OverView
The FIND Statement searches for whether a specific character is included, and if so, returns the position of that character.
Sample Code:Only Search
DATA: V_TEXT TYPE String. V_TEXT = 'AAAAFINDBBBBB'. FIND 'FIND' IN V_TEXT. IF SY-SUBRC = 0. WRITE 'OK'. ENIDF.
Explanation
In this example, the FIND instruction is used to check if there is a character ‘FIND ‘from the variable: V_TEXT. System variable: SY-SUBRC returns ‘0’ if it can be found, and ‘4’ if it cannot be found. Describe each process after branching with IF statement etc. I can do things.
Sample Code:Return search position
DATA: V_TEXT TYPE String,
V_OFF TYPE I,
V_CNT TYPE I.
V_TEXT = 'AAAAFINDBBBBB'.
FIND 'FIND' IN V_TEXT MATCH OFFSET V_OFF MATCH LENGTH V_LEN.
IF SY-SUBRC = 0.
WRITE V_TEXT+V_OFF(V_LEN).
ENIDF.
Explanation
In this example, the FIND command is used, and if the character “FIND” is found in the variable: V_TEXT, the position and length found will be returned. As in the previous case, the system variable: SY-SUBRC is checked, and if found, only the found character is cut out and output to the screen.
Sample Code:Multiple search
DATA: V_TEXT TYPE String,
V_LEN TYPE I.
V_TEXT = 'AAAAFINDBBBBBFINDCCC'.
FIND ALL OCCURRENCES OF 'FIND' IN V_TEXT MATCH COUNT V_CNT.
IF SY-SUBRC = 0.
WRITE V_CNT.
ENIDF.
Explanation
In this example, the FIND instruction is used to retrieve all the characters’FIND ‘from the variable: V_TEXT. In the example, the character FIND can be found twice, so the variable V_CNT is set to 2.
FIRST OCCURRENCES will be one search, ALL OCCURRENCES will be all searches. Although omitted in the above two examples, FIRST OCCURRENCES is used if the description is omitted.
Sample Code:Store result into internal table
DATA: V_TEXT TYPE String,
result_tab TYPE match_result_tab.
V_TEXT = 'AAAAFINDBBBBBFINDCCC'.
FIND ALL OCCURRENCES OF 'FIND'
IN V_TEXT
RESULTS result_tab.
Explanation
Honestly, I can’t think of a use, but it is possible to store the result in an internal table by specifying an internal table after RESULTS. The first line stores the position of the first character found, the number of digits, etc., and the second line stores the position of the next character found, the number of digits, etc. You can loop through the internal table and process each character.
Sample Code:Search string from internal table
DATA: itab TYPE TABLE OF string. FIND ALL OCCURRENCES OF 'FIND' IN TABLE itab RESPECTING CASE RESULTS result_tab.
Explanation
An internal table can also be specified as a search target as in the above example. It can be used as an internal table after reading the file. However, it is also possible to search for each line by looping, so it may be a syntax to use in consideration of performance and simplification of logic.
Summary
This time I introduced the FIND command, but there should be many requirements such as “I want to do this” only when there is a specific description from the characters. When dealing with XML etc., it is often used because it is often judged by the name of the tag. Also, each text (set on orders or purchase slips) can be used as a syntax for extracting a text input by the user and searching for a specific character when processing the text.
Post Views: 16,434
Регулярное выражение (Regular expression, REGEX) — механизм поиска подстроки в тексте по предопределенному шаблону. Использование регулярных выражений имеет смысл в случаях когда у нас нет четкого понимания того, что нужно найти. К примеру, если стоит задача найти в тексте определенное слово или фразу, то подойдет обычный поиск подстроки. А когда требуется найти неизвестный e-mail или последовательность из 25-ти английских букв или цифр, например XXXXX-XXXXX-XXXXX-XXXXX-XXXXX, то без регулярных выражений просто не обойтись.
Синтаксис регулярных выражений
Регулярное выражение состоит из паттерна — строки задающей правило поиска, также иногда называют шаблоном или маской. Паттерны могут состоять как из обычных символов, так и из спецсимволов (метасимволов). Например паттерн ‘ABAP’ состоит только из обычных символов, а паттерн ‘A.w{2}’ содержит как простой символ ‘A’, так и спец. символы ‘.’, ‘w’ и ‘{2}’. Рассмотрим спецсимволы более подробно.
Экранирование символов
| Спецсимвол | Значение | Пример |
|---|---|---|
| Делает спецсимволы обычными, а обычные специальными. | Выражение ‘s’ ищет просто символ ‘s’, а если поставить перед s, то ‘s’ уже обозначает пробельный символ. И наоборот, ‘a*’ ищет 0 или больше подряд идущих символов ‘a’, а чтобы найти а со звездочкой ‘a*’ — поставим перед спец. символом: ‘a*’. |
Символьные классы (наборы символов)
| Спецсимвол | Значение | Пример |
|---|---|---|
| . (точка) | Произвольный символ | ‘a.’ найдет ‘ab’ и ‘ap’ в ‘abaper’ |
| C | Произвольный символ | Тоже самое что и (точка). |
| d | Цифра от 0 до 9 | ‘d’ найдет ‘4’ в ‘abap4‘ |
| D | Любой символ кроме цифры | ‘D’ найдет точку в ‘3.1415′ |
| l | Любая буква в нижнем регистре | |
| L | Любой символ кроме буквы в нижнем регистре | |
| s | Любой пробельный символ (обычно пробел или табуляция) | |
| S | Любой символ кроме пробельного | |
| u | Любая буква в верхнем регистре | |
| U | Любой символ кроме буквы в верхнем регистре | |
| w | Обозначает любую букву, цифру и символ _ | |
| W | Любой символ кроме буквы, цифры и символа _ | |
| [xyz] | Набор символов. Находит любой из перечисленных символов. | ‘[ad]’ найдет две ‘a’ и ‘4’ в ‘abap4‘ |
| [^xyz] | Любой символ, кроме указанных в наборе | ‘[^ad]’ найдет ‘b’ и ‘p’ в ‘abap4′ |
| [a-d] | Диапазон символов | [a-d] — то же самое, что [abcd] |
| a f n r t v | Соответствующие контрольные символы | |
| [..] | Не используется. Зарезервировано для дальнейших улучшений. | |
| [==] | Не используется. Зарезервировано для дальнейших улучшений. |
Квантификация (поиск последовательностей)
| Спецсимвол | Значение | Пример |
|---|---|---|
| {n} | Находит ровно n повторений предшествующего элемента | ‘[1-4]{3}’ найдет ‘141’ в ‘3.1415926′ |
| {n,m} | Находят от n до m повторений элемента | ‘[1246]{2,3}’ найдет ‘141’ и ’26’ в ‘3.1415926‘ |
| {n,} | Находит n и более повторений элемента | ‘d{2,}’ найдет ‘1415926’ в ‘3.1415926‘ |
| {n,m}? | Не используется. Зарезервировано для дальнейших улучшений. | |
| ? | Обозначает, что элемент может как присутствовать, так и отсутствовать | Тоже самое что и {0,1} |
| * | Обозначает повторение 0 или более раз | Тоже самое что и {0,} |
| *? | Не используется. Зарезервировано для дальнейших улучшений. | |
| + | Обозначает повторение 1 или более раз | Тоже самое что и {1,} |
| +? | Не используется. Зарезервировано для дальнейших улучшений. | |
| x|y | Находит x или y | ‘ab|p’ найдет ‘ab’ и ‘p’ в ‘abap‘ |
| (x) | Находит x и запоминает. Это называется «запоминающие скобки». | ‘(b|s)a’ найдет ‘sa’ и ‘ba’ в ‘sap abap’ |
| (?:x) | Находит x, но не запоминает найденное. Это называется «незапоминающие скобки». | |
| 1, 2, 3 … | Найденные, с помощью «запоминающих скобках», группы. | ‘(+).*1’ найдет ‘+ google +’ в ‘Apple + google +‘ |
| Q … E | Определение строки буквенных символов | |
| (? … ) | Не используется. Зарезервировано для дальнейших улучшений. |
Позиция внутри строки
| Спецсимвол | Значение | Пример |
|---|---|---|
| ^ | Обозначает начало входных данных. | ‘^sap’ найдет ‘sap’ в ‘sap abap’ но ничего не найдет в ‘abap sap’ |
| A | Обозначает начало символьной строки. | Тоже самое что и ^ |
| $ | Обозначает конец входных данных. | ‘sap$’ найдет ‘sap’ в ‘abap sap‘ но ничего не найдет в ‘sap abap’ |
| Z | Обозначает конец символьной строки. | Тоже самое что и $ |
| < | Начало слова | ‘<w’ найдет ‘s’ и ‘a’ в ‘sap abap’ |
| > | Конец слова | ‘w>’ найдет две ‘p’ в ‘sap abap‘ |
| b | Начало или конец слова | ‘w?bw?’ найдет ‘s’, ‘a’ и две ‘p’ в ‘sap abap‘ |
| B | Пробел между символами в слове | |
| x(?=y) | Находит x, только если за x следует y. | ‘S(?=a)’ найдет символ, если после него идет ‘a’, например ‘sap abap’ |
| x(?!y ) | Находит x, только если за x не следует y. | ‘a(?!p)’ найдет ‘a’ в ‘sap abap’ |
Замена текста
| Спецсимвол | Значение | Пример |
|---|---|---|
| $0, $& | Найденное местоположение шаблона | Замена ‘abap’ на ‘+$0+’ в тексте ‘sap abap’ даст ‘sap +abap+’ |
| $1, $2, $3… | Найденные зарегистрированные подгруппы | Замена ‘([0-3]d).([01]d).(d{4})’ на ‘$3-$2-$1’ в тексте ‘01.02.2010’ даст ‘2010-02-01’ |
| $` | Текст перед найденного шаблона | |
| $’ | Текст после найденного шаблона |
Инструменты для работы с регулярными выражениями
ABAP предоставляет возможность использовать регулярные выражения в конструкциях FIND и REPLACE, добавляя ключевое слово REGEX.
Например, для поиска даты в формате DD.MM.YYYY, можно использовать FIND REGEX.
|
FIND ALL OCCURRENCES OF REGEX ‘[0-3]d.[01]d.d{4}’ IN text RESULTS match_result. |
Результат данной операции будет помещен во внутреннюю таблицу match_result.
А для замены формата даты DD.MM.YYYY на формат YYYY-MM-DD можно использовать REPLACE REGEX.
|
REPLACE ALL OCCURRENCES OF REGEX ‘([0-3]d).([01]d).(d{4})’ IN text WITH ‘$3-$2-$1’. |
Помимо FIND и REPLACE, механизм регулярных выражений реализован в классах CL_ABAP_REGEX и CL_ABAP_MATCHER. Классы позволяют более гибко использовать регулярные выражения.
Выражения FIND и REPLACE и методы классов CL_ABAP_REGEX и CL_ABAP_MATCHER хорошо задокументированы в документации SAP.
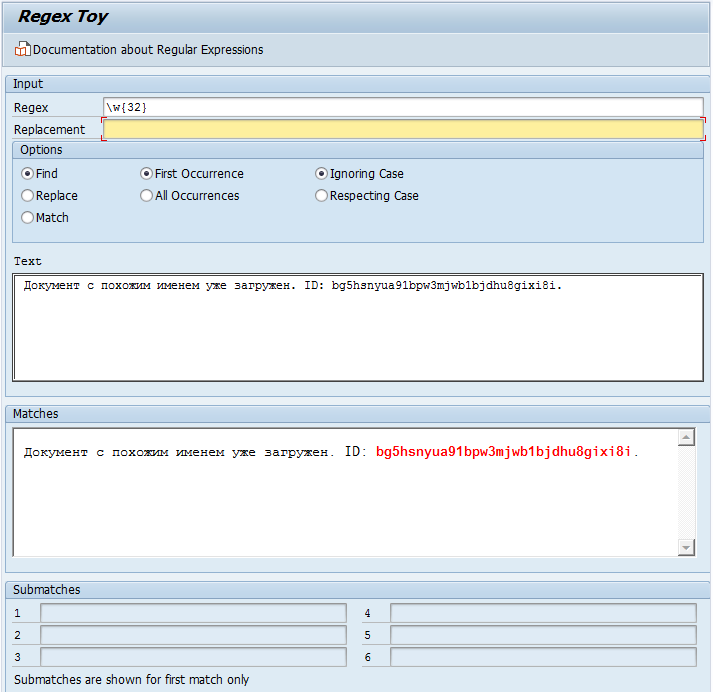
Тестирование
Для тестирования регулярных выражений в SAP используйте стандартную программу DEMO_REGEX_TOY
Регулярные выражения – это шаблоны для поиска в строках. Их можно
использовать для поиска, замены в строках или проверки входных данных. ABAP разработчики не очень часто используют данный функционал, хотя иногда это довольно удобно. К сожалению, и сам язык поддерживает далеко не все возможности регулярных выражений.
Нет смысла лишний раз описывать операторы, ознакомится с ним можно в документации.
Рассмотрим несколько простых примеров для поиска на конкретных примерах. Так будет немного понятнее.
Для работы с регулярными выражениями в ABAP есть оператор REGEX.
В первом примере найдем позицию буквы ‘t’. Тут все достаточно просто
|
DATA: lv_offset_0 TYPE i. DATA(string_0) = |First regex|. FIND REGEX ‘t’ IN string_0 MATCH OFFSET lv_offset_0. cl_demo_output=>write_data( lv_offset_0 ). cl_demo_output=>display( ). |
Но на практике скорее всего придется искать не заренее известное значение, а некоторое значение из диапазона. Допустим, нам надо найти числа в строке. Это будет выглядеть вот так:
|
DATA lt_result_tab TYPE match_result_tab. DATA(string_1) = |From: sender@gmail.com : summa: 32 summa_2: 55|. FIND ALL OCCURRENCES OF REGEX ‘[0-9]+’ IN string_1 RESULTS lt_result_tab. |
В lt_result_tab получим позиции цифр 32, 2, 55.
Как это работает:
1. [ ] – означает диапазон значений, в нашем случае это от 0 до 9.
2. + – повтор шаблона от 1 раза
a)Регулярное выражение последовательно ищет первый символ, который удовлетворяет первой позиции в шаблоне. “F” – не подходит, “r” – не подходит …., “3” – подходит.
б) Далее в шаблоне идет «+», который означает, что предыдущий шаблон нужно искать от 1 до бесконечности раз подряд. Значит в следующей позиции опять происходит поиск значения 0-9. Находим следующий символ результата – «2»
в)Переходим к следующему символу в строке – это пробел. «Пробел» не входит в диапазон искомых значений, значит все, что хотели мы нашли
г) Сохраняем результат в таблицу
в)Начинаем поиск заново, с участка строки на котором закончили.
….. Продолжаем итерации пока строка не закончится
Замечание
Но abap не был бы абапом если бы не поддерживал какую то странную версию регулярных выражений. Поэтому шаблон ‘[0-9]’ даст нам такой же результат как и ‘[0-9]+’. Хотя, по хорошему, должен выдать 3, 2, 2, 3, 3. Скорее всего причина в том, что в ABAP используется только жадный алгоритм.
В предыдущем примере, можно заметить, что двойка это часть слова summa_2 и не является отдельным числом. Давайте найдем только отдельностоящие цифры. Для этого немного усложним выражение
|
FIND ALL OCCURRENCES OF REGEX ‘(<[0-9]+)’ IN string_1 RESULTS lt_result_tab. |
В lt_result_tab получим позиции цифр 32, 55
< – символ начала слова. Означает, что следующий за ним элемент шаблона будем искать только если слово с него начинается.
Хорошо, а что если числа будут дробные ? Причем, нам надо найти только числа, у которых дробная часть имеет два символа.
|
DATA(string_11) = |summa_1 32.5656 rur, summa_2: 32.56 rur |. FIND ALL OCCURRENCES OF REGEX ‘(<[0-9]+.[0-9]{2,2}>)’ IN string_11 RESULTS result_tab. |
{n} – находит ровно n совпадений указанного элемента
{n,} – находит n и более совпадений указанного элемента
или как в нашем случае {n,m} –от n до m совпадений указанного элемента
Перед точкой можем увидеть знак «» – это экранирование элемента. Т.к. символ «.» является специальным символом и означает любой символ, а мы ищем именно точку. «.» – как раз говорит, что ищем символ точка.
> – найденный символ должен быть концом слова. Что позволяет исключить из выборки 32.5656, например.
Алгоритм:
1. «<» – говорит, что мы осуществляем поиск элемента шаблона с начала слова:
- Первое слово – «summa_1»;
- Анализируем первый символ. Он должен быть в диапазоне [0-9];
- Слово начинается на «s» и нам не подходит;
- Идем дальше и ищем новое слово по нашему шаблону (шаблон отрабатывает с самого начала);
- Слово «32.5656»;
- Анализируем первый символ. Он должен быть в диапазоне [0-9]. Так и есть;
- «+» – говорит о том, что символ может повторяться от 1 до n раз. Значит второй символ в слове подходит под наш шаблон;
- Переходим к анализу третьего символа в слове «.» Это не цифра – значит сдвигаемся по шаблону на следующее условие, а это у нас «.» что соответствует «.» в строке;
- Переходим к анализу следующего символа после точки – «5». В шаблоне мы тоже сместились на поиск символа от [0-9]. Пятерка нам подходит;
- Анализируем следующий символ «6». Он тоже должен быть [0-9], т.к. мы прописали, что данный элемент должен повторяться два раза. Но при этом «>»говорит, что данный элемент должен быть концом слова. В нашем слове следующий элемент «5»;
- Слово под шаблон не подходит;
- Опять пробуем найти совпадение по шаблону с самого начала (Ему удовлетворяет только 32.56 )
Еще немного усложним шаблон, что если мы не знаем, разделяются разряды «.» или «,»
|
DATA(lv_string_12) = |summa_1 32.5656 rur, summa_2: 32.56 rur; 66,88 rur|. FIND ALL OCCURRENCES OF REGEX ‘(<[0-9]+(.|,)[0-9]{2,2}>)’ IN lv_string_12 RESULTS lt_result_tab. |
В результате получим «32,56», «66,88» .
Алгоритм поиска точно такой же как и в прошлый раз, за тем исключением, что добавился оператор x|y – который ищет или x или y.
Думаю, что в целом, как работают выражения понятно.
Для работы с регулярными выражениями существуют классы CL_ABAP_MATCHER и CL_ABAP_REGEX. Их удобно использовать, например, в условиях.
Пример проверки, что в строке только числа и пробелы.
|
IF cl_abap_matcher=>matches( pattern = ‘^[0-9 ]+$’ text = ‘input data’ ) = abap_true. ENDIF. |
^ – начало входных данных;
$ – конец входных данных;
Означает, что наша шаблон должен от начала и до конца удовлетворять тому, что находится между знаками ^ и $.
Проверка, что введенные данные являются email:
|
IF cl_abap_matcher=>matches( pattern = ‘([a-zA-Z0-9_.+-]+@[a-zA-Z0-9.-]+.[[a-z]{2,4})’ text = ‘exaple@mail.ru’ ) = abap_true. ENDIF. |
Также можно менять значения в строках
Удаление лишних пробелов:
|
DATA lv_string TYPE string. CONCATENATE ” ” INTO lv_string SEPARATED BY space. DATA(lv_string_3) = |Double spaces. More spaces|. cl_demo_output=>write_data( lv_string_3 ). “Удаление лишних пробелов REPLACE ALL OCCURRENCES OF REGEX ‘s{2,}’ IN lv_string_3 WITH lv_string. cl_demo_output=>write_data( lv_string_3 ). cl_demo_output=>display( ). |
Алгоритм:
s – символ пробела;
{2,} –повторение предыдущего символа 2 и более раз подряд.
Один из самых популярных примеров – замена формата даты:
|
DATA(string_6) = ‘First date 2020-01-02. Second date 2020-12-31’. cl_demo_output=>write_data( lv_string_6 ). REPLACE ALL OCCURRENCES OF REGEX ‘(d{4})-(d{2})-(d{2})’ IN lv_string_6 WITH ‘$3.$2.$1’. cl_demo_output=>write_data( lv_string_6 ). cl_demo_output=>display( ). |
Алгоритм:
d – любое число;
(x) «круглые скобки» – запоминание x;
$1, $2… – найденные зарегестрированные группы.
Удаление всех символов в начале строки перед From:
|
DATA(lv_string_2) = |for del From: sender@gmail.com : summa: 32 rur|. “Удаление всех символов в начале строки перед From: cl_demo_output=>write_data( lv_string_2 ). REPLACE FIRST OCCURRENCE OF REGEX ‘^(C*)(?=From:)’ IN lv_string_2 WITH ”. cl_demo_output=>write_data( lv_string_2 ). cl_demo_output=>display( ). |
Также смотри хелп по следующим операторам сравнения:
—————————————————————-
Operator Meaning
CO Contains Only: True, if operand1 only contains characters from operand2. Upper/lower case and trailing blanks are taken into account for both operands. If operand2 is of type string and is initial, then the logical expression is false, unless operand1 is also of type string and is initial, in which case the logical expression is always true. If the result of the comparison is negative, sy-fdpos contains the offset of the first character in operand1, that is not contained in operand2. If the result of the comparison is positive, sy-fdpos contains the length of operand1.
CN Contains Not Only; True if a logical expression with CO is false, that is, if operand1 contains not only characters from operand2. sy-fdpos is set in the same way as for CO. If the comparison is true, sy-fdpos contains the offset of the first character in operand1 that is not contained in operand2. If the comparison is false, sy-fdpos contains the length of operand1.
CA Contains Any: True, if operand1 contains at least one character from operand2. Upper/lower case and trailing blanks are taken into account for both operands. If operand1 or operand2 is of type string and initial, the logical expression is always false. If result of the comparison is positive, sy-fdpos contains the offset of the first character in operand1 that is also contained in operand2. If the result of the comparison is negative, sy-fdpos contains the length of operand1.
NA Contains Not Any: True if a logical expression with CA is false, that is if operand1 does not contain any characters from operand2. If the result of the comparison is negative, sy-fdpos contains the offset of the first character in operand1 that is also contained in operand2. If the result of the comparison is true, sy-fdpos contains the le of operand1.
CS Contains String: True if the content of operand2 is contained in operand1. Upper/lower case is not taken into account, trailing blanks of the left operand are taken into account. If operand1 is of type string and initial, or of type c and contains only blank characters, the logical expression is false, unless operand2 is also of type string and initial, or of type c and only contains blank characters. In this case the logical expression is always true. If the result of the comparison is true, sy-fdpos contains the offset of operand2 in operand1. If the result of the comparison is negative, sy-fdpos contains the length of operand1.
NS Contains No String: True, if a logical expression with CS is false, that is if operand1 does not contain the content of operand2. If the result of the comparison is negative, sy-fdpos contains the offset of operand2. If the comparison is true, sy-fdpos contains the length of operand1.
CP Covers Pattern: True, if the content of operand1 fits the pattern in operand2. Wildcard characters can be used for forming the operand pattern, where “*” represents any character string, and “+” represents any character. Upper/lower case is not taken into account. If the comparison is true, sy-fdpos contains the offset of operand2 in operand1, whereby leading wildcard characters “*” in operand2 are ignored if operand2 also contains other characters. If the comparison is false, sy-fdpos contains the length of operand1. You can select characters in operand2 for a direct comparison by adding the escape symbol “#” before the required characters. For these characters, upper/lower case is taken into account, wildcard characters and the escape symbol itself do not receive special treatment, and trailing blanks in operands of type c are not cut off.
NP No Pattern: True, if a logical expression with CP is false, that is, if operand1 does not fit the pattern operand2. If the comparison is false, sy-fdpos contains the offset of operand2 in operand1, whereby leading wildcard characters “*” in operand2 are ignored if operand2 also contains other characters. If the
_________________
Hе иди по течению, не иди против течения – иди поперек него, если хочешь достичь берега.
Слова Ванталы. Дела Ванталы
![]()
1 Обзор
Символьные данные (также называемые строковыми) относятся к объектам данных широких символьных типов (включая типы C, N, D, T и String). Для строковых данных ABAP предоставляет некоторые уникальные операторы операций, эти операции не выполняют преобразование типов при обработке объектов данных и рассматриваются как типы C.
2. Обработка строковых данных
1. Подключите строку, используйте
CONCATENATECONCATENATE s1 ... sn INTO s_dest [SEPARATED BY sep].
Этот оператор соединяет строки s1 … sn и присваивает результат s_dest, где s_dest также может быть переменной в s1 … sn. Опция SEPARATED BY используется для указания строки в качестве разделителя, которая вставляется между s1 … sn при формировании новой строки. Если длина после соединения превышает заданную длину целевых данных, усечение присваивается c. Если результат усечен, SY-SUBRC возвращает 4, в противном случае значение возвращает 0. Чтобы избежать усечения, вы можете определить c как строку, а длина этого типа является адаптивной.
REPORT z_data_manipulation.
DATA: s1(9) TYPE c VALUE 'Fristname',
s2(10) TYPE c VALUE 'Secondname',
s3(20),
sep(1) TYPE c VALUE '.'.
CONCATENATE s1 s2 INTO s3.
WRITE / s3.
CONCATENATE s1 s2 INTO s3 SEPARATED BY sep.
WRITE / s3.

INTO
2. Разбейте строку и используйте
SPLITSPLIT s_source AT sep INTO s1...sn.
Это предложение ищет разделитель sep в исходной строке и разбивает мета-строку на маленькие строки в соответствии с разделителем и помещает их в поле назначения s1 … sn. Эти подстроки не включают разделитель. С типом оператора соединения, если результат усечен, SY-SUBRC возвращает 4, в противном случае значение возвращает 0. Если исходная подстрока может разбить больше указанного числа подстрок, последняя оставшаяся часть исходной подстроки, включая следующие разделители, будет записана в последнюю подстроку. Чтобы избежать этой ситуации, необходимо использовать внутреннюю таблицу для работы.SPLIT s_source AT sep INTO TABLE itab.
REPORT z_data_manipulation.
DATA : text TYPE string,
itab TYPE TABLE OF string.
text = 'ABAP is a programming language'.
SPLIT text AT space INTO TABLE itab.
LOOP AT itab INTO text.
WRITE / text.
ENDLOOP.
Оператор LOOP AT используется для циклического вывода каждой строки данных во внутренней таблице.

SPLIT
3. Найдите шаблон подстроки
Чтобы найти шаблон подстроки в строке, используйтеSEARCHутверждениеSEARCH c FOR str.
Измените предложение, чтобы найти строку str в поле c. Если найдено, верните SY-SUBRC в 0, SY-FDPOS вернет позицию строки в поле c (смещение в байтах от вычисления), в противном случае верните SY-SUBRC в 4. Так называемый шаблон означает, что искомая строка может не совпадать со строкой. Вы можете задать игнорирование или оставить пробел в конце строки, или использовать подстановочный знак «*» для расширения гибкости поиска. Существует несколько режимов:
- str искать str и игнорировать конечные пробелы
- .str. Поиск по ул., но не игнорируйте конечные пробелы
- * str Поиск слов, заканчивающихся на str
- str * Поиск слов, начинающихся с str
REPORT z_string_search.
DATA string(30) TYPE c VALUE 'This is a testing sentence.'.
WRITE: / 'Searched', 'SY-SUBRC', 'SY-FDPOS'.
SEARCH string FOR 'X'.
WRITE: / 'X', sy-subrc UNDER 'SY-SUBRC',
sy-fdpos UNDER 'SY-FDPOS'.
SEARCH string FOR 'itt '.
WRITE: / 'itt ',sy-subrc UNDER 'SY-SUBRC',
sy-fdpos UNDER 'SY-FDPOS'.
SEARCH string FOR '.e .'.
WRITE: / '.e .', sy-subrc UNDER 'SY-SUBRC',
sy-fdpos UNDER 'SY-FDPOS'.
SEARCH string FOR '*e'.
WRITE: / '*e ', sy-subrc UNDER 'SY-SUBRC',
sy-fdpos UNDER 'SY-FDPOS'.
SEARCH string FOR 's*'.
WRITE: / 's*', sy-subrc UNDER 'SY-SUBRC',
sy-fdpos UNDER 'SY-FDPOS'.

SEARCH
4. Чтобы заменить содержимое поля, используйте оператор REPLACE.
REPLACE str1 WITH str2 INTO s_dest [LENGTH len].
Этот оператор ищет поле s_dest, и если в нем появляется строка str1, замените первое вхождение на str2. Если длина не указана, ищется весь s_dest. Если указана длина len, будет выполняться поиск только первых байтов len. Если поле SY-SUBRC возвращает 0, это означает, что оно было заменено, а не ноль означает, что оно не было заменено.
REPORT z_string_replace.
DATA name TYPE string.
name = 'Michael-Cheong'.
WHILE sy-subrc = 0.
REPLACE '-' WITH ' ' INTO name.
ENDWHILE.
WRITE / name.

REPLIACE
5. Определите длину поля, исключая завершающие пробелы, используйте STRLEN, оператор обрабатывает операнд str как символьный тип данных, независимо от фактического типа, и без преобразования
[COMPUTE] n = STRLEN( str ).
REPORT z_string_strlen.
DATA: text(24) TYPE c VALUE 'ABAP Language',
len TYPE i.
len = strlen( text ).
WRITE: / 'Length of', text, 'is', len.

strlen
6. Другие операции
- SHIFT Сдвиг всей строки или подстроки
- CONDENSE удалить лишние пробелы в строке
- Перевести преобразование символов, таких как преобразование ABC в ABC
- CONVERT TEXT создает сортируемый формат
- OVERLAY Наложение одной строки на другую строку
- Когда назначается WRITE TO, тип объекта данных будет игнорироваться и обрабатываться как данные типа символа
3. Сравнение данных персонажа
Символьные логические выражения используются для определения отношения локализации между двумя строками
| оператор | смысл |
|---|---|
| s1 CO s2 | Если s1 содержит только символы в s2, логическое выражение истинно |
| s1 CN s2 | Если s1 содержит символы, отличные от s2, логическое выражение истинно |
| s1 CA s2 | Если s1 содержит любой из символов в s2, логическое выражение истинно |
| s1 NA s2 | Если s1 не содержит символов s2, логическое выражение имеет значение true |
| s1 CS s2 | Если s1 содержит строку s2, логическое выражение истинно |
| s1 NS s2 | Если s1 не содержит строку s2, логическое выражение имеет значение true |
| s1 CP s2 | Если s1 содержит шаблон s2, логическое выражение имеет значение true |
| s1 NP s2 | Если s1 не содержит шаблон s2, логическое выражение имеет значение true |
CO, CN, CA, NA чувствительны к регистру при сравнении, а конечные пробелы также находятся в пределах диапазона сравнения: при использовании CS, NS, CP, NP пробелы в конце игнорируются, а сравнение нечувствительно к регистру. После сравнения, если результат равен true, системное поле SY-FDPOS выдаст информацию о смещении s2 в s1.
REPORT z_string_replace.
DATA: s1 TYPE string,
s2 TYPE string.
s1 = 'SAP ABAP'.
s2 = 'ABAP'.
IF s1 CS s2.
WRITE: / s2, 'is in Position', sy-fdpos,
'of', s1, 'Stirng'.
ENDIF.

Сравнение строк
CP и NP называются логическими выражениями сравнения шаблонов, что означает использование подстановочных знаков.
«*» используется для замены любой строки, а «+» используется для замены любого отдельного символа.
Если вам необходимо различать прописные и строчные буквы или пробелы в конце, вы должны поставить escape-символ “#” перед соответствующим символом. Функции, которые можно указать с помощью «#», перечислены ниже:
- Прописные и строчные буквы, укажите регистр (например, # A, # b)
- Wildcard ““(войти#) Вернуть его в первоначальное намерение
- Подстановочный знак “+” (ввод # +), верните его в первоначальное значение
- Сам символ выхода (ввод ##), чтобы вернуть его в исходное значение
- Пробел в конце строки (input #_), укажите конечный пробел сравнения
3 Операция позиционирования подстроки
Используйте только указанную часть подстроки.
s [+o][(1)]
Его смысл состоит в том, чтобы выполнять операторную операцию над частью поля s, начиная с o-й позиции (смещение от 0) и имея длину 1. Если длина не указана, обрабатываются все биты между oth и концом поля s.
REPORT z_string_replace.
DATA: f1(8) VALUE 'ABCDEFGH',
f2(20) VALUE '12345678901234567890'.
f2+6(5) = f1+3(5).
WRITE : / f1, / f2.

Операция позиционирования
Как правило, смещение и длина должны быть указаны как числа без знака. Тем не менее, переменные могут быть определены динамически в следующих ситуациях:
- При присваивании значений полям с помощью операторов MOVE или операторов присваивания
- При использовании оператора WRITE TO для переноса значений в поле
- При назначении полей символам поля с помощью ASSIGN
- При использовании PERFORM для передачи данных в подпрограмму
Имеет смысл указать смещения для типов символов, числовых текстовых полей, шестнадцатеричных полей и полей даты и времени, не используйте указанные смещения для числовых полей типов F, I и P.
