how can i search an html page for a word fast?
and how can i get the html tag that the word is in? (so i can work with the entire tag)
asked Apr 14, 2009 at 16:08
![]()
Chen KinnrotChen Kinnrot
20.5k17 gold badges79 silver badges139 bronze badges
To find the element that word exists in, you’d have to traverse the entire tree looking in just the text nodes, applying the same test as above. Once you find the word in a text node, return the parent of that node.
var word = "foo",
queue = [document.body],
curr
;
while (curr = queue.pop()) {
if (!curr.textContent.match(word)) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE : // 3
if (curr.childNodes[i].textContent.match(word)) {
console.log("Found!");
console.log(curr);
// you might want to end your search here.
}
break;
case Node.ELEMENT_NODE : // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
this works in Firefox, no promises for IE.
What it does is start with the body element and check to see if the word exists inside that element. If it doesn’t, then that’s it, and the search stops there. If it is in the body element, then it loops through all the immediate children of the body. If it finds a text node, then see if the word is in that text node. If it finds an element, then push that into the queue. Keep on going until you’ve either found the word or there’s no more elements to search.
answered Apr 14, 2009 at 16:15
![]()
3
You can iterate through DOM elements, looking for a substring within them. Neither fast nor elegant, but for small HTML might work well enough.
I’d try something recursive, like: (code not tested)
findText(node, text) {
if(node.childNodes.length==0) {//leaf node
if(node.textContent.indexOf(text)== -1) return [];
return [node];
}
var matchingNodes = new Array();
for(child in node.childNodes) {
matchingNodes.concat(findText(child, text));
}
return matchingNodes;
}
answered Apr 14, 2009 at 16:14
![]()
vartecvartec
130k36 gold badges217 silver badges244 bronze badges
0
You can try using XPath, it’s fast and accurate
http://www.w3schools.com/Xpath/xpath_examples.asp
Also if XPath is a bit more complicated, then you can try any javascript library like jQuery that hides the boilerplate code and makes it easier to express about what you want found.
Also, as from IE8 and the next Firefox 3.5 , there is also Selectors API implemented. All you need to do is use CSS to express what to search for.
answered Apr 14, 2009 at 16:16
![]()
AzderAzder
4,6787 gold badges37 silver badges57 bronze badges
2
You can probably read the body of the document tree and perform simple string tests on it fast enough without having to go far beyond that – it depends a bit on the HTML you are working with, though – how much control do you have over the pages? If you are working within a site you control, you can probably focus your search on the parts of the page likely to be different page from page, if you are working with other people’s pages you’ve got a tougher job on your hands simply because you don’t necessarily know what content you need to test against.
Again, if you are going to search the same page multiple times and your data set is large it may be worth creating some kind of index in memory, whereas if you are only going to search for a few words or use smaller documents its probably not worth the time and complexity to build that.
Probably the best thing to do is to get some sample documents that you feel will be representative and just do a whole lot of prototyping based around the approaches people have offered here.
answered Apr 14, 2009 at 16:19
![]()
glenatronglenatron
10.9k13 gold badges63 silver badges109 bronze badges
form.addEventListener("submit", (e) => {
e.preventDefault();
var keyword = document.getElementById("search_input");
let words = keyword.value;
var word = words,
queue = [document.body],
curr;
while (curr = queue.pop()) {
if (!curr.textContent.toUpperCase().match(word.toUpperCase())) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE: // 3
if (curr.childNodes[i].textContent.toUpperCase().match(word.toUpperCase())) {
console.log("Found!");
console.log(curr);
curr.scrollIntoView();
}
break;
case Node.ELEMENT_NODE: // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
});
answered Dec 18, 2020 at 17:39
![]()
Недавно мы говорили о библиотеках и фреймворках — и обещали, что попробуем что-нибудь на них собрать. Настало время.
Сегодня мы возьмём популярную библиотеку jQuery и сделаем на её основе поиск по странице. Браузеры это умеют делать встроенными инструментами, но с помощью нашего метода можно будет более тонко всё настроить и сделать поле поиска видимым и удобным.
Нам понадобятся:
- библиотека jQuery — она обеспечит работу нашего поискового плагина, потому что плагин сделан тоже для jQuery.
- плагин highlight — поможет нам найти нужные слова в тексте и подсветить их приятным цветом (каким захотим)
- поле ввода и кнопка — отвечают за сам интерфейс поиска.
Общая идея
У нас есть сайт с неким текстом, и нам нужно быстро находить в нём нужные слова или части слов. Для этого мы в самом начале страницы делаем поле ввода, куда будем писать наши слова для поиска, и кнопку, которая этот поиск запускает.
Дальше скрипт берёт весь текст, находит в нём нужные фрагменты и подсвечивает их. Если он ничего не находит — пишет сообщение о том, что таких слов в тексте нет.
Готовим каркас
Сделаем как обычно — возьмём наш стандартный шаблон из предыдущих задач и немного поправим описания разделов. Сохраним его как .html-файл и открывать в браузере пока не будем — всё равно мы ничего не увидим на странице, кроме названия вкладки.
<html>
<!-- служебная часть -->
<head>
<!-- заголовок страницы -->
<title>Поиск на странице</title>
<!-- настраиваем служебную информацию для браузеров -->
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- задаём CSS-стили прямо здесь же, чтобы всё было в одном файле -->
<style type="text/css">
</style>
<!-- закрываем служебную часть страницы -->
</head>
<!-- началось содержимое страницы -->
<body>
<!-- пишем скрипт, который поможет нам с поиском -->
<script>
</script>
<!-- Здесь будет текст, в котором нам нужно что-то найти -->
<!-- закончилось содержимое страницы -->
</body>
<!-- конец всего HTML-документа -->
</html>Добавляем форму поиска и текст
Наша форма поиска — это поле ввода и кнопка, которая запускает скрипт. Мы не будем сильно настраивать внешний вид формы, при желании вы можете сделать это сами — все нужные знания для этого у вас уже есть. Если что-то забыли — посмотрите, как мы настраивали вид поля ввода в статье про планировщик задач.
Добавим код формы сразу после тега <body>:
<!-- говорим браузеру, что мы хотим разместить форму -->
<form id="search-highlight" method="post" action="#">
<!-- добавляем текстовое поле ввода, где будем писать наш поисковый запрос -->
<input type="text" name="term" id="term" />
<!-- добавляем кнопку, которая запускает поиск -->
<input type="submit" name="submit" id="submit" value="Найти" />
<!-- конец формы -->
</form>
<!-- сразу после формы будем писать, сколько совпадений мы нашли -->
<p class="results"></p>
<!-- а в этом блоке разместим наш основной текст -->
<div class="content">
Сюда вставим наш текст
</div>Осталось добавить сам текст в блок <div class="content">. Для простоты мы скопируем первые абзацы этой статьи и обернём их в HTML-теги. Вы можете вставить какой угодно текст, на работу скрипта это никак не повлияет.
<h2>Общая идея</h2>
<p>
У нас есть сайт с неким текстом, и нам нужно быстро находить в нём нужные слова или части слов. Для этого мы в самом начале страницы делаем поле ввода, куда будем писать наши слова для поиска, и кнопку, которая этот поиск запускает.
</p>
<p>
Дальше скрипт берёт весь текст, находит в нём нужные фрагменты и подсвечивает их. Если он ничего не находит — пишет сообщение, что таких слов в тексте нет.
</p>
Сохраняем, открываем в браузере:

Настраиваем стили
Стили отвечают за внешний вид всех элементов на странице. Главное, что нам нужно сделать, — нормальный внешний вид формы поиска и выбрать подсветку для найденных результатов. Это мы настроим в блоке <style> в начале страницы:
/*поле ввода*/
.searchtext {
font-size: 16px;
font-weight: bold;
height: 27px;
padding: 0 6px 0;
width: 250px;
/*делаем стильную границу вокруг поля*/
border: 1px solid rgba(0, 0, 0, 0.1);
}
/* выбираем цвет подсветки — светло-зелёный*/
.highlight {
background: #4cff00;
}
/*кнопка поиска*/
.search-button {
background-color: #0b2f3f;
font-weight: bold;
font-size: 12px;
/*устанавливаем высоту кнопки*/
height: 28px;
margin: 0;
color: #ffffff;
padding: 6px;
/*тоже делаем стильную границу у кнопки*/
border: 1px solid rgba(0, 0, 0, 0.1);
}
Сохраняем и обновляем страницу — теперь форма выглядит лучше:

Пишем скрипт
Задача скрипта — пробежаться по всему содержимому текста и сравнить все слова с тем, что мы ввели в строке поиска. Всю работу за нас сделает плагин highlight, нам остаётся только вывести количество найденных совпадений и очистить страницу от предыдущих результатов поиска.
<!-- подключаем библиотеку jQuery -->
<script src="http://thecode.local/wp-content/uploads/2019/06/jquery.js" type="text/javascript"></script>
<!--подключаем к ней плагин highlight.js -->
<script src='http://thecode.local/wp-content/uploads/2019/06/jqueryhighlight.js' />
</script>
<!-- говорим браузеру, что сейчас начнётся скрипт -->
<script type="text/javascript">
$(document).ready(function () {
// обрабатываем нажатие на кнопку
$("#submit").click(function () {
// очищаем переменную, в которой будет наш поисковый запрос
var term = "";
// и переменную, которая отвечает за количество найденных совпадений
var n = "0";
// убираем всю подсветку из прошлого поиска, если она была
$('body').removeHighlight();
// скрываем блок с текстом о количестве найденных результатов
$("p.results").hide().empty();
// с помощью магии jQuery берём текст из строки поиска и кладём его в переменную term
term = $('#term').attr('value');
// если строка поиска пустая — выводим сообщение
if ($('#term').val() == "") {
$("p.results").fadeIn().append("Вы ничего не ввели :(");
return false;
// иначе, если в строке поиска что-то было…
} else {
// в блоке content, где у нас находится весь текст, плагином подсвечиваем все найденные совпадения (если совпадений не будет — не будет и подсветки)
$('.content').highlight(term);
// берём количество совпадений
n = $("span.highlight").length;
// если совпадений нет — в разделе results пишем, что ничего не нашли
if (n == 0) {
$("p.results").fadeIn().append("Ничего такого в тексте нет");
// иначе в том же разделе пишем число совпадений
} else {
$("p.results").fadeIn().append('Найдено совпадений:' + n);
}
return false;
}
});
});Вставляем скрипт в HTML-файл, сохраняем и смотрим, что получилось в итоге:
А вот как всё будет работать:
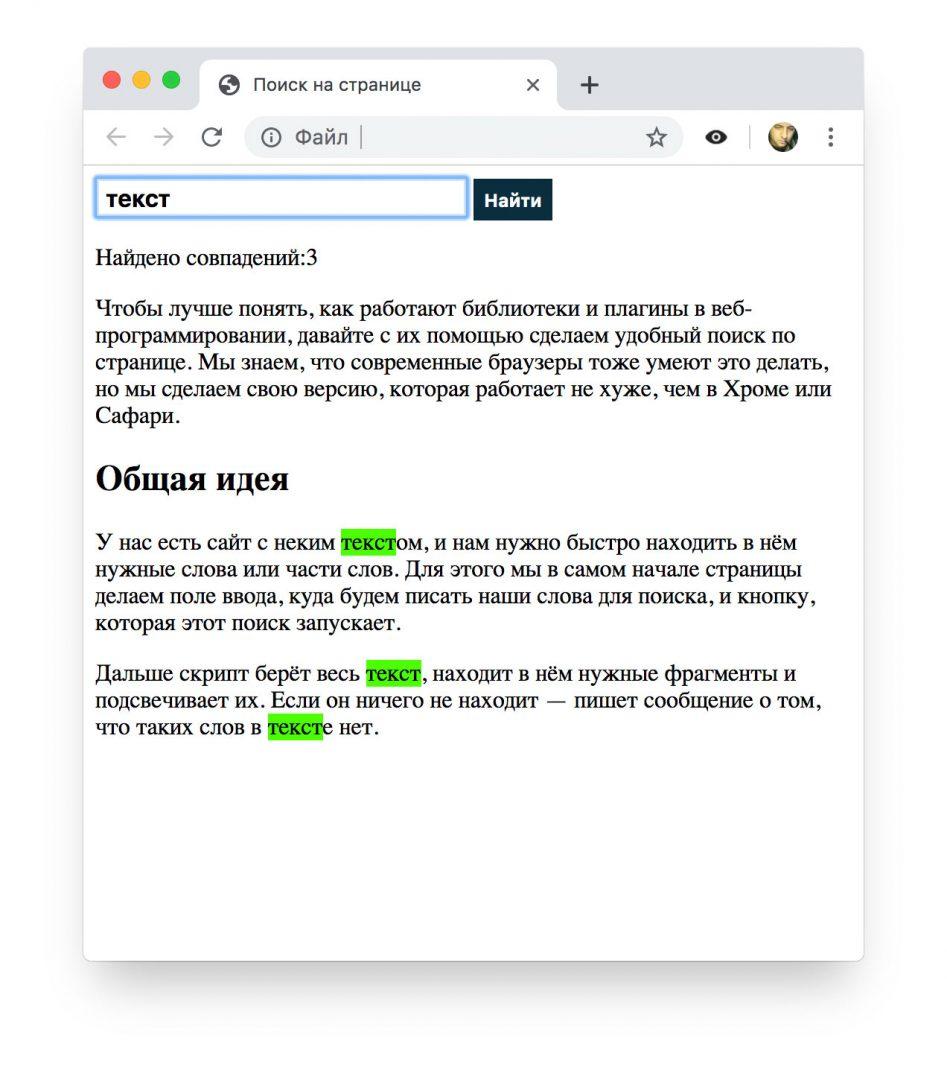
Общий код страницы
<html>
<!-- служебная часть -->
<head>
<!-- заголовок страницы -->
<title>Поиск на странице</title>
<!-- настраиваем служебную информацию для браузеров -->
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- задаём CSS-стили прямо здесь же, чтобы всё было в одном файле -->
<style type="text/css">
/*поле ввода*/
.searchtext {
font-size: 16px;
font-weight: bold;
height: 27px;
padding: 0 6px 0;
width: 250px;
/*делаем стильную границу вокруг поля*/
border: 1px solid rgba(0, 0, 0, 0.1);
}
/* выбираем цвет подсветки — светло-зелёный*/
.highlight {
background: #4CFF00;
}
/*кнопка поиска*/
.search-button {
background-color: #0B2F3F;
font-weight: bold;
font-size: 12px;
/*устанавливаем высоту кнопки*/
height: 28px;
margin: 0;
color: #ffffff;
padding: 6px;
/*тоже делаем стильную границу у кнопки*/
border: 1px solid rgba(0, 0, 0, 0.1);
}
</style>
<!-- закрываем служебную часть страницы -->
</head>
<!-- началось содержимое страницы -->
<body>
<!-- говорим браузеру, что мы хотим разместить форму -->
<form id="search-highlight" method="post" action="#">
<!-- добавляем текстовое поле ввода, где будем писать наш поисковый запрос -->
<input type="text" name="term" id="term" class="searchtext" />
<!-- добавляем кнопку, которая запускает поиск -->
<input type="submit" name="submit" id="submit" value="Найти" class="search-button" />
<!-- конец формы -->
</form>
<!-- подключаем библиотеку jQuery -->
<script src="http://thecode.local/wp-content/uploads/2019/06/jquery.js" type="text/javascript"></script>
<!-- подключаем к ней плагин highlight.js -->
<script src='http://thecode.local/wp-content/uploads/2019/06/jqueryhighlight.js' />
</script>
<!-- говорим браузеру, что сейчас начнётся скрипт -->
<script type="text/javascript">
$(document).ready(function () {
// обрабатываем нажатие на кнопку
$("#submit").click(function () {
// очищаем переменную, в которой будет наш поисковый запрос
var term = "";
// и переменную, которая отвечает за количество найденных совпадений
var n = "0";
// убираем всю подсветку из прошлого поиска, если она была
$('body').removeHighlight();
// скрываем блок с текстом о количестве найденных результатов
$("p.results").hide().empty();
// с помощью магии jQuery берём текст из строки поиска и кладём его в переменную term
term = $('#term').attr('value');
// если строка поиска пустая — выводим сообщение
if ($('#term').val() == "") {
$("p.results").fadeIn().append("Вы ничего не ввели :(");
return false;
// иначе, если в строке поиска что-то было…
} else {
// в блоке content, где у нас находится весь текст, плагином подсвечиваем все найденные совпадения (если совпадений не будет — не будет и подсветки)
$('.content').highlight(term);
// берём количество совпадений
n = $("span.highlight").length;
// если совпадений нет — в разделе results пишем, что ничего не нашли
if (n == 0) {
$("p.results").fadeIn().append("Ничего такого в тексте нет");
// иначе в том же разделе пишем число совпадений
} else {
$("p.results").fadeIn().append('Найдено совпадений:' + n);
}
return false;
}
});
});
</script>
<!-- сразу после формы будем писать, сколько совпадений мы нашли -->
<p class="results"></p>
<!-- а в этом блоке разместим наш основной текст -->
<div class="content">
<p>
Чтобы лучше понять, как работают библиотеки и плагины в веб-программировании, давайте с их помощью сделаем удобный
поиск по странице. Мы знаем, что современные браузеры тоже умеют это делать, но мы сделаем свою версию, которая
работает не хуже, чем в Хроме или Сафари.
<p>
<h2>Общая идея</h2>
<p>
У нас есть сайт с неким текстом, и нам нужно быстро находить в нём нужные слова или части слов. Для этого мы в
самом начале страницы делаем поле ввода, куда будем писать наши слова для поиска, и кнопку, которая этот поиск
запускает.
</p>
<p>
Дальше скрипт берёт весь текст, находит в нём нужные фрагменты и подсвечивает их. Если он ничего не находит —
пишет сообщение о том, что таких слов в тексте нет.
</p>
</div>
<!-- закончилось содержимое страницы -->
</body>
<!-- конец всего HTML-документа -->
</html>Как можно улучшить
Можно убрать кнопку «Найти» и запускать поиск при вводе текста в поле.
Можно сделать два поля ввода, подсвечивая найденное по каждому разными цветами. Это полезно, например, если нужно проанализировать, каких слов в тексте больше.
Регулярные выражения! О них отдельно напишем, это же просто праздник какой-то.
how can i search an html page for a word fast?
and how can i get the html tag that the word is in? (so i can work with the entire tag)
asked Apr 14, 2009 at 16:08
![]()
Chen KinnrotChen Kinnrot
20.5k17 gold badges79 silver badges139 bronze badges
To find the element that word exists in, you’d have to traverse the entire tree looking in just the text nodes, applying the same test as above. Once you find the word in a text node, return the parent of that node.
var word = "foo",
queue = [document.body],
curr
;
while (curr = queue.pop()) {
if (!curr.textContent.match(word)) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE : // 3
if (curr.childNodes[i].textContent.match(word)) {
console.log("Found!");
console.log(curr);
// you might want to end your search here.
}
break;
case Node.ELEMENT_NODE : // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
this works in Firefox, no promises for IE.
What it does is start with the body element and check to see if the word exists inside that element. If it doesn’t, then that’s it, and the search stops there. If it is in the body element, then it loops through all the immediate children of the body. If it finds a text node, then see if the word is in that text node. If it finds an element, then push that into the queue. Keep on going until you’ve either found the word or there’s no more elements to search.
answered Apr 14, 2009 at 16:15
![]()
3
You can iterate through DOM elements, looking for a substring within them. Neither fast nor elegant, but for small HTML might work well enough.
I’d try something recursive, like: (code not tested)
findText(node, text) {
if(node.childNodes.length==0) {//leaf node
if(node.textContent.indexOf(text)== -1) return [];
return [node];
}
var matchingNodes = new Array();
for(child in node.childNodes) {
matchingNodes.concat(findText(child, text));
}
return matchingNodes;
}
answered Apr 14, 2009 at 16:14
![]()
vartecvartec
130k36 gold badges217 silver badges244 bronze badges
0
You can try using XPath, it’s fast and accurate
http://www.w3schools.com/Xpath/xpath_examples.asp
Also if XPath is a bit more complicated, then you can try any javascript library like jQuery that hides the boilerplate code and makes it easier to express about what you want found.
Also, as from IE8 and the next Firefox 3.5 , there is also Selectors API implemented. All you need to do is use CSS to express what to search for.
answered Apr 14, 2009 at 16:16
![]()
AzderAzder
4,6787 gold badges37 silver badges57 bronze badges
2
You can probably read the body of the document tree and perform simple string tests on it fast enough without having to go far beyond that – it depends a bit on the HTML you are working with, though – how much control do you have over the pages? If you are working within a site you control, you can probably focus your search on the parts of the page likely to be different page from page, if you are working with other people’s pages you’ve got a tougher job on your hands simply because you don’t necessarily know what content you need to test against.
Again, if you are going to search the same page multiple times and your data set is large it may be worth creating some kind of index in memory, whereas if you are only going to search for a few words or use smaller documents its probably not worth the time and complexity to build that.
Probably the best thing to do is to get some sample documents that you feel will be representative and just do a whole lot of prototyping based around the approaches people have offered here.
answered Apr 14, 2009 at 16:19
![]()
glenatronglenatron
10.9k13 gold badges63 silver badges109 bronze badges
form.addEventListener("submit", (e) => {
e.preventDefault();
var keyword = document.getElementById("search_input");
let words = keyword.value;
var word = words,
queue = [document.body],
curr;
while (curr = queue.pop()) {
if (!curr.textContent.toUpperCase().match(word.toUpperCase())) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE: // 3
if (curr.childNodes[i].textContent.toUpperCase().match(word.toUpperCase())) {
console.log("Found!");
console.log(curr);
curr.scrollIntoView();
}
break;
case Node.ELEMENT_NODE: // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
});
answered Dec 18, 2020 at 17:39
![]()
Время на прочтение
3 мин
Количество просмотров 17K
Нужен был поиск на страничке, точнее в тексте, не серверный, а обычный. То есть — загрузил страничку где много текста, читаешь, и при надобности ищешь. Порылся в интернете и, к сожалению, готово варианта (с переходом между словами и прокруткой странички) не нашел, хотя в реализации нету ничего сложного — или плохо искал, или никому не надо было.
Вот как раз заканчиваю — решил поделиться первым вариантом.
Само собой используется библиотека jQuery.
За основу я взял статейку jQuery – подсветка слов в тексте или HTML отсюда (их пример). Как подключить к страничке скрипт там описано.
буду использовать ниже «слово» = «словосочетание» = «словосочетание букв иили символов».
Теперь начнем расширять функционал:
кнопки поиска, выделение следующего слова и предыдущего, и скролл странички к выделенному слову
1) делаем подсветку конкретного слова
в файл jquery.highlight.js добавляем
jQuery.fn.selectHighlight = function(number) {
return this.find("span.highlight:eq("+number+")").addClass('selectHighlight').end();
};
2) в стиль прописываем отображение выделяемого слова и меняем стиль подсветки для себя
.highlight { background-color: gray; color: white }
.selectHighlight { background-color: rgb(35, 140, 0) }
3)Создаем кнопки и поле ввода
<div id="search_block">
<label>
Search:
<input id="search_text" type="text" value=""/>
</label>
<input id="search_button" type="button" value="Search"/>
<input id="prev_search" type="button" value="<"/>
<input id="next_search" type="button" value=">"/>
<input id="clear_button" type="button" value="Clear"/>
</div>
4)приписываем кнопкам действия
копируем код:
(ниже опишу для чего эта функция)
function scroll_to_word(){
pos = $('#text .selectHighlight').position()
$('#content').jqxPanel('scrollTo', 0, pos.top - 5);
}
var search_number = 0; //индекс конкретного сочетания из найденных
var search_count = 0; //количество найденных сочетаний
//search - поиск слова по нажатию на кнопку "search_button"
$('#search_button').click(function() {
$('#text').removeHighlight();
txt = $('#search_text').val();
if (txt == '')
return;
$('#text').highlight(txt);
search_count = $('#text span.highlight').size() - 1;
search_number = 0;
$('#text').selectHighlight(search_number); //выделяем первое слово из найденных
scroll_to_word(); //скролим страничку к выделяемому слову
});
//clear - очистка выделения по нажатию на кнопку "clear_button"
$('#clear_button').click(function() {
$('#text').removeHighlight();
});
//prev_search - выделяем предыдущие слово из найденных и скролим страничку к нему
$('#prev_search').click(function() {
if (search_number == 0)
return;
$('#text .selectHighlight').removeClass('selectHighlight');
search_number--;
$('#text').selectHighlight(search_number);
scroll_to_word();
});
//next_search - выделяем следующее слово из найденных и скролим страничку к нему
$('#next_search').click(function() {
if (search_number == search_count)
return;
$('#text .selectHighlight').removeClass('selectHighlight');
search_number++;
$('#text').selectHighlight(search_number);
scroll_to_word();
});
5)
function scroll_to_word(){...} — функция скрола (перемотки) странички к нужному нам слову
ну вообще делается очень легко с помощью простого плагина jqueryscrollto, который берем отсюда, и ищем по классу .highlight и номером eq('+search_number +') (search_number — смотрим в список глобальных переменных скрипта).
jQuery('#content').scrollTo('.highlight('+search_number +')');
Но мне пришлось использовать этот набор плагинов (jqwidgets), так как был нужен собственный скрол для странички а не браузерный, поэтому я воспользовался их API:
scrollTo Method
Scroll to specific position.
Code examples
Invoke the scrollTo method.
$('#jqxPanel').jqxPanel('scrollTo', 10, 20);
function scroll_to_word(){
pos = $('#text .selectHighlight').position()
$('#content').jqxPanel('scrollTo', 0, pos.top - 5); // 5 - отступ в пикселях при прокрутке от верхнего края к выделяемому слову - для эстетического вида
}
Demo
Вот походу и все.
Прошу прощения за неоптимизированный код — вот только что закончил и решил поделится, это только начальная версия
При вводе строки по CTRL+F в коде надо помнить, что внутри строчки не должно быть никаких тегов, например изменения шрифта или стиля, иначе строчка может и не найтись в поиске по тексту HTML кода.
Например текст на странице такой:
2х2=4
Это же самое в HTML коде выглядит так:
2х2=<strong>4</strong>
Поиск ничего не даст
Такое бывает в тех случаях когда внутри строки используются теги; в этом случае надо найти и скопировать строчку на экране, затем преобразовать в HTML (фрагмент кода для преобразования приведен в ответе на вопрос Какие есть толковые способы перевести doc в html?) и только потом, зная как закодирована строчка, можно искать этот код в коде HTML.

