Как найти прямую ссылку
Просматривая в интернете различные файлы, может возникнуть желание поделиться ими. Для этого в первую очередь необходимо найти прямую ссылку на интересующий документ. Сделать это можно при помощи различных приложений, одним из которых является бесплатная программа Dropbox.

Вам понадобится
- – Dropbox.
Инструкция
Зайдите на официальный сайт программного обеспечения Dropbox по ссылке http://www.dropbox.com/. Нажмите на кнопку Download и выберите операционную систему, которая стоит на вашем компьютере. Также имеется возможность скачать версию программы для мобильных устройств.
Запустите установочный файл и установите программу на ваш компьютер. После этого в трее (правый угол панели задач, возле часов) появится ярлык приложения Dropbox, которое отвечает за выделенный каталог на диске. При этом любые изменения в каталоге фиксируются на сервере Dropbox. Запустите программу. Появится окно-запрос на создание аккаунта. Нажмите кнопку Yes и Next.
Заполните в регистрационном окне необходимые данные о вас: фамилию, имя, электронный адрес. После этого придумайте безопасный пароль и повторите его. Прочитайте пользовательское соглашение и поставьте галочку, что ознакомились с ним. Перейдите к следующему окну, в котором необходимо выбрать размер хранилища для скачиваемых файлов. Стоит отметить, что бесплатным является только место до 2 Гб, за большие объемы необходимо внести определенную плату. Появится сообщение о создании виртуальной папки, к которой можно получить доступ с любого компьютера, где установлена данная программа. Закончите настройку программы.
Выберите файл с компьютера, для которого вы хотите найти прямую ссылку. При этом название его должно быть написано на латинице. Зайдите в папку «Мои документы», перейдите в раздел Dropbox – Public и скопируйте в данный каталог ваш файл.
После этого запустится загрузка документа на сервер, прогресс которой можно посмотреть, наведя курсор на иконку приложения в трее. Зайдите заново в директорию Dropbox и нажмите правой кнопкой мышки на файл. Выберите пункт Dropbox и функцию Copy Public Link. Теперь вы можете скопировать прямую ссылку на файл в любое место.
Видео по теме
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Мало кто знает, что популярная социальная сеть ВКонтакте может помочь в поиске практически любой книги или документа.
Страница vk.com/docs, которую можно вызвать из любого аккаунта, выглядит очень скромно:
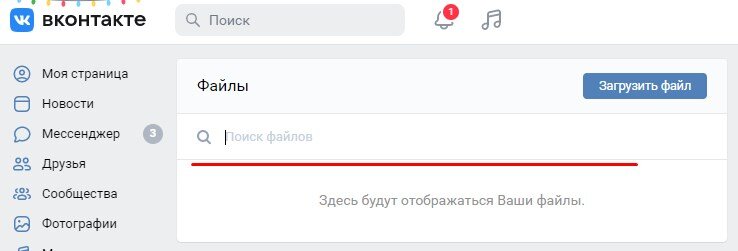
Красным я подчеркнула строку, куда надо ввести название книги или автора. Причем, не обязательно и то, и другое, потому что поиск ВК проводит не только среди своих загруженных документов, но и среди библиотеки общедоступных файлов в интернете.
Поэтому, результат будет не один, а несколько, среди них надо поискать нужное.
Примеры моего поиска книг
Сначала я решила найти книгу, которая прочитала недавно, и она произвела на меня большое впечатление “Дом, в котором…” М.Петросян. Ввела название только книги и получила объемную выдачу:
Нужная книга была найдена на втором скриншоте восьмой по счету, в удобном формате fb2. При нажатии на ссылку, она моментально скачалась на компьютер.
Далее я решила поискать зарубежную книгу, например, Стивен Кинг “Кристина”. Набрала “Кристина, Кинг”:
Первой в выдаче был архив на английском языке, а второй – то что надо. После скачивания и распаковки внутри обнаружилась искомая книга в формате fb2.
Обратите внимание, что третья ссылка имеет размер 0 КБ, пустой файл.
Затем я попробовала разыскать “Эфирное время” П.Дашковой. Файл нашелся, но только ознакомительная версия, бывает и так.
Я уже писала в другой статье, что у меня была навязчивая идея – найти и перечитать книгу “Могила Таме-Тунга”, которую я читала в детстве и она мне очень понравилась. Так вот, ВК нашел эту книгу, что меня удивило, потому что о ней мало кто знает.
Также можно искать документы, учебники, научную литературу. Я, как физик по специальности, попробовала найти Сборник задач по физике О.Волькенштейн, причем, ввела только фамилию:
Как видите, был найден и сам задачник, и решения задач к нему.
Как попасть на страницу поиска ВК
Выше я писала адрес, по которому производится поиск. Но это неудобно.
Можно переходить на страницу поиска книг ВКонтакте, используя пункт Файлы в меню слева:
Если у вас нет такой вкладки, ее можно добавить. Надо навести курсор мыши на любой пункт меню и нажать на появившийся значок шестеренки. Появится окно настройки пунктов меню:
Надо поставить галочку напротив пункта Файлы, и он будет отображаться в меню. Таким образом, эта полезная функция соцсети будет всегда под рукой.
Попробуйте сами, вам наверняка понравится!
P.S. Обратите внимание: судя по всему, документы и файлы, загруженные вами в ВК попадают в этот тотальный поиск и становятся общедоступными.
Спасибо, что дочитали, высказывайте свое мнение о сервисе, подписывайтесь на канал!
Содержание
- Url адрес файла на компьютере как узнать
- Что такое url адрес и как его найти?
- Что значит url ссылка на изображение, сайт, канал или видео?
- Какова структура url адреса или запроса?
- Что такое url blacklist
- URL адрес — что это такое и как узнать урл веб-страницы сайта, изображения или видео
- Что такое URL адрес и из чего он состоит?
- Структура УРЛ и некоторые особенности для вебмастеров
- Кодирование и декодирование URL
- Как узнать URL изображения, видео или страницы сайта?
Url адрес файла на компьютере как узнать
КАК ВЫЯСНИТЬ URL АДРЕС ССЫЛКИ ДЛЯ СКАЧИВАНИЯ ФАЙЛА
Чем привлекателен интернет, так это тем, что там почти всегда можно найти что-то полезное и интересное для пользователей интернета. Зачастую это могут быть различные файлы, или просто какая-либо информация (развлекательная или познавательная). Вся эта информация (и файлы в т.ч.) размещены на серверах, а доступ к ней мы получаем посредством указания URL адресов (или, попросту, ссылок) на эту информацию в специализированных программах интернет-браузерах, предназначенных для соединения компьютера пользователя с сервером (фактически, тоже компьютером), на котором хранится эта информация.
Общие понятия и рекомендации о поиске информации в интернете описаны в статье «ПОИСК ИНФОРМАЦИИ В ИНТЕРНЕТЕ (Освоение компьютера)» на этом сайте. Там же раскрывалось понятие и отмечалось значение URL-адреса в процессе доступа к информации, размещенной в интернете. Эта статья является продолжением вышеуказанной и посвящена вопросу, как выяснить URL-адрес ссылки для скачивания файла.
Вся информация, размещенная в интернете, обычно систематизирована по определенным признакам. В большинстве случаев отдельные файлы, предназначенные для скачивания, размещены на сайтах в разделах «файловый менеджер» или в облачных хранилищах, а сам процесс скачивания заключается в указании браузеру ссылок (точнее URL-адресов этих ссылок).

На Рис.1 представлен один из примеров процесса скачивания файлов из интернета и выяснения URL-адресов ссылок. В текстовом документе указана ссылка для скачивания торрент файла (см.1 Рис.1). При наведении на нее курсора и нажатии левой кнопкой мыши на эту ссылку происходит скачивание файла (см.2 Рис.1).
Чтобы узнать и скопировать URL-адрес этой ссылки, достаточно навести на нее курсор, и щелкнуть по ней правой кнопкой мыши. При этом появится контекстное меню (см.3 Рис.1). Если вы выберете пункт контекстного меню «Копировать адрес ссылки» (см.4 Рис.1), URL-адрес этой ссылки сохранится в буфере обмена компьютера. Вы можете сохранить его в документе, созданном с помощью любого текстового редактора, к примеру, в блокноте, или просто вставить в адресную строку вашего браузера (см.1 Рис.2). Правда, в последнем случае, после нажатия кнопки «Enter» на клавиатуре, вкладка с введенным в нее URL-адресом ссылки закроется (зависит от браузера), но скачивание файла произойдет.

Приведенный выше вариант – это способ узнать URL-адрес ссылки, который указан в явном виде. Т.е. на сайте не используется защиты от копирования адреса ссылки, и любой пользователь интернета, сохранив эту ссылку, имеет возможность повторно обратиться к ней в любое время или переслать ее своему знакомому. Но существует множество случаев, когда владельцы сайтов пытаются скрыть URL-адрес ссылки. Обычно, это делается в тех случаях, когда кто-то зарабатывает на предоставлении ссылок на файлы, пользующиеся популярностью, или хотят увеличить посещаемость своих сайтов за счет повторного посещения страницы пользователем интернета, на которой размещена эта ссылка. Обычно это (создание ссылок в неявном виде) делается с помощью кнопок «Скачать», размещенных на страницах сайтов.
Если ссылка для скачивания файла явно не указана на страницах сайта или в облачных хранилищах, но вам необходимо ее получить и сохранить, вы можете воспользоваться свойствами браузера, с помощью которого вы ранее уже скачивали этот файл. Для этого в окне браузера нажмите кнопку «Настройки» (см.2 Рис.2). Обращаю внимание, что для разных браузеров ее название может отличаться. В случае Google Chrome, как на моих рисунках, она сейчас называется «Настройка и управление Google Chrome». В случае Microsoft Edge, сейчас она называется «Настройки и прочее».
После нажатия кнопки «настройка браузера» перед вами откроется меню (см.3 Рис.2), в котором необходимо выбрать пункт «Загрузки» (см.4 Рис.2).

После нажатия на кнопку «Загрузки» перед вами откроется окно, в котором будут отражены все выполненные загрузки с помощью вашего браузера (см.1 Рис.3). Теперь вам остается только скопировать ссылку скачанного вами файла в буфер обмена (см.2 Рис.3) и сохранить ее в каком-нибудь текстовом файле.
И еще несколько особенностей выяснения URL-адресов файлов с помощью настроек браузеров и скачивания файлов из интернета:

Источник
Что такое url адрес и как его найти?
Всем привет! Теперь довольно часто мы сталкиваемся с таким понятием, как «url адрес». Но не всегда понимаем о чем идет речь. А ведь это составляющая интернета, без которых невозможна его работа. В этой статье речь и пойдет о том, что такое этот самый url адрес, как его найти, и что он из себя представляет.

Любая страничка в интернете имеет свой уникальный адрес, который необходимо набрать, что бы посетить ее или же переслать товарищу, если хотим поделиться найденной информацией. По сути, URL является параметром такого атрибута, как «href», при помощи которого создаются различные гиперссылки
URL строится аналогично адресу нашего места пребывания: улица, дом, квартира, этаж. Например, протокол HTTPS – это улица, номером дома может служить название сайта, а вот путь непосредственно к определенной странице сайта можно обозначить как квартиру. Аналогичным образом определяются и URL изображения или файла – это то место, где они располагаются.
Аббревиатура URL (Universal Resource Locator) означает – универсальный указатель ресурса. Т.е. – это и есть тот самый адрес сервера, на котором находится искомый ресурс. URL обладает определенной структурой, но об этом чуть позже.
Как это ни странно, но не все пользователи представляют себе, где взять этот самый URL-адрес. А здесь все зависит от того, какой именно URL нам необходимо найти. Если это адрес сайта, то его мы берем в адресной строке браузера.

Он может быть как длинным, так и коротким, в зависимости от того на главной странице сайта мы находимся или же на его других страничках. Кроме адреса сайта, адрес имеется и у отдельных файлов. Которые входят в состав контента сайта. И это не удивительно, ведь они где-то располагаются.
Например, мы просматриваем в ВК записи и наткнулись на интересную картинку. Нам захотелось поделиться ею, отправив ее адрес друзьям (пусть даже не в ВК). Нажав правой кнопкой мыши на картинке откроется окно, где находим «копировать URL картинки».

В результате будет скопирован ее адрес, который можно переслать любым известным способом. Если этот адрес вставить в текстовый редактор, то он будет выглядеть следующим образом:
В конце адресной строки вы видите окончание jpg, которое и указывает, что сохраненный вами адрес принадлежит файлу-картинке. Аналогичным образом будет выглядеть адрес и для любых других файлов, которые вы скачиваете с интернета. Только в конце будет стоять тот атрибут, который указывает на тип скачиваемого файла.
Самое интересное, понятие URL появилось в 1990 году в Женеве. «Изобретателем» этого термина стал Тим Бернерс-Ли. Первоначально URL нужен был для обозначения отдельных файлов, их расположения в мировой сети. Впоследствии его стали использовать для обозначения уже всех ресурсов интернета.
Что значит url ссылка на изображение, сайт, канал или видео?
Итак, что такое URL ссылка уже мы определились. Это адрес или ресурса, или файлов в интернете, их место расположение. При помощи URL можно определить, где находится тот или иной объект.
Просматривая на Яндексе картинки, вы можете спокойно найти ее ссылку, нажав правой кнопкой мыши. В открывшемся меню выбираем или «копировать адрес ссылки», или сохранить ее.

В первом варианте вы копируете именно ссылку, которую можно потом вставить в адресную строку любого другого браузера или же сохранить у себя в текстовом редакторе, что бы потом вновь посетить данное место с этим файлом. Во втором случае у вас на жестком диске сохраняется веб-страничка.
У каналов, например Ютуб, так же имеются свои адреса. Выяснить его довольно просто. Для начала вы входите в свой аккаунт на сайте youtube.com. Затем, в правом верхнем углу находите значок своего профиля, обычно это или ваше фото, или какая-либо аватарка. Нажав на нее, вы переходите на свою страничку, которая и является URL с идентификатором канала.
Например, youtube.com/channel/UCUZHFZ9jIKrLroW8LcyJEQQ. Это и есть стандартный адрес любого канала, а вот символы, которые идут в конце ссылки являются уникальным идентификатором. У каждого автора канала он свой.
Таким образом, любой URL-адрес любого объекта, будь то сайт или же картинка, видео, аккаунт в ВК или одноклассниках, отображается в адресной строке браузера. Скопировав его, вы сможете или сохранить эту ссылку, или отправить ее своим знакомым.
Какова структура url адреса или запроса?
Структура URL является иерархической. URL-адрес для размещения документа, изображения, станицы, и других прочих файлов выглядит следующим образом:

Сейчас основополагающим является такой параметр, как URI. Это Uniform Resource Identifier, что означает «Унифицированный идентификатор ресурса». Именно с его помощью можно идентифицировать любой ресурс в интернете. Это и сам сайт, и его файлы. Сюда же входит и адрес вашего электронного почтового ящика.
Этот самый URI состоит URL, который является Унифицированным Указателем Ресурса и URN (Uniform Resource Name), что переводится как Унифицированное Наименование Ресурса.
URN предназначен для идентификации конкретного объекта по его названию в пространстве имен. URL, как уже указывалось, характеризует местоположение этого объекта в интернете и обеспечивает к нему доступ. Таким образом, в URL входит имя сайта и его расположение. Что же касается URN, то это может быть или же только адрес сайта (или какого-либо ресурса), или же его имя, т.е., это тот метод с помощью которого мы попадает на искомый ресурс.

Если говорить об истории создания этих понятий – то это все тот же 1990 год. Правда, развитие в этом направлении не стоит на месте, в 1998 году выходит уже новая версия URI. Хотя мы и до сих пор используем термин URL, однако еще в 2002 году появилось сообщение, что он устарел и надо использовать вместо него термин URI.
Таким образом, URI – это сегодня наиболее общая система идентификации. Она может включать в себя как оба идентификатора URN и URL, так и каждый из них по отдельности.
Что такое url blacklist
Блеклист (blacklist) – это черный список тех сайтов, которые несут в себе вредоносный или вирусный материал. С такими сайтами мы сталкиваемся довольно часто. Например ваш браузер или антивирусник при попытке посетить какой-либо сайт выдал сообщение, что доступ на него запрещен, так как он может навредить системе.

Сейчас в интернете есть много сайтов, которые под видом невинной информации несут в себе определенную угрозу. Чаще всего такая надпись появляется на тех сайтах, которые предлагают купить что-либо, введя данные карты.
Ничего страшного в этом нет, существуют специальные сайты или блеклисты, которые отслеживают таких вредителей. Одним из популярных является блеклист от Google. Каждый пользователь может войти на такой блеклист и пожаловаться на тот или иной сайт.
Вот, впрочем и все. А для тех, кто хочет более подробно ознакомится с урлом сайта, как его оформить правильно и что это такое, советую посмотреть приведенное ниже видео.
Источник
URL адрес — что это такое и как узнать урл веб-страницы сайта, изображения или видео
Здравствуйте, уважаемые читатели блога Goldbusinessnet.com. Продолжаем изучение важнейших составляющих интернета, и на очереди у нас понятие «URL адрес» (урл по-простому), который юзеры вводят в адресную строку браузера (какой из них лучше?) в чистом виде.
И именно URL является тем базовым параметром атрибута href, с помощью которого создаются гиперссылки, входящие в состав гипертекста как основы Мировой Паутины. Благодаря урлу все пользователи получают возможность посетить нужный сайт и получить искомую информацию.
По большому счету, «URL» связан с терминами «URI» и «URN», краткое объяснение сути которых будут, безусловно, даны в соответствующем разделе настоящей публикации.

Кроме этого, разберем на наглядных примерах, из чего состоят урлы, какого вида они бывают и как находить адреса изображений, страниц сайта, видео и копировать их для своих нужд.
Что такое URL адрес и из чего он состоит?
Итак, начнем с самого начала, то есть с URI (Uniform Resource Identifier), аббревиатура которого в переводе с английского означает «Унифицированный идентификатор ресурса». Это уникальный набор символов, позволяющий идентифицировать любой ресурс в интернете: страницу вебсайта, файл, электронный почтовый ящик и т.д.
Составляющими URI являются URN (Uniform Resource Name — Унифицированное Наименование Ресурса) и URL (Uniform Resource Locator — Унифицированный Указатель Ресурса). Первый из них идентифицирует конкретный проект по его названию в пространстве имен, а второй указывает на его местоположение в интернете и обеспечивает доступ к нему посредством конкретного метода. Схематически это соотношение можно изобразить следующим образом:

URI является более общей системой идентификации. Она может включать в себя либо URN, либо URL, либо оба идентификатора вместе. То есть, URN и URL являются частными случаями URI. Попробую объяснить, что значит каждый термин, на наглядном примере из реальной жизни.
Допустим, имеется конкретный адрес (г. Нижний, ул. Верхняя, д.4, кв.15), до которого возможно добраться различными способами в зависимости от степени удаления пункта отправления. Имя владельца квартиры Василий Васильевич Пупкин.
Ну а полная информация, включающая адрес и имя находящегося по этому месту жительства человека — URI. Конечно, это в известной степени упрощенние, но зато оно помогает постичь суть без излишнего напряжения мысленных ресурсов.
Нас интересует в первую очередь унифицированный указатель, поскольку именно он является основной идентификационной системой, используемой широко на практике в глобальной сети. Поэтому далее мы и уделим основное время описанию структурных особенностей URL.
Структура УРЛ и некоторые особенности для вебмастеров
Итак, мы с вами определили в общих чертах, что же такое URL адрес. Это путь до любого файла (вебстраницы сайта, картинки, видео и др.). Начнем с простого примера. Вот как может выглядеть локатор в общем виде для одного из файлов, находящегося в определенной директории (папке):
В качестве реального примера привожу урл адрес файла, который содержит логотип этого блога:
Чуть выше я упомянул, что URL содержит не только указание на конкретное местоположение объекта в сети, но и то, каким способом можно получить к нему доступ. Так вот, протокол HTTP, стоящий в самом начале унифицированного указателя, как раз и является инструментом, который помогает открыть файл по указанному адресу в браузере.
У протокола передачи данных HTTP есть вариант HTTPS, обеспечивающий безопасное соединение и к переходу на который в последнее время склоняют вебмастеров поисковики (что, впрочем, будет благом для всех, особенно для коммерческих веб-ресурсов и проектов, где используется передача персональных данных пользователей).
Но вернемся к нашему примеру. После обозначения типа протокола «http://» (а в общем случае способа доступа, поскольку в урлах не всегда применяется протокол, но об этом ниже) идет уникальное название домена (читайте о доменных именах и о том, как их зарегистрировать). Кстати, доменное имя может быть указано и с WWW:
Тогда наблюдается присутствие в интернете двух разных ресурсов (с WWW и без) с одинаковым содержанием. С точки зрения поисковых систем это зеркала, являющиеся по своей сути дублями, которые жутко мешают продвижению проекта как в Яндексе, так и в Гугле.
К тому же, обратные ссылки, проставленные на ваш сайт с доноров, могут быть распределены в неизвестных пропорциях между зеркалами. Поэтому надо предпринять действия по определению главного домена и склейке зеркал, в том числе посредством 301-ого редиректа.
С доменным именем мы разобрались. Кстати, при создании сайта домен вашего веб-проекта будет считаться корневой папкой с точки зрения файловой структуры веб-сервера. Вследствие этого цепочку после двойного слеша можно воспринимать как последовательность вложенных друг в друга папок (их может быть несколько), где на конце урла находится нужный файл:
Этот файлик идентифицируется по названию и расширению, в нашем примере это «file.extension». Причем, расширение может быть самым различным (html, php, png и т.д.).
Но здесь надо иметь ввиду, что на веб-серверах во многих случаях используются Unix-подобные ОС, где, в отличие от Windows, расширения для файлов не являются обязательными и часто не применяются, поэтому запись «file.extension» может вполне быть принята за название файлика с точкой посередине. Эта информация нам может пригодиться в дальнейшем.
Для полноты картины нужно еще упомянуть об адресах страниц сайтов в интернете. Чаще всего встречаются урлы трех видов (ЧПУ), которые наиболее предпочтительны во всех смыслах:
Вроде бы, первый вариант больше всего отвечает разобранной нами схеме. Но в случае с URL страницы не все так однозначно. В теории это состоит следующим образом (попробую объяснить все на примере обычного блога, по-моему, он достаточно наглядный и понятный большинству).
Основываясь на приведенном мною в самом начале данного раздела статьи общем примере урла, возможно было бы рассуждать следующим образом. В соответствии с иерархией в блоге роль подпапок играют разделы (рубрики или категории) вебресурса, в которые включены отдельные вебстраницы (файлы). Ну а главная страница — это основная папка (корень сайта в файловой структуре сервера), содержащая рубрики.
При стандартных серверных настройках каждый URL, соответствующий каталогу (папке), должен заканчиваться слэшем, в этом случае обработчик «поймет», что необходимо отобразить листинг всех файлов, которые там содержатся, а не какой-то конкретный объект, поиск которого будет осуществляться, если слеша не будет (таким образом вы экономите ресурсы сервера).
В соответствии с этими рассуждениями локатор главной должен заканчиваться на «/», поскольку домен является корневой директорией:
По этой же причине такой же вид урла соответствует рубрикам сайта:
А вот статические или страницы записей выводятся в таком обличье:
Помните, чуть выше я упоминал о двух легитимных вариантах существования файлов в Unix-подобных операционных системах (с расширением и без)?
Если взять в качестве образца самый популярный в мире движок WordPress, то там все шаблоны, отвечающие за формирование различных страничек сайта (главной, рубрик, вебстраниц записей и т.д.) входят физически в одну директорию текущей темы.
Таким образом, содержание названных страниц в конечном виде существует лишь при просмотре в веб-браузере, а не физически на сервере. К слову, с файловым строением тем WP вы можете познакомиться перейдя по ссылке, этот материал даст вам дополнительные полезные сведения.
Кто привык копать глубоко и желает более подробно изучить этот архиважный аспект, отсылаю вас к очень качественному материалу, где он освещается на основе первоисточника в формате спецификации общего синтаксиса URL, и в котором красной нитью проходит утверждение, что урл вообще (вне зависимости от своего содержания) указывает на абстрактное местоположение ресурса, а не на его конкретное физическое расположение.
Более того, ни один из них не имеет сколь-нибудь заметного преимущества в глазах поисковых систем. Единственное, для обеспечения правильной индексации надо также установить 301 редирект в случае применения URL со слешем или без в конце.
Надеюсь, что предоставленная информация поможет вам определиться с настройкой урлов на своем сайте. Для проектов, работающих на WordPress, например, постоянные ссылки сайта можно легко настроить в соответствующем разделе админ-панели.
Важное замечание! Настройку ссылок желательно производить в начале создания проекта, дальнейшие изменения могут замедлить или приостановить продвижение сайта, поскольку переиндексация у поисковиков не происходит мгновенно.
Выше мы рассмотрели частные случаи различных типов локаторов, ну а общая блок-схема, демонстрирующая структуру URL, выглядит следующим образом:

Пожалуй, следует дать некоторые разъяснения по отдельным составляющим.
Схема. Как я уже отмечал выше, не всегда средством передачи данные служит протокол, хотя это наиболее распространенный вариант. Эту роль вполне может играть псевдопротокол (например, тот же mailto, являющийся средством отправки сообщения по электронной почте):
Для полноты информации вы можете ознакомиться с полным перечнем используемых схем на соответствующей страничке Википедии.
Кроме HTTP и HTTPS вебмастерами и разработчиками очень часто применяется на практике и FTP (тут об этом протоколе необходимые подробности), который очень удобен при работе с файлами своего проекта на сервере хостинга (что это такое и как купить место для сайта), если при этом воспользоваться помощью соответствующей программы (например, Файлзилла).
В таком случае для доступа к нужному файлу или папке понадобиться указать логин и пароль, а также порт (если он отличен от стандартного, применяемого по умолчанию):
Здесь в качестве хоста указано имя домена («goldbusinessnet.com»), но может быть использован и IP-адрес, идентифицирующий устройство в сети интернет (тут о взаимодействии ай-пи адресов, ДНС и доменных имен). Ну а «folder1/file.extansion» — это уточняющий URL-путь до объекта.
Для вебмастеров еще один нюанс заключается в том, что любой движок может генерировать локаторы, в которых присутствуют так называемые GET-параметры, следующие после знака «?» в конце урлов. Если их несколько (каждый может иметь свое значение), они разделяются «&»:
Страниц с такими адресами на сайте может набраться достаточное количество, причем их контент может быть тождественным с основными вебстраницами. Те, кто имеет свои блоги на Вордпрессе, могут столкнуться с ситуацией, когда наличие древовидных комментариев инициирует появление урлов с replytocom (правда, в последних версиях WP, по-моему, эта проблема уже не актуальна):
А это и есть самые настоящие дубли, большое количество которых способно существенно снизить скорость индексирования страничек, а значит, и косвенным образом замедлить продвижение веб- ресурса. Поэтому, думаю, будет уместным в этом месте дать гиперссылку, перейдя по которой вы узнаете, как бороться с самым разнообразным дублированным контентом на Вордпресс.
Если есть цель улучшить навигацию и направить посетителя не просто на нужную страницу, но в определенное место на ней, где есть искомая информация, то используют якорь (по-английски anchor), с помощью которого создаются хеш-ссылки:
К выше сказанному надо бы еще добавить, что в стандартных урлах рекомендуется использовать лимитированную выборку знаков: буквы латинского алфавита в нижнем регистре [a-z], цифры 8, точку [.], нижнее подчеркивание [_], и дефис [-].
Такие ограничения действуют со времени зарождения интернета, но с некоторых пор ввиду развития глобальной сети появилась необходимость формировать URL с применением символов национальных языков, включая русский. Такая возможность появилась, но для ее реализации требуется кодировка (encoding) любых знаков в формате ASCII, который понимают браузеры.
Кодирование и декодирование URL
Итак, после некоторых предпринятых соответствующими международными организациями усилий сайт может использовать для адресов своих страниц локаторы, включающие буквы практически любого языка. Нас интересует русский, поэтому можете проверить сие утверждение, введя в адресную строку браузера урл одной из страниц Русской Википедии:
Адрес корректно отобразится:

А после нажатия кнопки «Enter» откроется соответствующая страничка. Теперь попробуйте скопировать этот адрес в буфер обмена и вставить его в любой документ (например, в блокнот Windows). Получится такой набор:
Это и есть закодированные русские буквы, которые web-браузер автоматически преобразует в читабельный текст на кириллице. Кстати, в сети есть немало сервисов, которые предлагают быстрое кодирование и декодирование содержания URL, например, вот этот:

Конечно, для пользователей рунета гораздо более привлекательным является текст на русском, содержащийся в локаторе (кстати, и доменное имя может быть кириллическим).
Однако, формировать урлы на кириллице для страниц своего сайта я все-таки советую только в том случае, если проект имеет какие-то свои особенности, вследствие которых именно русские символы в URL будут эффективнее привлекать посетителей, особенно целевую аудиторию.
В других случаях все же оптимальнее будет применять латиницу (а для WordPress использовать плагины транслитерации для автоматического преобразования русских букв в постоянных ссылках в латинские), поскольку это исключает некоторые возможные ошибки, а поисковые системы не делают языковых предпочтений в этом аспекте при ранжировании.
Как узнать URL изображения, видео или страницы сайта?
При работе в интернете да и просто во время сёрфинга или поиска информации в сети очень часто нужно просмотреть или скопировать адрес того или иного объекта. Где же взять нужный урл на открытой в браузере веб-страничке? Что касается URL страницы сайта, то его можно подсмотреть в адресной строке:

Правда, если данные передаются по обычному протоколу HTTP, то он, скорее всего, будет скрыт. Однако, если вы выделите урл, щелкните по нему правой кнопкой мышки и скопируете, выбрав из появившегося контекстного меню нужный пункт:

То после его вставки в нужное место он будет отображаться полностью (включая протокол «http://»). В случае использования владельцами веб-ресурса HTTPS локатора, соответствующего защищенному соединению, адрес веб-страницы будет доступен в полном виде сразу же после выделения и последующего клика по нему:

С помощью того же контекстного меню можно найти и скопировать также URL нужной вам гиперссылки, содержащейся в тексте:

Иногда нужно узнать урл размещенной в web-пространстве картинки. Для этого опять используйте тот же метод:

Только имейте ввиду, что если будете «Копировать картинку», то в буфер обмена поместите не ее URL, а само изображение, которое потом можете вставить в необходимое место.
Точно также есть возможность узнать и скопировать адрес видео. Ежели находитесь, например, в пределах Ютуба на странице с видеороликом, то это делается либо из адресной строки браузера, либо в разделе «Поделиться», находящемся чуть ниже ролика:

В случае присутствия видео в контенте веб-странички его URL- адрес можно получить с похожей легкостью (достаточно щелкнуть правой кнопкой мыши прямо по плейеру):

Таким вот образом вы легко можете получать и копировать URL-адрес практически любого объекта. Кстати, контекстное меню может принимать различный вид в зависимости от применяемого веб-браузера, но суть его опций остается практически идентичной.
Источник
Секреты поиска. Как найти нужный документ .
 Всем привет, это следующий урок о том, как правильно искать информацию в сети с помощью Google. Есть одна хитрость, которая, впрочем как всегда, никаким секретом не является. Мало кто из нас задумывается, но логически это понимают все – интернет это далеко не только веб-страницы ресурсов. Это видео, фото и аудио файлы, это документы различных форматов и многое другое. Даже не всегда на том или ином ресурсе в силу каких-то обстоятельств (в том числе и по недосмотру владельца файла) мы имеем доступ к нему по прямой ссылке для скачивания. Но в сети они есть и Google их прекрасно видит. Файлы проиндексированы поисковой системой, а значит, они доступны и для нас. Так что найти нужный документ бывает проще, чем каждый из нас думает. Давайте найдём их.
Всем привет, это следующий урок о том, как правильно искать информацию в сети с помощью Google. Есть одна хитрость, которая, впрочем как всегда, никаким секретом не является. Мало кто из нас задумывается, но логически это понимают все – интернет это далеко не только веб-страницы ресурсов. Это видео, фото и аудио файлы, это документы различных форматов и многое другое. Даже не всегда на том или ином ресурсе в силу каких-то обстоятельств (в том числе и по недосмотру владельца файла) мы имеем доступ к нему по прямой ссылке для скачивания. Но в сети они есть и Google их прекрасно видит. Файлы проиндексированы поисковой системой, а значит, они доступны и для нас. Так что найти нужный документ бывает проще, чем каждый из нас думает. Давайте найдём их.
Перед тем, как перейти конкретно к поиску, стоит упомянуть о специальном сервисе Google, о котором, оказывается, мало кто знает. Это страница расширенного поиска:
https://www.google.com/advanced_search?hl=ru
Я нарочно оставлю это без комментариев, там всё по-русски. Изучайте и пользуйтесь. Это, скажем, страница продвинутого поиска без знания операторов Google.
У каждого из файлов есть своё расширение, которое определяет тип программы, с помощью которой ему положено открываться. По умолчанию тип сокрыт от глаз пользователя. Но не для Google. Даже не зная названия документа полностью, вы сможете (теоретически) попытаться найти нужный документ, зная, что он имеет вид, например, документа Word из набора Microsoft Office. Вобщем, Google понимает вот такие расширения:
Adobe Portable Document Format (PDF)
Adobe PostScript (PS)
MacWrite (MW)
Microsoft Excel (XLS)
Microsoft PowerPoint (PPT)
Microsoft Word (DOC)
Microsoft Works (WDB, WKS, WPS)
Microsoft Write (WRI)
Rich Text Format (RTF)
Text (ANS, TXT)
И некоторые другие, более специфичные. Если вы собираетесь найти нужный документ , например, обязательно в формате Word с расширением .docx, то можно попробовать задать этот параметр (без точки перед расширением) уже в поисковой строке. Это должно выглядеть так:
Название_документафайлафильмапесни filetype:тип_файла
Например:
Договор купли-продажи кактуса filetype:docx
По аналогии с известным вам исключением ненужной информации из поисковой выдачи, можно, наоборот, исключить из неё ненужные расширения и работать только с определёнными их типами. Используем, тем самым, оператор исключения «-». Например:
Договор купли-продажи кактуса -filetype:docx
Всё. В поисковой выдаче страниц с договором в формате Word не будет. Будут PDF, TXT, но не Word.
Как найти нужный документ на конкретном сайте или домене.
Нередко перед некоторыми пользователями ставится задача найти нужный документ или просто посмотреть некоторую информацию только на ресурсах, имеющих более высокую степень доверия по сравнению с остальными. Например, домены .com, .edu, .org принадлежат правительственным или образовательным учреждениям, которые имеют больший информационный вес. Или нам необходимо узнать информацию или новость из первоисточника. А про обрушение котировок на английской бирже лучше узнать не из израильского сайта, не так ли? Потому лучше было зондировать именно английские источники информации – это доменная зона британцев .uk. Или канадцев — .ca. Или французов – fr. И так далее.
Так вот, чтобы заняться поиском только по конкретной доменной зоне, укажите тип домена в поисковом запросе с помощью оператора “site:”. Например:
site:.edu (не забудьте точку перед названием домена)
И при наборе информации в определённой зоне:
Do it yourself.:ru
Google будет искать результаты только в русскоязычном интернете (рунете).
По аналогии с доменной зоной можно сократить место поиска до конкретного веб-сайта. Например, если нужно прочитать справку о том или ином событий в операционной системе Windows, есть смысл обратиться к первоисточнику. Ищите в пределах только официальной справки от Microsoft на официальном сайте. Для этого используйте тот же самый оператор в таком виде:
Ошибка 000240767 site:www.microsoft.com (точку перед адресом ставить нельзя!)
Все найденные результаты будут касаться только этого сайта.
Успехов
КАК ВЫЯСНИТЬ URL АДРЕС ССЫЛКИ ДЛЯ СКАЧИВАНИЯ ФАЙЛА
Чем привлекателен интернет, так это тем, что там почти всегда можно найти что-то полезное и интересное для пользователей интернета. Зачастую это могут быть различные файлы, или просто какая-либо информация (развлекательная или познавательная). Вся эта информация (и файлы в т.ч.) размещены на серверах, а доступ к ней мы получаем посредством указания URL адресов (или, попросту, ссылок) на эту информацию в специализированных программах интернет-браузерах, предназначенных для соединения компьютера пользователя с сервером (фактически, тоже компьютером), на котором хранится эта информация.
Общие понятия и рекомендации о поиске информации в интернете описаны в статье «ПОИСК ИНФОРМАЦИИ В ИНТЕРНЕТЕ (Освоение компьютера)» на этом сайте. Там же раскрывалось понятие и отмечалось значение URL-адреса в процессе доступа к информации, размещенной в интернете. Эта статья является продолжением вышеуказанной и посвящена вопросу, как выяснить URL-адрес ссылки для скачивания файла.
Вся информация, размещенная в интернете, обычно систематизирована по определенным признакам. В большинстве случаев отдельные файлы, предназначенные для скачивания, размещены на сайтах в разделах «файловый менеджер» или в облачных хранилищах, а сам процесс скачивания заключается в указании браузеру ссылок (точнее URL-адресов этих ссылок).

На Рис.1 представлен один из примеров процесса скачивания файлов из интернета и выяснения URL-адресов ссылок. В текстовом документе указана ссылка для скачивания торрент файла (см.1 Рис.1). При наведении на нее курсора и нажатии левой кнопкой мыши на эту ссылку происходит скачивание файла (см.2 Рис.1).
Чтобы узнать и скопировать URL-адрес этой ссылки, достаточно навести на нее курсор, и щелкнуть по ней правой кнопкой мыши. При этом появится контекстное меню (см.3 Рис.1). Если вы выберете пункт контекстного меню «Копировать адрес ссылки» (см.4 Рис.1), URL-адрес этой ссылки сохранится в буфере обмена компьютера. Вы можете сохранить его в документе, созданном с помощью любого текстового редактора, к примеру, в блокноте, или просто вставить в адресную строку вашего браузера (см.1 Рис.2). Правда, в последнем случае, после нажатия кнопки «Enter» на клавиатуре, вкладка с введенным в нее URL-адресом ссылки закроется (зависит от браузера), но скачивание файла произойдет.

Приведенный выше вариант – это способ узнать URL-адрес ссылки, который указан в явном виде. Т.е. на сайте не используется защиты от копирования адреса ссылки, и любой пользователь интернета, сохранив эту ссылку, имеет возможность повторно обратиться к ней в любое время или переслать ее своему знакомому. Но существует множество случаев, когда владельцы сайтов пытаются скрыть URL-адрес ссылки. Обычно, это делается в тех случаях, когда кто-то зарабатывает на предоставлении ссылок на файлы, пользующиеся популярностью, или хотят увеличить посещаемость своих сайтов за счет повторного посещения страницы пользователем интернета, на которой размещена эта ссылка. Обычно это (создание ссылок в неявном виде) делается с помощью кнопок «Скачать», размещенных на страницах сайтов.
Если ссылка для скачивания файла явно не указана на страницах сайта или в облачных хранилищах, но вам необходимо ее получить и сохранить, вы можете воспользоваться свойствами браузера, с помощью которого вы ранее уже скачивали этот файл. Для этого в окне браузера нажмите кнопку «Настройки» (см.2 Рис.2). Обращаю внимание, что для разных браузеров ее название может отличаться. В случае Google Chrome, как на моих рисунках, она сейчас называется «Настройка и управление Google Chrome». В случае Microsoft Edge, сейчас она называется «Настройки и прочее».
После нажатия кнопки «настройка браузера» перед вами откроется меню (см.3 Рис.2), в котором необходимо выбрать пункт «Загрузки» (см.4 Рис.2).

После нажатия на кнопку «Загрузки» перед вами откроется окно, в котором будут отражены все выполненные загрузки с помощью вашего браузера (см.1 Рис.3). Теперь вам остается только скопировать ссылку скачанного вами файла в буфер обмена (см.2 Рис.3) и сохранить ее в каком-нибудь текстовом файле.
И еще несколько особенностей выяснения URL-адресов файлов с помощью настроек браузеров и скачивания файлов из интернета:

- Метод копирования ссылок в буфер обмена для разных браузеров может отличаться. Например, метод выделения URL-адреса, описанный выше, подходит для Google Chrome. Для браузера Microsoft Edge копировать нужно с помощью контекстного меню, выбрав пункт «Копировать ссылку». И еще нужно учитывать, что разработчики интернет-браузеров постоянно вносят изменения (обновления) в свое ПО.
- Если скачиваемые файлы размешены на обычных сайтах в разделах «файловый менеджер», то, обычно, прямая ссылка, выявленная приведенными способами, должна работать. Если файл размещен в облачном хранилище, то, обычно, прямая ссылка на файл для скачивания работать не будет, т.к. в программном обеспечении облачных хранилищ существует 2-ух и более ступенчатая защита от несанкционированного скачивания. Попытка скачать файл, указав в браузере непосредственно его URL-адрес, приведет к появлению приблизительно такого окна, как на Рис.4. В таком случае вам придется получить «Ссылку на скачивание» от владельца файла, размещенного в облачном хранилище (см. Рис.5), которая не является прямой ссылкой на файл, или же поискать способ, как обойти защиту облачного хранилища (к примеру, получить логин и пароль доступа владельца сайта), что является незаконным действием.

Иценко Александр Иванович
