В прошлой статье я рассказывала, что составила для своего проекта словарь «Властелина Колец», причем для каждого англоязычного терма (слова/словосочетания) хранится перевод и список глав, в которых встречается это выражение. Все это составлено вручную. Однако мне не дает покоя, что многие вхождения термов могли быть пропущены.

В первой версии MVP я частично решила эту проблему обычным поиском по подстроке (b{term}, где b – граница слова), что позволило найти вхождения отдельных слов без учета морфологии или с некоторыми внешними флексиями (например, -s, -ed, -ing). Фактически это поиск подстроки с джокером на конце. Но для многословных выражений и неправильных глаголов, составляющих весомую долю моего словаря, этот способ не работал.
После пары безуспешных попыток установить Elasticsearch я, как типичный изобретатель велосипеда и вечного двигателя, решила писать свой код. Скудным словообразованием английского языка меня не запугать ввиду наличия опыта разработки полнотекстового поиска по документам на великом и могучем русском языке. Кроме того, для моей задачи часть вхождений уже все равно выбрана вручную и потому стопроцентная точность не требуется.
Подготовка словаря
Итак, дан словарь. Ну как дан – составлен руками за несколько месяцев упорного труда. Дан с точки зрения программиста. После прошлой статьи словарь подрос вдвое и теперь охватывает весь первый том («Братство Кольца»). В сыром виде состоит из 11.690 записей в формате «терм – перевод – номер главы». Хранится в Excel.
Как и в прошлый раз, я сгруппировала свой словарь по словарным гнездам с помощью функции pivot_table() из pandas. Осталось 5.404 записи, а после ручного редактирования – 5.354.
Больше всего меня беспокоили неправильные глаголы, поскольку в моем словаре они хранились в инфинитиве, а в романе чаще всего употреблялись в прошедшем времени. Ввиду так называемого аблаута (например, run – ran – run) установить инфинитив по словоформе прошедшего времени невозможно.
Я скачала словарь неправильных глаголов. Он насчитывал 294 штуки, многие из которых допускали два варианта. Пришлось проверить все вариации по тексту Толкиена, чтобы установить, какая форма характерна для его речи: например, cloven (p.p. от cleave) вместо cleft (что у него существительное). Оказалось, что многие неправильные глаголы у него правильные (например, burn), а leap даже существует в обеих версиях – leaped и leapt.
Теперь вариации неправильных глаголов унифицированы, а их список хранится в обычном текстовом файле:

Остается считать этот файл в датафрейм с помощью функции read_csv(), указав в качестве разделителей пробелы:
import pandas as pd
verb_data = pd.read_csv(pathlib.Path('c:/', 'ALL', 'LotR', 'неправильные глаголы.txt'),
sep=" ", header=None, names=["Inf", "Past", "PastParticiple"], index_col=0)Явно задаем index_col, чтобы сделать индексом первый столбец, хранящий инфинитивы глаголов, для удобства дальнейшего поиска.
Считаем наш главный словарь в другой датафрейм:
excel_data = pd.read_excel(pathlib.Path('c:/', 'ALL', 'LotR', 'словарь Толкиена сведенный.xlsx'), dtype = str)
df = pd.DataFrame(excel_data, columns=['Word', 'Russian', 'Chapters'])Теперь объявим функцию, которая для каждого словарного терма проверит наличие в нем неправильного глагола и в зависимости от результата сгенерирует словоформы. Для простоты будем считать, что неправильный глагол всегда стоит на первом месте.
def check_irrverbs(word):
global verb_data
# берем часть выражения до первого пробела
arr = word.split(' ')
w, *tail = arr # = arr[0], arr[1:]
# запоминаем хвост
tail = " ".join(tail)
# проверяем, не является ли она неправильным глаголом
if w in verb_data.index:
# формируем формы Past и Past Participle
# если они одинаковые, то достаточно хранить одну форму
if verb_data.loc[w]["Past"] == verb_data.loc[w]["PastParticiple"]:
return verb_data.loc[w]["Past"] + " " + tail
return ", ".join([v + " " + tail for v in verb_data.loc[w].tolist()])
return ""Таким образом, для выражения make up one’s mind функция вернет made up one’s mind.
Применяем функцию к датафрейму, сохраняя результаты в новый столбец, и затем экспортируем результат в новый Excel-файл:
df['IrrVerb'] = df['Word'].apply(check_irrverbs)
df.to_excel(pathlib.Path('c:/', 'ALL', 'LotR', 'словарь Толкиена сведенный.xlsx'))Теперь в Excel-таблице появился новый столбец, хранящий 2-ю (Past) и 3-ю (Past Participle) формы для всех неправильных глаголов, а для правильных столбец пуст.

Всего таких записей оказалось 662.
Спряжение потенциальных глаголов
Теперь сгенерируем все формы и для правильных, и для неправильных глаголов.
def generate_verbs(word, is_irrverb):
forms = []
# взять часть выражения до первого пробела
verb, tail = word, ""
pos = word.find(" ")
if pos >= 0:
verb = word[:pos]
tail = word[pos:]
consonant = "bcdfghjklmnpqrstvwxz"
last = verb[-1]
# глагол во 2 и 3 формах
if not is_irrverb:
if last in consonant:
forms.append(verb + last + "ed" + tail) # stop -> stopped
forms.append(verb + "ed" + tail) # и вариант без удвоения
elif last == "y":
if verb[-2] in consonant:
forms.append(verb[:-1] + "ied" + tail) # carry -> carried
else:
forms.append(verb + "ed" + tail) # play -> played
elif last == "e":
forms.append(verb + "d" + tail) # arrive -> arrived
else:
forms.append(verb + "ed" + tail)
# герундий, он же ing-овая форма глагола
if verb[-2:] == "ie":
forms.append(verb[:-2] + "ying" + tail) # lie -> lying
elif last == "e":
forms.append(verb[:-1] + "ing" + tail) # write -> writing
elif last in consonant:
forms.append(verb + last + "ing" + tail) # sit -> sitting
forms.append(verb + "ing" + tail) # sit -> sitting
else:
forms.append(verb + "ing" + tail)
return formsКак и прежде, для простоты будем считать глаголом часть выражения до первого пробела либо все выражение целиком, если оно не содержит пробелов. Посмотрим, на какую букву (переменная last) оканчивается предполагаемый глагол. Для этого нужен список либо гласных, либо согласных. Список гласных был бы короче, но так как нам понадобится проверять именно на согласную, то нагляднее будет хранить список consonant.
Для правильных глаголов вторая и третья формы создаются путем прибавления флексий -d, -ed, -ied в зависимости от последнего и предпоследнего звука. Так как учитывается еще и ударение, то проще всего сгенерировать оба варианта, из которых грамматически корректен будет только один. Для неправильных глаголов мы уже нашли обе формы и записали в отдельный столбец.
Герундий образуется одинаково для правильных и неправильных глаголов, но опять-таки надо учитывать последний символ и ударение, поэтому снова создаем оба варианта.
Все варианты записываются в список forms, который функция и возвращает.
Сложность заключается в том, что наш словарь не содержит информации о частях речи для каждого терма, да это и малоинформативно ввиду так называемой конверсии – одно и то же слово может быть и существительным, и глаголом в зависимости от места в предложении. Поэтому мы сейчас рассматриваем все хранящиеся в словаре выражения как потенциальные глаголы, так как перед нами не стоит задача построить грамматически корректную форму. Мы строим просто гипотезы. Если они не найдутся в тексте, то и не надо.
Подстановки
Кроме неправильных глаголов, словарь содержит еще один вид выражений, осложняющих полнотекстовый поиск, – подстановочные местоимения: притяжательное one’s, возвратное oneself и неопределенные somebody и something. В реальном тексте они должны заменяться на конкретные слова – соответственно, притяжательные местоимения (my, your, his и т.д.), возвратные местоимения (myself, yourself, himself и т.д.) и существительные. Поэтому надо сгенерировать все возможные формы с подстановками.
Начнем с one’s и oneself:
def replace_possessive_reflexive(word):
possessive = ["my", "mine", "your", "yours", "his", "her", "hers", "its", "our", "ours", "their", "theirs"]
reflexive = ["myself", "yourself", "himself", "herself", "itself", "ourselves", "yourselves", "themselves"]
# заменить one's на все варианты из possessive
if "one's" in word:
forms = list(map(lambda p: word.replace("one's", p), possessive))
elif "oneself" in word:
# заменить oneself на все варианты из reflexive
forms = list(map(lambda r: word.replace("oneself", r), reflexive))
else:
forms = [word]
return formsЗдесь мы для простоты предполагаем, что one’s и oneself не встречаются в одном выражении, а также не употребляются в реальном тексте. Если в терме есть одно из этих слов, то он интересует нас только с подстановками. В противном случае терм рассматривается как одна из форм самого себя, поэтому создается список, состоящий только из него.
Полный процесс замены обрабатывает также скобки и неопределенные местоимения:
def template_replace(word):
forms = []
forms = [word] if not "(" in word else [word.replace("(", "").replace(")", ""), re.sub("([^)]+)", "", word)]
forms = list(map(lambda f: f.replace("somebody", "S+").replace("something", "S+"), forms))
forms = list(map(replace_possessive_reflexive, forms))
return sum(forms, [])Замена происходит в три этапа, причем результат предыдущего подается на вход следующему.
-
Если терм содержит скобки, то рассматриваем два варианта – с их содержимым или без него: например, wild(ly) -> {wild, wildly}.
-
Что касается somebody и something, то они заменяются на S+ – группу любых непробельных символов, то есть на заготовку для будущего регулярного выражения.
-
Наконец вызываем рассмотренную выше функцию replace_possessive_reflexive() для обработки one’s и oneself.
В итоге получится многомерный список, который необходимо преобразовать в одномерный. В данном случае эта задача решается путем сложения с пустым списком.
Таким образом, основная идея данной реализации полнотекстового поиска – генерировать максимальное количество вариантов словоформ, чтобы затем искать их в тексте. Как велико это число? В простейшем случае, для термов, не содержащих неправильных глаголов и оканчивающихся на гласную, будет всего 3 формы – инфинитив, вторая/третья форма и герундий. Если терм кончается на согласную, то появляется второй вариант герундия. В худшем случае терм содержит скобки, притяжательное местоимение и неправильный глагол, оканчиваясь на согласную, тогда для первичного списка из 2 вариантов со скобками * 12 притяжательных местоимений будут сгенерированы по 24 формы инфинитива, двух вариантов герундия, а также прошедшего времени и причастия прошедшего времени, итого
![]()
Отдельной строкой, чтобы осознать масштаб этой цифры)
Впрочем, мой словарь не содержит настолько сложных случаев. Вот более характерный пример – hold one’s breath (сочетание неправильного глагола, оканчивающегося на гласную, и притяжательного местоимения). Из него будет сгенерировано 48 форм:
-
12 вариантов инфинитива: ‘hold my breath’, ‘hold mine breath’, ‘hold your breath’, ‘hold yours breath’, ‘hold his breath’, ‘hold her breath’, ‘hold hers breath’, ‘hold its breath’, ‘hold our breath’, ‘hold ours breath’, ‘hold their breath’, ‘hold theirs breath’
-
24 варианта герундия, с удвоенной согласной и с одинарной: ‘holdding my breath’, ‘holding my breath’, ‘holdding mine breath’, ‘holding mine breath’, ‘holdding your breath’, ‘holding your breath’, ‘holdding yours breath’, ‘holding yours breath’, ‘holdding his breath’, ‘holding his breath’, ‘holdding her breath’, ‘holding her breath’, ‘holdding hers breath’, ‘holding hers breath’, ‘holdding its breath’, ‘holding its breath’, ‘holdding our breath’, ‘holding our breath’, ‘holdding ours breath’, ‘holding ours breath’, ‘holdding their breath’, ‘holding their breath’, ‘holdding theirs breath’, ‘holding theirs breath’
-
12 вариантов прошедшего времени, совпадающего с past participle: ‘held my breath’, ‘held mine breath’, ‘held your breath’, ‘held yours breath’, ‘held his breath’, ‘held her breath’, ‘held hers breath’, ‘held its breath’, ‘held our breath’, ‘held ours breath’, ‘held their breath’, ‘held theirs breath’
Такие случаи довольно редки. Как уже говорилось, на весь 5-тысячный словарь нашлось всего 662 строки с неправильными глаголами. Что касается остальных сложных случаев, то в словаре 91 терм с притяжательными местоимениями, 31 – с подстановками somebody/something и 61 совмещает в себе и неправильный глагол, и какую-либо подстановку.
Поиск по тексту
Наконец приступаем к анализу оригинального текста, чтобы найти в нем пропущенные вхождения термов. Считаем датафрейм из Excel, не забывая, что заданные в списке columns заголовки столбцов должны фигурировать в первой строке листа Excel.
excel_data = pd.read_excel(pathlib.Path('c:/', 'ALL', 'LotR', 'словарь Толкиена сведенный.xlsx'), dtype = str)
df = pd.DataFrame(excel_data, columns=['Word', 'Russian', 'Chapters', 'IrrVerb'])Прежде чем работать с текстом романа, возьмем на себя смелость слегка подправить великого автора, изменив нумерацию глав на сквозную. Вместо двух книг по 12 и 10 глав соответственно получится одна с 22-мя главами.
После этого откроем текст, удалим символы перевода строки и табуляции. Сразу заменим часто встречающееся в нем слово Mr., чтобы оно не мешало разбивать текст по предложениям.
f = open(pathlib.Path('c:/', 'ALL', 'LotR', 'Fellowship.txt'))
text = f.read().replace('n', ' ').replace('t', ' ').replace('r', ' ').replace('Mr. ', 'Mr') # учтет Mr.BagginsТеперь разобьем текст по главам.
lotr = []
text = re.split('Chaptersd+', text)Тогда в 0-м элементе списка будет предисловие, в 1-м – глава 1 и т.д., то есть индексы будут соответствовать реальным номерам глав, что очень удобно.

for chapter in text:
lotr.append(re.split('[.?!]', chapter))Теперь нас ждет главная функция, обрабатывающая строку датафрейма. Прежде всего получим старый список глав, в которых встречается данный терм. Он хранится в отдельном столбце таблицы. Наша задача – постараться дополнить этот список и в любом случае не забыть хотя бы отсортировать его.
ch = list(map(int, vec[0].split(',')))Если терм оканчивается восклицательным или вопросительным знаком, то это неизменяемое устойчивое выражение, например, междометие. Для него никаких словоформ искать не нужно.
word = vec[1]
if word[-1:] == "!" or word[-1:] == "?":
forms = [word]Для любого другого терма начнем с проверки, входит ли в него неправильный глагол, то есть заполнен ли соответствующий столбец (isnan()). Для неправильного глагола выделим 2-ю и 3-ю формы, которые могут различаться или совпадать.
else:
is_irrverb = False if isinstance(vec[2], float) and math.isnan(vec[2]) else True
if is_irrverb:
pos = vec[2].find(", ")
if pos >= 0:
past = vec[2][:pos]
past_participle = vec[2][pos + 2:]
else:
past = past_participle = vec[2]Произведем замены с помощью функции template_replace(), получим список словоформ. Проспрягаем каждый элемент этого списка.
forms = template_replace(word)
forms = forms + sum(list(map(lambda f: generate_verbs(f, is_irrverb), forms)), [])Для неправильных глаголов отдельно произведем замены для 2-й и 3-й форм.
if is_irrverb:
forms = forms + template_replace(past)
if past_participle != past:
forms = forms + template_replace(past_participle)Затем ищем каждую словоформу в каждой главе кроме ранее найденных глав, содержащихся в старом списке ch. Для этого используем функцию filter(), передав ей лямбда-функцию, которая будет обрабатывать каждое предложение. Поиск производится по регулярному выражению b{f}, где b – граница слова, а f – словоформа. Как уже говорилось, указание левой границы слова позволяет реализовать поиск с джокером на конце подстроки. Несмотря на весь написанный ранее код, мы все еще нуждаемся в этом нехитром приеме, так как флексии никто не отменял. Кроме того, от регулярного выражения мы никуда не денемся, так как ранее заменяли somebody/something на S+.
for f in forms:
for i in range(1, len(lotr)): # 0-ю главу (предисловие) пока пропускаем
if not i in ch:
match = list(filter(lambda sentence: re.search(rf'b{f}', sentence, flags=re.IGNORECASE), lotr[i]))
if match:
ch.append(i)Этот код ищет все вхождения терма в главу, хотя для поставленной задачи нужно найти только первое. Зато этот вариант облегчает тестирование программы.
Новые номера глав сохраняются в тот же список ch, который в конце концов сортируется и возвращается.
ch.sort()
return chПолный код функции check_chapters() выглядит следующим образом.
def check_chapters(vec):
global lotr
ch = list(map(int, vec[0].split(',')))
word = vec[1]
if word[-1:] == "!" or word[-1:] == "?":
forms = [word]
else:
is_irrverb = False if isinstance(vec[2], float) and math.isnan(vec[2]) else True
if is_irrverb:
pos = vec[2].find(", ")
if pos >= 0:
past = vec[2][:pos]
past_participle = vec[2][pos + 2:]
else:
past = past_participle = vec[2]
forms = template_replace(word)
forms = forms + sum(list(map(lambda f: generate_verbs(f, is_irrverb), forms)), [])
if is_irrverb:
forms = forms + template_replace(past)
if past_participle != past:
forms = forms + template_replace(past_participle)
for f in forms:
for i in range(1, len(lotr)): # 0-ю главу (предисловие) пока пропускаем
if not i in ch:
match = list(filter(lambda sentence: re.search(rf'b{f}', sentence, flags=re.IGNORECASE), lotr[i]))
if match:
ch.append(i)
ch.sort()
return chОсталось только применить эту функцию к датафрейму, сохранив результат в новый столбец New chapters:
df['New chapters'] = df[['Chapters', 'Word', 'IrrVerb']].apply(check_chapters, axis=1)
df.to_excel(pathlib.Path('c:/', 'ALL', 'LotR', 'словарь Толкиена сведенный.xlsx'))Тестирование
Для тестирования была произведена выборка наиболее сложных термов – с неправильными глаголами и подстановками.
test = df[['Chapters', 'Word', 'IrrVerb']]
test = test[(test['IrrVerb'].str.len() > 0) & (test['Word'].str.contains("one's") | test['Word'].str.contains("something") | test['Word'].str.contains("somebody"))]
print(test.apply(check_chapters, axis=1))Вот термы, для которых было найдено более одного вхождения и которые поэтому являются самыми характерными (неупорядоченная нумерация сложилась потому, что поиск производился сначала по словоформам и лишь затем по главам):
|
Терм |
Найденные вхождения |
|
find one’s way |
Chapter 12: We could perhaps find our way through and come round to Rivendell from the north; but it would take too long, for I do not know the way, and our food would not last Chapter 2: He found his way into Mirkwood, as one would expect |
|
make one’s way |
Chapter 3: My plan was to leave the Shire secretly, and make my way to Rivendell; but now my footsteps are dogged, before ever I get to Buckland Chapter 16: Make your ways to places where you can find grass, and so come in time to Elrond’s house, or wherever you wish to go Chapter 6: Coming to the opening they found that they had made their way down through a cleft in a high sleep bank, almost a cliff Chapter 11: Merry’s ponies had escaped altogether, and eventually (having a good deal of sense) they made their way to the Downs in search of Fatty Lumpkin Chapter 12: They made their way slowly and cautiously round the south-western slopes of the hill, and came in a little while to the edge of the Road |
|
make up one’s mind |
Chapter 10: You must make up your mind Chapter 19: But before Sam could make up his mind what it was that he saw, the light faded; and now he thought he saw Frodo with a pale face lying fast asleep under a great dark cliff Chapter 16: The eastern arch will probably prove to be the way that we must take; but before we make up our minds we ought to look about us Chapter 22: ‘Yet we must needs make up our minds without his aid Chapter 4: I am leaving the Shire as soon as ever I can – in fact I have made up my mind now not even to wait a day at Crickhollow, if it can be helped Chapter 21: Sam had long ago made up his mind that, though boats were maybe not as dangerous as he had been brought up to believe, they were far more uncomfortable than even he had imagined |
|
one’s heart sink |
Chapter 11: ‘It is getting late, and I don’t like this hole: it makes my heart sink somehow Chapter 14: ” ‘”The Shire,” I said; but my heart sank |
|
shake one’s head |
Chapter 2: ‘They are sailing, sailing, sailing over the Sea, they are going into the West and leaving us,’ said Sam, half chanting the words, shaking his head sadly and solemnly Chapter 4: Too near the River,’ he said, shaking his head Chapter 9: ‘ ‘There’s some mistake somewhere,’ said Butterbur, shaking his head Chapter 14: ‘ he said, shaking his head Chapter 16: ‘I am too weary to decide,’ he said, shaking his head Chapter 12: ‘ When he heard what Frodo had to tell, he became full of concern, and shook his head and sighed Chapter 15: Gimli looked up and shook his head Chapter 22: Sam, who had been watching his master with great concern, shook his head and muttered: ‘Plain as a pikestaff it is, but it’s no good Sam Gamgee putting in his spoke just now |
|
sleep on something |
Chapter 3: ‘Well, see you later – the day after tomorrow, if you don’t go to sleep on the way Chapter 13: His head seemed sunk in sleep on his breast, and a fold of his dark cloak was drawn over his face Chapter 18: I cannot sleep on a perch |
|
spring to one’s feet |
Chapter 2: ’ cried Gandalf, springing to his feet Chapter 11: ‘ asked Frodo, springing to his feet Chapter 14: ‘ cried Frodo in amazement, springing to his feet, as if he expected the Ring to be demanded at once Chapter 16: With a suddenness that startled them all the wizard sprang to his feet Chapter 8: The hobbits sprang to their feet in alarm, and ran to the western rim Chapter 9: The local hobbits stared in amazement, and then sprang to their feet and shouted for Barliman |
|
take one’s advice |
Chapter 3: If I take your advice I may not see Gandalf for a long while, and I ought to know what is the danger that pursues me Chapter 11: When they saw them they were glad that they had taken his advice: the windows had been forced open and were swinging, and the curtains were flapping; the beds were tossed about, and the bolsters slashed and flung upon the floor; the brown mat was torn to pieces |
Таким образом, в большинстве случаев словоформы обрабатываются корректно.
Итоги
Учитывая вышеприведенный расчет со 120 словоформами, порожденными одной строкой словаря, поиск всех вхождений вместо первого, наличие регулярных выражений и громоздкость решения в целом, я не ожидала от программы быстрых результатов. Однако на ноутбуке с 4-ядерным Intel i5-8265U и 8 Гб ОЗУ словарь из 5 тыс. строк был проработан за 1.187 секунд. В итоге найдены 3.330 новых вхождений в дополнение к прежним 10.482, записанным вручную.

Вот так несколько десятков строк кода показали вполне удовлетворительные результаты для полнотекстового поиска с поддержкой морфологии английского языка. Программа работает достаточно корректно и быстро. Конечно, она не лишена недостатков – не застрахована от ложных срабатываний, не учтет флексию в середине многословного терма (например, takes his advice). Однако с поставленной задачей успешно справилась.
Содержание
- Поиск по тексту в Ворде
- Поиск по словам и фразам через панель «Навигация»
- Расширенный поиск в Ворде
- Метод 1: Вкладка «Главная»
- Метод 2: Через окно «Навигация»
- Поиск текста с определенным форматированием в Word с помощью чтения с экрана
- В этом разделе
- Поиск определенного стиля
- Поиск определенного форматирования
- Дополнительные сведения
- Техническая поддержка пользователей с ограниченными возможностями
- Поиск и замена в word
- Поиск слова в ворде
- Настроить поиск текста
- Навигация между страницами
- Команда заменить в ворде
- Найти выделенные курсивом слова
- Поиск по тексту в Ворде
- Самый простой поиск в Word – кнопка «Найти»
- Расширенный поиск в Ворде
- Как в Word найти слово в тексте – Расширенный поиск
- Направление поиска
- Поиск с учетом регистра
- Поиск по целым словам
- Подстановочные знаки
- Поиск омофонов
- Поиск по тексту без учета знаков препинания
- Поиск слов без учета пробелов
- Поиск текста по формату
- Специальный поиск от Ворд
- Опции, которые не приносят пользы
- Поиск в «Ворде». Как выполнить поиск в «Ворде» по слову
- Настройка функций расширенного поиска
- Видео
- Поиск слова в документе
- Поиск слова или фразы по тексту в Ворде ( )
- Команда заменить в ворде
- Настроить поиск текста
- Как в Word найти слово в тексте – Расширенный поиск
- Направление поиска
- Поиск с учетом регистра
- Поиск по целым словам
- Подстановочные знаки
- Поиск омофонов
- Поиск по тексту без учета знаков препинания
- Поиск слов без учета пробелов
- Поиск текста по формату
- Специальный поиск от Ворд
Поиск по тексту в Ворде
Бывают такие ситуации, когда в огромной статье нужно найти определённый символ или слово. Перечитывать весь текст – не вариант, необходимо воспользоваться быстрым способом – открыть поиск в Ворде. Существует несколько способов, с помощью которых можно легко совершать поиск по документу.
Поиск по словам и фразам через панель «Навигация»
Чтобы найти какую-либо фразу или слово в документе Ворд, надо открыть окно «Навигация». Найти данное окно можно с помощью шагов ниже:
Примечание. Поиск будет выдавать как точный вариант запроса фразы, так и производный. Наглядно можно увидеть на примере ниже.

Внимание. Если выделить определённое слово в тексте и нажать «Ctrl+F», то сработает поиск по данному слову. Причем в области поиска искомое слово уже будет написано.
Если случайно закрыли окно поиска, то нажмите сочетание клавиш «Ctrl+Alt+Y». Ворд повторно начнет искать последнюю искомую фразу.
Расширенный поиск в Ворде
Если понадобилось разыскать какой-то символ в определенном отрывке статьи, к примеру, знак неразрывного пробела или сноску, то в помощь расширенный поиск.
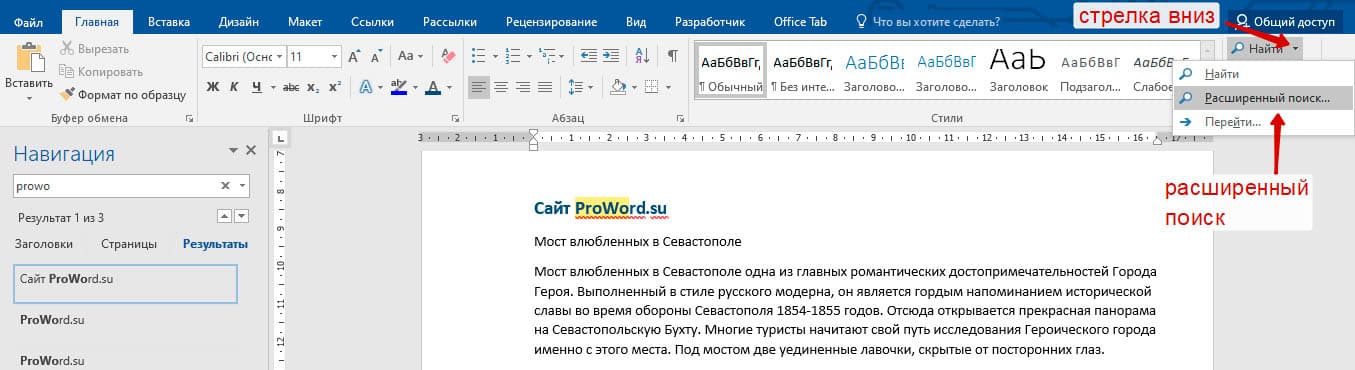
Метод 1: Вкладка «Главная»
Найти расширенный поиск можно нажав по стрелке на кнопке «Найти» во вкладке «Главная».

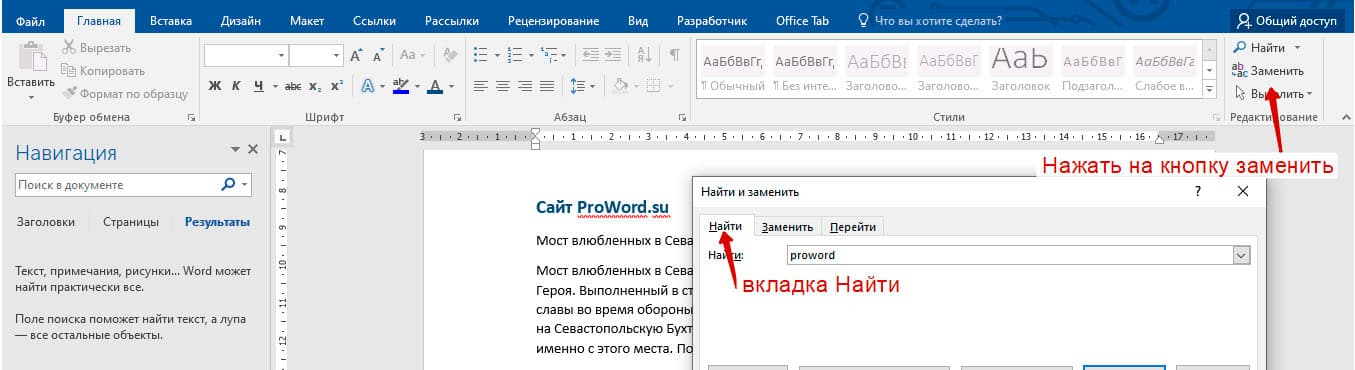
В новом окне в разделе «Найти» нужно кликнуть по кнопке «Больше». Тогда раскроется полный функционал данного поиска.

В поле «Найти» напишите искомую фразу или перейдите к кнопке «Специальный» и укажите нужный вариант для поиска.

Далее поставьте соответствующий вид документа, нажав по кнопке «Найти в», если нужно совершить поиск по всему документу то «Основной документ».

Когда надо совершить поиск по какому-то фрагменту в статье, изначально нужно его выделить и указать «Текущий фрагмент».

В окне «Найти и заменить» всплывет уведомление сколько элементов найдено Вордом.

Метод 2: Через окно «Навигация»
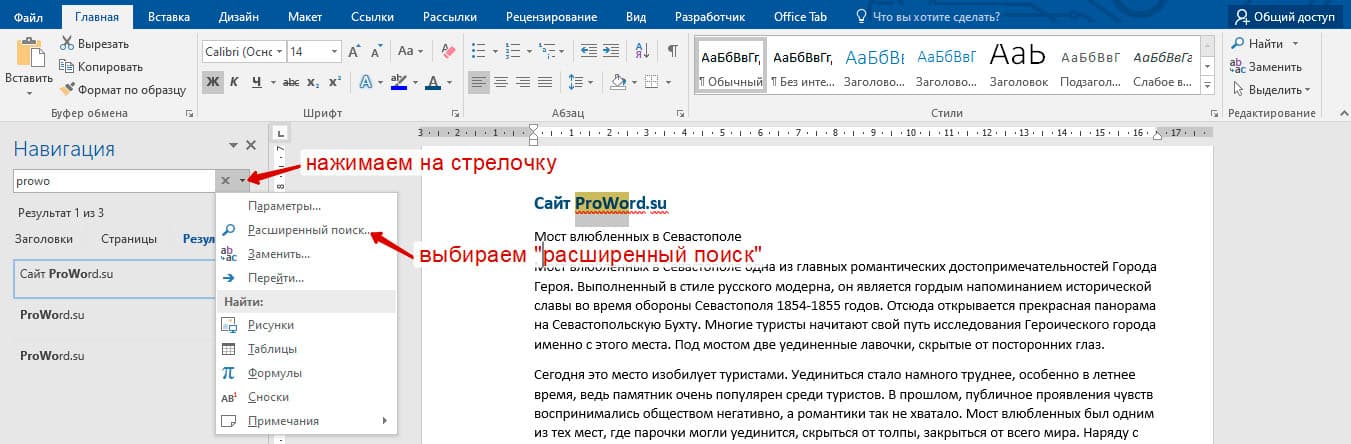
Открыть расширенный поиск можно через панель «Навигация».

Рядом со значком «Лупа» есть маленький треугольник, нужно нажать по нему и выбрать «Расширенный поиск».

Источник
Поиск текста с определенным форматированием в Word с помощью чтения с экрана
 Содержимое для средств чтения с экрана
Содержимое для средств чтения с экрана
Эта статья предназначена для людей с нарушениями зрения, использующих программы чтения с экрана совместно с продуктами Office. Она входит в набор содержимого Специальные возможности Office. Дополнительные общие сведения см. на домашней странице службы поддержки Microsoft.
Используйте Word клавиатурой и экранным устройством, чтобы узнать, где в документе используется определенный стиль или форматирование текста, и заменить его другим. Мы проверили эту функцию с помощью экранного диктора, но она может работать и с другими средствами чтения с экрана, если они соответствуют общепринятым стандартам и методам для специальных возможностей.
Новые возможности Microsoft 365 становятся доступны подписчикам Microsoft 365 по мере выхода, поэтому в вашем приложении эти возможности пока могут отсутствовать. Чтобы узнать о том, как можно быстрее получать новые возможности, станьте участником программы предварительной оценки Office.
Дополнительные сведения о средствах чтения с экрана см. в статье о работе средств чтения с экрана в Microsoft Office.
В этом разделе
Поиск определенного стиля
Иногда нужно найти все вхождения определенного стиля текста в документе, например «Сильное» или «Акцентировать», чтобы заменить его другим.
Нажмите клавиши CTRL+F. Вы услышите фразу «Навигация, Поиск в документе».
Нажимая клавиши SR+СТРЕЛКА ВПРАВО, пока не услышите «Дополнительные параметры, свернуто, элемент меню», нажмите клавиши ALT+СТРЕЛКА ВНИЗ, чтобы развернуть меню, а затем нажмите клавишу A, чтобы открыть диалоговое окно «Расширенный поиск». Вы услышите «Найти и заменить, окно, rich edit control, editing» (Окно поиска и замены, редактирование). Фокус будет находиться в текстовом поле «Найти».
Совет: Word запоминает параметры поиска, которые вы в последний раз использовали в диалоговом окни «Расширенный поиск», например если вы искали стиль «Сильное» и заменили его на «Акцент». Чтобы сбросить параметры поиска перед новым поиском, нажмите клавиши ALT+O, ALT+СТРЕЛКА ВВЕРХ, а затем нажмите клавиши ALT+T, чтобы выбрать параметр «Нет форматирования». Фокус вернется в текстовое поле «Найти».
Нажмите ALT+O, S, чтобы открыть диалоговое окно «Поиск стиля». Вы услышите :»Найти стиль, окно, найти стиль, нет стиля, ни один не выбран».
Нажимая клавишу СТРЕЛКА ВНИЗ, вы можете нажать клавишу СТРЕЛКА ВНИЗ, пока не прозвучит стиль, который вы хотите заменить, например «Акцентировать внимание», а затем нажмите клавишу ВВОД, чтобы выбрать его.
Совет: Чтобы перейти непосредственно к стилю, нужно нажать его первую букву. Например, чтобы перейти к кнопке «Акцент»,нажмите E. Если есть несколько стилей, которые начинаются с выбранной буквы, несколько раз нажмите клавишу, пока не будет озвучен выбранный стиль.
Нажмите ALT+P, чтобы переместить фокус на вкладку «Заменить». Про услышите «Выбрано, элемент вкладки «Заменить»». Нажимая клавишу TAB, вы не услышите «Заменить на, редактирование текста».
Совет: Word запоминает параметры замены, которые вы в последний раз использовали в диалоговом окни «Расширенный поиск», например при поиске стиля «Мощный» и заменяли его стилем «Акцент». Чтобы сбросить параметры замены перед новым поиском, нажмите клавиши ALT+O, ALT+СТРЕЛКА ВВЕРХ, а затем нажмите клавиши ALT+T, чтобы выбрать параметр «Нет форматирования». Фокус вернется в поле «Заменить на текстовое поле».
Нажмите ALT+O, S, чтобы открыть диалоговое окно «Поиск стиля». Вы услышите :»Найти стиль, окно, найти стиль, нет стиля, ни один не выбран».
Нажимая клавишу СТРЕЛКА ВНИЗ, вы можете нажать клавишу СТРЕЛКА ВНИЗ, пока не прозвучит нужный стиль, например «Акцентировать внимание», а затем нажмите клавишу ВВОД, чтобы выбрать его.
Совет: Чтобы перейти непосредственно к стилю, нужно нажать его первую букву. Например, чтобы перейти к кнопке «Акцент»,нажмите E. Если есть несколько стилей, которые начинаются с выбранной буквы, несколько раз нажмите клавишу, пока не будет озвучен выбранный стиль.
Нажмите ALT+A, чтобы заменить все вхождения первого стиля вторым. Вы услышите: «Диалоговое окно Microsoft Word, ОК, кнопка». Нажмите клавишу ВВОД, нажмите клавишу ESC, чтобы закрыть диалоговое окно «Расширенный поиск» и вернуть фокус в документ.
Поиск определенного форматирования
Иногда нужно найти все вхождения определенного форматирования текста в документе, например полужирное или налияние, чтобы заменить его другим.
Примечание: Если изменить форматирование, например полужирный текст во всем документе, он также изменит стиль шрифта везде, где используется этот стиль, но не наоборот. Поэтому мы рекомендуем использовать стили, а не форматирование вручную.
Нажмите клавиши CTRL+F. Вы услышите фразу «Навигация, Поиск в документе».
Нажимая клавиши SR+СТРЕЛКА ВПРАВО, пока не услышите «Дополнительные параметры, свернуто, элемент меню», нажмите клавиши ALT+СТРЕЛКА ВНИЗ, чтобы развернуть меню, а затем нажмите клавишу A, чтобы открыть диалоговое окно «Расширенный поиск». Вы услышите «Найти и заменить, окно, rich edit control, editing» (Окно поиска и замены, редактирование). Фокус будет находиться в текстовом поле «Найти».
Совет: Word запоминает параметры поиска, которые вы в последний раз использовали в диалоговом окни «Расширенный поиск», например, если вы искали полужирное форматирование и заменяли его на «Полужирный». Чтобы сбросить параметры поиска перед новым поиском, нажмите клавиши ALT+O, ALT+СТРЕЛКА ВВЕРХ, а затем нажмите клавиши ALT+T, чтобы выбрать параметр «Нет форматирования». Фокус вернется в текстовое поле «Найти».
Нажмите ALT+O, F, чтобы открыть диалоговое окно «Найти шрифт». Вы услышите сообщение «Найти шрифт, окно, шрифт, редактирование текста».
Нажмите клавиши ALT+Y, чтобы переместить фокус в меню «Нажатие клавиши «Шрифт», нажимайте клавишу СТРЕЛКА ВНИЗ, пока не будет озвучен стиль шрифта, который вы хотите заменить, например «Полужирный», а затем нажмите клавишу ВВОД, чтобы выбрать его.
Нажмите ALT+P, чтобы переместить фокус на вкладку «Заменить». Про услышите «Выбрано, элемент вкладки «Заменить»». Нажимая клавишу TAB, вы не услышите «Заменить на, редактирование текста».
Совет: Word запоминает параметры замены, которые использовались последним в диалоговом окни «Расширенный поиск», например, если вы искали полужирное форматирование и заменяли его на «Полужирный». Чтобы сбросить параметры замены перед новым поиском, нажмите клавиши ALT+O, ALT+СТРЕЛКА ВВЕРХ, а затем нажмите клавиши ALT+T, чтобы выбрать параметр «Нет форматирования». Фокус вернется в поле «Заменить на текстовое поле».
Нажмите ALT+O, F, чтобы открыть диалоговое окно «Найти шрифт». Вы услышите сообщение «Найти шрифт, окно, шрифт, редактирование текста».
Нажмите клавиши ALT+Y, чтобы переместить фокус в меню «Наконечник шрифта», нажимая клавишу СТРЕЛКА ВНИЗ, пока не будет озвучен нужный стиль шрифта, например «Обычный», а затем нажмите клавишу ВВОД, чтобы выбрать его.
Нажмите ALT+A, чтобы заменить все вхождения первого стиля шрифта на второе. Вы услышите: «Диалоговое окно Microsoft Word, ОК, кнопка». Нажмите клавишу ВВОД, нажмите клавишу ESC, чтобы закрыть диалоговое окно «Расширенный поиск» и вернуть фокус в документ.
Дополнительные сведения
Техническая поддержка пользователей с ограниченными возможностями
Корпорация Майкрософт стремится к тому, чтобы все наши клиенты получали наилучшие продукты и обслуживание. Если у вас ограниченные возможности или вас интересуют вопросы, связанные со специальными возможностями, обратитесь в службу Microsoft Disability Answer Desk для получения технической поддержки. Специалисты Microsoft Disability Answer Desk знакомы со многими популярными специальными возможностями и могут оказывать поддержку на английском, испанском, французском языках, а также на американском жестовом языке. Перейдите на сайт Microsoft Disability Answer Desk, чтобы узнать контактные сведения для вашего региона.
Если вы представитель государственного учреждения или коммерческой организации, обратитесь в службу Disability Answer Desk для предприятий.
Источник
Поиск и замена в word
Word предлагает функцию поиска, которая позволяет легко находить текст в документе. Можно не только найти слово или фразу, но также можно автоматически заменить найденный текст другим текстом. Все примеры, рассмотренные в этой статье выполнены в Word 2016
Поиск слова в ворде
Команда «Найти» может искать один символ, слово или группу слов. Для поиска слов или фраз с помощью команды «Найти» выполните следующую процедуру:

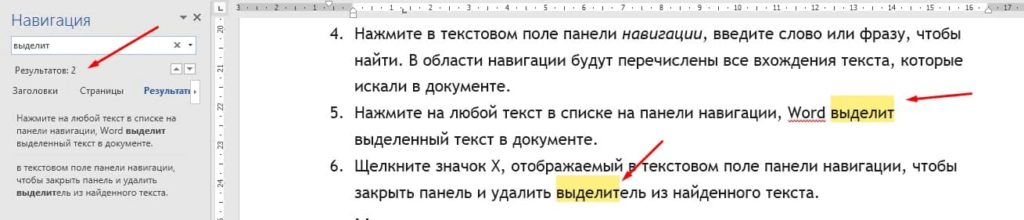
Панель навигации появится в левой части экрана. Нажмите в текстовом поле панели навигации, введите слово или фразу, чтобы найти. В области навигации будут перечислены все вхождения текста, которые искали в документе.
Нажмите на любой текст в списке на панели навигации, Word выделит текст в документе.
Настроить поиск текста
Щелкните значок увеличительного стекла в текстовом поле «Поиск документа» на панели навигации. Появляется раскрывающееся меню:
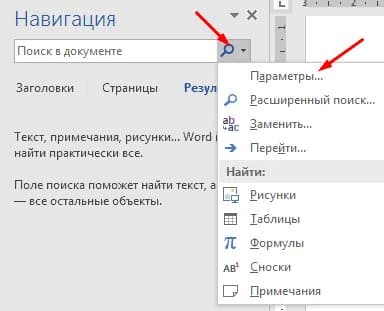
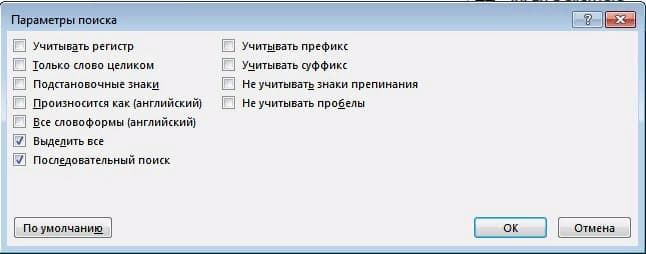
Нажмите «Параметры». Откроется диалоговое окно «Параметры поиска». Выберите один или несколько параметров в диалоговом окне.
Нажмите OK, чтобы диалоговое окно исчезло.
Навигация между страницами
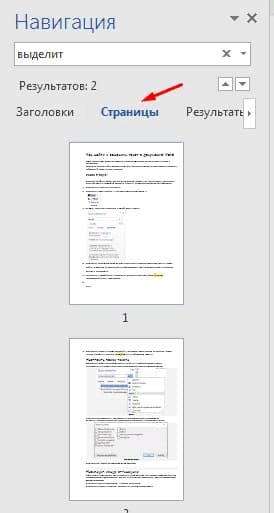
Word может отображать все страницы в виде эскизов. Вы можете просмотреть эти уменьшенные изображения и нажать на страницу, которую вы хотите просмотреть более подробно.
Нажмите вкладку Страницы в панели навигации.
Нажмите на эскиз страницы, которую вы хотите просмотреть.
Команда заменить в ворде
Вместо того, чтобы просто найти слово или фразу, вы можете найти текст и заменить его чем-то другим. Чтобы использовать команду «Найти и заменить», выполните процедуру:
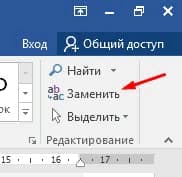
Найти выделенные курсивом слова
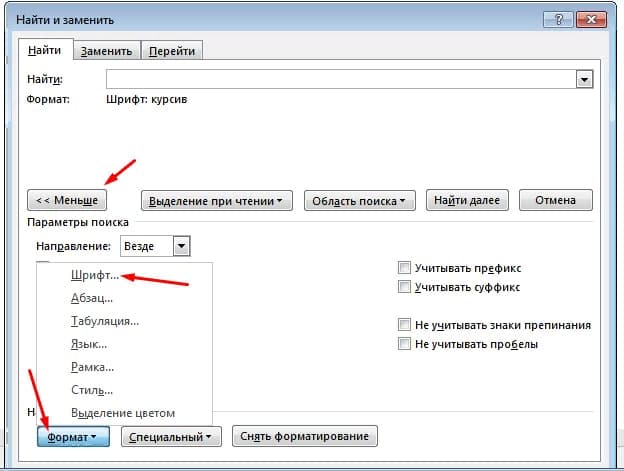
Для поиска в документе ворд определённого шрифта или, например, курсива выполните следующие шаги:
Шаг 1. Откройте «расширенный поиск» на вкладке «главная»

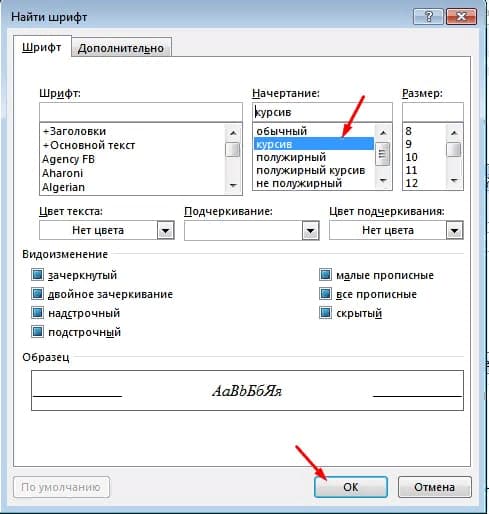
Шаг 2. Далее нажмите «Больше» и ниже «Формат» в списке выберите «Шрифт»
Шаг 3. В открывшемся окне «Найти шрифт» выберите курсив и нажните кнопку «Ок»
Таким же способом можно искать текст определённого цвета, рамки, стили и многое другое
Источник
Поиск по тексту в Ворде
Работая с текстом, особенно с большими объемами, зачастую необходимо найти слово или кусок текста. Для этого можно воспользоваться поиском по тексту в Ворде. Существует несколько вариантов поиска в Word:
Самый простой поиск в Word – кнопка «Найти»
Самый простой поиск в ворде – это через кнопку «Найти». Эта кнопка расположена во вкладке «Главная» в самом правом углу.
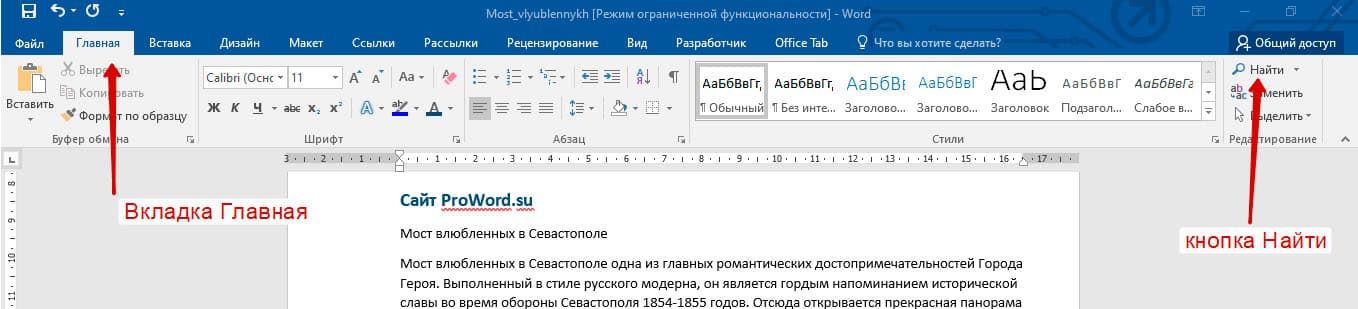
! Для ускорения работы, для поиска в Ворде воспользуйтесь комбинацией клавишей: CRL+F
После нажатия кнопки или сочетания клавишей откроется окно Навигации, где можно будет вводить слова для поиска.

! Это самый простой и быстрый способ поиска по документу Word.
Для обычного пользователя большего и не нужно. Но если ваша деятельность, вынуждает Вас искать более сложные фрагменты текста (например, нужно найти текст с синим цветом), то необходимо воспользоваться расширенной формой поиска.
Расширенный поиск в Ворде
Часто возникает необходимость поиска слов в Ворде, которое отличается по формату. Например, все слова, выделенные жирным. В этом как рас и поможет расширенный поиск.
Существует 3 варианта вызова расширенного поиска:
В любом случае все 3 варианта ведут к одной форме – «Расширенному поиску».
Как в Word найти слово в тексте – Расширенный поиск
После открытия отдельного диалогового окна, нужно нажать на кнопку «Больше»
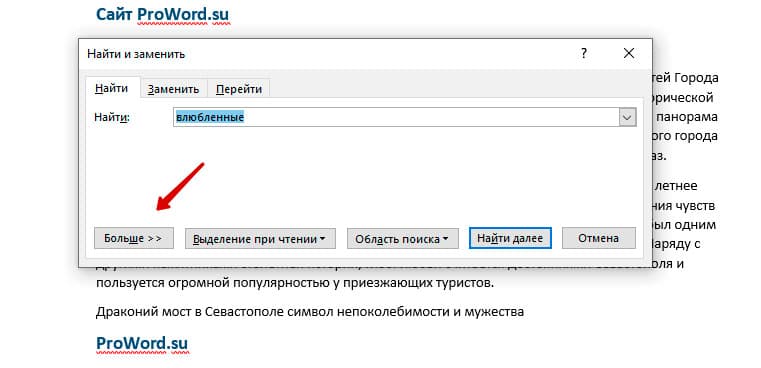
После нажатия кнопки диалоговое окно увеличится
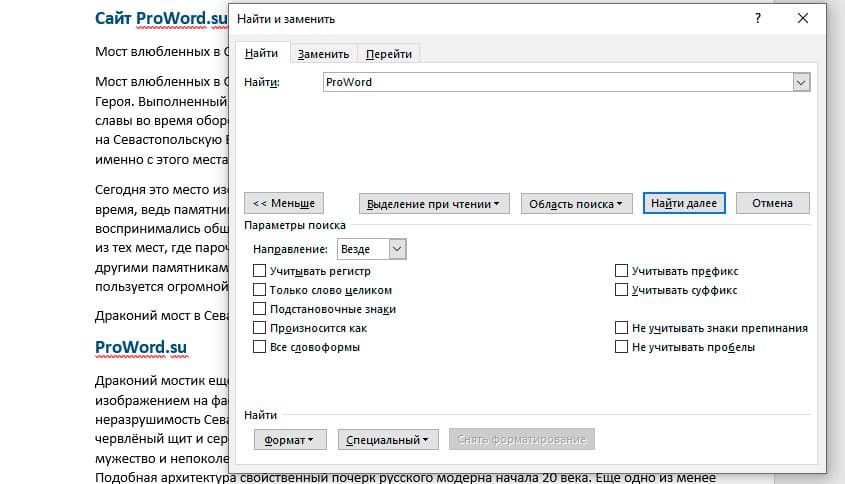
Перед нами высветилось большое количество настроек. Рассмотрим самые важные:
Направление поиска
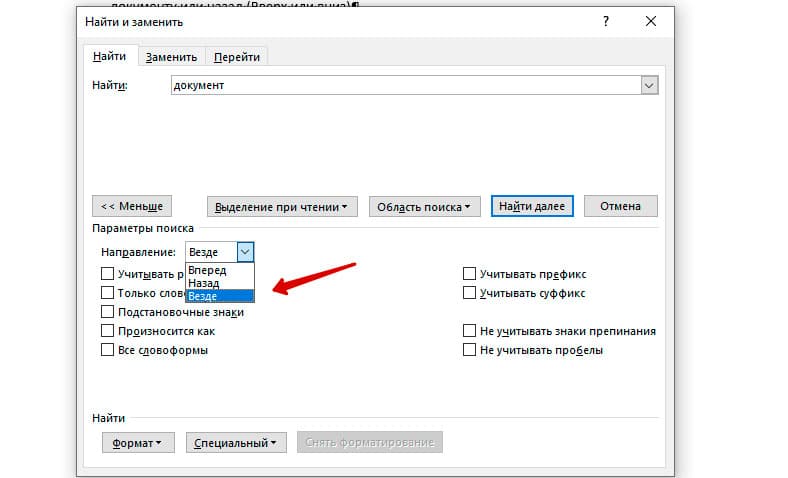
В настройках можно задать Направление поиска. Рекомендовано оставлять пункт «Везде». Так найти слово в тексте будет более реально, потому что поиск пройдет по всему файлу. Еще существуют режимы «Назад» и «Вперед». В этом режиме поиск начинается от курсора и идет вперед по документу или назад (Вверх или вниз)
Поиск с учетом регистра
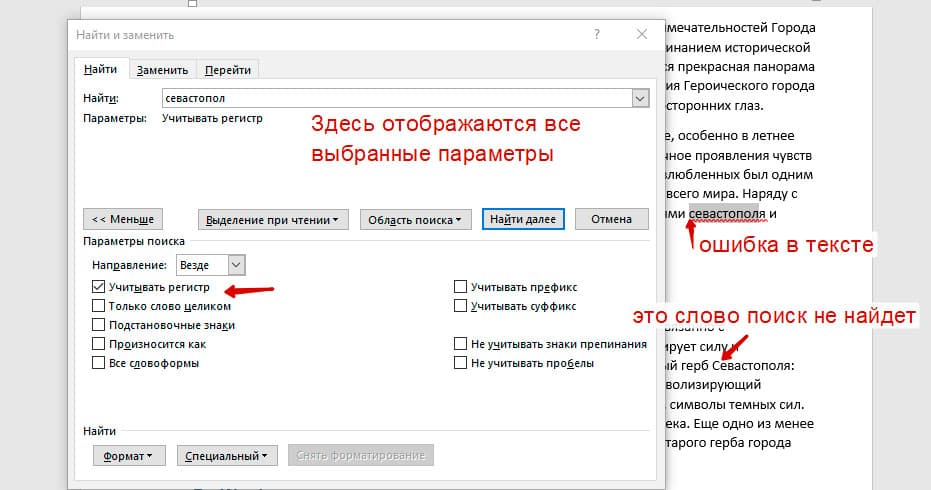
Поиск с учетом регистра позволяет искать слова с заданным регистром. Например, города пишутся с большой буквы, но журналист где-то мог неосознанно написать название города с маленькой буквы. Что бы облегчить поиск и проверку, необходимо воспользоваться этой конфигурацией:
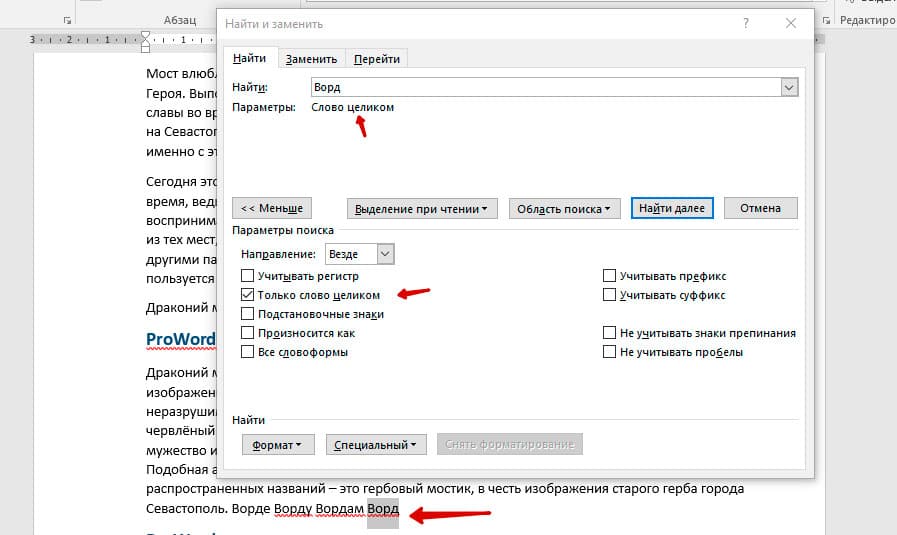
Поиск по целым словам
Если нажать на вторую галочку, «Только слово целиком», то поиск будет искать не по символам, а по целым словам. Т.е. если вбить в поиск только часть слова, то он его не найдет. Напимер, необходимо найти слово Ворд, при обычном поиске будут найдены все слова с разными окончаниями (Ворде, Ворду), но при нажатой галочке «Только слова целиком» этого не произойдет.
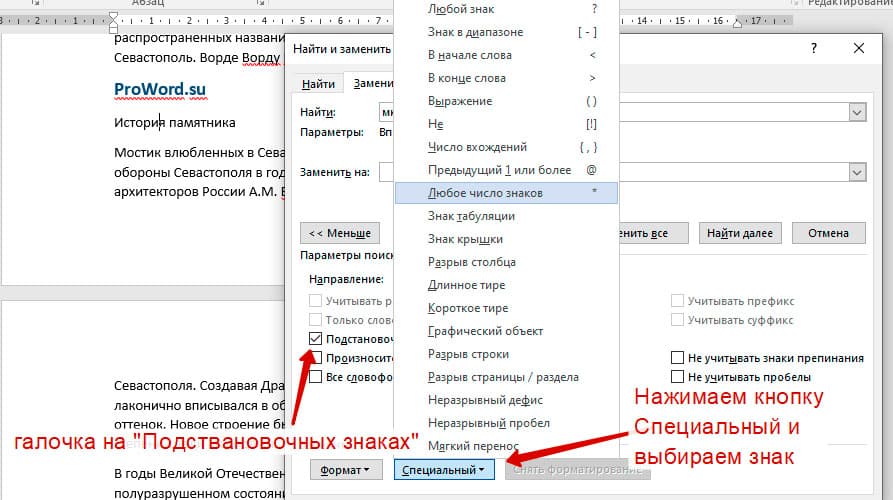
Подстановочные знаки
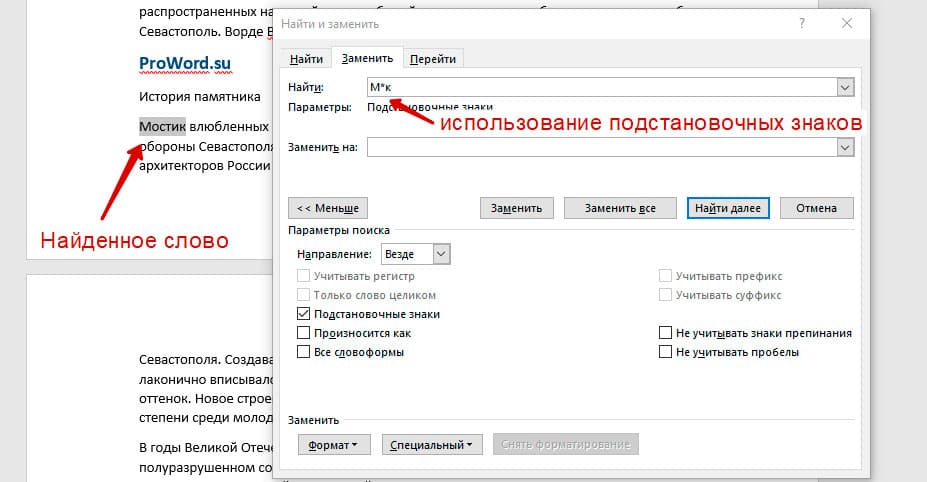
Более тяжелый элемент, это подстановочные знаки. Например, нам нужно найти все слова, которые начинаются с буквы м и заканчиваются буквой к. Для этого в диалоговом окне поиска нажимаем галочку «Подстановочные знаки», и нажимаем на кнопку «Специальный», в открывающемся списке выбираем нужный знак:
В результате Word найдет вот такое значение:
Поиск омофонов
Microsoft Word реализовал поиск омофонов, но только на английском языке, для этого необходимо выбрать пункт «Произносится как». Вообще, омофоны — это слова, которые произносятся одинаково, но пишутся и имеют значение разное. Для такого поиска необходимо нажать «Произносится как». Например, английское слово cell (клетка) произносится так же, как слово sell (продавать).
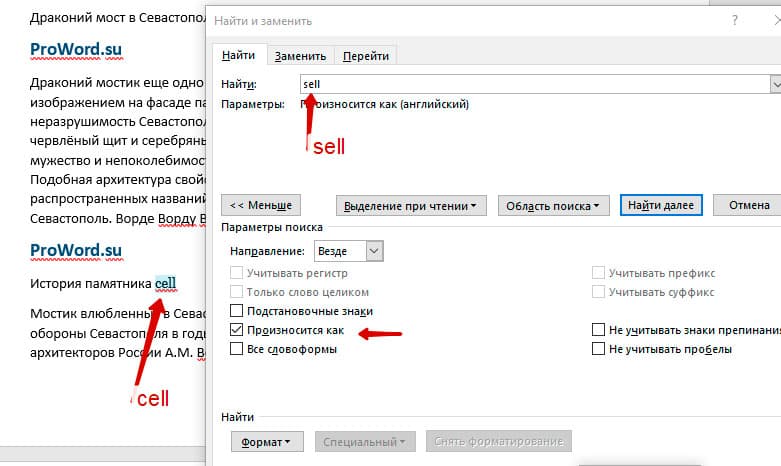
! из-за не поддержания русского языка, эффективность от данной опции на нуле
Поиск по тексту без учета знаков препинания
Очень полезная опция «Не учитывать знаки препинания». Она позволяет проводить поиск без учета знаков препинания, особенно хорошо, когда нужно найти словосочетание в тексте.
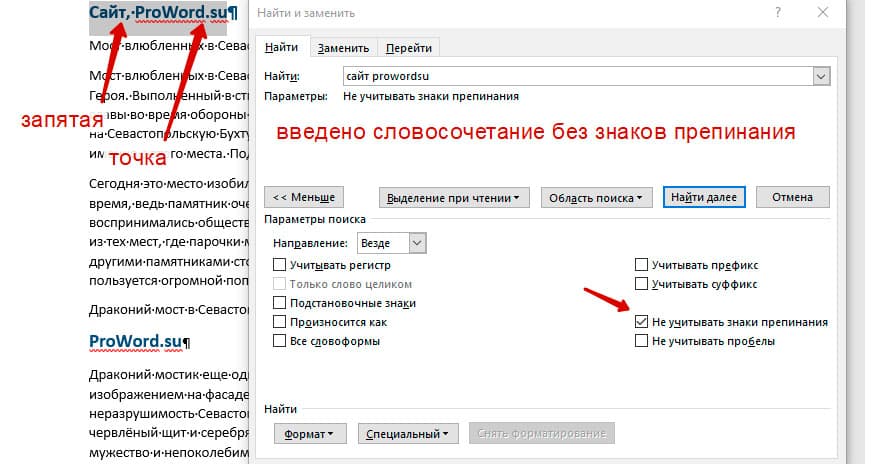
Поиск слов без учета пробелов
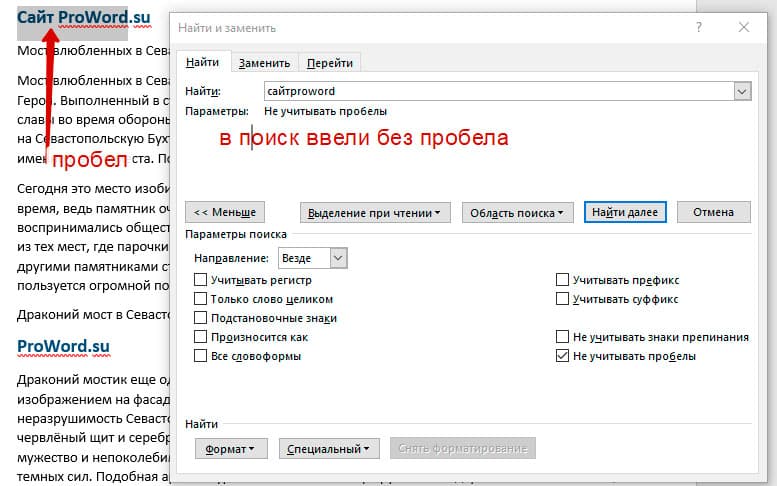
Включенная галочка «Не учитывать пробелы» позволяет находить словосочетания, в которых есть пробел, но алгоритм поиска Word как бы проглатывает его.
Поиск текста по формату
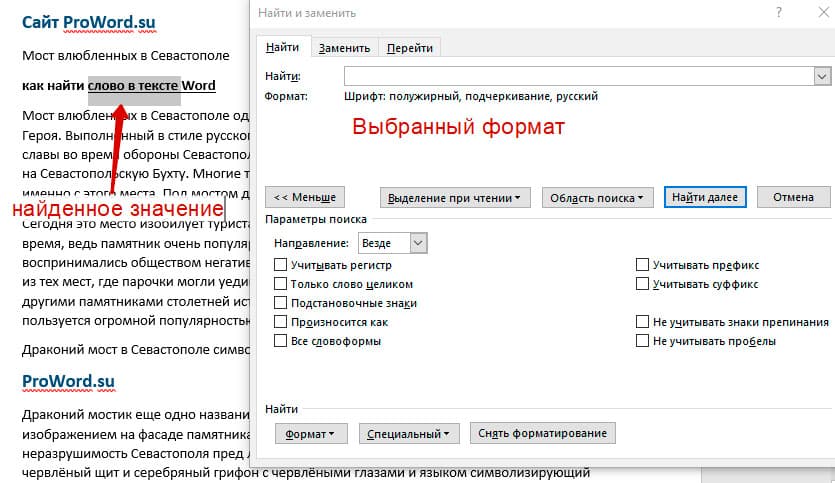
Очень удобный функционал, когда нужно найти текст с определенным форматированием. Для поиска необходимо нажать кнопку Формат, потом у Вас откроется большой выбор форматов:

Для примера в тексте я выделил Жирным текст «как найти слово в тексте Word». Весть текст выделен полужирным, а кусок текста «слово в тексте Word» сделал подчернутым.
В формате я выбрал полужирный, подчеркивание, и русский язык. В итоге Ворд наше только фрагмент «слово в тексте». Только он был и жирным и подчеркнутым и на русском языке.
После проделанных манипуляция не забудьте нажать кнопку «Снять форматирование». Кнопка находится правее от кнопки «Формат».
Специальный поиск от Ворд
Правее от кнопки формат есть кнопка «Специальный». Там существует огромное количество элементов для поиска
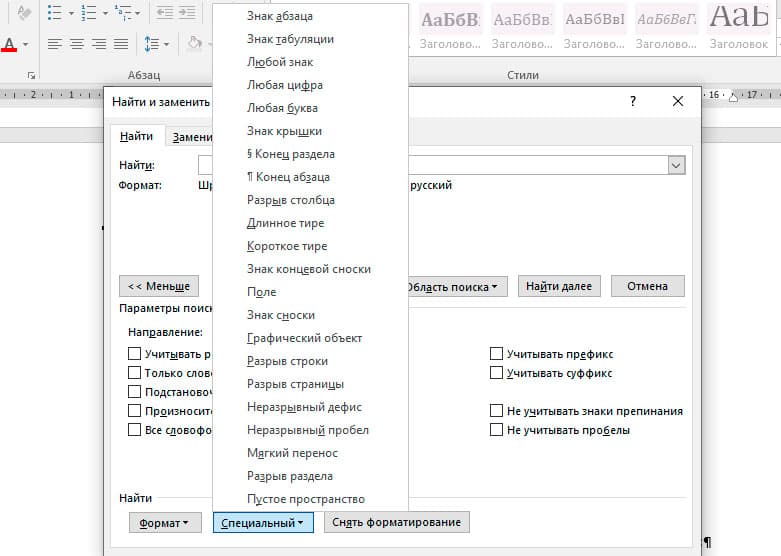
Через этот элемент можно искать:
Опции, которые не приносят пользы
!Это мое субъективное мнение, если у вас есть другие взгляды, то можете писать в комментариях.
Источник
Поиск в «Ворде». Как выполнить поиск в «Ворде» по слову
Настройка функций расширенного поиска
Минус основной функции поиска состоит в том, что она не учитывает многие вещи, такие как регистр букв в тексте. Это проблема, если Вы ищете в документе, который содержит много контента, например, книгу или диссертацию.
Вы можете настроить это, перейдя в группу «Редактирование» на вкладке «Главная», выбрав стрелку рядом с «Найти» и выбрав «Расширенный поиск» в раскрывающемся списке.

Откроется окно «Найти и заменить». Выберите «Больше».

В группе «Параметры поиска» установите флажок рядом с параметрами, которые хотите включить.

Теперь при следующем поиске текста в Word поиск будет работать с выбранными дополнительными параметрами.
Видео
Поиск слова в документе
Поиск в «Ворде» по слову заключается на самом деле в поиске по нужному сочетанию знаков. Так, если нужно найти все формы слова «девочка», целесообразно не прописывать в строке поиска все слово, а прописать только его константную, неизменяемую часть «девочк» – тогда, нажимая клавишу «Найти далее», можно перемещаться по всем случаям употребления этого слова в документе.
В том случае, если формы слова значительно отличаются друг от друга, возможно, придется осуществить поиск неоднократно. Например, это касается слова «парень», так как из-за чередования в корне оно не содержит букву «е» в словоформах косвенных падежей между буквами «р» и «н». При этом сокращение слова до первых трех букв «пар» включит в результаты поиска массу слов, не имеющих отношения к искомому. Поэтому целесообразно сначала найти все случаи употребления слова «парень» в именительном падеже единственного числа, а затем – все остальные случаи, прописав в строке поиска сочетание «парн» (оно содержится во всех косвенных падежах единственного числа и во всех падежах множественного числа – «парня», «парни», «парнями» и т. п.).
Поиск слова или фразы по тексту в Ворде ( )
Для того, чтобы найти фразу или слово в тексте в программе Ворд с помощью этого способа Вам будет нужно:
1. Перейти на вкладку «Главная» и открыть меню кнопки «Найти».
2. Затем, перед Вами откроется список. В этом списке Вам будет нужно нажать на «Расширенный поиск».
3. После этого, перед Вами откроется окно. В этом окне Вам будет нужно нажать на кнопку «Больше».
4. В строке под названием «Найти» напишите фразу или слово, которое Вам необходимо найти в Вашем тексте в программе Ворд.
5. А также, Вы можете указать вид Вашего текста в Ворде. Для этого, Вам будет нужно открыть меню кнопки «Найти в». Например, в том случае, если Вам необходимо найти фразу или слово по всему тексту, то Вам будет нужно выбрать «Основной текст».
6. После этого, в окне «Найти» в Ворде будет написано число слов или фраз, которые Вам было необходимо найти в Вашем тексте в программе Ворд.
Команда заменить в ворде
Вместо того, чтобы просто найти слово или фразу, вы можете найти текст и заменить его чем-то другим. Чтобы использовать команду «Найти и заменить», выполните процедуру:
Настроить поиск текста
Щелкните значок увеличительного стекла в текстовом поле «Поиск документа» на панели навигации. Появляется раскрывающееся меню:

Нажмите «Параметры». Откроется диалоговое окно «Параметры поиска». Выберите один или несколько параметров в диалоговом окне.

Нажмите OK, чтобы диалоговое окно исчезло.
Как в Word найти слово в тексте – Расширенный поиск
После открытия отдельного диалогового окна, нужно нажать на кнопку «Больше»

После нажатия кнопки диалоговое окно увеличится

Перед нами высветилось большое количество настроек. Рассмотрим самые важные:
Направление поиска
В настройках можно задать Направление поиска. Рекомендовано оставлять пункт «Везде». Так найти слово в тексте будет более реально, потому что поиск пройдет по всему файлу. Еще существуют режимы «Назад» и «Вперед». В этом режиме поиск начинается от курсора и идет вперед по документу или назад (Вверх или вниз)

Поиск с учетом регистра
Поиск с учетом регистра позволяет искать слова с заданным регистром. Например, города пишутся с большой буквы, но журналист где-то мог неосознанно написать название города с маленькой буквы. Что бы облегчить поиск и проверку, необходимо воспользоваться этой конфигурацией:

Поиск по целым словам
Если нажать на вторую галочку, «Только слово целиком», то поиск будет искать не по символам, а по целым словам. Т.е. если вбить в поиск только часть слова, то он его не найдет. Напимер, необходимо найти слово Ворд, при обычном поиске будут найдены все слова с разными окончаниями (Ворде, Ворду), но при нажатой галочке «Только слова целиком» этого не произойдет.

Подстановочные знаки
Более тяжелый элемент, это подстановочные знаки. Например, нам нужно найти все слова, которые начинаются с буквы м и заканчиваются буквой к. Для этого в диалоговом окне поиска нажимаем галочку «Подстановочные знаки», и нажимаем на кнопку «Специальный», в открывающемся списке выбираем нужный знак:

В результате Word найдет вот такое значение:

Поиск омофонов
Microsoft Word реализовал поиск омофонов, но только на английском языке, для этого необходимо выбрать пункт «Произносится как». Вообще, омофоны — это слова, которые произносятся одинаково, но пишутся и имеют значение разное. Для такого поиска необходимо нажать «Произносится как». Например, английское слово cell (клетка) произносится так же, как слово sell (продавать).

! из-за не поддержания русского языка, эффективность от данной опции на нуле
Поиск по тексту без учета знаков препинания
Очень полезная опция «Не учитывать знаки препинания». Она позволяет проводить поиск без учета знаков препинания, особенно хорошо, когда нужно найти словосочетание в тексте.

Поиск слов без учета пробелов
Включенная галочка «Не учитывать пробелы» позволяет находить словосочетания, в которых есть пробел, но алгоритм поиска Word как бы проглатывает его.

Поиск текста по формату
Очень удобный функционал, когда нужно найти текст с определенным форматированием. Для поиска необходимо нажать кнопку Формат, потом у Вас откроется большой выбор форматов:

Для примера в тексте я выделил Жирным текст «как найти слово в тексте Word». Весть текст выделен полужирным, а кусок текста «слово в тексте Word» сделал подчернутым.
В формате я выбрал полужирный, подчеркивание, и русский язык. В итоге Ворд наше только фрагмент «слово в тексте». Только он был и жирным и подчеркнутым и на русском языке.

После проделанных манипуляция не забудьте нажать кнопку «Снять форматирование». Кнопка находится правее от кнопки «Формат».
Специальный поиск от Ворд
Правее от кнопки формат есть кнопка «Специальный». Там существует огромное количество элементов для поиска

Через этот элемент можно искать:
Источник
используя приставки и/или суффиксы,
создаёт несуществующее слово
которое отсутствует в парадигме данного слова
я не разу на пляж не ехала
Когда Николас проснулся они были обокрадены
что нужны такие фирмы и организации чтобы помогать этому экологическую региону [вм. которые бы помогали этому региону]
Это возможно, если участники согласились [вм. Если бы все участники согласились]
Сема взял черепаху в руки, взял все своё принадлежности
(NB Тег AgrCase не используется в случаях нарушения падежного управления: ср. с этом значением vs стречала с мою подрушку. Ошибка в управлении описывается тегом Gov)
(NB Тег Gov не используется в случаях нарушения согласования по падежу: ср. стречала с мою подрушку vs с этом значением. Ошибка в падежном согласовании описывается тегом AgrCase)
Люди думают, что легко найти хороших друзья [вм. найти хороших друзей]
именно «Иваново детство»?»
На большей части моей жизни я не знала, что такое друг
У ног башни [вм. у подножия башни] расположен великолепный парк в котором можно прекрасно отдохнуть и насладиться духом этого города
Ближние каникулы [вм. ближайшие]
Эти мысли застряли в голове [вм. засели в голове]
(используются только
в сочетании с тегами
ошибок, приведёнными выше)
но я совсем забыла что мне нужно здават 2 бумаги через неделю [калька “paper”]

Наш великий и могучий русский язык не только красив, но и очень сложен. Часто даже интуитивное представление носителей языка идет вразрез с формальным. Например, кто из нас вспомнит, что формально «лучший» − форма слова «хороший», так как является превосходной степенью этого прилагательного? В то же время «прекрасный» и «прекрасно» − это разные слова, так как принадлежат разным частям речи: «прекрасный» − прилагательное, «прекрасно» − наречие.
Результаты машинного разбора еще разительнее отличаются от нашего интуитивного представления. В данной статье мы разберем, как видит словоформы Яндекс и как это влияет на поисковую выдачу.
Отличия машинных словоформ
В нашем языке несколько сотен тысяч слов, причем каждое из них имеет по десятку, а то и не одному, словоформ. Каждая словоформа, в свою очередь, имеет несколько свойств (падеж, род, число, наклонение и т.д.). Если взять любое прилагательное, то оно может находиться в семи падежах, краткой форме, двух числах, трех родах, двух степенях, быть одушевленными или неодушевленным. Таким образом, каждое прилагательное имеет 129 словоформ. Более половины из них будут отличаться окончаниями.
Некоторые морфологические словари ради экономии места группируют слова по окончаниям в определенные морфологические группы. Например, прилагательные «ползучий» и «могучий» имеют одинаковые окончания в одних и тех же словоформах. Такие слова объединяются, и для них указывается только основа, общая для всех словоформ, и номер морфологической группы: «могучий, могуч*, группа №21».
Большинство электронных баз работают по схожему принципу. Если сохранять все словоформы по отдельности, придется выделить около 500МБ памяти, в то время как для группы хватит 10. Конечно, 500МБ для крупного сервера − это совсем не много, однако нужно учесть, что работы над морфологией Яндекса велись около 10 лет назад, а тогда покупка сотен серверов с большим объемом памяти была дорогостоящим удовольствием. С тех времен правила русского языка не менялись, а потому не было необходимости переписывать морфологию − тем более, что любое ее системное изменение привело бы к необходимости переписывания других частей кода.
Синонимы и словоформы
В результатах поиска словоформы выделяются жирным. Впрочем, как и синонимы. Именно поэтому мы точно не можем сказать, считает ли поисковая система слова в снипете и запросе как формы одного слова или синонимы? Чтобы отключить подсветку синонимов и оставить только словоформы, в Яндексе можно воспользоваться оператором «+».

Большая часть современных морфологических баз данных основаны на словаре Зализняка, в котором ради экономии места на страницах были введены морфологические группы. Однако ввиду того, что Зализняк и его коллеги работали над словарем более 40 лет назад, он грешит некоторыми «архаизмами». Например, глаголы, их причастия и деепричастия (написать/написавший) считаются словоформами, в то время как глаголы совершенного и несовершенного вида (писать/написать) − нет.

Проведя проверку в Яндексе на такие архаизмы (их можно найти в базе АОТ.ru), вы выясните, что он содержит их практически в полном составе. Правда, стоит учесть, что Яндекс применяет базу «синонимов», и одной из целей является именно исправление разницы восприятия словоформ людьми и машинами. Так, если в запросе «делать дымовую шашку» жирным выделится и слово «сделать», то если добавить «+» перед словом «делать», то подсветка слова «сделать» исчезнет.
Как понимает словоформы Google
Английский язык далеко не так сложен, как русский. Не такая богатая у него и морфология: у слов бывает лишь несколько словоформ. Именно поэтому необходимости в группировке слов с целью оптимизации памяти не возникает. Возможно, именно ради общности кода русской и английской версий морфология Google не использует группы, а потому лишена недостатков Яндекса.
Если вы введете в этой поисковой системе запрос «сделанный», то искаться будет вовсе не слово «делать», как Яндекс. Ради эксперимента можете набрать в Яндексе и Гугле фразу «как сделанный пирог». Почти всегда Google выделяет жирным только словоформы, однако отключить подсвечивание слова «сделать», когда вы ищете «делать», в это поисковой системе не получится. Таким образом, получается, что в Гугле «делать» и «сделать» − словоформы, а в Яндексе − синонимы.
Как это ни странно, в Google русская морфология реализована правильнее, чем в Яндексе. Еще более парадоксален тот факт, что такая система − это следствие того, что Гугл пришел к нам из Америки. Впрочем, не всегда «правильнее» значит «лучше». Выдача какой поисковой системы релевантнее − очень спорный вопрос. Как и то, что именно поисковик должен выдавать в ответ на запрос «как сделанный пирог».
Разница в результатах ранжирования
То, что Яндекс подсвечивает или не досвечивает словоформы с помощью плюса, обозначает, что часть словоформ определяются сразу морфологией, другие − как синонимы. Очень может быть, что Яндекс не делает разницы в ранжировании для морфологических и синонимальных словоформ.
Сегодня не существует ни метода для оценивания разницы выдачи, ни программных средств для ее расчета. Вручную проанализировать выдачу по нескольким сотням запросов очень сложно. Таким образом, доказать, что существует какая-либо разница в ранжировании различных типов словоформ, невозможно. Единственный путь − найти косвенные подтверждения.
Если запрашивать у поисковика машинные словоформы, то число найденных страниц будет отличаться не более чем на 1%. А вот при запросе словоформ-синонимов разница намного существеннее, от 10 до 30%:
- «сделать гугл стартовой страницей» – 5 миллионов
- «сделал гугл стартовой страницей» – 5 миллионов
- «делать гугл стартовой страницей» – 7 миллионов
- «делал гугл стартовой страницей» – 7 миллионов
Интересно сравнить и изменения в выдаче между Google и Яндексом. В первой поисковой системе разницы между запросами «как правильно делать пирог» и «как правильно сделать пирог» практически нет. В Яндексе в первой десятке совпадут только 2 запроса из десяти, да и те существенно поменяют позиции.
Есть и группа слов, которые выделяются жирным по очень странному принципу. Например, если ввести слово «купить», то будут подсвечиваться и его словоформы несовершенного вида (например, «покупать»), причем даже если вы поставите «+». Все дело в том, что Яндекс ввел для этого слова исключение, хотя для WordStat «купить» и «покупать» так и остались разными словами. Если бы по синонимам и словоформам результаты выдачи были одинаковыми, то никакого резона делать исключения для этого слова не было бы.
«Купить» очень популярный запрос (WordStat свидетельствует, что у него более 40 миллионов показов в месяц), поэтому были предприняты дополнительные действия для улучшения его ранжирования. Может, улучшение результатов выдачи от введения прямой связи между «покупать» и «купить» и неочевидно, но разработчикам и асессорам виднее. Существует еще один пример, по которому улучшение выдачи не вызывает сомнений.
Речь идет о словах «варить» и «варка». По WordStat «варить» имеет миллион показов, «варка» − около 100 тысяч. Однако если статью не проверял SEO-специалист, то называться она будет «Варка кофе», а вовсе не «Как варить кофе». Польза от такого исключения для ранжирования налицо.
Как говорится, исключения лишь подтверждают правила. Мы же на основе проведенных исследований можем говорить, что морфологические словоформы ранжируются выше, чем словоформы-синонимы.
Высокочастотные запросы
Выделение синонимов жирным выключается не только при добавлении «+». Обратите внимание: если набрать в строке поиска «гостиницы Москвы», то слово «отели» подсвечиваться не будет. А вот если ввести «гостиницы Москвы центр» или «гостиницы Киева», то подсветка снова включится. Значит, существует некий порог, который, видимо, зависит от количества страниц в индексе или релевантности первых сайтов, а не от частотности запроса. Как только этот порог преодолевается, синонимы не включаются в выдачу, чтобы не ухудшить ее результаты.
Общие правила распознавания словоформ
Совершенный и несовершенный вид глагола − синонимы, а не словоформы
- актуально лишь для Яндекса
- делать≠сделать
- исключения: купить/покупать, выщипать/выщипать, отправить/отправлять
Глаголы, причастия и деепричастия являются словоформами
- актуально лишь для Яндекса
- сделать = сделанный = сделал = сделавший и т.д.
так как причастия склоняются по числу, роду и падежу, как прилагательные, и по залогу, как глаголы, то у каждого глагола по Яндексу более 100 словоформ. А у слова «купить», которое является исключением, их еще больше. Причастия можно использовать для улучшения ранжирования глаголов (например, «купленный», «купивший» для слова «купить»).

Разные части речи не являются словоформами друг друга
- актуально лишь для Яндекса
- покупка ≠ покупатель ≠ покупать
- красиво спеть ≠ петь красиво
- силач ≠ сильный
- исключения: варить/варка, а также все глаголы, причастия и деепричастия
Все словоформы существительных имеют один род
- актуально и для Яндекса, и для Google
- красавец ≠ красавица
- учитель ≠ учительница
Превосходная степень прилагательного является одной из словоформ
- актуально лишь для Яндекса
- хороший = лучший
- добрый = добрейший = добрейшего = добрейшая = добрейшее
- красивый = красивейший и т.д.
- обратите внимание: прекрасный ≠ красивый (эти слова являются синонимами)
Сравнительная степень прилагательного является одной из его словоформ
- актуально и для Яндекса, и для Google
- добрый = добрее
- красивый = красивее
- обратите внимание: в Google хороший ≠ лучше, поскольку эту словоформу поисковик относит к превосходной степени.
В Google объединение слов происходит по интуитивному их сходству, а не по формальным правилам русского языка, что отлично видно на примере «хороший»-«лучше». У остальных прилагательных сравнительная степень относится к обычной, а не превосходной форме.
Как уже говорилось выше, скорее всего релевантность словоформ-синонимов в поисковых системах ниже, чем у морфологических словоформ. Поэтому, если вы оптимизируете страницу, лучше используйте словоформы в машинном представлении. Особенно актуален этот совет, если вы вставляете популярное уточнение в шаблон ресурса, поскольку таким образом вы изменяете до нескольких тысяч страниц.
P.S. Нужно отметить, что несмотря на то, что структура морфологической базы Яндекса очень похожа на словарь Зализняка, это ни в коем случае нельзя считать плагиатом, ведь способы правильной реализации определенных вещей всегда схожи. К тому же принцип структурирования нельзя считать объектом авторского права.
Поиск по формам слов – это вид полнотекстового поиска, при котором кроме слова в его исходной форме выполняется поиск также других известных словоформ.
Например, производится поиск слова в форме единственого и множественного числа, в различных формах глаголов, в различных падежах, спряжениях и т. д.
Причем слова в запросе могут быть представлены не только в некой начальной форме, а в любой форме, для которой будут найдены все остальные поддерживаемые варианты форм слов.
Поиск по формам слов по умолчанию выполняется только для английских слов.
Однако система полнотекстового поиска GroupDocs.Search предоставляет интерфейс для реализации поиска по формам слов для любого языка.
Примером поиска по формам слов является запрос “did”, для которого в тексте будут найдены также слова “do”, “does”, “doing”, “done”.
