
Наиболее распространенной формой статистических показателей, используемой в экономических исследованиях, являются средние показатели (средняя величина).
Средняя величина – представляет обобщенную количественную характеристику признака в статистической совокупности в конкретных условиях места и времени.
Показатель в форме средней величины выражает типичные черты и дает обобщающую характеристику однотипных явлений по одному из варьирующих признаков. Он отражает уровень этого признака, отнесенный к единице совокупности.
Важнейшее свойство средней величины заключается в том, что она отражает то общее, что присуще всем единицам исследуемой совокупности.
Значения признака отдельных единиц совокупности колеблются в ту или иную сторону под влиянием множества факторов, среди которых могут быть как основные, так и случайные.
- Например, курс акций корпорации в основном определяется финансовыми результатами ее деятельности. В то же время, в отдельные дни и на отдельных биржах эти акции в силу сложившихся обстоятельств могут продаваться по более высокому или заниженному курсу.
Сущность средней заключается, в том, что в ней взаимопогашаются отклонения значений признака отдельных единиц совокупности, обусловленные действием случайных факторов, и учитываются изменения, вызванные действием факторов основных. Это позволяет средней отражать типичный уровень признака и абстрагироваться от индивидуальных особенностей, присущих отдельным единицам.
ВИДЫ СРЕДНИХ ВЕЛИЧИН наиболее часто применяемых на практике:
- средняя арифметическая;
- средняя гармоническая;
- средняя геометрическая;
- средняя квадратическая.
Выбор средней величины зависит от содержания осредняемого признака и конкретных данных, по которым ее приходится вычислять.
- Средняя арифметическая простая (невзвешенная) – вычисляется когда каждый вариант совокупности встречается только один раз.
- Средняя арифметическая (взвешенная) – варианты повторяются различное число раз, при этом число повторений вариантов называется частотой, или статистическим весом.
ФОРМУЛЫ СРЕДНИХ ВЕЛИЧИН
- Средняя арифметическая простая – самый распространенный вид средней величины, рассчитывается по формуле (8.8):

(8.8 -формула средней арифметической простой)
- где хi – вариант, а n – количество единиц совокупности.
- Пример вычисления средней арифметической простой. Провели опрос о желаемом размере заработной платы у пяти сотрудников офиса. По результатам опроса выяснили, что желаемый размер заработной платы составляет соответственно для каждого сотрудника: 50000, 100000, 200000, 350000, 500000 рублей человек. Рассчитаем среднюю арифметическую простую по формуле (8.8):
 Вывод: в среднем желаемый размер заработной платы по результатам опроса 5-ти человек составил 240 тысяч рублей.
Вывод: в среднем желаемый размер заработной платы по результатам опроса 5-ти человек составил 240 тысяч рублей.
- Средняя арифметическая взвешенная формула 8.9.

(8.9 -формула средней арифметической взвешенной)
- где хi – вариант, а fi – частота или статистический вес.
- Пример вычисления средней арифметической взвешенной. Результаты опроса всех работников офиса приведены в табл. 8.2.
Таблица 8.2 – Результаты опроса работников офиса
|
Желаемый размер заработной платы, тыс.руб хi |
Количество работников fi | хifi |
| 1 | 2 | 3 |
|
50 100 200 350 500 |
6
10 20 9 5 |
300
1000 4000 3150 2500 |
| Итого | 50 | 10950 |
Пример. Вычислим (ориентируясь на итоговые строки таблицы) желаемый размер заработной платы, 50 сотрудников офиса (используем формулу 8.9):

Пример вычисления средней арифметической взвешенной
Вывод: в среднем желаемый размер заработной платы по результатам опроса 50 человек составил 219 тысяч рублей.
Среднеарифметическая – всегда обобщающая количественная характеристика варьирующего признака совокупности.
- Средняя гармоническая вычисляется в тех случаях, когда приходится суммировать не сами варианты, а обратные им величины.
- Средняя гармоническая простая представлена ниже:

(8.10 – формула средней гармонической простой)
Средняя гармоническая взвешенная определяется по формуле

(8.11- формула средней гармонической взвешенной)
где xi – вариант, n – количество вариантов, Vi – веса для обратных значений xi.
Средняя гармоническая невзвешенная. Эта форма средней, используемая значительно реже, чем взвешенная. Для иллюстрации области ее применения воспользуемся упрощенным условным примером.
- Пример (вычисление средней гармонической простой (невзвешенной)).
Предположим, в фирме, специализирующейся на торговле по почте на основе предварительных заказов, упаковкой и отправкой товаров занимаются два работника. Первый из них на обработку одного заказа затрачивает 5 мин., второй – 15 мин.
- Каковы средние затраты времени на 1 заказ, если общая продолжительность рабочего времени у работников равна?
На первый взгляд, ответ на этот вопрос заключается в осреднении индивидуальных значений затрат времени на 1 заказ, т.е. если используем среднюю арифметическую простую получим: (5+15):2=10, мин.
- Проверим обоснованность такого подхода на примере одного часа (60 минут) работы. За этот час первый работник обрабатывает 12 заказов (60:5), второй – 4 заказа (60:15), что в сумме составляет 16 заказов.
Если же заменить индивидуальные значения их предполагаемым средним значением, то общее число обработанных обоими работниками заказов в данном случае уменьшится: (60/10) + (60/10) = 12 заказов (что не соответствует истине).
- Подойдем к решению через исходное соотношение средней. Для определения средних затрат времени необходимо общие затраты времени за любой интервал (например, за час) разделить на общее число обработанных за этот интервал двумя работниками заказов, т.е. используем среднюю гармоническую:

Пример вычисления средней гармонической простой (невзвешенной)
Если теперь мы заменим индивидуальные значения их средней величиной, то общее количество обработанных за час заказов не изменится: (60/7,5) + (60/7,5) = 16 заказов
- Подведем итог: средняя гармоническая невзвешенная может использоваться вместо взвешенной в тех случаях, когда значения Wj для единиц совокупности равны (в рассмотренном примере рабочий день у сотрудников одинаковый).
Пример (вычисление средней гармонической взвешенной) В ходе торгов на валютной бирже за первый час работы заключено пять сделок. Данные о сумме продажи рублей и курсе рубля по отношению к доллару США приведены в табл.8.3.
Таблица 8.3 – Данные о ходе торгов на валютной бирже (цифры условные)
Номер сделки Сумма продажи V, млн руб. Курс рубля x, руб. за 1 дол. V/x 1 2 3 4 1
2
3
4
5
455,00
327,50
528,00
266,00
332,50
65,00 65,50
66,00
66,50
66,50
7,00
5,00
8,00
4,00
5,00
итого 1909,00 – 29,00 Для того чтобы определить средний курс рубля по отношению к доллару, нужно найти соотношение между суммой продажи рублей, которые затрачены на покупку долларов в ходе всех сделок, и суммой приобретенных в результате этих сделок долларов.

- Вывод: средний курс за один доллар составил 65,83 руб.;
- Если бы для расчета среднего курса была использована средняя арифметическая простая:
 то, за один доллар, по данному курсу на покупку 29 млн дол. нужно было бы затратить 1899,5 млн.руб., что не соответствует действительности.
то, за один доллар, по данному курсу на покупку 29 млн дол. нужно было бы затратить 1899,5 млн.руб., что не соответствует действительности.
Средняя геометрическая используется для анализа динамики явлений и позволяет определить средний коэффициент роста. При расчете средней геометрической индивидуальные значения признака обычно представляют собой относительные показатели динамики, построенные в виде цепных величин как отношение каждого уровня ряда к предыдущему уровню.
- Средняя геометрическая простая рассчитывается по формуле 8.12

(8.12)
- Если использовать частоты m, получим формулу средней геометрической взвешенной
- Средняя геометрическая взвешенная рассчитывается по формуле 8.13

(8.13)
Средняя квадратическая применяется, когда изучается вариация признака. В качестве вариантов используются отклонения фактических значений признака либо от средней арифметической, либо от заданной нормы.
Для несгруппированных данных используют формулу средней квадратической простой
Средняя квадратическая простая (формула 8.14)

8.14
Для сгруппированных данных используют формулу средней квадратической взвешенной
Средняя квадратическая взвешенная (формула 8.15)

(8.15) – Формула -средняя квадратическая взвешенная
Средние арифметическая, гармоническая, геометрическая и квадратическая, рассчитанные для одного и того же ряда вариантов, отличаются друг от друга. Их численное значение возрастает с ростом показателя степени в формуле степенной средней правило мажорантности средних А.Я. Боярского, т.е.

Мода и Медиана (структурные средние) формулы и примеры вычисления см. по ссылке
Например, средняя арифметическая для интервального ряда
При расчете средней арифметической для
интервального вариационного ряда
сначала определяют среднюю для каждого
интервала, как полусумму верхней и
нижней границ, а затем — среднюю всего
ряда. В случае открытых интервалов
значение нижнего или верхнего интервала
определяется по величине интервалов,
примыкающих к ним.
Пример
3. Определить
средний возраст студентов вечернего
отделения.
|
Возраст |
Число |
Среднее |
Произведение |
|
до |
65 |
(18 + |
1235 |
|
20 — |
125 |
(20 + |
2625 |
|
22 — |
190 |
(22 + |
4560 |
|
26 — |
80 |
(26 + |
2240 |
|
30 и |
40 |
(30 + |
1280 |
|
Итого |
500 |
11940 |
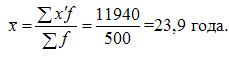
Средние, вычисляемые из интервальных
рядов являются приближенными.
-
Структурные средние величины
Кроме степенных средних в статистике
для относительной характеристики
величины варьирующего признака и
характеристики рядов распределения
пользуются структурными средними: модой
и медианой.
Мода
Мода— это наиболее часто
встречающийся вариант ряда. Мода
применяется, например, при определении
размера одежды, обуви, пользующейся
наибольшим спросом у покупателей.
Модой для дискретного ряда является
варианта, обладающая наибольшей частотой.
При вычислении моды для интервального
вариационного ряда необходимо:
-
сначала определить модальный интервал
(по максимальной частоте), -
затем — значение модальной величины
признака по формуле:
![]()
где:
-
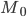 —
—
значение моды -
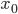 —
—
нижняя граница модального интервала -
i —
величина интервала -
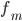 —
—
частота модального интервала -
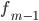 —
—
частота интервала, предшествующего
модальному -
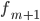 —
—
частота интервала, следующего за
модальным
Определение моды графически:
Мода определяется по гистограмме
распределения. Для этого
правую вершину модального
прямоугольника соединяют с правым
верхним углом предыдущего прямоугольника
, а левую
вершину модального прямоугольника –
с левым верхним углом
последующего прямоугольника. Абсцисса
точки пересечения этих прямых и будет
модой распределения.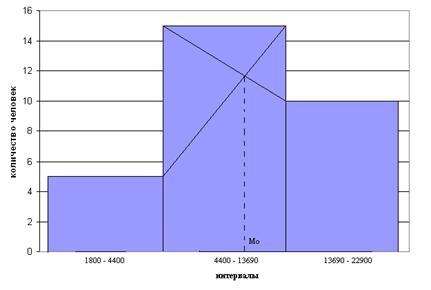
Медиана
Медиана — это значение признака,
который делит вариационный ряд на две
равные по численности части.
Медиана для дискретного ряда.
Для определения медианы в дискретном
рядус нечетнымколичеством
единиц наблюдения сначалапорядковый
номер медианыпо формуле: ![]() ,
,
а затем определяют, какое значение
варианта обладает накопленной частотой,
равной номеру медианы.
Если ряд содержит четное
число элементов, то
медиана будет равна средней из двух
значений признака, находящихся в
середине. Номер первого из этих признаков
определяется по формуле: ![]() ,
,
для второго – ![]() .
.
![]()
= n
(количество элементов в ряду).
Медиана для интервального ряда
При вычислении медианы для
интервального вариационного ряда сначала
определяют медианный интервал, в пределах
которого находится медиана.
Для этого:
-
определяется номер медианы
по формуле: ,
,
полученное значение округляется до
целого большего числа. -
затем по
накопленной частоте определяется
интервал, в который входит элемент с
таким номером, -
затем — значение медианы по формуле:
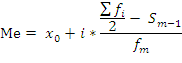
где:
-
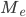 —
—
искомая медиана -
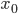 —
—
нижняя граница интервала, который
содержит медиану -
i
— ширина интервала -
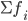 —
—
сумма частот или число членов ряда -
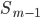 –
–
накопленная частота интервала,
предшествующего медианному -
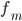 —
—
частота медианного интервала
Пример.
Найти моду и медиану для интервального
ряда.
|
Возрастные |
Число |
Сумма |
|
До 20 |
346 |
346 |
|
20 — 25 |
872 |
1218 |
|
25 |
1054 |
2272 |
|
30 — 35 |
781 |
3053 |
|
35 — 40 |
212 |
3265 |
|
40 — 45 |
121 |
3386 |
|
45 лет |
76 |
3462 |
|
Итого |
3462 |
Решение:
-
Определим моду
В
данном примере модальный интервал
находится в пределах возрастной группы
25-30 лет, так как на этот интервал приходится
наибольшая частота (1054).
Рассчитаем
величину моды:
![]()
Это значит, что модальный
возраст студентов равен 27 годам.
-
Определим медиану.
Медианный интервал
находится в возрастной группе 25-30 лет,
так как в пределах этого интервала
расположена варианта, которая делит
совокупность на две равные части (Σfi/2
= 3462/2 = 1731). Далее подставляем в формулу
необходимые числовые данные и получаем
значение медианы:
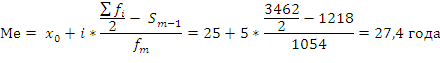
Это значит, что одна половина студентов
имеет возраст до 27,4 года, а другая свыше
27,4 года.
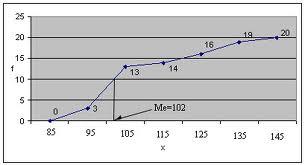
Графически медиана
определяется по кумуляте. Для ее
определения высоту наибольшей ординаты,
которая соответствует сумме всех частот,
делят пополам. Через полученную точку
проводят прямую,
параллельную оси абсцисс,
до
пересечения ее с кумулятой. Абсцисса
точки пересечения является медианой.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
План урока:
Понятие выборки и генеральной совокупности
Среднее арифметическое выборки
Упорядоченный ряд и таблица частот
Размах выборки
Мода выборки
Медиана выборки
Ошибки в статистике
Понятие выборки и генеральной совокупности
Слово статистика, образованное от латинского status(состояние дел), появилось только в 1746 году, когда его употребил немец Готфрид Ахенвалль. Однако ещё в Древнем Китае проводились переписи населения, в ходе которых правители собирали информацию о своих владениях и жителях, проживающих в них.
В основе любого статистического исследования лежит массив информации, который называют выборкой данных. Покажем это на примере. Пусть в классе, где учится 20 учеников, проводился тест по математике, содержавший 25 вопросов. В результате учащиеся показали следующие результаты:

Ряд чисел, приведенный во второй строке таблицы (12, 19, 19, 14, 17, 16, 18, 20, 15, 25, 13, 20, 25, 16, 17, 12, 24, 13, 21, 13), будет выборкой. Также ее могут называть рядом данных или выборочной совокупностью.

В примере с классом выборка состоит из 20 чисел. Эту величину (количество чисел в ряду) называют объемом выборки. Каждое отдельное число в ряду именуют вариантой выборки.
В примере со школьным классом в выборку попали все его ученики. Это позволяет точно определить, насколько хорошо учащиеся написали математический тест. Однако иногда необходимо проанализировать очень большие группы населения, состоящие из десятков и даже сотен миллионов человек. Например, необходимо узнать, какая часть населения страны курит. Опросить каждого жителя государства невозможно, поэтому в ходе исследования опрашивают лишь его малую часть. В этом случае статистики выделяют понятие генеральная совокупность.

Так, если с помощью опроса 10 тысяч человек ученые делают выводы о распространении курения в России, то все российское население будет составлять генеральную совокупность исследования, а опрошенные 10 тысяч людей вместе образуют выборку.
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.

Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:

При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Размах выборки
Следующий важная характеристика ряда данных – это размах выборки.

Если выборка представлена в виде упорядоченного ряда данных, то достаточно вычесть из последнего числа ряда первое число. Так, размах выборки результатов теста в классе равен:
25 – 12 = 13,
так как самые лучшие ученики смогли решить все 25 заданий, а наихудший учащийся ответил правильно только на 13 вопросов.
Размах выборки характеризует стабильность, однородность исследуемых свойств. Например, пусть два спортсмена-стрелка в ходе соревнований производят по 5 выстрелов по круговой мишени, где за попадание начисляют от 0 до 10 очков. Первый стрелок показал результаты 8, 9, 9, 8, 9 очков. Второй же спортсмен в своих попытках показал результаты 7, 10, 10, 6, 10. Средние арифметические этих рядов равны:
(8+9+9+8+9):5 = 43:5 = 8,6;
(7+10+10+6+10):5 = 43:5 = 8,6.
Получается, что в среднем оба стрелка стреляют одинаково точно, однако первый спортсмен демонстрирует более стабильные результаты. У его выборки размах равен
9 – 8 = 1,
в то время как размах выборки второго спортсмена равен
10 – 6 = 4.
Размах выборки может быть очень важен в метеорологии. Например, в Алма-Ате и Амстердаме средняя температура в течение года почти одинакова и составляет 10°С. Однако в Алма-Ате в январе и феврале иногда фиксируются температуры ниже -30°С, в то время как в Амстердаме за всю историю наблюдений она никогда не падала ниже -20°С.
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны. Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Медиана выборки
Иногда, например, при расчете средней зарплаты, среднее арифметическое не вполне адекватно отражает ситуацию. Это происходит из-за наличия в выборке чисел, очень сильно отличающихся от среднего. Так, из-за огромных зарплат некоторых начальников большинство рядовых сотрудников компаний обнаруживают, что их зарплата ниже средней. В таких случаях целесообразно использовать такую характеристику, как медиану ряда. Это такое значение, которое делит ряд данных пополам. В упорядоченном ряде 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25 медианой будет равна 12, так как именно она находится в середине ряда:

Однако таким образом можно найти только медиану ряда, в котором находится нечетное количество чисел. Если же их количество четное, то за медиану условно принимают среднее арифметическое двух средних чисел. Так, для ряда 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25, 30, содержащего 12 чисел, медиана будет равна среднему значению 12 и 15, которые занимают 6-ое и 7-ое место в ряду:


Вернемся к примеру с математическим тестом в школе. Так как его сдавали 20 учеников, а 20 – четное число, то для расчета медианы следует найти среднее арифметическое 10-ого и 11-ого числа в упорядоченном ряде
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Эти места занимают числа 17 и 17 (выделены жирным шрифтом). Медиана ряда будет равна
(17+17):2 = 34:2 = 17.
Три приведенные основные статистические характеристики выборки, а именно среднее арифметическое, мода и медиана, называются мерами центральной тенденции. Они позволяют одним числом указать значение, относительно которого группируются все числа ряда.
Рассмотрим для наглядности ещё один пример. Врач в ходе диспансеризации измерил вес мальчиков в классе. В результате он получил 10 значений (в кг):
39, 41, 67, 36, 60, 58, 46, 44, 39, 69.
Найдем среднее арифметическое, размах, моду и медиану для этого ряда.
Решение. Сначала перепишем ряд в упорядоченном виде:
36, 39, 39, 41, 44, 46, 58, 60, 67, 69.
Так как в ряде 10 чисел, то объем выборки равен 10. Найдем среднее арифметическое. Для этого сложим все числа в ряде и поделим их на объем выборки (то есть на 10):
(36+39+39+41+44+46+58+60+67+69):10 =
= 499:10 = 49,9 кг.
Размах выборки равен разнице между наибольшей и наименьшей вариантой в ней. Самый тяжелый мальчик весит 69 кг, а самый легкий – 36 кг, а потому размах ряда равен
69 – 36 = 33 кг.
В упорядоченном ряде только одно число, 39, встречается дважды, а все остальные числа встречаются по одному разу. Поэтому мода ряда будет равна 39 кг.
В выборке 10 чисел, а это четное число. Поэтому для нахождения медианы надо найти два средних по счету значение найти их среднее. На 5-ом и 6-ом месте в ряде находятся числа 44 и 46. Их среднее арифметическое равно
(44+46):2 = 90:2 = 45 кг.
Поэтому и медиана ряда будет равна 45 кг.
Ошибки в статистике
Статистика является очень мощным инструментом для исследований во всех областях человеческой деятельности. Однако иногда ее иронично называют самой точной из лженаук. Известно и ещё одно высказывание, приписываемое политику Дизраэли, согласно которому существует просто ложь, наглая ложь и статистика. С чем же связана такая репутация этой дисциплины?
Дело в том, что некоторые люди и организации часто манипулируют данными статистики, чтобы убедить других в своей правоте или преимуществах товара, которые они продают. Требуются определенные навыки, чтобы правильно пользоваться статистикой. Одна из самых распространенных ошибок – это неправильный выбор выборки.
В 1936 году перед президентскими выборами в США был проведен телефонный опрос, который показал, что с большим преимуществом победу должен одержать Альфред Лендон. Однако на выборах Франклин Рузвельт набрал почти вдвое больше голосов. Ошибка была связана с тем, что в те годы телефон могли позволить себе только богатые люди, которые в большинстве своем поддерживали Лендона. Однако бедные люди (а их, конечно же, больше, чем богатых) голосовали за Рузвельта.
Ещё один пример – это агитация в конце XIX века в США к службе на флоте. Пропагандисты в своей рекламе указывали, что, согласно статистике, смертность на флоте во время войны (испано-американской) составляет 0,09%, в то время как среди населения Нью-Йорка она равнялась 0,16%. Получалось, что служить на флоте в военное время безопаснее, чем жить мирной жизнью. Однако на самом деле причина таких цифр заключается в том, что во флот всегда отбирали молодых мужчин с хорошим здоровьем, которые не могли умереть от «старческих» болезней, в то время как в население Нью-Йорка входят больные и старые люди.
При указании среднего значения исследователь может использовать разные характеристики – среднее арифметическое, медиана, мода. При этом почти всегда среднее арифметическое несколько больше медианы. Именно поэтому большинство людей, узнающих о средней зарплате в стране, удивляются, так как они столько не зарабатывают. Правильнее ориентироваться на медианную зарплату.
Ну и наконец, нельзя забывать, что любая статистика может показать только корреляцию между двумя величинами, но это не всегда означает причинно-следственную связь. Так, известно, что чем больше в городе продается мороженого, тем больше в это же время людей тонет на пляжах. Означает ли это, что поедание мороженого увеличивает риск во время плавания? Нет. Дело в том, что оба этих показателя, продажи мороженого и количество утонувших, зависят от третьей величины – температуры в городе. Чем жарче на улице, тем большее количество людей ходят на пляж и тем больше мороженого продается в магазинах.
В поисках средних значений: разбираемся со средним арифметическим, медианой и модой

В поисках средних значений: разбираемся со средним арифметическим, медианой и модой

Иногда при работе с данными нужно описать множество значений каким-то одним числом. Например, при исследовании эффективности сотрудников, уровня вовлеченности в аккаунте, KPI или времени ответа на сообщения клиентов. В таких случаях используют меры центральной тенденции. Их можно называть проще — средние значения.
Но в зависимости от вводных данных, находить среднее значение нужно по-разному. Основной набор задач закрывается с использованием среднего арифметического, медианы и моды. Но если выбрать неверный способ — выводы будут необъективны, а результаты исследования нельзя будет признать действительными. Чтобы не допустить ошибку, нужно понимать особенности разных способов нахождения средних значений.

Cтратег, аналитик и контент-продюсер. Работает с агентством «Палиндром».

Как считать среднее арифметическое
Использовать среднее арифметическое стоит тогда, когда множество значений распределяются нормально ― это значит, что значения расположены симметрично относительно центра. Как выглядит нормальное распределение на графике и в таблице, можно посмотреть на примере:
![]()

Если данные распределяются как в примерах — вам повезло. Можно без лишних заморочек считать среднее арифметическое и быть уверенным, что выводы будут объективны. Однако, нормальное распределение на практике встречается крайне редко, поэтому среднее арифметическое в большинстве случаев лучше не использовать.
Как рассчитать
Сумму значений нужно поделить на их количество. Например, вы хотите узнать средний ER за 4 дня при нормальном распределении значений и без аномальных выбросов. Для этого считаем среднее арифметическое: складываем ER всех дней и делим полученное число на количество дней.

Если хотите автоматизировать вычисления и узнать среднее арифметическое для большого числа показателей — используйте Google Таблицы:
- Заполните таблицу данными.
- Щелкните по пустой ячейке, в которую хотите записать среднее арифметическое.
- Введите «=AVERAGE(» и выделите ряд чисел, для которых нужно вычислить среднее арифметическое. Нажмите «Enter» после ввода формулы.

Когда можно не использовать
Если данные распределены ненормально, то наши расчеты не будут отражать реальную картину. На ненормальность распределения указывают:
- Отсутствие симметрии в расположении значений.
- Наличие ярко выраженных выбросов.
Как пример ненормального распределения (с выбросами) можно рассматривать среднее время ответа на комментарии по неделям:

Если посчитать среднее значение для такого набора данных с помощью среднего арифметического, то получится завышенное число. В итоге наши выводы будут более позитивными, чем реальное положение дел. Еще стоит учитывать, что выбросы могут не только завышать среднее значение, но и занижать его. В таком случае вы получите более скромный показатель, который не будет соответствовать реальности.
Например, в группе «Золотое Яблоко» во ВКонтакте иногда публикуют конкурсные посты. Они набирают более высокие показатели вовлеченности чем обычные публикации. Если посчитать средний ER с учетом конкурсов, мы получим 0,37%, а без учета конкурсов — только 0,29%. Аналогичная ситуация с числом комментариев. С конкурсами в среднем получаем 917 комментариев, а без конкурсов — всего лишь 503. Очевидно, что из-за розыгрышей средние показатели вовлеченности завышаются. В этом случае конкурсные посты следует исключить из анализа, чтобы объективно оценить эффективность контента в группе.

Еще часто бывает так, что данных очень много, заметны явные выбросы, но на их обработку и исключение аномальных значений не хватит ни времени, ни терпения. Тем более нет гарантий, что исключив выбросы, вы получите нормальное распределение. В таком случае лучше подсчитать средние значения, используя медиану.
Как найти медиану и когда ее применять
Если вы имеете дело с ненормальным распределением или замечаете значительные выбросы — используйте медиану. Так можно получить более адекватное среднее значение, чем при использовании среднего арифметического. Чтобы понять, как работать с медианой, рассмотрим аналогичный пример с ненормальным распределением времени ответов на комментарии.
Ниже в таблице уже введены данные из графика и рассчитано среднее время ответа с помощью среднего арифметического и медианы. Из расчетов видна наглядная разница между средним арифметическим и медианой ― она составляет 17 минут. Такое различие появляется из-за низкого темпа работы на выходных и в нестандартных ситуациях, когда к ответу на сообщения нужно относиться с особой ответственностью (события конца февраля). Подобные выбросы сильно завышают среднее арифметическое, а вот на медиану они практически не влияют. Поэтому если хотите посчитать среднее значение избегая влияния выбросов, — используйте медиану. Такие данные будут без искажений.

Как рассчитать
Разберем на примере. В аккаунте опубликовали семь постов и они набрали разное количество комментариев: 35, 105, 2, 15, 2, 31, 1. Чтобы вычислить медиану, нужно пройти два этапа:
- Расположите числа в порядке возрастания. Итоговый ряд будет выглядеть так: 1, 2, 2, 15, 31, 35, 105.
- Найдите середину сформированного ряда. В центре стоит число 15 — его и нужно считать медианой.
Немного сложнее найти медиану, если вы работаете с четным количеством чисел. Например, вы собрали количество лайков на последних шести постах: 32, 48, 36, 201, 52, 12. Чтобы найти медиану, выполните три действия:
- Расставьте числа по возрастанию: 12, 32, 36, 48, 52, 201.
- Возьмите два из них, наиболее близких к центру. В нашем случае — это 36 и 48.
- Сложите два этих числа и разделите на два: (36 + 48) / 2 = 42. Результат и есть медиана.
Чтобы вычислять медиану быстрее и обрабатывать большие объемы данных — используйте Google Таблицы:
- Внесите данные в таблицу.
- Щелкните по свободной ячейке, в которую хотите записать медиану.
- Введите формулу «=MEDIAN(» и выделите ряд чисел, для которых нужно рассчитать медиану. Нажмите «Enter», чтобы все посчиталось.

Когда можно не использовать
Если данные распределены нормально и вы не видите заметных выбросов — медиану можно не использовать. В этом случае значение среднего арифметического будет очень близким к медиане. Можете выбрать любой способ нахождения среднего, с которым вам работать проще. Результат от этого сильно не изменится.
Что такое мода и где ее использовать
Мода ― это самое популярное/часто встречающееся значение. Например, стоит задача узнать, сколько комментариев чаще всего набирают посты в аккаунте. В этом случае можно не высчитывать среднее арифметическое или медиану ― лучше и проще использовать моду.
Еще пример. Нужно узнать, в какое время аудитория чаще всего взаимодействует с публикациями. Для этого можно посчитать данные вручную или использовать готовую таблицу из LiveDune (вкладка «Вовлеченность» ― таблица «Лучшее время для поста»). По ее данным ― больше всего реакций пользователи оставляют в среду в 16 часов. Это время и есть мода. Таким образом, если вам нужно найти самое популярное значение, а не классическое среднее — проще использовать моду.

Как рассчитать
Чтобы найти наиболее часто встречающееся значение в наборе данных, нужно посмотреть, какое число встречается в ряду чаще всех. Например, для ряда 5, 4, 2, 4, 7 ― модой будет число 4.
Иногда в ряде значений встречается несколько мод. Например, ряду 7, 7, 21, 2, 5, 5 свойственны две моды — 7 и 5. В этом случае совокупность чисел называется мультимодальной. Также поиск моды можно упростить с помощью Google Таблиц:
- Внесите значения в таблицу.
- Щелкните по ячейке, в которую хотите записать моду.
- Введите формулу «=MODE(» и выделите ряд чисел, для которых нужно вычислить моду. Нажмите «Enter».

Однако важно иметь в виду, что табличная функция выдает только самую меньшую моду. Поэтому будьте внимательны — можно упустить из виду несколько мод.
Когда использовать не стоит
Моду нет смысла использовать, если вас не просят найти самое популярное значение. Там, где надо найти классическое среднее значение, про моду лучше забыть.
Памятка по использованию
Среднее арифметическое
Как находим: сумма чисел / количество чисел.
Используем: если данные распределены нормально и нет ярких выбросов.
Не используем: если видим явные выбросы или ненормальное распределение.
Медиана
Как находим: располагаем числа в порядке возрастания и находим середину сформированного ряда.
Используем: если работаем с ненормальным распределением или видим выбросы.
Не используем: если выбросов нет и распределение нормальное.
Мода
Как находим: определяем значение, которое чаще всего встречается в ряду чисел.
Используем: если нужно найти не среднее, а самое популярное значение.
Не используем: если нужно найти классическое среднее значение.
Только важные новости в ежемесячной рассылке
Нажимая на кнопку, вы даете согласие на обработку персональных данных.

Подписывайся сейчас и получи гайд аудита Instagram аккаунта
Маркетинговые продукты LiveDune — 7 дней бесплатно
Наши продукты помогают оптимизировать работу в соцсетях и улучшать аккаунты с помощью глубокой аналитики
![]()
Анализ своих и чужих аккаунтов по 50+ метрикам в 6 соцсетях.
Оптимизация обработки сообщений: операторы, статистика, теги и др.
Автоматические отчеты по 6 соцсетям. Выгрузка в PDF, Excel, Google Slides.
Контроль за прогрессом выполнения KPI для аккаунтов Инстаграм.
Аудит Инстаграм аккаунтов с понятными выводами и советами.
Поможем отобрать «чистых» блогеров для эффективного сотрудничества.
ОБЩАЯ ТЕОРИЯ СТАТИСТИКИ
Тема
4. СРЕДНИЕ ВЕЛИЧИНЫ
4.1.
Средние показатели
Средняя величина есть обобщающая количественная характеристика
совокупности однотипных явлений по одному варьирующему признаку.
Она отражает определённый уровень достигнутый в процессе развития
явления к определённому периоду или моменту времени.
Средняя величина – абстрактная величина. Поэтому анализ проводимый при
ней всегда дополняется показом индивидуальных величин.
Среднее может быть вычислено только для какой-то однородной
совокупности.
Расчёт средней необходимо сочетать с группировкой.
В статистике рассчитывают индивидуальные и общие средние.
Общее среднее затушёвывает существенные (существующие) отличия между
явлениями таким образом во многих случаях они становятся фиктивными.
Признак по которым находится среднее
называется усредняемое (Х). Величина усредняемого признака у каждой единицы
совокупности называется индивидуальное значение.
Значение признака, которое встречается у
крупных единиц или отдельных единиц и не повторяется называется вариантами
признака (Х1, Х2, …).
Средняя арифметическая.
Средняя
арифметическая простая (рассчитывается по несгруппированным данным):
.  ,
,
где x1 ,x2, …, xn-значение признака (варианты), n– число вариантов.
Средняя арифметическая взвешенная (рассчитывается
по сгруппированным данным):
![]() ,
,
где f1, f2, …, fn – веса
(частоты) значений признака.
f– частота повторения соответствующих вариантов в статистике называется
весом.
Пример: 1) Вычислить средний возраст выпуска, возраст
которого: 24,22,25,24,25,24,22,22,24,26 лет.
Расчёт по средней арифметической простой:
![]()
2)
Расчёт по средней
арифметической взвешенной.
|
Возраст (х) |
Число выпускников (f) |
Сумма возрастов (хf) |
|
22 24 25 26 |
3 4 2 1 |
66 96 50 26 |
|
Сумма |
10 |
238 |
![]() .
.
Свойства средней арифметической:
1)
Сумма отклонений
значений признака от средней арифметической равно 0.
 .
.
2)
Если от каждого
варианта вычесть или к каждому варианту прибавить какое-либо постоянное число,
то среднее увеличится или уменьшится на то же самое число.
3)
Если каждый вариант
умножить или разделить на какое-либо число, то среднее уменьшится или
увеличится во столько же раз.
4)
Если веса или частоты
разделить или умножить на какое-либо число, то величина средней не изменится.
Это свойство даёт возможность частоты заменять их удельными весами
![]() ,
,
где р – удельный вес, выраженный в процентах.
Если удельный вес выражается в доле, то
![]() .
.
Средняя гармоническая.
Рассчитывается, когда 1) среднее арифметическое по
имеющимся данным рассчитать невозможно, 2) расчет средней гармонической более
удобен.
Средняя гармоническая простая:  .
.
Средняя гармоническая взвешенная:  .
.
Пример: требуется вычислить
производительность труда рабочей силы, если первому рабочему требуется для
изготовления единицы продукции 0,25 часа, второму – 1/3 часа, третьему – 1/2
часа.
 .
.
Средняя геометрическая.
Средняя геометрическая простая:
![]() .
.
Средняя геометрическая взвешенная:
![]() .
.
Наиболее широкое применение этот вид средней получил в анализе динамики
для определения среднего темпа роста.
Средняя квадратическая.
Средняя квадратическая простая:
 .
.
Средняя квадратическая взвешенная:
 .
.
Пример: Оценка за ответ на первый вопрос – 2, на
второй вопрос – 5.



4.2.
Структурные средние
Для того чтобы определить среднее в некоторых случаях нет
необходимости, или возможности прибегать к расчёту степенных средних в этих
случаях появляется возможность или необходимость расчёта структурной средней.
Если величина средней (ср. арифметической) зависит от всех значений
признака, встречаемых в данном распределении, то значение структурной средней
определяется структурой распределения, местом распределения. Отсюда их
названия.
Медиана – значение признака, приходящееся на
середину ранжированной (упорядоченной) совокупности. Медиана делит совокупность
на две равные части.
Медиана в интервальном ряду рассчитывается следующим образом:
Для определения медианы прежде всего исчисляют её порядковый номер по
формуле
![]()
или
![]()
(для интервальных
рядов) и строят ряд накопленных частот. Накопленной частоте, которая равна
порядковому номеру медианы или первая его превышает, в дискретном вариационном
ряду соответствует вариант, являющийся медианой, а в интервальном вариационном
ряду – медианный интервал.

где Х0 – нижняя граница медианного
интервала,
d – величина медианного интервала,
fi – частота i-го интервала,
Sме-1
– сумма накопленных весов по интервалу
предшествующему медианному,
fMe
– частота медианного интервала.
Пример: Имеются
данные о з/п рабочих:
|
Месячная з/п (руб) х |
Количество рабочих, fi |
Накопленные частоты, Si |
|
До 800 |
1 |
1 |
|
800- 1000 |
2 |
3 |
|
1000- 1200 |
4 |
7 |
|
1200- 1400 |
1 |
8 |
|
1400 и более |
2 |
10 |
|
Итого |
10 |
![]() ,
,
 .
.
Мода – значение признака, которое чаще других
встречается в данном ряду распределения.
Мода для дискретного ряда определяется как варианта, имеющая
наибольшую частоту.
Для интервального ряда:
![]() ,
,
где Х0 –нижняя граница модального
интервала,
d – величина модального интервала,
fMo-1 – частота (вес) интервала,
предшествующего модальному,
fMo – частота (вес) модального интервала,
fMo+1 – частота (вес) интервала, следующего за модальным.
Пример: (См. предыдущую задачу)
![]() .
.
Квартили – значения признака, делящие
ранжированную совокупность на четыре равновеликие части.
Рассчитывают 1-й и 3-й квартили.
 ,
,
XQ1 – нижняя граница интервала, содержащего
нижний квартиль (интервал определяется по накопленной частоте, первой
превышающей 25%),
d – величина интервала,
fQ1 – частота квартильного интервала,
SQ1-1 – сумма накопленных частот в интервале, предшествующего квартильному.
Q2=Мe.
 ,
,
обозначения
аналогичны 1-му квартилю с изменением на верхний.
Децили – варианты, делящие ранжированный ряд
на десять равных частей.
Вычисляются они по той же схеме, что и медиана, и квартили. Обычно
рассчитывают только первый и девятый децили:
 ,
,
 .
.
Значения признака, делящие ряд на сто частей, называются перцентилями.
Расчёт средних всегда производится одновременно с
количественным анализом, изучаемых совокупностей, средние величины
рассчитываются не всегда, когда на лицо количественная вариация признаков.
Средняя величина должна быть рассчитываема для количественно-однородной
совокупности.
Это требование состоит в том, что среднее нельзя применить к таким
совокупностям, отдельные части которых подчинены различным законам развития
относительных величин признака.
Тема 5. ПОКАЗАТЕЛИ
ВАРИАЦИИ
5.1.
Меры вариации
Колеблемость, многообразие, изменяемость величины признака у единиц
совокупности называются вариацией.
Вариация существует в пространстве и во времени.
Вариация в пространстве – колеблемость значений
признака по отдельным территориям.
Вариация во времени – изменение значений признака в
различные периоды (или моменты) времени.
Для измерения вариации используются такие показатели,
как размах вариации, среднее линейное отклонение, дисперсия, среднее
квадратическое отклонение, коэффициент вариации.
Простейший показатель – размах вариации.
R=Xmax – Xmin.
Из приведённой формы видно, что величина этого показателя целиком
зависит от случайности расположения крайних членов ряда.
Его недостаток в том, что варьирование значения признака из основной
массы членов ряда не находит отражения в этом показателе. В то же время
колеблимость признака складывается из всех его значений.
Среднее линейное отклонение:
![]() – простая,
– простая,
 – взвешенная.
– взвешенная.
Показывает в среднем отклонение вариантов признака от их средней
величины.
Дисперсия:
простая,
![]()
взвешенная.
 –
–
Это средняя величина квадратов отклонений.
Среднее квадратическое отклонение:
 .
.
Это обобщающая характеристика размеров вариации признака в
совокупности. Оно выражается в тех же единицах измерения, что и признак.
Для расчёта дисперсии в дискретном рядах используется следующая
формула.
![]() ,
,
где  ,
,  .
.
Пример: Распределение коров колхозной фермы по
годовому удою молока и расчёт абсолютных показателей вариации.
|
Годовой удой молока от коровы тыс.кг. (Хi) |
Число коров, fi |
Средняя величина признака, сер. интерв. |
Хifi |
Хi–Х |
|Xi–X|fi |
(Xi–X)2 |
(Xi–X)2fi |
|
До-2 |
4 |
1,5 |
6 |
-1,3 |
5,2 |
1,69 |
6,76 |
|
2-3 |
2 |
2,5 |
5 |
-0,3 |
0,6 |
0,09 |
0,18 |
|
3-4 |
2 |
3,5 |
7 |
+0,7 |
1,4 |
0,49 |
0,98 |
|
4-5 |
1 |
4,5 |
4,5 |
+1,7 |
1,7 |
2,89 |
2,89 |
|
5 и более |
1 |
5,5 |
5,6 |
+2,1 |
2,7 |
7,29 |
7,29 |
|
Итого |
10 |
28 |
11,6 |
18,1 |
1) Находим среднюю арифметическую

2) Среднее линейное отклонение:
 тыс.кг.
тыс.кг.
2)
Дисперсия
 тыс.кг.
тыс.кг.
4) Среднее квадратическое отклонение:
![]()
![]() тыс.кг.
тыс.кг.
Дисперсия обладает рядом свойств, некоторые из которых позволяют упростить
её вычисление.
1. Дисперсия постоянной величины равна 0
2. Если все варианты значений признака уменьшить на одно число то
дисперсия не изменится.![]()
3. Если все варианты значений признака уменьшить (увеличить) в одно и тоже
число раз (в К раз), то дисперсия уменьшится (увеличится) в К2
раз.
Дисперсия и среднее квадратическое отклонение – наиболее широко
применяемые показатели вариации, т.к. они входят в большинство теорем теории
вероятности, которая служит фундаментом математической статистики.
Коэффициент вариации.
![]()
Он используется не только для сравнения оценки вариации, но и для
характеристики однородной совокупности.
Совокупность считается однородной если коэффициент вариации <=0,33.
В статистике наряду с показателем вариации количественного признака
определяется показатель вариации качественного или альтернативного
признака.
Альтернативными признаками являются признаки, которым
обладают одни единицы совокупности и не обладают другие.
При статистическом выражении колеблимости признака, наличие изучаемого
признака обозначается «1», а его отсутствие «0».
Доля вариантов обладающих изучаемым признаком обозначается р, а
доля вариантов не обладающих изучаемым признаком обозначается q.
Найдём среднее:
![]() .
.
Дисперсия альтернативного признака:
![]() .
.
Пример: имеется совокупность новорождённых –
205 человек, девочки – 100.
Доля девочек р=100/205=0,488
Доля мальчиков q =105/205=0,512
Дисперсия альт. призн.= 0,488·0,512= 0,2498
p+q не может быть >1
p·q не может быть >0.25
5.2. Виды дисперсий
Общая дисперсия измеряет вариацию признака во всей совокупности под
влиянием всех факторов, обусловивших эту вариацию.

Межгрупповая дисперсия отражает вариацию
изучаемого признака, которая возникает под влиянием признака фактора,
положенного в основу группировки. Она характеризует колеблимость групповых
(частных) средних около общей средней
 ,
,
где ![]() – среднее по определённой группе; ni
– среднее по определённой группе; ni
– численность отдельных групп.
Внутригрупповая дисперсия отражает случайную
вариацию, т.е. часть вариации, происходящую под влиянием неучтенных факторов и
не зависящую от признака-фактора, положенного в основание группировки.
 .
.
Средняя из внутригрупповых дисперсий:
 .
.
Правило сложения дисперсий:
![]() .
.
Можно рассчитать относительные показатели.
1.
Эмпирический коэффициент детерминации
![]()
Он показывает долю (удельный вес) общей вариации изучаемого признака,
обусловленную вариацией группировочного признака.
2. Эмпирическое корреляционное отношение

Оно характеризует влияние признака, положенного в
основание группировки, на вариацию результативного признака. Чем больше это
число, тем больше зависимость результативного признака от факторов положенных
в основу группировки.
Пример:
|
Тип хозяйства |
Посевная площадь тысяч гект. |
Средняя урожайность |
Среднее |
|
1 |
300 |
20 |
2 |
|
2 |
100 |
10 |
2,5 |
![]()
1)
Находим среднюю урожайности по двум типах хозяйств
![]()
2)
Средняя из групп дисперсий
(22ּ300+2,52ּ100)/400=4,5625
3)
Определяем межгрупповую дисперсию
![]()
4)
Определяем общую дисперсию
![]()
5)
![]()
Эти данные свидетельствуют о том, что фактор положенный в основу
группировки оказывает существенное влияние на среднюю урожайность.
Выбор знака: если вариация факторного и результативного признака идёт в
одном направлении, то берётся знак «+», а если нет, то «–», сам по себе знак не
характеризует тесноту связи. Помимо расчета общей дисперсии и её составных
частей по абсолютным данным можно производить расчёт дисперсии доли.
5.3.
Теоретическое распределение в анализе вариационных рядов
При анализе изучаемых явлений в совокупности с другими, аналогичными по
своей сущности, часто удается обнаружить закономерность, связанную с их
возникновением. Наиболее часто закономерности описывают с помощью нормального
распределения:
 .
.
Чем больше случайных величин действует вместе, тем точнее подчиненность
закону нормального распределения.
Примеры нормального распределения: 1) распределение отклонений в
производственном процессе при нормальном уровне организации и технологии, 2)
распределение населения определенного возраста по размеру обуви и т.д.
Соответствие эмпирического распределения нормальному можно оценивать с
помощью особых статистических показателей – критериев согласия.
Критерий согласия Пирсона (хи-квадрат)
 ,
,
где fэ и fт – эмпирические и теоретические частоты
соответственно.
Затем с помощью «хи-квадрат» и числа степеней свободы (n-1) находят по специальным таблицам вероятность ![]() .
.
При Р>0,5 считается, что эмпирическое и теоретическое распределения
близки, при 0,2<P<0,5 – удовлетворительное, в
остальных случаях – недостаточное.
Критерий Романовского (С)
 ,
,
где γ – число степеней свободы (число групп минус три).
При С<3 различие несущественно, эмпирическое распределение близкое к
нормальному.
Критерий Колмогорова (λ)
 ,
,
где D – максимальное значение разности между
накопленными эмпирическими и теоретическими частотами,
fi – эмпирические частоты.
Далее по таблицам вероятностей определяем ![]() . Чем
. Чем
ближе к 1, тем лучше.
Тема 6. ИЗУЧЕНИЕ ДИНАМИКИ СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ
ЯВЛЕНИЙ
6.1. Понятие рядов динамики
Изучение изменения различных явлений во времени – одна из важнейших
задач статистики. Решается эта задача путем составления и анализа так
называемых рядов динамики (иногда их также называют временными или
хронологическими рядами).
Динамика – процесс развития, движения
социально-экономических явлений во времени.
Ряды динамики – ряды изменяющихся во времени
значений статистического показателя, расположенных в хронологическом порядке.
Составными элементами ряда динамики являются показатели уровней ряда и
периоды времени (годы, кварталы, месяцы, сутки) или моменты (даты) времени.
Обозначения:
y – уровни ряда,
t – моменты или периоды времени, к которым относятся уровни.
Ряды динамики, как правило, представляют в виде таблицы или графически.
При графическом изображении ряда динамики на оси абсцисс строится шкала времени
t, а на оси ординат – шкала уровней ряда у (арифметическая или иногда
логарифмическая).
Одна из первых задач изучения рядов динамики – выявить основную
тенденцию (закономерность) в изменении уровней ряда, именуемую трендом.
Закономерность в изменении уровней ряда в одних случаях проявляется довольно
наглядно, в других – может затушевываться колебаниями, вызванными случайными и
неслучайными причинами.
Виды рядов динамики.
В одних рядах уровни могут быть выражены абсолютными показателями, в
других – средними или относительными. В зависимости от вида показателей уровней
ряда ряды динамики также подразделяют на ряды абсолютных, относительных и
средних величин (показателей).
На основе рядов абсолютных величин образуются ряды динамики
относительных и средних величин, поэтому ряды абсолютных величин рассматривают
как исходные, а ряды относительных и средних величин — как производные.
Ряды относительных величин могут характеризовать: темпы роста (или
снижения) определенного показателя; изменение удельного веса того или иного
показателя в совокупности (например, удельного веса (доли) городского населения
или доли приватизированных предприятий в той или иной отрасли); изменение показателей
интенсивности отдельных явлений (например, производство продукции на душу
населения, уровень рождаемости и смертности на 1000 человек населения) и др.
Примерами рядов динамики средних величин служат данные о среднегодовой
численности занятых в экономике (или безработных), о средней заработной плате в
отдельных отраслях, о среднем размере пенсий, о средней урожайности отдельных
сельскохозяйственных культур и др.
Кроме того, уровни рядов динамики могут относиться к определенным
моментам времени (датам) или же периодам (интервалам). В соответствии с этим в
статистике различают моментные и интервальные ряды динамики
Моментным называется ряд, уровни которого характеризуют
значение показателя (явления) по состоянию на определенные моменты времени
(дату).
Интервальным называется ряд, уровни которого
характеризуют значение показателя, достигнутое за определенный период (интервал).
Отметим отличительную особенность интервальных рядов абсолютных
величин: их уровни можно дробить и складывать (суммировать). Так, зная добычу
угля по годам, можно разделить каждый уровень на 12 и получить новые данные – о
среднемесячной добыче угля за указанный период. Или же, суммируя данные о
численности родившихся по месяцам, можно получить численность родившихся за
год. Подобные действия с уровнями моментного ряда лишены смысла.
Суммируя уровни интервальных рядов абсолютных величин, можно строить
ряды с нарастающим итогом.
6.2.
Показатели изменения уровней ряда динамики
Анализ рядов динамики начинается с определения того, как именно
изменяются уровни ряда (увеличиваются, уменьшаются или остаются неизменными) в
абсолютном и относительном выражении.
Анализ скорости и интенсивности развития явления во времени
осуществляется с помощью статистических показателей, которые получаются в
результате сравнения уровней между собой. При этом сравниваемый уровень
называют отчетным, а уровень, с которым производят сравнение, – базисным.
Чтобы проследить за направлением и размером изменений уровней во
времени, для рядов динамики рассчитывают такие показатели, как:
–
абсолютные приросты (изменения) уровней;
–
темпы роста;
–
темпы прироста (снижения) уровней.
Абсолютный прирост (Δy) характеризует размер изменения
уровня ряда за определенный промежуток времени. Он рассчитывается как разность
между двумя уровнями ряда. Абсолютный прирост показывает, на сколько (в
единицах измерения показателей ряда) уровень одного периода больше или меньше
уровня какого-либо предшествующего периода, и, следовательно, может иметь знак
«+» (при увеличении уровней) или «–» (при уменьшении уровней).
Δyi=yi – yi-1, i=1..n.
В зависимости от базы сравнения абсолютные приросты могут
рассчитываться как цепные и как базисные.
Вычитая из каждого уровня предыдущий
Δу
= yi – yi-1,
получаем
абсолютные изменения уровней ряда за отдельные периоды как цепные.
Вычитая
из каждого уровня начальный
Δу
= yi – y0,
получаем
накопленные итоги прироста (изменения) показателя с начала изучаемого периода,
т.е. абсолютные изменения рассчитываются как базисные.
Если значения цепных абсолютных изменений постоянны, то уровни ряда
изменяются равномерно. Если же абсолютные приросты от периода к периоду
возрастают (или убывают), то уровни изменяются ускоренно (или замедленно). В
этом случае рассчитывается показатель ускорения как разность между двумя
смежными цепными абсолютными приростами.
Абсолютное ускорение (Δ′) – показывает,
насколько данная скорость больше (меньше) предыдущей.
Δ′=Δyi–Δyi-1
Наряду с абсолютными изменениями уровней ряда важно измерить также их
относительное изменение.
Темп роста (Тр) – показатель интенсивности
изменения уровня ряда, относительный показатель, рассчитываемый как отношение
двух уровней ряда.
В зависимости от базы сравнения темпы роста могут рассчитываться как
цепные, когда каждый уровень сопоставляется с уровнем предыдущего периода, и
как базисные, когда все уровни сопоставляются с уровнем одного какого-то
периода, принятого за базу сравнения (часто это начальный уровень ряда). Соответственно,
цепные темпы роста характеризуют интенсивность изменения в каждом отдельном
периоде, а базисные – за отрезок времени, отделяющий данный уровень от
базисного.
Базисный темп роста:
![]() .
.
Цепной темп роста:
![]()
Темпы роста как относительные величины могут выражаться в виде
коэффициентов, т.е. простого кратного отношения (если база сравнения
принимается за единицу), и в процентах (если база сравнения принимается за 100
единиц). Говоря о темпах, чаще всего имеют в виду отношение уровней в
процентах.
Выраженные в коэффициентах темпы роста показывают, во сколько раз
уровень данного периода больше уровня базы сравнения или какую часть его
составляет. При процентном выражении темп роста показывает, сколько процентов
составляет уровень данного периода по сравнению с уровнем базы сравнения.
Между цепными и базисными коэффициентами роста существует связь,
позволяющая при необходимости переходить от цепных к базисным и наоборот.
В частности:
–
произведение цепных коэффициентов роста равно
базисному;
–
результат деления двух базисных коэффициентов равен
цепному
Темп прироста (Тпр) характеризует
относительную скорость изменения уровня ряда в единицу времени, это относительный
показатель, показывающий, на сколько процентов данный уровень больше (или
меньше) другого, принимаемого за базу сравнения. Показатель Тпр
можно рассчитать двояко:
–
путем вычитания 100% из темпа роста (снижения),
–
как процентное отношение абсолютного прироста к
тому уровню, по сравнению с которым рассчитан абсолютный прирост.
![]()
Абсолютное значение одного процента прироста
Абсолютное значение 1% прироста равно одной сотой предыдущего уровня
![]()
Для базисных абсолютных приростов и темпов прироста расчет не имеет
смысла, так как при сравнении всех накопленных приростов с одним и тем же
первоначальным уровнем для всех периодов будет получаться одно и то же значение
1% прироста.
Каждый ряд динамики можно рассматривать как некую совокупность изменяющихся
во времени показателей, которые можно обобщать в виде средних величин. Такие
обобщенные (средние) показатели особенно необходимы при сравнении изменений
того или иного показателя в разные периоды, в разных странах и т. д.
Средний уровень
ряда динамики. Для разных видов
рядов динамики средний уровень рассчитывается различным образом.
Для моментного равноотстоящего ряда динамики по средней хронологической:
 .
.
Для моментного ряда динамики с неравноотстоящими уровнями:
 ,
,
где ti – длительность интервала времени
между уровнями.
Для интервального ряда с равноотстоящими уровнями:
![]()
Для интервального ряда с неравноотстоящими уровнями:

Средний абсолютный прирост

Средний темп роста

Средний темп прироста
![]()
При анализе динамики социально-экономических явлений необходимо
параллельно использовать показатели скорости и интенсивности изменения уровней.
6.3. Анализ основной тенденции в рядах динамики
Описание тенденции в ряду динамики производится с
помощью методов сглаживания. Методы сглаживания разделяются на две основные
группы:
1)
сглаживание или
механическое выравнивание отдельных членов ряда динамики с использованием
фактических значений соседних уровней;
2)
выравнивание с применением
кривой, проведенной между конкретными уровнями таким образом, чтобы она
отображала тенденцию, присущую ряду, и освободила его от незначительных
колебаний.
Метод усреднения по левой и правой половине. Ряд динамики разделяют на две части, находят
для каждой из них среднее арифметическое значение и проводят через полученные
точки линию тренда на графике.
Метод укрупнения интервалов. Производится укрупнение периодов времени, к которым
относятся уровни ряда. Например, ряд ежесуточного выпуска продукции заменяется
рядом месячного выпуска продукции.
Метод скользящей средней. Вычисляется средний уровень из определенного числа
первых по порядку уровней ряда, затем – начиная со второго, далее – с третьего
и т.д.
Алгоритм расчета скользящей средней:
1.
Определяем интервал
сглаживания, т.е. число входящих в него уровней m (m<n).
2.
Вычислить среднее значение
уровней, образующих интервал сглаживания, по формуле
 ,
,
где m – число уровней, входящих в интервал сглаживания,
i – порядковый номер уровня в интервале сглаживания,
p – при нечетном m равно: p=(m-1)/2.
При четном m проводят центрирование:
находят среднюю из двух смежных скользящих средних для отнесения полученного
уровня к определенной дате.
3. Сдвинуть интервал сглаживания на одну точку вправо, затем вычислить все
последующие сглаженные значения, производя одновременно сдвиги.
Пример:
|
Год |
Центнеров с 1 га |
Скользящие трехлетние суммы |
Трехлетние скользящие средние |
|
1982 1983 1984 1985 1986 1987 1988 1989 |
9,5 13,7 12,1 14,0 13,2 15,6 15,4 14,0 |
– – 35,3 39,8 39,3 42,8 44,2 45 |
– 11,77 13,27 13,1 14,27 14,73 15 – |
Тема
7. ИНДЕКСНЫЕ МЕТОДЫ
7.1. Понятие индексов
В статистике под индексами понимаются относительные
величины, выражающие изменение сложных экономических явлений во времени,
пространстве и по сравнению с планом. В связи с этим различают динамические
индексы, характеризующие изменения явлений во времени; индексы выполнения
плана и территориальные индексы.
Индексы относятся либо к элементам сложного экономического явления,
либо ко всему явлению в целом. Показатели характеризующие изменение более или
менее однородных объектов входящих в состав сложных явлений называются
индивидуальные индексы
Принятые обозначения:
Q, q – физический объём;
p – цена единицы товара;
z – себестоимость единицы продукции;
pq – стоимость продукции или товарооборот;
zq – издержки производства.
7.2. Индивидуальные и общие индексы
Индивидуальные индексы (i) – это обычные относительные величины.
Индивидуальный индекс объёма:
![]() =
=![]() ,
,
q0 – базисный период (пояснить);
q1 – текущий период (пояснить).
Индивидуальный индекс цены:
![]() .
.
Индивидуальный индекс товарооборота:
![]()
Индекс как индивидуальный так и общий получает название по названию
индексированной величины. Индексы как индивидуальные так и общие обозначаются
либо в виде коэффициента, либо в виде процентов.
Явления общественные и социальные, изучаемые в экономике состоят из
несопоставимых элементов. Таким образом, основным вопросом построения индексов,
общих и сводных состоит в том, чтобы обеспечить эту сопоставимость
Самый лёгкий способ сопоставления – сложные явления разбиваются на
простые элементы которые в известной мере являются однородными.
Общий индекс обозначается – I. Различают агрегатные и средневзвешенные индексы.
Основной формой сводного индекса является агрегатный индекс. Для
того, чтобы его построить необходимо свести различные элементы сложного явления
к такому виду, который делает их соизмеримыми.
 – агрегатный индекс физического объёма
– агрегатный индекс физического объёма
продукции(Ласпейреса).
 – агрегатный индекс физического объёма
– агрегатный индекс физического объёма
продукции(Пааше).
 – агрегатный индекс цены (Ласпейреса).
– агрегатный индекс цены (Ласпейреса).
 – агрегатный индекс цены (Пааше).
– агрегатный индекс цены (Пааше).
 – агрегатный индекс товарооборота.
– агрегатный индекс товарооборота.
 – индекс издержек
– индекс издержек
производства.
Та часть индекса, которая не изменяется, называется весом.
Веса свободного индекса в агрегатной форме выбираются исходя из
следующих данных:
Если индексируемая величина – суть количественный
показатель, то вес выбирается на уровне базисного периода.
В том случае если индексируется величина – качественный признак вес
принимается на уровне текущего периода. Такой подход к выбору весов даёт нам
возможность записать следующее равенство индексов
![]()
Итак, в целом по совокупности, состоящей из элементов, непосредственно
несоизмеримых (различные виды продукции, товарные группы и т.д.), изменение
физического объема реализации и цен характеризуется с помощью агрегатных
индексов, формулы построения которых сведены в табл. 1.
Таблица 1
Агрегатные индексы
|
Формулы индексов |
Название индексов |
|
|
Индекс физического объема и других первичных |
Индекс цен и других вторичных признаков |
|
|
По формуле Ласпейреса (по базисным весам) |
|
|
|
По формуле Пааше (по отчетным весам) |
|
|
|
Индекс Фишера |
|
|
Пример:
|
Товары |
Ед. измер |
Базисный период |
Текущий период |
Индивидуаль-ный индекс |
|||
|
P0 , (руб) |
Q0 (ед.) |
P1 |
Q1 |
|
|
||
|
Капуста |
Кг. |
17 |
350000 |
15 |
420000 |
0,882 |
1,2 |
|
Молоко |
Литры |
28 |
25400 |
35 |
23600 |
1,25 |
0,929 |
|
Яйца |
Десятки |
120 |
125 |
120 |
140 |
1 |
1,29 |
Индекс товарооборота:
Это значит товарооборот текущего периода по отношению к базисному вырос
на 7% этот показатель отражает изменение товарооборота под влиянием р и q.
Индекс физического объёма продукции (Ласпейраса):
Это значит товарооборот в текущем периоде возрос на 17% в связи с
изменением объёма реализации.
Индекс цены (Пааше):
Индекс цены показал нам, что стоимость продукции в текущем периоде по
сравнению с базисным сократился на 9% под влиянием изменения цен.
7.3.
Средние индексы
Агрегатная форма индекса – его основная форма, но не единственная в
ряде случаев для удобства расчётов в том случае если мы располагаем значениями
индивидуальных индексов на практике удобно использовать средние индексы.
Средний индекс – индекс, вычисленный как
средняя величина из индивидуальных индексов.
Средний гармонический индекс цены:

Средний арифметический индекс физического объема:

Цепные индексы – ряд индексов одного и того же
явления, вычисленных с меняющейся от индекса к индексу базой сравнения.
![]() ,
,
![]() .
.
7.4. Индексы структурных сдвигов
При изучении динамики показателей приходится
определять изменение средней величины индексируемого показателя, которое
обусловлено взаимодействием двух факторов – изменением значения индексируемого
показателя у отдельных групп единиц и изменением структуры явления, т.е.
изменением доли отдельных групп единиц совокупности в общей их численности. Для
этого вычисляются три индекса: переменного состава, постоянного состава и
структурных сдвигов.
Индекс переменного состава – индекс,
выражающий соотношение средних уровней изучаемого явления, относящихся к разным
периодам времени. Он отражает изменение не только индексируемой величины, но и
структуры совокупности (весов).
 – индекс п.с. себестоимости продукции.
– индекс п.с. себестоимости продукции.
Индекс постоянного (фиксированного) состава –
индекс, исчисленный с весами, зафиксированными на уровне одного какого-либо
периода, и показывающий изменение только индексируемой величины. Это агрегатный
индекс.
 – индекс ф.с. себестоимости продукции.
– индекс ф.с. себестоимости продукции.
Индекс структурных сдвигов – индекс,
характеризующий влияние изменения структуры изучаемого явления на динамику
среднего уровня этого явления.
 – индекс с.с. себестоимости продукции.
– индекс с.с. себестоимости продукции.
Существует взаимосвязь между этими индексами: ![]() .
.
Пример: по имеющимся данным о себестоимости
единицы продукции на трех предприятиях в текущем и базисном периодах получили
следующие индексы структурных сдвигов
![]() средняя себестоимость по трем
средняя себестоимость по трем
предприятиям снизилась в текущем периоде по сравнению с базисным на 3,25%.
![]() себестоимость в текущем периоде по
себестоимость в текущем периоде по
сравнению с базисным возросла в среднем на 2,1%.
![]() изменение доли предприятий в общем объеме
изменение доли предприятий в общем объеме
произведенной продукции привело к снижению себестоимости на 5,24%.
Рекомендуемая литература
1.
Елисеева И.И., Юзбашев М.М. Общая теория
статистики: Учебник. – М.: ИНФРА-М, 1998.
2.
Ефимова М.Р., Петрова Е.В., Румянцев В.Н. Общая
теория статистики: Учебник. Изд. 2-е, испр. и доп. – М.: ИНФРА-М, 2001. – 416
с. – (Серия «Высшее образование»).
3.
Практикум по теории статистики: Учеб. Пособие / Под
ред. проф. Р.А. Шмойловой. – М.: Финансы и статистика, 2001.- 416 с.: ил.
4.
Теория статистики: Учебник / Под ред. проф. Р.А.
Шмойловой. – 3-е изд., перераб. – М.: Финансы и статистика, 2001.- 506 с.: ил.
5.
Теория статистики: Учебно-практическое пособие для
системы дистанционного образования /Под ред. В.Г. Минашкина. – М.: МЭСИ, 1998.
Виктория
Николаевна Шайкина
общая теория статистики
Учебное
пособие
Под ред.
В.В. Лихолетова
Технический
редактор А.В. Миних
Издательство Южно-Уральского государственного университета
Подписано
в печать
Формат
60х84 1/16. Печать офсетная. Усл. печ. л. Уч.-изд. л.
Тираж 100 экз. Заказ . Цена р.
Отпечатано
в типографии Издательства ЮУрГУ. 454080,
г. Челябинск,
пр. им. В.И.Ленина, 76
.
