Как найти статью в газете,чтобы можно было ее прочесть полностью?
Знаток
(492),
закрыт
13 лет назад
Saroman
Мастер
(2477)
13 лет назад
у всех сразу вопрос “какая газета”. И что ту сложного? Пойти в библиотеку или на сервер этой самой газеты. Ваш вопрос поставлен не до конца.. . непонятно.
Ольга Летчфорд
Мыслитель
(8692)
13 лет назад
Только в самой центральной библиотеке в Вашем городе. Там храняться подшивки всх газет. У нас в Нижнем Новгороде – это центральная библиотека им. В. И. Ленина. Это я про центральные газеты, а про какие Вы спрашивате- непонятно. Сейчас газет всяких уйма.
Источник: Из личного опыта
Интернет-журнал «Науковедение» ISSN 2223-5167 http ://naukovedenie.ru/ Том 7, №4 (2015) http ://naukovedenie. ru/index.php?p=vol7-4 URL статьи: http://naukovedenie.ru/PDF/74TVN415.pdf DOI: 10.15862/74TVN415 (http://dx.doi.org/10.15862/74TVN415)
УДК 004.912
Бородащенко Антон Юрьевич
ГКОУ ВПО «Академия Федеральной службы охраны Российской Федерации»
Россия, Орёл1 Сотрудник Кандидат технических наук E-mail: bay55@mail.ru
Потемкин Алексей Владимирович
ГКОУ ВПО «Академия Федеральной службы охраны Российской Федерации»
Россия, Орёл Сотрудник E-mail: alex.potemkin85@mail.ru
Сазонова Елена Александровна
ГКОУ ВПО «Академия Федеральной службы охраны Российской Федерации»
Россия, Орёл Сотрудник Кандидат педагогических наук E-mail: gea.07@mail.ru
Шекшуев Сергей Васильевич
Россия, Орёл E-mail: danger_x@live.ru
Алгоритм поиска схожих публикаций средств массовой информации
1 302034, г. Орёл, ул. Приборостроительная, д. 35
Аннотация. В настоящей статье приводится описание алгоритма поиска схожих публикаций средств массовой информации, основанного на статистической мере TF-ГОF. Обосновывается актуальность разработки такого алгоритмов. Подробно раскрывается содержание этапов построения алгоритма, приводятся практические результаты проверки эффективности.
В статье проведен анализ существующих подходов к определению подобия текстовых сообщений. Показано, что они не обеспечивают высокую точность из-за использования хэш-функций, так как изменение одного символа в цепочке слов приводит к неправильному определению сходства сообщений. Для решения этой проблемы, а также для увеличения показателей точности и полноты отбора информации из различных источников, авторами был предложен алгоритм поиска схожих публикаций средств массовой информации, основанный на статистической мере TF-IDF. Приведена функциональная модель алгоритма в нотации IDEF0. На основе функциональной модели разработана блок-схема алгоритма поиска схожих публикаций средств массовой информации.
Для оценки эффективности предложенного алгоритма проведен натурный эксперимент по определению сходства публикаций средств массовой информации. Представлены примеры таких публикаций. На основе предлагаемого алгоритма разработано программное средство. В статье представлена экранная форма пользовательского интерфейса программы. Приведены результаты определения схожих публикаций разработанным алгоритмом и алгоритмом шинглов.
Ключевые слова: публикация; средство массовой информации; текст; дубликат; обработка текстов; алгоритм шинглов; подобие текстов; хэш-функция; точность; полнота.
Ссылка для цитирования этой статьи:
Бородащенко А.Ю., Потемкин А.В., Сазонова Е.А., Шекшуев С.В. Алгоритм поиска схожих публикаций средств массовой информации // Интернет-журнал «НАУКОВЕДЕНИЕ» Том 7, №4 (2015) http://naukovedenie.ru/PDF/74TVN415.pdf (доступ свободный). Загл. с экрана. Яз. рус., англ. DOI: 10.15862/74TVN415
Повсеместное использование информационных технологий привело к тому, что в различных коммерческих компаниях и государственных организациях накопились огромные массивы документов, обрабатываемые с помощью приложений различного назначения: систем электронного документооборота, управления электронной почтой, бухгалтерского учета и прочих. Наряду с этим наблюдается постоянный рост количества используемой в электронном виде информации. В сложившихся условиях становятся актуальными новые подходы к обработке информационных массивов, способные объединить разнородные информационные системы. Одним из таких подходов является внедрение специализированного класса аппаратно-программных комплексов – информационно-аналитических систем [1].
В настоящее время выделяют пять классов информационно-аналитических систем, исходя из их функциональных возможностей:
• лингвистические процессоры;
• системы анализа структурированной информации;
• системы визуализации текстовой информации;
• информационно-поисковые системы;
• системы анализа текстовой информации.
Наиболее сложными среди указанных классов систем являются системы анализа текстовой информации, так как они включают в себя в качестве подсистем все остальные перечисленные классы. Такие системы обладают возможностью анализа текстов с использованием синтаксических и семантических механизмов. Как правило, алгоритмы функционирования данных систем основаны на анализе терминов, встречающихся в документах, и их взаимного расположения. На основе этих алгоритмов выявляются темы документов и наиболее значимые фрагменты текстов. К основным функциям данных систем можно отнести [1]:
• получение данных из источников информации, преобразование их к единому формату [2];
• полнотекстовый, контекстный, тематический, атрибутивный, нечеткий поиск документов [3];
• построение таблиц, графиков, гистограмм, отражающих характеристики выборок объектов и документов;
• полнотекстовое индексирование текстов и реквизитов документов и размещение результатов предварительной обработки в системной базе данных, а также публикация документов для доступа к ним пользователей;
• ручное редактирование результатов автоматической обработки документов;
• автоматическая классификация, кластеризация, реферирование, аннотирование, создание дайджестов и другие операции анализа текстов [4-8].
Исходя из вышеизложенного, можно сказать, что на сегодняшний день системы анализа текстовой информации обладают широкими возможностями по работе с текстами, но не лишены и недостатков, одним из которых является повторная обработка дублированной информации. Только в сети Интернет важные сообщения многократно дублируются на экспоненциально растущем количестве сайтов, в то время как количество заслуживающих внимания источников растет не такими высокими темпами, скорее всего, линейно [9]. Модули
поиска схожих документов должны быть реализованы в информационно-поисковых системах, в системах анализа структурированной информации и системах визуализации текстовой информации для увеличения оперативности работы за счет исключения из результатов обработки одинаковых документов, а так же и в системах анализа текстовой информации как в классе систем, включающих в себя все вышеперечисленные системы. Однако в настоящее время указанная задача в информационно-аналитических системах должным образом не реализована.
Многие системы анализа текстовой информации включают в себя модули проверки документов на схожесть, основанные на так называемом алгоритме шинглов. Чаще всего он применяется для очистки поисковой выдачи, то есть для отсеивания документов, содержащих уже найденную информацию, а также поиска плагиата. Реализация данного алгоритма подразумевает четыре этапа:
• канонизация текстов;
• разбиение текстов на шинглы;
• нахождение контрольных сумм;
• поиск одинаковых последовательностей.
Рассмотрим эти этапы подробнее. Канонизация текстов представляет собой очистку текстов от знаков препинания, предлогов, союзов, местоимений и других лексических единиц, которые не несут смысла при сравнении, а также от стоп-слов.
Разбиение текстов на шинглы, реализуемое на втором этапе, представляет собой выделение последовательностей слов, идущих друг за другом, в среднем по десять штук. Следует отметить, что для наилучшего результата выборка происходит внахлест, а не встык. Пример выделение шинглов внахлест представлен на рисунке 1.
Рисунок 1. Выделение шинглов из текстов (разработано авторами)
На третьем этапе для каждого шингла находится его контрольная сумма (хэш-функции crc32, md5 и др.) [10].
Последний этап представляет собой сравнение контрольных сумм. Возможно сравнение каждой пары этих значений, однако для повышения производительности обычно сравнивают выборки значений контрольных сумм (например, только те, которые делятся на 25) [11].
Описанный алгоритм показывает достаточно низкую точность. Это напрямую связано с хэш-функциями. Достаточно изменить один символ в тексте, как контрольная сумма шингла полностью изменяется.
Для решения этой проблемы, а также для увеличения показателей точности и полноты отбора информации из различных источников, авторами был предложен алгоритм поиска схожих публикаций средств массовой информации, основанный на статистической мере TF X IDF. Функциональная модель предлагаемого алгоритма в нотации IDEF0 представлена на рисунке 2.
Рисунок 2. Контекстная диаграмма алгоритма анализа документов на схожесть
(разработано авторами)
В блоке 1 контекстной диаграммы производится канонизация текстов. Этот этап аналогичен этапу канонизации текстов в алгоритме шинглов, описанному выше.
В блоке 2 диаграммы производится вычисление численного значения TF X IDF для каждого слова, что является основным направлением, обеспечивающим повышение показателей точности и полноты отбора информации из различных источников. TF X IDF -статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью массива документов. Раскроем структуру формулы. TF – отношение числа вхождения некоторого слова к общему количеству слов документа:
TF (1)
где щ есть число вхождений слова в документ, пк – общее число слов в данном документе. IDF – инверсия частоты, с которой некоторое слово встречается в документах коллекции:
IDI
IDF = log-
(2)
где |D| – количество документов в массиве, l(di з ti)l – количество документов, в которых встречается ti. Большой вес в TF X IDF получают слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах, то есть слова, имеющие высокую смысловую нагрузку в рамках конкретного документа. Если же некоторое слово встречается в каждом документе массива, то его смысловая нагрузка минимальна, и оно получает малый вес, т.е. |D| = l(di з ti)l,IDF = logl = 0,TF X IDF = 0.
В третьем блоке происходит присвоение значения TF XIDF словам-синонимам, полученным из тезауруса. Этап является необязательным.
В четвертом блоке производится создание метрики документов на основе вычисленных значений TF X IDF.
В пятом блоке производится индексирование текстов по метрикам (например, тексты могут быть упорядочены по схожести). Для определения тематической близости двух документов используется простое скалярное произведение двух векторов (метрик) з1т(й1, й2), которое соответствует косинусу угла между векторами – образами документов й1и ё2. Очевидно, что з1т(й1,й2) принадлежит множеству [0, 1]. Чем больше значение з1т(й1, й2), тем более близки документы ё1и ё2. Аналогично мерой близости документа № и q является величина [9]:
Показатели полноты и точности существенно повышается в результате использования словаря тезауруса, что позволяет выявлять дубли, исходя из смысла текстов. В предлагаемом алгоритме отсутствует главный недостаток алгоритма шинглов, связанный с перестановкой или изменением символов текста.
Таким образом, на содержательном уровне задача поиска схожих публикаций средств массовой информации состоит в разработке алгоритма поиска схожих текстовых документов, позволяющего рассчитать значение коэффициента схожести двух текстов. На основе полученного значения возможно принятие решения об отсеивании конкретного документа как дубля. В отличие от существующих систем при поиске дублей применяется выделение ключевых слов документов и их статистический анализ с использованием метрики TF X IDF. Исходными данными являются массив текстовых документов и текст-эталон, отражающий требуемые пользователем результаты информационного поиска. Массив должен состоять минимум из одного текста.
На основе представленной выше модели авторами разработан алгоритм поиска схожих публикаций средств массовой информации, представленный на рисунке 3.
Рассмотрим работу алгоритма на примере нескольких сообщений СМИ, выгруженных из сети Интернет. В качестве текста-эталона выберем первый документ.
Первый текстовый документ:
Медведев – преемник: Это позитивный сигнал Западу.
10 декабря 2007 16:24.
Сегодня лидеры четырех партий – “Единой России”, “Справедливой России”, “Аграрной партии” и “Гражданской силы” предложили Путину кандидатуру Дмитрия Медведева в качестве претендента на пост Президента России. Путин выбор одобрил.
– Я думаю, что это очень сильный и честный ход президента, – говорит Александр РАР, директор программ России и СНГ Германского совета по внешней политике. – Он показывает, что рассуждения о закулисных играх, о будущем преемнике как марионетке Путина абсолютно беспочвенны.
Российский президент сделал очень рискованный ход для себя: он пошел вразрез с интересами силовиков, которые не поддерживали Медведева, предлагали другие кандидатуры, а то и настаивали на третьем сроке Путина. Но теперь фракция силовиков в российском истеблишменте оказывается весьма ослабленной.
Для Запада же был дан ясный сигнал, что Россия делает ставку на экономические реформы и будет проводить политику открытости, продолжать интегрироваться в мировое сообщество.
(3)
Второй текстовый документ:
Александр РАР, директор программ России и СНГ Германского совета по внешней политике:
– Я думаю, что это очень сильный и честный ход президента, – говорит – Он показывает, что рассуждения о закулисных играх, о будущем преемнике как марионетке Путина абсолютно беспочвенны.
Российский президент сделал очень рискованный ход для себя: он пошел вразрез с интересами силовиков, которые не поддерживали Медведева, предлагали другие кандидатуры, а то и настаивали на третьем сроке Путина. Но теперь фракция силовиков в российском истеблишменте оказывается весьма ослабленной.
Для Запада же был дан ясный сигнал, что Россия делает ставку на экономические реформы и будет проводить политику открытости, продолжать интегрироваться в мировое сообщество.
Начало
2 —
/Ввод текстовой информации
3
Разбиение текстов на слова
4
Приведение слов к нормальным формам
5
Удаление повторяющихся слов
6
Удаление служебных частей речи
7
Нахождение меры ТР X ЮГ
для
каждого слова
8
Создание метрики текстов
9
Сравнение текстов по метрике
Отсеивание дублей
11
Сохранение проанализированных текстов
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
-12-
Вывод результата
конец
1
Рисунок 3. Алгоритм поиска схожих публикаций средств массовой информации
(разработано авторами)
Третий текстовый документ:
Геннадий Гудков: поддержав Медведева, Путин открывает новую страницу российской власти.
По мнению Геннадия Гудкова, члена фракции “Справедливая Россия” Госдумы прошлого созыва, выбор кандидатуры первого вице-премьера в качестве политического преемника нынешнего президента страны может означать начало реформы политического курса в строну либерализации:
“В условиях выдвижения кандидатуры Дмитрия Медведева вполне возможно усиление роли политических партий и российского парламента в политической жизни общества. Следует отметить, что отказ президента Путина от третьего срока и изменения конституции является очень важным шагом для построения в России стабильного государства, в котором смена власти не грозит политическими катастрофами, а является рутинным и понятным обществу действом”, – указал Гудков.
Политик подчеркнул, – “Если в ближайшее время действительно произойдет ротация в Кремле, тогда мы стабилизируем путь к цивилизованной смене власти в России. Ибо самый большой крест, который несет наша страна уже много столетий, – несменяемость единоличной власти”.
“Ни для кого не секрет, что сегодня силовики обладают всеми рычагами для продвижения своего кандидата. Своим же решением Владимир Путин отходит от традиционной силовой линии и открывает новую страницу в истории российской власти”, -отметил Геннадий Гудков.
Четвертый текстовый документ:
Политолог: Путин поддержал Медведева, чтобы было время еще подумать.
Выдвижение первого вице-премьера Дмитрия Медведева на пост президента РФ дает возможность Владимиру Путину поразмыслить, по какому сценарию дальше действовать. Медведев удобен тем что, он пригоден для обоих основных сценариев”, – отметил политолог Борис Макаренко.
Один сценарий, считает политолог, таков: Путин рассматривает ситуацию после 2008 года, как интерлюдию между своим вторым сроком и следующим сроком. “Тогда надо было бы подбирать кандидата по возможности более “бесцветного”, (ну это условно, сценарий Зубкова) “, – пояснил Макаренко.
Согласно второму сценарию, считает политолог, “Путин передает власть и постепенно сокращает объем своего влияния в политике, и тогда надо было брать Иванова”.
“А Медведев, это что-то среднее. С ним возможно годик-другой посмотреть, подумать”, – подытожил Макаренко. По сообщению РИА-Новости.
Во втором блоке введенные сообщения разбиваются на слова. В третьем блоке слова приводятся к нормальным формам (например, для существительного это именительный падеж единственное число, для глагола – неопределенная форма и др.). Четвертый блок представляет процесс удаление повторяющихся слов. Количество таких слов существенно возрастает после приведения слов к нормальным формам. В блоке 5 производится удаление служебных частей речи (союзов, междометий и др.), а так же стоп-слов. В седьмом блоке производится вычисление значений TF X IDF для каждого слова. В восьмом блоке создаются метрики документов. В девятом блоке производится сравнение текстов по найденным метрикам. В блоках 10 и 11 производится индексирование текстов.
Проанализировав результаты работы алгоритма можно рассчитать коэффициенты схожести текстов по формуле (3).
Результаты поиска схожих текстов средств массовой информации предложенным и существующим алгоритмами представлены в таблице 1. В левой половине таблицы 1 отражено сравнение представленных выше текстов алгоритмом шинглов без хэш-функции и длиной шингла 4 слова.
Таблица 1
Результаты поиска схожих публикаций (разработано авторами)
Алгоритм шинглов Разработанный алгоритм
тексты 1 2 3 4 тексты 1 2 3 4
1 1 0,5667 0,0000 0,0000 1 1 0,69504 0,04154 0,01418
2 0,9153 1 0,0000 0,0000 2 0,69504 1 0,02198 0,01214
3 0,0000 0,0000 1 0,0000 3 0,04154 0,02198 1 0,04032
4 0,0000 0,0000 0,0000 1 4 0,01418 0,01214 0,04032 1
Полученные результаты можно интерпретировать следующим образом: второй текст несет схожую с первым текстом информацию, третий и четвертый тексты существенно отличаются от первого, но имеются некоторый повторяющиеся слова. Анализ таблицы показывает, что значение сравнения двух текстов между собой алгоритмом шинглов является несимметричным, т.е. зависит от того, какой текст взять за эталон. Например, результатом сравнения второго текста с первым алгоритмом шинглов является 0,9153, т.е. почти весь второй текст содержится в первом, а первого со вторым 0,5667, т.е. чуть больше половины первого текста содержится во втором. При использовании разработанного алгоритма получается симметричное значение, т.е. результат сравнения первого текста со вторым равен результату сравнения второго текста с первым.
Экранная форма программного продукта, реализующего описанный алгоритм, представлена на рисунке 4.
Рисунок 4. Экранная форма пользовательского интерфейса (разработано авторами)
Заключение
Таким образом, авторами предложен алгоритм поиска схожих публикаций средств массовой информации устойчивый к различным воздействиям на тексты документов для «обмана» алгоритма шинглов, а именно: перестановкам слов в тексте, заменам слов на синонимы, перефразированию. Использование разработанного алгоритма позволяет повысить полноту и точность выделения схожей информации из массива документов. Конкретные значения изменения полноты и точности зависят от конкретного массива документов. Например, для массива абсолютно разных сообщений средств массовой информации по различным темам, изменения полноты и точности определения схожей информации может и не быть, а для массива, состоящего из схожих сообщений из разных источников по одному событию, полнота и точность выделения схожей информации приближается к 1.
ЛИТЕРАТУРА
1. Беляев К.В., Босов А.В., Краюшкин Д.В. Обзор и сравнительный анализ информационно аналитических систем. М.: ИПИ РАН, 2008. 135 с.
2. Бородащенко А.Ю., Глотов Д.В., Бочков С.М. Алгоритм контент-анализа новостного потока RSS-каналов // Информационные технологии. 2010. №9. С. 25-28.
3. Бочков М.В., Бородащенко А.Ю. Перспективы развития методов семантической фильтрации текстовых документов // Информационные технологии. 2012. №4. С. 2-7.
4. Бородащенко А.Ю. Анализ текстов на семантическое сходство на основе аппарата теории графов // Информационные системы и технологии. 2008. №1-2. С. 46-52.
5. Бочков М.В., Бородащенко А.Ю., Потемкин А.В. Алгоритм оценки ангажированности публикаций средств массовой информации на основе комплексного использования методов интеллектуального анализа данных // Вестник компьютерных и информационных технологий. 2009. №1. С. 36-40.
6. Бородащенко А.Ю., Яковлев В.А. Алгоритм фильтрации текстовой информации на основе марковской модели // Информационные технологии. 2011. №5. С. 2-5.
7. Потемкин А.В. Распознавание информационных операций средств массовой информации сети Интернет // Интернет-журнал «Науковедение», 2015. №3 [Электронный ресурс]-М.: Науковедение, 2015. – Режим доступа: http://naukovedenie.ru/PDF/139TVN315.pdf, свободный. – Загл. с экрана. – Яз. рус., англ.
8. Бородащенко А.Ю., Гончаров Д.С. Алгоритм выявления новых событий // Информационные технологии. 2013. №7. С. 26-31.
9. Ландэ Д.В., Снарский А.А., Безсуднов А.В. Интернетика. Навигация в сложных сетях. Модели и алгоритмы. М.: Либроком, 2009. 264 с.
10. Национальный открытый университет ИНТУИТ [Электронный ресурс]. Хэш-функции и аутентификация сообщений. Часть 1 – Режим доступа: http://www.intuit.ru/studies/courses/28/28/lecture/458, свободный. Яз. рус.
11. Broder A. Identifying and Filtering Near-Duplicate Documents, C0M’00 // Proceedings of the 11th Annual Symphosium on Combinatorial Pattern Matching. 2000. P. 1-10.
Рецензент: Толкунов Александр Александрович, сотрудник, кандидат
технических наук, ГКОУ ВПО «Академия Федеральной службы охраны Российской
Федерации».
Borodaschenco Anton Yur’evich
The Academy of the Federal Guard Service of the Russian Federation
Russia, Orel E-mail: bay55@mail.ru
Potemkin Alexey Vladimirovich
The Academy of the Federal Guard Service of the Russian Federation
Russia, Orel E-mail: alex.potemkin85@mail.ru
Sazonova Elena Aleksandrovna
The Academy of the Federal Guard Service of the Russian Federation
Russia, Orel E-mail: gea.07@mail.ru
Shekshuev Sergey Vasil’evich
Russia, Orel E-mail: danger_x@live.ru
The mass media similar publication finding algorithm
Abstract. This article describes the algorithm of similar publications search of the mass media, based on a statistical measure TF-IDF. It grounds actuality of algorithm building. The maintenance phases of algorithm construction are disclosed in detail. The practical results of testing the effectiveness are given.
The article analyzes the existing approaches to determining the similarity of text messages. It has been shown that they do not provide high precision, because of the use of hash functions, since changing one character in the string of words leads to incorrect determination of the similarity of messages. To solve this problem, as well as to increase the precision and recall of information selection from various sources, the authors proposed a algorithm of similar publications search of the mass media, based on the statistical measure TF-IDF. The functional model of the algorithm in IDEF0 notation is described. On the basis of the functional model the flowchart of similar publications search is designed.
To assess the effectiveness of the proposed algorithm a full-scale experiment to determine the similarity of the publications of the mass media was carried out. Examples of such publications are given. Based on the proposed algorithm the software tool was developed. The article presents a screen form of the user interface of the program. The results of the determination of similar publications of the developed algorithm and shingles algorithm are given.
Keywords: publishing; mass media; text; duplicate; word processing; shingles algorithm; the similarity of texts; hash function; precision; recall.
REFERENCES
1. Belyaev K.V., Bosov A.V., Krayushkin D.V. Obzor i sravnitel’nyy analiz informatsionno analiticheskikh sistem. M.: IPI RAN, 2008. 135 s.
2. Borodashchenko A.Yu., Glotov D.V., Bochkov S.M. Algoritm kontent-analiza novostnogo potoka RSS-kanalov // Informatsionnye tekhnologii. 2010. №9. S. 25-28.
3. Bochkov M.V., Borodashchenko A.Yu. Perspektivy razvitiya metodov semanticheskoy fil’tratsii tekstovykh dokumentov // Informatsionnye tekhnologii. 2012. №4. S. 2-7.
4. Borodashchenko A.Yu. Analiz tekstov na semanticheskoe skhodstvo na osnove apparata teorii grafov // Informatsionnye sistemy i tekhnologii. 2008. №1-2. S. 46-52.
5. Bochkov M.V., Borodashchenko A.Yu., Potemkin A.V. Algoritm otsenki angazhirovannosti publikatsiy sredstv massovoy informatsii na osnove kompleksnogo ispol’zovaniya metodov intellektual’nogo analiza dannykh // Vestnik komp’yuternykh i informatsionnykh tekhnologiy. 2009. №1. S. 36-40.
6. Bopodashchenko A.Yu., Yakovlev V.A. Algoritm fil’tratsii tekstovoy informatsii na osnove mapkovskoy modeli // Informatsionnye tekhnologii. 2011. №5. S. 2-5.
7. Potemkin A.V. Raspoznavanie informatsionnykh operatsiy sredstv massovoy informatsii seti Internet // Internet-zhurnal «Naukovedenie», 2015. №3 [Elektronnyy resurs]-M.: Naukovedenie, 2015. – Rezhim dostupa: http://naukovedenie.ru/PDF/139TVN315.pdf, svobodnyy. – Zagl. s ekrana. – Yaz. rus., angl.
8. Borodashchenko A.Yu., Goncharov D.S. Algoritm vyyavleniya novykh sobytiy // Informatsionnye tekhnologii. 2013. №7. S. 26-31.
9. Lande D.V., Snarskiy A.A., Bezsudnov A.V. Internetika. Navigatsiya v slozhnykh setyakh. Modeli i algoritmy. M.: Librokom, 2009. 264 s.
10. Natsional’nyy otkrytyy universitet INTUIT [Elektronnyy resurs]. Khesh-funktsii i autentifikatsiya soobshcheniy. Chast’ 1 – Rezhim dostupa: http://www.intuit.ru/studies/courses/28/28/lecture/458, svobodnyy. Yaz. rus.
11. Broder A. Identifying and Filtering Near-Duplicate Documents, C0M’00 // Proceedings of the 11th Annual Symphosium on Combinatorial Pattern Matching. 2000. P. 1-10.
Новость – основа, на которой, камень за камнем, слово за словом, возводится вся журналистика. И даже несмотря на то, что в современном обществе новость живет не дольше 2-3 дней, она все же является «царицей» практически любого СМИ. О том, где и как где журналисты добывают новости, мы спросили наших экспертов.
Анна Астахова, редактор международного еженедельника расследований
«Совершенно секретно», член Международного союза журналистов

В журналистике я с 1995 года. И могу сказать, что журналист имеет разные возможности получения новостей в зависимости от опыта работы. Приходя в редакцию впервые, журналист становится «палочкой-выручалочкой» для более опытных коллег, они поручают ему свои базы контактов для получения новостей из первых рук, им уже давно лень самим созваниваться, списываться с пресс-службами и экспертами. Главный инструмент молодого журналиста – умение общаться, вытащить из этих очень разных людей информацию, новости. Сходить на казалось бы скучное мероприятие, притащить оттуда новости, мнения, слухи. И правильно передать старшим коллегам. Но вот эти год-два «на побегушках» – самые нужные и самые активные, самые позитивные. Увы, к 2015 году все меньше и меньше молодых специалистов прикрепляют к старшим коллегам, все меньше вкладываются в них редакторы… И то, что раньше было не просто традицией редакций, а ее неотъемлемой частью, уходит в виртуальность. Новости ищут через Интернет, зачастую даже не проверяя их в пяти источниках. Так рождаются фейки и распространяются ошибки. Сдал молодой журналист новость, редактор ее не проверил, выставил на портал или отдал в печать… И никто не несет ответственности.
Второй этап – самостоятельный поиск новостей, тут часто журналисты прибегают к самым разным способам. Если ты ленив, то для тебя – ленты новостей агентств и других изданий. Читай, фиксируй свои темы, вытаскивай новости из них. Если ленив, но технически подкован, подписывайся на новости-рассылки разных ведомств, пиар-агентств, информационных порталов. И получай с утра в почту набор новостей. Если не ленив, то ищи по теме новости через поисковики и соцсети, потом находи контакты участников новости и бери у них блиц-интервью. Если активен и любишь адреналин – ходи помимо этого на любые мероприятия, светские тусовки и общайся, слушай, записывай.
Третий этап – профессиональная усталость журналиста, он расставил уже все свои сети (свои контакты) везде, он сидит и ждет новости, которые падают ему «в ноги», в почту или в телефон. Он выбирает из новостей. Он гурман. Он четко знает, что для отличной работы в неделю ему необходимо ровно 15 новостей и ни одной больше. Он умеет различить среди новостей «черный пиар», «белый пиар», «святую простоту» и «эксклюзив», а также «информационную бомбу». Тут и за сто лет ничего не изменится. Профессионалов знают по именам, их ценят, им сами приносят новости. А если не приносят, то опытный человек знает, с какой полки взять новость или как ее сделать самому с помощью знакомых или даже незнакомых экспертов.
Анна Дубровская, обозреватель информационного портала Банки.ру

Мои основные источники инфоповодов – это публичные заявления чиновников, топ-менеджеров кредитных организаций и, конечно же, личные встречи с банкирами (я пишу статьи на финансовые и банковские темы). Относительно встреч могу сказать, что их лучше совмещать с интервью, то есть три четверти времени тратить на интервью для своего издания, а оставшиеся полчаса – на беседу тет-а-тет с выключенным диктофоном. Так можно «убить» сразу нескольких «зайцев»: выпустить интервью со спикером, до этого часть информации из интервью дать в виде новостей и, если повезет, «нарыть» что-то особенное – выпустить полноценную статью-эксклюзив о планах конкретной компании или о новых трендах на рынке.
Не бойтесь задавать в ходе интервью уточняющие вопросы, если что-то недопоняли, не бойтесь показаться глупым – пусть лучше спикер оценит ваше желание изучить материал как можно глубже, чем все интервью будет уличать вас в некомпетентности в «его» теме. По крайней мере в моей практике нередко честность и открытость журналиста перед интервьюируемым помогала наладить не только рабочие, но и дружеские отношения.
Конечно, нельзя забывать о посещении различных конференций, пресс-ланчей и деловых вечеринок. Вероятно, тему для статьи вы там не найдете, но точно обзаведетесь полезными контактами. Причем не лишним будет знакомиться с людьми из абсолютно разных сфер – вы можете оказаться друг другу взаимно полезны совершенно неожиданным образом.
Бывает эффективно «посидеть» на сайте госзакупок – иногда там попадаются необоснованно дорогие тендеры компаний, ну или просто забавные. Из этого тоже временами получаются новости. Конечно, объем информации на этом сайте огромный и между делом его не помониторишь, но если есть свободное время, не чурайтесь таким источником.
Вообще любая работа с открытыми базами данных (будь то судебные решения, аукционы, профессиональные форумы специалистов или народные форумы-«отзовики») – это важная часть деятельности современного журналиста. Даже в законопроекте, который вроде бы уже описан коллегами из других СМИ, можно найти интересный подпункт, не замеченный менее «въедливыми» конкурентами. Даже если вы не обнаружите в просмотренной тонне материалов ничего такого, что бы вам пригодилось, то в любом случае получите опыт: какие источники «выкинуть» из своего ежедневного обзора, а какие мониторить более тщательно, где искать ту или иную информацию.
Помню, когда я только начинала работать в ежедневном издании, мне очень помог такой подход. Я, во-первых, наблюдала за тем, что делают мои коллеги, как они добывают инфоповоды, а во-вторых, читала статьи в ведущих СМИ и пыталась понять, как тот или иной журналист узнал про описанную им сделку или событие.
Сейчас, проработав в журналистике пять лет, я беру на заметку компании, выпускающие интересные исследования, и знакомлюсь с ними, иногда прошу сделать исследование именно для меня, сама придумываю форму опроса.
Многие журналисты считают, что общаться нужно преимущественно со спикерами, а пресс-службу компании по возможности следует избегать. Я с этим мнением категорически не согласна. Мой опыт показывает, что пиарщик – такой же «инфоповодник», как и спикер, просто нужно знать к нему подход и правильно выстраивать общение.
Валерия Семенова, руководитель проекта «ДОМ» Lenta.ru

Подход к созданию новостей, естественно, определяется спецификой издания – требования к новостям могут принципиально различаться даже для отраслевых проектов одной и той же сферы. На примере недвижимости: если соответствующий отдел в информагентстве сделает ставку на оперативность и эксклюзивность, то отраслевой b2c-проект, скорее всего, поставит во главу угла полноту и взвешенность информации, поскольку его задача звучит, скорее, не «быть первым с этой информацией», а «объяснить конечному потребителю этой информации, что к чему».
Поводом для создания новости могут стать: то или иное высказывание представителя профессионального сообщества либо представителя власти; пресс-релиз компании; опубликованный аналитический отчет; законодательная инициатива; происшествие; сообщение в ленте информационного агентства; пост в социальной сети и т. п. Задача отраслевого b2c-издания по недвижимости в любом случае будет состоять в том, чтобы понять, какие последствия инфоповод может повлечь за собой для конечного потребителя – читателя (а это человек, вступающий с недвижимостью в те или иные отношения: купли-продажи, аренды и пр.), и рассказать об этом так, чтобы картина стала ясной для непрофессионала – человека, не являющегося частью журналистского либо риелторского сообщества.
Понятно, что «разжевать» весь обширный материал в новостной заметке получится вряд ли, это задача больших материалов. Соответственно, крайне важно дать к новости соответствующий контекст с помощью имеющихся в распоряжении конкретного проекта средств: это грамотный бэк, врезы и ссылки на нужные материалы, видеоролики и т. п. – так, чтобы интересующийся вопросом читатель смог при желании самостоятельно сделать нужные умозаключения, выходящие за рамки собственно новостного повода.
Источник: Медиастанция
Авторское право на систему визуализации содержимого портала iz.ru, а также на исходные
данные, включая тексты, фотографии, аудио- и видеоматериалы, графические изображения, иные
произведения и товарные знаки принадлежит ООО «МИЦ «Известия». Указанная информация
охраняется в соответствии с законодательством РФ и международными соглашениями.
Частичное цитирование возможно только при условии гиперссылки на iz.ru.
АО «АБ «РОССИЯ» — партнер рубрики «Экономика»
Сайт функционирует при финансовой поддержке Министерства цифрового развития, связи и массовых коммуникаций Российской Федерации.
Ответственность за содержание любых рекламных материалов, размещенных на портале, несет
рекламодатель.
Новости, аналитика, прогнозы и другие материалы, представленные на данном сайте, не являются
офертой или рекомендацией к покупке или продаже каких-либо активов.
Зарегистрировано Федеральной службой по надзору в сфере связи, информационных технологий и
массовых коммуникаций.
Свидетельства о регистрации
ЭЛ №
ФС 77 – 76208 от 8 июля 2019 года,
ЭЛ №
ФС 77 – 72003 от 26 декабря 2019 года
Все права защищены © ООО «МИЦ «Известия», 2023
Поиск в интернет-версии системы ГАРАНТ
На данной странице мы рассмотрим следующие поисковые возможности интернет-версии системы ГАРАНТ:
- Базовый поиск;
- Расширенный поиск. Поиск по реквизитам;
- Расширенный поиск. Поиск по ситуации;
- Расширенный поиск. Поиск по публикации;
- Расширенный поиск. Поиск по судебной практике;
- Расширенный поиск. Поиск лекарственных средств;
- Дополнительные виды поиска.
1. Базовый поиск
Самым популярным поисковым инструментом в интернет-версии системы ГАРАНТ является «Базовый поиск».
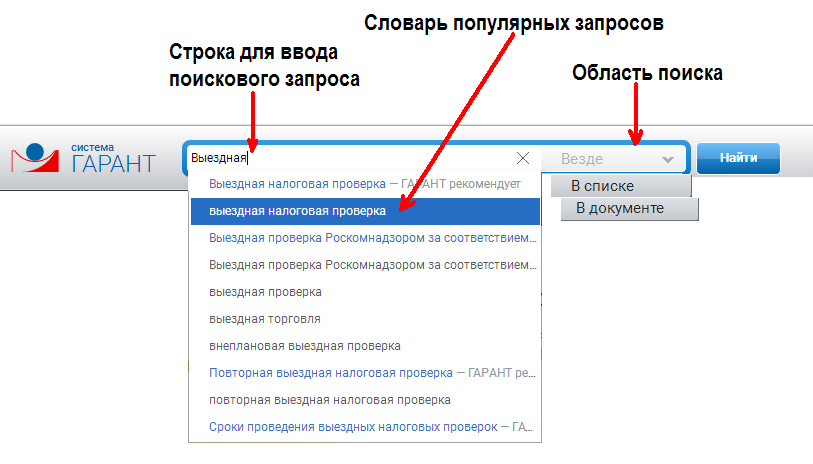
Базовый поиск – это поиск в одну строку, понимающий общепринятые аббревиатуры,
сокращения и профессиональный сленг.
Панель Базового поиска находится в верхней части экрана.
При этом для большей наглядности строка для ввода запроса подсвечивается синим цветом.
Работать с «Базовым поиском» очень легко – нужно просто начать вводить запрос.
Система поймет пользователя и предложит наиболее оптимальные формулировки.
Например, чтобы подготовиться к предстоящей выездной налоговой проверке,
пользователю необходимо найти информацию, касающуюся особенностей её проведения.
Для этого в строку Базового поиска нужно ввести запрос «выездная налоговая проверка».
Система построит список, материалы которого упорядочены таким образом,
чтобы пользователь мог найти ответ уже в первых документах.
Рассмотрим, например, НК РФ. Документ сразу открывается на статье 89,
где содержится информация по этому запросу.
Для наглядности искомый контекст выделен в тексте документа цветом,
что существенно экономит ваше время и упрощает анализ правовой информации.
Выключить подсветку найденного контекста можно, нажав соответствующую кнопку на панели инструментов.
Обратите внимание.
Список последних запросов, введенных ранее в строке базового поиска,
можно вызвать, нажав в строке базового поиска клавишу управления курсором «Вниз».
В списках с помощью Базового поиска можно проводить уточняющий поиск документов,
содержащих нужный контекст. Требуется лишь убедиться, что переключатель области поиска
содержит значение «В списке». Когда необходимо провести Базовый поиск по всему
информационному банку, измените значение в переключателе области поиска на «Везде».
Также с помощью Базового поиска всегда можно найти контекст в тексте любого документа.
Например, нам необходимо понять, каким образом может происходить истребование документов
в процессе проверки. Для этого в режиме просмотра текста документа в строке Базового
поиска удалим ранее введенный контекст, введём текст нового запроса
«истребование документов» и нажмём кнопку «Найти».
Система осуществит поиск контекста, и мы сразу увидим, в каких статьях
и разделах содержится интересующая нас информация.
Заметим, в строке Базового поиска имеется подсказка, указывающая,
сколько раз в тексте встречается искомый контекст.
Переходя по найденным фрагментам, можно видеть, на каком вхождении мы находимся в данный момент.
Ещё одной удобной возможностью Базового поиска является функция исправления опечаток.
Если при вводе запроса в написании слова произойдет случайная ошибка, система предупредит о ней,
а при однозначности возможной замены исправит её самостоятельно.
Логикой Базового поиска можно управлять с помощью управляющих символов:
*, “” (парные кавычки), ! (восклицательный знак).
Правила заполнения строки запроса Базового поиска такие же, как в настольной версии
(описаны здесь).
Таким образом, можно сделать вывод о том, что Базовый поиск – это мощный
и одновременно простой поисковый инструмент, позволяющий находить информацию
как во всем информационном банке, так и в списке найденных документов,
а также в тексте открытого документа.
2. Расширенный поиск. Поиск по реквизитам
Иногда бывают ситуации, когда требуется получить подборку документов,
соответствующих определённым критериям, например, изданных конкретным органом
государственной власти за интересующий нас период времени.
В этом случае нам поможет Поиск по реквизитам.

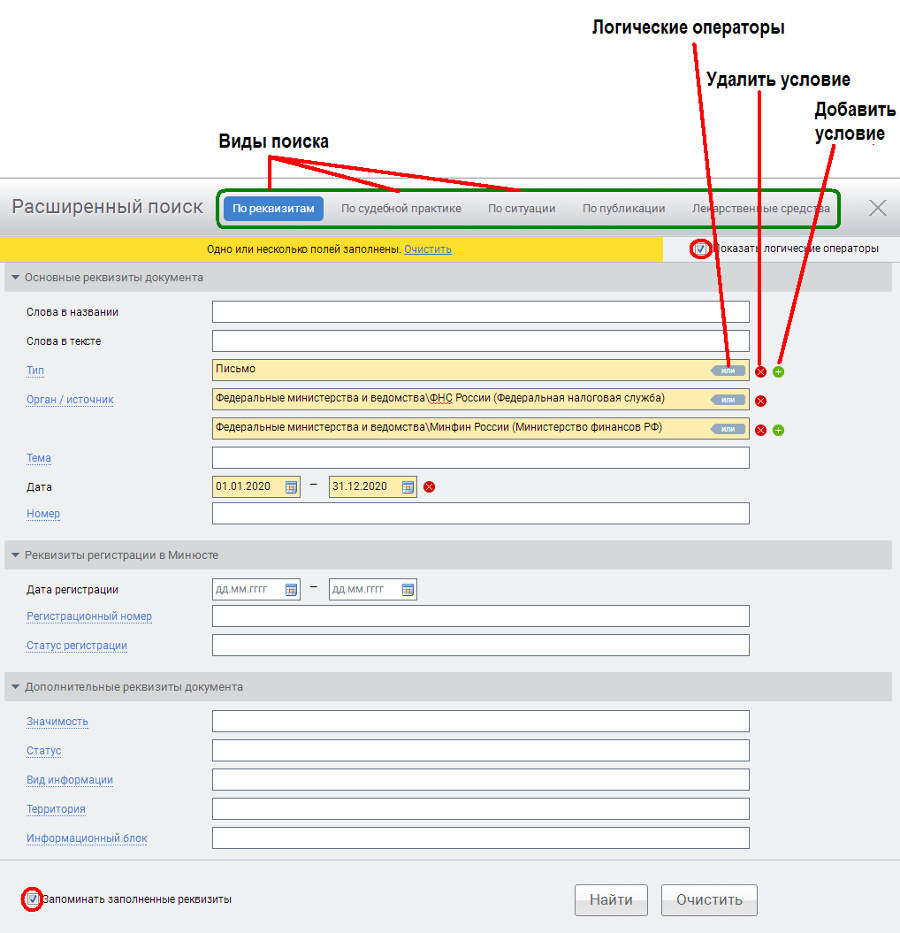
Поиск по реквизитам – это точный поисковый инструмент, позволяющий находить
документы по заранее известным реквизитам.
В карточке запроса реквизиты документа разделены на отдельные группы, каждая из которых заполняется
в зависимости от решаемой задачи:
- Основные реквизиты,
- Реквизиты регистрации в Минюсте,
- Дополнительные реквизиты.
Заносить в карточку всю известную информацию о документе не требуется.
Зачастую бывает достаточно одного реквизита, такого как «Номер» документа.
В некоторые реквизиты можно вводить несколько различных вариантов,
связывая их друг с другом с помощью логических операторов И, ИЛИ, КРОМЕ.
Например в ситуации, когда нужно найти документы, принятые совместно несколькими органами,
или документы, затрагивающие какую-либо тему из перечня альтернативных тематик.
В этом случае после заполнения нужного реквизита первым вариантом
следует добавить следующий вариант при помощи кнопки с зеленым плюсиком.
Кнопка с красным крестиком позволяет удалить лишний вариант.
Опция «Показать логические операторы» не только отображает текущие операторы,
но и позволяет изменять их в соответствии с решаемой задачей.
Обратите внимание.
При заполнении поля «Номер» документа в карточке поиска по реквизитам
система предлагает выбрать номер из словаря существующих значений.
Данный список отображается после ввода второго символа номера.
После ввода первого символа номера список не отображается, поскольку в этом случае он может содержать
большое количество подходящих значений, для отображения которых браузеру может не хватить памяти.
В ситуациях, когда список подходящих номеров не отображается, можно
принудительно отобразить словарь, нажав в поле «Номер» клавишу управления курсором «Вниз».
Итак, поиск по реквизитам позволяет находить информацию, когда известны все или некоторые реквизиты документа.
3. Расширенный поиск. Поиск по ситуации
Поиск по ситуации оптимален для нахождения подборки действующих документов по конкретной ситуации.
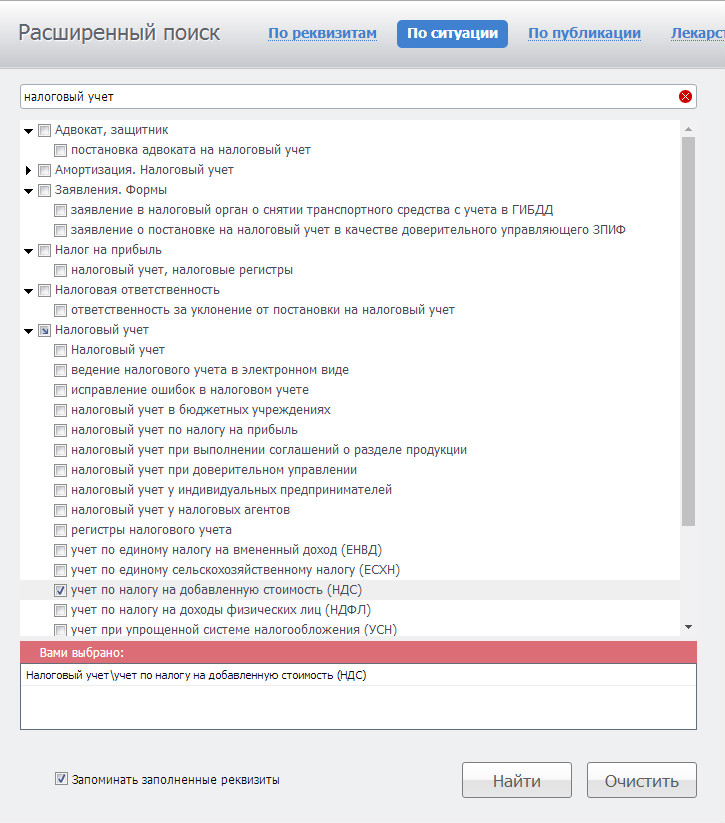
Перейти к этому виду поиска можно также с помощью расширенного поиска.
В карточке запроса представлен список ситуаций,
каждая из которых содержит несколько более узких вложенных тем.
Для получения подборки материалов по интересующему вопросу начните вводить запрос в строку фильтра.
Для экономии времени вы можете ввести лишь основу слова.
Система самостоятельно учтет возможные окончания и подберёт подходящие ситуации.
Отметьте одну или несколько ситуаций и постройте список.
В полученном списке представлены действующие законы, подзаконные акты,
а также авторские комментарии по выбранным темам.
Таким образом, если вас интересует небольшой список актуальных документов по конкретной ситуации,
вы всегда можете воспользоваться «Поиском по ситуации».
4. Расширенный поиск. Поиск по публикации
В интернет-версии системы ГАРАНТ можно с легкостью найти нужную публикацию или
составить подборку материалов ведущих бухгалтерских и юридических периодических изданий.
Для этого достаточно воспользоваться «Поиском по публикации».
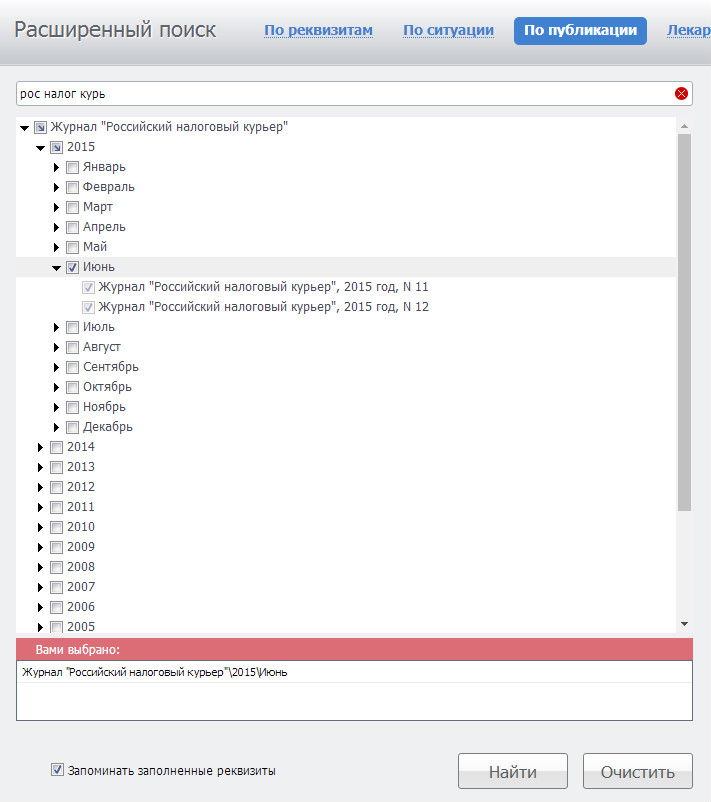
Например, вам потребовалось ознакомиться со статьями, опубликованными в журнале
«Российский налоговый курьер» в июне 2015 года.
Для этого обратимся к карточке поиска по публикации.
В основном окне представлен полный перечень изданий, подключенных в систему ГАРАНТ.
Нажав левой кнопкой мыши на знак слева от названия издания, вы увидите год,
затем месяц и номер выпуска.
Нужные издания можно найти с помощью строки фильтра.
Впишем в неё «рос налог курьер».
Для удобства работы выбранный выпуск журнала наглядно представлен в дополнительном окне.
Строим список. В результате получаем список статей из интересующего журнала.
Таким образом, если вам необходимо найти подборку статей, опубликованных в различных средствах массовой информации,
лучше всего работать с «Поиском по публикации».
5. Расширенный поиск. Поиск по судебной практике
Для более точного поиска судебных решений в системе ГАРАНТ
имеется специализированная карточка поиска по судебной практике.
В ней помимо стандартных реквизитов документа вы можете
выбрать вид судопроизводства,
обозначить ключевую тему для быстрого ознакомления с судебными решениями, принятыми по заданной тематике,
указать сторону спора, обеспечив этим поиск решений, стороной которых был интересующий вас орган власти,
и при необходимости указать фамилию судьи.
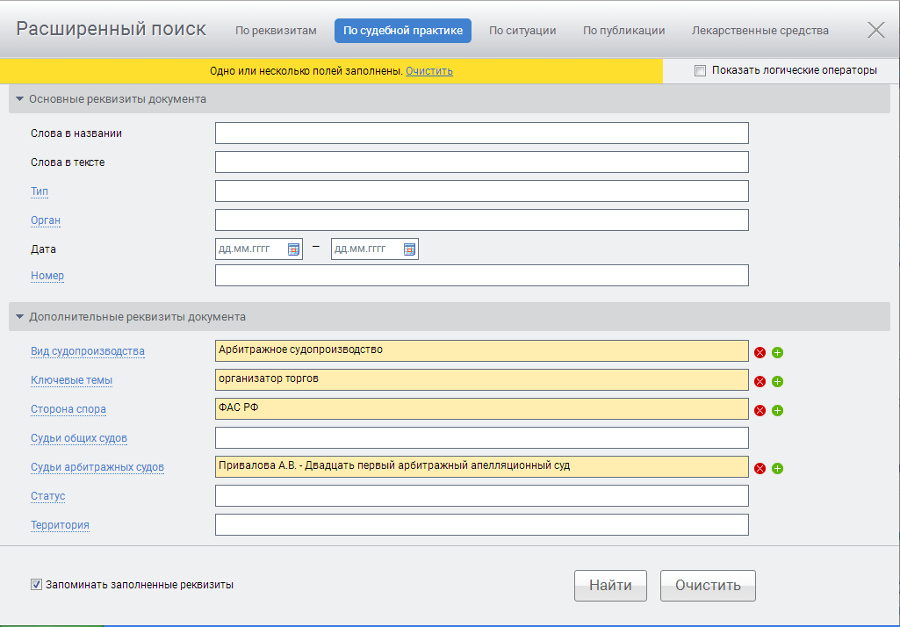
Для уточнения запроса можно использовать и другие реквизиты, такие как
слова в тексте или слова в названии.
Осуществлять поиск материалов судебной практики можно как в основном комплекте
системы ГАРАНТ, где в полной мере представлены документы высших судов и арбитражных судов округов,
так и в специальных архивах.
В Архиве судебных решений содержится несколько десятков миллионов актов,
принятых судами общей юрисдикции и арбитражными судами первой инстанции.
Перейти в Архив судебных решений можно из вкладки «Все решения ГАРАНТа» (раздел «Специальные базы данных»)
или из профессионального меню.
Если вас интересуют решения мировых судей, вы можете провести поиск в Архиве практики мировых судей.
6. Расширенный поиск. Поиск лекарственных средств
Несколько слов о возможности быстрого поиска лекарственных средств, доступной пользователям,
в комплектах которых имеется продукт «ГАРАНТ-ИнФарм».
С помощью специализированной карточки поиска лекарственных средств можно быстро найти необходимые сведения о лекарствах.
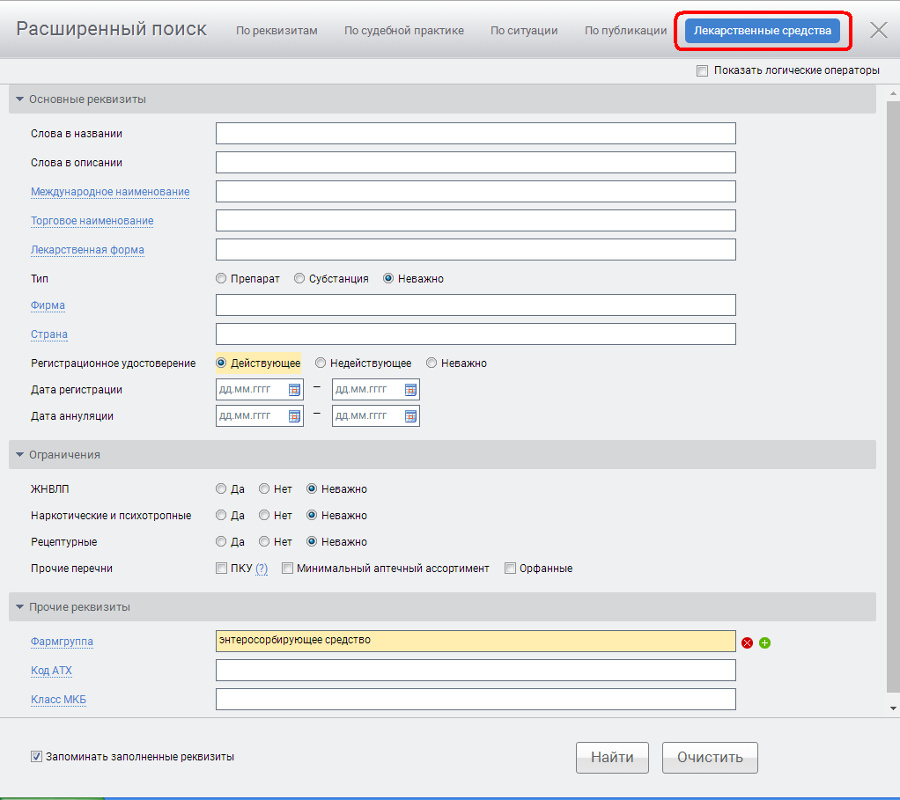
Карточка поиска лекарственных средств доступна
по ссылке из профессионального меню
(пункт «Расширенный поиск лекарственных средств» раздела «Фармацевтика»),
а также на вкладке «Лекарственные средства» расширенного поиска.
Она содержит множество самых разных реквизитов,
которые можно использовать в процессе поиска.
Результатом является подборка лекарственных препаратов, соответствующих всем указанным критериям.
7. Дополнительные виды поиска
Помимо рассмотренных в интернет-версии системы ГАРАНТ реализованы также
следующие виды поиска:
- Поиск связанных документов;
- Поиск похожих документов;
-
Поиск в Правовом календаре
(документы, изменившие или меняющие свой правовой статус в интересующий вас период времени; -
Поиск по последним поступлениям
(позволяет увидеть, какие документы за период времени появились в комплекте).
Последние 2 вида поиска находятся в профессиональном меню.
