Skip to content
В этом руководстве вы познакомитесь с различными методами сравнения таблиц Excel и определения различий между ними. Узнайте, как просматривать две таблицы рядом, как использовать формулы для создания отчета о различиях, выделить несовпадения с помощью условного форматирования и многое другое.
Когда у вас есть две похожие книги Эксель или, лучше сказать, две версии одной и той же книги, что вы обычно хотите с ними делать в первую очередь? Сравнить их на предмет различий, а затем, возможно, объединить в один файл. Кроме того, такая операция может помочь вам обнаружить потенциальные проблемы, такие как битые ссылки, повторяющиеся записи, несогласованные формулы.
- Визуальное сравнение таблиц.
- Быстрое выделение различий.
- Использование формулы сравнения.
- Как вывести различия на отдельном листе.
- Как можно использовать функцию ВПР.
- Выделение различий условным форматированием.
- Сопоставление при помощи сводной таблицы.
- Сравнение таблиц при помощи Pover Query.
- Инструмент сравнения таблиц Ultimate Suite.
Итак, давайте более подробно рассмотрим различные методы сравнения таблиц Excel и выявления различий между ними.
Просмотр рядом, чтобы сравнить таблицы.
Если у вас относительно небольшие файлы и вы внимательны к деталям, этот быстрый и простой способ сравнения может вам подойти. Я говорю о режиме «Просмотр рядом», который позволяет расположить два окна Excel рядом. Вы можете использовать этот метод для визуального сравнения двух таблиц или двух листов из одной книги.
Сравните 2 книги.
Предположим, у вас есть отчеты о продажах за два месяца, и вы хотите просмотреть их оба одновременно, чтобы понять, какие товары показали лучшие результаты в этом месяце, а какие – в прошлом.
Чтобы просмотреть два файла Эксель рядом, сделайте следующее:
- Откройте оба файла.
- Перейдите на вкладку «Вид» и нажмите кнопку «Рядом». (1) Это оно!
По умолчанию два отдельных окна Excel отображаются горизонтально.
Чтобы разделить окна по вертикали, нажмите кнопку «Упорядочить все» (3) и выберите «Рядом» (4):
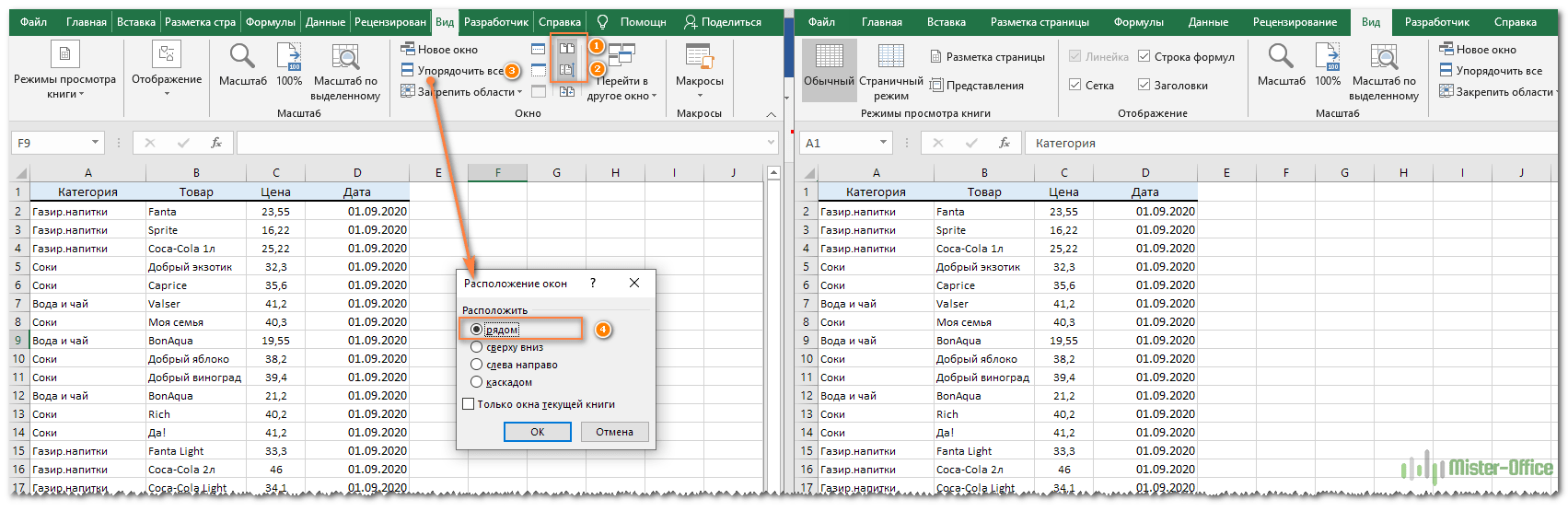
В результате два отдельных окна будут расположены, как на скриншоте.
Если вы хотите прокручивать оба листа одновременно, чтобы сравнивать данные строка за строкой, убедитесь, что параметр синхронной прокрутки (2) включен. Он обычно включается автоматически, как только вы активируете режим одновременного просмотра двух книг.
Расположите рядом несколько таблиц Excel.
Чтобы просматривать более двух файлов одновременно, откройте все книги, которые вы хотите сравнить, и нажмите кнопку «Рядом».
Появится диалоговое окно «Сравнить рядом», в котором вы выберете файлы, которые будут отображаться вместе с активной книгой.
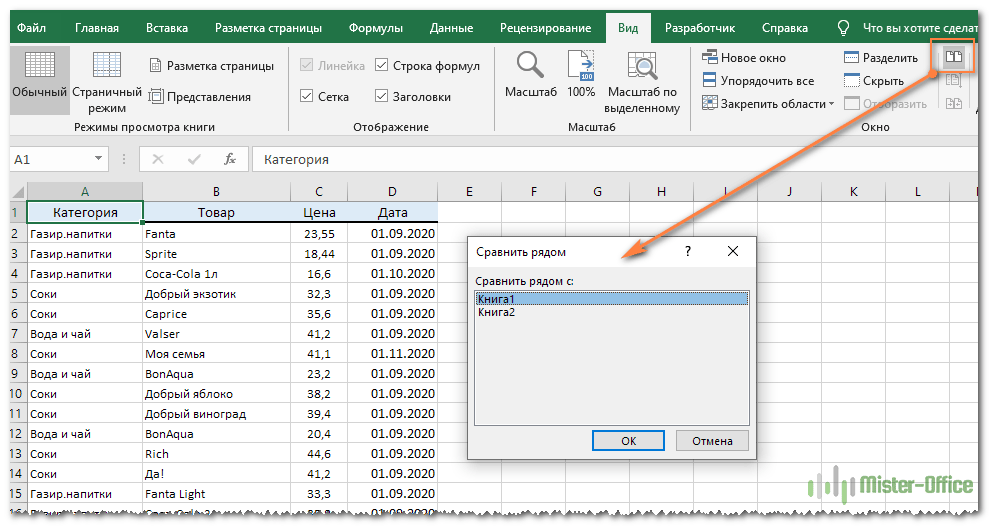
Чтобы просмотреть все открытые файлы одновременно, нажмите кнопку «Упорядочить все» и выберите предпочтительное расположение: мозаичное, горизонтальное, вертикальное или каскадное.
Для небольших таблиц вы легко сможете визуально сравнить их данные. Хотя, конечно, риск ошибки из-за человеческого фактора здесь присутствует.
Сравните два листа в одной книге.
Иногда 2 листа, которые вы хотите сравнить, находятся в одной книге. Чтобы просмотреть их рядом, выполните следующие действия.
- Откройте файл, перейдите на вкладку «Вид» и нажмите кнопку «Новое окно».

- Это действие откроет тот же файл в дополнительном окне.
- Включите режим просмотра «Рядом», нажав соответствующую кнопку на ленте.
- Выберите лист 1 в первом окне и лист 2 во втором окне.
Быстрое выделение значений, которые различаются.
Это также не очень обременительный способ. Если вам просто нужно найти и удостовериться в наличии или же отсутствии отличий между записями, вам нужно на вкладке «Главная», выбрать кнопку «Найти и выделить», предварительно выделив диапазон, где надо сравнить данные в Эксель.
В открывшемся меню выберите пункт «Выделить группу ячеек…» и в появившемся диалоговом окне выберите «отличия по строкам».
К сожалению, это нормально работает только для сравнения 2 столбцов (или строк), а не всей таблицы целиком. Кроме того, строки должны быть одинаковым образом отсортированы, поскольку ячейки сравниваются построчно. Если у вас товары отсортированы по-разному, либо вообще различный ассортимент, то никакой пользы от этого метода не будет.
Формула сравнения.
Это самый простой способ соотнесения таблиц в Excel, который позволяет идентифицировать в них ячейки с разными значениями.
Простейший вариант – сопоставление двух таблиц, находящихся на одном листе. Можно соотносить как числовые, так и текстовые значения, всего-навсего прописав в одной из соседних ячеек формулу их равенства. В результате при тождестве ячеек мы получим сообщение ИСТИНА, в противном случае — ЛОЖЬ.
Предположим, у нас имеется два прайс-листа (старый и новый), в которых на некоторые товары различаются цены. При этом порядок следования товаров одинаков. Поэтому мы можем при помощи простейшей формулы прямо на этом же листе сравнить идентичные ячейки с данными.
=G3=C3
Результатом будет являться либо ИСТИНА (в случае совпадения), либо ЛОЖЬ (при отрицательном результате).

Таким же образом можно производить сравнение данных в таблицах, которые расположены на разных листах. Процедура сравнения практически точно такая, как была описана выше, кроме того факта, что при создании формулы придется переключаться между листами. В нашем случае выражение будет иметь следующий вид:
=G3=Лист2!C3
Если ваши таблицы достаточно велики, то довольно утомительно будет просматривать колонку I на предмет поиска слова ЛОЖЬ. Поэтому может быть полезным сразу определить — а есть ли вообще несовпадения?
Можно подсчитать общее количество расхождений и сразу вывести это число где-нибудь отдельно.
=СУММПРОИЗВ(–(C3:C25<>G3:G25))
или можно сделать это формулой массива
{=СУММ(–(C3:C25<>G3:G25))}
Если формула возвращает ноль, значит, данные полностью совпадают. Ну а ежели результат положительный, то нужны более детальные исследования. О них мы и поговорим далее.
Как произвести сравнение на отдельном листе.
Чтобы сравнить два листа Эксель на предмет различий, просто откройте новый пустой лист, введите следующую формулу в ячейку A1, а затем скопируйте ее вниз и вправо, перетащив маркер заполнения:
=ЕСЛИ(Лист1!A1 <> Лист2!A1; “Лист1:”&Лист1!A1&” — Лист2:”&Лист2!A1; “”)
Поскольку мы используем относительные ссылки на ячейки, формула будет меняться в зависимости от расположения столбца и строки. В результате формула в A1 будет сравнивать ячейки A1 в Лист1 и Лист2, формула в B1 будет сравнивать ячейку B1 на обоих листах и так далее. Результат будет выглядеть примерно так:

В результате вы получите отчет о различиях на новом листе. Думаю, это достаточно информативно.
Как вы можете видеть на приведенном выше рисунке, формула сравнивает 2 листа, находит ячейки с разными значениями и отображает различия в соответствующих местах.
Обратите внимание, что в отчете о различиях (ячейка D4) даты представлены числами, поскольку в таком виде они хранятся во внутренней системе Excel, что не очень удобно для анализа различий между ними.
Как сравнить две таблицы при помощи формулы ВПР.
Предположим, у нас снова 2 прайс-листа. Однако, в отличие от предыдущего примера, они содержат разное количество товаров, да и сами товары расположены в произвольном порядке. Поэтому описанный выше способ, когда мы построчно сравнивали две таблицы, здесь не сработает.
Нам необходимо последовательно взять каждый товар из одной таблицы, найти его во второй, извлечь оттуда его цену и сравнить с первоначальной ценой. Здесь нам не обойтись без формул поиска. Поможет нам функция ВПР.
Для наглядности расположим обе таблицы на одном листе.

Формула
=ЕСЛИОШИБКА(ВПР(F3;$B$3:$C$18;2;0);0)
берёт наименование товара из второго прайса, ищет его в первом, и в случае удачи извлекает соответствующую цену из первой таблицы. Она будет записана рядом с новой ценой в столбце H. Если поиск завершился неудачей, то есть такого товара ранее не было, то ставим 0. Таким образом, старая и новая цена оказываются рядом, и их легко сравнить простейшей операцией вычитания. Что и сделано в столбце I.
Аналогично можно сопоставлять и данные на разных листах. Просто нужно соответствующим образом изменить ссылки в формуле, указав в них имя листа.
Вот еще один пример. Возьмём за основу более новую информацию, то есть второй прайс. Выведем только сведения о том, какие цены и на какие товары изменились. А то, что не изменилось, выводить в итоговом отчёте не будем.

Разберём действия пошагово. Формула в ячейке J3 ищет наименование товара из первой позиции второй таблицы внутри первой. Если таковое найдено, извлекается соответствующая этому товару старая цена и сразу же сравнивается с новой. Если они одинаковы, то в ячейку записывается пустота «».
=ЕСЛИ(ЕСЛИОШИБКА(ВПР(F3;$B$3:$C$18;2;0);0)=G3;””;ЕСЛИОШИБКА(ВПР(F3;$B$3:$C$18;2;0);0))
Таким образом, в ячейке J3 будет указана старая цена, если ее удастся найти, а также если она не равна новой.
Далее если ячейка J3 не пустая, то в I3 будет указано наименование товара —
=ЕСЛИ(J3<>””;F3;””)
а в K3 – его новая цена:
=ЕСЛИ(J3<>””;G3;””)
Ну а далее в L3 просто найдем разность K3-J3.
Таким образом, в отчёте сравнения мы видим только несовпадения значений второй таблицы по сравнению с первой.
И еще один пример, который может быть полезен. Попытаемся сравнить в итоговой таблице оба прайс-листа с эталонным общим списком товаров.

В ячейке B2 запишем формулу
=ЕСЛИ(ЕНД(ВПР(A2;Прайс1!$B$3:$B$19;1;0));”Нет”;ВПР(A2;Прайс1!$B$3:$C$19;2;0))
Так мы выясним, какие цены из второй таблицы встречаются в первой.
Для каждой цены из первого прайса проверяем, совпадает ли она с новыми данными —
=ЕСЛИ(ЕНД(ВПР(A2;Прайс2!$B$3:$B$22;1;0));”Нет”;ВПР(A2;Прайс2!$B$3:$C$22;2;0))
Эталонный список находится у нас в столбце A. В результате мы получили своего рода сводную таблицу цен – старых и новых.
Еще несколько примеров использования функции ВПР для сравнения таблиц вы можете найти в этой статье.
Выделение различий между таблицами цветом.
Чтобы закрасить ячейки с разными значениями на двух листах выбранным вами цветом, используйте функцию условного форматирования Excel:
- На листе, где вы хотите выделить различия, выберите все используемые ячейки. Для этого щелкните верхнюю левую ячейку используемого диапазона, обычно A1, и нажмите
Ctrl + Shift + End, чтобы расширить выделение до последней использованной ячейки. - На вкладке Главная кликните Условное форматирование > Новое правило и создайте его со следующей формулой:
=A1<>Лист2!A1
Где Лист2 – это имя другого листа, который вы сравниваете с текущим.
В результате ячейки с разными значениями будут выделены выбранным вами цветом:

Если вы не очень хорошо знакомы с условным форматированием, вы можете найти подробные инструкции по созданию правила в следующем руководстве: Условное форматирование Excel в зависимости от значения ячейки.
Сравнение при помощи сводной таблицы.
Хороший вариант сравнения — объединить таблицы в единую сводную, и там уже сопоставлять данные между собой.
Вернемся к нашему примеру с двумя прайс-листами. Объединим наши данные на одном листе. Чтобы отличить данные одной таблицы от другой, добавим вспомогательный столбец D и укажем в нем, откуда именно взяты данные:
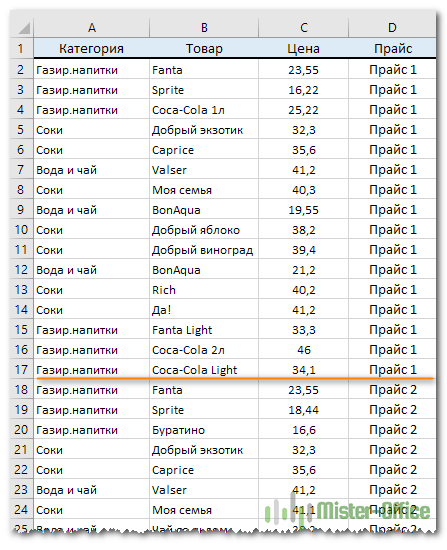
А теперь приступим к созданию сводной таблицы. Я не буду подробно останавливаться на том, как мы это будем делать. Все шаги подробно описаны в статье Как сделать сводную таблицу в Excel.
Поместим поле Товар в область строк, поле Прайс в область столбцов и поле Цена в область значений.
Как видно на скриншоте ниже, для каждого товара, встречающегося хотя бы в одном из прайсов, указана цена.

Сводная таблица автоматически сформирует общий список всех товаров из старого и нового прайсов и сортирует их по алфавиту. Причём, без повторов. У новых товаров нет старой цены, у удаленных товаров — новой цены. Легко увидеть изменения цен, если таковые были.
Общие итоги здесь смысла не имеют, и их можно отключить на вкладке Конструктор – Общие итоги – Отключить для строк и столбцов.
Если изменятся цены, то достаточно просто обновить созданную сводную, щелкнув по ней правой кнопкой мыши – Обновить. А вот если изменится список товаров или добавится новый файл для сравнения, то придется заново формировать исходный массив или же добавлять в него новые данные.
Плюсы: такой подход на порядок быстрее работает с большими объемами данных, чем ВПР. Можно сравнить данные нескольких таблиц.
Минусы: надо вручную копировать данные в одну большую таблицу и добавлять столбец с названием исходного файла.
Сравнение таблиц с помощью Power Query
Power Query – это бесплатная надстройка для Microsoft Excel, позволяющая загружать в него данные практически из любых источников и преобразовывать потом их желаемым образом. В Excel 2016 эта надстройка уже встроена по умолчанию на вкладке Данные, а для более ранних версий ее нужно отдельно скачать с сайта Microsoft и установить.
Перед загрузкой наших прайс-листов в Power Query их необходимо преобразовать сначала в умные таблицы. Для этого выделим диапазон с данными и нажмем на клавиатуре сочетание Ctrl+T или выберем на ленте вкладку Главная – Форматировать как таблицу. Имена созданных таблиц можно изменить на вкладке Конструктор (я оставлю стандартные Таблица1 и Таблица2, которые генерируются по умолчанию).
Загрузите первый прайс в Power Query с помощью кнопки Из таблицы/диапазона на вкладке Данные.

После загрузки вернемся обратно в Excel из Power Query командой Закрыть и загрузить – Закрыть и загрузить в…
В появившемся затем окне выбираем «Только создать подключение».

Повторите те же действия с новым прайс-листом.
Теперь создадим третий запрос, который будет объединять и сравнивать данных из предыдущих двух. Для этого выберем на вкладке Данные – Получить данные – Объединить запросы – Объединить. Все шаги вы видите на скриншоте ниже.

В окне объединения выберем в выпадающих списках наши таблицы, выделим в них столбцы с названиями товаров и в нижней части определим способ объединения – Полное внешнее.
После нажатия на ОК должна появиться таблица из четырёх столбцов, где в четвертой колонке нужно развернуть вложенное содержимое с помощью двойной стрелки в шапке.

После нажатия вы увидите список столбцов из второго прайса. Выбираем Товар и Цена. Получаем следующую картину:

А теперь сравним цены. Идем на вкладку Добавление столбца и жмем на кнопку Условный столбец. А затем в открывшемся окне вводим несколько условий проверки с соответствующими им значениями, которые нужно отобразить:

Теперь осталось вернуться на вкладку Главная и нажать Закрыть и загрузить.
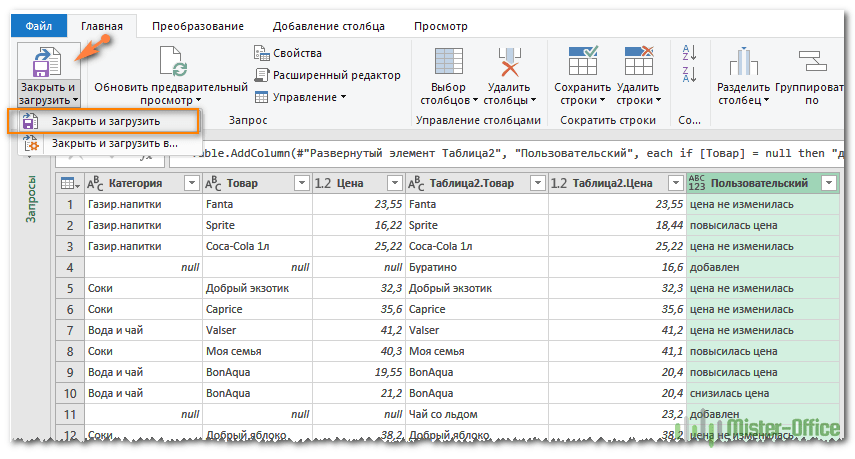
Получаем новый лист в нашей рабочей книге:

Примечание. Если в будущем в наших прайс-листах произойдут любые изменения (добавятся или удалятся строки, изменятся цены и т.д.), то достаточно будет лишь обновить наши запросы сочетанием клавиш Ctrl+Alt+F5 или кнопкой Обновить все на вкладке Данные.
Ведь все данные извлекаются из «умных» таблиц Excel, которые автоматически меняют свой размер при добавлении либо удалении из них какой-либо информации. Однако, помните, что имена столбцов в исходных таблицах не должны меняться, иначе получим ошибку “Столбец такой-то не найден!” при попытке обновить запрос.
Это, пожалуй, самый красивый и удобный способ из всех стандартных. Шустро работает с большими таблицами. Не требует ручных правок при изменении размеров.
Как видите, есть несколько способов сравнить две таблицы Excel, используя формулы или условное форматирование. Однако эти методы не подходят для комплексного сравнения из-за следующих ограничений:
- Они находят различия только в значениях, но не могут сравнивать формулы или форматирование ячеек.
- Многие из них не могут идентифицировать добавленные или удаленные строки и столбцы. Как только вы добавите или удалите строку / столбец на одном листе, все последующие строки / столбцы будут отмечены как отличия.
- Они хорошо работают на уровне листа, но не могут обнаруживать структурные различия на уровне книги Excel, к примеру добавление и удаление листов.
Эти проблемы решаются путем использования дополнений к Excel, о чем мы поговорим далее.
Как сравнить таблицы при помощи Ultimat Suite для Excel
Последняя версия Ultimate Suite включает более 60 новых функций и улучшений, самым интересным из которых является «Сравнение таблиц» – инструмент для сравнения листов или диапазонов данных в Excel.
Чтобы сделать сравнение более интуитивным и удобным, надстройка разработана следующим образом:
- Мастер шаг за шагом проведет вас через процесс и помогает настраивать различные параметры.
- Вы можете выбрать алгоритм сравнения, наиболее подходящий для ваших наборов данных.
- Вместо отчета о различиях сравниваемые листы отображаются в режиме просмотра различий, чтобы вы могли сразу просмотреть все различия и управлять ими по очереди.
Теперь давайте попробуем использовать этот инструмент на наших примерах электронных таблиц из предыдущего примера и посмотрим, отличаются ли результаты.
- Нажмите кнопку «Сравнить листы (Compare Two Sheets)» на вкладке «Данные Ablebits » в группе « Объединить »:

- Появится окно мастера с предложением выбрать два листа, которые вы хотите сравнить на предмет различий.
По умолчанию выбираются все листы, но вы также можете выбрать текущую таблицу ![]() или определенный диапазон
или определенный диапазон ![]() , нажав соответствующую кнопку:
, нажав соответствующую кнопку:

- На следующем шаге вы выбираете алгоритм сравнения:
- Без ключевых столбцов (по умолчанию) — лучше всего подходит для сложных документов, таких как счета-фактуры или контракты.
- По ключевым столбцам — подходит для таблиц, организованных по столбцам, которые имеют один или несколько уникальных идентификаторов, таких как номера заказов или артикулы товаров.
- По ячейке — лучше всего использовать для сравнения таблиц с одинаковым макетом и размером, таких как балансы или статистические отчеты.
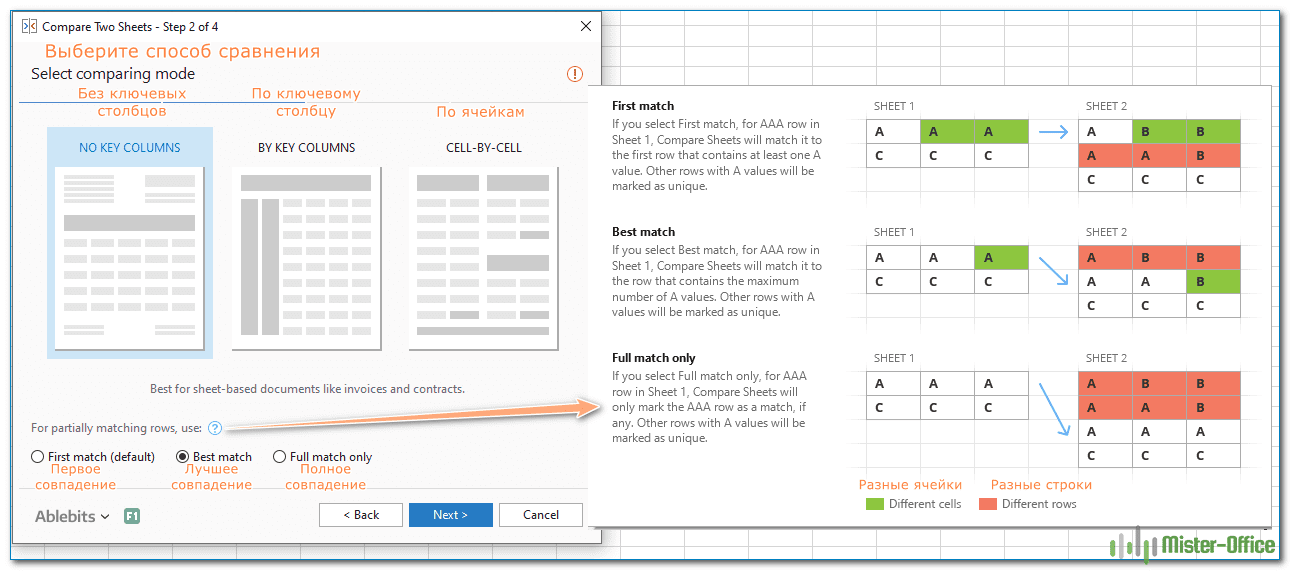
Совет. Если вы не уверены, какой алгоритм подходит вам, выберите вариант по умолчанию (без ключевых столбцов). Какой бы алгоритм вы ни выбрали, надстройка найдет все различия, только выделит их по-разному (целые строки или отдельные ячейки).
На этом же шаге вы можете выбрать предпочтительный тип соответствия:
- Первое совпадение (по умолчанию) – сравнивает строку на листе 1 с первой найденной строкой на листе 2, которая имеет хотя бы одну совпадающую ячейку.
- Наилучшее совпадение – сравнивает строку на листе 1 со строкой на листе 2, которая имеет максимальное количество совпадающих ячеек.
- Полное совпадение – находит на обоих листах строки, которые имеют одинаковые значения во всех ячейках, и отмечает все остальные строки как уникальные.
В этом примере мы сначала будем искать наилучшее совпадение, используя режим сравнения без ключевых столбцов, который установлен по умолчанию.
- На следующем шаге укажите, какие различия следует выделить, а какие игнорировать, и как помечать различия.
Скрытые строки и столбцы не имеют значения, и мы говорим надстройке игнорировать их:
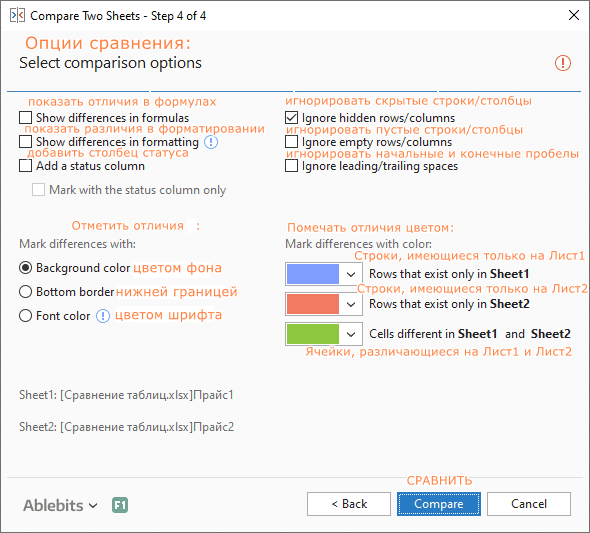
- Нажмите кнопку «Сравнить (Compare)» и подождите немного, пока программа обработает ваши данные и создаст их резервные копии. Резервные копии всегда создаются автоматически, поэтому вы можете не беспокоиться о сохранности своих данных.
После обработки листы открываются друг рядом с другом в специальном режиме просмотра различий с выбранным способом выделения отличий:
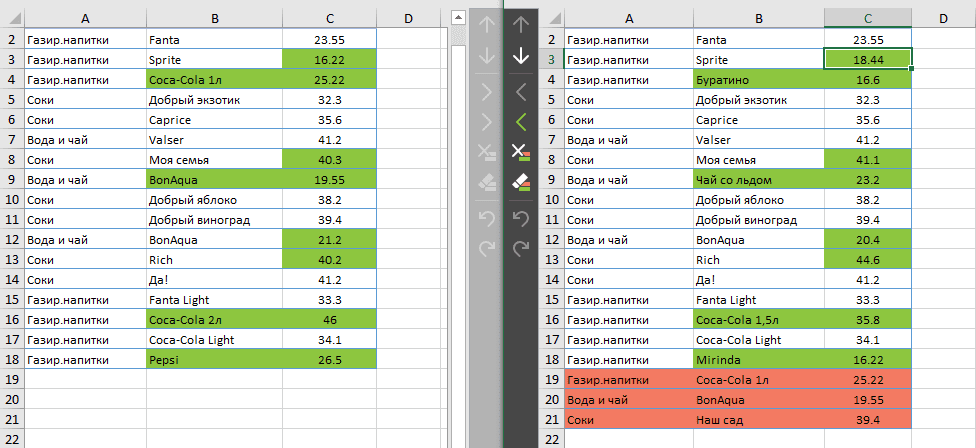
На скриншоте выше различия выделены цветами по умолчанию:
- Красные строки – строки, существующие только на Листе 2 (справа).
- Зеленые ячейки – различные ячейки в частично совпадающих строках.
А вот если мы выберем второй алгоритм сравнения — по ключевому столбцу, то нам будет предложено указать его. В нашем случае вполне можно ключевым столбцом обозначить «Товар».
После этого мы видим немного другой результат сравнения:

Как видите, основным здесь действительно является факт совпадения значений в столбцах B. Строки, в которых нет такого совпадения, сразу выделяются красным или фиолетовым. А вот если совпадение есть, тогда идем в столбец С и сравниваем записанную там цену. Зелёные ячейки как раз и показывают нам товары, которые имеются в обоих прайс-листах, но цена на них изменилась.
Не знаю как вам, но мне второй вариант представляется более информативным.
А что же дальше делать с этим сравнением?
Чтобы помочь вам просматривать различия и управлять ими, на каждом листе есть собственная вертикальная панель инструментов. Для неактивного рабочего листа (справа на нашем скриншоте) эта панель отключена. Чтобы активировать панель инструментов, просто выберите любую ячейку на соответствующем листе.
Используя её, вы последовательно просматриваете найденные различия и решаете, объединить их или игнорировать:
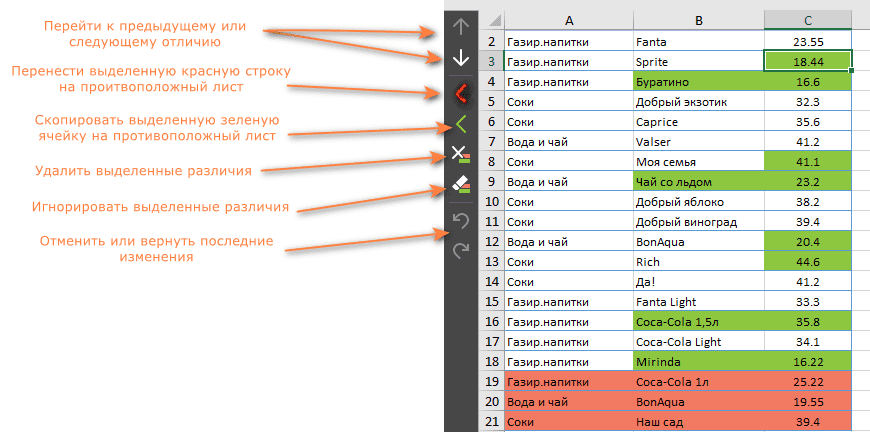
Как только последнее различие будет устранено, вам будет предложено сохранить книги и выйти из режима просмотра различий.
Если вы еще не закончили обработку различий, но хотели бы сделать перерыв, нажмите кнопку «Выйти из просмотра различий» в нижней части панели инструментов и выберите один из следующих вариантов:
- Сохраните внесенные вами изменения и сохраните оставшиеся различия (Save workbooks and keep difference marks),
- Сохраните внесенные вами изменения и удалите оставшиеся различия (Save workbooks and remove difference marks),
- Восстановите исходные книги из резервных копий (Restore workbooks from backup copies).

Вот как вы можете сравнить два листа в Excel при помощи инструмента сравнения Compare Two Sheets (надеюсь, он вам понравился 🙂
Если вам интересно попробовать, полнофункциональная ознакомительная версия доступна для загрузки здесь .
Колонки сравнивают для того, чтобы, например, в отчетах не было дубликатов. Или, наоборот, для проверки правильности заполнения — с поиском непохожих значений. И проще всего выполнять сравнение двух столбцов на совпадение в Excel — для этого есть 6 способов.

1 Сравнение с помощью простого поиска
При наличии небольшой по размеру таблицы заниматься сравнением можно практически вручную. Для этого достаточно выполнить несколько простых действий.
- Перейти на главную вкладку табличного процессора.
- В группе «Редактирование» выбрать пункт поиска.
- Выделить столбец, в котором будет выполняться поиск совпадений — например, второй.
- Вручную задавать значения из основного столбца (в данном случае — первого) и искать совпадения.
Если значение обнаружено, результатом станет выделение нужной ячейки. Однако с помощью такого способа можно работать только с небольшими столбцами. И, если это просто цифры, так можно сделать и без поиска — определяя совпадения визуально. Впрочем, если в колонках записаны большие объемы текста, даже такая простая методика позволит упростить поиск точного совпадения.

2 Операторы ЕСЛИ и СЧЕТЕСЛИ
Еще один способ сравнения значений в двух столбцах Excel подходит для таблиц практически неограниченного размера. Он основан на применении условного оператора ЕСЛИ и отличается от других методик тем, что для анализа совпадений берется только указанная в формуле часть, а не все значения массива. Порядок действий при использовании методики тоже не слишком сложный и подойдет даже для начинающего пользователя Excel.
- Сравниваемые столбцы размещаются на одном листе. Не обязательно, чтобы они находились рядом друг с другом.
- В третьем столбце, например, в ячейке J6, ввести формулу такого типа: =ЕСЛИ(ЕОШИБКА(ПОИСКПОЗ(H6;$I$6:$I$14;0));»;H6)
- Протянуть формулу до конца столбца.
Результатом станет появление в третьей колонке всех совпадающих значений. Причем H6 в примере — это первая ячейка одного из сравниваемых столбцов. А диапазон $I$6:$I$14 — все значения второй участвующей в сравнении колонки. Функция будет последовательно сравнивать данные и размещать только те из них, которые совпали. Однако выделения обнаруженных совпадений не происходит, поэтому методика подходит далеко не для всех ситуаций.
Еще один способ предполагает поиск не просто дубликатов в разных колонках, но и их расположения в пределах одной строки. Для этого можно применить все тот же оператор ЕСЛИ, добавив к нему еще одну функцию Excel — И. Формула поиска дубликатов для данного примера будет следующей: =ЕСЛИ(И(H6=I6); «Совпадают»; «») — ее точно так же размещают в ячейке J6 и протягивают до самого низа проверяемого диапазона. При наличии совпадений появится указанная надпись (можно выбрать «Совпадают» или «Совпадение»), при отсутствии — будет выдаваться пустота.
Тот же способ подойдет и для сравнения сразу большого количества колонок с данными на точное совпадение не только значения, но и строки. Для этого применяется уже не оператор ЕСЛИ, а функция СЧЕТЕСЛИ. Принцип написания и размещения формулы похожий.
Она имеет вид =ЕСЛИ(СЧЕТЕСЛИ($H6:$J6;$H6)=3; «Совпадают»;») и должна размещаться в верхней части следующего столбца с протягиванием вниз. Однако в формулу добавляется еще количество сравниваемых колонок — в данном случае, три.
Если поставить вместо тройки двойку, результатом будет поиск только тех совпадений с первой колонкой, которые присутствуют в одном из других столбцов. Причем, тройные дубликаты формула проигнорирует. Так же как и совпадения второй и третьей колонки.
3 Формула подстановки ВПР
Принцип действия еще одной функции для поиска дубликатов напоминает первый способ использованием оператора ЕСЛИ. Но вместо ПОИСКПОЗ применяется ВПР, которую можно расшифровать как «Вертикальный Просмотр». Для сравнения двух столбцов из похожего примера следует ввести в верхнюю ячейку (J6) третьей колонки формулу =ВПР(H6;$I$6:$I$15;1;0) и протянуть ее в самый низ, до J15.
С помощью этой функции не просто просматриваются и сравниваются повторяющиеся данные — результаты проверки устанавливаются четко напротив сравниваемого значения в первом столбце. Если программа не нашла совпадений, выдается #Н/Д.
4 Функция СОВПАД
Достаточно просто выполнить в Эксель сравнение двух столбцов с помощью еще двух полезных операторов — распространенного ИЛИ и встречающейся намного реже функции СОВПАД. Для ее использования выполняются такие действия:
- В третьем столбце, где будут размещаться результаты, вводится формула =ИЛИ(СОВПАД(I6;$H$6:$H$19))
- Вместо нажатия Enter нажимается комбинация клавиш Ctr + Shift + Enter. Результатом станет появление фигурных скобок слева и справа формулы.
- Формула протягивается вниз, до конца сравниваемой колонки — в данном случае проверяется наличие данных из второго столбца в первом. Это позволит изменяться сравниваемому показателю, тогда как знак $ закрепляет диапазон, с которым выполняется сравнение.
Результатом такого сравнения будет вывод уже не найденного совпадающего значения, а булевой переменной. В случае нахождения это будет «ИСТИНА». Если ни одного совпадения не было обнаружено — в ячейке появится надпись «ЛОЖЬ».
Стоит отметить, что функция СОВПАД сравнивает и числа, и другие виды данных с учетом верхнего регистра. А одним из самых распространенных способом использования такой формулы сравнения двух столбцов в Excel является поиска информации в базе данных. Например, отдельных видов мебели в каталоге.

5 Сравнение с выделением совпадений цветом
В поисках совпадений между данными в 2 столбцах пользователю Excel может понадобиться выделить найденные дубликаты, чтобы их было легко найти. Это позволит упростить поиск ячеек, в которых находятся совпадающие значения. Выделять совпадения и различия можно цветом — для этого понадобится применить условное форматирование.
Порядок действий для применения методики следующий:
- Перейти на главную вкладку табличного процессора.
- Выделить диапазон, в котором будут сравниваться столбцы.
- Выбрать пункт условного форматирования.
- Перейти к пункту «Правила выделения ячеек».
- Выбрать «Повторяющиеся значения».
- В открывшемся окне указать, как именно будут выделяться совпадения в первой и второй колонке. Например, красным текстом, если цвет остальных сообщений стандартный черный. Затем указать, что выделяться будут именно повторяющиеся ячейки.
Теперь можно снять выделение и сравнить совпадающие значения, которые будут заметно отличаться от остальной информации. Точно так же можно выделить, например, и уникальную информацию. Для этого следует выбрать вместо «повторяющихся» второй вариант — «уникальные».
6 Надстройка Inquire
Начиная с версий MS Excel 2013 табличный процессор позволяет воспользоваться еще одной методикой — специальной надстройкой Inquire. Она предназначена для того, чтобы сравнивать не колонки, а два файла .XLS или .XLSX в поисках не только совпадений, но и другой полезной информации.
Для использования способа придется расположить столбцы или целые блоки информации в разных книгах и удалить все остальные данные, кроме сравниваемой информации. Кроме того, для проверки необходимо, чтобы оба файла были одновременно открытыми.
Процесс использования надстройки включает такие действия:
- Перейти к параметрам электронной таблицы.
- Выбрать сначала надстройки, а затем управление надстройками COM.
- Отметить пункт Inquire и нажать «ОК».
- Перейти к вкладке Inquire.
- Нажать на кнопку Compare Files, указать, какие именно файлы будут сравниваться, и выбрать Compare.
- В открывшемся окне провести сравнения, используя показанные совпадения и различия между данными в столбцах.
У каждого варианта сравнения — свое цветовое решение. Так, зеленым цветом на примере выделены отличия. У совпадающих данных отсутствует выделение. А сравнение расчетных формул показало, что результаты отличаются все — и для выделения использован бирюзовый цвет.
Читайте также:
- 5 программ для совместной работы с документами
-
Как в Экселе протянуть формулу по строке или столбцу: 5 способов
При анализе данных с помощью Excel очень часто приходится искать некоторые значения по определенным критериям и подставлять их в другие таблицы. В таких задачах на помощью приходит функция ВПР, но у нее есть два существенных недостатка. Во-первых, функция ВПР возвращает только первое найденное значение. Например, у меня есть перечень заказов и необходимо получить номера всех заказов, которые оформил конкретный менеджер. Фамилия менеджера выбирается из выпадающего списка (выделено желтым) и ниже должны выводиться соответствующие номера заказов (зеленая область).
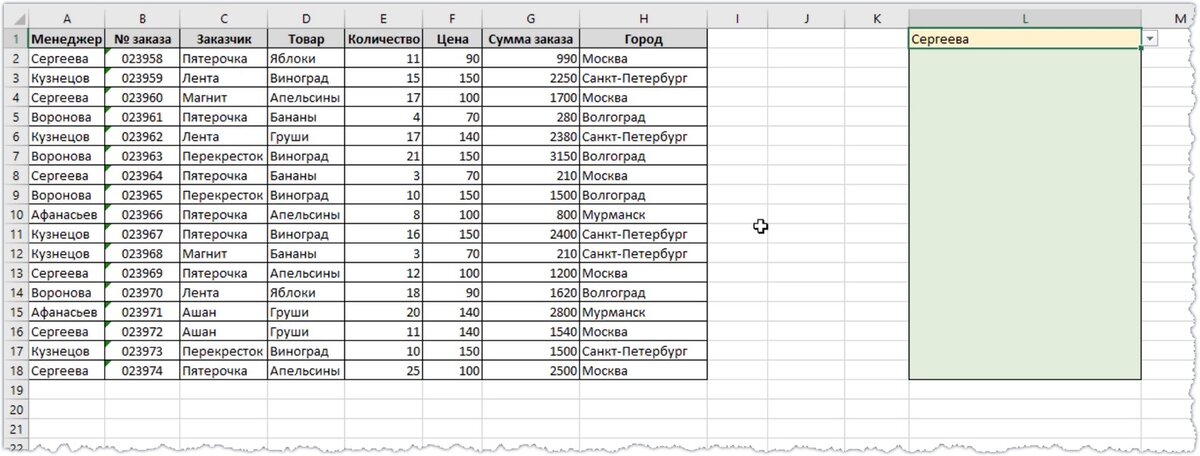
Если использовать стандартную функцию ВПР, то она найдет первый подходящий заказ и вернет ТОЛЬКО его номер.
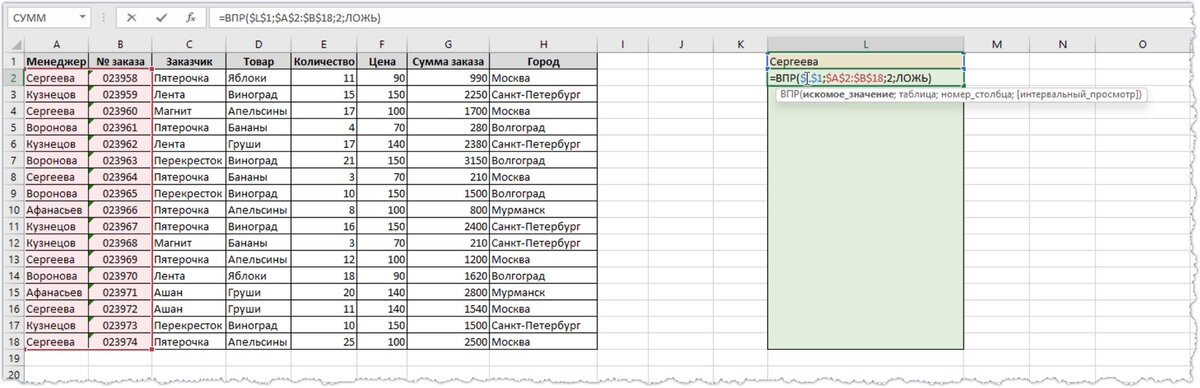
Еще одним недостатком функции ВПР является то, что она ищет значения только в левом крайнем столбце выделенного диапазона. То есть если бы столбец с фамилиями менеджеров находился правее столбца с номерами заказов, то функцию ВПР вообще не удалось бы использовать.
Этот недостаток устраняется с помощью сочетания функций ИНДЕКС и ПОИСКПОЗ, которые являются более гибкой альтернативой функции ВПР, но и эти функции не решают поставленную задачу.
Как же быть, если нужно вернуть все значения, соответсвующие определенному критерию? В этом также поможет функция ИНДЕКС.
Напомню, что функция ИНДЕКС возвращает значение, которое находится в указанном номере строки выделенного диапазона. То есть мы должны выбрать некоторый диапазон значений и вторым аргументом указать номер строки в этом диапазоне. Подчеркиваю, не номер строки листа Эксель, а номер строки выделенного диапазона значений.
Функция ИНДЕКС может возвращать не только одно значение, а массив значений. И именно это нам и нужно. Чтобы функция вернула массив значений, мы должны в нее подставить массив номеров нужным нам строк. Поэтому основной задачей для нас сейчас как раз и будет получение этого массива.
Давайте рассмотрим упрощенную таблицу, чтобы в ней не было отвлекающей информации. У нас есть таблица, состоящая из двух столбцов – Менеджер и Номер заказа. Также есть выпадающий список с фамилиями менеджеров и некоторая область листа, в которую мы будем выводить все заказы, связанные с выбранным менеджером.
Итак, сначала мы должны определить все строки в основной таблице, относящиеся к выбранному в списке менеджеру. Давайте сделаем это с помощью вспомогательного столбца и функции ЕСЛИ.
Если значение из текущей ячейки первого столбца таблицы (А2) равно значению, выбранному в выпадающем списке (L1), то определим номер строки, в котором это значение находится. Для этого воспользуемся функцией СТРОКА, которая как раз и предназначена для решения этой задачи. Так как формулу мы будем протягивать по диапазону, то не забываем зафиксировать ссылку на ячейку с выпадающем списком.
Протягиваем формулу.
Так как мы не указали в функции ЕСЛИ значение, которое появится в случае невыполнения условия, то в соответствующих ячейках выводится логическое выражение ЛОЖЬ. Это неважно, так как нас будут интересовать только цифры.
Мы получили номера строк листа Эксель, но в функцию ИНДЕКС необходимо подставить номер строки в выделенном диапазоне. В данном примере основная таблица располагается в верху листа и в первой строке находится шапка с названиями столбцов, поэтому, чтобы получить необходимые значения, мы можем откорректировать формулу и отнять единицу от полученного значения. В итоге во вспомогательном столбце появится массив необходимых нам чисел.
Если же таблица находится в другой части листа, то нужно будет либо вручную прописать необходимое корректировочное значение (то есть отступ от первой строки листа), либо можно автоматизировать этот процесс с помощью все той же функции СТРОКА, но об этом я расскажу чуть позже, чтобы сейчас не усложнять формулу.
Итак, теперь нам нужно отсортировать столбец, чтобы в начале были цифры. Сделать это можно, например, с помощью функции НАИМЕНЬШИЙ, которая возвращает указанное по счету наименьшее значение в выбранном диапазоне.
Выбираем диапазон (С2:С18) и затем необходимо указать цифру, определяющую, какое по порядку наименьшее число нужно вывести. Если укажем 1, то получим первое наименьшее значение в диапазоне, если 2, то второе, и так далее. Именно таким образом мы и сможем отсортировать полученный список с помощью формулы. Создадим вспомогательный столбец со значениями по порядку и подставим эти значения в функцию НАИМЕНЬШИЙ.
Мы получили необходимый нам перечень номеров строк и можем вернуться к функции ИНДЕКС. Фактически нам нужно подтянуть значения из второго столбца основной таблицы, поэтому в качестве диапазона указываем его. В качестве строки, соответственно, только что рассчитанные значения.
Чтобы избавиться от ошибки ЧИСЛО! воспользуемся функцией ЕСЛИОШИБКА. Обернем ей полученную функцию и в случае ошибки выведем пустоту.
Мы достигли необходимого результата, но для этого пришлось создать несколько вспомогательных столбцов. Давайте свернем все промежуточные вычисления в одну формулу, но это будет не простая формула, а формула массива, поэтому нам нужно будет поменять некоторые ссылки на диапазоны, к которым они относятся. А если точнее, то в функции ЕСЛИ нужно будет заменить относительные ссылки на ячейки столбца А соответствующим диапазоном и не забываем зафиксировать его. Также не забываем сделать формулу формулой массива, нажав сочетание клавиш Ctrl + Shift + Enter. Растянем формулу на весь зарезервированный диапазон таблицы и получаем необходимый результат.
Все вспомогательные столбцы, кроме столбца с нумерацией (столбец F) можно удалить. Давайте сделаем так, чтобы и этот столбец был не нужен. Значения столбца F используются в функции НАИМЕНЬШИЙ и нам нужно сделать так, чтобы подобный ряд чисел создавался автоматически и не зависел от того, где находится таблица с формулами. Для этого можно воспользоваться функцией СТРОКА и определить номер строки листа Эксель первой ячейки основной таблицы. Затем этот номер будем вычитать из номера последующих строк. Чтобы значения «не сползали» при протягивании формулы, зафиксируем ссылку на первую ячейку диапазона.
Все отлично, кроме того, что все значения нужно увеличить на единицу. Дополним формулу и получим нужный нам результат.
Осталось скопировать формулу и подставить ее в формулу массива, после чего и последний вспомогательный столбец можно будет удалить.
Ну и по аналогии можно решить проблему зависимости формулы от расположения исходной таблицы. Сейчас ее заголовки расположены в первой строке листа и поэтому формула четко привязана к этому положению.
Мы можем внести в функцию ЕСЛИ аналогичную формулу с двумя функциями СТРОКА. То есть отнимем от уже имеющейся функции СТРОКА со всем диапазоном столбца номер строки первой ячейки этого диапазона и прибавим единицу.
Теперь формула никак не привязана к положению исходной таблице на листе и она выполняет поставленную задачу – возвращает все искомые значения из указанного диапазона.
Ссылки на мои ресурсы по Excel
★ YouTube-канал по Excel
★ Телеграм
★ Серия видеокурсов “Microsoft Excel Шаг за Шагом”
★ Авторские книги и курсы

Инструкции
Гид по ВПР в Excel и Google Таблицах
Что это за функция и как с ней работать
Если нужно объединить данные в таблицах, можно вручную перепроверять и переносить значения с одного места на другое. Но это сложно и долго, плюс легко ошибиться.
Чтобы было быстрее и проще работать, в Google Таблицах и Excel есть множество функций. Одна из таких — ВПР (VLOOKUP). Она мгновенно и точно находит нужные данные в указанном диапазоне, позволяет автоматически переносить их с одного листа на другой (или с одной таблицы на другую, если использовать вместе с функцией IMPORTRANGE).
Чтобы самостоятельно поработать с шаблоном и примерами из статьи, можно открыть эту таблицу, выбрать «Файл → Создать копию».
Как работает ВПР
ВПР (VLOOKUP) — функция поиска и извлечения данных, которая:
- принимает определенный набор символов в качестве запроса;
- ищет совпадение с этим запросом в крайнем левом столбце заданного диапазона;
- копирует значения из ячейки, которая находится в соседнем столбце, но на этой же строке.
Так, ВПР используют магазины, когда нужно объединить или сравнить две таблицы. К примеру, таблицу заказов (какой товар заказали) и прайс-лист (по какой цене заказали, сколько денег ушло на закупку партии и так далее). Или, допустим, ВПР можно использовать, чтобы вычислить скидку для клиента или размер прибыли работника в зависимости от количества продаж.
Функция принимает четыре параметра: запрос, диапазон, номер столбца и сортировки. Подробнее о каждом:
Запрос показывает, что мы ищем в таблице. Например, наименование товара.
Диапазон отражает, где мы ищем запрос. Например, в диапазоне B2:C20. И если будет совпадение с ячейкой B1, функция ничего не вернет, так как эта ячейка не входит в указанный диапазон.
Индекс — номер столбца, который определяет, из какого столбца возвращать значение. Например, если в качестве диапазона указать B2:D11, то столбец C будет вторым, а D — третьим.
Важно: нельзя указать, в каком столбце искать совпадение с запросом — ВПР всегда «смотрит» только в крайнем левом столбце диапазона. Правда, есть лайфхаки, как обойти это ограничение, о которых мы расскажем позже.
Сортировка говорит, отсортированы значения в таблице или нет. 1 или ИСТИНА (TRUE) — да, 0 или ЛОЖЬ (FALSE) — нет.
Как правило, указывают 0 — в таком случае ВПР будет искать только точное совпадение с запросом. В противном случае функция выберет значения, которые примерно похожи на запрос — то есть меньшие или равные ему.
К тому же неточный поиск работает только в отношении чисел. Если ищем по словам, нужно обязательно передавать последним параметром 0 (ЛОЖЬ, FALSE).
А что если будет несколько ячеек, которые соответствуют искомому запросу? Тогда функция все равно выдаст только один результат — завершит работу, как только наткнется на первое совпадение.
Как пользоваться функцией ВПР
Разберемся на примере. Допустим, магазин электроники постоянно торгует разными видами товаров и в очередной раз закупил новую партию.
Прайс-лист магазину выслали в отдельной таблице, поэтому теперь информацию из полученной таблицы нужно перенести в собственную, в которой ведется учет.
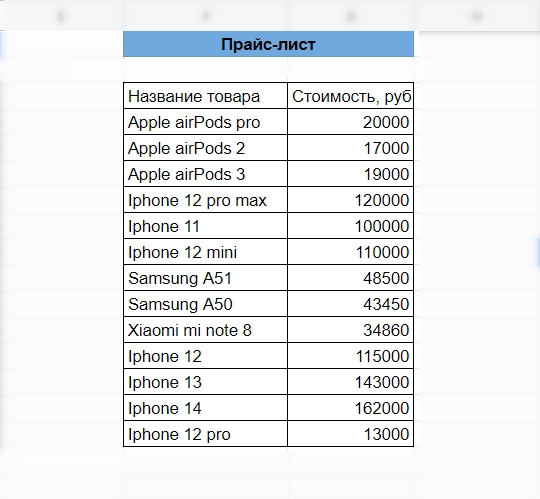
Полученная таблица со списком товаров и ценой
Перенести данные можно вручную, если товаров не очень много. Но если таблица состоит из сотни наименований — это проще сделать с ВПР.
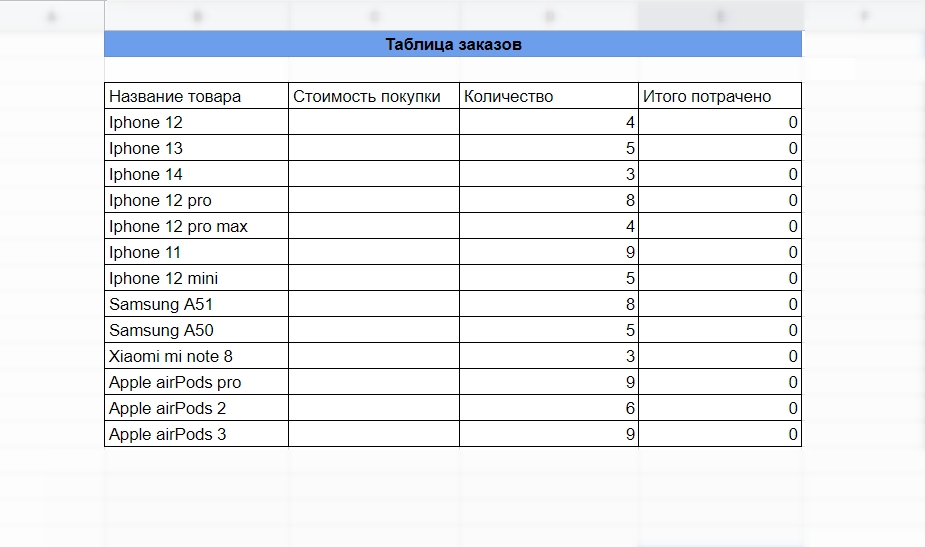
А это — таблица, в которую нужно передать данные из предыдущей
Шаг 1: Выбираем функцию и запрос
Для этого в ячейке «стоимость покупки» набираем равно «=» и пишем ВПР. После этого нажимаем на ячейку с запросом в столбце «название товара». Либо прописываем в скобках координаты ячейки. В нашем случае это «B4».
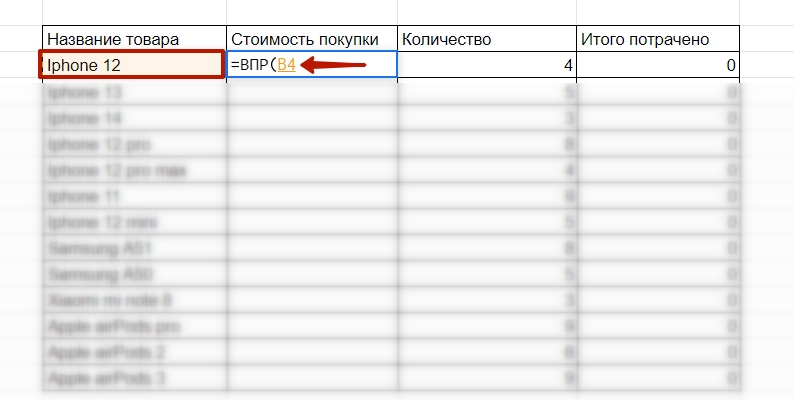
Первый этап работы — выбираем запрос
Шаг 2: Настраиваем диапазон запроса
После того, как выбрали запрос, настраиваем диапазон. Для этого выделяем всю вторую таблицу, из которой в будущем функция будет искать информацию.
Важно! Выделяйте только ячейки, в которых нужно искать запросы. Помните, что ВПР ищет совпадения только по первому столбцу (крайнему слева).
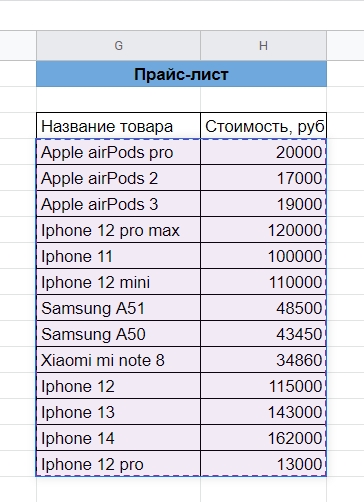
Второй этап — настраиваем диапазон ячеек
Чтобы выбрать диапазон, можно прямо во время написания формулы просто переключиться на нужный лист и выделить там ячейки. Чтобы все нормально вставилось, важно никуда не переключаться — данные сбросятся, если, например, нажать на другой лист.
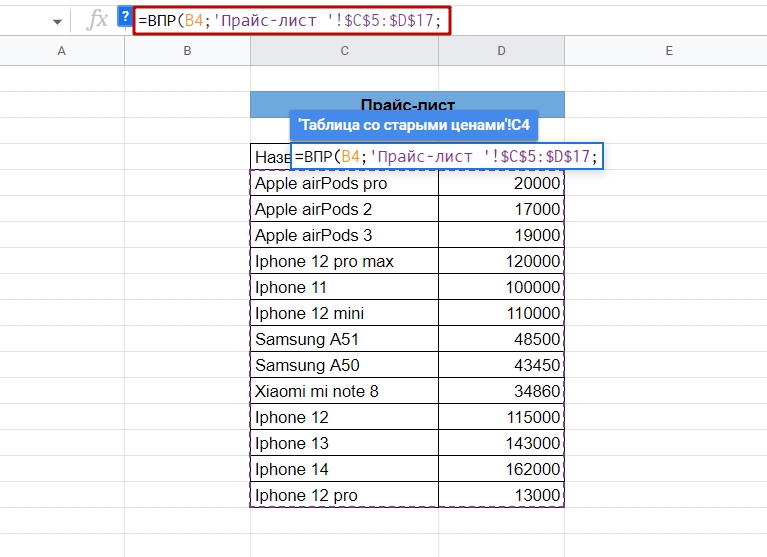
Переносим диапазон из одной таблицы в другую
Шаг 3: Выбираем номер столбца
Индекс (номер столбца) передаем следующим после диапазона.
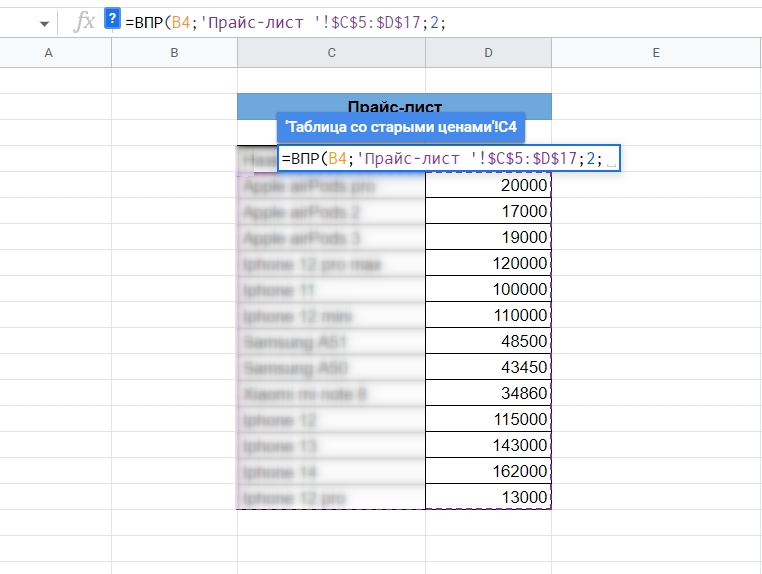
Третий этап — выбираем столбец
Важно: столбцы считаются внутри выбранного диапазона.
Так, в нашем примере нужно взять и перенести информацию о стоимости электроники, которая находится в столбце D. Если смотреть на весь лист, то D — это четвертый по счету столбец. А вот в диапазоне C:D столбец D — это именно второй по счету.
Шаг 4: Выбираем параметр «отсортировано» или «не отсортировано»
На этом этапе функция определяет, что искать: точное или неточное (меньшее или равное) совпадение с запросом. Напомню, что здесь есть два варианта:
0 (ЛОЖЬ, FALSE). ВПР выбирает точь-в-точь подходящий вариант. Как правило, используют именно такой режим поиска.
1 (ИСТИНА, TRUE). Функция выбирает примерно подходящий вариант, меньший или равный, но не больший. Это нужно гораздо реже, и имеет смысл, только если значения в диапазоне отсортированы.
Допустим, нам нужно сопоставить размер скидки для клиента с количеством покупок. Для этого создаем отдельную таблицу с диапазоном скидок. Важно, чтобы диапазон был возрастающий. Например, 5, 7, 9, 12, 15. Иначе функция работать не будет.
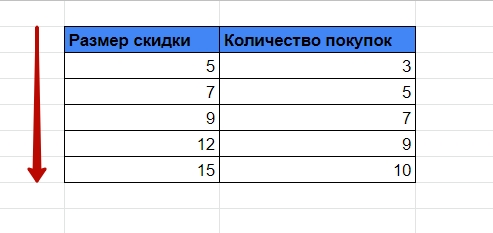
Сортируем запрос на примере скидок
Теперь прописываем функцию. Ячейка запроса — количество покупок, диапазон — вторая таблица с количеством покупок и размером скидки, номер столбца — второй, сортировка — «ИСТИНА» или «1».
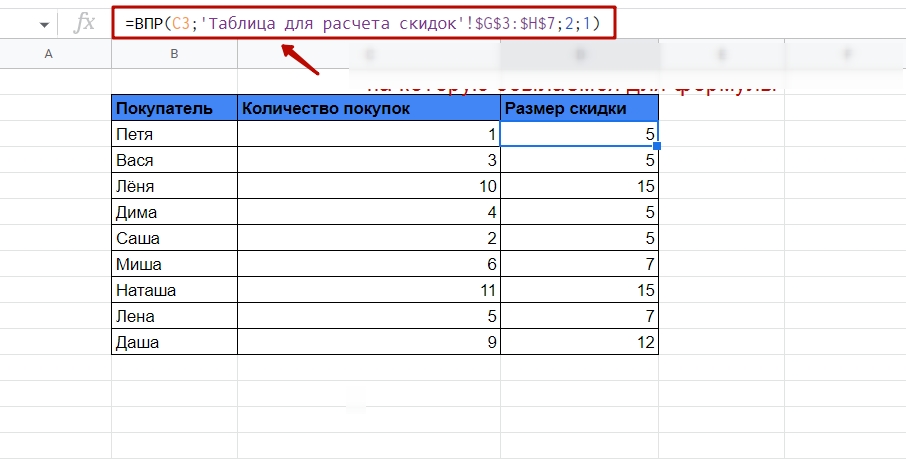
Вот так выглядит формула для расчета скидок
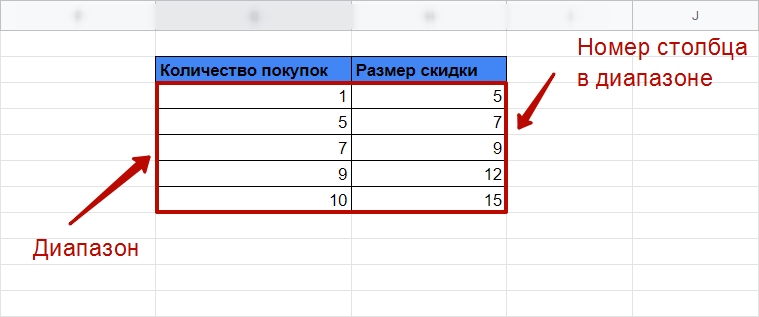
Все еще сортируем запрос
В итоге получаем таблицу с расчетами скидок для клиентов.
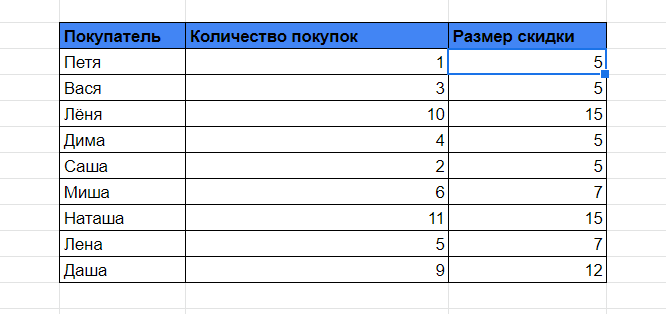
Ура! Все работает
Шаг 5: Настраиваем функцию под всю таблицу
Мы прописали функцию для одной ячейки. Чтобы не прописывать ее для каждой отдельно, можно просто протянуть — выделить ячейку с формулой, зажать точку в правом нижнем углу и потянуть вниз.
Но перед этим важно зафиксировать значения диапазона. Для этого нужно поставить знаки доллара как минимум после названий столбцов («G» и «H» в нашем случае), а лучше и перед тоже. Это можно сделать вручную или выделить диапазон и нажать «F4» на клавиатуре.
В противном случае при протягивании формула будет меняться, например, так: G4:H16 → G5:H17 → G6:H18 и так далее. А нам важно искать все значения в определенном диапазоне.
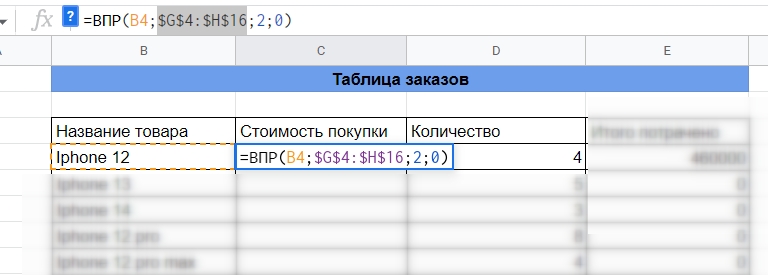
Пятый этап — настроили функцию для всей таблицы
Как сравнить таблицы с помощью ВПР
ВПР также используют, чтобы сравнить таблицы. Например, если изменилась цена на товары, можно быстро сравнить две таблицы и рассчитать процент изменений.
Для начала подтягиваем в таблицу старые цены. Формула будет выглядеть так:
=ВПР(A4;’Таблица со старыми ценами’!$B$4:$C$16;2;0)
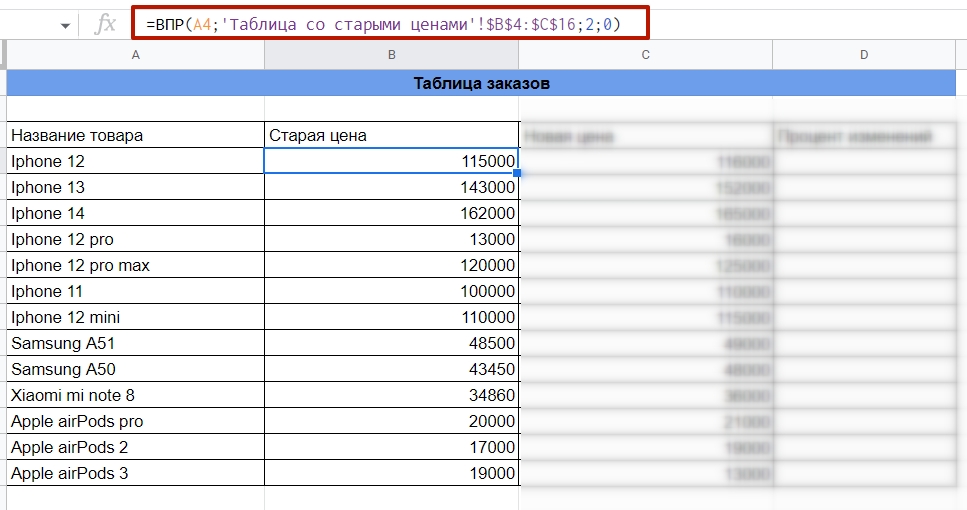
Подтягиваем в таблицу данные со старыми ценами
После этого добавляем данные из таблицы с новыми ценами. Формула будет такой:
=ВПР(A4;$G$4:$H$16;2;0)
Таблица для сравнения старых и новых цен
Теперь можно сравнить цены. Чтобы не делать это вручную, прописывайте формулу: новая цена – старая цена / новая цена. А в формате чисел выберите процент.
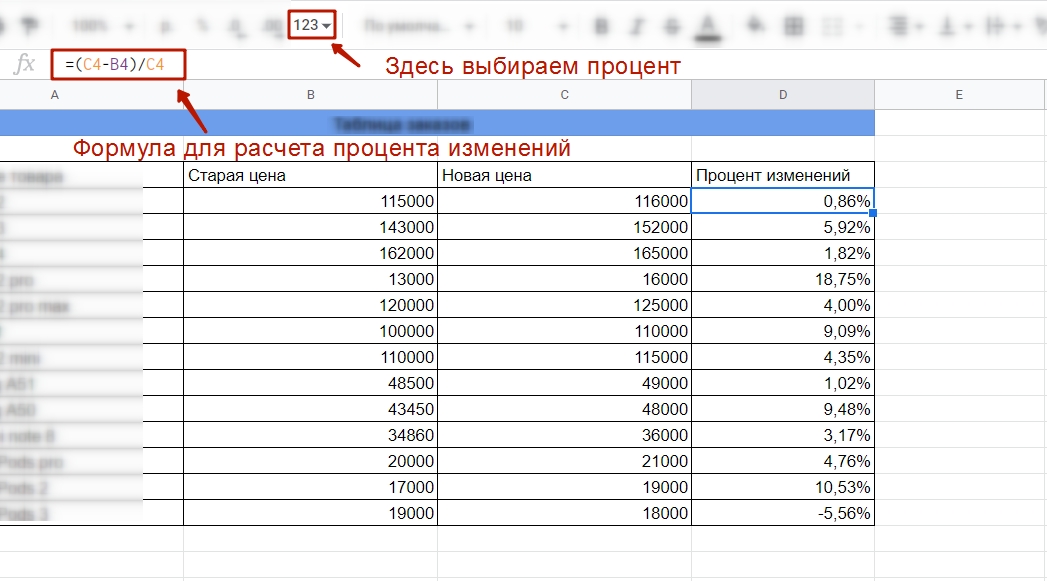
Сравниваем цены в процентном отношении
Как работать с ВПР, если искомое значение — слева, а не справа
Допустим, мы купили технику с разными ценами, кодами товаров и количеством. Попробуем узнать цену конкретной модели через код товара и формулы ВПР.
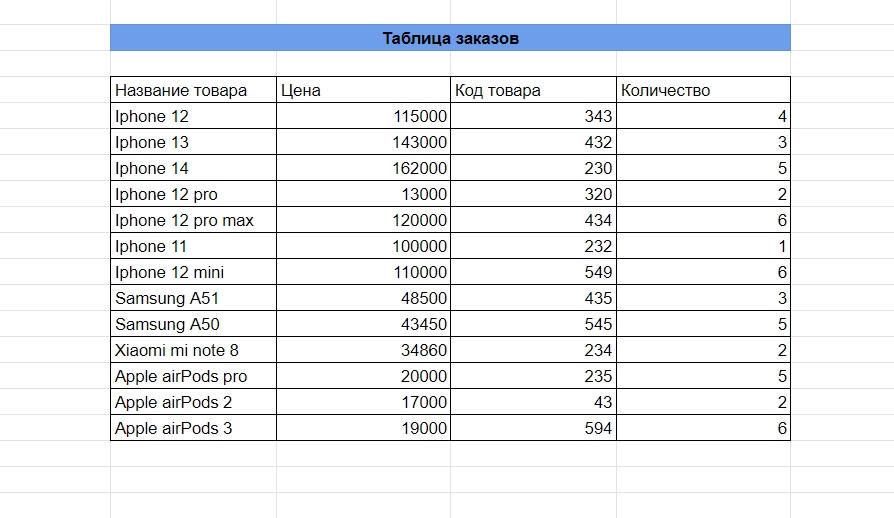
Вот такую табличку мы получили от поставщика: с названием товара, ценой, кодом и количеством
Прописать ВПР без изменений в таблице нельзя — по правилам формулы поиск производится по крайнему левому столбцу диапазона.
Поэтому самый простой способ — скопировать столбец «Цена» и перенести его в правый, после «Код товара». После этого внести новый столбец в диапазон и работать с ВПР как и прежде.
Если такой вариант не подходит, есть более сложный — через массивы.
Массив в Excel и Google Таблицах — это определенный набор данных, можно сказать, та же таблица, только «виртуальная».
Массивы могут быть одномерными, то есть состоять только из строк вроде {12} или столбцов вида {1;2}. Или же многомерными — включать и столбцы, и строки.
Для поиска цены создадим отдельные поля «Код товара» и «Цена».
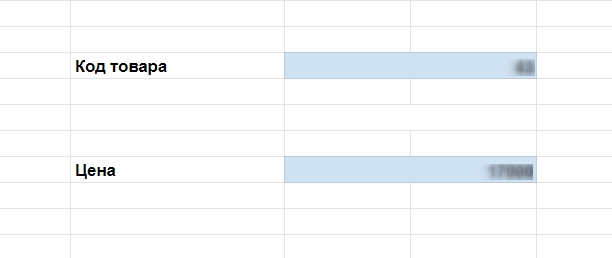
Поля можно создавать в листе с товарами или в новом
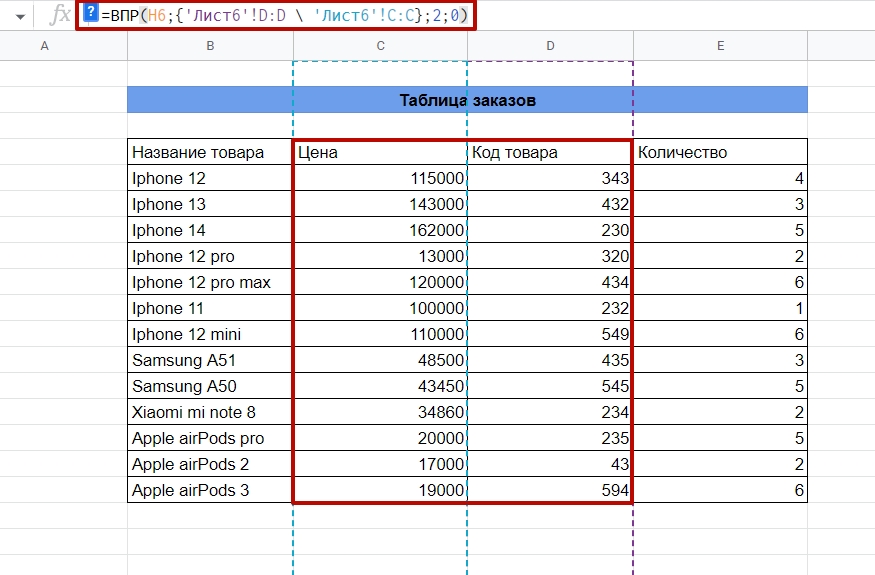
И прописываем ВПР для ячейки «Цена». Функция будет вида
=ВПР(H6;{‘Лист6’!D:D ‘Лист6’!C:C};2;0), где:
- H6 — номер ячейки с кодом товара.
- Лист6 — название листа, в котором находится наша таблица с ценами, кодами и количеством товаров.
- D:D — диапазон столбца с кодами товаров.
- C:C — диапазон столбца с ценами товаров.
- 2 — номер столбца из диапазона.
- 0 — точное соответствие.
Фигурными скобками как раз создаем массив, а обратной косой чертой показываем, что данные разделяются по столбцам. Тем самым меняем столбцы исходной таблицы местами — теперь сначала идет D:D, а только потом C:C. Такой лайфхак по обходу ограничения функции ВПР.
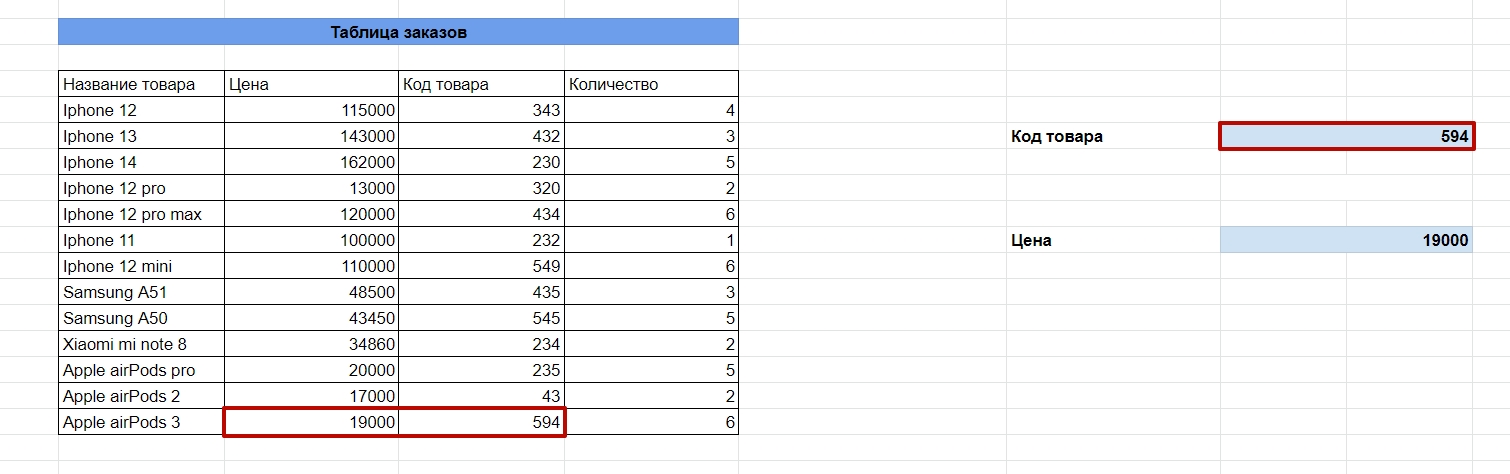
Так выглядит формула с массивами
В итоге, когда введем в ячейку «Код товара» соответствующие данные, получим информацию о стоимости устройств.
Проверяем, как все работает
Есть и другие способы работать с ВПР, если искомое значение слева. Например, с помощью функции СУММЕСЛИ, ВЫБОР, ИНДЕКС и ПОСКПОЗ — о таком варианте рассказывали на сайте «Планета Excel». Другую полезную инструкцию по работе с массивами выкладывали в телеграм-канале «Google Таблицы».
Как использовать символьные шаблоны ВПР
Мы рассказывали о том, что в ВПР есть неточный поиск, который работает только с цифрами. Но для неточного поиска по словам тоже кое-что есть.
Разберемся на примере наших товаров. Попробуем найти ячейку, в которой встречается слово Iphone с любыми словами и цифрами до и после него.
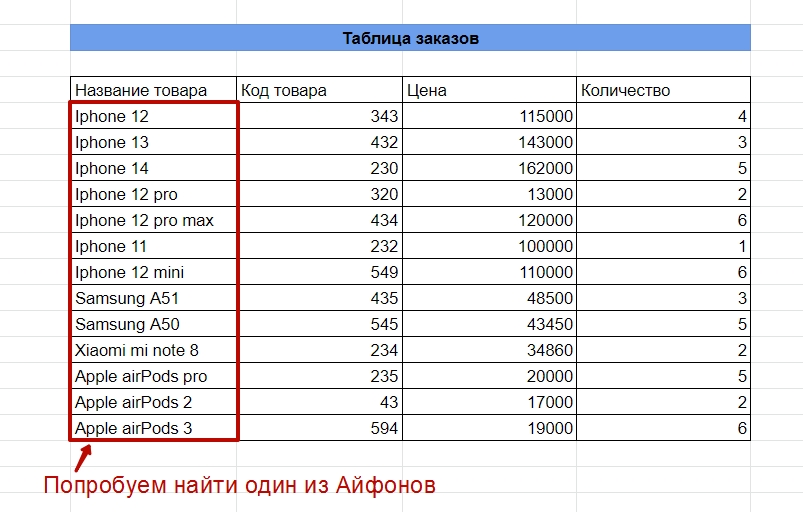
Ищем Iphone из списка
Для этого прописываем формулу:
=ВПР(«*Iphone*»;диапазон;1;0)
Звездочки означают любое количество любых символов (в том числе их отсутствие). То есть условию будут соответствовать и «Apple Iphone», и «Iphone 12», и «Iphone».
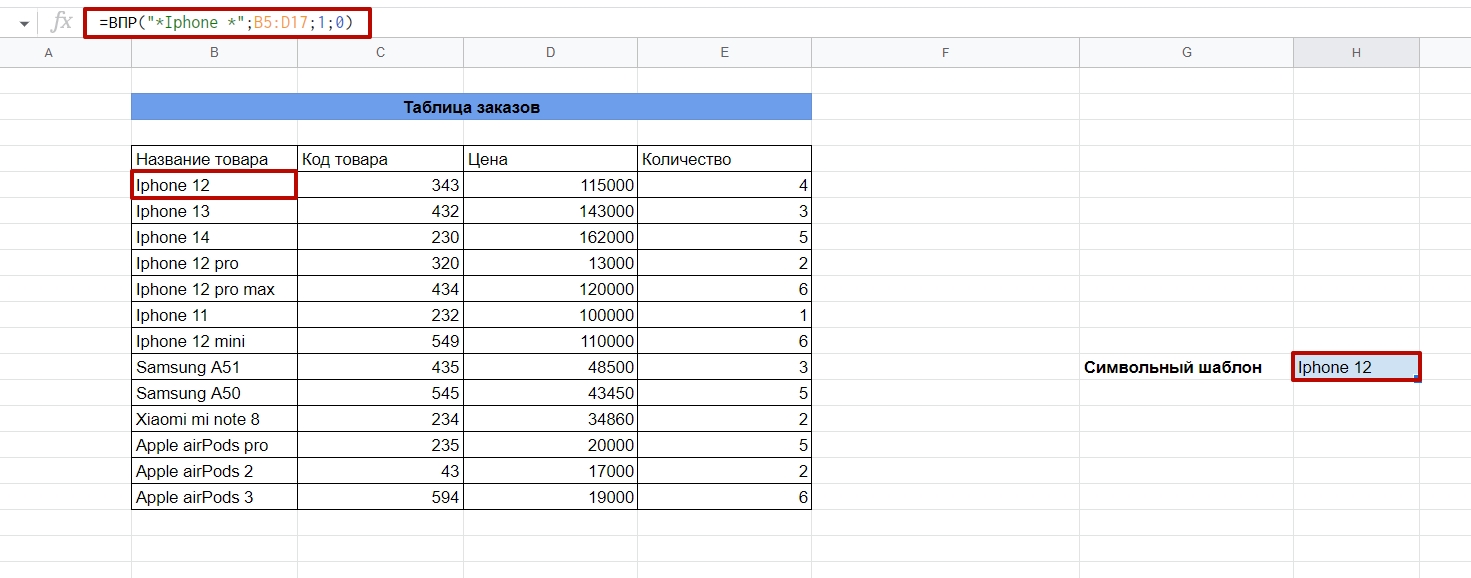
Проверяем, как работает фильтрация со звездочкой
А чтобы найти ячейку со словом Iphone с определенным количеством знаков после него, нужно составить формулу вида:
=ВПР(«*Iphone ?? ???»;диапазон;1;0)
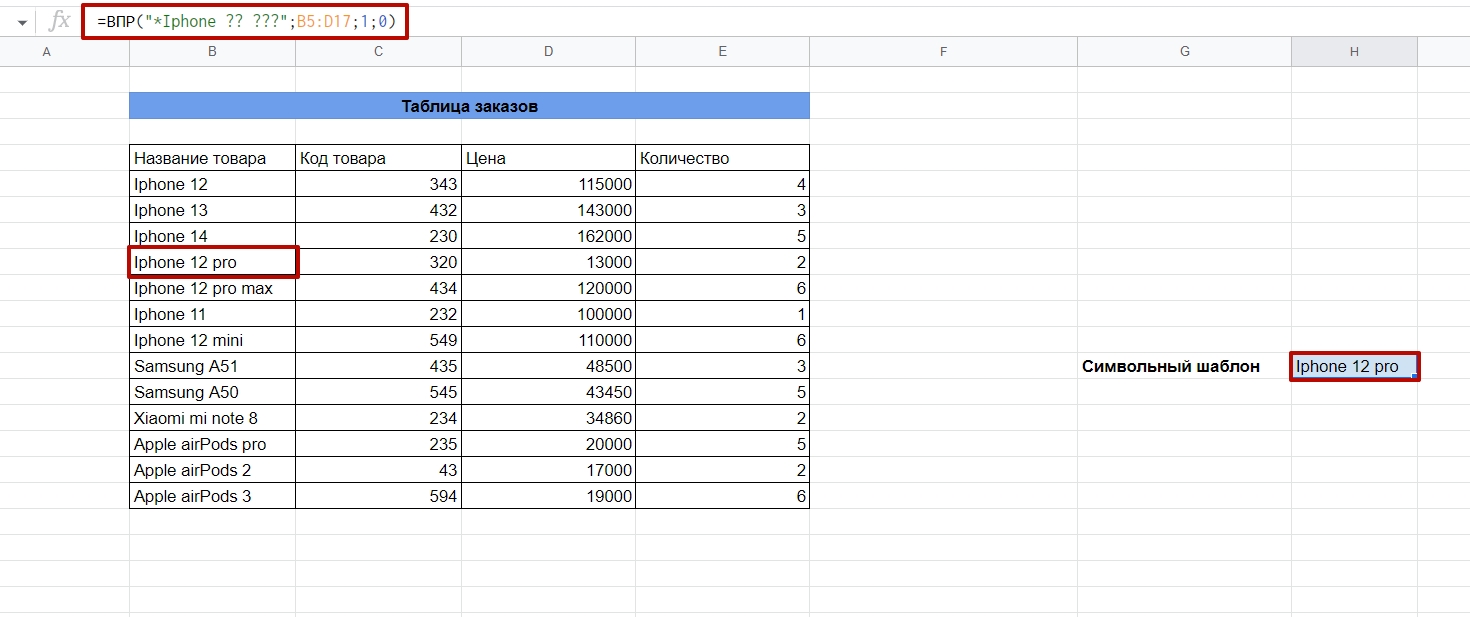
А теперь смотрим, как работает более строгая фильтрация. Каждый знак вопроса — один символ.
Напоминаем: если в таблице есть несколько ячеек, которые соответствуют запросу из формулы, то функция выдаст только первое вхождение по порядку.
Также ВПР можно настроить для нескольких условий одновременно, о таком способе рассказывал в своем блоге Евгений Намоконов. Пригодится, например, чтобы быстро найти стоимость битого Iphone 12 из таблицы.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Хитрости »
15 Май 2011 516133 просмотров
Как найти значение в другой таблице или сила ВПР
- Задача и её решение при помощи ВПР
- Описание аргументов ВПР
- Что важно всегда помнить при работе с ВПР
- Как избежать ошибки #Н/Д(#N/A) в ВПР?
- Как при помощи ВПР искать значение по строке, а не столбцу?
- Решение при помощи ПОИСКПОЗ
- Работа с критериями длиннее 255 символов
Если в двух словах, то ВПР позволяет сравнить данные двух таблиц на основании значений из одного столбца.
Чтобы чуть лучше понять принцип работы ВПР лучше начать с некоего практического примера. Возьмем две таблицы:

рис.1
На картинке выше для удобства они показаны рядом, но на самом деле могут быть расположены на разных листах и даже в разных книгах. Таблицы по сути одинаковые, но фамилии в них расположены в разном порядке, и к тому же в одной заполнены все столбцы, а во второй столбцы ФИО и Отдел. И из первой таблицы необходимо подставить во вторую дату для каждой фамилии. Для трех записей это не проблема и руками сделать – все очевидно. Но в жизни это таблицы на тысячи записей и поиск с подстановкой данных вручную может занять не один час. Вот где ВПР(VLOOKUP) будет весьма кстати. Все, что необходимо – записать в ячейку
C2
второй таблицы(туда, куда необходимо подставить даты из первой таблицы) такую формулу:
=ВПР($A2;Лист1!$A$1:$C$4;3;0)
=VLOOKUP($A2,Лист1!$A$1:$C$4,3,0)
Записать формулу можно либо непосредственно в ячейку, либо воспользовавшись диспетчером функций, выбрав в категории Ссылки и массивы(References & Arrays) функцию ВПР(VLOOKUP) и по отдельности указав нужные критерии. Теперь копируем(
Ctrl
+
C
) ячейку с формулой(С2), выделяем все ячейки столбца
С
до конца данных и вставляем(
Ctrl
+
V
).
Теперь разберем поподробнее саму функцию, её аргументы и некоторые особенности.
ВПР ищет заданное нами значение(аргумент искомое_значение) в первом столбце указанного диапазона(аргумент таблица). Поиск значения всегда происходит сверху вниз(собственно, поэтому функция и называется ВПР: Вертикальный ПРосмотр). Как только функция находит заданное значение – поиск прекращается, ВПР берет строку с найденным значением и смотрит на аргумент номер_столбца. Именно из этого столбца берётся значение, которое мы и видим как итог работы функции. Т.е. в нашем конкретном случае, для ячейки С2 второй таблицы, функция берет фамилию “Петров С.А.”(ячейка $A2 второй таблицы) и ищет её в первом столбце указанной таблицы(Лист1!$A$1:$C$4), т.е. в столбце А. Как только находит(это ячейка А3)
ВПР может вернуть только одно значений – первое, подходящее под критерий. Если искомое значение не найдено(отсутствует в таблице), то результатом функции будет ошибка #Н/Д(#N/A). Не надо этого бояться – это даже полезно. Вы точно будете знать, каких записей нет и таким образом можете сравнивать две таблицы друг с другом. Иногда получается так, что Вы видите: данные есть в обеих таблицах, но ВПР выдает #Н/Д. Значит данные в Ваших таблицах не идентичны. В какой-то из них есть лишние неприметные пробелы(обычно перед значением или после), либо знаки кириллицы перемешаны со знаками латиницы. Так же #Н/Д будет, если критерии числа и в искомой таблице они записаны как текст(как правило в левом верхнем углу такой ячейки появляется зеленый треугольничек), а в итоговой – как числа. Или наоборот.
Описание аргументов ВПР
- Искомое_значение($A2) – это то значение из одной таблицы, которые мы ищем в другой таблице. Т.е. для первой записи второй таблицы это будет Петров С.А.. Здесь можно указать либо непосредственно текст критерия(в этом случае он должен быть в кавычках – =ВПР(“Петров С.А”;Лист1!$A$1:$C$4;3;0), либо ссылку на ячейку, с данным текстом(как в примере функции). Есть небольшой нюанс: так же можно применять символы подстановки: “*” и “?”. Это очень удобно, если необходимо найти значения лишь по части строки. Например, можно не вводить полностью “Петров С.А”, а ввести лишь фамилию и знак звездочки – “Петров*”. Тогда будет выведена любая запись, которая начинается на “Петров”. Если же надо найти запись, в которой в любом месте строки встречается фамилия “Петров”, то можно указать так: “*петров*”. Если хотите найти фамилию Петров и неважно какие инициалы будут у имени-отчества(если ФИО записаны в виде Иванов И.И.), то здесь в самый раз такой вид: “Иванов ?.?.”.
Часто необходимо для каждой строки указать свое значение(в столбце А Фамилии и надо их все найти). В таком случае всегда указываются ссылки на ячейки столбца А. Например, в ячейке A2 записано: Иванов. Так же известно, что Иванов есть в другой таблице, но после фамилии могут быть записаны и имя и отчество(или еще что-то). Но нам нужно найти только строку, которая начинается на фамилию. Тогда необходимо записать следующим образом: A2&”*”. Эта запись будет равнозначна “Иванов*”. В A2 записано Иванов, амперсанд(&) используется для объединения в одну строку двух текстовых значений. Звездочка в кавычках (как и положено быть тексту внутри формулы). Таким образом и получаем:
A2&”*” =>
“Иванов”&”*” =>
“Иванов*”
А полная формула в итоге будет выглядеть так: =ВПР(A2&”*”;Лист1!$A$1:$C$4;3;0)
Очень удобно, если значений для поиска много.
Если надо определить есть ли хоть где-то слово в строке, то звездочки ставим с обеих сторон: “*”&A1&”*” - Таблица(Лист1!$A$1:$C$4) – указывается диапазон ячеек, в первом столбце которых будет просматриваться аргумент Искомое_значение. Диапазон должен содержать данные от первой ячейки с данными до самой последней. Это не обязательно должен быть указанный в примере диапазон. Если строк 100, то Лист1!$A$2:$C$100. Диапазон в аргументе таблица всегда должен быть “закреплен”, т.е. содержать знаки доллара($) перед названием столбцов и перед номерами строк(Лист1!$A$1:$C$4).
- Номер_столбца(3) – указывается номер столбца в аргументе Таблица, значения из которого нам необходимо записать в итоговую ячейку в качестве результата. В примере это Дата принятия – т.е. столбец №3. Если бы нужен был отдел, то необходимо было бы указать номер столбца 2, а если бы нам понадобилось просто сравнить есть ли фамилии одной таблицы в другой, то можно было бы указать и 1. Номер столбца всегда указывается числом и не должен быть больше числа столбцов в аргументе Таблица.
если аргумент Таблица имеет слишком большое кол-во столбцов и необходимо вернуть результат из последнего столбца, то совсем необязательно высчитывать их количество. Можно использовать формулу, которая подсчитывает количество столбцов в указанном диапазоне: =ВПР($A2;Лист1!$A$1:$C$4;ЧИСЛСТОЛБ(Лист1!$A$1:$C$4);0). К слову в данном случае Лист1! тоже можно убрать, т.к. функция ЧИСЛОСТОЛБ просто подсчитывает количество столбцов в переданном ей диапазоне и неважно на каком он листе: =ВПР($A2;Лист1!$A$1:$C$4;ЧИСЛСТОЛБ($A$1:$C$4);0).
- Интервальный_просмотр(0) – очень интересный аргумент. Может быть равен либо ИСТИНА либо ЛОЖЬ. Так же допускается указать 1 или 0. 1 = ИСТИНА, 0 = ЛОЖЬ. Если в ВПР указать данный параметр равный 0 или ЛОЖЬ, то будет происходить поиск точного соответствия заданному Искомому_значению. Это не имеет никакого отношения к знакам подстановки(“*” и “?”). Если же использовать 1 или ИСТИНА, то…Совсем в двух словах не объяснить. Если вкратце – ВПР будет искать наиболее похожее значение, подходящее под Искомомое_значение. Иногда очень полезно. Правда, если использовать данный параметр, то необходимо, чтобы список в аргументе Таблица был отсортирован по возрастанию. Обращаю внимание на то, что сортировка необходима только в том случае, если аргумент Интервальный_просмотр равен ИСТИНА или 1. Если же 0 или ЛОЖЬ – сортировка не нужна. Этот аргумент необходимо использовать осторожно – не стоит указывать 1 или ИСТИНА, если нужно найти точное соответствие и уж тем более не стоит использовать, если не понимаете принцип его работы.
Подробнее про работу ВПР с интервальным просмотром, равным 1 или ИСТИНА можно ознакомиться в статье ВПР и интервальный просмотр(range_lookup)
- Таблица всегда должна начинаться с того столбца, в котором ищем Искомое_значение. Т.е. ВПР не умеет искать значение во втором столбце таблицы, а значение возвращать из первого. В лучшем случае ничего найдено не будет и получим ошибку #Н/Д(#N/A), а в худшем результат будет совсем не тот, который должен быть
- аргумент Таблица должен быть “закреплен”, т.е. содержать знаки доллара($) перед названием столбцов и перед номерами строк(Лист1!$A$1:$C$4). Это и есть закрепление(если точнее, то это называется абсолютной ссылкой на диапазон). Как это делается. Выделяете текст ссылки и жмете клавишу F4 до тех пор, пока не увидите, что и перед обозначением имени столбца и перед номером строки не появились доллары. Если этого не сделать, то при копировании формулы из одной ячейки в остальные аргумент Таблица будет “съезжать” и результат может быть совсем не таким, какой ожидался(в лучшем случае получите ошибку #Н/Д(#N/A)
- номер_столбца не должен превышать общее кол-во столбцов в аргументе таблица, а сама Таблица соответственно должна содержать столбцы от первого(в котором ищем) до последнего(из которого необходимо возвращать значения). В примере указана Лист1!$A$1:$C$4 – всего 3 столбца(A, B, C). Значит не получится вернуть значение из столбца D(4), т.к. в таблице только три столбца. Т.е. если мы запишем формулу так: =ВПР($A2;Лист1!$A$1:$C$4;4;0) – мы получим ошибку #ССЫЛКА!(#REF!).
Если аргументом Таблица указан диапазон $B$1:$C$4 и необходимо вернуть данные из столбца С, то правильно будет указать номер столбца 2. Т.к. аргумент Таблица($B$1:$C$4) содержит только два столбца – В и С. Если же попытаться указать номер столбца 3(каким по счету он является на листе), то получим ошибку #ССЫЛКА!(#REF!), т.к. третьего столбца в указанном диапазоне просто нет.
Многие наверняка заметили, что на картинке у меня попутаны отделы для ФИО(в обеих таблицах ФИО относятся к разным отделам). Это не ошибка записи. В прилагаемом к статье примере показано, как можно одной формулой подставить и отделы и даты, не меняя вручную аргумент Номер_столбца: =ВПР($A2;Лист1!$A$1:$C$4;СТОЛБЕЦ();0). Такой подход сработает, если в обеих таблицах одинаковый порядок столбцов.
Как избежать ошибки #Н/Д(#N/A) в ВПР?
Еще частая проблема – многие не хотят видеть #Н/Д результатом, если совпадение не найдено. Это можно обойти при помощи специальных функций.
Для пользователей Excel 2003 и старше:
=ЕСЛИ(ЕНД(ВПР($A2;Лист1!$A$1:$C$4;3;0));””;ВПР($A2;Лист1!$A$1:$C$4;3;0))
=IF(ISNA(VLOOKUP($A2,Лист1!$A$1:$C$4,3,0)),””,VLOOKUP($A2,Лист1!$A$1:$C$4,3,0))
Теперь если ВПР не найдет совпадения, то ячейка будет пустой.
А пользователям версий Excel 2007 и выше будет удобнее использовать функцию
ЕСЛИОШИБКА(IFERROR)
:
=ЕСЛИОШИБКА(ВПР($A2;Лист1!$A$1:$C$4;3;0);””)
=IFERROR(VLOOKUP($A2,Лист1!$A$1:$C$4,3,0);””)
Подробнее про различие между использованием ЕСЛИ(ЕНД и ЕСЛИОШИБКА я разбирал в статье: Как в ячейке с формулой вместо ошибки показать 0
Но я бы не рекомендовал использовать
ЕСЛИОШИБКА(IFERROR)
, не убедившись, что ошибки появляются только для реально отсутствующих значений. Иногда ВПР может вернуть #Н/Д и в других ситуациях:
- искомое значение состоит более чем из 255 символов(решение этой проблемы приведено ниже в этой статье: Работа с критериями длиннее 255 символов)
- искомое значение является числом с большим кол-вом знаков после запятой. Excel не может правильно воспринимать такие числа и в итоге ВПР может вернуть ошибку. Правильным решением здесь будет округлить искомое значение хотя бы до 4-х или 5-ти знаков после запятой(конечно, если это допустимо):
=ВПР(ОКРУГЛ($A2;5);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(ROUND($A2,2),Лист1!$A$1:$C$4,3,0) - искомое значение содержит специальные или непечатаемые символы.
В этом случае придется либо избавиться от непечатаемых символов в искомом аргументе:
=ВПР(ПЕЧСИМВ($A2);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(CLEAN($A2),Лист1!$A$1:$C$4,3,0)
либо добавить перед всеми специальными символами(такими как звездочка или вопр.знак) знак тильды(~), чтобы сделать эти знаки просто знаками, а не знаками специального значения(так же работа со специальными(служебными) символами описывалась в статье: Как заменить/удалить/найти звездочку). Добавить символ перед знаком той же тильды можно при помощи функции ПОДСТАВИТЬ(SUBSTITUTE):
=ВПР(ПОДСТАВИТЬ($A2;”~”;”~~”);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(SUBSTITUTE(A2,”~”,”~~”),Лист1!$A$1:$C$4,3,0)
Если необходимо добавить тильду сразу перед несколькими знаками, то делает это обычно так(на примере подстановки одновременно для тильды и звездочки):
=ВПР(ПОДСТАВИТЬ(ПОДСТАВИТЬ($A2;”~”;”~~”);”*”;”~*”);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(SUBSTITUTE(SUBSTITUTE(A2,”~”,”~~”),”*”,”~*”),Лист1!$A$1:$C$4,3,0)
На самом деле ответ будет коротким – ВПР всегда ищет сверху вниз. Слева направо она не умеет. Но зато слева направо умеет искать её сестра ГПР(HLookup) – Горизонтальный
ПР
осмотр.
ГПР ищет заданное значение(аргумент
искомое_значение
) в первой строке указанного диапазона(аргумент
таблица
) и возвращает для него значение из строки таблицы, указанной аргументом номер_строки. Поиск значения всегда происходит слева направо и заканчивается сразу, как только значение найдено. Если значение не найдено, функция возвращает значение ошибки
#Н/Д(#N/A)
.
Если надо найти значение “Иванов” в строке 2 и вернуть значение из строки 5 в таблице
A2:H10
, то формула будет выглядеть так:
=ГПР(“Иванов”;$A$2:$H$10;5;0)
=HLOOKUP(“Иванов”,$A$2:$H$10,5,0)
Все правила и синтаксис функции точно такие же, как у ВПР:
-в искомом значении можно применять символы астерикса(*) и вопр.знака(?) – “Иванов*”;
-таблица должна быть закреплена –
$A$2:$H$10
;
-интервальный просмотр работает по тому же принципу(0 или ЛОЖЬ точный просмотр слева-направо, 1 или ИСТИНА – интервальный).
Общий принцип работы
ПОИСКПОЗ(MATCH)
очень похож на ВПР – функция ищет заданное значение в массиве (в столбце или строке) и возвращает его позицию(порядковый номер в заданном массиве). Т.е. ищет
Искомое_значение
в аргументе
Просматриваемый_массив
и в качестве результата выдает номер позиции найденного значения в
Просматриваемом_массиве
. Именно номер позиции, а не само значение. Если бы мы хотели применить её для таблицы выше, то она была бы такой:
=ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0)
=MATCH($A2,Лист1!$A$1:$A$4,0)
- Искомое_значение($A2) – непосредственно значение или ссылка на ячейку с искомым значением. Если опираться на пример выше – то это ФИО. Здесь все ровно так же, как и с ВПР. Так же допустимы символы подстановки * и ? и ровно в таком же исполнении.
- Просматриваемый_массив(Лист1!$A$1:$A$4) – указывается ссылка на столбец, в котором необходимо найти искомое значение. В отличии от той же ВПР, где указывается целая таблица, это должен быть именно один столбец, в котором мы собираемся искать Искомое_значение. Если попытаться указать более одного столбца, то функция вернет ошибку.Справедливости ради надо отметить, что можно указать либо столбец, либо строку
- Тип_сопоставления(0) – то же самое, что и Интервальный_просмотр в ВПР. С теми же особенностями. Отличается разве что возможностью поиска наименьшего от искомого или наибольшего.
С основным разобрались. Но ведь нам надо вернуть не номер позиции, а само значение. Значит ПОИСКПОЗ в чистом виде нам не подходит. По крайней мере одна, сама по себе. Но если её использовать вместе с функцией ИНДЕКС(INDEX)(которая возвращает из указанного диапазона значение на пересечении заданных строки и столбца) – то это то, что нам нужно и даже больше.
=ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0);2)
Такая формула результатом вернет то же, что и ВПР.
Аргументы функции ИНДЕКС
Массив(Лист1!$A$2:$C$4). В качестве этого аргумента мы указываем диапазон, из которого хотим получить значения. Может быть как один столбец, так и несколько. В случае, если столбец один, то последний аргумент функции указывать не обязательно или он всегда будет равен 1(столбец-то всего один). К слову – данный аргумент может совершенно не совпадать с тем, который мы указываем в аргументе Просматриваемый_массив функции ПОИСКПОЗ.
Далее идут Номер_строки и Номер_столбца. Именно в качестве Номера_строки мы и подставляем ПОИСКПОЗ, которая возвращает нам номер позиции в массиве. На этом все и строится. ИНДЕКС возвращает значение из Массива, которое находится в указанной строке(Номер_строки) Массива и указанном столбце(Номер_столбца), если столбцов более одного. Важно знать, что в данной связке кол-во строк в аргументе Массив функции ИНДЕКС и кол-во строк в аргументе Просматриваемый_массив функции ПОИСКПОЗ должно совпадать. И начинаться с одной и той же строки. Это в обычных случаях, если не преследуются иные цели.
Так же как и в случае с ВПР, ИНДЕКС в случае не нахождения искомого значения возвращает #Н/Д. И обойти подобные ошибки можно так же:
Для всех версий Excel(включая 2003 и раньше):
=ЕСЛИ(ЕНД(ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0));””;ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$2:$A$4;0);2))
Для версий 2007 и выше:
=ЕСЛИОШИБКА(ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0);2);””)
Есть у ИНДЕКС-ПОИСКПОЗ и еще одно преимущество перед ВПР. Дело в том, что ВПР не может искать значения, длина строки которых содержит более 255 символов. Это случается редко, но случается. Можно, конечно, обмануть ВПР и урезать критерий:
=ВПР(ПСТР($A2;1;255);ПСТР(Лист1!$A$1:$C$4;1;255);3;0)
но это формула массива. Да и к тому же далеко не всегда такая формула вернет нужный результат. Если первые 255 символов идентичны первым 255 символам в таблице, а дальше знаки различаются – формула этого уже не увидит. Да и возвращает формула исключительно текстовые значения, что в случаях, когда возвращаться должны числа, не очень удобно.
Поэтому лучше использовать такую хитрую формулу:
=ИНДЕКС(Лист1!$A$1:$C$4;СУММПРОИЗВ(ПОИСКПОЗ(ИСТИНА;Лист1!$A$1:$A$4=$A2;0));2)
Здесь я в формулах использовал одинаковые диапазоны для удобочитаемости, но в примере для скачивания они различаются от указанных здесь.
Сама формула построена на возможности функции СУММПРОИЗВ преобразовывать в массивные вычисления некоторых функций внутри неё. В данном случае ПОИСКПОЗ ищет позицию строки, в которой критерий равен значению в строке. Подстановочные символы здесь применить уже не получится.
Ну и все же я рекомендовал бы Вам прочитать подробнее про данные функции в справке.
В прилагаемом к статье примере Вы найдете примеры использования всех описанных случаев и пример того, почему ИНДЕКС и ПОИСКПОЗ порой предпочтительнее ВПР.
Скачать пример
 Tips_All_VLookUp.xls (26,0 KiB, 17 477 скачиваний)
Tips_All_VLookUp.xls (26,0 KiB, 17 477 скачиваний)
Так же см.:
ВПР и интервальный просмотр(range_lookup)
ВПР по двум и более критериям
ВПР с возвратом всех значений
ВПР с поиском по нескольким листам
![]() ВПР_МН
ВПР_МН
![]() ВПР_ВСЕ_КНИГИ
ВПР_ВСЕ_КНИГИ
Как заменить/удалить/найти звездочку?
Статья помогла? Поделись ссылкой с друзьями!
![]() Видеоуроки
Видеоуроки
Поиск по меткам
Access
apple watch
Multex
Power Query и Power BI
VBA управление кодами
Бесплатные надстройки
Дата и время
Записки
ИП
Надстройки
Печать
Политика Конфиденциальности
Почта
Программы
Работа с приложениями
Разработка приложений
Росстат
Тренинги и вебинары
Финансовые
Форматирование
Функции Excel
акции MulTEx
ссылки
статистика
