I have a shopping cart that displays product options in a dropdown menu and if they select “yes”, I want to make some other fields on the page visible.
The problem is that the shopping cart also includes the price modifier in the text, which can be different for each product. The following code works:
$(document).ready(function() {
$('select[id="Engraving"]').change(function() {
var str = $('select[id="Engraving"] option:selected').text();
if (str == "Yes (+ $6.95)") {
$('.engraving').show();
} else {
$('.engraving').hide();
}
});
});
However I would rather use something like this, which doesn’t work:
$(document).ready(function() {
$('select[id="Engraving"]').change(function() {
var str = $('select[id="Engraving"] option:selected').text();
if (str *= "Yes") {
$('.engraving').show();
} else {
$('.engraving').hide();
}
});
});
I only want to perform the action if the selected option contains the word “Yes”, and would ignore the price modifier.
![]()
cнŝdk
31.2k7 gold badges55 silver badges77 bronze badges
asked Aug 13, 2010 at 21:25
3
Like this:
if (str.indexOf("Yes") >= 0)
…or you can use the tilde operator:
if (~str.indexOf("Yes"))
This works because indexOf() returns -1 if the string wasn’t found at all.
Note that this is case-sensitive.
If you want a case-insensitive search, you can write
if (str.toLowerCase().indexOf("yes") >= 0)
Or:
if (/yes/i.test(str))
The latter is a regular expression or regex.
Regex breakdown:
/indicates this is a regexyesmeans that the regex will find those exact characters in that exact order/ends the regexisets the regex as case-insensitive.test(str)determines if the regular expression matchesstr
To sum it up, it means it will see if it can find the lettersy,e, andsin that exact order, case-insensitively, in the variablestr
RedGuy11
3446 silver badges14 bronze badges
answered Aug 13, 2010 at 21:28
SLaksSLaks
863k176 gold badges1900 silver badges1961 bronze badges
2
You could use search or match for this.
str.search( 'Yes' )
will return the position of the match, or -1 if it isn’t found.
answered Aug 13, 2010 at 21:29
hookedonwinterhookedonwinter
12.4k19 gold badges61 silver badges74 bronze badges
2
It’s pretty late to write this answer, but I thought of including it anyhow. String.prototype now has a method includes which can check for substring. This method is case sensitive.
var str = 'It was a good date';
console.log(str.includes('good')); // shows true
console.log(str.includes('Good')); // shows false
To check for a substring, the following approach can be taken:
if (mainString.toLowerCase().includes(substringToCheck.toLowerCase())) {
// mainString contains substringToCheck
}
Check out the documentation to know more.
answered May 7, 2016 at 13:38
MunimMunim
2,6061 gold badge19 silver badges28 bronze badges
1
Another way:
var testStr = "This is a test";
if(testStr.contains("test")){
alert("String Found");
}
** Tested on Firefox, Safari 6 and Chrome 36 **
az7ar
5,1572 gold badges17 silver badges23 bronze badges
answered Feb 20, 2013 at 19:44
Andy BrahamAndy Braham
9,4694 gold badges46 silver badges56 bronze badges
1
ECMAScript 6 introduces String.prototype.includes, previously named contains.
It can be used like this:
'foobar'.includes('foo'); // true
'foobar'.includes('baz'); // false
It also accepts an optional second argument which specifies the position at which to begin searching:
'foobar'.includes('foo', 1); // false
'foobar'.includes('bar', 1); // true
It can be polyfilled to make it work on old browsers.
answered Apr 16, 2016 at 23:00
OriolOriol
270k62 gold badges428 silver badges505 bronze badges
0
The includes() method determines whether one string may be found within another string, returning true or false as appropriate.
Syntax :-string.includes(searchString[, position])
searchString:-A string to be searched for within this string.
position:-Optional. The position in this string at which to begin searching for searchString; defaults to 0.
string = 'LOL';
console.log(string.includes('lol')); // returns false
console.log(string.includes('LOL')); // returns true
answered Nov 18, 2016 at 17:45
Parth RavalParth Raval
3,9793 gold badges23 silver badges36 bronze badges
0
You can use this Polyfill in ie and chrome
if (!('contains' in String.prototype)) {
String.prototype.contains = function (str, startIndex) {
"use strict";
return -1 !== String.prototype.indexOf.call(this, str, startIndex);
};
}
answered Jul 3, 2013 at 14:09
robkorvrobkorv
5397 silver badges5 bronze badges
0
If you are capable of using libraries, you may find that Lo-Dash JS library is quite useful. In this case, go ahead and check _.contains() (replaced by _.includes() as of v4).
(Note Lo-Dash convention is naming the library object _.
Don’t forget to check installation in the same page to set it up for your project.)
_.contains("foo", "oo"); // → true
_.contains("foo", "bar"); // → false
// Equivalent with:
_("foo").contains("oo"); // → true
_("foo").contains("bar"); // → false
In your case, go ahead and use:
_.contains(str, "Yes");
// or:
_(str).contains("Yes");
..whichever one you like better.
answered Oct 1, 2015 at 6:18
![]()
SelfishSelfish
5,9553 gold badges42 silver badges63 bronze badges
0
I know that best way is str.indexOf(s) !== -1; http://hayageek.com/javascript-string-contains/
I suggest another way(str.replace(s1, "") !== str):
var str = "Hello World!", s1 = "ello", s2 = "elloo";
alert(str.replace(s1, "") !== str);
alert(str.replace(s2, "") !== str);answered Oct 1, 2015 at 6:05
![]()
You can also check if the exact word is contained in a string. E.g.:
function containsWord(haystack, needle) {
return (" " + haystack + " ").indexOf(" " + needle + " ") !== -1;
}
Usage:
containsWord("red green blue", "red"); // true
containsWord("red green blue", "green"); // true
containsWord("red green blue", "blue"); // true
containsWord("red green blue", "yellow"); // false
This is how jQuery does its hasClass method.
answered Mar 26, 2015 at 15:43
bashausbashaus
1,6021 gold badge16 silver badges33 bronze badges
you can define an extension method and use it later.
String.prototype.contains = function(it)
{
return this.indexOf(it) != -1;
};
so that you can use in your page anywhere like:
var str="hello how are you";
str.contains("are");
which returns true.
Refer below post for more extension helper methods.
Javascript helper methods
answered Mar 3, 2015 at 13:08
![]()
Vikas KottariVikas Kottari
4952 gold badges10 silver badges24 bronze badges
None of the above worked for me as there were blank spaces but this is what I did
tr = table.getElementsByTagName("tr");
for (i = 0; i < tr.length; i++) {
td = tr[i].getElementsByTagName("td")[0];
bottab.style.display="none";
bottab2.style.display="none";
if (td) {
var getvar=td.outerText.replace(/s+/, "") ;
if (getvar==filter){
tr[i].style.display = "";
}else{
tr[i].style.display = "none";
}
}
}
answered Jul 17, 2017 at 0:14
![]()
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
While preprocessing data using pandas dataframe there may be a need to find the rows that contain specific text. In this article we will discuss methods to find the rows that contain specific text in the columns or rows of a dataframe in pandas.
Dataset in use:
| job | Age_Range | Salary | Credit-Rating | Savings | Buys_Hone |
|---|---|---|---|---|---|
| Own | Middle-aged | High | Fair | 10000 | Yes |
| Govt | Young | Low | Fair | 15000 | No |
| Private | Senior | Average | Excellent | 20000 | Yes |
| Own | Middle-aged | High | Fair | 13000 | No |
| Own | Young | Low | Excellent | 17000 | Yes |
| Private | Senior | Average | Fair | 18000 | No |
| Govt | Young | Average | Fair | 11000 | No |
| Private | Middle-aged | Low | Excellent | 9000 | No |
| Govt | Senior | High | Excellent | 14000 | Yes |
Method 1 : Using contains()
Using the contains() function of strings to filter the rows. We are filtering the rows based on the ‘Credit-Rating’ column of the dataframe by converting it to string followed by the contains method of string class. contains() method takes an argument and finds the pattern in the objects that calls it.
Example:
Python3
import pandas as pd
df = pd.read_csv("Assignment.csv")
df = df[df['Credit-Rating'].str.contains('Fair')]
print(df)
Output :
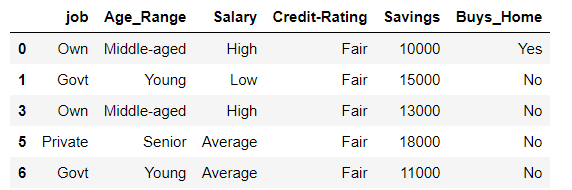
Rows containing Fair as Savings
Method 2 : Using itertuples()
Using itertuples() to iterate rows with find to get rows that contain the desired text. itertuple method return an iterator producing a named tuple for each row in the DataFrame. It works faster than the iterrows() method of pandas.
Example:
Python3
import pandas as pd
df = pd.read_csv("Assignment.csv")
for x in df.itertuples():
if x[2].find('Young') != -1:
print(x)
Output :
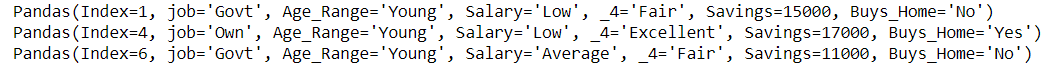
Rows with Age_Range as Young
Method 3 : Using iterrows()
Using iterrows() to iterate rows with find to get rows that contain the desired text. iterrows() function returns the iterator yielding each index value along with a series containing the data in each row. It is slower as compared to the itertuples because of lot of type checking done by it.
Example:
Python3
import pandas as pd
df = pd.read_csv("Assignment.csv")
for index, row in df.iterrows():
if 'Govt' in row['job']:
print(index, row['job'], row['Age_Range'],
row['Salary'], row['Savings'], row['Credit-Rating'])
Output :

Rows with job as Govt
Method 4 : Using regular expressions
Using regular expressions to find the rows with the desired text. search() is a method of the module re. re.search(pattern, string): It is similar to re.match() but it doesn’t limit us to find matches at the beginning of the string only. We are iterating over the every row and comparing the job at every index with ‘Govt’ to only select those rows.
Example:
Python3
from re import search
import pandas as pd
df = pd.read_csv("Assignment.csv")
for ind in df.index:
if search('Govt', df['job'][ind]):
print(df['job'][ind], df['Savings'][ind],
df['Age_Range'][ind], df['Credit-Rating'][ind])
Output :

Rows where job is Govt
Last Updated :
07 Apr, 2021
Like Article
Save Article
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
grep [OPTIONS] PATTERN [FILE...]
Пункты в квадратных скобках необязательны.
OPTIONS— Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.-
PATTERN— Шаблон поиска. -
FILE— Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
grep bash /etc/passwdРезультат должен выглядеть примерно так:
root:x:0:0:root:/root:/bin/bash
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
grep "Gnome Display Manager" /etc/passwdИнвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или --invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
grep -v nologin /etc/passwdroot:x:0:0:root:/root:/bin/bash
colord:x:124:124::/var/lib/colord:/bin/false
git:x:994:994:git daemon user:/:/usr/bin/git-shell
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
ps -ef | grep www-datawww-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
root 18272 17714 0 16:00 pts/0 00:00:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn www-data
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
ps -ef | grep www-data | grep -v grepwww-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или --recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или --dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
grep -r linuxize.com /etcВывод будет включать совпадающие строки с префиксом полного пути к файлу:
/etc/hosts:127.0.0.1 node2.linuxize.com
/etc/nginx/sites-available/linuxize.com: server_name linuxize.com www.linuxize.com;
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
grep -R linuxize.com /etcОбратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
/etc/hosts:127.0.0.1 node2.linuxize.com
/etc/nginx/sites-available/linuxize.com: server_name linuxize.com www.linuxize.com;
/etc/nginx/sites-enabled/linuxize.com: server_name linuxize.com www.linuxize.com;
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или --files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
grep -l linuxize.com *.confРезультат будет выглядеть примерно так:
tmux.conf
haproxy.conf
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
grep -Rl linuxize.com /tmpПоиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или --ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
grep Zebra /usr/share/wordsНо если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
grep -i Zebra /usr/share/wordsУказание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
zebra
zebra's
zebras
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
grep gnu /usr/share/wordscygnus
gnu
interregnum
lgnu9d
lignum
magnum
magnuson
sphagnum
wingnut
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или --word-regexp ).
Символы слова включают буквенно-цифровые символы ( az , AZ и 0-9 ) и символы подчеркивания ( _ ). Все остальные символы считаются несловесными символами.
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
grep -w gnu /usr/share/wordsgnu
Показать номера строк
Параметр -n (или --line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
grep -n 10000 /etc/servicesРезультат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
10423:ndmp 10000/tcp
10424:ndmp 10000/udp
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или --count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
regular expressiongrep -c '/usr/bin/zsh' /etc/passwd
4
Бесшумный режим
-q (или --quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
if grep -q PATTERN filename
then
echo pattern found
else
echo pattern not found
fi
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
-
Используйте символ
^(каретка) для сопоставления выражения в начале строки. В следующем примере строкаkangarooбудет соответствовать только в том случае, если она встречается в самом начале строки.grep "^kangaroo" file.txt -
Используйте символ
$(доллар), чтобы найти выражение в конце строки. В следующем примере строкаkangarooбудет соответствовать только в том случае, если она встречается в самом конце строки.grep "kangaroo$" file.txt -
Используйте расширение
.(точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается сkanзатем имеет два символа и заканчивается строкойroo, вы можете использовать следующий шаблон:grep "kan..roo" file.txt -
Используйте
[ ](скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащиеacceptили «accent, вы можете использовать следующий шаблон:grep "acce[np]t" file.txt -
Используйте
[^ ]для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащихco(any_letter_except_l)a, напримерcoca,cobaltи т. Д., Но не будет соответствовать строкам, содержащимcola,grep "co[^l]a" file.txt
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или --extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
-
Сопоставьте и извлеките все адреса электронной почты из данного файла:
grep -E -o "b[A-Za-z0-9._%+-][email protected][A-Za-z0-9.-]+.[A-Za-z]{2,6}b" file.txt -
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
grep -E -o '(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' file.txt
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
grep 'fatal|error|critical' /var/log/nginx/error.logЕсли вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
grep -E 'fatal|error|critical' /var/log/nginx/error.logСтроки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или --before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
grep -B 5 root /etc/passwdПечатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или --after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
grep -A 5 root /etc/passwdВыводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.

При работе с базой данных SQL вам может понадобиться найти записи, содержащие определенные строки. В этой статье мы разберем, как искать строки и подстроки в MySQL и SQL Server.
Содержание
- Использование операторов WHERE и LIKE для поиска подстроки
- Поиск подстроки в SQL Server с помощью функции CHARINDEX
- Поиск подстроки в SQL Server с помощью функции PATINDEX
- MySQL-запрос для поиска подстроки с применением функции SUBSTRING_INDEX()
Я буду использовать таблицу products_data в базе данных products_schema. Выполнение команды SELECT * FROM products_data покажет мне все записи в таблице:

Поскольку я также буду показывать поиск подстроки в SQL Server, у меня есть таблица products_data в базе данных products:

Поиск подстроки при помощи операторов WHERE и LIKE
Оператор WHERE позволяет получить только те записи, которые удовлетворяют определенному условию. А оператор LIKE позволяет найти определенный шаблон в столбце. Эти два оператора можно комбинировать для поиска строки или подстроки.
Например, объединив WHERE с LIKE, я смог получить все товары, в которых есть слово «computer»:
SELECT * FROM products_data WHERE product_name LIKE '%computer%'

Знаки процента слева и справа от «computer» указывают искать слово «computer» в конце, середине или начале строки.
Если поставить знак процента в начале подстроки, по которой вы ищете, это будет указанием найти такую подстроку, стоящую в конце строки. Например, выполнив следующий запрос, я получил все продукты, которые заканчиваются на «er»:
SELECT * FROM products_data WHERE product_name LIKE '%er'

А если написать знак процента после искомой подстроки, это будет означать, что нужно найти такую подстроку, стоящую в начале строки. Например, я смог получить продукт, начинающийся на «lap», выполнив следующий запрос:
SELECT * FROM products_data WHERE product_name LIKE 'lap%'

Этот метод также отлично работает в SQL Server:

Поиск подстроки в SQL Server с помощью функции CHARINDEX
CHARINDEX() — это функция SQL Server для поиска индекса подстроки в строке.
Функция CHARINDEX() принимает 3 аргумента: подстроку, строку и стартовую позицию для поиска. Синтаксис выглядит следующим образом:
CHARINDEX(substring, string, start_position)
Если функция находит совпадение, она возвращает индекс, по которому найдено совпадение, а если совпадение не найдено, возвращает 0. В отличие от многих других языков, отсчет в SQL начинается с единицы.
Пример:
SELECT CHARINDEX('free', 'free is the watchword of freeCodeCamp') position;

Как видите, слово «free» было найдено на позиции 1. Это потому, что на позиции 1 стоит его первая буква — «f»:

Можно задать поиск с конкретной позиции. Например, если указать в качестве позиции 25, SQL Server найдет совпадение, начиная с текста «freeCodeCamp»:
SELECT CHARINDEX('free', 'free is the watchword of freeCodeCamp', 25);

При помощи CHARINDEX можно найти все продукты, в которых есть слово «computer», выполнив этот запрос:
SELECT * FROM products_data WHERE CHARINDEX('computer', product_name, 0) > 0
Этот запрос диктует следующее: «Начиная с индекса 0 и до тех пор, пока их больше 0, ищи все продукты, названия которых содержат слово «computer», в столбце product_name». Вот результат:

Поиск подстроки в SQL Server с помощью функции PATINDEX
PATINDEX означает «pattern index», т. е. «индекс шаблона». Эта функция позволяет искать подстроку с помощью регулярных выражений.
PATINDEX принимает два аргумента: шаблон и строку. Синтаксис выглядит следующим образом:
PATINDEX(pattern, string)
Если PATINDEX находит совпадение, он возвращает позицию этого совпадения. Если совпадение не найдено, возвращается 0. Вот пример:
SELECT PATINDEX('%ava%', 'JavaScript is a Jack of all trades');

Чтобы применить PATINDEX к таблице, я выполнил следующий запрос:
SELECT product_name, PATINDEX('%ann%', product_name) position
FROM products_data
Но он только перечислил все товары и вернул индекс, под которым нашел совпадение:

Как видите, подстрока «ann» нашлась под индексом 3 продукта Scanner. Но скорее всего вы захотите, чтобы выводился только тот товар, в котором было найдено совпадение с шаблоном.
Чтобы обеспечить такое поведение, можно использовать операторы WHERE и LIKE:
SELECT product_name, PATINDEX('%ann%', product_name) position
FROM products_data
WHERE product_name LIKE '%ann%'

Теперь запрос возвращает то, что нужно.
MySQL-запрос для поиска строки с применением функции SUBSTRING_INDEX()
Помимо решений, которые я уже показал, MySQL имеет встроенную функцию SUBSTRING_INDEX(), с помощью которой можно найти часть строки.
Функция SUBSTRING_INDEX() принимает 3 обязательных аргумента: строку, разделитель и число. Числом обозначается количество вхождений разделителя.
Если вы укажете обязательные аргументы, функция SUBSTRING_INDEX() вернет подстроку до n-го разделителя, где n — указанное число вхождений разделителя. Вот пример:
SELECT SUBSTRING_INDEX("Learn on freeCodeCamp with me", "with", 1);
В этом запросе «Learn on freeCodeCamp with me» — это строка, «with» — разделитель, а 1 — количество вхождений разделителя. В этом случае запрос выдаст вам «Learn on freeCodeCamp»:

Количество вхождений разделителя может быть как положительным, так и отрицательным. Если это отрицательное число, то вы получите часть строки после указанного числа разделителей. Вот пример:
SELECT SUBSTRING_INDEX("Learn on freeCodeCamp with me", "with", -1);

От редакции Techrocks: также предлагаем почитать «Индексы и оптимизация MySQL-запросов».
Заключение
Из этой статьи вы узнали, как найти подстроку в строке в SQL, используя MySQL и SQL Server.
CHARINDEX() и PATINDEX() — это функции, с помощью которых можно найти подстроку в строке в SQL Server. Функция PATINDEX() является более мощной, так как позволяет использовать регулярные выражения.
Поскольку в MySQL нет CHARINDEX() и PATINDEX(), в первом примере мы рассмотрели, как найти подстроку в строке с помощью операторов WHERE и LIKE.
Перевод статьи «SQL Where Contains String – Substring Query Example».
Практически любой, у кого есть компьютер или кто с ним работает, знает сочетание клавиш Ctrl + F для поиска текста. Буква «F» означает «Найти», «найти» на английском языке и может использоваться, например, для поиска текста на веб-странице. Этот ярлык также доступен во многих приложениях, есть программы, которые используют букву «B» для поиска, но эти ярлыки работают, только если мы находимся внутри приложения и с открытым файлом. В Linux у нас есть очень мощные инструменты, которые мы можем запускать из Терминала и, если захотим, найдем любой текст, который есть в нашей команде, воспользуемся командой GREP.
GREP Это команда, которая поможет нам найти текст в указанном нами файле. Его название происходит от g / re / p, команды, которая работает для чего-то подобного в текстовом редакторе Unix / Linux. Как и многие другие команды, GREP Имеет много доступные варианты, которые мы добавим в виде букв и каждый будет служить своей задаче. Объединив эти параметры, мы сможем выполнять сложный поиск в одном или нескольких файлах. Здесь мы покажем вам все, что вам нужно знать.
Индекс
- 1 с помощью grep мы найдем любой текст в любом файле
- 2 С помощью grep мы также можем искать файлы
- 3 Как выполнять рекурсивный поиск
- 4 Как выполнять точный поиск слов
- 5 Узнайте, сколько раз слово появляется в файле
- 6 Обратный поиск
- 7 Доступ к системной информации с помощью grep
- 8 Как вывести список только совпадающих имен файлов
con GREP найдем любой текст в любом файле
Прежде всего мы объясним доступные варианты:
- –i: не будет различать верхний и нижний регистр.
- –w: заставить его находить только определенные слова.
- –v: выбирает строки, которые не совпадают.
- –n: показывает номер строки с запрошенными словами.
- –h: удаляет префикс из имени файла Unix в выводе.
- –r: рекурсивный поиск в каталогах.
- –R: как -r, но следуйте всем символическим ссылкам.
- –l: показывает только имена файлов с выделенными строками.
- –c– Показывает только одно количество выбранных строк для каждого файла.
- -Цвет: Отображает совпадающие шаблоны в цветах.
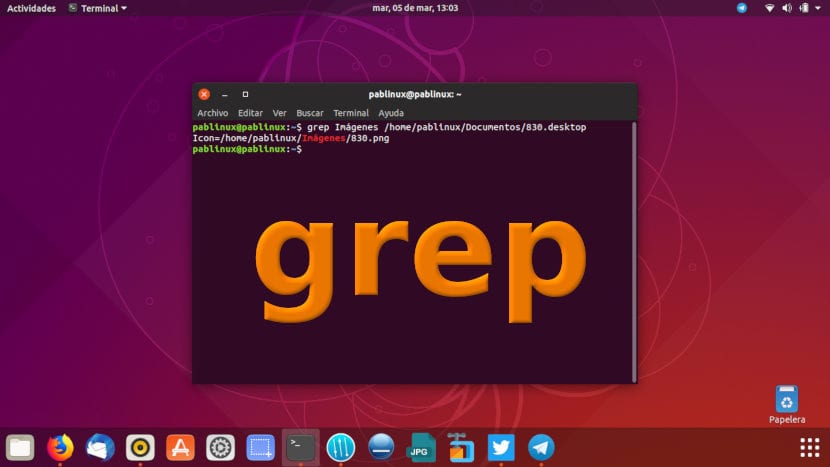
На изображении, которое вы указали в заголовке этой статьи, я искал слово «Изображения» в файле «830.desktop», который находится по этому пути. Как видите, я написал:
grep Imágenes /home/pablinux/Documentos/830.desktop
Имейте в виду, что в этой статье мы напишем примеры, которые необходимо изменить в соответствии с нашими поисковыми предпочтениями. Когда мы говорим «Файл», «Слово» и т. Д., Мы будем ссылаться на файл с его путем.. Если бы я просто написал «grep Images 830.desktop», я бы получил сообщение о том, что файл не существует. Или так было бы, если бы файл не находился в корневом каталоге.
Другие примеры:
- grep -i images /home/pablinux/Documentos/830.desktop, где «изображения» – это слово, которое мы хотим найти, а остальное – файл с его путем. В этом примере выполняется поиск «изображений» в файле «830.desktop» без учета регистра.
- grep -R изображения: он будет искать во всех строках каталога и всех его подкаталогах, где найдено слово «изображения».
- grep -c пример test.txt: это будет искать нас и показывать общее количество раз, когда “example” появляется в файле с именем “test.txt”.
Если мы хотим найти файл 830.desktop, мы напишем следующую команду:
grep 830.desktop
Это выполнит найдите файл «830.desktop» в личной папкеДругими словами, если файл находится в личной папке другого пользователя, он не будет найден. Это самая нормальная вещь в мире, потому что у пользователя нет разрешения на доступ к чужому контенту без своего пароля.
Как выполнять рекурсивный поиск
GREP это также позволяет нам выполнять поиск в соответствии с повторяющимися правилами или рекомендациями. Например, прочтите все файлы в каждом каталоге, содержащие слово «Pablinux». Для этого напишем:
grep -r Pablinux /home/
Хорошо:
grep -R Pablinux /home/
Мы увидим результаты для «Pablinux» в отдельной строке, перед которой будет указано имя файла, в котором он был найден. Если мы не хотим видеть имена файлов в выводе данных, мы будем использовать опцию -h (от «скрыть»; скрыть):
grep -h -R Pablinux /home/
Мы можем объединить варианты вместе и написать «-hR» без кавычек.
Как выполнять точный поиск слов
Иногда есть файлы, которые содержат то, что мы хотим найти для чего-то еще. Например, это может произойти с нами в сложных словах, и, выполнив поиск по слову «леса», мы можем найти «рейнджеров». Если мы хотим найти точное слово мы будем использовать опцию -w:
grep -w bosques /home/pablinux/Documentos/vacaciones.txt
Вышеупомянутая команда будет искать «леса», игнорируя рейнджеров, в файле «vacation.txt» по указанному пути. Если мы хотим найти два разных слова, мы воспользуемся командой задать расширенное:
egrep -w bosques|plantas /ruta/del/archivo
Узнайте, сколько раз слово появляется в файле
GREP он также способен посчитайте, сколько раз встречается слово в файле. Для этого мы будем использовать опцию -c:
grep -c prueba /ruta/al/archivo
Добавив параметр -n, мы увидим номер строки, в которой появляется слово.
Обратный поиск
Мы также можем сделать обратное, то есть искать строки, не содержащие слова. Для этого мы будем использовать параметр -v, который будет выглядеть следующим образом:
grep -v la ruta/al/archivo
Приведенная выше команда отобразит все строки, в которых нет слова «the». Это может пригодиться в документах или списках, в которых слово повторяется много раз, и по какой-то причине нам нужен доступ к остальным строкам.
Доступ к системной информации с помощью GREP
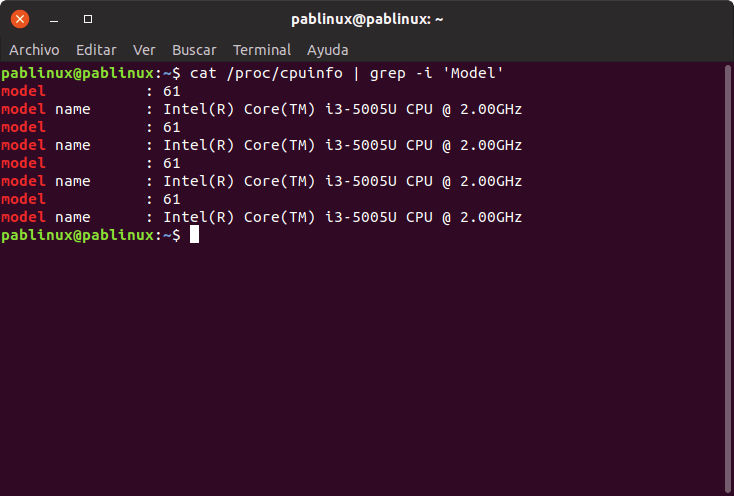
GREP он не только способен выполнять поиск в файлах. Это также возможность просматривать системную информацию. На предыдущем снимке экрана мы видим, как он показывает нам, какая у нас модель ПК (я знаю, что это не самый мощный ноутбук в мире). Для этого мы использовали команду:
cat /proc/cpuinfo | grep -i 'Model'
Хорошо:
grep -i 'Model' /proc/cpuinfo
Если мы хотим увидеть имена дисковых накопителей, мы напишем:
dmesg | egrep '(s|h)d[a-z]'
Как вывести список только совпадающих имен файлов
Если мы хотим увидеть список только с именами файлов, которые соответствуют поисковому запросу, мы будем использовать параметр -l, как показано ниже:
grep -l 'main' *.c
И если мы хотим видеть слово в цветах, мы напишем:
grep --color palabra /ruta/al/archivo
Как видите, команда GREP является очень мощный инструмент Это стоит особенно в тех случаях, когда мы не помним, где мы что-то написали или в программировании. Кроме того, он помогает нам узнавать информацию о системе так, как это понравится любителям Терминалов. Было ли вам полезно это руководство по команде поиска текстов? GREP?
Содержание статьи соответствует нашим принципам редакционная этика. Чтобы сообщить об ошибке, нажмите здесь.
