Большинство используемых нами веб- и мобильных приложений постоянно взаимодействуют с глобальной сетью. Почти все подобные коммуникации совершаются с помощью запросов по протоколу HTTP. Рассказываем о них подробнее.

Большинство используемых нами веб- и мобильных приложений постоянно взаимодействуют с глобальной сетью. Почти все подобные коммуникации совершаются с помощью запросов по протоколу HTTP. Рассказываем о них подробнее.
Базово о протоколе HTTP
HTTP (HyperText Transfer Protocol, дословно — «протокол передачи гипертекста») представляет собой протокол прикладного уровня, используемый для доступа к ресурсам Всемирной Паутины. Под термином гипертекст следует понимать текст, в понятном для человека представлении, при этом содержащий ссылки на другие ресурсы.
Данный протокол описывается спецификацией RFC 2616. На сегодняшний день наиболее распространенной версией протокола является версия HTTP/2, однако нередко все еще можно встретить более раннюю версию HTTP/1.1.
В обмене информацией по HTTP-протоколу принимают участие клиент и сервер. Происходит это по следующей схеме:
- Клиент запрашивает у сервера некоторый ресурс.
- Сервер обрабатывает запрос и возвращает клиенту ресурс, который был запрошен.
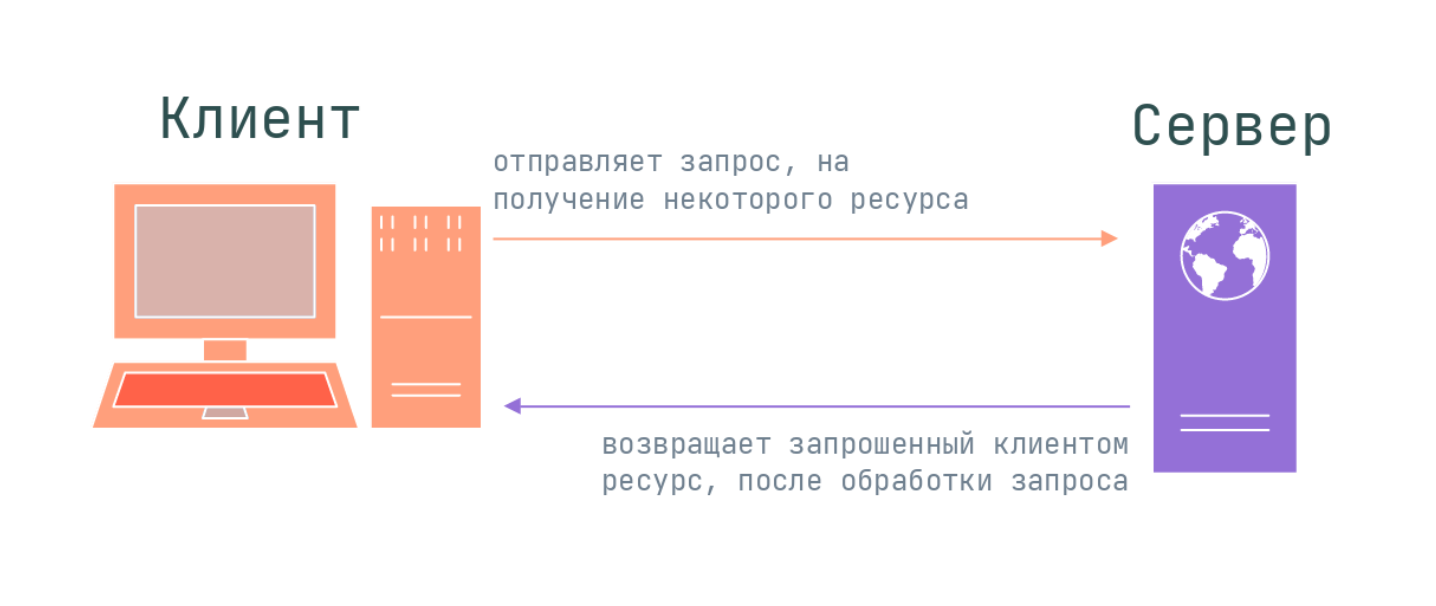
По умолчанию для коммуникации по HTTP используется порт 80, хотя вместо него может быть выбран и любой другой порт. Многое зависит от конфигурации конкретного веб-сервера.
Подробнее о протоколе HTTP читайте по ссылке →
HTTP-сообщения: запросы и ответы
Данные между клиентом и сервером в рамках работы протокола передаются с помощью HTTP-сообщений. Они бывают двух видов:
- Запросы (HTTP Requests) — сообщения, которые отправляются клиентом на сервер, чтобы вызвать выполнение некоторых действий. Зачастую для получения доступа к определенному ресурсу. Основой запроса является HTTP-заголовок.
- Ответы (HTTP Responses) — сообщения, которые сервер отправляет в ответ на клиентский запрос.
Само по себе сообщение представляет собой информацию в текстовом виде, записанную в несколько строчек.
В целом, как запросы HTTP, так и ответы имеют следующую структуру:
- Стартовая строка (start line) — используется для описания версии используемого протокола и другой информации — вроде запрашиваемого ресурса или кода ответа. Как можно понять из названия, ее содержимое занимает ровно одну строчку.
- HTTP-заголовки (HTTP Headers) — несколько строчек текста в определенном формате, которые либо уточняют запрос, либо описывают содержимое тела сообщения.
- Пустая строка, которая сообщает, что все метаданные для конкретного запроса или ответа были отправлены.
- Опциональное тело сообщения, которое содержит данные, связанные с запросом, либо документ (например HTML-страницу), передаваемый в ответе.
Рассмотрим атрибуты HTTP-запроса подробнее.
Стартовая строка
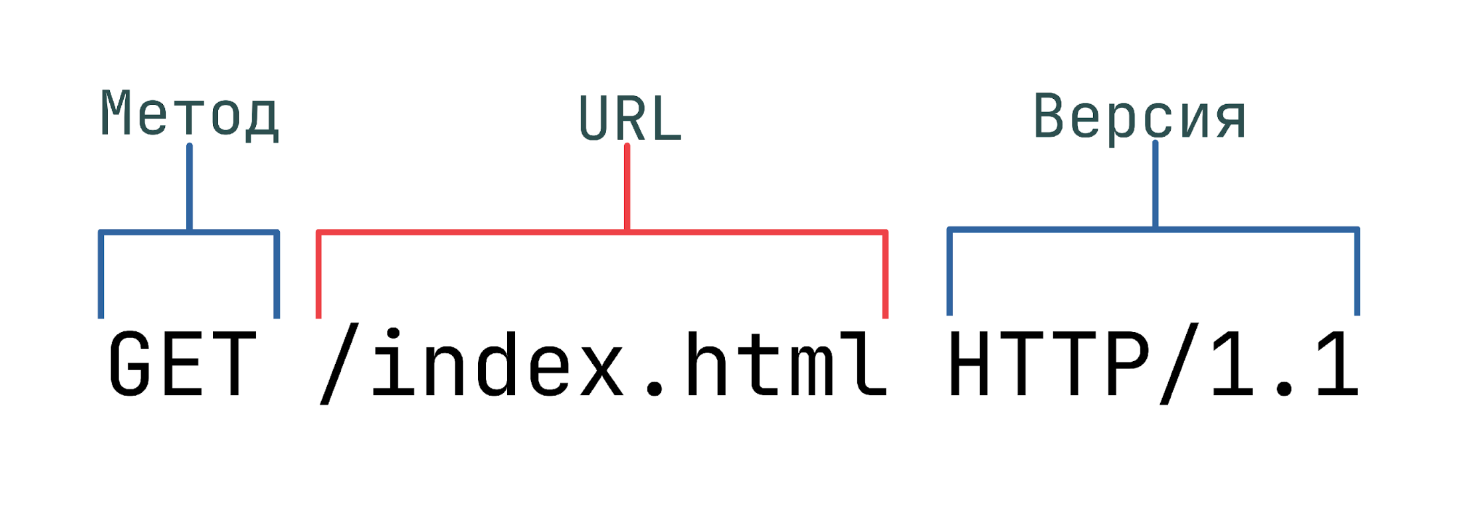
Стартовая строка HTTP-запроса состоит из трех элементов:
- Метод HTTP-запроса (method, реже используется термин verb). Обычно это короткое слово на английском, которое указывает, что конкретно нужно сделать с запрашиваемым ресурсом. Например, метод GET сообщает серверу, что пользователь хочет получить некоторые данные, а POST — что некоторые данные должны быть помещены на сервер.
- Цель запроса. Представлена указателем ресурса URL, который состоит из протокола, доменного имени (или IP-адреса), пути к конкретному ресурсу на сервере. Дополнительно может содержать указание порта, несколько параметров HTTP-запроса и еще ряд опциональных элементов.
- Версия используемого протокола (либо HTTP/1.1, либо HTTP/2), которая определяет структуру следующих за стартовой строкой данных.
В примере ниже стартовая строка указывает, что в качестве метода используется GET, обращение будет произведено к ресурсу /index.html, по версии протокола HTTP/1.1:
Разберемся с каждым из названных элементов подробнее.
Методы
Методы позволяют указать конкретное действие, которое мы хотим, чтобы сервер выполнил, получив наш запрос. Так, некоторые методы позволяют браузеру (который в большинстве случаев является источником запросов от клиента) отправлять дополнительную информацию в теле запроса — например, заполненную форму или документ.
Ниже приведены наиболее используемые методы и их описание:
Разберемся с каждым из названных элементов подробнее.
| Метод | Описание |
| GET | Позволяет запросить некоторый конкретный ресурс. Дополнительные данные могут быть переданы через строку запроса (Query String) в составе URL (например ?param=value).О составляющих URL мы поговорим чуть позже. |
| POST | Позволяет отправить данные на сервер. Поддерживает отправку различных типов файлов, среди которых текст, PDF-документы и другие типы данных в двоичном виде. Обычно метод POST используется при отправке информации (например, заполненной формы логина) и загрузке данных на веб-сайт, таких как изображения и документы. |
| HEAD | Здесь придется забежать немного вперед и сказать, что обычно сервер в ответ на запрос возвращает заголовок и тело, в котором содержится запрашиваемый ресурс. Данный метод при использовании его в запросе позволит получить только заголовки, которые сервер бы вернул при получении GET-запроса к тому же ресурсу. Запрос с использованием данного метода обычно производится для того, чтобы узнать размер запрашиваемого ресурса перед его загрузкой. |
| PUT | Используется для создания (размещения) новых ресурсов на сервере. Если на сервере данный метод разрешен без надлежащего контроля, то это может привести к серьезным проблемам безопасности. |
| DELETE | Позволяет удалить существующие ресурсы на сервере. Если использование данного метода настроено некорректно, то это может привести к атаке типа «Отказ в обслуживании» (Denial of Service, DoS) из-за удаления критически важных файлов сервера. |
| OPTIONS | Позволяет запросить информацию о сервере, в том числе информацию о допускаемых к использованию на сервере HTTP-методов. |
| PATCH | Позволяет внести частичные изменения в указанный ресурс по указанному расположению. |
URL
Получение доступа к ресурсам по HTTP-протоколу осуществляется с помощью указателя URL (Uniform Resource Locator). URL представляет собой строку, которая позволяет указать запрашиваемый ресурс и еще ряд параметров.
Использование URL неразрывно связано с другими элементами протокола, поэтому далее мы рассмотрим его основные компоненты и строение:
Поле Scheme используется для указания используемого протокола, всегда сопровождается двоеточием и двумя косыми чертами (://).
Host указывает местоположение ресурса, в нем может быть как доменное имя, так и IP-адрес.
Port, как можно догадаться, позволяет указать номер порта, по которому следует обратиться к серверу. Оно начинается с двоеточия (:), за которым следует номер порта. При отсутствии данного элемента номер порта будет выбран по умолчанию в соответствии с указанным значением Scheme (например, для http:// это будет порт 80).
Далее следует поле Path. Оно указывает на ресурс, к которому производится обращение. Если данное поле не указано, то сервер в большинстве случаев вернет указатель по умолчанию (например index.html).
Поле Query String начинается со знака вопроса (?), за которым следует пара «параметр-значение», между которыми расположен символ равно (=). В поле Query String могут быть переданы несколько параметров с помощью символа амперсанд (&) в качестве разделителя.
Не все компоненты необходимы для доступа к ресурсу. Обязательно следует указать только поля Scheme и Host.
Версии HTTP
Раз уж мы упомянули версию протокола как элемента стартовой строки, то стоит сказать об основных отличиях версий HTTP/1.X от HTTP/2.X.
Последняя стабильная, наиболее стандартизированная версия протокола первого поколения (версия HTTP/1.1) вышла в далеком 1997 году. Годы шли, веб-страницы становились сложнее, некоторые из них даже стали приложениями в том виде, в котором мы понимаем их сейчас. Кроме того, объем медиафайлов и скриптов, которые добавляли интерактивность страницам, рос. Это, в свою очередь, создавало перегрузки в работе протокола версии HTTP/1.1.
Стало очевидно, что у HTTP/1.1 есть ряд значительных недостатков:
- Заголовки, в отличие от тела сообщения, передавались в несжатом виде.
- Часто большая часть заголовков в сообщениях совпадала, но они продолжали передаваться по сети.
- Отсутствовала возможность так называемого мультиплексирования — механизма, позволяющего объединить несколько соединений в один поток данных. Приходилось открывать несколько соединений на сервере для обработки входящих запросов.
С выходом HTTP/2 было предложено следующее решение: HTTP/1.X-сообщения разбивались на так называемые фреймы, которые встраивались в поток данных.
Фреймы данных (тела сообщения) отделялись от фреймов заголовка, что позволило применять сжатие. Вместе с появлением потоков появился и ранее описанный механизм мультиплексирования — теперь можно было обойтись одним соединением для нескольких потоков.
Единственное о чем стоит сказать в завершение темы: HTTP/2 перестал быть текстовым протоколом, а стал работать с «сырой» двоичной формой данных. Это ограничивает чтение и создание HTTP-сообщений «вручную». Однако такова цена за возможность реализации более совершенной оптимизации и повышения производительности.
Заголовки
HTTP-заголовок представляет собой строку формата «Имя-Заголовок:Значение», с двоеточием(:) в качестве разделителя. Название заголовка не учитывает регистр, то есть между Host и host, с точки зрения HTTP, нет никакой разницы. Однако в названиях заголовков принято начинать каждое новое слово с заглавной буквы. Структура значения зависит от конкретного заголовка. Несмотря на то, что заголовок вместе со значениями может быть достаточно длинным, занимает он всего одну строчку.
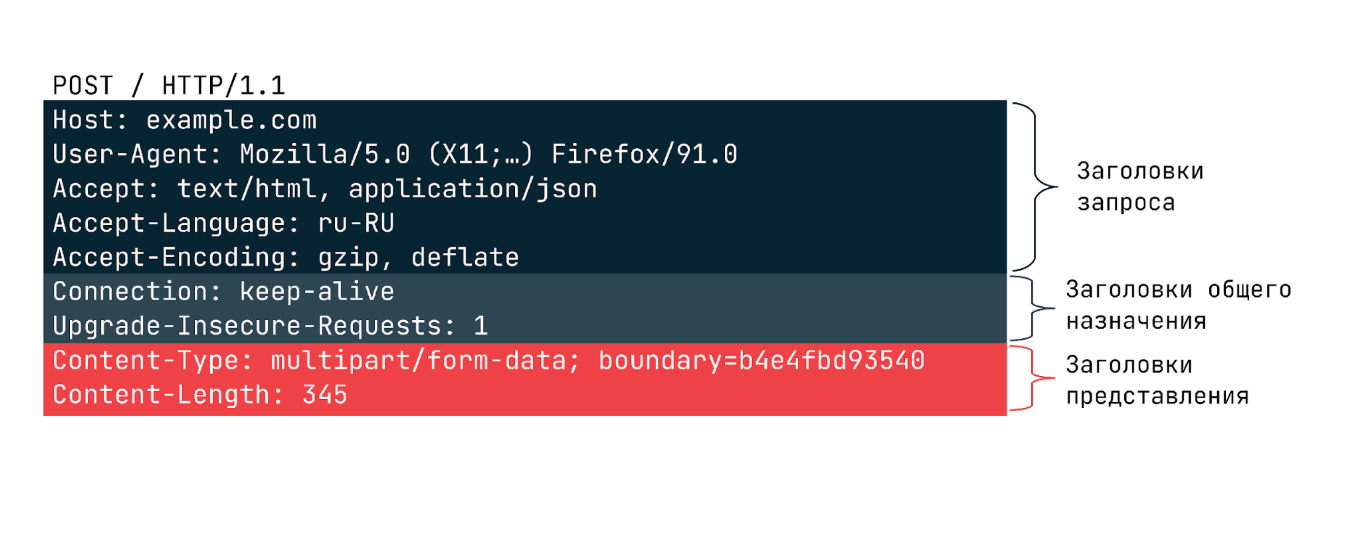
В запросах может передаваться большое число различных заголовков, но все их можно разделить на три категории:
- Общего назначения, которые применяются ко всему сообщению целиком.
- Заголовки запроса уточняют некоторую информацию о запросе, сообщая дополнительный контекст или ограничивая его некоторыми логическими условиями.
- Заголовки представления, которые описывают формат данных сообщения и используемую кодировку. Добавляются к запросу только в тех случаях, когда с ним передается некоторое тело.
Ниже можно видеть пример заголовков в запросе:
Самые частые заголовки запроса
| Заголовок | Описание |
| Host | Используется для указания того, с какого конкретно хоста запрашивается ресурс. В качестве возможных значений могут использоваться как доменные имена, так и IP-адреса. На одном HTTP-сервере может быть размещено несколько различных веб-сайтов. Для обращения к какому-то конкретному требуется данный заголовок. |
| User-Agent | Заголовок используется для описания клиента, который запрашивает ресурс. Он содержит достаточно много информации о пользовательском окружении. Например, может указать, какой браузер используется в качестве клиента, его версию, а также операционную систему, на которой этот клиент работает. |
| Refer | Используется для указания того, откуда поступил текущий запрос. Например, если вы решите перейти по какой-нибудь ссылке в этой статье, то вероятнее всего к запросу будет добавлен заголовок Refer: https://selectel.ru |
| Accept | Позволяет указать, какой тип медиафайлов принимает клиент. В данном заголовке могут быть указаны несколько типов, перечисленные через запятую (‘ , ‘). А для указания того, что клиент принимает любые типы, используется следующая последовательность — */*. |
| Cookie | Данный заголовок может содержать в себе одну или несколько пар «Куки-Значение» в формате cookie=value. Куки представляют собой небольшие фрагменты данных, которые хранятся как на стороне клиента, так и на сервере, и выступают в качестве идентификатора. Куки передаются вместе с запросом для поддержания доступа клиента к ресурсу. Помимо этого, куки могут использоваться и для других целей, таких как хранение пользовательских предпочтений на сайте и отслеживание клиентской сессии. Несколько кук в одном заголовке могут быть перечислены с помощью символа точка с запятой (‘ ; ‘), который используется как разделитель. |
| Authorization | Используется в качестве еще одного метода идентификации клиента на сервере. После успешной идентификации сервер возвращает токен, уникальный для каждого конкретного клиента. В отличие от куки, данный токен хранится исключительно на стороне клиента и отправляется клиентом только по запросу сервера. Существует несколько типов аутентификации, конкретный метод определяется тем веб-сервером или веб-приложением, к которому клиент обращается за ресурсом. |
Тело запроса
Завершающая часть HTTP-запроса — это его тело. Не у каждого HTTP-метода предполагается наличие тела. Так, например, методам вроде GET, HEAD, DELETE, OPTIONS обычно не требуется тело. Некоторые виды запросов могут отправлять данные на сервер в теле запроса: самый распространенный из таких методов — POST.
Ответы HTTP
HTTP-ответ является сообщением, которое сервер отправляет клиенту в ответ на его запрос. Его структура равна структуре HTTP-запроса: стартовая строка, заголовки и тело.
Строка статуса (Status line)
Стартовая строка HTTP-ответа называется строкой статуса (status line). На ней располагаются следующие элементы:
- Уже известная нам по стартовой строке запроса версия протокола (HTTP/2 или HTTP/1.1).
- Код состояния, который указывает, насколько успешно завершилась обработка запроса.
- Пояснение — короткое текстовое описание к коду состояния. Используется исключительно для того, чтобы упростить понимание и восприятие человека при просмотре ответа.

Коды состояния и текст статуса
Коды состояния HTTP используются для того, чтобы сообщить клиенту статус их запроса. HTTP-сервер может вернуть код, принадлежащий одной из пяти категорий кодов состояния:
| Категория | Описание |
| 1xx | Коды из данной категории носят исключительно информативный характер и никак не влияют на обработку запроса. |
| 2xx | Коды состояния из этой категории возвращаются в случае успешной обработки клиентского запроса. |
| 3xx | Эта категория содержит коды, которые возвращаются, если серверу нужно перенаправить клиента. |
| 4xx | Коды данной категории означают, что на стороне клиента был отправлен некорректный запрос. Например, клиент в запросе указал не поддерживаемый метод или обратился к ресурсу, к которому у него нет доступа. |
| 5xx | Ответ с кодами из этой категории приходит, если на стороне сервера возникла ошибка. |
Полный список кодов состояния доступен в спецификации к протоколу, ниже приведены только самые распространенные коды ответов:
| Категория | Описание |
| 200 OK | Возвращается в случае успешной обработки запроса, при этом тело ответа обычно содержит запрошенный ресурс. |
| 302 Found | Перенаправляет клиента на другой URL. Например, данный код может прийти, если клиент успешно прошел процедуру аутентификации и теперь может перейти на страницу своей учетной записи. |
| 400 Bad Request | Данный код можно увидеть, если запрос был сформирован с ошибками. Например, в нем отсутствовали символы завершения строки. |
| 403 Forbidden | Означает, что клиент не обладает достаточными правами доступа к запрошенному ресурсу. Также данный код можно встретить, если сервер обнаружил вредоносные данные, отправленные клиентом в запросе. |
| 404 Not Found | Каждый из нас, так или иначе, сталкивался с этим кодом ошибки. Данный код можно увидеть, если запросить у сервера ресурс, которого не существует на сервере. |
| 500 Internal Error | Данный код возвращается сервером, когда он не может по определенным причинам обработать запрос. |
Помимо основных кодов состояния, описанных в стандарте, существуют и коды состояния, которые объявляются крупными сетевыми провайдерами и серверными платформами. Так, коды состояния, используемые Selectel, можно посмотреть здесь.
Заголовки ответа
Response Headers, или заголовки ответа, используются для того, чтобы уточнить ответ, и никак не влияют на содержимое тела. Они существуют в том же формате, что и остальные заголовки, а именно «Имя-Значение» с двоеточием (:) в качестве разделителя.
Ниже приведены наиболее часто встречаемые в ответах заголовки:
| Категория | Пример | Описание |
| Server | Server: ngnix | Содержит информацию о сервере, который обработал запрос. |
| Set-Cookie | Set-Cookie:PHPSSID=bf42938f | Содержит куки, требуемые для идентификации клиента. Браузер парсит куки и сохраняет их в своем хранилище для дальнейших запросов. |
| WWW-Authenticate | WWW-Authenticate: BASIC realm=»localhost» | Уведомляет клиента о типе аутентификации, который необходим для доступа к запрашиваемому ресурсу. |
Тело ответа
Последней частью ответа является его тело. Несмотря на то, что у большинства ответов тело присутствует, оно не является обязательным. Например, у кодов «201 Created» или «204 No Content» тело отсутствует, так как достаточную информацию для ответа на запрос они передают в заголовке.
Безопасность HTTP-запросов, или что такое HTTPs
HTTP является расширяемым протоколом, который предоставляет огромное количество возможностей, а также поддерживает передачу всевозможных типов файлов. Однако, вне зависимости от версии, у него есть один существенный недостаток, который можно заметить если перехватить отправленный HTTP-запрос:
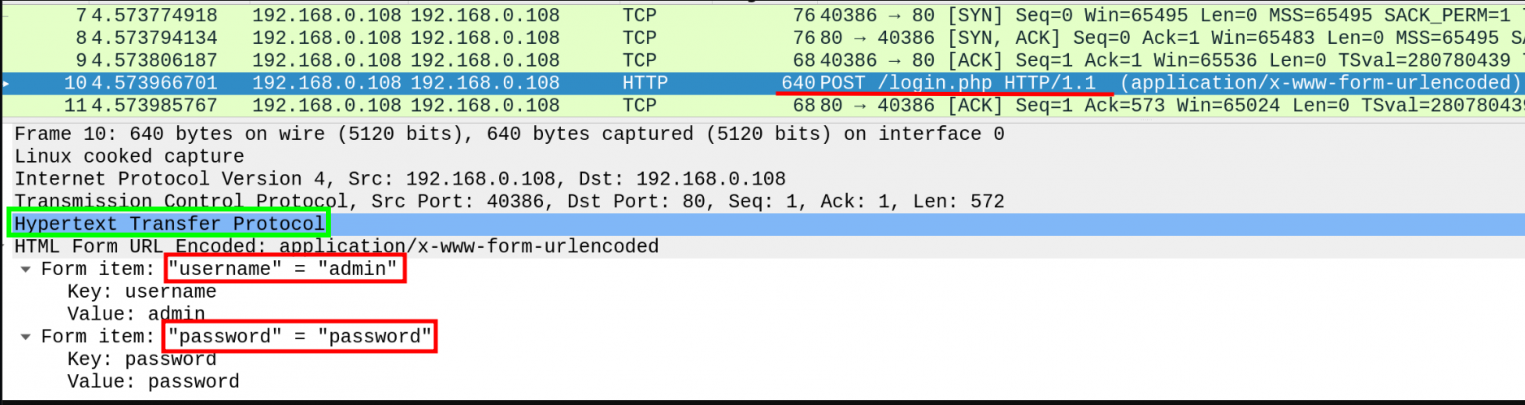
Да, все верно: данные передаются в открытом виде. HTTP сам по себе не предоставляет никаких средств шифрования.
Но как же тогда работают различные банковские приложения, интернет-магазины, сервисы оплаты услуг и прочие приложения, в которых циркулирует чувствительная информация пользователей?
Время рассказать про HTTPs!
HTTPs (HyperText Transfer Protocol, secure) является расширением HTTP-протокола, который позволяет шифровать отправляемые данные, перед тем как они попадут на транспортный уровень. Данный протокол по умолчанию использует порт 443.
Теперь если мы перехватим не HTTP , а HTTPs-запрос, то не увидим здесь ничего интересного:
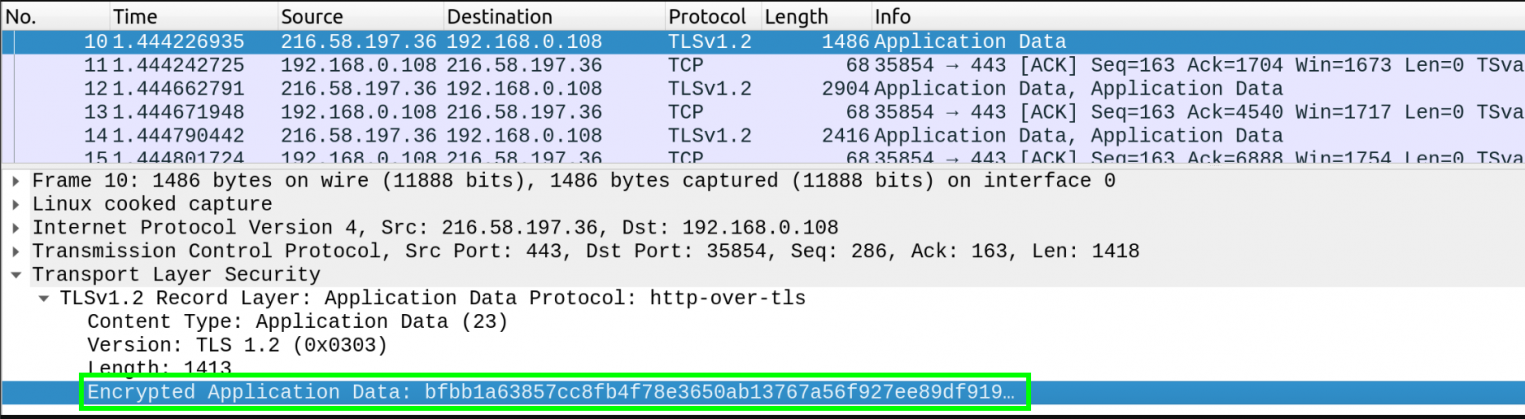
Данные передаются в едином зашифрованном потоке, что делает невозможным получение учетных данных пользователей и прочей критической информации средствами обычного перехвата.
Три межсетевых экрана для любых потребностей бизнеса.
Если хотите подробнее узнать о деталях работы протокола, читайте статью в нашем блоге →
Как отправить HTTP-запрос и прочитать его ответ
Теория это, конечно, отлично, но ничего так хорошо не закрепляет материал, как практика
Мы рассмотрим несколько способов, как написать HTTP-запрос в браузер, послать HTTP-запрос на сервер и получить ответ:
- Инструменты разработчика в браузере.
- Утилита cURL.
Инструменты разработчика
Основной программой на наших устройствах, которая работает с HTTP-протоколом, в большинстве случаев является браузер. Помимо обычных пользователей, с браузерами часто работают и разработчики веб-приложений. Именно их инструментами мы воспользуемся для работы с запросами и ответами.
По нажатию комбинации клавиш [Ctrl+Shift+I] или просто [F12] в подавляющем большинстве современных браузеров у нас откроется окно инструментов разработчика, которая представляет собой панель с несколькими вкладками. Нужная нам вкладка обычно называется Network. Перейдем в нее, а в адресной строке введем URL того сайта, на который хотим попасть. В качестве примера воспользуемся сайтом блога Selectel — https://selectel.ru/blog/.
После нажатия Enter сайт начнет загружаться, а открытая вкладка Network — заполняться различными элементами, начиная все больше напоминать приборную панель самолета.
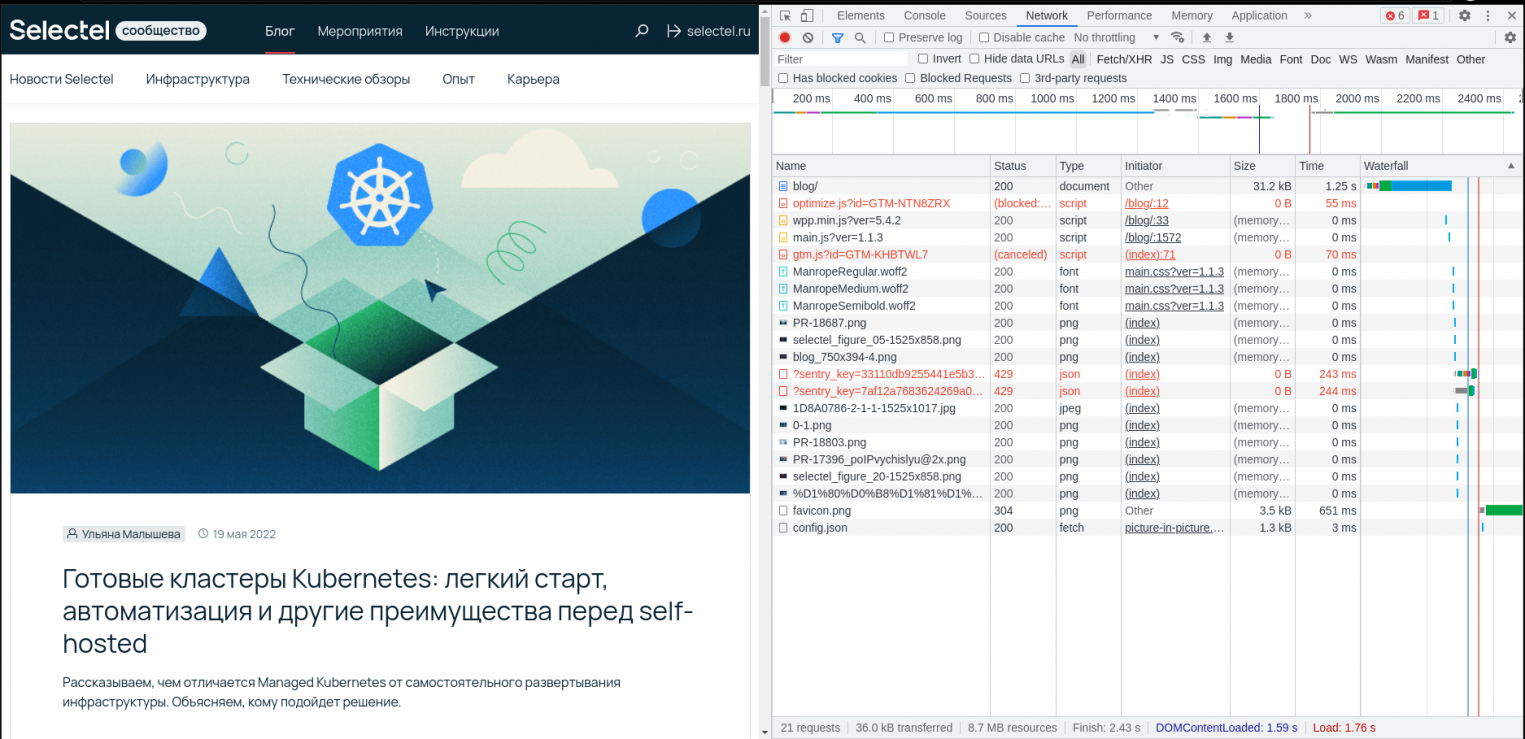
Не спешите пугаться. Это всего лишь список ресурсов, которые нужны для правильного отображения и работы сайта.
Нажав на любой из них, мы можем увидеть детали обработки отправленного запроса:
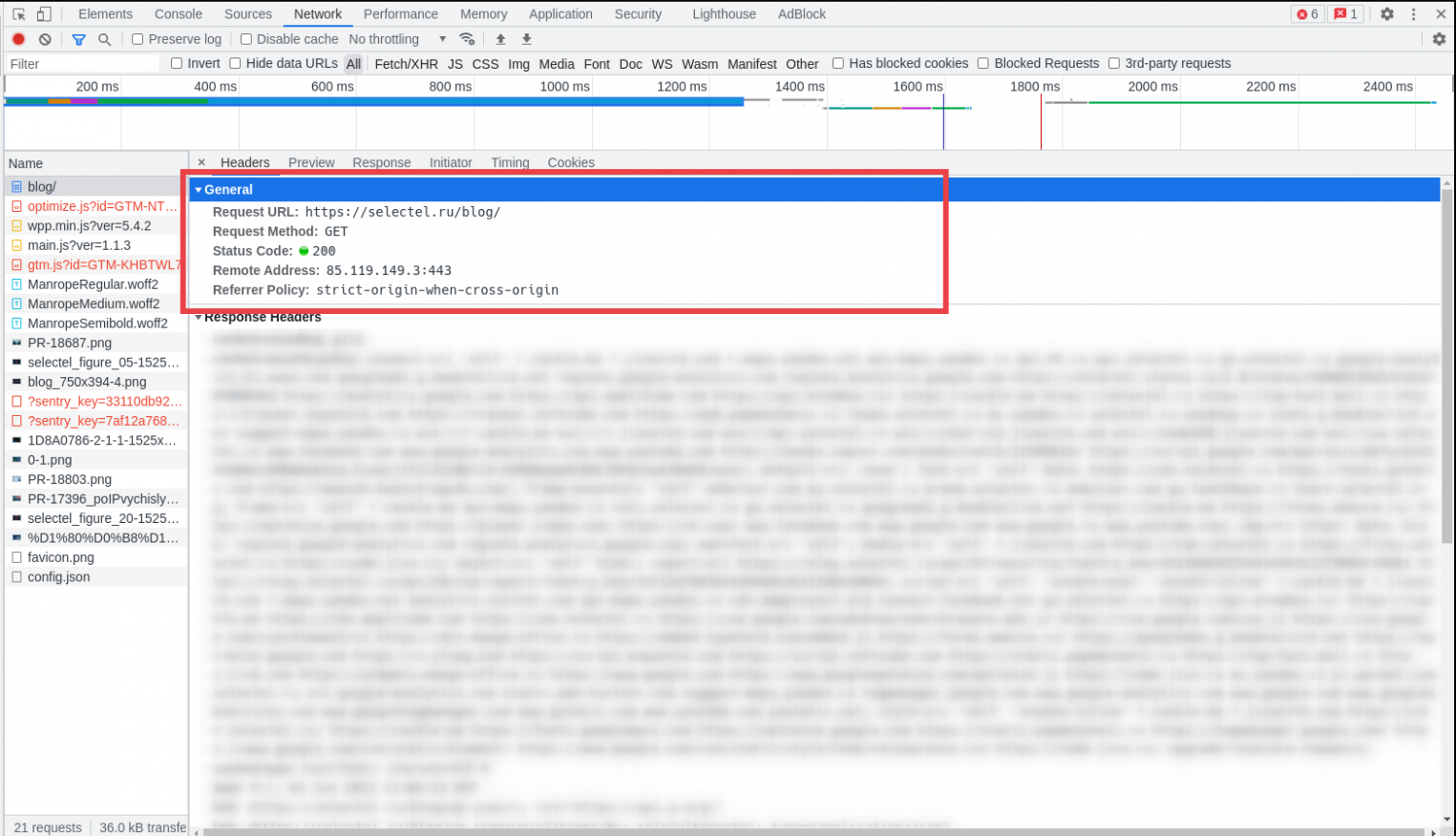
В данном запросе, например:
- URL, к которому было совершено обращение — https://selectel.ru/blog,
- Метод, который был использован в запросе — GET,
- И в качестве кода возврата сервер вернул нам страницу с кодом статуса — 200 OK
Утилита cURL
Следующий инструмент, с помощью которого мы сможем послать запрос на тот или иной сервер, это утилита cURL.
cURL (client URL) является небольшой утилитой командной строки, которая позволяет работать с HTTP и рядом других протоколов.
Для отправки запроса и получения ответа мы можем воспользоваться флагом -v и указанием URL того ресурса, который мы хотим получить. «Схему» HTTP-запроса можно увидеть на скрине ниже:

После запуска утилита выполняет:
- подключение к серверу,
- самостоятельно разрешает все вопросы, необходимые для отправки запроса по HTTPs,
- отправляет запрос, содержимое которого мы можем видеть благодаря флагу -v,
- принимая ответ от сервера, отображает его в командной строке «как-есть».
Помимо этого, у данной утилиты есть огромное количество опций, которые предоставляют возможности по детальной настройке отправляемых запросов. Все эти возможности и делают ее такой популярной у веб-разработчиков и других специалистов, которым приходится работать с протоколом HTTP.
Заключение
HTTP представляет собой расширяемый протокол прикладного уровня, на котором работает весь веб-сегмент интернета. В данной статье мы рассмотрели принцип его работы, структуру, «компоненты» HTTP-запросов. Коснулись вопросов отличия версий протокола, HTTPs — его расширения, добавляющего шифрование. Разобрали устройство запроса, поняли, как можно отправить HTTP-запрос и получить ответ от сервера.
search32
13
22
До Firefox 53 имя pathname и search возвращали неверные значения для пользовательских протоколов. Для данного protocol:host/x?a=true&b=false , pathname вернет «/ x? A = true & b = false», а search вернет «», а не «/ x» и «? A = true & b = false» соответственно. Смотрите ошибку 1310483 .
No
19
10
4.4.3
32
22
До Firefox 53 имя pathname и search возвращали неверные значения для пользовательских протоколов. Для данного protocol:host/x?a=true&b=false , pathname вернет «/ x? A = true & b = false», а search вернет «», а не «/ x» и «? A = true & b = false» соответственно. Смотрите ошибку 1310483 .
19
10
2.0
Уважаемые знатоки, помогите разобраться.
Мне нужно в тексте сообщения найти текст который начинается на http/https://site.ru… и заменить его на нормальную ссылку. т.е. < a href=”сюда записать http/https://site.ru…” >сюда site.ru< /a >
Для чего методом гугла и “должно работать” написал регулярку
/^(http[s]*://)([a-zA-Z0-9._-]+)/*([a-zA-Zа-яёА-ЯЁ0-9._-/&=?%]*)$/
сайт regex101.com говорит что вроде как работает, хотя выглядит ужасно)))
если я правильно понимаю, то preg_replace или preg_replace_callback поможет.
осталась реализация, но как это правильно сделать не понятно…
задан 29 янв 2020 в 22:15
4
попробуй банально так
http/(.+?)...
ну и второй вариант )
http.?://(.+?)s
ответ дан 29 янв 2020 в 22:29
2
Пример:
$text = "
Текст текст текст любой - https://yandex.ru Вот так!
";
preg_match_all('~http[s]?://(S+)~',$text,$res);
$newSite = '<a href="'.$res[0][0].'"/>'.$res[1][0].'</a>';
$text = preg_replace("/(^|[n ])([w]*?)((ht|f)tp(s)?://[w]+[^ ,"nrt<]*[^ .])/is", $newSite, $text);
print_r($text);
ответ дан 29 янв 2020 в 22:57
![]()
Denis640KbDenis640Kb
14k5 золотых знаков21 серебряный знак45 бронзовых знаков
Являетесь вы программистом или нет, вы видели его повсюду в Интернете. На данный момент в адресной строке браузера отображается нечто, что начинается с «https: //». Даже ваш первый скрипт Hello World отправил HTTP-header без вашего понимания. В этой статье мы собираемся узнать об основах HTTP-заголовков и о том, как их можно использовать в наших веб-приложениях.
Что такое HTTP Headers?
HTTP значит “Hypertext Transfer Protocol” (Протокол передачи гипертекста). Всемирная паутина использует этот протокол. Он был создан в начале 1990-х годов. Почти всё, что вы видите в вашем браузере, передаётся на ваш компьютер через HTTP. Например, когда вы открыли страницу этой статьи, ваш браузер отправил более 40 HTTP-запросов и получил HTTP-ответы для каждого из них.
Заголовки HTTP являются основной частью этих HTTP-запросов и ответов, и они несут информацию о браузере клиента, запрошенной странице, сервере и многом другом.
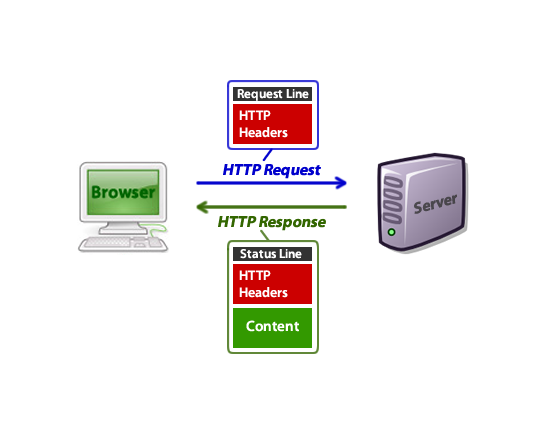

Пример
Когда вы вводите URL-адрес в адресной строке, ваш браузер отправляет HTTP-запрос, и он может выглядеть так:
1 |
GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1 |
2 |
Host: net.tutsplus.com |
3 |
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729) |
4 |
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 |
5 |
Accept-Language: en-us,en;q=0.5 |
6 |
Accept-Encoding: gzip,deflate |
7 |
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 |
8 |
Keep-Alive: 300 |
9 |
Connection: keep-alive |
10 |
Cookie: PHPSESSID=r2t5uvjq435r4q7ib3vtdjq120 |
11 |
Pragma: no-cache |
12 |
Cache-Control: no-cache |
Первая строка – это “Request Line”, которая содержит некоторую базовую информацию по запросу. Остальные – HTTP заголовки.
После этого запроса ваш браузер получает ответ HTTP, который может выглядеть так:
1 |
HTTP/1.x 200 OK |
2 |
Transfer-Encoding: chunked |
3 |
Date: Sat, 28 Nov 2009 04:36:25 GMT |
4 |
Server: LiteSpeed |
5 |
Connection: close |
6 |
X-Powered-By: W3 Total Cache/0.8 |
7 |
Pragma: public |
8 |
Expires: Sat, 28 Nov 2009 05:36:25 GMT |
9 |
Etag: "pub1259380237;gz" |
10 |
Cache-Control: max-age=3600, public |
11 |
Content-Type: text/html; charset=UTF-8 |
12 |
Last-Modified: Sat, 28 Nov 2009 03:50:37 GMT |
13 |
X-Pingback: https://net.tutsplus.com/xmlrpc.php |
14 |
Content-Encoding: gzip |
15 |
Vary: Accept-Encoding, Cookie, User-Agent |
16 |
|
17 |
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
|
18 |
<html xmlns="http://www.w3.org/1999/xhtml"> |
19 |
<head>
|
20 |
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> |
21 |
<title>Top 20+ MySQL Best Practices - Nettuts+</title> |
22 |
<!-- ... rest of the html ... -->
|
Первая строка – это «Строка состояния», за которой следуют «HTTP-заголовки», до пустой строки. После этого начинается «содержимое» (в данном случае – HTML вывод).
Когда вы смотрите на исходный код веб-страницы в своём браузере, вы видите только часть HTML, а не заголовки HTTP, хотя они фактически были переданы вместе.
Эти HTTP-запросы также отправляются и принимаются для других вещей, таких как изображения, CSS-файлы, файлы JavaScript и т. д. Именно поэтому я сказал ранее, что ваш браузер отправил не менее 40 или более HTTP-запросов, поскольку вы загрузили только эту страницу статьи.
Теперь давайте рассмотрим структуру более подробно.
Как увидеть HTTP Headers
Для анализа HTTP-заголовков я использую следующие расширения Firefox:
- Firebug


- Live HTTP Headers


В PHP:
- getallheaders() получает запросы headers. Вы можете использовать массив $_SERVER.
- headers_list() получает отзывы headers.
Далее в этой статье мы увидим примеры кода в PHP.
Структура запроса HTTP

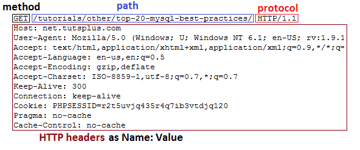
Первая строка HTTP-запроса называется линией запроса и состоит из трёх частей:
- “method” указывает, какой это запрос. Наиболее распространённые методы GET, POST и HEAD.
- “path” , как правило, является частью URL-адреса, который идёт после host (домена). Например, если запрос “https://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/” , часть path будет “/tutorials/other/top-20-mysql-best-practices/”.
- Часть “protocol” содержит “HTTP” и версию, которая обычно 1.1 в современных браузерах.
Остальная часть запроса содержит HTTP headers как пары “Name: Value” в каждой строке. Они содержат различную информацию о HTTP-запросе и вашем браузере. Например, строка “User-Agent” предоставляет информацию о версии браузера и операционной системе, которую вы используете. “Accept-Encoding” сообщает серверу, может ли ваш браузер принимать сжатый output, например gzip.
Возможно, вы заметили, что данные cookie также передаются внутри HTTP-заголовка. И если бы ссылочный url, это было бы в header тоже.
Большинство этих заголовков являются необязательными. Этот HTTP-запрос мог быть таким же маленьким:
1 |
GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1 |
2 |
Host: net.tutsplus.com |
И вы всё равно получите правильный ответ от веб-сервера.
Методы запроса
Три наиболее часто используемых метода запроса: GET, POST и HEAD. Вы, вероятно, уже знакомы с первыми двумя, начиная с написания html-форм.
GET: получение документа
Это основной метод, используемый для извлечения html, изображений, JavaScript, CSS и т. д. С использованием этого метода запрошено большинство данных, загружаемых в ваш браузер.
Например, при загрузке статьи Nettuts +, самая первая строка HTTP-запроса выглядит так:
1 |
GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1 |
2 |
... |
Как только html загрузится, браузер начнет отправлять GET-запрос изображений, который может выглядеть так:
1 |
GET /wp-content/themes/tuts_theme/images/header_bg_tall.png HTTP/1.1 |
2 |
... |
Веб-формы можно настроить под метод GET. Вот пример.
1 |
<form method="GET" action="foo.php"> |
2 |
|
3 |
First Name: <input type="text" name="first_name" /> <br /> |
4 |
Last Name: <input type="text" name="last_name" /> <br /> |
5 |
|
6 |
<input type="submit" name="action" value="Submit" /> |
7 |
|
8 |
</form>
|
Когда эта форма отправлена, HTTP-запрос начинается так:
1 |
GET /foo.php?first_name=John&last_name=Doe&action=Submit HTTP/1.1 |
2 |
... |
Вы можете видеть, что каждый ввод формы был добавлен в строку запроса.
POST: отправка данных на сервер
Даже если вы можете отправлять данные на сервер с помощью GET и строки запроса, во многих случаях POST будет предпочтительнее. Отправка больших объёмов данных с помощью GET нецелесообразна и имеет ограничения.
Запросы POST чаще всего отправляются веб-формами. Давайте изменим предыдущий пример формы на метод POST.
1 |
<form method="POST" action="foo.php"> |
2 |
|
3 |
First Name: <input type="text" name="first_name" /> <br /> |
4 |
Last Name: <input type="text" name="last_name" /> <br /> |
5 |
|
6 |
<input type="submit" name="action" value="Submit" /> |
7 |
|
8 |
</form>
|
Отправка этой формы создает HTTP-запрос следующим образом:
1 |
POST /foo.php HTTP/1.1 |
2 |
Host: localhost |
3 |
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729) |
4 |
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 |
5 |
Accept-Language: en-us,en;q=0.5 |
6 |
Accept-Encoding: gzip,deflate |
7 |
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 |
8 |
Keep-Alive: 300 |
9 |
Connection: keep-alive |
10 |
Referer: http://localhost/test.php |
11 |
Content-Type: application/x-www-form-urlencoded |
12 |
Content-Length: 43 |
13 |
|
14 |
first_name=John&last_name=Doe&action=Submit |
Здесь нужно отметить три важных момента:
- Путь в первой строке просто /foo.php, и больше нет строки запроса.
- Добавлены заголовки Content-Type и Content-Length, которые предоставляют информацию об отправляемых данных.
- Все данные теперь отправляются после заголовков, в том же формате, что и строка запроса.
Запросы POST метода также могут быть сделаны через AJAX, приложения, cURL и т. д. И все формы загрузки файлов необходимы для использования метода POST.
HEAD: получение информации заголовка
HEAD идентичен GET, за исключением того, что сервер не возвращает содержимое HTTP-ответа. Когда вы отправляете запрос HEAD, это означает, что вас интересуют только код ответа и HTTP headers, а не сам документ.
«Когда вы отправляете запрос HEAD, это означает, что вас интересуют только код ответа и HTTP headers, а не сам документ».
С помощью этого метода браузер может проверить, был ли документ изменён для целей caching. Он также может проверить, существует ли документ вообще.
Например, если у вас много ссылок на веб-сайте, вы можете периодически отправлять HEAD-запросы каждой из них, чтобы проверить наличие неработающих ссылок. Это будет намного быстрее, чем при использовании GET.
Структура ответа HTTP
После того, как браузер отправляет HTTP-запрос, сервер отвечает HTTP-ответом. Исключая контент, он выглядит так:


Первой порцией данных является протокол. Обычно это снова HTTP/1.x или HTTP/1.1 на современных серверах.
Следующая часть – это код состояния, за которым следует короткое сообщение. Код 200 означает, что наш запрос GET был успешным и сервер вернёт содержимое запрошенного документа сразу после headers.
Мы все видели “404” pages. Это число фактически приходит из части кода состояния HTTP-ответа. Если запрос GET будет создан для path, который сервер не может найти, он ответил бы 404, а не 200.
Остальная часть ответа содержит headers так же, как HTTP-запрос. Эти значения могут содержать информацию о софте сервера при последнем изменении страницы/файла, типе mime и прочее…
Опять же, большинство этих headers на самом деле являются необязательными.
Коды статуса HTTP
- 200 используются для успешных запросов.
- 300 для перенаправления.
- 400 используются, если возникла проблема с запросом.
- 500 используются, если возникла проблема с сервером.
200 OK
Как упоминалось ранее, этот код состояния отправляется в ответ на успешный запрос.
206 Partial Content
Если приложение запрашивает только диапазон запрошенного файла, возвращается код 206.
Это часто используется с менеджерами закачек, которые могут остановить и возобновить загрузку или разделить загрузку на части.
404 Not Found


Когда запрашиваемая страница или файл не найдена, сервер отправляет код ответа 404.
401 Unauthorized
Защищённые паролем веб-страницы отправляют этот код. Если вы не ввели логин правильно, вы можете увидеть следующее в вашем браузере.


Обратите внимание, что это относится только к страницам, защищённым паролем HTTP, которые вызывают запросы для входа следующим образом:


403 Forbidden
Если вам не разрешен доступ к странице, этот код может быть отправлен в ваш браузер. Это часто происходит, когда вы пытаетесь открыть URL-адрес для папки, в которой нет индексной страницы. Если параметры сервера не позволяют отображать содержимое папки, вы получите ошибку 403.
Например, на моем локальном сервере я создал папку изображений. Внутри этой папки я помещаю файл .htaccess с этой строкой: “Options -Indexes”. Теперь, когда я пытаюсь открыть http://localhost/images/ – я вижу это:


Существуют другие способы блокировки доступа и 403 могут быть отправлены. Например, вы можете блокировать по IP-адресу с помощью некоторых директив htaccess.
1 |
order allow,deny |
2 |
deny from 192.168.44.201 |
3 |
deny from 224.39.163.12 |
4 |
deny from 172.16.7.92 |
5 |
allow from all |
302 (or 307) Moved Temporarily & 301 Moved Permanently
Эти два кода используются для перенаправления браузера. Например, когда вы используете службу сокращения URL, такую как bit.ly, именно так они перенаправляют людей, которые идут по ссылке.
302 и 301 обрабатываются браузером очень похоже, но они могут иметь различные значения для spiders поисковых систем. Например, если ваш сайт не готов для обслуживания, вы можете перенаправить его в другое место с помощью 302. Поисковая система продолжит проверку вашей страницы в будущем. Но если вы перенаправите с использованием 301, это сообщит spider, что ваш сайт переехал в это место навсегда. За более точной информацией: http://www.nettuts.com перейдите на https://net.tutsplus.com/ используя 301 код вместо 302.
500 Internal Server Error


Этот код обычно отображается при сбое веб-скрипта. Большинство скриптов CGI не выводят ошибки непосредственно в браузер, в отличие от PHP. Если есть фатальные ошибки, они просто отправят код статуса 500. И тогда программист должен искать в журналах ошибок сервера, чтобы найти сообщения об ошибках.
Complete List
Вы можете найти полный список кодов состояния HTTP с их пояснениями here.
Заголовки HTTP в запросах HTTP
Теперь мы рассмотрим некоторые из наиболее распространенных HTTP headers , найденных в HTTP requests.
Почти все эти заголовки можно найти в массиве $ _SERVER в PHP. Вы также можете использовать функцию getallheaders() для извлечения всех заголовков одновременно.
Host
HTTP-запрос отправляется на определенные IP-адреса. Но так как большинство серверов способны размещать несколько сайтов под одним IP, они должны знать, какое доменное имя ищет браузер.
Это в основном имя host, включая домен и поддомен.
В PHP его можно найти, как $_SERVER[‘HTTP_HOST’] или $_SERVER[‘SERVER_NAME’].
User-Agent
1 |
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729) |
Этот заголовок может содержать несколько частей информации, таких как:
- Имя и версия браузера.
- Название и версия операционной системы.
- Язык по умолчанию.
Именно так веб-сайты могут собирать определённую общую информацию о своих системах surfers. Например, они могут определить, использует ли surfer мобильный браузер и перенаправляет их на мобильную версию своего веб-сайта, который лучше работает с низким разрешением.
В PHP может быть выражен так: $_SERVER[‘HTTP_USER_AGENT’].
1 |
if ( strstr($_SERVER['HTTP_USER_AGENT'],'MSIE 6') ) { |
2 |
echo "Please stop using IE6!"; |
3 |
}
|
Accept-Language
1 |
Accept-Language: en-us,en;q=0.5 |
Этот заголовок отображает настройки языка по умолчанию. Если сайт имеет разные языковые версии, он может перенаправить нового surfer на основе этих данных.
Он может содержать несколько языков, разделённых запятыми. Первый – это предпочтительный язык, и каждый из перечисленных языков может иметь значение «q», которое представляет собой оценку предпочтения пользователя для языка (min. 0 max. 1).
В PHP его можно найти так: $ _SERVER [“HTTP_ACCEPT_LANGUAGE”].
1 |
if (substr($_SERVER['HTTP_ACCEPT_LANGUAGE'], 0, 2) == 'fr') { |
2 |
header('Location: http://french.mydomain.com'); |
3 |
}
|
Accept-Encoding
1 |
Accept-Encoding: gzip,deflate |
Большинство современных браузеров поддерживают gzip и отправляют это в header. Затем веб-сервер может отправить выходной HTML-код в сжатом формате. Это позволяет уменьшить размер до 80% для экономии пропускной способности и времени.
В PHP его можно найти так: $ _SERVER [“HTTP_ACCEPT_ENCODING”]. Однако, когда вы используете функцию обратного вызова ob_gzhandler(), она будет проверять значение автоматически, поэтому вам это не нужно.
1 |
// enables output buffering
|
2 |
// and all output is compressed if the browser supports it
|
3 |
ob_start('ob_gzhandler'); |
If-Modified-Since
Если веб-документ уже сохранен в кеше в браузере и вы посещаете его снова, ваш браузер может проверить, был ли документ обновлён, отправив следующее:
1 |
If-Modified-Since: Sat, 28 Nov 2009 06:38:19 GMT |
Если он не изменялся с этой даты, сервер отправляет код ответа «304 Not Modified», а содержимое – нет, и браузер загружает содержимое из cache.
В PHP его можно найти так: $ _SERVER [‘HTTP_IF_MODIFIED_SINCE’].
1 |
// assume $last_modify_time was the last the output was updated
|
2 |
|
3 |
// did the browser send If-Modified-Since header?
|
4 |
if(isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])) { |
5 |
|
6 |
// if the browser cache matches the modify time
|
7 |
if ($last_modify_time == strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE'])) { |
8 |
|
9 |
// send a 304 header, and no content
|
10 |
header("HTTP/1.1 304 Not Modified"); |
11 |
exit; |
12 |
}
|
13 |
|
14 |
}
|
Существует также HTTP-заголовок Etag, который можно использовать для проверки текущего кэша. Мы поговорим об этом в ближайшее время.
Cookie
Как следует из названия, это отправляет файлы cookie, хранящиеся в вашем браузере для этого домена.
1 |
Cookie: PHPSESSID=r2t5uvjq435r4q7ib3vtdjq120; foo=bar |
Это пары name=value, разделённые точками с запятой. Cookies могут также содержать id сеанса.
В PHP отдельные cookie-файлы могут быть доступны с помощью массива $ _COOKIE. Вы можете напрямую обращаться к переменным сеанса, используя массив $ _SESSION, и если вам нужен id сеанса, вы можете использовать функцию session_id () вместо cookie.
1 |
echo $_COOKIE['foo']; |
2 |
// output: bar
|
3 |
echo $_COOKIE['PHPSESSID']; |
4 |
// output: r2t5uvjq435r4q7ib3vtdjq120
|
5 |
session_start(); |
6 |
echo session_id(); |
7 |
// output: r2t5uvjq435r4q7ib3vtdjq120
|
Referer
Как следует из названия, этот HTTP header содержит ссылочный url.
Например, если я зашел на домашнюю страницу Nettuts + и нажал ссылку на статью, этот header будет отправлен в мой браузер:
1 |
Referer: https://net.tutsplus.com/ |
В PHP его можно найти как $ _SERVER [‘HTTP_REFERER’].
1 |
if (isset($_SERVER['HTTP_REFERER'])) { |
2 |
|
3 |
$url_info = parse_url($_SERVER['HTTP_REFERER']); |
4 |
|
5 |
// is the surfer coming from Google?
|
6 |
if ($url_info['host'] == 'www.google.com') { |
7 |
|
8 |
parse_str($url_info['query'], $vars); |
9 |
|
10 |
echo "You searched on Google for this keyword: ". $vars['q']; |
11 |
|
12 |
}
|
13 |
|
14 |
}
|
15 |
// if the referring url was:
|
16 |
// http://www.google.com/search?source=ig&hl=en&rlz=&=&q=http+headers&aq=f&oq=&aqi=g-p1g9
|
17 |
// the output will be:
|
18 |
// You searched on Google for this keyword: http headers
|
Возможно, вы заметили, что слово «referrer» написано с ошибкой, как «referer». К сожалению, он превратился в официальную спецификацию HTTP подобным образом и застрял.
Authorization
Когда веб-страница запрашивает авторизацию, браузер открывает окно входа в систему. Когда вы вводите имя пользователя и пароль в этом окне, браузер отправляет другой HTTP-запрос, но на этот раз он содержит этот header
1 |
Authorization: Basic bXl1c2VyOm15cGFzcw== |
Данные внутри header имеют кодировку base64. Например, base64_decode (‘bXl1c2VyOm15cGFzcw ==’) возвратит ‘myuser: mypass’
В PHP эти значения можно найти как $ _SERVER [‘PHP_AUTH_USER’] и $ _SERVER [‘PHP_AUTH_PW’].
Подробнее об этом будет, когда мы поговорим о заголовке WWW-Authenticate.
Заголовки HTTP в ответах HTTP
Теперь мы рассмотрим некоторые из наиболее распространенных HTTP headers, найденных в HTTP-ответах.
В PHP вы можете установить заголовки ответа, используя функцию header(). PHP уже отправляет определённые заголовки автоматически, для загрузки содержимого и настройки файлов cookie и прочее… Вы можете увидеть headers, которые отправляются или будут отправляться с помощью функции headers_list (). Вы можете проверить, были ли уже отправлены заголовки с помощью функции headers_sent().
Cache-Control
Определение из w3.org: «Поле заголовка Cache-Control используется для указания директив, которые ДОЛЖНЫ выполняться всеми механизмами кэширования по цепочке запросов/ответов». Эти «механизмы кэширования» включают шлюзы и прокси, которые может использовать ваш интернет-провайдер.
Пример:
1 |
Cache-Control: max-age=3600, public |
“public” означает, что ответ может быть кэширован кем угодно. “max-age” указывает, сколько секунд действителен кеш. Разрешение кэширования вашего сайта может снизить нагрузку на сервер и пропускную способность, а также увеличить время загрузки в браузере.
Кэширование также может быть предотвращено с помощью директивы “no-cache”.
1 |
Cache-Control: no-cache |
Подробности смотрите в w3.org.
Content-Type
Этот header указывает “mime-type” документа. Затем браузер определяет, как интерпретировать содержимое на основании этого. Например, страница html (или PHP-скрипт с выходом html) может возвращать это:
1 |
Content-Type: text/html; charset=UTF-8 |
“text” – это тип, а “html” – подтип документа. Заголовок также может содержать больше информации, такой как charset.
Для gif-изображения это может быть отправлено.
1 |
Content-Type: image/gif |
Браузер может использовать внешнее приложение или расширение браузера на основе mime-type. Например, это приведет к загрузке Adobe Reader:
1 |
Content-Type: application/pdf |
При загрузке напрямую Apache обычно может обнаружить mime-тип документа и отправить соответствующий header. Кроме того, большинство браузеров имеют некоторую степень отказоустойчивости и автоопределение типов mime, если заголовки указаны неверно или отсутствуют.
Вы можете найти список общих типов mime here.
В PHP вы можете использовать функцию finfo_file() для определения mime-типа файла.
Content-Disposition
Этот header указывает браузеру открыть окно загрузки файла, вместо того, чтобы пытаться проанализировать содержимое. Пример:
1 |
Content-Disposition: attachment; filename="download.zip" |
Это заставит браузер сделать это:


Обратите внимание, что соответствующий заголовок Content-Type также должен быть отправлен вместе с этим:
1 |
Content-Type: application/zip |
2 |
Content-Disposition: attachment; filename="download.zip" |
Content-Length
Когда контент будет передаваться браузеру, сервер может указать его размер (в байтах), используя этот header.
Это особенно полезно при загрузке файлов. Именно так браузер может определить ход загрузки.
Например, вот сценарий-макет, который я написал, имитирует медленную загрузку.
1 |
// it's a zip file
|
2 |
header('Content-Type: application/zip'); |
3 |
// 1 million bytes (about 1megabyte)
|
4 |
header('Content-Length: 1000000'); |
5 |
// load a download dialogue, and save it as download.zip
|
6 |
header('Content-Disposition: attachment; filename="download.zip"'); |
7 |
|
8 |
// 1000 times 1000 bytes of data
|
9 |
for ($i = 0; $i < 1000; $i++) { |
10 |
echo str_repeat(".",1000); |
11 |
|
12 |
// sleep to slow down the download
|
13 |
usleep(50000); |
14 |
}
|
Вот результат:


Теперь я собираюсь закомментировать заголовок Content-Length
1 |
// it's a zip file
|
2 |
header('Content-Type: application/zip'); |
3 |
// the browser won't know the size
|
4 |
// header('Content-Length: 1000000');
|
5 |
// load a download dialogue, and save it as download.zip
|
6 |
header('Content-Disposition: attachment; filename="download.zip"'); |
7 |
|
8 |
// 1000 times 1000 bytes of data
|
9 |
for ($i = 0; $i < 1000; $i++) { |
10 |
echo str_repeat(".",1000); |
11 |
|
12 |
// sleep to slow down the download
|
13 |
usleep(50000); |
14 |
}
|
Теперь результат такой:


Браузер может только сказать, сколько байтов было загружено, но он не знает общую сумму. И индикатор выполнения не показывает прогресс.
Etag
Это еще один header, который используется для кеширования. Это выглядит так:
1 |
Etag: "pub1259380237;gz" |
Веб-сервер может отправлять этот header с каждым документом, который он обслуживает. Значение может быть основано на последней изменённой дате, размере файла или даже контрольной сумме файла. Браузер затем сохраняет это значение, так как он кэширует документ. В следующий раз, когда браузер запрашивает тот же файл, он отправляет это в HTTP-запросе:
1 |
If-None-Match: "pub1259380237;gz" |
Если значение Etag документа совпадает с этим, сервер будет отправлять код 304 вместо 200, и никакого содержимого. Браузер будет загружать содержимое из своего кеша.
Last-Modified
Как следует из названия, этот header указывает дату последнего изменения документа в формате GMT:
1 |
Last-Modified: Sat, 28 Nov 2009 03:50:37 GMT |
1 |
$modify_time = filemtime($file); |
2 |
|
3 |
header("Last-Modified: " . gmdate("D, d M Y H:i:s", $modify_time) . " GMT"); |
Это предлагает браузеру другой способ для cache документа. Браузер может отправить это в HTTP-запросе:
1 |
If-Modified-Since: Sat, 28 Nov 2009 06:38:19 GMT |
Мы уже говорили об этом ранее в разделе “If-Modified-Since”.
Location
Этот заголовок используется для перенаправления. Если код ответа 301 или 302, сервер также должен отправить этот header. Например, когда вы перейдете на страницу http://www.nettuts.com, ваш браузер получит следующее:
1 |
HTTP/1.x 301 Moved Permanently |
2 |
... |
3 |
Location: https://net.tutsplus.com/ |
4 |
... |
В PHP вы можете перенаправить surfer так:
1 |
header('Location: https://net.tutsplus.com/'); |
По умолчанию, это отправит 302 код ответа. Если вы хотите вместо 301 отправить:
1 |
header('Location: https://net.tutsplus.com/', true, 301); |
Set-Cookie
Когда веб-сайт хочет установить или обновить файл cookie в вашем браузере, он будет использовать этот header.
1 |
Set-Cookie: skin=noskin; path=/; domain=.amazon.com; expires=Sun, 29-Nov-2009 21:42:28 GMT |
2 |
Set-Cookie: session-id=120-7333518-8165026; path=/; domain=.amazon.com; expires=Sat Feb 27 08:00:00 2010 GMT |
Каждый файл cookie отправляется как отдельный header. Обратите внимание, что файлы cookie, установленные с помощью JavaScript, не проходят через HTTP headers.
В PHP вы можете установить cookie-файлы, используя функцию setcookie(), а PHP отправляет соответствующие HTTP headers.
1 |
setcookie("TestCookie", "foobar"); |
Что приводит к отправке этого заголовка:
1 |
Set-Cookie: TestCookie=foobar |
Если дата истечения срока действия не указана, cookie удаляется, когда окно браузера закрыто.
WWW-Authenticate
Сайт может отправить этот header для аутентификации пользователя через HTTP. Когда браузер увидит этот header, он откроет диалоговое окно входа в систему.
1 |
WWW-Authenticate: Basic realm="Restricted Area" |
Что будет выглядеть так:
В руководстве PHP есть section, в котором приведены образцы кода, как это сделать в PHP.
1 |
if (!isset($_SERVER['PHP_AUTH_USER'])) { |
2 |
header('WWW-Authenticate: Basic realm="My Realm"'); |
3 |
header('HTTP/1.0 401 Unauthorized'); |
4 |
echo 'Text to send if user hits Cancel button'; |
5 |
exit; |
6 |
} else { |
7 |
echo "<p>Hello {$_SERVER['PHP_AUTH_USER']}.</p>"; |
8 |
echo "<p>You entered {$_SERVER['PHP_AUTH_PW']} as your password.</p>"; |
9 |
}
|
Content-Encoding
Этот header обычно устанавливается, когда возвращаемое содержимое сжимается.
В PHP, если вы используете функцию обратного вызова ob_gzhandler(), она будет автоматически установлена.
Заключение
Спасибо за прочтение. Надеюсь, эта статья послужит хорошей отправной точкой для изучения HTTP Headers. Пожалуйста, оставьте свои комментарии и вопросы ниже, и я постараюсь дать как можно больше ответов.
Если он обнаруживает, что строка не содержит «HTTP: //», финальная строка – «HTTP: // HTTP: //foo.foo», если она имеет перед собой «http: //».
Потому что он возвращает 0 для этой строки, которая вычисляется как false. Строки индексируются нулями и, как таковые, если http:// находится в начале строки, позиция равна 0, а не 1.
Вам нужно сравнить его для строгого неравенства с логическим ложным использованием !== :
if(strpos($URL, "http://") !== false)
@ Метод BoltClock будет работать.
В качестве альтернативы, если ваша строка является URL-адресом, вы можете использовать parse_url () , который вернет компоненты URL-адреса в ассоциативном массиве, например:
print_r(parse_url("http://www.google.com.au/")); Array ( [scheme] => http [host] => www.google.com.au [path] => / )
scheme – это то, что вам нужно. Вы можете использовать parse_url () в сочетании с in_array чтобы определить, существует ли http в строке URL.
$strUrl = "http://www.google.com?query_string=10#fragment"; $arrParsedUrl = parse_url($strUrl); if (!empty($arrParsedUrl['scheme'])) { // Contains http:// schema if ($arrParsedUrl['scheme'] === "http") { } // Contains https:// schema else if ($arrParsedUrl['scheme'] === "https") { } } // Don't contains http:// or https:// else { }
Редактировать:
Вы можете использовать $url["scheme"]=="http" как предлагалось @mario вместо in_array() , это было бы лучшим способом сделать это: D
if(preg_match("@^http://@i",$String)) $String = preg_replace("@(http://)+@i",'http://',$String); else $String = 'http://'.$String;
Вы должны помнить о https:// . Попробуй это:
private function http_check($url) { $return = $url; if ((!(substr($url, 0, 7) == 'http://')) && (!(substr($url, 0, 8) == 'https://'))) { $return = 'http://' . $url; } return $return; }
вы проверяете, содержит ли строка “HTTP: //” ИЛИ Нет
Ниже код отлично работает.
<?php $URL = 'http://google.com'; $weblink = $URL; if(strpos($weblink, "http://") !== false){ } else { $weblink = "http://".$weblink; } ?> <a class="weblink" <?php if($weblink != 'http://'){ ?> href="<?php echo $weblink; ?>"<?php } ?> target="_blank">Buy Now</a>
Наслаждайтесь парнями
Вы можете использовать substr_compare () [PHP Docs] .
Будьте осторожны с тем, что возвращает функция. Если строки совпадают, он возвращает 0. Для других значений возврата вы можете проверить документы PHP. Существует также параметр для проверки строчных символов. Если вы укажете TRUE, тогда он будет проверять буквы верхнего регистра.
Поэтому вы можете просто написать следующее в своей проблеме:
if((substr_compare($URL,"http://",0,7)) === 0) $URL = $URL; else $URL = "http://$URL";
Однострочное решение:
$sURL = 'http://'.str_ireplace('http://','',$sURL);
