Во время серфинга в Интернете (или даже в автономном режиме) вы, вероятно, встретите множество символов. Некоторые из них являются обычными, но для других вам, вероятно, понадобится помощь в идентификации символа.
К счастью, в Интернете есть множество ресурсов по идентификаторам символов, которые могут вам помочь. Мы покажем вам, как узнать, что означает символ, с помощью различных методов.
1. Определите символы с помощью Symbols.com

Удачно названный Symbols.com – отличное место для начала поиска. Наряду с избранными подборками и категориями на домашней странице вы можете использовать его поисковую систему по символам, чтобы найти то, что вы ищете. Просто введите запрос вверху, и вы увидите соответствующие ему символы.
Это замечательно, если вы хотите найти символ по тексту (например, поиск символа «кошерный»). Но во многих случаях вы увидите символ и задаетесь вопросом, каково его значение. К счастью, на сайте есть и другие способы определения символа.
В нижнем левом углу страницы вы увидите раздел « Графический указатель ». Это позволяет искать символ на основе его характеристик. Он предоставляет несколько простых раскрывающихся списков, позволяющих указать, является ли форма открытой или закрытой, имеет ли она цвета, изогнутые ли линии или прямые и т. Д.
Введите как можно больше информации, затем нажмите « Поиск», чтобы найти символы, соответствующие вашим критериям. Если это не поможет вам найти то, что вы ищете, вы можете использовать категории символов для просмотра по группам, таким как знаки валюты , предупреждающие символы и другие.
Если это не поможет, вы можете выполнить поиск по алфавиту, используя буквы в верхней части экрана. Если вы не ищете ничего особенного, кнопка « Случайно» поможет вам узнать что-то новое.
2. Нарисуйте символ, чтобы узнать его значение.

Если вас озадачило то, что вы видели в офлайне, имеет смысл найти символ по картинке. Вы найдете несколько сайтов, которые предлагают функцию рисования символа и узнаете, что он означает.
Один из них – Shapecatcher . Просто нарисуйте символ, который хотите найти, с помощью мыши или сенсорного экрана и нажмите кнопку « Распознать» . Сервис вернет символы, соответствующие вашему рисунку.
Если вы не видите совпадения, нарисуйте его еще раз и попробуйте еще раз. На сайте используются только бесплатные шрифты Unicode, поэтому на нем могут быть не все возможные символы. Попробуйте Mausr для аналогичной альтернативы рисования символов, если она вам не подходит.
3. Поиск символов с помощью Google

Если вы натолкнулись на незнакомый значок во время просмотра веб-страниц, вам не нужно беспокоиться о поиске его на сайте с идентификатором символа. Просто запустите поиск символов с помощью Google, и вы получите ответ в течение нескольких секунд.
В Chrome, как и в большинстве других браузеров, вы можете легко искать в Google любой текст. Просто выделите его на странице, щелкните правой кнопкой мыши и выберите « Искать в Google по запросу [термин]» . Это откроет новую вкладку с поиском Google по запросу. Если в вашем браузере по какой-то причине этого нет, вы можете просто скопировать символ, как любой другой текст, и вставить его в Google.
В любом случае Google должен указать вам правильное направление, чтобы узнать значение этого символа.
4. Просмотрите список символов.

Юникод (стандарт кодирования текста) поддерживает ряд общих символов, благодаря чему они могут выглядеть как стандартный текст. Хотя у них нет выделенных клавиш на стандартной клавиатуре, вместо этого вы можете использовать несколько методов для ввода иностранных символов .
Если вы не смогли найти искомый символ с помощью любого из вышеперечисленных методов, возможно, вы сможете найти его, просмотрев все символы, поддерживаемые Unicode. Взгляните на список Compart “других символов” Unicode-символов, и вы можете найти тот, который вам интересен. Если вы предпочитаете альтернативу, посмотрите таблицу Unicode-символов .
Конечно, в Юникоде поддерживаются не все символы. Дорожные знаки, религиозные символы и повседневные потребительские символы не входят в его состав. Возможно, вам придется покопаться на странице списка символов в Википедии для поиска таких значков или просмотреть список символов Ancient-Symbols для менее техничных символов.
5. Изучите символы Emoji.

Хотя вы можете утверждать, что с технической точки зрения это не символы, смайлики часто сбивают с толку людей. В конце концов, есть сотни смайлов, которые нужно отслеживать, плюс постоянно появляются изменения в дизайне и новые.
Во-первых, мы рекомендуем ознакомиться с нашим руководством по значениям смайликов . Это поможет вам быстрее освоить некоторые из наиболее распространенных.
Если у вас все еще есть вопросы о символах эмодзи, загляните в Emojipedia . Здесь вы можете искать определенный смайлик, просматривать по категориям и читать новости об эмодзи. Страница каждого смайлика сообщает вам не только его официальное значение, но и то, для чего он часто используется.

Мы завершаем обсуждение раскрытия значений символов упоминанием финансовых символов. Они явно отличаются от символов, упомянутых выше, но они по-прежнему являются символом, который вы можете захотеть найти.
MarketWatch , один из наших любимых финансовых сайтов, позволяющих не отставать от рынка , предлагает удобный инструмент поиска символов. Если вы знаете интересующий вас символ, введите его, чтобы увидеть подробную информацию об этой компании. Если вы не уверены, что это, введите название компании, и вы увидите совпадения для него.
Зайдя на страницу компании, вы можете увидеть все виды данных, такие как тенденции, новости и конкуренты.
Легко узнать, что означает любой символ
Теперь вы знаете, куда обращаться, если встретите незнакомый символ. Выполняете ли вы быстрый поиск в Google или рисуете символ, который видели офлайн, вам больше не нужно гадать, что означают эти значки.
Между тем, у многих платформ и сервисов есть свои символы, о которых вам также следует знать.
Распознать объекты на изображении онлайн бесплатно
Обнаруживает объекты на изображениях бесплатно на любом устройстве, с помощью современного браузера, такого как Chrome, Opera или Firefox
При поддержке aspose.com и aspose.cloud
Добавить метки
Добавить баллы
Порог: %
Цвет:
Допустимые метки:
Заблокированные метки:
Aspose.Imaging Распознавание позволяет легко обнаруживать и классифицировать объекты на растровых и векторных изображениях.
Распознавание – это бесплатное приложение, основанное на Aspose.Imaging, профессиональном .NET / Java API, предлагающее расширенные функции обработки изображений на месте и готовое для использования на стороне клиента и сервера.
Требуется облачное решение? Aspose.Imaging Cloud предоставляет SDK для популярных языков программирования, таких как C#, Python, PHP, Java, Android, Node.js, Ruby, которые созданы на основе Cloud REST API и постоянно развиваются.
Aspose.Imaging Распознавание
- Обнаруживает объекты на изображении с помощью метода Single Shot Detection(SSD)
- Обнаруженные объекты обводятся прямоугольниками и могут быть подписаны
- Полный список поддерживаемых объектов содержит более 180 элементов
Как распознать объекты на изображении
- Кликните внутри области перетаскивания файла, чтобы выбрать и загрузить файл изображения, или перетащите файл туда
- Нажмите кнопку Старт, чтобы начать процесс обнаружения объектов.
- После запуска процесса на странице появляется индикатор, отображающий ход его выполнения. После того, как все объекты будут обнаружены, изображение с результатами появится на странице.
- Обратите внимание, что исходные и получившиеся изображения не хранятся на наших серверах
Часто задаваемые вопросы
-
❓ Как я могу обнаружить объекты на изображении?
Во-первых, вам нужно добавить файл изображения: перетащить его на форму или по ней чтобы выбрать файл. Затем задайте настройки и нажмите кнопку «Старт». КАк только процесс распознавания будет завершен, полученное изображение будет отображено.
-
⏱️ Сколько времени требуется для распознавания объектов на изображении?
Это зависит от размера входного изображения. Обычно это занимает всего несколько секунд
-
❓ Какой метод обнаружения объектов вы используете?
В настоящее время мы используем только метод Single Show Detection (SSD)
-
❓ Какие объекты вы можете обнаружить на изображениях?
-
💻 Какие форматы изображений вы поддерживаете?
Мы поддерживаем изображения форматов JPG (JPEG), J2K (JPEG-2000), BMP, TIF (TIFF), TGA, WEBP, CDR, CMX, DICOM, DJVU, DNG, EMF, GIF, ODG, OTG, PNG, SVG и WMF.
-
🛡️ Безопасно ли обнаруживать объекты с помощью бесплатного приложения Aspose.Imaging Object Detection?
Да, мы удаляем загруженные файлы сразу после завершения операции обнаружения объектов. Никто не имеет доступа к вашим файлам. Обнаружение объектов абсолютно безопасно.
Когда пользователь загружает свои файлы из сторонних сервисов, они обрабатываются таким же образом.
Единственное исключение из вышеуказанных политик возможно, когда пользователь решает поделиться своими файлами через форум, запросив бесплатную поддержку, в этом случае только наши разработчики имеют доступ к ним для анализа и решения проблемы.
Мы занимаемся закупкой трафика из Adwords (рекламная площадка от Google). Одна из регулярных задач в этой области – создание новых баннеров. Тесты показывают, что баннеры теряют эффективность с течением времени, так как пользователи привыкают к баннеру; меняются сезоны и тренды. Кроме того, у нас есть цель захватить разные ниши аудитории, а узко таргетированные баннеры работают лучше.
В связи с выходом в новые страны остро встал вопрос локализации баннеров. Для каждого баннера необходимо создавать версии на разных языках и с разными валютами. Можно просить это делать дизайнеров, но эта ручная работа добавит дополнительную нагрузку на и без того дефицитный ресурс.
Это выглядит как задача, которую несложно автоматизировать. Для этого достаточно сделать программу, которая будет накладывать на болванку баннера локализованную цену на “ценник” и call to action (фразу типа “купить сейчас”) на кнопку. Если печать текста на картинке реализовать достаточно просто, то определение положения, куда нужно его поставить — не всегда тривиально. Перчинки добавляет то, что кнопка бывает разных цветов, и немного отличается по форме.
Этому и посвящена статья: как найти указанный объект на картинке? Будут разобраны популярные методы; приведены области применения, особенности, плюсы и минусы. Приведенные методы можно применять и для других целей: разработки программ для камер слежения, автоматизации тестирования UI, и подобных. Описанные трудности можно встретить и в других задачах, а использованные приёмы использовать и для других целей. Например, Canny Edge Detector часто используется для предобработки изображений, а количество ключевых точек (keypoints) можно использовать для оценки визуальной “сложности” изображения.
Надеюсь, что описанные решения пополнят ваш арсенал инструментов и трюков для решения проблем.
Код приведён на Python 3.6 (репозиторий); требуется библиотека OpenCV. От читателя ожидается понимание основ линейной алгебры и computer vision.
Фокусироваться будем на нахождении самой кнопки. Про нахождение ценников будем помнить (так как нахождение прямоугольника можно решить и более простыми способами), но опустим, так как решение будет выглядеть аналогичным образом.
Template matching
Первая же мысль, которая приходит в голову — почему бы просто не взять и найти на картинке регион, который наиболее похож на кнопку в терминах разницы цветов пикселей? Это и делает template matching — метод, основанный на нахождении места на изображении, наиболее похожем на шаблон. “Похожесть” изображения задается определенной метрикой. То есть, шаблон “накладывается” на изображение, и считается расхождение между изображением и и шаблоном. Положение шаблона, при котором это расхождение будет минимальным, и будет означать место искомого объекта.
В качестве метрики можно использовать разные варианты, например — сумма квадратов разниц между шаблоном и картинкой (sum of squared differences, SSD), или использовать кросс-корреляцию (cross-correlation, CCORR). Пусть f и g — изображение и шаблон размерами (k, l) и (m, n) соответственно (каналы цвета пока будем игнорировать); i,j — позиция на изображении, к которой мы “приложили” шаблон.


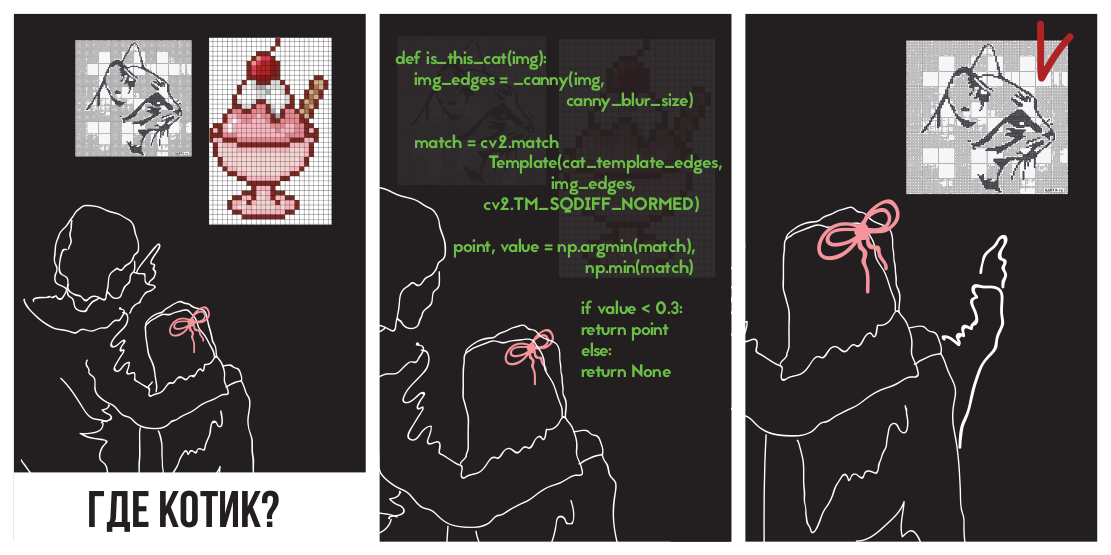
Попробуем применить разницу квадратов для нахождения котёнка

На картинке

(картинка взята с ресурса PETA Caring for Cats).
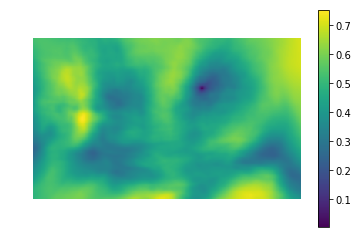
Левая картинка — значения метрики похожести места на картинке на шаблон (т.е. значения SSD для разных i,j). Темная область — это и есть место, где разница минимальна. Это и есть указатель на место, которое наиболее похоже на шаблон — на правой картинке это место обведено.

Кросс-корреляция на самом деле является сверткой двух изображений. Свёртки можно реализовать быстро, используя быстрое преобразование Фурье. Согласно теореме о свёртке, после преобразования Фурье свёртка превращается в простое поэлементное умножение:

Где  — оператор свёртки. Таким образом мы можем быстро посчитать кросс-корреляцию. Это даёт общую сложность O(kllog(kl)+mnlog(mn)), против O(klmn) при реализации “в лоб”. Квадрат разницы также можно реализовать с помощью свёртки, так как после раскрытия скобок он превратится в разницу между суммой квадратов значений пикселей изображения и кросс-корреляции:
— оператор свёртки. Таким образом мы можем быстро посчитать кросс-корреляцию. Это даёт общую сложность O(kllog(kl)+mnlog(mn)), против O(klmn) при реализации “в лоб”. Квадрат разницы также можно реализовать с помощью свёртки, так как после раскрытия скобок он превратится в разницу между суммой квадратов значений пикселей изображения и кросс-корреляции:



Детали можно посмотреть в этой презентации.
Перейдём к реализации. К счастью, коллеги из нижненовгородского отдела Intel позаботились о нас, создав библиотеку OpenCV, в ней уже реализован поиск шаблона с помощью метода matchTemplate (кстати используется именно реализация через FFT, хотя в документации это нигде не упоминается), использующий разные метрики расхождений:
- CV_TM_SQDIFF — сумма квадратов разниц значений пикселей
- CV_TM_SQDIFF_NORMED — сумма квадрат разниц цветов, отнормированная в диапазон 0..1.
- CV_TM_CCORR — сумма поэлементных произведений шаблона и сегмента картинки
- CV_TM_CCORR_NORMED — сумма поэлементных произведений, отнормированное в диапазон -1..1.
- CV_TM_CCOEFF — кросс-коррелация изображений без среднего
- CV_TM_CCOEFF_NORMED — кросс-корреляция между изображениями без среднего, отнормированная в -1..1 (корреляция Пирсона)
Применим их для поиска котёнка:

Видно, что только TM_CCORR не справился со своей задачей. Это вполне объяснимо: так как он представляет собой скалярное произведение, то наибольшее значение этой метрики будет при сравнении шаблона с белым прямоугольником.
Можно заметить, что эти метрики требуют попиксельного соответствия шаблона в искомом изображении. Любое отклонение гаммы, света или размера приведут к тому, что методы не будут работать. Напомню, что это именно наш случай: кнопки могут быть разного размера и разного цвета.
Проблему разного цвета и света можно решить применив фильтр нахождения граней (edge detection filter). Этот метод оставляет лишь информацию о том, в каком месте изображения находились резкие перепады цвета. Примененим Canny Edge Detector (его подробнее разберём чуть дальше) к кнопкам разного цвета и яркости. Слева приведены исходные баннеры, а справа — результат применения фильтра Canny.

В нашей случае, также существует проблема разных размеров, однако она уже была решена. Лог-полярная трансформация преобразует картинку в пространство, в котором изменение масштаба и поворот будут проявляться как смещение. Используя эту трансформацию, мы можем восстановить масштаб и угол. После этого, отмасштабировав и повернув шаблон, можно найти и позицию шаблона на исходной картинке. Во всей этой процедуре также можно использовать FFT, как описано в статье An FFT-Based Technique for Translation, Rotation, and Scale-Invariant Image Registration . В литературе рассматривается случай, когда по горизонтали и вертикали шаблон изменяется пропорционально, и при этом коэффициент масштаба варьируется в небольших пределах (2.0… 0.8). К сожалению, изменение размеров кнопки может быть бо́льшим и непропорциональным, что может привести к некорректному результату.
Применим полученную конструкцию (фильтр Canny, восстановление только масштаба через лог-полярную трансформацию, получение положения через нахождения места с минимальным квадратичным расхождением), для нахождения кнопки на трех картинках. В качестве шаблона будем использовать большую желтую кнопку:

При этом на баннерах кнопки будут разных типов, цветов и размеров:

В случае с изменением размера кнопки метод сработал некорректно. Это связано с тем, что метод предполагает изменение размеров кнопок в одинаковое количество раз и по горизонтали, и по вертикали. Однако, это не всегда так. На правой картинке размер кнопки по вертикали не изменился, а по горизонтали — уменьшился сильно. При слишком большом изменении размера искажения, вызванные логполярным преобразованием, делают поиск нестабильным. В связи с этим метод не смог обнаружить кнопку в третьем случае.
Keypoint detection
Можно попробовать другой подход: давайте вместо того, чтобы искать кнопку целиком, найдём её типичные части, например, углы кнопки, или элементы бордюра (по контуру кнопки есть декоративная обводка). Кажется, что найти углы и бордюр проще, так как это мелкие (а значит, простые) объекты. То, что лежит между четырёх углов и бордюра — и будет кнопкой. Класс методов нахождения ключевых точек называется “keypoint detection”, а алгоритмы сравнения и поиска картинок с помощью ключевых точек — “keypoint matching”. Поиск шаблона на картинке сводится к применению алгоритма обнаружения ключевых точек к шаблону и картинке, и сопоставлению ключевых точек шаблона и картинки.
Обычно “ключевые точки” находят автоматически, находя пиксели, окружение которых которых обладает определёнными свойствами. Было придумано множество способов и критериев их нахождения. Все эти алгоритмы являются эвристиками, которые находят какие-то характерные элементы изображения, как правило — углы или резкие перепады цвета. Хороший детектор должен работать быстро, и быть устойчивым к трансформациям картинки (при изменении картинки ключевые точки не должны переставать находиться/двигаться).
Harris corner detector
Одним из самых базовых алгоритмов считается Harris corner detector. Для картинки (тут и дальше мы считаем, что оперируем “интенсивностью” — изображением, переведенной в grayscale) он пытается найти точки, в окрестностях которых перепады интенсивности больше определенного порога. Алгоритм выглядит так:
-
От интенсивности
 находятся производные по оси X и Y ( и соответственно). Их можно найти, например, применив фильтр Собеля.
находятся производные по оси X и Y ( и соответственно). Их можно найти, например, применив фильтр Собеля. -
Для пикселя считаем квадрат
, квадрат и произведения и . Некоторые источники обозначают их как , и — что не добавляет понятности, так как можно подумать, что это вторые производные интенсивности (а это не так). -
Для каждого пикселя считаем суммы в некой окрестности (больше 1 пикселя) w следующие характеристики:
Как и в Template Detection, эту процедуру для больших окон можно провести эффективно, если использовать теорему о свертке.
-
Для каждого пикселя посчитать значение
эвристики R Значение
подбирается эмпирически в диапазоне [0.04, 0.06] Если у какого-то пикселя больше определенного порога, то окрестность этого пикселя содержит угол, и мы отмечаем его как ключевую точку.
-
Предыдущая формула может создавать кластеры лежащих рядом друг с другом ключевых точек, в таком случае стоит их убрать. Это можно сделать проверив для каждой точки является ли у неё значение
максимальным среди непосредственных соседей. Если нет — то ключевая точка отфильтровывается. Эта процедура называется non-maximum suppression.
 находятся производные по оси X и Y (
находятся производные по оси X и Y ( ,
,  и
и 


 эвристики R
эвристики R 
 подбирается эмпирически в диапазоне [0.04, 0.06] Если
подбирается эмпирически в диапазоне [0.04, 0.06] Если  этого пикселя содержит угол, и мы отмечаем его как ключевую точку.
этого пикселя содержит угол, и мы отмечаем его как ключевую точку.
 Формула
Формула  выбрана так неспроста.
выбрана так неспроста.  — компоненты структурного тензора — матрицы, описывающую поведение градиента в окрестности:
— компоненты структурного тензора — матрицы, описывающую поведение градиента в окрестности:

Эта матрица многими свойствами и формой похожа на матрицу ковариации. Например, они обе положительно полуопределённые матрицы, но этим сходство не ограничивается. Напомню, что у матрицы ковариации есть геометрическая интерпретация. Собственные вектора матрицы ковариации указывают на направления наибольшей дисперсии исходных данных (на которых ковариация была посчитана), а собственные числа — на разброс вдоль оси:

Картинка взята из http://www.visiondummy.com/2014/04/geometric-interpretation-covariance-matrix/
Точно так же ведут себя и собственные числа структурного тензора: они описывают разброс градиентов. На ровной поверхности собственные числа структурного тензора будут маленькими (потому что разброс самих градиентов будет маленьким). Собственные числа структурного тензора, построенного на кусочке картинки с гранью, будут сильно различаться: одно число будет большим (и соответствовать собственному вектору, направленному перпендикулярно грани), а второе — маленьким. На тензоре угла оба собственных числа будут большие. Исходя из этого, мы можем построить эвристику ( — собственные числа структурного тензора).
— собственные числа структурного тензора).

Значение этой эвристики будет большое, когда оба собственных числа — большие.
Сумма собственных чисел — это след матрицы, который можно рассчитать как сумму элементов на диагонали (а если взглянуть на формулы A и B, то станет понятно, что это еще и сумма квадратов длин градиентов в области):

Произведение собственных чисел — определитель матрицы, который в случае 2×2 тоже легко выписать:

Таким образом, мы можем эффективно посчитать , выразив её в терминах компонентов структурного тензора.
FAST
Метод Харриса хорош, но существует множество альтернатив ему. Рассматривать так же подробно, как метод выше, все не будем, упомянем лишь несколько популярных, чтобы показать интересные приёмы и сравнить их в действии.

Пиксели, проверяемые алгоритмом FAST
Альтернатива методу Харриса — FAST. Как подсказывает название, FAST работает гораздо быстрее вышеописанного метода. Этот алгоритм пытается найти точки, которые лежат на краях и углах объектах, т.е. в местах перепада контраста. Их нахождение происходит следующим образом: FAST строит вокруг пикселя-кандидата окружность радиуса R, и проверяет, есть ли на ней непрерывный отрезок из пикселей длины t, который темнее (или светлее) пикселя-кандидата на K единиц. Если это условие выполняется, то пиксель считается “ключевой точкой”. При определённых t мы можем реализовать эту эвристику эффективно, добавив несколько предварительных проверок, которые будут отсекать пиксели гарантированно не являющиеся углами. Например, при  и
и  , достаточно проверить, есть ли среди 4 крайних пикселей 3 последовательных, которые строго темнее/светлее центра на K (на картинке — 1, 5, 9, 13). Это условие позволяет эффективно отсечь кандидатов, точно не являющихся ключевыми точками.
, достаточно проверить, есть ли среди 4 крайних пикселей 3 последовательных, которые строго темнее/светлее центра на K (на картинке — 1, 5, 9, 13). Это условие позволяет эффективно отсечь кандидатов, точно не являющихся ключевыми точками.
SIFT
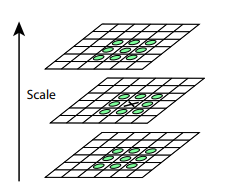
Оба предыдущих алгоритма не устойчивы к изменениям размера картинки. Они не позволяют найти шаблон на картинке, если масштаб объекта был изменён. SIFT (Scale-invariant feature transform) предлагает решение этой проблемы. Возьмем изображение, из которого извлекаем ключевые точки, и начнём постепенно уменьшать его размер с каким-то небольшим шагом, и для каждого варианта масштаба будем находить ключевые точки. Масштабирование — тяжелая процедура, но уменьшение в 2/4/8/… раз можно провести эффективно, пропуская пиксели (в SIFT эти кратные масштабы называются “октавами”). Промежуточные масштабы можно аппроксимировать, применяя к картинке гауссовский блюр с разным размером ядра. Как мы уже описали выше, это можно сделать вычислительно эффективно. Результат будет похож на то, как если бы мы сначала уменьшили картинку, а потом увеличили ее до исходного размера — мелкие детали теряются, изображение становится “замыленным”.
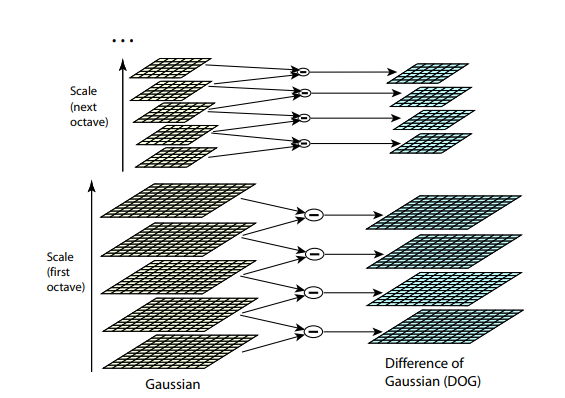
После этой процедуры посчитаем разницу между соседними масштабами. Большие (по модулю) значения в этой разнице получатся, если какая-то мелкая деталь перестает быть видна на следующем уровне масштаба, или, наоборот, следующий уровень масштаба начинает захватывает какую-то деталь, которая на предыдущем не была видна. Этот прием называется DoG, Difference of Gaussian. Можно считать, что большое значение в этой разнице уже является сигналом того, что в этом месте на изображении есть что-то интересное. Но нас интересует тот масштаб, для которого эта ключевая точка будет наиболее выразительной. Для этого будем считать ключевой точкой не только точку, которая отличается от своего окружения, но и отличается сильнее всего среди разных масштабов изображений. Другими словами, выбирать ключевую точку мы будем не только в пространстве X и Y, а в пространстве  . В SIFT это делается путём нахождения точек в DoG (Difference of Gaussians), которые являются локальными максимумами или минимумами в
. В SIFT это делается путём нахождения точек в DoG (Difference of Gaussians), которые являются локальными максимумами или минимумами в  кубе пространства вокруг неё:
кубе пространства вокруг неё:
Алгоритмы нахождения ключевых точек и построения дескрипторов SIFT и SURF запатентованы. То есть, для их коммерческого использования необходимо получать лицензию. Именно поэтому они недоступны из основного пакета opencv, а только из отдельного пакет opencv_contrib. Однако, пока что наше исследование носит исключительно академический характер, поэтому ничто не мешает поучаствовать SIFT в сравнении.
Дескрипторы
Попробуем применить какой-нибудь детектор (например, Харриса) к шаблону и картинке.


После нахождения ключевых точек на картинке и шаблоне надо как-то сопоставить их друг с другом. Напомню, что мы пока извлекли только положения ключевых точек. То, что обозначает эта точка (например, в какую сторону направлен найденный угол), мы пока не определили. А такое описание может помочь при сопоставлении точек изображения и шаблона друг с другом. Часть точек шаблона на картинке может быть сдвинута искажениями, закрыта другими объектами, поэтому опираться исключительно на положение точек относительно друг друга кажется ненадежным. Поэтому давайте для каждой ключевой точки возьмём её окрестность чтобы построить некое описание (дескриптор), которое потом позволит взять пару точек (одну точку из шаблона, одну из картинки), и сравнить их схожесть.
BRIEF
Если мы сделаем дескриптор в виде бинарного массива (т.е. массив из 0 и 1), то мы их сможем сравнивать крайне эффективно, сделав XOR двух дескрипторов, и посчитать количество единичек в результате. Как составить такой вектор? Например, мы можем выбрать N пар точек в окрестности ключевой точки. Затем, для i-й пары проверить, является ли первая точка ярче второй, и если да — то в i-ю позицию дескриптора записать 1. Таким образом мы можем составить массив длины N. Если мы будем выбирать в качестве одной из точек всех пар какую-то одну точку в окрестности (например, центр окрестности — саму ключевую точку), то такой дескриптор будет неустойчивым к шуму: достаточно немного поменяться яркости всего одного пикселя, чтобы весь дескриптор “поехал”. Исследователи обнаружили, что достаточно эффективно выбрать точки случайно (из нормального распределения с центром в ключевой точке). Это положено в основу алгоритма BRIEF.

Часть рассмотренных авторами методов генераций пар. Каждый отрезок символизирует пару сгенерированных точек. Авторы обнаружили, что вариант GII работает чуть лучше остальных вариантов.
После того, как мы выбрали пары, их стоит зафиксировать (т.е. пары генерировать не при каждом запуске расчёта дескриптора, а сгенерировать один раз, и запомнить). В реализации от OpenCV эти пары и вовсе сгенерированы заранее и захардкожены.
Дескриптор SIFT
SIFT также может эффективно считать дескрипторы, используя результаты применения гауссового размытия на разных октавах на картинке. Для расчёта дескриптора SIFT выбирает регион 16х16 вокруг ключевой точки, и разбивает его на блоки 4х4 пикселя. Для каждого пикселя считается градиент (мы оперируем в том же масштабе и октаве, в котором была найдена ключевая точка). Градиенты в каждом блоке распределяются на 8 групп по направлению (вверх, вверх-вправо, вправо, и т.д.). В каждой группе длины градиентов складываются — получается 8 чисел, которые можно представить как вектор, описывающий направление градиентов в блоке. Этот вектор нормируется для устойчивости к изменению яркости. Так, для каждого блока рассчитывается 8-мерный вектор единичной длины. Эти вектора конкатенируются в один большой дескриптор длины 128 (в окрестности 4*4 = 16 блоков, в каждом по 8 значений). Для сравнения дескрипторов используется Евклидово расстояние.
Сравнение
Находя пары наиболее подходящих друг к другу ключевых точек (например — жадно составляя пары, начиная с самых похожих по дескрипторам), мы наконец-таки сможем сравнить шаблон и картинку:

Котик нашелся — но тут у нас имеется попиксельное соответствие между шаблоном и фрагментом картинки. А что будет в случае кнопки?
Предположим, перед нами прямоугольная кнопка. Если ключевая точка расположена на углу, то три четверти локали точки будет именно то, что лежит за пределами кнопки. А то, что лежит за пределами кнопки, сильно меняется от картинки к картинке, в зависимости от того, поверх чего расположена кнопка. Какая доля дескриптора будет оставаться постоянной при изменении фона? В дескрипторе BRIEF, так как координаты пары выбираются в локали случайно и независимо, бит дескриптора будет оставаться постоянным только в случае, когда обе точки лежат на кнопке. Другими словами, в BRIEF всего 1/16 дескриптора не будет меняться. В SIFT ситуация чуть лучше — из-за блочной структуры 1/4 дескриптора меняться не будет.
В связи с этим дальше будем использовать дескриптор SIFT.
Сравнение детекторов
Теперь применим все полученные знания для решения нашей задачи. В нашем случае требования к детектору ключевых точек достаточно: инвариантность к изменению размера нам ни к чему, равно как и крайне высокая производительность. Сравним все три детектора.
| Harris corner detector | FAST | SIFT |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
SIFT нашел крайне мало ключевых точек на кнопке. Это объяснимо — кнопка представляет собой достаточно небольшой и плоский объект, и изменение масштаба не помогает найти ключевые точки.
Также, ни один детектор не справился с третьим случаем. Это объяснимо и ожидаемо. Обычно вышеописанные методы применяют для того, чтобы найти объект из шаблона на снимке, на котором он может быть частично скрыт, быть повернут, или немного искажен. В нашем случае мы хотим найти не точно такой же объект , а объект, достаточно похожий на шаблон (кнопку) . Это немного другая задача. Так, изменение самой формы кнопки (например, радиуса скругления углов, или толщины рамки точек) меняет ключевые точки в них, и их дескрипторы. Кроме того, ключевые точки будут находиться на углу кнопки. Из-за положения на краю точки будут неустойчивы: на их точное расположение и дескрипторы влияет то, что нарисовано рядом с кнопкой.
Вывод — метод хорош, и корректно отрабатывает ситуации, когда искомый объект повернут, его размер изменен, или объект частично скрыт (что хорошо для поиска сложных объектов, или ценника, например). Однако, если на объекте мало точек, за которые можно “зацепиться”, или форма объекта меняется слишком сильно, то ключевые точки и их на шаблоне и изображении могут не совпасть. Также, фон с большим количеством мелких деталей может сместить “ключевые точки” или изменить их дескрипторы.
Мы можем придумать матчинг, который бы использовал координаты ключевых точек. Вместо того, чтобы искать пары точек на шаблоне и картинке, окрестность которых похожа, можно искать такие наборы точек, взаимоположение ключевых точек на шаблоне и картинке будут похожи. В общем случае это достаточно сложная (и вычислительно, и с точки зрения программирования) задача, особенно в ситуации, когда некоторые точки могут быть сдвинуты или отсутствовать. Но, учитывая, что у нас ключевые точки — углы, нам достаточно найти такие группы, которые будут примерно образовывать прямоугольник нужных пропорций, и внутри которого не будет ключевых точек. Постепенно мы подходим к следующему методу:
Contour detection
Обычно кнопка — это какой-то прямоугольный объект (иногда — со скруглёнными углами), стороны которого параллельны осям координат. Тогда давайте попробуем выделить зоны перепады контраста (грани/edges), и среди них найдем грани, очертания которых похожи на контур нужного нам объекта. Этот метод называется contour detection.
Edge detection
В отличии от keypoint detection, нам интересны не только ключевые точки-углы, но и рёбра. Однако, основные идеи мы можем взять оттуда. Сгладим изображение Гауссовым фильтром, и как в Harris corner detector. Затем посчитаем производные интенсивности  и
и  . Так как нам не нужно отличать углы от ребер, то не надо считать структурный тензор — достаточно посчитать силу градиента:
. Так как нам не нужно отличать углы от ребер, то не надо считать структурный тензор — достаточно посчитать силу градиента:  (кстати, это корень из
(кстати, это корень из  , или из суммы диагонали структурного тензора). После этого, оставим только пиксели, которые являются локальными максимумами в терминах
, или из суммы диагонали структурного тензора). После этого, оставим только пиксели, которые являются локальными максимумами в терминах  (используя уже расмотренный non-maximum suppression), но в качестве локали будем выбирать не 8 соседних пикселей, а те пиксели из этих 8, в сторону которого направлен I, и с противоположной стороны:
(используя уже расмотренный non-maximum suppression), но в качестве локали будем выбирать не 8 соседних пикселей, а те пиксели из этих 8, в сторону которого направлен I, и с противоположной стороны:
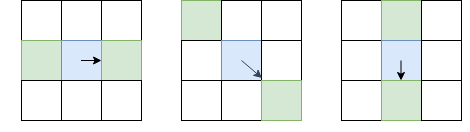
Синим отмечен рассматриваемый пиксель, стрелка — направление I. Зелёные пиксели — те, которые будут учитываться при non-maximum suppression.
Такой необычный выбор пикселей для сравнения обусловлен тем, что мы не хотим делать разрывы в границе. В левой картинке грань проходит сверху вниз, и так как non-maximum suppression не будет проводить сравнения интенсивности с пикселями выше и ниже синего, мы получим непрерывную грань.
Очевидно, одного non-maximum suppression недостаточно, и надо применить какую-то фильтрацию, чтобы убрать ребра со слишком низким Il. Для этого применим приём “double thresholding”: уберем все пиксели с Il, силой градиента, ниже порога Low, все пиксели выше порога High назначим “сильными ребрами”. Пиксели, у которых сила градиента лежит между Low и High, назовём “слабыми ребрами”, оставим только если они соединены с “сильными ребрами”:
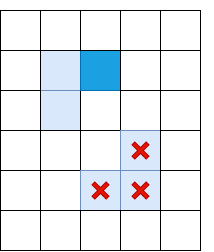
Светло-синим отмечены “слабые ребра”, тёмно-синим — сильные. Ребра в нижней части отсеиваются, так как они не соеденены ни с одним сильным ребром.
Мы только что описали Canny Edge Detector. Он крайне широко применяется и по сей день в качестве простой и быстрой процедуры, позволяющей найти контуры объектов.
Border tracking
Следующее действие — среди карты с найденными гранями выделить контуры. Найдем связанные компоненты (острова смежных пикселей, прошедших все проверки), и проверим каждый из них, насколько он похож на кнопку. После применения non-maximum suppression в Canny, у нас есть гарантии того, что ребра будут получаться толщиной в один пиксель, но давайте на будем на нее опираться. Для каждого пикселя, который был отнесен к грани, и рядом с которым есть пиксель не-грань, отнесем к “бордюру”. Перемещаясь от одного пикселя бордюра к другому, мы либо придём обратно в тот же пиксель (и тогда мы нашли контур), либо в тупик (тогда можно попробовать вернуться назад, если где-то по пути была развилка):

Полный алгоритм border tracking, учитывающий разные краевые случаи (например, когда объект с толстой гранью сгенерировал два контура, внутренний и внешний), описан тут. После применения этого алгоритма у нас останется набор контуров, которые потенциально могут быть кнопками.
Фильтрация контуров
Как узнать, что наш контур — кнопка? Для прямоугольников и многоугольников есть отличный > метод, основанный на упрощении контура. Достаточно постепенно “схлопывать” ребра, если они находятся почти на одной прямой, а затем посчитать количество оставшихся ребер, и проверить углы между ними. К сожалению, для нашего случая эти методы не подходят — наш прямоугольник имеет скругленные углы. Также, есть contour matching для фигур, имеющих сложную геометрию — но это тоже не про нас, так как у нас всего лишь прямоугольник (в статье приводятся примеры с контуром человека). Поэтому лучше сделать фильтр, основанный на свойства самой фигуры. Мы знаем, что:
- Кнопка достаточно большая (площадь больше 100 пикселей)
- Стороны параллельны осям координат
- Отношение площади фигуры к площади ограничивающего прямоугольника должна быть достаточно близка к единице. Мы устанавливаем порог в 0.8, так как кнопка — прямоугольник со сторонами параллельными осям координат, и недостающие 20% — это и есть скругленные углы.
Кроме того, по опыту применения детекторов ключевых точек мы помним, что могут быть проблемы с ситуациями, когда под кнопкой лежит контрастный объект. Поэтому после применения Canny размоем грани, чтобы закрыть мелкие дырки, которые могли возникнуть из-за таких объектов.
Применим получившийся подход:

Применение Canny filter (2 картинка) нашло нужные очертания, но из-за сложной формы кнопки и градиента нашлось сразу много контуров, и из-за non-max suppression некоторые из них не были замкнуты. Применение размытия (3 картинка) исправило проблему.
Тестирование подхода
Запустим в получившейся картинке поиск контуров. Покрасим контуры, прошедшие проверки, красным цветом. Если таких несколько, то нам нужно выбрать среди них наиболее удачный вариант. Выберем контур наибольшей площади, и покрасим его в зелёный цвет.
|  |
|  |
|  |
|
Получившаяся конструкция нашла кнопки на тестовых изображениях. Прогон на всех баннерах показал, что изредка (1 случай из ~20) она вместо кнопки выделяет прямоугольные плашки iOS Appstore и Google Apps, или другие прямоугольные объекты (чехлы телефонов). Поэтому добавив возможность ручного указания положения на тот редкий случай неверного определения, мы реализовали этот вариант в инструменте локализации.
Заключение
Подведем итоги. “Классический” CV без deep learning по-прежнему работает, и на его основе можно решить задачи. Они неприхотливы и не требуют большого количества размеченных данных, мощного железа, и их проще отлаживать. Однако, они вводят дополнительные предположения, и поэтому с их помощью не каждую задачу можно решить эффективно.
- Template Matching — самый простой способ, основывается на нахождении места в изображении, наиболее похожем (по какой-то простой метрике) на шаблон. Эффективен при попиксельном совпадении. Можно сделать устойчивым к поворотам и небольшим изменениям размеров, но при больших изменениях может работать некорректно.
- Keypoint detection/matching — находим ключевые точки, сопоставляем точки изображения и шаблона. Детекторы устойчивы к поворотам, изменениям масштаба (в зависимости от выбранного детектора и дескриптора), а сопоставление — к частичным перекрытиям. Но этот метод хорошо работает только если в объекте нашлось достаточно “ключевых точек”, и локали точки шаблона и изображения совпадают достаточно хорошо (т.е. на шаблоне и картинке — один и тот же объект).
- Contour detection — нахождение контуров объектов, и поиске контура, похожего на контур искомого объекта. Это решение учитывает только форму объекта, и игнорирует его содержимое и цвет (что может быть как и плюсом, так и минусом).
Осведомленный читатель может заметить, что наша задача может быть решена и с помощью современных обучаемых методов computer vision. Например, сеть YOLO возвращает bounding box искомого объекта — а именно это нас и интересует. Да, мы успешно протестировали и запустили решение, основанные на глубоком обучении — но в качестве второй итерации (уже после того, как инструмент локализации был запущен и начал работать). Эти решения более устойчивы к изменениям параметров кнопок, и имеют много положительных свойств: например, вместо того, чтобы подбирать руками пороги и параметры, можно просто добавлять в тренировочное множество примеры баннеров, на которых сеть ошибается (Active Learning). Использование глубокого обучение для нашей задачи имеет свои проблемы и интересные моменты. Например — многие современные методы computer vision требуют большого количества размеченных картинок, а у нас разметки не было (как и во многих реальных случаях), а общее количество разных баннеров не превышает нескольких тысяч. Поэтому мы решили разметить небольшое количество изображений сами, и написать генератор, который будет на их основе создавать другие похожие баннеры. В этом направлении есть немало интересных приёмов. Есть много других подводных камней, да и сама задача определения положения объекта computer vision обширна, и имеет много способов решения. Поэтому было принято решение ограничить поле обзора статьи, и решения, основанные на глубоком обучении, не были рассмотрены.
Код с блокнотами, которые реализуют описанные методы и рисуют картинки статьи, можно найти в репозитории).
Во время серфинга в Интернете (или даже в автономном режиме) вы, вероятно, сталкивались с множеством символов. Некоторые из них являются общими, но для других вам, вероятно, нужна помощь в определении символа.
В Интернете есть ресурсы, чтобы помочь. Мы покажем вам, как узнать, что означает символ, используя различные методы.
1. Посетите сайт Symbols.com

Удачно названный Symbols.com — отличное место для начала поиска. Наряду с избранными подборками и категориями на главной странице, вы можете использовать поисковую систему по символам, чтобы найти то, что вы ищете. Просто введите запрос вверху, и вы увидите символы, которые ему соответствуют.
Прекрасно, если вы хотите найти символ по тексту (например, ищите символ «кошерный»). Но во многих случаях вы увидите символ и удивитесь его значению. К счастью, сайт предлагает другие способы идентификации символа.
В нижнем левом углу страницы вы увидите раздел Графический указатель . Это позволяет вам искать символ на основе его характеристик. Он предоставляет несколько простых раскрывающихся списков, позволяющих указать, является ли фигура открытой или закрытой, имеет ли она цвета, являются ли линии изогнутыми или прямыми и т. П.
Введите столько информации, сколько вы знаете, затем нажмите « Поиск», чтобы найти символы, соответствующие вашим критериям. Если это не поможет вам найти то, что вы ищете, вы можете использовать категории Символов для просмотра по группам, таким как знаки валюты , символы предупреждения и другие.
В противном случае вы можете искать в алфавитном порядке, используя буквы в верхней части экрана. Если вы не ищете что-то конкретное, кнопка Случайный может помочь вам узнать что-то новое.
2. Нарисуйте символ, чтобы узнать его значение

Если вы озадачены тем, что вы видели в автономном режиме, имеет смысл найти символ на картинке. Вы найдете несколько сайтов, которые предлагают эту функциональность.
Одним из них является Shapecatcher . Просто нарисуйте символ, который хотите найти, с помощью мыши или сенсорного экрана и нажмите кнопку « Распознать» . Сервис вернет символы, соответствующие вашему рисунку.
Если вы не видите совпадения, нарисуйте его еще раз и попробуйте еще раз. На сайте используются только бесплатные шрифты Unicode, поэтому он может содержать не все возможные символы. Попробуйте Mausr для аналогичной альтернативы, если эта не работает для вас.
3. Поиск символов с помощью Google

Если во время работы в Интернете вы встретите незнакомый значок, вам не нужно беспокоиться о его поиске на сайте с символьным идентификатором. Просто запустите поиск по символам в Google, и вы получите ответ в течение нескольких секунд.
В Chrome, наряду с большинством других браузеров, вы можете легко найти в Google любой текст. Просто выделите его на странице, щелкните правой кнопкой мыши и выберите « Поиск в Google» для «[term]» . Откроется новая вкладка с поиском в Google по этому термину. Если в вашем браузере по какой-то причине этого нет, вы можете просто скопировать символ, как любой другой текст, и вставить его в Google.
В любом случае, Google должен указать вам правильное направление, чтобы найти значение этого символа.
4. Просмотрите список символов

Unicode (стандарт для кодирования текста) поддерживает ряд общих символов, как они могут выглядеть как стандартный текст. Хотя они не имеют специальных клавиш на стандартной клавиатуре, вы можете использовать ALT-коды для ввода символов. вместо этого.
Если вы не можете найти символ, который вы ищете, используя любой из вышеперечисленных методов, вы можете найти его, просматривая все символы, которые поддерживает Unicode. Посмотрите на список Compart «других символов» символов Unicode, и вы можете найти тот, который вас интересует. Если вы предпочитаете альтернативу, посмотрите таблицу символов Unicode .
Конечно, не все символы поддерживаются в Юникоде. Дорожные знаки, религиозные символы и повседневные потребительские символы не являются частью этого. Возможно, вам придется покопаться в странице со списком символов Википедии для таких иконок.
5. Изучите символы эмодзи

Хотя вы можете утверждать, что они не являются технически символами, смайлики часто вводят людей в заблуждение. В конце концов, есть сотни смайликов, которые нужно отслеживать, плюс изменения в дизайне и новые постоянно появляющиеся.
Во-первых, мы рекомендуем ознакомиться с нашим руководством по значениям смайликов для лица Это поможет вам освоить некоторые наиболее распространенные из них.
Если у вас все еще есть вопросы по поводу символов эмодзи, загляните в Emojipedia . Здесь вы можете искать определенные эмодзи, просматривать по категориям и читать новости эмодзи. Страница каждого смайлика рассказывает вам не только о его официальном значении, но и о том, для чего он часто используется.
6. Используйте инструмент поиска символов на бирже

Мы завершаем наше обсуждение открытия значений символов, упоминая финансовые символы. Они явно отличаются от символов, упомянутых выше, но они все еще являются типом символов, которые вы, возможно, захотите найти.
MarketWatch , один из наших любимых финансовых сайтов, чтобы не отставать от рынка , предлагает удобный инструмент поиска символов. Если вы знаете интересующий вас символ, введите его, чтобы узнать подробности об этой компании. Если вы не уверены, что это, введите название компании, и вы увидите совпадения для него.
После того как вы попали на страницу компании, вы можете увидеть все виды данных, такие как тренды, новости и конкуренты.
Знание значения любого символа
Теперь вы знаете, куда обращаться, когда сталкиваетесь с незнакомым символом. Будь то быстрый поиск в Google или поиск чего-то, что вы видели в автономном режиме, вам не нужно догадываться, что означают эти значки.
У Facebook есть свой набор символов, которые вы можете не понять. Если это так, взгляните на наш справочник по многим символам
Нередко можно встретить фотографии, на которых скрыта некоторая информация от глаз других лиц. Это может казаться адреса электронной почты, номера мобильного телефона или иных личных данных. Если возникает необходимость в том, чтобы получить скрытую таким образом информацию, следует знать несколько методов, при помощи которых можно достичь желаемых результатов.
Как замазать текст на скриншоте или фото
На фото или сделанном скриншоте может содержаться информация, которую следует скрыть от глаз других лиц. Для этого могут использоваться разные инструменты, например, встроенный в устройство редактор или фотошоп.
Какие варианты для замазывания текста имеются:
- замазывание при помощи фломастера — выбирается просто зачеркивание, фломастер может быть любого цвета и толщины;
- применение геометрических фигур — подходящий вариант, когда нужно скрыть целый блок информации, например, может использоваться квадрат или круг;
- размытие фона — красивый и удобный эффект, в английском языке он носит название «Blur», применяется чаще всего в дорогих редакторах.
Применив эти простые методы, можно без проблем справиться со скрытием нужной информации на фото или скриншоте, выложив их в социальных сетях или форумах.
Как увидеть замазанный текст на скриншоте встроенными средствами
Определенные детали замазываются на скриншоте при помощи специально разработанных фото редакторов. Скачать их можно из приложения Play Market, в нем представлен широкий выбор подходящих программ. Многие мобильные устройства содержат встроенный функционал для обработки изображений и текста.
Чтобы увидеть замазанный текст, потребуется три главных инструмента — блеск, контраст и экспозиция. Хорошие инструменты для работы можно найти в программах «Snapseed» и «Adobe Photoshop».
Какие действия нужно выполнить:
- загрузить нужную фотографию в программу;
- нажать на кнопку Tools, находящуюся в нижнем углу экрана;
- выбрать из предложенного списка нужные инструменты — сюда относится правильно подобранная экспозиция и не стоит забывать о тени;
- правило 100 — все ставится по максимуму, в том числе, с инструментом «светлые участки»;
- контрастность устанавливается на показателе — 100.
Применив все указанные действия, появится скрытое изображение и текст. Весь секрет в том, что параметры убирают закрашенный слой на нужном фото или скриншоте.
Как убрать замазку с фото на Android
Если необходимо убрать замазывание на Android, пользователь может использовать несколько вариантов:
- через приложение Touch Retouch;
- при помощи редактора Snapseed.
Первый вариант простой. Его суть сводится к применению специального приложения Touch Retouch. Установить его следует через Гугл Плей, введя название в строку поиска. После завершения установки пользователь получит универсальный софт, при помощи которого можно удалить ненужные затирания на фото. Как работать с редактированием фото:
- нажать на меню «Remove Object».

- загрузить фото в приложение;
- щелкнуть на инструмент в виде петли (лассо), находящийся в нижней панели программы;

- обвести надпись и дождаться появления красного фона;
- нажать на галочку и увидеть нужное изображение и текст.
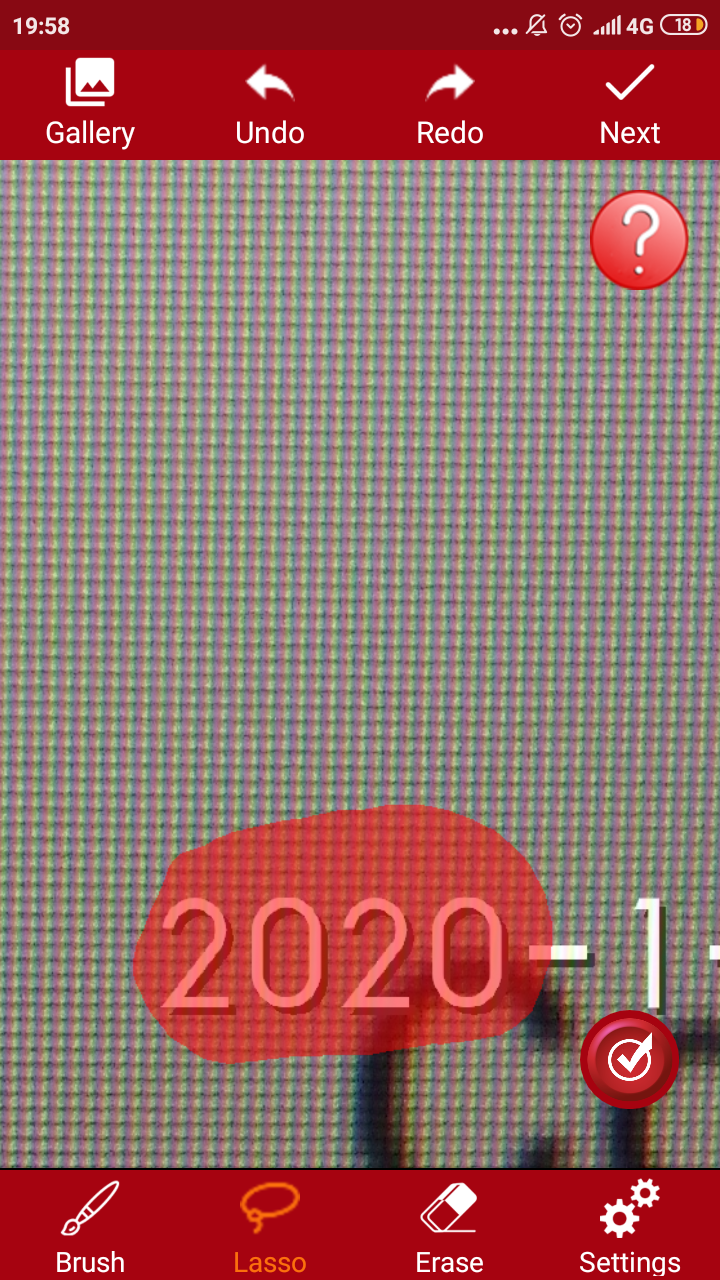
Фрагмент удалится автоматически. Программа сама закрасит очищенную область в нужный тон. Сложно понять, что на этом месте ранее была какая-то надпись.
При помощи приложения Snapseed от Google, пользователь может производить обработку фотографий и удалять ненужные объекты. Программа доступна полностью бесплатно и работает на всех устройствах системы Android. Никаких проблем с установкой не возникает. Чтобы удалить надпись с фотографии, потребуется выполнить ряд следующих действий:
- добавить снимок в приложение и нажать на значок «+»;

- перейти во вкладку с инструментами, выбрать раздел «точечно»;
- приблизить надпись и нажать по ней;
- так как инструмент удаляет объект точечно, важно свершать действия с особым вниманием;
- приблизить надпись и аккуратно нажать на нее.
Чтобы отменить действие, следует нажать на значок в виде стрелочки. Чтобы сохранить результат обработанного изображения, нужно нажать на галочку, располагающуюся в правом нижнем углу экрана. Готовый снимок, сохранится в галерее. При желании, его можно сразу отправить другим пользователь через социальные сети.
Как убрать замазанную часть на фотографии на ios
Чтобы увидеть замазанную часть на снимке на устройствах, работающих на ios, следует воспользоваться встроенным приложением-редактором «фото». Как лучше убрать замазанную часть, следует рассмотреть на примере:
- на скриншоте замазывает отдельный текст при помощи маркера;
![]()
- снимок загружается в приложение;
- все осветляющие настройки ставятся на максимум;
![]()
- через несколько секунд появится изображение, на котором будет отчетливо видна часть замазанного текста.
Любой инструмент для редактирования, заложенный в меню обработки, к числу которого относится маркер, можно настроить по степени прозрачности. Речь идет об ее уменьшении или увеличении. Все, что требуется, нажать на инструмент и прокрутить ползунок в правую сторону, до самого конца. Когда цифра с любого инструмента исчезнет, это будет означать достижение нулевой степени прозрачности. Высветлить, при таком раскладе, замазанный фрагмент не получится.
Если цифра с маркера или иного инструмента исчезла, значит, достигнута нулевая степень прозрачности, и высветлить замазанный фрагмент не получится.
Нет гарантий, что профессиональный редактор сможет помочь увидеть изображение и текст. Возможно, после совершения определенных манипуляций, замазанные данные попадутся тем, кто достаточно хорошо разбирается в обработке снимков.
Как посмотреть замазанный текст на фото с помощью приложений
Получение должного результата для проявления текста, замазанного кистью, зависит от того, какой формат имеет само изображение. В каждом снимке хранится информация разного вида. Например рисунки векторных изображений могут быть представлены в виде файла, где имеется описание координат геометрических объектов. Графические изображения по наиболее распространенным форматам JPEG, PNG поддаются проще всего обработке. Такие картинки можно изменять, если не применялись дополнительные инструменты с целью закрасить текст.
Чтобы иметь возможность обработать фото и получить желаемый результат, лучше использовать качественные редакторы, имеющие большой набор инструментов.
| Наименование | Описание | Цена | Рейтинг |
| PaintShop | Программа имеет два интерфейса — основной и полную версию. Пользователь может использовать простые инструменты или набор для профессионала. В приложении обширный функционал — работа со слоями, большое количество фильтров, коррекция объектива и пр. | 6,300 рублей | ★★★★★ |
| Affinity Photo | Для новичков интерфейс приложения может показаться сложным. Для профессионалов, данная программа — это лучший выбор. После ее приобретения открывается широкий спектр возможностей. Самая сильная сторона — работа с цветами | от 899 рублей | ★★★★★ |
| Snapseed | Хороший и универсальный фоторедактор, подходящий тем, кто любит вручную изучать настройки и подходить к обработке изображений особо тщательно. Программа включает возможность менять фокусировку на изображении. Snapseed привязано к сервисам Google. | 0 рублей | ★★★★ |
| Gimp | Популярный аналог Photoshop, имеющий практический одинаковый набор инструментов. В нем можно рисовать, пробовать применение различных слоев, ретуширование фото и создание коллажей. Отлично подходит для графического дизайна и обработки фотографий. | от 400 рублей | ★★★★ |
| Paint.net | Отличный графический редактор для Windows. Программа работает со слоями. Имеет усовершенствованные свойства инструментов. Каждый слой поддается корректировке отдельно и может меняться по очередности. Paint.net имеет немного меньше функций, чем Photoshop, но их вполне достаточно для выполнений простых задач. | от 500 рублей | ★★★★ |
PaintShop
Разнообразные рабочие пространства
10
Итого
8.2
Отличный редактор. Идеальный вариант для профессионального использования
Affinity Photo
Разнообразные рабочие пространства
10
Итого
8.6
Редактор подходит как для профессионалов, так и для любителей обрабатывать личные фото
Snapseed
Разнообразные рабочие пространства
8
Доступное использование
10
Итого
9.2
Легкий в управлении редактор, позволяет совершать необходимые действия как с компьютера, так и телефона
Gimp
Разнообразные рабочие пространства
8
Доступное использование
10
Итого
9.2
Приемлемая цена за отличного качества редактор, имеет обширный набор функций
Paint.net
Разнообразные рабочие пространства
7
Доступное использование
10
Итого
9
Подходящая замена Photoshop. Позволяет быстро обрабатывать фотографии, применяя различные инструменты
Как защитить скриншот или фото
Если возникает необходимость спрятать ненужный текст в редакторе, в первую очередь, следует применить кисть и наложить двойной слой на текст. Возможность применения такой функции заложена во многих телефонных программах и компьютерных редакторах Paint.NET, Photoshop, CorelDRAW.
Проще всего слои представить в виде нескольких прозрачных листов стандартного формата А4. Они накладываются друг на друга. Изображение может складываться из нескольких элементов, располагающихся на каждом слое по отдельности.
Еще один не менее интересный инструмент для защиты изображений, является размытие. Необходимо сразу задавать максимальное значение, чтобы невозможно было увидеть даже силуэт элемента.
Вариант зарисовки идеально работает, если используется вместо выделяющего цвета — цвет фона. Например, текст на снимке черными буквами, а сам фон белый. В таком случае, нужно использовать белый маркер, который сможет спрятать текст таким образом, что его невозможно будет проявить никакими способами.
Пользователи довольно часто допускают ошибки, которые приводят к утечке их личных данных в сеть. При работе с изображениями в формате PNG, не следует размещать на главном слое важные данные. Он сохраняет все слои, хоть это и не видно на конечном результате.
При обработке различными приложениями, слои на снимке могут быть видны. Наложение всевозможных фильтров для коррекции фото — еще один не самый надежный вариант, чтобы скрыть данные на изображении. Многие из фильтров, после применения, не стирают имеющиеся пиксели, а лишь смещают их. Если будет проводиться грамотная обработка, данные могут быть без проблем получены сторонними пользователями.
Отличный редактор для того, чтобы сохранить нужную информацию в тайне — ScreenPic. Это графический дизайн, имеющий целый арсенал подходящих инструментов. Самый лучший из них — фломастер. Им можно просто зачеркнуть, чтобы скрыть важное от чужих глаз. В распоряжении пользователя вся цветовая гамма, выбор толщины фломастера. Как вариант, можно использовать геометрические фигуры — круги, квадраты или прямоугольники.

Вячеслав
Несколько лет работал в салонах сотовой связи двух крупных операторов. Хорошо разбираюсь в тарифах и вижу все подводные камни. Люблю гаджеты, особенно на Android.
Задать вопрос
Какие настройки лучше выставить, чтобы увидеть скрытый текст на изображении?
Находясь в редакторе, необходимо настроить следующие пункты:
– экспозиция
– блеск
– светлые участки
– тени
– контраст. Все параметры выставляются на 100. В минус выводится только контраст.
После выставления таких настроек, лучше приблизить замазанный участок и можно увидеть, что за ним скрыто.
Можно ли увидеть замазанный фрагмент на фото на iOS?
Да, это возможно, через инструменты редактирования, в меню для обработки изображений Они показывают степень прозрачности слоя тонера. Чем выше его показатель, тем лучше. Лучшие показатели:
грифель – 97
маркер – 80
карандаш – 50
Какие фоторедакторы лучше выбирать для работы?
Все зависит от того, насколько профессионально замазывался текст на исходном изображении. ВО многих мобильных устройствах имеются неплохие редакторы. Более продвинутые программы предназначены для профессионалов и за доступ к ним придется заплатить деньги.
