Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
grep [OPTIONS] PATTERN [FILE...]
Пункты в квадратных скобках необязательны.
OPTIONS— Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.-
PATTERN— Шаблон поиска. -
FILE— Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
grep bash /etc/passwdРезультат должен выглядеть примерно так:
root:x:0:0:root:/root:/bin/bash
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
grep "Gnome Display Manager" /etc/passwdИнвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или --invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
grep -v nologin /etc/passwdroot:x:0:0:root:/root:/bin/bash
colord:x:124:124::/var/lib/colord:/bin/false
git:x:994:994:git daemon user:/:/usr/bin/git-shell
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
ps -ef | grep www-datawww-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
root 18272 17714 0 16:00 pts/0 00:00:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn www-data
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
ps -ef | grep www-data | grep -v grepwww-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или --recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или --dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
grep -r linuxize.com /etcВывод будет включать совпадающие строки с префиксом полного пути к файлу:
/etc/hosts:127.0.0.1 node2.linuxize.com
/etc/nginx/sites-available/linuxize.com: server_name linuxize.com www.linuxize.com;
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
grep -R linuxize.com /etcОбратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
/etc/hosts:127.0.0.1 node2.linuxize.com
/etc/nginx/sites-available/linuxize.com: server_name linuxize.com www.linuxize.com;
/etc/nginx/sites-enabled/linuxize.com: server_name linuxize.com www.linuxize.com;
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или --files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
grep -l linuxize.com *.confРезультат будет выглядеть примерно так:
tmux.conf
haproxy.conf
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
grep -Rl linuxize.com /tmpПоиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или --ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
grep Zebra /usr/share/wordsНо если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
grep -i Zebra /usr/share/wordsУказание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
zebra
zebra's
zebras
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
grep gnu /usr/share/wordscygnus
gnu
interregnum
lgnu9d
lignum
magnum
magnuson
sphagnum
wingnut
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или --word-regexp ).
Символы слова включают буквенно-цифровые символы ( az , AZ и 0-9 ) и символы подчеркивания ( _ ). Все остальные символы считаются несловесными символами.
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
grep -w gnu /usr/share/wordsgnu
Показать номера строк
Параметр -n (или --line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
grep -n 10000 /etc/servicesРезультат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
10423:ndmp 10000/tcp
10424:ndmp 10000/udp
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или --count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
regular expressiongrep -c '/usr/bin/zsh' /etc/passwd
4
Бесшумный режим
-q (или --quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
if grep -q PATTERN filename
then
echo pattern found
else
echo pattern not found
fi
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
-
Используйте символ
^(каретка) для сопоставления выражения в начале строки. В следующем примере строкаkangarooбудет соответствовать только в том случае, если она встречается в самом начале строки.grep "^kangaroo" file.txt -
Используйте символ
$(доллар), чтобы найти выражение в конце строки. В следующем примере строкаkangarooбудет соответствовать только в том случае, если она встречается в самом конце строки.grep "kangaroo$" file.txt -
Используйте расширение
.(точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается сkanзатем имеет два символа и заканчивается строкойroo, вы можете использовать следующий шаблон:grep "kan..roo" file.txt -
Используйте
[ ](скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащиеacceptили «accent, вы можете использовать следующий шаблон:grep "acce[np]t" file.txt -
Используйте
[^ ]для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащихco(any_letter_except_l)a, напримерcoca,cobaltи т. Д., Но не будет соответствовать строкам, содержащимcola,grep "co[^l]a" file.txt
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или --extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
-
Сопоставьте и извлеките все адреса электронной почты из данного файла:
grep -E -o "b[A-Za-z0-9._%+-][email protected][A-Za-z0-9.-]+.[A-Za-z]{2,6}b" file.txt -
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
grep -E -o '(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' file.txt
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
grep 'fatal|error|critical' /var/log/nginx/error.logЕсли вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
grep -E 'fatal|error|critical' /var/log/nginx/error.logСтроки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или --before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
grep -B 5 root /etc/passwdПечатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или --after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
grep -A 5 root /etc/passwdВыводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
grep (GNU or BSD)
You can use grep tool to search recursively the current folder, like:
grep -r "class foo" .
Note: -r – Recursively search subdirectories.
You can also use globbing syntax to search within specific files such as:
grep "class foo" **/*.c
Note: By using globbing option (**), it scans all the files recursively with specific extension or pattern. To enable this syntax, run: shopt -s globstar. You may also use **/*.* for all files (excluding hidden and without extension) or any other pattern.
If you’ve the error that your argument is too long, consider narrowing down your search, or use find syntax instead such as:
find . -name "*.php" -execdir grep -nH --color=auto foo {} ';'
Alternatively, use ripgrep.
ripgrep
If you’re working on larger projects or big files, you should use ripgrep instead, like:
rg "class foo" .
Checkout the docs, installation steps or source code on the GitHub project page.
It’s much quicker than any other tool like GNU/BSD grep, ucg, ag, sift, ack, pt or similar, since it is built on top of Rust’s regex engine which uses finite automata, SIMD and aggressive literal optimizations to make searching very fast.
It supports ignore patterns specified in .gitignore files, so a single file path can be matched against multiple glob patterns simultaneously.
You can use common parameters such as:
-i– Insensitive searching.-I– Ignore the binary files.-w– Search for the whole words (in the opposite of partial word matching).-n– Show the line of your match.-C/--context(e.g.-C5) – Increases context, so you see the surrounding code.--color=auto– Mark up the matching text.-H– Displays filename where the text is found.-c– Displays count of matching lines. Can be combined with-H.
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
- Консольные окружения — интерфейсы, в которых работа выполняется в текстовом режиме.
- Интерфейс — механизм взаимодействия пользователя с аппаратной частью компьютера.
- Оператор — элемент, задающий законченное действие над каким-либо объектом операционной системы (файлом, папкой, текстовой строкой и т. д.).
- Текстовые массивы данных — совокупность строк, записанных в переменную или файл.
- Переменная — поименованная область памяти, позволяющая осуществлять запись и чтение данных, которые в нее записываются. Она может принимать любые значения: числовые, строковые и т. д.
- Потоковый текстовый редактор — программа, поддерживающая потоковую обработку текстовой информации в консольном режиме.
- Регулярные выражения — формальный язык поиска части кода или фрагмента текста (в том числе строки) для дальнейших манипуляций над найденными объектами.
- Bash-скрипты — файл с набором инструкций для выполнения каких-либо манипуляций над строкой, текстом или другими объектами операционной системы.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство «=»: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность «==»: возвращается «TRUE», если первая строка эквивалентна второй (дом == дом).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность «str1 !== str2»: «TRUE», если одна строковая переменная не равна другой по смысловому значению (дерево !== огонь).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, «дерево > огонь», поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 < str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, «огонь < дерево», поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 «-z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения «-n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных
- Чтобы сравнить две строки, нужно написать bash-скрипт с именем test.

- Далее необходимо открыть терминал и запустить test на выполнение командой:
./test
- Предварительно необходимо дать файлу право на исполнение командой:
chmod +x test
- После указания пароля скрипт выдаст сообщение на введение первого и второго слова. Затем требуется нажать клавишу «Enter» для получения результата сравнения.


Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
- Для практического изучения команд, с помощью которых выполняется работа с текстом в интерпретаторе bash, необходимо создать текстовый файл txt.
- После этого нужно наполнить его произвольным текстом, разделив его на строки. Новая строка не должна сливаться с другими элементами.
- Далее нужно перейти в директорию, в которой находится файл, и запустить терминал с помощью сочетания клавиш — Ctrl+Alt+T.
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep. Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep [options] pattern [file_name1 file_name2 file_nameN] (где «options» — дополнительные параметры для указания настроек поиска и вывода результата; «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; «file_name1 file_name2 file_nameN» — имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep [options] pattern (где «instruction» — команда интерпретатора bash, «options» — дополнительные параметры для указания настроек поиска и вывода результата, «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).
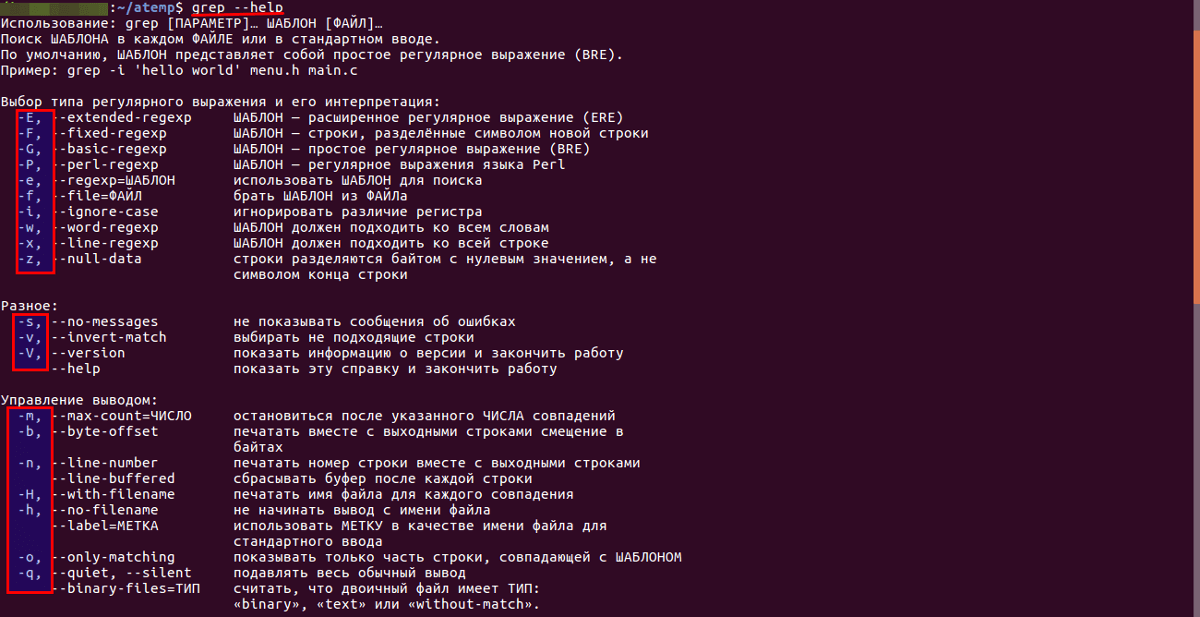
Основные опции
- Отобразить в консоли номер блока перед строкой — -b.
- Число вхождений шаблона строки — -с.
- Не выводить имя файла в результатах поиска — -h.
- Без учета регистра — -i.
- Отобразить только имена файлов с совпадением строки — -l.
- Показать номер строки — -n.
- Игнорировать сообщения об ошибках — -s.
- Инверсия поиска (отображение всех строк, в которых не найден шаблон) — -v.
- Слово, окруженное пробелами, — -w.
- Включить регулярные выражения при поиске — -e.
- Отобразить вхождение и N строк до и после него — -An и -Bn соответственно.
- Показать строки до и после вхождения — -Cn.
Практическое применение grep
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
grep Bourne firstfile.txt
- Без учета регистра:
grep -i "Bourne"txt
Вывод нескольких строк
- Строка с вхождением и две после нее:
grep -A2 "Bourne"txt
- Строка с вхождением и три до нее:
grep -B3 "Bourne"txt
- Строка, содержащая вхождение, и одну до и после нее:
grep -C1 "Bourne"txt
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
- Вывод строки, в начале которой встречается слово «Фамилия».
 В регулярных выражения для обозначения начала строки используется специальный символ «^».
В регулярных выражения для обозначения начала строки используется специальный символ «^».
grep "^Фамилия" firstfile.txt
Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
grep "^Ф" firstfile.txt
- Конец строки, заканчивающийся словом «оболочка». Для обозначения конца строки используется мета-символ «$».
grep «оболочка$» firstfile.txt Если требуется вывести символ конца строки, то следует применять конструкцию
grep «а.$» firstfile.txt. В этом случае будут выведены все строки, заканчивающиеся на литеру «а».

- Строки, содержащие числа.
grep -C1 "Bourne"txt
Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
grep "[0-9]"txt

Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
grep -r "оболочка$"
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
grep -h -r "оболочка$"
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ «w»:
grep -w "и" firstfile.txt
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
grep -w "и | но" firstfile.txt
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.
![]()
- Число вхождений:
grep -с "Bourne"txt
- Номера строк с совпадениями:
grep -n "Bourne"txt
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
grep -v "Unix" firstfile.txt
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
grep -I "Unix" *.txt
Использование sed
Потоковый текстовый редактор «sed» встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).
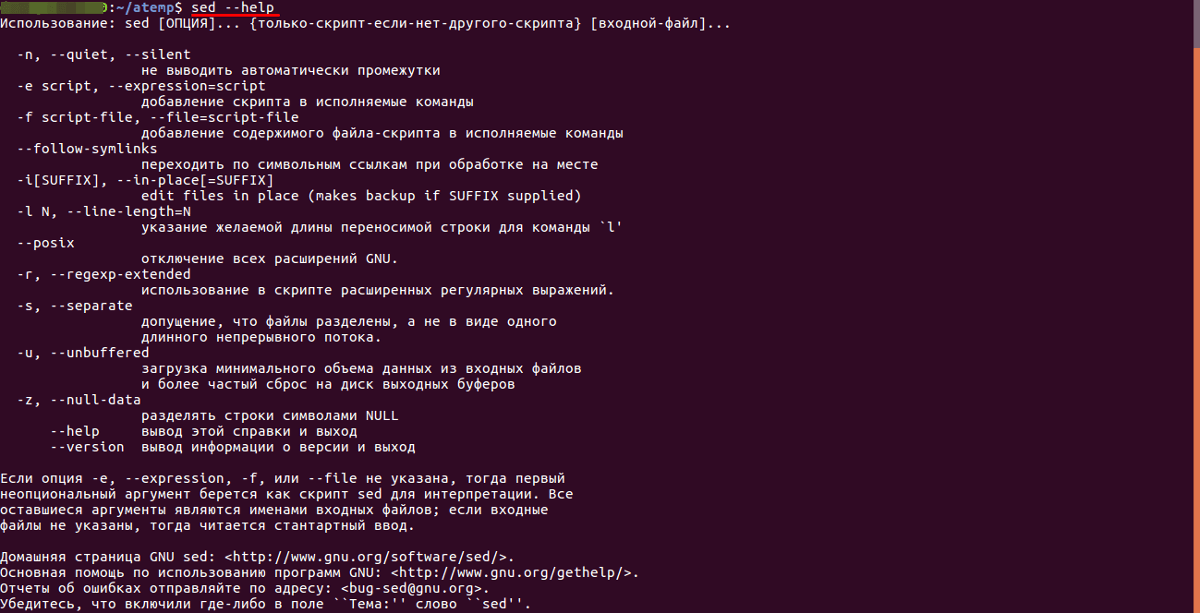
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
sed --help
Распространенные конструкции с sed
Замена слова
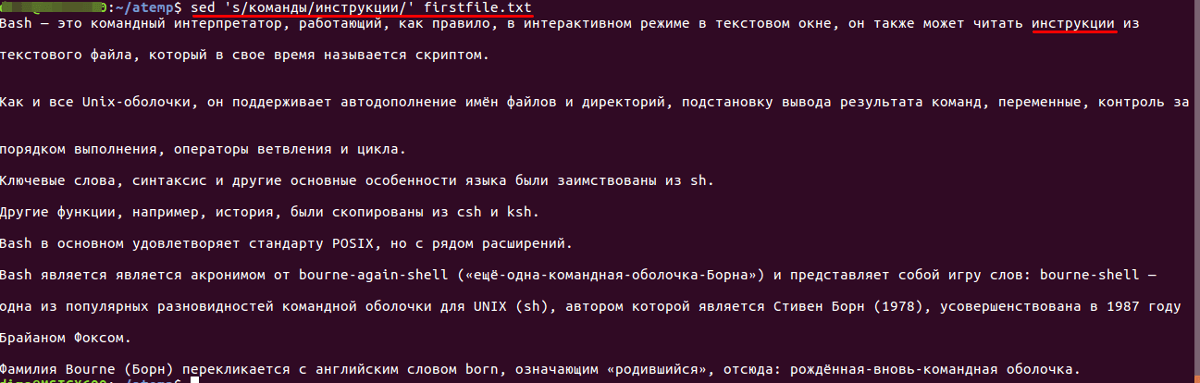
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
- Для первого вхождения:
sed 's/команды/инструкции/' firstfile.txt

- Для всех вхождений (используется параметр инструкции — g):
sed 's/команды/инструкции/g' firstfile.txt
- Замена подстроки с несколькими условиями (используется ключ — -e):
sed -e 's/команды/инструкции/g' -e 's/команд/инструкций/g' firstfile.txt
- Заменить часть строки, если она содержит определенный набор символов (например, POSIX):
sed '/POSIX/s/Bash/оболочка/g' firstfile.txt
- Выполнить замену во всех строках, начинающихся на «Bash»
sed '/^Bash/s/Bash/оболочка/g' firstfile.txt
- Произвести замену только в строках, которые заканчиваются на «Bash»:
sed '/команды/s/Bash/оболочка/g' firstfile.txt
- Заменить слово с пробелом на слово с тире:
sed 's/Bash /оболочка-/g' firstfile.txt
- Заменить символ переноса строки на пробел
sed 's/n/ /g' firstfile.txt
- Перенос строки обозначается символом — n.
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i:
sed -i 's/команды/инструкции/' firstfile.txt
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
sed -i '1d' firstfile.txt
- Удалить строку из файла, содержащую слово «окне»:
sed '/окне/d' firstfile.txt
После выполнения команды будет удалена первая строка, поскольку она содержит указанное слово.
- Удалить пустые строки:
sed '/^$/d' firstfile.txt
- Убрать пробелы в конце строки:
sed 's/ *$//' firstfile.txt
- Табуляция удаляется при помощи конструкции:
sed 's/t*$//' firstfile.txt
- Удалить последний символ в строке:
sed 's/ ;$//' firstfile.txt
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
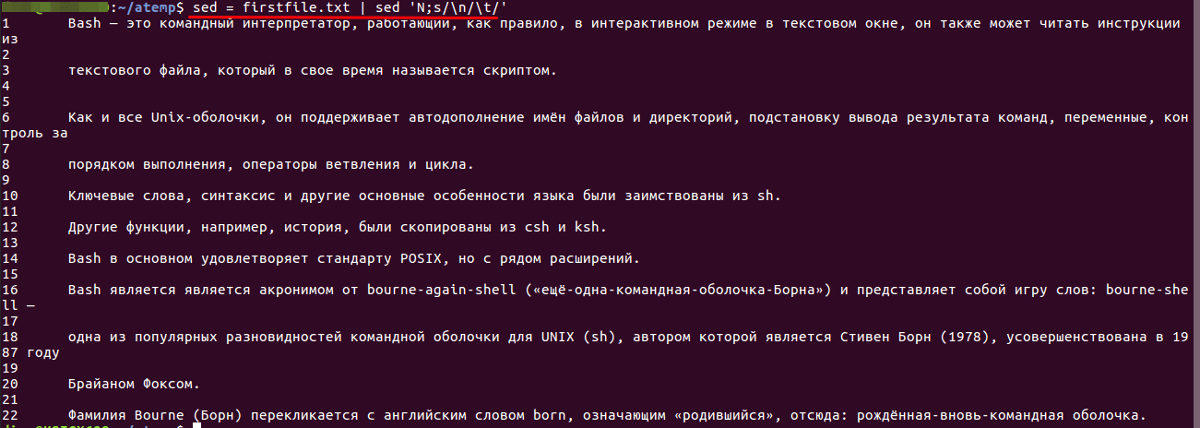
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
sed = firstfile.txt | sed 'N;s/n/t/'
Удаление всех чисел из текста
sed -i 's/[0-9] [0-9]//g' firstfile.txt
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду «y»:
sed 'y/1978/1977/g' firstfile.txt
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
sed '3s/директорий/папок' firstfile.txt
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
sed '3,4s/директорий/папок' firstfile.txt
Вставка содержимого файла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда:
sed ‘5r input_file.txt’ firstfile.txt (где «5r» — 5 строка, «input_file.txt» — исходный файл и «firstfile.txt» — файл, в который требуется вставить массив текста).
