I’m working with Python, and I’m trying to find out if you can tell if a word is in a string.
I have found some information about identifying if the word is in the string – using .find, but is there a way to do an if statement. I would like to have something like the following:
if string.find(word):
print("success")
![]()
mkrieger1
18.1k4 gold badges52 silver badges63 bronze badges
asked Mar 16, 2011 at 1:10
0
What is wrong with:
if word in mystring:
print('success')
Martin Thoma
122k155 gold badges604 silver badges939 bronze badges
answered Mar 16, 2011 at 1:13
fabrizioMfabrizioM
46.2k15 gold badges100 silver badges118 bronze badges
13
if 'seek' in 'those who seek shall find':
print('Success!')
but keep in mind that this matches a sequence of characters, not necessarily a whole word – for example, 'word' in 'swordsmith' is True. If you only want to match whole words, you ought to use regular expressions:
import re
def findWholeWord(w):
return re.compile(r'b({0})b'.format(w), flags=re.IGNORECASE).search
findWholeWord('seek')('those who seek shall find') # -> <match object>
findWholeWord('word')('swordsmith') # -> None
answered Mar 16, 2011 at 1:52
Hugh BothwellHugh Bothwell
54.9k8 gold badges84 silver badges99 bronze badges
6
If you want to find out whether a whole word is in a space-separated list of words, simply use:
def contains_word(s, w):
return (' ' + w + ' ') in (' ' + s + ' ')
contains_word('the quick brown fox', 'brown') # True
contains_word('the quick brown fox', 'row') # False
This elegant method is also the fastest. Compared to Hugh Bothwell’s and daSong’s approaches:
>python -m timeit -s "def contains_word(s, w): return (' ' + w + ' ') in (' ' + s + ' ')" "contains_word('the quick brown fox', 'brown')"
1000000 loops, best of 3: 0.351 usec per loop
>python -m timeit -s "import re" -s "def contains_word(s, w): return re.compile(r'b({0})b'.format(w), flags=re.IGNORECASE).search(s)" "contains_word('the quick brown fox', 'brown')"
100000 loops, best of 3: 2.38 usec per loop
>python -m timeit -s "def contains_word(s, w): return s.startswith(w + ' ') or s.endswith(' ' + w) or s.find(' ' + w + ' ') != -1" "contains_word('the quick brown fox', 'brown')"
1000000 loops, best of 3: 1.13 usec per loop
Edit: A slight variant on this idea for Python 3.6+, equally fast:
def contains_word(s, w):
return f' {w} ' in f' {s} '
answered Apr 11, 2016 at 20:32
user200783user200783
13.6k12 gold badges68 silver badges132 bronze badges
6
You can split string to the words and check the result list.
if word in string.split():
print("success")
Martin Thoma
122k155 gold badges604 silver badges939 bronze badges
answered Dec 1, 2016 at 18:26
CorvaxCorvax
7627 silver badges12 bronze badges
3
find returns an integer representing the index of where the search item was found. If it isn’t found, it returns -1.
haystack = 'asdf'
haystack.find('a') # result: 0
haystack.find('s') # result: 1
haystack.find('g') # result: -1
if haystack.find(needle) >= 0:
print('Needle found.')
else:
print('Needle not found.')
Martin Thoma
122k155 gold badges604 silver badges939 bronze badges
answered Mar 16, 2011 at 1:13
Matt HowellMatt Howell
15.7k7 gold badges48 silver badges56 bronze badges
0
This small function compares all search words in given text. If all search words are found in text, returns length of search, or False otherwise.
Also supports unicode string search.
def find_words(text, search):
"""Find exact words"""
dText = text.split()
dSearch = search.split()
found_word = 0
for text_word in dText:
for search_word in dSearch:
if search_word == text_word:
found_word += 1
if found_word == len(dSearch):
return lenSearch
else:
return False
usage:
find_words('çelik güray ankara', 'güray ankara')
answered Jun 22, 2012 at 22:51
Guray CelikGuray Celik
1,2811 gold badge14 silver badges13 bronze badges
0
If matching a sequence of characters is not sufficient and you need to match whole words, here is a simple function that gets the job done. It basically appends spaces where necessary and searches for that in the string:
def smart_find(haystack, needle):
if haystack.startswith(needle+" "):
return True
if haystack.endswith(" "+needle):
return True
if haystack.find(" "+needle+" ") != -1:
return True
return False
This assumes that commas and other punctuations have already been stripped out.
IanS
15.6k9 gold badges59 silver badges84 bronze badges
answered Jun 15, 2012 at 7:23
daSongdaSong
4071 gold badge5 silver badges9 bronze badges
1
Using regex is a solution, but it is too complicated for that case.
You can simply split text into list of words. Use split(separator, num) method for that. It returns a list of all the words in the string, using separator as the separator. If separator is unspecified it splits on all whitespace (optionally you can limit the number of splits to num).
list_of_words = mystring.split()
if word in list_of_words:
print('success')
This will not work for string with commas etc. For example:
mystring = "One,two and three"
# will split into ["One,two", "and", "three"]
If you also want to split on all commas etc. use separator argument like this:
# whitespace_chars = " tnrf" - space, tab, newline, return, formfeed
list_of_words = mystring.split( tnrf,.;!?'"()")
if word in list_of_words:
print('success')
Martin Thoma
122k155 gold badges604 silver badges939 bronze badges
answered Dec 18, 2017 at 11:44
tstempkotstempko
1,1761 gold badge15 silver badges17 bronze badges
2
As you are asking for a word and not for a string, I would like to present a solution which is not sensitive to prefixes / suffixes and ignores case:
#!/usr/bin/env python
import re
def is_word_in_text(word, text):
"""
Check if a word is in a text.
Parameters
----------
word : str
text : str
Returns
-------
bool : True if word is in text, otherwise False.
Examples
--------
>>> is_word_in_text("Python", "python is awesome.")
True
>>> is_word_in_text("Python", "camelCase is pythonic.")
False
>>> is_word_in_text("Python", "At the end is Python")
True
"""
pattern = r'(^|[^w]){}([^w]|$)'.format(word)
pattern = re.compile(pattern, re.IGNORECASE)
matches = re.search(pattern, text)
return bool(matches)
if __name__ == '__main__':
import doctest
doctest.testmod()
If your words might contain regex special chars (such as +), then you need re.escape(word)
answered Aug 9, 2017 at 10:11
Martin ThomaMartin Thoma
122k155 gold badges604 silver badges939 bronze badges
Advanced way to check the exact word, that we need to find in a long string:
import re
text = "This text was of edited by Rock"
#try this string also
#text = "This text was officially edited by Rock"
for m in re.finditer(r"bofb", text):
if m.group(0):
print("Present")
else:
print("Absent")
Martin Thoma
122k155 gold badges604 silver badges939 bronze badges
answered Nov 2, 2016 at 8:39
![]()
RameezRameez
5545 silver badges11 bronze badges
What about to split the string and strip words punctuation?
w in [ws.strip(',.?!') for ws in p.split()]
If need, do attention to lower/upper case:
w.lower() in [ws.strip(',.?!') for ws in p.lower().split()]
Maybe that way:
def wcheck(word, phrase):
# Attention about punctuation and about split characters
punctuation = ',.?!'
return word.lower() in [words.strip(punctuation) for words in phrase.lower().split()]
Sample:
print(wcheck('CAr', 'I own a caR.'))
I didn’t check performance…
answered Dec 26, 2020 at 5:18
marciomarcio
5167 silver badges19 bronze badges
You could just add a space before and after “word”.
x = raw_input("Type your word: ")
if " word " in x:
print("Yes")
elif " word " not in x:
print("Nope")
This way it looks for the space before and after “word”.
>>> Type your word: Swordsmith
>>> Nope
>>> Type your word: word
>>> Yes
Martin Thoma
122k155 gold badges604 silver badges939 bronze badges
answered Feb 26, 2015 at 14:23
PyGuyPyGuy
433 bronze badges
1
I believe this answer is closer to what was initially asked: Find substring in string but only if whole words?
It is using a simple regex:
import re
if re.search(r"b" + re.escape(word) + r"b", string):
print('success')
Martin Thoma
122k155 gold badges604 silver badges939 bronze badges
answered Aug 25, 2021 at 13:25
Milos CuculovicMilos Cuculovic
19.5k50 gold badges159 silver badges264 bronze badges
One of the solutions is to put a space at the beginning and end of the test word. This fails if the word is at the beginning or end of a sentence or is next to any punctuation. My solution is to write a function that replaces any punctuation in the test string with spaces, and add a space to the beginning and end or the test string and test word, then return the number of occurrences. This is a simple solution that removes the need for any complex regex expression.
def countWords(word, sentence):
testWord = ' ' + word.lower() + ' '
testSentence = ' '
for char in sentence:
if char.isalpha():
testSentence = testSentence + char.lower()
else:
testSentence = testSentence + ' '
testSentence = testSentence + ' '
return testSentence.count(testWord)
To count the number of occurrences of a word in a string:
sentence = "A Frenchman ate an apple"
print(countWords('a', sentence))
returns 1
sentence = "Is Oporto a 'port' in Portugal?"
print(countWords('port', sentence))
returns 1
Use the function in an ‘if’ to test if the word exists in a string
answered Mar 18, 2022 at 9:37
iStuartiStuart
3953 silver badges6 bronze badges

В этой статье поговорим про строки в Python, особенности поиска, а также о том, как искать подстроку или символ в строке.

Но сначала давайте вспомним основные методы для обработки строк в Python:
• isalpha(str): если строка в Python включает в себя лишь алфавитные символы, возвращается True;
• islower(str): True возвращается, если строка включает лишь символы в нижнем регистре;
• isupper(str): True, если символы строки в Python находятся в верхнем регистре;
• startswith(str): True, когда строка начинается с подстроки str;
• isdigit(str): True, когда каждый символ строки — цифра;
• endswith(str): True, когда строка в Python заканчивается на подстроку str;
• upper(): строка переводится в верхний регистр;
• lower(): строка переводится в нижний регистр;
• title(): для перевода начальных символов всех слов в строке в верхний регистр;
• capitalize(): для перевода первой буквы самого первого слова строки в верхний регистр;
• lstrip(): из строки в Python удаляются начальные пробелы;
• rstrip(): из строки в Python удаляются конечные пробелы;
• strip(): из строки в Python удаляются и начальные, и конечные пробелы;
• rjust(width): когда длина строки меньше, чем параметр width, слева добавляются пробелы, строка выравнивается по правому краю;
• ljust(width): когда длина строки в Python меньше, чем параметр width, справа от неё добавляются пробелы для дополнения значения width, при этом происходит выравнивание строки по левому краю;
• find(str[, start [, end]): происходит возвращение индекса подстроки в строку в Python. В том случае, если подстрока не найдена, выполняется возвращение числа -1;
• center(width): когда длина строки в Python меньше, чем параметр width, слева и справа добавляются пробелы (равномерно) для дополнения значения width, причём происходит выравнивание строки по центру;
• split([delimeter[, num]]): строку в Python разбиваем на подстроки в зависимости от разделителя;
• replace(old, new[, num]): в строке одна подстрока меняется на другую;
• join(strs): строки объединяются в одну строку, между ними вставляется определённый разделитель.
Обрабатываем строку в Python
Представим, что ожидается ввод числа с клавиатуры. Перед преобразованием введенной нами строки в число можно легко проверить, введено ли действительно число. Если это так, выполнится операция преобразования. Для обработки строки используем такой метод в Python, как isnumeric():
string = input("Введите какое-нибудь число: ") if string.isnumeric(): number = int(string) print(number)Следующий пример позволяет удалять пробелы в конце и начале строки:
string = " привет мир! " string = string.strip() print(string) # привет мир!Так можно дополнить строку пробелами и выполнить выравнивание:
print("iPhone 7:", "52000".rjust(10)) print("Huawei P10:", "36000".rjust(10))В консоли Python будет выведено следующее:
iPhone 7: 52000 Huawei P10: 36000Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!" index = welcome.find("wor") print(index) # 6 # ищем с десятого индекса index = welcome.find("wor",10) print(index) # 21 # ищем с 10-го по 15-й индекс index = welcome.find("wor",10,15) print(index) # -1Замена в строке
Чтобы в Python заменить в строке одну подстроку на другую, применяют метод replace():
• replace(old, new): подстрока old заменяется на new;
• replace(old, new, num): параметр num показывает, сколько вхождений подстроки old требуется заменить на new.Пример замены в строке в Python:
phone = "+1-234-567-89-10" # дефисы меняются на пробелы edited_phone = phone.replace("-", " ") print(edited_phone) # +1 234 567 89 10 # дефисы удаляются edited_phone = phone.replace("-", "") print(edited_phone) # +12345678910 # меняется только первый дефис edited_phone = phone.replace("-", "", 1) print(edited_phone) # +1234-567-89-10Разделение на подстроки в Python
Для разделения в Python используется метод split(). В зависимости от разделителя он разбивает строку на перечень подстрок. В роли разделителя в данном случае может быть любой символ либо последовательность символов. Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter;
• split(delimeter, num): параметром num указывается, какое количество вхождений delimeter применяется для разделения. При этом оставшаяся часть строки добавляется в перечень без разделения на подстроки.Соединение строк в Python
Рассматривая простейшие операции со строками, мы увидели, как объединяются строки через операцию сложения. Однако есть и другая возможность для соединения строк — метод join():, объединяющий списки строк. В качестве разделителя используется текущая строка, у которой вызывается этот метод:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # символ разделителя - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # символ разделителя - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | EnglishА если вместо списка в метод join передать простую строку, разделитель будет вставляться уже между символами:
word = "hello" joined_word = "|".join(word) print(joined_word) # h|e|l|l|o


When you’re working with a Python program, you might need to search for and locate a specific string inside another string.
This is where Python’s built-in string methods come in handy.
In this article, you will learn how to use Python’s built-in find() string method to help you search for a substring inside a string.
Here is what we will cover:
- Syntax of the
find()method- How to use
find()with no start and end parameters example - How to use
find()with start and end parameters example - Substring not found example
- Is the
find()method case-sensitive?
- How to use
find()vsinkeywordfind()vsindex()
The find() Method – A Syntax Overview
The find() string method is built into Python’s standard library.
It takes a substring as input and finds its index – that is, the position of the substring inside the string you call the method on.
The general syntax for the find() method looks something like this:
string_object.find("substring", start_index_number, end_index_number)
Let’s break it down:
string_objectis the original string you are working with and the string you will call thefind()method on. This could be any word you want to search through.- The
find()method takes three parameters – one required and two optional. "substring"is the first required parameter. This is the substring you are trying to find insidestring_object. Make sure to include quotation marks.start_index_numberis the second parameter and it’s optional. It specifies the starting index and the position from which the search will start. The default value is0.end_index_numberis the third parameter and it’s also optional. It specifies the end index and where the search will stop. The default is the length of the string.- Both the
start_index_numberand theend_index_numberspecify the range over which the search will take place and they narrow the search down to a particular section.
The return value of the find() method is an integer value.
If the substring is present in the string, find() returns the index, or the character position, of the first occurrence of the specified substring from that given string.
If the substring you are searching for is not present in the string, then find() will return -1. It will not throw an exception.
How to Use find() with No Start and End Parameters Example
The following examples illustrate how to use the find() method using the only required parameter – the substring you want to search.
You can take a single word and search to find the index number of a specific letter:
fave_phrase = "Hello world!"
# find the index of the letter 'w'
search_fave_phrase = fave_phrase.find("w")
print(search_fave_phrase)
#output
# 6
I created a variable named fave_phrase and stored the string Hello world!.
I called the find() method on the variable containing the string and searched for the letter ‘w’ inside Hello world!.
I stored the result of the operation in a variable named search_fave_phrase and then printed its contents to the console.
The return value was the index of w which in this case was the integer 6.
Keep in mind that indexing in programming and Computer Science in general always starts at 0 and not 1.
How to Use find() with Start and End Parameters Example
Using the start and end parameters with the find() method lets you limit your search.
For example, if you wanted to find the index of the letter ‘w’ and start the search from position 3 and not earlier, you would do the following:
fave_phrase = "Hello world!"
# find the index of the letter 'w' starting from position 3
search_fave_phrase = fave_phrase.find("w",3)
print(search_fave_phrase)
#output
# 6
Since the search starts at position 3, the return value will be the first instance of the string containing ‘w’ from that position and onwards.
You can also narrow down the search even more and be more specific with your search with the end parameter:
fave_phrase = "Hello world!"
# find the index of the letter 'w' between the positions 3 and 8
search_fave_phrase = fave_phrase.find("w",3,8)
print(search_fave_phrase)
#output
# 6
Substring Not Found Example
As mentioned earlier, if the substring you specify with find() is not present in the string, then the output will be -1 and not an exception.
fave_phrase = "Hello world!"
# search for the index of the letter 'a' in "Hello world"
search_fave_phrase = fave_phrase.find("a")
print(search_fave_phrase)
# -1
Is the find() Method Case-Sensitive?
What happens if you search for a letter in a different case?
fave_phrase = "Hello world!"
#search for the index of the letter 'W' capitalized
search_fave_phrase = fave_phrase.find("W")
print(search_fave_phrase)
#output
# -1
In an earlier example, I searched for the index of the letter w in the phrase “Hello world!” and the find() method returned its position.
In this case, searching for the letter W capitalized returns -1 – meaning the letter is not present in the string.
So, when searching for a substring with the find() method, remember that the search will be case-sensitive.
The find() Method vs the in Keyword – What’s the Difference?
Use the in keyword to check if the substring is present in the string in the first place.
The general syntax for the in keyword is the following:
substring in string
The in keyword returns a Boolean value – a value that is either True or False.
>>> "w" in "Hello world!"
True
The in operator returns True when the substring is present in the string.
And if the substring is not present, it returns False:
>>> "a" in "Hello world!"
False
Using the in keyword is a helpful first step before using the find() method.
You first check to see if a string contains a substring, and then you can use find() to find the position of the substring. That way, you know for sure that the substring is present.
So, use find() to find the index position of a substring inside a string and not to look if the substring is present in the string.
The find() Method vs the index() Method – What’s the Difference?
Similar to the find() method, the index() method is a string method used for finding the index of a substring inside a string.
So, both methods work in the same way.
The difference between the two methods is that the index() method raises an exception when the substring is not present in the string, in contrast to the find() method that returns the -1 value.
fave_phrase = "Hello world!"
# search for the index of the letter 'a' in 'Hello world!'
search_fave_phrase = fave_phrase.index("a")
print(search_fave_phrase)
#output
# Traceback (most recent call last):
# File "/Users/dionysialemonaki/python_article/demopython.py", line 4, in <module>
# search_fave_phrase = fave_phrase.index("a")
# ValueError: substring not found
The example above shows that index() throws a ValueError when the substring is not present.
You may want to use find() over index() when you don’t want to deal with catching and handling any exceptions in your programs.
Conclusion
And there you have it! You now know how to search for a substring in a string using the find() method.
I hope you found this tutorial helpful.
To learn more about the Python programming language, check out freeCodeCamp’s Python certification.
You’ll start from the basics and learn in an interactive and beginner-friendly way. You’ll also build five projects at the end to put into practice and help reinforce your understanding of the concepts you learned.
Thank you for reading, and happy coding!
Happy coding!
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Текстовые переменные str в Питоне
Строковый тип str в Python используют для работы с любыми текстовыми данными. Python автоматически определяет тип str по кавычкам – одинарным или двойным:
>>> stroka = 'Python'
>>> type(stroka)
<class 'str'>
>>> stroka2 = "code"
>>> type(stroka2)
<class 'str'>
Для решения многих задач строковую переменную нужно объявить заранее, до начала исполнения основной части программы. Создать пустую переменную str просто:
stroka = ''
Или:
stroka2 = ""
Если в самой строке нужно использовать кавычки – например, для названия книги – то один вид кавычек используют для строки, второй – для выделения названия:
>>> print("'Самоучитель Python' - возможно, лучший справочник по Питону.")
'Самоучитель Python' - возможно, лучший справочник по Питону.
>>> print('"Самоучитель Python" - возможно, лучший справочник по Питону.')
"Самоучитель Python" - возможно, лучший справочник по Питону.
Использование одного и того же вида кавычек внутри и снаружи строки вызовет ошибку:
>>> print(""Самоучитель Python" - возможно, лучший справочник по Питону.")
File "<pyshell>", line 1
print(""Самоучитель Python" - возможно, лучший справочник по Питону.")
^
SyntaxError: invalid syntax
Кроме двойных " и одинарных кавычек ', в Python используются и тройные ''' – в них заключают текст, состоящий из нескольких строк, или программный код:
>>> print('''В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.''')
В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.
Длина строки len в Python
Для определения длины строки используется встроенная функция len(). Она подсчитывает общее количество символов в строке, включая пробелы:
>>> stroka = 'python'
>>> print(len(stroka))
6
>>> stroka1 = ' '
>>> print(len(stroka1))
1
Преобразование других типов данных в строку
Целые и вещественные числа преобразуются в строки одинаково:
>>> number1 = 55
>>> number2 = 55.5
>>> stroka1 = str(number1)
>>> stroka2 = str(number2)
>>> print(type(stroka1))
<class 'str'>
>>> print(type(stroka2))
<class 'str'>
Решение многих задач значительно упрощается, если работать с числами в строковом формате. Особенно это касается заданий, где нужно разделять числа на разряды – сотни, десятки и единицы.
Сложение и умножение строк
Как уже упоминалось в предыдущей главе, строки можно складывать – эта операция также известна как конкатенация:
>>> str1 = 'Python'
>>> str2 = ' - '
>>> str3 = 'самый гибкий язык программирования'
>>> print(str1 + str2 + str3)
Python - самый гибкий язык программирования
При необходимости строку можно умножить на целое число – эта операция называется репликацией:
>>> stroka = '*** '
>>> print(stroka * 5)
*** *** *** *** ***
Подстроки
Подстрокой называется фрагмент определенной строки. Например, ‘abra’ является подстрокой ‘abrakadabra’. Чтобы определить, входит ли какая-то определенная подстрока в строку, используют оператор in:
>>> stroka = 'abrakadabra'
>>> print('abra' in stroka)
True
>>> print('zebra' in stroka)
False
Для обращения к определенному символу строки используют индекс – порядковый номер элемента. Python поддерживает два типа индексации – положительную, при которой отсчет элементов начинается с 0 и с начала строки, и отрицательную, при которой отсчет начинается с -1 и с конца:
| Положительные индексы | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Пример строки | P | r | o | g | l | i | b |
| Отрицательные индексы | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Чтобы получить определенный элемент строки, нужно указать его индекс в квадратных скобках:
>>> stroka = 'программирование'
>>> print(stroka[7])
м
>>> print(stroka[-1])
е
Срезы строк в Python
Индексы позволяют работать с отдельными элементами строк. Для работы с подстроками используют срезы, в которых задается нужный диапазон:
>>> stroka = 'программирование'
>>> print(stroka[7:10])
мир
Диапазон среза [a:b] начинается с первого указанного элемента а включительно, и заканчивается на последнем, не включая b в результат:
>>> stroka = 'программa'
>>> print(stroka[3:8])
грамм
Если не указать первый элемент диапазона [:b], срез будет выполнен с начала строки до позиции второго элемента b:
>>> stroka = 'программa'
>>> print(stroka[:4])
прог
В случае отсутствия второго элемента [a:] срез будет сделан с позиции первого символа и до конца строки:
>>> stroka = 'программa'
>>> print(stroka[3:])
граммa
Если не указана ни стартовая, ни финальная позиция среза, он будет равен исходной строке:
>>> stroka = 'позиции не заданы'
>>> print(stroka[:])
позиции не заданы
Шаг среза
Помимо диапазона, можно задавать шаг среза. В приведенном ниже примере выбирается символ из стартовой позиции среза, а затем каждая 3-я буква из диапазона:
>>> stroka = 'Python лучше всего подходит для новичков.'
>>> print(stroka[1:15:3])
yoлшв
Шаг может быть отрицательным – в этом случае символы будут выбираться, начиная с конца строки:
>>> stroka = 'это пример отрицательного шага'
>>> print(stroka[-1:-15:-4])
а нт
Срез [::-1] может оказаться очень полезным при решении задач, связанных с палиндромами:
>>> stroka = 'А роза упала на лапу Азора'
>>> print(stroka[::-1])
арозА упал ан алапу азор А
Замена символа в строке
Строки в Python относятся к неизменяемым типам данных. По этой причине попытка замены символа по индексу обречена на провал:
>>> stroka = 'mall'
>>> stroka[0] = 'b'
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Но заменить любой символ все-таки можно – для этого придется воспользоваться срезами и конкатенацией. Результатом станет новая строка:
>>> stroka = 'mall'
>>> stroka = 'b' + stroka[1:]
>>> print(stroka)
ball
Более простой способ «замены» символа или подстроки – использование метода replace(), который мы рассмотрим ниже.
Полезные методы строк
Python предоставляет множество методов для работы с текстовыми данными. Все методы можно сгруппировать в четыре категории:
- Преобразование строк.
- Оценка и классификация строк.
- Конвертация регистра.
- Поиск, подсчет и замена символов.
Рассмотрим эти методы подробнее.
Преобразование строк
Три самых используемых метода из этой группы – join(), split() и partition(). Метод join() незаменим, если нужно преобразовать список или кортеж в строку:
>>> spisok = ['Я', 'изучаю', 'Python']
>>> stroka = ' '.join(spisok)
>>> print(stroka)
Я изучаю Python
При объединении списка или кортежа в строку можно использовать любые разделители:
>>> kort = ('Я', 'изучаю', 'Django')
>>> stroka = '***'.join(kort)
>>> print(stroka)
Я***изучаю***Django
Метод split() используется для обратной манипуляции – преобразования строки в список:
>>> text = 'это пример текста для преобразования в список'
>>> spisok = text.split()
>>> print(spisok)
['это', 'пример', 'текста', 'для', 'преобразования', 'в', 'список']
По умолчанию split() разбивает строку по пробелам. Но можно указать любой другой символ – и на практике это часто требуется:
>>> text = 'цвет: синий; вес: 1 кг; размер: 30х30х50; материал: картон'
>>> spisok = text.split(';')
>>> print(spisok)
['цвет: синий', ' вес: 1 кг', ' размер: 30х30х50', ' материал: картон']
Метод partition() поможет преобразовать строку в кортеж:
>>> text = 'Python - простой и понятный язык'
>>> kort = text.partition('и')
>>> print(kort)
('Python - простой ', 'и', ' понятный язык')
В отличие от split(), partition() учитывает только первое вхождение элемента-разделителя (и добавляет его в итоговый кортеж).
Оценка и классификация строк
В Python много встроенных методов для оценки и классификации текстовых данных. Некоторые из этих методов работают только со строками, в то время как другие универсальны. К последним относятся, например, функции min() и max():
>>> text = '12345'
>>> print(min(text))
1
>>> print(max(text))
5
В Python есть специальные методы для определения типа символов. Например, isalnum() оценивает, состоит ли строка из букв и цифр, либо в ней есть какие-то другие символы:
>>> text = 'abracadabra123456'
>>> print(text.isalnum())
True
>>> text1 = 'a*b$ra cadabra'
>>> print(text1.isalnum())
False
Метод isalpha() поможет определить, состоит ли строка только из букв, или включает специальные символы, пробелы и цифры:
>>> text = 'программирование'
>>> print(text.isalpha())
True
>>> text2 = 'password123'
>>> print(text2.isalpha())
False
С помощью метода isdigit() можно определить, входят ли в строку только цифры, или там есть и другие символы:
>>> text = '1234567890'
>>> print(text.isdigit())
True
>>> text2 = '123456789o'
>>> print(text2.isdigit())
False
Поскольку вещественные числа содержат точку, а отрицательные – знак минуса, выявить их этим методом не получится:
>>> text = '5.55'
>>> print(text.isdigit())
False
>>> text1 = '-5'
>>> print(text1.isdigit())
False
Если нужно определить наличие в строке дробей или римских цифр, подойдет метод isnumeric():
>>> text = '½⅓¼⅕⅙'
>>> print(text.isdigit())
False
>>> print(text.isnumeric())
True
Методы islower() и isupper() определяют регистр, в котором находятся буквы. Эти методы игнорируют небуквенные символы:
>>> text = 'abracadabra'
>>> print(text.islower())
True
>>> text2 = 'Python bytes'
>>> print(text2.islower())
False
>>> text3 = 'PYTHON'
>>> print(text3.isupper())
True
Метод isspace() определяет, состоит ли анализируемая строка из одних пробелов, или содержит что-нибудь еще:
>>> stroka = ' '
>>> print(stroka.isspace())
True
>>> stroka2 = ' a '
>>> print(stroka2.isspace())
False
Конвертация регистра
Как уже говорилось выше, строки относятся к неизменяемым типам данных, поэтому результатом любых манипуляций, связанных с преобразованием регистра или удалением (заменой) символов будет новая строка.
Из всех методов, связанных с конвертацией регистра, наиболее часто используются на практике два – lower() и upper(). Они преобразуют все символы в нижний и верхний регистр соответственно:
>>> text = 'этот текст надо написать заглавными буквами'
>>> print(text.upper())
ЭТОТ ТЕКСТ НАДО НАПИСАТЬ ЗАГЛАВНЫМИ БУКВАМИ
>>> text = 'зДесь ВСе букВы рАзныЕ, а НУжнЫ проПИСНыЕ'
>>> print(text.lower())
здесь все буквы разные, а нужны прописные
Иногда требуется преобразовать текст так, чтобы с заглавной буквы начиналось только первое слово предложения:
>>> text = 'предложение должно начинаться с ЗАГЛАВНОЙ буквы.'
>>> print(text.capitalize())
Предложение должно начинаться с заглавной буквы.
Методы swapcase() и title() используются реже. Первый заменяет исходный регистр на противоположный, а второй – начинает каждое слово с заглавной буквы:
>>> text = 'пРИМЕР иСПОЛЬЗОВАНИЯ swapcase'
>>> print(text.swapcase())
Пример Использования SWAPCASE
>>> text2 = 'тот случай, когда нужен метод title'
>>> print(text2.title())
Тот Случай, Когда Нужен Метод Title
Поиск, подсчет и замена символов
Методы find() и rfind() возвращают индекс стартовой позиции искомой подстроки. Оба метода учитывают только первое вхождение подстроки. Разница между ними заключается в том, что find() ищет первое вхождение подстроки с начала текста, а rfind() – с конца:
>>> text = 'пример текста, в котором нужно найти текстовую подстроку'
>>> print(text.find('текст'))
7
>>> print(text.rfind('текст'))
37
Такие же результаты можно получить при использовании методов index() и rindex() – правда, придется предусмотреть обработку ошибок, если искомая подстрока не будет обнаружена:
>>> text = 'Съешь еще этих мягких французских булок!'
>>> print(text.index('еще'))
6
>>> print(text.rindex('чаю'))
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
ValueError: substring not found
Если нужно определить, начинается ли строка с определенной подстроки, поможет метод startswith():
>>> text = 'Жила-была курочка Ряба'
>>> print(text.startswith('Жила'))
True
Чтобы проверить, заканчивается ли строка на нужное окончание, используют endswith():
>>> text = 'В конце всех ждал хэппи-енд'
>>> print(text.endswith('енд'))
True
Для подсчета числа вхождений определенного символа или подстроки применяют метод count() – он помогает подсчитать как общее число вхождений в тексте, так и вхождения в указанном диапазоне:
>>> text = 'Съешь еще этих мягких французских булок, да выпей же чаю!'
>>> print(text.count('е'))
5
>>> print(text.count('е', 5, 25))
2
Методы strip(), lstrip() и rstrip() предназначены для удаления пробелов. Метод strip() удаляет пробелы в начале и конце строки, lstrip() – только слева, rstrip() – только справа:
>>> text = ' здесь есть пробелы и слева, и справа '
>>> print('***', text.strip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.lstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.rstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
Метод replace() используют для замены символов или подстрок. Можно указать нужное количество замен, а сам символ можно заменить на пустую подстроку – проще говоря, удалить:
>>> text = 'В этой строчке нужно заменить только одну "ч"'
>>> print(text.replace('ч', '', 1))
В этой строке нужно заменить только одну "ч"
Стоит заметить, что метод replace() подходит лишь для самых простых вариантов замены и удаления подстрок. В более сложных случаях необходимо использование регулярных выражений, которые мы будем изучать позже.
Практика
Задание 1
Напишите программу, которая получает на вход строку и выводит:
- количество символов, содержащихся в тексте;
- True или False в зависимости от того, являются ли все символы буквами и цифрами.
Решение:
text = input()
print(len(text))
print(text.isalpha())
Задание 2
Напишите программу, которая получает на вход слово и выводит True, если слово является палиндромом, или False в противном случае. Примечание: для сравнения в Python используется оператор ==.
Решение:
text = input().lower()
print(text == text[::-1])
Задание 3
Напишите программу, которая получает строку с именем, отчеством и фамилией, написанными в произвольном регистре, и выводит данные в правильном формате. Например, строка алеКСандр СЕРГЕЕВИЧ ПушкиН должна быть преобразована в Александр Сергеевич Пушкин.
Решение:
text = input()
print(text.title())
Задание 4
Имеется строка 12361573928167047230472012. Напишите программу, которая преобразует строку в текст один236один573928один670472304720один2.
Решение:
text = '12361573928167047230472012'
print(text.replace('1', 'один'))
Задание 5
Напишите программу, которая последовательно получает на вход имя, отчество, фамилию и должность сотрудника, а затем преобразует имя и отчество в инициалы, добавляя должность после запятой.
Пример ввода:
Алексей
Константинович
Романов
бухгалтер
Вывод:
А. К. Романов, бухгалтер
Решение:
first_name, patronymic, last_name, position = input(), input(), input(), input()
print(first_name[0] + '.', patronymic[0] + '.', last_name + ',', position)
Задание 6
Напишите программу, которая получает на вход строку текста и букву, а затем определяет, встречается ли данная буква (в любом регистре) в тексте. В качестве ответа программа должна выводить True или False.
Пример ввода:
ЗонтИК
к
Вывод:
True
Решение:
text = input().lower()
letter = input()
print(letter in text)
Задание 7
Напишите программу, которая определяет, является ли введенная пользователем буква гласной. В качестве ответа программы выводит True или False, буквы могут быть как в верхнем, так и в нижнем регистре.
Решение:
vowels = 'аиеёоуыэюя'
letter = input().lower()
print(letter in vowels)
Задание 8
Напишите программу, которая принимает на вход строку текста и подстроку, а затем выводит индексы первого вхождения подстроки с начала и с конца строки (без учета регистра).
Пример ввода:
Шесть шустрых мышат в камышах шуршат
ша
Вывод:
16 33
Решение:
text, letter = input().lower(), input()
print(text.find(letter), text.rfind(letter))
Задание 9
Напишите программу для подсчета количества пробелов и непробельных символов в введенной пользователем строке.
Пример ввода:
В роще, травы шевеля, мы нащиплем щавеля
Вывод:
Количество пробелов: 6, количество других символов: 34
Решение:
text = input()
nospace = text.replace(' ', '')
print(f"Количество пробелов: {text.count(' ')}, количество других символов: {len(nospace)}")
Задание 10
Напишите программу, которая принимает строку и две подстроки start и end, а затем определяет, начинается ли строка с фрагмента start, и заканчивается ли подстрокой end. Регистр не учитывать.
Пример ввода:
Программирование на Python - лучшее хобби
про
про
Вывод:
True
False
Решение:
text, start, end = input().lower(), input(), input()
print(text.startswith(start))
print(text.endswith(end))
Подведем итоги
В этой части мы рассмотрели самые популярные методы работы со строками – они пригодятся для решения тренировочных задач и в разработке реальных проектов. В следующей статье будем разбирать методы работы со списками.
***
📖 Содержание самоучителя
- Особенности, сферы применения, установка, онлайн IDE
- Все, что нужно для изучения Python с нуля – книги, сайты, каналы и курсы
- Типы данных: преобразование и базовые операции
- Методы работы со строками
- Методы работы со списками и списковыми включениями
- Методы работы со словарями и генераторами словарей
- Методы работы с кортежами
- Методы работы со множествами
- Особенности цикла for
- Условный цикл while
- Функции с позиционными и именованными аргументами
- Анонимные функции
- Рекурсивные функции
- Функции высшего порядка, замыкания и декораторы
- Методы работы с файлами и файловой системой
- Регулярные выражения
- Основы скрапинга и парсинга
- Основы ООП: инкапсуляция и наследование
- Основы ООП – абстракция и полиморфизм
- Графический интерфейс на Tkinter
***
Материалы по теме
- ТОП-15 трюков в Python 3, делающих код понятнее и быстрее
In this Python tutorial, you’ll learn to search a string in a text file. Also, we’ll see how to search a string in a file and print its line and line number.
After reading this article, you’ll learn the following cases.
- If a file is small, read it into a string and use the
find()method to check if a string or word is present in a file. (easier and faster than reading and checking line per line) - If a file is large, use the mmap to search a string in a file. We don’t need to read the whole file in memory, which will make our solution memory efficient.
- Search a string in multiple files
- Search file for a list of strings
We will see each solution one by one.
Table of contents
- How to Search for a String in Text File
- Example to search for a string in text file
- Search file for a string and Print its line and line number
- Efficient way to search string in a large text file
- mmap to search for a string in text file
- Search string in multiple files
- Search file for a list of strings
How to Search for a String in Text File
Use the file read() method and string class find() method to search for a string in a text file. Here are the steps.
- Open file in a read mode
Open a file by setting a file path and access mode to the
open()function. The access mode specifies the operation you wanted to perform on the file, such as reading or writing. For example, r is for reading.fp= open(r'file_path', 'r') - Read content from a file
Once opened, read all content of a file using the
read()method. Theread()method returns the entire file content in string format. - Search for a string in a file
Use the
find()method of a str class to check the given string or word present in the result returned by theread()method. Thefind()method. The find() method will return -1 if the given text is not present in a file - Print line and line number
If you need line and line numbers, use the
readlines() method instead ofread()method. Use the for loop andreadlines()method to iterate each line from a file. Next, In each iteration of a loop, use the if condition to check if a string is present in a current line and print the current line and line number
Example to search for a string in text file
I have a ‘sales.txt’ file that contains monthly sales data of items. I want the sales data of a specific item. Let’s see how to search particular item data in a sales file.
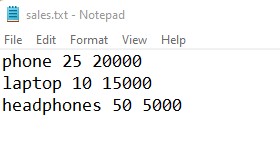
def search_str(file_path, word):
with open(file_path, 'r') as file:
# read all content of a file
content = file.read()
# check if string present in a file
if word in content:
print('string exist in a file')
else:
print('string does not exist in a file')
search_str(r'E:demosfiles_demosaccountsales.txt', 'laptop')Output:
string exists in a file
Search file for a string and Print its line and line number
Use the following steps if you are searching a particular text or a word in a file, and you want to print a line number and line in which it is present.
- Open a file in a read mode.
- Next, use the
readlines()method to get all lines from a file in the form of a list object. - Next, use a loop to iterate each line from a file.
- Next, In each iteration of a loop, use the if condition to check if a string is present in a current line and print the current line and line number.
Example: In this example, we’ll search the string ‘laptop’ in a file, print its line along with the line number.
# string to search in file
word = 'laptop'
with open(r'E:demosfiles_demosaccountsales.txt', 'r') as fp:
# read all lines in a list
lines = fp.readlines()
for line in lines:
# check if string present on a current line
if line.find(word) != -1:
print(word, 'string exists in file')
print('Line Number:', lines.index(line))
print('Line:', line)Output:
laptop string exists in a file line: laptop 10 15000 line number: 1
Note: You can also use the readline() method instead of readlines() to read a file line by line, stop when you’ve gotten to the lines you want. Using this technique, we don’t need to read the entire file.
Efficient way to search string in a large text file
All above way read the entire file in memory. If the file is large, reading the whole file in memory is not ideal.
In this section, we’ll see the fastest and most memory-efficient way to search a string in a large text file.
- Open a file in read mode
- Use for loop with
enumerate()function to get a line and its number. Theenumerate()function adds a counter to an iterable and returns it in enumerate object. Pass the file pointer returned by theopen()function to theenumerate(). - We can use this enumerate object with a for loop to access the each line and line number.
Note: The enumerate(file_pointer) doesn’t load the entire file in memory, so this is an efficient solution.
Example:
with open(r"E:demosfiles_demosaccountsales.txt", 'r') as fp:
for l_no, line in enumerate(fp):
# search string
if 'laptop' in line:
print('string found in a file')
print('Line Number:', l_no)
print('Line:', line)
# don't look for next lines
breakExample:
string found in a file Line Number: 1 Line: laptop 10 15000
mmap to search for a string in text file
In this section, we’ll see the fastest and most memory-efficient way to search a string in a large text file.
Also, you can use the mmap module to find a string in a huge file. The mmap.mmap() method creates a bytearray object that checks the underlying file instead of reading the whole file in memory.
Example:
import mmap
with open(r'E:demosfiles_demosaccountsales.txt', 'rb', 0) as file:
s = mmap.mmap(file.fileno(), 0, access=mmap.ACCESS_READ)
if s.find(b'laptop') != -1:
print('string exist in a file')Output:
string exist in a file
Search string in multiple files
Sometimes you want to search a string in multiple files present in a directory. Use the below steps to search a text in all files of a directory.
- List all files of a directory
- Read each file one by one
- Next, search for a word in the given file. If found, stop reading the files.
Example:
import os
dir_path = r'E:demosfiles_demosaccount'
# iterate each file in a directory
for file in os.listdir(dir_path):
cur_path = os.path.join(dir_path, file)
# check if it is a file
if os.path.isfile(cur_path):
with open(cur_path, 'r') as file:
# read all content of a file and search string
if 'laptop' in file.read():
print('string found')
breakOutput:
string found
Search file for a list of strings
Sometimes you want to search a file for multiple strings. The below example shows how to search a text file for any words in a list.
Example:
words = ['laptop', 'phone']
with open(r'E:demosfiles_demosaccountsales.txt', 'r') as f:
content = f.read()
# Iterate list to find each word
for word in words:
if word in content:
print('string exist in a file')Output:
string exist in a file
Python Exercises and Quizzes
Free coding exercises and quizzes cover Python basics, data structure, data analytics, and more.
- 15+ Topic-specific Exercises and Quizzes
- Each Exercise contains 10 questions
- Each Quiz contains 12-15 MCQ
