3.1. Показатели центральной тенденции
Простейший пример такого показателя нам уже встречался – это среднее арифметическое значение. Но средней
дело не ограничивается, впрочем, обо всём по порядку:
3.1.1. Генеральная и выборочная средняя
Пусть исследуется некоторая генеральная совокупность объёма ![]() , а именно её числовая характеристика
, а именно её числовая характеристика ![]() , не важно, дискретная или непрерывная.
, не важно, дискретная или непрерывная.
Генеральной средней называют среднее арифметическое всех значений этой совокупности:
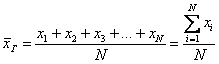
Если среди чисел ![]() есть одинаковые (что
есть одинаковые (что
характерно для дискретного ряда), то формулу можно записать в более компактном
виде:
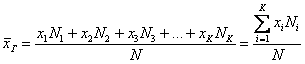 , где:
, где:
варианта ![]() повторяется
повторяется ![]() раз;
раз;
варианта ![]() –
– ![]() раз;
раз;
варианта ![]() –
– ![]() раз;
раз;
…
варианта ![]() –
– ![]() раз.
раз.
Живой пример вычисления генеральной средней встретился в Примере 2, но чтобы не занудничать, я даже не буду
напоминать его содержание. Далее.
Как мы помним, обработка всей генеральной совокупности часто затруднена либо невозможна, и поэтому из неё организуют представительную выборку объема ![]() , и на основании исследования этой выборки делают вывод обо всей совокупности.
, и на основании исследования этой выборки делают вывод обо всей совокупности.
Выборочной средней называется среднее арифметическое всех значений выборки:
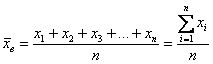
и при наличии одинаковых вариант формула запишется компактнее:
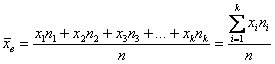 – как сумма произведений вариант
– как сумма произведений вариант ![]() на соответствующие частоты
на соответствующие частоты ![]() , делённая на объём совокупности
, делённая на объём совокупности ![]() .
.
Выборочная средняя ![]() позволяет достаточно
позволяет достаточно
точно оценить истинное значение ![]() , при этом, чем
, при этом, чем
больше выборка, тем точнее будет эта оценка.
Практику начнём с дискретного вариационного ряда и знакомого условия:
Пример 8
По результатам выборочного исследования ![]() рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4,
рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4,
4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3.
Это числа из Примера 4, но теперь нам требуется: вычислить выборочную среднюю, и, не отходя от станка, найти моду
и медиану.
Как решать задачу? Если нам даны первичные данные (конкретные варианты ![]() ), то их можно тупо просуммировать и разделить результат на объём
), то их можно тупо просуммировать и разделить результат на объём
выборки:
![]() – средний квалификационный разряд рабочих
– средний квалификационный разряд рабочих
цеха.
Но здесь удобнее составить вариационный ряд:
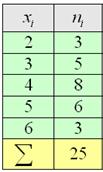
и использовать «цивилизованную» формулу:
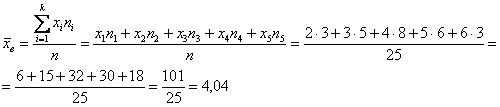
 3.1.2. Мода
3.1.2. Мода
 3. Основные показатели статистической совокупности
3. Основные показатели статистической совокупности
| Оглавление |
Сегодня на уроке мы вспомним, что является модой, медианой и
средним арифметическим выборки. Узнаем, что называется размахом выборки.
Выясним, что называют отклонением от среднего. Познакомимся с величиной,
которую называют дисперсией. Узнаем, что называют средним квадратичным
отклонением.
Прежде, чем приступить к рассмотрению новой темы, давайте
вспомним, что совокупность данных иногда бывает полезно оценить одним числом – мерой
центральной тенденции числовых значений её элементов. К таким характеристикам
относятся мода, медиана и среднее.
Итак, мода – это значение случайной величины, имеющее
наибольшую частоту в рассматриваемой выборке.
Медиана – это число (значение
случайной величины), разделяющее упорядоченную выборку на две равные по
количеству данных части.
При этом если в упорядоченной выборке нечётное количество
данных, то медиана равна серединному из них. Если в упорядоченной выборке чётное
количество данных, то медиана равна среднему арифметическому двух
серединных чисел.
Среднее (или среднее
арифметическое) выборки – это число, равное отношению суммы всех чисел
выборки к их количеству. Если рассматривается совокупность значений случайной
величины , то её
среднее обозначают .
Отметим, что не каждую выборку имеет смысл оценивать с помощью
центральных тенденций.
Так, например, посмотрите на следующую выборку ,
,
,
Это выборка выигрышей (в рублях) четырёх человек. Здесь мода равна
. Медиана
также равна . Среднее
равно .
Очевидно, что ни мода, ни медиана, ни среднее не могут выступать в
роли единой объективной характеристики данной выборки. Это объясняется тем, что
наименьшие значения этой выборки существенно отличаются от наибольшего. А вот
разность наибольшего и наименьшего значений соизмерима с наибольшим значением ().
Сформулируем определение. Разность наибольшего и наименьшего
значений случайной величины выборки называется её размахом и
обозначается буквой R.
Для рассматриваемой выборки размах равен разности и
, то есть
равен .
Размах показывает, насколько велик разброс значений случайной
величины в выборке. Однако, зная размах выборки, невозможно охарактеризовать
отличие её элементов друг от друга, отличие каждого элемента от среднего
значения.
А как сравнить две выборки, которые имеют одинаковые размахи и
одинаковые средние значения?
Давайте рассмотрим пример. На место столяра претендуют двое
рабочих. Для каждого из них установили испытательный срок, в течение которого
они должны изготавливать одинаковые стулья из дерева. В следующей таблице приведены
результаты претендентов.
Каждый из рабочих за пять дней изготовил деталей. Следовательно, средняя производительность труда за день у
обоих рабочих одинаковая и равна стульев в
день.
Моды у предложенных совокупностей отсутствуют. Чтобы найти
медианы, расположим значения в порядке возрастания.
,
,
,
,
;
,
,
,
,
.
Количество данных в обоих случаях нечётно. Слева и справа от числа
находятся по
два элемента. Получается, что медианы одинаковые ( и
).
В качестве критерия сравнения совокупностей в данном случае может
выступать стабильность производительности труда. Её можно оценить с
помощью отклонений от среднего значения элементов совокупности.
Давайте сформулируем определение. Отклонением от среднего
называют разность между рассматриваемым значением случайной величины и средним
значением выборки.
Например, если значение , а значение
, то
отклонение от среднего
равно .
Отклонение от среднего может быть как положительным, так и
отрицательным.
Найдём отклонение от среднего и внесём найденные значения в
таблицу.
Покажем на нашем примере, что сумма отклонений всех значений
выборки от среднего значения равна .
,
.
Поэтому характеристикой стабильности элементов совокупности может
служить сумма квадратов отклонений от среднего.
Давайте найдём квадраты отклонений от среднего и суммы квадратов
отклонений.
Видим, что у второго рабочего сумма квадратов отклонений от
среднего больше, чем у первого, то есть можно записать неравенство .
На практике это означает, что второй рабочий имеет нестабильную
производительность труда: в какие-то дни он работает не в полную силу, а
какие-то навёрстывает упущенное, а это всегда сказывается на качестве
продукции.
Получается, что работодатель захочет взять на место столяра
первого рабочего, ведь у первого рабочего сумма квадратов отклонений от средней
производительности меньше.
В рассмотренном примере рабочие работали одинаковое количество
дней. Если бы рабочие работали разное количество дней и производили в среднем
за день одинаковое число деталей, то стабильность работы каждого из них можно
было бы оценить по величине среднего арифметического квадратов отклонений.
Такая величина называется дисперсией, что в переводе с латинского
означает «рассеяние», и обозначается буквой .
Для случайной величины , принимающей
различных
значений и имеющей среднее значение , дисперсия
находится по формуле
Давайте решим задачу. Два столяра изготавливали одинаковые
стулья из дерева. При этом первый столяр трудился полную рабочую неделю, а
второй – дня.
Сведения об их дневной выработке представлены в таблице. Сравните стабильность
работы столяров.
Итак, найдём средние значения выборок данных величин X и Y.
,
.
Таким образом, мы получили, что найденные значения равны.
Далее найдём отклонения от среднего для всех значений величин X и Y.
Затем найдём квадраты отклонений от среднего. Найдём сумму
квадратов отклонений от среднего всех значений величин X и Y.
Теперь найдём дисперсию совокупности значений случайной величины X, то есть среднее
арифметическое квадратов отклонений.
Найдём дисперсию совокупности значений случайной величины Y.
Таким образом мы получили, что .
Следовательно, второй столяр работает стабильнее первого.
Отметим, что если значения ,
, …,
случайной
величины повторяются
с частотами ,
, …,
соответственно,
то дисперсию величины можно
вычислить по формуле
,
где .
Используя знак суммы Ʃ, данную формулу можно записать более
компактно.
, где
.
Пусть величина имеет
некоторую размерность (например, миллиметры). Тогда её среднее значение и отклонение
от среднего имеют ту же
размерность, что и сама величина (в миллиметрах). А вот квадрат отклонения и дисперсия
имеют
размерности квадрата этой величины (в квадратных миллиметрах).
Для оценки степени отклонения от среднего значения удобно иметь
дело с величиной той же размерности, что и сама величина . С этой
целью используются значения .
Сформулируем определение. Корень квадратный из дисперсии называют средним
квадратичным отклонением и обозначают , то есть
.
Давайте найдём среднее квадратичное отклонение от среднего
значения выборки:
см,
см,
см,
см,
см.
Вообще, дисперсию и среднее квадратичное отклонение в статистике
называют также мерами рассеивания значений случайной величины около
среднего значения.
Продолжаем изучать элементарные задачи по математике. Сегодня мы поговорим о статистике.
Статистика — это раздел математики в котором изучаются вопросы сбора, измерения и анализа информации, представленной в числовой форме. Происходит слово статистика от латинского слова status (состояние или положение дел).
Так, с помощью статистики мы можем узнать свое положение дел, касающихся финансов. С начала месяца можно вести дневник расходов и по окончании месяца, воспользовавшись статистикой, узнать сколько денег в среднем мы тратили каждый день или какая потраченная сумма была наибольшей в этом месяце либо узнать какую сумму мы тратили наиболее часто.
На основе этой информации можно провести анализ и сделать определенные выводы: следует ли в следующем месяце немного сбавить аппетит, чтобы тратить меньше денег, либо наоборот позволить себе не только хлеб с водой, но и колбасу.
Выборка. Объем. Размах
Что такое выборка? Если говорить простым языком, то это отобранная нами информация для исследования. Например, мы можем сформировать следующую выборку — суммы денег, потраченных в каждый из шести дней. Давайте нарисуем таблицу в которую занесем расходы за шесть дней

Выборка состоит из n-элементов. Вместо переменной n может стоять любое число. У нас имеется шесть элементов, поэтому переменная n равна 6
n = 6
Элементы выборки обозначаются с помощью переменных с индексами ![]() . Последний
. Последний ![]() элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.
элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.

Обозначим элементы нашей выборки через переменные ![]()
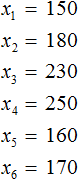
Количество элементов выборки называют объемом выборки. В нашем случае объем равен шести.
Размахом выборки называют разницу между самым большим и маленьким элементом выборки.
В нашем случае, самым большим элементом выборки является элемент 250, а самым маленьким — элемент 150. Разница между ними равна 100
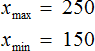
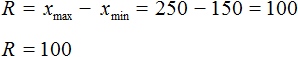
Среднее арифметическое
Понятие среднего значения часто используется в повседневной жизни.
Примеры:
- средняя зарплата жителей страны;
- средний балл учащихся;
- средняя скорость движения;
- средняя производительность труда.
Речь идет о среднем арифметическом — результате деления суммы элементов выборки на их количество.
Среднее арифметическое — это результат деления суммы элементов выборки на их количество.
![]()
Вернемся к нашему примеру
Узнаем сколько в среднем мы тратили в каждом из шести дней:
![]()
Средняя скорость движения
При изучении задач на движение мы определяли скорость движения следующим образом: делили пройденное расстояние на время. Но тогда подразумевалось, что тело движется с постоянной скоростью, которая не менялась на протяжении всего пути.
В реальности, это происходит довольно редко или не происходит совсем. Тело, как правило, движется с различной скоростью.
Когда мы ездим на автомобиле или велосипеде, наша скорость часто меняется. Когда впереди нас помехи, нам приходиться сбавлять скорость. Когда же трасса свободна, мы ускоряемся. При этом за время нашего ускорения скорость изменяется несколько раз.
Речь идет о средней скорости движения. Чтобы её определить нужно сложить скорости движения, которые были в каждом часе/минуте/секунде и результат разделить на время движения.
Задача 1. Автомобиль первые 3 часа двигался со скоростью 66,2 км/ч, а следующие 2 часа — со скоростью 78,4 км/ч. С какой средней скоростью он ехал?

Сложим скорости, которые были у автомобиля в каждом часе и разделим на время движения (5ч)
![]()
Значит автомобиль ехал со средней скоростью 71,08 км/ч.
Определять среднюю скорость можно и по другому — сначала найти расстояния, пройденные с одной скоростью, затем сложить эти расстояния и результат разделить на время. На рисунке видно, что первые три часа скорость у автомобиля не менялась. Тогда можно найти расстояние, пройденное за три часа:
66,2 × 3 = 198,6 км.
Аналогично можно определить расстояние, которое было пройдено со скоростью 78,4 км/ч. В задаче сказано, что с такой скоростью автомобиль двигался 2 часа:
78,4 × 2 = 156,8 км.
Сложим эти расстояния и результат разделим на 5
![]()
Задача 2. Велосипедист за первый час проехал 12,6 км, а в следующие 2 часа он ехал со скоростью 13,5 км/ч. Определить среднюю скорость велосипедиста.

Скорость велосипедиста в первый час составляла 12,6 км/ч. Во второй и третий час он ехал со скоростью 13,5. Определим среднюю скорость движения велосипедиста:
![]()
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
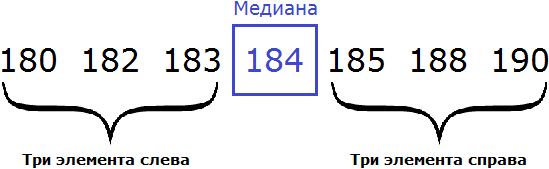
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
![]()
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
![]()
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
![]()
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Частота
Частота это число, которое показывает сколько раз в выборке встречается тот или иной элемент.
Предположим, что в школе проходят соревнования по подтягиваниям. В соревнованиях участвует 36 школьников. Составим таблицу в которую будем заносить число подтягиваний, а также число участников, которые выполнили столько подтягиваний.
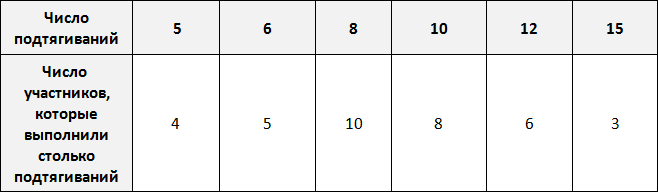
По таблице можно узнать сколько человек выполнило 5, 10 или 15 подтягиваний. Так, 5 подтягиваний выполнили четыре человека, 10 подтягиваний выполнили восемь человек, 15 подтягиваний выполнили три человека.
Количество человек, повторяющих одно и то же число подтягиваний в данном случае являются частотой. Поэтому вторую строку таблицы переименуем в название «частота»:

Такие таблицы называют таблицами частот.
Частота обладает следующим свойством: сумма частот равна общему числу данных в выборке.
Это означает, что сумма частот равна общему числу школьников, участвующих в соревнованиях, то есть тридцати шести. Проверим так ли это. Сложим частоты, приведенные в таблице:
4 + 5 + 10 + 8 + 6 + 3 = 36
Относительная частота
Относительная частота это в принципе та же самая частота, которая была рассмотрена ранее, но только выраженная в процентах.
Относительная частота равна отношению частоты на общее число элементов выборки.
Вернемся к нашей таблице:
Пять подтягиваний выполнили 4 человека из 36. Шесть подтягиваний выполнили 5 человек из 36. Восемь подтягиваний выполнили 10 человек из 36 и так далее. Давайте заполним таблицу с помощью таких отношений:

Выполним деление в этих дробях:

Выразим эти частоты в процентах. Для этого умножим их на 100. Умножение на 100 удобно выполнить передвижением запятой на две цифры вправо:

Теперь можно сказать, что пять подтягиваний выполнили 11% участников, 6 подтягиваний выполнили 14% участников, 8 подтягиваний выполнили 28% участников и так далее.
Понравился урок?
Вступай в нашу новую группу Вконтакте и начни получать уведомления о новых уроках
Возникло желание поддержать проект?
Используй кнопку ниже


План урока:
Понятие выборки и генеральной совокупности
Среднее арифметическое выборки
Упорядоченный ряд и таблица частот
Размах выборки
Мода выборки
Медиана выборки
Ошибки в статистике
Понятие выборки и генеральной совокупности
Слово статистика, образованное от латинского status(состояние дел), появилось только в 1746 году, когда его употребил немец Готфрид Ахенвалль. Однако ещё в Древнем Китае проводились переписи населения, в ходе которых правители собирали информацию о своих владениях и жителях, проживающих в них.
В основе любого статистического исследования лежит массив информации, который называют выборкой данных. Покажем это на примере. Пусть в классе, где учится 20 учеников, проводился тест по математике, содержавший 25 вопросов. В результате учащиеся показали следующие результаты:

Ряд чисел, приведенный во второй строке таблицы (12, 19, 19, 14, 17, 16, 18, 20, 15, 25, 13, 20, 25, 16, 17, 12, 24, 13, 21, 13), будет выборкой. Также ее могут называть рядом данных или выборочной совокупностью.

В примере с классом выборка состоит из 20 чисел. Эту величину (количество чисел в ряду) называют объемом выборки. Каждое отдельное число в ряду именуют вариантой выборки.
В примере со школьным классом в выборку попали все его ученики. Это позволяет точно определить, насколько хорошо учащиеся написали математический тест. Однако иногда необходимо проанализировать очень большие группы населения, состоящие из десятков и даже сотен миллионов человек. Например, необходимо узнать, какая часть населения страны курит. Опросить каждого жителя государства невозможно, поэтому в ходе исследования опрашивают лишь его малую часть. В этом случае статистики выделяют понятие генеральная совокупность.

Так, если с помощью опроса 10 тысяч человек ученые делают выводы о распространении курения в России, то все российское население будет составлять генеральную совокупность исследования, а опрошенные 10 тысяч людей вместе образуют выборку.
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.

Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:

При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Размах выборки
Следующий важная характеристика ряда данных – это размах выборки.

Если выборка представлена в виде упорядоченного ряда данных, то достаточно вычесть из последнего числа ряда первое число. Так, размах выборки результатов теста в классе равен:
25 – 12 = 13,
так как самые лучшие ученики смогли решить все 25 заданий, а наихудший учащийся ответил правильно только на 13 вопросов.
Размах выборки характеризует стабильность, однородность исследуемых свойств. Например, пусть два спортсмена-стрелка в ходе соревнований производят по 5 выстрелов по круговой мишени, где за попадание начисляют от 0 до 10 очков. Первый стрелок показал результаты 8, 9, 9, 8, 9 очков. Второй же спортсмен в своих попытках показал результаты 7, 10, 10, 6, 10. Средние арифметические этих рядов равны:
(8+9+9+8+9):5 = 43:5 = 8,6;
(7+10+10+6+10):5 = 43:5 = 8,6.
Получается, что в среднем оба стрелка стреляют одинаково точно, однако первый спортсмен демонстрирует более стабильные результаты. У его выборки размах равен
9 – 8 = 1,
в то время как размах выборки второго спортсмена равен
10 – 6 = 4.
Размах выборки может быть очень важен в метеорологии. Например, в Алма-Ате и Амстердаме средняя температура в течение года почти одинакова и составляет 10°С. Однако в Алма-Ате в январе и феврале иногда фиксируются температуры ниже -30°С, в то время как в Амстердаме за всю историю наблюдений она никогда не падала ниже -20°С.
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны. Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Медиана выборки
Иногда, например, при расчете средней зарплаты, среднее арифметическое не вполне адекватно отражает ситуацию. Это происходит из-за наличия в выборке чисел, очень сильно отличающихся от среднего. Так, из-за огромных зарплат некоторых начальников большинство рядовых сотрудников компаний обнаруживают, что их зарплата ниже средней. В таких случаях целесообразно использовать такую характеристику, как медиану ряда. Это такое значение, которое делит ряд данных пополам. В упорядоченном ряде 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25 медианой будет равна 12, так как именно она находится в середине ряда:

Однако таким образом можно найти только медиану ряда, в котором находится нечетное количество чисел. Если же их количество четное, то за медиану условно принимают среднее арифметическое двух средних чисел. Так, для ряда 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25, 30, содержащего 12 чисел, медиана будет равна среднему значению 12 и 15, которые занимают 6-ое и 7-ое место в ряду:


Вернемся к примеру с математическим тестом в школе. Так как его сдавали 20 учеников, а 20 – четное число, то для расчета медианы следует найти среднее арифметическое 10-ого и 11-ого числа в упорядоченном ряде
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Эти места занимают числа 17 и 17 (выделены жирным шрифтом). Медиана ряда будет равна
(17+17):2 = 34:2 = 17.
Три приведенные основные статистические характеристики выборки, а именно среднее арифметическое, мода и медиана, называются мерами центральной тенденции. Они позволяют одним числом указать значение, относительно которого группируются все числа ряда.
Рассмотрим для наглядности ещё один пример. Врач в ходе диспансеризации измерил вес мальчиков в классе. В результате он получил 10 значений (в кг):
39, 41, 67, 36, 60, 58, 46, 44, 39, 69.
Найдем среднее арифметическое, размах, моду и медиану для этого ряда.
Решение. Сначала перепишем ряд в упорядоченном виде:
36, 39, 39, 41, 44, 46, 58, 60, 67, 69.
Так как в ряде 10 чисел, то объем выборки равен 10. Найдем среднее арифметическое. Для этого сложим все числа в ряде и поделим их на объем выборки (то есть на 10):
(36+39+39+41+44+46+58+60+67+69):10 =
= 499:10 = 49,9 кг.
Размах выборки равен разнице между наибольшей и наименьшей вариантой в ней. Самый тяжелый мальчик весит 69 кг, а самый легкий – 36 кг, а потому размах ряда равен
69 – 36 = 33 кг.
В упорядоченном ряде только одно число, 39, встречается дважды, а все остальные числа встречаются по одному разу. Поэтому мода ряда будет равна 39 кг.
В выборке 10 чисел, а это четное число. Поэтому для нахождения медианы надо найти два средних по счету значение найти их среднее. На 5-ом и 6-ом месте в ряде находятся числа 44 и 46. Их среднее арифметическое равно
(44+46):2 = 90:2 = 45 кг.
Поэтому и медиана ряда будет равна 45 кг.
Ошибки в статистике
Статистика является очень мощным инструментом для исследований во всех областях человеческой деятельности. Однако иногда ее иронично называют самой точной из лженаук. Известно и ещё одно высказывание, приписываемое политику Дизраэли, согласно которому существует просто ложь, наглая ложь и статистика. С чем же связана такая репутация этой дисциплины?
Дело в том, что некоторые люди и организации часто манипулируют данными статистики, чтобы убедить других в своей правоте или преимуществах товара, которые они продают. Требуются определенные навыки, чтобы правильно пользоваться статистикой. Одна из самых распространенных ошибок – это неправильный выбор выборки.
В 1936 году перед президентскими выборами в США был проведен телефонный опрос, который показал, что с большим преимуществом победу должен одержать Альфред Лендон. Однако на выборах Франклин Рузвельт набрал почти вдвое больше голосов. Ошибка была связана с тем, что в те годы телефон могли позволить себе только богатые люди, которые в большинстве своем поддерживали Лендона. Однако бедные люди (а их, конечно же, больше, чем богатых) голосовали за Рузвельта.
Ещё один пример – это агитация в конце XIX века в США к службе на флоте. Пропагандисты в своей рекламе указывали, что, согласно статистике, смертность на флоте во время войны (испано-американской) составляет 0,09%, в то время как среди населения Нью-Йорка она равнялась 0,16%. Получалось, что служить на флоте в военное время безопаснее, чем жить мирной жизнью. Однако на самом деле причина таких цифр заключается в том, что во флот всегда отбирали молодых мужчин с хорошим здоровьем, которые не могли умереть от «старческих» болезней, в то время как в население Нью-Йорка входят больные и старые люди.
При указании среднего значения исследователь может использовать разные характеристики – среднее арифметическое, медиана, мода. При этом почти всегда среднее арифметическое несколько больше медианы. Именно поэтому большинство людей, узнающих о средней зарплате в стране, удивляются, так как они столько не зарабатывают. Правильнее ориентироваться на медианную зарплату.
Ну и наконец, нельзя забывать, что любая статистика может показать только корреляцию между двумя величинами, но это не всегда означает причинно-следственную связь. Так, известно, что чем больше в городе продается мороженого, тем больше в это же время людей тонет на пляжах. Означает ли это, что поедание мороженого увеличивает риск во время плавания? Нет. Дело в том, что оба этих показателя, продажи мороженого и количество утонувших, зависят от третьей величины – температуры в городе. Чем жарче на улице, тем большее количество людей ходят на пляж и тем больше мороженого продается в магазинах.

Эксперт по предмету «Математика»
Задать вопрос автору статьи
Генеральная средняя
Пусть нам дана генеральная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность — совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная средняя — среднее арифметическое значений вариант генеральной совокупности.
Пусть значения вариант $x_1, x_2,dots ,x_k$ имеют, соответственно, частоты $n_1, n_2,dots ,n_k$. Тогда генеральная средняя вычисляется по формуле:
![]()
Сделаем домашку
с вашим ребенком за 380 ₽
Уделите время себе, а мы сделаем всю домашку с вашим ребенком в режиме online
Бесплатное пробное занятие
*количество мест ограничено
Рассмотрим частный случай. Пусть все варианты $x_1, x_2,dots ,x_k$ различны. В этом случае $n_1, n_2,dots ,n_k=1$. Получаем, что в этом случае генеральная средняя вычисляется по формуле:
Выборочная средняя
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 3
Выборочная совокупность — часть отобранных объектов из генеральной совокупности.
Определение 4
Выборочная средняя — среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1, x_2,dots ,x_k$ имеют, соответственно, частоты $n_1, n_2,dots ,n_k$. Тогда выборочная средняя вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1, x_2,dots ,x_k$ различны. В этом случае $n_1, n_2,dots ,n_k=1$. Получаем, что в этом случае выборочная средняя вычисляется по формуле:
«Средняя выборки: генеральная, выборочная» 👇
!!! В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной средних значений за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Примеры задач на нахождение средней выборки
Пример 1
В магазин завезли 10 видов шоколадных конфет. По ним проведена следующая выборка по цене за килограмм: 70, 65, 97, 83, 120, 107, 77, 88, 100, 86. Построить ряд распределения данной генеральной совокупности и найти её генеральное среднее.
Решение.
Видим, что все значения вариант различны, поэтому частоты равны единице. Ряд распределения можно записать следующим образом, перечислив значения вариант в порядке возрастания:
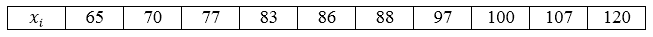
Рисунок 1.
Так как наша совокупность является генеральной и все варианты различны, то мы будем пользоваться следующей формулой:
[overline{x_г}=frac{sumlimits^k_{i=1}{x_i}}{n}]
Получим:
[overline{x_г}=frac{65+70+77+83+86+88+97+100+107+120}{10}=89,3]
Ответ: 89,3.
Пример 2
Выборочная совокупность задана следующей таблицей распределения:

Рисунок 2.
Найти среднее выборочное данной совокупности.
Решение.
Для нахождения значения выборочной средней будем пользоваться следующей формулой:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}]
Обычно, для наглядности и удобности вычислений составляется расчетная таблица, в которую входят необходимые промежуточные вычисления. В нашем случае составим таблицу со следующей «шапкой»:
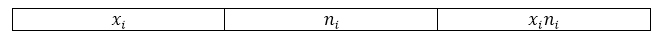
Рисунок 3.
Внизу таблицы также добавляется строка «итог», в которой подсчитывается сумма по всем значениям столбцов. Проведя необходимые вычисления, получим следующую расчетную таблицу:

Рисунок 4.
Используя формулу, получим:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}=frac{305}{20}=15,25]
Ответ: 15,25.
Пример 3
Проводится социальный опрос среди 100 пенсионеров об уровне их пенсии. Получена следующая таблица распределения результатов опроса (размер пенсии указан в тысячах рублей):

Рисунок 5.
Найти среднее выборочное данной совокупности.
Данная совокупность является выборочной, поэтому будем пользоваться следующей формулой:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}]
Составим, для начала, расчетную таблицу.
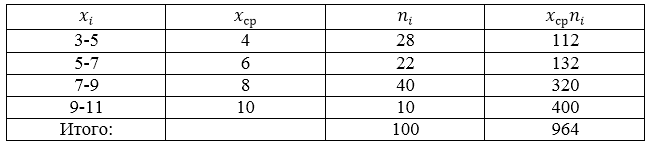
Рисунок 6.
Получаем:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}=frac{964}{100}=9,64]
Ответ: 9,64.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
