Колонки сравнивают для того, чтобы, например, в отчетах не было дубликатов. Или, наоборот, для проверки правильности заполнения — с поиском непохожих значений. И проще всего выполнять сравнение двух столбцов на совпадение в Excel — для этого есть 6 способов.

1 Сравнение с помощью простого поиска
При наличии небольшой по размеру таблицы заниматься сравнением можно практически вручную. Для этого достаточно выполнить несколько простых действий.
- Перейти на главную вкладку табличного процессора.
- В группе «Редактирование» выбрать пункт поиска.
- Выделить столбец, в котором будет выполняться поиск совпадений — например, второй.
- Вручную задавать значения из основного столбца (в данном случае — первого) и искать совпадения.
Если значение обнаружено, результатом станет выделение нужной ячейки. Однако с помощью такого способа можно работать только с небольшими столбцами. И, если это просто цифры, так можно сделать и без поиска — определяя совпадения визуально. Впрочем, если в колонках записаны большие объемы текста, даже такая простая методика позволит упростить поиск точного совпадения.

2 Операторы ЕСЛИ и СЧЕТЕСЛИ
Еще один способ сравнения значений в двух столбцах Excel подходит для таблиц практически неограниченного размера. Он основан на применении условного оператора ЕСЛИ и отличается от других методик тем, что для анализа совпадений берется только указанная в формуле часть, а не все значения массива. Порядок действий при использовании методики тоже не слишком сложный и подойдет даже для начинающего пользователя Excel.
- Сравниваемые столбцы размещаются на одном листе. Не обязательно, чтобы они находились рядом друг с другом.
- В третьем столбце, например, в ячейке J6, ввести формулу такого типа: =ЕСЛИ(ЕОШИБКА(ПОИСКПОЗ(H6;$I$6:$I$14;0));»;H6)
- Протянуть формулу до конца столбца.
Результатом станет появление в третьей колонке всех совпадающих значений. Причем H6 в примере — это первая ячейка одного из сравниваемых столбцов. А диапазон $I$6:$I$14 — все значения второй участвующей в сравнении колонки. Функция будет последовательно сравнивать данные и размещать только те из них, которые совпали. Однако выделения обнаруженных совпадений не происходит, поэтому методика подходит далеко не для всех ситуаций.
Еще один способ предполагает поиск не просто дубликатов в разных колонках, но и их расположения в пределах одной строки. Для этого можно применить все тот же оператор ЕСЛИ, добавив к нему еще одну функцию Excel — И. Формула поиска дубликатов для данного примера будет следующей: =ЕСЛИ(И(H6=I6); «Совпадают»; «») — ее точно так же размещают в ячейке J6 и протягивают до самого низа проверяемого диапазона. При наличии совпадений появится указанная надпись (можно выбрать «Совпадают» или «Совпадение»), при отсутствии — будет выдаваться пустота.
Тот же способ подойдет и для сравнения сразу большого количества колонок с данными на точное совпадение не только значения, но и строки. Для этого применяется уже не оператор ЕСЛИ, а функция СЧЕТЕСЛИ. Принцип написания и размещения формулы похожий.
Она имеет вид =ЕСЛИ(СЧЕТЕСЛИ($H6:$J6;$H6)=3; «Совпадают»;») и должна размещаться в верхней части следующего столбца с протягиванием вниз. Однако в формулу добавляется еще количество сравниваемых колонок — в данном случае, три.
Если поставить вместо тройки двойку, результатом будет поиск только тех совпадений с первой колонкой, которые присутствуют в одном из других столбцов. Причем, тройные дубликаты формула проигнорирует. Так же как и совпадения второй и третьей колонки.
3 Формула подстановки ВПР
Принцип действия еще одной функции для поиска дубликатов напоминает первый способ использованием оператора ЕСЛИ. Но вместо ПОИСКПОЗ применяется ВПР, которую можно расшифровать как «Вертикальный Просмотр». Для сравнения двух столбцов из похожего примера следует ввести в верхнюю ячейку (J6) третьей колонки формулу =ВПР(H6;$I$6:$I$15;1;0) и протянуть ее в самый низ, до J15.
С помощью этой функции не просто просматриваются и сравниваются повторяющиеся данные — результаты проверки устанавливаются четко напротив сравниваемого значения в первом столбце. Если программа не нашла совпадений, выдается #Н/Д.
4 Функция СОВПАД
Достаточно просто выполнить в Эксель сравнение двух столбцов с помощью еще двух полезных операторов — распространенного ИЛИ и встречающейся намного реже функции СОВПАД. Для ее использования выполняются такие действия:
- В третьем столбце, где будут размещаться результаты, вводится формула =ИЛИ(СОВПАД(I6;$H$6:$H$19))
- Вместо нажатия Enter нажимается комбинация клавиш Ctr + Shift + Enter. Результатом станет появление фигурных скобок слева и справа формулы.
- Формула протягивается вниз, до конца сравниваемой колонки — в данном случае проверяется наличие данных из второго столбца в первом. Это позволит изменяться сравниваемому показателю, тогда как знак $ закрепляет диапазон, с которым выполняется сравнение.
Результатом такого сравнения будет вывод уже не найденного совпадающего значения, а булевой переменной. В случае нахождения это будет «ИСТИНА». Если ни одного совпадения не было обнаружено — в ячейке появится надпись «ЛОЖЬ».
Стоит отметить, что функция СОВПАД сравнивает и числа, и другие виды данных с учетом верхнего регистра. А одним из самых распространенных способом использования такой формулы сравнения двух столбцов в Excel является поиска информации в базе данных. Например, отдельных видов мебели в каталоге.

5 Сравнение с выделением совпадений цветом
В поисках совпадений между данными в 2 столбцах пользователю Excel может понадобиться выделить найденные дубликаты, чтобы их было легко найти. Это позволит упростить поиск ячеек, в которых находятся совпадающие значения. Выделять совпадения и различия можно цветом — для этого понадобится применить условное форматирование.
Порядок действий для применения методики следующий:
- Перейти на главную вкладку табличного процессора.
- Выделить диапазон, в котором будут сравниваться столбцы.
- Выбрать пункт условного форматирования.
- Перейти к пункту «Правила выделения ячеек».
- Выбрать «Повторяющиеся значения».
- В открывшемся окне указать, как именно будут выделяться совпадения в первой и второй колонке. Например, красным текстом, если цвет остальных сообщений стандартный черный. Затем указать, что выделяться будут именно повторяющиеся ячейки.
Теперь можно снять выделение и сравнить совпадающие значения, которые будут заметно отличаться от остальной информации. Точно так же можно выделить, например, и уникальную информацию. Для этого следует выбрать вместо «повторяющихся» второй вариант — «уникальные».
6 Надстройка Inquire
Начиная с версий MS Excel 2013 табличный процессор позволяет воспользоваться еще одной методикой — специальной надстройкой Inquire. Она предназначена для того, чтобы сравнивать не колонки, а два файла .XLS или .XLSX в поисках не только совпадений, но и другой полезной информации.
Для использования способа придется расположить столбцы или целые блоки информации в разных книгах и удалить все остальные данные, кроме сравниваемой информации. Кроме того, для проверки необходимо, чтобы оба файла были одновременно открытыми.
Процесс использования надстройки включает такие действия:
- Перейти к параметрам электронной таблицы.
- Выбрать сначала надстройки, а затем управление надстройками COM.
- Отметить пункт Inquire и нажать «ОК».
- Перейти к вкладке Inquire.
- Нажать на кнопку Compare Files, указать, какие именно файлы будут сравниваться, и выбрать Compare.
- В открывшемся окне провести сравнения, используя показанные совпадения и различия между данными в столбцах.
У каждого варианта сравнения — свое цветовое решение. Так, зеленым цветом на примере выделены отличия. У совпадающих данных отсутствует выделение. А сравнение расчетных формул показало, что результаты отличаются все — и для выделения использован бирюзовый цвет.
Читайте также:
- 5 программ для совместной работы с документами
-
Как в Экселе протянуть формулу по строке или столбцу: 5 способов
При анализе данных с помощью Excel очень часто приходится искать некоторые значения по определенным критериям и подставлять их в другие таблицы. В таких задачах на помощью приходит функция ВПР, но у нее есть два существенных недостатка. Во-первых, функция ВПР возвращает только первое найденное значение. Например, у меня есть перечень заказов и необходимо получить номера всех заказов, которые оформил конкретный менеджер. Фамилия менеджера выбирается из выпадающего списка (выделено желтым) и ниже должны выводиться соответствующие номера заказов (зеленая область).
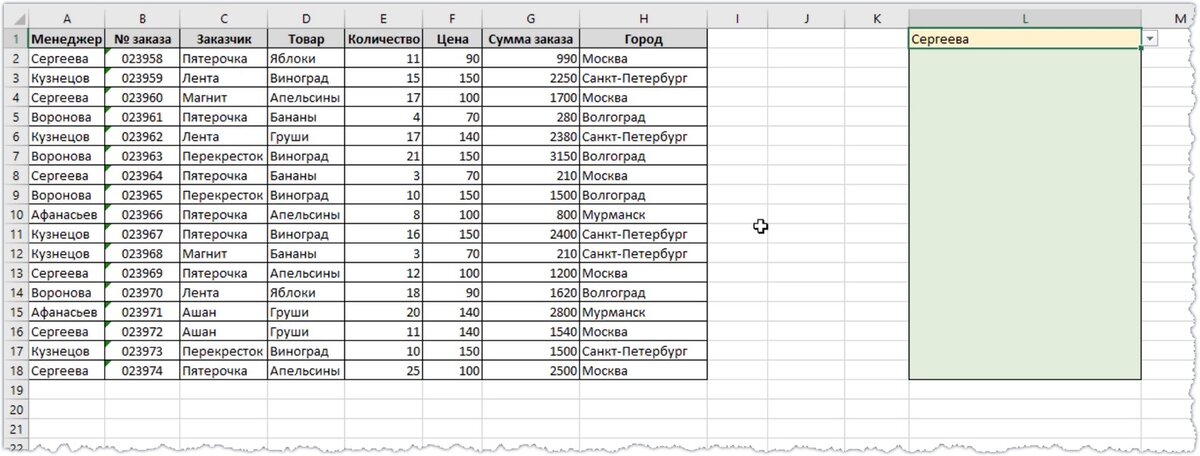
Если использовать стандартную функцию ВПР, то она найдет первый подходящий заказ и вернет ТОЛЬКО его номер.
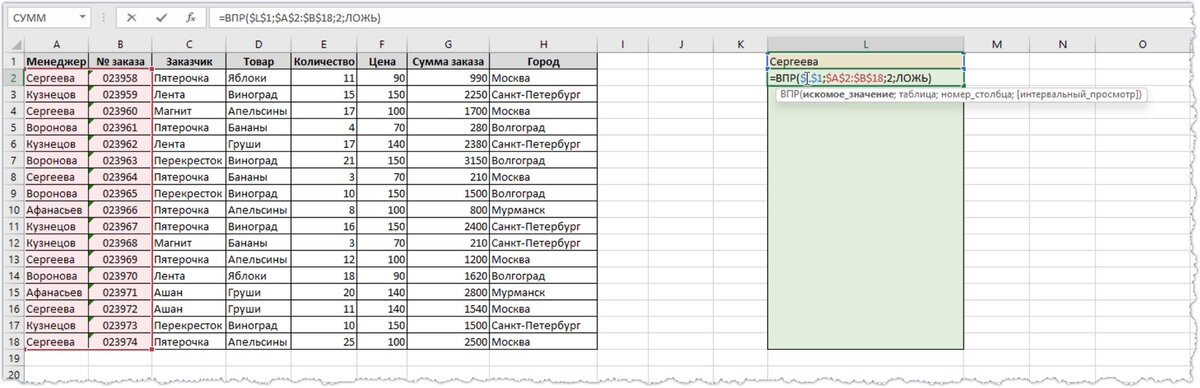
Еще одним недостатком функции ВПР является то, что она ищет значения только в левом крайнем столбце выделенного диапазона. То есть если бы столбец с фамилиями менеджеров находился правее столбца с номерами заказов, то функцию ВПР вообще не удалось бы использовать.
Этот недостаток устраняется с помощью сочетания функций ИНДЕКС и ПОИСКПОЗ, которые являются более гибкой альтернативой функции ВПР, но и эти функции не решают поставленную задачу.
Как же быть, если нужно вернуть все значения, соответсвующие определенному критерию? В этом также поможет функция ИНДЕКС.
Напомню, что функция ИНДЕКС возвращает значение, которое находится в указанном номере строки выделенного диапазона. То есть мы должны выбрать некоторый диапазон значений и вторым аргументом указать номер строки в этом диапазоне. Подчеркиваю, не номер строки листа Эксель, а номер строки выделенного диапазона значений.
Функция ИНДЕКС может возвращать не только одно значение, а массив значений. И именно это нам и нужно. Чтобы функция вернула массив значений, мы должны в нее подставить массив номеров нужным нам строк. Поэтому основной задачей для нас сейчас как раз и будет получение этого массива.
Давайте рассмотрим упрощенную таблицу, чтобы в ней не было отвлекающей информации. У нас есть таблица, состоящая из двух столбцов – Менеджер и Номер заказа. Также есть выпадающий список с фамилиями менеджеров и некоторая область листа, в которую мы будем выводить все заказы, связанные с выбранным менеджером.
Итак, сначала мы должны определить все строки в основной таблице, относящиеся к выбранному в списке менеджеру. Давайте сделаем это с помощью вспомогательного столбца и функции ЕСЛИ.
Если значение из текущей ячейки первого столбца таблицы (А2) равно значению, выбранному в выпадающем списке (L1), то определим номер строки, в котором это значение находится. Для этого воспользуемся функцией СТРОКА, которая как раз и предназначена для решения этой задачи. Так как формулу мы будем протягивать по диапазону, то не забываем зафиксировать ссылку на ячейку с выпадающем списком.
Протягиваем формулу.
Так как мы не указали в функции ЕСЛИ значение, которое появится в случае невыполнения условия, то в соответствующих ячейках выводится логическое выражение ЛОЖЬ. Это неважно, так как нас будут интересовать только цифры.
Мы получили номера строк листа Эксель, но в функцию ИНДЕКС необходимо подставить номер строки в выделенном диапазоне. В данном примере основная таблица располагается в верху листа и в первой строке находится шапка с названиями столбцов, поэтому, чтобы получить необходимые значения, мы можем откорректировать формулу и отнять единицу от полученного значения. В итоге во вспомогательном столбце появится массив необходимых нам чисел.
Если же таблица находится в другой части листа, то нужно будет либо вручную прописать необходимое корректировочное значение (то есть отступ от первой строки листа), либо можно автоматизировать этот процесс с помощью все той же функции СТРОКА, но об этом я расскажу чуть позже, чтобы сейчас не усложнять формулу.
Итак, теперь нам нужно отсортировать столбец, чтобы в начале были цифры. Сделать это можно, например, с помощью функции НАИМЕНЬШИЙ, которая возвращает указанное по счету наименьшее значение в выбранном диапазоне.
Выбираем диапазон (С2:С18) и затем необходимо указать цифру, определяющую, какое по порядку наименьшее число нужно вывести. Если укажем 1, то получим первое наименьшее значение в диапазоне, если 2, то второе, и так далее. Именно таким образом мы и сможем отсортировать полученный список с помощью формулы. Создадим вспомогательный столбец со значениями по порядку и подставим эти значения в функцию НАИМЕНЬШИЙ.
Мы получили необходимый нам перечень номеров строк и можем вернуться к функции ИНДЕКС. Фактически нам нужно подтянуть значения из второго столбца основной таблицы, поэтому в качестве диапазона указываем его. В качестве строки, соответственно, только что рассчитанные значения.
Чтобы избавиться от ошибки ЧИСЛО! воспользуемся функцией ЕСЛИОШИБКА. Обернем ей полученную функцию и в случае ошибки выведем пустоту.
Мы достигли необходимого результата, но для этого пришлось создать несколько вспомогательных столбцов. Давайте свернем все промежуточные вычисления в одну формулу, но это будет не простая формула, а формула массива, поэтому нам нужно будет поменять некоторые ссылки на диапазоны, к которым они относятся. А если точнее, то в функции ЕСЛИ нужно будет заменить относительные ссылки на ячейки столбца А соответствующим диапазоном и не забываем зафиксировать его. Также не забываем сделать формулу формулой массива, нажав сочетание клавиш Ctrl + Shift + Enter. Растянем формулу на весь зарезервированный диапазон таблицы и получаем необходимый результат.
Все вспомогательные столбцы, кроме столбца с нумерацией (столбец F) можно удалить. Давайте сделаем так, чтобы и этот столбец был не нужен. Значения столбца F используются в функции НАИМЕНЬШИЙ и нам нужно сделать так, чтобы подобный ряд чисел создавался автоматически и не зависел от того, где находится таблица с формулами. Для этого можно воспользоваться функцией СТРОКА и определить номер строки листа Эксель первой ячейки основной таблицы. Затем этот номер будем вычитать из номера последующих строк. Чтобы значения «не сползали» при протягивании формулы, зафиксируем ссылку на первую ячейку диапазона.
Все отлично, кроме того, что все значения нужно увеличить на единицу. Дополним формулу и получим нужный нам результат.
Осталось скопировать формулу и подставить ее в формулу массива, после чего и последний вспомогательный столбец можно будет удалить.
Ну и по аналогии можно решить проблему зависимости формулы от расположения исходной таблицы. Сейчас ее заголовки расположены в первой строке листа и поэтому формула четко привязана к этому положению.
Мы можем внести в функцию ЕСЛИ аналогичную формулу с двумя функциями СТРОКА. То есть отнимем от уже имеющейся функции СТРОКА со всем диапазоном столбца номер строки первой ячейки этого диапазона и прибавим единицу.
Теперь формула никак не привязана к положению исходной таблице на листе и она выполняет поставленную задачу – возвращает все искомые значения из указанного диапазона.
Ссылки на мои ресурсы по Excel
★ YouTube-канал по Excel
★ Телеграм
★ Серия видеокурсов “Microsoft Excel Шаг за Шагом”
★ Авторские книги и курсы
Поиск и удаление повторений
Excel для Microsoft 365 Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Excel Starter 2010 Еще…Меньше
В некоторых случаях повторяющиеся данные могут быть полезны, но иногда они усложняют понимание данных. Используйте условное форматирование для поиска и выделения повторяющихся данных. Это позволит вам просматривать повторения и удалять их по мере необходимости.
-
Выберите ячейки, которые нужно проверить на наличие повторений.
Примечание: В Excel не поддерживается выделение повторяющихся значений в области “Значения” отчета сводной таблицы.
-
На вкладке Главная выберите Условное форматирование > Правила выделения ячеек > Повторяющиеся значения.
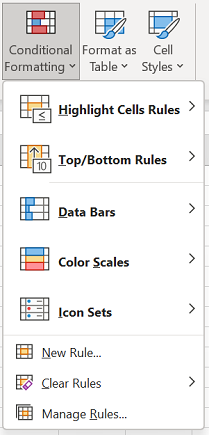
-
В поле рядом с оператором значения с выберите форматирование для применения к повторяющимся значениям и нажмите кнопку ОК.
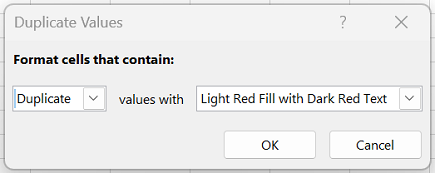
Удаление повторяющихся значений
При использовании функции Удаление дубликатов повторяющиеся данные удаляются безвозвратно. Чтобы случайно не потерять необходимые сведения, перед удалением повторяющихся данных рекомендуется скопировать исходные данные на другой лист.
-
Выделите диапазон ячеек с повторяющимися значениями, который нужно удалить.
-
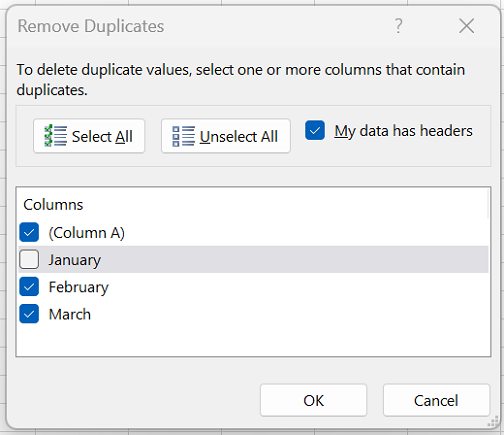
На вкладке Данные нажмите кнопку Удалить дубликаты и в разделе Столбцы установите или снимите флажки, соответствующие столбцам, в которых нужно удалить повторения.
Например, на данном листе в столбце “Январь” содержатся сведения о ценах, которые нужно сохранить.
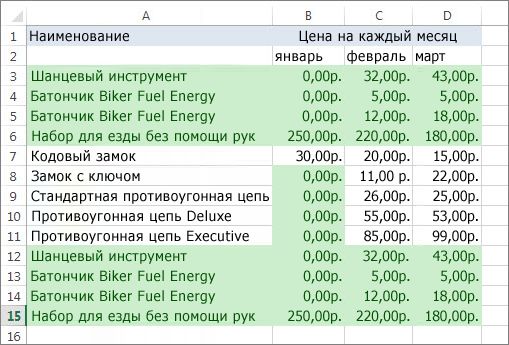
Поэтому флажок Январь в поле Удаление дубликатов нужно снять.
-
Нажмите кнопку ОК.
Примечание: Количество повторяющихся и уникальных значений, заданных после удаления, может включать пустые ячейки, пробелы и т. д.
Дополнительные сведения

Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
- Найти и выделить цветом дубликаты в Excel
- Формула проверки наличия дублей в диапазонах
- Внутри диапазона
- !SEMTools, поиск дублей внутри диапазона
- Найти дубли ячеек в столбце, кроме первого
- Найти в столбце дубли ячеек, включая первый
- Найти дубли в столбце без учета лишних пробелов
Найти повторяющиеся значения в столбцах Excel — на поверку не такая уж и простая задача. Есть пара встроенных инструментов, таких как условное форматирование и инструмент удаления дубликатов, но они не всегда подходят для решения реальных задач.
Поиск дублей в Excel может быть очень разным, и, в зависимости от вводных, производиться тоже будет по-разному.
Ключевых моментов несколько:
- Какие конкретно повторяющиеся значения — повторы слов в ячейках, сами повторяющиеся ячейки или повторяющиеся строки?
- Если ячейки, то:
- Какие ячейки мы готовы считать дубликатами — все кроме первой или включая ее?
- Считаем ли дублями строки, отличающиеся только пробелами до/после слов или лишними пробелами между словами?
- Где мы будем искать дубли — в одном столбце, в двух столбцах или в нескольких?
- А может, нам нужно найти неявные дубли?
Сначала рассмотрим простые примеры.
Для выделения дубликатов ячеек подходит инструмент условное форматирование. В процедуре есть ряд готовых правил, в том числе и для повторяющихся значений.
Найти инструмент можно на вкладке программы “Главная”:
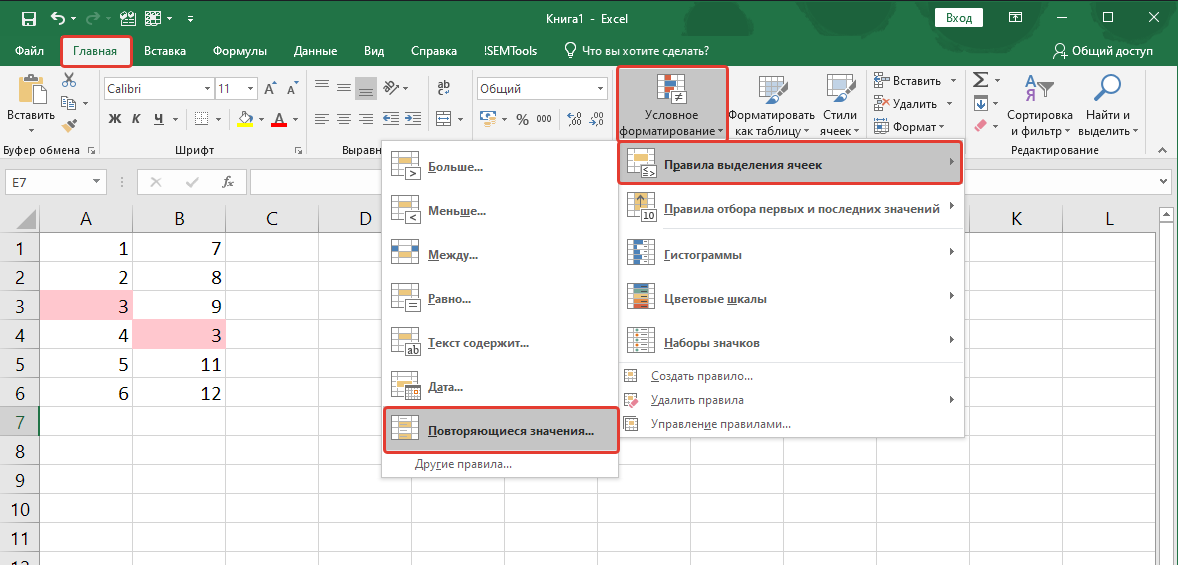
Процедура интуитивно понятна:
- Выделяем диапазон, в котором хотим найти дубликаты.
- Вызываем процедуру.
- Выбираем форматирование для отобранных ячеек (есть предустановленные форматы или же можно задать свой вариант).
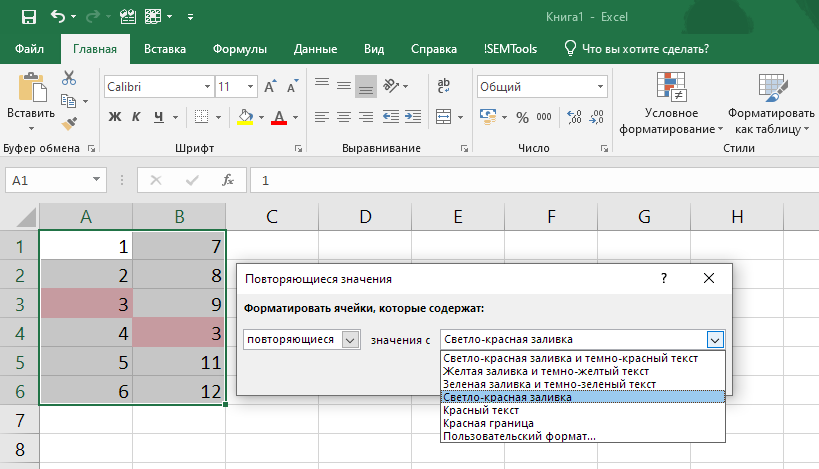
Важно понимать, что процедура находит дубликаты внутри всего диапазона и поэтому может не быть применима для сравнения двух столбцов. Достаточно иметь дубликаты внутри одного столбца — и процедура подсветит их оба, хотя во втором их не будет:
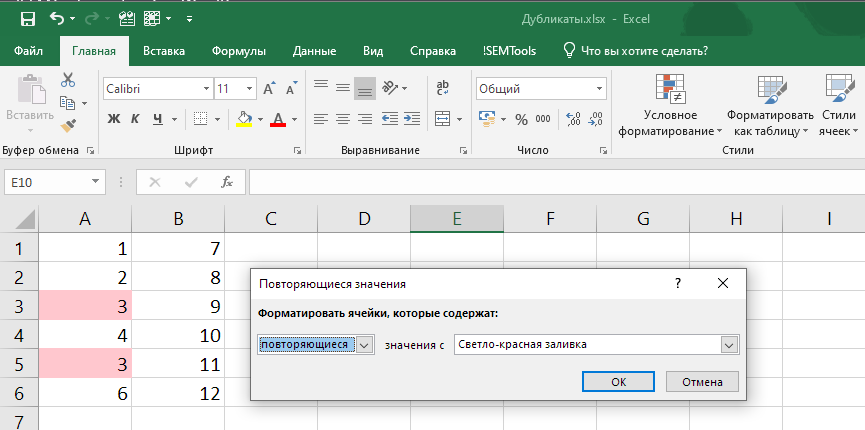
Данное поведение является неочевидным, и об этом факте часто забывают. Если дальше вы планируете удалять повторы, можете потерять оба варианта в одном столбце.
Как избежать подобной ситуации, если хочется найти именно дубли в другом столбце? Простейшее решение: удалить дубли внутри каждого столбца перед применением условного форматирования.
Но есть и другие решения. О них дальше.
Формула проверки наличия дублей в диапазонах
Использование собственной формулы для проверки дубликатов в списке или диапазоне имеет ряд преимуществ, единственная задача — составление такой формулы. Но её я возьму на себя.
Внутри диапазона
Чтобы проверить, есть ли в диапазоне повторяющиеся значения, можно использовать такую формулу массива:
=СУММПРОИЗВ(СЧЁТЕСЛИ(диапазон;тот-же-диапазон)-1)>0
Так выглядит на практике применение формулы:

В чем же преимущество такой формулы, ведь она полностью дублирует опцию условного форматирования, спросите вы.
А дело все в том, что формулу несложно видоизменить и улучшить.
Например, можно улучшить эффективность формулы, добавив в нее функцию СЖПРОБЕЛЫ .Это позволит находить дубликаты, отличающиеся незаметными лишними пробелами:
=СУММПРОИЗВ(--(СЖПРОБЕЛЫ(ячейка)=СЖПРОБЕЛЫ(диапазон)))>1
Эта формула слегка отличается, так как проверяет встречаемость в диапазоне значения одной ячейки.
Если внести ее как правило отбора условного форматирования, она позволит выявлять неявные дубли. Ниже демонстрация того, как работает формула:
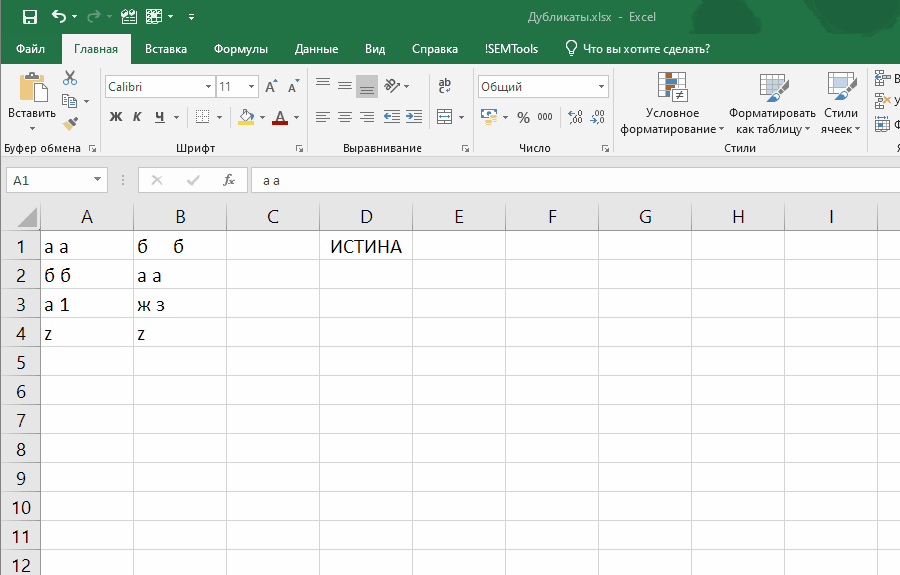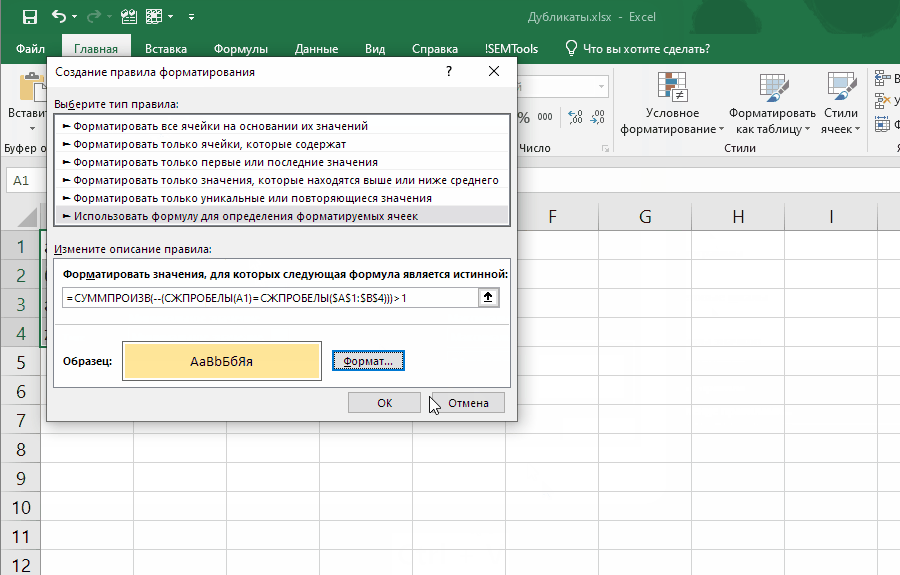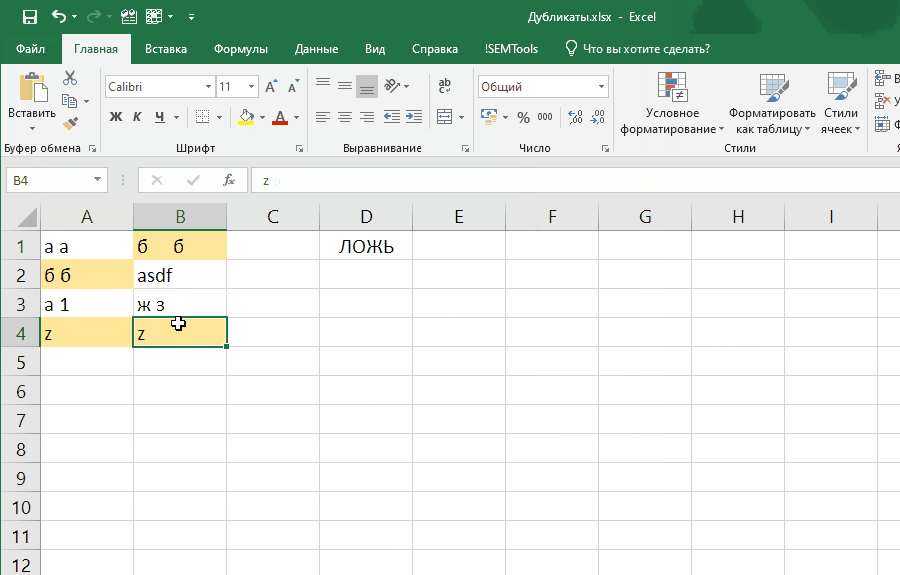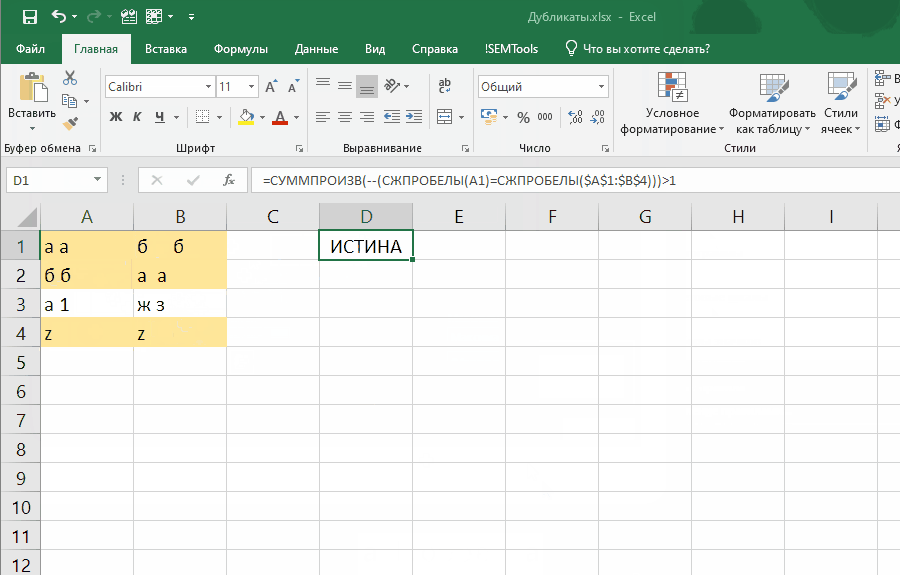
Обратите внимание на один момент в этой демонстрации: диапазон закреплен ($A$1:$B$4), а искомая ячейка (A1) нет. Именно это позволяет условному форматированию находить все дубликаты в диапазоне.
!SEMTools, поиск дублей внутри диапазона
Когда-то я потратил немало времени, пользуясь перечисленными выше методами поиска повторяющихся значений. Все они мне не нравились. Причина была одна: это попросту медленно. Поэтому я решил сделать отдельные процедуры для поиска и удаления дубликатов в Excel в своей надстройке.
Давайте покажу, как они работают.
Найти дубли ячеек в столбце, кроме первого
Процедура позволяет выделить все вторые, третьи и т.д. повторяющиеся значения в столбце.

Найти в столбце дубли ячеек, включая первый
Зачастую нужно найти в столбце все повторяющиеся ячейки, включая первую, для того, чтобы далее отфильтровать их все.

Найти дубли в столбце без учета лишних пробелов
Если мы считаем дубликатами фразы, отличающиеся количеством пробелов между словами или после, наша задача — сначала избавиться от лишних пробелов, и далее произвести тот же поиск дубликатов.
Для первой операции есть отдельный инструмент «Удалить лишние пробелы»:

Найти повторяющиеся значения в Excel и решить сотни других задач поможет надстройка !SEMTools.
Скачайте прямо сейчас и убедитесь сами!
Смотрите также:
- Удалить дубли без смещения строк;
- Удалить неявные дубли;
- Найти повторяющиеся слова в Excel;
- Удалить повторяющиеся слова внутри ячеек.
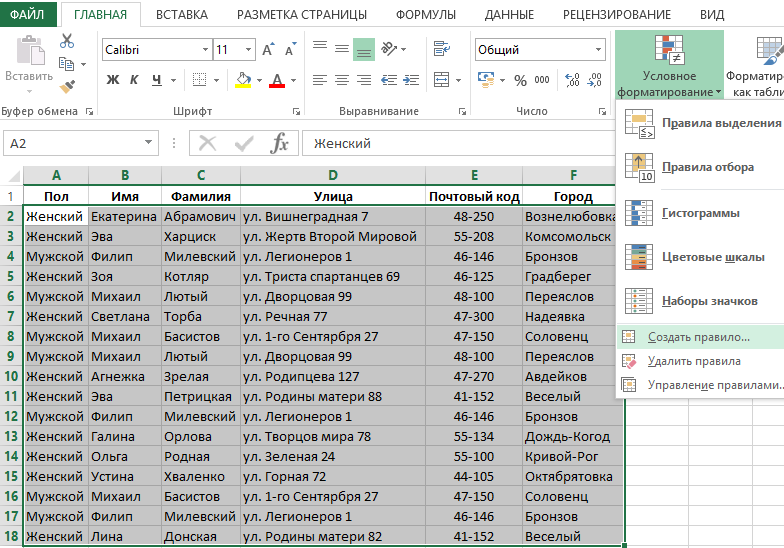
Достаточно часто рабочие таблицы Excel содержат повторяющиеся записи, которые многократно дублируются. Но не всегда повторение свидетельствует об ошибке ввода данных. Иногда несколько раз повторяющиеся записи с одинаковыми значениями были сделаны намеренно. Тогда проблема может возникнуть при обработке, поиске данных или анализе в такой таблице. Чтобы облегчить себе работу с такими таблицами, рекомендуем автоматически объединить одинаковые строки в таблице Excel, выделив их цветом.
Как объединить одинаковые строки одним цветом?
Чтобы найти объединить и выделить одинаковые строки в Excel следует выполнить несколько шагов простых действий:
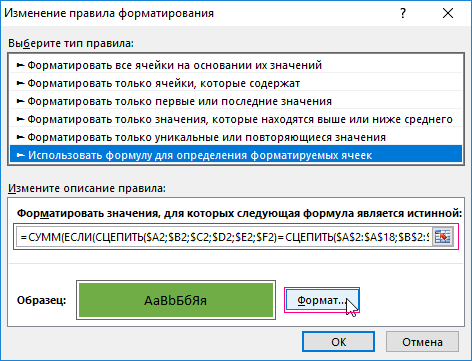
- Выделите весь диапазон данных табличной части A2:F18. Начинайте выделять значения из ячейки A2, так чтобы после выделения она оставалась активной как показано ниже на рисунке. И выберите инструмент: «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило».
- В появившемся окне «Создание правила форматирования» выберите опцию: «Использовать формулу для определения форматированных ячеек».
- В поле ввода введите формулу:
- Нажмите на кнопку формат, чтобы задать цвет заливки для ячеек, например – зеленый. И нажмите на всех открытых окнах кнопку ОК.
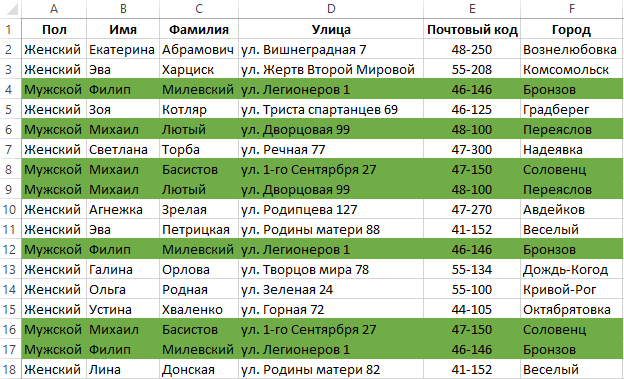
В результате выделились все строки, которые повторяются в таблице хотя-бы 1 раз.
Как выбрать строки по условию?
Форматирование для строки будет применено только в том случаи если формула возвращает значения ИСТИНА. Принцип действия формулы следующий:
Первая функция =СЦЕПИТЬ() складывает в один ряд все символы из только одной строки таблицы. При определении условия форматирования все ссылки указываем на первую строку таблицы.
Абсолютные и относительные адреса ссылок в аргументах функций позволяют нам распространять формулу на все строки таблицы.
Вторая функция =СЦЕПИТЬ() по очереди сложить значение ячеек со всех выделенных строк.
Обе выше описанные функции работают внутри функции =ЕСЛИ() где их результаты сравниваются между собой. Это значит, что в каждой ячейке выделенного диапазона наступает сравнение значений в текущей строке со значениями всех строк таблицы.
Как только при сравнении совпадают одинаковые значения (находятся две и более одинаковых строк) это приводит к суммированию с помощью функции =СУММ() числа 1 указанного во втором аргументе функции =ЕСЛИ(). Функция СУММ позволяет сложить одинаковые строки в Excel.
Если строка встречается в таблице только один раз, то функция =СУММ() вернет значение 1, а целая формула возвращает – ЛОЖЬ (ведь 1 не является больше чем 1).
Если строка встречается в таблице 2 и более раза формула будет возвращать значение ИСТИНА и для проверяемой строки присвоится новый формат, указанный пользователем в параметрах правила (заливка ячеек зеленым цветом).
Как найти и выделить дни недели в датах?
Допустим таблица содержит транзакции с датами их проведения. Необходимо найти одну из них, но неизвестны все детали. Известно только, что транзакция проведена во вторник или в среду. Чтобы облегчить себе поиск, выделим цветом все даты этих дней недели (вторник, среда). Для этого будем использовать условное форматирование.
- Выделите диапазон данных в таблице A2:B11 и выберите инструмент: «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило».
- В появившемся окне «Создание правила форматирования» выберите опцию: «Использовать формулу для определения форматированных ячеек».
- В поле ввода введите формулу:
- Нажмите на кнопку формат, чтобы задать цвет заливки для ячеек, например – зеленый. И нажмите на всех открытых окнах кнопку ОК.
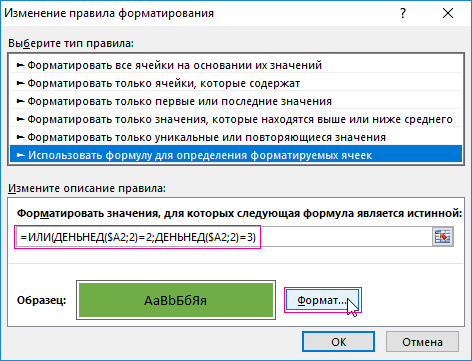
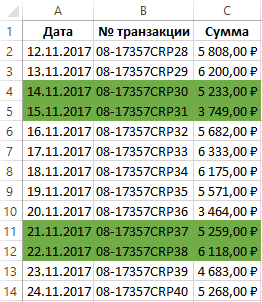
Все транзакции, проводимые во вторник или в среду выделены цветом.
