Время на прочтение
9 мин
Количество просмотров 25K
Продолжение (начало – здесь)
1.3. Поисковые системы – специализированные и не очень
В общем случае результаты поиска в первую очередь зависят от поставленной задачи и корректности запроса. Но эти результаты чаще всего, с одной стороны,
а) избыточны
и с другой стороны — б) неполны.
К счастью, и авторы и издатели, как правило, заинтересованы в том, чтобы информация о публикациях индексировалась поисковиками, но тут есть нюансы: не всегда разрешается индексация содержимого pdf-файлов, и в некоторых случаях разрешена индексация сайтов только определёнными поисковиками (например, крупнейшая отечественная электронная библиотека elibrary.ru одно время запрещала для google индексацию большинства файлов).
Кроме всего прочего, результаты запроса зависят от порядка слов и от IP-адреса, с которого осуществляется поиск.
Если говорить о поиске публикаций, то вопрос «какой поисковой системой пользоваться» имеет один ответ – Google (это если не считать специализированные библиографические поисковые системы, о них ниже).
Во-первых, google достаточно полно индексирует содержимое Сети. Во-вторых, большое количество настроек расширенного поиска (в т.ч. с использование операторов) сильно облегчают работу. В третьих, как я уже указывал, содержимое пдф-файлов googl’ом индексируется даже в том случае, когда пдф состоит из изображений и текстовый слой в файле отсутствует.

Ка известно, в гугле любят пошутить. Вот такой у меня однажды вылез результат при попытке найти книгу Pander, C. H. (1830). Beiträge zur Geognosie des Russischen Reiches. St.Petersburg, Karl Kray. 150 S.
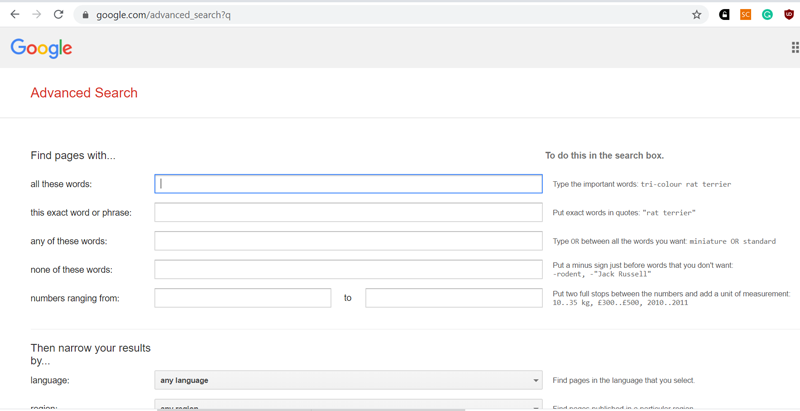
Настройки расширенного поиска google. На Яндексе, к сожалению, большая часть настроек расширенного поиска из имевшихся ранее давно сгинула, остались мелочи типа поиска по расширению файла (только вместо гугловского filetype: используется оператор mime: )
Для поиска публикаций наиболее полезными являются расширенные настройки и операторы, позволяющие ограничивать поиск файлами определённого формата (например, pdf c помощью filetype:pdf ), определёнными сайтами / доменами. Например, если мне понадобится посмотреть, на каких китайских сайтах выложены публикации в формате pdf, где упоминаются аммониты, то поможет вот такой запрос: ammonites filetype:pdf site:cn. Ну а “+” и “-” используются для указания обязательных или нежелательных терминов. К примеру, при поиски информации по головоногим моллюскам — аммонитам обычно не нужны сведения об одноимённом взрывчатом веществе или племени, некогда обитавшем на Ближнем Востоке и регулярно упоминающемся в Библии. Соответственно, запрос можно подкорректировать таким образом: аммониты filetype:pdf -взрывчатка -Библия
Если ищется какая-то конкретная публикация, то желательно часть её названия или всё название взять в кавычки.
Ещё немаловажно, что у гугла есть два отдельных проекта, имеющих прямое отношение к поиску публикаций:
1) Google books – это фактически отдельная поисковая система, индексирующая содержимое огромного количества книг, журналов, сборников и других изданий. При этом существенная часть публикаций доступна для скачивания в виде пдф (как правило, это старые издания, от начала ХХ века и старше); в зависимости от IP список доступных для скачивания изданий может существенно различаться, максимально число работ доступно пользователям из США.
Довольно много публикаций доступно для просмотра целиком или частично. Такие работы можно скачать с помощью специальных программ типа EDS Google Book downloader или плагинов (таких как Greasemonkey для Mozilla в сочетании с программой для автоматической загрузки файлов, например Download Master).
И, наконец, немалую пользу можно получить даже от той информации, которая присутствует в публикациях, которые вообще недоступны для просмотра в каком-либо виде кроме фрагментов в несколько строк (snippet view). С такими публикациями, правда, есть две основные сложности:
а) можно, конечно, попробовать поискать такие работы где-то ещё, но вероятность того что с ними можно будет ознакомиться только в библиотеке довольно велика.
б) в названиях источников (особенно тех, которые исходно даны не латиницей) путаницы очень и очень много, и отображаемая информация обычно неполна.
Тем не менее информация, содержащаяся в таких фрагментах может быть очень важной и практически не находимой другими способами
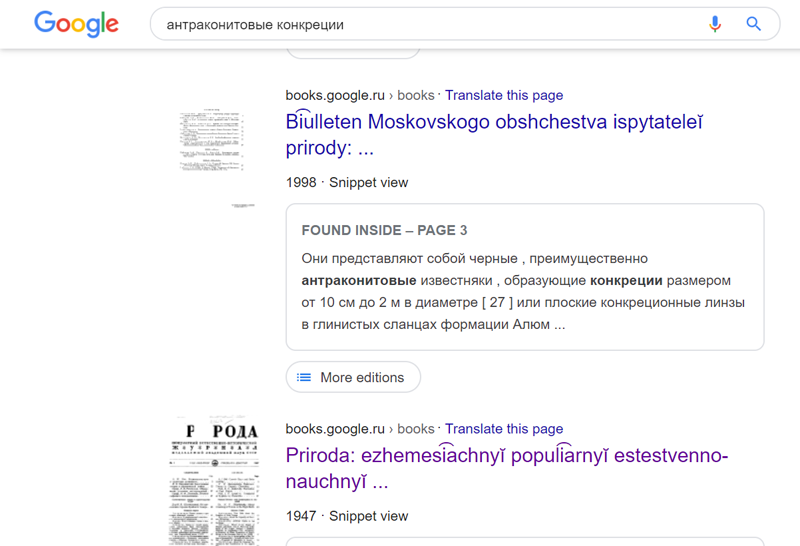
Так выглядит типичный вариант выдачи на google books в формате snippet view: как правило, отсутствует часть нужной библиографической информации (номер выпуска для журнала, иногда — важные части названия издания). Хорошо, если у журнала выходит 2 номера в год. А если 20? А если название указано с ошибкой?
2) Google Scholar (в русскоязычном варианте Академия Google ). Это библиографическая поисковая система, которая неплохо ищет как сами статьи, так и ссылки на них, заодно позволяя сразу скопировать названия публикаций, отформатированные согласно популярным типам цитирования (APA, Harvard, ГОСТ и т.д.). К числу удобств данной системы стоит отнести то, что индексируются не только сайты издателей, но и специализированные социальные сети и самые разные сайты, где нередко безвозмездно выкладываются научные работы, и все ссылки на полнотекстовые версии группируются в единый кластер. Тем не менее, Google Scholar индексирует не все публикации – это легко проверить с помощью идентичного поискового запроса «ключевые слова» filetype:pdf в Google и Google Scholar. Особенно это ярко это различие проявляется с редко встречающимися ключевыми словами.
Ну а наиболее полезная функция google scholar – это возможность подписки на самые разные оповещения (об этом подробнее — в продолжении данного поста)
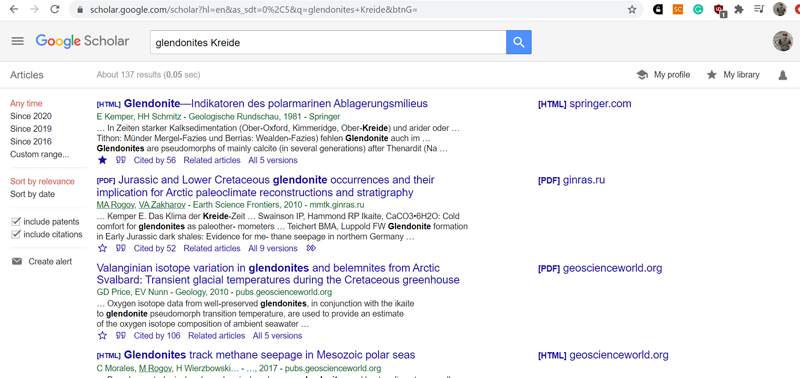
Выдача поиска по ключевым словам на google scholar. Обратите внимание на варианты сортировки, возможности выбора временного диапазона и кластеры статей.
Библиографические поисковые системы (БПС), ориентированные на работу с публикациями, сейчас весьма разнообразны и многочисленны. Кроме перечисленных выше проектов Google можно отметить следующие сайты, которые могут рассматриваться как БПС:
1) сайты, индексирующие огромное количество публикаций по всему миру. В первую очередь это Scopus и Web of Science, доступные по подписке (в случае со Scopus доступ также предоставляется рецензентам Elsevier’овских журналов), а также крупнейший сайт, присваивающий DOI публикациям (CrossRef) или агрегатор информации о публикациях, грантах, исследователях и т.д. Dimensions.
Все они кроме Dimensions позволяют искать информацию по ограниченному массиву данных – это преимущественно название / ключевые слова / резюме. В худшую сторону тут выделяется CrossRef – там поиск идёт только по названию, причём со строгой привязкой к форме слова. Правда, в CrossRef существенно больше проиндексировано русскоязычных публикаций, чем в других БПС из этого пункта, и плюс к тому это наиболее удобный способ решить задачу типа «у меня есть название публикации, надо найти её DOI» (все DOI так не найти – это не единственный регистратор цифровых идентификаторов к публикациям, есть ещё DataCite, например – но универсального сервиса для решения такой задачи, как ни странно, просто нет).
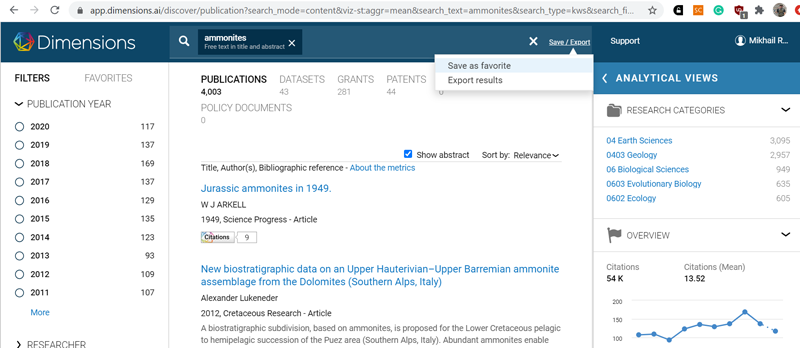
Простой поиск в Dimensions
Dimensions – совсем недавно появившийся очень интересный проект, в первую очередь благодаря множеству самых разнообразных настроек, широкому охвату публикаций (индексируются только публикации с DOI, их пока немного меньше чем есть на CrossRef) и полнотекстовому поиску. Вернее, тут можно выбирать разные опции поиска (полнотекстовый / по резюме / по названию и ключевым словам). Результаты можно сортировать самыми разнообразными способами (дата / релевантность / число ссылок / число альтметрик), и ограничивать по разным параметрам (источник / автор / годы / тематика и многое другое ). У Dimensions есть разные версии (включая платную и корпоративную), здесь рассматривается только бесплатный вариант (с другими пока не доводилось иметь дело). Отдельно можно искать информацию как по публикациям, так и по базам данных и грантам (последняя опция доступна только по подписке).
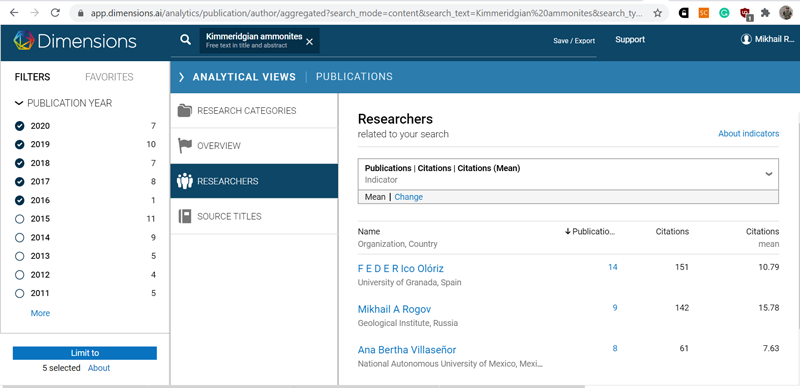
Во вкладке Analytical view можно посмотреть, например, кто или в каких журналах публиковался по интересующей нас тематике в то или иное время (в данном случае — с 2016 по 2020 годы). Ну а нажав на фамилию автора, можно посмотреть с кем вместе он публиковался, в каких журналах и т.д.
Дополнительные опции предлагаются во вкладке Analytical view. Они позволяют легко понять, кто сейчас или в любом выбранном временном диапазоне занимается той или иной тематикой, в какие журналы эти люди пишут статьи и с какими соавторами. Это удобный способ для поиска потенциальных соавторов и рецензентов, особенно для тех, кто только начал заниматься какой-либо тематикой и не очень хорошо себе представляет что с ней в мировом масштабе делается. Для тех исследователей, у которых в статьях имеется ORCID, в профиле приводится и этот идентификатор, и Scopus author ID, а также (при наличии) цепляющийся к ним «автоматом» ResearcherID / профиль на Publons. Повторюсь – Dimensions это крайне полезный проект, причём интуитивно понятный. Можно просто тыкать на все кнопки подряд и залезать во все вкладки.
2) также в качестве специализированных БПС можно рассматривать сайты крупнейших международных издателей (Elsevier, Wiley, Springer, Taylor & Francis и т.д.) и распространителей (Ingentaconnect, GeoscienceWorld) научных изданий. Впрочем, ограничение результатов поиска тем или иным издателем или распространителем на пользу, как правило, не идёт и скорее может быть полезно для того, чтобы кратко ознакомиться с той или иной темой.
3) в какой-то мере функции БПС выполняют научные социальные сети (Academia.edu, ResearchGate ), а также «гибрид» социальный сети и библиографического менеджера Mendeley (доступна как оффлайн-версия в виде программы, так и её онлайн-вариант; сейчас, после покупки Mendeley компанией Elsevier там доступны многие опции Scopus). Впрочем, содержимое научных социальных сетей хорошо индексируется googl’ом, и тут разве что есть смысл регулярно просматривать ленту обновлений в поисках чего-нибудь совсем нового.
4) в отдельную категорию БПС можно выделить региональные или специализированные сайты, где в основном имеются данные о публикациях, изданных в какой-либо стране или нескольких странах (например, Национальная электронная библиотека elibrary.ru в России, Национальный институт информатики в Японии, Национальная библиотека Франции ), а также специализированные сайты, посвящённые каким-то конкретным научным направлениям (например, BiodiversityHeritageLibrary (BHL))
Характерной особенностью таких порталов является то, что они крайне неохотно дают индексировать своё содержимое сторонним поисковикам, так что если нужно найти что-то французское или японское – надёжнее заглянуть на соответствующие сайты и поискать там.
До недавнего времени на сайте Национальной библиотеки Франции весь интерфейс был франкоязычный, пока они туда в конце концов не приделали сначала англоязычную версию сайта, а затем и автоматический перевод по IP
Отдельно следует сказать про BHL. Это крайне полезный проект для всех исследователей, которые так или иначе связаны с изучением современных или ископаемых организмов. Данную библиотеку отличает широкий охват источников (включая разные редкости) и наличие специальных поисковых инструментов (таких как поиск по таксону во вкладке Advanced search – если кто-то собирает материалы по той или иной группе животных и растений, это очень хороший способ быстро найти публикации по теме). Из недостатков BHL можно отметить то, что нередко текстовый слой может быть распознан неверно (с ошибочно выбранным языком), а также чудовищное качество иллюстраций по умолчанию (качество плохого размытого .djvu ).
Поскольку для таксономических исследований качество изображений обычно имеет большое значение, то здесь наиболее правильным подходом является скачивание нужной публикации в формате jp2, а потом – обработка файлов (сначала переформатирование в обычный jpg / tiff, потом обработка ScanTailor и OCR). Кстати, все публикации с BHL размещаются на archive.org, и иногда удобнее проводить полнотекстовый поиск именно по archive.org (это может быть актуально в случае поиска каких-либо редкостей – тут может попасться кое-что интересное, в том числе загруженное пользователями.
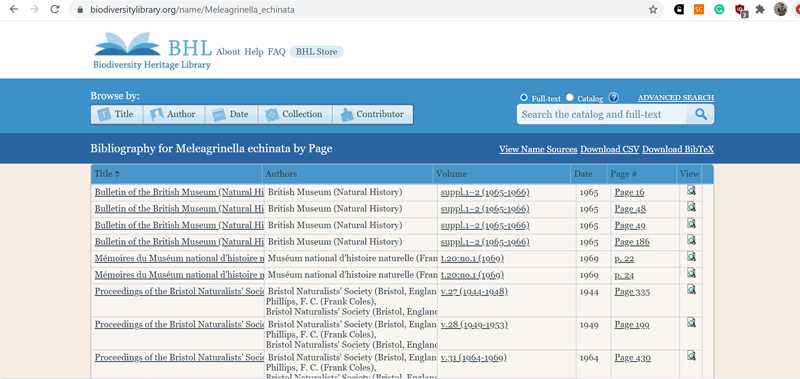
Пример выдачи при поиске по таксону на BHL
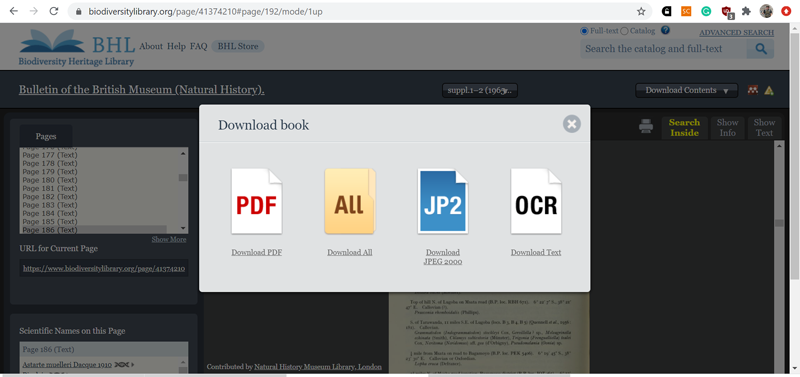
Если нужен качественный пдф — лучше сохранить файл способом «Download Content — Download book — Download JPEG 2000», а потом обработать
И, конечно, в случае необходимости найти русскоязычные публикации не обойтись без поиска в elibrary в сочетании с cyberleninka. Хотя в elibrary охват источников намного больше, регулярно встречается ситуация, когда в elibrary за ту или иную статью предлагают заплатить – а на сайте Киберленинки та же статья лежит в отрытом доступе.
Несмотря на ряд недостатков, заложенных в elibrary, кажется, с рождения (отсутствие возможности скачать даже работу открытого доступа без ввода логина / пароля; отсутствие англоязычной версии и опции подписки на те или иные обновления) поиск там достаточно приличный. Но если есть необходимость регулярно отслеживать информацию по русскоязычным журналам, стоит сделать также отдельный каталог ссылок на сайты необходимых изданий – на elibrary не угадаешь, когда и почему они могут вдруг закрыть доступ к тем или иным изданиям. И ещё один момент – в том случае, когда журнал отсутствует в открытом доступе и распространяется только за деньги как через elibrary, так и через сайт издательства, то на сайте издательства статьи могут быть дешевле (такова ситуация, например, с журналом «Нефтяное хозяйство»).
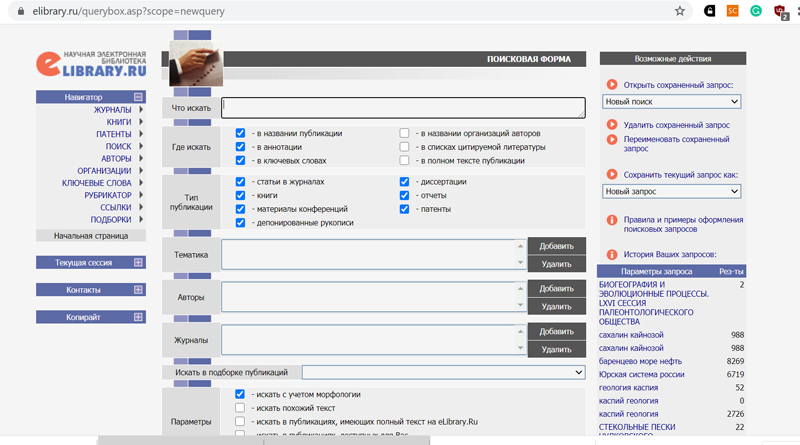
Настройки расширенного поиска на elibrary (на заглавной странице сайта — слева сверху ссылка «расширенный поиск»). Здесь же сохраняется история предыдущих поисковых запросов
5) в качестве БПС можно рассматривать и крупнейшие «пиратские» проекты, обеспечивающие свободный доступ к научным публикациям – SciHub и LibGen, поскольку на них в том или ином виде реализована возможность поиска по названию публикации или ключевым словам.
И если sci-hub может быть скорее использован в качестве удобного дополнения к поиску на Dimensions, то на LibGen регулярно появляются редкие монографии, которых в других местах нет – они сканируются энтузиастами и размещаются на ЛибГене в частном порядке.
И напоследок отдельно стоит сказать про поиск диссертаций. Хотя многие диссертации (как современные российские, так и иногда достаточно старые зарубежные) выложены в Интернете в открытом доступе и индексируются поисковиками, для получения информации о свежих диссертациях, которые только планируется защитить, имеет смысл заглядывать на сайт ВАКа. Там сейчас диссертации можно искать по специальностям, ключевым словам, дате защиты и другим параметрам (при этом отдельно поиск ведётся по ВАКовским диссертациям, а отдельно – по тем, которые защищаются на советах организаций, обладающих правом самостоятельного присуждения степеней). Но есть нюанс – если у вас установлен uBlock Origin, то он блокирует поиск по данному сайту.
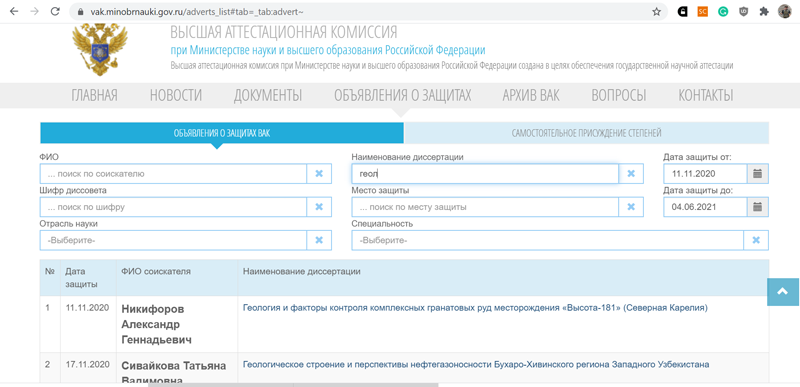
Пример поиска по сайту ВАК
Продолжение: часть 3
Полнотекстовый поиск осуществляется по названиям статей, авторам, аннотациям, ключевым словам, а также по распознанным текстам (OCR). Возвращаются только первые несколько сотен релевантных документов, поэтому если вы не нашли то что хотели на 4-5 странице, попробуйте уточнить свой поиск с помощью языка запросов. Кроме того, результаты поиска сортируются по релевантности, а не по дате. Чтобы найти новые статьи, попробуйте использовать фильтр по годам для отображения недавно опубликованных научных статей, отсортированных по релевантности. Чтобы найти статьи, относящиеся к конкретной научной области или опубликованные в конкретном журнале, попробуйте использовать фильтры по теме каталога OECD или журналу.
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Где искать научные статьи и работы для своих исследований

«КиберЛенинка»
https://cyberleninka.ru/
Один из самых известных образовательных сайтов в Рунете. Система выстроена на основе собственной программы, задача которой – популяризация науки в целом и научной деятельности в частности.
В каталоге представлены основные дисциплины, он регулярно пополняется публикациями из журналов с индексированием ВАК и РИНЦ. Большая часть статей – на русском языке. Ресурс бесплатный, необходима регистрация.
«eLibrary»
https://elibrary.ru/
Сюда активно вносятся статьи из журналов ВАК и РИНЦ. В новостном блоге всегда можно узнать последние новости о прекращении индексирования. Просмотр большинства статей является бесплатным, но необходима предварительная регистрация.
Для просмотра отдельных статей необходимо предварительно получать специальный пароль организации или учебного заведения. В некоторых университетах публикация материалов на этом сайте студентами и их научными руководителями считается обязательным этапом к лицензированию учебных кафедр и всего вуза.
Читать далее: Публикация статей РИНЦ
«Scholar.ru»
http://www.scholar.ru/
Российская электронная база научных публикаций, в которой можно искать необходимый журнал и работать бесплатно в режимах простого и расширенного поиска. Сайт индексирует любую статью или исследование, рефераты диссертаций и монографии. Для работы необходима предварительная регистрация.
«Math-Net.ru»
http://www.mathnet.ru/
Сайт заявлен как общероссийский математический портал, в котором будущие и действующие математики и другие специалисты по техническим направленностям могут получить информацию по своей сфере. Работа портала ведется с 2006 года.
Доступ к большей части изданий бесплатный, но посмотреть их можно при наличии зарегистрированного аккаунта. Система объединяет больше 100 индексируемых журналов на русском языке. Также размещены семинары и конференции.
«ЭБС «Университетская Библиотека Онлайн»
http://biblioclub.ru/index.php?page=book_blocks&view=main_ub
Университетская электронно-библиотечная система предоставляет бесплатно доступ к первоисточникам для студентов учебных заведений. Помимо журналов, база данных, содержит справочники, словари, энциклопедии, а также аудио- и видеоматериалы.
«Российская государственная библиотека»
https://www.rsl.ru/
Научный сайт внедрил с недавнего времени обновленный алгоритм поиска в собственном каталоге для того, чтобы узнавать много полезной информации для изучения различных отраслей. В свободном доступе есть огромная коллекция авторитетных статей и научных работ, которые можно почитать в режиме онлайн.
Чтобы найти нужное издание, нужно ввести в поиске ключевые слова, например ФИО автора или точное название статьи. К сожалению, не все издания оцифрованы в электронный формат. К тому же даже в здании библиотеки в Москве нельзя брать некоторые оригиналы на дом.
Ссылки по теме: Публикация статьи в журнале ВАК
«Индикатор»
https://indicator.ru/
Международный проект о науке в России и мире на русском языке. Помимо каталога статей, портал активно заполняется новостями по тематикам. Цифровая энциклопедия распределена по тегам, в которой размещены результаты дискуссионных клубов и достижения научной деятельности.
«Академия Google»
https://scholar.google.com/
Это уникальная платформа для научных специалистов, в которой можно находить, смотреть и определять интересные работы в режиме «открытый доступ». В этом поможет грамотно составленный алгоритм поиска. Работы можно экспортировать на рабочий стол или самому загрузить в базу и опубликовать, имея лишь активный Google-аккаунт.
«ScienceResearch»
https://www.scienceresearch.com/scienceresearch/desktop/en/search.html
Англоязычный сервис, который на платной основе способен помочь вести поиск публикаций иностранных ученых. Сервис предоставляет библиографическое описание.
Автор:
![]()
Читайте также
Рано или поздно перед каждым из нас появляется важный вопрос: как найти качественную информацию и не оплошать с недостоверными источниками? Информации в Сети много, но вот её релевантность слишком важна, чтобы использовать первый попавшийся источник как истину в последней инстанции. На самом деле, это не так сложно. Давайте разбираться!
[Upd]: Из-за технической неполадки пришлось с помощью администрации сайта и подсайта распубликовать статью, чтобы всё исправить. Изменений в материале нет.
Конечно, если просто необходимо найти какое-то определение или произвести уточнение уже имеющихся данных, можно просто воспользоваться Гуглом (или любой другой доступной поисковой системой), но, когда речь заходит о более серьёзных изысканиях, на них уже нельзя всецело полагаться.
Стоит отметить, что данная статья посвящена поиску достоверной научной информации в виде статей, диссертаций, журналов и прочей специализированной литературы. Она рассчитана на людей, которые нашли какую-то интересную научную информацию и желают проверить её релевантность.
Где и как стоит искать информацию?
Для начала, необходимо определить, что именно Вас интересует – научные статьи или патенты.
Для описания первого случая стоит ввести условные обозначения:
[1] – Индексирует русскоязычные источники информации (РИНЦ);
[2] – Не индексирует русскоязычные источники информации;
[3] – Интерфейс поддерживает русский язык;
[4] – Интерфейс на английском языке;
[5] – Для использования необходима регистрация.
А теперь, после указания всех ключей, можно перейти к списку источников:
-
Научная электронная библиотека. Это российский информационный портал, в котором собраны электронные версии журналов по теме технологии, науки, химии, медицины и образования. [1, 3, 5]
- Академия Google. Поисковая система научной электронной литературы от Google. Максимально проста и удобна в использовании. В результатах поиска выдаёт ссылки на различные журналы/статьи/диссертации/рефераты и многое другое, что может послужить источником информации. [1, 3, 4]
- Поисковая система научных публикаций. Не хранит полные тексты научных статей, зато выдаёт ссылки на публикации вместе со всей информацией (автор, дата публикации, аннотации, DOI). [3]
- ПоискВАК. Ищет публикации из перечня ВАК старого списка. [1, 3]
- ScienceDirect. Является крупнейшим в мире ресурсом информации о науке, технологии и медицине. Часть журналов находятся в свободном доступе. [1, 4]
- Science Research Portal. Способна производить полнотекстовый пойск. Содержит множество крупных издательств – Elsevier, Highwire, IEEE, Nature, Taylor & Francis и др. Может искать информацию в открытых научных базах данных. [1, 4]
- CiteSeer Publications ResearchIndex. Индексирует статьи в формате PDF. Многие статьи можно бесплатно скачать. Также способная выдавать информацию о публикации (автор, дата публикации, аннотации, DOI). [4]
-
Ingenta. Включает в себя описание англоязычных научных статей. Пополняется начиная с 1988 года и имеет в своей базе более 13 миллионов записей. [2, 4]
-
Scopus. Огромная база данных, индексирующая более 22 тысяч различных журналов. Есть издания на русском языке. В свободном доступе только каталог авторов. [2, 4, 5]
-
CAS Source Index (CASSI) Search Tool. Представляет собой ресурс по поиску информации о журналах, индексируемых CAS (Chemical Abstracts Service), начиная с 1907 года (аббревиатура и полное название, ISSN и др.). [4]
-
Википедия. Как мы все знаем, Вики – свободно редактируемый источник информации, но в конце интересующей Вас статьи может быть приведён список используемой литературы, по которой можно произвести дальнейший поиск. [1, 3, 4]
Как скачать статью, если её нет в открытом доступе?
Ответом на этот вопрос послужат 2 всем известных источника:
- Sci-hub
- Library Genesis
Если интересующей Вас статьи нет в свободном доступе, то узнав DOI и введя его в строке поиска первого источника, можно получить доступ к необходимой информации.
При использовании второго источника достаточно в строке поиска указать автора или название статьи.
Патентный поиск
Это более сложный метод поиска информации, включающий в себя отбор документов и данных касательно определённой темы. Обычно требует много времени и сил. А если этим занимается какая-то специализированная организация, ещё и много денег.
Для него так же существуют собственные базы данных:
-
Федеральный институт промышленной собственности. Есть бесплатный ограниченный доступ к базам. Получить его можно зайдя в кабинет на странице поиска используя в качестве логина и пароля слово «guest», написанное строчными буквами.
-
Всероссийский институт научной и технической информации (ВИНИТИ). Доступ платный.
-
Международный центр научной и технической информации (МЦНТИ). Есть бесплатный доступ.
-
Государственная публичная научно-техническая библиотека (ГПНТБ). Предоставляет бесплатный поиск в базах данных, в том числе к базам авторефератов диссертаций.
- Всемирная организация по интеллектуальной собственности.
-
Европейская патентная организация.
P.S. Автор не агитирует использовать пиратские методы получения научных статей или информации и напоминает, что очень важно поддерживать издательства – так они смогут и дальше выпускать научную литературу. Эта информация является совершенно открытой.
P.P.S. Напоминаю о существовании прекрасного Дискорд-сервера, где всем начинающим авторам окажут посильную поддержку.
«Лайфхакер» рассказывает об основных принципах подбора и тестирования идей, а ещё о сервисах, которые в этом помогут.
Когда речь заходит о темах, SEO-специалисты обычно составляют семантическое ядро, то есть полный перечень поисковых запросов, которые охватывают тематику сайта. Но если медиа пишет обо всём, ядро может насчитывать миллионы ключевых слов. Собирать его и группировать запросы долго и трудно, без помощи профессиональных сеошников тут не обойтись. Да и пользоваться таким массивом информации не очень удобно.
Если вы пока не готовы нанимать SEO-специалистов и хотите только поэкспериментировать с поиском, посмотреть, сколько трафика он может приносить, попробуйте подбирать темы вручную, точечно. Это даст свои плоды.
«Лайфхакер» начал использовать эту стратегию 5 лет назад. С тех пор мы написали 4 тысячи статей, которые приносят в месяц до 17 млн сеансов только из поиска. Мы много экспериментировали и, конечно, не всегда успешно. Да, какие-то материалы не выстрелили, а какие-то стали постоянными источниками трафика. Например, подборка рецептов домашнего майонеза привлекла с 2018 года около 3 млн посетителей из поиска, а советы о том, как понизить давление, — почти 4 млн.
Алина Машковцева, Шеф-редактор «Лайфхакера»
Какие темы надо искать
Если говорить точнее, наша задача — найти ключевые слова, которые люди чаще всего вводят в поисковую строку браузера. И важно помнить, какие варианты тут могут быть.
Самые разные
Если вы только начинаете реализовывать поисковый потенциал, нормально использовать очевидные запросы. Но рано или поздно они закончатся и придёт черёд самого интересного — исследования того, какие ещё темы могут приносить трафик из поиска.
Так вот, практически любые. Потому что люди ищут разное, в том числе очень неожиданное.
Например, первые шаги большинство из нас сделало в возрасте около года. Кажется, что ходьба-то простое и понятное занятие. Тем не менее вопрос, как правильно это делать, задают «Яндексу» 857 раз в месяц.
Поэтому экспериментировать во всём, что касается контента, в принципе хорошая привычка.
Довольно узкие
Чаще всего пользователи ищут что-то конкретное. Чтобы они нашли это именно на вашем сайте, нужно попытаться думать как они. Причём ещё на этапе подбора темы.
Например, вряд ли получится написать хороший текст под ключевое слово «фильмы». Ведь совсем непонятно, что должно быть внутри и как привести содержание в соответствие с запросом пользователя. Зато «фильмы о маньяках», или «фильмы, получившие „Оскар“», или «лучшие фильмы 2021 года» — это совсем другое дело. Начинка понятна и автору, и читателю.
Если вам кажется, что вы нащупали гениальную тему, не поленитесь сходить с ней в поисковик и просмотреть хотя бы первую страницу выдачи. Предложения там не обязательно соответствуют вашему ключу на 100%. Зато они показывают, что и как ищут ваши потенциальные читатели. Роботы хорошо угадывают потребности людей, потому что анализируют большой массив данных. И если вы хотите привлечь как можно больше посетителей, пренебрегать этими сведениями не стоит.
Информационные
Вообще, ключи можно разделить на три вида:
- Информационные. В этих случаях пользователям нужны какие-то сведения, инструкции. Например, о том, как приготовить кабачки, избавиться от тараканов или выбрать лучшее облачное хранилище.
- Коммерческие, или транзакционные. Люди хотят не слов, а конкретных предложений, где можно что-то купить, заказать, скачать и так далее. Эти глаголы, однокоренные слова, а также «цена» и указание на город, например «торты в Москве», — признаки того, что в выдачу со статьёй не пробиться.
- Остальные. По этим ключам непонятно, что нужно пользователю. Например, человек вводит «кондиционер в машину». Но что он собирается с ним делать? Купить? Выбрать? Установить?
Информационные ключи — то, что нужно медиа. Транзакционные стоит оставить магазинам. Даже если ваша инструкция случайно и попадёт в коммерческую выдачу, вряд ли она заинтересует пользователя. Он не за этим пришёл в поисковик. А значит, трафика не будет.
Ещё можно рассмотреть ключи из группы «Остальные», потому что в выдаче обычно предложения компаний чередуются со статьями.
Естественно, мнения поисковых систем по поводу вида запроса могут отличаться от вашего. Поэтому проверяйте выдачу вручную или пользуйтесь специальными сервисами. Например, «Проверка ключевых слов на коммерциализацию» от Александра Арсёнкина бесплатно показывает, что думает «Яндекс».
Запрос «купить кондиционер» сервис счёл коммерческим с показателем в 100% (что было предсказуемо), а «выбрать кондиционер» — напротив, информационным. Соответственно, для медиа лучше подойдёт второй вариант.
Ещё один инструмент Арсёнкина подсказывает, сайтов каких типов больше в топ-10, топ-20, топ-30 по вашему запросу. Выдачу «Яндекса» сервис проверяет бесплатно, Google — по подписке.
Где искать идеи материалов для поиска
Имейте в виду: большая часть инструментов, о которых мы будем говорить дальше, показывает прошлое. Чтобы писать о трендах, нужно следить за инфополем и изучать Google Trends.
В голове
Это самый очевидный источник идей. Тексты, ориентированные на поисковики, отвечают на вопросы людей — таких же, как вы. Так что, если периодически притормаживать свой поток мыслей и вычленять из него ключевики, это уже может привести к появлению множества полезных статей.
Записывайте идеи, даже если они кажутся странными или наивными. Во-первых, людей интересует разное. Во-вторых, идею можно докрутить. Но об этом чуть ниже.
Начните с собственных мыслей в любом случае. Это облегчит использование многих сервисов.
В сервисе «Подбор слов» от «Яндекса»
Инструмент, также известный как «Яндекс.Вордстат», помогает одновременно искать идеи и оценивать их потенциал.
Если вписать в поле ввода сервиса слово или фразу, то в левой колонке он покажет все известные «Яндексу» запросы, содержащие этот ключ. В правой колонке — похожие на него варианты.
Если кликать по каждому из ключевиков, можно увидеть ещё больше запросов, связанных с каждым из них. Но имейте в виду: по числам рядом с запросами оценивать перспективность темы нельзя. Они обозначают сумму показов разных вариантов. Так, число рядом с фразой «фильмы про любовь» — это совокупность показов по всем запросам с этими словами: «русские фильмы про любовь», «смотреть фильмы про любовь» и так далее.
Иногда бывает, что идея текста очень масштабная и её хочется сузить. Но непонятно, в какую сторону копать. Например, вы планируете написать про лучшие настольные игры — но какие? В этом случае (и в любом другом, если хочется посмотреть многословные запросы) возьмите фразу в поле ввода в кавычки. А внутри них повторите существительное, глагол или вообще местоимение или предлог два, три и больше раз — столько, сколько слов вы хотите видеть в запросе.
Например, в ответ на запрос «лучшие настольные игры для для для» сервис покажет ключевики из шести слов, где три — «лучшие настольные игры», а остальные — подобранные «Вордстатом» для них как популярное добавление: «для компании взрослых», «для всей семьи» или «для 7 лет».
В «Планировщике ключевых слов» от Google
Чтобы пользоваться этим инструментом, нужно зарегистрироваться в Google Ads. При этом среднее число показов будет представлять собой вилку с довольно большим разбросом.
И всё же сервис может стать хорошим источником новых идей. Ведь он работает немного по другим алгоритмам, чем «Яндекс.Вордстат».
В Ubersuggest
Идеальный вариант для тех, кому не хочется регистрироваться в Google Ads, — сервис от известного онлайн-маркетолога Нила Пателя. Бесплатная версия Ubersuggest позволяет получить довольно много информации.
Введите в разделе Keyword Ideas идею, которую хотите проработать.
Во вкладке Related появятся ключи, содержащие ваше слово или интересующую фразу. В колонке Volume — количество запросов в течение месяца. Если кликнуть на стрелку, вы бесплатно получите выгрузку топ-10 выдачи Google по запросу.
В поисковых подсказках «Яндекса», Google и YouTube
Когда вы начинаете что-то вводить в поисковике, он пытается угадать, что вы ищете, и предлагает варианты. Алгоритм делает это на основании истории поиска, вашего региона и трендов. Последнее особенно интересно: благодаря подсказкам можно найти запрос, который набирает популярность, и прокатиться на гребне волны хайпа.
Если не хочется искать подсказки вручную, есть сервисы. Например, Serpstat. В бесплатной версии можно выбрать раздел «Поисковые подсказки» и проверить, какие слова соседствуют с началом ключевой фразы.
Среди фраз-ассоциаций поисковых систем
Алгоритмы пытаются не только предугадать, но и уточнить ваш запрос. Поэтому внизу поисковой страницы появляются ассоциативно связанные с изначальным ключевиком фразы. Не исключено, что именно там скрываются идеи для ваших будущих статей.
У конкурентов
После выхода книги Остина Клеона «Кради как художник» стало нестыдно признаваться, что можно подсматривать чужие идеи и трансформировать их во что-то более прекрасное. Чем и стоит заняться, если свежие мысли перестали приходить в голову.
Все прекрасно понимают, как это делать вручную: читайте чужие сайты и думайте, что хорошо бы смотрелось на вашем. Но можно использовать и специальные сервисы. Об этом поговорим подробнее.
Для начала стоит определиться с конкурентами. Чем более нишевыми будут сайты, тем проще будет с ними работать: почти не придётся отсеивать нерелевантные ключи. Из этого вытекает следующая рекомендация: если вы пишете на разные темы, ищите конкурентов в каждой нише в отдельности.
Определять подходящие варианты можно тремя способами:
- Использовать специальные сервисы. Например, SimilarWeb позволяет вбить в поисковую строку адрес сайта и увидеть конкурентов на вкладке Competitors. Аналогично работает SE Ranking. Когда речь идёт о нишевом сайте, эти инструменты могут помочь. Но если говорить о «Лайфхакере», конкурентами оказываются такие же медиакомбайны.
- Изучать рейтинги. Например, Liveinternet и Rambler. В них можно выбрать тематику и посмотреть наиболее популярные сайты по ней.
- Вручную перебрать общие запросы, а потом обратиться к сервисам. Самый действенный способ, одновременно и самый сложный. Нужно придумать несколько запросов, связанных с конкретной тематикой, вбить их в Google или «Яндекс» и посмотреть, какие сайты находятся в выдаче. А потом уже их прогнать через сервисы, указанные в первом пункте.
Однако найти конкурентов — полдела, нужно выяснить, по каким запросам они получают трафик. Для этого подойдут, например, старая версия MegaIndex и «Букварикс». Вводите адрес сайта — получаете ключи.
Как проверить идею
Вы провели большую работу и составили длинный список тем. Теперь нужно понять, действительно ли они могут привести читателей из поиска. Это делается в несколько шагов.
Выясните, часто ли ищут ключевые слова
Введите ключевую фразу в «Яндекс.Вордстате» и возьмите её в кавычки. Сервис покажет, сколько раз конкретный ключевик без дополнительных слов, но в разных формах показывал «Яндекс» в прошлом месяце.
Кроме кавычек, фиксирующих количество слов, у «Вордстата» есть и другие операторы. Они будут нужны вам намного реже, но знать о них стоит:
- + позволяет учесть служебные части речи (союзы, предлоги, частицы) и местоимения.
- [ ] закрепляют порядок слов. При этом учитываются все словоформы, служебные части речи, местоимения.
- ! фиксирует форму слова (число, падеж, время).
Операторы могут использоваться совместно. Считается, что кавычки и восклицательный знак позволяют получить так называемую точную частоту запроса, которую лучше использовать для прогнозирования трафика на сайт. Но в большинстве случаев вам хватит и кавычек.
Проверьте разные формулировки
Пробуйте использовать синонимы слов в ключевике, однокоренные слова. Результат может быть разным. Например, выдачу по запросу «как получить налоговый вычет» «Яндекс» показывал 2 402 раза в сентябре 2021 года.
А вот «как оформить налоговый вычет» — всего 711 раз.
Если в ключевике есть иноязычные слова, попробуйте написать их латиницей и кириллицей. Android и «андроид» в запросе могут дать разные результаты.
Учтите сезонность
«Яндекс.Вордстат» показывает количество запросов за прошлый месяц. Но некоторые темы сильно связаны с сезоном. Например, в январе мало кто ищет, что приготовить из кабачков. Зато в августе таких запросов даже больше, чем мемов, как все раздают друг другу кабачки, потому что не знают, что с ними делать.
Проверить сезонность можно, выбрав опцию «История запросов».
К сожалению, на вкладке «История» работает только оператор +. Поэтому вы сможете лишь приблизительно оценить потенциал запроса.
Убедитесь, что вы ещё не публиковали такой текст
Если у вас на сайте или в блоге уже есть материал, который высоко выдаётся по запросу, то второй писать на эту тему вряд ли стоит. Кажется, если два текста будут в топе, трафика станет в два раза больше. На самом же деле статьи могут начать конкурировать друг с другом и одна из них просто перестанет приводить читателей, потому что уйдёт ниже в выдаче.
О чём стоит помнить, чтобы получить от поисковиков максимум
- Важно экспериментировать. Почти любая статья может приносить поисковый трафик. Так что стоит проверять каждую идею.
- Ключевик должен точно соответствовать будущей статье. Поэтому всегда ставьте себя на место пользователя, вбивающего запрос в поисковую строку. Пробуйте думать как он, удовлетворять его ожидания. Если сомневаетесь, изучите поисковую выдачу по запросу.
- Конкурировать с магазинами не стоит. Поэтому забудьте о ключевиках с «ценой», глаголами «купить», «скачать», «заказать» и прочими однокоренными словами, а также с указанием на населённый пункт.
- Идеи можно искать везде, в том числе в собственной голове. Но стоит проверять их с помощью сервисов, чтобы убедиться, что тема интересует не только вас.
- На работу с «Яндекс.Вордстатом» уходит не так много времени. Но она позволяет конкретизировать тему и получить больше трафика. Ну или понять, что тратить ресурс медиа на её отработку не стоит.
