В статье мы расскажем, в каких случаях может понадобиться история сайта, как ее посмотреть. Приведем примеры основных сервисов, которые позволят заглянуть в прошлое страницы. Объясним, как посмотреть сохраненную копию страницы в поисковых систeмах и как восстановить сайт из архива.

Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
● Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
● Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
● Нужно восстановить сайт, когда нет его бэкапа.
● Нужно проанализировать конкурентов. Этот способ понадобится, чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие «фишки» стоит позаимствовать.
● Необходимо посмотреть страницу, если она теперь недоступна напрямую.
● Интересно, как выглядел ресурс 10-20 лет назад.
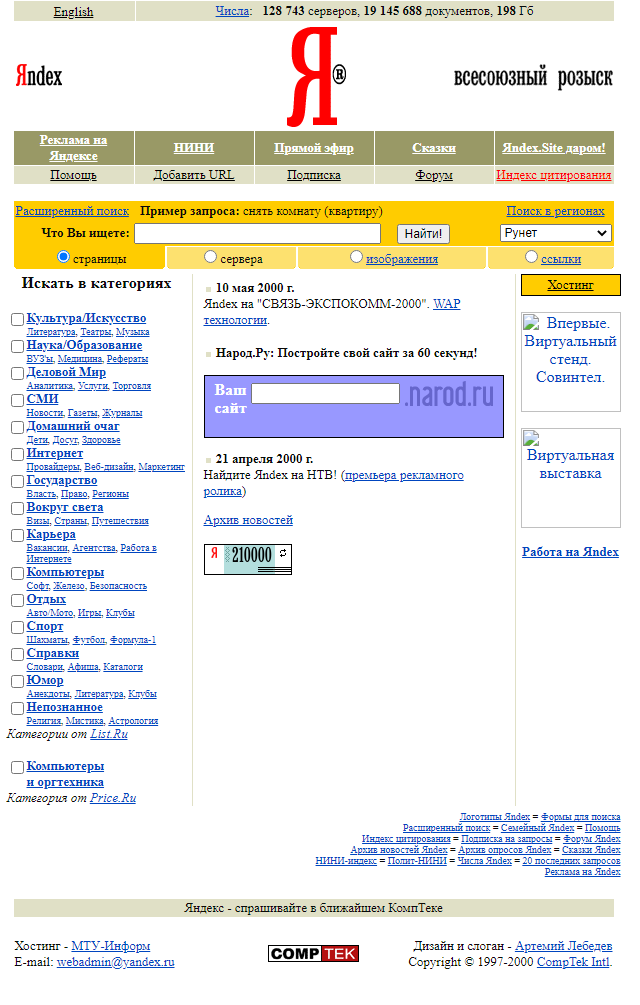
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Как посмотреть сайт в прошлом?
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.
График ниже показывает количество сохранений: первое было в 1998 году.
Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:
Как выгрузить сайт из ВебАрхива, расскажем дальше.
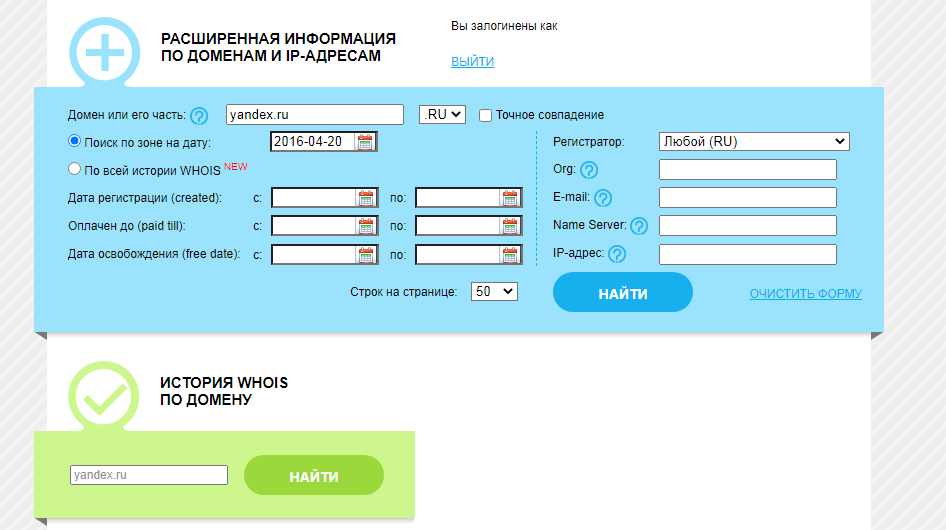
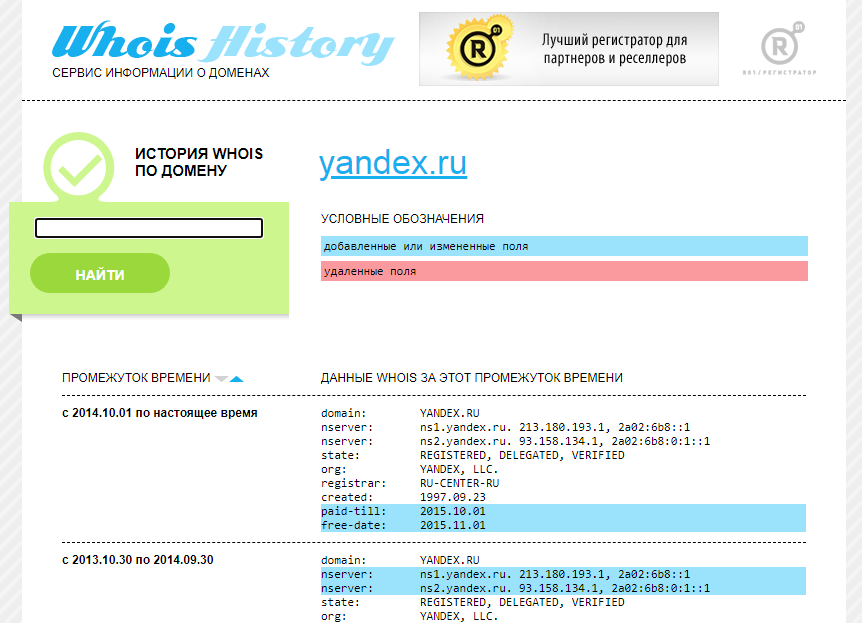
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/и вводим данные в поиске по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
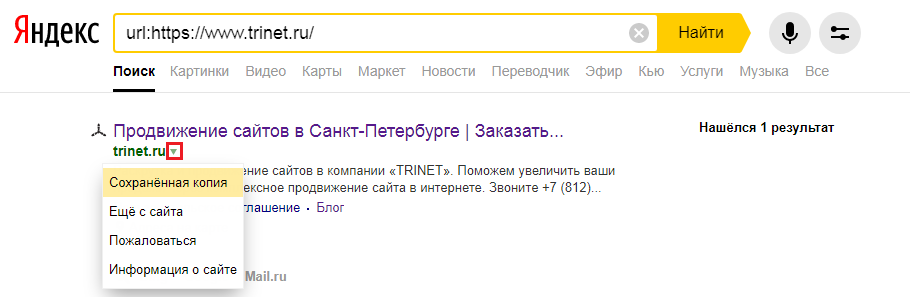
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:
Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
● использовать оператор site:, либо указать сразу необходимый URL
● найти страницу в выдаче
● нажать на стрелочку рядом с URL
● выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/и нажать кнопку «Восстановить».
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента, обращайтесь к нашим специалистам.
И до встречи в следующей публикации!
Find the Wayback Machine useful?
DONATE

deviantart.com
Oct 15, 2013 21:28:20

cl.cam.ac.uk
Feb 29, 2000 18:34:39

foodnetwork.com
Oct 20, 2013 22:40:56

yahoo.com
Dec 20, 1996 15:45:10

spiegel.com
Oct 01, 2013 15:26:30

imdb.com
Oct 21, 2013 16:53:47

stackoverflow.com
Oct 14, 2013 21:22:10

ubl.com
Dec 27, 1996 20:38:47

bloomberg.com
Oct 01, 2013 23:10:45

reference.com
Oct 18, 2013 07:12:58

feedmag.com
Dec 23, 1996 10:53:17

wikihow.com
Oct 21, 2013 20:56:46

nbcnews.com
Oct 21, 2013 17:24:52

goodreads.com
Oct 21, 2013 00:42:42

obamaforillinois.com
Nov 09, 2004 04:28:06

geocities.com
Feb 22, 1997 17:47:51

amazon.com
Feb 04, 2005 00:47:33

nytimes.com
Oct 01, 2013 01:42:36

bbc.co.uk
Oct 01, 2013 00:13:32

huffingtonpost.com
Oct 21, 2013 17:11:12

reddit.com
Oct 01, 2013 03:15:39

cnet.com
Oct 21, 2013 02:07:03

whitehouse.gov
Dec 27, 1996 06:25:41

aol.com
Oct 01, 2013 05:01:31

yelp.com
Oct 19, 2013 02:44:53

etsy.com
Jun 01, 2013 01:38:52

foxnews.com
Oct 01, 2013 01:08:27

well.com
Jan 08, 1997 06:53:37

w3schools.com
Oct 19, 2013 00:55:10

buzzfeed.com
Oct 21, 2013 17:32:21

nasa.gov
Dec 31, 1996 23:58:47

mashable.com
Oct 21, 2013 02:16:14

nfl.com
Oct 21, 2013 07:39:25
![]()
Tools
Banish broken links from your blog.
Help users get where they were going.
![]()
Save Page Now
Capture a web page as it appears now for use as a trusted citation in the future.
Only available for sites that allow crawlers.
Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
- Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
- Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
- Нужно восстановить сайт, когда нет его бэкапа.
- Нужно проанализировать конкурентов. Этот способ понадобится чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие “фишки” стоит позаимствовать.
- Необходимо посмотреть страницу, если она теперь недоступна напрямую.
- Интересно , как выглядел ресурс 10-20 лет назад.
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

График ниже показывает количество сохранений: первое было в 1998 году.

Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.

Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:

Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site:, либо указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.

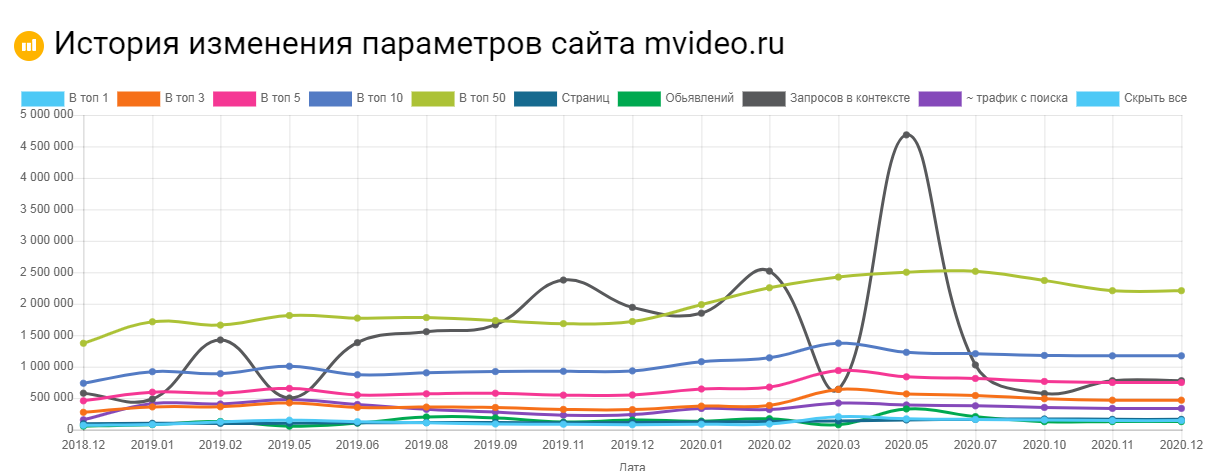
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
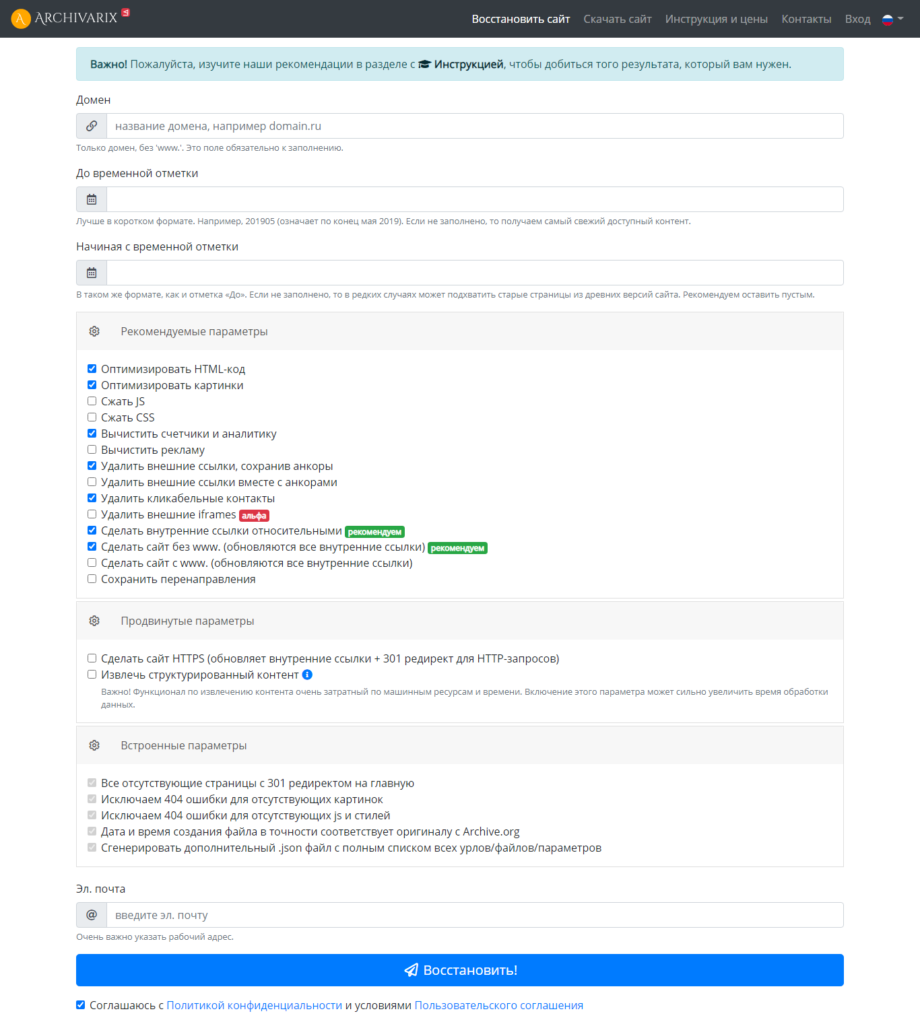
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
Ссылка на сервис https://www.rush-analytics.ru/land/skachivanie-kopiy-saytov-iz-wayback-machine
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
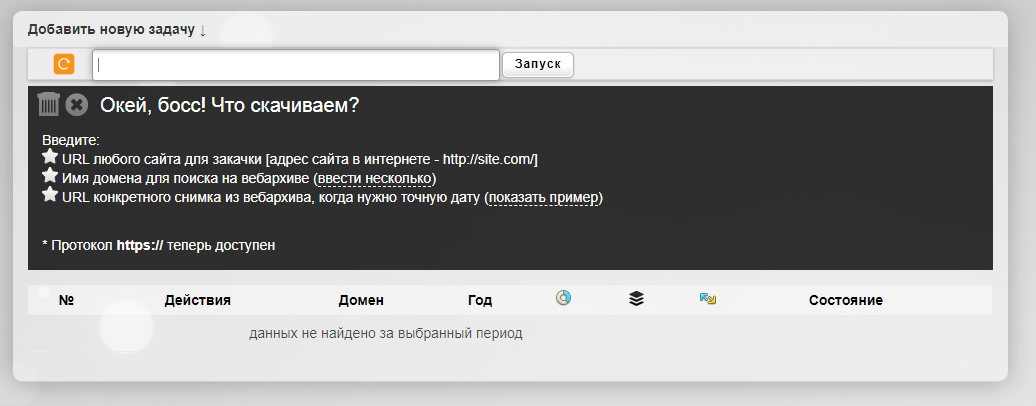
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.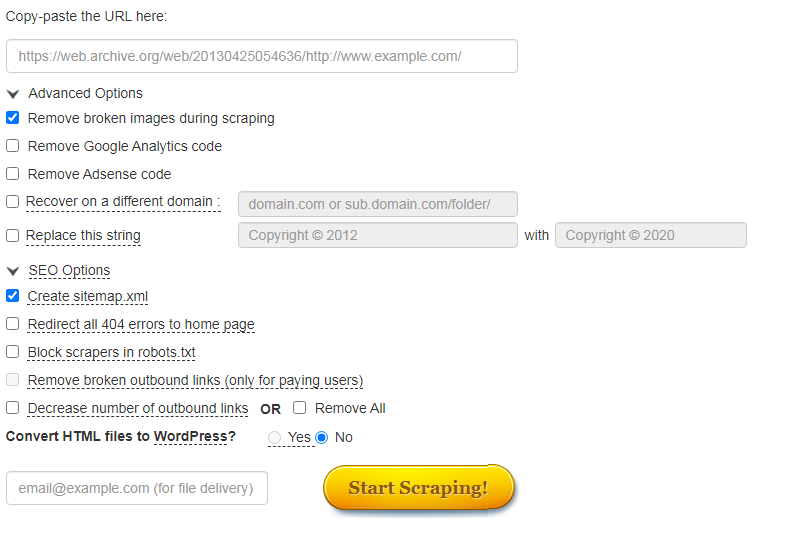
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
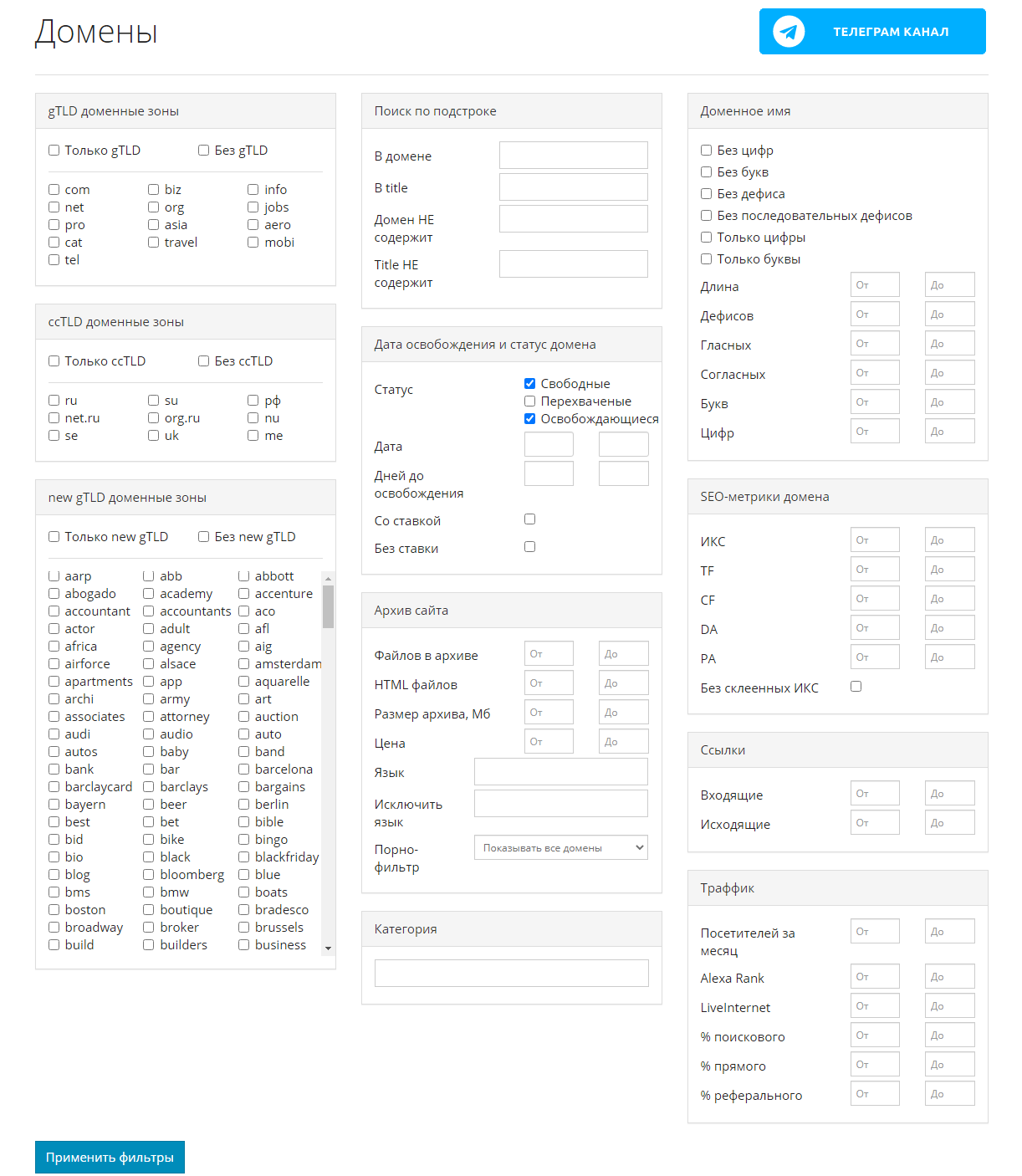
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента или комплексные услуги по продвижению и созданию сайтов, обращайтесь к нашим специалистам.
И до встречи в следующей публикации!
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Веб-архив: импортозамещение
Время на прочтение
3 мин
Количество просмотров 29K
Понадобилось найти старую версию одного сайта. В Wayback Machine (https://archive.org/web/) версии от нужной даты не оказалось, и я решил поискать альтернативные архивы интернетов. В основном находились сервисы, реализующие идею «вы нам дайте URL, а мы его заархивируем» (типа уважаемого мной http://archive.md), то есть совсем не то, что было нужно в данный момент.
И тут вдруг находится искомое — http://web-arhive.ru/ Сначала порадовался за соотечественников, сделавших полезный сервис, но через несколько минут меня начали терзать смутные сомнения…
При внимательном рассмотрении даты создания снимков на archive.org и на web-arhive.ru оказались полностью совпадающими. Поковырявшись ещё, я сделал вывод, что web-arhive.ru представляет собой прокси: получает запрос, пересылает его на archive.org, парсит ответ, вычищает из него интерфейсные куски и все упоминания о Wayback Machine, меняет URL ссылок внутри на свои, заворачивает в собственный интерфейс и отдаёт ничего не подозревающему пользователю.
Интересно, как к этому отнесётся archive.org, когда узнает? Во втором абзаце правил использования сказано: «Access to the Archive’s Collections is provided at no cost to you and is granted for scholarship and research purposes only.»
Сайт выглядит так (с отключённым блокировщиком рекламы):
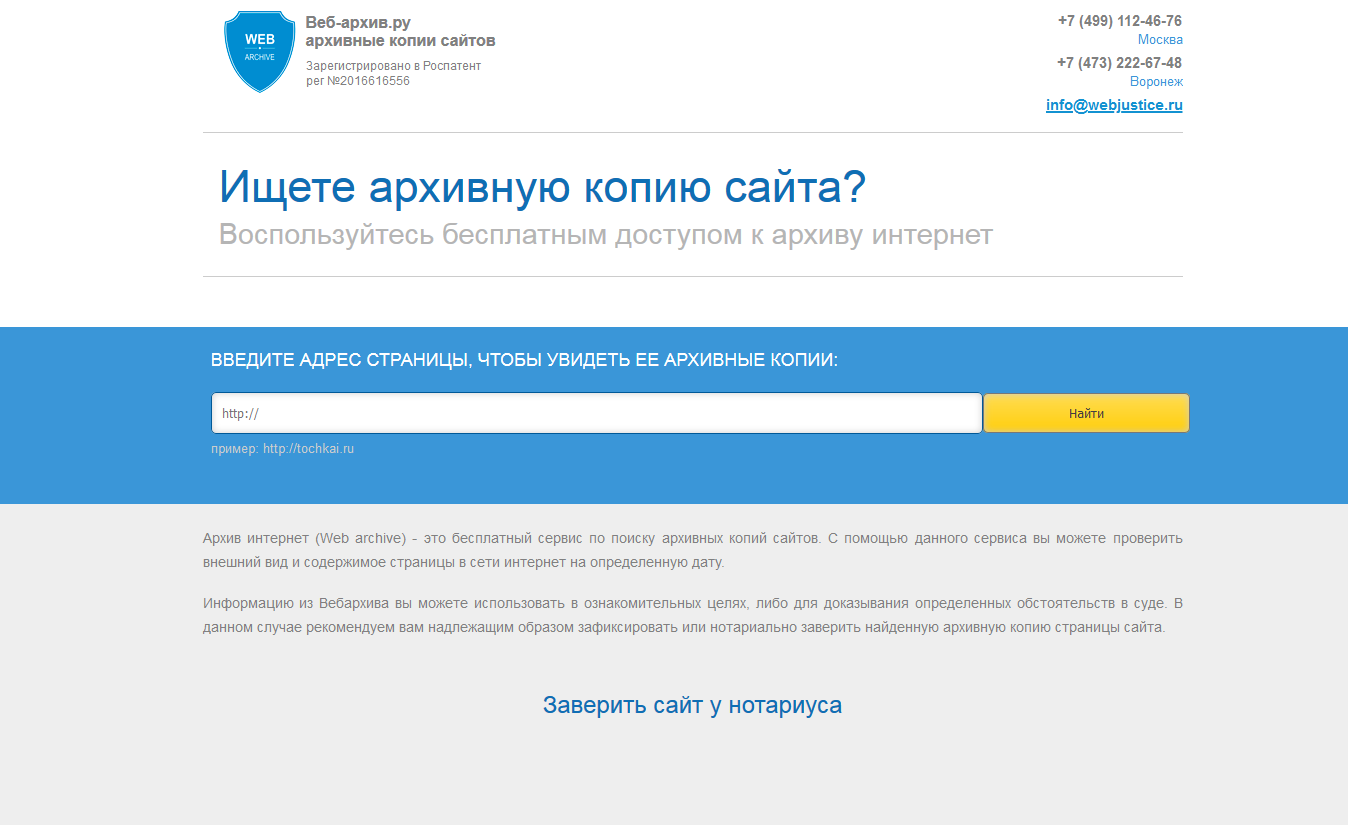
Смысл его существования, видимо, сводится к ссылке «Заверить сайт у нотариуса».
Также в глаза бросается нажористый шильдик «Зарегистрировано в Роспатент, рег №2016616556».
Стало любопытно почитать, что же там зарегистрировано, и…
http://patinfo.ru/files/fips/pevm2016/_TXT/2016616556.txt
РОССИЙСКАЯ ФЕДЕРАЦИЯ
ФЕДЕРАЛЬНАЯ СЛУЖБА ПО ИНТЕЛЛЕКТУАЛЬНОЙ СОБСТВЕННОСТИ
ГОСУДАРСТВЕННАЯ РЕГИСТРАЦИЯ ПРОГРАММЫ ДЛЯ ЭВМНомер регистрации (свидетельства): 2016616556
Дата регистрации: 15.06.2016
Номер и дата поступления заявки: 2016612809 29.03.2016
Дата публикации: 20.07.2016
Контактные реквизиты:
(8-473)222-67-48, bastionvrn@yandex.ruАвторы:
Седых Евгений Николаевич,
Дубинин Сергей ВикторовичПравообладатель:
Седых Евгений НиколаевичНазвание программы для ЭВМ:
Программный комплекс по доступу к архивным копиям сайтов в сети Интернет «Веб-архив.ру» версия 1.0Реферат:
Программный комплекс предназначен для доступа к архивным копиям страниц (сайтов) в сети Интернет, хранящимся в архиве Интернет, в том числе текста, фотоизображений, графических изображений, размещенных на страницах сайтов. Программный комплекс обеспечивает выполнение следующих функций: направление запроса к архиву Интернет в отношении архивной копии страницы, адрес которой задается пользователем в интерфейсе программного комплекса; получение ответа от архива Интернет о количестве, дате и времени архивных копий страницы, адрес которой задан пользователем; отображение архивной копии страницы в сети Интернет в интерфейсе браузера в том виде, в котором данная страница существовала на дату, выбранную пользователем из доступных дат; инициирование процедуры автоматической фиксации информации, отображаемой на архивной копии заданной страницы в виде графического образа (скриншота) заданной страницы.Тип реализующей ЭВМ: Сервер
Язык программирования: РНР
Вид и версия операционной системы: FreeBSD 8.3-STABLE
Объем программы для ЭВМ: 355 Мб
В принципе, всё честно написано про это чудо-ПО (вернее даже, целый программный комплекс, это вам не хрен собачий!) Ах, да, они ещё и скриншотик умеют делать. Ладно, хоть что-то новое от себя привнесли.
Можно было бы и не докапываться особо до них, но:
— они на первых местах в Гугле и Яндексе по запросам типа «веб архив», «архив сайтов», «архив интернета» (где-то сразу под archive.org, а где-то и вообще на первом месте),
— люди воспринимают web-arhive.ru как самостоятельный сервис (например, https://qna.habr.com/q/440257) и публикуют ссылки на архивные страницы на нём,
— разные SEO-информационные сайты говорят про от 600 до 2300 уникальных посетителей в день.
То есть, это не маргинальная фиговина в дальнем углу интернета, а что-то, путающееся у людей под ногами.
Так-то!
UPD
В комментариях жалуются на слово «импортозамещение» в заголовке.
Не воспринимайте его как «по заказу государства». Оно имелось в виду в ироничном смысле. Как по мне, один в один тот случай, когда на мониторах логотипы переклеивали.
