Errorbar is the plotted chart that refers to the errors contained in the data frame, which shows the confidence & precision in a set of measurements or calculated values. Error bars help in showing the actual and exact missing parts as well as visually display the errors in different areas in the data frame. Error bars are the descriptive behavior that holds information about the variances in data as well as advice to make proper changes to build data more insightful and impactful for the users.
Here we discuss how we plot errorbar with mean and standard deviation after grouping up the data frame with certain applied conditions such that errors become more truthful to make necessary for obtaining the best results and visualizations.
Modules Needed:
pip install numpy pip install pandas pip install matplotlib
Here is the DataFrame from which we illustrate the errorbars with mean and std:
Python3
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.DataFrame({
'insert': [0.0, 0.1, 0.3, 0.5, 1.0],
'mean': [0.009905, 0.45019, 0.376818, 0.801856, 0.643859],
'quality': ['good', 'good', 'poor', 'good', 'poor'],
'std': [0.003662, 0.281895, 0.306806, 0.243288, 0.322378]})
print(df)
Output:
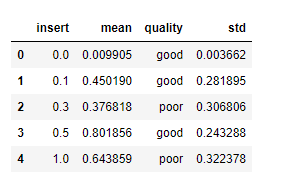
Sample DataFrame
groupby the subplots with mean and std to get error bars:
Python3
fig, ax = plt.subplots()
for key, group in df.groupby('quality'):
group.plot('insert', 'mean', yerr='std',
label=key, ax=ax)
plt.show()
Output:
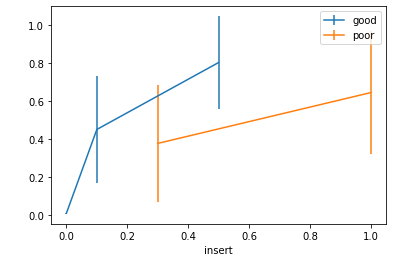
Example 1: ErrorBar with group-plot
Now we see error bars using NumPy keywords of mean and std:
Python3
qual = df.groupby("quality").agg([np.mean, np.std])
qual = qual['insert']
qual.plot(kind = "barh", y = "mean", legend = False,
xerr = "std", title = "Quality", color='green')
Output:
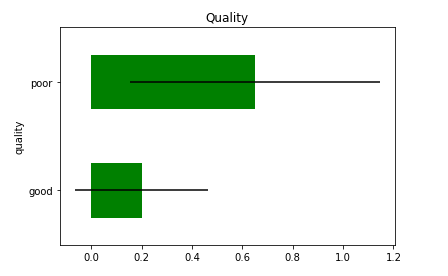
Example 2: ErrorBar with Bar Plot
By the above example, we can see that errors in poor quality are higher than good instead of more good values in the data frame.
Now, we move with another example with data frame below:
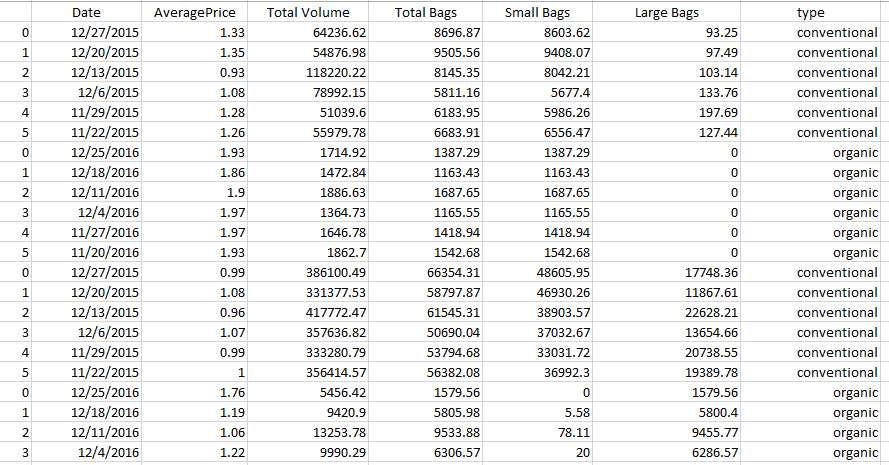
Dataset – Toast
By the above data frame, we have to manipulate this data frame to get the errorbars by using the ‘type’ column having different prices of the bags. To manipulation and perform calculations, we have to use a df.groupby function that has a prototype to check the field and execute the function to evaluate result.
We are using two inbuilt functions of mean and std:
df.groupby("col_to_group_by").agg([func_1, func_2, func_3, .....])
Python3
df = pd.read_csv('Toast.csv')
df_prices = df.groupby("type").agg([np.mean, np.std])
As we have to evaluate the average price, so apply this groupby on ‘AveragePrice’. Also, check the result of prices and with the visualization display the errorbars
Python3
prices = df_prices['AveragePrice']
prices.head()
Output:
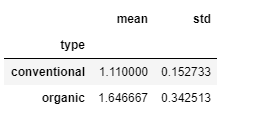
Result: the aggregate value of groupby()
Errorbar using Mean:
Python3
prices.plot(kind = "barh", y = "mean", legend = False,
title = "Average Prices")
Output:
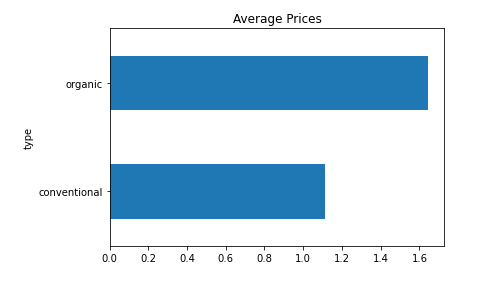
Example 3: Errorbar with Mean
By the above visualization, it’s clear that organic has a higher mean price than conventional.
Errorbar using Standard Deviation (std):
Python3
prices.plot(kind = "barh", y = "mean", legend = False,
title = "Average Prices", xerr = "std")
Output:
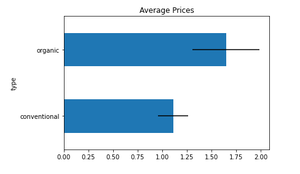
Example 4: Errorbar with Std
Advantages of Errorbars:
- Errorbars are more obstacles.
- They are easy to execute with good estimation values.
- Relatively uniform because of complex interpretation power with a data frame.
Last Updated :
23 Jul, 2021
Like Article
Save Article
17 авг. 2022 г.
читать 1 мин
Вы можете использовать функцию DataFrame.std() для вычисления стандартного отклонения значений в кадре данных pandas.
На практике можно использовать следующие методы для расчета стандартного отклонения:
Метод 1: рассчитать стандартное отклонение одного столбца
df['column_name'].std( )
Метод 2: вычислить стандартное отклонение нескольких столбцов
df[[ ' column_name1', 'column_name2']].std( )
Метод 3: вычислить стандартное отклонение всех числовых столбцов
df.std( )
Обратите внимание, что функция std() автоматически игнорирует любые значения NaN в DataFrame при вычислении стандартного отклонения.
В следующих примерах показано, как использовать каждый метод со следующими пандами DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'],
'points': [25, 12, 15, 14, 19, 23, 25, 29],
'assists': [5, 7, 7, 9, 12, 9, 9, 4],
'rebounds': [11, 8, 10, 6, 6, 5, 9, 12]})
#view DataFrame
print(df)
team points assists rebounds
0 A 25 5 11
1 A 12 7 8
2 B 15 7 10
3 B 14 9 6
4 B 19 12 6
5 B 23 9 5
6 C 25 9 9
7 C 29 4 12
Метод 1: рассчитать стандартное отклонение одного столбца
В следующем коде показано, как рассчитать стандартное отклонение одного столбца в DataFrame:
#calculate standard deviation of 'points' column
df['points'].std( )
6.158617655657106
Стандартное отклонение оказывается равным 6,1586 .
Метод 2: вычислить стандартное отклонение нескольких столбцов
В следующем коде показано, как рассчитать стандартное отклонение нескольких столбцов в DataFrame:
#calculate standard deviation of 'points' and 'rebounds' columns
df[['points', 'rebounds']]. std()
points 6.158618
rebounds 2.559994
dtype: float64
Стандартное отклонение столбца «Очки» составляет 6,1586 , а стандартное отклонение столбца «Подборы» — 2,5599 .
Метод 3: вычислить стандартное отклонение всех числовых столбцов
В следующем коде показано, как рассчитать стандартное отклонение каждого числового столбца в DataFrame:
#calculate standard deviation of all numeric columns
df.std()
points 6.158618
assists 2.549510
rebounds 2.559994
dtype: float64
Обратите внимание, что Pandas не рассчитывали стандартное отклонение столбца «команда», поскольку это не числовой столбец.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Как рассчитать среднее значение столбцов в Pandas
Как рассчитать медиану столбцов в Pandas
Как рассчитать максимальное значение столбцов в Pandas
Сегодня мы представим стандартное отклонение с помощью метода stdev() в Python. Стандартное отклонение – это статистическая единица, которая представляет собой вариацию данных, то есть отображает отклонение значений данных от центрального значения (среднего значения данных).
Обычно стандартное отклонение рассчитывается по следующей формуле:
Стандартное отклонение = (Дисперсия) ^ 1/2
Теперь давайте начнем с реализации и расчета стандартного отклонения с использованием встроенной функции в Python.
Содержание
- Начало работы с функцией
- Стандартное отклонение с модулем NumPy
- Стандартное отклонение с модулем Pandas
- Заключение
Начало работы с функцией
Модуль содержит различные встроенные функции для выполнения анализа данных и других статистических функций. Функция statistics.stdev() используется для вычисления стандартного отклонения значений данных, переданных функции в качестве аргумента.
Синтаксис:
statistics.stdev(data)
Пример:
import statistics data = range(1,10) res_std = statistics.stdev(data) print(res_std)
В приведенном выше примере мы создали данные чисел от 1 до 10 с помощью функции range(). Далее мы применяем функцию stdev() для оценки стандартного отклонения значений данных.
Вывод:
2.7386127875258306
Стандартное отклонение с модулем NumPy
Модуль NumPy преобразует элементы данных в форму массива для выполнения числовых манипуляций с ними.
Кроме того, функцию numpy.std() можно использовать для вычисления стандартного отклонения всех значений данных, присутствующих в массиве NumPy.
Синтаксис:
numpy.std(data)
Нам нужно импортировать модуль NumPy в среду Python, чтобы получить доступ к его встроенным функциям, используя приведенный ниже код:
import numpy
Пример:
import numpy as np import pandas as pd data = np.arange(1,30) res_std = np.std(data) print(res_std)
В приведенном выше примере мы сгенерировали массив элементов от 1 до 30 с помощью функции numpy.arange(). После этого мы передаем массив в функцию numpy.std() для вычисления стандартного отклонения элементов массива.
Вывод:
8.366600265340756
Стандартное отклонение с модулем Pandas
Модуль Pandas преобразует значения данных в DataFrame и помогает нам анализировать огромные наборы данных и работать с ними. Функция pandas.DataFrame.std() используется для вычисления стандартного отклонения значений столбца данных определенного DataFrame.
Синтаксис:
pandas.DataFrame.std()
Пример 1:
import numpy as np import pandas as pd data = np.arange(1,10) df = pd.DataFrame(data) res_std = df.std() print(res_std)
В приведенном выше примере мы преобразовали массив NumPy в DataFrame и применили функцию DataFrame.std(), чтобы получить стандартное отклонение значений данных.
Вывод:
0 2.738613 dtype: float64
Пример 2:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.read_csv("C:/mtcars.csv")
res_std = data['qsec'].std()
print(res_std)
В приведенном выше примере мы использовали набор данных и рассчитали стандартное отклонение столбца данных qsec с помощью функции DataFrame.std().
Входной набор данных:

Вывод:
1.7869432360968431
Заключение
Таким образом, в этой статье мы поняли, как работает функция Python stdev() вместе с модулем NumPy и Pandas.
( 4 оценки, среднее 3 из 5 )

Помогаю в изучении Питона на примерах. Автор практических задач с детальным разбором их решений.
The Python Pandas library provides a function to calculate the standard deviation of a data set. Let’s find out how.
The Pandas DataFrame std() function allows to calculate the standard deviation of a data set. The standard deviation is usually calculated for a given column and it’s normalised by N-1 by default. The degrees of freedom of the standard deviation can be changed using the ddof parameter.
In this article I will make sure the reason why we use the standard deviation is clear and then we will look at how to use Pandas to calculate the standard deviation for your data.
Let’s get started!
Standard Deviation and Mean Relationship
I have read many articles that explain the standard deviation with Pandas simply by showing how to calculate it and which parameters to pass.
But, the most important thing was missing…
An actual explanation of what calculating the standard deviation of a set of data means (e.g. for a column in a dataframe).
The standard deviation tells how much a set of data deviates from its mean. It is a measure of how spread out a given set of data is. The more spread out the higher the standard deviation.
With a low standard deviation most data is distributed around the mean. On the other side a high standard deviation tells that data is distributed over a wider range of values.
Why do we use standard deviation?
To understand if a specific data point is in line with the rest of the data points (it’s expected) or if it’s unexpected compared to the rest of the data points.
Pandas Standard Deviation of a DataFrame
Let’s create a Pandas Dataframe that contains historical data for Amazon stocks in a 3 month period. The data comes from Yahoo Finance and is in CSV format.
Here you can see the same data inside the CSV file. In our analysis we will just look at the Close price.
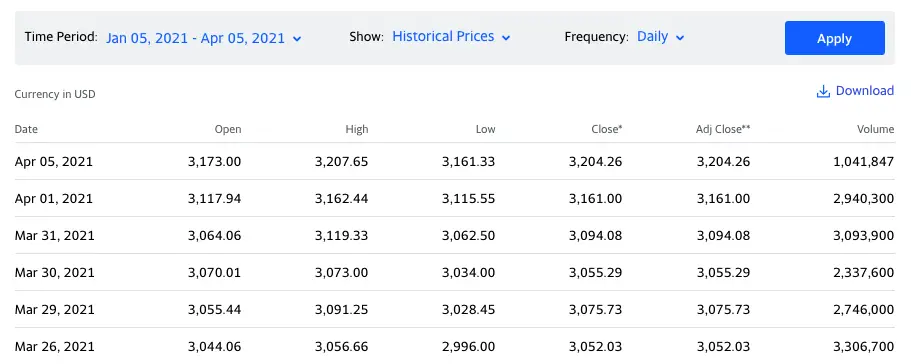
And this is how we can create the dataframe from the data. The file AMZN.csv is in the same directory of our Python program.
import pandas as pd
df = pd.read_csv('AMZN.csv')
print(df)This is the Pandas dataframe we have created from the CSV file:
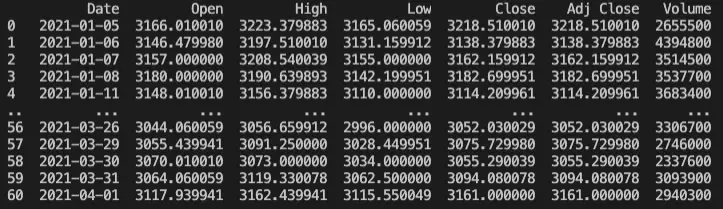
If you want to see the full data in the dataframe you can use the to_string() function:
print(df.to_string())And now let’s calculate the standard deviation of the dataframe using the std() function:
>>> print(df.std())
Open 1.077549e+02
High 1.075887e+02
Low 1.097788e+02
Close 1.089106e+02
Adj Close 1.089106e+02
Volume 1.029446e+06
dtype: float64You can see the standard deviation for multiple columns in the dataframe.
Calculate the Standard Deviation of a DataFrame Column
Now let’s move our focus to one of the columns in the dataframe, the ‘Close’ column.
We will see how to calculate the standard deviation of a specific column. We will then refactor our code to make it more generic.
This will help us for a deeper analysis we will perform in the next section on this one column.
To calculate the standard deviation of the ‘Close’ column you have two options (I personally prefer the first one):
>>> print(df['Close'].std())
108.91061129873428
>>> print(df.std()['Close'])
108.91061129873428So, let’s stick to the first option. If you want to calculate the mean for the same column with Pandas you can use the mean() function:
>>> print(df['Close'].mean())
3169.820640639344Later on we will use the mean together with the standard deviation to get another piece of data for our analysis.
Now, we will refactor our code to create a generic function that returns a dataframe from a CSV file. We will also write a generic print statement that shows mean and standard deviation values for a given stock.
import pandas as pd
def get_dataframe_from_csv(filename):
df = pd.read_csv(filename)
return df
stock = "AMZN"
df = get_dataframe_from_csv('{}.csv'.format(stock))
print("Stock: {} - Mean: {} - Standard deviation: {}".format(stock, df['Close'].mean(), df['Close'].std()))Notice that:
- The stock variable is used to generate the name of the CSV file and also to print the name of the stock in the final message.
- We are using the Python string format method to print our message.
The output of our program is:
Stock: AMZN - Mean: 3169.820640639344 - Standard deviation: 108.91061129873428Standard Deviation For Multiple DataFrames
I would like to make our code work for an arbitrary number of stocks…
…to do that we have to make a few changes.
The code that prints the mean and standard deviation will become a function that we can call for each stock.
Nothing changes in the logic of the code compared to the previous section, we are just refactoring it to make it more flexible.
Let’s add the following function:
def get_stats(stock):
df = get_dataframe_from_csv('{}.csv'.format(stock))
return df['Close'].mean(), df['Close'].std()What kind of Python data type do you think this function returns?
>>> stock = "AMZN"
>>> stats = get_stats(stock)
>>> print(stats)
(3169.820640639344, 108.91061129873428)The function returns a tuple where the first element is the mean and the second element is the standard deviation.
And now that we have the data we need in this tuple we can print the same message as before:
print("Stock: {} - Mean: {} - Standard deviation: {}".format(stock, stats[0], stats[1]))Before continuing with this tutorial run it on your machine and make sure it works as expected.
Standard Deviation For Multiple DataFrames
Our code is ready to calculate the standard deviation for multiple stocks.
I want to enhance our program so it can calculate the standard deviation of the close price for three different stocks: Amazon, Google and Facebook.
You can retrieve the historical data in CSV format for Google and Facebook from Yahoo Finance in the same way we have done it in the first section for Amazon (the historical period is the same).
Now, we can simply update our code to use a for loop that goes through each one of the stocks stored in a Python list:
stocks = ["AMZN", "GOOG", "FB"]
for stock in stocks:
stats = get_stats(stock)
print("Stock: {} - Mean: {} - Standard deviation: {}".format(stock, stats[0], stats[1]))That’s super simple! Nothing else changes in our code. And here is what we got:
Stock: AMZN - Mean: 3169.820640639344 - Standard deviation: 108.91061129873428
Stock: GOOG - Mean: 1990.8854079836065 - Standard deviation: 127.06676441921294
Stock: FB - Mean: 269.7439343114754 - Standard deviation: 11.722428896760924You can now compare the three stocks using the standard deviation.
This doesn’t give us enough information to understand which one has performed the best but it’s a starting point to analyse our data.
Coefficient of Variation With Pandas
But, how can we compare the stats we have considering that the values of the mean for the three stocks are very different from each other?
An additional statistical metric that can help us compare the three stocks is the coefficient of variation.
The coefficient of variation is the ratio between the standard deviation and the mean.
Let’s add it to our code.
We could print its value as ratio between the standard deviation and the mean directly in the final print statement…
…but instead I will calculate it inside the get_stats() function. In this way I can continue expanding this function if I want to add more metrics in the future.
The function becomes:
def get_stats(stock):
df = get_dataframe_from_csv('{}.csv'.format(stock))
mean = df['Close'].mean()
std = df['Close'].std()
cov = std / mean
return mean, std, covThen we can add the coefficient of variation to the print statement:
stocks = ["AMZN", "GOOG", "FB"]
for stock in stocks:
stats = get_stats(stock)
print("Stock: {} - Mean: {} - Standard deviation: {} - Coefficient of variation: {}".format(stock, stats[0], stats[1], stats[2]))The final output is:
Stock: AMZN - Mean: 3169.820640639344 - Standard deviation: 108.91061129873428 - Coefficient of variation: 0.034358603733732805
Stock: GOOG - Mean: 1990.8854079836065 - Standard deviation: 127.06676441921294 - Coefficient of variation: 0.06382424820115978
Stock: FB - Mean: 269.7439343114754 - Standard deviation: 11.722428896760924 - Coefficient of variation: 0.043457618154352805Difference Between Pandas and NumPy Standard Deviation
The NumPy module also allows to calculate the standard deviation of a data set.
Let’s calculate the standard deviation for Amazon Close prices in both ways to see if there is any difference between the two.
You would expect to see the same value considering that the standard deviation should be based on a standard formula.
We will use the following dataframe:
stock = "AMZN"
df = get_dataframe_from_csv('{}.csv'.format(stock))Standard deviation using Pandas
>> print(df['Close'].std())
108.91061129873428Standard deviation using NumPy
>>> import numpy as np
>>> print(np.std(df['Close']))
108.01421242306225The two values are similar but they are not the same…
When I look at the official documentation for both std() functions I notice a difference.
The Pandas documentation says that the standard deviation is normalized by N-1 by default.

According to the NumPy documentation the standard deviation is calculated based on a divisor equal to N - ddof where the default value for ddof is zero. This means that the NumPy standard deviation is normalized by N by default.

Let’s update the NumPy expression and pass as parameter a ddof equal to 1.
>>> print(np.std(df['Close'], ddof=1))
108.91061129873428This time the value is the same returned by Pandas.
If you are interested in understanding more about the difference between a divisor equal to N or N-1 you can have a look here.
Plot Standard Deviation With Matplotlib
An important part of data analysis is also being able to plot a given dataset.
Let’s take the dataset for the Amazon stock…
We will plot all the values using Matplotlib and we will also show how data points relate to the mean.
import pandas as pd
import matplotlib.pyplot as plt
def get_dataframe_from_csv(filename):
df = pd.read_csv(filename)
return df
stock = "AMZN"
df = get_dataframe_from_csv('{}.csv'.format(stock))
data = df['Close']
mean = df['Close'].mean()
std = df['Close'].std()
min_value = min(data)
max_value = max(data)
plt.title("AMZN Dataset")
plt.ylim(min_value - 100, max_value + 100)
plt.scatter(x=df.index, y=df['Close'])
plt.hlines(y=mean, xmin=0, xmax=len(data))
plt.show()We have centered the graph based on the minimum and maximum of the ‘Close’ data points (plt.ylim).
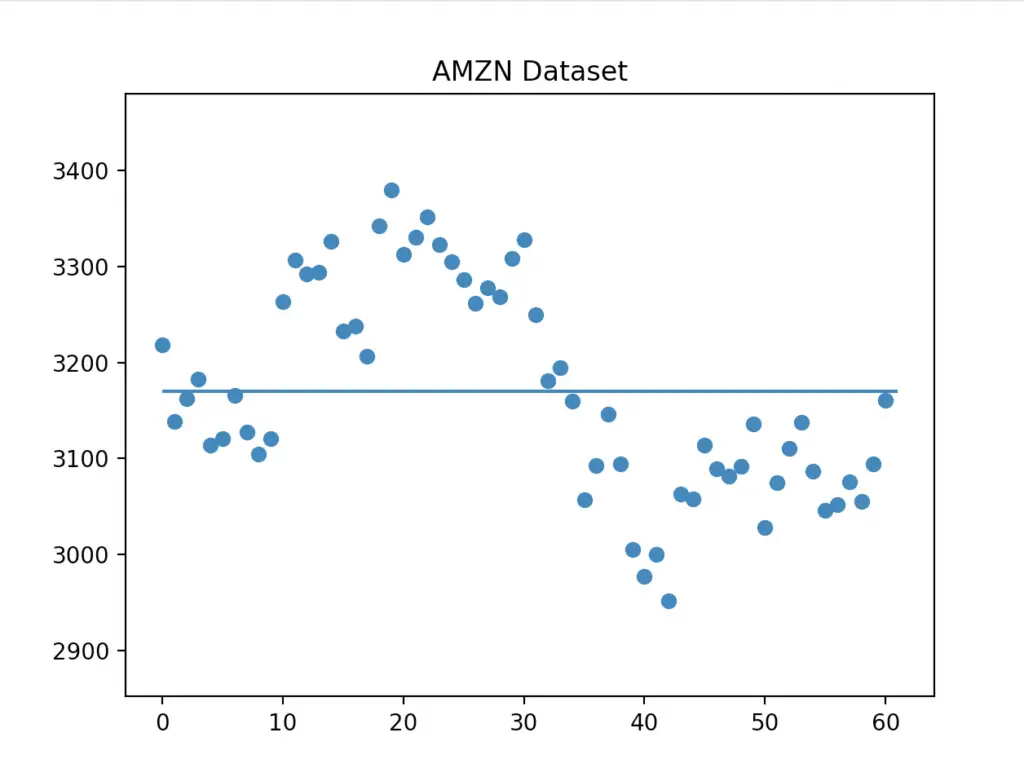
We can also show how many data points fall within one or two standard deviations from the mean. Let’s do that by adding the following lines before plt.show().
plt.hlines(y=mean - std, xmin=0, xmax=len(data), colors='r')
plt.hlines(y=mean + std, xmin=0, xmax=len(data), colors='r')
plt.hlines(y=mean - 2*std, xmin=0, xmax=len(data), colors='g')
plt.hlines(y=mean + 2*std, xmin=0, xmax=len(data), colors='g')And here is the final graph:
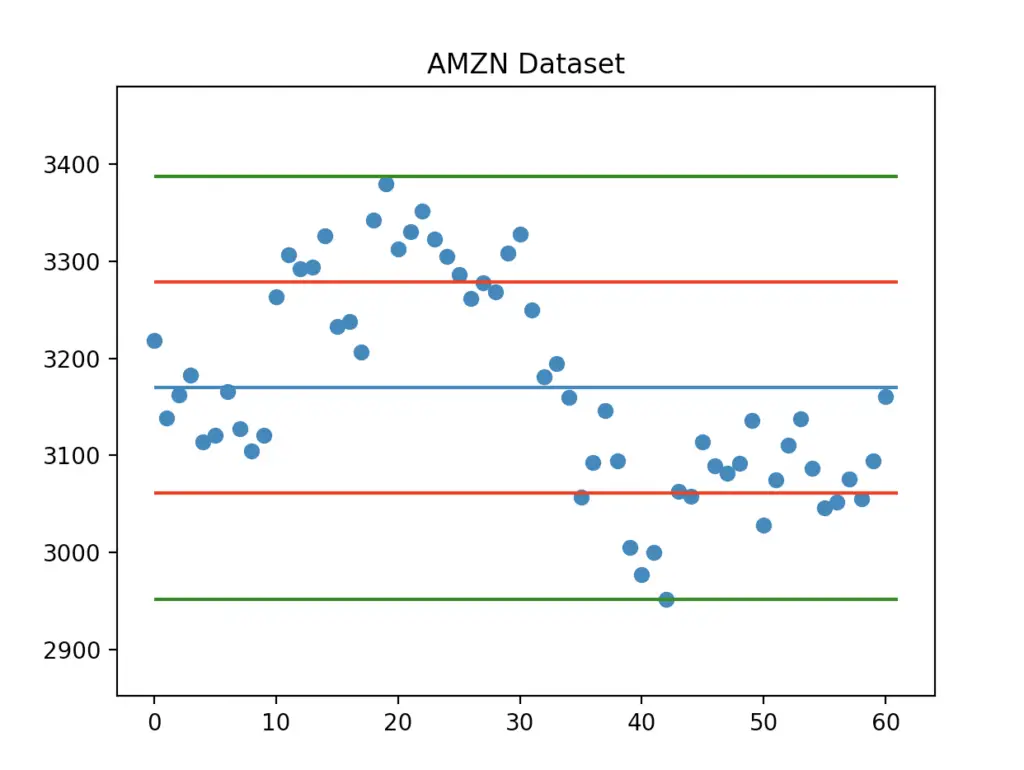
Now you also know how to plot data points, mean and standard deviation using Matplotlib.
Conclusion
In this tutorial we have seen how mean and standard deviation relate to each other and how you can calculate the standard deviation for a set of data in Python.
Being able to plot this data with Matplotlib also helps you in the data analysis.
You can download the full source code of this tutorial and the CSV files here.
And you, what will you use to calculate the standard deviation of your data? Pandas or NumPy?
If you are getting started with Data Science have a look and this introduction to Data Science in Python created by DataCamp.

I’m a Software Engineer and Programming Coach. I want to help you in your journey to become a Super Developer!
Standard deviation is a measure of spread in the values. It’s used in a number of statistical tests and it can be handy to know how to quickly calculate it in pandas. In this tutorial, we will look at how to get the standard deviation of one or more columns in a pandas dataframe.
How to calculate the standard deviation of pandas column?
You can use the pandas series std() function to get the standard deviation of a single column or the pandas dataframe std() function to get the standard deviation of all numerical columns in the dataframe. The following is the syntax:
# std dev of single column df['Col'].std() # std dev of all numerical columns in dataframe df.std()
Let’s create a sample dataframe that we will be using throughout this tutorial to demonstrate the usage of the methods and syntax mentioned.
import pandas as pd
# create a dataframe
df = pd.DataFrame({
'sepal_length': [5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0],
'sepal_width': [3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4],
'petal_length': [1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.5],
'petal_width': [0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.2],
'sepices': ['setosa']*8
})
# display the dataframe
print(df)
Output:
sepal_length sepal_width petal_length petal_width sepices 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa 5 5.4 3.9 1.7 0.4 setosa 6 4.6 3.4 1.4 0.3 setosa 7 5.0 3.4 1.5 0.2 setosa
The sample dataframe is taken form a section of the Iris dataset. This sample has petal and sepal dimensions of eight data points of the “Setosa” species.
Standard deviation of a single column
First, let’s see how to get the standard deviation of a single dataframe column.
You can use the pandas series std() function to get the std dev of individual columns (which essentially are pandas series). For example, let’s get the std dev of the “sepal_length” column in the above dataframe.
# std dev of sepal_length column print(df['sepal_length'].std())
Output:
0.27483761439387144
You see that we get the standard deviation of the values in the “sepal_length” column as a scaler value.
Standard deviation of more than one columns
First, create a dataframe with the columns you want to calculate the std dev for and then apply the pandas dataframe std() function. For example, let’s get the std dev of the columns “petal_length” and “petal_width”
# std dev of more than one columns print(df[['petal_length', 'petal_width']].std())
Output:
petal_length 0.119523 petal_width 0.074402 dtype: float64
We get the result as a pandas series. Here, we first created a subset of the dataframe “df” with only the columns “petal_length” and “petal_width” and then applied the std() function.
Standard deviation of all the columns
To get the std dev of all the columns, use the same method as above but this time on the entire dataframe. Let’s use this function on the dataframe “df” created above.
# std dev of all the columns print(df.std())
Output:
sepal_length 0.274838 sepal_width 0.290012 petal_length 0.119523 petal_width 0.074402 dtype: float64
You can see that we get the standard deviation of all the numerical columns present in the dataframe.
Note that you can also use the pandas describe() function to look at statistics including the standard deviation of columns in the dataframe.
# get dataframe statistics df.describe()
Output:
For more on the pandas dataframe std() function, refer to its documention.
You might also be interested in: Pandas – Get Mean of one or more Columns
With this, we come to the end of this tutorial. The code examples and results presented in this tutorial have been implemented in a Jupyter Notebook with a python (version 3.8.3) kernel having pandas version 1.0.5
Subscribe to our newsletter for more informative guides and tutorials.
We do not spam and you can opt out any time.
Tutorials on getting statistics for pandas dataframe values –
- Pandas – Get Mean of one or more Columns
- Pandas – Get Standard Deviation of one or more Columns
- Pandas – Get Median of One or More Columns
- Get correlation between columns of Pandas DataFrame
- Cumulative Sum of Column in Pandas DataFrame
- Pandas – Count Missing Values in Each Column
- Get Rolling Window estimates in Pandas
- Get the number of rows in a Pandas DataFrame
- Pandas – Count of Unique Values in Each Column
-

Piyush is a data professional passionate about using data to understand things better and make informed decisions. He has experience working as a Data Scientist in the consulting domain and holds an engineering degree from IIT Roorkee. His hobbies include watching cricket, reading, and working on side projects.
View all posts
