,2 and 4 are negligible, so it comes down to personal style and preference. Given that .index uses ValueError to let you know it didn’t find anything, rather than e.g. returning None, an EAFP-approach seems fitting to me.
Here are the 4 code variants and results from timeit (in milliseconds) for different lengths of input and sparsity of matches
@version("WhileTrueBreak", versions)
def indices2(iter, val):
i = -1
while True:
try:
i = iter.index(val, i+1)
except ValueError:
break
else:
yield i
@version("WhileErrFalse", versions)
def indices5(iter, val):
i = -1
err = False
while not err:
try:
i = iter.index(val, i+1)
except ValueError:
err = True
else:
yield i
@version("RemainingSlice", versions)
def indices1(iter, val):
i = 0
while val in iter[i:]:
i = iter.index(val, i)
yield i
i += 1
@version("LastOccurrence", versions)
def indices4(iter,val):
i = 0
last = len(iter) - tuple(reversed(iter)).index(val)
while i < last:
i = iter.index(val, i)
yield i
i += 1
Length: 100, Ocurrences: 4.0%
{'WhileTrueBreak': 0.0074799987487494946, 'WhileErrFalse': 0.006440002471208572, 'RemainingSlice': 0.01221001148223877, 'LastOccurrence': 0.00801000278443098}
Length: 1000, Ocurrences: 1.2%
{'WhileTrueBreak': 0.03101000329479575, 'WhileErrFalse': 0.0278000021353364, 'RemainingSlice': 0.08278000168502331, 'LastOccurrence': 0.03986000083386898}
Length: 10000, Ocurrences: 2.05%
{'WhileTrueBreak': 0.18062000162899494, 'WhileErrFalse': 0.1810499932616949, 'RemainingSlice': 2.9145700042136014, 'LastOccurrence': 0.2049500006251037}
Length: 100000, Ocurrences: 1.977%
{'WhileTrueBreak': 1.9361200043931603, 'WhileErrFalse': 1.7280600033700466, 'RemainingSlice': 254.4725100044161, 'LastOccurrence': 1.9101499929092824}
Length: 100000, Ocurrences: 9.873%
{'WhileTrueBreak': 2.832529996521771, 'WhileErrFalse': 2.9984100023284554, 'RemainingSlice': 1132.4922299943864, 'LastOccurrence': 2.6660699979402125}
Length: 100000, Ocurrences: 25.058%
{'WhileTrueBreak': 5.119729996658862, 'WhileErrFalse': 5.2082200068980455, 'RemainingSlice': 2443.0577100021765, 'LastOccurrence': 4.75954000139609}
Length: 100000, Ocurrences: 49.698%
{'WhileTrueBreak': 9.372120001353323, 'WhileErrFalse': 8.447749994229525, 'RemainingSlice': 5042.717969999649, 'LastOccurrence': 8.050809998530895}
Python hosting: Host, run, and code Python in the cloud!
Arrays are usually referred to as lists. For convience, lets call them arrays in this article.
Python has a method to search for an element in an array, known as index().
We can find an index using:
x = ['p','y','t','h','o','n']
print(x.index('o'))
Arrays start with the index zero (0) in Python:
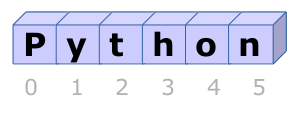
Python character array
If you would run x.index(‘p’) you would get zero as output (first index).
Related course:
- Python Crash Course: Master Python Programming
Array duplicates: If the array contains duplicates, the index() method will only return the first element.
Find multiple occurences
If you want multiple to find multiple occurrences of an element, use the lambda function below.
get_indexes = lambda x, xs: [i for (y, i) in zip(xs, range(len(xs))) if x == y]
Find in string arrays
To find an element in a string array use:
x = ["Moon","Earth","Jupiter"]
print(x.index("Earth"))
You could use this code if you want to find multiple occurrences:
x = ["Moon","Earth","Jupiter","Neptune","Earth","Venus"]
get_indexes = lambda x, xs: [i for (y, i) in zip(xs, range(len(xs))) if x == y]
print(get_indexes("Earth",x))
Find in numeric array
The index method works on numeric arrays too:
x = [5,1,7,0,3,4]
print(x.index(7))
To find multiple occurrences you can use this lambda function:
x = [5,1,7,0,3,4,5,3,2,6,7,3,6]
get_indexes = lambda x, xs: [i for (y, i) in zip(xs, range(len(xs))) if x == y]
print(get_indexes(7,x))
Часто нам нужно найти символ в строке python. Для решения этой задачи разработчики используют метод find(). Он помогает найти индекс первого совпадения подстроки в строке. Если символ или подстрока не найдены, find возвращает -1.
Синтаксис
string.find(substring,start,end)Метод find принимает три параметра:
substring(символ/подстрока) — подстрока, которую нужно найти в данной строке.start(необязательный) — первый индекс, с которого нужно начинать поиск. По умолчанию значение равно 0.end(необязательный) — индекс, на котором нужно закончить поиск. По умолчанию равно длине строки.
Параметры, которые передаются в метод, — это подстрока, которую требуются найти, индекс начала и конца поиска. Значение по умолчанию для начала поиска — 0, а для конца — длина строки.
В этом примере используем метод со значениями по умолчанию.
Метод find() будет искать символ и вернет положение первого совпадения. Даже если символ встречается несколько раз, то метод вернет только положение первого совпадения.
>>> string = "Добро пожаловать!"
>>> print("Индекс первой буквы 'о':", string.find("о"))
Индекс первой буквы 'о': 1
Поиск не с начала строки с аргументом start
Можно искать подстроку, указав также начальное положение поиска.
В этом примере обозначим стартовое положение значением 8 и метод начнет искать с символа с индексом 8. Последним положением будет длина строки — таким образом метод выполнит поиска с индекса 8 до окончания строки.
>>> string = "Специалисты назвали плюсы и минусы Python"
>>> print("Индекс подстроки 'али' без учета первых 8 символов:", string.find("али", 8))
Индекс подстроки 'али' без учета первых 8 символов: 16
Поиск символа в подстроке со start и end
С помощью обоих аргументов (start и end) можно ограничить поиск и не проводить его по всей строке. Найдем индексы слова «пожаловать» и повторим поиск по букве «о».
>>> string = "Добро пожаловать!"
>>> start = string.find("п")
>>> end = string.find("ь") + 1
>>> print("Индекс первой буквы 'о' в подстроке:", string.find("о", start, end))
Индекс первой буквы 'о' в подстроке: 7
Проверка есть ли символ в строке
Мы знаем, что метод find() позволяет найти индекс первого совпадения подстроки. Он возвращает -1 в том случае, если подстрока не была найдена.
>>> string = "Добро пожаловать!"
>>> print("Есть буква 'г'?", string.find("г") != -1)
Есть буква 'г'? False
>>> print("Есть буква 'т'?", string.find("т") != -1)
Есть буква 'т'? True
Поиск последнего вхождения символа в строку
Функция rfind() напоминает find(), а единое отличие в том, что она возвращает максимальный индекс. В обоих случаях же вернется -1, если подстрока не была найдена.
В следующем примере есть строка «Добро пожаловать!». Попробуем найти в ней символ «о» с помощью методов find() и rfind().
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом rfind:", string.rfind("о"))
Поиск 'о' методом rfind: 11
Вывод показывает, что find() возвращает индекс первого совпадения подстроки, а rfind() — последнего совпадения.
Второй способ поиска — index()
Метод index() помогает найти положение данной подстроки по аналогии с find(). Единственное отличие в том, что index() бросит исключение в том случае, если подстрока не будет найдена, а find() просто вернет -1.
Вот рабочий пример, показывающий разницу в поведении index() и find():
>>> string = "Добро пожаловать"
>>> print("Поиск 'о' методом find:", string.find("о"))
Поиск 'о' методом find: 1
>>> print("Поиск 'о' методом index:", string.index("о"))
Поиск 'о' методом index: 1
В обоих случаях возвращается одна и та же позиция. А теперь попробуем с подстрокой, которой нет в строке:
>>> string = "Добро пожаловать"
>>> print("Поиск 'г' методом find:", string.find("г"))
Поиск 'г' методом find: 1
>>> print("Поиск 'г' методом index:", string.index("г"))
Traceback (most recent call last):
File "pyshell#21", line 1, in module
print("Поиск 'г' методом index:", string.index("г"))
ValueError: substring not found
В этом примере мы пытались найти подстроку «г». Ее там нет, поэтому find() возвращает -1, а index() бросает исключение.
Поиск всех вхождений символа в строку
Чтобы найти общее количество совпадений подстроки в строке можно использовать ту же функцию find(). Пройдемся циклом while по строке и будем задействовать параметр start из метода find().
Изначально переменная start будет равна -1, что бы прибавлять 1 у каждому новому поиску и начать с 0. Внутри цикла проверяем, присутствует ли подстрока в строке с помощью метода find.
Если вернувшееся значение не равно -1, то обновляем значением count.
Вот рабочий пример:
my_string = "Добро пожаловать"
start = -1
count = 0
while True:
start = my_string.find("о", start+1)
if start == -1:
break
count += 1
print("Количество вхождений символа в строку: ", count )
Количество вхождений символа в строку: 4Выводы
- Метод
find()помогает найти индекс первого совпадения подстроки в данной строке. Возвращает -1, если подстрока не была найдена. - В метод передаются три параметра: подстрока, которую нужно найти,
startсо значением по умолчанию равным 0 иendсо значением по умолчанию равным длине строки. - Можно искать подстроку в данной строке, задав начальное положение, с которого следует начинать поиск.
- С помощью параметров
startиendможно ограничить зону поиска, чтобы не выполнять его по всей строке. - Функция
rfind()повторяет возможностиfind(), но возвращает максимальный индекс (то есть, место последнего совпадения). В обоих случаях возвращается -1, если подстрока не была найдена. index()— еще одна функция, которая возвращает положение подстроки. Отличие лишь в том, чтоindex()бросает исключение, если подстрока не была найдена, аfind()возвращает -1.find()можно использовать в том числе и для поиска общего числа совпадений подстроки.
