Чтобы избежать
недостоверности случайной погрешности
единичного замера, можно усреднить
несколько измерений. Полученное таким
образом среднее значение представляет
собой всё же случайную величину, так
как n измеренных
величин представляют лишь выборку из
генеральной совокупности. Это среднее
значение в свою очередь имеет нормальное
распределение и то же самое математическое
ожидание![]() ,
,
но среднеквадратичное отклонение у
него меньше, чем при единичном измерении.
Между среднеквадратичным отклонением
средней величины![]() и среднеквадратичным отклонением
и среднеквадратичным отклонением
единичного измерения имеется следующее
соотношение:
![]() (5.1)
(5.1)
Усреднение
позволяет уменьшить доверительную
границу погрешности при заданной
доверительной вероятности пропорционально
1/![]() .
.
 Соотношение
Соотношение
(5.1) устанавливает связь между теоретическими
значениями![]() и
и![]() ,
,
в большинстве случаев не имеющимися в
наличии. Ведь среднеквадратичное
отклонение![]() могло
могло
бы быть вычислено по очень большому,
теоретически бесконечно большому числу
измеренных величин. Если число измерений
невелико, то для![]() вычисляют оценкуS
вычисляют оценкуS
по тем же
самым n
измеренным значениям, по которым
определяется средняя величина
![]() .Но
.Но
в этом случае
![]() и доверительная граница уже не могут
и доверительная граница уже не могут
быть определены из соотношения (5.1).
Определение этих величин основано наt-распределении
Стьюдента и осуществляется следующим
образом:
1 .
.
Выбирают доверительную вероятностьР(например, 95, 99 % и т.п.).
2. Определяют S:

г деn
деn
– объём
выборки; n
–1 = nf
– число степеней свободы
3.
По зависимости (рис.5.2) определяюткоэффициент
Стьюдента с
с
= f
(Р, %, nf).
4.Определяют доверительные
границы погрешности средней величины
![]() :
:
Е![]()
5.4. Систематическая погрешность
Систематическая
погрешность Еsпо определению равна
Еs=
![]() ,
,
где
![]() – математическое ожидание показания;
– математическое ожидание показания;![]() –
–
истинное значение.
Как уже отмечалось,значение![]() практически не может быть точно определено
практически не может быть точно определено
и поэтому заменяется оценкой![]() – средним значением измерительных
– средним значением измерительных
величин, полученных при независимых
повторных измерениях одной и той же
величины
Еs
![]() .
.
В связи с тем, что систематическая
погрешность является воспроизводимой,
её можно определить при поверке и учесть
при проведении измерений.
Так как точно
определено может быть только среднее
значение, а не математическое ожидание
![]() ,
,
то градуировочная зависимость имеет
смысл лишь в том случае, если результирующая
случайная погрешность определения
среднего значения при градуировке
существенно меньше, чем систематическая
погрешность. Поэтому градуировка по
одиночному измерению без априорного
знания случайной погрешности или
доверительного интервала лишена смысла.
Доверительный
интервал среднего значения в данном
случае необходимо проверить по методике,
описанной выше.
Если используемые
при градуировке меры или приборы
сравнения имеют значительное рассеяние,
то результирующая погрешность должна
определяться на основе законов
распространения погрешности.
5.5. Распространение погрешностей
Если результат
измерения определяется на основе
математической обработки отдельных
измеряемых величин, то погрешность
вводится и в этот результат. Поэтому
говорят о распространении погрешности.
Различным структурам систематических
и случайных погрешностей соответствуют
разные законы распространения
погрешностей.
5.5.1.
Систематические погрешности. Результат
измерения
![]() определяется по
определяется по![]() различным измеренным величинам
различным измеренным величинам![]() i
i
. В статике эта связь в общем виде
описывается уравнением
![]() =
=
f (![]() ,…,
,…,![]() i,…
i,…
![]()
![]() )
)
.
При малых
отклонениях отдельных измеренных
величин результирующее отклонение
можно рассчитать, используя ряд Тейлора:
![]()
![]() .
.
Если под малыми
отклонениями
![]() понимать систематическую погрешностьЕs
понимать систематическую погрешностьЕs![]() ,
,
т.е. отклонение от действительного
значения, то систематическая погрешность
результата измерения определяется по
следующей формуле:
Е![]()
Следует отметить,
что систематическая погрешность может
иметь знак плюс или минус, вследствие
чего возникает возможность её компенсации.
Особое значение
для требований, предъявляемых к
систематическим погрешностям, имеют
частные производные
![]() .
.
Эти коэффициенты воздействия, или
весовые коэффициенты, показывают, с
каким весом отдельные систематические
погрешности участвуют в образовании
систематической погрешности результата
измерения.
5.5.2.Случайные
погрешности. Случайная погрешность,
рассматриваемая как единичное явление
по своей природе не может быть предсказана
заранее. Однако можно высказать суждение
о её статистических свойствах. При
нормальном распределении погрешности
среднеквадратичное отклонение![]() является мерой, характеризующей плотность
является мерой, характеризующей плотность
распределения погрешности. Поэтому
вопрос о распространении погрешности
сводится к способу распространения
статистической характеристики![]() или
или
доверительных границ. В этом случае
требуется определить среднеквадратичное
отклонение![]() результата измерения
результата измерения![]() при известных среднеквадратичных
при известных среднеквадратичных
отклонениях![]() влияющих величин
влияющих величин![]() .
.
Если отдельные
влияющие величины взаимно независимы
и для среднеквадратичных отклонений
справедливо неравенство
![]() «
«![]() ,
,
то![]() можно вычислить по следующей формуле:
можно вычислить по следующей формуле:
![]()
Если вместо
среднеквадратичных отклонений
![]() представить их оценки – рассеяния
представить их оценки – рассеяния
![]() ,
,
то получим соотношение (правда, не
строгое) для определения![]() результата
результата
измерения:
![]()
![]() .
.
Для увеличения
точности расчёта результата измерения
можно использовать средние значения
влияющих величин:
![]()
Если для
усреднения каждой из
![]() влияющих
влияющих
величин использованы по![]() значений, то среднеквадратичное
значений, то среднеквадратичное
отклонение или рассеяние уменьшается
согласно (5.1):
![]() или
или![]() .
.
Если рассеяние
![]() влияющих
влияющих
величин заранее неизвестно, то можно
определить его одновременно с усреднением![]() ,
,
используя те же
![]() значений.
значений.
Доверительные границы погрешности
среднего результата измерения определяют
по формуле:
![]()
![]() .
.
Величину
![]() определяют по рис. 1.3-8 для выбранной
определяют по рис. 1.3-8 для выбранной
доверительной вероятностиР (%)и
при числе степеней свободы
![]() =n –1.
=n –1.
5.5.3. Предел
погрешности. Предел погрешности
применяют для задания максимального
гарантированного значения погрешности.
Этот предел содержит как оценённую
систематическую, так и случайную
погрешность. Пределы погрешностей
отдельных измеренных величин могут
иметь положительные, отрицательные или
неопределённые знаки. При неопределённых
знаках предел погрешности результата
измерения определяется суммированием
абсолютных величин пределов погрешности
отдельных измеренных значений:
![]() .
.
Если знаки
пределов погрешности измеренных величин
известны, то положительный и отрицательный
пределы погрешности результата измерения
вычисляются отдельно:
![]() ;
;![]()
![]() ;
;![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Результат любого измерения не определён однозначно и имеет случайную составляющую.
Поэтому адекватным языком для описания погрешностей является язык вероятностей.
Тот факт, что значение некоторой величины «случайно», не означает, что
она может принимать совершенно произвольные значения. Ясно, что частоты, с которыми
возникает те или иные значения, различны. Вероятностные законы, которым
подчиняются случайные величины, называют распределениями.
2.1 Случайная величина
Случайной будем называть величину, значение которой не может быть достоверно определено экспериментатором. Чаще всего подразумевается, что случайная величина будет изменяться при многократном повторении одного и того же эксперимента. При интерпретации результатов измерений в физических экспериментах, обычно случайными также считаются величины, значение которых является фиксированным, но не известно экспериментатору. Например смещение нуля шкалы прибора. Для формализации работы со случайными величинами используют понятие вероятности. Численное значение вероятности того, что какая-то величина примет то или иное значение определяется либо как относительная частота наблюдения того или иного значения при повторении опыта большое количество раз, либо как оценка на основе данных других экспериментов.
Замечание.
Хотя понятия вероятности и случайной величины являются основополагающими, в литературе нет единства в их определении. Обсуждение формальных тонкостей или построение строгой теории лежит за пределами данного пособия. Поэтому на начальном этапе лучше использовать «интуитивное» понимание этих сущностей. Заинтересованным читателям рекомендуем обратиться к специальной литературе: [5].
Рассмотрим случайную физическую величину x, которая при измерениях может
принимать непрерывный набор значений. Пусть
P[x0,x0+δx] — вероятность того, что результат окажется вблизи
некоторой точки x0 в пределах интервала δx: x∈[x0,x0+δx].
Устремим интервал
δx к нулю. Нетрудно понять, что вероятность попасть в этот интервал
также будет стремиться к нулю. Однако отношение
w(x0)=P[x0,x0+δx]δx будет оставаться конечным.
Функцию w(x) называют плотностью распределения вероятности или кратко
распределением непрерывной случайной величины x.
Замечание. В математической литературе распределением часто называют не функцию
w(x), а её интеграл W(x)=∫w(x)𝑑x. Такую функцию в физике принято
называть интегральным или кумулятивным распределением. В англоязычной литературе
для этих функций принято использовать сокращения:
pdf (probability distribution function) и
cdf (cumulative distribution function)
соответственно.
Гистограммы.
Проиллюстрируем наглядно понятие плотности распределения. Результат
большого числа измерений случайной величины удобно представить с помощью
специального типа графика — гистограммы.
Для этого область значений x, размещённую на оси абсцисс, разобьём на
равные малые интервалы — «корзины» или «бины» (англ. bins)
некоторого размера h. По оси ординат будем откладывать долю измерений w,
результаты которых попадают в соответствующую корзину. А именно,
пусть k — номер корзины; nk — число измерений, попавших
в диапазон x∈[kh,(k+1)h]. Тогда на графике изобразим «столбик»
шириной h и высотой wk=nk/n.
В результате получим картину, подобную изображённой на рис. 2.1.
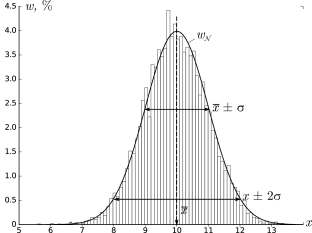
σ=1,0, h=0,1, n=104)
Высоты построенных столбиков будут приближённо соответствовать значению
плотности распределения w(x) вблизи соответствующей точки x.
Если устремить число измерений к бесконечности (n→∞), а ширину корзин
к нулю (h→0), то огибающая гистограммы будет стремиться к некоторой
непрерывной функции w(x).
Самые высокие столбики гистограммы будут группироваться вблизи максимума
функции w(x) — это наиболее вероятное значение случайной величины.
Если отклонения в положительную и отрицательную стороны равновероятны,
то гистограмма будет симметрична — в таком случае среднее значение ⟨x⟩
также будет лежать вблизи этого максимума. Ширина гистограммы будет характеризовать разброс
значений случайной величины — по порядку величины
она, как правило, близка к среднеквадратичному отклонению sx.
Свойства распределений.
Из определения функции w(x) следует, что вероятность получить в результате
эксперимента величину x в диапазоне от a до b
можно найти, вычислив интеграл:
| Px∈[a,b]=∫abw(x)𝑑x. | (2.1) |
Согласно определению вероятности, сумма вероятностей для всех возможных случаев
всегда равна единице. Поэтому интеграл распределения w(x) по всей области
значений x (то есть суммарная площадь под графиком w(x)) равен единице:
Это соотношение называют условием нормировки.
Среднее и дисперсия.
Вычислим среднее по построенной гистограмме. Если размер корзин
h достаточно мал, все измерения в пределах одной корзины можно считать примерно
одинаковыми. Тогда среднее арифметическое всех результатов можно вычислить как
Переходя к пределу, получим следующее определение среднего значения
случайной величины:
где интегрирование ведётся по всей области значений x.
В теории вероятностей x¯ также называют математическим ожиданием
распределения.
Величину
| σ2=(x-x¯)2¯=∫(x-x¯)2w𝑑x | (2.3) |
называют дисперсией распределения. Значение σ есть
срекднеквадратичное отклонение в пределе n→∞. Оно имеет ту
же размерность, что и сама величина x и характеризует разброс распределения.
Именно эту величину, как правило, приводят как характеристику погрешности
измерения x.
Доверительный интервал.
Обозначим как P|Δx|<δ вероятность
того, что отклонение от среднего Δx=x-x¯ составит величину,
не превосходящую по модулю значение δ:
| P|Δx|<δ=∫x¯-δx¯+δw(x)𝑑x. | (2.4) |
Эту величину называют доверительной вероятностью для
доверительного интервала |x-x¯|≤δ.
2.2 Нормальное распределение
Одним из наиболее примечательных результатов теории вероятностей является
так называемая центральная предельная теорема. Она утверждает,
что сумма большого количества независимых случайных слагаемых, каждое
из которых вносит в эту сумму относительно малый вклад, подчиняется
универсальному закону, не зависимо от того, каким вероятностным законам
подчиняются её составляющие, — так называемому нормальному
распределению (или распределению Гаусса).
Доказательство теоремы довольно громоздко и мы его не приводим (его можно найти
в любом учебнике по теории вероятностей). Остановимся
кратко на том, что такое нормальное распределение и его основных свойствах.
Плотность нормального распределения выражается следующей формулой:
| w𝒩(x)=12πσe-(x-x¯)22σ2. | (2.5) |
Здесь x¯ и σ
— параметры нормального распределения: x¯ равно
среднему значению x, a σ —
среднеквадратичному отклонению, вычисленным в пределе n→∞.
Как видно из рис. 2.1, распределение представляет собой
симметричный
«колокол», положение вершины которого
соответствует x¯ (ввиду симметрии оно же
совпадает с наиболее вероятным значением — максимумом
функции w𝒩(x)).
При значительном отклонении x от среднего величина
w𝒩(x)
очень быстро убывает. Это означает, что вероятность встретить отклонения,
существенно большие, чем σ, оказывается пренебрежимо
мала. Ширина «колокола» по порядку величины
равна σ — она характеризует «разброс»
экспериментальных данных относительно среднего значения.
Замечание. Точки x=x¯±σ являются точками
перегиба графика w(x) (в них вторая производная по x
обращается в нуль, w′′=0), а их положение по высоте составляет
w(x¯±σ)/w(x¯)=e-1/2≈0,61
от высоты вершины.
Универсальный характер центральной предельной теоремы позволяет широко
применять на практике нормальное (гауссово) распределение для обработки
результатов измерений, поскольку часто случайные погрешности складываются из
множества случайных независимых факторов. Заметим, что на практике
для приближённой оценки параметров нормального распределения
случайной величины используются выборочные значения среднего
и дисперсии: x¯≈⟨x⟩, sx≈σx.
Вычислим некоторые доверительные вероятности (2.4) для нормально Замечание. Значение интеграла вида ∫e-x2/2𝑑x Вероятность того, что результат отдельного измерения x окажется Вероятность отклонения в пределах x¯±2σ: а в пределах x¯±3σ: Иными словами, при большом числе измерений нормально распределённой Пример. В сообщениях об открытии бозона Хиггса на Большом адронном коллайдере Полученные значения доверительных вероятностей используются при означает, что измеренное значение лежит в диапазоне (доверительном Замечание. Хотя нормальный закон распределения встречается на практике довольно Теперь мы можем дать количественный критерий для сравнения двух измеренных Пусть x1 и x2 (x1≠x2) измерены с Допустим, одна из величин известна с существенно большей точностью: Пусть погрешности измерений сравнимы по порядку величины: Замечание. Изложенные здесь соображения применимы, только если x¯ иx-x0σ2=2w(x)σ1=1
Доверительные вероятности.
распределённых случайных величин.
(его называют интегралом ошибок) в элементарных функциях не выражается,
но легко находится численно.
в пределах x¯±σ оказывается равна
P|Δx|<σ=∫x¯-σx¯+σw𝒩𝑑x≈0,68.
величины можно ожидать, что лишь треть измерений выпадут за пределы интервала
[x¯-σ,x¯+σ]. При этом около 5%
измерений выпадут за пределы [x¯-2σ;x¯+2σ],
и лишь 0,27% окажутся за пределами
[x¯-3σ;x¯+3σ].
говорилось о том, что исследователи ждали подтверждение результатов
с точностью «5 сигма». Используя нормальное распределение (2.5)
нетрудно посчитать, что они использовали доверительную вероятность
P≈1-5,7⋅10-7=0,99999943. Такую точность можно назвать фантастической.
стандартной записи результатов измерений. В физических измерениях
(в частности, в учебной лаборатории), как правило, используется P=0,68,
то есть, запись
интервале) x∈[x¯-δx;x¯+δx] с
вероятностью 68%. Таким образом погрешность ±δx считается
равной одному среднеквадратичному отклонению: δx=σ.
В технических измерениях чаще используется P=0,95, то есть под
абсолютной погрешностью имеется в виду удвоенное среднеквадратичное
отклонение, δx=2σ. Во избежание разночтений доверительную
вероятность следует указывать отдельно.
часто, стоит помнить, что он реализуется далеко не всегда.
Полученные выше соотношения для вероятностей попадания значений в
доверительные интервалы можно использовать в качестве простейшего
признака нормальности распределения: в частности, если количество попадающих
в интервал ±σ результатов существенно отличается от 2/3 — это повод
для более детального исследования закона распределения ошибок.Сравнение результатов измерений.
величин или двух результатов измерения одной и той же величины.
погрешностями σ1 и σ2 соответственно.
Ясно, что если различие результатов |x2-x1| невелико,
его можно объяснить просто случайными отклонениями.
Если же теория предсказывает, что вероятность обнаружить такое отклонение
слишком мала, различие результатов следует признать значимым.
Предварительно необходимо договориться о соответствующем граничном значении
вероятности. Универсального значения здесь быть не может,
поэтому приходится полагаться на субъективный выбор исследователя. Часто
в качестве «разумной» границы выбирают вероятность 5%,
что, как видно из изложенного выше, для нормального распределения
соответствует отклонению более, чем на 2σ.
σ2≪σ1 (например, x1 — результат, полученный
студентом в лаборатории, x2 — справочное значение).
Поскольку σ2 мало, x2 можно принять за «истинное»:
x2≈x¯. Предполагая, что погрешность измерения
x1 подчиняется нормальному закону с и дисперсией σ12,
можно утверждать, что
различие считают будет значимы, если
σ1∼σ2. В теории вероятностей показывается, что
линейная комбинация нормально распределённых величин также имеет нормальное
распределение с дисперсией σ2=σ12+σ22
(см. также правила сложения погрешностей (2.7)). Тогда
для проверки гипотезы о том, что x1 и x2 являются измерениями
одной и той же величины, нужно вычислить, является ли значимым отклонение
|x1-x2| от нуля при σ=σ12+σ22.
Пример. Два студента получили следующие значения для теплоты испарения
некоторой жидкости: x1=40,3±0,2 кДж/моль и
x2=41,0±0,3 кДж/моль, где погрешность соответствует
одному стандартному отклонению. Можно ли утверждать, что они исследовали
одну и ту же жидкость?
Имеем наблюдаемую разность |x1-x2|=0,7 кДж/моль,
среднеквадратичное отклонение для разности
σ=0,22+0,32=0,36 кДж/моль.
Их отношение |x2-x1|σ≈2. Из
свойств нормального распределения находим вероятность того, что измерялась
одна и та же величина, а различия в ответах возникли из-за случайных
ошибок: P≈5%. Ответ на вопрос, «достаточно»
ли мала или велика эта вероятность, остаётся на усмотрение исследователя.
его стандартное отклонение σ получены на основании достаточно
большой выборки n≫1 (или заданы точно). При небольшом числе измерений
(n≲10) выборочные средние ⟨x⟩ и среднеквадратичное отклонение
sx сами имеют довольно большую ошибку, а
их распределение будет описываться не нормальным законом, а так
называемым t-распределением Стъюдента. В частности, в зависимости от
значения n интервал ⟨x⟩±sx будет соответствовать несколько
меньшей доверительной вероятности, чем P=0,68. Особенно резко различия
проявляются при высоких уровнях доверительных вероятностей P→1.
2.3 Независимые величины
Величины x и y называют независимыми если результат измерения одной
из них никак не влияет на результат измерения другой. Для таких величин вероятность того, что x окажется в некоторой области X, и одновременно y — в области Y,
равна произведению соответствующих вероятностей:
Обозначим отклонения величин от их средних как Δx=x-x¯ и
Δy=y-y¯.
Средние значения этих отклонений равны, очевидно, нулю: Δx¯=x¯-x¯=0,
Δy¯=0. Из независимости величин x и y следует,
что среднее значение от произведения Δx⋅Δy¯
равно произведению средних Δx¯⋅Δy¯
и, следовательно, равно нулю:
| Δx⋅Δy¯=Δx¯⋅Δy¯=0. | (2.6) |
Пусть измеряемая величина z=x+y складывается из двух независимых
случайных слагаемых x и y, для которых известны средние
x¯ и y¯, и их среднеквадратичные погрешности
σx и σy. Непосредственно из определения (1.1)
следует, что среднее суммы равно сумме средних:
Найдём дисперсию σz2. В силу независимости имеем
| Δz2¯=Δx2¯+Δy2¯+2Δx⋅Δy¯≈Δx2¯+Δy2¯, |
то есть:
Таким образом, при сложении независимых величин их погрешности
складываются среднеквадратичным образом.
Подчеркнём, что для справедливости соотношения (2.7)
величины x и y не обязаны быть нормально распределёнными —
достаточно существования конечных значений их дисперсий. Однако можно
показать, что если x и y распределены нормально, нормальным
будет и распределение их суммы.
Замечание. Требование независимости
слагаемых является принципиальным. Например, положим y=x. Тогда
z=2x. Здесь y и x, очевидно, зависят друг от друга. Используя
(2.7), находим σ2x=2σx,
что, конечно, неверно — непосредственно из определения
следует, что σ2x=2σx.
Отдельно стоит обсудить математическую структуру формулы (2.7).
Если одна из погрешностей много больше другой, например,
σx≫σy,
то меньшей погрешностью можно пренебречь, σx+y≈σx.
С другой стороны, если два источника погрешностей имеют один порядок
σx∼σy, то и σx+y∼σx∼σy.
Эти обстоятельства важны при планирования эксперимента: как правило,
величина, измеренная наименее точно, вносит наибольший вклад в погрешность
конечного результата. При этом, пока не устранены наиболее существенные
ошибки, бессмысленно гнаться за повышением точности измерения остальных
величин.
Пример. Пусть σy=σx/3,
тогда σz=σx1+19≈1,05σx,
то есть при различии двух погрешностей более, чем в 3 раза, поправка
к погрешности составляет менее 5%, и уже нет особого смысла в учёте
меньшей погрешности: σz≈σx. Это утверждение
касается сложения любых независимых источников погрешностей в эксперименте.
2.4 Погрешность среднего
Выборочное среднее арифметическое значение ⟨x⟩, найденное
по результатам n измерений, само является случайной величиной.
Действительно, если поставить серию одинаковых опытов по n измерений,
то в каждом опыте получится своё среднее значение, отличающееся от
предельного среднего x¯.
Вычислим среднеквадратичную погрешность среднего арифметического
σ⟨x⟩.
Рассмотрим вспомогательную сумму n слагаемых
Если {xi} есть набор независимых измерений
одной и той же физической величины, то мы можем, применяя результат
(2.7) предыдущего параграфа, записать
| σZ=σx12+σx22+…+σxn2=nσx, |
поскольку под корнем находится n одинаковых слагаемых. Отсюда с
учётом ⟨x⟩=Z/n получаем
Таким образом, погрешность среднего значения x по результатам
n независимых измерений оказывается в n раз меньше погрешности
отдельного измерения. Это один из важнейших результатов, позволяющий
уменьшать случайные погрешности эксперимента за счёт многократного
повторения измерений.
Подчеркнём отличия между σx и σ⟨x⟩:
величина σx — погрешность отдельного
измерения — является характеристикой разброса значений
в совокупности измерений {xi}, i=1..n. При
нормальном законе распределения примерно 68% измерений попадают в
интервал ⟨x⟩±σx;
величина σ⟨x⟩ — погрешность
среднего — характеризует точность, с которой определено
среднее значение измеряемой физической величины ⟨x⟩ относительно
предельного («истинного») среднего x¯;
при этом с доверительной вероятностью P=68% искомая величина x¯
лежит в интервале
⟨x⟩-σ⟨x⟩<x¯<⟨x⟩+σ⟨x⟩.
2.5 Результирующая погрешность опыта
Пусть для некоторого результата измерения известна оценка его максимальной
систематической погрешности Δсист и случайная
среднеквадратичная
погрешность σслуч. Какова «полная»
погрешность измерения?
Предположим для простоты, что измеряемая величина в принципе
может быть определена сколь угодно точно, так что можно говорить о
некотором её «истинном» значении xист
(иными словами, погрешность результата связана в основном именно с
процессом измерения). Назовём полной погрешностью измерения
среднеквадратичное значения отклонения от результата измерения от
«истинного»:
Отклонение x-xист можно представить как сумму случайного
отклонения от среднего δxслуч=x-x¯
и постоянной (но, вообще говоря, неизвестной) систематической составляющей
δxсист=x¯-xист=const:
Причём случайную составляющую можно считать независимой от систематической.
В таком случае из (2.7) находим:
| σполн2=⟨δxсист2⟩+⟨δxслуч2⟩≤Δсист2+σслуч2. | (2.9) |
Таким образом, для получения максимального значения полной
погрешности некоторого измерения нужно квадратично сложить максимальную
систематическую и случайную погрешности.
Если измерения проводятся многократно, то согласно (2.8)
случайная составляющая погрешности может быть уменьшена, а систематическая
составляющая при этом остаётся неизменной:
Отсюда следует важное практическое правило
(см. также обсуждение в п. 2.3): если случайная погрешность измерений
в 2–3 раза меньше предполагаемой систематической, то
нет смысла проводить многократные измерения в попытке уменьшить погрешность
всего эксперимента. В такой ситуации измерения достаточно повторить
2–3 раза — чтобы убедиться в повторяемости результата, исключить промахи
и проверить, что случайная ошибка действительно мала.
В противном случае повторение измерений может иметь смысл до
тех пор, пока погрешность среднего
σ⟨x⟩=σxn
не станет меньше систематической.
Замечание. Поскольку конкретная
величина систематической погрешности, как правило, не известна, её
можно в некотором смысле рассматривать наравне со случайной —
предположить, что её величина была определена по некоторому случайному
закону перед началом измерений (например, при изготовлении линейки
на заводе произошло некоторое случайное искажение шкалы). При такой
трактовке формулу (2.9) можно рассматривать просто
как частный случай формулы сложения погрешностей независимых величин
(2.7).
Подчеркнем, что вероятностный закон, которому подчиняется
систематическая ошибка, зачастую неизвестен. Поэтому неизвестно и
распределение итогового результата. Из этого, в частности, следует,
что мы не можем приписать интервалу x±Δсист какую-либо
определённую доверительную вероятность — она равна 0,68
только если систематическая ошибка имеет нормальное распределение.
Можно, конечно, предположить,
— и так часто делают — что, к примеру, ошибки
при изготовлении линеек на заводе имеют гауссов характер. Также часто
предполагают, что систематическая ошибка имеет равномерное
распределение (то есть «истинное» значение может с равной вероятностью
принять любое значение в пределах интервала ±Δсист).
Строго говоря, для этих предположений нет достаточных оснований.
Пример. В результате измерения диаметра проволоки микрометрическим винтом,
имеющим цену деления h=0,01 мм, получен следующий набор из n=8 значений:
Вычисляем среднее значение: ⟨d⟩≈386,3 мкм.
Среднеквадратичное отклонение:
σd≈9,2 мкм. Случайная погрешность среднего согласно
(2.8):
σ⟨d⟩=σd8≈3,2
мкм. Все результаты лежат в пределах ±2σd, поэтому нет
причин сомневаться в нормальности распределения. Максимальную погрешность
микрометра оценим как половину цены деления, Δ=h2=5 мкм.
Результирующая полная погрешность
σ≤Δ2+σd28≈6,0 мкм.
Видно, что σслуч≈Δсист и проводить дополнительные измерения
особого смысла нет. Окончательно результат измерений может быть представлен
в виде (см. также правила округления
результатов измерений в п. 4.3.2)
d=386±6мкм,εd=1,5%.
Заметим, что поскольку случайная погрешность и погрешность
прибора здесь имеют один порядок величины, наблюдаемый случайный разброс
данных может быть связан как с неоднородностью сечения проволоки,
так и с дефектами микрометра (например, с неровностями зажимов, люфтом
винта, сухим трением, деформацией проволоки под действием микрометра
и т. п.). Для ответа на вопрос, что именно вызвало разброс, требуются
дополнительные исследования, желательно с использованием более точных
приборов.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=±1 м/c.
Результаты измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=162,0м/с,
среднеквадратичное отклонение σv=13,8м/c, случайная
ошибка для средней скорости
σv¯=σv/6=5,6м/с.
Поскольку разброс экспериментальных данных существенно превышает погрешность
каждого измерения, σv≫δv, он почти наверняка связан
с реальным различием скоростей пули в разных выстрелах, а не с ошибками
измерений. В качестве результата эксперимента представляют интерес
как среднее значение скоростей ⟨v⟩=162±6м/с
(ε≈4%), так и значение σv≈14м/с,
характеризующее разброс значений скоростей от выстрела к выстрелу.
Малая инструментальная погрешность в принципе позволяет более точно
измерить среднее и дисперсию, и исследовать закон распределения выстрелов
по скоростям более детально — для этого требуется набрать
бо́льшую статистику по выстрелам.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=10 м/c. Результаты
измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=163,3м/с,
σv=12,1м/c, σ⟨v⟩=5м/с,
σполн≈11,2м/с. Инструментальная
погрешность каждого измерения превышает разброс данных, поэтому в
этом опыте затруднительно сделать вывод о различии скоростей от выстрела
к выстрелу. Результат измерений скорости пули:
⟨v⟩=163±11м/с,
ε≈7%. Проводить дополнительные выстрелы при такой
большой инструментальной погрешности особого смысла нет —
лучше поработать над точностью приборов и методикой измерений.
2.6 Обработка косвенных измерений
Косвенными называют измерения, полученные в результате расчётов,
использующих результаты прямых (то есть «непосредственных»)
измерений физических величин. Сформулируем основные правила пересчёта
погрешностей при косвенных измерениях.
2.6.1 Случай одной переменной
Пусть в эксперименте измеряется величина x, а её «наилучшее»
(в некотором смысле) значение равно x⋆ и оно известно с
погрешностью σx. После чего с помощью известной функции
вычисляется величина y=f(x).
В качестве «наилучшего» приближения для y используем значение функции
при «наилучшем» x:
Найдём величину погрешности σy. Обозначая отклонение измеряемой
величины как Δx=x-x⋆, и пользуясь определением производной,
при условии, что функция y(x) — гладкая
вблизи x≈x⋆, запишем
где f′≡dydx — производная фукнции f(x), взятая в точке
x⋆. Возведём полученное в квадрат, проведём усреднение
(σy2=⟨Δy2⟩,
σx2=⟨Δx2⟩), и затем снова извлечём
корень. В результате получим
Пример. Для степенной функции
y=Axn имеем σy=nAxn-1σx, откуда
σyy=nσxx,или εy=nεx,
то есть относительная погрешность степенной функции возрастает пропорционально
показателю степени n.
Пример. Для y=1/x имеем ε1/x=εx
— при обращении величины сохраняется её относительная
погрешность.
Упражнение. Найдите погрешность логарифма y=lnx, если известны x
и σx.
Упражнение. Найдите погрешность показательной функции y=ax,
если известны x и σx. Коэффициент a задан точно.
2.6.2 Случай многих переменных
Пусть величина u вычисляется по измеренным значениям нескольких
различных независимых физических величин x, y, …
на основе известного закона u=f(x,y,…). В качестве
наилучшего значения можно по-прежнему взять значение функции f
при наилучших значениях измеряемых параметров:
Для нахождения погрешности σu воспользуемся свойством,
известным из математического анализа, — малые приращения гладких
функции многих переменных складываются линейно, то есть справедлив
принцип суперпозиции малых приращений:
где символом fx′≡∂f∂x обозначена
частная производная функции f по переменной x —
то есть обычная производная f по x, взятая при условии, что
все остальные аргументы (кроме x) считаются постоянными параметрами.
Тогда пользуясь формулой для нахождения дисперсии суммы независимых
величин (2.7), получим соотношение, позволяющее вычислять
погрешности косвенных измерений для произвольной функции
u=f(x,y,…):
| σu2=fx′2σx2+fy′2σy2+… | (2.11) |
Это и есть искомая общая формула пересчёта погрешностей при косвенных
измерениях.
Отметим, что формулы (2.10) и (2.11) применимы
только если относительные отклонения всех величин малы
(εx,εy,…≪1),
а измерения проводятся вдали от особых точек функции f (производные
fx′, fy′ … не должны обращаться в бесконечность).
Также подчеркнём, что все полученные здесь формулы справедливы только
для независимых переменных x, y, …
Остановимся на некоторых важных частных случаях формулы
(2.11).
Пример. Для суммы (или разности) u=∑i=1naixi имеем
σu2=∑i=1nai2σxi2.
(2.12)
Пример. Найдём погрешность степенной функции:
u=xα⋅yβ⋅…. Тогда нетрудно получить,
что
σu2u2=α2σx2x2+β2σy2y2+…
или через относительные погрешности
εu2=α2εx2+β2εy2+…
(2.13)
Пример. Вычислим погрешность произведения и частного: u=xy или u=x/y.
Тогда в обоих случаях имеем
εu2=εx2+εy2,
(2.14)
то есть при умножении или делении относительные погрешности складываются
квадратично.
Пример. Рассмотрим несколько более сложный случай: нахождение угла по его тангенсу
u=arctgyx.
В таком случае, пользуясь тем, что (arctgz)′=11+z2,
где z=y/x, и используя производную сложной функции, находим
ux′=uz′zx′=-yx2+y2,
uy′=uz′zy′=xx2+y2, и наконец
σu2=y2σx2+x2σy2(x2+y2)2.
Упражнение. Найти погрешность вычисления гипотенузы z=x2+y2
прямоугольного треугольника по измеренным катетам x и y.
По итогам данного раздела можно дать следующие практические рекомендации.
-
•
Как правило, нет смысла увеличивать точность измерения какой-то одной
величины, если другие величины, используемые в расчётах, остаются
измеренными относительно грубо — всё равно итоговая погрешность
скорее всего будет определяться самым неточным измерением. Поэтому
все измерения имеет смысл проводить примерно с одной и той же
относительной погрешностью. -
•
При этом, как следует из (2.13), особое внимание
следует уделять измерению величин, возводимых при расчётах в степени
с большими показателями. А при сложных функциональных зависимостях
имеет смысл детально проанализировать структуру формулы
(2.11):
если вклад от некоторой величины в общую погрешность мал, нет смысла
гнаться за высокой точностью её измерения, и наоборот, точность некоторых
измерений может оказаться критически важной. -
•
Следует избегать измерения малых величин как разности двух близких
значений (например, толщины стенки цилиндра как разности внутреннего
и внешнего радиусов): если u=x-y, то абсолютная погрешность
σu=σx2+σy2
меняется мало, однако относительная погрешность
εu=σux-y
может оказаться неприемлемо большой, если x≈y.
Случайные погрешности в лабораторных работах по физике можно оценивать только с использованием калькулятора
О теории случайных погрешностей
Теория случайных погрешностей была создана К.Ф.Гауссом в первой половине XIX в. в связи с его занятиями астрономией и геодезией.
Напомним, что случайные погрешности δi = xi – a проявляются при проведении серии измерений одной и той же физической величины в неизменных условиях одним и тем же методом.
Одним из фундаментальных положений теории Гаусса является “принцип арифметической середины”. В соответствии с этим принципом за истинное значение величины а принимается среднее значение
![]()
при n → ∞, если метод не сопровождается систематическими погрешностями.
Для случайных погрешностей характерны следующие свойства:
- Положительные и отрицательные случайные погрешности встречаются с одинаковой вероятностью, т. е. одинаково часто.
- Среднее арифметическое из алгебраической суммы случайных погрешностей при неограниченном возрастании числа наблюдений стремится к нулю, т. е.

- Малые по абсолютной величине случайные погрешности встречаются с большей вероятностью, чем большие.
Основная идея теории Гаусса может быть выражена следующим образом
Возможные конкретные значения случайной погрешности, как и сам результат измерения, предсказать невозможно. Однако после того как экспериментатор определил измеряемый параметр и метод его измерения, сразу “возник” объективный закон, неизвестный исследователю. Этот закон определяет совокупность случайных погрешностей, которые возникают в процессе измерений.
Всегда можно эмпирически (на конкретных опытах) выявить закон распределения случайных погрешностей, который обычно выражается в виде так называемой функции распределения f(δ). Этот закон позволяет определить вероятность, с которой погрешность может оказаться в интервале от δ1 до δ2. Вероятность эта равна площади заштрихованной криволинейной трапеции, представленной на графике функции распределения.

Гауссу удалось определить универсальный закон распределения, которому подчиняется огромный класс случайных погрешностей измерений самых разных величин различными методами.
Этот закон носит название нормального закона распределения. Конечно, существуют измерения, погрешность которых не распределена по нормальному закону. Однако всегда можно определить степень их отклонения от нормального закона.
Функция распределения φ(δ), открытая Гауссом, имеет следующие свойства:

1) Функция δ(φ) четная, т. е. δ-(φ-)δ(φ), и в силу этого симметрична относительно оси координат.
2) Функция δ(φ) имеет максимум при значениях случайной погрешности, равных нулю.
3) Функция δ(φ) имеет две точки перегиба, расположенные симметрично относительно оси координат. Координаты точек перегиба равны ±σ.
4) Касательные к кривой δ(φ) в точках перегиба отсекают на оси абcцисс отрезки, равные ±2σ.
5) Максимальное значение функции δ(φ) равно
![]()
6) Площадь под всей кривой δ(φ) стремится к 1. Площадь криволинейной трапеции, ограниченной прямыми, проходящими через точки δ1,2 = ±σ, составляет 0,68 от всей площади; если прямые проходят через точки δ3,4 = ±2σ, то площадь составляет 0,95; площадь криволинейной трапеции, ограниченной прямыми δ5,6 = ±3σ, равна 0,99.
Параметр σ, определяющий все фундаментальные свойства нормального закона, называется средним квадратическим отклонением. Этот параметр может быть определен после получения достаточно большой серии результатов измерений x1, х2, х3, …, хn. Тогда

Важность параметра σ состоит в том, что он позволяет определить границы случайных погрешностей. Действительно, вероятность получения случайных погрешностей, превосходящих по абсолютной величине 3σ, равна 1%.
При обычной организации измерений не представляется возможности провести не только бесконечно большое число измерений, но и провести просто большое их число.
Специальные исследования показали, что такая граница может быть определена при небольшом числе опытов в серии.
В такой серии из k измерений находят так называемую среднюю квадратичную погрешность

Затем Δхкв увеличивают в S раз.
Число S называется коэффициентом Стьюдента (коэффициент был предложен в 1908 г. английским математиком В. С. Госсетом, публиковавшим свои работы под псевдонимом Стьюдент – студент). Коэффициент Стьюдента позволяет определить границу случайной погрешности серии: Δхслуч = S Δхкв.
Таблица коэффициентов S для различного числа опытов в серии

Погрешность среднего арифметического
После проведения серии равноточных измерений и нахождения хср и σ легко определяется интервал, к которому с вероятностью 99% принадлежит результат любого следующего измерения. Этот интервал равен [хср ± 3σ], если в серии достаточно много измерений, и имеет вид [хср ± S Δхкв] при небольшом числе опытов. Это означает, что 3σ (или S Δхкв) характеризует погрешность каждого опыта серии. Итак, среднее квадратичное отклонение серии опытов есть погрешность каждого опыта серии. Именно поэтому вводится обозначение σх или ΔSкв.х. Однако среднее арифметическое есть разумная комбинация всех измерений, и поэтому следует ожидать, что истинное значение находится в более узком интервале около хср, чем [xcp ± 3σх].
Понять, почему должно быть именно так, помогут следующие рассуждения
Выполняется N серий по n опытов в каждой. В каждой серии из n опытов определяется среднее значение хср. Таких средних значений получается N: хср1, хср2, …, xcpN. Для этой совокупности средних определяется среднее квадратичное отклонение
![]()
Величина σх ср характеризует предельное распределение средних значений, это и есть величина, которая позволяет найти интервал, в котором находится истинное значение измеряемой в опыте величины [хср ± 3σх ср]. На практике такая процедура никогда не реализуется не только потому, что это очень трудоемко, но и потому, что теория погрешностей позволяет по результатам одной серии определить погрешность среднего. Это делается на основе фундаментального результата теории погрешностей:
стандартное отклонение среднего σх ср в ![]() раз меньше стандартного отклонения каждого опыта серии σх, т.е.
раз меньше стандартного отклонения каждого опыта серии σх, т.е.
![]()
Итак, если в серии с достаточно большим числом опытов определено хср, то граница случайной погрешности среднего равна
![]()
Если в серии небольшое число опытов, то граница случайной погрешности среднего находится по формуле:

Все расчеты случайных погрешностей возможны только с использованием режима статистических расчетов (см. раздел “Статистические расчеты”), следуя методическим рекомендациям, приведенным ниже.
Использование калькулятора CASIO fx-82EX СLASSWIZ для оценки случайных погрешностей
- Включаем калькулятор, клавиша [ON]
- Нажимаем клавишу [SHIFT](SETUP)
- Входим в режим статистики. Нажимаем клавишу [2]
- Выбираем режим 1-Variable. Нажимаем клавишу [1]
- Заполняем таблицу
- Нажимаем клавишу [OPTN]
- Выбираем режим 1-Variable. Нажимаем клавишу [3]
- На дисплее получаем ряд характеристик
8.1. Первая сверху – значение среднего значения
8.2. Вторая снизу – случайная погрешность каждого опыта серии σх - Вычисляем погрешность среднего

- Находим границу случайной погрешности среднего

Пример
Измерялась скорость тела, брошенного горизонтально. В десяти опытах были получены следующие значения дальности полета L (в мм): 250, 245, 250, 262, 245, 248, 262, 260, 260, 248. Дальность полета тела измерялась линейкой с основной погрешностью Δ1 = 1мм. Высота, с которой брошено тело, в опыте равнялась Н = 1 м и измерялась мерной лентой с основной погрешностью Δ2 = 1 см и ценой деления С2 =1 см.

Решение
Сначала определим среднее значение дальности полета тела и вычислим его начальную скорость. Для этого сведем все данные в таблицу и проведем их первичную обработку.

Так как

Легко определить среднее значение скорости по результатам серии опытов:
![]()
Граница относительной погрешности измерения скорости:

В этой формуле ΔL – граница абсолютной погрешности измерения дальности полета, Δg – погрешность округления g, ΔН – погрешность прямого однократного измерения высоты.
ΔН = 1 см + 0,5 см = 1,5 см
ΔL складывается из погрешности линейки Δ1 и случайной погрешности ΔLслуч.:
ΔL = Δ1 + ΔLслуч.
Так как ΔLкв = 7мм, то при оценке ΔLслуч. нет смысла учитывать погрешность линейки Δ1 = 1мм.
Определим погрешность измерения скорости в любом однократном опыте, который можно провести на данной установке. В этом случае в формулу для εv следует вместо ∆L подставить его границу ∆L = S ∆Lкв. Здесь S = 3,2 (см. таблицу коэффициентов S для различного числа опытов в серии).
Имеем:
![]()
Первое слагаемое в этой сумме равно 0,09; слагаемое в скобках (0,01 + 0,0075) = 0,0175. Следовательно, εv = 0,09. Граница абсолютной погрешности каждого опыта серии не превосходит
εv = ε0 = 0,565 ∙ 0,09 = 0,05 м/с
Это значит, если на данной установке провести еще один опыт, то гарантировать можно, что значение скорости, рассчитанное по его результатам, будет принадлежать интервалу [(0,56 – 0,05)м/с; (0,56 + 0,05)м/с].
Найдем границу случайной погрешности среднего значения скорости тела, брошенного горизонтально. Для этого в формулу для εv следует вместо ∆L подставить границу случайной погрешности среднего:
![]()
Таким образом,
![]()
Относительная погрешность среднего равна
0,027 + 0,01 + 0,0075
Последним слагаемым в этой сумме можно пренебречь. Итак, ср = 0,04 = 4%. Мы видим, что погрешность среднего в два раза меньше погрешности каждого опыта. Граница абсолютной погрешности среднего равна:
![]()
Таким образом, из серии 10 опытов по измерению скорости можно сделать вывод о том, что в любой другой такой серии из 10 опытов на данной установке среднее значение скорости будет находиться в интервале [(0,56 – 0,02)м/с; (0,56 + 0,02)м/с]. Этому же интервалу принадлежит неизвестное значение скорости, которое получится, если проделать серию с очень большим числом опытов, т. е. такое значение, которое можно назвать истинным значением.
В статье представлен метод расчета случайной погрешности прямого измерения. К прямым измерениям относят нахождение величины из опытных данных с помощью прибора. К прямым измерениям можно отнести измерение длины линейкой, времени секундомером, объема цилиндром и так далее.
1. Измерим n раз некоторую величину X при одинаковых условиях. В результате получим набор значений X1, X2, X3,…,Xn.
2. Далее вычислим среднее арифметическое значение величины X по формуле:
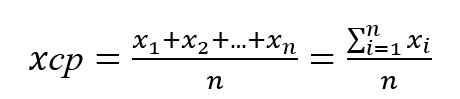
Для увеличения точности измерений необходимо увеличить количество измерений. При многократном увеличении числа измерений среднее арифметическое значение измеряемой величины будет стремиться к её истинному значению. То есть следует учитывать, что при конечном числе они будут равны друг другу лишь приближенно. Поэтому необходимо определять степень этого приближения, чтобы данное количество было достаточным для оценки результата.
3. Найдем среднее квадратичное отклонение среднего арифметического:
При этом значение случайной погрешности в случае небольшого числа измерений можно представить в виде
где t – это коэффициент Стьюдента, зависящий от доверительной вероятности и числа измерений . Значения коэффициента Стьюдента для доверительной вероятности приведены в таблице.
Таблица 1
Значения коэффициента Стьюдента.
