Классический криптоанализ
Время на прочтение
9 мин
Количество просмотров 147K

На протяжении многих веков люди придумывали хитроумные способы сокрытия информации — шифры, в то время как другие люди придумывали еще более хитроумные способы вскрытия информации — методы взлома.
В этом топике я хочу кратко пройтись по наиболее известным классическим методам шифрования и описать технику взлома каждого из них.
Шифр Цезаря
Самый легкий и один из самых известных классических шифров — шифр Цезаря отлично подойдет на роль аперитива.
Шифр Цезаря относится к группе так называемых одноалфавитных шифров подстановки. При использовании шифров этой группы «каждый символ открытого текста заменяется на некоторый, фиксированный при данном ключе символ того же алфавита» wiki.
Способы выбора ключей могут быть различны. В шифре Цезаря ключом служит произвольное число k, выбранное в интервале от 1 до 25. Каждая буква открытого текста заменяется буквой, стоящей на k знаков дальше нее в алфавите. К примеру, пусть ключом будет число 3. Тогда буква A английского алфавита будет заменена буквой D, буква B — буквой E и так далее.
Для наглядности зашифруем слово HABRAHABR шифром Цезаря с ключом k=7. Построим таблицу подстановок:
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
| h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z | a | b | c | d | e | f | g |
И заменив каждую букву в тексте получим: C(‘HABRAHABR’, 7) = ‘OHIYHOHIY’.
При расшифровке каждая буква заменяется буквой, стоящей в алфавите на k знаков раньше: D(‘OHIYHOHIY’, 7) = ‘HABRAHABR’.
Криптоанализ шифра Цезаря
Малое пространство ключей (всего 25 вариантов) делает брут-форс самым эффективным и простым вариантом атаки.
Для вскрытия необходимо каждую букву шифртекста заменить буквой, стоящей на один знак левее в алфавите. Если в результате этого не удалось получить читаемое сообщение, то необходимо повторить действие, но уже сместив буквы на два знака левее. И так далее, пока в результате не получится читаемый текст.
Аффиный шифр
Рассмотрим немного более интересный одноалфавитный шифр подстановки под названием аффиный шифр. Он тоже реализует простую подстановку, но обеспечивает немного большее пространство ключей по сравнению с шифром Цезаря. В аффинном шифре каждой букве алфавита размера m ставится в соответствие число из диапазона 0… m-1. Затем при помощи специальной формулы, вычисляется новое число, которое заменит старое в шифртексте.
Процесс шифрования можно описать следующей формулой:
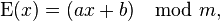 ,
,
где x — номер шифруемой буквы в алфавите; m — размер алфавита; a, b — ключ шифрования.
Для расшифровки вычисляется другая функция:
 ,
,
где a-1 — число обратное a по модулю m. Это значит, что для корректной расшифровки число a должно быть взаимно простым с m.
С учетом этого ограничения вычислим пространство ключей аффиного шифра на примере английского алфавита. Так как английский алфавит содержит 26 букв, то в качестве a может быть выбрано только взаимно простое с 26 число. Таких чисел всего двенадцать: 1, 3, 5, 7, 9, 11, 15, 17, 19, 21, 23 и 25. Число b в свою очередь может принимать любое значение в интервале от 0 до 25, что в итоге дает нам 12*26 = 312 вариантов возможных ключей.
Криптоанализ аффиного шифра
Очевидно, что и в случае аффиного шифра простейшим способом взлома оказывается перебор всех возможных ключей. Но в результате перебора получится 312 различных текстов. Проанализировать такое количество сообщений можно и в ручную, но лучше автоматизировать этот процесс, используя такую характеристику как частота появления букв.
Давно известно, что буквы в естественных языках распределены не равномерно. К примеру, частоты появления букв английского языка в текстах имеют следующие значения:

Т.е. в английском тексте наиболее встречающимися буквами будут E, T, A. В то время как самыми редкими буквами являются J, Q, Z. Следовательно, посчитав частоту появления каждой буквы в тексте мы можем определить насколько частотная характеристика текста соответствует английскому языку.
Для этого необходимо вычислить значение:
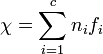 ,
,
где ni — частота i-й буквы алфавита в естественном языке. И fi — частота i-й буквы в шифртексте.
Чем больше значение χ, тем больше вероятность того, что текст написан на естественном языке.
Таким образом, для взлома аффиного шифра достаточно перебрать 312 возможных ключей и вычислить значение χ для полученного в результате расшифровки текста. Текст, для которого значение χ окажется максимальным, с большой долей вероятности и является зашифрованным сообщением.
Разумеется следует учитывать, что метод не всегда работает с короткими сообщениями, в которых частотные характеристики могут сильно отличатся от характеристик естественного языка.
Шифр простой замены
Очередной шифр, относящийся к группе одноалфавитных шифров подстановки. Ключом шифра служит перемешанный произвольным образом алфавит. Например, ключом может быть следующая последовательность букв: XFQABOLYWJGPMRVIHUSDZKNTEC.
При шифровании каждая буква в тексте заменяется по следующему правилу. Первая буква алфавита замещается первой буквой ключа, вторая буква алфавита — второй буквой ключа и так далее. В нашем примере буква A будет заменена на X, буква B на F.
При расшифровке буква сперва ищется в ключе и затем заменяется буквой стоящей в алфавите на той же позиции.
Криптоанализ шифра простой замены
Пространство ключей шифра простой замены огромно и равно количеству перестановок используемого алфавита. Так для английского языка это число составляет 26! = 288. Разумеется наивный перебор всех возможных ключей дело безнадежное и для взлома потребуется более утонченная техника, такая как поиск восхождением к вершине:
- Выбирается случайная последовательность букв — основной ключ. Шифртекст расшифровывается с помощью основного ключа. Для получившегося текста вычисляется коэффициент, характеризующий вероятность принадлежности к естественному языку.
- Основной ключ подвергается небольшим изменениям (перестановка двух произвольно выбранных букв). Производится расшифровка и вычисляется коэффициент полученного текста.
- Если коэффициент выше сохраненного значения, то основной ключ заменяется на модифицированный вариант.
- Шаги 2-3 повторяются пока коэффициент не станет постоянным.
Для вычисления коэффициента используется еще одна характеристика естественного языка — частота встречаемости триграмм.
Чем ближе текст к английскому языку тем чаще в нем будут встречаться такие триграммы как THE, AND, ING. Суммируя частоты появления в естественном языке всех триграмм, встреченных в тексте получим коэффициент, который с большой долей вероятности определит текст, написанный на естественном языке.
Шифр Полибия
Еще один шифр подстановки. Ключом шифра является квадрат размером 5*5 (для английского языка), содержащий все буквы алфавита, кроме J.

При шифровании каждая буква исходного текста замещается парой символов, представляющих номер строки и номер столбца, в которых расположена замещаемая буква. Буква a будет замещена в шифртексте парой BB, буква b — парой EB и так далее. Так как ключ не содержит букву J, перед шифрованием в исходном тексте J следует заменить на I.
Например, зашифруем слово HABRAHABR. C(‘HABRAHABR’) = ‘AB BB EB DA BB AB BB EB DA’.
Криптоанализ шифра Полибия
Шифр имеет большое пространство ключей (25! = 283 для английского языка). Однако единственное отличие квадрата Полибия от предыдущего шифра заключается в том, что буква исходного текста замещается двумя символами.
Поэтому для атаки можно использовать методику, применяемую при взломе шифра простой замены — поиск восхождением к вершине.
В качестве основного ключа выбирается случайный квадрат размером 5*5. В ходе каждой итерации ключ подвергается незначительным изменениям и проверяется насколько распределение триграмм в тексте, полученном в результате расшифровки, соответствует распределению в естественном языке.
Перестановочный шифр
Помимо шифров подстановки, широкое распространение также получили перестановочные шифры. В качестве примера опишем Шифр вертикальной перестановки.
В процессе шифрования сообщение записывается в виде таблицы. Количество колонок таблицы определяется размером ключа. Например, зашифруем сообщение WE ARE DISCOVERED. FLEE AT ONCE с помощью ключа 632415.
Так как ключ содержит 6 цифр дополним сообщение до длины кратной 6 произвольно выбранными буквами QKJEU и запишем сообщение в таблицу, содержащую 6 колонок, слева направо:

Для получения шифртекста выпишем каждую колонку из таблицы в порядке, определяемом ключом: EVLNE ACDTK ESEAQ ROFOJ DEECU WIREE.
При расшифровке текст записывается в таблицу по колонкам сверху вниз в порядке, определяемом ключом.
Криптоанализ перестановочного шифра
Лучшим способом атаки шифра вертикальной перестановки будет полный перебор всех возможных ключей малой длины (до 9 включительно — около 400 000 вариантов). В случае, если перебор не дал желаемых результатов, можно воспользоваться поиском восхождением к вершине.
Для каждого возможного значения длины осуществляется поиск наиболее правдоподобного ключа. Для оценки правдоподобности лучше использовать частоту появления триграмм. В результате возвращается ключ, обеспечивающий наиболее близкий к естественному языку текст расшифрованного сообщения.
Шифр Плейфера
Шифр Плейфера — подстановочный шифр, реализующий замену биграмм. Для шифрования необходим ключ, представляющий собой таблицу букв размером 5*5 (без буквы J).
Процесс шифрования сводится к поиску биграммы в таблице и замене ее на пару букв, образующих с исходной биграммой прямоугольник.
Рассмотрим, в качестве примера следующую таблицу, образующую ключ шифра Плейфера:
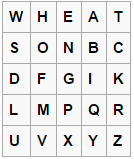
Зашифруем пару ‘WN’. Буква W расположена в первой строке и первой колонке. А буква N находится во второй строке и третьей колонке. Эти буквы образуют прямоугольник с углами W-E-S-N. Следовательно, при шифровании биграмма WN преобразовывается в биграмму ES.
В случае, если буквы расположены в одной строке или колонке, результатом шифрования является биграмма расположенная на одну позицию правее/ниже. Например, биграмма NG преобразовывается в биграмму GP.
Криптоанализ шифра Плейфера
Так как ключ шифра Плейфера представляет собой таблицу, содержащую 25 букв английского алфавита, можно ошибочно предположить, что метод поиска восхождением к вершине — лучший способ взлома данного шифра. К сожалению, этот метод не будет работать. Достигнув определенного уровня соответствия текста, алгоритм застрянет в точке локального максимума и не сможет продолжить поиск.
Чтобы успешно взломать шифр Плейфера лучше воспользоваться алгоритмом имитации отжига.
Отличие алгоритма имитации отжига от поиска восхождением к вершине заключается в том, что последний на пути к правильному решению никогда не принимает в качестве возможного решения более слабые варианты. В то время как алгоритм имитации отжига периодически откатывается назад к менее вероятным решениям, что увеличивает шансы на конечный успех.
Суть алгоритма сводится к следующим действиям:
- Выбирается случайная последовательность букв — основной-ключ. Шифртекст расшифровывается с помощью основного ключа. Для получившегося текста вычисляется коэффициент, характеризующий вероятность принадлежности к естественному языку.
- Основной ключ подвергается небольшим изменениям (перестановка двух произвольно выбранных букв, перестановка столбцов или строк). Производится расшифровка и вычисляется коэффициент полученного текста.
- Если коэффициент выше сохраненного значения, то основной ключ заменяется на модифицированный вариант.
- В противном случае замена основного ключа на модифицированный происходит с вероятностью, напрямую зависящей от разницы коэффициентов основного и модифицированного ключей.
- Шаги 2-4 повторяются около 50 000 раз.
Алгоритм периодически замещает основной ключ, ключом с худшими характеристиками. При этом вероятность замены зависит от разницы характеристик, что не позволяет алгоритму принимать плохие варианты слишком часто.
Для расчета коэффициентов, определяющих принадлежность текста к естественному языку лучше всего использовать частоты появления триграмм.
Шифр Виженера
Шифр Виженера относится к группе полиалфавитных шифров подстановки. Это значит, что в зависимости от ключа одна и та же буква открытого текста может быть зашифрована в разные символы. Такая техника шифрования скрывает все частотные характеристики текста и затрудняет криптоанализ.
Шифр Виженера представляет собой последовательность нескольких шифров Цезаря с различными ключами.
Продемонстрируем, в качестве примера, шифрование слова HABRAHABR с помощью ключа 123. Запишем ключ под исходным текстом, повторив его требуемое количество раз:
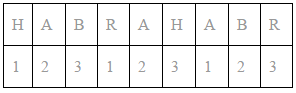
Цифры ключа определяют на сколько позиций необходимо сдвинуть букву в алфавите для получения шифртекста. Букву H необходимо сместить на одну позицию — в результате получается буква I, букву A на 2 позиции — буква C, и так далее. Осуществив все подстановки, получим в результате шифртекст: ICESCKBDU.
Криптоанализ шифра Виженера
Первая задача, стоящая при криптоанализе шифра Виженера заключается в нахождении длины, использованного при шифровании, ключа.
Для этого можно воспользоваться индексом совпадений.
Индекс совпадений — число, характеризующее вероятность того, что две произвольно выбранные из текста буквы окажутся одинаковы.
Для любого текста индекс совпадений вычисляется по формуле:
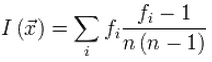 ,
,
где fi — количество появлений i-й буквы алфавита в тексте, а n — количество букв в тексте.
Для английского языка индекс совпадений имеет значение 0.0667, в то время как для случайного набора букв этот показатель равен 0.038.
Более того, для текста зашифрованного с помощью одноалфавитной подстановки, индекс совпадений также равен 0.0667. Это объясняется тем, что количество различных букв в тексте остается неизменным.
Это свойство используется для нахождения длины ключа шифра Виженера. Из шифртекста по очереди выбираются каждая вторая буквы и для полученного текста считается индекс совпадений. Если результат примерно соответствует индексу совпадений естественного языка, значит длина ключа равна двум. В противном случае из шифртекста выбирается каждая третья буква и опять считается индекс совпадений. Процесс повторяется пока высокое значение индекса совпадений не укажет на длину ключа.
Успешность метода объясняется тем, что если длина ключа угадана верно, то выбранные буквы образуют шифртекст, зашифрованный простым шифром Цезаря. И индекс совпадений должен быть приблизительно соответствовать индексу совпадений естественного языка.
После того как длина ключа будет найдена взлом сводится к вскрытию нескольких шифров Цезаря. Для этого можно использовать способ, описанный в первом разделе данного топика.
P.S.
Исходники всех вышеописанных шифров и атак на них можно посмотреть на GitHub.
Ссылки
1. Криптоанализ классических шифров на сайте practicalcryptography.com.
2. Частотные характеристики английского языка на сайте practicalcryptography.com
3. Описание алгоритма имитации отжига на wikipedia
4. Описание поиска восхождением к вершине на wikipedia
Шифр Виженера — метод полиалфавитного шифрования буквенного текста с использованием ключевого слова.
В шифре Цезаря каждая буква алфавита сдвигается на несколько позиций; например в шифре Цезаря при сдвиге +3, A стало бы D, B стало бы E и так далее.
Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига. Для зашифровывания может использоваться таблица алфавитов, называемая tabula recta или квадрат (таблица) Виженера. Применительно к латинскому алфавиту таблица Виженера составляется из строк по 26 символов, причём каждая следующая строка сдвигается на несколько позиций. Таким образом, в таблице получается 26 различных шифров Цезаря. На каждом этапе шифрования используются различные алфавиты, выбираемые в зависимости от символа ключевого слова. Например, предположим, что исходный текст имеет такой вид:
ATTACKATDAWN
Человек, посылающий сообщение, записывает ключевое слово («LEMON») циклически до тех пор, пока его длина не будет соответствовать длине исходного текста:
LEMONLEMONLE
 Квадрат Виженера, или таблица Виженера, может быть использована для шифрования и расшифровывания
Квадрат Виженера, или таблица Виженера, может быть использована для шифрования и расшифровывания
Первый символ исходного текста (“A”) зашифрован последовательностью L, которая является первым символом ключа. Первый символ зашифрованного текста (“L”) находится на пересечении строки L и столбца A в таблице Виженера. Точно так же для второго символа исходного текста используется второй символ ключа; то есть второй символ зашифрованного текста (“X”) получается на пересечении строки E и столбца T. Остальная часть исходного текста шифруется подобным способом.
Исходный текст: ATTACKATDAWN Ключ: LEMONLEMONLE Зашифрованный текст: LXFOPVEFRNHR
Расшифровывание производится следующим образом: находим в таблице Виженера строку, соответствующую первому символу ключевого слова; в данной строке находим первый символ зашифрованного текста. Столбец, в котором находится данный символ, соответствует первому символу исходного текста. Следующие символы зашифрованного текста расшифровываются подобным образом.
Инструмент предназначен для шифрования и дешифрования текста, используя шифр Виженера. Зашифровать можно как русский текст, так и английский.
Поделиться страницей в социальных сетях:
Оптимальная цена щебня в Москве с доставкой от 8 м3 для юр. лиц и ИП. . аренда авто в алматы
![]()
Загрузить PDF
![]()
Загрузить PDF
С той самой поры, как человечество доросло до письменной речи, для защиты сообщений используются коды и шифры. Греки и египтяне использовали шифры для защиты личной переписки. Собственно говоря, именно из этой славной традиции и произрастает современная традиция взлома кодов и шифров. Криптоанализ изучает коды и методы их взлома, и это занятие в современных реалиях может принести немало пользы. Если вы хотите этому научиться, то можно начать с изучения самых распространенных шифров и всего, что с ними связано. В общем, читайте эту статью!
-

1
Начните с поиска слов из одной буквы. Большинство шифров на основе относительно простой замены легче всего взломать банальным перебором с подстановкой. Да, придется повозиться, но дальше будет только сложнее.
- Слова из одной буквы в русском языке – это местоимения и предлоги (я, в, у, о, а). Чтобы найти их, придется внимательно изучить текст. Угадывайте, проверяйте, закрепляйте или пробуйте новые варианты – иного метода разгадки шифра нет.
- Вы должны научиться читать шифр. Взламывать его – это не столь важно. Учитесь выхватывать шаблоны и правила, лежащие в основе шифра, и тогда его взлом не будет представлять для вас принципиальной сложности.
-

2
Ищите наиболее часто употребляемые символы и буквы. К примеру, в английском языке такими являются “e”, “t” и “a”. Работая с шифром, используйте свое знание языка и структуры предложений, на основе чего делайте гипотезы и предположения. Да, на все 100% вы редко будете уверены, но разгадывание шифров – это игра, где от вас требуется делать догадки и исправлять собственные ошибки!
- Двойные символы и короткие слова ищите в первую очередь, старайтесь начать расшифровку именно с них. Легче, как никак, работать с двумя буквами, чем с 7-10.
-

3
Обращайте внимание на апострофы и символы вокруг. Если в тексте есть апострофы, то вам повезло! Так, в случае английского языка, использование апострофа означает, что после зашифрованы такие знаки, как s, t, d, m, ll или re. Соответственно, если после апострофа идут два одинаковых символа, то это наверняка L![1]
-

4
Попробуйте определить, какой у вас тип шифра. Если вы, разгадывая шифр, в определенный момент поймете, к какому из вышеописанных типов он относится, то вы его практически разгадали. Конечно, такое будет случаться не так уж и часто, но чем больше шифров вы разгадаете, тем проще вам будет потом.
- Цифровая замена и клавиатурные шифры в наши дни распространены более всего. Работая над шифром, первым делом проверяйте, не такого ли он типа.
Реклама
-

1
Шифры замещения. Строго говоря, шифры замещения кодируют сообщение, замещая одни буквы другими, согласно заранее определенному алгоритму. Алгоритм – и есть ключ к разгадке шифра, если разгадать его, то и раскодировать сообщение проблемы не составит.
- Даже если в коде есть цифры, кириллица или латиница, иероглифы или необычные символы – пока используются одни и те же типы символов, то вы, вероятно, работаете именно с шифром замещения. Соответственно, вам надо изучить используемый алфавит и вывести из него правила замещения.
-

2
Квадратный шифр. Простейшее шифрование, используемое еще древними греками, работающее на основе использования таблицы цифр, каждая из которых соответствует какой-то букве и из которых впоследствии и составляются слова. Это действительно простой код, своего рода – основа основ. Если вам надо разгадать шифр в виде длинной строки цифр – вероятно, что пригодятся именно методы работы с квадратным шифром.
- Самая простая форма этого шифра такова: от 1 до 6 строк и столько же столбцов заполняются буквами слева направо и сверху вниз по клеткам. Каждая буква затем представляется в виде числа из двух цифр, где первая цифра – номер колонки, а вторая – номер строки.
- Так, к примеру, слово “wikihow” в этом шифре будет записано как “52242524233452”.
- Есть и более простая версия этого шифра, когда цифра означает порядковый номер буквы в алфавите.[2]
-

3
Шифр Цезаря. Цезарь умел не только делать три дела одновременно, он еще и понимал в шифровании. Цезарь создал хороший, простой, понятный и, в то же время, устойчивый ко взлому шифр, который в его честь и назвали. Шифр Цезаря – это первый шаг на пути к изучению сложных кодов и шифров. Суть шифра Цезаря в том, что все символы алфавита сдвигаются в одну сторону на определенное количество символов. Например, сдвиг на 3 символа влево будет менять А на Д, Б на Е и т.д.
- Более простая версия этого шифра сдвигает все на букву вперед.
- Слово “wikihow”, записанное шифром Цезаря, будет представлять собой “zlnlkrz”.[3]
[4]
-

4
Следите за клавиатурными шаблонами. На основе традиционной раскладки клавиатуры типа QWERTY в наше время создаются различные шифры, работающие по принципу смещения и замещения. Буквы смещаются влево, вправо, вверх и вниз на определенное количество символов, что и позволяет создать шифр. В случае таких шифров надо знать, в какую сторону были смещены символы.
- Так, меняя колонки на одну позицию вверх, “wikihow” превращается в “28i8y92”.
-

5
Полиалфавитные шифры. Простые замещающие шифры опираются на создание шифрующим своего рода алфавита для шифрования. Но уже в Средние века это стало слишком ненадежно, слишком просто для взлома. Тогда криптография сделала шаг вперед и стала сложнее, начав использовать для шифрования символы сразу нескольких алфавитов. Что и говорить, надежность шифрования сразу повысилась.
- Шифр Тритемиуса, использующий таблицу символов 26х26 клеток, это усовершенствованный шифр Цезаря, то есть шифр подстановки. По алгоритму шифрования, каждый символ сообщения смещается на символ, отстающий от данного на некоторый шаг. Здесь шаг смещения делается переменным, то есть зависящим от каких-либо дополнительных факторов.
- Шифрующие также используют специальные кодовые слова в отношении конкретных колонок для каждой буквы в зашифрованном сообщений. Например, если кодовое слово – это “wikihow”, то действовать надо так: надо смотреть w-ряд и колонку первой буквы зашифрованного кода, чтобы узнать первую буквы сообщения. Такие шифры сложно разгадать, не имея на руках кодового слова.[5]
[6]
Реклама
-

1
Будьте терпеливы. Взломать шифр – это терпение, терпение и еще раз терпение. Ну и упорство, конечно же. Это медленная, кропотливая работа, сопряженная с большим количеством разочарования из-за частых ошибок и необходимости постоянно подбирать символы, слова, методы и т.д. Хороший дешифровальщик просто обязан быть терпеливым.
-

2
Пишите собственные шифры. Конечно, криптограммы – это одно, а полиалфавитные шифры без кодовых слов – совсем другое, но все же собственные шифры писать надо. Именно через это занятие вы сможете понять образ мышления тех, кто шифрует сообщения тем или иным образом. Это как “щит и меч” – чем острее меч, тем надежнее щит. Многие дешифровальщики и сами не последние люди в плане составления шифров. Изучайте все более и более сложные методы, учитесь расшифровывать их – и вы достигнете вершин мастерства.
- Многому можно поучиться из расшифровки кодов и шифров, используемых преступниками. Некоторые из них – это просто шедевры, исключительно сложные и надежные.[7]
- Многому можно поучиться из расшифровки кодов и шифров, используемых преступниками. Некоторые из них – это просто шедевры, исключительно сложные и надежные.[7]
-

3
Решайте известные и до сих пор неразгаданные шифры. ФБР, к примеру, регулярно дает сообществу любителей криптографии пищу для ума, публикуя различные шифры и предлагая всем желающим их разгадать. Решайте их, отправляйте свои ответы… возможно, скоро вы смените работу.[8]
- Криптос, скульптура, расположенная у штаб-квартиры ЦРУ, это, пожалуй, самый известный из всех неразгаданных кодов. Созданный как тест для агентов, Криптос представляет собой 4 панели с 4 разными шифрами. На расшифровку первых трех панелей ушло 10 лет. 4-я панель так и осталась загадкой.[9]
- Криптос, скульптура, расположенная у штаб-квартиры ЦРУ, это, пожалуй, самый известный из всех неразгаданных кодов. Созданный как тест для агентов, Криптос представляет собой 4 панели с 4 разными шифрами. На расшифровку первых трех панелей ушло 10 лет. 4-я панель так и осталась загадкой.[9]
-

4
Наслаждайтесь сложностью работы и атмосферой загадки! Дешифрование – это как если погрузиться в роман Дэна Брауна с головой, но по-настоящему! Сложность, загадочность, предвкушение открытия – все это таинственный и волнующий мир шифров.
Реклама
Советы
- В английском языке буква “е” используется чаще всех прочих.
- Если шифр напечатан, то есть шанс, что печатали его специальным шрифтом – типа Windings. И это может быть… двойным шифром!
- Не опускайте руки, если шифр не поддается уже долгое время. Это нормально.
- Чем длиннее шифр, тем проще его взломать.
- Одна буква в шифре вовсе не обязательно соответствует одной букве дешифрованного сообщения. Верно и обратное.
- Буква в шифре практически никогда не обозначает саму себя (“а” – это не “а”).
Реклама
Предупреждения
- Помните, что не все шифры можно разгадать.
- Некоторые шифры нельзя разгадать, не имея буквально гигабайтов дополнительной информации. Да, даже с ключом на руках. Может потребоваться специальная программа, либо просто долгая игра в “угадай символ”.
Реклама
Что вам понадобится
- Шифр
- Ручка и бумага
Об этой статье
Эту страницу просматривали 95 363 раза.
Была ли эта статья полезной?
Криптоанализ зашифрованного текста

Предположим, что мы перехватили это зашифрованное сообщение. Задача состоит в том, чтобы дешифровать его. Мы знаем, что текст написан на английском языке и что он зашифрован с помощью одноалфавитного шифра замены, но мы ничего не знаем о ключе. Поиск всех возможных ключей практически невыполним, поэтому нам следует применить частотный анализ. Далее мы шаг за шагом будем выполнять криптоанализ зашифрованного текста, но если вы чувствуете уверенность в своих силах, то можете попытаться провести криптоанализ самостоятельно.
При виде такого зашифрованного текста любой криптоаналитик немедленно приступит к анализу частоты появления всех букв; его результат приведен в таблице 2. Нет ничего удивительного в том, что частотность букв различна. Вопрос заключается в том, можем ли мы на основе частотности букв установить, какой букве алфавита соответствует каждая из букв зашифрованного текста. Зашифрованный текст сравнительно короткий, поэтому мы не можем непосредственно применять частотный анализ. Было бы наивным предполагать, что наиболее часто встречающаяся в зашифрованном тексте буква O является и наиболее часто встречающейся буквой в английском языке — e или что восьмая по частоте появления в зашифрованном тексте буква Y соответствует восьмой по частоте появления в английском языке букве h. Бездумное применение частотного анализа приведет к появлению тарабарщины. Например, первое слово РС<2 будет расшифровано как аоv.
Таблица 2 Частотный анализ зашифрованного сообщения.
Начнем, однако, с того, что обратим внимание только на три буквы, которые в зашифрованном тексте появляются более тридцати раз: O, X и P. Естественно предположить, что эти наиболее часто встречающиеся в зашифрованном тексте буквы представляют собой, по всей видимости, наиболее часто встречающиеся буквы английского алфавита, но не обязательно в том же порядке. Другими словами, мы не можем быть уверены, что O = e, X = t и P = а, но мы можем сделать гипотетическое допущение, что:
O = e, t или а, X = e, t или а, P = e, t или а.
Чтобы быть уверенным в своих дальнейших действиях и идентифицировать три чаще всего встречающихся буквы: O, X и P, нам потребуется применить частотный анализ более тонким образом. Вместо простого подсчета частоты появления трех букв, мы можем проанализировать, как часто они появляются рядом с другими буквами. Например, появляется ли буква O перед или после некоторых других букв, или же она стремится стоять рядом только с некоторыми определенными буквами? Ответ на этот вопрос будет убедительно свидетельствовать, является ли буква O гласной или согласной. Если O является гласной, то она должна появляться перед и после большинства других букв, если же она представляет собой согласную, то она будет стремиться избегать соседства со множеством букв. Например, буква e может появиться перед и после практически любой другой буквы, в то время как буква t перед или после букв b, d, g, j, k, m, q и v встречается редко.
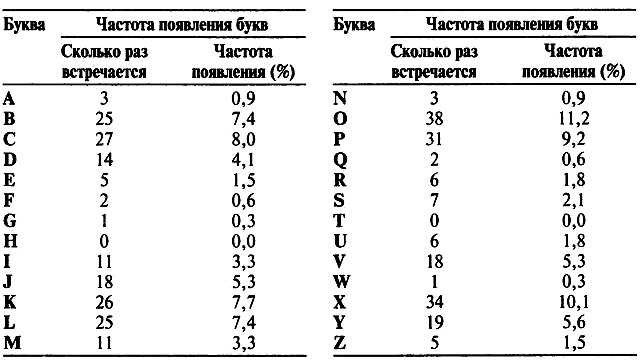
В нижеприведенной таблице показано, насколько часто каждая из трех чаще всего встречающихся в зашифрованном тексте букв: O, X и P появляется перед или после каждой буквы. O, к примеру, появляется перед А в 1 случае, но никогда сразу после нее, поэтому в первой ячейке стоит 1. Буква O соседствует с большинством букв, и существует всего 7 букв, которых она совершенно избегает, что показано семью нулями в ряду O. Буква X общительна в не меньшей степени, так как она тоже стоит рядом с большинством букв и чурается только 8 из них. Однако буква P гораздо менее дружелюбна. Она приветлива только к нескольким буквам и сторонится 15 из них. Это свидетельствует о том, что O и X являются гласными, а P представляет собой согласную.

Теперь зададимся вопросом, каким гласным соответствуют O и X. Скорее всего, что они представляют собой e и а — две наиболее часто встречающиеся гласные в английском языке, но будет ли O = e и X = а, или же O = а, а X = e? Интересной особенностью в зашифрованном тексте является то, что сочетание ОО появляется дважды, а XX не попадается ни разу. Так как в открытом английском тексте сочетание букв ее встречается значительно чаще, чем аа, то, по всей видимости, O = e и X = а.
На данный момент мы с уверенностью определили две буквы в зашифрованном тексте. Наш вывод, что X = а, основан на том, что в зашифрованном тексте в некоторых позициях X стоит отдельным словом, а а — это одно из всего двух слов в английском языке, состоящих из одной буквы. В зашифрованном тексте есть еще одна отдельно стоящая буква, Y, и это означает, что она представляет собой второе однобуквенное английское слово — і. Поиск однобуквенных слов является стандартным криптоаналитическим приемом, и я включил его в список советов по криптоанализу в Приложении В. Этот прием срабатывает только потому, что в данном зашифрованном тексте между словами остались пробелы. Но зачастую криптографы удаляют все пробелы, чтобы затруднить противнику дешифрование сообщения.
Хотя у нас есть пробелы между словами, однако следующий прием сработает и там, где зашифрованный текст был преобразован в непрерывную строку символов. Данный прием позволит нам определить букву h после того, как мы нашли букву e. В английском языке буква h часто стоит перед буквой e (как, например, в the, then, they и т. п.), но очень редко после e. В нижеприведенной таблице показана частота появления буквы O, которая, как мы полагаем, является буквой e, перед и после всех других букв в зашифрованном тексте. На основе этой таблицы можно предположить, что В представляет собой букву h, потому что она появляется перед O в 9 случаях, но никогда не стоит после нее. Никакая другая буква в таблице не имеет такой асимметричной связи с O.
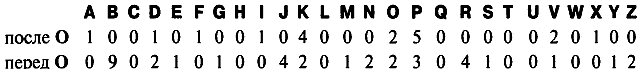
Каждая буква в английском языке характеризуется своими собственными, присущими только ей индивидуальными особенностями, среди которых частота ее появления и ее связь с другими буквами.
Именно эти индивидуальные особенности позволяют нам установить истинное значение буквы, даже когда она была скрыта с использованием шифра одноалфавитной замены.
Теперь мы уже гарантированно определили значение четырех букв: O = e, X = a, Y = i и B = h и можем приступить к замене отдельных букв в зашифрованном тексте их эквивалентами для открытого текста. При замене я буду придерживаться следующего правила: буквы зашифрованного текста останутся прописными, а подставляемые буквы для открытого текста будут строчными. Это поможет нам отличить те буквы, которые нам еще только предстоит определить, от тех, значение которых мы уже установили.

Этот несложный шаг даст нам возможность определить еще несколько букв, поскольку сейчас мы можем отгадать отдельные слова в зашифрованном тексте. К примеру, самыми часто встречающимися трехбуквенными словами в английском языке являются the и and, и их сравнительно легко найти в тексте: Lhe, которое появляется шесть раз, и aPV, которое появляется пять раз. Следовательно, L, по всей видимости, является буквой t, P — n, а V — d. Теперь мы можем заменить и эти буквы в зашифрованном тексте, подставив вместо них их действительные значения:

Как только будут определены несколько букв, дальнейший процесс дешифрования пойдет очень быстро. Так, в начале второго предложения стоит слово Cn. В каждом слове есть гласная, поэтому C должна быть гласной. Нам осталось определить только две гласные: u и o; u не подходит, значит, C должна быть буквой o. У нас также есть слово Khe, в котором К может быть либо t, либо s. Но мы уже знаем, что L = t, поэтому совершенно очевидно, что К = s. Установив значения этих двух букв, подставим их в зашифрованный текст, в результате чего получим фразу thoMsand and one niDhts. Здравый смысл подсказывает, что это должно быть thousand and one nights, и, скорее всего, данный отрывок взят из «Тысячи и одной ночи». Отсюда получаем, что M = u, I = f, J = r, D = g, R = I и S = m.
Мы можем постараться определить другие буквы, подбирая другие слова, но давайте вместо этого посмотрим, что нам известно об алфавите открытого текста и о шифралфавите. Эти два алфавита образуют ключ и применяются криптографом для выполнения замены, благодаря которой сообщение становится зашифрованным. Ранее, определив истинные значения букв в зашифрованном тексте, мы успешно подобрали элементы шифралфавита. То, чего мы достигли на данный момент, представлено ниже, в алфавите открытого текста и шифралфавите.
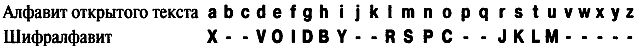
Анализируя частично заполненную строку шифралфавита, мы можем завершить криптоанализ. Последовательность VOIDBY в шифралфавите дает возможность предположить, что в качестве ключа криптограф использовал ключевую фразу. Можно догадаться, что ключевой фразой здесь будет A VOID BY GEORGES PEREC, которая, после того как будут убраны пробелы и повторы букв, сократится до AVOIDBYGERSPC. После нее буквы следуют в алфавитном порядке, при этом те из них, которые уже встречались в ключевой фразе, пропускаются. В данном частном случае криптограф расположил ключевую фразу не в начале шифралфавита, а начиная с третьей буквы. Это допустимо, поскольку ключевая фраза начинается с буквы A, криптограф же хочет избежать зашифровывания a как A. Наконец, определив шифралфавит, мы можем полностью дешифровать весь зашифрованный текст, и криптоанализ будет закончен.
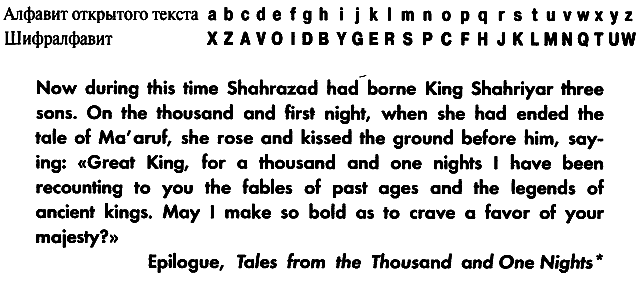
[7]
Криптография для новичков, где все разжевано и разложено по полочкам. Вы познакомитесь с шифрами, их особенностями и криптоанализом – атакой на шифротекст.

Урок №1 Криптография: шифр Цезаря
Это, если хотите, школьная программа криптографии, первый класс. Шифр Цезаря научились вскрывать еще в IX веке, поэтому сегодня он почти бесполезен, но как база – урок просто отличный. Начинается терминологией и подробным объяснением того, что из себя представляет и как работает ключ. Далее затрагивается шифр Цезаря, принципы его работы, а также способ быстрой дешифровки.
https://www.youtube.com/watch?v=gF_YRW9-eLY
Урок №2 Шифр простой замены
Этот урок тоже начинается короткой терминологией и объяснением разницы между закрытым текстом и шифром. Автор всегда ссылается на достоверные источники. Курс плавно перетекает в возможность шифровать цифрами и подробным описанием того, как это делается.
https://www.youtube.com/watch?v=bDHYdwqpmuM
Если вы посмотрели оба урока, считайте, что основы криптографии вы уже поняли.
Урок №3 Атака по маске
А вот здесь начинается интересное. Автор не зацикливается только на шифровании, но и объясняет тонкости атак на подобные тексты. Он приводит много примеров, что хорошо сказывается на понимании. Затрагиваются преимущество перевода шифротекста в числа и умение анализировать полученную «картинку». Это полезно, если вы планируете разрабатывать приложения, рассчитанные на вскрытие шифротекста, ведь чтобы передать логическое решение будущей программе, сперва нужно самостоятельно к этому решению прийти.
https://www.youtube.com/watch?v=PgqL_GTqtwA
Примеры уроков хорошо визуализированы, демонстрируется поэтапное выполнение, поэтому проблем с пониманием быть не должно.
Урок №4 Частотный анализ
Еще один способ анализа с применением диаграммы частоты по алфавиту. Перечисляются слабые и сильные стороны частотного анализа, рассказывается, в каких случаях он будет по-настоящему мощным инструментом, а в каких – бесполезным. Снова приводятся визуализированные примеры с применением метода, так что под конец урока вы обязательно поймете принцип работы частотного анализа.
https://www.youtube.com/watch?v=5bM93uVmehw
Урок №5 Полиалфавитные шифры. Шифр Гронсфельда
До этого затрагивались только моноалфавитные шифры и соответствующие типы замены. А вот пятый урок открывает новый раздел в криптографии под названием «Полиалфавитные шифры». Введение ознаменовано набором терминов и примеров, которые помогают разобраться во «множественном» шифровании. Затрагивается и шифр Гронсфельда, который также применяет ключ, как и шифр Цезаря, но делает это иначе. Полиалфавитные шифры намного эффективнее, ведь такой текст сложнее вскрыть. Почему? Смотрите в видеоуроке.
https://www.youtube.com/watch?v=S8Coc22uNdg
Урок №6 Шифр Виженера
Здесь расписывается самый популярный полиалфавитные шифр – шифр Виженера. Разобравшись с ним, можете считать, что криптография вам далась, и можно смело переходить к реализации знаний в своих приложениях.
Да, этот шифр по сей день терзает умы многих криптоаналитиков, ведь здесь используется далеко не простой ключ и такой же нелегкий способ подбора символов. Конкретно этот урок не научит вскрывать подобный шифротекст, но хорошо объяснит суть.
https://www.youtube.com/watch?v=oPTWao7j4Uk
Урок №7 Криптоанализ Виженера. Метод индекса совпадений
Даже шифр Виженера не так «зубаст», как может показаться. Существует метод индекса совпадений, который работает не с самим зашифрованным словом, а именно с ключом, и от этого уже плавно двигается в сторону разгадки. Здесь уже применяются сложные формулы и вычисления, поэтому рекомендуем внимательно следить за решением задачи.
https://www.youtube.com/watch?v=xWA2FJ74TBg
Урок №8 Криптоанализ Виженера часть 2. Автокорреляционный метод
Автокорреляционный метод более простой, но точно так же напичканный формулами, в которые придется вникнуть. В этом уроке объясняется лишь альтернативный поиск длины ключа, а все остальное, что касается вскрытия, – как и в предыдущем уроке.
https://www.youtube.com/watch?v=cl3G-4Gyf2A
Ссылка на канал.
Также рекомендуем посмотреть:
- Лучшие хакерские ресурсы: ТОП-10 YouTube каналов
- 61 репозиторий для хакеров на Github
- Математика для программистов: 7 крутых YouTube-каналов
- 4 книги, которые разбудят в вас математика
