Совет: Попробуйте использовать новые функции ПРОСМОТРX и XMATCH, а также улучшенные версии функций, описанные в этой статье. Эти новые функции работают в любом направлении и возвращают точные совпадения по умолчанию, что упрощает и упрощает работу с ними по сравнению с предшественниками.
Предположим, у вас есть список номеров офисов, и вам нужно знать, какие сотрудники работают в каждом из них. Таблица очень угрюмая, поэтому, возможно, вам кажется, что это сложная задача. С функцией подытов на самом деле это довольно просто.
Функции ВВ., а также ИНДЕКС и ВЫБОРПОЗ — одни из самых полезных функций в Excel.
Примечание: Мастер подметок больше не доступен в Excel.
Ниже в качестве примера по выбору вы можете найти пример использования в этой области.
=ВПР(B2;C2:E7,3,ИСТИНА)
В этом примере B2 является первым аргументом —элементом данных, который требуется для работы функции. В случае СРОТ ВЛ.В.ОВ этот первый аргумент является искомой значением. Этот аргумент может быть ссылкой на ячейку или фиксированным значением, таким как “кузьмина” или 21 000. Вторым аргументом является диапазон ячеек C2–:E7, в котором нужно найти и найти значение. Третий аргумент — это столбец в диапазоне ячеек, содержащий ищите значение.
Четвертый аргумент необязателен. Введите истина или ЛОЖЬ. Если ввести ИСТИНА или оставить аргумент пустым, функция возвращает приблизительное совпадение значения, указанного в качестве первого аргумента. Если ввести ЛОЖЬ, функция будет соответствовать значению, заведомо первому аргументу. Другими словами, если оставить четвертый аргумент пустым или ввести ИСТИНА, это обеспечивает большую гибкость.
В этом примере показано, как работает функция. При вводе значения в ячейку B2 (первый аргумент) в результате поиска в ячейках диапазона C2:E7 (2-й аргумент) выполняется поиск в ней и возвращается ближайшее приблизительное совпадение из третьего столбца в диапазоне — столбца E (третий аргумент).
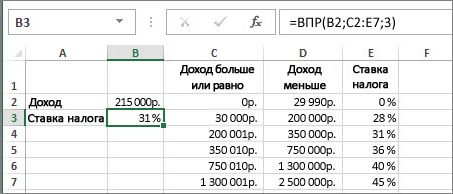
Четвертый аргумент пуст, поэтому функция возвращает приблизительное совпадение. Иначе потребуется ввести одно из значений в столбец C или D, чтобы получить какой-либо результат.
Если вы хорошо разучились работать с функцией ВГТ.В.В., то в равной степени использовать ее будет легко. Вы вводите те же аргументы, но выполняется поиск в строках, а не в столбцах.
Использование индекса и MATCH вместо ВРОТ
При использовании функции ВПРАВО существует ряд ограничений, которые действуют только при использовании функции ВПРАВО. Это означает, что столбец, содержащий и look up, всегда должен быть расположен слева от столбца, содержащего возвращаемого значения. Теперь, если ваша таблица не построена таким образом, не используйте В ПРОСМОТР. Используйте вместо этого сочетание функций ИНДЕКС и MATCH.
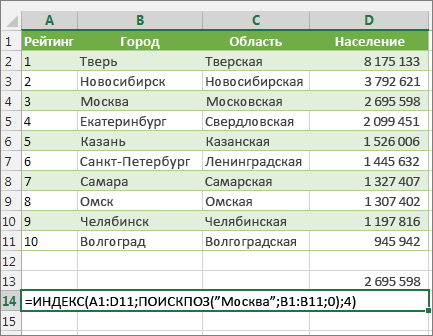
В данном примере представлен небольшой список, в котором искомое значение (Воронеж) не находится в крайнем левом столбце. Поэтому мы не можем использовать функцию ВПР. Для поиска значения “Воронеж” в диапазоне B1:B11 будет использоваться функция ПОИСКПОЗ. Оно найдено в строке 4. Затем функция ИНДЕКС использует это значение в качестве аргумента поиска и находит численность населения Воронежа в четвертом столбце (столбец D). Использованная формула показана в ячейке A14.
Дополнительные примеры использования индексов и MATCH вместо В ПРОСМОТР см. в статье билла Https://www.mrexcel.com/excel-tips/excel-vlookup-index-match/ Билла Джилена (Bill Jelen), MVP корпорации Майкрософт.
Попробуйте попрактиковаться
Если вы хотите поэкспериментировать с функциями подытовки, прежде чем попробовать их с собственными данными, вот примеры данных.
Пример работы с ВЛОКОНПОМ
Скопируйте следующие данные в пустую таблицу.
Совет: Прежде чем врезать данные в Excel, установите для столбцов A–C ширину в 250 пикселей и нажмите кнопку “Перенос текста” (вкладка “Главная”, группа “Выравнивание”).
|
Плотность |
Вязкость |
Температура |
|
0,457 |
3,55 |
500 |
|
0,525 |
3,25 |
400 |
|
0,606 |
2,93 |
300 |
|
0,675 |
2,75 |
250 |
|
0,746 |
2,57 |
200 |
|
0,835 |
2,38 |
150 |
|
0,946 |
2,17 |
100 |
|
1,09 |
1,95 |
50 |
|
1,29 |
1,71 |
0 |
|
Формула |
Описание |
Результат |
|
=ВПР(1,A2:C10,2) |
Используя приблизительное соответствие, функция ищет в столбце A значение 1, находит наибольшее значение, которое меньше или равняется 1 и составляет 0,946, а затем возвращает значение из столбца B в той же строке. |
2,17 |
|
=ВПР(1,A2:C10,3,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 1, находит наибольшее значение, которое меньше или равняется 1 и составляет 0,946, а затем возвращает значение из столбца C в той же строке. |
100 |
|
=ВПР(0,7,A2:C10,3,ЛОЖЬ) |
Используя точное соответствие, функция ищет в столбце A значение 0,7. Поскольку точного соответствия нет, возвращается сообщение об ошибке. |
#Н/Д |
|
=ВПР(0,1,A2:C10,2,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 0,1. Поскольку 0,1 меньше наименьшего значения в столбце A, возвращается сообщение об ошибке. |
#Н/Д |
|
=ВПР(2,A2:C10,2,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 2, находит наибольшее значение, которое меньше или равняется 2 и составляет 1,29, а затем возвращает значение из столбца B в той же строке. |
1,71 |
Пример ГВ.Г.В.В.
Скопируйте всю таблицу и вставьте ее в ячейку A1 пустого листа Excel.
Совет: Прежде чем врезать данные в Excel, установите для столбцов A–C ширину в 250 пикселей и нажмите кнопку “Перенос текста” (вкладка “Главная”, группа “Выравнивание”).
|
Оси |
Подшипники |
Болты |
|
4 |
4 |
9 |
|
5 |
7 |
10 |
|
6 |
8 |
11 |
|
Формула |
Описание |
Результат |
|
=ГПР(“Оси”;A1:C4;2;ИСТИНА) |
Поиск слова “Оси” в строке 1 и возврат значения из строки 2, находящейся в том же столбце (столбец A). |
4 |
|
=ГПР(“Подшипники”;A1:C4;3;ЛОЖЬ) |
Поиск слова “Подшипники” в строке 1 и возврат значения из строки 3, находящейся в том же столбце (столбец B). |
7 |
|
=ГПР(“П”;A1:C4;3;ИСТИНА) |
Поиск буквы “П” в строке 1 и возврат значения из строки 3, находящейся в том же столбце. Так как “П” найти не удалось, возвращается ближайшее из меньших значений: “Оси” (в столбце A). |
5 |
|
=ГПР(“Болты”;A1:C4;4) |
Поиск слова “Болты” в строке 1 и возврат значения из строки 4, находящейся в том же столбце (столбец C). |
11 |
|
=ГПР(3;{1;2;3:”a”;”b”;”c”;”d”;”e”;”f”};2;ИСТИНА) |
Поиск числа 3 в трех строках константы массива и возврат значения из строки 2 того же (в данном случае — третьего) столбца. Константа массива содержит три строки значений, разделенных точкой с запятой (;). Так как “c” было найдено в строке 2 того же столбца, что и 3, возвращается “c”. |
c |
Примеры индекса и match
В последнем примере функции ИНДЕКС и MATCH совместно возвращают номер счета с наиболее ранней датой и соответствующую дату для каждого из пяти городов. Так как дата возвращается как число, для ее формата используется функция ТЕКСТ. Функция ИНДЕКС использует результат, возвращенный функцией ПОИСКПОЗ, как аргумент. Сочетание функций ИНДЕКС и ПОИСКПОЗ используется в каждой формуле дважды — сперва для возврата номера счета, а затем для возврата даты.
Скопируйте всю таблицу и вставьте ее в ячейку A1 пустого листа Excel.
Совет: Перед тем как вировать данные в Excel, установите для столбцов A–D ширину в 250 пикселей и нажмите кнопку “Перенос текста” (вкладка “Главная”, группа “Выравнивание”).
|
Счет |
Город |
Дата выставления счета |
Счет с самой ранней датой по городу, с датой |
|
3115 |
Казань |
07.04.12 |
=”Казань = “&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Казань”,$B$2:$B$33,0),1)& “, Дата выставления счета: ” & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Казань”,$B$2:$B$33,0),3),”m/d/yy”) |
|
3137 |
Казань |
09.04.12 |
=”Орел = “&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Орел”,$B$2:$B$33,0),1)& “, Дата выставления счета: ” & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Орел”,$B$2:$B$33,0),3),”m/d/yy”) |
|
3154 |
Казань |
11.04.12 |
=”Челябинск = “&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Челябинск”,$B$2:$B$33,0),1)& “, Дата выставления счета: ” & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Челябинск”,$B$2:$B$33,0),3),”m/d/yy”) |
|
3191 |
Казань |
21.04.12 |
=”Нижний Новгород = “&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Нижний Новгород”,$B$2:$B$33,0),1)& “, Дата выставления счета: ” & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Нижний Новгород”,$B$2:$B$33,0),3),”m/d/yy”) |
|
3293 |
Казань |
25.04.12 |
=”Москва = “&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Москва”,$B$2:$B$33,0),1)& “, Дата выставления счета: ” & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(“Москва”,$B$2:$B$33,0),3),”m/d/yy”) |
|
3331 |
Казань |
27.04.12 |
|
|
3350 |
Казань |
28.04.12 |
|
|
3390 |
Казань |
01.05.12 |
|
|
3441 |
Казань |
02.05.12 |
|
|
3517 |
Казань |
08.05.12 |
|
|
3124 |
Орел |
09.04.12 |
|
|
3155 |
Орел |
11.04.12 |
|
|
3177 |
Орел |
19.04.12 |
|
|
3357 |
Орел |
28.04.12 |
|
|
3492 |
Орел |
06.05.12 |
|
|
3316 |
Челябинск |
25.04.12 |
|
|
3346 |
Челябинск |
28.04.12 |
|
|
3372 |
Челябинск |
01.05.12 |
|
|
3414 |
Челябинск |
01.05.12 |
|
|
3451 |
Челябинск |
02.05.12 |
|
|
3467 |
Челябинск |
02.05.12 |
|
|
3474 |
Челябинск |
04.05.12 |
|
|
3490 |
Челябинск |
05.05.12 |
|
|
3503 |
Челябинск |
08.05.12 |
|
|
3151 |
Нижний Новгород |
09.04.12 |
|
|
3438 |
Нижний Новгород |
02.05.12 |
|
|
3471 |
Нижний Новгород |
04.05.12 |
|
|
3160 |
Москва |
18.04.12 |
|
|
3328 |
Москва |
26.04.12 |
|
|
3368 |
Москва |
29.04.12 |
|
|
3420 |
Москва |
01.05.12 |
|
|
3501 |
Москва |
06.05.12 |
Skip to content
В этом руководстве показано, как использовать ИНДЕКС и ПОИСКПОЗ в Excel и чем они лучше ВПР.
В нескольких недавних статьях мы приложили немало усилий, чтобы объяснить основы функции ВПР новичкам и предоставить более сложные примеры формул ВПР опытным пользователям. А теперь я постараюсь если не отговорить вас от использования ВПР, то хотя бы показать вам альтернативный способ поиска нужных значений в Excel.
- Краткий обзор функций ИНДЕКС и ПОИСКПОЗ
- Как использовать формулу ИНДЕКС ПОИСКПОЗ
- ИНДЕКС+ПОИСКПОЗ вместо ВПР?
- Поиск справа налево
- Двусторонний поиск в строках и столбцах
- ИНДЕКС ПОИСКПОЗ для поиска по нескольким условиям
- Как найти среднее, максимальное и минимальное значение
- Что делать с ошибками поиска?
Для чего это нужно? Потому что функция ВПР имеет множество ограничений, которые могут помешать вам получить желаемый результат во многих ситуациях. С другой стороны, комбинация ПОИСКПОЗ ИНДЕКС более гибкая и имеет много замечательных возможностей, которые во многих отношениях превосходят ВПР.
Функции Excel ИНДЕКС и ПОИСКПОЗ — основы
Поскольку целью этого руководства является демонстрация альтернативного способа выполнения поиска в Excel с использованием комбинации функций ИНДЕКС и ПОИСКПОЗ, мы не будем подробно останавливаться на их синтаксисе и использовании. Тем более, что это подробно рассмотрено в других статьях, ссылки на которые вы можете найти в конце этого руководства. Мы рассмотрим лишь минимум, необходимый для понимания общей идеи, а затем подробно рассмотрим примеры формул, раскрывающие все преимущества использования ПОИСКПОЗ и ИНДЕКС вместо ВПР.
Функция ИНДЕКС
Функция ИНДЕКС (в английском варианте – INDEX) возвращает значение в массиве на основе указанных вами номеров строк и столбцов. Синтаксис функции ИНДЕКС прост:
ИНДЕКС(массив,номер_строки,[номер_столбца])
Вот простое объяснение каждого параметра:
- массив – это диапазон ячеек, именованный диапазон или таблица.
- номер_строки — это номер строки в массиве, из которого нужно вернуть значение. Если этот аргумент опущен, требуется следующий – номер_столбца.
- номер_столбца — это номер столбца, из которого нужно вернуть значение. Если он опущен, требуется номер_строки.
Дополнительные сведения см. в статье Функция ИНДЕКС в Excel .
А вот пример формулы ИНДЕКС в самом простом виде:
=ИНДЕКС(A1:C10;2;3)
Формула выполняет поиск в ячейках с A1 по C10 и возвращает значение ячейки во 2-й строке и 3-м столбце, т. е. в ячейке C2.
Очень легко, правда? Однако при работе с реальными данными вы вряд ли когда-нибудь будете заранее знать, какие строки и столбцы вам нужны. Здесь вам пригодится ПОИСКПОЗ.
Функция ПОИСКПОЗ
Она ищет нужное значение в диапазоне ячеек и возвращает относительное положение этого значения в диапазоне.
Синтаксис функции ПОИСКПОЗ следующий:
ПОИСКПОЗ(искомое_значение, искомый_массив, [тип_совпадения])
- искомое_значение — числовое или текстовое значение, которое вы ищете.
- диапазон_поиска – диапазон ячеек, в которых будем искать.
- тип_совпадения — указывает, следует ли искать точное соответствие или наиболее близкое совпадение:
- 1 или опущено — находит наибольшее значение, которое меньше или равно искомому значению. Требуется сортировка массива поиска в порядке возрастания.
- 0 — находит первое значение, точно равное искомому значению. В комбинации ИНДЕКС/ПОИСКПОЗ вам почти всегда нужно точное совпадение, поэтому вы чаще всего устанавливаете третий аргумент вашей функции в 0.
- -1 — находит наименьшее значение, которое больше или равно искомому значению. Требуется сортировка массива поиска в порядке убывания.
Например, если диапазон B1:B3 содержит значения «яблоки», «апельсины», «лимоны», приведенная ниже формула возвращает число 3, поскольку «лимоны» — это третья по счету запись в этом диапазоне:
=ПОИСКПОЗ(“лимоны”;B1:B3;0)
Дополнительные сведения см . в статье Функция ПОИСКПОЗ в Excel .
На первый взгляд полезность функции ПОИСКПОЗ может показаться сомнительной. Кого волнует положение значения в диапазоне? Что мы действительно хотим определить, так это само значение.
Однако, относительная позиция искомого значения (т. е. номера строки и столбца, в которых оно находится) — это именно то, что нам нужно указать для аргументов номер_строки и номер_столбца функции ИНДЕКС. Как вы помните, ИНДЕКС может найти значение на пересечении заданной строки и столбца, но сама не может определить, какую именно строку и столбец ей нужно выбрать.
Вот поэтому совместное использование ИНДЕКС и ПОИСКПОЗ открывает перед нами массу возможностей для поиска в Excel.
Как использовать формулу ИНДЕКС ПОИСКПОЗ в Excel
Теперь, когда вы знаете основы, я считаю, что вы уже начали понимать, как ПОИСКПОЗ и ИНДЕКС работают вместе. Короче говоря, ИНДЕКС извлекает нужное значение по номерам столбцов и строк, а ПОИСКПОЗ предоставляет ей эти номера. Вот и все!
Для вертикального поиска вы используете функцию ПОИСКПОЗ только для определения номера строки, указывая диапазон столбцов непосредственно в самой формуле:
ИНДЕКС ( столбец для возврата значения ; ПОИСКПОЗ ( искомое значение ; столбец для поиска ; 0))
Все еще не совсем понимаете эту логику? Возможно, будет проще разобрать на примере. Предположим, у вас есть список национальных столиц и их население:

Чтобы найти население определенной столицы, скажем, Индии, используйте следующую формулу ПОИСКПОЗ ИНДЕКС:
=ИНДЕКС(C2:C10; ПОИСКПОЗ(“Индия”;A2:A10;0))
Теперь давайте проанализируем, что на самом деле делает каждый компонент этой формулы:
- Функция ПОИСКПОЗ ищет искомое значение “Индия” в диапазоне A2:A10 и возвращает число 2, поскольку это слово занимает второе место в массиве поиска.
- Этот номер поступает непосредственно в аргумент номер_строки функции ИНДЕКС, предписывая вернуть значение из этой строки.
Таким образом, приведенная выше формула превращается в ИНДЕКС(C2:C10;2), которая означает, что нужно искать в ячейках от C2 до C10 и извлекать значение из второй ячейки в этом диапазоне, то есть из C3, потому что мы начинаем отсчет со второй строки.
Но указывать название города в формуле не совсем правильно, так как для каждого нового поиска придется корректировать эту формулу. Введите его в какую-нибудь отдельную ячейку, скажем, F1, укажите ссылку на ячейку для ПОИСКПОЗ, и вы получите формулу динамического поиска:
=ИНДЕКС(C2:C10;ПОИСКПОЗ(F1;A2:A10;0))

Важное замечание! Количество строк в аргументе массив функции ИНДЕКС должно совпадать с количеством строк в аргументе просматриваемый_массив в ПОИСКПОЗ, иначе формула выдаст неверный результат.
Вы спросите: «А почему бы нам просто не использовать обычную формулу ВПР? Какой смысл тратить время на то, чтобы разобраться в хитросплетениях ИНДЕКС ПОИСКПОЗ в Excel?»
Вот как это будет выглядеть:
=ВПР(F1; A2:C10; 3; 0)
Конечно, так проще. Но этот наш элементарный пример предназначен только для демонстрационных целей, чтобы вы поняли, как именно функции ИНДЕКС и ПОИСКПОЗ работают вместе. Действительно, ВПР была бы здесь более уместна. Другие примеры, которые вы найдёте ниже, покажут вам реальную силу этой комбинации, которая легко справляется со многими сложными задачами, когда ВПР будет бессильна.
ИНДЕКС+ПОИСКПОЗ вместо ВПР?
Решая, какую функцию использовать для вертикального поиска, большинство знатоков Excel сходятся во мнении, что ПОИСКПОЗ+ИНДЕКС намного лучше, чем ВПР. Однако многие до сих пор остаются с ВПР, во-первых, потому что это проще, а, во-вторых, потому что они не до конца понимают все преимущества использования формулы ПОИСКПОЗ ИНДЕКС в Excel. Без такого понимания никто не захочет тратить свое время на изучение более сложного синтаксиса.
Ниже я укажу на ключевые преимущества ИНДЕКС ПОИСКПОЗ перед ВПР, а уж вам решать, является ли это достойным дополнением к вашему арсеналу знаний в Excel.
4 основные причины использовать ИНДЕКС ПОИСКПОЗ вместо ВПР
- Поиск справа налево. Как известно любому образованному пользователю, ВПР не может искать влево. Это означает, что искомое значение всегда должно находиться в крайнем левом столбце таблицы. А извлекать нужное значение мы будем из столбца, который находится правее. ИНДЕКС+ПОИСКПОЗ может легко выполнять поиск влево! Здесь это показано в действии: Как выполнить поиск значения слева в Excel .
- Можно безопасно вставлять или удалять столбцы. Формулы ВПР не работают или выдают неверные результаты, когда новый столбец удаляется из таблицы поиска или добавляется в нее, поскольку синтаксис ВПР требует указания порядкового номера столбца, из которого вы хотите извлечь данные. Естественно, когда вы добавляете или удаляете столбцы, этот номер в формуле автоматически не меняется, а нужный столбец уже оказывается на новом месте.
С функциями ИНДЕКС и ПОИСКПОЗ вы указываете диапазон возвращаемых столбцов, а не номер одного из них. В результате вы можете вставлять и удалять столько столбцов, сколько хотите, не беспокоясь об обновлении каждой связанной с ними формулы.
- Нет ограничений на размер искомого значения. При использовании функции ВПР общая длина ваших критериев поиска не может превышать 255 символов, иначе вы получите ошибку #ЗНАЧ!. Таким образом, если ваш набор данных содержит длинные строки, ИНДЕКС ПОИСКПОЗ — единственное работающее решение.
- Более высокая скорость обработки. Если ваши таблицы относительно небольшие, вряд ли будет какая-то существенная разница в производительности Excel. Но если ваши рабочие листы содержат сотни или тысячи строк и, следовательно, сотни или тысячи формул, ИНДЕКС ПОИСКПОЗ будет работать намного быстрее, чем ВПР. Причина в том, что Excel будет обрабатывать только столбцы поиска и возврата, а не весь массив таблицы.
Влияние ВПР на производительность Excel может быть особенно заметным, если ваша книга содержит сложные формулы массива. Чем больше значений содержит ваш массив и чем больше формул массива содержится в книге, тем медленнее работает Excel.
ИНДЕКС ПОИСКПОЗ в Excel – примеры формул
Уяснив, почему все же стоит изучать ИНДЕКС ПОИСКПОЗ, давайте перейдем к самому интересному и посмотрим, как можно применить теоретические знания на практике.
Формула для поиска справа налево
Как уже упоминалось, ВПР не может получать значения слева от столбца поиска. Таким образом, если ваши значения поиска не находятся в самом левом столбце, нет никаких шансов, что формула ВПР принесет вам желаемый результат. Функция ПОИСКПОЗ ИНДЕКС в Excel более универсальна и не имеет особого значения, где расположены столбцы поиска и возврата.
Для этого примера мы добавим столбец «Ранг» слева от нашей основной таблицы и попытаемся выяснить, какое место занимает столица России по численности населения среди других перечисленных столиц.
Записав искомое значение в G1, используйте следующую формулу для поиска в C2:C10 и возврата соответствующего значения из A2:A10:
=ИНДЕКС(A2:A10; ПОИСКПОЗ(G1;C2:C10;0))

Совет. Если вы планируете использовать формулу ПОИСКПОЗ ИНДЕКС более чем для одной ячейки, обязательно зафиксируйте оба диапазона абсолютными ссылками (например, $A$2:$A$10 и $C$2:$C$10), чтобы они не изменялись при копировании формулы.
Двусторонний поиск в строках и столбцах
В приведенных выше примерах мы использовали ИНДЕКС ПОИСКПОЗ вместо классической функции ВПР, чтобы вернуть значение из точно указанного столбца. Но что, если вам нужно искать в нескольких строках и столбцах? То есть, сначала нужно найти подходящий столбец, а уж потом извлечь из него значение? Другими словами, что, если вы хотите выполнить так называемый матричный или двусторонний поиск?
Это может показаться сложным, но формула очень похожа на базовую функцию ПОИСКПОЗ ИНДЕКС в Excel, но с одним отличием.
Просто используйте две функции ПОИСКПОЗ, вложенных друг в друга: одну – для получения номера строки, а другую – для получения номера столбца.
ИНДЕКС(массив; ПОИСКПОЗ(значение_поиска1 ; столбец_поиска ; 0); ПОИСКПОЗ(значение_поиска2 ; столбец_поиска ; 0))
А теперь, пожалуйста, взгляните на приведенную ниже таблицу и давайте составим формулу двумерного поиска, чтобы найти население (в миллионах) в данной стране за данный год.
С целевой страной в G1 (значение_поиска1) и целевым годом в G2 (значение_поиска2) формула принимает следующий вид:
=ИНДЕКС(B2:D11; ПОИСКПОЗ(G1;A2:A11;0); ПОИСКПОЗ(G2;B1:D1;0))

Как работает эта формула?
Всякий раз, когда вам нужно понять сложную формулу Excel, разделите ее на более мелкие части и посмотрите, что делает каждая отдельная функция:
ПОИСКПОЗ(G1;A2:A11;0); – ищет в A2:A11 значение из ячейки G1 («США») и возвращает его позицию, которая равна 3.
ПОИСКПОЗ(G2;B1:D1;0) – просматривает диапазон B1:D1, чтобы получить позицию значения из ячейки G2 («2015»), которая равна 3.
Найденные выше номера строк и столбцов становятся соответствующими аргументами функции ИНДЕКС:
ИНДЕКС(B2:D11, 3, 3)
В результате вы получите значение на пересечении 3-й строки и 3-го столбца в диапазоне B2:D11, то есть из D4. Несложно?
ИНДЕКС ПОИСКПОЗ для поиска по нескольким условиям
Если у вас была возможность прочитать наши материалы по ВПР в Excel, вы, вероятно, уже протестировали формулу для ВПР с несколькими условиями . Однако существенным недостатком этого подхода является необходимость добавления вспомогательного столбца. Хорошей новостью является то, что функция ПОИСКПОЗ ИНДЕКС в Excel также может выполнять поиск по нескольким условиям без изменения или реструктуризации исходных данных!
Вот общая формула ИНДЕКС ПОИСКПОЗ с несколькими критериями:
{=ИНДЕКС( диапазон_возврата; ПОИСКПОЗ (1; ( критерий1 = диапазон1 ) * ( критерий2 = диапазон2 ); 0))}
Примечание. Это формула массива , которую необходимо вводить с помощью сочетания клавиш Ctrl + Shift + Enter.
Предположим, что в таблице ниже вы хотите найти значение на основе двух критериев: Покупатель и Товар.
Следующая формула ИНДЕКС ПОИСКПОЗ отлично работает:
=ИНДЕКС(C2:C10; ПОИСКПОЗ(1; (F1=A2:A10) * (F2=B2:B10); 0))
Где C2:C10 — это диапазон, из которого возвращается значение, F1 — это критерий1, A2:A10 — это диапазон для сравнения с критерием 1, F2 — это критерий 2, а B2:B10 — это диапазон для сравнения с критерием 2.
Не забудьте правильно ввести формулу, нажав Ctrl + Shift + Enter, и Excel автоматически заключит ее в фигурные скобки, как показано на скриншоте ниже:

Рис5
Если вы не хотите использовать формулы массива, добавьте в формулу в F4 еще одну функцию ИНДЕКС и завершите ее ввод обычным нажатием Enter:
=ИНДЕКС(C2:C10; ПОИСКПОЗ(1; ИНДЕКС((F1=A2:A10) * (F2=B2:B10); 0; 1); 0))
Разберем пошагово, как это работает.
Здесь используется тот же подход, что и в обычном сочетании ИНДЕКС ПОИСКПОЗ, где просматривается один столбец. Чтобы оценить несколько критериев, вы создаете два или более массива значений ИСТИНА и ЛОЖЬ, которые представляют совпадения и несовпадения для каждого отдельного критерия, а затем перемножаете соответствующие элементы этих массивов. Операция умножения преобразует ИСТИНА и ЛОЖЬ в 1 и 0 соответственно и создает массив, в котором единицы соответствуют строкам, которые удовлетворяют всем условиям. Функция ПОИСКПОЗ со значением поиска 1 находит первую «1» в массиве и передает ее позицию в ИНДЕКС, которая возвращает значение в этой позиции из указанного столбца.
Вторая формула без массива основана на способности функции ИНДЕКС работать с массивами. Второй вложенный ИНДЕКС имеет 0 в номер_строки , так что он будет передавать весь массив столбцов в ПОИСКПОЗ.
Среднее, максимальное и минимальное значение при помощи ИНДЕКС ПОИСКПОЗ
Microsoft Excel имеет специальные функции для поиска минимального, максимального и среднего значения в диапазоне. Но что, если вам нужно получить значение из другой ячейки, связанной с этими значениями? Например, получить название города с максимальным населением или узнать товар с минимальными продажами? В этом случае используйте функцию МАКС , МИН или СРЗНАЧ вместе с ИНДЕКС ПОИСКПОЗ.
Максимальное значение.
Предположим, нам нужно в списке городов найти столицу с самым большим населением. Чтобы найти наибольшее значение в столбце С и вернуть соответствующее ему значение из столбца В, находящееся в той же строке, используйте эту формулу:
=ИНДЕКС(B2:B10; ПОИСКПОЗ(МАКС(C2:C10); C2:C10; 0))
Скриншот с примером находится чуть ниже.
Минимальное значение
Теперь найдём город с самым маленьким населением в списке. Чтобы найти наименьшее число в столбце С и получить соответствующее ему значение из столбца В:
=ИНДЕКС(B2:B10; ПОИСКПОЗ(МИН(C2:C10); C2:C10; 0))
Ближайшее к среднему
Теперь мы находим город, население которого наиболее близко к среднему значению. Чтобы вычислить позицию, наиболее близкую к среднему значению показателя, рассчитанному из D2:D10, и получить соответствующее значение из столбца C, используйте следующую формулу:
=ИНДЕКС(B2:B10; ПОИСКПОЗ(СРЗНАЧ(C2:C10); C2:C10; -1 ))
В зависимости от того, как организованы ваши данные, укажите 1 или -1 для третьего аргумента (тип_совпадения) функции ПОИСКПОЗ:
- Если ваш столбец поиска (столбец D в нашем случае) отсортирован по возрастанию , поставьте 1. Формула вычислит наибольшее значение, которое меньше или равно среднему значению.
- Если ваш столбец поиска отсортирован по убыванию , введите -1. Формула вычислит наименьшее значение, которое больше или равно среднему значению.
- Если ваш массив поиска содержит значение , точно равное среднему, вы можете ввести 0 для точного совпадения. Никакой сортировки не требуется.
В нашем примере данные в столбце D отсортированы в порядке убывания, поэтому мы используем -1 для типа соответствия. В результате мы получаем «Токио», так как его население (13 189 000) является ближайшим, превышающим среднее значение (12 269 006).

Что делать с ошибками поиска?
Как вы, наверное, заметили, если формула ИНДЕКС ПОИСКПОЗ в Excel не может найти искомое значение, она выдает ошибку #Н/Д. Если вы хотите заменить это стандартное сообщение чем-то более информативным, оберните формулу ПОИСКПОЗ ИНДЕКС в функцию ЕСНД . Например:
=ЕСНД(ИНДЕКС(C2:C10; ПОИСКПОЗ(F1;A2:A10;0)); “Не найдено”)
И теперь, если кто-то вводит значение, которое не существует в диапазоне поиска, формула явно сообщит пользователю, что совпадений не найдено:

Если вы хотите перехватывать все ошибки, а не только #Н/Д, используйте функцию ЕСЛИОШИБКА вместо ЕСНД:
=ЕСЛИОШИБКА(ИНДЕКС(C2:C10; ПОИСКПОЗ(F1;A2:A10;0)); “Что-то пошло не так!”)
Пожалуйста, имейте в виду, что во многих ситуациях было бы не совсем правильно скрывать все такие ошибки, потому что они предупреждают вас о возможных проблемах в вашей формуле.
Итак, еще раз об основных преимуществах формулы ИНДЕКС ПОИСКПОЗ.
-
Возможен ли “левый” поиск?
-
Повлияет ли на результат вставка и удаление столбцов?
Вы можете вставлять и удалять столько столбцов, сколько хотите. На результат ИНДЕКС ПОИСКПОЗ это не повлияет.
-
Возможен ли поиск по строкам и столбцам?
Можно сначала найти подходящий столбец, а уж потом извлечь из него значение. Общий вид формулы:
ИНДЕКС(массив; ПОИСКПОЗ(значение_поиска1 ; столбец_поиска ; 0); ПОИСКПОЗ(значение_поиска2 ; столбец_поиска ; 0))
Подробную инструкцию смотрите здесь. -
Как сделать поиск ИНДЕКС ПОИСКПОЗ по нескольким условиям?
Можно выполнять поиск по двум или более условиям без добавления дополнительных столбцов. Вот формула массива, которая решит проблему:
{=ИНДЕКС( диапазон_возврата; ПОИСКПОЗ (1; ( критерий1 = диапазон1 ) * ( критерий2 = диапазон2 ); 0))}
Вот как можно использовать ИНДЕКС и ПОИСКПОЗ в Excel. Я надеюсь, что наши примеры формул окажутся полезными для вас.
Вот еще несколько статей по этой теме:
Ссылка на это место страницы:
#title
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
- Скачать файл
Ссылка на это место страницы:
#punk01
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }
{ = INDEX( диапазон ; MATCH( FALSE; ISBLANK ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
{ = INDEX( B3:B11; MATCH( FALSE; ISBLANK ( B3:B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая “тестирует” ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
{ = INDEX( B3:B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Ссылка на это место страницы:
#punk02
= ВПР ( “*”; диапазон; 1; ЛОЖЬ)
= VLOOKUP ( “*”; диапазон; 1; FALSE)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( “*” ; B5: B11 ; 1 ; ЛОЖЬ)
= VLOOKUP ( “*” ; B5:B11 ; 1 ; FALSE)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Ссылка на это место страницы:
#punk03
= ГПР ( “*”; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( “*”; диапазон; 1; FALSE)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( “*”; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( “*”; диапазон; 1; FALSE)
Значение поиска является “*”, групповым символом, который соответствует одному или более текстовому значению.
Ссылка на это место страницы:
#punk04
= ГПР ( “*”; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( “*”; диапазон; 1; FALSE)
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Ссылка на это место страницы:
#punk05
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
=LOOKUP(2;1/SEARCH($E$4:$E$7;B4);$E$4:$E$7)
Ссылка на это место страницы:
#punk06
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) – МИН( СТРОКА( список )) + 1 ); n )
= SMALL( IF( логический тест; СТРОКА( список ) – MIN( ROW( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) – МИН( СТРОКА( список )) + 1 ); F5 )
= SMALL( IF( список = E5 ; ROW( список ) – MIN( ROW( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления “красных” в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были “отфильтрованы” функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk07
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) – СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }
{ = INDEX( массив; SMALL( IF( величины = знач ; ROW ( величины ) – ROW ( INDEX( величины; 1 ; 1 )) + 1 ); n-й )) }

Эта формула возвращает позицию второго появления “красных” в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были “отфильтрованы” функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk08
= ВПР( id_формулы; стол; 4; 0 )
= VLOOKUP( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных.
Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&”-“&I6;B4:G11;4;0)
=VLOOKUP(J3&”-“&I6;B4:G11;4;0)
Ссылка на это место страницы:
#punk09
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
{ = INDEX( результаты ;MATCH( TRUE ; ISNUMBER( SEARCH( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
= INDEX( результаты ; MATCH( TRUE ; ISNUMBER( SEARCH ( вещи ; B5 )); 0 ))
Эта формула использует два названных диапазона: E5: E8 называется “вещи” и F5: F8 называется “Результаты”. Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Ссылка на это место страницы:
#punk10
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
{ = MATCH( TRUE ; ISERROR(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
{ = MATCH( TRUE ; ISERROR( B4:B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Ссылка на это место страницы:
#punk11
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )

Для того, чтобы найти “следующее наибольшее” значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )
Ссылка на это место страницы:
#punk12
{ = ОБЪЕДИНИТЬ ( “;” ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; “” )) }
{ = ОБЪЕДИНИТЬ ( “;” ; TRUE ; IF( диапазон1 = E5 ; диапазон2 ; “” )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( “;” ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; “” )) }
Эта формула использует “имя” – именованный диапазон (B5: B11) и “группа” – (C5: C11).
Ссылка на это место страницы:
#punk13
{ = ПОИСКПОЗ( “*” & номер & “*” ; ТЕКСТ( диапазон ; “0” ); 0 ) }
{ = MATCH( “*” & номер & “*” ; TEXT( диапазон ; “0” ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки “*” и “?”. Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, “*” & 99 & “*” = “* 99 *” (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( “*” & Е5 & “*” ; В5: В10 & “” ; 0 )
= MATCH ( “*” & Е5 & “*” ; В5: В10 & “” ; 0 )
Ссылка на это место страницы:
#punk14
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&”*”;$B$3:$E$12;2;0)
=VLOOKUP($H$2&”*”;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Ссылка на это место страницы:
#punk15
= ПОИСКПОЗ ( “* текст *” ; диапазон; 0 )
= MATCH ( “* текст *” ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

=ПОИСКПОЗ(“*”&E6&”*”;B5:B10;0)
=MATCH(“*”&E6&”*”;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или “индекс” в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой “*” (один или несколько символов) или знаком вопроса “?” (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Ссылка на это место страницы:
#punk16
Файлы статей доступны только зарегистрированным пользователям.
1. Введите свою почту
2. Нажмите Зарегистрироваться
3. Обновите страницу
Вместо этого блока появится ссылка для скачивания материалов.

Привет! Меня зовут Дмитрий. С 2014 года Microsoft Cretified Trainer. Вместе с командой управляем этим сайтом. Наша цель – помочь вам эффективнее работать в Excel.
Изучайте наши статьи с примерами формул, сводных таблиц, условного форматирования, диаграмм и макросов. Записывайтесь на наши курсы или заказывайте обучение в корпоративном формате.

Подписывайтесь на нас в соц.сетях:
На чтение 7 мин. Просмотров 31.2k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
В этой заметке речь пойдет об альтернативе функции ВПР в виде связки из двух функций ИНДЕКС и ПОИСКПОЗ.
Поговорим о преимуществах такого решения, разберем работу каждой из функций отдельно и связку функций, для ее использования вместо ВПР.
Итак, поехали.
Преимущества ИНДЕКС и ПОИСКПОЗ
Связка функций ИНДЕКС и ПОИСКПОЗ фактически полностью заменяет функцию ВПР и лишена ее недостатков, которые вытекают из синтаксиса самой функции.
Напомню, что функция ВПР возвращает значение из диапазона, который может находиться только справа от столбца со значениями где происходит поиск. ИНДЕКС и ПОИСКПОЗ могут осуществлять поиск в любом столбце диапазона.
Кроме этого, в функции ВПР указывается неразрывный диапазон, включающий все столбцы между столбцом, в котором происходит поиск искомого значения и столбцом, откуда необходимо значение вернуть.
Однако при работе с данными может возникнуть необходимость удалить или вставить столбец в рамках ранее выбранного диапазона и тогда функцию ВПР придется корректировать и изменять диапазон.
В формуле с функциями ИНДЕКС и ПОИСКПОЗ указываются конкретные столбцы или только необходимые диапазоны значений, поэтому удаление или добавление столбцов на их работу не оказывает никакого влияния.
Ну и для того, чтобы понять работу связки функций ИНДЕКС и ПОИСКПОЗ разберемся с синтаксисом каждой функции отдельно.
Функция ИНДЕКС
Функция ИНДЕКС возвращает значение, которое находится в указанном номере строки выделенного диапазона.
Например, найдем имя «Ольга» в соответствующем столбце.
Первое, что мы указываем – это где будет производиться поиск. Нас будет интересовать только один столбец, поэтому выбираем его.
Далее мы должны указать номер строки в выделенном диапазоне, из которого будет возвращено значение. Здесь все по аналогии с функцией ВПР – указывается номер строки в выделенном диапазоне, а не номер строки таблицы Excel.
В мое примере это третья строка. Аргументы в квадратных скобках являются необязательными, поэтому их можно не указывать.
Будет возвращено имя Ольга.
Если будет выбран диапазон, состоящий из нескольких столбцов, то нужно будет указать и номер строки, и номер столбца в диапазоне, на пересечении которых находится ячейка с нужным значением.
Например, если мы выделим диапазон со всеми данными и нам нужен будет адрес Ольги, то укажем, что он находится в третьей строке и втором столбце выделенного диапазона.
Функция ИНДЕКС возвращает нужное нам значение, но в отличии от ВПР координаты этой ячейки приходится задавать вручную. Чтобы автоматизировать процесс воспользуемся функцией ПОИСКПОЗ.
Функция ПОИСКПОЗ
Функция ПОИСКПОЗ производит поиск указанного значения в диапазоне ячеек и возвращает относительную позицию ячейки с искомым значением. То есть фактически эта функция возвращает координаты этой ячейки, а это как раз то, чего не хватает функции ИНДЕКС для полноценной замены функции ВПР.
Например, нам нужно узнать, какие координаты в диапазоне имеет «Ольга». Создадим формулу с функцией ПОИСКПОЗ и введем интересующее нас имя. Напомню, что текст вводится в кавычках.
Мы указали что искать, а теперь нужно указать где будет производиться поиск – выбираем значения столбца «Имя».
Ну и последний аргумент функции ПОИСКПОЗ очень напоминает аналогичный аргумент интервальный просмотр функции ВПР, но он может принимать три значения – меньше, больше и точное совпадение.
Если речь идет о поиске текстовых данных, то всегда выбираем точное совпадение. Другие параметры актуальны только при работе с числовыми данными. Поэтому указываем ноль и в итоге получаем цифру 3, что соответствует третьей строке в выделенном диапазоне.
Ну а теперь объединим функции ИНДЕКС и ПОИСКПОЗ в полноценную замену функции ВПР.
Связка фукнций ИНДЕКС и ПОИСКПОЗ
Давайте найдем телефон Ивана. Создаем формулу с функцией ИНДЕКС.
Так как нам нужен телефон, то искать мы его будем в соответствующем столбце таблицы, поэтому выделяем его. Далее мы должны указать номер строки в этом диапазоне и тут на помощь приходит функция ПОИСКПОЗ. Так как нас интересует телефон Ивана, то мы бы хотели получить номер строки, в которой находится его имя. Указываем, что мы будем искать – имя “Иван”, затем указываем где мы его будем искать – соответствующий диапазон столбца «Имя». Ищем текст, поэтому точное совпадение – 0.
Получаем верный результат.
Формула проделала ровно тоже, с чем легко справится функция ВПР, но давайте решим задачи, которые ВПР не по зубам.
Преимущества ИНДЕКС + ПОИСКПОЗ
Неоспоримым преимуществом связки функций ИНДЕКС и ПОИСКПОЗ перед ВПР является то, что мы можем производить поиск данных влево, что может быть крайне важным при работе с таблицами, имеющими некоторую стандартизированную форму, то есть когда нет возможности поменять столбцы местами.
Также в аргументах функции мы можем указать только интересующие нас диапазоны, а значит конечная формула не будет чувствительна к вставке новых столбцов или удалению уже ненужных столбцов с данными из таблицы.
Давайте рассмотрим это на примере, но сначала просто попрактикуемся и подставим цену из прайс-листа с помощью связки функций ИНДЕКС и ПОИСКПОЗ.
Создаем формулу с функцией ИНДЕКС и выбираем диапазон с ценами. Далее подключаем функцию ПОИСКПОЗ и в качестве искомого значения указываем наименование товара. Затем указываем соответствующий диапазон в прайс-листе.
Что касается диапазонов, то здесь действует тоже правило, что и при работе с функцией ВПР – если мы планируем копировать формулу по диапазону, то нужно ОБЯЗАТЕЛЬНО фиксировать ссылки, превращая их в абсолютные. Иначе при протягивании формулы диапазон в ней будет «сползать» и функция выдаст ошибку. Поочередно выделяем диапазоны в формуле и нажимаем клавишу F4 для преобразования их ссылок в абсолютные.
В результате формула сработает верно и можно будет рассчитать сумму заказа.
Фактически получили тот же результат, что и с помощью функции ВПР, но теперь давайте подставим город, основываясь на фамилии менеджера. В таблице с филиалами столбец с менеджерами находится правее столбца с городам и поэтому функция ВПР тут бесполезна.
Создаем формулу с функцией ИНДЕКС и указываем столбец с городами, так как именно город нас будет интересовать в конечном итоге. Не забываем фиксировать диапазон. Затем с помощью функции ПОИСКПОЗ находим номер соответствующей строки. Сделать это можно по фамилии менеджера, которая присутствует в обеих таблицах.
Получаем нужный результат. При этом если вдруг понадобится добавить столбец в таблицу с филиалами, то данные никуда не денутся, так как они будут привязаны к конкретным столбцам таблицы.
Это прекрасно видно и из следующего примера.
Здесь у нас есть меню и два одинаковых заказа. Один посчитан с помощью ВПР, второй с помощью ИНДЕКС и ПОИСКПОЗ.
Если меню изменится и в него будет внесен еще один столбец, то расчеты с функцией ВПР будут неверными, так как теперь в них будет участвовать не цена, а вес порции в граммах.
Диапазон в формуле расширился, но номер столбца в аргументах по-прежнему ведет на третий столбец в диапазоне, хотя теперь он уже стал четвертым.
Тем не менее, во втором чеке все посчитано верно и вставка столбцов никак не повлияла на конечный результат.
Ну и еще одним преимуществом связки функций является то, что мы можем искать не только в столбцах, но и в строках.
Например, стандартная ситуация для многих кафе – напитки имеют различные объемы от чего зависит их цена. Исходные данные – это напиток и его размер. Необходимо найти цену.
Для этого воспользуемся функцией ИНДЕКС и укажем весь диапазон цен. Ну а для того, чтобы определить координаты конкретной ячейки воспользуемся функцией ПОИСКПОЗ. Причем задействуем ее дважды – для поиска нужной строки по названию напитка и для поиска нужного столбца по его размеру.
В итоге получаем верный результат.
Ошибки и проблемы
Функции ИНДЕКС и ПОИСКПОЗ делают поиск данных в массиве максимально гибким и позволяют решать задачи, на которые функция ВПР не способна. Но и у этого решения есть особенности, которые нужно учитывать, чтобы не столкнуться с проблемами.
Пожалуй самой распространенной ошибкой, как и в случае с ВПР, являются относительные ссылки в диапазонах.
Как я уже упоминал, здесь действует простое правило – если формулу с функциями ИНДЕКС и ПОИСКПОЗ предполагается копировать по диапазону, то обязательно нужно фиксировать ссылки, делая их абсолютными.
Вторая ошибка, с которой вы можете столкнуться – ССЫЛКА!
Связано ее появление с тем, что массивы в функциях ИНДЕКС и ПОИСКПОЗ имеют различные размеры.
Если искомое значение из одного диапазона выходит за границы второго, то появляется эта ошибка. Стоит проверить соответствие диапазонов и подкорректировать их размеры.
Ну и общая для всех функций просмотра проблема – это производительность или скорость работы. Она заметно падает при обработке значительных массивов данных.
Безусловно, здесь очень многое зависит от десятков или даже сотен факторов, однако в любом случае для ускорения вычислений я бы рекомендовал пользоваться умными таблицами.
Да, не всегда это возможно, но в тех случаях, когда данные могут быть оформлены умными таблицами, всегда используйте их.
Умные таблицы – это очень мощный инструмент Excel, позволяющий значительно ускорить рутинные операции и повысить эффективность вашей работы. И более подробно об умных таблицах я расскажу в следующей заметке.
