Сре́днее арифмети́ческое взве́шенное — математическое понятие, обобщающее среднее арифметическое. Среднее арифметическое взвешенное набора чисел  с весами
с весами  определяется как
определяется как

Основные числа и веса могут быть и вещественными, и комплексными. При этом сумма весов не может быть 0, но могут быть некоторые, не все веса, равные 0.
Если все веса  равны между собой, получается обычное среднее арифметическое. Существуют также взвешенные версии среднего геометрического и среднего гармонического, среднего степенного и их обобщения — среднего по Колмогорову.
равны между собой, получается обычное среднее арифметическое. Существуют также взвешенные версии среднего геометрического и среднего гармонического, среднего степенного и их обобщения — среднего по Колмогорову.
Иногда сумма весов равна 1 (например, в голосованиях в процентах как весах), тогда формула упрощается:

Примеры использования[править | править код]
В физике[править | править код]
- Средняя скорость тела
Если тело в течение промежутка времени  движется со скоростью
движется со скоростью  , затем в течение следующего промежутка времени
, затем в течение следующего промежутка времени  — со скоростью
— со скоростью  и так далее до последнего промежутка времени
и так далее до последнего промежутка времени  , в течение которого оно движется со скоростью
, в течение которого оно движется со скоростью  , то средняя скорость движения тела за суммарный промежуток времени (
, то средняя скорость движения тела за суммарный промежуток времени ( ) будет равна взвешенному среднему арифметическому скоростей
) будет равна взвешенному среднему арифметическому скоростей  с набором весов
с набором весов  :
:

- Центр масс
Другим примером использования данного понятия в физике является центр масс системы материальных точек, который задаётся формулой:

где  — радиус-вектор центра масс,
— радиус-вектор центра масс,
 — радиус-вектор i-й точки системы,
— радиус-вектор i-й точки системы,
 — масса i-й точки.
— масса i-й точки.
- Температура смеси нескольких порций одной жидкости с разными температурами
 ,
,

где  — полученная температура смеси,
— полученная температура смеси,
 — температура i-й порции,
— температура i-й порции,
— масса i-й порции.
В экономике[править | править код]
- Средневзвешенный курс валюты

где  — средневзвешенный курс,
— средневзвешенный курс,
 — цена по i-ой сделке,
— цена по i-ой сделке,
 — объем i-ой сделки.
— объем i-ой сделки.
См. также[править | править код]
- Парадокс Симпсона
- Медианта
Средняя арифметическая взвешенная
Если в исходных данных отдельные
значения усредняемого признака
повторятся, то расчет средней проводится
по сгруппированным данным или
вариационным рядам. В подобных случаях
для расчета необходимо применять
среднюю арифметическую взвешенную
– среднюю сгруппированных
величин.
 (4.12)
(4.12)
где
 –
–
частость, т. е. удельный вес статистических
единиц, обладающих определенным значением
признака в общем объеме совокупности.
Пример: рассчитать среднюю продажную
цену товара по данным, приведенным в
таблице 4.1:
Таблица 4.1 – Объём продаж и цена товара
А в магазинах города
|
Магазины |
Цена единицы |
Объем продаж, |
|
Космос |
20 |
25000 |
|
Ариадна |
18 |
40000 |
|
Вега |
19 |
40000 |
|
Итого |
? |
105000 |
Использовать среднюю арифметическую
простую в данном случае нельзя, так как
в разных магазинах продано разное
количество товара А. Для расчёта средней
продажной цены товара А. следует применить
среднюю арифметическую взвешенную:

При применении средней арифметической
простой средняя продажная цена товара
составляла бы: х = (20 + 18 + 19) / 3 = 19 руб. ,
т.е. оказалась бы завышенной.
Определение средней арифметической взвешенной по интервальному ряду
Сначала находят центры (середины)
интервалов, а затем их умножают на веса,
произведения суммируют и делят на сумму
весов.
Пример.Требуется определить
среднемесячную заработную плату одного
рабочего по следующим данным (табл. 4.2)
Таблица 4.2 – Исходные данные:
|
Исходные |
Расчетные |
||
|
месячная |
Число |
Середины |
– |
|
xi |
fi |
|
|
|
4000-5000 |
10 |
4500 |
45000 |
|
5000-6000 |
20 |
5500 |
110000 |
|
6000-7000 |
48 |
6500 |
312000 |
|
7000-8000 |
60 |
7500 |
450000 |
|
8000-9000 |
42 |
8500 |
357000 |
|
9000-10000 |
20 |
9500 |
190000 |
|
Итого |
200 |
– |
1464000 |
![]()
Средняя арифметическая обладает рядом
полезных свойств, к важнейшим из которых
относятся:
1. Средняя арифметическая постоянной
величины равна этой величине:
![]() =
=
АприА=const;
2 . Алгебраическая сумма отклонений
вариант от их средней арифметической
равна нулю:
![]() (4.13)
(4.13)
3. Если все варианты уменьшить (увеличить)
на постоянное число А, то средняя
арифметическая из них уменьшится
(увеличится) на это же число:
![]() (4.14)
(4.14)
4. Если все варианты увеличить (уменьшить)
в одно и то же число раз, то средняя
арифметическая увеличится (уменьшится)
во столько же раз:
![]()
(4.14)5.
Если все веса средней одинаково увеличить
(уменьшить) в несколько раз, то средняя
арифметическая не изменится.
 (4.15)
(4.15)
Средняя гармоническая простая
Имеет более сложную конструкцию, чем
средняя арифметическая. Используется
в тех случаях, когдастатистическая
информация не содержит частот по
отдельнымзначениям признака, а
представлена произведением значения
признака начастоту. Средняя
гармоническая как вид степенной средней
выглядит следующим образом:
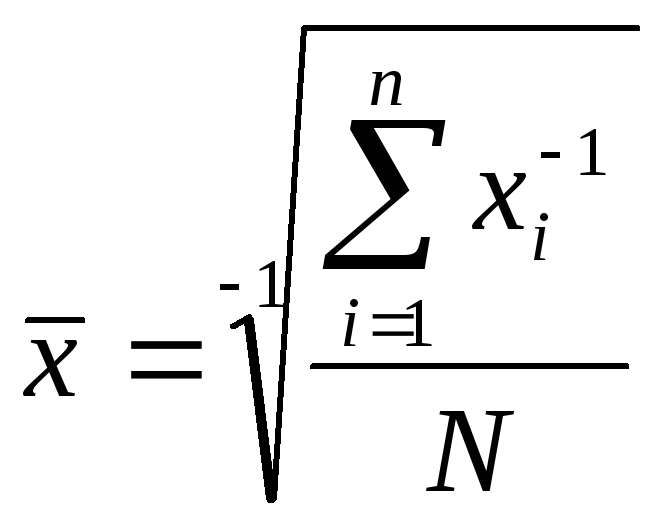 (4.16)
(4.16)
Если исходные данные несгруппированны,
то применяется средняя гармоническая
простая:
 (4.17)
(4.17)
К ней прибегают в случаях определения,
например, средних затрат труда, материалов
и т. д. на единицу продукции по нескольким
предприятиям.
Рассмотрим пример
использования средней гармонической
простой:
Три предприятия производят микроволновые
печи. Себестоимость их производства на
1-ом предприятии составила 4000 руб., на
2-ом – 3000 руб., на 3-ем – 5000 руб. Необходимо
определить среднюю себестоимость
производства микроволновой печи при
условии, что на каждом предприятии общие
затраты на ее изготовление составляют
600 тыс. руб.
Применять среднюю арифметическую в
данном случае нельзя, так как предприятия
выпускают разное количество микроволновых
печей: первое – 150 шт. (600000/4000); второе –
200 шт. (600000/3000); третье – 120 шт. (600000/5000).
Среднюю себестоимость микроволновой
печи можно получить, если общие затраты
трех предприятий разделить на общий
выпуск:
![]()
К аналогичному результату можно прийти,
используя формулу средней гармонической
простой:

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Наиболее распространенной формой статистических показателей, используемой в экономических исследованиях, являются средние показатели (средняя величина).
Средняя величина – представляет обобщенную количественную характеристику признака в статистической совокупности в конкретных условиях места и времени.
Показатель в форме средней величины выражает типичные черты и дает обобщающую характеристику однотипных явлений по одному из варьирующих признаков. Он отражает уровень этого признака, отнесенный к единице совокупности.
Важнейшее свойство средней величины заключается в том, что она отражает то общее, что присуще всем единицам исследуемой совокупности.
Значения признака отдельных единиц совокупности колеблются в ту или иную сторону под влиянием множества факторов, среди которых могут быть как основные, так и случайные.
- Например, курс акций корпорации в основном определяется финансовыми результатами ее деятельности. В то же время, в отдельные дни и на отдельных биржах эти акции в силу сложившихся обстоятельств могут продаваться по более высокому или заниженному курсу.
Сущность средней заключается, в том, что в ней взаимопогашаются отклонения значений признака отдельных единиц совокупности, обусловленные действием случайных факторов, и учитываются изменения, вызванные действием факторов основных. Это позволяет средней отражать типичный уровень признака и абстрагироваться от индивидуальных особенностей, присущих отдельным единицам.
ВИДЫ СРЕДНИХ ВЕЛИЧИН наиболее часто применяемых на практике:
- средняя арифметическая;
- средняя гармоническая;
- средняя геометрическая;
- средняя квадратическая.
Выбор средней величины зависит от содержания осредняемого признака и конкретных данных, по которым ее приходится вычислять.
- Средняя арифметическая простая (невзвешенная) – вычисляется когда каждый вариант совокупности встречается только один раз.
- Средняя арифметическая (взвешенная) – варианты повторяются различное число раз, при этом число повторений вариантов называется частотой, или статистическим весом.
ФОРМУЛЫ СРЕДНИХ ВЕЛИЧИН
- Средняя арифметическая простая – самый распространенный вид средней величины, рассчитывается по формуле (8.8):

(8.8 -формула средней арифметической простой)
- где хi – вариант, а n – количество единиц совокупности.
- Пример вычисления средней арифметической простой. Провели опрос о желаемом размере заработной платы у пяти сотрудников офиса. По результатам опроса выяснили, что желаемый размер заработной платы составляет соответственно для каждого сотрудника: 50000, 100000, 200000, 350000, 500000 рублей человек. Рассчитаем среднюю арифметическую простую по формуле (8.8):
 Вывод: в среднем желаемый размер заработной платы по результатам опроса 5-ти человек составил 240 тысяч рублей.
Вывод: в среднем желаемый размер заработной платы по результатам опроса 5-ти человек составил 240 тысяч рублей.
- Средняя арифметическая взвешенная формула 8.9.
 Вывод: в среднем желаемый размер заработной платы по результатам опроса 5-ти человек составил 240 тысяч рублей.
Вывод: в среднем желаемый размер заработной платы по результатам опроса 5-ти человек составил 240 тысяч рублей.
(8.9 -формула средней арифметической взвешенной)
- где хi – вариант, а fi – частота или статистический вес.
- Пример вычисления средней арифметической взвешенной. Результаты опроса всех работников офиса приведены в табл. 8.2.
Таблица 8.2 – Результаты опроса работников офиса
|
Желаемый размер заработной платы, тыс.руб хi |
Количество работников fi | хifi |
| 1 | 2 | 3 |
|
50 100 200 350 500 |
6
10 20 9 5 |
300
1000 4000 3150 2500 |
| Итого | 50 | 10950 |
Пример. Вычислим (ориентируясь на итоговые строки таблицы) желаемый размер заработной платы, 50 сотрудников офиса (используем формулу 8.9):

Пример вычисления средней арифметической взвешенной
Вывод: в среднем желаемый размер заработной платы по результатам опроса 50 человек составил 219 тысяч рублей.
Среднеарифметическая – всегда обобщающая количественная характеристика варьирующего признака совокупности.
- Средняя гармоническая вычисляется в тех случаях, когда приходится суммировать не сами варианты, а обратные им величины.
- Средняя гармоническая простая представлена ниже:

(8.10 – формула средней гармонической простой)
Средняя гармоническая взвешенная определяется по формуле

(8.11- формула средней гармонической взвешенной)
где xi – вариант, n – количество вариантов, Vi – веса для обратных значений xi.
Средняя гармоническая невзвешенная. Эта форма средней, используемая значительно реже, чем взвешенная. Для иллюстрации области ее применения воспользуемся упрощенным условным примером.
- Пример (вычисление средней гармонической простой (невзвешенной)).
Предположим, в фирме, специализирующейся на торговле по почте на основе предварительных заказов, упаковкой и отправкой товаров занимаются два работника. Первый из них на обработку одного заказа затрачивает 5 мин., второй – 15 мин.
- Каковы средние затраты времени на 1 заказ, если общая продолжительность рабочего времени у работников равна?
На первый взгляд, ответ на этот вопрос заключается в осреднении индивидуальных значений затрат времени на 1 заказ, т.е. если используем среднюю арифметическую простую получим: (5+15):2=10, мин.
- Проверим обоснованность такого подхода на примере одного часа (60 минут) работы. За этот час первый работник обрабатывает 12 заказов (60:5), второй – 4 заказа (60:15), что в сумме составляет 16 заказов.
Если же заменить индивидуальные значения их предполагаемым средним значением, то общее число обработанных обоими работниками заказов в данном случае уменьшится: (60/10) + (60/10) = 12 заказов (что не соответствует истине).
- Подойдем к решению через исходное соотношение средней. Для определения средних затрат времени необходимо общие затраты времени за любой интервал (например, за час) разделить на общее число обработанных за этот интервал двумя работниками заказов, т.е. используем среднюю гармоническую:

Пример вычисления средней гармонической простой (невзвешенной)
Если теперь мы заменим индивидуальные значения их средней величиной, то общее количество обработанных за час заказов не изменится: (60/7,5) + (60/7,5) = 16 заказов
- Подведем итог: средняя гармоническая невзвешенная может использоваться вместо взвешенной в тех случаях, когда значения Wj для единиц совокупности равны (в рассмотренном примере рабочий день у сотрудников одинаковый).
Пример (вычисление средней гармонической взвешенной) В ходе торгов на валютной бирже за первый час работы заключено пять сделок. Данные о сумме продажи рублей и курсе рубля по отношению к доллару США приведены в табл.8.3.
Таблица 8.3 – Данные о ходе торгов на валютной бирже (цифры условные)
Номер сделки Сумма продажи V, млн руб. Курс рубля x, руб. за 1 дол. V/x 1 2 3 4 1
2
3
4
5
455,00
327,50
528,00
266,00
332,50
65,00 65,50
66,00
66,50
66,50
7,00
5,00
8,00
4,00
5,00
итого 1909,00 – 29,00 Для того чтобы определить средний курс рубля по отношению к доллару, нужно найти соотношение между суммой продажи рублей, которые затрачены на покупку долларов в ходе всех сделок, и суммой приобретенных в результате этих сделок долларов.

- Вывод: средний курс за один доллар составил 65,83 руб.;
- Если бы для расчета среднего курса была использована средняя арифметическая простая:
 то, за один доллар, по данному курсу на покупку 29 млн дол. нужно было бы затратить 1899,5 млн.руб., что не соответствует действительности.
то, за один доллар, по данному курсу на покупку 29 млн дол. нужно было бы затратить 1899,5 млн.руб., что не соответствует действительности.
Средняя геометрическая используется для анализа динамики явлений и позволяет определить средний коэффициент роста. При расчете средней геометрической индивидуальные значения признака обычно представляют собой относительные показатели динамики, построенные в виде цепных величин как отношение каждого уровня ряда к предыдущему уровню.
- Средняя геометрическая простая рассчитывается по формуле 8.12

 то, за один доллар, по данному курсу на покупку 29 млн дол. нужно было бы затратить 1899,5 млн.руб., что не соответствует действительности.
то, за один доллар, по данному курсу на покупку 29 млн дол. нужно было бы затратить 1899,5 млн.руб., что не соответствует действительности.
(8.12)
- Если использовать частоты m, получим формулу средней геометрической взвешенной
- Средняя геометрическая взвешенная рассчитывается по формуле 8.13

(8.13)
Средняя квадратическая применяется, когда изучается вариация признака. В качестве вариантов используются отклонения фактических значений признака либо от средней арифметической, либо от заданной нормы.
Для несгруппированных данных используют формулу средней квадратической простой
Средняя квадратическая простая (формула 8.14)

8.14
Для сгруппированных данных используют формулу средней квадратической взвешенной
Средняя квадратическая взвешенная (формула 8.15)

(8.15) – Формула -средняя квадратическая взвешенная
Средние арифметическая, гармоническая, геометрическая и квадратическая, рассчитанные для одного и того же ряда вариантов, отличаются друг от друга. Их численное значение возрастает с ростом показателя степени в формуле степенной средней правило мажорантности средних А.Я. Боярского, т.е.

Мода и Медиана (структурные средние) формулы и примеры вычисления см. по ссылке
The weighted arithmetic mean is similar to an ordinary arithmetic mean (the most common type of average), except that instead of each of the data points contributing equally to the final average, some data points contribute more than others. The notion of weighted mean plays a role in descriptive statistics and also occurs in a more general form in several other areas of mathematics.
If all the weights are equal, then the weighted mean is the same as the arithmetic mean. While weighted means generally behave in a similar fashion to arithmetic means, they do have a few counterintuitive properties, as captured for instance in Simpson’s paradox.
Examples[edit]
Basic example[edit]
Given two school classes — one with 20 students, one with 30 students — and test grades in each class as follows:
- Morning class = {62, 67, 71, 74, 76, 77, 78, 79, 79, 80, 80, 81, 81, 82, 83, 84, 86, 89, 93, 98}
- Afternoon class = {81, 82, 83, 84, 85, 86, 87, 87, 88, 88, 89, 89, 89, 90, 90, 90, 90, 91, 91, 91, 92, 92, 93, 93, 94, 95, 96, 97, 98, 99}
The mean for the morning class is 80 and the mean of the afternoon class is 90. The unweighted mean of the two means is 85. However, this does not account for the difference in number of students in each class (20 versus 30); hence the value of 85 does not reflect the average student grade (independent of class). The average student grade can be obtained by averaging all the grades, without regard to classes (add all the grades up and divide by the total number of students):

Or, this can be accomplished by weighting the class means by the number of students in each class. The larger class is given more “weight”:

Thus, the weighted mean makes it possible to find the mean average student grade without knowing each student’s score. Only the class means and the number of students in each class are needed.
Convex combination example[edit]
Since only the relative weights are relevant, any weighted mean can be expressed using coefficients that sum to one. Such a linear combination is called a convex combination.
Using the previous example, we would get the following weights:


Then, apply the weights like this:

Mathematical definition[edit]
Formally, the weighted mean of a non-empty finite tuple of data  ,
,
with corresponding non-negative weights  is
is

which expands to:

Therefore, data elements with a high weight contribute more to the weighted mean than do elements with a low weight. The weights may not be negative in order for the equation to work[a]. Some may be zero, but not all of them (since division by zero is not allowed).
The formulas are simplified when the weights are normalized such that they sum up to 1, i.e.,  .
.
For such normalized weights, the weighted mean is equivalently:
- .

Note that one can always normalize the weights by making the following transformation on the original weights:
- .

The ordinary mean  is a special case of the weighted mean where all data have equal weights.
is a special case of the weighted mean where all data have equal weights.
If the data elements are independent and identically distributed random variables with variance  , the standard error of the weighted mean,
, the standard error of the weighted mean,  , can be shown via uncertainty propagation to be:
, can be shown via uncertainty propagation to be:

Variance-defined weights[edit]
For the weighted mean of a list of data for which each element  potentially comes from a different probability distribution with known variance
potentially comes from a different probability distribution with known variance  , all having the same mean, one possible choice for the weights is given by the reciprocal of variance:
, all having the same mean, one possible choice for the weights is given by the reciprocal of variance:

The weighted mean in this case is:

and the standard error of the weighted mean (with inverse-variance weights) is:

Note this reduces to  when all
when all  .
.
It is a special case of the general formula in previous section,

The equations above can be combined to obtain:

The significance of this choice is that this weighted mean is the maximum likelihood estimator of the mean of the probability distributions under the assumption that they are independent and normally distributed with the same mean.
Statistical properties[edit]
Expectancy[edit]
The weighted sample mean,  , is itself a random variable. Its expected value and standard deviation are related to the expected values and standard deviations of the observations, as follows. For simplicity, we assume normalized weights (weights summing to one).
, is itself a random variable. Its expected value and standard deviation are related to the expected values and standard deviations of the observations, as follows. For simplicity, we assume normalized weights (weights summing to one).
If the observations have expected values

then the weighted sample mean has expectation

In particular, if the means are equal,  , then the expectation of the weighted sample mean will be that value,
, then the expectation of the weighted sample mean will be that value,

Variance[edit]
Simple i.i.d. case[edit]
When treating the weights as constants, and having a sample of n observations from uncorrelated random variables, all with the same variance and expectation (as is the case for i.i.d random variables), then the variance of the weighted mean can be estimated as the multiplication of the unweighted variance by Kish’s design effect (see proof):

With  ,
,  , and
, and 
However, this estimation is rather limited due to the strong assumption about the y observations. This has led to the development of alternative, more general, estimators.
Survey sampling perspective[edit]
From a model based perspective, we are interested in estimating the variance of the weighted mean when the different  are not i.i.d random variables. An alternative perspective for this problem is that of some arbitrary sampling design of the data in which units are selected with unequal probabilities (with replacement).[1]: 306
are not i.i.d random variables. An alternative perspective for this problem is that of some arbitrary sampling design of the data in which units are selected with unequal probabilities (with replacement).[1]: 306
In Survey methodology, the population mean, of some quantity of interest y, is calculated by taking an estimation of the total of y over all elements in the population (Y or sometimes T) and dividing it by the population size – either known ( ) or estimated (
) or estimated ( ). In this context, each value of y is considered constant, and the variability comes from the selection procedure. This in contrast to “model based” approaches in which the randomness is often described in the y values. The survey sampling procedure yields a series of Bernoulli indicator values (
). In this context, each value of y is considered constant, and the variability comes from the selection procedure. This in contrast to “model based” approaches in which the randomness is often described in the y values. The survey sampling procedure yields a series of Bernoulli indicator values ( ) that get 1 if some observation i is in the sample and 0 if it was not selected. This can occur with fixed sample size, or varied sample size sampling (e.g.: Poisson sampling). The probability of some element to be chosen, given a sample, is denoted as
) that get 1 if some observation i is in the sample and 0 if it was not selected. This can occur with fixed sample size, or varied sample size sampling (e.g.: Poisson sampling). The probability of some element to be chosen, given a sample, is denoted as  , and the one-draw probability of selection is
, and the one-draw probability of selection is  (If N is very large and each
(If N is very large and each  is very small). For the following derivation we’ll assume that the probability of selecting each element is fully represented by these probabilities.[2]: 42, 43, 51 I.e.: selecting some element will not influence the probability of drawing another element (this doesn’t apply for things such as cluster sampling design).
is very small). For the following derivation we’ll assume that the probability of selecting each element is fully represented by these probabilities.[2]: 42, 43, 51 I.e.: selecting some element will not influence the probability of drawing another element (this doesn’t apply for things such as cluster sampling design).
Since each element () is fixed, and the randomness comes from it being included in the sample or not (), we often talk about the multiplication of the two, which is a random variable. To avoid confusion in the following section, let’s call this term:  . With the following expectancy:
. With the following expectancy: ![{displaystyle E[y'_{i}]=y_{i}E[I_{i}]=y_{i}pi _{i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0038fb0f5c8a920edac3ebe739518b3b2715bed9) ; and variance:
; and variance: ![{displaystyle V[y'_{i}]=y_{i}^{2}V[I_{i}]=y_{i}^{2}pi _{i}(1-pi _{i})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c92dd55d7d63d5b92648d0647865f83b3b88dc68) .
.
When each element of the sample is inflated by the inverse of its selection probability, it is termed the  -expanded y values, i.e.:
-expanded y values, i.e.:  . A related quantity is
. A related quantity is  -expanded y values:
-expanded y values:  .[2]: 42, 43, 51, 52 As above, we can add a tick mark if multiplying by the indicator function. I.e.:
.[2]: 42, 43, 51, 52 As above, we can add a tick mark if multiplying by the indicator function. I.e.: 
In this design based perspective, the weights, used in the numerator of the weighted mean, are obtained from taking the inverse of the selection probability (i.e.: the inflation factor). I.e.:  .
.
Variance of the weighted sum (pwr-estimator for totals)[edit]
If the population size N is known we can estimate the population mean using  .
.
If the sampling design is one that results in a fixed sample size n (such as in pps sampling), then the variance of this estimator is:

Proof
The general formula can be developed like this:

The population total is denoted as  and it may be estimated by the (unbiased) Horvitz–Thompson estimator, also called the -estimator. This estimator can be itself estimated using the pwr-estimator (i.e.: -expanded with replacement estimator, or “probability with replacement” estimator). With the above notation, it is:
and it may be estimated by the (unbiased) Horvitz–Thompson estimator, also called the -estimator. This estimator can be itself estimated using the pwr-estimator (i.e.: -expanded with replacement estimator, or “probability with replacement” estimator). With the above notation, it is:  .[2]: 51
.[2]: 51
The estimated variance of the pwr-estimator is given by:[2]: 52

where  .
.
The above formula was taken from Sarndal et al. (1992) (also presented in Cochran 1977), but was written differently.[2]: 52 [1]: 307 (11.35) The left side is how the variance was written and the right side is how we’ve developed the weighted version:

And we got to the formula from above.
An alternative term, for when the sampling has a random sample size (as in Poisson sampling), is presented in Sarndal et al. (1992) as:[2]: 182

With . Also,  where
where  is the probability of selecting both i and j.[2]: 36 And
is the probability of selecting both i and j.[2]: 36 And  , and for i=j:
, and for i=j:  .[2]: 43
.[2]: 43
If the selection probability are uncorrelated (i.e.:  ), and when assuming the probability of each element is very small, then:
), and when assuming the probability of each element is very small, then:

Proof
We assume that  and that
and that

Variance of the weighted mean (π-estimator for ratio-mean)[edit]
The previous section dealt with estimating the population mean as a ratio of an estimated population total ( ) with a known population size (), and the variance was estimated in that context. Another common case is that the population size itself () is unknown and is estimated using the sample (i.e.: ). The estimation of can be described as the sum of weights. So when
) with a known population size (), and the variance was estimated in that context. Another common case is that the population size itself () is unknown and is estimated using the sample (i.e.: ). The estimation of can be described as the sum of weights. So when  we get
we get  . With the above notation, the parameter we care about is the ratio of the sums of s, and 1s. I.e.:
. With the above notation, the parameter we care about is the ratio of the sums of s, and 1s. I.e.:  . We can estimate it using our sample with:
. We can estimate it using our sample with:  . As we moved from using N to using n, we actually know that all the indicator variables get 1, so we could simply write:
. As we moved from using N to using n, we actually know that all the indicator variables get 1, so we could simply write:  . This will be the estimand for specific values of y and w, but the statistical properties comes when including the indicator variable
. This will be the estimand for specific values of y and w, but the statistical properties comes when including the indicator variable  .[2]: 162, 163, 176
.[2]: 162, 163, 176
This is called a Ratio estimator and it is approximately unbiased for R.[2]: 182
In this case, the variability of the ratio depends on the variability of the random variables both in the numerator and the denominator – as well as their correlation. Since there is no closed analytical form to compute this variance, various methods are used for approximate estimation. Primarily Taylor series first-order linearization, asymptotics, and bootstrap/jackknife.[2]: 172 The Taylor linearization method could lead to under-estimation of the variance for small sample sizes in general, but that depends on the complexity of the statistic. For the weighted mean, the approximate variance is supposed to be relatively accurate even for medium sample sizes.[2]: 176 For when the sampling has a random sample size (as in Poisson sampling), it is as follows:[2]: 182
- .

We note that if  , then either using or
, then either using or  would give the same estimator, since multiplying by some factor would lead to the same estimator. It also means that if we scale the sum of weights to be equal to a known-from-before population size N, the variance calculation would look the same. When all weights are equal to one another, this formula is reduced to the standard unbiased variance estimator.
would give the same estimator, since multiplying by some factor would lead to the same estimator. It also means that if we scale the sum of weights to be equal to a known-from-before population size N, the variance calculation would look the same. When all weights are equal to one another, this formula is reduced to the standard unbiased variance estimator.
Proof
The Taylor linearization states that for a general ratio estimator of two sums ( ), they can be expanded around the true value R, and give:[2]: 178
), they can be expanded around the true value R, and give:[2]: 178

And the variance can be approximated by:[2]: 178, 179
![{displaystyle {widehat {V({hat {R}})}}={frac {1}{{hat {Z}}^{2}}}sum _{i=1}^{n}sum _{j=1}^{n}left({check {Delta }}_{ij}{frac {y_{i}-{hat {R}}z_{i}}{pi _{i}}}{frac {y_{j}-{hat {R}}z_{j}}{pi _{j}}}right)={frac {1}{{hat {Z}}^{2}}}left[{widehat {V({hat {Y}})}}+{hat {R}}{widehat {V({hat {Z}})}}-2{hat {R}}{hat {C}}({hat {Y}},{hat {Z}})right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/095d393824e32fa11f9af47749b2ff266d98b9d8)
.
The term  is the estimated covariance between the estimated sum of Y and estimated sum of Z. Since this is the covariance of two sums of random variables, it would include many combinations of covariances that will depend on the indicator variables. If the selection probability are uncorrelated (i.e.:
is the estimated covariance between the estimated sum of Y and estimated sum of Z. Since this is the covariance of two sums of random variables, it would include many combinations of covariances that will depend on the indicator variables. If the selection probability are uncorrelated (i.e.:  ), this term would still include a summation of n covariances for each element i between
), this term would still include a summation of n covariances for each element i between  and
and  . This helps illustrate that this formula incorporates the effect of correlation between y and z on the variance of the ratio estimators.
. This helps illustrate that this formula incorporates the effect of correlation between y and z on the variance of the ratio estimators.
When defining  the above becomes:[2]: 182
the above becomes:[2]: 182

If the selection probability are uncorrelated (i.e.: ), and when assuming the probability of each element is very small (i.e.:  ), then the above reduced to the following:
), then the above reduced to the following:

A similar re-creation of the proof (up to some mistakes at the end) was provided by Thomas Lumley in crossvalidated.[3]
We have (at least) two versions of variance for the weighted mean: one with known and one with unknown population size estimation. There is no uniformly better approach, but the literature presents several arguments to prefer using the population estimation version (even when the population size is known).[2]: 188 For example: if all y values are constant, the estimator with unknown population size will give the correct result, while the one with known population size will have some variability. Also, when the sample size itself is random (e.g.: in Poisson sampling), the version with unknown population mean is considered more stable. Lastly, if the proportion of sampling is negatively correlated with the values (i.e.: smaller chance to sample an observation that is large), then the un-known population size version slightly compensates for that.
Note that for the trivial case in which all the weights are equal to 1, the above formula is just like the regular formula for the variance of the mean (but notice that it uses the maximum likelihood estimator for the variance instead of the unbiased variance. I.e.: dividing it by n instead of (n-1)).
Bootstrapping validation[edit]
It has been shown, by Gatz et al. (1995), that in comparison to bootstrapping methods, the following (variance estimation of ratio-mean using Taylor series linearization) is a reasonable estimation for the square of the standard error of the mean (when used in the context of measuring chemical constituents):[4]: 1186
![{displaystyle {widehat {sigma _{{bar {x}}_{w}}^{2}}}={frac {n}{(n-1)(n{bar {w}})^{2}}}left[sum (w_{i}x_{i}-{bar {w}}{bar {x}}_{w})^{2}-2{bar {x}}_{w}sum (w_{i}-{bar {w}})(w_{i}x_{i}-{bar {w}}{bar {x}}_{w})+{bar {x}}_{w}^{2}sum (w_{i}-{bar {w}})^{2}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cc9b0e2d49dc34fc74facf7cbe5065bea29ad1bc)
where  . Further simplification leads to
. Further simplification leads to

Gatz et al. mention that the above formulation was published by Endlich et al. (1988) when treating the weighted mean as a combination of a weighted total estimator divided by an estimator of the population size,[5] based on the formulation published by Cochran (1977), as an approximation to the ratio mean. However, Endlich et al. didn’t seem to publish this derivation in their paper (even though they mention they used it), and Cochran’s book includes a slightly different formulation.[1]: 155 Still, it’s almost identical to the formulations described in previous sections.
Replication-based estimators[edit]
Because there is no closed analytical form for the variance of the weighted mean, it was proposed in the literature to rely on replication methods such as the Jackknife and Bootstrapping.[1]: 321
Other notes[edit]
For uncorrelated observations with variances , the variance of the weighted sample mean is[citation needed]

whose square root can be called the standard error of the weighted mean (general case).[citation needed]
Consequently, if all the observations have equal variance,  , the weighted sample mean will have variance
, the weighted sample mean will have variance

where  . The variance attains its maximum value,
. The variance attains its maximum value,  , when all weights except one are zero. Its minimum value is found when all weights are equal (i.e., unweighted mean), in which case we have
, when all weights except one are zero. Its minimum value is found when all weights are equal (i.e., unweighted mean), in which case we have  , i.e., it degenerates into the standard error of the mean, squared.
, i.e., it degenerates into the standard error of the mean, squared.
Note that because one can always transform non-normalized weights to normalized weights all formula in this section can be adapted to non-normalized weights by replacing all  .
.
[edit]
Weighted sample variance[edit]
See also: § Correcting for over- or under-dispersion
Typically when a mean is calculated it is important to know the variance and standard deviation about that mean. When a weighted mean  is used, the variance of the weighted sample is different from the variance of the unweighted sample.
is used, the variance of the weighted sample is different from the variance of the unweighted sample.
The biased weighted sample variance  is defined similarly to the normal biased sample variance
is defined similarly to the normal biased sample variance  :
:

where  for normalized weights. If the weights are frequency weights (and thus are random variables), it can be shown[citation needed] that is the maximum likelihood estimator of for iid Gaussian observations.
for normalized weights. If the weights are frequency weights (and thus are random variables), it can be shown[citation needed] that is the maximum likelihood estimator of for iid Gaussian observations.
For small samples, it is customary to use an unbiased estimator for the population variance. In normal unweighted samples, the N in the denominator (corresponding to the sample size) is changed to N − 1 (see Bessel’s correction). In the weighted setting, there are actually two different unbiased estimators, one for the case of frequency weights and another for the case of reliability weights.
Frequency weights[edit]
If the weights are frequency weights (where a weight equals the number of occurrences), then the unbiased estimator is:

This effectively applies Bessel’s correction for frequency weights.
For example, if values  are drawn from the same distribution, then we can treat this set as an unweighted sample, or we can treat it as the weighted sample
are drawn from the same distribution, then we can treat this set as an unweighted sample, or we can treat it as the weighted sample  with corresponding weights
with corresponding weights  , and we get the same result either way.
, and we get the same result either way.
If the frequency weights  are normalized to 1, then the correct expression after Bessel’s correction becomes
are normalized to 1, then the correct expression after Bessel’s correction becomes

where the total number of samples is  (not ). In any case, the information on total number of samples is necessary in order to obtain an unbiased correction, even if has a different meaning other than frequency weight.
(not ). In any case, the information on total number of samples is necessary in order to obtain an unbiased correction, even if has a different meaning other than frequency weight.
Note that the estimator can be unbiased only if the weights are not standardized nor normalized, these processes changing the data’s mean and variance and thus leading to a loss of the base rate (the population count, which is a requirement for Bessel’s correction).
Reliability weights[edit]
If the weights are instead non-random (reliability weights[definition needed]), we can determine a correction factor to yield an unbiased estimator. Assuming each random variable is sampled from the same distribution with mean  and actual variance
and actual variance  , taking expectations we have,
, taking expectations we have,
![{displaystyle {begin{aligned}operatorname {E} [{hat {sigma }}^{2}]&={frac {sum limits _{i=1}^{N}operatorname {E} [(x_{i}-mu )^{2}]}{N}}\&=operatorname {E} [(X-operatorname {E} [X])^{2}]-{frac {1}{N}}operatorname {E} [(X-operatorname {E} [X])^{2}]\&=left({frac {N-1}{N}}right)sigma _{text{actual}}^{2}\operatorname {E} [{hat {sigma }}_{mathrm {w} }^{2}]&={frac {sum limits _{i=1}^{N}w_{i}operatorname {E} [(x_{i}-mu ^{*})^{2}]}{V_{1}}}\&=operatorname {E} [(X-operatorname {E} [X])^{2}]-{frac {V_{2}}{V_{1}^{2}}}operatorname {E} [(X-operatorname {E} [X])^{2}]\&=left(1-{frac {V_{2}}{V_{1}^{2}}}right)sigma _{text{actual}}^{2}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d62874f46e78f0496b47f4486c021e9eb22858ea)
where  and
and  . Therefore, the bias in our estimator is
. Therefore, the bias in our estimator is  , analogous to the
, analogous to the  bias in the unweighted estimator (also notice that
bias in the unweighted estimator (also notice that  is the effective sample size). This means that to unbias our estimator we need to pre-divide by
is the effective sample size). This means that to unbias our estimator we need to pre-divide by  , ensuring that the expected value of the estimated variance equals the actual variance of the sampling distribution.
, ensuring that the expected value of the estimated variance equals the actual variance of the sampling distribution.
The final unbiased estimate of sample variance is:
- [6]
![{displaystyle {begin{aligned}s_{mathrm {w} }^{2} &={frac {{hat {sigma }}_{mathrm {w} }^{2}}{1-(V_{2}/V_{1}^{2})}}\[4pt]&={frac {sum limits _{i=1}^{N}w_{i}(x_{i}-mu ^{*})^{2}}{V_{1}-(V_{2}/V_{1})}},end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/23b28261b4ed6ca5bdeecd11ed28f046fd28469b)
where ![{displaystyle operatorname {E} [s_{mathrm {w} }^{2}]=sigma _{text{actual}}^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1e66ef0f88392a42e686e1a9e49af5913784cc65) .
.
The degrees of freedom of the weighted, unbiased sample variance vary accordingly from N − 1 down to 0.
The standard deviation is simply the square root of the variance above.
As a side note, other approaches have been described to compute the weighted sample variance.[7]
Weighted sample covariance[edit]
In a weighted sample, each row vector  (each set of single observations on each of the K random variables) is assigned a weight
(each set of single observations on each of the K random variables) is assigned a weight  .
.
Then the weighted mean vector  is given by
is given by

And the weighted covariance matrix is given by:[8]

Similarly to weighted sample variance, there are two different unbiased estimators depending on the type of the weights.
Frequency weights[edit]
If the weights are frequency weights, the unbiased weighted estimate of the covariance matrix  , with Bessel’s correction, is given by:[8]
, with Bessel’s correction, is given by:[8]

Note that this estimator can be unbiased only if the weights are not standardized nor normalized, these processes changing the data’s mean and variance and thus leading to a loss of the base rate (the population count, which is a requirement for Bessel’s correction).
Reliability weights[edit]
In the case of reliability weights, the weights are normalized:

(If they are not, divide the weights by their sum to normalize prior to calculating  :
:

Then the weighted mean vector can be simplified to

and the unbiased weighted estimate of the covariance matrix  is:[9]
is:[9]

The reasoning here is the same as in the previous section.
Since we are assuming the weights are normalized, then  and this reduces to:
and this reduces to:

If all weights are the same, i.e.  , then the weighted mean and covariance reduce to the unweighted sample mean and covariance above.
, then the weighted mean and covariance reduce to the unweighted sample mean and covariance above.
Vector-valued estimates[edit]
The above generalizes easily to the case of taking the mean of vector-valued estimates. For example, estimates of position on a plane may have less certainty in one direction than another. As in the scalar case, the weighted mean of multiple estimates can provide a maximum likelihood estimate. We simply replace the variance by the covariance matrix and the arithmetic inverse by the matrix inverse (both denoted in the same way, via superscripts); the weight matrix then reads:[10]

The weighted mean in this case is:

(where the order of the matrix–vector product is not commutative), in terms of the covariance of the weighted mean:

For example, consider the weighted mean of the point [1 0] with high variance in the second component and [0 1] with high variance in the first component. Then


then the weighted mean is:
![{displaystyle {begin{aligned}{bar {mathbf {x} }}&=left(mathbf {C} _{1}^{-1}+mathbf {C} _{2}^{-1}right)^{-1}left(mathbf {C} _{1}^{-1}mathbf {x} _{1}+mathbf {C} _{2}^{-1}mathbf {x} _{2}right)\[5pt]&={begin{bmatrix}0.9901&0\0&0.9901end{bmatrix}}{begin{bmatrix}1\1end{bmatrix}}={begin{bmatrix}0.9901\0.9901end{bmatrix}}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9523e98fd64fd5737eea95630a6f685d2ffe0956)
which makes sense: the [1 0] estimate is “compliant” in the second component and the [0 1] estimate is compliant in the first component, so the weighted mean is nearly [1 1].
Accounting for correlations[edit]
In the general case, suppose that ![{displaystyle mathbf {X} =[x_{1},dots ,x_{n}]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/18c0397e91d602c23fe004c2854a7adafd9d6ea5) , is the covariance matrix relating the quantities , is the common mean to be estimated, and
, is the covariance matrix relating the quantities , is the common mean to be estimated, and  is a design matrix equal to a vector of ones
is a design matrix equal to a vector of ones ![{displaystyle [1,dots ,1]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ab3aa20491720cf4c921e1f448bb538e2c16154) (of length
(of length  ). The Gauss–Markov theorem states that the estimate of the mean having minimum variance is given by:
). The Gauss–Markov theorem states that the estimate of the mean having minimum variance is given by:

and

where:

Decreasing strength of interactions[edit]
Consider the time series of an independent variable  and a dependent variable
and a dependent variable  , with observations sampled at discrete times . In many common situations, the value of at time depends not only on but also on its past values. Commonly, the strength of this dependence decreases as the separation of observations in time increases. To model this situation, one may replace the independent variable by its sliding mean
, with observations sampled at discrete times . In many common situations, the value of at time depends not only on but also on its past values. Commonly, the strength of this dependence decreases as the separation of observations in time increases. To model this situation, one may replace the independent variable by its sliding mean  for a window size
for a window size  .
.

Exponentially decreasing weights[edit]
In the scenario described in the previous section, most frequently the decrease in interaction strength obeys a negative exponential law. If the observations are sampled at equidistant times, then exponential decrease is equivalent to decrease by a constant fraction  at each time step. Setting
at each time step. Setting  we can define normalized weights by
we can define normalized weights by

where is the sum of the unnormalized weights. In this case is simply

approaching  for large values of .
for large values of .
The damping constant  must correspond to the actual decrease of interaction strength. If this cannot be determined from theoretical considerations, then the following properties of exponentially decreasing weights are useful in making a suitable choice: at step
must correspond to the actual decrease of interaction strength. If this cannot be determined from theoretical considerations, then the following properties of exponentially decreasing weights are useful in making a suitable choice: at step  , the weight approximately equals
, the weight approximately equals  , the tail area the value
, the tail area the value  , the head area
, the head area  . The tail area at step is
. The tail area at step is  . Where primarily the closest observations matter and the effect of the remaining observations can be ignored safely, then choose such that the tail area is sufficiently small.
. Where primarily the closest observations matter and the effect of the remaining observations can be ignored safely, then choose such that the tail area is sufficiently small.
Weighted averages of functions[edit]
The concept of weighted average can be extended to functions.[11] Weighted averages of functions play an important role in the systems of weighted differential and integral calculus.[12]
Correcting for over- or under-dispersion[edit]
See also: § Weighted sample variance
Weighted means are typically used to find the weighted mean of historical data, rather than theoretically generated data. In this case, there will be some error in the variance of each data point. Typically experimental errors may be underestimated due to the experimenter not taking into account all sources of error in calculating the variance of each data point. In this event, the variance in the weighted mean must be corrected to account for the fact that  is too large. The correction that must be made is
is too large. The correction that must be made is

where  is the reduced chi-squared:
is the reduced chi-squared:

The square root  can be called the standard error of the weighted mean (variance weights, scale corrected).
can be called the standard error of the weighted mean (variance weights, scale corrected).
When all data variances are equal, , they cancel out in the weighted mean variance,  , which again reduces to the standard error of the mean (squared),
, which again reduces to the standard error of the mean (squared),  , formulated in terms of the sample standard deviation (squared),
, formulated in terms of the sample standard deviation (squared),

See also[edit]
- Average
- Central tendency
- Mean
- Standard deviation
- Summary statistics
- Weight function
- Weighted average cost of capital
- Weighted geometric mean
- Weighted harmonic mean
- Weighted least squares
- Weighted median
- Weighted moving average
- Weighted sum of variables
- Weighting
- Standard error of a proportion estimation when using weighted data
- Ratio estimator
Notes[edit]
- ^ Technically, negatives may be used if all the values are either zero or negatives. This fills no function however as the weights work as absolute values.
References[edit]
- ^ a b c d Cochran, W. G. (1977). Sampling Techniques (3rd ed.). Nashville, TN: John Wiley & Sons. ISBN 978-0-471-16240-7
- ^ a b c d e f g h i j k l m n o p q Carl-Erik Sarndal, Bengt Swensson, Jan Wretman (1992). Model Assisted Survey Sampling. ISBN 9780387975283.
{{cite book}}: CS1 maint: uses authors parameter (link) - ^ Thomas Lumley (https://stats.stackexchange.com/users/249135/thomas-lumley), How to estimate the (approximate) variance of the weighted mean?, URL (version: 2021-06-08): https://stats.stackexchange.com/q/525770
- ^ Gatz, Donald F.; Smith, Luther (June 1995). “The standard error of a weighted mean concentration—I. Bootstrapping vs other methods”. Atmospheric Environment. 29 (11): 1185–1193. Bibcode:1995AtmEn..29.1185G. doi:10.1016/1352-2310(94)00210-C. – pdf link
- ^ Endlich, R. M., et al. “Statistical analysis of precipitation chemistry measurements over the eastern United States. Part I: seasonal and regional patterns and correlations.” Journal of Applied Meteorology (1988-2005) (1988): 1322-1333. (pdf)
- ^ “GNU Scientific Library – Reference Manual: Weighted Samples”. Gnu.org. Retrieved 22 December 2017.
- ^ “Weighted Standard Error and its Impact on Significance Testing (WinCross vs. Quantum & SPSS), Dr. Albert Madansky” (PDF). Analyticalgroup.com. Retrieved 22 December 2017.
- ^ a b Price, George R. (April 1972). “Extension of covariance selection mathematics” (PDF). Annals of Human Genetics. 35 (4): 485–490. doi:10.1111/j.1469-1809.1957.tb01874.x. PMID 5073694. S2CID 37828617.
- ^ Mark Galassi, Jim Davies, James Theiler, Brian Gough, Gerard Jungman, Michael Booth, and Fabrice Rossi. GNU Scientific Library – Reference manual, Version 1.15, 2011.
Sec. 21.7 Weighted Samples - ^ James, Frederick (2006). Statistical Methods in Experimental Physics (2nd ed.). Singapore: World Scientific. p. 324. ISBN 981-270-527-9.
- ^ G. H. Hardy, J. E. Littlewood, and G. Pólya. Inequalities (2nd ed.), Cambridge University Press, ISBN 978-0-521-35880-4, 1988.
- ^ Jane Grossman, Michael Grossman, Robert Katz. The First Systems of Weighted Differential and Integral Calculus, ISBN 0-9771170-1-4, 1980.
Further reading[edit]
- Bevington, Philip R (1969). Data Reduction and Error Analysis for the Physical Sciences. New York, N.Y.: McGraw-Hill. OCLC 300283069.
- Strutz, T. (2010). Data Fitting and Uncertainty (A practical introduction to weighted least squares and beyond). Vieweg+Teubner. ISBN 978-3-8348-1022-9.
External links[edit]
- David Terr. “Weighted Mean”. MathWorld.
- Tool to calculate Weighted Average
![]()
Загрузить PDF
![]()
Загрузить PDF
Вычислить средневзвешенную величину, также известную как среднее взвешенное, не так просто, как найти среднее арифметическое. Среднее взвешенное — это величина, вычисляемая на основе чисел, «ценность» или «вес» которых не равнозначны. Например, если нужно вычислить среднее взвешенное оценки, помните, что оценки за разные задания составляют определенные проценты от финальной оценки. Метод вычисления зависит от того, равна ли сумма всех весов 1 (100 %) или нет.
-
1
Запишите все числа, среднее взвешенное которых нужно вычислить. Например, если нужно найти среднее взвешенное оценок, сначала запишите все оценки.[1]
- Например, вы получили 82 балла за тесты, 90 баллов за экзамен и 76 баллов за курсовую работу.
-
2
Определите вес (или «ценность») каждого числа. Например, оценка за тест составляет 20 % от финальной оценки, оценка за экзамен — 35 %, оценка за курсовую работу — 45 %. В этом случае сумма весов равна 1 (или 100 %).[2]
- Чтобы использовать проценты в вычислениях, необходимо преобразовать их в десятичные дроби. Полученные числа называются «весовыми коэффициентами».
Совет: чтобы преобразовать проценты в десятичную дробь, добавьте десятичную запятую в конец процентов, а затем переместите ее на 2 позиции влево. Например, 75 % = 0,75.
-
3
Умножьте каждое число (х) на соответствующий весовой коэффициент (w). Затем сложите полученные значения, чтобы вычислить среднее взвешенное.[3]
- Например, если за тест вы получили 82 балла, а оценка за тест составляет 20 % от финальной оценки, умножьте 82 x 0,2. В этом случае х = 82 и w = 0,2.
-
4
Сложите полученные значения, чтобы найти среднее взвешенное. Формула для вычисления среднего взвешенного, когда сумма весов равна 1: x1(w1) + x2(w2) + x3(w3) + …, где x1, ч2, … — это числа, w1, w2, … — это соответствующие весовые коэффициенты.[4]
Чтобы найти среднее взвешенное, просто умножьте каждое число на его весовой коэффициент, а затем сложите полученные значения.- В нашем примере: 82(0,2) + 90(0,35) + 76(0,45) = 16,4 + 31,5 + 34,2 = 82,1. Это означает, что за предмет вы получили 82,1%.
Реклама




-
1
Запишите все числа, среднее взвешенное которых нужно вычислить. Помните, что сумма весов не всегда равна 1 (или 100 %), но в любом случае сначала запишите все нужные числа.[5]
- Например, нужно вычислить среднюю продолжительность вашего ежедневного сна в течение 15 недель, причем продолжительность сна менялась — вы спали 5, 8, 4, 7 и так далее часов в сутки.
-
2
Определите вес (или «ценность») каждого числа. Например, допустим, что в течение 15 недель было несколько недель, когда вы спали дольше. Такие недели имеют больший вес (потому что вы спали дольше, чем обычно). В качестве весового коэффициента используйте количество недель, связанное со средней продолжительностью сна. Например:[6]
- 9 недель, в течение которых продолжительность сна в среднем составляла 7 часов в сутки.
- 3 недели, в течение которых продолжительность сна в среднем составляла 5 часов в сутки.
- 2 недели, в течение которых продолжительность сна в среднем составляла 8 часов в сутки.
- 1 неделя, в течение которой продолжительность сна в среднем составляла 4 часа в сутки.
- Количество недель, связанное с количеством часов, является весовым коэффициентом. В нашем примере вы спали 7 часов в сутки в течение большинства недель, а бо́льшая или меньшая продолжительность сна приходится на меньшее число недель.
-
3
Вычислите сумму весов. Для этого просто сложите все веса. В нашем примере сумма весов f = 15, потому что вы исследуете продолжительность сна в течение 15 недель. [7]
- Общее количество недель, которые вы рассматриваете, складывается следующим образом: 3 недели + 2 недели + 1 неделя + 9 недель = 15 недель.
-
4
Умножьте числа на соответствующие веса, а затем сложите результаты. В нашем примере умножьте среднюю продолжительность сна на соответствующее число недель. Вы получите:[8]
- 5(часов в сутки)*3(недели) + 8(часов в сутки)*2(недели) + 4(часа в сутки)*1(неделя) + 7(часов в сутки)*9(недель) = 5(3) + 8(2) + 4( 1) + 7(9) = 15 + 16 + 4 + 63 = 98
-
5
Разделите полученный результат на сумму весов, чтобы найти среднее взвешенное. В нашем примере:[9]
- 98/15 = 6,53. Это означает, что средняя продолжительность вашего ежедневного сна в течение 15 недель составила 6,53 часа.
Реклама





Об этой статье
Эту страницу просматривали 94 831 раз.
