Автоопределение кодировки текста
Время на прочтение
6 мин
Количество просмотров 51K

Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandiacpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
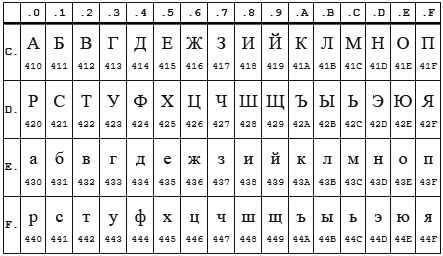
Таблица KOI8-r

В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед

Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожогах от молока, переборщил с проверкой входного параметра типа io.Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r'
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
if !reflect.ValueOf(r).IsValid() {
return ASCII, fmt.Errorf("input reader is nil")
}
...Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
//test input interfase
if r == nil {
return ASCII, nil
}
//make slice of byte from input reader
buf, err := bufio.NewReader(r).Peek(ReadBufSize)
if (err != nil) && (err != io.EOF) {
return ASCII, err
}
...вызов bufio.NewReader( r ).Peek(ReadBufSize) спокойно проходит следующий тест:
var data *os.File
res, err := CodePageDetect(data)В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
- перевёл тесты на testify и они действительно стали более читабельны
- исправил в тестах пути к файлам данных для совместимости с Linux
- прошёлся линтером — таки он нашёл одну реальную ошибку (проклятущий copy/past)
Продолжаю добавлять тесты, выявился случай не определения UTF16. Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв
Содержание:
1. Функция «КодСимвола()» в системе кодировки Unicode
2. Код символа в кодировке СР1251
3. Код в ОЕМ
Приветствую, коллеги! В данной статье речь пойдёт о том, как получать коды символов в 1С в стандартном виде, а также в кодировке СР1251 и кодировке ОЕМ. Кроме теоретических сведений, каждый случай будет рассмотрен на практическом примере.
Кодом символа называется особая подборка значений, состоящая только из чисел, соответствующих символам алфавитов, цифрам, знакам пунктуации и специальным символам. Код символов также называют кодовой станцией.
Чтобы проводить кодировку в операционной системе Windows, используют таблицы кодировки ASCII – American Standard Code for Interchange of Information. Стоит отметить, что в системе ASCII первые 120 символов принадлежат базовой таблице символов. А первые 32 кода в базовой таблице (включая нулевой) – это коды управления.
1. Функция «КодСимвола()» в системе кодировки Unicode
Специальную функция в системе 1С, которая помогает найти код символа, – это «КодСимвола()». Её синтаксис выглядит следующим образом:
\"")
Рисунок 1 Синтаксис функции “КодСимвола()”
Параметра у функции «КодСимвола()» два, рассмотрим их:
· «ИсходнаяСтрока» – это параметр строчного типа, который содержит исходную строку; данный параметр является обязательным;
· «НомерСимвола» – этот параметр числового типа обозначает порядковый номер символа внутри строки, код которого нам необходим. Нумерация символов внутри строки начинается с единицы, значение по умолчанию также «1».
Результатом работы данной функции является значение, которое она возвращает – это число, которое и является кодом символа, расположенным в строке, которая была передана строке с позицией, указанной номером. Полученный код принадлежит системе кодировки Unicode.
Данную функцию можно использовать на тонком клиенте, на веб-клиенте, на мобильном клиенте, на толстом клиенте, на сервере, при внешнем соединении, а также для мобильного приложения и на клиенте, и на сервере.
Рассмотрим, как выглядит и работает функция «КодСимвола()» на примере:
» в системе кодировки Unicode")
Рисунок 2 Функция «КодСимвола()» в системе кодировки Unicode
2. Код символа в кодировке СР1251
Иногда бывают случаи, когда нужно, например, получить контрольную сумму в строке, а для этого нужен код каждого из символов строки. Функция «КодСимвола()» возвращает код из системы кодировки Unicode. Рассмотрим пример для получения иной кодировки символа – СР1251:

Рисунок 3 Получение кода символа СР1251
3. Код в ОЕМ
Рассмотрим, как происходит получение кода в ОЕМ при помощи платформы 1С. Решение данной задачи основывается на значениях строк с типом «ДвоичныеДанные». Суть метода заключается в том, что первичная строка отправляется в файл при помощи объекта с типом «ТекстовыйДокумент». При этом используется кодировка ОЕМ. Далее появляется новый объект с типом «ДвоичныеДанные», который также основывается на файле и происходит анализ представления объекта в виде строки. При помощи строкового представления появляется возможность видеть байты, что и является кодом символов, в виде шестнадцатеричного представления. После этого остаётся только сделать преобразование из кодов шестнадцатеричного вида в коды десятичного вида.
Далее приведён пример такой функции, которая выполняет всё вышеописанное и преобразует строку в код ОЕМ:

Рисунок 4 Преобразование строки в код ОЕМ
Специалист компании «Кодерлайн»
Анна Лисовая
Работа с кодировкой символов на Python, да и на любом другом языке, временами выглядит довольно сложной. На Stack Overflow можно найти тысячи вопросов, посвящённых таким исключениям, как UnicodeDecodeError и UnicodeEncodeError. Данное руководство призвано прояснить сложные аспекты работы с этими исключениями и продемонстрировать, что работа с текстовыми и двоичными данными на Python 3 может быть приятной. В Python хорошо реализована поддержка Юникода, однако для работы с кодировкой всё же потребуется приложить усилия.
Вводная часть статьи даст общее понимание работы с Юникодом, не привязанное к какому-то определённому языку, однако практические примеры будут приведены именно на Python, а их описание будет довольно лаконичным.
Изучив эту статью, вы:
- Освоите концепции кодировки символов и системы нумерации;
- Поймёте, как кодировка работает с объектами
strиbytes; - Узнаете, как в Python поддерживается система нумерации посредством различных форм литералов
int; - Познакомитесь со встроенными функциями языка, относящимися к кодировке и системе нумерации.
Система нумерации и кодировка символов настолько тесно связаны, что их придётся раскрыть в одном руководстве, в противном случае материал будет неполным.
Прим. Статья ориентирована на Python 3, а все примеры кода созданы с помощью оболочки CPython 3.7.2. Большая часть более ранних версий Python 3 также будут корректно обрабатывать код. Если вы всё ещё используете Python 2 и различия в обработке текста и бинарных данных между 2 и 3 версиями языка вас отпугивают, это руководство может помочь вам преодолеть барьер.
Что такое кодировка символов?
Существуют десятки, если не сотни, кодировок символов. Понять эту концепцию легче всего, разобрав одну из самых простых, ASCII.
Независимо от того, занимаетесь вы самообразованием или получили более формальное образование в сфере IT , наверняка пару раз вы уже видели таблицу ASCII. Эта таблица — хорошее начало для изучения принципов кодировки, так как она простая и маленькая (как вы увидите дальше, даже слишком маленькая).
Она охватывает следующее:
- Символы английского алфавита в нижнем регистре: от a до z;
- Символы английского алфавита в верхнем регистре: от A до Z;
- Некоторые знаки препинания и символы: например «$» или «!»;
- Символы, отображаемые как пустое место: пробел (« »), символ новой строки, возврата каретки, горизонтальной и вертикальной табуляции и несколько других;
- Некоторые непечатаемые символы: такие как бекспейс, «b», которые просто невозможно отобразить, так, как к примеру, букву А.
Приведём формальное определение кодировки символов.
На самом высоком уровне — это способ перевода символов (таких как буквы, знаки пунктуации, служебные знаки, пробелы и контрольные символы) в целые числа и затем непосредственно в биты. Каждый символ может быть закодирован уникальным двоичным кодом. Если вы плохо знакомы с концепцией битов, не волнуйтесь, мы вскоре о ней поговорим.
Группы символов выделяют в отдельные категории. Каждому символу соответствует кодовая точка, которую можно рассматривать просто как целое число. В таблице ASCII символы сегментированы следующим образом:
| Диапазон кодовых точек | Класс |
|---|---|
| от 0 до 31 | Контрольные и неотображаемые символы |
| от 32 до 64 | Знаки пунктуации, символы, числа и пробел |
| от 65 до 90 | Буквы английского алфавита в верхнем регистре |
| от 91 до 96 | Дополнительные графемы, такие как [ и |
| от 97 до 122 | Буквы английского алфавита в нижнем регистре |
| от 123 до 126 | Дополнительные графемы, такие как { и | |
| 127 | Контрольный неотображаемый символ (DEL) |
Всего кодировка ASCII содержит 128 символов. В таблице ниже вы видите исчерпывающий набор знаков, которые позволяет отобразить эта кодировка. Если вы не видите какого-то символа, значит вы просто не сможете его вывести с помощью ASCII.
| Кодовая точка | Символ (имя) | Кодовая точка | Символ (имя) |
|---|---|---|---|
| 0 | NUL (Null) | 64 | @ |
| 1 | SOH (Start of Heading) | 65 | A |
| 2 | STX (Start of Text) | 66 | B |
| 3 | ETX (End of Text) | 67 | C |
| 4 | EOT (End of Transmission) | 68 | D |
| 5 | ENQ (Enquiry) | 69 | E |
| 6 | ACK (Acknowledgment) | 70 | F |
| 7 | BEL (Bell) | 71 | G |
| 8 | BS (Backspace) | 72 | H |
| 9 | HT (Horizontal Tab) | 73 | I |
| 10 | LF (Line Feed) | 74 | J |
| 11 | VT (Vertical Tab) | 75 | K |
| 12 | FF (Form Feed) | 76 | L |
| 13 | CR (Carriage Return) | 77 | M |
| 14 | SO (Shift Out) | 78 | N |
| 15 | SI (Shift In) | 79 | O |
| 16 | DLE (Data Link Escape) | 80 | P |
| 17 | DC1 (Device Control 1) | 81 | Q |
| 18 | DC2 (Device Control 2) | 82 | R |
| 19 | DC3 (Device Control 3) | 83 | S |
| 20 | DC4 (Device Control 4) | 84 | T |
| 21 | NAK (Negative Acknowledgment) | 85 | U |
| 22 | SYN (Synchronous Idle) | 86 | V |
| 23 | ETB (End of Transmission Block) | 87 | W |
| 24 | CAN (Cancel) | 88 | X |
| 25 | EM (End of Medium) | 89 | Y |
| 26 | SUB (Substitute) | 90 | Z |
| 27 | ESC (Escape) | 91 | [ |
| 28 | FS (File Separator) | 92 | |
| 29 | GS (Group Separator) | 93 | ] |
| 30 | RS (Record Separator) | 94 | ^ |
| 31 | US (Unit Separator) | 95 | _ |
| 32 | SP (Space) | 96 | ` |
| 33 | ! |
97 | a |
| 34 | " |
98 | b |
| 35 | # |
99 | c |
| 36 | $ |
100 | d |
| 37 | % |
101 | e |
| 38 | & |
102 | f |
| 39 | ' |
103 | g |
| 40 | ( |
104 | h |
| 41 | ) |
105 | i |
| 42 | * |
106 | j |
| 43 | + |
107 | k |
| 44 | , |
108 | l |
| 45 | - |
109 | m |
| 46 | . |
110 | n |
| 47 | / |
111 | o |
| 48 | 0 |
112 | p |
| 49 | 1 |
113 | q |
| 50 | 2 |
114 | r |
| 51 | 3 |
115 | s |
| 52 | 4 |
116 | t |
| 53 | 5 |
117 | u |
| 54 | 6 |
118 | v |
| 55 | 7 |
119 | w |
| 56 | 8 |
120 | x |
| 57 | 9 |
121 | y |
| 58 | : |
122 | z |
| 59 | ; |
123 | { |
| 60 | < |
124 | | |
| 61 | = |
125 | } |
| 62 | > |
126 | ~ |
| 63 | ? |
127 | DEL (delete) |
Модуль string
Модуль string — простой и удобный инструмент, разграничивающий содержащиеся в ASCII символы по группам, разделяя их в строки-константы. Вот как выглядит основная часть модуля:
# From lib/python3.7/string.py
whitespace = ' tnrvf'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_letters = ascii_lowercase + ascii_uppercase
digits = '0123456789'
hexdigits = digits + 'abcdef' + 'ABCDEF'
octdigits = '01234567'
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[]^_`{|}~"""
printable = digits + ascii_letters + punctuation + whitespaceБольшинство этих констант исчерпывающе описаны их идентификаторами. Мы вкратце коснёмся констант hexdigits и octdigits.
Мы можем использовать определённые в модуле константы для рутинных операций:
>>> import string
>>> s = "What's wrong with ASCII?!?!?"
>>> s.rstrip(string.punctuation)
'What's wrong with ASCII'Прим. Обратите внимание, string.printable включает string.whitespace. Это несколько не соответствует тому, как печатаемые символы определяет метод str.isprintable(), который не рассматривает ни один из символов {'v', 'n', 'r', 'f', 't'} как печатаемый.
Это различие происходит из определения метода: str.isprintable() рассматривает что-либо печатаемым, если «все символы рассматриваются как печатаемые методом repr().
Что такое биты
Настало время вспомнить, что такое бит, базовая единица информации, которой оперируют вычислительные устройства.
Бит — это сигнал, который имеет два возможных состояния. Есть различные способы символического отображения этих состояний:
- 0 или 1;
- «да» или «нет»;
TrueилиFalse;- «включено» или «выключено».
Таблица ASCII из предыдущего раздела использует то, что обычно назвали бы числами (от 0 до 127), однако для наших целей важно понимать, что это десятичные числа (с основанием 10).
Каждое из этих десятичных чисел можно выразить последовательностью бит (числом с основанием 2). Вот таблица соотношения двоичных и десятичных чисел:
| Десятичное | Двоичное (кратко) | Двоичное (в байте) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | 10 | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| 10 | 1010 | 00001010 |
Обратите внимание, что при увеличении десятичного числа n для его отображения (а следовательно и для отображения символа, относящегося к этому числу) требуется всё больше значимых бит.
Вот удобный метод представить строки ASCII как последовательность бит. Каждый символ из строки ASCII переводится в последовательность из 8 нолей и единиц с пробелами между этими последовательностями:
>>> def make_bitseq(s: str) -> str:
... if not s.isascii():
... raise ValueError("ASCII only allowed")
... return " ".join(f"{ord(i):08b}" for i in s)
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'
>>> make_bitseq("CAPS")
'01000011 01000001 01010000 01010011'
>>> make_bitseq("$25.43")
'00100100 00110010 00110101 00101110 00110100 00110011'
>>> make_bitseq("~5")
'01111110 00110101'Прим. Обратите внимание, что метод .isascii() появился в Python 3.7.
Строковой литерал f-string f"{ord(i):08b}" использует мини-язык форматирования Format Specification Mini-Language, а именно его возможность замещения полей при форматировании строк.
- левая часть выражения,
ord(i), представляет объект, значение которого будет отформатировано и отображено при выводе.ord()возвращает кодовую точку одиночного символаstrв десятичном выражении; - Правая сторона выражения определяет форматирование объекта.
08означает ширина 8, заполнение нулями, аbработает как команда вывести число в двоичном (binary) эквиваленте.
На самом деле этот метод можно использовать разве что для развлечения. Он выдаст ошибку для любого символа, не представленного в ASCII-таблице. Позже мы рассмотрим, как эта проблема решается в других кодировках.
Нам нужно больше бит
Исходя из определения бита, можно вывести следующую закономерность: при определённом количестве бит n с их помощью можно выразить 2n разных значений.
def n_possible_values(nbits: int) -> int:
return 2 ** nbitsВот что это означает:
- 1 бит позволяет выразить 21 == 2 возможных значения;
- 8 бит позволяют выразить 28 == 256 возможных значений;
- 64 бита позволяют выразить 264 == 18 446 744 073 709 551 616 возможных значений.
В качестве естественного вывода из приведённой выше формулы мы можем установить следующее: для того, чтобы вычислить количество бит, необходимых для выражения определённого числа разных значений, нам нужно найти n в уравнении 2n=x, где переменная x известна.
Вот как можно это рассчитать:
>>> from math import ceil, log
>>> def n_bits_required(nvalues: int) -> int:
... return ceil(log(nvalues) / log(2))
>>> n_bits_required(256)
8Округление вверх в методе n_bits_required() требуется для расчёта значений, которые не являются чистой степенью двойки. К примеру, вам нужно сохранить набор из 110 различных символов. Для этого потребуется log(110) / log(2) == 6.781 бит, но поскольку бит для вычислительной техники является мельчайшей неделимой величиной, для отображения 110 различных значений нам понадобится 7 бит, при этом несколько значений останутся невостребованными.
>>> n_bits_required(110)
7Всё сказанное служит для обоснования одной идеи: ASCII, строго говоря, семибитная кодировка. Эта таблица содержит 128 кодовых точек, и, соответственно, символов, от 0 до 127 включительно. Это требует 7 бит:
>>> n_bits_required(128) # от 0 до 127
7
>>> n_possible_values(7)
128Проблема заключается в том, что современные компьютеры не используют для хранения чего-либо семибитные последовательности. Основной единицей хранения информации современных вычислительных устройств являются восьмибитные последовательности, байты.
Прим. В этой статье под байтом подразумевается группа из 8 бит, как повелось с 60-х годов прошлого века. Если вам не по душе это новомодное название, можете называть их октетами.
То, что ASCII-таблица использует 7 бит из доступных 8, означает, что память вычислительного устройства, занятого строками символов ASCII, наполовину пуста. Для того, чтобы лучше понять, почему это происходит, вернитесь к приведённой выше таблице соответствия двоичных и десятичных чисел. Вы можете выразить числа 0 и 1 с помощью 1 бита, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001 соответственно.
Прим. перев. Если быть точным, то пустой остаётся только одна восьмая часть памяти. Однако с помощью именно этого незадействованного бита можно было бы создать вдвое больше кодовых точек.
Вы можете выразить числа от 0 до 3 всего двумя битами, от 00 до 11, или использовать 8 бит, чтобы выразить их как 00000000, 00000001, 00000010 и 00000011. Самая большая кодовая точка ASCII, 127, требует только 7 значимых бит.
С учётом этого взгляните, как метод make_bitseq() преобразует строки ASCII в строки, состоящие из байт, где каждый символ требует один байт:
>>> make_bitseq("bits")
'01100010 01101001 01110100 01110011'Неэффективное использование восьмибитной структуры памяти современных вычислительных устройств привело к появлению неструктурированного семейства конфликтующих кодировок, задействующих оставшуюся незанятой половину кодовых точек, доступных в одном байте.
Несмотря на попытку задействовать дополнительный бит, эти конфликтующие кодировки не могли отобразить все возможные символы, используемые человечеством в письменности.
Со временем появилась одна большая схема кодировки, которая объединила их. Однако, прежде чем мы до этого доберёмся, поговорим немного о краеугольных камнях схем кодировки символов — системах счисления.
Изучаем основы: другие системы счисления
В ASCII-таблице, как мы увидели, каждый символ соответствует числу от 0 до 127.
Этот диапазон чисел выражен в десятичной системе счисления. Именно эту систему используют для счёта люди, просто потому что на руках у нас по 10 пальцев.
Однако существуют и другие системы счисления, которые, в частности, широко используются в исходном коде CPython. Следует понимать, что действительное число не изменяется, а системы счисления просто по-разному его выражают.
Вопрос, какое число записано в строке "11" покажется странным, ведь для большинства очевидно, что это одиннадцать.
Однако в строке может быть представлено и другое число, в зависимости от системы счисления. Помимо десятичной, используются такие общепринятые альтернативы:
- Двоичная: с основой 2;
- Восьмеричная: с основой 8;
- Шестнадцатеричная (hex): с основой 16.
Что же мы подразумеваем, говоря что определённая система счисления имеет основу N?
Один из способов объяснения разных систем счисления заключается в том, чтобы представить, что у вас N пальцев.
Если же вам требуется более подробное объяснение систем счисления, обратитесь к книге Чарльза Петцольда «Код». В этой книге детально объясняются основы работы вычислительной техники.
Конструктор int() — один из способов показать, как разные системы счисления преобразуют одну и ту же строку с помощью Python. Если вы передадите str в int(), Python по умолчанию будет считать, что строка содержит число в десятичной системе. Однако вы можете дать другие указания:
>>> int('11')
11
>>> int('11', base=10) # 10 установлено по умолчанию
11
>>> int('11', base=2) # Двоичная
3
>>> int('11', base=8) # Восьмеричная
9
>>> int('11', base=16) # Шестнадцатеричная
17Чаще в Python для обозначения того, что целое число представлено в системе счисления, отличной от десятичной, используют префиксы-литералы. Для каждой из трёх альтернативных систем существует свой литерал.
| Тип литерала | Префикс | Пример |
|---|---|---|
| Нет | Нет | 11 |
| Binary literal | 0b или 0B |
0b11 |
| Octal literal | 0o или 0O |
0o11 |
| Hex literal | 0x или 0X |
0x11 |
Всё это — разновидности целочисленных литералов. Результаты применения префиксов будут такими же, как и в случае использования int() с определением параметра base. Для Python всё это просто целые числа:
>>> 11
11
>>> 0b11 # Двоичный литерал
3
>>> 0o11 # Восьмеричный литерал
9
>>> 0x11 # Шестнадцатеричный литерал
17В таблице ниже отражено, как можно ввести десятичные числа от 0 до 20 в двоичном, восьмеричном и шестнадцатеричном эквиваленте. Любой из этих способов можно использовать как в оболочке интерпретатора Python, так и в исходном коде, и все эти числа будут рассматриваться как относящиеся к типу int.
| Десятичные | Двоичные | Восмеричные | Шестнадцатеричные |
|---|---|---|---|
0 |
0b0 |
0o0 |
0x0 |
1 |
0b1 |
0o1 |
0x1 |
2 |
0b10 |
0o2 |
0x2 |
3 |
0b11 |
0o3 |
0x3 |
4 |
0b100 |
0o4 |
0x4 |
5 |
0b101 |
0o5 |
0x5 |
6 |
0b110 |
0o6 |
0x6 |
7 |
0b111 |
0o7 |
0x7 |
8 |
0b1000 |
0o10 |
0x8 |
9 |
0b1001 |
0o11 |
0x9 |
10 |
0b1010 |
0o12 |
0xa |
11 |
0b1011 |
0o13 |
0xb |
12 |
0b1100 |
0o14 |
0xc |
13 |
0b1101 |
0o15 |
0xd |
14 |
0b1110 |
0o16 |
0xe |
15 |
0b1111 |
0o17 |
0xf |
16 |
0b10000 |
0o20 |
0x10 |
17 |
0b10001 |
0o21 |
0x11 |
18 |
0b10010 |
0o22 |
0x12 |
19 |
0b10011 |
0o23 |
0x13 |
20 |
0b10100 |
0o24 |
0x14 |
Кстати, вы можете сами убедиться, что подобные способы записи чисел очень часто используется в Стандартной Библиотеке Python. Найдите папку lib/python3.7/ в своей системе, перейдите в неё и введите команду:
$ grep -nri --include "*.py" -e "b0x" lib/python3.7Команда сработает в любой Unix-системе с утилитой grep. С её помощью вы найдёте все шестнадцатеричные литералы. Для поиска двоичных используйте b0b, а для восьмеричных — b0o.
Для чего же нужны альтернативные литералы целых чисел? Если коротко, числа 2, 8 и 16, в отличие от 10, являются степенями двойки. Основанные на них системы счисления выражают численные значения способами, более удобными для обработки бинарными вычислительными устройствами. К примеру, 65536, или 216, в шестнадцатеричной системе просто 10000 или, используя литерал, 0x10000.
Введение в Юникод
Как видите, проблема ASCII в том, что этой таблицы недостаточно для отображения знаков, символов и глифов, использующихся во всех языках и диалектах мира. Её недостаточно даже для английского языка.
Юникод служит тем же целям, что и ASCII, но содержит намного больший набор кодовых точек. В период времени между появлением ASCII и принятием Юникода использовалось ещё несколько различных кодировок, но рассматривать их подробно нет смысла, так как Юникод и одна из его схем, UTF-8, в настоящее время стали использоваться практически повсеместно.
Вы можете представить Юникод как расширенную версию ASCII-таблицы — с 1 114 112 возможными кодовыми точками, от 0 до 1 114 111. Это 17*(216) или 0x10ffff в шестнадцатеричном представлении. Фактически, ASCII является частью Юникода, так как первые 128 символов этих кодировок полностью совпадают.
Чтобы соблюсти технические детали, сам по себе Юникод не является кодировкой. Он скорее реализуется в различных кодировках символов, как вы вскоре увидите. По структуре Юникод скорее ассоциативный массив (что-то вроде dict) или база данных, состоящая из таблицы с двумя колонками. В этой таблице разные символы (такие как "a", "¢", или даже "ቈ") соотносятся с различными целыми положительными числами. Кодировка же должна предоставлять несколько больше возможностей.
Юникод содержит практически любой символ, который только можно представить, включая дополнительные непечатаемые. Например, кодовая точка 8207 соответствует отметке RTL, которая используется для смены направления письма. Она полезна в текстах, где абзацы на одном из европейских языков соседствуют с абзацами на арабских языках.
Прим. Кстати, если уж мы хотим быть совсем точны в деталях, то надо отметить ещё один факт. Исторически сложилось, что в Юникоде доступны только 1 111 998 кодовых точек.
Юникод и UTF-8
Довольно скоро стало понятно, что все необходимые символы невозможно вместить в таблицу, используя только один байт. Современные, более ёмкие кодировки требовали использования больших объёмов.
Ранее мы упоминали, что Юникод сам по себе не является кодировкой. И вот почему.
Юникод не содержит указаний по извлечению из текста бит, он работает только с кодовыми точками. В нём нет стандарта конверсии текста в двоичные данные и обратно.
Юникод является абстрактным стандартом кодировки. Для практического его применения чаще всего используют схему UTF-8. Стандарт Юникод (таблица соответствий символов кодовыми точкам) определяет несколько различных кодировок на основе единого набора символов.
Как и менее распространённые UTF-16 и UTF-32, UTF-8 — формат кодировки для отображения символов Юникода в двоичном виде, используя один или несколько байт на один символ. UTF-16 и UTF-32 мы обсудим чуть позже, но пока нам интересен UTF-8 как самый популярный формат.
Сначала требуется разобрать термины «кодирование» и «декодирование».
Кодирование и декодирование в Python 3
Тип данных str в Python 3 рассчитан на представление текста в удобном для чтения формате и может содержать любые символы Юникода.
Тип bytes, напротив, представляет двоичные данные, последовательность байт, без указания на кодировку.
Кодирование и декодирование — это процесс перехода данных из одной формы в другую.
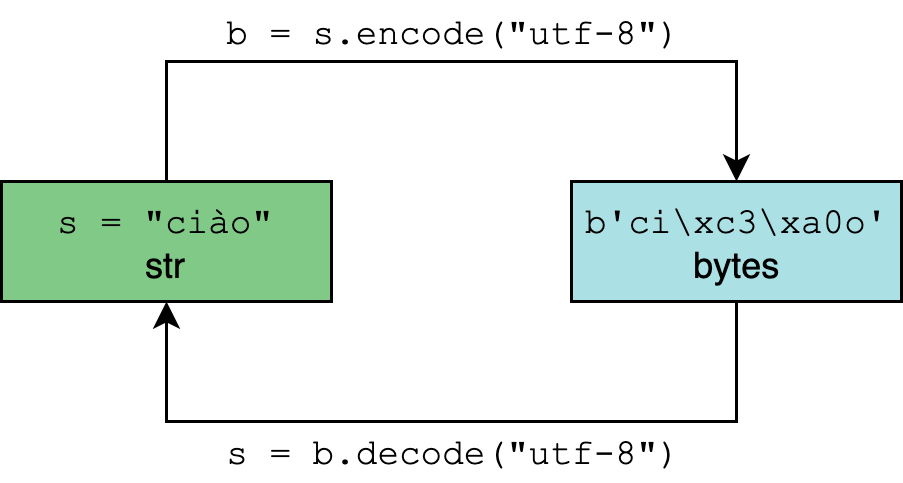
В методах .encode() и .decode() по умолчанию используется параметр "utf-8", однако для большей уверенности этот параметр можно определить самостоятельно:
>>> "résumé".encode("utf-8")
b'rxc3xa9sumxc3xa9'
>>> "El Niño".encode("utf-8")
b'El Nixc3xb1o'
>>> b"rxc3xa9sumxc3xa9".decode("utf-8")
'résumé'
>>> b"El Nixc3xb1o".decode("utf-8")
'El Niño'str.encode() возвращает объект типа bytes. И литералы этого типа объектов (такие как b"rxc3xa9sumxc3xa9"), и его отображение допускают только символы ASCII.
Вот почему при вызове "El Niño".encode("utf-8"), ASCII-совместимое "El" отображается как есть, а n с тильдой экранируется в "xc3xb1". Этой с виду неудобочитаемой последовательностью представлены два байта, 0xc3 и 0xb1 в шестнадцатеричной системе:
>>> " ".join(f"{i:08b}" for i in (0xc3, 0xb1))
'11000011 10110001'Таким образом символ ñ требует два байта для бинарного представления с помощью UTF-8.
Прим. Если вы введёте help(str.encode), скорее всего, увидите параметр по умолчанию encoding='utf-8'. Однако имейте в виду, что настройки Windows для Python 3.6 могут отличаться, поэтому использовать методы кодирования и декодирования без указания необходимой кодировки (например "résumé".encode()) следует с осторожностью.
Python 3: всё на Юникоде
Python 3 полностью реализован на Юникоде, а точнее на UTF-8. Вот что это означает:
- По умолчанию предполагается, что исходный код Python 3 написан с помощью UTF-8. Это значит, что вам не нужно использовать определение
# -*- coding: UTF-8 -*-в начале файлов.pyв этой версии языка. - Все тексты (объекты формата
str) реализованы на Юникоде. Кодированный текст представлен двоичными данными (bytes). Типstrможет содержать любой символ-литерал из Юникода (например"Δv / Δt"), и все они хранятся в Юникоде. - Любой из символов Юникода приемлем в качестве идентификатора. Например, вы можете использовать выражение
résumé = "~/Documents/resume.pdf". - В модуле
reпо умолчанию установлен флагre.UNICODE, а неre.ASCII. Это означает, чтоr"w"соответствует буквам из Юникода, а не просто символам ASCII. - По умолчанию
encodingвstr.encode()вbytes.decode()установлен в UTF-8.
Нужно отметить также нюанс, касающийся встроенного метода open(). Его параметр encoding зависит от платформы и определяется значением locale.getpreferredencoding():
>>> # Mac OS X High Sierra
>>> import locale
>>> locale.getpreferredencoding()
'UTF-8'
>>> # Windows Server 2012; другие сборки Windows могут использовать UTF-16
>>> import locale
>>> locale.getpreferredencoding()
'cp1252'Мы делаем упор на эти моменты, чтобы вы вдруг не подумали, что кодировка UTF-8 является универсальной. Она действительно широко распространена, но вы вполне можете столкнуться и с другими вариантами. Не будет лишним предусмотреть это в коде.
Один байт, два байта, три байта, четыре…
Одна из важнейших особенностей UTF-8 состоит в том, что это кодировка с переменным размером.
Вспомните раздел, посвящённый ASCII. Любой символ в этой таблице требует максимум одного байта пространства. Это можно быстро проверить с помощью следующего генератора:
>>> all(len(chr(i).encode("ascii")) == 1 for i in range(128))
TrueС UTF-8 дела обстоят по-другому. Символы Юникода могут занимать от одного до четырёх байт. Вот пример четырёхбайтного символа:
>>> ibrow = "?"
>>> len(ibrow)
1
>>> ibrow.encode("utf-8")
b'xf0x9fxa4xa8'
>>> len(ibrow.encode("utf-8"))
4
>>> # Вызов list() с объектом типа bytes возвращает
>>> # значение каждого байта
>>> list(b'xf0x9fxa4xa8')
[240, 159, 164, 168]Это небольшая, но важная особенность метода len():
- Размер единичного символа Юникода в объекте
strязыка Python всегда будет равен 1, вне зависимости от количества занимаемых байт. - Длина того же символа в объекте типа
bytesбудет варьироваться от 1 до 4.
Таблица ниже показывает, сколько байт занимают основные типы символов.
| Десятичный диапазон | Шестнадцатеричный диапазон |
Включённые символы | Примеры |
|---|---|---|---|
| от 0 до 127 | от "u0000" до "u007F" |
U.S. ASCII | "A", "n", "7", "&" |
| от 128 до 2047 | от "u0080" до "u07FF" |
Большая часть латинских алфавитов* | "ę", "±", "ƌ", "ñ" |
| от 2048 до 65535 | от "u0800" до "uFFFF" |
Дополнительные части многоязыковых символов (BMP)** | "ത", "ᄇ", "ᮈ", "‰" |
| от 65536 до 1114111 | от "U00010000" до "U0010FFFF" |
Другое*** | "?", "?", "?", "?", |
*Такие как английский, арабский, греческий, ирландский.
**Масса языков и символов, в основном китайский, японский и корейский с разделением по томам (а также ASCII и латиница).
***Дополнительные символы китайского, японского, корейского и вьетнамского, а также другие символы и эмоджи.
Прим. У UTF-8 есть и другие технические особенности. Те, кто работает на Python, редко с ними сталкиваются, поэтому мы не будем раскрывать их в этой статье, но упомянем вкратце, чтобы сохранить полноту картины. Так, UTF-8 использует коды-префиксы, указывающие на количество байт в последовательности. Такой приём позволяет декодеру группировать байты в условиях кодировки с переменным размером. Количество байт в последовательности определяется первым её байтом. Другие технические подробности можно найти на странице Википедии, посвящённой UTF-8 или на официальном сайте.
Особенности UTF-16 и UTF-32
Рассмотрим альтернативные кодировки, UTF-16 и UTF-32. Различие между ними и UTF-8 в основном практическое. Продемонстрируем величину расхождения с помощью перевода туда и обратно:
>>> letters = "αβγδ"
>>> rawdata = letters.encode("utf-8")
>>> rawdata.decode("utf-8")
'αβγδ'
>>> rawdata.decode("utf-16") # ?
'뇎닎돎듎'В данном случае, когда мы кодируем четыре буквы греческого алфавита в двоичные данные с помощью UTF-8, а декодируем обратно в текст с использованием UTF-16, на выходе получается строка с совершенно другими символами (из корейского алфавита).
Так происходит, если для кодирования и декодирования применяют разные кодировки. Два варианта декодирования одного бинарного объекта могут вернуть текст даже на другом языке.
Таблица ниже демонстрирует количество байт, используемых в разных кодировках:
| Кодировка | Байт на символ (включительно) | Варьируемая длина |
|---|---|---|
| UTF-8 | От 1 до 4 | Да |
| UTF-16 | От 2 до 4 | Да |
| UTF-32 | 4 | Нет |
Любопытный аспект семейства UTF: UTF-8 не всегда занимает меньше памяти, чем UTF-16. Хотя с точки зрения математики это выглядит маловероятным, однако это возможно:
>>> text = "記者 鄭啟源 羅智堅"
>>> len(text.encode("utf-8"))
26
>>> len(text.encode("utf-16"))
22Так получается из-за того, что кодовые точки в диапазоне от U+0800 до U+FFFF (от 2048 до 65535 в десятичной системе) в кодировке UTF-8 занимают три байта, а в UTF-16 только два.
Это не означает, что нужно работать с UTF-16, независимо от того, насколько часто вы работаете с символами в этом диапазоне. Один из самых важных поводов придерживаться UTF-8 — в мире кодировок лучше держаться вместе с большинством.
Кроме того, в 2019 году компьютерная память стоит дёшево, и экономия четырёх байт за счёт использования нестандартной кодировки вряд ли стоит усилий.
Прим. перев. Есть и более весомые причины использовать UTF-8. Среди них её обратная совместимость с ASCII, а также то, что это самосинхронизирующаяся кодировка.
Вы освоили самую сложную часть статьи. Теперь посмотрим, как всё изученное реализуется на Python.
В Python есть несколько встроенных функций, каким-либо образом относящихся к системам счисления и кодировке:
ascii()bin()bytes()chr()hex()int()oct()ord()str()
Логически их можно сгруппировать по назначению.
ascii(),bin(),hex()иoct()предназначены для различного представления вводных данных. Все они возвращаютstr. Первая,ascii(), производит представление объекта в ASCII, экранируя не входящие в эту таблицу символы. Оставшиеся три дают соответственно двоичное, шестнадцатеричное и восьмеричное представление целого числа. Все эти функции меняют только представление объекта, не изменяя непосредственно вводные данные.bytes(),str()иint()— конструкторы классов соответствующих типов:bytes,str, иint. Все они предлагают способы подогнать данные под желаемый тип.ord()иchr()выполняют противоположные действия.ord()конвертирует символ в десятичную кодовую точку, аchr()принимает в качестве аргумента целое число, и возвращает символ, кодовой точкой которого это число является.
В таблице ниже эти функции разобраны более подробно:
| Функция | Форма | Тип аргументов | Тип возвращаемых данных | Назначение |
|---|---|---|---|---|
ascii() |
ascii(obj) |
Различный | str |
Представление объекта символами ASCII. Не входящие в таблицу символы экранируются |
bin() |
bin(number) |
number: int |
str |
Бинарное представление целого чиста с префиксом "0b" |
bytes() |
bytes(последовательность_целых_чисел)
|
Различный | bytes |
Приводит аргумент к двоичным данным, типу bytes |
chr() |
chr(i) |
i: int
|
str |
Преобразует кодовую точку (целочисленное значение) в символ Юникода |
hex() |
hex(number) |
number: int |
str |
Шестнадцатеричное представление целого числа с префиксом "0x" |
int() |
int([x])
|
Различный | int |
Приводит аргумент к типу int |
oct() |
oct(number) |
number: int |
str |
Восьмеричное представление целого числа с префиксом "0o" |
ord() |
ord(c) |
c: str
|
int |
Возвращает значение кодовой точки символа Юникода |
str() |
str(object=’‘)
|
Различный | str |
Приводит аргумент к текстовому представлению, типу str |
Дальше можно посмотреть полезные примеры использования этих функций.
ascii():
>>> ascii("abcdefg")
"'abcdefg'"
>>> ascii("jalepeño")
"'jalepe\xf1o'"
>>> ascii((1, 2, 3))
'(1, 2, 3)'
>>> ascii(0xc0ffee) # Шестнадцатеричный литерал (int)
'12648430'bin():
>>> bin(0)
'0b0'
>>> bin(400)
'0b110010000'
>>> bin(0xc0ffee) # Шестнадцатеричный литерал (int)
'0b110000001111111111101110'
>>> [bin(i) for i in [1, 2, 4, 8, 16]] # `int` + обработка списка
['0b1', '0b10', '0b100', '0b1000', '0b10000']bytes():
>>> # Последовательность целых чисел
>>> bytes((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
b'hello world'
>>> bytes(range(97, 123)) # Последовательность целых чисел
b'abcdefghijklmnopqrstuvwxyz'
>>> bytes("real ?", "utf-8") # Строка + кодировка
b'real xf0x9fx90x8d'
>>> bytes(10)
b'x00x00x00x00x00x00x00x00x00x00'
>>> bytes.fromhex('c0 ff ee')
b'xc0xffxee'
>>> bytes.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython'chr():
>>> chr(97)
'a'
>>> chr(7048)
'ᮈ'
>>> chr(1114111)
'U0010ffff'
>>> chr(0x10FFFF) # Шестнадцатеричный литерал (int)
'U0010ffff'
>>> chr(0b01100100) # Двоичный литерал (int)
'd'hex():
>>> hex(100)
'0x64'
>>> [hex(i) for i in [1, 2, 4, 8, 16]]
['0x1', '0x2', '0x4', '0x8', '0x10']
>>> [hex(i) for i in range(16)]
['0x0', '0x1', '0x2', '0x3', '0x4', '0x5', '0x6', '0x7',
'0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']int():
>>> int(11.0)
11
>>> int('11')
11
>>> int('11', base=2)
3
>>> int('11', base=8)
9
>>> int('11', base=16)
17
>>> int(0xc0ffee - 1.0)
12648429
>>> int.from_bytes(b"x0f", "little")
15
>>> int.from_bytes(b'xc0xffxee', "big")
12648430oct():
>>> ord("a")
97
>>> ord("ę")
281
>>> ord("ᮈ")
7048
>>> [ord(i) for i in "hello world"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]str():
>>> str("str of string")
'str of string'
>>> str(5)
'5'
>>> str([1, 2, 3, 4]) # Like [1, 2, 3, 4].__str__(), but use str()
'[1, 2, 3, 4]'
>>> str(b"xc2xbc cup of flour", "utf-8")
'¼ cup of flour'
>>> str(0xc0ffee)
'12648430'Литералы для строк на Python
Вместо использования конструктора str(), объект этого типа чаще вводят напрямую:
>>> meal = "shrimp and grits"Выглядит достаточно просто. Но есть один аспект, о котором нужно помнить. Поскольку Python позволяет использовать все возможности Юникода, можно «напечатать» символы, которых вы никогда не найдёте на клавиатуре. Можно скопировать и вставить их прямо в оболочку интерпретатора:
>>> alphabet = 'αβγδεζηθικλμνξοπρςστυφχψ'
>>> print(alphabet)
αβγδεζηθικλμνξοπρςστυφχψКроме ввода через консоль реальных, неэкранированых символов Юникода, существуют и другие способы ввода текстовых строк.
Самые насыщенные разделы документации Python посвящены лексическому анализу. В частности, раздел о строках и литералах. Возможно, для понимания данного аспекта языка этот раздел придётся неоднократно перечитать.
Кроме прочего, там говорится о шести возможных способах ввода одного символа Юникода.
Первый, и самый распространённый метод, как вы уже видели — прямой ввод. Проблема состоит в поиске необходимых сочетаний клавиш. Здесь и могут пригодиться другие способы получения и представления символов. Вот полный список:
| Экранирующая последовательность | Значение | Как отобразить "a" |
|---|---|---|
"ooo" |
Символ с восьмеричным значением ooo |
"141" |
"xhh" |
Символ с шестнадцатеричным значением hh |
"x61" |
"N{name}" |
Символ с именем name в базе данных Юникода |
"N{LATIN SMALL LETTER A}" |
"uxxxx" |
Символ с шестнадцатибитным (двухбайтным) шестнадцатеричным значением xxxx |
"u0061" |
"Uxxxxxxxx" |
Символ с тридцатидвухбитным (четырёхбайтным) шестнадцатеричным значением xxxxxxxx |
"U00000061" |
Это соответствие можно проверить на практике:
>>> (
... "a" ==
... "x61" ==
... "N{LATIN SMALL LETTER A}" ==
... "u0061" ==
... "U00000061"
... )
TrueНужно однако упомянуть и два основных затруднения при использовании этих методов:
- Не каждый способ работает со всеми символами. Шестнадцатеричное представление числа 300 выглядит как
0x012c, а это значение просто не поместится в экранирующий код"xhh", так как в нём допускаются всего две цифры. Самая большая кодовая точка, которую можно втиснуть в этот формат —"xff"("ÿ"). Аналогичо"ooo"можно использовать только до"777"("ǿ"). - Для
xhh,uxxxx, иUxxxxxxxxтребуется вводить ровно столько цифр, сколько указано в примерах. Это может стать неприятным сюрпризом, поскольку обычно основанные на Юникоде таблицы содержат кодовые точки для символов с префиксомU+и варьирующимся количеством шестнадцатеричных символов. В этих таблицах кодовые точки отображают только значимые цифры.
Например, если вы обратитесь к сайту unicode-table.com с целью получить данные готического символа faihu (или fehu), "?", его кодовая точка будет U+10346.
Как же можно разместить его в "uxxxx" или "Uxxxxxxxx"? В "uxxxx" эту кодовую точку вместить невозможно, поскольку она соответствует четырёхбайтному символу. А чтобы представить его в "Uxxxxxxxx", придётся выровнять последовательность с левой стороны:
>>> "U00010346"
'?'Это также значит, что экранирующая последовательность "Uxxxxxxxx" — единственная последовательность, способная вместить любой символ Юникода.
Прим. Вот код небольшой, но удобной функции, переводящей записи типа "U+10346" в приемлемый для Python формат с помощью str.zfill():
>>> def make_uchr(code: str):
... return chr(int(code.lstrip("U+").zfill(8), 16))
>>> make_uchr("U+10346")
'?'
>>> make_uchr("U+0026")
'&'Другие поддерживаемые Python кодировки
Пока что мы рассказали про 4 разные кодировки символов:
- ASCII;
- UTF-8;
- UTF-16;
- UTF-32.
Однако существует большое количество и других вариантов кодировки.
Один из примеров — Latin-1 (другое название ISO-8859-1). Это базовая кодировка для Hypertext Transfer Protocol (HTTP) в спецификации RFC 2616. Для Windows существует собственный вариант Latin-1, который называется cp1252.
Прим. Кодировка ISO-8859-1 всё ещё широко используется. Библиотека requests неукоснительно придерживается спецификации RFC 2616, используя её по умолчанию для содержимого отзывов HTTP/HTTPS. Если в заголовке Content-Type находится слово «text» и не выбрана другая кодировка, requests использует ISO-8859-1.
Полный список допустимых кодировок можно найти в документации модуля codecs, входящего в набор стандартных библиотек Python.
Среди этих кодировок стоит упомянуть ещё одну, зачастую весьма полезную. Это "unicode-escape". Если вы декодировали str и хотите быстро получить представление содержащихся в ней экранированных литералов Юникода, можно определить эту кодировку в .encode:
>>> alef = chr(1575) # Или "u0627"
>>> alef_hamza = chr(1571) # Или "u0623"
>>> alef, alef_hamza
('ا', 'أ')
>>> alef.encode("unicode-escape")
b'\u0627'
>>> alef_hamza.encode("unicode-escape")
b'\u0623'Вы знаете, что говорят насчёт предположений…
Хотя Python по умолчанию предполагает, что файлы и код созданы на основе кодировки UTF-8, вам, как программисту, не следует делать аналогичное предположение относительно сторонних данных.
Когда вы получаете данные в двоичном коде из внешних источников, из файла или по сетевому соединению, стоит проверить, указана ли кодировка. Если нет — вы можете уточнить.
Все операции ввода-вывода осуществляют в байтах, наборе нулей и единиц, пока вы не сообщите системе кодировку для преобразования этих данных в текст.
Приведём пример того, что может пойти не так. Допустим, вы подписаны на API, который передаёт вам рецепт блюда дня. Вы получаете его в формате bytes и раньше всегда без проблем декодировали с использованием .decode("utf-8") . Но именно в этот день часть рецепта выглядела так:
>>> data = b"xbc cup of flour"Похоже, нам потребуется мука, но сколько?
>>> data.decode("utf-8")
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 0: invalid start byteА вот и та самая неприятная ошибка UnicodeDecodeError. Подобное вполне может произойти, когда вы делаете предположение об используемой кодировке. Уточняем у разработчика ресурса, предоставляющего API. Выясняется, что полученный вами файл был закодирован с помощью Latin-1:
>>> data.decode("latin-1")
'¼ cup of flour'Именно в этом и крылась проблема. В Latin-1 каждый символ кодируется одним байтом, в вот в UTF-8 символ «¼» требует два байта ("xc2xbc").
Как видите, делать предположения относительно кодировки полученных данных довольно рискованно. Обычно это UTF-8, однако в тех случаях, когда это не так, у вас могут возникнуть проблемы.
Если уж у вас нет другого выхода и кодировку приходится угадывать, обратите внимание на библиотеку chardet. В ней используются разработанные в Mozilla методы, позволяющие сделать обоснованное предположение насчёт кодировки данных. Однако учтите, что такие инструменты должны быть вашим последним средством, не стоит прибегать к ним, если есть возможность решить вопрос другим способом.
Всякая всячина: unicodedata
Нельзя не упомянуть также модуль unicodedata. Он позволяет взаимодействовать с базой данных символов Юникода (Unicode Character Database, UCD).
>>> import unicodedata
>>> unicodedata.name("€")
'EURO SIGN'
>>> unicodedata.lookup("EURO SIGN")
'€'Подводим итоги
Итак, в этой статье вы познакомились со следующими концепциями кодировки символов в Python:
- Фундаментальные принципы кодировки символов и систем счисления;
- Целочисленные, двоичные, восьмеричные, шестнадцатеричные, строковые и байтовые литералы в Python;
- Встроенные функции языка, работающие с кодировкой и системами счисления;
- Особенности обработки текстовых и двоичных данных.
Дополнительные источники
Ещё больше информации можно получить из следующих материалов (на английском языке):
- UTF-8 Everywhere Manifesto.
- Joel Spolsky: Минимальный уровень знаний о Юникоде и наборах символов, требующийся каждому разработчику ПО (Без отговорок!).
- David Zentgraf: Что обязательно должен знать о кодировках и наборах символов каждый программист для работы с текстом.
- Mozilla: Комплексный подход к определению языков и кодировок.
- Wikipedia.
- John Skeet: Юникод и .NET.
- Network Working Group, RFC 3629: UTF-8, формат преобразования ISO 10646.
- Unicode Technical Standard #18: Регулярные выражения Юникода.
В документации языка нашему вопросу посвящены два раздела:
- What’s New in Python 3.0;
- Unicode HOWTO.
Перевод статьи Unicode & Character Encodings in Python: A Painless Guide
Как узнать код символа
При отображении текстов компьютер использует кодировочные таблицы, в которых каждому знаку или управляющему символу (например, символу перевода строки) сопоставлен уникальный шестнадцатеричный код. Зная коды символов можно, например, вставлять в текстовые документы знаки, отсутствующие на клавиатуре. Для просмотра кодов в составе ОС Windows есть специальная утилита, но это не единственный доступный пользователю компьютера способ.
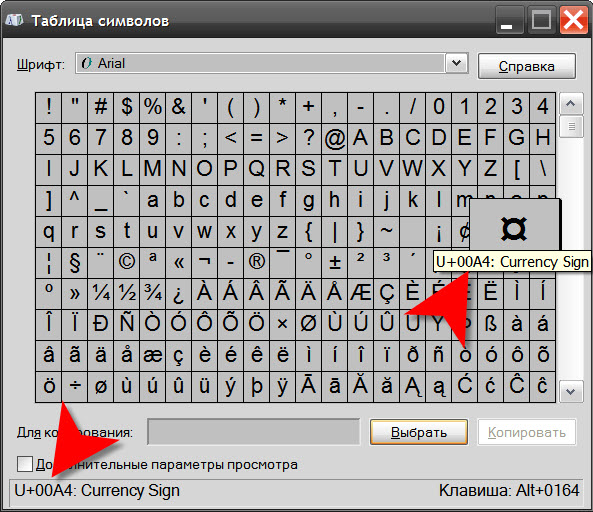
Инструкция
Воспользуйтесь компонентом «Таблица символов» операционной системы, чтобы узнать код нужного вам знака. Запустить ее можно ссылкой в главном меню на кнопке «Пуск» – раскрыв его, перейдите в раздел «Все программы», затем в подраздел «Стандартные», потом в секцию «Служебные», а там выберите пункт «Таблица символов». Есть более короткий путь: нажмите сочетание клавиш win + r, чтобы открыть диалог запуска программ, затем наберите команду charmap и щелкните кнопку «OK».
Найдите в таблице символ, код которого вас интересует, и щелкните его мышкой. Шестнадцатеричный код, который будет и порядковым номером этого знака в юникод-таблице, вы увидите в левом нижнем углу окна утилиты – он написан с префиксом U+. Через двоеточие там же помещено название символа на английском языке. В правом нижнем углу, после префикса Alt+ размещен порядковый номер этого символа в ASCII-таблице.
Аналогичная таблица символов есть и в текстовом редакторе Microsoft Office Word. Чтобы до нее добраться надо перейти на вкладку «Вставка» и в группе команд «Символы» раскрыть выпадающий список на кнопке «Символ». Самый нижний пункт в этом списке («Другие символы») и открывает таблицу символов. После того, как вы найдете и выделите интересующий вас знак, его код можно будет увидеть в поле «Код знака».
Воспользуйтесь размещенными в интернете таблицами соответствия кодов символам в качестве альтернативы программным средствам. Правда, в большинстве случаев такие таблицы ориентированы на применение кодов для размещения символов в веб-страницах. Например, по адресу http://vvz.nw.ru/Lessons/SymbolCodes/symbolcodes.htm можно найти готовые к вставке в HTML-исходники коды десяти тысяч символов. Если отбросить префикс &# и точку с запятой в конце, то можно использовать очищенный код символа по своему усмотрению не только в HTML-документах.
Видео по теме
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Кодировка символов (часто называемая также кодовой страницей) – это набор числовых значений, которые ставятся в соответствие группе алфавитно-цифровых символов, знаков пунктуации и специальных символов.
Для кодировки символов в Windows используется таблица ASCII (American Standard Code for Interchange of Information).
В ASCII первые 128 символов всех кодовых страниц состоят из базовой таблицы символов. Первые 32 кода базовой таблицы, начиная с нулевого, размещают управляющие коды.
| Символ | Код | Клавиши | Значение |
| nul | 0 | Ctrl + @ | Нуль |
| soh | 1 | Ctrl + A | Начало заголовка |
| stx | 2 | Ctrl + B | Начало текста |
| etx | 3 | Ctrl + C | Конец текста |
| eot | 4 | Ctrl + D | Конец передачи |
| enq | 5 | Ctrl + E | Запрос |
| ack | 6 | Ctrl + F | Подтверждение |
| bel | 7 | Ctrl + G | Сигнал (звонок) |
| bs | 8 | Ctrl + H | Забой (шаг назад) |
| ht | 9 | Ctrl + I | Горизонтальная табуляция |
| lf | 10 | Ctrl + J | Перевод строки |
| vt | 11 | Ctrl + K | Вертикальная табуляция |
| ff | 12 | Ctrl + L | Новая страница |
| cr | 13 | Ctrl + M | Возврат каретки |
| so | 14 | Ctrl + N | Выключить сдвиг |
| si | 15 | Ctrl + O | Включить сдвиг |
| dle | 16 | Ctrl + P | Ключ связи данных |
| dc1 | 17 | Ctrl + Q | Управление устройством 1 |
| dc2 | 18 | Ctrl + R | Управление устройством 2 |
| dc3 | 19 | Ctrl + S | Управление устройством 3 |
| dc4 | 20 | Ctrl + T | Управление устройством 4 |
| nak | 21 | Ctrl + U | Отрицательное подтверждение |
| syn | 22 | Ctrl + V | Синхронизация |
| etb | 23 | Ctrl + W | Конец передаваемого блока |
| can | 24 | Ctrl + X | Отказ |
| em | 25 | Ctrl + Y | Конец среды |
| sub | 26 | Ctrl + Z | Замена |
| esc | 27 | Ctrl + [ | Ключ |
| fs | 28 | Ctrl + | Разделитель файлов |
| gs | 29 | Ctrl + ] | Разделитель группы |
| rs | 30 | Ctrl + ^ | Разделитель записей |
| us | 31 | Ctrl + _ | Разделитель модулей |
| 32 пробел | 48 0 | 64 @ | 80 P | 96 ` | 112 p |
| 33 ! | 49 1 | 65 A | 81 Q | 97 a | 113 q |
| 34 “ | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 T | 100 d | 116 t |
| 37 % | 53 5 | 69 E | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 H | 88 X | 104 h | 120 x |
| 41 ) | 57 9 | 73 I | 89 Y | 105 i | 121 y |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 { |
| 44 , | 60 < | 76 L | 92 | 108 l | 124 | |
| 45 — | 61 = | 77 M | 93 ] | 109 m | 125 } |
| 46 . | 62 > | 78 N | 94 ^ | 110 n | 126 ~ |
| 47 / | 63 ? | 79 O | 95 _ | 111 o | 127 |
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы:
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 ™ | 169 © | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 < | 155 > | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 ® | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ~ | тильда |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| [ | левая открывающая квадратная скобка |
| ] | правая закрывающая квадратная скобка |
| { | левая открывающая фигурная скобка |
| } | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| : | двоеточие |
| ‘ | машинописный апостроф, одинарная кавычка |
| “ | двойная кавычка |
| , | запятая |
| . | точка |
| / | слэш, косая черта, знак дроби |
| < | левая открытая угловая скобка, знак меньше |
| > | правая закрытая угловая скобка, знак больше |
| обратный слэш, обратная косая черта | |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t.
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:


Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR:
#ifdef _UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
Для перекодирования строки в формат Unicode без изменения кодировки файла используется макроопределение
_T(“строка”)
Прототип макроса содержится в файле tchar.h.
Назад: Представление данных и архитектура ЭВМ
