Screaming Frog SEO Spider – один из наиболее важных инструментов в арсенале оптимизатора. Этот сервис просто незаменим при анализе интернет-ресурса, так как позволяет автоматизировать сбор и структурирование самых важных данных о сайте, тем самым сильно ускоряя работу.

Если вы занимаетесь развитием собственного веб-проекта, или продвижением сайтов клиентов, то Screaming Frog наверняка вам знаком. Но используете ли вы доступные возможности на 100%? В этой статье мы подготовили максимально подробное руководство по использованию данного инструмента. Надеемся, вы сможете найти здесь много нового и полезного.
Базовое сканирование сайта
Как сканировать весь сайт
Приступая к сканированию сайта, важно наперед определить, какую информацию вы хотите получить, насколько велик сайт, и какую часть сайта вам нужно сканировать, чтобы получить доступ к нужным данным.
Примечание: Иногда для масштабных ресурсов лучше ограничить сканер подразделом URL-адресов, чтобы получить хороший репрезентативный образец данных. Это делает размеры файлов и экспорт данных более управляемыми. Мы рассмотрим это более подробно ниже.
Для сканирования всего сайта, включая все дочерние домены, вам нужно внести небольшие изменения в конфигурацию spider, чтобы начать.
По умолчанию Screaming Frog сканирует только субдомен, который вы ввели. Любые дополнительные субдомены, с которыми сталкивается spider, будут рассматриваться, как внешние ссылки. Для обхода дополнительных поддоменов, необходимо изменить настройки в меню Spider Configuration. Отметив Crawl All Subdomains, вы убедитесь, что SEO Spider сканирует любые ссылки, которые он встречает, на другие поддомены на вашем сайте.
Шаг 1:

Шаг 2:
Если вы запускаете сканирование из определенной подпапки или подкаталога и по-прежнему хотите, чтобы Screaming Frog сканировал весь сайт, установите флажок Crawl Outside of Start Folder.
По умолчанию SEO Spider настроен только на сканирование подпапки или подкаталога, который вы сканируете. Если вы хотите сканировать весь сайт и запускать из определенного подкаталога, убедитесь, что для конфигурации задан обход за пределами начальной папки.
Совет: Чтобы сэкономить время и место на диске, помните о ресурсах, которые могут вам не понадобиться при сканировании. Снимите флажки с изображения, CSS, JavaScript и SWF-ресурсов, чтобы уменьшить размер обхода.
Как сканировать один подкаталог
Если вы хотите ограничить сканирование одной папкой, просто введите URL-адрес и нажмите Start, не изменяя никаких настроек по умолчанию. Если вы перезаписали исходные настройки по умолчанию, сбросьте настройки по умолчанию в меню File.

Если вы хотите начать сканирование в определенной папке, но нужно продолжить сканирование в остальных частях субдомена, обязательно выберите Crawl Outside Of Start Folder в настройках Spider Configuration, прежде, чем вводить ваш конкретный стартовый URL.

Как сканировать определенный набор поддоменов или подкаталогов
Чтобы ограничить просмотр определенным набором поддоменов или подкаталогов, вы можете использовать RegEx, чтобы установить эти правила в параметрах Include или Exclude в меню Configuration.
Exclusion (Исключение)
В этом примере мы просмотрели каждую страницу на elit-web.ru, исключая страницы blog на каждом поддомене.
Шаг 1:
Перейдите в Configuration > Exclude, используйте подстановочные регулярные выражения для определения URL или параметров, которые вы хотите исключить.

Шаг 2:
Проверьте свое регулярное выражение, чтобы убедиться, что оно исключает ожидаемые страницы до начала сканирования:

Include (Включение)
В приведенном ниже примере мы хотели просмотреть только подпапку команды на elit-web.ru. Опять же, используйте закладку Test, чтобы протестировать несколько URL и убедиться, что RegEx правильно настроен для вашего правила inclusion.
Это отличный способ сканирования больших сайтов. На самом деле, Screaming Frog рекомендует этот метод, если вам нужно разделить и сканировать сайт с большим числом обратных ссылок.

Как получить список всех страниц на моем сайте
По умолчанию, Screaming Frog настроен на сканирование всех изображений, JavaScript, CSS и флэш-файлов, с которыми сталкивается SEO Spider. Чтобы сканировать (crawl) только HTML, вам придется снять выделение с пунктов Check Images, Check CSS, Check JavaScript и Check SWF в меню Spider Configuration.

Запуск SEO Spider с этими настройками без галочки, по сути, предоставит вам список всех страниц вашего сайта, на которые есть внутренние ссылки, указывающие на них.
После завершения сканирования перейдите на вкладку Internal и отфильтруйте результаты по HTML. Нажмите кнопку Export, и у вас будет полный список в формате CSV.

Совет: Если вы склонны использовать одни и те же настройки для каждого сканирования, Screaming Frog теперь позволяет вам сохранить настройки конфигурации:

Как получить список всех страниц в определенном подкаталоге
В дополнение к снятию флажка Check Images, Check CSS, Check JavaScript и Check SWF, вы также захотите снять флажок Check Links Outside Folder в настройках Spider Configuration. Запуск SEO Spider с этими настройками без флажка, даст вам список всех страниц в вашей стартовой папке (если они не являются страницами, на которые нет внутренних или внешних ссылок).
Как найти все субдомены на сайте и проверить внутренние ссылки
Есть несколько разных способов найти все поддомены на сайте.
Способ 1
Используя Screaming Frog для идентификации всех поддоменов на данном сайте, перейдите в Configuration > Spider и убедитесь, что выбрана опция Crawl all Subdomains. Как и при сканировании всего сайта, это поможет сканировать любой поддомен, связанный с обходом сайта. Тем не менее, это не найдет поддоменов, которые не связаны ссылками.

Способ 2
Используйте Google, (расширение для браузера Scraper Chrome) для идентификации всех проиндексированных поддоменов, мы можем найти все индексируемые субдомены для данного домена.

Шаг 1:
Начните вводить в поисковике: site: оператор поиска в Google, чтобы ограничить результаты для вашего конкретного домена. Затем используйте оператор поиска -inurl, чтобы сузить результаты поиска, удалив основной домен. Появится список поддоменов, которые были проиндексированы в Google, в котором не будет основного домена.
Шаг 2:
Используйте расширение Scraper, чтобы извлечь все результаты в Google Sheet. Просто щелкните правой кнопкой мыши URL-адрес в поисковой выдаче, нажмите Scrape Similar и экспортируйте в Google Doc.
Шаг 3:
В вашем Документе Google Doc используйте следующую функцию, чтобы обрезать URL-адрес до субдомена:
=LEFT(A2,SEARCH («/»,A2,9))
По сути, приведенная выше формула должна помочь удалить любые подкаталоги, страницы или имена файлов в конце сайта. Эта формула, позволяет не экспортировать в Excel то, что находится слева от конечной косой черты. Стартовое число 9 является важным, потому что мы просим его начать искать косую черту «/» после 9-го символа. Это составляет протокол: https://, длиной в 8 символов.
Дублируйте список и загрузите его в Screaming Frog в режиме списка (List Mode) – вы можете вручную вставить список доменов, использовать функцию вставки (paste) или загрузить (upload) CSV.

Способ 3
Введите URL-адрес корневого домена в инструменты (tools), чтобы найти сайты, которые могут существовать на том же IP-адресе. Также вы можете воспользоваться поисковыми системами, специально предназначенными для поиска поддоменов, например FindSubdomains. Создайте бесплатную учетную запись для входа и экспорта списка поддоменов. Затем загрузите список в Screaming Frog, используя режим списка (List Mode).
Как только SEO Spider закончит работу, вы сможете увидеть код состояния, а также любые ссылки на домашних страницах поддоменов, текст привязки и дубликаты заголовков страниц, среди прочего.
Как сканировать интернет-магазин или другой большой сайт
Изначально Screaming Frog не был создан для сканирования сотен тысяч страниц, но благодаря некоторым обновлениям он становится многофункциональнее с каждым днем.
Последняя версия Screaming Frog была обновлена, чтобы полагаться на хранилище базы данных для обходов. В версии 11.0 Screaming Frog позволял пользователям сохранять все данные на диске в базе данных, а не просто хранить их в оперативной памяти. Это открыло возможность сканирования очень больших сайтов в один клик.
В версии 12.0 сканирование автоматически сохраняет обходы в базе данных. Это позволяет получить к ним доступ и открыть с помощью File > Crawls в меню верхнего уровня (на случай, если вы удивляетесь, куда пошла команда open?)
Хотя использование обхода базы данных помогает Screaming Frog лучше управлять большими объемами информации, это, конечно, не единственный способ сканирования большого сайта.
Во-первых, вы можете увеличить выделение памяти в SEO Screaming Frog.
Во-вторых, вы можете разбить сканирование по подкаталогу или сканировать только определенные части сайта, используя настройки Include / Exclude.
В-третьих, вы можете не сканировать изображения, JavaScript, CSS и flash. Отменив выбор этих параметров в меню Configuration, сэкономив тем самым память, сканируя только HTML.
Совет: До недавнего времени Screaming Frog SEO Spider мог приостанавливаться или зависать при сканировании большого сайта. Теперь, когда хранилище базы данных является настройкой по умолчанию, вы можете восстановить обходы, чтобы выбрать, где вы остановились. Кроме того, вы также можете получить доступ к URL-адресам в очереди. Это может дать вам представление о любых дополнительных параметрах или правилах, которые вы можете исключить для сканирования большого сайта.

Как сканировать сайт, размещенный на старом сервере, или как сканировать сайт без сбоев
В некоторых случаях старые серверы могут не обрабатывать количество URL-запросов по умолчанию в секунду. Мы рекомендуем включить ограничение на количество сканируемых URL-адресов в секунду, чтобы на всякий случай не усложнять работу сервера сайта. Лучше всего, чтобы клиент знал, когда вы планируете сканировать сайт, на случай, если у него может быть защита от неизвестных пользовательских агентов. С одной стороны, им может понадобиться внести в белый список ваш IP или пользовательский агент (User-Agent), прежде, чем вы будете сканировать сайт. В худшем случае вы можете отправить слишком много запросов на сервер и непреднамеренно завершить работу сайта.
Чтобы изменить скорость сканирования, выберите Speed в меню Configuration и во всплывающем окне выберите максимальное количество потоков, которые должны работать одновременно. В этом меню вы также можете выбрать максимальное количество URL-адресов, запрашиваемых в секунду.

Совет: Если вы обнаружите, что при сканировании возникает много ошибок сервера, перейдите на вкладку Advanced в меню Spider Configuration и увеличьте значение Response Timeout и 5xx Response Retries, чтобы получить лучшие результаты.

Как сканировать сайт, который требует куки
Хотя поисковые роботы не принимают файлы cookie, если вы сканируете сайт и хотите разрешить использование файлов cookie, просто выберите Allow Cookies на вкладке Advanced в меню Spider Configuration.

Как сканировать, используя другой пользовательский агент (User-Agent)
Чтобы сканировать с использованием другого пользовательского агента, выберите User Agent в меню Configuration, затем выберите поискового бота из выпадающего списка или введите нужные строки пользовательского агента.

Поскольку Google теперь ориентирован на мобильные устройства, попробуйте просканировать сайт как смартфон Googlebot или измените User-Agent, чтобы он был как смартфон Googlebot. Это важно по двум причинам:
- Сканирование сайта, имитирующее пользовательского агента (user-agent) смартфон Googlebot, может помочь определить любые проблемы, возникающие у Google при сканировании и отображении контента вашего сайта.
- Использование модифицированной версии пользовательского агента смартфона Googlebot поможет вам различать ваши обходы и обходы Google при анализе журналов сервера.
Как сканировать страницы, требующие аутентификации
Когда Screaming Frog встречает страницу, защищенную паролем, появляется всплывающее окно, в котором вы можете ввести требуемое имя пользователя и пароль.
Аутентификация на основе форм является очень мощной функцией и может потребовать рендеринга JavaScript для эффективной работы.
Примечание: проверку подлинности на основе форм следует использовать экономно и только опытным пользователям. Сканер запрограммирован так, что он кликает каждую ссылку на странице, это может привести к появлению ссылок для выхода из системы, создания сообщений или даже удаления данных.
Чтобы управлять аутентификацией, перейдите к Configuration > Authentication.
Чтобы отключить запросы на аутентификацию, отмените выбор Authentication на основе стандартов в окне Authentication в меню Configuration.

Внутренние ссылки
Как получить информацию обо всех внутренних и внешних ссылках на моем сайте (якорный текст, директивы, ссылки на страницу и т. д.)
Если вам не нужно проверять изображения, JavaScript, Flash или CSS на сайте, отмените выбор этих параметров в меню Spider Configuration, чтобы сэкономить время и память.

Как только SEO Spider завершит сканирование, используйте меню Bulk Export, чтобы экспортировать CSV All Links. Это предоставит вам все ссылки, а также соответствующий якорный текст, директивы и т. д.

Все ссылки могут быть в большом отчете. Помните об этом при экспорте. Для большого сайта этот экспорт может занять несколько минут.
Для быстрого подсчета количества ссылок на каждой странице перейдите на вкладку Internal и отсортируйте по Outlinks. Страницы, где более 100 ссылок, возможно, потребуется пересмотреть.

Как найти неработающие внутренние ссылки на странице или сайте
Как и в предыдущем пункте, отмените выбор JavaScript, Flash или CSS сайта в меню Spider Configuration, если вам не нужно проверять изображения.
После того, как SEO Spider завершит сканирование, отсортируйте результаты вкладки Internal по Status Code. Любой 404, 301 или другой код состояния будут легко доступны для просмотра.
Нажав на любой отдельный URL в результатах сканирования, вы увидите изменение информации в нижнем окне программы. Нажав на вкладку In Links в нижнем окне, вы увидите список страниц, которые ссылаются на выбранный URL, а также якорный текст и директивы, используемые в этих ссылках. Вы можете использовать эту функцию для определения страниц, на которых необходимо обновить внутренние ссылки.
Чтобы экспортировать полный список страниц, которые содержат неработающие или перенаправленные ссылки, выберите Redirection (3xx) In Links или Client Error (4xx) In Links или Server Error (5xx) In Links в меню Advanced Export, и вы получите CSV-экспорт данных.
Чтобы экспортировать полный список страниц, которые содержат неработающие или перенаправленные ссылки, посетите меню Bulk Export. Прокрутите вниз до кода ответов и посмотрите следующие отчеты:
- No Response Inlinks;
- Redirection (3xx) Inlinks;
- Redirection (JavaScript) Inlinks;
- Redirection (Meta Refresh) Inlinks;
- Client Error (4xx) Inlinks;
- Server Error (5xx) Inlinks.

Просмотр всех этих отчетов должен дать вам адекватное представление о том, какие внутренние ссылки следует обновить, чтобы они указывали на каноническую версию URL и эффективно распределяли качественные ссылки.
Как найти неработающие исходящие ссылки на странице или сайте (или все исходящие ссылки в целом)
После отмены выбора Check Images, Check CSS, Check JavaScript и Check SWF в настройках Spider Configuration убедитесь, что Check External Links остается выбранной.
После того, как SEO Spider завершит сканирование, нажмите на вкладку External в верхнем окне, отсортируйте по Status Code Вы легко сможете найти URL с кодом состояния, отличными от 200. После нажатия на любой отдельный URL, просканируйте результаты, а затем, нажав на вкладку In Links в нижнем окне, вы увидите список страниц, которые указывают на выбранный URL-адрес. Вы можете использовать эту функцию для определения страниц, на которых необходимо обновить исходящие ссылки.
Чтобы экспортировать полный список исходящих ссылок, нажмите External Links на вкладке Bulk Export.

Для получения полного списка всех местоположений и текста привязки исходящих ссылок выберите All Outlinks в меню Bulk Export. Отчет All Outlinks также будет включать исходящие ссылки на ваши субдомены. Если вы хотите исключить свой домен, воспользуйтесь отчетом External Links, упомянутым выше.
Как найти ссылки, которые перенаправляются
После завершения сканирования выберите вкладку Response Codes в основном пользовательском интерфейсе и выполните фильтрацию по коду состояния. Поскольку Screaming Frog использует регулярные выражения для поиска, отправьте в качестве фильтра следующие критерии: 301 | 302 | 307. Это должно дать вам довольно солидный список всех ссылок, которые возвращались с каким-либо перенаправлением, независимо от того, был ли контент постоянно перемещен, найден и перенаправлен, или временно перенаправлен из-за настроек HSTS (это вероятная причина 307 перенаправлений в Screaming Frog ).
Сортируйте по Status Code, и вы сможете разбить результаты по типу. Нажмите на вкладку In Links в нижнем окне, чтобы просмотреть все страницы, на которых используется ссылка для перенаправления.
Если вы экспортируете напрямую из этой вкладки, то увидите только те данные, которые отображаются в верхнем окне (оригинальный URL, код состояния и куда он перенаправляется).
Чтобы экспортировать полный список страниц, содержащих перенаправленные ссылки, вам нужно будет выбрать Redirection (3xx) In Links в меню Advanced Export. Это вернет CSV, который включает в себя местоположение всех ваших перенаправленных ссылок. Чтобы показать только внутренние перенаправления, отфильтруйте столбец Destination в CSV, чтобы включить только ваш домен.
Совет: Используйте функцию VLOOKUP (ВПР) между двумя вышеупомянутыми файлами экспорта, чтобы сопоставить столбцы Source и Destination с окончательным расположением URL-адреса.
Пример формулы:
= ВПР ([@ Destination], ‘response_codes_redirection_ (3xx) .csv’ $ A $ 3: $ F $ 50,6, FALSE)
Где response_codes_redirection_ (3xx) .csv – это файл CSV, содержащий URL-адреса перенаправления, а 50 – количество строк в этом файле.
Для чего нужны данные о ссылках
Грамотное распределение внутренних ссылок может повысить эффективность поискового продвижения, особенно когда вы занимаетесь стратегическим подходом к распределению PageRank и качественных ссылок, ранжирование ключевых слов и привязки к ключевым словам.
Контент сайта
Как определить страницы с неинформативным контентом
После завершения сканирования SEO Spider перейдите на вкладку Internal, отфильтруйте их по HTML, затем прокрутите вправо до столбца Word Count. Сортируйте столбец Word Count по убыванию, чтобы найти страницы с низким содержанием текста. Вы можете перетащить столбец Word Count влево, чтобы лучше сопоставить значения низкого количества слов с соответствующими URL-адресами. Нажмите Export на вкладке Internal, если вы предпочитаете вместо этого управлять данными в CSV.
Как получить список ссылок на изображения на определенной странице
Если вы уже просмотрели весь сайт или подпапку, просто выберите страницу в верхнем окне, а затем нажмите вкладку Image Info в нижнем окне, чтобы просмотреть все изображения, найденные на этой странице. Изображения будут перечислены в столбце To.
Совет: Щелкните правой кнопкой мыши любую запись в нижнем окне, чтобы скопировать или открыть URL-адрес.
Кроме того, вы также можете просматривать изображения на одной странице, сканируя только этот URL. Убедитесь, что в настройках конфигурации SEO Spider задана глубина сканирования 1, затем после сканирования страницы перейдите на вкладку Images, и вы увидите все изображения, найденные screaming frog.
Как найти изображения, в которых отсутствует текст alt или изображения с длинным текстом alt
Во-первых, вы должны убедиться, что в меню Spider Configuration выбран Check Images. После того, как SEO Spider закончил анализировать, перейдите на вкладку Images и отфильтруйте по Missing Alt Text или Alt Text Over 100 Characters. Вы можете найти страницы, где находится любое изображение, нажав на вкладку Image Info в нижнем окне. Страницы будут перечислены в столбце From.
Наконец, если вы предпочитаете CSV, используйте меню Bulk Export, чтобы экспортировать All Images или Images Missing Alt Text Inlinks, чтобы увидеть полный список изображений, где они находятся, и любой связанный с ним текст alt или проблемы с alt Text.

Кроме того, используйте правую боковую панель, чтобы перейти к разделу изображений для обхода. Здесь вы можете легко экспортировать список всех изображений, пропущенным текстом alt.

Как найти каждый файл CSS на моем сайте
В меню Spider Configuration выберите Crawl и Store CSS перед сканированием, затем, когда сканирование завершится, отфильтруйте результаты на вкладке Internal с помощью CSS.

Как найти каждый файл JavaScript на сайте
В меню Spider Configuration выберите Check JavaScript перед сканированием, затем, когда сканирование завершится, отфильтруйте результаты на вкладке Internal по JavaScript.
Как определить все плагины jQuery, используемые на сайте, и на каких страницах они используются
Во-первых, убедитесь, что в меню Spider Configuration выбран Check JavaScript. После того, как SEO Spider завершил сканирование, отфильтруйте вкладку Internal по JavaScript, затем найдите jquery. Это предоставит вам список файлов плагинов. Сортируйте список по Address для более удобного просмотра при необходимости, затем просмотрите InLinks в нижнем окне или экспортируйте данные в CSV, чтобы найти страницы, где используется файл. Они будут в столбце From.
Кроме того, вы можете использовать меню Advanced Export, чтобы экспортировать CSV All Links и отфильтровать столбец Destination, чтобы отображались только URL-адреса с jquery.
Совет: Не все плагины jQuery вредны для SEO. Если вы видите, что сайт использует jQuery, лучше всего убедиться, что контент, который вы хотите проиндексировать, включен в источник страницы и обслуживается при загрузке страницы, а не после. Если вы все еще не уверены, установите плагин Google для получения дополнительной информации о том, как он работает.
Как определить места со встроенным flash
В меню Spider Configuration выберите Check SWF перед сканированием, затем, когда сканирование завершится, отфильтруйте результаты на вкладке Internal по Flash.
Это становится все более важным, чтобы находить и идентифицировать контент, который поставляется Flash, и предлагать альтернативный код для него. Flash постепенно устаревает для Chrome. Потому этот функционал действительно нужно использовать, чтобы определить, если есть проблемы с критическим контентом и Flash на сайте.
Примечание: этот метод находит только файлы .SWF, которые связаны на странице. Если флэш-память загружается через JavaScript, вам нужно использовать пользовательский фильтр.
Как найти любые внутренние PDF-файлы
После завершения сканирования в Screaming Frog отфильтруйте результаты на вкладке Internal по PDF.
Как понять сегментацию контента внутри сайта или группы страниц
Если вы хотите найти на своем сайте страницы с определенным типом контента, установите специальный фильтр для HTML-кода, уникального для этой страницы. Это следует сделать перед запуском screaming frog.
Как найти страницы с кнопками социальных сетей
Чтобы найти страницы, содержащие кнопки социальных сетей, вам нужно установить собственный фильтр перед запуском. Чтобы установить пользовательский фильтр, перейдите в меню Configuration и нажмите Custom. Оттуда введите любой фрагмент кода из исходного кода страницы.

В приведенном выше примере фильтр для facebook.com/plugins/like.php.
Как найти страницы, которые используют iframes
Чтобы найти страницы, которые используют iframe, установите пользовательский фильтр для < iframe перед запуском.
Как найти страницы, которые содержат встроенный видео или аудио контент
Чтобы найти страницы, содержащие встроенное видео или аудиоконтент, установите специальный фильтр для фрагмента кода встраивания для Youtube или любого другого медиаплеера, используемого на сайте.

Метаданные и директивы
Как идентифицировать страницы с длинными заголовками страниц, метаописаниями или URL-адресами
После завершения сканирования, перейдите на вкладку Page Titles и отфильтруйте по Over 65 Characters, чтобы увидеть слишком длинные заголовки страниц. Вы можете сделать то же самое на вкладке Meta Description или на вкладке URI.

Как найти повторяющиеся заголовки страниц, метаописания или URL
После того, как SEO Spider закончил сканировать, перейдите на вкладку Page Titles, затем выберите Duplicate. Вы можете сделать то же самое на вкладках Meta Description или URI.

Как найти дублированный контент или URL-адреса, которые необходимо переписать / перенаправить / канонизировать
После того, как SEO Spider завершил сканирование, перейдите на вкладку URI, затем отфильтруйте по Underscores, Uppercase или Non ASCII Characters, чтобы просмотреть URL, которые потенциально могут быть переписаны в более стандартную структуру. Выберите Duplicate, и вы увидите все страницы с несколькими версиями URL. Отфильтруйте по Parameters, и вы увидите URL-адреса, содержащие параметры.

Кроме того, если вы перейдете на вкладку Internal, отфильтруете по HTML и прокрутите столбец Hash в крайнем правом углу, вы увидите уникальные серии букв и цифр для каждой страницы. Если вы нажмете Export, вы можете использовать условное форматирование в Excel, чтобы выделить дублирующиеся значения в этом столбце, в конечном счёте, будут вам показаны страницы, которые идентичны и требуют решения.

Как определить все страницы, содержащие мета-директивы, например: nofollow / noindex / noodp / canonical и т. д.
После того, как SEO Spider закончил проверку, нажмите на вкладку Directives. Чтобы увидеть тип директивы, просто прокрутите вправо, чтобы увидеть, какие столбцы заполнены, или используйте фильтр, чтобы найти любой из следующих тегов:
- index;
- noindex;
- follow;
- nofollow;
- noarchive;
- nosnippet;
- noodp;
- noydir;
- noimageindex;
- notranslate;
- unavailable_after;
- refresh.

Как проверить корректность работы файла robots.txt
По умолчанию Screaming Frog будет выполнять требования robots.txt. В качестве приоритета он будет следовать директивам, сделанным специально для пользовательского агента (user agent) Screaming Frog. Если для пользовательского агента (user-agent) Screaming Frog нет никаких директив, то SEO Spider будет следовать любым директивам для робота Googlebot, а если нет специальных директив для робота Googlebot, он будет следовать глобальным директивам для всех пользовательских агентов.
SEO Spider будет следовать только одному набору директив, поэтому, если существуют правила, установленные специально для Screaming Frog, он будет следовать только этим правилам, а не правилам для робота Google или каких-либо глобальных правил. Если вы хотите заблокировать определенные части сайта от SEO Spider, используйте обычный синтаксис robots.txt с пользовательским агентом Screaming Frog SEO Spider. Если вы хотите игнорировать robots.txt, просто выберите эту опцию в настройках Spider Configuration.
Configuration > Robots.txt > Settings

Как найти или проверить разметку схемы или другие микроданные на моем сайте
Чтобы найти каждую страницу, содержащую разметку схемы или любые другие микроданные, вам нужно использовать пользовательские фильтры. Просто нажмите Custom → Search в меню конфигурации и введите нужный элемент footprint.
Чтобы найти каждую страницу, содержащую разметку схемы, просто добавьте следующий фрагмент кода в пользовательский фильтр: itemtype = http://schema.org
Чтобы найти конкретный тип разметки, вам нужно быть более конкретным. Например, с помощью пользовательского фильтра для ‹span itemprop = ratingValue› вы получите все страницы, содержащие разметку схемы для оценок.
Начиная с Screaming Frog 11.0, Spider SEO также предлагает нам возможность сканировать, извлекать и проверять структурированные данные непосредственно из сканирования. Проверяйте любые структурированные данные JSON-LD, Microdata или RDFa в соответствии с рекомендациями Schema.org и спецификациями Google в режиме реального времени во время сканирования. Чтобы получить доступ к инструментам проверки структурированных данных, выберите параметры в Config > Spider > Advanced.

Теперь в главном интерфейсе есть вкладка Structured Data, которая позволит вам переключаться между страницами, которые содержат структурированные данные, и которые могут иметь ошибки или предупреждения проверки:

Вы также можете выполнить массовый экспорт проблем со структурированными данными, посетив Reports> Structured Data > Validation Errors & Warnings.

Карта сайта
Как создать XML Sitemap
После того, как SEO Spider завершит сканирование вашего сайта, нажмите меню Siteamps и выберите XML Sitemap.

Открыв настройки конфигурации XML-карты сайта, вы можете включать или исключать страницы по коду ответов, последним изменениям, приоритетам, частоте изменений, изображениям и т. Д. По умолчанию Screaming Frog включает только 2xx URL-адресов, но это правило можно исправить.

В идеале, ваша карта сайта XML должна содержать только 200 статусных, единичных, предпочтительных (канонических) версий каждого URL-адреса, без параметров или других дублирующих факторов. После внесения любых изменений нажмите ОК. Файл XML-файла сайта будет загружен на ваше устройство и позволит вам редактировать соглашение об именах по вашему усмотрению.
Создание XML-файла Sitemap путем загрузки URL-адресов
Вы также можете создать карту сайта XML, загрузив URL-адреса из существующего файла или вставив вручную в Screaming Frog.
Измените Mode с Spider на List и нажмите на выпадающий список Upload, чтобы выбрать любой из вариантов.


Нажмите кнопку Start и Screaming Frog будет сканировать загруженные URL-адреса. После сканирования URL вы будете следовать тому же процессу, который указан выше.
Как проверить мой существующий XML Sitemap
Вы можете легко загрузить существующую XML-карту сайта или индекс карты сайта, чтобы проверить наличие ошибок или несоответствий при сканировании.
Перейдите в меню Mode в Screaming Frog и выберите List. Затем нажмите Upload в верхней части экрана, выберите Download Sitemap или Download Sitemap Index, введите URL-адрес карты сайта и начните сканирование. Как только SEO Spider закончит сканирование, вы сможете найти любые перенаправления, 404 ошибки, дублированные URL-адреса и многое другое. Вы можете легко экспортировать и выявленные ошибки.
Определение отсутствующих страниц в XML Sitemap
Вы можете настроить параметры сканирования, чтобы обнаруживать и сравнивать URL-адреса в ваших XML-файлах сайта с URL-адресами в пределах вашего сайта.
Перейдите в Configuration -> Spider в главной навигации, и внизу есть несколько опций для XML-карт сайтов – Auto discover XML sitemaps через ваш файл robots.txt или вручную введите ссылку XML-карты сайта в поле. *Important note – если ваш файл robots.txt не содержит правильных целевых ссылок на все XML-карты сайта, которые вы хотите сканировать, вы должны ввести их вручную.

После обновления настроек сканирования XML-файла Sitemap перейдите к пункту Crawl Analysis в навигации, затем нажмите Configure и убедитесь, что кнопка Sitemaps отмечена. Сначала запустите полное сканирование сайта, затем вернитесь к Crawl Analysis и нажмите Start.

После завершения анализа сканирования вы сможете увидеть любые расхождения при сканировании, такие как URL-адреса, обнаруженные в рамках полного сканирования сайта, которые отсутствуют в карте сайта XML.
Общие проблемы
Как определить, почему определенные разделы сайта не индексируются или не ранжируются
Хотите знать, почему некоторые страницы не индексируются? Во-первых, убедитесь, что они не были случайно помещены в файл robots.txt или помечены как noindex. Затем вы должны убедиться, что SEO Spider может добраться до страниц, проверив ваши внутренние ссылки. Страницу, которая не имеет внутренних ссылок на вашем сайте, часто называют «сиротами» (Orphaned Page).
Чтобы выявить потерянные страницы, выполните следующие действия:
Перейдите в Configuration -> Spider в главной навигации, и внизу есть несколько опций для XML-карт сайтов – Auto discover XML sitemaps через ваш файл robots.txt или вручную введите ссылку XML-карты сайта в поле. *Important note – если ваш файл robots.txt не содержит правильных целевых ссылок на все XML-карты сайта, которые вы хотите сканировать, вы должны ввести их вручную.
Перейдите в Configuration → API Access → Google Analytics – используя API, вы можете получить аналитические данные для конкретной учетной записи и просмотра. Чтобы найти бесхозные страницы из органического поиска, убедитесь, что они разделены на органический трафик.

Вы также можете перейти к разделу General → Crawl New URLs Discovered In Google Analytics, если вы хотите, чтобы URL-адреса, обнаруженные в GA, были включены в ваш полный обход сайта. Если это не включено, вы сможете просматривать только новые URL-адреса, извлеченные из GA, в отчете Orphaned Pages.

Перейдите в Configuration → API Access → Google Search Console – используя API, вы можете получить данные GSC для конкретной учетной записи и просмотра. Чтобы найти бесхозные страницы, вы можете искать URL-адреса, на которых получены клики и показы, которые не включены в ваш просмотр. Вы также можете перейти к разделу General → Crawl New URLs Discovered In Google Search Console, если вы хотите, чтобы URL-адреса, обнаруженные в GSC, были включены в ваш полный обход сайта. Если этот параметр не включен, вы сможете просматривать только новые URL-адреса, извлеченные из GSC, в отчете Orphaned Pages.
Просканируйте весь сайт. После завершения сканирования перейдите в Crawl Analysis -> Start и дождитесь его завершения.
Просмотрите потерянные URL-адреса на каждой из вкладок или выполните Bulk Expor всех потерянных URL-адресов, перейдя в Reports → Orphan Pages.

Если у вас нет доступа к Google Analytics или GSC, вы можете экспортировать список внутренних URL-адресов в виде файла .CSV, используя фильтр HTML на вкладке Internal.
Откройте файл CSV и на втором листе вставьте список URL-адресов, которые не индексируются или плохо ранжируются. Используйте VLOOKUP, чтобы увидеть, были ли URL-адреса в вашем списке на втором листе найдены при сканировании.
Как найти медленные страницы на моем сайте
После того, как SEO Spider завершил сканирование, перейдите на вкладку Response Codes и отсортируйте по столбцу Response Time по возрастанию, чтобы найти страницы, которые могут страдать от медленной скорости загрузки.

Как найти вредоносное ПО или спам на моем сайте
Во-первых, вам необходимо идентифицировать след вредоносного ПО или спама. Далее в меню Configuration нажмите Custom → Search и введите искомый элемент, который вы ищете.

Вы можете ввести до 10 различных фильтров для сканирования. Наконец, нажмите OK и продолжайте сканирование сайта или списка страниц.

Когда SEO Spider завершит сканирование, выберите вкладку Custom в верхнем окне, чтобы просмотреть все страницы, содержащие ваш отпечаток. Если вы ввели более одного пользовательского фильтра, вы можете просмотреть каждый, изменив фильтр по результатам.
PPC и аналитика
Как проверить список URL-адресов PPC навалом
Сохраните список в формате .txt или .csv, затем измените настройки Mode на List.

Затем выберите файл для загрузки и нажмите Start или вставьте свой список вручную в Screaming Frog. Посмотрите код состояния каждой страницы, перейдя на вкладку Internal.
Зачистка
Как очистить метаданные для списка страниц
Итак, вы собрали множество URL, но вам нужна дополнительная информация о них? Установите режим List, затем загрузите список URL-адресов в формате .txt или .csv. После того, как SEO Spider будет готов, вы сможете увидеть код состояния, исходящие ссылки, количество слов и, конечно же, метаданные для каждой страницы в вашем списке.
Как очистить сайт для всех страниц, которые содержат определенный размер?
Во-первых, вам нужно определить след. Затем в меню Configuration нажмите Custom → Search или Extraction и введите искомый элемент, который вы ищете.

Вы можете ввести до 10 различных следов на сканирование. Наконец, нажмите OK и продолжайте сканирование сайта или списка страниц. В приведенном ниже примере я хотел найти все страницы с надписью УСЛУГИ в разделе цен, поэтому я нашел и скопировал HTML-код из исходного кода страницы.

Когда SEO Spider завершит проверку, выберите вкладку Custom в верхнем окне, чтобы просмотреть все страницы, содержащие ваш отпечаток. Если вы ввели более одного пользовательского фильтра, вы можете просмотреть каждый, изменив фильтр по результатам.
Ниже приведены некоторые дополнительные общие следы, которые вы можете почерпнуть с веб-сайтов, которые могут быть полезны для ваших аудитов SEO:
- http://schema.org – найти страницы, содержащие schema.org;
- youtube.com/embed/|youtu.be|<video|player.vimeo.com/video/|wistia.(com|net)/embed|sproutvideo.com/embed/|view.vzaar.com|dailymotion.com/ embed / | Players.brightcove.net/ | play.vidyard.com/ | kaltura.com/ (p | kwidget) / – найти страницы, содержащие видеоконтент.
Совет: Если вы извлекаете данные о продукте с клиентского сайта, вы можете сэкономить некоторое время, попросив клиента извлечь их непосредственно из его базы данных. Описанный выше метод предназначен для сайтов, к которым у вас нет прямого доступа.
Перезапись URL
Как найти и удалить идентификатор сеанса или другие параметры из моих просканированных URL
Чтобы идентифицировать URL с идентификаторами сеансов или другими параметрами, просто просмотрите ваш сайт с настройками по умолчанию. Когда SEO Spider закончил анализировать, нажмите на вкладку URI и выберите Parameters, чтобы просмотреть все URL-адреса, содержащие параметры.
Чтобы удалить параметры, отображаемые для просматриваемых URL-адресов, выберите URL Rewriting в меню конфигурации, затем на вкладке Remove Parameters нажмите Add, чтобы добавить все параметры, которые вы хотите удалить из URL-адресов, и нажмите OK. Вам придется снова запустить Screaming Frog с этими настройками, чтобы произошла перезапись.

Как переписать просканированные URL-адреса (например, заменить .com на .co.uk или написать все URL-адреса строчными буквами)
Чтобы переписать любой URL, который вы сканируете, выберите URL Rewriting в меню Configuration, затем на вкладке Regex Replace нажмите Add, чтобы добавить RegEx для того, что вы хотите заменить.

После того, как вы добавили все нужные правила, вы можете проверить их на вкладке Test, введя тестовый URL в поле URL before rewriting. URL after rewriting будет автоматически обновляться в соответствии с вашими правилами.

Если вы хотите установить правило, согласно которому все URL-адреса возвращаются в нижнем регистре, просто выберите Lowercase discovered URLs на вкладке Options. Это удалит любое дублирование URL-адресами с заглавными буквами при сканировании.

Помните, что вам придется запустить SEO Spider с этими настройками, чтобы перезапись URL произошла.
Исследование ключевых слов
Как узнать, какие страницы мои конкуренты ценят больше всего
Конкуренты будут пытаться распространить популярность ссылок и привлечь трафик на свои наиболее ценные страницы, ссылаясь на них внутри. Любой SEO-ориентированный конкурент, вероятно, также будет ссылаться на важные страницы из блога своей компании. Найдите ценные страницы вашего конкурента, просканировав их сайт, а за тем отсортировав вкладку Internal по столбцу Inlinks по возрастанию, чтобы увидеть, какие страницы имеют больше внутренних ссылок.

Чтобы просмотреть страницы, ссылки на которые есть в блоге вашего конкурента, отмените выбор Check links outside folder в меню Spider Configuration и просмотрите папку / поддомен блога. Затем на вкладке External отфильтруйте результаты с помощью поиска по URL основного домена. Прокрутите до крайнего правого края и отсортируйте список по столбцу Inlinks, чтобы увидеть, какие страницы связаны чаще всего.

Совет: Перетащите столбцы влево или вправо, чтобы улучшить просмотр данных.
Как узнать, какой якорный текст используют мои конкуренты для внутренних ссылок
В меню Bulk Export выберите All Anchor Text, чтобы экспортировать CSV-файл, содержащий весь текст привязки на сайте, где он используется и с чем он связан.

Как узнать, какие метатеги keywords (если они есть) конкуренты добавили на свои страницы
После того, как SEO Spider закончил сканировать, посмотрите на вкладку Meta Keywords, чтобы увидеть их, найденные для каждой страницы. Сортируйте по столбцу Meta Keyword 1, чтобы расположить алфавитный список и визуально отделить пустые записи или просто экспортировать весь список.
Создание ссылок
Как проанализировать список предполагаемых ссылок
Если вы создали список URL-адресов, которые необходимо проверить, вы можете загрузить и отсканировать их в режиме List, чтобы собрать больше информации о страницах. После завершения сканирования, проверьте коды состояния на вкладке Response Codes и просмотрите исходящие ссылки, типы ссылок, текст привязки и директивы nofollow на вкладке Outlinks в нижнем окне. Это даст вам представление о том, на какие сайты ссылаются эти страницы и как. Чтобы просмотреть вкладку Outlinks, убедитесь, что в верхнем окне выбран интересующий вас URL.
Конечно, вы захотите использовать пользовательский фильтр, чтобы определить, ссылаются ли эти страницы уже на вас.

Вы также можете экспортировать полный список выходных ссылок, нажав All Outlinks в Bulk Export Menu. Это не только предоставит вам ссылки на внешние сайты, но также покажет все внутренние ссылки на отдельных страницах вашего списка.

Как найти неработающие ссылки для расширения возможностей
Итак, вы нашли сайт, с которого хотите получить ссылку? Используйте Screaming Frog, чтобы найти неработающие ссылки на нужной странице или на сайте в целом, затем обратитесь к владельцу сайта, предложив свой сайт в качестве замены неработающей ссылки, где это применимо, или просто укажите на неработающую ссылку в качестве знака доброй воли.
Как проверить мои обратные ссылки и просмотреть текст привязки
Загрузите свой список обратных ссылок и запустите SEO Spider в режиме List. Затем экспортируйте полный список исходящих ссылок, нажав All Out Links в Advanced Export Menu. Это предоставит вам URL-адреса и анкорный текст / текст alt для всех ссылок на этих страницах. Затем вы можете использовать фильтр в столбце Destination CSV, чтобы определить, связан ли ваш сайт и какой текст привязки / текст alt включен.
Как убедиться, что ссылки удаляются по запросу в процессе очистки
Установите пользовательский фильтр, содержащий URL-адрес вашего корневого домена, затем загрузите список обратных ссылок и запустите SEO Spider в режиме List. Когда SEO Spider завершит сканирование, выберите вкладку Custom, чтобы просмотреть все страницы, которые все еще ссылаются на вас.
Дополнительная информация

Знаете ли вы, что, щелкнув правой кнопкой мыши по любому URL в верхнем окне ваших результатов, вы можете выполнить любое из следующих действий?
- Скопировать или открыть URL;
- Повторно сканировать URL или удалить его из своего сканирования;
- Экспортировать информацию об URL, в ссылках, выходных ссылках или информации об изображении для этой страницы
- Проверить индексацию страницы в Google;
- Проверить обратные ссылки на страницу в Majestic, OSE, Ahrefs и Blekko.
- Посмотреть на кэшированную версию / дату кеша страницы;
- Смотреть старые версии страницы;
- Проверить HTML-код страницы
- Открыть robots.txt для домена, на котором находится страница;
- Поиск других доменов на том же IP.

Аналогично, в нижнем окне, щелкнув правой кнопкой мыши, вы можете скопировать или открыть URL-адрес в столбце To для From выбранной строки.
Как редактировать метаданные
Режим SERP позволяет вам просматривать фрагменты SERP на устройстве, чтобы визуально показать, как ваши метаданные будут отображаться в результатах поиска.
-
Загрузите URL, заголовки и метаописания в Screaming Frog, используя документ .CSV или Excel.
Если вы уже провели сканирование своего сайта, то можете экспортировать URL-адреса, перейдя в Reports → SERP Summary. Это легко отформатирует URL и мета, которые вы хотите загрузить и отредактировать.
- Mode → SERP → Upload File.
- Редактируйте метаданные в Screaming Frog.

Массовый экспорт обновленных метаданных для отправки напрямую разработчикам для обновления.
Как сканировать JavaScript-сайта
Все чаще веб-сайты создаются с использованием таких JavaScript-фреймворков, как Angular, React и т. д. Google настоятельно рекомендует использовать решение для рендеринга, поскольку робот Googlebot все еще пытается сканировать содержимое JavaScript. Если вы определили сайт, созданный с использованием JavaScript, следуйте приведенным ниже инструкциям, чтобы сканировать сайт.
Configuration → Spider → Rendering → JavaScript

Измените настройки рендеринга в зависимости от того, что вы ищете. Вы можете настроить время ожидания, размер окна (мобильный, планшет, рабочий стол и т. д.)
Нажмите OK и сканируйте веб-сайт.
В нижней части навигации щелкните вкладку Rendered Page, чтобы увидеть, как страница отображается. Если ваша страница не отображается должным образом, проверьте наличие заблокированных ресурсов или увеличьте лимит времени ожидания в настройках конфигурации. Если ни один из вариантов не поможет решить, как ваша страница отображается, возможно, возникнет более серьезная проблема.

Вы можете просмотреть и массово экспортировать любые заблокированные ресурсы, которые могут повлиять на сканирование и визуализацию вашего сайта, перейдя в Bulk Export → Response Codes.

Просмотр оригинального HTML и визуализированного HTML
Если вы хотите сравнить необработанный HTML и визуализированный HTML, чтобы выявить какие-либо несоответствия или убедиться, что важный контент находится в DOM, перейдите в Configuration → Spider -> Advanced и нажмите hit store HTML и store rendered HTML.

В нижнем окне вы сможете увидеть необработанный и визуализированный HTML. Это может помочь выявить проблемы с тем, как ваш контент отображается и просматривается сканерами.

В заключение
Мы надеемся, что это руководство даст вам лучшее представление о том, какие возможности вам доступны в Screaming Frog, а также поможет сэкономить часы работы.
Оригинал статьи взят с сайта Elit-Web
Ниже вы найдете обновленное руководство о том, как SEO-специалисты, профессионалы контекстной рекламы и эксперты по цифровому маркетингу могут использовать краулер Screaming Frog (также называемый поисковым роботом, пауком или ботом) для оптимизации своего рабочего процесса.
Оглавление статьи
- 1 Основы краулинга
- 1.1 Как сканировать весь сайт
- 1.2 Как сканировать один подкаталог
- 1.3 Как сканировать определенный набор поддоменов или подкаталогов
- 1.4 Я хочу получить список всех страниц моего сайта
- 1.5 Я хочу получить список всех страниц в определенном подкаталоге
- 1.6 Как найти все поддомены на сайте и проверить внутренние ссылки.
- 1.7 Как сканировать сайт электронной коммерции или другой крупный сайт
- 1.8 Как сканировать сайт, расположенный на старом сервере — или как просканировать сайт, не положив его
- 1.9 Как просмотреть сайт, на котором используются файлы cookie
- 1.10 Как сканировать, используя другой пользовательский агент
- 1.11 Как сканировать страницы, требующие аутентификации
- 2 Внутренние ссылки
- 2.1 Мне нужна информация обо всех внутренних и внешних ссылках на моем сайте (якорный текст, директивы, ссылки на страницу и т.д.).
- 2.2 Как найти неработающие внутренние ссылки на странице или сайте
- 2.3 Как найти неработающие исходящие ссылки на странице или сайте (или все исходящие ссылки в целом)
- 2.4 Как найти ссылки, которые перенаправляются
- 3 Контент сайта
- 3.1 Как определить страницы с “тонким” контентом
- 3.2 Мне нужен список ссылок на изображения на определенной странице
- 3.3 Как найти изображения, у которых отсутствует alt-текст, или изображения, у которых alt-текст длинный
- 3.4 Как найти все CSS файлы на моем сайте
- 3.5 Как найти каждый файл JavaScript на моем сайте
- 3.6 Как определить все плагины jQuery, используемые на сайте, и на каких страницах они используются
- 3.7 Как найти, где на сайте внедрен flash
- 3.8 Как найти все внутренние PDF файлы, на которые есть ссылки на сайте
- 3.9 Как понять сегментацию контента внутри сайта или группы страниц
- 3.10 Как найти страницы, на которых есть кнопки поделиться в соцсетях
- 3.11 Как найти страницы, использующие iframes
- 3.12 Как найти страницы, содержащие встроенное видео или аудио содержимое
- 4 Мета-данные и директивы
- 4.1 Как определить страницы с длинными заголовками, мета-описаниями или URL-адресами
- 4.2 Как найти дублирующиеся заголовки страниц, мета-описания или URL-адреса
- 4.3 Как найти дублированный контент и/или URL, которые необходимо переписать/перенаправить/канонизировать
- 4.4 Как определить все страницы, которые включают мета-директивы, например: nofollow/noindex/noodp/canonical и т.д.
- 4.5 Как проверить, что мой файл robots.txt работает так, как нужно
- 4.6 Как найти или проверить разметку Schema или другие микроданные на моем сайте
- 5 Sitemap
- 5.1 Как создать XML Sitemap
- 5.2 Создание карты сайта XML путем загрузки URL-адресов
- 5.3 Как проверить существующий XML Sitemap
- 6 Устранение общих неполадок
- 6.1 Как определить, почему определенные разделы моего сайта не индексируются или не ранжируются
- 6.2 Как проверить, была ли миграция/редизайн моего сайта успешной
- 6.3 Как найти медленно загружающиеся страницы на моем сайте
- 6.4 Как найти вредоносное ПО или спам на моем сайте
- 7 PPC и аналитика
- 7.1 Как проверить, что мой код Google Analytics находится на каждой странице или на определенном наборе страниц моего сайта
- 7.2 Как проверить список PPC URLs в массовом порядке
- 8 Скраппинг
- 8.1 Как произвести скраппинг метаданных для списка страниц
- 8.2 Как найти на сайте все страницы, содержащие определенное посадочное место
- 9 Переписывание URL
- 9.1 Как найти и удалить идентификатор сеанса или другие параметры из моих просмотренных URL
- 9.2 Как переписать URL (например: заменить .com на .co.uk, или писать все URL в нижнем регистре)
- 10 Исследование ключевых слов
- 10.1 Как узнать, какие страницы наиболее ценны для моих конкурентов
- 10.2 Как узнать, какой анкорный текст используют мои конкуренты для внутренней перелинковки
- 10.3 Как узнать, какие мета ключевые слова (если таковые имеются) добавили мои конкуренты на свои страницы
- 11 Линкбилдинг
- 11.1 Как проанализировать список перспективных мест размещения ссылок
- 11.2 Как найти неработающие ссылки, чтобы использовать их для аутрич-возможностей
- 11.3 Как проверить мои обратные ссылки и просмотреть анкорный текст
- 11.4 Я нахожусь в процессе очистки своих обратных ссылок и мне нужно проверить, что ссылки удаляются в соответствии с запросом
- 11.5 Бонусный раунд
- 11.6 Как редактировать метаданные
- 11.7 Как просканировать сайт с JavaScript
- 12 Просмотр оригинального HTML и рендеринга HTML
- 12.1 Заключительные замечания
Основы краулинга
Как сканировать весь сайт
До начала краулинга сайта будет полезным оценить, какую информацию вы хотите получить, насколько велик сайт и какую часть сайта вам нужно сканировать, чтобы получить представление обо всем сайте. Иногда на больших сайтах лучше ограничить работу краулера только некоторыми URL-адресами, чтобы получить репрезентативную выборку данных. В этом случае размеры файлов и экспорт данных становятся более управляемыми. Подробнее об этом мы расскажем ниже. Для сканирования всего сайта, включая все поддомены, вам потребуется внести небольшие изменения в конфигурацию паука, чтобы начать работу.
По умолчанию Screaming Frog сканирует только тот поддомен, который вы указали. Любые дополнительные поддомены, которые встречает паук, будут рассматриваться как внешние ссылки. Для того чтобы просканировать дополнительные поддомены, необходимо изменить настройки в меню Configuration паука. Установив флажок ‘Crawl All Subdomains’, вы убедитесь, что паук просматривает все ссылки на другие поддомены вашего сайта, которые он встречает.
Шаг 1:
Шаг 2:
Кроме того, если вы начинаете поиск из определенной подпапки или подкаталога, но при этом хотите, чтобы Screaming Frog просмотрел весь сайт, установите флажок «Crawl Outside of Start Folder».
По умолчанию SEO Spider настроен на краулинг только той подпапки или поддиректории, из которой вы начинаете сканирование. Если вы хотите сканировать весь сайт и начинать с определенного подкаталога, убедитесь, что в конфигурации установлен режим просмотра за пределами начальной папки.
Профессиональный совет:
Чтобы сэкономить время и дисковое пространство, не забывайте о ресурсах, которые могут не понадобиться в процессе сканирования. Веб-сайты содержат ссылки не только на страницы. Снимите флажки с Изображений, CSS, JavaScript и SWF ресурсов, чтобы уменьшить размер краулинга.
Как сканировать один подкаталог
Если вы хотите ограничить краулинг одной папкой, просто введите URL и нажмите старт, не изменяя никаких настроек по умолчанию. Если вы переписали исходные настройки по умолчанию, сбросьте их в меню ‘File’.
Если вы хотите начать поиск в определенной папке, но продолжить поиск по остальной части поддомена, обязательно выберите «Crawl Outside Of Start Folder» в настройках конфигурации паука перед вводом конкретного начального URL.
Как сканировать определенный набор поддоменов или подкаталогов
Если вы хотите ограничить краулинг определенным набором поддоменов или подкаталогов, вы можете использовать RegEx, чтобы установить эти правила в настройках Include или Exclude в меню Configuration.
Исключение:
В этом примере мы сканировали все страницы на сайте seerinteractive.com, исключая страницы «О сайте» на каждом поддомене.
Шаг 1:
Перейдите в меню Configuration > Exclude (Конфигурация > Исключить); используйте регулярное выражение с подстановочным знаком, чтобы определить URL-адреса или параметры, которые вы хотите исключить.
Шаг 2:
Проверьте регулярное выражение, чтобы убедиться, что оно исключает те страницы, которые вы ожидали исключить, прежде чем начать сканирование:
Включение:
В приведенном ниже примере мы хотели просканировать только подпапку «Команда» на сайте seerinteractive.com. Снова используйте вкладку «Тест» для проверки нескольких URL-адресов и убедитесь, что RegEx правильно настроен для вашего правила включения.
Это отличный способ краулинга по большим сайтам; на самом деле, Screaming Frog рекомендует этот метод, если вам нужно разделить и подчинить себе краулинг по большому домену.
Я хочу получить список всех страниц моего сайта
По умолчанию Screaming Frog настроен на сканирование всех изображений, JavaScript, CSS и флеш-файлов, которые встречаются пауку. Чтобы проверять только HTML, вам нужно снять флажки ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ и ‘Check SWF’ в меню Spider Configuration.
Запуск паука с этими настройками без галочек, по сути, предоставит вам список всех страниц вашего сайта, на которые ведут внутренние ссылки.
После завершения сканирования перейдите на вкладку ‘Internal’ («Внутренние») и отфильтруйте результаты по «HTML». Нажмите «Экспорт», и вы получите полный список в формате CSV.
Совет профессионала:
Если вы склонны использовать одни и те же настройки для каждого краулинга, Screaming Frog теперь позволяет сохранять параметры конфигурации:
Я хочу получить список всех страниц в определенном подкаталоге
В дополнение к снятию флажков ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ и ‘Check SWF’, вы также должны снять флажок ‘Check Links Outside Folder’ в настройках конфигурации паука. Запуск паука с этими настройками без галочки даст вам список всех страниц в вашей начальной папке (если они не являются страницами-сиротами) Примечание: страницы-сироты — это страницы, которые не связаны ни с одной другой страницей / разделом сайта, поэтому если пользователь попал на неё, он не сможет перейти с этой страницы на другую.
Как найти все поддомены на сайте и проверить внутренние ссылки.
Существует несколько различных способов найти все поддомены на сайте.
Способ 1:
Используйте Screaming Frog для определения всех поддоменов на данном сайте. Перейдите в раздел Configuration > Spider и убедитесь, что выбрана опция «Crawl all Subdomains». Как и при описанном выше сканировании всего сайта, это поможет сканировать все поддомены, на которые есть ссылки на сайте. Однако это не поможет найти поддомены, которые являются “сиротливыми” или на которые нет ссылок.
Метод 2:
Используйте Google для определения всех проиндексированных поддоменов.
С помощью расширения Scraper Chrome и некоторых операторов расширенного поиска можно найти все индексируемые поддомены для данного домена.
Шаг 1:
Начните с использования оператора поиска site: в Google, чтобы ограничить результаты конкретным доменом. Затем используйте оператор поиска -inurl, чтобы сузить результаты поиска, удалив основной домен. Вы должны увидеть список субдоменов, которые были проиндексированы в Google и не содержат основного домена.
Шаг 2:
Используйте расширение Scraper, чтобы извлечь все результаты в лист Google. Просто щелкните правой кнопкой мыши URL в поисковой выдаче, нажмите «Scrape Similar» и экспортируйте в Google Doc.
Шаг 3:
В Google Doc используйте следующую функцию, чтобы обрезать URL до поддомена:
=LEFT(A2,SEARCH(«/»,A2,9))
По сути, приведенная выше формула должна помочь отсечь любые подкаталоги, страницы или имена файлов в конце сайта. Эта формула, по сути, говорит sheets или Excel возвращать то, что находится слева от косой черты. Начальное число 9 является важным, потому что мы просим начать поиск косой черты после 9-го символа. Это учитывает протокол: https://, длина которого составляет 8 символов.
Дедублируйте список и загрузите его в Screaming Frog в режиме списка — вы можете вставить список доменов вручную, использовать функцию вставки или загрузить CSV.
Способ 3:
Введите URL корневого домена в инструменты, помогающие искать сайты, которые могут существовать на том же IP, или в поисковые системы, созданные специально для поиска поддоменов, например FindSubdomains. Создайте бесплатную учетную запись, чтобы войти в систему и экспортировать список поддоменов. Затем загрузите список в Screaming Frog с помощью режима списка.
После завершения работы паука вы сможете увидеть коды состояния, а также все ссылки на домашних страницах поддоменов, якорный текст и дублирующиеся заголовки страниц.
Как сканировать сайт электронной коммерции или другой крупный сайт
Изначально Screaming Frog не был создан для просмотра сотен тысяч страниц, но благодаря обновлениям он становится все ближе к этому.
В версии 11.0 Screaming Frog позволил пользователям сохранять все данные на диске в базе данных, а не просто хранить их в оперативной памяти. Это впервые открыло возможность обхода очень больших сайтов.
В версии 12.0 краулер автоматически сохраняет данные в базе данных. Это позволяет получить к ним доступ и открыть их с помощью команды «File > Crawls» в меню верхнего уровня — на случай, если вы запаникуете и задумаетесь, куда делась команда open!
Хотя использование базы данных краулинга помогает Screaming Frog лучше управлять большими сканами, это, конечно, не единственный способ краулить большой сайт.
Во-первых, вы можете увеличить объем памяти, выделяемой пауку.
Во-вторых, вы можете разбить краулинг по подкаталогам или сканировать только определенные части сайта с помощью настроек Include/Exclude («Включить/Исключить»).
В-третьих, вы можете отказаться от просмотра изображений, JavaScript, CSS и flash. Отменив выбор этих опций в меню Конфигурация, вы можете сэкономить память, выполняя сканирование только HTML.
Профессиональный совет:
До недавнего времени Screaming Frog SEO Spider мог приостановиться или упасть при просмотре большого сайта. Теперь, когда хранение базы данных установлено по умолчанию, вы можете восстановить краулинг, чтобы продолжить работу с того места, на котором остановились. Кроме того, вы можете получить доступ к URL-адресам, поставленным в очередь. Это может дать вам представление о дополнительных параметрах или правилах, которые необходимо исключить при краулинге большого сайта.
Как сканировать сайт, расположенный на старом сервере — или как просканировать сайт, не положив его
В некоторых случаях старые серверы могут быть не в состоянии обрабатывать стандартное количество запросов URL в секунду. На самом деле, мы рекомендуем на всякий случай включить ограничение на количество URL-адресов для просмотра в секунду, чтобы проявить уважение к серверу сайта. Лучше всего сообщить клиенту о том, что вы планируете провести сканирование сайта, на всякий случай, если у него есть защита от неизвестных пользовательских агентов. С одной стороны, им может понадобиться внести ваш IP или User Agent в белый список до того, как вы пройдете по сайту. Худший сценарий может заключаться в том, что вы посылаете слишком много запросов на сервер и непреднамеренно разрушаете сайт.
Чтобы изменить скорость краулинга, выберите «Speed» в меню «Configuration» и во всплывающем окне выберите максимальное количество потоков, которые должны работать одновременно. В этом же меню вы можете выбрать максимальное количество URL-адресов, запрашиваемых в секунду.
Профессиональный совет:
Если вы обнаружите, что в результате вашей проверки возникает много ошибок сервера, перейдите на вкладку ‘Advanced’ в меню Spider Configuration и увеличьте значение ‘Response Timeout’ и ‘5xx Response Retries’, чтобы получить лучшие результаты.
Как просмотреть сайт, на котором используются файлы cookie
Хотя поисковые боты не принимают cookies, если вы сканируете сайт и вам нужно разрешить cookies, просто выберите ‘Allow Cookies’ во вкладке ‘Advanced’ в меню Spider Configuration.
Как сканировать, используя другой пользовательский агент
Чтобы выполнить поиск с использованием другого агента пользователя, выберите ‘User Agent’ в меню ‘Configuration’, затем выберите поискового бота из выпадающего списка или введите желаемые строки агента пользователя.
Поскольку Google теперь ориентируется на мобильные устройства, попробуйте просмотреть сайт под именем Googlebot Smartphone или измените User-Agent, чтобы он имитировал Googlebot Smartphone. Это важно по двум разным причинам:
- Краулинг, имитирующий пользовательский агент Googlebot Smartphone, может помочь определить любые проблемы, возникающие у Google при краулинге и рендеринге содержимого вашего сайта.
- Использование модифицированной версии агента Googlebot Smartphone поможет вам отличить ваши краулинги от краулингов Google при анализе журналов сервера.
Как сканировать страницы, требующие аутентификации
Когда паук Screaming Frog наткнется на страницу, защищенную паролем, появится всплывающее окно, в котором вы сможете ввести имя пользователя и пароль.
Аутентификация на основе форм — очень мощная функция, и для ее эффективной работы может потребоваться рендеринг JavaScript. Примечание: Аутентификация на основе форм должна использоваться редко и только опытными пользователями. Краулер запрограммирован на переход по каждой ссылке на странице, поэтому потенциально это может привести к ссылкам на выход из системы, создание сообщений или даже удаление данных.
Чтобы управлять аутентификацией, перейдите в раздел Configuration > Authentication.
Чтобы отключить запросы на аутентификацию, отмените выбор ‘Standards Based Authentication’ в окне ‘Authentication’ в меню Configuration.
Внутренние ссылки
Мне нужна информация обо всех внутренних и внешних ссылках на моем сайте (якорный текст, директивы, ссылки на страницу и т.д.).
Если вам не нужно проверять изображения, JavaScript, flash или CSS на сайте, отмените выбор этих опций в меню Spider Configuration, чтобы сэкономить время обработки и память.
После того как паук закончит проверку, воспользуйтесь меню Bulk Export, чтобы экспортировать CSV ‘All Links’. Это позволит вам получить все местоположения ссылок, а также соответствующий якорный текст, директивы и т.д.
Все ссылки могут быть большим отчетом. Помните об этом при экспорте. Для большого сайта этот экспорт может занять несколько минут.
Чтобы быстро подсчитать количество ссылок на каждой странице, перейдите на вкладку «Internal» и отсортируйте по «Outlinks». Все, что превышает 100, может потребовать пересмотра.
Как найти неработающие внутренние ссылки на странице или сайте
Если вам не нужно проверять изображения, JavaScript, flash или CSS сайта, снимите выделение этих опций в меню конфигурации паука, чтобы сэкономить время обработки и память.
После того как паук закончит сканирование, отсортируйте результаты на вкладке «Internal» по «Status Code». Любые 404, 301 или другие коды статуса будут легко просматриваться.
При нажатии на любой отдельный URL-адрес в результатах сканирования вы увидите изменение информации в нижнем окне программы. Перейдя на вкладку ‘In Links’ в нижнем окне, вы увидите список страниц, которые ссылаются на выбранный URL, а также якорный текст и директивы, используемые в этих ссылках. Вы можете использовать эту функцию для выявления страниц, на которых необходимо обновить внутренние ссылки.
Чтобы экспортировать полный список страниц, содержащих неработающие или перенаправленные ссылки, выберите «Redirection (3xx) In Links» или «Client Error (4xx) In Links» или «Server Error (5xx) In Links» в меню «Advanced Export», и вы получите экспорт данных в формате CSV.
Чтобы экспортировать полный список страниц, содержащих неработающие или перенаправленные ссылки, зайдите в меню Bulk Export. Прокрутите вниз до кодов ответов и просмотрите следующие отчеты:
- No Response Inlinks (Входящие ссылки без ответа)
- Redirection (3xx) Inlinks (Перенаправление (3xx) Входящие ссылки)
- Redirection (JavaScript) Inlinks (Перенаправление (JavaScript) Внутренние ссылки)
- Redirection (Meta Refresh) Inlinks (Перенаправление (Meta Refresh) Входящие ссылки)
- Client Error (4xx) Inlinks (Ошибка клиента (4xx) Входящие ссылки)
- Server Error (5xx) Inlinks (Ошибка сервера (5xx) Ссылки)
Просмотр всех этих отчетов должен дать нам адекватное представление о том, какие внутренние ссылки должны быть обновлены, чтобы они указывали на каноническую версию URL и эффективно распределяли ссылочный капитал.
Как найти неработающие исходящие ссылки на странице или сайте (или все исходящие ссылки в целом)
После удаления выбора ‘Check Images’, ‘Check CSS’, ‘Check JavaScript’ и ‘Check SWF’ в настройках конфигурации паука, убедитесь, что ‘Check External Links’ остается выбранным.
После того как паук закончит сканирование, перейдите на вкладку ‘External’ в верхнем окне, отсортируйте по ‘Status Code’ и вы легко сможете найти URL с кодами состояния, отличными от 200. Если щелкнуть на любом отдельном URL-адресе в результатах сканирования, а затем перейти на вкладку ‘In Links’ в нижнем окне, вы найдете список страниц, которые указывают на выбранный URL-адрес. Вы можете использовать эту функцию для определения страниц, на которых необходимо обновить исходящие ссылки.
Чтобы экспортировать полный список исходящих ссылок, нажмите «Внешние ссылки» на вкладке «Массовый экспорт».
Для получения полного списка всех местоположений и якорного текста исходящих ссылок выберите ‘All Outlinks’ в меню ‘Bulk Export’. Отчет «All Outlinks» будет включать исходящие ссылки на ваши поддомены; если вы хотите исключить ваш домен, перейдите к отчету «External Links», о котором говорилось выше.
Как найти ссылки, которые перенаправляются
После того, как паук закончил сканирование, выберите вкладку ‘Response Codes’ в главном пользовательском интерфейсе и отфильтруйте по Status Code. Поскольку Screaming Frog использует регулярные выражения для поиска, используйте следующие критерии в качестве фильтра: 301|302|307. Это должно дать вам довольно солидный список всех ссылок, которые вернулись с каким-либо перенаправлением, независимо от того, был ли контент постоянно перемещен, найден и перенаправлен, или временно перенаправлен из-за настроек HSTS (это вероятная причина 307 перенаправления в Screaming Frog). Отсортируйте по ‘Status Code’, и вы сможете разбить результаты по типам. Перейдите на вкладку ‘In Links’ в нижнем окне, чтобы просмотреть все страницы, на которых используется перенаправляющая ссылка.
Если вы экспортируете данные непосредственно с этой вкладки, вы увидите только те данные, которые показаны в верхнем окне (исходный URL, код состояния и место, куда перенаправляет ссылка).
Чтобы экспортировать полный список страниц, включающих перенаправляющие ссылки, вам нужно выбрать ‘Redirection (3xx) In Links’ в меню ‘Advanced Export’. В результате вы получите CSV, содержащий расположение всех ваших перенаправленных ссылок. Чтобы показать только внутренние перенаправления, отфильтруйте столбец ‘Destination’ в CSV, чтобы включить только ваш домен.
Совет:
Используйте VLOOKUP между двумя вышеуказанными экспортными файлами, чтобы сопоставить столбцы Source и Destination с окончательным местоположением URL.
Пример формулы:
=VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,FALSE)
(Где ‘response_codes_redirection_(3xx).csv’ — CSV файл, содержащий URL перенаправления, а ’50’ — количество строк в этом файле).
Контент сайта
Как определить страницы с “тонким” контентом
После того, как паук закончил сканирование, перейдите на вкладку ‘Internal’, отфильтруйте по HTML, затем прокрутите страницу вправо до столбца ‘Word Count’. Отсортируйте столбец ‘Word Count’ от низкого к высокому, чтобы найти страницы с низким содержанием текста. Вы можете перетащить столбец ‘Word Count’ влево, чтобы лучше сопоставить низкие значения количества слов с соответствующими URL-адресами. Нажмите кнопку «Export» на вкладке «Internal», если вы предпочитаете работать с данными в формате CSV.
Мне нужен список ссылок на изображения на определенной странице
Если вы уже просканировали весь сайт или подкаталог, просто выберите страницу в верхнем окне, затем нажмите на вкладку ‘Image Info’ в нижнем окне, чтобы просмотреть все изображения, которые были найдены на этой странице. Изображения будут перечислены в столбце «To».
Совет профессионала:
Щелкните правой кнопкой мыши на любой записи в нижнем окне, чтобы скопировать или открыть URL-адрес.
Кроме того, вы можете просмотреть изображения на одной странице, выполнив поиск только по этому URL. Убедитесь, что глубина просмотра установлена на ‘1’ в настройках конфигурации паука, затем, когда страница будет просмотрена, перейдите на вкладку ‘Images’, и вы увидите все изображения, которые нашел паук.
Как найти изображения, у которых отсутствует alt-текст, или изображения, у которых alt-текст длинный
Во-первых, вы должны убедиться, что опция ‘Check Images’ выбрана в меню Spider Configuration. После того, как паук закончит поиск, перейдите на вкладку ‘Images’ и отфильтруйте изображения по ‘Missing Alt Text’ или ‘Alt Text Over 100 Characters’. Вы можете найти страницы, на которых находится любое изображение, нажав на вкладку ‘Image Info’ в нижнем окне. Страницы будут перечислены в колонке ‘From’.
Наконец, если вы предпочитаете CSV, используйте меню ‘Bulk Export’ для экспорта ‘All Images’ или ‘Images Missing Alt Text Inlinks’, чтобы увидеть полный список изображений, где они расположены и любой связанный с ними alt text или проблемы с alt text.
Кроме того, используйте правую боковую панель для перехода к разделу «Images»; здесь вы можете легко экспортировать список всех изображений с отсутствующим alt-текстом.
Как найти все CSS файлы на моем сайте
В меню Spider Configuration выберите ‘Crawl’ и ‘Store’ CSS перед просмотром, затем, когда просмотр будет завершен, отфильтруйте результаты во вкладке ‘Internal’ по ‘CSS’.
Как найти каждый файл JavaScript на моем сайте
В меню Spider Configuration выберите ‘Check JavaScript’ перед просмотром, затем, когда просмотр будет завершен, отфильтруйте результаты во вкладке ‘Internal’ по ‘JavaScript’.
Как определить все плагины jQuery, используемые на сайте, и на каких страницах они используются
Во-первых, убедитесь, что опция ‘Check JavaScript’ выбрана в меню Spider Configuration. После того как паук закончит поиск, отфильтруйте вкладку ‘Internal’ по ‘JavaScript’, а затем выполните поиск по ‘jquery’. В результате вы получите список файлов плагинов. При необходимости отсортируйте список по ‘Address’ для более удобного просмотра, затем просмотрите ‘InLinks’ в нижнем окне или экспортируйте данные в CSV, чтобы найти страницы, на которых используется файл. Они будут находиться в колонке ‘From’.
Также вы можете использовать меню ‘Advanced Export’ для экспорта CSV ‘All Links’ и отфильтровать столбец ‘Destination’, чтобы показать только URL-адреса с ‘jquery’.
Профессиональный совет:
Не все плагины jQuery вредны для SEO. Если вы видите, что на сайте используется jQuery, лучше всего убедиться, что контент, который вы хотите проиндексировать, включен в исходный текст страницы и передается при ее загрузке, а не после. Если вы все еще не уверены, погуглите плагин, чтобы получить больше информации о том, как он работает.
Как найти, где на сайте внедрен flash
В меню Spider Configuration выберите ‘Check SWF’ перед началом сканирования, затем, когда сканирование будет завершено, отфильтруйте результаты на вкладке ‘Internal’ по ‘Flash’.
Это становится все более важным для поиска и идентификации содержимого, передаваемого с помощью Flash, и предложения альтернативного кода для этого содержимого. Chrome находится в процессе повсеместного отказа от Flash; это действительно то, что следует использовать для выявления проблем с критическим содержимым и Flash на сайте.
Примечание: Этот метод позволяет найти только файлы .SWF, связанные со страницей. Если Flash подтягивается через JavaScript, вам нужно будет использовать специальный фильтр.
Как найти все внутренние PDF файлы, на которые есть ссылки на сайте
После того, как паук закончил поиск, отфильтруйте результаты во вкладке ‘Internal’ по ‘PDF’.
Как понять сегментацию контента внутри сайта или группы страниц
Если вы хотите найти страницы вашего сайта, содержащие определенный тип контента, установите пользовательский фильтр для отпечатка HTML, уникального для данной страницы. Это нужно сделать *до* запуска паука.
Как найти страницы, на которых есть кнопки поделиться в соцсетях
Чтобы найти страницы, содержащие кнопки поделиться в соцсетях, вам нужно установить пользовательский фильтр перед запуском паука. Чтобы установить пользовательский фильтр, перейдите в меню Конфигурация и нажмите ‘Custom’. Оттуда введите любой фрагмент кода из источника страницы.
В приведенном выше примере я хотел найти страницы, содержащие кнопку Facebook «Мне нравится», поэтому я создал фильтр для facebook.com/plugins/like.php.
Как найти страницы, использующие iframes
Чтобы найти страницы, использующие iframe, установите пользовательский фильтр для <iframe перед запуском паука.
Как найти страницы, содержащие встроенное видео или аудио содержимое
Чтобы найти страницы, содержащие встроенное видео или аудио содержимое, установите пользовательский фильтр для фрагмента кода вставки для Youtube или любого другого медиаплеера, который используется на сайте.
Мета-данные и директивы
Как определить страницы с длинными заголовками, мета-описаниями или URL-адресами
После того, как паук закончил сканирование, перейдите на вкладку ‘Page Titles’ и отфильтруйте их по ‘Over 60 Characters’, чтобы увидеть слишком длинные заголовки страниц. То же самое можно сделать на вкладке ‘Meta Description’ или на вкладке ‘URI’.
Как найти дублирующиеся заголовки страниц, мета-описания или URL-адреса
После того, как паук закончил поиск, перейдите на вкладку ‘Page Titles’, затем отфильтруйте их по ‘Duplicate’. То же самое можно сделать на вкладках ‘Meta Description’ или ‘URI’.
Как найти дублированный контент и/или URL, которые необходимо переписать/перенаправить/канонизировать
После того, как паук закончил поиск, перейдите на вкладку ‘URI’, затем отфильтруйте по ‘Underscores’, ‘Uppercase’ или ‘Non ASCII Characters’ для просмотра URL, которые потенциально могут быть переписаны в более стандартную структуру. Отфильтруйте по ‘Duplicate’ и вы увидите все страницы, которые имеют несколько версий URL. Фильтр по ‘Параметрам’ позволяет увидеть URL-адреса, содержащие параметры.
Кроме того, если вы перейдете на вкладку ‘Internal’, отфильтруете по ‘HTML’ и прокрутите колонку ‘Hash’ в крайнем правом углу, вы увидите уникальную серию букв и цифр для каждой страницы. Если вы нажмете кнопку «Экспорт», вы сможете использовать условное форматирование в Excel, чтобы выделить дублирующиеся значения в этом столбце, что в конечном итоге покажет вам страницы, которые идентичны и требуют внимания.
Как определить все страницы, которые включают мета-директивы, например: nofollow/noindex/noodp/canonical и т.д.
После того, как паук закончил сканирование, перейдите на вкладку ‘Directives’. Чтобы увидеть тип директивы, просто прокрутите страницу вправо и посмотрите, какие столбцы заполнены, или воспользуйтесь фильтром, чтобы найти любой из следующих тегов:
- index
- noindex
- follow
- nofollow
- noarchive
- nosnippet
- noodp
- noydir
- noimageindex
- notranslate
- unavailable_after
- refresh
Как проверить, что мой файл robots.txt работает так, как нужно
По умолчанию, Screaming Frog будет соблюдать инструкции robots.txt. В первую очередь, он будет следовать директивам, сделанным специально для пользовательского агента Screaming Frog. Если нет директив специально для агента пользователя Screaming Frog, то паук будет следовать любым директивам для Googlebot, а если нет специальных директив для Googlebot, то паук будет следовать глобальным директивам для всех агентов пользователя. Паук будет следовать только одному набору директив, поэтому если есть правила, установленные специально для Screaming Frog, он будет следовать только этим правилам, а не правилам для Googlebot или любым глобальным правилам. Если вы хотите заблокировать определенные части сайта от паука, используйте обычный синтаксис robots.txt с агентом пользователя ‘Screaming Frog SEO Spider’. Если вы хотите игнорировать robots.txt, просто выберите эту опцию в настройках конфигурации паука.
Configuration > Robots.txt > Settings
Как найти или проверить разметку Schema или другие микроданные на моем сайте
Чтобы найти каждую страницу, которая содержит разметку Schema или любые другие микроданные, вам необходимо использовать пользовательские фильтры. Просто нажмите на ‘Custom’ → ‘Search’ в меню конфигурации и введите искомый след.
Чтобы найти каждую страницу, содержащую разметку Schema, просто добавьте следующий фрагмент кода в пользовательский фильтр: itemtype=http://schema.org
Чтобы найти определенный тип разметки, вам придется уточнить его. Например, используя пользовательский фильтр для ‘span itemprop=»ratingValue»‘, вы получите все страницы, содержащие разметку Schema для оценок.
Начиная с версии Screaming Frog 11.0, SEO-паук также предлагает нам возможность сканировать, извлекать и проверять структурированные данные непосредственно из краулинга. Проверяйте любые структурированные данные JSON-LD, Microdata или RDFa в соответствии с рекомендациями Schema.org и спецификациями Google в режиме реального времени по мере сканирования. Чтобы получить доступ к инструментам проверки структурированных данных, выберите опции в разделе «Config > Spider > Advanced».
В главном интерфейсе появится вкладка «Структурированные данные» (Structured Data), которая позволяет переключаться между страницами, содержащими структурированные данные, отсутствующими структурированными данными, а также страницами с ошибками проверки или предупреждениями:
Вы также можете экспортировать проблемы со структурированными данными в массовом порядке, посетив раздел «Reports > Structured Data > Validation Errors & Warnings.».
Sitemap
Как создать XML Sitemap
После того, как паук закончил сканирование вашего сайта, нажмите на меню «Sitemaps» и выберите «XML Sitemap».
Открыв настройки конфигурации XML Sitemap, вы сможете включить или исключить страницы по кодам ответа, последним изменениям, приоритету, частоте изменений, изображениям и т.д. По умолчанию Screaming Frog включает только URL-адреса 2xx, но это хорошее правило — всегда перепроверять.
В идеале, ваша XML sitemap должна включать только единственную, предпочтительную (каноническую) версию каждого URL со статусом 200, без параметров или других дублирующих факторов. После внесения всех изменений нажмите кнопку OK. Файл XML sitemap загрузится на ваше устройство, и вы сможете отредактировать соглашение об именовании по своему усмотрению.
Создание карты сайта XML путем загрузки URL-адресов
Вы также можете создать XML sitemap, загрузив URL-адреса из существующего файла или вставив их вручную в Screaming Frog.
Измените «Режим» с «Паук» на «Список» и нажмите на выпадающий список «Загрузить», чтобы выбрать любой из вариантов.
Нажмите кнопку «Старт», и Screaming Frog начнет просматривать загруженные URL-адреса. После того, как URL будут просмотрены, вы будете следовать тому же процессу, что и выше.
Как проверить существующий XML Sitemap
Вы можете легко загрузить существующую XML карту сайта или индекс карты сайта, чтобы проверить ее на наличие ошибок или несоответствий.
Перейдите в меню ‘Mode’ в Screaming Frog и выберите ‘List’. Затем нажмите «Upload» в верхней части экрана, выберите «Download Sitemap» или «Download Sitemap Index», введите URL-адрес карты сайта и начните сканирование. После того как паук закончит сканирование, вы сможете найти любые перенаправления, ошибки 404, дублированные URL и многое другое. Вы можете легко экспортировать выявленные ошибки.
Выявление отсутствующих страниц в XML Sitemap
Вы можете настроить параметры краулинга для обнаружения и сравнения URL-адресов в XML-карте сайта с URL-адресами в краулинге сайта.
Перейдите в ‘Configuration’ -> ‘Spider’ в главной навигации и внизу есть несколько опций для XML sitemaps — автоматическое обнаружение XML sitemaps через файл robots.txt или ручной ввод ссылки XML sitemap в поле. *Важное замечание — если ваш файл robots.txt не содержит надлежащих ссылок назначения на все XML sitemap, которые вы хотите получить, вы должны ввести их вручную.
После обновления настроек краулинга XML Sitemap перейдите к разделу «Crawl Analysis» в навигации, затем нажмите «Configure» и убедитесь, что кнопка Sitemaps отмечена. Сначала необходимо выполнить полное сканирование сайта, затем вернуться в «Crawl Analysis» и нажать кнопку Start.
После завершения Crawl Analysis вы сможете увидеть любые несоответствия, например, URL-адреса, которые были обнаружены в ходе полного обхода сайта и отсутствуют в XML sitemap.
Устранение общих неполадок
Как определить, почему определенные разделы моего сайта не индексируются или не ранжируются
Интересуетесь, почему определенные страницы не индексируются? Во-первых, убедитесь, что они не были случайно помещены в robots.txt или помечены как noindex. Затем необходимо убедиться, что пауки могут добраться до страниц, проверив внутренние ссылки. Страница, на которую нет внутренней ссылки на вашем сайте, часто называется «сиротской”.
Для того чтобы определить все подобные страницы, выполните следующие действия:
- Перейдите в ‘Configuration’ -> ‘Spider’ в главной навигации, там внизу есть несколько опций для XML sitemap — Автоматическое обнаружение XML sitemap через ваш файл robots.txt или ручной ввод ссылки XML sitemap в поле. *Важное замечание — если ваш файл robots.txt не содержит надлежащих ссылок назначения на все XML sitemap, которые вы хотите получить, вам следует ввести их вручную.
- Перейдите в раздел ‘Configuration → API Access’ → ‘Google Analytics’ — с помощью API вы можете получить данные аналитики для определенного аккаунта и вида. Чтобы найти страницы-«сироты» из органического поиска, убедитесь, что проведена сегментация по ‘Organic Traffic’
- Вы также можете зайти в General → ‘Crawl New URLs Discovered In Google Analytics’, если хотите, чтобы URLs, обнаруженные в GA, были включены в полный обход сайта. Если эта функция не включена, вы сможете просматривать новые URL, полученные из GA, только в отчете Orphaned Pages (“сиротским” страницам).
- Перейдите в раздел ‘Configuration → API Access’ → ‘Google Search Console’ — с помощью API вы можете получить данные GSC для определенного аккаунта и вида. Чтобы найти страницы-«сироты», вы можете искать URL-адреса, получающие клики и впечатления, которые не включены в ваш краулинг.
- Вы также можете зайти в General → ‘Crawl New URLs Discovered In Google Search Console’, если хотите, чтобы URLs, обнаруженные в GSC, были включены в полный обход сайта. Если эта функция не включена, вы сможете просматривать новые URL-адреса, полученные из GSC, только в отчете Orphaned Pages.
- Выполните сканирование всего сайта. После завершения обхода перейдите в меню ‘Crawl Analysis –> Start’ и дождитесь его завершения.
- Просмотрите “сиротские” URL-адреса на каждой из вкладок или экспортируйте все осиротевшие URL-адреса оптом, перейдя в Reports → Orphan Pages.
Если у вас нет доступа к Google Analytics или GSC, вы можете экспортировать список внутренних URL в файл .CSV, используя фильтр ‘HTML’ на вкладке ‘Internal’.
Откройте CSV-файл и на втором листе вставьте список URL, которые не индексируются или плохо ранжируются. Используйте VLOOKUP, чтобы проверить, были ли URL из вашего списка на втором листе найдены в ходе сканирования.
Как проверить, была ли миграция/редизайн моего сайта успешной
У @ipullrank есть отличный Whiteboard Friday на эту тему, но общая идея в том, что вы можете использовать Screaming Frog для проверки того, перенаправляются ли старые URL, используя режим ‘List’ для проверки кодов состояния. Если старые URL-адреса выдают 404, то вы будете знать, какие URL-адреса еще нужно перенаправить.
Как найти медленно загружающиеся страницы на моем сайте
После того, как паук закончил сканирование, перейдите на вкладку ‘Response Codes’ и отсортируйте по столбцу ‘Response Time’ от высокого к низкому, чтобы найти страницы, которые могут страдать от низкой скорости загрузки.
Как найти вредоносное ПО или спам на моем сайте
Во-первых, вам нужно определить посадочное место вредоносного ПО или спама. Далее, в меню Конфигурация, нажмите на ‘Custom’ → ‘Search’ и введите посадочное место, которое вы ищете.
Вы можете ввести до 10 различных посадочных мест для каждого сканирования. Наконец, нажмите OK и перейдите к просмотру сайта или списка страниц.
Когда паук закончит сканирование, выберите вкладку «Custom» в верхнем окне, чтобы просмотреть все страницы, содержащие ваши посадочные места. Если вы ввели более одного пользовательского фильтра, вы можете просмотреть каждый из них, изменив фильтр на результатах.
PPC и аналитика
Как проверить, что мой код Google Analytics находится на каждой странице или на определенном наборе страниц моего сайта
Начните с выбора Пользовательских фильтров в разделе Конфигурация.
Определите, что вы хотите искать в фильтрах. Обычно один фильтр показывает страницы, содержащие нужную информацию, а другой — страницы, не содержащие ее. Например, фильтры 1 и 2 обычно представляют собой страницы, содержащие или не содержащие номер UA.
Для примера ниже использован номер UA компании SEER: UA-11852503-1.
Если сайт использует кросс-доменное отслеживание, поскольку он охватывает несколько доменов или субдоменов, возьмите строку кода для кросс-доменного отслеживания и поместите ее в фильтры 3 и 4. Сделайте один фильтр Contains, а другой — Does Not Contain.
Для примера ниже использованы setDomainName’, ‘seerinteractive.com.
Для фильтра 5 попробуйте добавить фрагмент из второй части кода GA. Я был удивлен количеством сайтов, которые отбрасывают вторую часть и сохраняют только верхнюю часть кода.
Для примера ниже использован google-analytics.com/ga.js.
После того как все настройки выполнены, введите URL-адрес в Screaming Frog и нажмите кнопку Start.
Оттуда перейдите на вкладку Custom. Данные, которые отображаются, будут относиться к любому из ваших фильтров. Вы можете быстро проверить данные фильтров на наличие проблем или экспортировать данные из каждого фильтра в CSV для дальнейшего анализа или отправки клиенту.
Как проверить список PPC URLs в массовом порядке
Сохраните ваш список в формате .txt или .csv, затем измените настройки ‘Mode’ на ‘List’.
Затем выберите файл для загрузки и нажмите ‘Start’ или вставьте список вручную в Screaming Frog. Посмотрите код состояния каждой страницы на вкладке «Internal».
Скраппинг
Как произвести скраппинг метаданных для списка страниц
Итак, вы собрали кучу URL, но вам нужно больше информации о них? Установите режим ‘List’, затем загрузите список URL в формате .txt или .csv. После того, как паук закончит работу, вы сможете увидеть коды статуса, исходящие ссылки, количество слов и, конечно же, метаданные для каждой страницы из вашего списка.
Как найти на сайте все страницы, содержащие определенное посадочное место
Сначала вам нужно определить посадочное место. Далее, в меню Конфигурация, нажмите на ‘Custom’ → ‘Search’ или ‘Extraction’ и введите посадочное место, которое вы ищете.
Вы можете ввести до 10 различных посадочных мест для каждого краулинга. Наконец, нажмите OK и приступайте к краулингу сайта или списка страниц. В приведенном ниже примере я хотел найти все страницы, на которых в разделе цен написано «Пожалуйста, позвоните», поэтому я нашел и скопировал HTML-код из источника страницы.
Когда паук закончит краулинг, выберите вкладку «Custom» в верхнем окне, чтобы просмотреть все страницы, содержащие ваше посадочное место. Если вы ввели более одного пользовательского фильтра, вы можете просмотреть каждый из них, изменив фильтр в результатах.
Ниже приведены дополнительные общие посадочные места, которые вы можете соскраппить с веб-сайтов и которые могут быть полезны для вашего SEO-аудита:
- http://schema.org — Поиск страниц, содержащих schema.org
- youtube.com/embed/|youtu.be|<video|player.vimeo.com/video/|wistia.(com|net)/embed|sproutvideo.com/embed/|view.vzaar.com|dailymotion.com/embed/|players.brightcove.net/|play.vidyard.com/|kaltura.com/(p|kwidget)/ — Поиск страниц, содержащих видеоконтент.
Профессиональный совет:
Если вы извлекаете данные о продуктах с сайта клиента, вы можете сэкономить себе время, попросив клиента извлечь данные непосредственно из его базы данных. Приведенный выше метод предназначен для сайтов, к которым у вас нет прямого доступа.
Переписывание URL
Как найти и удалить идентификатор сеанса или другие параметры из моих просмотренных URL
Чтобы определить URL с идентификатором сессии или другими параметрами, просто выполните сканирование вашего сайта с настройками по умолчанию. Когда паук закончит работу, перейдите на вкладку «URI» и отфильтруйте «Parameters», чтобы просмотреть все URL-адреса, содержащие параметры.
Чтобы убрать параметры из URL, которые вы сканируете, выберите в меню конфигурации ‘URL Rewriting’, затем на вкладке ‘Remove Parameters’ нажмите ‘Add’, чтобы добавить параметры, которые вы хотите убрать из URL, и нажмите ‘OK’. Вам придется запустить паука снова с этими настройками, чтобы переписывание произошло.
Как переписать URL (например: заменить .com на .co.uk, или писать все URL в нижнем регистре)
Чтобы переписать любой URL, выберите ‘URL Rewriting’ в меню Configuration, затем во вкладке ‘Regex Replace’ нажмите ‘Add’, чтобы добавить RegEx для того, что вы хотите заменить.
После добавления всех необходимых правил вы можете протестировать правила на вкладке ‘Тест’, введя тестовый URL в поле ‘URL before rewriting’. ‘URL after rewriting’ будет автоматически обновлен в соответствии с вашими правилами.
Если вы хотите установить правило, чтобы все URL возвращались в нижнем регистре, просто выберите ‘Lowercase discovered URLs’ на вкладке ‘Options’. Это устранит дублирование URL с заглавными буквами.
Помните, что вам придется запустить паука с этими настройками, чтобы произошло переписывание URL.
Исследование ключевых слов
Как узнать, какие страницы наиболее ценны для моих конкурентов
Как правило, конкуренты пытаются увеличить популярность ссылок и привлечь трафик на свои наиболее ценные страницы, размещая на них внутренние ссылки. Любой SEO-мыслящий конкурент, вероятно, также будет ссылаться на важные страницы из своего блога. Чтобы найти ценные страницы конкурентов, просмотрите их сайт, а затем отсортируйте вкладку «Internal» по столбцу «Inlinks» от наибольшего к наименьшему, чтобы увидеть, на каких страницах больше всего внутренних ссылок.
Чтобы просмотреть страницы, на которые ведут ссылки из блога конкурента, снимите флажок ‘Check links outside folder’ («Проверять ссылки вне папки») в меню «Конфигурация паука» и просмотрите папку/поддомен блога. Затем на вкладке ‘External’ отфильтруйте результаты, используя поиск по URL-адресу основного домена. Прокрутите список вправо и отсортируйте его по колонке ‘Inlinks’, чтобы увидеть, на какие страницы чаще всего ссылаются.
Профессиональный совет:
Перетаскивайте столбцы влево или вправо, чтобы улучшить вид данных.
Как узнать, какой анкорный текст используют мои конкуренты для внутренней перелинковки
В меню ‘Bulk Export’ выберите ‘All Anchor Text’, чтобы экспортировать CSV, содержащий весь анкорный текст на сайте, где он используется и на что он ссылается.
Как узнать, какие мета ключевые слова (если таковые имеются) добавили мои конкуренты на свои страницы
После того, как паук закончил работу, посмотрите на вкладку ‘Meta Keywords’, чтобы увидеть все мета ключевые слова, найденные для каждой страницы. Отсортируйте по столбцу ‘Meta Keyword 1’, чтобы упорядочить список по алфавиту и визуально отделить пустые записи, или просто экспортируйте весь список.
Линкбилдинг
Как проанализировать список перспективных мест размещения ссылок
Если вы провели скраппинг или иным образом составили список URL, которые необходимо проверить, вы можете загрузить и просмотреть их в режиме ‘List’, чтобы собрать больше информации о страницах. Когда паук закончит сканирование, проверьте коды состояния на вкладке «Response Codes» и просмотрите исходящие ссылки, типы ссылок, якорный текст и директивы nofollow на вкладке «Outlinks» в нижнем окне. Это даст вам представление о том, на какие сайты и как ссылаются эти страницы. Чтобы просмотреть вкладку «Outlinks», убедитесь, что интересующий вас URL выбран в верхнем окне.
Конечно, вы захотите использовать пользовательский фильтр, чтобы определить, ссылаются ли эти страницы уже на вас.
Вы также можете экспортировать полный список внешних ссылок, нажав на «All Outlinks» в «Bulk Export Menu». Это не только покажет вам ссылки на внешние сайты, но и покажет все внутренние ссылки на отдельных страницах в вашем списке.
Как найти неработающие ссылки, чтобы использовать их для аутрич-возможностей
Итак, вы нашли сайт, с которого вы хотели бы получить ссылку? Используйте Screaming Frog для поиска битых ссылок на нужной странице или на сайте в целом, затем свяжитесь с владельцем сайта, предложите свой сайт в качестве замены битой ссылки, если это возможно, или просто предложите битую ссылку в знак доброй воли.
Как проверить мои обратные ссылки и просмотреть анкорный текст
Загрузите список обратных ссылок и запустите паука в режиме ‘List’. Затем экспортируйте полный список исходящих ссылок, нажав на ‘All Out Links’ в ‘Advanced Export Menu’. В результате вы получите URL-адреса и якорный текст/alt-текст для всех ссылок на этих страницах. Затем вы можете использовать фильтр в столбце ‘Destination’ в CSV, чтобы определить, есть ли на вашем сайте ссылки и какой якорный текст/alt текст включен.
Я нахожусь в процессе очистки своих обратных ссылок и мне нужно проверить, что ссылки удаляются в соответствии с запросом
Установите пользовательский фильтр, содержащий URL вашего корневого домена, затем загрузите список обратных ссылок и запустите паука в режиме ‘List’. Когда паук закончит сканирование, выберите вкладку ‘Custom’, чтобы просмотреть все страницы, которые все еще ссылаются на вас.
Бонусный раунд
Знаете ли вы, что, щелкнув правой кнопкой мыши на любом URL в верхнем окне результатов, вы можете сделать любое из следующих действий?
- Скопировать или открыть URL
- Повторно просканировать URL или удалить его из просмотра
- Экспортировать информацию об URL, входящие ссылки, исходящие ссылки или информацию об изображении для этой страницы.
- Проверить индексацию страницы в Google, Bing и Yahoo
- Проверить обратные ссылки страницы в Majestic, OSE, Ahrefs и Blekko
- Посмотреть кэшированную версию/дату кэширования страницы
- Посмотреть более старые версии страницы
- Проверить валидность HTML страницы
- Открsnm robots.txt для домена, на котором расположена страница
- Искать другие домены на том же IP
Аналогично, в нижнем окне, щелкнув правой кнопкой мыши, вы можете:
- Скопировать или открыть URL-адрес в столбце «To» или «From» для выбранной строки.
Как редактировать метаданные
Режим SERP Mode позволяет просматривать сниппеты поисковой выдачи по устройствам, чтобы наглядно показать, как ваши метаданные будут отображаться в результатах поиска.
- Загрузите URL, заголовки и метаописания в Screaming Frog с помощью документа .CSV или Excel
- Если вы уже выполнили сканирование своего сайта, вы можете экспортировать URL-адреса, перейдя в раздел ‘Reports → SERP Summary’. Это позволит легко отформатировать URL-адреса и мета-описания, которые вы хотите повторно загрузить и отредактировать.
- Mode → SERP → Upload File
- Редактирование метаданных в Screaming Frog
- Массовый экспорт обновленных метаданных для отправки непосредственно разработчикам для обновления
Как просканировать сайт с JavaScript
Все чаще сайты строятся с использованием JavaScript-фреймворков, таких как Angular, React и т. д. Google настоятельно рекомендует использовать решение для рендеринга, поскольку Googlebot все еще с трудом справляется с содержимым на javascript. Если вы обнаружили сайт, построенный с использованием javascript, следуйте приведенным ниже инструкциям, чтобы сканировать его.
- ‘Configuration → Spider → Rendering → JavaScript
- Измените настройки рендеринга в зависимости от того, что вы ищете. Вы можете настроить время ожидания, размер окна (мобильное, планшетное, настольное и т.д.).
- Нажмите OK и сканируйте сайт.
В нижней навигации перейдите на вкладку Rendered Page («Рендеринг страницы»), чтобы посмотреть, как отображается страница. Если страница отображается некорректно, проверьте наличие заблокированных ресурсов или увеличьте лимит тайм-аута в настройках конфигурации. Если ни один из этих способов не помогает решить проблему рендеринга страницы, возможно, необходимо выявить более серьезную проблему.
Вы можете просмотреть и экспортировать в массовом порядке все заблокированные ресурсы, которые могут влиять на краулинг и рендеринг вашего сайта, перейдя в раздел ‘Bulk Export’ → ‘Response Codes’.
Просмотр оригинального HTML и рендеринга HTML
Если вы хотите сравнить исходный HTML и рендеринг HTML, чтобы выявить любые несоответствия или убедиться, что важное содержимое находится в DOM, перейдите в ‘Configuration’ → ‘Spider’ -> ‘Advanced’ и нажмите store HTML & store rendered HTML.
В нижнем окне вы сможете увидеть необработанный и преобразованный HTML. Это может помочь выявить проблемы с тем, как ваше содержимое отображается и просматривается краулерами.
Заключительные замечания
В заключение, я надеюсь, что это руководство даст вам лучшее представление о том, что Screaming Frog может сделать для вас. Оно сэкономило мне бесчисленное количество часов, поэтому я надеюсь, что оно поможет и вам!
Кстати, я не связан со Screaming Frog; я просто считаю, что это потрясающий инструмент.
Источник: https://www.seerinteractive.com/blog/screaming-frog-guide/
Доброго времени суток, Друзья. Сегодня, я решил поднять тему, которая должна быть интересной практически всем, кто, так или иначе, связан с созданием сайтов.
Ни для кого, ни секрет, что скачав бесплатно шаблон, для своего сайта, независимо от движка, который используется, для управления контентом. Мы можем столкнуться с проблемой исходящих ссылок, которые ставятся различными вебмастерами, необязательно авторами. Парочку ссылок может оставить автор шаблона, затем еще парочку могут оставить те кто, например, перевел шаблон, те, кто выложил… И в общем итоге, исходящих ссылок может быть довольно солидное количество.

Я не буду поднимать тему, стоит ли оставлять ссылки автора шаблона или нет. Принимать решение только Вам. Порой шаблоны настолько заспамлены ссылками, что довольно остро встает вопрос, как удалить исходящие ссылки с сайта. Но прежде, чем удалять ссылки, их необходимо найти.
Как найти внешние ссылки в исходном коде?
Способов поиска, я думаю не мало. Можно искать исходящие ссылки, с помощью различных сервисов, плагинов или модулей для движков. Например, как написано в этой статье. Но самый простой и точный способ — это поиск исходящих ссылок вручную. Возможно, у Вас появилось чувство, что руками искать придется довольно долго. Или что данный процесс довольно трудоемкий, нежели воспользоваться каким-либо сервисом или утилитой. Но на самом деле, все очень просто, а надежность данного метода ни сравнима, ни с чем.
И, кроме того, у нас есть ни один вариант поиска. Сначала рассмотрим вариант поиска, с помощью исходного кода. В данном случае, необходимо хотя бы образно понимать структуру используемого шаблона. То есть, из каких основных файлов состоит шаблон. К примеру, wordpress, состоит из главной страницы index.php или home.php, файла полной новости single.php, файла страниц page.php футера, хэдера и сайдбара. Зачем это нужно?
Это нужно для того, чтобы понять, где проверить сайт на исходящие ссылки. Например, если мы проверим главную страницу сайта — это не даст нам гарантии, что ссылок на сайте нет, так как, проверив главную страницу, мы проверим только файлы: index.php, header.php, footer.php и sidebar.php. Однако ссылки могут быть спрятаны в записи или на страницах, то есть в файлах single.php и page.php.
Отсюда можно сделать вывод, что стоит проверить как минимум три страницы: главную, страницу с записью и обычную страницу с какой-либо информацией, например, «О сайте».
Теперь, разберем, как найти внешние ссылки? Заходим на страницу сайта и нажимаем сочетание клавиш Ctrl+U. Откроется новая вкладка с исходным кодом сайта. Вот в нем-то мы наверняка сможем найти исходящую ссылку, даже если в файле, она зашифрована. Для того, чтобы найти, достаточно нажать сочетание клавиш Ctrl+F, после чего появится форма поиска. И в поле формы написать начало любого адреса в сети интернет, это протокол. То есть, пишем http и жмем «Enter». После этого, абсолютно все ссылки на сайте будут подсвечены в коде.
А дальше дело за малым — вычислить ссылки, которые не были установлены нами. И удалить их в файлах. Чтобы найти, в каком файле они запрятаны, достаточно воспользоваться следующим вариантом поиска внешних ссылок.
Как найти ссылку на сайте?
Следующий вариант — это поиск ссылок в самих файлах сайта. Допустим, мы скачали шаблон для сайта, и сразу его можно проверить на наличие исходящих ссылок. Для этого, можно воспользоваться текстовым редактором NotePad++.
Чтобы найти ссылку на сайте, открываем редактор. В верхнем меню нажимаем на кнопку поиск, и из выпавшего списка выбираем «Найти в файлах». Дальше уже дело техники. Вводим в поле «Найти» протокол, используемый гиперссылками — http. И в поле «Папка» выбираем местонахождение шаблона на компьютере. После чего, нажимаем на кнопку «Найти все». Затем, программа выведет результаты поиска в нижней части окна. Где просмотрев ссылки, мы можем вычислить те, которые явно не относятся к шаблону.
Но у данного варианта, в отличие от первого, есть один большой недостаток, если ссылка зашифрована, то найти по протоколу ее не удастся. Хотя можно поменять цель поиска. И вместо http попробовать найти нечто подобное: base64. Довольно часто закодированные ссылки содержат такой кусок кода. Но все же данный вариант менее надежный, в отличии от первого.
Также, стоит отметить, что закодированные ссылки могут повлиять на работу шаблона, после удаления кода. Поэтому, перед удалением, следует cделать резервную копию сайта или файлов.
Оба способа могут показаться не такими уж понятными для начинающих, так как найдя ссылку, мы не всегда можем сразу определить ее точное местонахождение в файлах шаблона, модуля или плагина. Однако, при хорошем понимании структуры шаблона и методов подключения дополнительных файлов, довольно просто найти исходящие ссылки с сайта.
А как ищите Вы исходящие ссылки на сайте? Хотелось бы узнать методы, которыми пользуетесь Вы.
А у меня на этом все. Удачи!
Исходящие ссылки – один из важнейших факторов раскрутки сайта. Ведь ссылки на ресурсы сомнительного содержания, могут очень даже повредить в деле продвижения сайта. В этой статье мы рассмотрим все варианты, как найти ссылки ведущие на другие сайты.
Когда нужно искать исходящие ссылки?
Конечно, работая над своим сайтом или блогом, вы так и так будете контролировать исходящие ссылки. Но есть бывают ситуации, когда ссылки расставляли не вы, а теперь их нужно разыскать и почистить. Например удалить не ауктуальные или “битые” ссылки. Когда это бывает?
- Вы купили сайт.
- Вы только что создали сайт.
- Вы значительно изменили дизайн сайта (этот пункт, особенно касается, если сайт создан на популярной CMS WordPress или на других CMS).
Вы купили сайт. Понятно, вы не знаете, что на этом сайте, какие индексируемые, какие неиндексируемые. И вообще, вы не знаете, не оставил ли прежний хозяин несколько «лишних ссылок» на сайт, над которым он сейчас работает.
Вы только что создали сайт. Сделаю предположение, что вы не с нуля создали сайт. А значит, использовали ряд готовых шаблонов. Ну а в шаблонах, нередко можно встретить ссылки, которые оставляют создатели этих шаблонов. Ну а зачем вам ссылка, которая ведет на «чужой» сайт?
Если вы решили сменить дизайн сайта, то вы тоже можете столкнуться с тем, что поставленный новый шаблон, также будет содержать исходящие ссылки.
Как найти ссылки ведущие на другие сайты.
Можно воспользоваться различными онлайн сервисами, можно использовать программы. Какой метод использовать, решать вам. Ну а сейчас, я вас познакомлю с несколькими такими сайтами и с одной программой.
Один из лучших сервисов для поиска исходящих ссылок, вы сможете найти на сайте linkpad.ru. Этот сайт больше известен, как сервис поиска обратных ссылок, но он также хорош и в деле поиска исходящих ссылок. Но если поиск обратных ссылок в нем платный, то поиск исходящих ссылок, в нем бесплатный.
Для работы в сервисе, необходимо в нем зарегистрироваться. Вводите в строку интересующий вас сайт, нажимаете кнопку «Найти ссылки», и получаете отчет.
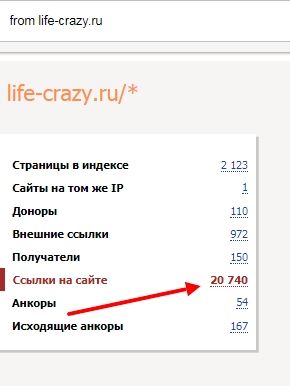
Теперь, нужно выбрать пункт – «Ссылки на сайте», нажать на ссылку с цифрой, после чего, вверху справа нажать на кнопку «Экспорт CSV». В результате, вы скачаете файл, который можно открыть в программе Excel, и проверить свои исходящие ссылки.
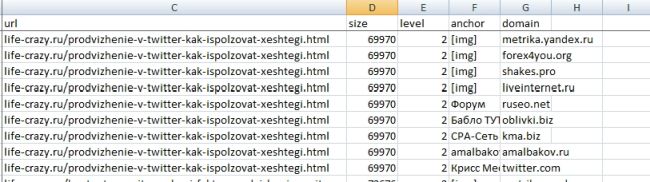
Таким образом, я смогу увидеть все исходящие ссылки с сайта, включая рекламные.
Есть и другой сайт для поиска исходящих ссылок, это my-seotools.ru на котором вы найдете простой, но довольно мощный инструмент, для поиска исходящих ссылок. Для поиска, выберите пункт – «Поиск исходящих ссылок».
Введите адрес своего сайта, и получайте постраничный отчет.
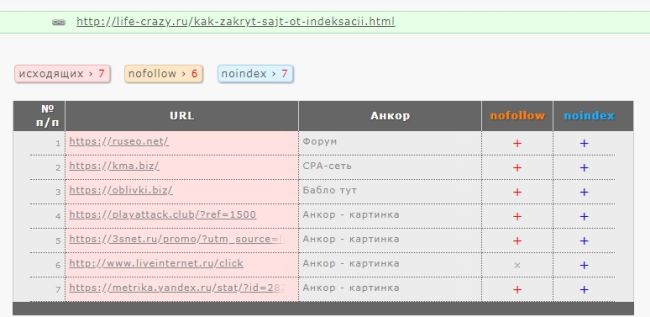
Что хорошо в этом сервисе, это то, что в отчете показаны не только сами исходящие ссылки, но и показано, закрыты ли тегами nofollow и noindex. Но плохо то, что сервис только лишь условно бесплатный. Без регистрации вы сможете проверить десять страниц, с регистрацией вы сможете проверить пятьдесят страниц, ну а дальше уже придется платить. Впрочем, цена проверки, отнюдь не кусачая. А учитывая то, что проверка обычно проводится только один раз, то я проблем с этим не вижу.
Ну и последний онлайн сервис для проверки исходящих ссылок, с которым я хочу вас познакомить, находится на сайте mainspy.ru. Сервис полностью бесплатный, но есть и недостаток. Для поиска исходящих ссылок, придется каждую страницу вводить отдельно, а ведь у многих сайтов, но очеень много страниц. Да еще не забывайте, есть еще страницы с категориями, с архивами и прочие другие страницы.
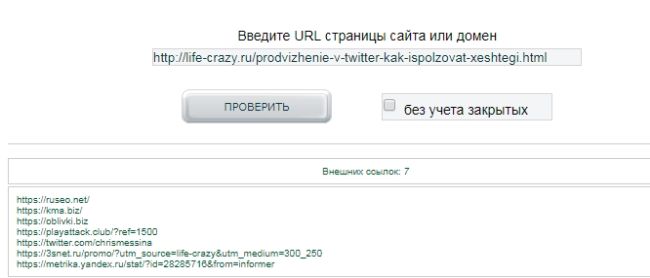
Программы для поиска наличия ссылок на сайте.
Помимо онлайн сервисов, вы можете проверить исходящие ссылки при помощи бесплатных программ.
Программа Majento SiteAnalyzer
Эту программу вы можете скачать с официального сайта. Запустив ее, вы сможете проверить вообще все ссылки на вашем сайте, то есть, и внутренние ссылки, и исходящие ссылки.
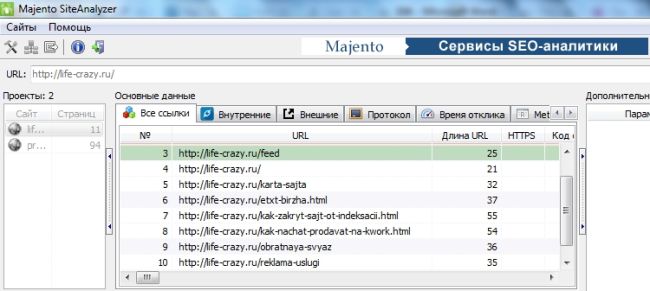
В одном окне вы можете увидеть все ссылки, но можно посмотреть и только исходящие ссылки. К сожалению, кроме самого показа исходящих ссылок, эта программа больше ничего не делает. То есть, нельзя посмотреть, с какой страницы ведут эти ссылки, нельзя посмотреть атрибуты nofollow и noindex.
Программа Xenu
Эта программа на английском языке, авторы, судя по домену, из Германии, но освоить ее не будет проблемой, она имеет простой интерфейс. Найти и скачать ее можно по запросу “скачать Xenu”.
После запуска, нужно зайти в меню File и выбрать пункт Check URL…
Ввести интересующий сайт и нажать кнопку OK.
Когда программа закончит сканирование, она вам предложит создать отчет. Нажимаем кнопку «Нет». Выбираем интересующую ссылку, вызываем контекстное меню, и выбираем пункт «URL properties»
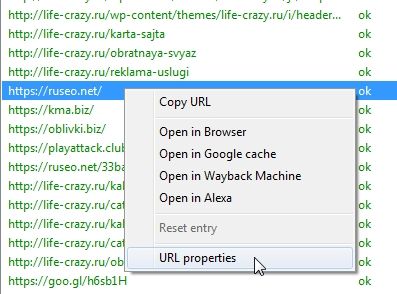
И получаем страницы, на которых находится данная исходящая ссылка.
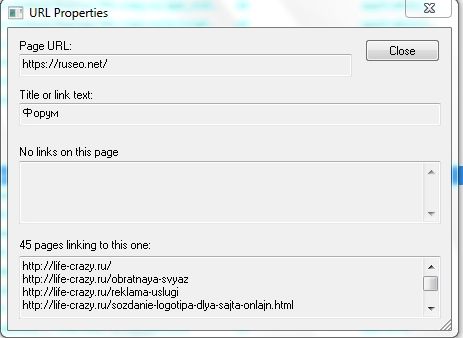
Плагин WordPress для поиска исходящих ссылок.
При работе с известной CMS WordPress, очень важно убедится, нет ли «плохих» исходящих ссылок, которые частенько ставят в темах. Проверить «обычные» ссылки, вы можете при помощи инструментов, про которые я написал выше. Но для WordPress, есть еще один инструмент. Он проверяет именно темы на наличие скрытых ссылок.
Для этих целей, хорошо подойдет плагин «Theme Authenticity Checker (TAC)» который вы можете скачать с официального репозитория WordPress. Его единственная задача, определить, нет ли «плохих» ссылок в самом WordPress. При этом, исходящие ссылки с обычных страниц, он не ищет.
После установки плагина, в консоли WordPress, в меню «Внешний вид», появится пункт – «TAC». Зайдя в него, можно увидеть, в порядке ли ваша тема.
Заключение.
Исходящие ссылки, являются важным параметром сайта. В зависимости от качества этих самых ссылок, они могут влиять как в лучшую сторону, если вы ссылаетесь на качественные сайты, но могут стать и отрицательным фактором, если вы ссылаетесь на «плохие» сайты.
Тем самым, не стоит игнорировать исходящие ссылки, и необходимо их проверить. Хотя, для обычного сайта, проверку можно сделать всего один раз, и убедится, что все у вас нормально.
Исходящие ссылки: что это такое?
Исходящие ссылки — это ссылки, размещенные на сайте, которые ведут на сторонний ресурс. Как и другие ссылки, они могут быть с анкором и без.
Общий вид исходящей ссылки:

Какие бывают

Есть 2 типа исходящих ссылок:
- Nofollow ссылки (условно неиндексируемые). Почему «условно» разберемся далее по тексту.
- Dofollow ссылки (индексируемые).
Обычные (dofollow) ссылки — это естественные исходящие ссылки. Такие ссылки не имеют каких-то атрибутов. Каждая ссылка по умолчанию является dofollow. Она отправляет сигнал в Google PageRank о том, что по целевой ссылке следует переходить ботам.

Nofollow ссылки — это исходящие ссылки, котором вы не доверяете. Вы должны изменить код, добавив в него тег rel = ”nofollow”. Он отправляет сигнал в Google PageRank, что не стоит переходить по ссылке.

Атрибуты исходящих ссылок

Вы можете указать у исходящих ссылок разные атрибуты. Используя их, вы просите Google не учитывать такие ссылки при расчете PR. А теперь подробнее про каждый.
В своем посте от 10 сентября 2019 года Google анонсировал 2 новых атрибута ссылок «sponsored» и «ugc» вдобавок к «nofollow».
Атрибут rel = “sponsored” используется для идентификации ссылок, созданных в рекламных, спонсорских или других коммерческих целях. Используя этот атрибут, вы сообщаете поисковику, что ссылка была размещена по предварительному соглашению двух сторон.
Атрибут rel = ”ugc” (User-generated content) или в переводе «пользовательский контент» предназначен для ссылок в комментариях, сообщениях на форуме и т. д.
Раньше Google блокировал все nofollow ссылки и не учитывал их в расчете Pagerank. С 1 марта 2020 года все 3 атрибута будут рассматриваться как «подсказки» для сканирования и индексации. Т.е. Гугл будет видеть эти атрибуты, анализировать ссылки и решать стоит учитывать их или нет.
«Ссылки содержат ценную информацию, которая может помочь нам улучшить поиск. Например, слова в ссылках (анкоры) описывают контент, на который они указывают. Просмотр всех ссылок, с которыми мы сталкиваемся, также может помочь нам лучше понять неестественные шаблоны ссылок. Переходя к модели подсказок, мы больше не теряем эту важную информацию, но при этом позволяем владельцам сайтов указывать, что некоторым ссылкам не следует передавать вес».
Google об исходящих ссылках
«Ссылки на другие веб-сайты — это отличный способ принести пользу вашим посетителям. Часто ссылки помогают пользователям узнать больше, проверить ваши источники и лучше понять, насколько ваш контент соответствует интересующим их вопросам».
Дэнни Салливан (представитель поискового отдела компании Google) делится своими мыслями:
«Я думаю, что ссылки — это часть приписывания авторства. Вы журналист. Вы пишете рассказ, вы цитируете свои источники. Если эти источники находятся в сети и содержат дополнительную информацию для читателя, ссылка на них должна быть указана. Это просто хорошая журналистика. Это должно быть стандартом».
Источник.
Мэтт Каттс (бывший руководитель группы по веб-спаму в Google):
«Я бы не рекомендовал закрывать комментарии, пытаясь «накопить» ваш PageRank. Google меньше доверяет сайтам, когда они ссылаются на спамерские сайты, зато наша система одобряет ссылки на хорошие сайты».
Источник.
В самой же справке Гугла написано следующее:

Таким образом в Гугле считают, что можно и нужно ссылаться на качественные ресурсы.

Если коротко, то сомнительные ссылки закрывайте через атрибут rel=”nofollow”.
Как проверить и найти исходящие ссылки
Выделим 4 способа (платная программа, бесплатная программа, сервис, плагин), как можно выполнить поиск и проверку исходящих ссылок.
Netpeak Spider

Netpeak Spider — многофункциональный инструмент, который делает полноценный SEO-аудит сайт. В том числе с помощью этой платной программы можно найти все исходящие ссылки на сайте, а затем узнать, какой код они возвращают (т.е. проверить не битые ли они). Единственный минус, что данные из программы нужно будет почистить от дубликатов по столбцу «URL».
Xenu
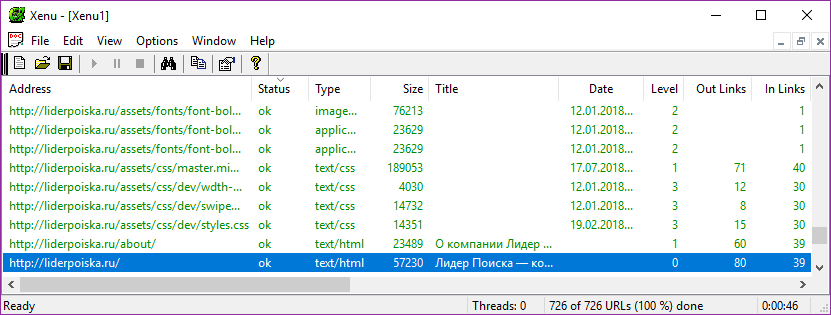
Xenu — бесплатная программа для анализа внешних ссылок. Как работать с ней написано в нашей отдельной статье.
Ahrefs
Ahrefs — это платный сервис для проверки ссылок, как входящих так и исходящих. Удобство использования заключается в том, что в одном месте отображается вся нужная информация: рейтинг домена, тип ссылки, количество ссылок на сайт и откуда они идут.
Free Backlink Checker by LRT
Бесплатный плагин для Google Chrome и Яндекс.Браузера, который может постранично анализировать исходящие ссылки с сайта. Более подробная информация об этом расширении в нашей статье.
Влияют ли на SEO?
Конечно, да. Другой вопрос в какой степени.
Компания Reboot Online Marketing Ltd проверила эксперимент. Было придумано 2 новых, вымышленных слова («Ancludixis» и «Phylandocic»), о которых Google не имел информации.
Гугл ничего не нашел по запросу «Phylandocic»
Было создано 10 новых сайтов. Для каждого написаны уникальные тексты одинаковой длины и структуры. Оба выдуманных слова встречались в текстах одинаковое количество раз. С 5 сайтов было проставлено по 3 исходящие ссылки на авторитетные ресурсы. Другие 5 сайтов были без исходящих ссылок.

Текст без исходящих ссылок

Текст с исходящими ссылками
Эксперимент длился 5 месяцев, в течение этого времени отслеживались позиции сайтов. После чего были подведены итоги.
Результат такой: 5 сайтов, которые ссылались на внешние ресурсы, оказались выше других 5. Отсюда простой вывод: наличие качественных исходящих ссылок дает положительный эффект (при прочих равных условиях).

Сайты с исходящими ссылками выше сайтов без ссылок по запросу «Phylandocic»

Сайты с исходящими ссылками выше сайтов без ссылок по запросу «Ancludixis»
Сколько исходящих ссылок должно быть на одной странице?
Три штуки. А если серьезно, то сколько нужно, столько и размещайте. А вот ссылаться на авторитетные сайты «лишь бы было» не стоит. Есть мнение, что если на странице чересчур много исходящих линков (больше 100?!), то это отвлекает внимание от содержимого контента. Вдобавок такая страница имеет меньший PR, чем страница с небольшим количеством ссылок.
Когда нужно использовать?
Используйте исходящие ссылки, если хотите предоставить доказательства, повысить достоверность информации. Например, для интернет-магазина это могут быть ссылки на сайты отзовиков. Для интернет-агентств — ссылки на рейтинги СМИ. Для статей — ссылки на справочники, научные исследования.
Когда не нужно использовать?
На конверсионных страницах. Например на товарных страницах, каталогах, страницах услуг и так далее. Т.е. внешние ссылки не уместны тогда, когда важно удержать посетителя на странице.
Можно ли ссылаться на прямых конкурентов?
Можно. А если у вас новостной ресурс, то это и вовсе обязательно. Однако если вы ведете свой блог, то отдайте предпочтение зарубежным ресурсам.
Наши советы

- Следите за исходящими ссылками. Со временем страницы, на которые вы ссылаетесь, могут быть удалены. Битые ссылки нужно оперативно заменять.
- Ссылайтесь на страницы с актуальной информацией. Например, если есть 2 статьи по защите от DDoS-атак 2005 и 2020 годов, то предпочтение стоит отдать последней.
- Настройте открытие ссылок в новых окнах. Для этого используйте атрибут target с параметром _blank.

- Не ставьте ссылки на сайты со спамом и агрессивной рекламой.
- Ссылайтесь на разные авторитетные источники на странице. Так у вас получится сборник лучших материалов интернета в одном месте.
- Меньше ставьте nofollow ссылок. Другими словами, откажитесь от контента в котором не уверены.
- Используйте анкоры по существу. То есть они должны описывать содержимое, которое будет открыто по ссылке.


В 2021 ужесточились требования к контенту для YMYL-страниц (т.е. для страниц, которые способны влиять на здоровье, благополучие, безопасность и финансовую стабильность посетителей). Так, Google отдает предпочтение тем материалам, которые отвечают требованиям E-A-T (экспертность, авторитетность и достоверность). Как раз исходящие ссылки на авторитетные ресурсы помогут удовлетворить этим параметрам.
Подкрепрепляйте свои мысли доказательствами и другими мнениями. Через исходящие ссылки происходит некая ассоциация. Вы сообщаете поисковикам, что работаете в тех же кругах, что и крупнейшие имена в своей отрасли.
Известный за рубежом SEO-специалист Брайан Дин так же включил исходящие ссылки в список факторов ранжирования 2021 года.

Примеры использования
Вывод
Исходящие ссылки являются рабочей составляющей SEO-продвижения. И их влияние в 2021 году только усилилось. Поэтому самое время начать активно ссылаться на другие сайты, не забывая про наши рекомендации.
Да, и используйте эту статью в качестве исходящей ссылки на своих ресурсах 😉

