Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
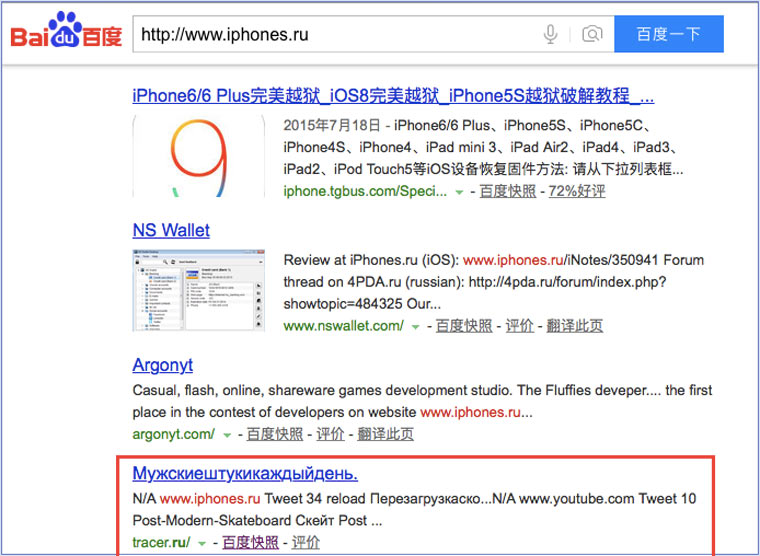
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
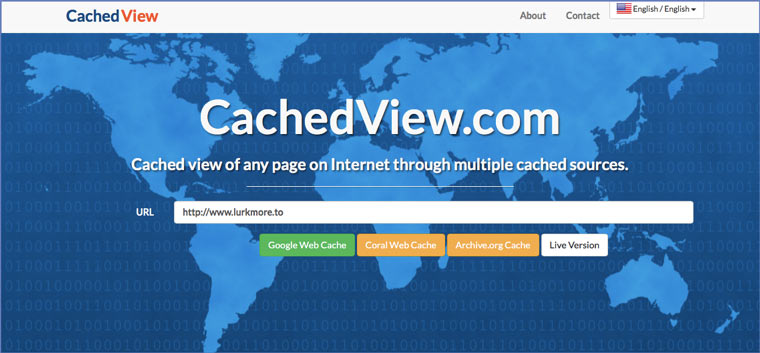
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
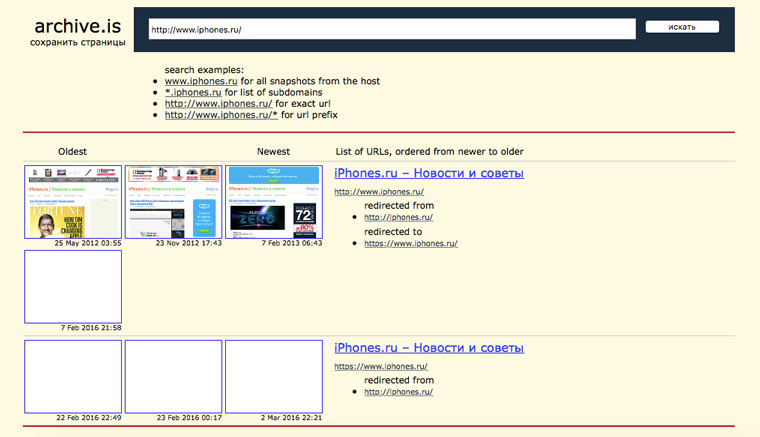
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
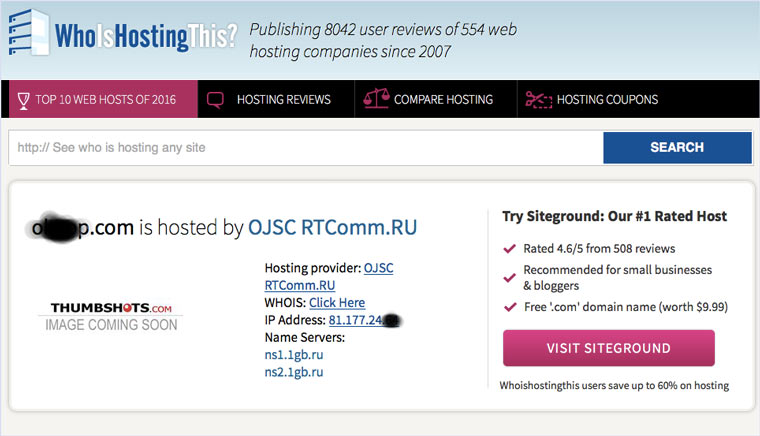
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
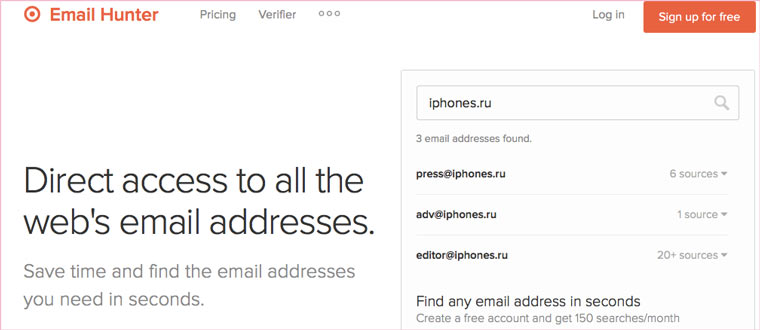
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
Как правило, владельцы сайтов упоминают дату публикации или дату последнего обновления или и то, и другое в статьях, чтобы проинформировать пользователей о действительности содержания. Это лучший способ для веб-мастеров, особенно для сообщений в блогах с ограничением по времени. Без даты публикации пользователям сложно сделать вывод о том, актуальна ли статья на текущую дату или нет.
Однако существует множество веб-сайтов, на которых дата публикации не указана, и иногда она может понадобиться для понимания действительности или цитирования или ссылки на нее на вашей странице. Если вы ищете дату последнего обновления, ознакомьтесь с нашей статьей о том, как найти дату последнего обновления веб-страницы.
Как узнать дату публикации веб-страницы?
- Проверить метаданные на веб-странице
- Посмотрите на структуру URL
- Проверьте XML Sitemap
- Просмотреть исходный код веб-страницы
- Проверить в поиске Google
- Использовать запрос в поиске Google
1. Сканирование через веб-страницу
Дата публикации — это одна из метаданных, необходимых для создания веб-страницы в Интернете. Это часть схема и поисковым системам эта дата нужна, чтобы понимать первоначально опубликованную дату и отображать ее в соответствующих результатах поиска. Многие владельцы веб-сайтов указывают дату публикации в виде метаданных под заголовком сообщения в блоге. Однако некоторые авторы могут отображать дату публикации под статьей в зависимости от дизайна сайта.
На нашем сайте мы показываем дату публикации под заголовком. Мы заменяем дату публикации на дату последнего обновления, чтобы показать дату последнего изменения, которая актуальна для читателей.
2. Посмотрите на структуру URL.
Есть разные способы показать URL-адрес веб-страницы в адресной строке браузера. Популярные системы управления контентом, такие как WordPress, позволяют владельцам веб-сайтов устанавливать URL-адрес со структурой по месяцам и годам. Посмотрите на URL-адрес страницы. Если автор использует структурированный способ создания URL с месяцем и годом, это может помочь вам понять возможный месяц / год, в котором была опубликована страница. Например, URL-адрес может быть таким — https://www.webnots.com/2015/05/this-is-my-page/. Здесь вы можете предположить, что статья была опубликована в мае 2015 года.
Вот пример URL-адреса CNN, опубликованного 2 мая 2019 г. —https://edition.cnn.com/2019/05/02 /Азия / гора-Эверест-мусор-очистка-scli-intl / index.html
Если URL-адрес веб-страницы имеет другую структуру, проверьте URL-адреса изображений на сайте. Иногда изображения могут иметь URL-адреса на основе месяца, хотя URL-адрес страницы имеет другую структуру (мы используем изображения таким образом).
Связанный: Как узнать количество обратных ссылок на веб-страницу?
3. Проверьте XML Sitemap.
Если вы не можете найти дату публикации в статье, просмотрите XML-карту сайта веб-сайта.
- Вы можете получить доступ к XML-карте сайта, используя URL-адрес «https://www.website.com/sitemap.xml».
- Вы должны найти дату публикации, если веб-страница не обновляется после публикации. В противном случае, как правило, дата публикации будет заменена датой последнего изменения.

4. Проверьте исходный код.
Просмотрите исходный код страницы, щелкнув правой кнопкой мыши и найдите раздел заголовка между тегами. Теги могут содержать дату публикации или последнего обновления этой страницы. В большинстве случаев вы найдете дату последнего изменения, поскольку она должна быть частью данных HTTP-заголовка веб-страницы. Вы можете проверить заголовок любой веб-страницы с помощью этого инструмента проверки заголовка HTTP.

5. Проверьте интернет-архив.
Интернет-архив имеет историю всех общедоступных веб-страниц. Вы можете выполнить поиск веб-страницы и найти первый проиндексированный снимок. Хотя это не дата публикации, она должна быть примерно ближе к дате публикации.
Связанный: Как узнать количество посетителей сайта?
6. Найдите дату публикации страницы с помощью Google
Если вы не можете найти дату публикации страницы в вышеупомянутых методах, Google может помочь в этом.
Помимо исходной даты публикации статьи есть еще одна дата, называемая «индексированной датой». Это дата, когда поисковые системы впервые индексируют страницу, чтобы отобразить ее в результатах поиска. Учитывая тот факт, что Google имеет возможность индексировать страницы в течение нескольких часов после публикации, обычно дата публикации и дата индексации, отображаемые в результатах поиска, совпадают или с простой разницей в часах или днях. Таким образом, поиск проиндексированной даты в Google может помочь найти исходную дату публикации веб-страницы или сообщения в блоге.
- Шаг 1 — Откройте google.com, введите запрос «inurl: https: //www.webnots.com/» в поле поиска и нажмите клавишу ВВОД. Вы увидите результаты поиска, показывающие все страницы, содержащие https://www.webnots.com/ в URL-адресе.
- Шаг 2 — теперь перейдите в адресную строку браузера и добавьте «& as_qdr = y15”В конце URL-адреса и нажмите Enter.
- Шаг 3 — вы увидите те же результаты поиска, но с датой индексации перед метаописанием, как показано на рисунке ниже. И это приблизительная дата публикации веб-страницы, на которую вы можете ссылаться.
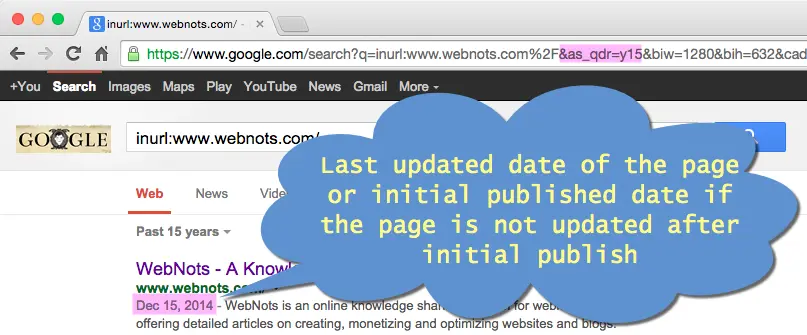
Дата, отображаемая в Google, является индексированной датой, которая будет соответствовать дате публикации, если статья не была обновлена после первоначальной публикации. Однако, если статья была обновлена, Google повторно проиндексирует обновленное содержание, и дату, указанную в поиске, следует рассматривать как дату последнего обновления.
Зачем нужно знать дату публикации?
Еще одна причина, по которой владельцы сайтов ищут дату публикации статей, — это миграция. Предположим, у вас есть сайт с отдельными страницами и вы хотите перенести весь сайт на новую хостинговую платформу в качестве блога. Типичным примером здесь может быть перенос сайта с контентом, созданного с помощью Weebly, на платформы для ведения блогов, такие как WordPress.
Как правило, на страницах не указана дата публикации, и в сообщениях в блогах должна быть указана дата. При миграции вы можете назначить дату публикации в качестве исходной даты публикации страницы вместо текущей даты. Здесь вы можете найти исходную дату публикации страниц старого сайта, используя вышеуказанный метод.
Почему я не могу найти дату публикации?
К сожалению, многие популярные блоги скрывают дату публикации, поэтому пользователи не могут найти исходную дату публикации. Они используют эту практику, чтобы переработать старый контент. Например, если исходный заголовок блога — «Как создать веб-сайт в 2020 году?», Его можно легко изменить на «… .2021» и так далее для каждого года без обновления содержимого.
Некоторые системы управления контентом, такие как WordPress, позволяют автору изменять исходную дату публикации в любое время. Кроме того, всякий раз, когда владелец сайта устанавливает 301 редирект, страница будет с новым контентом и новой датой публикации, в то время как исходная дата публикации может быть намного раньше с другим URL.

Во всех вышеперечисленных случаях вы не сможете найти правильную дату публикации, поскольку она была намеренно изменена или скрыта владельцем. По нашему мнению, сокрытие статьи с привязкой к дате — это плохая практика SEO, чтобы обмануть пользователей и, следовательно, поисковые системы.
Работа с сохраненной копией страницы
Содержание:
- Зачем нужна сохраненная копия страницы и как её посмотреть
- Как посмотреть сохраненную копию в Google
- Как посмотреть сохраненную копию веб-страницы в Яндекс
- Почему сохраненной страницы может не быть
- Специализированные веб-архивы
- Wayback Machine
- Archive.Today
- Расширения для браузеров
- Cached Page
- Выводы
Чтобы пользователь нашел документ в поисковой выдаче, недостаточно добавления его на сервер. Контент должен быть проиндексирован (добавлен поисковыми роботами в индекс) поисковыми системами Яндекс и Google. Поэтому, наличие сохраненной копии — показатель что поисковый бот был на странице. Рассмотрим, что можно посмотреть и какие ошибки обнаружить с помощью сохраненной копии веб-страницы.
Роботы Яндекса и Google добавляют копии найденных веб-страниц в специальное место в облаке — кеш. При этом новая копия страницы перезаписывает старую. Поэтому в кеше отображаются свежие версии веб-страниц.
Сохраненная копия — это версия веб-страницы, которая сохранена в кэше поисковой системы. Условно это бесплатная резервная копия от поисковых систем.
На самом деле веб-страницы сохраняют:
- Поисковые системы. В них находится находится последняя проиндексированная версия страницы. Такие «снимки» используют SEO-специалисты, чтобы увидеть какие данные обнаружил на странице поисковый бот;
- Специализированные сервисы. Занимаются сохранением содержимого веб-страницы. Основная задача таких сервисов сохранить страницы в конкретный момент времени. С помощью них вы можете узнать как выглядел сайт или страница несколько лет назад.
Зачем нужна сохраненная копия страницы и как её посмотреть
На сайтах регулярно происходит добавление нового и редактирование существующего контента. Периодически изменяется его дизайн, добавляются и/или удаляются графические элементы. Это трудоемкая работа в процессе, которой могут возникнуть ошибки: потеряться контент, «съехать дизайн», удалиться блок или перестать индексироваться часть материала. Выявить, как выглядела страницы до определенного момента, поможет сохраненная копия.
Пример из практики:
Есть у нас технически сложный проект, который при заполнении объема памяти перестает, корректно работать. Если по простому, то вместо работающего сайта, мы видим ошибку базы данных.
Время от времени сайт отваливается по ночам, а утром разработчики все исправляют. И тут важный момент, сохраненные копии, позволяют понять успели ли поисковые системы проиндексировать сломанный сайт или нет. А также позволяют выявить, какие именно страницы успел переобойти бот.
Как посмотреть сохраненную копию в Google
Рассмотрим на примере страницы https://discript.ru/prodvizhenie-sajtov/kolomna/. Перед url адресом пропишите оператор «site:». В сниппете (блок информации о странице веб-сайта) результата, нажмите на иконку в виде треугольника, выберите соответствующий пункт.
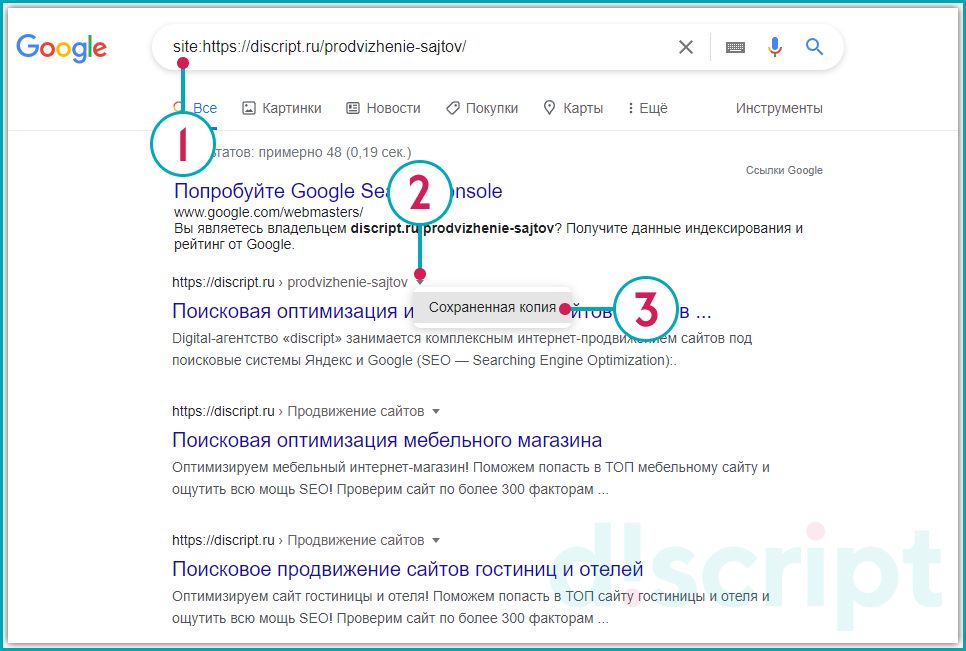
Сохраненная копия в Google
Откроется сохраненная копия веб-страницы. Google выведет окно с сообщением, что открылся «снимок» страницы.
Разберем представленную информацию:
- Дату фиксации. В данном параметре указано, когда был сделан слепок страницы. Поэтому сопоставив указанную дату с датой внесения правок, можно предположить успел ли поисковый бот обойти страницу или еще нет (Важно! данный метод не гарантирует 100% верную информацию, т.к. данные хранятся в кеше и могут отличаться в зависимости от вашего место нахождения) ;
- Полная версия. Отображается версия страница, как должен был ее увидеть пользователь.
- Текстовая версия. Позволяет просмотреть контент веб-страницы без применения стилей. Такой формат позволяет увидеть скрытые от пользователя элементы, но доступные для поисковых роботов Яндекса и Google;
- Исходный код. Выводит исходный код HTML-страницы. Это требуется для изучения тега Title и мета тегов, таких как Description. Данное представление позволяет изучить, как сверстана веб-страница, и нет ли на ней критических ошибок.
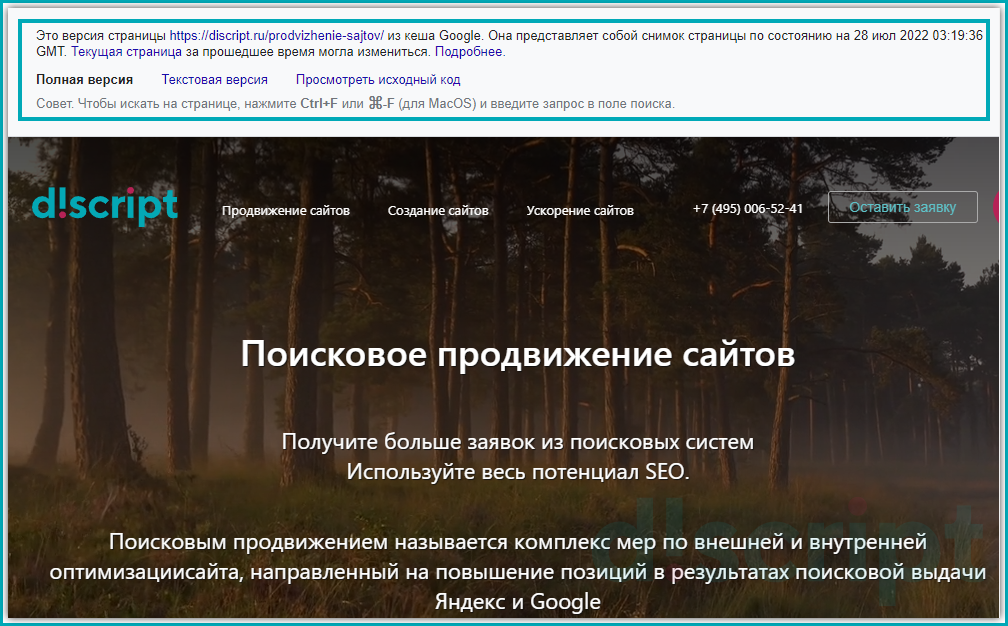
Просмотр версии страницы из кеша Google
Как посмотреть сохраненную копию веб-страницы в Яндекс
Рассмотрим на примере страницы https://discript.ru/site-development/. В строку поиска обязательно пропишите оператор «url:» перед url-адресом. нажмите на значок в виде трех горизонтальных точек, выберите «Сохраненная копия».
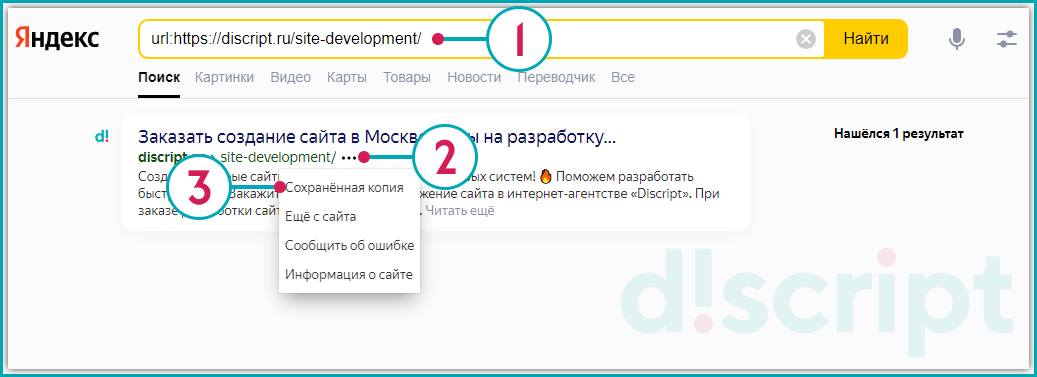
Пример поиска сохраненной страницы в Яндексе
Далее Яндекс предоставит следующие данные:
- Дата индексации. Данное значение информирует в какой момент выполнен слепок страницы.
- Полная версия страницы. Отображение страницы со всеми стилями.
- Текстовая версия страницы. Текстовая версия, аналогично позволяет изучить страницу без стилей и получить всю скрытую информацию. Часто именно при проверке текстовой копии обнаруживаются сквозные блоки текста на страницах. Т.к. при использовании стилей они скрыты.
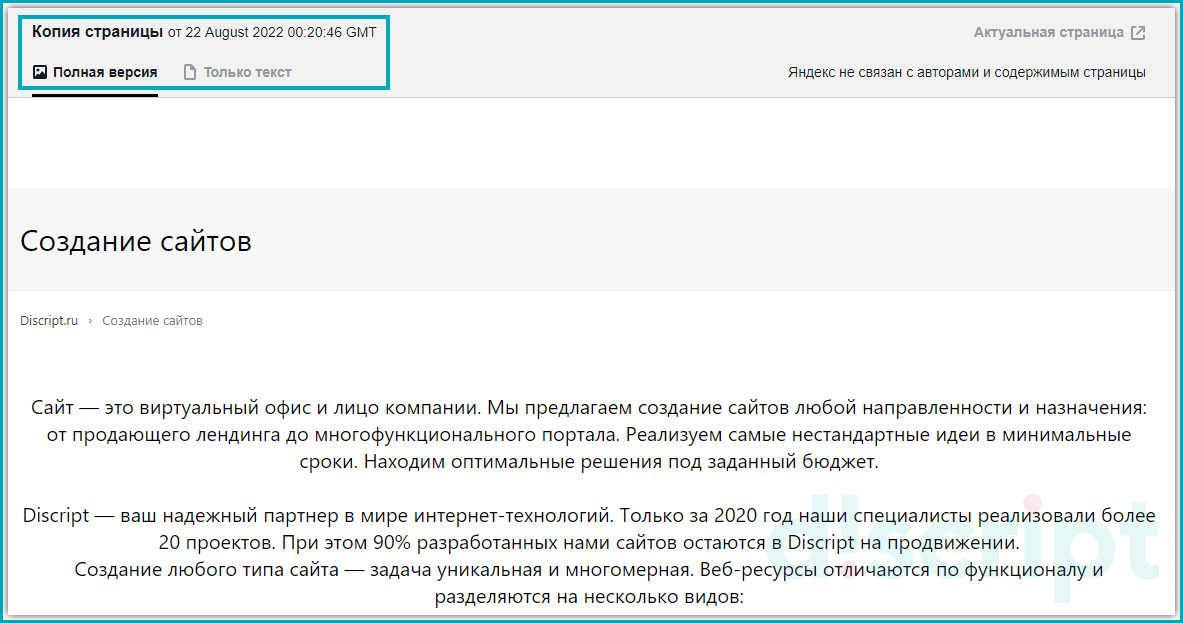
Предоставление данных о копии страницы в Яндексе
Почему сохраненной страницы может не быть
Это происходит в результате:
- Сбой работы поисковых систем. Разработчики Яндекса даже говорят, что нет стопроцентной гарантии, что страница сохранится. Конкретная причина не указывается.
- HTML-код содержит мета тег мета-тег «robots» со значением «noarchive», что означает запрет на кэширование (локальное сохранение данных для получения быстрого доступа к странице при следующих запросах).
Что предпринять если в ПС нет сохраненной копии, а посмотреть содержимое нужно? Попробуйте изучить специализированные площадки и расширения.
Рассмотренными выше способами можно посмотреть:
- Мобильную версию веб-сайта. Пропишите url мобильной версии в Яндексе или Google. Из выдачи перейдите на нее далее, как в примере рассмотренном выше.
- Адаптивную версию. Перейдя в сохраненную копию (так же как в примере выше). Открываем инструменты разработчика. Клавиша F12 в обозревателе. Или нажать ПКМ на пустом месте страницы, выбрать «Посмотреть код». Переходим в раздел мобильное отображение и перезагружаем веб-страницу.
Специализированные веб-архивы
Выше мы обсуждали, что существуют сервисы, задачи которых сохранять в истории страницы сайтов. Сейчас рассмотрим их подробнее и расскажем, как с ними работать.
И начнем с самого популярного и известно.
Wayback Machine
Сервис Wayback Machine — бесплатным онлайн-архивом, задача которого является сохранить и архивировать информацию размещенную в открытых интернет‑ресурсах. Wayback Machine является частью некоммерческого проекта Интернет Архива. На его серверах хранятся копии веб-сайтов, книг, аудио, фото, видео.
Чтобы открыть копию страницы перейдите на https://archive.org/, далее откроется поисковая форма, куда пропишите URL страницы. Нажмите кнопку «GO».

Онлайн-архив Wayback Machine
Сервис отобразит имеющиеся в архиве снимки.
Далее выберите в календаре нужную дату и откройте страницы. Результатом вывода будет открытие страницы, которую зафиксировали роботы за выбранную дату.
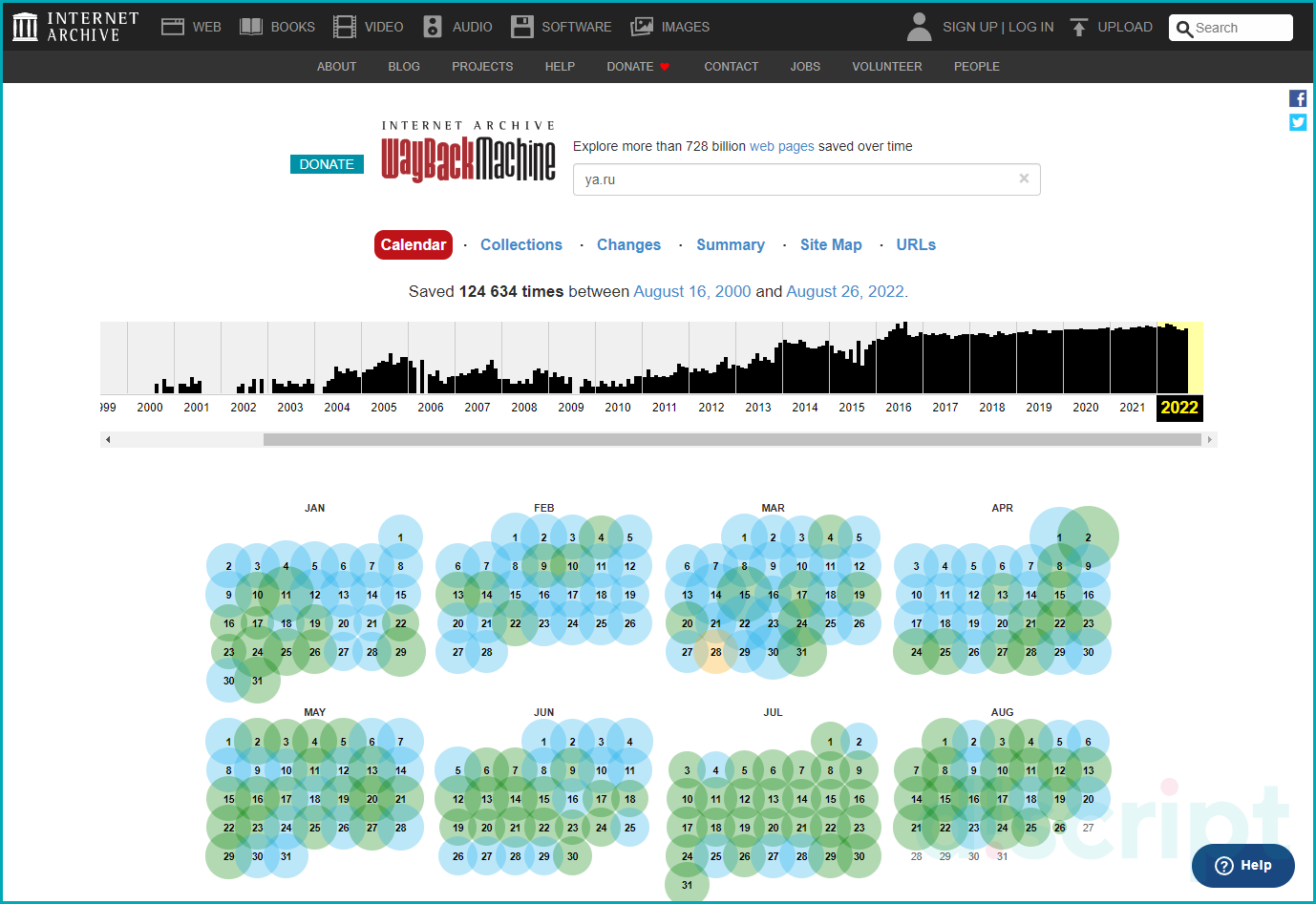
Календарь Wayback Machine
Кроме просмотра снимков страниц, сервис поможет:
- Проанализировать robots.txt. Сервис будет сканировать веб-сайты вне зависимости от настроек robots.txt;
- Узнать данные о домене. Актуально перед покупкой. Уточните какая информация размещалась на нем. Если вы купите «заспамленный» или домен под «санкциями» (например была размещена информация для взрослых) новый контент будет плохо ранжироваться. Если же ранее на нем размещалась информация, которая подходит по тематике и качеству для вашего будущего ресурса, тогда вы сможете использовать ее на этом же домене.
- Найти в архивных копиях пропавшую информацию.
- Если, например, на веб-сайте наблюдается спад трафика, откройте сохраненную версия сайта до момента уменьшения посещаемости. Проанализируйте, какие были сделаны изменения, чтобы разобраться в причине падения посещаемости.
Archive.Today
Archive.Today — бесплатный некоммерческий севрис сохраняющий веб-страницы в оналйн режиме. Особенность — сохраняет не только статические страницы, но и генерируемые Веб 2.0-проектами страницы. Например, карты Google.
Основное отличие от Wayback Machine, что Archive.Today сохраняет веб-страницы только по запросу пользователей. При этом сервер полностью сохраняет:
- HTML-страницы,
- CSS файлы,
- JS файлы,
- PDF,
- аудио файлы,
- пр.
Важно, помнить, что Archive.Today игнорирует файл robots.txt поэтому в нем можно сохранить страницы недоступные для Wayback Machine.
Обратите внимание, общий в Размер заархивированной страницы со всеми изображениями не должен превышать 50 МБ.
У Archive.Today есть собственное приложение для браузера Mozilla Firefox. Ссылка на ПО https://addons.mozilla.org/en-US/firefox/addon/archive-page/
Для начала работы с Archive.Today перейдите по адресу: https://archive.md/. Чтобы получить результат укажите в форму интересующий URL-адрес.
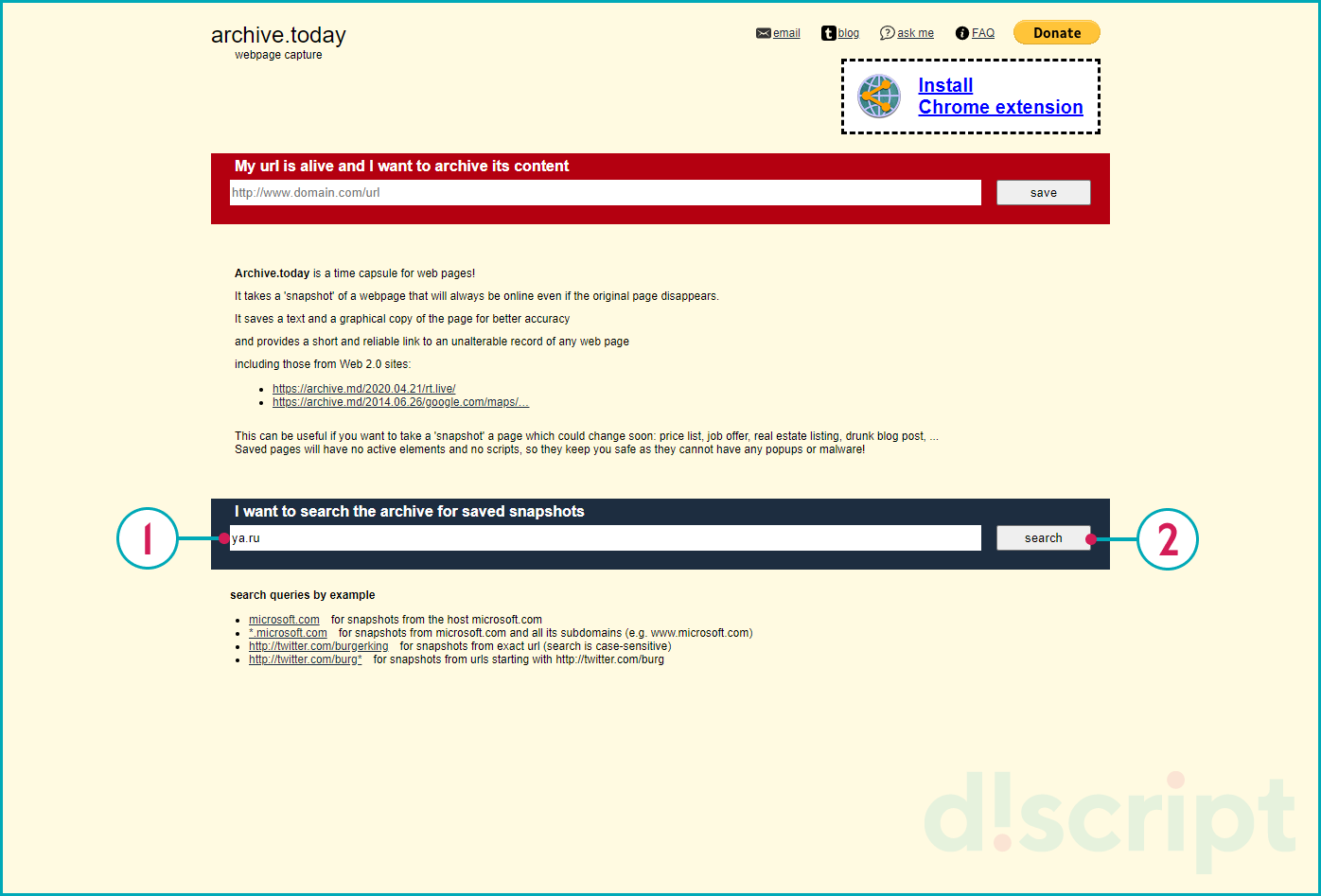
Сервис Archive.Today
Откроется страница с сохраненными снимками и информацией о дате создания копии.
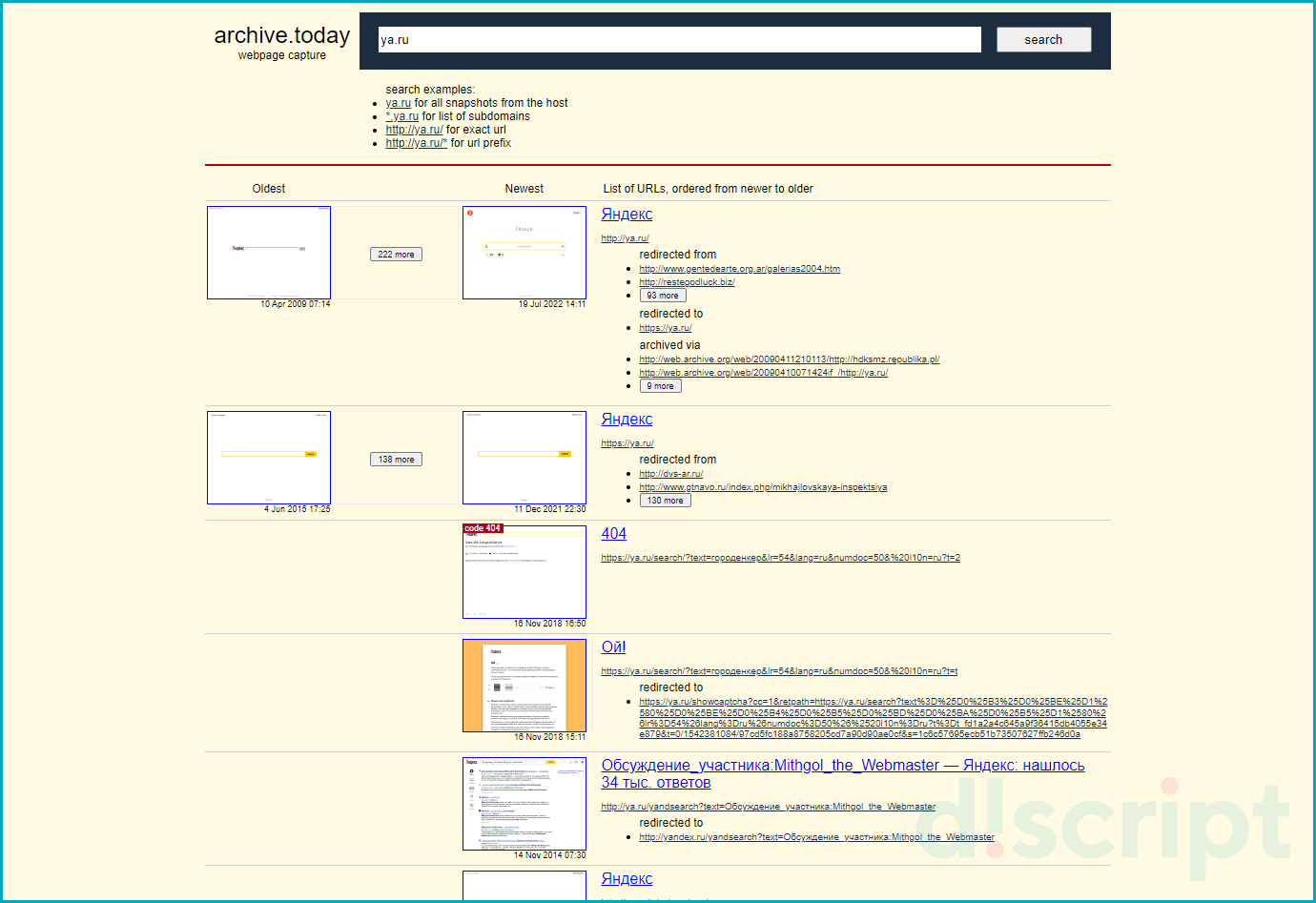
Страница с сохраненными снимками в сервисе Archive.Today
Вы можете скачать сохраненную копию виде архива. И восстановить версию страницы у себе на сервере.
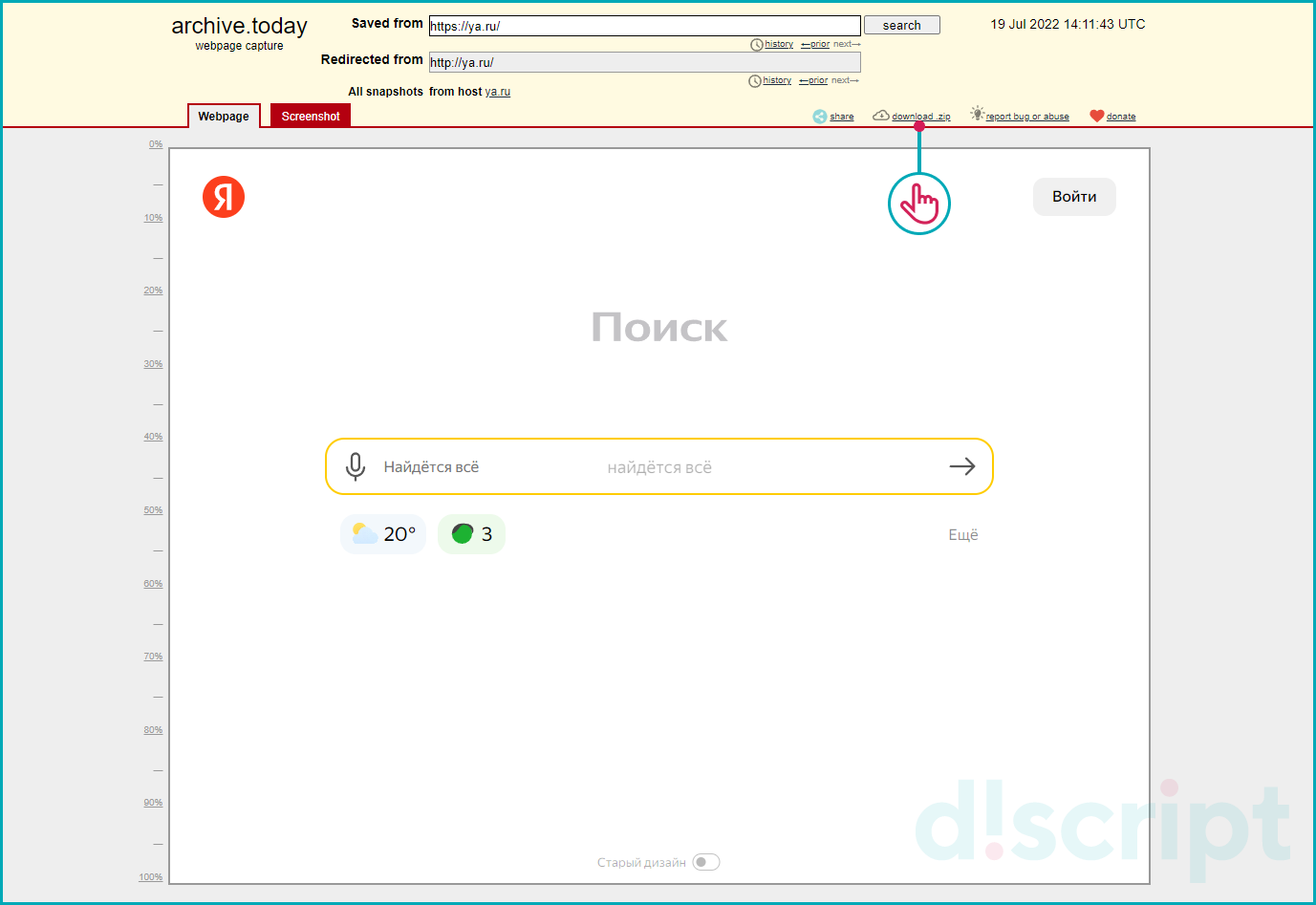
Сохранение страницы в сервисе Archive.Today
Расширения для браузеров
Существуют, плагины для браузеров, позволяющие создавать и просматривать сохраненные версии страниц.
Например, расширение Web Cache Viewer позволяет:
- Загружать веб-страницу из локального кэша на компьютере;
- Автоматически находить страницу при помощи сервиса Wayback Machine.
Перейдя по ссылке, рассмотренной, выше, нажмите кнопку «Установить».
Сервис Web Cache Viewer
После инсталляции расширения в браузере, нажмите правой кнопкой мыши пустом месте страницы для просмотра версии из Google или Wayback Machine.
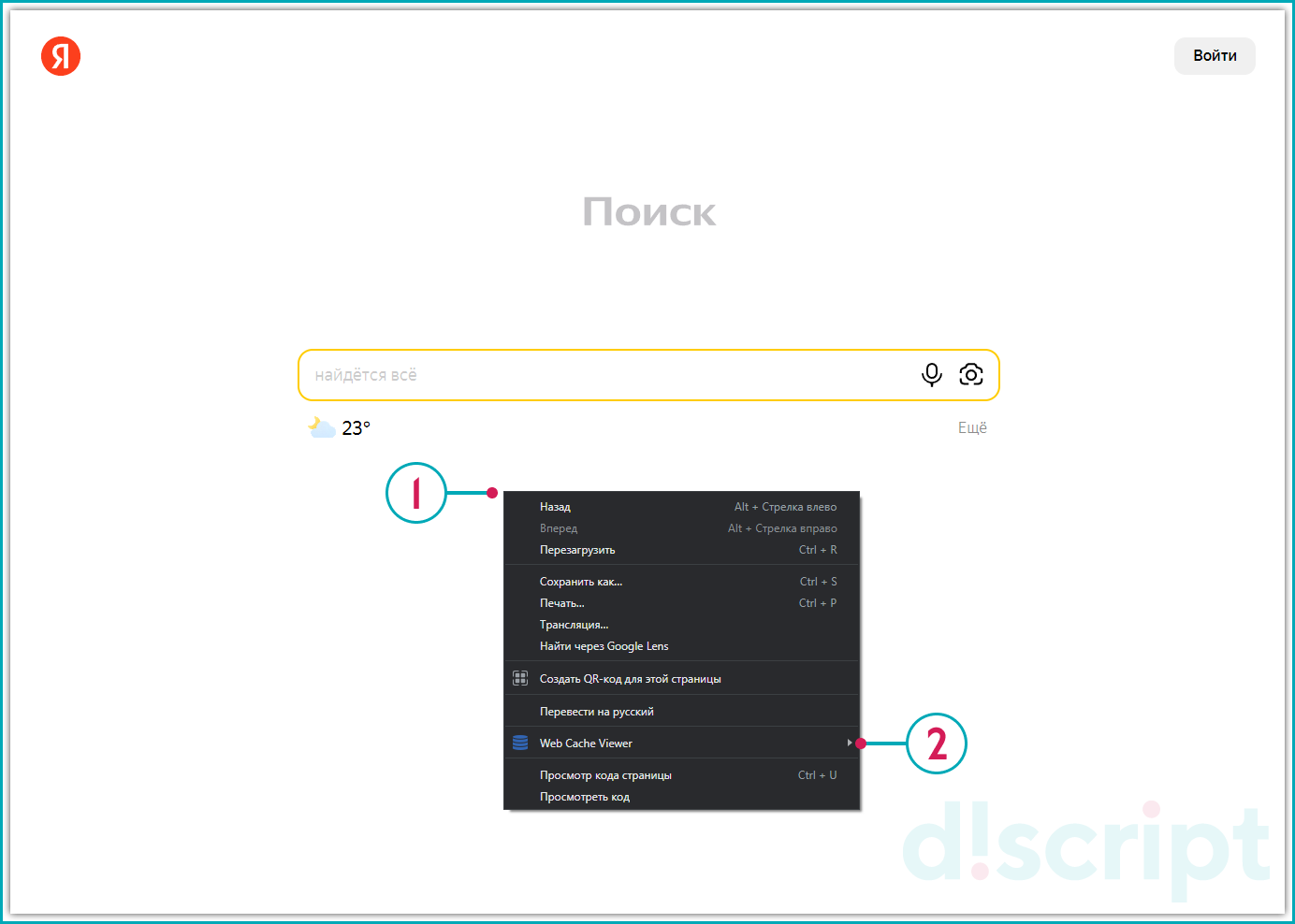
Просмотр версии из Google или Wayback Machine
Для пользователей Firefox существует аналогичное дополнение со схожим функционалом Web Archives.
Cached Page
Веб-сайт Cached Page ищет копии веб-страниц в поиске Google, Интернет Архиве, WebSite. Используйте площадку, если описанные выше способы не помогли найти сохраненную копию веб-сайта.
Пропишите название сайта в специальную форму. Для поиска нажмите одну из трех кнопок. Сервис предложит произвести поиск веб-страницы в:
- Веб-кэш Google;
- Интернет Архив;
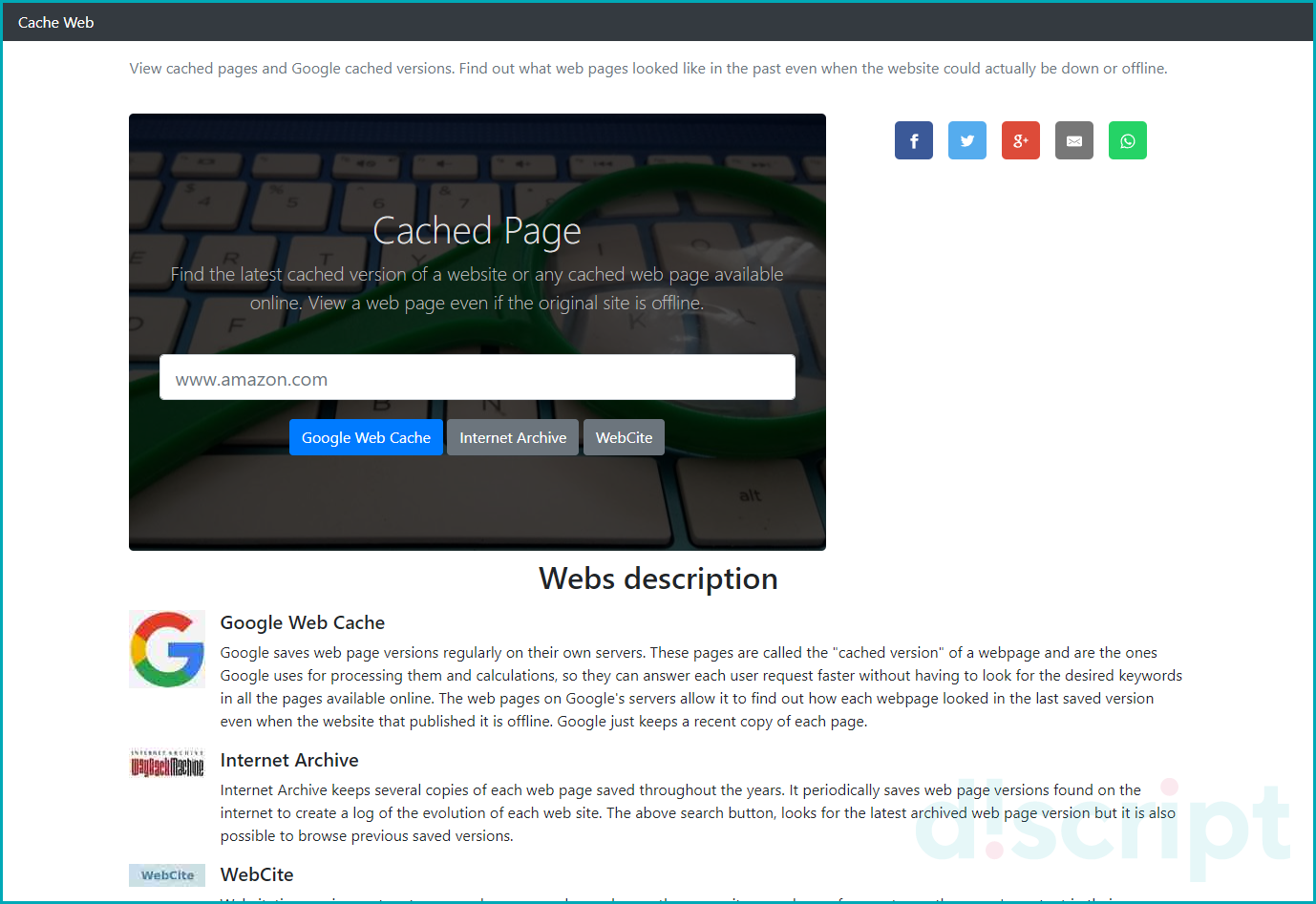
Поиск в сервисе Cached Page
Например, прописав в форму адрес https://discript.ru/prodvizhenie-sajtov/lyubercy/, и нажав кнопку «Архив Интернета», произойдет переход на страницу сервиса Wayback Machine. Если страница сохранена в БД сервиса, она отобразится на странице.
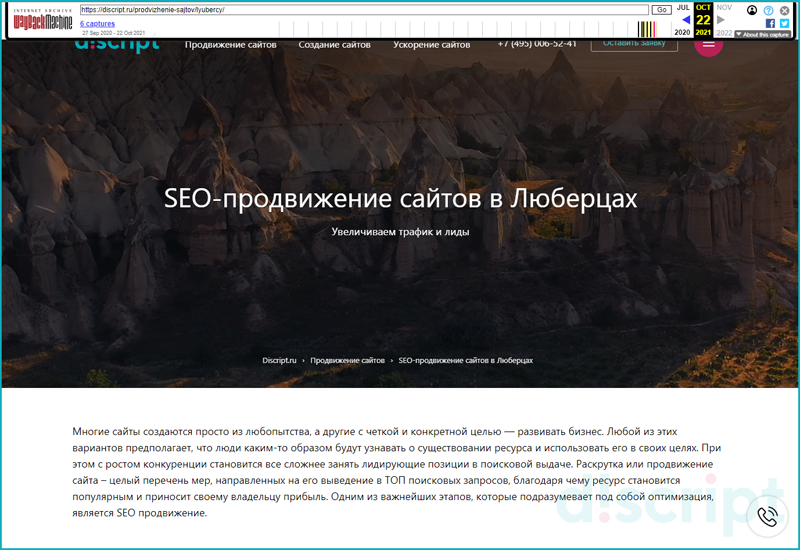
Отображение страницы в сервисе Wayback Machine
Выводы
Работая с сохраненными копиями страниц, можно выявить достаточного много полезных нюансов.
Сохраненные копии позволяют:
- Узнать, поисковый бот успел ли обойти вашу страницу после внесенных правок.
- Как бот воспринимает информацию со страницы. Все ли учитывает или остались места, которые ПС не видят.
- Выявить, какие элементы пропали и когда.
- Выявить, какие страницы успел обойти поисковый бот, после того, как сайт перестал быть доступным.
- Создать копии страниц.
- Восстановить копию сайта, когда забыли оплатить домен.
Сохраненная копия веб-страницы поможет определить, какая версия документа проиндексирована поисковыми роботами и участвует в ранжировании. Поэтому наличие «снимка» страницы в Яндексе и Google говорит об успешной проведенной индексации.
Другие статьи
Главная
Как найти созданные, опубликованные и измененные даты для веб-страницы
Как найти созданные, опубликованные и измененные даты для веб-страницы
Поиск созданной, опубликованной или последней измененной даты для веб-страниц не так прост, как может показаться. Хотя есть несколько способов найти даты веб-страниц, ни один из них не является надежным 100%, потому что независимо от используемого метода не существует стандартного для знакомства веб-страниц. Самый авторитетный способ найти даты – это сам контент страницы, и даже это имеет свои недостатки, поскольку ничто не требует, чтобы даты были точными в первую очередь. В большинстве случаев лучшее, что может быть достигнуто, будет приблизительным.

Некоторые из методов, которые можно использовать для поиска созданных, опубликованных или измененных дат для веб-страниц:
- Содержимое веб-страницы
- Заголовки HTTP
- Плагины для браузера
- Javascript в адресной строке
- Машина Wayback
- Кэш Google
- RSS Подача
1. Содержимое веб-страницы (предпочтительный метод, когда это возможно)
Страницы часто имеют первую опубликованную, обновленную или опубликованную дату где-то на странице. Как упоминалось ранее, хотя это наиболее точный метод, он все еще имеет свои проблемы. Автор может оставить дату или использовать неправильную дату – либо намеренно, либо непреднамеренно. Тем не менее, получение дат из содержимого веб-страницы является наиболее точным и авторитетным методом.
2. Заголовки HTTP
Поле Last-Modified является необязательным полем ответа, которое отражает дату, когда сервер происхождения считает, что ресурс был изменен. Поскольку это необязательное поле, оно может существовать или не существовать. Кроме того, поскольку не существует стандартного определения того, что означает поле даты последней модификации, оно часто является неточным или неправильным, поскольку это поле также отражает любые изменения, внесенные на страницу, такие как комментарии пользователей или любые изменения, отличные от содержимого.
3. Плагины для браузера
Существуют плагины браузера, которые могут читать поле даты последней модификации веб-страницы, но этот метод по-прежнему подвержен проблемам, описанным выше для заголовков HTTP.
4. Javascript в адресной строке
Это быстрый и простой способ получить дату из поля Дата последней модификации сайта в заголовках HTTP. Чтобы использовать его, просто скопируйте и вставьте строку JavaScript ниже в адресную строку:
JavaScript: предупреждение (document.lastModified)
Внимание: С динамически созданным контентом это не сработает. Кроме того, новые интернет-браузеры с Омнибокс требуется, чтобы пользователь вручную вводил javascript: даже после того, как они вставляют весь string.
5. Машина Wayback
Машина обратного пути была создана некоммерческой организацией, Интернет-архивом. Он архивирует сайты из World Wide Web и другую информацию в Интернете. Существует ряд ограничений на использование этого метода, включая:
- не все страницы на сайте могут быть включены
- не все сайты включены. Вебмастерам может потребоваться, чтобы они не были включены
- часто он не включает все изменения, внесенные на веб-сайты
- он может быть несовременным. Может потребоваться несколько месяцев для появления страниц
- определяемые пользователем даты не могут быть указаны, но только даты, сканированные веб-гусеничным устройством Way Back Machine
6. Кэш Google
Google Cache отображает веб-страницу при последнем обходе Google. Существует несколько проблем с этим методом, включая:
- нет способа узнать, когда последний раз сканирование страницы
- невозможно указать диапазон дат кеша
- изменения в веб-сайтах не отслеживаются
Чтобы использовать Google Cache, введите следующие данные в адресную строку вашего веб-браузера, изменив имя в конце URL-адреса на соответствующий сайт:
https://webcache.googleusercontent.com/search?q=cache:https://www.NameOfWebsite.com
7. Новостная лента
Многие, но не все сайты включают в себя RSS-канал. Если это так, опубликованная дата для страницы может содержаться в ее XML-файле. RSS-файлы XML могут иметь любое имя, но часто используют такие имена, как index.xml или feed.xml. Если он существует, он май можно просмотреть файл в веб-браузере, чтобы найти даты. Для получения дополнительной информации см. Открытие файлов XML с помощью браузера, Более простой и простой вариант – просмотр RSS-канала для страницы с помощью устройства чтения RSS-каналов.
Заключение
Если возможно, наиболее авторитетный и надежный метод поиска созданных, опубликованных или измененных дат из содержимого веб-страницы. Если в содержании отсутствуют даты, для получения приблизительных дат можно использовать одну или комбинацию вышеуказанных методов.
Источник
![]()
Download Article
![]()
Download Article
This wikiHow teaches you how to find the address of a website on your computer, phone, or tablet. If you’re looking for the website of a company, person, product, or organization, you can usually find the URL using a search engine like Google, Bing, or DuckDuckGo. If you’re already viewing the website of the URL you need, you can copy it from the address bar and paste it anywhere you wish, such as into an email, text message, or another browser tab.
Steps
-

1
Go to https://www.google.com in a web browser. You can visit Google’s homepage in any web browser on your computer, phone, or tablet, such as Chrome, Edge, or Safari.
- If you’re already browsing the website you want to find the URL for, skip down to Step 6.
- Google is the most popular search engine, but there are many alternatives. If you don’t find what you’re looking for on Google (or just prefer to use something different), check out Bing or DuckDuckGo.
-

2
Type the name of what you’re looking for into the search bar. This is the bar at the top of the page. For example, if you’re looking for the URL of Geico, the insurance company, you could type Geico or Geico Insurance.
- If you’re searching for something with multiple words (such as a first and last name or a longer business name), try placing your search in quotation marks for more precise results. Example: "Robyn Fenty" or "Jersey Shore".
- If you’re trying to find a person or business with a common name, it can be helpful to include the location and/or a helpful keyword in your search. Example: Vinnie's Pizza in Belmar NJ or "Joey Roberts" lawyer New Orleans.
Advertisement
-

3
Run your search. If you’re using a computer, press the Enter or Return key on your keyboard. If you’re on a phone or tablet, tap the search or Enter key. A list of search results will appear.
-

4
Review the search results. The first several search results are usually ads promoted by Google. You’ll see the word “Ad” in bold black letters at the beginning of all advertisements. Scroll past the ads to find the search results.
- If you’re using a computer, all or part of the website’s URL appears just above the link you click to view the site. For example, if you searched for wikiHow, you’ll see www.wikihow.com above it.
- Not all search results are for official websites. For example, if you’re searching for a company, you may see search results for that company’s Instagram, Twitter, and Facebook pages, as well as their website. You may also see search results for similar companies and reviews of that company.
-

5
Click a link to view the website. This redirects you to the website.
-

6
Find the URL of the website. The website’s URL is in the address bar, which is usually at the top of your web browser window. This bar may be at the bottom of the window in Chrome on some Androids.
-

7
Copy the URL. If you want to paste the URL into a message, post, or another app, you can copy and paste it from the address bar.
- If you’re using a PC or Mac, click the URL to highlight it, and then press Control + C (PC) or Command + C (Mac) to copy it.
- On a phone or tablet, tap and hold the URL in the address bar, and then tap Copy when the menu appears.
-

8
Paste the URL. Now that the URL is copied to your clipboard, you can paste it anywhere you wish:
- If you’re using a PC or Mac, right-click (or press Control as you click on a Mac) the place you’d like to paste the URL, and then click Paste on the menu.
- On a phone or tablet, tap and hold the place you want to paste the URL, and then tap Paste when it appears on the menu.
Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
Advertisement
Video
About This Article
Article SummaryX
1. Go to Google.com.
2. Search for a product, company, person, or anything you wish.
3. Click a website to open it.
4. Find the URL in the bar at the top of the browser.
Did this summary help you?
Thanks to all authors for creating a page that has been read 582,208 times.
